
余传明
Chuanming YU
中图分类号:
TP391
通讯作者:
Corresponding authors:
收稿日期:
2016-07-22
修回日期:
2016-09-24
网络出版日期:
2016-11-30
版权声明:
2017 《北京大学学报(自然科学版)》编辑部 《北京大学学报(自然科学版)》编辑部 所有
基金资助:
展开
摘要 从评论利益相关者内容与行为特征相结合的角度, 提出一种基于个人-群体-商户的主体关系模型(IGMRM)。选择93家店铺中9558个不同IP的97804条评论作为样本数据进行实验, 结果表明, IGMRM在识别虚假评论者、存在信用操纵的商铺以及虚假评论者群体的 F1 值分别达到 82.62%、59.26%和95.12%。使用基于评论内容的逻辑回归模型和 K 最邻近模型作为基线分类方法, 识别虚假评论者的 F1 值分别为52.63%和76.75%, 表明IGMRM在识别虚假评论者方面优于传统方法。
关键词:
Abstract A novel individual-group-merchant relation model is proposed to automatically identify fake reviews on E-commerce platforms, which focuses on the characteristics of fake reviewers’ behaviors instead of review contents. Three sets of indicators are proposed, i.e. individual indicators, group indicators and merchants’ indicators. To validate the model, an empirical study of fake review identification from a Chinese E-commerce platform is implemented. A number of 97804 reviews posted from 9558 different IP addresses, which are related to 93 online stores, are selected as test data. Results show that the F1-measure values of the proposed model on identifying fake reviewers, online merchants and groups with credit manipulation are 82.62%, 59.26% and 95.12%, respectively. Utilizing logistic regression and K nearest neighbor classifier based on the comments of the content as the baseline methods, the F1-measure values are 52.63% and 76.75%, respectively. Thus, the IGMRM model outperforms traditional methods in identifying fake reviewers.
Keywords:
随着电子商务的发展, 客户评论在网上交易中扮演着重要的角色。潜在买家通常首先阅读产品的评论, 并倾向于购买那些带有较多正面评论的产品。由于正面意见通常会带来显著收益, 于是一些不法商家或者个人通过幕后的评论操纵来提升其产品的声誉和人气, 从而获取更多利益[1]。研究表明, 在网络评论中存在一定数量的虚假评论者, 他们通过相互协作来发布虚假评论, 这些团体被称为虚假评论者群体[2]。
Jindal 等[3-5]在针对虚假评论的研究中提出一些指标来挖掘虚假评论者的行为。这些研究专注于个人在网络平台上的虚假评论行为, 却忽略了与发布虚假评论相关的商家。Xu 等[6]提出基于 KNN 和图的分类方法, 开展与群体级别的虚假评论者相关的实验, 验证了虚假评论群体的存在。Wang 等[7]根据由评论者、群体和商家构成的关系图, 揭示他们之间的联系。但是, 如何量化虚假评论个人、群体和商家的行为特征, 如何揭示虚假评论个体、群体以及商家之间的关系, 目前还没有系统性的相关研究。鉴于此, 本文尝试构建虚假评论个体、群体和商家的行为指标体系, 提出基于个人-群体-商户的主体关系模型(indivual-group-merchant relation model, IGMRM), 并验证其有效性, 以期为识别虚假评论个人、群体和商家提供一种新思路。
