
姜杰, 夏睿
南京理工大学计算机科学与工程学院, 南京 210094
Jie JIANG, Rui XIA
中图分类号:
TP391
通讯作者:
Corresponding authors:
收稿日期:
2016-08-2
修回日期:
2016-09-25
网络出版日期:
2016-11-30
版权声明:
2017 《北京大学学报(自然科学版)》编辑部 《北京大学学报(自然科学版)》编辑部 所有
基金资助:
展开
摘要 针对现有文本情感分析方法的不足, 设计了一种针对中文微博的基于词典的规则情感分类方法和用于机器学习方法的基本特征模板。提出一种机器学习与规则相融合的微博情感分类方法, 将用规则方法得到的多样化情感信息进行转化, 扩展并嵌入基本特征模板, 形成更有效的融合特征模板。通过 3 种分类模型集成, 提高微博情感分类的性能。
关键词:
Abstract Based on the shortcomings of sentiment analysis, this paper implemented a rule-based sentiment classification method and designed a basic feature set for machine learning methods. A sentiment analysis method via a combination of rule-based and machine learning methods is proposed. An effective integration feature set is obtained by adding various rule-based features to the basic feature set after expanding and converting them. The proposed method outperforms the baseline of any single method. Finally ensemble of three different classifiers is used to make further improvement on the performance of microblog sentiment classification.
Keywords:
随着社交网络的蓬勃发展, 互联网上产生大量用户参与的关于人物、事件、产品等的评论数据, 这些数据蕴含着大量的用户观点和行为信息。文本情感分析技术可以发掘这些信息中存在的主观情感信息, 在产品信息反馈、商品推荐算法、舆情监控、热点事件跟踪等方面有重要应用。微博作为发布便捷、传播速度快、用户交互性强的短文本, 已成为最普及、最重要的社交媒体之一, 对微博的情感分析也成为文本情感分析的研究热点。与对英文微博 Twitter 的分析相比, 对中文微博的情感分析目前还处于起步阶段。情感分类任务的主流方法一般分为基于词典的规则方法和统计机器学习方法, 也不断有研究者对两种方法的结合进行尝试和探索。
基于词典的方法是根据情感词典中的先验情感信息计算微博情感的倾向性[1-2]。Turney[1]计算了待分析文本中其他词与正/负向种子情感词的点互信息(PMI)作为这些词与正负向情感的关联度, 并根据关联度的总和, 判断文本的情感倾向性。Maite等[2]通过详细的规则算法计算词、短语、句子、篇章的情感倾向性(Semantic Orientation, SO), 使用精确量化和设置阈值的方式, 判断文本的情感倾向性。周红照等[3]提出在短语级别上, 褒贬性名词(如很阳光、很屌丝)和语义偏移型名词(如失去信心、没有原则)对情感分析有重要作用。还有一些研究关注情感词典的构建。Jijkoun等[4]生成特定主题相关的情感词典, Mohammad等[5]基于Twitter的远程标注数据, 使用PMI公式学习出适用于社交媒体情感分析的词典。上述研究他们都在一定程度上减小了社交媒体主题分布发散以及表达方式多样化给情感分析带来的负面影响。
