
栗青生 , 徐强
, 徐强
Qingsheng LI
中图分类号:
TP391
通讯作者:
Corresponding authors:
收稿日期:
2016-07-30
修回日期:
2016-09-23
网络出版日期:
2016-11-30
版权声明:
2017 《北京大学学报(自然科学版)》编辑部 《北京大学学报(自然科学版)》编辑部 所有
基金资助:
展开
摘要 提出一种基于汉字结构和风格的字形生成模型。该模型将汉字字形抽象为汉字结构和汉字风格两种模式, 并在结构中将汉字笔画抽象为连续的笔元, 通过笔元的特征点构造笔元向量、径向量、弦向量和轭向量, 进行笔画风格的重建。通过这种方法, 动态产生可用于True type个性化汉字字形设计的字形, 实现汉字字形的Web存储和在客户端的特征字形输出, 克服了现代汉字由于汉字数量巨大而在字形设计方面的不足, 为个性化汉字信息的云端存储和云端字形服务提供了一种有效的策略和方法, 为设计更深层次的汉字信息服务奠定了基础。
关键词:
Abstract This paper presents a Chinese generation model based on Chinese characters structure and style. The model is descripted by the stroke element, stroke element vector, path vector, string vector and yoke vector, including structure of Chinese characters and style of Chinese character. It can be used to dynamically generate the outline of the personalization True type font, and the methods of store the Chinese character on the Web and output to client is implemented. The best way to overcome the problem on Chinese font design and font generation is founded. This model is efficacious in Chinese information cloud storage and cloud service, and also provides an effective strategy and methods for the design of a deeper cloud character information service.
Keywords:
编码汉字系统产生于汉字进入计算机非常困难的年代, 迄今为止, 仍然服务于信息技术的进步, 但是, 伴随着网络信息技术的跨越式发展, 汉字信息处理的环境已经发生深刻的变化, 传统的编码汉字系统在互联网时代表现出诸多不足。
目前, 汉字系统是按照一字一码进行编码, 只有在计算机中安装了某种字形的字库文件, 汉字文档才能被正确使用, 否则, 文档会显示乱码。编码汉字系统是为信息交换的便利而设计, 但随着个性化和数字技术的高度发展, 这种传统的编码机制表现出很多不足。特别是针对中国历代文字、文献的数字化出版问题, 目前还没有一种有效的解决方案。同时, 对于日常汉字的个性化表达(例如, 错字字形的表达、手书字形的表达等)都存在很大困难。因此, 针对不同领域中汉字的表示方式、存储方式及生成和输出方式的研究意义重大。
1) 汉字的笔画和部件难以输入。编码汉字系统中, 只有编了码的文字才可输入。目前, 很多汉字(特别是古文字)尚无编码。
2) 汉字笔画难以分解。传统编码汉字字形中, 除楷体字库中有笔画的分解信息外, 其他汉字笔画分解非常困难。