当前关于虚假评论的识别主要分为两类: 一类是采用有监督的机器学习方法, 将虚假评论的识别过程视为一个分类过程, 结合心理学与计算语言学方法, 抽取评论的语言内容线索, 利用有监督的支持向量机、决策树等分类器, 对手工标注的虚假评论集进行学习, 建立统计模型来检测虚假评论[8]。这类有监督的机器学习算法的准确率在极大程度上依赖于人工标注。对于海量的评论数据, 人工所能识别的虚假评论数量极为有限, 极大地制约了虚假评论识别研究的发展[9]。尽管已采取一系列的方法来改进标注集的准确度, 但在真实商业情境下的分类效果不理想。例如, Ott 等[10]利用亚马逊的 AMT工具, 模拟生成虚假评论数据作为标注集, 在虚拟评论分类识别中取得很好的效果, 但在真实的商业数据集(Yelp 的评论数据)中, 由于真实数据与模拟数据的差异性, 导致识别效果不理想[11]。可见, 受限于高质量标注集的获取, 有监督的分类方法对虚假评论的识别有一定的局限性。
另一类是采用非监督的方法进行虚假评论识别。Li 等[12]提出基于 PU-Learing 的半监督方法, 使用少量的标注数据和大量的非标注数据来识别虚假评论。Mukherjee 等[2]率先使用非监督算法, 探讨虚假评论者的行为特征, 建立群体、个人和产品间的3个二元关系模型, 然后根据每组模型中二者之间的关系, 进行相互迭代推理, 得到一组稳定的标识评论者群体虚假程度的数据, 并据此识别虚假评论者, 进而识别虚假评论。Mukherjee 等[13]探索了聚类算法在虚假评论识别中的有效性, 通过分析虚假评论发布人和真实评论发布人行为上的差异, 区分虚假评论者和正常评论者, 进而识别虚假评论。Akoglu 等[14]从网络结构特征入手, 结合评论者和产品的网络结构信息来发现虚假评论者, 能够很好地避免人工标注的数据集质量和数量问题, 也极大地提升了虚假评论识别的效率。
在国内, 邱云飞等[15]从虚假评论者的行为目的出发, 研究了 5 种行为模式, 以此为指标进行标注, 设计了有监督的线性回归模型, 预测潜在的虚假评论者。孙升芸等[16]定义了虚假评论者常见的三类行为模式, 通过人工评判以及计算 NDCG (norma-lize discount cumulative gain)值的方法来计算虚假评论者的虚假程度(spam score)。李霄等[17]从评论、评论者和被评论的商品角度选择多个特征, 使用支持向量机模型识别虚假商品评论。邓莎莎等[18]结合心理学的欺骗理论, 根据欺骗语言线索提取特征, 并验证其在虚假评论识别中的有效性。宋海霞等[8]在研究评论者的行为特征基础上, 提出基于评论者行为特征的自适应聚类的虚假评论检测方法。此外, 还有学者从虚假评论发布者行为动机、虚假评论形成路径等角度着手, 力图还原虚假评论者行为。孟美任等[19]将虚假评论者的评论动机分为推销、诋毁、干扰和无意义等 4 个方面, 并逐个分析其特点和危害性。陈燕方等[20]分析了虚假评论涉及的四大主体——在线评论者、在线商家、电商平台、虚假评论——构成的虚假评论的六大路径及其动因和特点, 对虚假评论者的行为特征研究奠定了一定的基础。
本文用虚假度(degree of fakeness)来衡量评论个人、群体及商家虚假程度的指标。为了统一所有指标的量纲, 减少数据倾斜带来的误差, 我们将虚假度的值定义在[0, 1]范围内, 越接近 1, 虚假度越高; 越接近0, 虚假度越低。
通过对电商网站数据进行统计和分析, 我们建立了多项行为指标。
在评论者层面, 注册账号率(register user ratio, RUR)和注册账号时间间隔(user register window, URW)是对评论者注册账号行为异常性的度量, 能够有效地揭示虚假评论者和正常评论者在注册账号数量和时间间隔上的差异性。对样本数据的统计表明, 正常评论者在特定时间内注册账号的数量通常在一定的范围之内。如果评论者在短时间内账号注册数量超过一定阈值, 则存在异常的可能性高于普通用户。与此类似, 正常评论者注册多个账号的注册时间间隔通常高于一定的阈值, 如果评论者注册账号时间间隔低于该阈值, 则存在异常的可能性有所提升。
发布评论数量比(review ratio, RR)、各商铺评论数量比(review per merchant ratio, RMR)和对各商铺评论时间间隔(review per merchant time window, RMTW)度量评论者发布评论的数量和时间间隔的异常性, 能够有效地揭示评论者对所有商铺或某一特定商铺发表评论的数量和时间间隔的差异性。普通用户在一段时间内, 发布评论的数量和时间间隔通常在一定范围之内, 若发布评论的数量和时间间隔越过正常范围, 则存在异常的可能性较大。
与 RR 和 RMTW 类似, 群组对各商家发布评论数量比率(group review per merchant ratio, GMR)和群组对各商家发布评论时间间隔(group review per merchant time window, GMTW)从评论者群体角度对其发布评论数量和时间间隔的异常性进行度量。