机器学习方法将情感分析看做一个模式分类问题, 建立分类模型来预测微博的情感极性。机器学习需要有标注的监督数据, 特征工程也起着至关重要的作用。文献[6-7]表明, 常用的分类算法和特征选择方法在情感分类问题中有各自的适应情况, 但都无法带来性能的实质性变化。Pang 等[6]通过机 器学习的方法, 将电影评论分为褒义评论和贬义评论。他们比较了朴素贝叶斯、最大熵和支持向量机这 3 种分类模型在不同特征(如 N-GRAM词、词性标注等)以及不同模型参数下的性能差异, 在使用支持向量机模型、unigram 词特征和 BOOL 特征权重时, 达到最高的正确率。Kouloumpis 等[8]研究了 Twitter 情感检测任务监督机器学习框架下语言特征的作用。夏睿等[9]设计了一种级联混合情感分类模型, 有效地抽取文本依存句法树中的父子节点词对作为扩展特征。Cui 等[10]通过实验证明, 当训练语料较少时, unigram效果较优; 随着训练语料 的增多, N-gram (N>3)发挥越来越重要的作用[11]。Jiang 等[12]提出一个加入主题相关特征、考虑关联微博信息的方法来解决主题相关的微博情感分类问题。Xia 等[13]在电影评论和商品评论语料上的实验结果证实, 训练不同的分类器模型并进行集成, 能够获得比单一的分类模型更好的情感分类性能。Go 等[14]提出基于远程监督(distantly supervised)的微博情感分类方法, 采用朴素贝叶斯、最大熵模型和支持向量机3种分类模型, 在Twitter语料上获得高于80%的分类性能。Liu 等[15]提出一种基于表情的平滑语言模型方法, 结合使用人工标注(fully supervised)和自然标注(distantly supervised)两种类型数据帮助Twitter 的情感分析。随着深度学习模型的广泛应用, 深度学习在情感分类任务上也渐渐发挥优势。Tang 等[16-17]提出一种word embedding的深度特征表示方法来学习词嵌入的情感信息, 基于此构建的Twitter情感分析系统在SemEval-2014取得很好的性能。Vo 等[18]提出一种基于分布式词表示和深度学习的Twitter情感分类特征抽取方法, 取得优于句法特征的分类性能。从整体上来看, 机器学习方法的表现好于规则方法。
单独使用规则方法或机器学习方法无法避免各自的局限性, 很多研究尝试将两种方法相结合。谢丽星等[19]提出基于 SVM 层次结构的多策略的微博情感分析方法, 基于 SVM 分类模型对句子级微博进行类别预测, 然后在句子级预测结果上, 使用词典的规则方法或再训练SVM 分类器对整条微博进行预测。在特征工程方面, 他们虽然加入情感词典相关特征, 但仅限于情感词数量。Mohammad 等[5]建立了一个当前最好的基于 SVM 的 Twitter 情感分析系统, 在SemEval2013-Task2的情感分类任务上取得第一名。他们重点研究 Twitter 情感分析的特征工程, 比较了 N-gram, POS, lexicon, emoticon, negation 等 11 组特征对情感分析的影响。实验证明, 他们使用的多个手工标注词典和自动学习词典是最重要的一组特征。同样, 他们的情感词典特征没有考虑更多的语义规则, 也没有对子句单元的情感极性加以利用。Qiu 等[20]认为基于词典的规则方法召回率低而精确率高, 将词典分类的结果作为分类模型的训练语料, 形成一个层级迭代的分类框架。词典方法在微博的情感分类中未必能表现出很高的精确率, 由此产生的训练语料因而会包含过多的噪声。
为了充分利用规则情感分析的结果, 本文提出一种规则算法与统计学习方法相结合的情感分析方法, 从规则算法中获取多个有效情感信息, 将每一个情感信息量扩展为多维向量, 嵌入向量空间模型中。实验结果证明, 与简单地加入情感词特征相比, 这种嵌入方式可以让机器学习算法更充分地利用规则特征, 达到更好的分类性能。本文的主要贡献有以下三方面。
1) 针对中文微博文本特点, 提出一种基于词典和特殊语言结构建模的规则化情感计算方法。
2) 提出微博情感规则化特征抽取方法和基于规则化特征嵌入的机器学习与规则融合方法。
3) 基于本文算法建立的情感分类系统在第七届中文倾向性分析评测比赛 (Chinese Opinion Ana-lysis Evaluation COAE-2015)的任务 1(微博情感分类)中取得最好的分类性能。
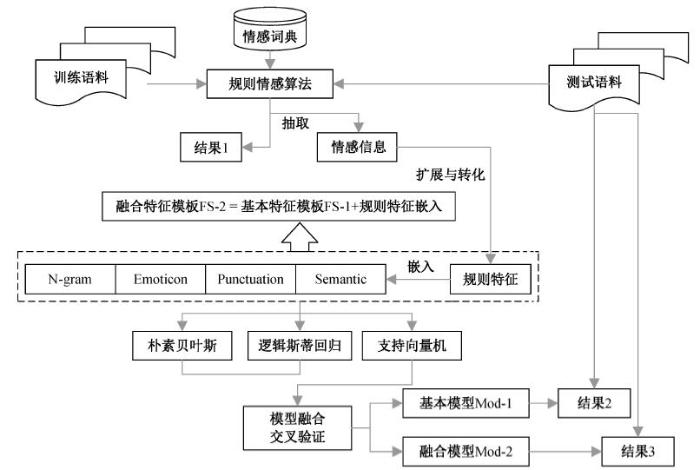