3) 汉字错字难以编辑。汉字教学中, 错字和不规范字是最基本的教学元素, 但目前的编码汉字系统却没有办法实现, 这不仅影响数字化汉语教学的发展, 也为自然语言的深度计算研究带来困难。
4) 汉字个性化难以体现。数字化时代汉字失去了非常重要的特征——个性化字体, 尽管可以由字库开发商制作个人字体, 但实现还是非常困难。
1) 异体字的编码问题。汉字编码解决了汉字的交换问题和常用汉字的数字化出版问题, 但是对异体字和古汉字的编码非常困难, 影响了汉字数字化和信息化技术的发展。
2) “提笔忘字”问题。编码汉字时代, 只要输入拼音就可以自动引导出汉字, 使得汉字的书写失去了意义。一字一码、整字编码是导致提笔忘字现象的重要因素。
3) 个人字库问题。数字化时代, 很难见到“见信如面”的问候方式, 尽管在个人终端上可以按照自己的风格书写, 但对方收到的短信或微信, 都会变成“黑”“宋”“楷”“仿”4张面孔。
经过几十年的发展, 汉字信息处理技术研究已经从宏观走向微观、从通用走向个性化、从规模处理走向精细处理, 用户对个性化的汉字表达和快速汉字生成技术的需求日益增强。例如, 在云计算环境下, 原来的单机文件系统已经扩展到网络和分布式文件服务系统, 信息文档不再是一种静态内容和单一版本, 而是具有动态性、时空立体性、多用户性、多安全等级、多媒体性与多版本性的“活”性文档。如何动态地表示这些“活”结构化的信息和文档, 是实现汉字信息在云计算服务时代个性化表示的关键。
汉字的个性化表示属性有很多方面, 其中最基本的属性是汉字结构和汉字的风格。汉字是汉字结构和笔画风格高度融合的艺术。传统的信息存储方式是以结构化文档的方式(如数据库)进行存储, 与此相关的汉字是以标准的信息编码形式进行计算, 这一策略的最大缺点是很难对汉字的结构和风格进行独立计算。与英文字母相比, 汉字数量巨大, 结构复杂, 实现个性化表示几乎不可能; 在风格上, 汉字笔画的书写变化多端, 很难用统一的形式化方法表达。近年来, 研究者分别从笔画分解[1-2]、汉字生成[3-4]、笔画生成[5-6]以及汉字的编码和描述技术等方面进行了研究。
汉字自动化生成技术的主要目的是解决汉字字形的快速生成以及个性化的计算机书写。目前汉字的生成技术主要分为两类: 一类是基于汉字编码的静态生成方法, 另一类是基于汉字描述的动态生成方法。
汉字的静态生成方法是基于现代汉字固定的编码属性, 以固定的汉字结构, 对汉字的笔画和结构进行构造的汉字计算模型。
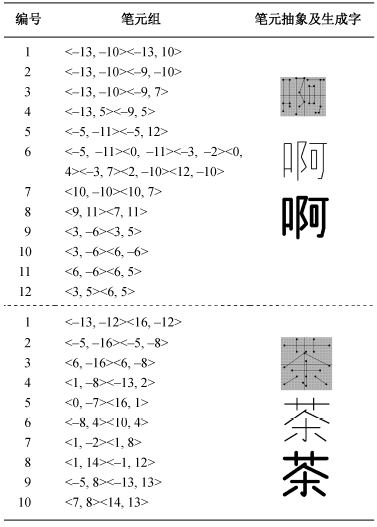
1) 基于部件的拼字方法。利用汉字由偏旁部首组成的特点, 通过设计少量的汉字笔画和部件, 拼成整个汉字的方法, 如表1所示。尽管部件拼字的结果是一种新字形的动态组合, 但由于笔画结构的可变性较差, 因此也属于静态的汉字生成方法。
表1 部件拼字方法
Table 1 Synthetic method of Chinese characters components
2) 笔画组字法。基于不同汉字中笔画风格的不同, 分别设计不同的笔画来组成不同字体。
3) 系列字生成法。将一种风格的字做成从粗到细的一系列字库, 以适应正文、大小标题等不同应用。系列字的风格相同, 只是笔画的粗细不同。可以先做出最粗和最细两款字, 然后自动生成中间粗细不等的字。
虽然上述3种方法可以实现部分字形的自动化生成, 但基本上都是针对某一字体而言, 并且对生成的部件和笔画的依赖性较大(例如, 黑体字可以生成不同的黑变体, 隶书体可以生成隶变体), 并且在生成变体的质量和数量上还需要很大的改进。
编码是复杂对象的简单表示, 其主要目的是信息交换, 缺乏对汉字字形的特征空间描述, 因此编码汉字系统不适合汉字字形的动态组合和生成。为了解决这一问题, 一些学者通过定义汉字的结构和生成规则, 动态地生成汉字。为了与编码汉字的生成方法相区别, 本文将此方法归结为基于描述汉字的动态生成方法。目前, 主要的动态汉字生成方法有以下几种。
