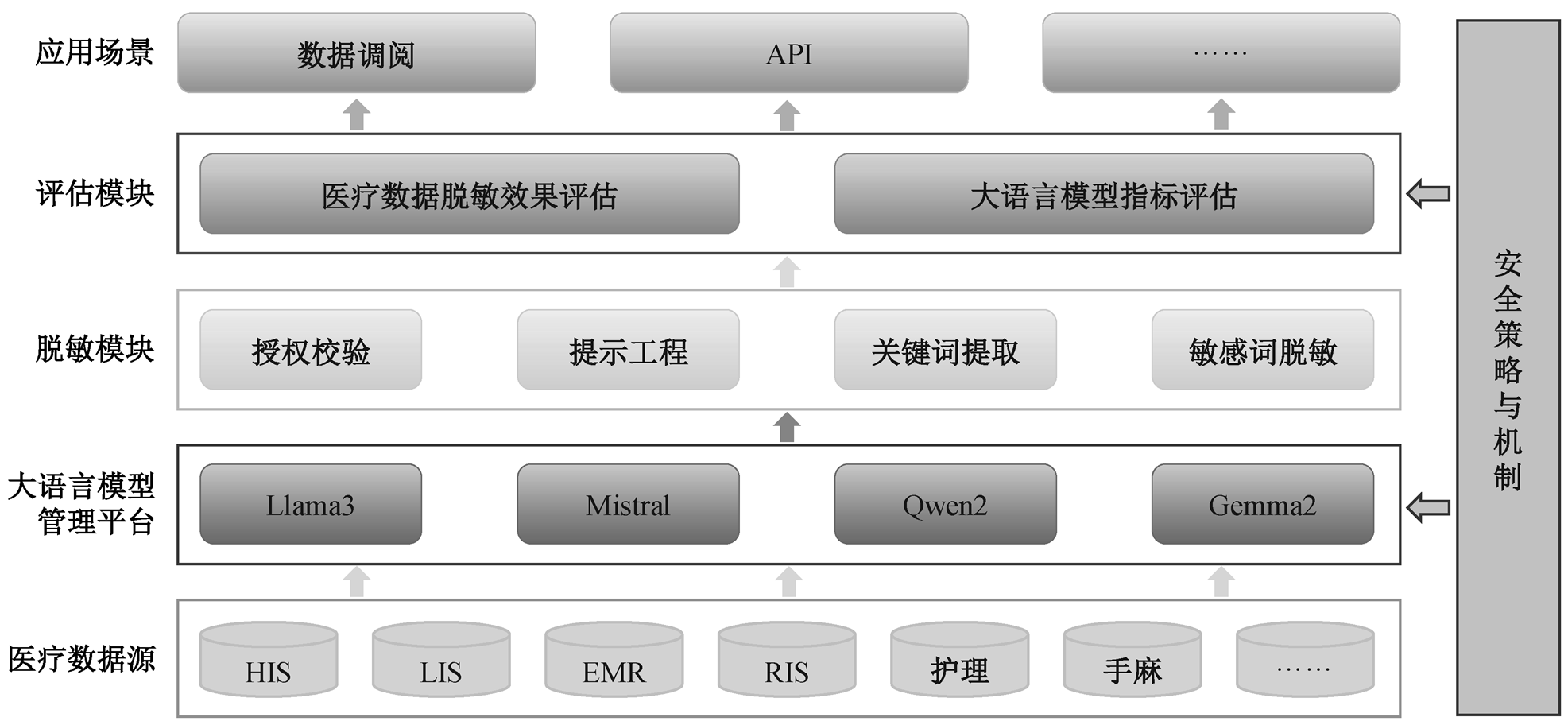
图1 基于大语言模型的医疗脱敏系统
Fig. 1 Medical desensitization system based on large language model
北京大学学报(自然科学版) 第61卷 第6期 2025年11月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 61, No. 6 (Nov. 2025)
doi: 10.13209/j.0479-8023.2025.092
摘要 为了有效地保护患者隐私与数据安全, 探索不同主流大语言模型在医疗文书中脱敏的表现, 设计一套基于大语言模型的医疗脱敏系统。该系统分别以主流开源大语言模型 Gemma2, Llama3, Qwen2 和 Mistral 为研究对象, 使用大语言模型管理框架工具 Ollama 进行私有化部署; 通过构建统一 Prompt 提示工程模版作为大语言模型输入, 以接口形式调用大语言模型能力获取医疗文书中目标敏感词, 然后对医疗文书进行敏感词替换, 完成医疗文书的脱敏工作。在虚拟专用服务器上, 单份医疗文书敏感词识别均可在 52.420~123.380s内完成; 在 5 类医疗文书脱敏、12 类敏感词识别以及大语言模型的处理实效性上, Gemma2 的整体表现最佳, 其后依次为 Llama3, Qwen2 和 Mistral。结果表明, 在无 GPU 算力的情况下, 虚拟专用服务器可通过部署大语言模型来高质量地完成敏感词识别和处理, 可以极大地提高医疗文书脱敏的准确性。
关键词 大语言模型; 隐私保护; 数据脱敏; 电子病历; 虚拟专用服务器
随着大数据技术的迅速发展, 医疗行业已进入数据化、智能化的新时代。医疗数据的丰富性和复杂性为医学研究、疾病预防以及个性化治疗提供了前所未有的机会, 特别是在疾病诊断、治疗决策以及药物研发等方面。然而, 医疗数据往往包含大量敏感的个人信息, 尤其是涉及患者隐私的姓名、身份证号、住址和病史等信息。因此, 在医疗数据的共享和利用过程中, 如何有效地保护患者隐私成为了亟待解决的问题[1], 医疗数据脱敏技术应运而生。医疗数据脱敏技术旨在通过一定的算法和处理手段, 将敏感信息从数据中移除或模糊化, 以确保在数据流通和使用过程中, 个人隐私不会被泄露[2]。
传统的医疗数据脱敏方法通常采用基础规则(如正则匹配、字典)的方式, 如替换、掩盖、删除或泛化特定的敏感信息。这些方法在一定程度上解决了隐私保护的问题, 但在面对海量非结构化数据(如医生的诊断记录和医学影像报告等)时, 其效率和准确性常常受到限制。此外, 传统脱敏方法往往无法处理复杂的上下文关联信息, 容易导致数据的可用性和真实性受损, 进而影响医学研究和应用的效果。