本文构建一个机器学习与规则方法融合的情感分类系统。在测试语料上直接运行本文提出的规则情感分析算法得到规则方法结果 1。对于机器学习方法, 将 N-gram、表情符号(emoticon)、标点符号(punctuation)和语义特征(semantic) 4 种基本特征串联形成基本特征模板 FS-1; 使用规则情感分析算法, 从训练语料中抽取重要情感信息, 经过转化与扩展形成规则特征, 嵌入基本特征模板中, 形成融合特征模板 FS-2。基于这两个特征模板, 使用3种分类算法(朴素贝叶斯、逻辑斯蒂回归和支持向量机)训练模型, 并将它们的结果集成, 通过交叉验证找到最佳参数, 分别得到基本模型Mod-1和融合模型Mod-2。同样根据不同的特征集构建测试语料 样本, 使用对应的模型分类, 得到结果 2 和结果 3。实验结果表明, 机器学习方法的结果好于规则方法, 而基于融合特征集的分类模型性能优于基本特征集的分类模型。图1为系统框架。
基于词典的规则方法是一种直观有效的情感分析方法。情感词典提供了一个词语在情感上的先验知识, 也就是该词语在大多数语境下的情感极性及其强度等信息。词典情感词的得分则是对词语情感倾向性程度相对合理的量化。
1.1.1 Rule-Method-1
经典的基于词典的情感分析方法通常用式(1)计算情感倾向性, 即对情感词得分进行累加, 得到文本片段的整体情感倾向值:
$\text{SO}=\sum\limits_{k=1}^{M}{\text{score}(\text{ter}{{\text{m}}_{k}})}$, (1)
其中, M为样本词数, score(termk)为第k个词在情感词典中的情感极性值。本文将这种规则方法称为Rule-Method-1, 此方法忽略了导致情感变化的特殊语言结构, 如否定、转折、情感强化和削弱等。
1.1.2 Rule-Method-2
在式(1)基础上, 文献[2]考虑了导致情感变化的特殊语言结构, 提出一种有效的规则化英文情感分析方法。该方法面向英文产品评论文本。本文针对中文微博文本, 提出情感计算规则化方法, 称为Rule-Method-2。
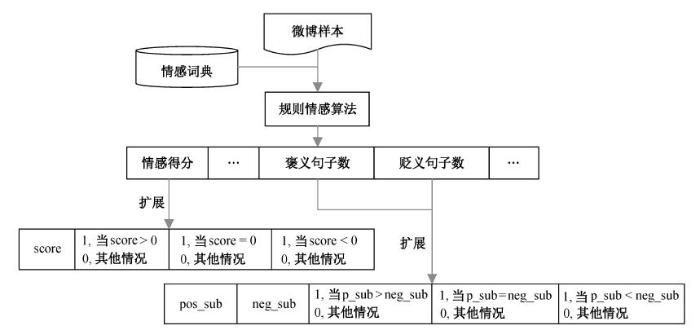
首先, 收集该方法所依赖的相关情感词典(词典来源见表 1)。然后, 根据式(2)计算微博的情感倾向性 SO。对微博字符串进行中文分词, 按照预设的标点符号分割成N个子句单元; 对每一个子句单元 subk, 使用 cal_sub_so 函数计算子句单元的sub_so; 将N个 sub_so 相加, 得到该条微博的情感倾向性SO, 根据SO判断样本的情感类别。
$\text{SO}=\sum\limits_{k=1}^{N}{\text{cal}\_\text{sub}\_\text{so}(\text{su}{{\text{b}}_{k}})}$。 (2)
表 1 情感词典
Table 1 Sentiment lexicons
在计算子句单元sub_so的过程中, 我们分析了中文微博的语言表达特点和情感表达的复杂性(如反意、虚拟等语义现象), 设定6项细化的情感分析语义规则, 如表2所示。Cal_sub_so算法如下。
输入: 经过分词的微博子句字符串sub;
输出: 子句的情感倾向性得分sub_so;
1 初始化情感得分sub_so为0;
2 使用表2中的规则1和2, 匹配所有出现的固定情感句和表情词, 将得分加入sub_so;
3 将sub按照空格解析为列表L, 遍历L中的每一个词term:
3.1 如果 term 是情感词, 使用表2中的规则 3 和 4, 检测否定和加强(减弱)语义, 将最终得分加入 sub_so;
3.2 如果 term 是转折词, 递归计算剩余子句的得分, 然后乘以转折变化系数后加上之前的得分, 作为该子句的sub_so;
3.3 如果 term 是褒贬型或偏移型名词, 使用表 2 中的规则6, 检测是否构成短语, 将得分加入sub_so;
表 2 情感分析语义规则
Table 2 Semantic rules for sentiment analysis
4 返回sub_so。
机器学习方法将文本转化为特征向量, 在此基础上建立统计机器学习模型。本文使用向量空间模型表示文本, 表 3 列出本文使用包含 4 种特征的基本特征模板FS-1。
表 3 基本特征模板FS-1