1) 基于汉字部件和笔画描述的动态组字方法。此方法针对表示信息的汉字数量巨大, 汉字的机器组字、组词效率较低等问题, 使用特殊标签表示汉字的不同部件和笔画, 代表性的有香港浸会大学Candy等[7]提出的Han Glyph, 以及美国加州大学伯克利分校 Cook[8]提出的基于笔画和汉字部件的字形描述语言CDL (character description language) 等。Han Glyph 和 CDL 兼顾部件和笔画描述方法的组合, 将汉字分为控制点、骨架和轮廓 3 个层次结构, 将部件描述进一步细化成笔画描述。在 CDL的基础上, Peebles[9]提出一种将字形和结构融合, 进行综合描述的方法——SCML (structural character modeling language)。
以组字为目的的汉字部件和笔画的描述, 绝大部分使用数字标签对汉字的结构进行标记, 其目的是实现汉字智能输入和文档的智能识别, 特点是在汉字整体结构描述的基础上, 加入汉字笔画结构的描述, 在笔画分解、识别和计算上优于用整字为单位的字词描述方案。
2) 以罕用字的表示为目的的汉字字形的笔段描述。笔段描述是将汉字部件描述继续细化的描述方法, 笔段是笔画的子集, 可以是笔画或笔画的一部分。文献[10]就是基于笔段的汉字形式化描述, 提出基于笔段网格的生僻字、错字输入方案。
3) 以动态组字和生成字形为目的的笔元描述。笔元是有方向的笔段[11]。依据汉字的书写特性, 在笔段描述的同时加入汉字书写过程中行笔方向性属性描述, 并且将笔画或笔段之间的连接点以界点、驻点或势点进行分类描述, 使描述过程更加简洁, 更适合汉字(包括各类字体)的字形计算。
汉字字体的生成技术与汉字字形描述技术有直接的关系, 科学的汉字字形描述方案有利于汉字字形的自动化生成和识别。本文基于描述汉字的动态特性, 探讨汉字字形的生成技术, 研究新的字形生成算法, 为个性化汉字字形服务奠定理论基础。
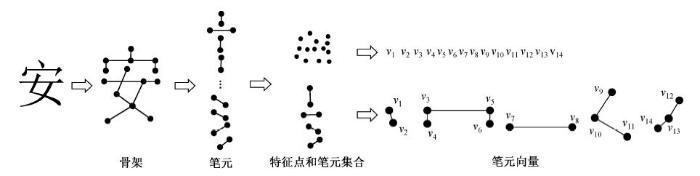
编码汉字系统是一种信息交换系统(或信息转换系统), 而不是完整的字形服务系统, 因此不能提供大范围的字形服务。为了解决此问题, 必须扩展现有汉字系统的字形服务功能, 建立一种与汉字字形服务相适应的汉字服务系统。本文将汉字字形分解为结构和风格两个层次, 其中, 结构层用于服务器端汉字字形结构的存储, 风格层用于客户端各类汉字笔画的生成。以“安”为例, 说明汉字可以分解成部件, 部件可以再分解成笔元, 如图 1 所示, 其中, v表示组成笔元的特征点。
字符是信息表示的基本元素, 汉字是一种特殊的字符, 一般由基本笔画按照一定的空间关系和构字规范构成偏旁部首, 再由偏旁部首根据一定的间架结构布局构成汉字字符。因此, 汉字是一种具有层次结构的字符, 层结构是汉字的一个基本特征。汉字层结构的数据表示可以通过以下方式来实现。
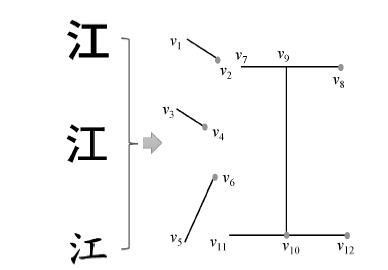
1) 汉字结构的抽象。为了向用户提供更大范围的字形服务, 将不同字形抽象为相同或相似的结构, 实现汉字结构和风格分离。如图 2 所示, 3 个不同字体的“江”字抽象为相同的结构。
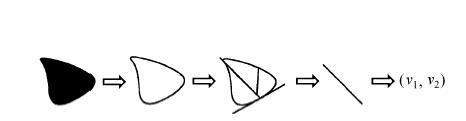
2) 汉字笔画的抽象。汉字笔画的抽象是将一个完整的笔画抽象为一个或多个二元组的过程。以点笔画为例, 抽象过程包括提取轮廓、确定轮廓特征点、特征点矢量化转换和笔画矢量提取等几个步骤, 如图 3 所示。
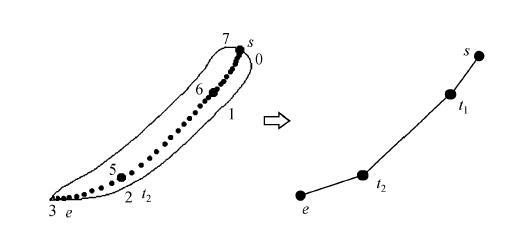
3) 书写汉字的抽象。书写汉字是个性化汉字的最基本表现形式, 在线书写汉字的抽象不仅要抽象汉字的书写特征, 还要给出书写速度、运笔方向和方式等特征的抽象描述。因此, 手写汉字的笔画可以抽象为落笔点、收笔点及行笔过程中特征点的集合{s, i1, i2, …, in, e}, 分析特征点的集合就可以抽象出若干笔元。图 4 为在撇笔画的特征点集合中, 抽象出3个笔元的示意图。