在商家指标部分, 转化率(conversion rate ratio, CRR)和商龄率(shop age ratio, SAR)量化了店铺日成交量与日访问人数的比值及其与店铺年龄之间的关系。店铺浏览量通常远大于成交量, 若两者数量极为接近(尤其是对于新开店铺而言), 则存在信用操纵的可能性高于普通店铺。
转化率异常时间比(CR above_avg days ratio, CRaDR)量化了店铺的异常行为所占比率, 可以解决商家为了规避电商平台的检查而将信用操纵行为分散到不同时间段的问题。
2.1.1 评论个人行为的指标体系
1) 注册账号率(RUR)为
$\text{RUR}(u)=\left\{ \begin{array}{*{35}{l}} \frac{|{{u}_{\text{ }\!\!~\!\!\text{ }i}}|}{{{\lambda }_{1}}},\ \ |{{u}_{\text{ }\!\!~\!\!\text{ }i}}|\le {{\lambda }_{1}}, \\ 1,\ \ \ \ \ \ \ , \\\end{array} \right.$ (1)
其中, |ui|表示每个用户对应注册的帐号数, λ1表示根据分析结果定义的虚假评论者单个用户注册账号阈值。
2) 注册账号时间间隔(URW)为
式(2)中, avg(|ti|)=avg(|max_create_timei_min_create_ timei|)/user_cnt 表示每个用户对应的多个账号注册时间间隔天数平均值, γ1是正常账号注册时间间隔阈值。
3) 发布评论数量比(RR)为
其中, |ur|表示每个用户对应的发布评论数, λ2是根据分析结果定义的虚假评论者单个用户发布评论数阈值。
4) 各商铺评论数量比(RMR)为
其中, $|{{u}_{{{m}_{i}}}}|$表示每个用户对某个商铺发布的评论数, λ3是虚假评论者单个用户发布评论阈值。
5) 对各商铺评论内容相似度(review per merchant content similarity, RMCS)。采用余弦相似度算法量化用户评论内容相似度:
其中,
6) 评论内容相似度(review content similarity, RCS)。RCS 是用来衡量用户发布所有评论相似度的指标, 取RMCS均值:
$\text{RCS}(u)=\text{avg}(\text{RMCS}(u,{{m}_{i}}))$, (6)
其中, avg(RMCS(u,mi))为每个用户在不同商家做出评论内容相似度之和除以被评论商户数。
7) 对各商铺评论时间间隔(RMTW)为
其中, $\text{L}{{\text{T}}_{{{m}_{il}}}}$表示单个用户对该商铺评论的最晚时间, $\text{F}{{\text{T}}_{{{m}_{ik}}}}$表示单个 IP 对商铺评论的最早时间, γ2表示评论者对同一家商铺进行多次评论的时间间隔阈值。
8) 评论时间间隔(review time window, RTW)为每个用户在不同商家做出评论时间间隔之和除以被评论商家数:
$\text{RTW}(u)=\text{avg}(\text{RMTW}(u,{{m}_{i}}))$。 (8)
2.1.2 评论者群体行为的指标体系
本文采用 Eclat 频繁项集挖掘算法, 识别同时对至少3家店铺有评论行为的用户项集, 并将该集合作为虚假评论者群体候选项集, 再通过构建群体行为指标体系, 衡量群体虚假度。
1) 群组对各商家发布评论数量比率(GMR)。虚假评论者群体为了尽可能地完成任务, 提升店铺信誉度, 发布的评论数量比正常评论者群体高。
$|{{g}_{{{m}_{i}}}}|$表示每个群组对某个商铺发布的评论数之和, λ4是虚假评论者群体(用户组)发布评论阈值。
2) 群组对各商家发布评论内容相似度(group review per merchant content similarity, GMCS)为
$\text{GMCS}({{g}_{j}},{{m}_{i}})=\text{avg}(\text{si}{{\text{m}}_{g}}({{r}_{{{m}_{il}}}},{{r}_{{{m}_{ik}}}}))$。 (10)
3) 群组对各商家发布评论时间间隔(group review per merchant time window, GMTW)为
$\text{GMTW}({{g}_{j}},{{m}_{i}})=1-\frac{\text{L}{{\text{T}}_{g({{m}_{il}})}}-\text{F}{{\text{T}}_{g({{m}_{ik}})}}}{{{\gamma }_{3}}},\text{L}{{\text{T}}_{g({{m}_{il}})}}-\text{F}{{\text{T}}_{g({{m}_{ik}})}}\le {{\gamma }_{3}},$ (11)
其中, $\text{L}{{\text{T}}_{g({{m}_{il}})}}$表示某一候选组对该商铺评论的最晚时间, $\text{F}{{\text{T}}_{g({{m}_{ik}})}}$表示该候选组对商铺评论的最早时间, γ3 表示评论者对同一家商铺进行多次评论的时间间隔阈值。