Table 3 Basic feature set template FS-1
我们使用 3 种经典的z机器学习模型 (朴素贝叶斯 NB、逻辑斯特回归 LR 和支持向量机 SVM)训练分类器, 并且考虑了基于 3 种分类算法的集成学习。集成方法如式(3)所示:
$\text{p }\!\!\_\!\!\text{ av}{{\text{g}}_{j}}=\alpha \times \text{p }\!\!\_\!\!\text{ n}{{\text{b}}_{j}}+\beta \times \text{p }\!\!\_\!\!\text{ l}{{\text{r}}_{j}}+\gamma \times \text{p }\!\!\_\!\!\text{ sv}{{\text{m}}_{j}}$, (3)
其中, p_nbj, p_lrj 和 p_svmj 分别指朴素贝叶斯模型、逻辑斯蒂回归模型和支持向量机模型预测该样本为第j类的概率, α, β, γ分别是模型所占的权重系数。将得到的加权融合概率p_avgj作为样本预测的依据。权重参数α, β, γ可以根据经验事先指定, 也可以由训练集进行交叉验证得到。
将规划与机器学习方法相结合的方法比较简单。谢丽星等[7]将情感词、表情词的数量信息解析为特征, Mohammad 等[5]将情感词的累加和、首尾词的情感极性解析为特征。本文提出一种基于特征嵌入的机器学习与规则融合方法, 如图2所示。
使用 Rule-Method-2 抽取规则情感特征。对有强度标记的情感词典, 抽取情感词得分、表情得分、总得分(情感词得分+表情得分)、褒/贬情感词数量以及褒/贬情感子句数量共7维特征。对没有强度标记的情感词典, 情感词的强度默认为±1, 抽取褒/贬情感词数量、情感词得分共3种特征。
将情感词得分和表情得分与 0 值进行比较, 拓展为 4 维 BOOL 向量。类似地, 通过褒义与贬义情感词数量之间、褒义贬义子句数量之间的相互比较, 也相应地拓展出额外的特征。比如对某一条微博样本, 抽取出的 7 维特征为(3.2, 0.8, 4.0, 4, 1, 2, 1), 通过与 0 比较, 情感得分 3.2 扩展为 4 维特征(3.2, 1, 0, 0); 褒义词数量 4 和贬义词数量 1 相互比较, 拓展为5维特征(4, 1, 1, 0, 0)。
将以上抽取的特征嵌入基本特征模板(表 3)中, 训练机器学习分类器, 并进行测试。通过上述规则化特征的嵌入, 实现机器学习与规则方法的融合, 其优势主要体现在三方面。
1) 特征粒度不限于词语级, 还包含句子级。
2) 基于有强度标记的词典以及多种语义规则, 可以提高规则情感分析的精确率, 抽取出的规则特征包含更准确的情感信息。
3) 由特征的数值扩展出它们的数值关系特征, 一方面满足分类模型对特征权重的需求(朴素贝叶斯模型只能识别整数特征值), 另一方面, 特征值的扩展使得模型学习到更多的情感知识。
从自然语言处理与中文计算会议(NLP&CC)和中文倾向性分析评测(COAE)的情感句识别评测 任务语料中, 抽取正面和负面情感样本用于实验。NLP&CC语料包含2000条负面类别和2000条正面类别样本; COAE语料包含622条负面类别和943条正面类别样本。语料的正负类别样本数量较为平衡, 所以采用正确率作为评价指标:
$\text{ACCURACY}=T/N$, (4)
其中, T为预测和真实类别一致的样本数量, N为全部样本数量。
对于基础情感词典(有强度标记), 将两种基于词典的分类方法进行比较(见表 4)。结果显示, 本文提出的规则情感分析算法Rule-Method-2 比 Rule- Method-1(直接累加情感词得分)更有效。但是, Rule-Method-2 在否定的处理上还存在缺陷, 仍需改进。
表 4 基于词典的不同规则方法的分类性能
Table 4 Performance of different lexicon-based methods %