汉字的风格是汉字书写和形成过程中表现出来的个体特色和特征的概括, 结构相同的汉字可以有不同的风格。汉字风格主要通过笔画的风格以及偏旁、部首的风格来体现。
1) 汉字笔画和部件的风格。同一字体的标准字形或同一类型的笔画和部件在不同的汉字中可以有不同的风格表现, 即使是标准的印刷字体, 这一现象也很普遍。如图5所示, 同属于一种笔画的“斜钩”和同一部件“曰”在不同汉字或不同偏旁部首中都存在细微的变化。
图5 笔画和部件的不同风格 Fig. 5 Chinese characters stroke and compenent in different styles
2) 汉字的风格。不同笔画和部件的组合构成不同的汉字风格。汉字的风格表示十分丰富, 目前印刷汉字字体的不同主要是通过风格来体现。图6为微软美黑、琥珀、仿宋和楷书4种字体的风格示意图。
汉字的不同风格源于不同的字体设计[1,8-9]。图7示意王选在方正字库设计中对楷体字形的风格 定义。
基于笔画的汉字计算机自动生成技术采用与人工设计汉字字体类似的方法, 通过输入不同的笔画生成指令, 完成笔画的计算机设计, 然后再根据汉字的结构对笔画进行组合, 形成新的汉字字形。
3) 书写汉字的风格。汉字的书写风格因人而异, 千变万化, 如图 8 所示。如何将这些不同的风格输入计算机, 让机器和人一样有不同的输出风格, 是汉字计算的重要内容之一。
为了更好地实现汉字结构和风格的描述, 文献[2, 6, 11]提出一种汉字动态描述方法。该方法定义比汉字笔画更小的描述单位——笔元, 基于笔元设计点笔画的生成过程和方法。本文在此基础上将此描述方案加以扩展, 最大限度地克服目前汉字字库整字编码以及只能在客户端文件存储的不足, 实现基于笔元描述的多级汉字存储和云端存储功能, 为汉字的动态生成和Web服务奠定基础。
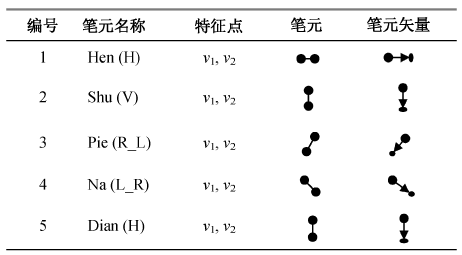
1) 笔元。笔元是汉字笔画的特征点之间、特征点与驻点之间或驻点与驻点之间的一个有方向的线段。
设T(vs, ve)是汉字笔画的两个特征点, vz1, vz2, …, vzn是其中 n 个驻点, 则汉字的笔元可以表示为
Y(vzi, vzj )。
如果用笔元Y表示汉字的笔画, 则有
T(vs, ve)= Y(vz1, vz2)+ Y(vz2, vz3)+… + Y(vzi, vzj ) ,
其中, i, j∈{1, 2, 3,…, n}。可以看出, 汉字的笔元集合是特征点集合的一个子集。这个集合在汉字字形的空间变换中有重要作用。事实上, 每一个汉字笔画中的驻点是随机的或不确定的, 称为动态的。因此, 用笔元描述的汉字是动态汉字。
2) 基本笔元和组合笔元。汉字的基本笔元是与组成汉字的基本笔画相对应的笔元, 这些笔元只有两个特征点, 如表 2 所示。它的表达式为
S12 = (x1, y1, x2, y2)。
除基本笔元外, 其他笔画或部件的组合称为组合笔元, 如表3所示, 其表达式(以撇笔画为例)为
CPie = Pie1+ Pie2+…+ Piei。
表3 特征点组合笔元
Table 3 Feature point of combination strokes elements
3) 扩展笔元。由一个或多个基本笔元和组合笔元组成, 是更接近汉字部件的笔元。例如, 汉字中的提笔画可以由撇笔画的表达式扩展表示为
Ti=-Pie。
同样, 汉字的左钩和右钩可以表示为
RGou=-Pie,
LGou=-Na。
因此, 扩展笔元的表达式可以表示为如表 4 所示的特征表达式。
表4 扩展笔元
Table 4 Feature point of extension strokes elements
从字形描述的角度分析, 汉字笔画特征可以分为字形特征和结构特征。字形特征是汉字外观表征, 结构特征是汉字内在表征。汉字特征点的描述中, 在汉字笔画特征点确定的情况下, 如果改变汉字描述中的驻点或笔元的数量, 不会改变汉字或笔画所包含的结构信息。