4) 群组规模比(group size ratio, GSR)[2]为
$\text{GSR}({{g}_{j}})=\frac{|{{g}_{j}}|}{\left| \text{max}(g) \right|},$ (12)
|gj|表示某一群组内虚假评论者人数, |max(g)|表示虚假评论组人数最大值。
2.1.3 商家行为的指标体系
以往关于虚假评论识别的研究中, 很少关注商家的行为指标。由于商家的主动作弊行为对虚假评论识别有很大的影响, 故本文纳入商家虚假评论行为指标。
1) 转化率(CRR)为
其中, |Transi|表示在统计期内店铺单日成交量, 即进店参观顾客交易行为数量; |UV|表示在统计期内的独立访客数。
2) 商龄率(SAR)为
$\text{SAR}({{m}_{i}})=1-\frac{|\text{CurDate}-\text{AffltDat}{{\text{e}}_{i}}|}{\max (|\text{CurDate}-\text{AffltDat}{{\text{e}}_{i}}|)},$ (14)
其中,CurDate表示统计截止日期,AffltDatei表示在线商铺正式营业日期,CurDate-AffltDatei表示截至统计日期, 店铺的运营时间。
3) 转化率异常时间比(CRaDR)为
$\text{CRaDR}({{m}_{i}})=\frac{\text{days}(\text{cr}>\text{av}{{\text{g}}_{\text{cr}}}\times 1.5)}{\text{shop}\_\text{age}\_\text{days}},$ (15)
其中,$\text{ }\!\!~\!\!\text{ days}(\text{cr}>\text{av}{{\text{g}}_{\text{cr}}}\times 1.5)$表示在统计期内日转化率大于该店铺平均转化率 150%的天数, $\text{CRaDR}({{m}_{i}})$表示自商铺开店以来进行信用操纵的频率。
本文通过构建关系矩阵模型, 进行虚假评论者主体关系建模。假定$U=\{{{u}_{i}}\},\ M=\{{{m}_{j}}\},\ G=\{{{g}_{k}}\}$分别代表个人(以独立 IP 为标识)、商户和群组的集合。$f({{u}_{i}}),\ f({{m}_{j}})$和$f({{g}_{k}})$代表个人、商户以及群组的虚假程度, 并以[0, 1]范围内的值进行标识, 越 接近 1, 虚假度越高, 越接近 0, 虚假度越低。., ${{F}_{M}}=\left[ f({{m}_{j}}) \right]$和${{F}_{G}}=\left[ f({{g}_{k}}) \right]$分别表示个人、商户以及群组等虚假评论行为主体的虚假度向量。由于U, M和G的虚假度相互影响, 我们建立 3 组关系矩阵, 即商户-个人(M-U)关系矩阵、个人-群体(U-G)关系矩阵和群体-商家(G-M)关系矩阵。然后, 根据每组模型中二者之间的相互影响程度进行迭代推理, 得到一组稳定的数据。
2.2.1 商户-个人(M-U)关系模型
商户-个人(M-U)关系模型描述商户与个人之间虚假程度的相互影响。商户虚假度越高, 则其相关评论者虚假度越高; 评论者虚假度越高, 则其评论的商户虚假度也越高。利用涉及商户-个人虚假度的指标RMR(ui, mj), RMCS(ui,mj), RMTW(ui,mj), CRR(mj), SAR(mj)和 CRaDR(mj), 来计算商户与评论者个人虚假度的相互影响程度。为了简化模型, 采用取均值的方式:
${{w}_{1}}({{u}_{i}},{{m}_{j}})=\frac{1}{6}\left[ \begin{align} & \text{RMR}({{u}_{i}},{{m}_{j}})+\text{RMCS}({{u}_{i}},{{m}_{j}})+ \\ & \text{RMTW}({{u}_{i}},{{m}_{j}})+\text{CRR}({{m}_{j}})+ \\ & \text{SAR}({{m}_{j}})+\text{CRaDR}({{m}_{j}}) \\ \end{align} \right]$,
${{W}_{UM}}={{\left[ {{w}_{1}}({{u}_{i}},{{m}_{j}}) \right]}_{\left| U \right|\times \left| M \right|}}$。 (16)
商户与个人虚假度相互影响的过程可以用下式表示:
$f({{u}_{i}})=\underset{j=1}{\overset{\left| M \right|}{\mathop \sum }}\,\ {{W}_{1}}({{u}_{i}},{{m}_{j}})f({{m}_{j}}),\ {{F}_{U}}={{W}_{UM}}{{F}_{M}},$ (17)