以token-unigram (all)作为基本的实验设置, 分别添加 token-bigram, pos-unigram 和 pos-bigram 到特征集, 使用信息增益(IG)的特征选择方法, 控制添加特征的数量, 找到使得分类正确率最高时的特征数量以及对应的正确率, 其中 token 指示词, pos指示词性。从表 5 可以看出, token-bigram, pos-unigram 和 pos-bigram 对分类性能没有实质性的提高, 偶尔在个别分类模型的性能上出现波动, 但影响不大。所以下面的实验都以 token-unigram (all)作为基本的实验设置, 不再变动。
表 5 N-gram模型分类效果比较
Table 5 Performance of N-gram language mode %
表 6为基本特征模板FS-1下NB, LR和SVM三种分类器集成的分类结果。限于篇幅, 我们仅给出集成效果最好(各个基分类器权重系数相等, α = β = γ)时的融合效果。在不同的语料上, 不同的分类模型分类能力表现出一定的差异。通过模型集成, 总能得到比在当前任务表现更好的模型和更高的正确率, 表明模型融合可以实现分类模型的优势互补, 在整体上略有提高。
表 6 不同分类器及其融合后的分类正确率
Table 6 Accuracy of different classification models %
将本文的规则特征与简单的累加情感词得分特征进行比较, 结果如表 7 所示。累加情感得分特征指添加 Rule-Method-1 计算得出的情感得分作为一维特征, 规则情感特征是 1.3 节提出的特征。从表7 看出, 规则情感特征带来的性能提升远远大于累加情感得分特征。
表7 累加情感得分特征与规则情感特征的比较
Table 7 Compare of features based on Rule-Method-1 and Rule-Method-2 %
通过减法规则, 每次选择一组特征移除, 比较不同规则情感特征对分类性能的贡献。表 8 中“剔除情感得分”表示从全部特征的特征模板中去除情感得分特征后的分类性能。表 8 显示, 规则情感特征在两个测试语料上都带来约 4%的性能提升, 说明规则情感特征嵌入的有效性。去除情感得分、表情得分特征, 均带来 1%~2%的正确率下降。褒贬子句数量(NLPCC 这个语料本身是句子级的样本, 所以此特征作用较小)的有效性说明, 即使在微博这种短篇幅的文本上, 要完成篇章级别的情感极性分类, 也需充分利用细粒度(句子级、短语级)情感分析结果。其他特征带来的性能变化都比较小, 说明它们包含的情感信息可能具有重叠性。
表 8 不同规则情感特征贡献比较
Table 8 Contributions of different rule-based features %
基于本文算法建立的情感分析系统参加了第七届中文倾向性分析评测比赛 (Chinese Opinion Ana-lysis Evaluation COAE-2015)的任务 1(微博情感分类)。该任务是根据微博文本, 将微博分为正面、负面和中性 3 个情感类别, 评测所用资源为官方发布的限定资源。表 9 是测试集上的评测结果, 本文基于特征嵌入的机器学习和规则融合系统取得限定资源方式下最高的分类正确率。
表 9 COAE-2015任务1评测结果(限定资源)
Table 9 Submission Result of COAE-2015 Task-1(restricted resource)
规则和机器学习是微博情感分类任务常见的两种方法, 各有缺陷, 需要有效融合以提升情感分类性能。本文针对中文微博文本特点, 提出一种基于词典和特殊语言结构建模的规则化情感计算方法。
在此基础上, 提出一种机器学习与规则相融合的微博情感分类方法, 将规则方法得到的多样化情感信息进行转化扩展, 嵌入机器学习模型的特征空间, 实现了机器学习与规则方法的融合。在 COAE 和NLPCC 两个微博语料上取得分类性能的较大提升。基于本文算法建立的情感分类系统在 COAE2015微博情感分类任务(限定资源)比赛中取得最好的分类成绩。
未来将进行两个方面的工作: 1) 通过更准确和深入的规则方法, 挖掘更多的先验情感信息, 比如提高否定句的处理准确率、虚拟句情感的识别等; 2) 鉴于文献[5]发现从大规模未标注语料中自动学习出的情感词典带来的性能增益要大大高于手工标注的情感词典, 可以尝试从未标注语料中自动学习情感词典, 以提高分类性能。
The authors have declared that no competing interests exist.
