
Acta Scientiarum Naturalium Universitatis Pekinensis ›› 2017, Vol. 53 ›› Issue (2): 295-304.DOI: 10.13209/j.0479-8023.2017.035
• Orginal Article • Previous Articles Next Articles
Dandan WANG, Jin’an XU†( ), Yufeng CHEN, Yujie ZHANG, Xiaohui YANG
), Yufeng CHEN, Yujie ZHANG, Xiaohui YANG
Received:2016-07-22
Revised:2016-09-30
Online:2017-03-20
Published:2017-03-20
Contact:
Jin’an XU
通讯作者:
徐金安
基金资助:CLC Number:
Dandan WANG, Jin’an XU, Yufeng CHEN, Yujie ZHANG, Xiaohui YANG. A Tree-to-String EBMT Method by Integrating Joint Model of Chinese Segmentation and Dependency Parsing[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2017, 53(2): 295-304.
王丹丹, 徐金安, 陈钰枫, 张玉洁, 杨晓晖. 融合词法句法分析联合模型的树到串EBMT方法[J]. 北京大学学报自然科学版, 2017, 53(2): 295-304.
Add to citation manager EndNote|Ris|BibTeX
URL: https://xbna.pku.edu.cn/EN/10.13209/j.0479-8023.2017.035
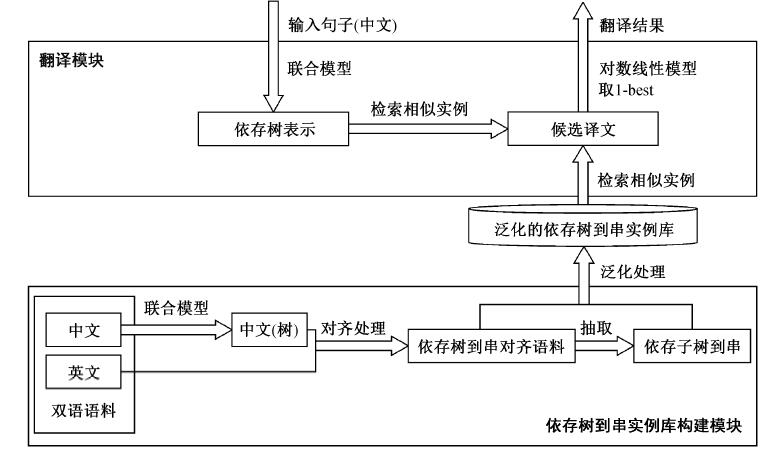
Fig. 1 Framework of EBMT system
Fig. 2 Dependency tree based on character
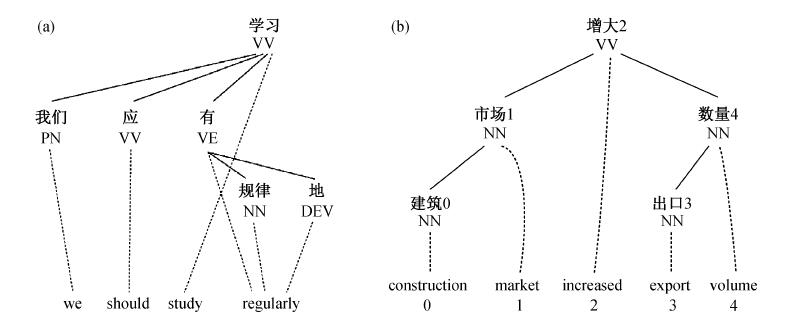
Fig. 3 Tree-to-string aligned bilingual example (sentence level)
| 中文依存子树 | 英文词串 | 英文词串对应位置[p, q] |
|---|---|---|
| 建筑(0) NN — 市场(1) NN | construction (0) market (1) | [ |
| 出口(3) NN — 数量(4) NN | export (3) volume (4) | [ |
Table 1 Projection of dependency subtree-to-string
| 中文依存子树 | 英文词串 | 英文词串对应位置[p, q] |
|---|---|---|
| 建筑(0) NN — 市场(1) NN | construction (0) market (1) | [ |
| 出口(3) NN — 数量(4) NN | export (3) volume (4) | [ |
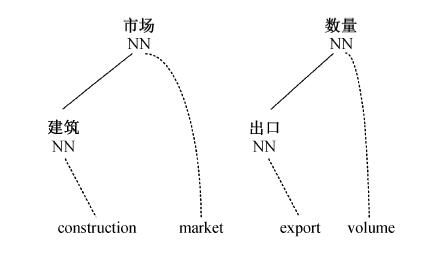
Fig. 4 Extracted example fragment pairs (phrase level)
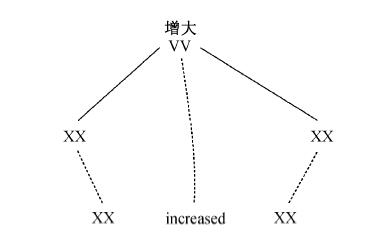
Fig. 5 Generalized dependency tree-to-string aligned example
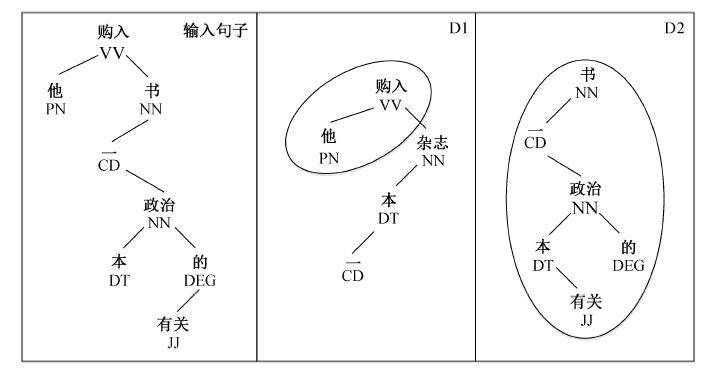
Fig. 6 Alternative similar case retrieval
| 系统 | BLEU5 | NIST |
|---|---|---|
| KyotoEBMT | 24.31 | 5.6563 |
| Stan-Tree-to-string | 23.96 | 5.5873 |
| Tree-to-string (SMT) | 24.07 | 5.6497 |
| 本文方法 | 24.41 | 5.6580 |
Table 2 Contrast experiments of machine translation systems
| 系统 | BLEU5 | NIST |
|---|---|---|
| KyotoEBMT | 24.31 | 5.6563 |
| Stan-Tree-to-string | 23.96 | 5.5873 |
| Tree-to-string (SMT) | 24.07 | 5.6497 |
| 本文方法 | 24.41 | 5.6580 |
| 项目 | 内容 |
|---|---|
| 原文 | 建筑对外开放呈现新格局 |
| 参考译文 | The opening of construction industry to the outside present a new structure. |
| KyotoEBMT | The opening up outside of construction industry to present a new structure. |
| Stan-Tree-to-string | The opening of construction industry to the outside show a new pattern. |
| Tree-to-string (SMT) | Opening of construction industry to the outside show a new pattern. |