$f({{m}_{j}})=\underset{i=1}{\overset{\left| U \right|}{\mathop \sum }}\,\ {{W}_{1}}({{u}_{i}},{{m}_{j}})f({{u}_{i}}),\ \ {{F}_{M}}={{W}^{\text{T}}}_{UM}{{F}_{U}}$。 (18)
式(17)表示依据商户的虚假度以及 M-U 关系矩阵计算的用户虚假度; 式(18)表示依据计算出来的用户虚假度, 对商户虚假度进行迭代更新, 为下一轮迭代计算做准备。
2.2.2 个人-群体(U-G)关系模型
如果某一组内成员具有较高的虚假程度, 那么这个组的虚假程度显然也更高。同样地, 在一个具有高度虚假程度群内的成员, 其自身虚假程度也会受到影响。基于个人和群组行为指标体系, 利用式(19)计算个人对群体虚假程度的贡献值。
${{w}_{2}}({{g}_{k}},{{u}_{i}})=\frac{1}{6}[\text{RUR}({{u}_{i}})+\text{URW}({{u}_{i}})+\text{RR}({{u}_{i}})+$
$\text{RCS}({{u}_{i}})+\text{RTW}({{u}_{i}})+\text{GSR}({{g}_{k}})]$,
${{W}_{GU}}={{w}_{2}}{{({{g}_{k}},{{u}_{i}})}_{\left| G \right|\times \left| U \right|}}$。 (19)
群组与个体成员虚假度相互影响的过程可以用下式表示:
$f({{g}_{k}})=\underset{i=1}{\overset{\left| U \right|}{\mathop \sum }}\,{{w}_{2}}({{g}_{k}},{{u}_{i}})f({{u}_{i}}),\ \ \ {{F}_{G}}={{W}_{GU}}{{F}_{U}}$, (20)
$f({{u}_{i}})=\underset{k=1}{\overset{\left| G \right|}{\mathop \sum }}\,{{w}_{2}}({{g}_{k}},{{u}_{i}})f({{g}_{k}}),\ \ \ {{F}_{U}}={{W}^{\text{T}}}_{GU}{{F}_{G}}$。 (21)
通过式(20)计算群组的虚假度, 再由更新后的群组的虚假度计算用户的虚假度。
2.2.3 群体-商家(G-M)关系模型
采用下式揭示商户与群组之间行为特征的关系:
${{w}_{3}}({{m}_{j}},{{g}_{k}})=\frac{1}{3}[\text{GMR}({{m}_{j}},{{g}_{k}})+\text{GMCS}({{m}_{j}},{{g}_{k}})+\text{GMTW}({{m}_{j}},{{g}_{k}})],$
${{W}_{MG}}={{[{{w}_{3}}({{m}_{j}},{{g}_{k}})]}_{\left| M \right|\times \left| G \right|}}$。 (22)
群组及商户之间的虚假度相互影响用以下公式表示:
$f({{m}_{j}})=\underset{k=1}{\overset{\left| G \right|}{\mathop \sum }}\,{{w}_{3}}({{m}_{j}},{{g}_{k}})f({{g}_{k}}),\ \ {{F}_{M}}={{W}_{MG}}{{F}_{G}}$, (23)
$f({{g}_{k}})=\underset{j=1}{\overset{\left| M \right|}{\mathop \sum }}\,{{w}_{3}}({{m}_{j}},{{g}_{k}})f({{m}_{j}}),\ \ {{F}_{G}}={{W}^{\text{T}}}_{MG}{{F}_{M}}$。 (24)
2.2.4 虚假度迭代流程
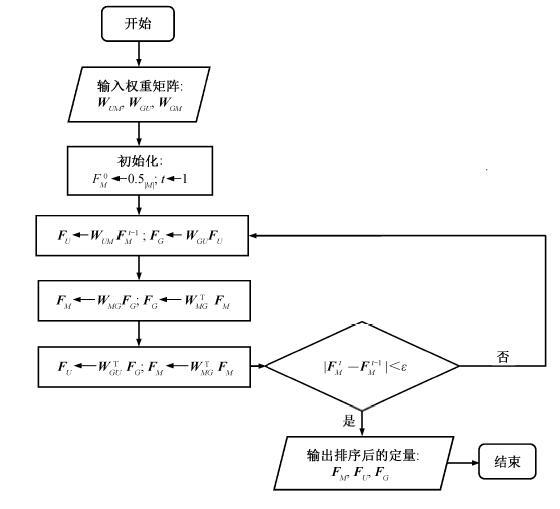
通过前面构建的 3 个主体关系矩阵, 迭代计算各自的虚假度。首先初始定义某一主体的虚假度向量(例如商户的虚假度初始值设为 0.5), 然后迭代计算其他主体的虚假度, 将上一轮迭代的输出作为下一轮迭代的输入, 直到输出一组稳定的数据, 并对其进行排序。这组数据包含所有评论者个体的虚假度、群组虚假度以及商铺虚假度。具体实现流程如图1所示。