文献[11-13]中通过定义特征点的权向量实现了点笔画的动态生成, 通过基本笔元和扩展笔元的定义实现了特殊字形的输出, 其基本原理都是针对笔元所描述的稀疏数据进行插值处理。本文通过扩展笔元的定义, 研究笔元描述在多种类型笔画变换过程中的可行性。
基于汉字笔画结构的复杂性, 对于特殊字形(包括手写字形)的笔元描述过程, 将特征向量和权向量模型进行扩展, 以建立更加规范的笔元结构数学模型。
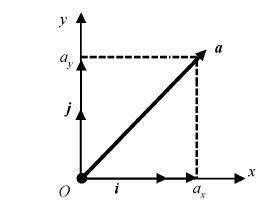
空间中的任意物理量都可以分解为互为正交的分量, 一旦确定了分量, 就可以使用标准的代数运算进行计算。以x, y平面内的矢量a为例, a=axi+axj, i和j分别表示沿x和y方向的单位矢量, 如图9所示。
根据以上分析, 给出笔元向量的定义。
定义1 笔元向量是从笔元始结点出发, 且与笔元有相同方向的向量, 一个笔元可以有多个笔元向量, 每一个笔元向量的模的长度小于或等于笔元的长度。
例如, 长度为 L 的笔元有 n 个笔元向量r1, r2, r3 , …, rn, 其模长为|ri|, 且
|ri|≤L。
定义 2 与单位向量一样, 单位笔元是具有单位大小的笔元。设U是单位笔元, 则U的分量必须满足:
$\sqrt{U_{x}^{2}+U_{y}^{2}}=1$,
其中Ux和Uy分别表示单位笔元在x和y方向上的分量。
由以上两个定义可以推出如下结论。
1) 任意一个笔元向量都可以表示为单位笔元向量的线性组合。例如, 笔元向量 rpq(-12, -20)和两个单位笔元向量U1(1, 0)与U2(0, 1)有如下关系:
${{r}_{pq}}=-12{{U}_{1}}-20{{U}_{2}}$。
2) 多个笔元向量可以表示为矩阵表达式。例如, r1, r2, r3, …, rn等n个笔元向量可以表示成如下矩阵表达式:
$\left( \begin{align} & {{r}_{1}} \\ & {{r}_{2}} \\ & \ \vdots \\ & m \\ \end{align} \right)=[i\ \ \ j]\ \ \ \left( \begin{matrix} {{a}_{11}} & {{a}_{12}} \\ {{a}_{21}} & {{a}_{22}} \\ \vdots & \vdots \\ {{a}_{n1}} & {{a}_{nn}} \\\end{matrix} \right)$.。
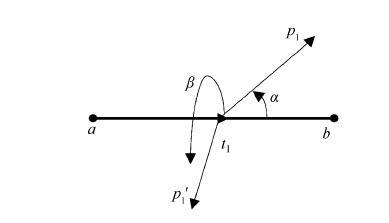
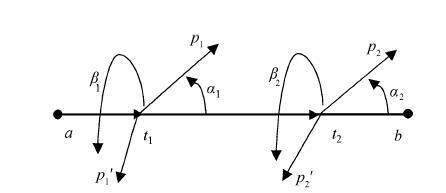
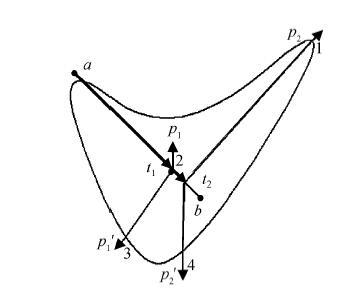
按照定义 1, 每一个基本笔元都是由始结点和尾结点组成笔元向量, 这个笔元中还可以有若干个同方向的笔元向量。以横笔画的生成为例, 设始结点 a 和尾结点 b 为两个特征点, 基于特征点 a, 沿笔元的方向可以建立 5 个笔元向量, 分别为at1, at2, at3, at4 和 at5, 由于这 5 个笔元向量都源于同一起点, 且都在同一个基本笔元上, 因此这一组向量称为基向量。基于每个基向量, 分别建立与基向量之间夹角为 α(0°≤α<180°)和 β(180°<α<360°)的两个径向量 ap1 和 ap1′。每一个基向量都对应两个径向量, 例如, 基向量 at1 对应的两个径向量 t1p1 和 t1p1′的表示如图 10 所示。为了便于理解, 我们给出这两个向量的定义。
定义 3 基本笔元上的笔元向量称为基向量。基向量始于笔元的始点, 且始终与笔元保持同一方向。例如, 图 10 中的 at1就是笔元 ab 上的一个基向量。
定义 4 在每一个基向量的两侧都可以建立两个不同方向的向量, 与基向量首尾相接, 且与基向量有不同的方向, 这个向量就称为径向量。每一个基向量都对应两个径向量, 如图 10 中基向量 at1 对应的两个径向量就是t1p1和t1p1′。