在这一背景下, 大语言模型(large language model, LLM)[3–5]的兴起为医疗数据脱敏提供了新的思路。大语言模型基于深度学习技术, 通过对海量文本数据的训练, 具备强大的自然语言处理能力, 能够在无需明确规则的前提下, 理解和生成复杂的语言表达。因此, 在处理医疗文本数据时, 大语言模型能够自动识别包含患者隐私的敏感信息, 并对敏感信息进行精确的替换或掩盖, 从而达到脱敏目的[6–8]。
考虑到目前医疗机构普遍缺少 GPU 算力, 在保证医疗数据不出院的情况下, 本研究致力于探索大语言模型在无 GPU 算力支持[9]医疗病历脱敏中的应用, 并分析目前主流开源大语言模型 Gemma2[10], Llama3[11], Qwen2[12]和 Mistral[13]在医疗病历脱敏中的表现。
本研究通过基于开源大语言模型管理框架的工具 Ollama[14], 设计一套基于大语言模型的医疗脱敏系统(图 1)。考虑到医疗机构 GPU 算力不足以及医疗病历隐私安全的情况, 本研究基于虚拟专用服务器(VPS)(CPU: 8 核, 内存: 64GB, 系统: ubuntu,存储: 44G), 私有化部署主流开源大语言模型 Gem-ma2, Llama3, Qwen2 和 Mistral, 探究其在医疗病历文书中的脱敏效果。虚拟专用服务器基于戴尔 Power-Edge-R740 机架式服务器(处理器为 Intel (R)Xeon(R) Silver 4214RCPU@2.40GHz), 使用 VMware ESXi技术配置完成。
根据硬件配置, 我们选取处于同级别的大语言模型版本, 不同开源大语言模型主要参数的对比如表1 所示。我们选取门诊记录、入院记录、手术记录、出院记录和患者病情告知书 5 类常用的医疗电子病历文书, 每类文书通过随机种子方式选取 100份, 共计 500 份作为预处理数据集。依据《健康医疗数据安全指南》GB/T 39725—2020[15], 选取患者的姓名、出生日期、性别、职业、住址、工作单位、电话、收入、婚姻状态以及联系人的姓名、电话和地址共 12 类作为本次目标敏感词。
图1 基于大语言模型的医疗脱敏系统
Fig. 1 Medical desensitization system based on large language model
表1 不同开源大语言模型主要参数对比
Table 1 Comparison of main parameters of different open source large language models

大语言模型模型参数/B模型大小/GB量化位数上下文长度/K上下文窗口/KGQA Gemma295.4Q4 8 8Yes Llama384.7Q4 8 8Yes Qwen274.4Q43232Yes Mistral74.1Q43232Yes