| 本文方法 | The opening to the outside of construction industry present a new structure. |
Table 3 Translation results comparison of different translation systems
| 项目 | 内容 |
|---|---|
| 原文 | 建筑对外开放呈现新格局 |
| 参考译文 | The opening of construction industry to the outside present a new structure. |
| KyotoEBMT | The opening up outside of construction industry to present a new structure. |
| Stan-Tree-to-string | The opening of construction industry to the outside show a new pattern. |
| Tree-to-string (SMT) | Opening of construction industry to the outside show a new pattern. |
| 本文方法 | The opening to the outside of construction industry present a new structure. |
| 项目 | 内容 |
|---|---|
| 原文 | 城建是外商投资新热点。 |
| 参考译文 | Urban construction is a new hot spot of foreign business to invest. |
| KyotoEBMT | Urban construction is a new hot spot of foreign business investment. |
| Stan-Tree-to-string | Urban construction is a new hot spot of foreign investment. |
| Tree-to-string (SMT) | Urban construction is new hotspot of foreign investment. |
| 本文方法 | Urban construction is foreign business investment hotspot. |
Table 4 Unsatisfactory translation of the proposed method
| 项目 | 内容 |
|---|---|
| 原文 | 城建是外商投资新热点。 |
| 参考译文 | Urban construction is a new hot spot of foreign business to invest. |
| KyotoEBMT | Urban construction is a new hot spot of foreign business investment. |
| Stan-Tree-to-string | Urban construction is a new hot spot of foreign investment. |
| Tree-to-string (SMT) | Urban construction is new hotspot of foreign investment. |
| 本文方法 | Urban construction is foreign business investment hotspot. |
| [1] | Nagao M. A framework of a mechanical translation between Japanese and English by analogy principle. Artificial & Human Intelligence, 1984, 25(3): 351‒351 |
| [2] | Dandapat S, Morrissey S, Way A, et al.Combining EBMT, SMT, TM and IR technologies for quality and scale // ESIRMT and HyTra. Avignon, 2012: 48-58 |
| [3] | Xuan H W, Li W, Tang G Y. An advanced review of Hybrid Machine Translation (HMT). Procedia Engi-neering, 2012, 29: 3017‒3022 |
| [4] | Somers H, McLean I, Jones D. Experiments in multilingual example based generation // Proceedings of the 3rd Conference on the Cognitive Science of Natural Language Processing (CSNLP 1994). Tokyo, 1994: 149‒164 |
| [5] | Phillips A B, Brown R D. Cunei machine translation platform: system description // Proceedings of the 3rd Workshop on Example-Based Machine Translation. Santiago, 2009: 29‒36 |
| [6] | Och F J, Tillmann C, Ney H, et al. Improved alignment models for statistical machine translation // Proceedings of EMNLP. Aachen, 1999: 20‒28 |