定义 5 由基向量和径向量共同组成的向量称为弦向量。在图10中, 弦向量$\overline{a{{p}_{1}}}$的表达式为
$a{{t}_{1}}+{{t}_{1}}{{p}_{1}}=a{{p}_{1}},$
同样弦向量$a{{{p}'}_{1}}$的表达式为
$a{{t}_{1}}+{{t}_{1}}{{p}_{1}}=a{{{p}'}_{1}}$。
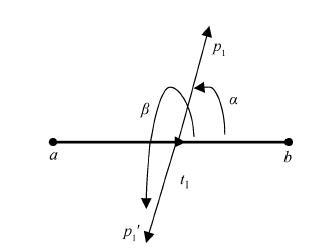
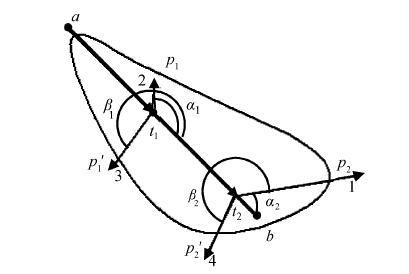
定义 6 径向量和两个笔元向量正方向的夹角分别为α和β, 如果α和β满足: α不为0°且β不为180°; 同时β-α=180°, 则称两个径向量为轭向量。同一笔元向量的轭向量共线, 但方向相反, 如图 11所示。
笔元向量、径向量、弦向量和轭向量是决定笔元风格的重要向量。以下以 Bezier 曲线的风格变换为例, 说明笔元风格生成的原理。Beztier 曲线表达式为
$C(t)=\sum\limits_{k=0}^{n}{{{P}_{k}}{{B}_{k,n}}(t)},\ \ t\in [0,\ 1],k=0,\ 1,\ ...,\ n,$
${{B}_{k,n}}(t)=C_{n}^{k}{{t}^{k}}{{(1-t)}^{n-k}}=\frac{n!}{k!(n-k)!}{{t}^{k}}{{(1-t)}^{n-k}}t\in [0,\ 1],\ \ \ k=0,\ 1,\ ...,\ n$。
设二次贝塞尔曲线的 3 个控制点, 为 cp[i], i = 0, 1, 2。取cp[0]=(x1, y1)为笔元的始点, cp[1]和cp[2]可以通过建立笔元向量的径向量或轭向量取得。设笔元向量与轭向量正方向的夹角为 α, 表 5示意在不同夹角取值时不同的点笔画风格。
表 5说明通过修改笔元向量与轭向量的夹角, 可以得到不同的点的风格。同样, 通过修改轭向量的模长, 可以得到相同角度下的另类风格, 如表 6所示。
根据笔元向量的定义, 一个笔元可以定义多个笔元向量, 因此, 可以通过增加笔元向量的方法得到多个轭向量, 再通过控制多个轭向量的变换, 产生更多的笔画风格。
基本笔元内有始结点和尾结点两个特征点, 为了保证稀疏数据的稳定性, 可以通过在一个笔元中增加笔元向量来实现。增加一个笔元向量, 就可以得到对应的径向量和轭向量, 不仅增加了未来生成笔画过程中曲线控制点的数量, 还可以对笔元始结点端和尾结点端的笔画风格进行更加细微的计算。
设一个笔元中两个笔元向量分别是$a{{t}_{1}}$和$a{{t}_{2}}$, 分别对应两组径向量${{t}_{1}}{{p}_{1}}$, ${{t}_{1}}{{{p}'}_{1}}$以及${{t}_{2}}{{p}_{2}}$, ${{t}_{2}}{{{p}'}_{2}}$, 对应的轭向量分别为${{{p}'}_{1}}{{p}_{1}}$和${{{p}'}_{2}}{{p}_{2}}$, 如图 12 所示。
图13为基于两个笔元向量的笔元风格生成示例。
图13 两个笔元向量的风格生成 Fig. 13 Style generation diagram for two stroke elements vectors
组合笔元的风格生成可以选择与基本笔元类似的解决方案, 使用一个或多个笔元向量进行风格建模。与基本笔元相比, 由于扩展笔元增加了可以进行灵活控制的特征点, 因此也可以直接进行曲线拟合。表 7 列出基于 5 个特征点的Bezier曲线的拟合实例。
扩展笔元由若干基本笔元和组合笔元构成, 因此, 可以使用基本笔元与组合笔元类似的生成方法, 实现扩展笔元风格的重建。图 14 示意基于两个笔元向量的扩展笔元(Ti)的风格生成。
为了验证本文所提描述方法在汉字字形结构表示中的性能, 我们使用不同的字体进行实验。