Thumbs up or thumbs down? semantic orientation applied to unsupervised classification of reviews Lexicon-based methods for sentiment analysis. 语义特征在评价对象抽取与极性判定中的作用 Generating focused topic-specific sentiment lexicons NRC-Canada: building the state-of-the-art in sentiment analysis of tweets Thumbs up?: sentiment classification using machine learning tech-niques 基于机器学习的中文微博情感分类实证研究 Twitter sentiment analysis: the good the bad and the omg! 情感文本分类混合模型及特征扩展策略 Comparative experiments on sentiment classification for online product reviews 文本情感分析 Target-dependent twitter sentiment classification Ensemble of feature sets and classification algorithms for sentiment classification. Twitter sentiment classification using distant supervision [R]. CS224N Project Report, Emoticon smoothed language models for Twitter sentiment analysis Learning sentiment-specific word embedding for twitter sentiment classi-fication Coooolll: a deep learning system for Twitter sentiment classification Target-dependent twitter sentiment classification with rich automatic features 基于层次结构的多策略中文微博情感分析和特征抽取 SELC: a self-supervised model for sentiment classification
/
1 机器学习与规则融合的情感分类方法
1.1 微博情感分类规则方法
词典名称 来源和内容 基础词典(有强度标记) 对大连理工大学中文情感词汇本体库的情感词强度归一化处理后, 作为有强度标记的基础情感词典 基础词典(无强度标记) 合并了台湾大学中文情感极性词典(NTUSD)、清华大学李军中文褒贬义词典(TSING)、知网词典 (HOWNET) 3个情感词典作为无强度标记的基础情感词典 网络词典 将积累的带有情感倾向性的网络词汇(如“给力”、“坑爹”、“逗比”等)标记强度, 作为网络情感词典 表情情感词典 对新浪微博热门表情词标注后, 作为表情情感词典 程度词典和否定词典 采用知网词典(HOWNET)中的程度词典和否定词典, 用于分析不同语境下的情感变化
序号 规则名称 规则解释 1 固定情感句 一些带有较强的情感极性的、以网络流行语和熟语为主的固定情感句, 如“我就呵呵了”、“便宜没好货”等, 经过分词拆分可能损失情感信息。本文在分词前就在文本中检测匹配这些固定情感句 2 表情词 表情词是微博常见的特有的符号, 能直接地反映情感倾向。匹配到词典中存在的表情词后, 直接赋予相应得分 3 否定 检测到情感词后, 在设定的窗口范围内搜索否定词。如果找到否定词, 则对情感词极性和强度进行反转 4 强化(减弱) 程度词对情感词有强化或减弱的作用。对程度词典进行强化与减弱的系数标注。例如, 分词后的例句“这个 电影 真心 好看”中“好看”的情感得分 0.5, 经过加强系数为 0.8的“真心”修饰后, 情感得分变为(1+0.8)×0.5 = 0.9 5 转折 转折词分为两种: 前置转折词(如“尽管”、“虽然”等)和后置转折词(如“但是”、“可是”等)。本文对前置转折词后面剩余的子句内容情感得分进行整体削弱, 对后置转折词则进行整体加强 6 褒贬性名词与语
义偏移型名词文献[3]提出的褒贬型名词和语义偏移型名词频率较高且带有情感倾向性, 因此, 我们在约 4 GB 的微博语料中, 通过模式匹配搜集了较多的褒贬型名词(如“很屌丝”、“很阳光”)和语义偏移型名词(如“良心”、“责任心”、“品味”等)以及其对应的前置副词(如“有”、“存在”、“失去”等), 人工标注情感极性和强度。当出现二者之一(如语义偏移型名词“良心”)时, 在设定的窗口范围内寻找前置副词。如果找到(如“没 良心”), 则赋予这个短语相应情感得分