| [7] | Sato S. MBT1: example-based word selection. Journal of Japanese Society for Artificial Intelligence, 1991, 6(4): 592‒592 |
| [8] | Sato S. MBT2: a method for combining fragments of examples in example-based translation. Artificial Intelligence, 1995, 75(1): 31‒31 |
| [9] | Nakazawa T, Kurohashi S. EBMT system of Kyoto team in PatentMT task at NTCIR-9 // Proceedings of the 9th NTCIR Workshop Meeting on Evaluation of Information Access Technologies (NTCIR-9). Tokyo, 2011: 657‒660 |
| [10] | Vandeghinste V, Martens S. Top-down transfer in example-based MT // Proceedings of the 3rd Inter-national Workshop on Example-Based Machine Translation. Dublin, 2009: 69‒76 |
| [11] | Al-Adhaileh M H, Kong T E, Yusoff Z. A synchro-nization structure of SSTC and its applications in machine translation // Proceedings of the 2002 COLING workshop on Machine translation in Asia — Volume 16. Taipei: Association for Computational Linguistics, 2002, 38(5): 1‒8 |
| [12] | Liu Z, Wang H, Wu H. Example-based machine translation based on tree-string correspondence and statistical generation. Machine Translation, 2006, 20 (1): 25‒25 |
| [13] | 郭振, 张玉洁, 苏晨, 等. 基于字符的中文分词、词性标注和依存句法分析联合模型. 中文信息学报, 2014, 28(6): 1‒1 |
| [14] | Och F J, Ney H. A systematic comparison of various statistical alignment models. Computational Linguis-tics, 2003, 29(1): 19‒19 |
| [15] | Och F J, Ney H. The Alignment template approach to statistical machine translation. Computational Linguis- tics, 2004, 30(4): 417‒417 |
| [16] | Brown R D. Example-based machine translation in the pangloss system // Proceedings of the 16th conference on Computational linguistics — Volume 1. Pennsylvania: Association for Computational Linguis-tics, 1996: 169‒174 |
| [17] | Sato S, Nagao M. Toward memory-based translation // Proceedings of the 13th conference on Computational linguistics-Volume 3. Helsinki: Association for Com-putational Linguistics, 1990: 247‒252 |
| [18] | 刘群, 李素建. 基于《知网》的词汇语义相似度计算. 中文计算语言学, 2002, 7(2): 59‒59 |
| [19] | 殷乐. EBMT中基于依存结构的翻译知识获取和翻译系统的实现[D]. 北京: 北京交通大学, 2014 |
| [1] | LIU Qiuhui, ZHANG Kunli, XU Hongfei, YU Shiwen, ZAN Hongying. Research on Automatic Recognition of Auxiliary “DE” [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(3): 466-474. |
| [2] | KE Yonghong, ZHU Yongfu, SUI Zhifang, YU Shiwen. A Method for Semantic Roles Labeling Consistency Calculation Based on Multi-features [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(3): 475-480. |
| [3] | YANG Meng, LI Peifeng, ZHU Qiaoming. An Approach of Sentence Similarity on Tree-LSTM [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(3): 481-486. |