使用“curl -fsSL https://ollama.com/install.sh | sh”命令安装大语言模型管理框架工具 Ollama。然后, 使用“ollama pull 名称:版本”命令, 分别拉取并安装 Gemma2:9B, Llama3:8B, Qwen2:7B 以及 Mistral: 7B 开源大语言模型。最后, 通过配置“OLLAMA_ HOST=IP:端口”, 并且将此服务设置仅为大语言模型 API 服务器调用, 确保资源的指定应用方安全使用。
通过界面化方式添加提示工程(Prompt)模板[16],实现不同大语言模型的统一输入, 调用其能力。提示工程(Prompt)模板内容如图 2 所示, 其中“{%S%}”为自定义占位符, 在实际调用中, 将替换为目标文本内容。
本研究的系统模块采用微服务架构, 将大语言模型、功能接口及其管理端分别部署于不同虚拟专用服务器。大语言模型 API 服务采用 Model-View-Controller(MVC)[17]软件架构模式, 功能接口基于开放标准(RFC 7519)的 JSON Web Token(JWT)[18], 实现轻量级身份验证和授权机制。
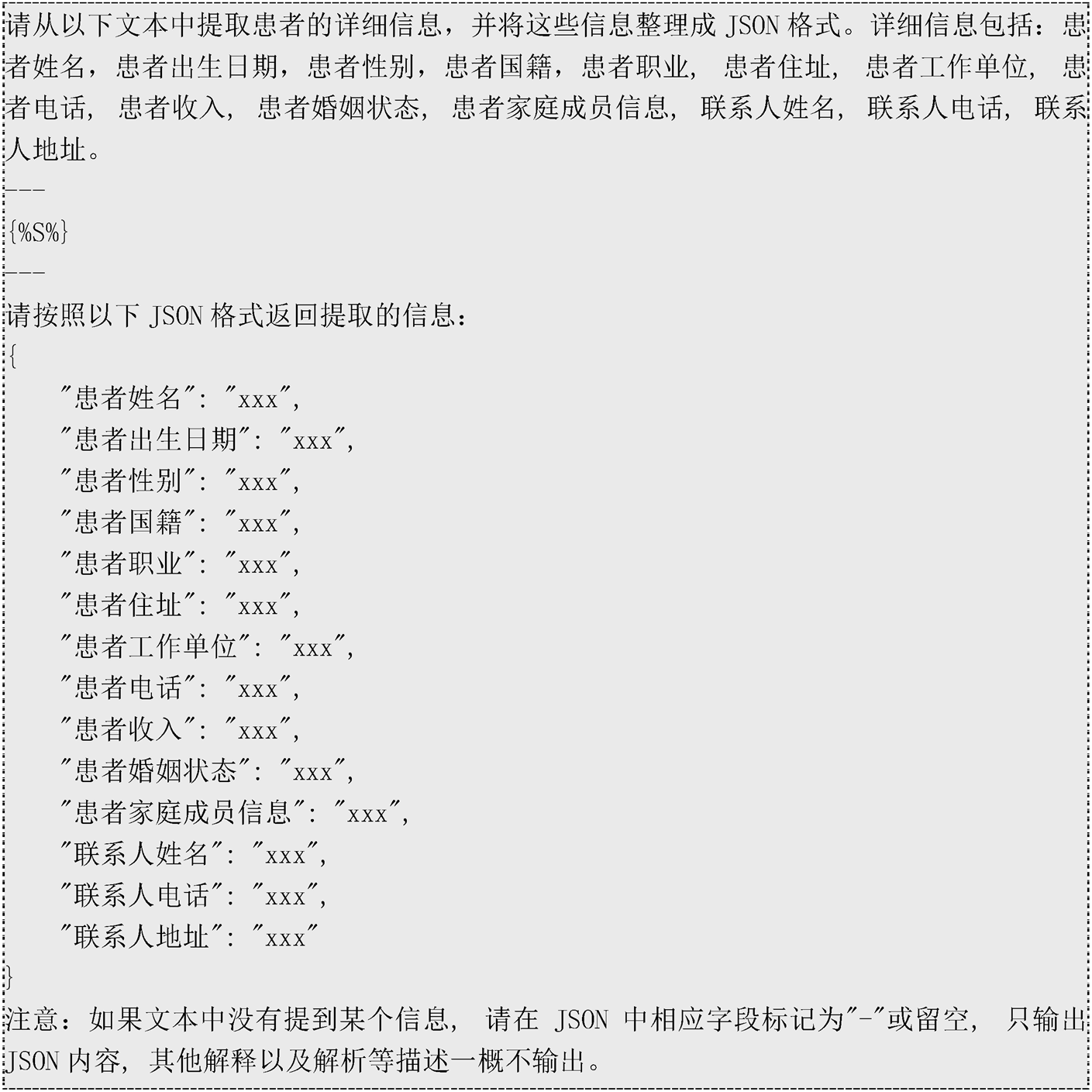
图2 大语言模型识别医疗敏感词的提示工程模板
Fig. 2 Large language model recognition of medical sensitive words prompt project template
1)获取授权。应用方通过分配的账号和密钥发起请求, 调用授权接口, 获取授权 Token (包含用户唯一标识、请求时间戳以及过期时间)。
2)大语言模型敏感词识别。应用方通过已经获得的授权 Token 以及需要识别的病历文本内容, 调用敏感词识别接口, 获取大语言模型识别出的敏感词。
将识别出的敏感词按照长度进行排序, 然后在原始病历文书中依次进行替换, 最终完成病历文书的敏感词脱敏。
对 5 类医疗文书(门诊记录、入院记录、出院记录、手术记录和患者病情告知书)以及 12 类敏感词进行准确率评估。医疗文书脱敏准确率 P1 的计算方法为
P1=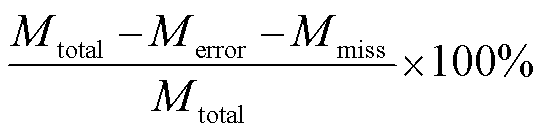 ,
,
其中, Mtotal为实际脱敏总医疗文书数量, Merror为文书脱敏错误数量, Mmiss为文书未脱敏数量。每份医疗文书上任何一个敏感词脱敏错误或未脱敏, 则将本份医疗文书标记为脱敏失败[19]。敏感词脱敏准确率P2的计算方法为
P2=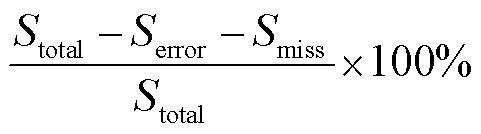 ,
,