本文以国内某大型电商平台的部分商家数据为样本, 进行实证研究。选择食品领域的 100 家商铺的 100000 条评论数据作为样本, 再根据评论数据中记录的用户信息, 关联提取用户数据, 剔除不合理的数据(比如IP为 127.0.0.1 的用户评论、网吧、学校等公用 IP 地址数据), 最终选取 93 家店铺、9558 个 IP 代表的不同评论者以及 97804 条评论数据作为样本。为了检验模型的有效性, 我们从数据集中随机抽取部分数据进行人工标注。选择 3名对电商领域网络评论有深入了解的专业人员作为评论标注者, 通过投票的方式进行标注, 如果对一条评论 3 人都认为是虚假评论, 则该评论的虚假度置为 1; 如果 3 人都认为是真实评论, 则虚假度置为0; 如果 3 人意见不统一, 则该条评论不加入测试集。为了提高标注的准确性, 我们为标注者提供包括评论文本内容在内的评论发布账号、时间、对应商家等数据。验证所使用的数据集为 13925 条人工标注数据, 涉及 114 个用户、55 个商家和 82 个群体。
统计样本数据, 以验证所定义指标是否合理。
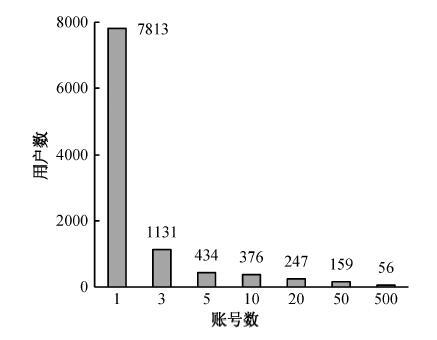
1) 注册账号率(RUR)。通过对样本数据的分析, 得到如图 2 所示的用户-账号数频率分布。从图 2可知, 在样本数据中, 8944个用户(独立IP地址)对应的注册账户数小于等于 3, 占样本数据量的87.55%; 838个用户对应的注册账户数大于等于 10, 占样本数据量的8.20%。因此取评论者账号阈值(式(1)中的λ1)为10。
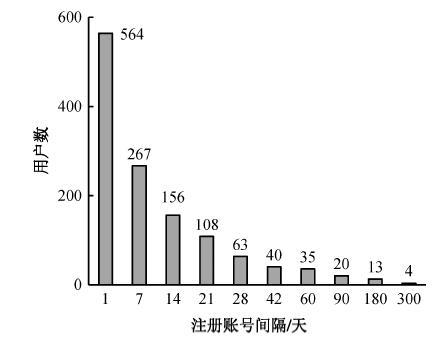
2) 注册账号时间间隔(URW)。样本数据中账号注册时间间隔分布(以对应账号数大于 3 的用户为例)如图 3 所示。样本数据中共有 1270 个用户注册超过 3 个的账号, 其中注册账号时间间隔小于 1天的用户有 564 个, 仅 37 个用户注册账号时间间隔大于 90 天, 占样本数据量的3%。考虑到部分用户因账号遗忘需重新注册的因素, 将时间间隔阈值(式(2)中的γ1)定为7天。
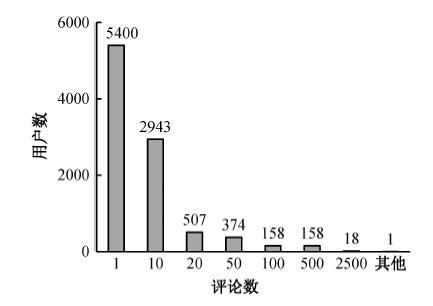
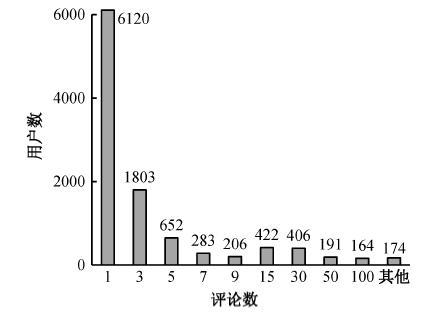
3) 发布评论数量比(RR)。样本数据分析结果表明, 超过 80%的用户在统计期内(2014 年 7 月 1 日至 12 月 31 日)发布的评论数少于 10 条, 在相同时间段内, 部分用户发布的评论数量显著高于其他用户, 如图4所示。
从图 4 可知, 5400 个用户在统计期内仅发布了1条评论, 9224个用户发布评论小于等于50条; 335个用户在统计期内发布评论多于 100 条, 显著高于正常用户。这表明, 大量用户在线消费后, 往往不会或者仅进行少量评论。通过对335个用户的评论数据进行分析, 发现这些用户存在信用操纵的可能性较高, 由此定义指标发布评论数量比(RR)对应阈值λ2为100。
4) 对各商户评论数量比(RMR)。图 5 显示每个用户对某个商铺的评论数频率分布。从图 5 可知, 在统计期内, 约 5%的用户对单个商户发布评论数大于等于 50, 其余 95%的用户对同一商户评论数在 50 以内, 由此将单个用户对商户评论阈值λ3设为50。
图5 U-M评论数频率分布 Fig. 5 Frequency distribution of review numbers by a user toward a merchant
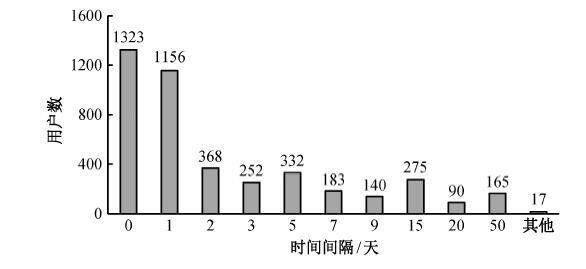
5) 对各商户评论时间间隔(RMTW)。根据对样本数据分析, 对同一店铺发布评论数多于 1 条的 IP评论时间间隔频率分布情况如图6所示。根据对样本数据的分析, 用户对同一家店铺的重复评论的平均时间间隔为3.62天, 用户对同一家店铺的评论时间越集中, 那么该用户的虚假度越高。
图6 对各商铺评论时间间隔频率分布 Fig. 6 Frequency distribution of U-M Review per Merchant Time Window
通过初步的统计设置阈值, 使用逻辑回归对现有个人虚假度指标(RUR, URW, RR, RCS和RTW)进行假设检验, 结果如表1所示。
表1 个人行为指标评估
Table 1 Individual behavior indicators’ evaluation
从表 1 可以看出, RR 和RTW的效果非常显著, RUR比较显著, URW和RCS(评论内容相似度)的p值显著。
通过式(16)、(19)和(22), 计算 3 组贡献度矩阵${{W}_{UM}},\ {{W}_{UG}}$和${{W}_{GM}}$, 将其作为虚假评论识别模型的输入, 然后根据式(17)~(18)以及(20)~(24)进行迭代。每次迭代后, 都对个人、商家和群组的虚假度向量进行标准化处理。设置迭代终止条件参数ε < 0.001, 取虚假度向量中的前k个对象, 将其判断为假, 其余为真。采用 P, R 和 F1 值评价实验结果, 表2为个人、商家和群组取不同k值时对应的分类效果(F1值排名前8)。
表2 IGMRM模型的实验结果
Table 2 Experimental results of the IGMRM model