| [4] | ZHANG Yu, ZENG Li, ZOU Lei. Regular Path Queries on Large Graph Data [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(2): 236-242. |
| [5] | WEI Xing, WANG Wei, CHEN Jingping, XIE Yanlu, ZHANG Jinsong. A Study of Articulatory Features Based Detection of Mandrain Pronunciation Erroneous Tendency for Automatic Annotation [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(2): 243-248. |
| [6] | LIN Xinyi, YAN Rui, ZHAO Dongyan. A Hybrid Optimization Framework Fusing Word- and Sentence-Level Information for Extractive Summarization [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(2): 229-235. |
| [7] | ZHOU Nan, ZHAO Yue, LI Yaoqiang, XU Xiaona, CAIWANG Lamu, WU Licheng. Study on Continuous Speech Recognition Based on Bottleneck Features for Lhasa-Tibetan Dialect [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(2): 249-254. |
| [8] | TAN Yiming, WANG Mingwen, LI Maoxi. Neural Post-Editing Based on Machine Translation Quality Estimation [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(2): 255-261. |
| [9] | WU Huanqin, ZHANG Hongyang, LI Jingmei, ZHU Junguo, YANG Muyun, LI Sheng. Training Machine Translation Quality Estimation Model Based on Pseudo Data [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(2): 279-285. |
| [10] | Lü Shuning, DONG Zhian. Domain Term Extraction Using URL-Key [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(2): 262-270. |
| [11] | WANG Wenchao, Lü Xueqiang, ZHANG Kai, ZHOU Jianshe. Research on Automatic Writing of Football Game News [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2018, 54(2): 271-278. |
| [12] | Wenhao YING, Xinyan XIAO, Sujian LI, Yajuan LÜ, Zhifang SUI. Improving Query-Focused Summarization with CNN-Based Similarity [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2017, 53(2): 197-203. |
| [13] | Qingsheng LI, Qiang XU, Jianguo XIAO, Quan LIU, Jiefang ZHANG. A Structure and Style Model for Chinese Character Dynamic Generation [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2017, 53(2): 219-229. |
| [14] | Yujing CHEN, Xueqiang LÜ, Jianshe ZHOU, Ning LI. Research on Automatic Writing of NBA Sports News [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2017, 53(2): 211-218. |
| [15] | Lilin ZHANG, Maoxi LI, Wenyan XIAO, Jianyi WAN, Mingwen WANG. Improve Automatic Evaluation of Machine Translation Using Specific-Domain Paraphrase [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2017, 53(2): 230-238. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||