其中, Stotal为实际脱敏总敏感词数量, Serror为敏感词脱敏错误数量, Smiss为敏感词未脱敏数量。敏感词如果没有被完全脱敏处理, 则记为脱敏失败。
本研究中 5 类医疗文书的平均长度如下: 出院记录 688 个字符, 门诊记录 708 个字符, 手术记录1862 个字符, 患者病情告知书 682 个字符, 入院记录 1075 个字符。5 类医疗文书脱敏分别在虚拟专用服务器上的响应及处理效果如表2 所示。可以看出, 各类医疗文书的大语言模型中位处理时长从高到低依次为 Mistral, Gemma2, Llama3 和 Qwen2, 在虚拟主机服务器环境中, 每份病历文书的中位处理时间介于 52.420~123.380s 之间; 大语言模型中位响应时间介于 0.015~0.560s 之间, 不同模型医疗文书的加载时间和处理时间均存在显著的统计学差异(P< 0.001)。
5 类医疗文书中 12 类敏感词的脱敏准确率如表3 所示。可以看出, Gemma2 的各敏感词脱敏效果最佳(除患者姓名和患者性别略低外, 其余均在 99%以上), Llama3, Qwen2 和 Mistral 的性能稍逊于 Gemma2, 三者在不同类别敏感词上表现各异。
5 类医疗文书的脱敏准确率如表4 所示。可以看出, Gemma2 的整体效果也表现最佳, 后面依次为Llama3, Qwen2 和 Mistral。在手术记录中, 由于患者姓名和患者性别普遍未被识别出, 导致医疗文书的脱敏准确率较低。
针对医疗文书脱敏准确率较低的问题, 我们对文本内容预先进行切分处理。考虑到文本中均含关键词“手术经过: ”, 依据此关键词将文本切分为两段, 平均长度分别为 442 和 1420 个字符。按照上述实验流程, 使用大语言模型, 对患者姓名和患者性别进行识别和脱敏处理, 脱敏效果如表5 所示。可以看出, 将较长的手术记录文书分段处理后, 能够提升其脱敏准确率。
利用典型医疗数据脱敏技术(自然语言识别+名词集+规则集), 对本研究构建的数据集进行验证, 在 5 类医疗文书上的准确率如表6 所示。可以看出, 在本研究构建的数据集上, 5 类医疗文书的脱敏平均准确率为 91%。
开源大语言模型基础版本在医疗文书脱敏的应用中, Gemma2 对入院记录、出院记录、门诊记录和患者病情告知书 4 类医疗文书脱敏的平均准确率高达 96.75%, 表明开源大语言模型具有良好的医疗数据隐私保护效果。相较于传统脱敏的技术[19–20], 大语言模型对上下文语义的理解明显更强, 并且直接减少了规则匹配的时间, 大语言模型的资源占用略高于典型的传统脱敏技术。同时, 本文的研究提升了脱敏准确率, 且无须额外维护敏感词库以及规则等集合。至于手术记录中患者姓名和患者性别未识别而导致脱敏准确率偏低, 可能是由于一次输入较多内容以及文中出现的姓名偏多。