1) 基本笔元描述及重建实验。标准字形比较规范, 适合用基本笔元进行描述, 我们选择标准字形中的黑体字形进行结构描述实验。首先对一级黑体汉字字库中的每一个汉字进行基于基本笔元结构的抽象, 得到汉字字形描述库, 然后再将汉字描述库中的每一个字形进行汉字结构重建。实验结果如表 8 所示, 表明了使用基本笔元描述汉字结构的有 效性。
2) 扩展笔元描述及重建实验。汉字手写字形结构比较复杂, 如果用基本笔元来描述, 容易丢失个性化特征, 因此使用扩展笔元描述其结构。
我们选择与手写字形相近的行楷字形进行实验。为了更好地进行比较, 实验中使用与基本笔元描述实验相同的汉字。表 9 为实验结果, 表明了使用扩展笔元描述汉字字形的有效性。
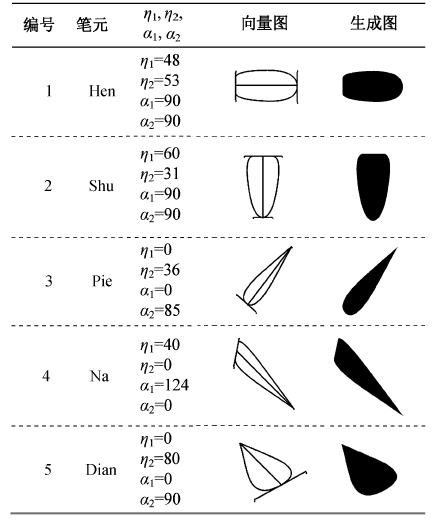
1) 基本笔元汉字风格的生成。实验中, 我们建立了基于两个笔元向量的汉字风格的生成系统, 通过定义5种基本笔元的轭向量, 建立 5 种笔元的风格模型, 其中η1和η2表示两个轭向量的模长之和, α1和α2表示两组轭向量与笔元正方向的夹角:
${{\eta }_{1}}=|{{t}_{1}}{{p}_{1}}|+|{{t}_{1}}{{{p}'}_{1}}|$,
${{\eta }_{2}}=|{{t}_{2}}{{p}_{2}}|+|{{t}_{2}}{{{p}'}_{2}}|$。
根据两个轭向量的变化生成的基本笔元的风格如表10所示。
2) 扩展笔元汉字风格的生成。我们按照 3 个结点的组合笔元曲线拟合的风格生成方式, 对扩笔元的风格生成进行实验, 表 11 列出原始字形和风格化后字形的对比示例。
与传统的汉字生成技术相比, 基于笔元描述的汉字动态生成技术具有以下优点。
1) 生成汉字的结构可以控制。由于笔元汉字描述库存储的是汉字字形的结构信息, 因此, 对任何字形结构进行十分灵活的编辑(包括增加、删除笔元和驻点的操作)同时, 也可以输出汉字信息的局部结构以及独立笔画, 使汉字的部件输入和笔画输入成为可能, 当然也可以实现错字的计算机输入和编辑。
2) 生成汉字的风格可以控制。汉字的优美不仅源于汉字独特的结构信息, 更与汉字的多种风格密切相关。通用的生成方法中, 要实现汉字从一种笔画风格变换为另一种笔画风格, 通常需要复杂的数字计算, 并且效果也不尽如人意, 而使用笔元描述汉字可以得到很好的效果。
3) 个性化汉字的描述易于实现。笔元汉字为个性化书写汉字的存储与表达找到一种完美的解决方案。传统的编码汉字受编码唯一性的信息交换原则限制, 不可能实现个性化汉字的完美表达, 而动态的生成方案可以确保“一码多形”的实现。
4) 方便网络存储和 Web 服务。抽象的特征信息和丰富的字形输出为汉字的远程存储提供了便利, 不仅实现了汉字信息服务的个性化和多元化, 同时为汉字 Web 字形和下一代计算机中汉字字形的表达提供了一种有效的解决方案。
5) 生成汉字效率高、速度快。笔元描述实现了汉字设计的机器生产, 因此比其他人工设计以及部首组字等方法的生成效率高得多。
图 15列出基于笔元的汉字字形描述库汉字生成方法与其他生成方法的比较结果。
图15 汉字生成方法比较 Fig. 15 Comparison of different Chinese character generation method
本文基于汉字的编码技术与描述技术, 将汉字字形的自动化设计技术概括为静态和动态两种形式, 并研究汉字的动态生成技术, 提出一种以基本笔元、组合笔元和扩展笔元为基本描述单位的汉字字形结构的抽象描述方案, 建立了基于字形结构的汉字动态生成模型和基于字形结构的汉字笔画风格生成模型。与现有的汉字生成技术相比, 本文提出的动态生成模型具有实时性和动态性以及更好的网络存储和网络控制属性, 能够快速生成不同风格的汉字字形, 为汉字字形的设计和汉字字形的服务提供了一种新思路。
The authors have declared that no competing interests exist.