表2显示, k值越接近人工标注的虚假个数, 分类效果越好。当k值为104时, 虚假评论者识别的F1 值达到82.47%。当k值为 40 时, 商家的F1值最高为 58.28%。当 k 值为 80 时, 群组的 F1 值为95.12%。在识别效果方面, F1 值从高到低依次为群组、个人、商家, 表明 IGMRM 能够较好地识别虚假群组和个人, 而对商家的识别效果一般。这可能与在标注存在信用操纵商家的过程中, 不同专家之间的分歧比标注个人和群组时大有关。
实验得到的商户、评论者 IP 和评论者群体代表的用户虚假度排序结果如表 3~5 所示。限于篇幅, 仅列出排名前10的结果。
表 3 商户虚假度排名
Table 3 Merchants’ fake degree rank
表4 用户虚假度排名
Table 4 Users’ fake degree rank
表5 群组虚假度排名
Table 5 Groups’ fake degree rank
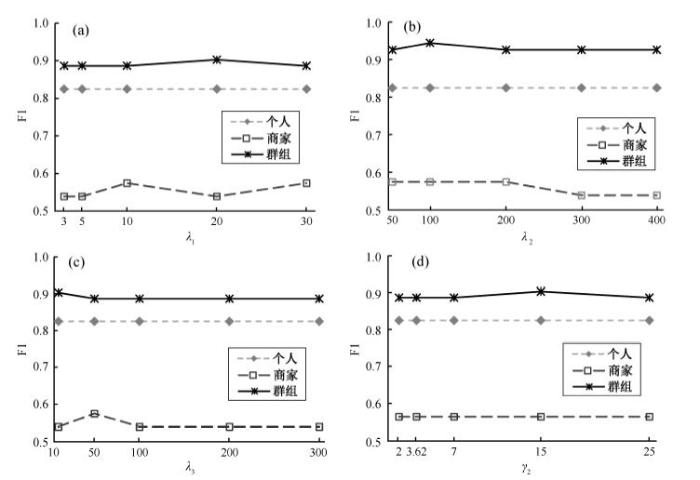
为了检验模型中先验参数的变化对实验结果的影响, 从而增强模型的可用度和可信度, 我们对RUR, RR, RMR和RMTW等4项指标涉及的先验参数(λ1, λ2, λ3和γ2)进行调整, 并取得相应的实验结果, 如图 7所示。
图7 先验参数的变化对实验结果的影响 Fig. 7 Influence of threshold tuning to the experimental results
从图 7(a)可以看出, 先验参数λ1 在 3~30 之间时, 虚假评论者识别的 F1 值无显著变化; 在λ1 取值为10和30时, 商家的F1值取得最优(0.5744, K=34); 在λ1取值为 20 时,群组的 F1 值取得最优(0.9026, K=68)。图 7(b)表明, 先验参数λ2 在50~400 之间时, 虚假评论者识别的 F1 值无显著变化; 在λ2取值为 100 时, 商家和群组的 F1 值取得最优(商家为0.5744, K=34; 群组为 0.9441, K=76)。从图 7(c)可以看出, 先验参数λ3在 10~300 之间时, 虚假评论者识别的 F1 值无显著变化; 在λ3取值为50时, 商家的F1值取得最优(0.5744, K=34); 在λ3取值为 10 时, 群组的 F1 值取得最优(0.9026, K=68)。图 7(d)表明, 先验参数γ2在 2~25 之间时, 识别虚假评论者和商铺的 F1 值无显著变化; 在γ2取值为 15 时, 群组的 F1 值取得最优(0.9026, K=68)。从实验结果看, 先验参数的调整对虚假评论者、商铺和群组的影响较小(F1 值变化均小于5%), 表明本模型对参数变化具有较强的适应性。
为了检验模型的有效性, 我们选择逻辑回归模型(LR)和 K 最邻近模型(KNN)作为基线方法, 在识别虚假评论者方面将IGMRM模型与基线模型进行比较。将同一用户或商家的所有评论合并, 并以归一化的tf-idf表示, 使用LR和KNN作为分类器进行分类。
如表6所示, 在虚假评论者识别方面, IGMRM的P, R, F三项指标均优于LR和KNN算法, 表明综合个人、群体和商家3个层面的因素, 将行为指标与内容分析结合, 能够有效地提高虚假评论者的识别性能。同时, IGMRM与支持向量机(SVM)相结合(IGMRM+SVM), 即采用IGMRM模型的个人、群体和商家特征作为支持向量机的输入, 能够取得更高的 P, R, F 值, 分别达到 92.86%、86.47%和87.89%, 表明将 IGMRM模型与监督模型相结合, 能够显著提升识别效果。
表6 3种方法的分类效果比较
Table 6 Comparision among three methods
本文在分析当前虚假评论识别现状的基础上, 从评论利益相关者内容与行为特征相结合的角度提出一种基于个人、群体和商户的主体关系模型, 系统地对个体、群体和商户的行为特征进行量化, 并对它们之间的关系进行定量揭示, 有效地提高了虚假评论识别的性能。实验结果证实, 虚假评论的识别依赖于信用操纵行为主体的假设, 将虚假评论识别的任务转化为识别存在信用操纵的利益相关者, 即个人、群组和商户。通过本文的识别模型, 不仅能够识别出虚假产品评论者, 也能识别存在信用炒作行为的商家和群体, 并且不需要手动标记训练集, 消除了分类模型的训练时间, 因而可扩展到大型数据集, 也更容易被采用, 其高扩展性和易用性有助于净化商业竞争和建立更好的信用操作监督机制。
本研究存在以下的局限性。1) 使用文本相似度计算的方法时, 未考虑文本的语义相似度。尽管内容分析不是本文研究的重点, 但我们认为更高级的基于语义的内容分析可能会取得更好的效果。2) 计算影响矩阵的过程中, 直接将相关指标取平均值, 虽然简化了算法, 但未考虑每个指标影响的差异。未来, 我们将进一步探究权重的动态变化对虚假评论者、群体和商家的识别效果。
The authors have declared that no competing interests exist.