1.2 微博情感分类机器学习方法
序号 规则名称 规则解释 1 N-gram N-gram语言模型基于这样一种假设: 在一句话中, 第n个词的出现只与前n-1个词相关, 整个句子出现的概率就是各个词出现概率的乘积。假设一个经过分词处理的文本字符串为“功能 略微 强大”, 我们提取出unigram特征“功能”、“略微”、“强大”和bigram特征“功能-略微”、“略微-强大” 2 表情符号 表情符号是微博文本中特有的元素, 与情感表达有着十分密切的联系。虽然表情符号和其他词共同出现在文本中, 但我们将其抽取出来作为单独的特征, 不与N-gram特征相混合 3 标点符号 标点符号中的感叹号和问号往往伴随着情感信息, 连续的叹号和问号反映情感的强烈程度。因此, 我们将单个感叹号、问号的数量, 连续感叹号或问号(如“!!!”、“???”、“?!?”)的数量都加入特征模板 4 语义特征 我们定义语义特征为与情感表达存在关联的词语, 包括主观指示词数量(如“觉得”、“认为”)、虚拟指示词数量(如“假如”、“要是”)、语气词数量(如“啊”、“哇”)、第一人称词数量(如“我”、“我们”)以及否定词的数量(如“不”、“没有”)
1.3 基于特征嵌入的机器学习与规则融合方法
2 实验与分析
2.1 实验语料
2.2 基于词典的规则情感分类方法
语料 Rule-Method-1 Rule-Method-2 COAE 65.24 67.10 NLP&CC 76.65 79.38
2.3 基于机器学习的情感分类结果
语料 N-gram LR NB SVM COAE token-unigram (all) 69.9068 69.0144 68.8221 + token-bigram 70.2283 (500) 70.5539 (500) 69.0114 (500) + pos-unigram 69.9068 (0) 69.0144 (0) 68.8221 (0) + pos-bigram 70.2293 (10) 69.9088 (15) 68.8221 (0) NLP&CC token-unigram (all) 80.5998 80.9283 81.6158 + token-bigram 81.2977 (1000) 80.9283 (0) 81.8700 (500) + pos-unigram 81.1441 (10) 80.9283 (0) 81.6158 (0) + pos-bigram 80.5998 (0) 81.0727 (5) 81.6158 (0)
语料 LR NB SVM ENSEMBLE COAE 69.9068 69.0144 68.8221 70.7682 NL&PCC 80.5998 80.9283 81.6158 81.8605
2.4 基于特征嵌入机器学习和规则融合方法系统性能
语料 特征模板 LR NB SVM ENSEMBLE COAE 基本特征+累加情感得分特征 72.85 70.54 70.80 72.02 基本特征+规则情感特征 74.51 74.75 72.32 74.75 NLPCC 基本特征+累加情感得分特征 82.81 81.94 82.41 83.35 基本特征+规则情感特征 84.55 84.58 83.86 85.56
语料 规则情感特征 LR NB SVM ENSEMBLE COAE 无规则情感特征 69.90 69.01 68.82 70.76 使用全部情感特征 74.51 74.75 72.32 74.75 剔除情感得分 73.65 73.13 71.85 73.82 剔除表情得分 73.09 72.71 71.75 73.24 剔除褒贬情感词数 74.21 73.93 72.01 74.38 剔除褒贬子句数 73.42 72.08 71.20 73.45 NLPCC 无规则情感特征 80.59 80.92 81.61 81.86 使用全部情感特征 84.55 84.58 83.86 85.56 剔除情感得分 83.22 83.37 81.97 83.33 剔除表情得分 83.66 83.80 82.89 84.06 剔除褒贬情感词数 84.40 84.51 83.64 84.49 剔除褒贬子句数 84.38 84.50 83.79 84.21
系统 正确率/% 平均 50.85 本文(最好) 58.80
3 结论
参考文献
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
[20]

〈
〉
{kind=link}
{kind=link}
{kind=link}
{kind=link}