Model-based analysis of Chinese calligraphy images. Dynamic generation and editing system for wrongly written chinese characters font. Structure and modeling of the network of two-Chinese-character compound words in the Japanese language. Basic processe of Chinese character based on cubic B-spline wavelet transform. Generating Chinese characters based on stroke splitting and feature extraction. A human-computer interactive dynamic description method for Jiaguwen characters. Chinese character synthesis using METAPOST A specification for CDL (Character Description Language) SCML: a structural representation for Chinese characters [D]. 一种笔段网格汉字字形描述方法 基于特征加权的汉字点笔画生成研究 基于云端信息保护的汉字计算模型
A cognitive model for understanding Chinese character
/
, Qiang XU
1 引言
1.1 表示方式的不足
1.2 编码方式的不足
2 汉字的自动化生成技术
2.1 基于编码汉字的静态生成方法
偏旁 声旁 丁 勺 月 票 襄 亻 停 仢 仴 僄 儴 氵 汀 汋 㳉 漂 瀼 扌 打 扚 抈 摽 攘 钅 钉 钓 钥 镖 镶 木 朾 杓 枂 標 欀
2.2 基于描述汉字的动态生成方法
3 汉字的结构和风格
3.1 汉字的结构
3.2 汉字的风格
4 汉字结构信息的笔元描述
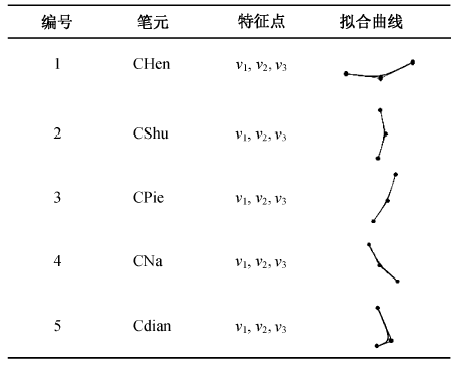
编号 组合笔元名称 特征点 组合笔元表达式 1 CHen(H) v1, v2, …, vi CHen = Hen1+ Hen2+…+ Heni 2 CShu(V) v1, v2, …, vi CShu = Shu1+ Shu2+…+ Shui 3 CPie(R_L) v1, v2, …, vi CPie = Pie1+ Pie2+…+ Piei 4 CNa(L_R) v1, v2, …, vi CNa = Na1+ Na2+…+ Nai 5 Cdian v1, v2, …, vi CDian=Dian1+ Dian2+…+ Diani
编号 扩展笔元名称 特征点 扩展笔元表达式 1 Ti (-Pie) v1, v2 Ti =-Pie 2 RGou( -Na) v1, v2 Gou =-Pie 3 LGou( -Na) v1, v2 Gou =-Na
5 汉字笔画风格的动态生成
5.1 笔元的矢量分析
5.2 笔元的风格分析
5.3 基本笔元风格的生成
5.4 组合笔元的风格生成
5.5 扩展笔元的风格生成
6 实验及结果分析
6.1 汉字结构描述及重建实验
6.2 汉字风格生成实验
6.3 与传统的生成方法比较
7 结语
参考文献
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]

〈
〉








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}