网络口碑再传播意愿影响因素的实证研究 Spotting fake reviewer groups in consumer reviews Analyzing and detecting review spam Opinion spam and analysis
Review spam detection Uncovering Collusive spammers in Chinese review websites Review graph based online store review spammer detection 基于自适应聚类的虚假评论检测 产品评论垃圾识别研究综述 Finding deceptive opinion spam by any stretch of the imagination // The 49th Meeting of the Association for Computational Linguistics: Human Language Technologies. Strouds-burg, Spotting fake reviews via collective positive-unlabeled learning. Castellanos M and Ghost R. Spotting opinion spammers using behavioral footprints Opinion fraud detection in online reviews by network effects 基于用户行为的产品垃圾评论者检测研究 基于评论行为的商品垃圾评论的识别研究 垃圾商品评论信息的识别研究 基于欺骗语言线索的虚假评论识别 虚假商品评论信息发布者行为动机分析 在线商品虚假评论形成路径研究
/
1 相关研究
2 数据与方法
2.1 行为指标
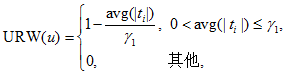
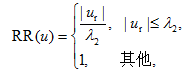
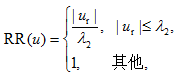
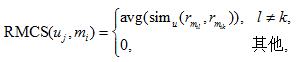
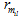
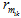

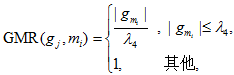
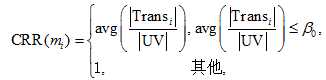
2.2 虚假评论者的主体关系建模
3 实验结果与分析
3.1 实验数据
3.2 虚假评论识别指标体系的参数确定及有效性评估
指标 估值 标准误差 z值 Pr(>|z|) Intercept -3.5174 0.5886 -5.976 2.29×10-9*** RUR -5.4879 1.9562 -2.805 5.03×10-3** URW 2.5755 1.2074 2.133 3.291×10-2* RR 50.6619 11.9434 4.424 2.22×10-5*** RCS 2.3308 1.0796 2.159 3.085×10-2* RTW 3.5696 0.8075 4.421 9.85×10-6***
3.3 IGMRM模型实验分析
象 k P R F1 个人 90 0.7992 0.7543 0.7737 92 0.8044 0.7719 0.7863 4 0.8103 0.7894 0.7989 6 0.8168 0.8070 0.8116 8 0.8245 0.8245 0.8245 00 0.8152 0.8245 0.8195 02 0.8052 0.8245 0.8137 04 0.8165 0.8421 0.8262 商家 30 0.5471 0.4909 0.5094 32 0.5690 0.5272 0.5424 34 0.5907 0.5636 0.5744 36 0.5774 0.5636 0.5698 38 0.5636 0.5636 0.5636 40 0.5866 0.6 0.5926 42 0.5721 0.6 0.5833 44 0.5553 0.6 0.5717 群组 66 0.9786 0.8292 0.8874 68 0.9630 0.8292 0.8863 70 0.9637 0.8536 0.9010 72 0.9644 0.8780 0.9154 74 0.9654 0.9024 0.9298 76 0.9668 0.9268 0.9441 78 0.9505 0.9268 0.9385 80 0.9512 0.9512 0.9512
商家编号 f(m) 排名 12**73 7.461918×10-1 1 7**09 5.370122×10-1 2 14**68 3.934663×10-1 3 10**30 2.677272×10-5 4 7**72 1.714189×10-5 5 7**96 1.453285×10-5 6 12**22 1.339835×10-5 7 12**29 1.184025×10-5 8 12**76 1.018929×10-5 9 10**92 8.861665×10-6 10
个人编号(IP) f(u) 排名 111.*. *.140 0.379819 1 222.*.*.179 0.3325661 2 122.*.*.223 0.3296828 3 42.*.*.160 0.3249425 4 42.*.*.100 0.3037860 5 222.*.*.110 0.2878484 6 42.*.*.74 0.2876034 7 125.*.*.19 0.2819457 8 42.*.*.246 0.2724028 9 61.*.*.244 0.2243581 10
群组编号(IP) f (g) 排名 "111.*.*.140" "122.*.*.223" "125.*.*.19""222.*.*.179""222.*.*.110""42.*.*.38""42.*.*.160""42.*.*.74""58.*.*.60""61.*.*.244" 0.1246993 1 "111.*.*.140" "122.*.*.223" "125.*.*.19""222.*.*.179""222.*.*.110""42.*.*.246""42.*.*.160""42.*.*.74""58.*.*.60""61.*.*.244" 0.1246467 2 "111.*.*.140" "122.*.*.223" "125.*.*.19""222.*.*.179""222.*.*.110""42.*.*.100""42.*.*.160""42.*.*.74""58.*.*.60""61.*.*.244" 0.1246448 3 "111.*.*.140" "122.*.*.223" "125.*.*.19""222.*.*.179""222.*.*.110""42.*.*.38""42.*.*.246""42.*.*.160""42.*.*.74""61.*.*.244" 0.1245663 4 "111.*.*.140" "122.*.*.223" "125.*.*.19""222.*.*.179""222.*.*.110""42.*.*.38""42.*.*.100""42.*.*.160""42.*.*.74""61.*.*.244" 0.1245570 5 "111.*.*.140" "122.*.*.223" "125.*.*.19""222.*.*.179""222.*.*.110""42.*.*.38""42.*.*.246""42.*.*.160""42.*.*.74""58.*.*.60" 0.1245103 6 "111.*.*.140" "122.*.*.223" "125.*.*.19""222.*.*.179""222.*.*.110""42.*.*.246""42.*.*.100""42.*.*.160""42.*.*.74""61.*.*.244" 0.1245025 7 "111.*.*.140" "122.*.*.223" "125.*.*.19""222.*.*.179""222.*.*.110""42.*.*.38""42.*.*.100""42.*.*.160""42.*.*.74""58.*.*.60" 0.1245014 8 "111.*.*.140" "122.*.*.223" "125.*.*.19""222.*.*.179""222.*.*.110""42.*.*.246""42.*.*.100""42.*.*.160""42.*.*.74""58.*.*.60" 0.1244561 9 "111.*.*.140" "122.*.*.223" "125.*.*.19""222.*.*.179""222.*.*.110""42.*.*.38""42.*.*.100""42.*.*.160""58.*.*.60""61.*.*.244" 0.1244181 10
3.4 模型的适应性分析
3.5 与其他方法对比分析
模型 P R F LR 0.4555 0.7857 0.5263 KNN 0.7481 0.7926 0.7675 IGMRM 0.8165 0.8421 0.8262
4 结语
参考文献
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
[20]

〈
〉
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}