对于一次输入较多内容的问题, 我们进行分段处理, 结果表明, Gemma2 的脱敏准确率升至 99%, Llama3, Qwen2 和Mistral 处理后的准确率也大幅提升。出现姓名偏多的问题主要是涉及手术的相关医务人员较多导致, 后续可结合院内工作人员姓名集合, 使用员工编号进行替换, 降低对大语言模型识别患者姓名效果的影响。另外, 本研究选取的同级别大语言模型在参数上也略有差异, Gemma2 在参数数量上高于其他 3个模型。
表2 不同大语言模型对 5 类医疗文书的响应及处理时间对比
Table 2 Comparison of response and processing time of 5 types of medical documents by different large language models

大语言模型门诊记录入院记录手术记录加载时间处理时间加载时间处理时间加载时间处理时间 Gemma20.559 [0.050, 0.058]80.917 [66.842, 114.441]0.055 [0.050, 0.058]118.028 [105.834, 131.868]0.056 [0.051, 0.058]110.846 [102.516, 127.480] Llama30.033 [0.033, 0.034]70.848 [57.597, 95.382]0.034 [0.033, 0.035]95.848 [87.333, 104.51]0.033 [0.033, 0.035]100.788 [77.698, 112.923] Mistral0.015 [0.015, 0.017]87.827 [74.005, 111.702]0.016 [0.015, 0.017]123.380 [108.801, 138.082]0.016 [0.015, 0.018]88.003 [86.420, 94.592] Qwen20.031 [0.030, 0.033]52.420 [41.832, 78.250]0.031 [0.031, 0.033]73.828 [65.920, 82.875]0.031 [0.030, 0.036]79.577 [67.725, 93.553] H296.91280.246311.265221.524280.87580.065 P<0.001<0.001<0.001<0.001<0.001<0.001 大语言模型出院记录患者病情告知书 加载时间处理时间加载时间处理时间 Gemma20.560 [0.050, 0.058]72.837 [52.319, 103.677]0.056 [0.048, 0.057]79.411 [73.511, 83.432] Llama30.033 [0.033, 0.034]64.198 [45.674, 87.129]0.033 [0.032, 0.034]65.308 [61.877, 71.497] Mistral0.016 [0.015, 0.017]78.847 [56.382, 94.590]0.016 [0.015, 0.017]79.633 [42.406, 88.860] Qwen20.031 [0.030, 0.033]53.590 [46.140, 73.236]0.031 [0.030, 0.033]53.178 [50.237, 56.820] H244.23434.575243.975142.569 P<0.001<0.001<0.001<0.001
说明: H为多组间 Kruskal-Wallis 非参数检验的统计值; 数据格式为 M [P25, P75], M 为中位数, P25 为第 25 百分位数, P75 为第 75 百分位数。
表3 不同大语言模型对 12 类敏感词的脱敏准确率(%)
Table 3 Desensitization accuracy of 12 sensitive words by different large language models (%)
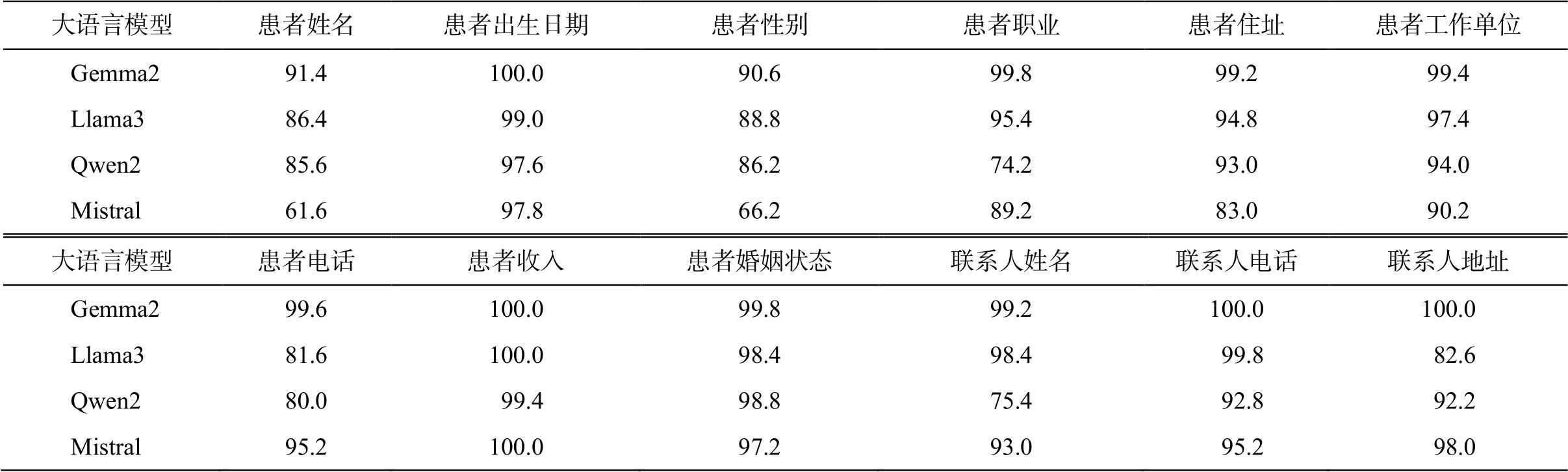
大语言模型患者姓名患者出生日期患者性别患者职业患者住址患者工作单位 Gemma291.4100.090.699.899.299.4 Llama386.4 99.088.895.494.897.4 Qwen285.6 97.686.274.293.094.0 Mistral61.6 97.866.289.283.090.2 大语言模型患者电话患者收入患者婚姻状态联系人姓名联系人电话联系人地址 Gemma299.6100.099.899.2100.0100.0 Llama381.6100.098.498.4 99.8 82.6 Qwen280.0 99.498.875.4 92.8 92.2 Mistral95.2100.097.293.0 95.2 98.0
表4 不同大语言模型对 5 类医疗文书的脱敏准确率(%)
Table 4 Desensitization accuracy of 5 types of medical documents using different major language models (%)

大语言模型门诊记录入院记录手术记录出院记录患者病情告知书 Gemma29399599996 Llama39089478198 Qwen27461376090 Mistral5171112789
表5 大语言模型对手术记录文书分段处理后脱敏准确率(%)
