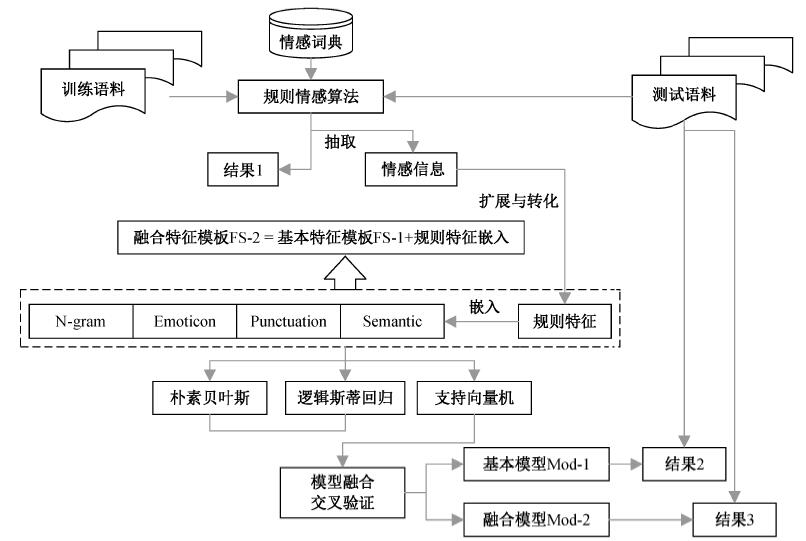
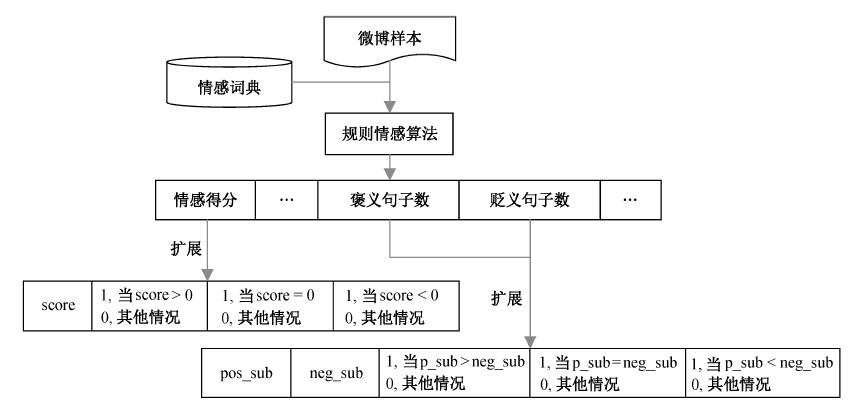
| [1] |
Turney P D. Thumbs up or thumbs down? semantic orientation applied to unsupervised classification of reviews // Proceedings of the 40th annual meeting on association for computational linguistics. Philadel-phia, 2002: 417-424
|
| [2] |
Taboada M, Brooke J, Tofiloski M, et al.Lexicon-based methods for sentiment analysis. Computational Linguistics, 2011, 37(2): 267-307
|
| [3] |
周红照, 侯明午, 颜彭莉, 等. 语义特征在评价对象抽取与极性判定中的作用. 北京大学学报: 自然科学版, 2014, 50(1): 93-99
|
| [4] |
Jijkoun V, de Rijke M, Weerkamp W. Generating focused topic-specific sentiment lexicons // Procee-dings of the 48th Annual Meeting of the Association for Computational Linguistics. Uppsala, 2010: 585-594
|
| [5] |
Mohammad S M, Kiritchenko S, Zhu X.NRC-Canada: building the state-of-the-art in sentiment analysis of tweets // Proceedings of the 7th Inter-national Workshop on Semantic Evaluation (SemEval). Atlanta, 2013: 321-327
|
| [6] |
Pang B, Lee L, Vaithyanathan S.Thumbs up?: sentiment classification using machine learning tech-niques // Proceedings of Empirical Methods in Natural Language. Philadelphia, 2002: 79-86
|
| [7] |
刘志明, 刘鲁. 基于机器学习的中文微博情感分类实证研究. 计算机工程与应用, 2012, 48(1): 1-4
|
| [8] |
Kouloumpis E, Wilson T, Moore J D.Twitter sentiment analysis: the good the bad and the omg! // Proceedings of the Fifth International AAAI Confe-rence on Weblogs and Social Media. Barcelona, 2011: 538-541
|
| [9] |
夏睿, 宗成庆. 情感文本分类混合模型及特征扩展策略. 智能系统学报, 2011, 6(6): 483-488
|
| [10] |
Cui H, Mittal V, Datar M.Comparative experiments on sentiment classification for online product reviews // Proceedings of the Twenty-First National Confe-rence on Artificial Intelligence. Boston, 2006: 1265-1270
|
| [11] |
赵妍研, 秦兵, 刘挺. 文本情感分析. 软件学报, 2010, 21(8): 1834-1848
|
| [12] |
Jiang L, Yu M, Zhou M, et al.Target-dependent twitter sentiment classification // Proceedings of the 49th Annual Meeting of the Association for Compu-tational Linguistics. Portland, 2011: 151-160
|
| [13] |
Xia R, Zong C, Li S.Ensemble of feature sets and classification algorithms for sentiment classification. Information Sciences, 2011, 181(6): 1138-1152
|
| [14] |
Go A, Bhayani R, Huang L.Twitter sentiment classification using distant supervision [R]. CS224N Project Report, Stanford, 2009
|
| [15] |
Liu K L, Li W J, Guo M.Emoticon smoothed language models for Twitter sentiment analysis // AAAI. Toronto, 2012: 1678-1684
|
| [16] |
Tang D, Wei F, Yang N, et al.Learning sentiment-specific word embedding for twitter sentiment classi-fication // Meeting of the Association for Compu-tational Linguistics. Baltimore, 2014: 1555-1565
|
| [17] |
Tang D, Wei F, Qin B, et al.Coooolll: a deep learning system for Twitter sentiment classification // Procee-dings of the 8th International Workshop on Semantic Evaluation (SemEval). Dublin, 2014: 208-212
|
| [18] |
Vo D T, Zhang Y.Target-dependent twitter sentiment classification with rich automatic features // Pro-ceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI). Buenos Aires, 2015: 1347-1353
|
| [19] |
谢丽星, 周明, 孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取. 中文信息学报, 2012, 26(1): 73-83
|
| [20] |
Qiu L, Zhang W, Hu C, et al.SELC: a self-supervised model for sentiment classification // Proceedings of the 18th ACM conference on Information and know-ledge management. Hong Kong, 2009: 929-936
|