Table 5 Desensitization accuracy of surgical record documents after segmented processing using major language models (%)

大语言模型患者姓名患者性别手术记录分段前分段后分段前分段后分段前分段后 Gemma25999591005999 Llama3479655 994796 Qwen2519054 943761 Mistral137814 871177
表6 典型医疗数据脱敏技术对 5 类医疗文书的脱敏准确率(%)
Table 6 Accuracy of typical medical data desensitization technology in desensitizing 5 types of medical documents (%)

脱敏技术门诊记录入院记录手术记录出院记录患者病情告知书 自然语言识别+名词集+规则集9091869394
本研究验证了在没有 GPU 算力的情况下, 普通虚拟专用服务器也可以使用大语言模型完成文本的语言理解与推理, 单份医疗文书的中位处理时间为52.420~123.380s。此方法可拓展到其他内容的识别与提取。
本文的研究成果目前已经应用到某专科医院的临床试验中, 临床试验监查员(CRA)在进行定期访视时, 通过对患者的病历进行脱敏处理来保障患者的隐私安全。
尽管本研究取得一些成效, 但仍然存在一些改进空间。例如, 对于脱敏准确率较低的敏感词, 可以通过收集相关语料集, 使用 LlamaFactory[21]等微调工具进行微调, 并结合文本检索增强技术(RAG)来提升敏感词识别[22]; 针对单份文书处理时间较长的问题, 在没有 GPU 服务器的情况下, 可以将大语言模型部署在显卡 16GB 的电脑上, 借助其显卡来缩短单份文本的处理时间。
另外, 我们还未完全建立一套评估脱敏后数据可用性的指标, 这些指标应当包括数据的完整性、一致性和可解释性等, 以便更好地从多个维度来评估脱敏效果及可用性。
为了有效地保护患者隐私与数据安全, 探索不同主流大语言模型在医疗文书中脱敏的表现, 本研究设计一套基于大语言模型的医疗脱敏系统, 对 5类医疗文书和 12 类敏感词进行识别和脱敏处理。研究结果表明, 基于大语言模型的医疗脱敏系统在医疗数据隐私保护方面提高了准确率。在无 GPU算力的情况下, 虚拟专用服务器也能部署大语言模型, 实现医疗敏感词的理解与识别。对主流开源大语言模型 Gemma2, Llama3, Qwen2 以及 Mistral 的对比分析表明, Gemma2 在医疗文书脱敏处理中表现最佳。目前, 此系统已应用到实际场景中, 但仍然需要进一步研究和改进, 以便更好地保障患者的隐私安全。
参考文献
[1] 郭进京, 张雪, 林鑫, 等. 国内患者隐私泄露情形及隐私保护现状分析. 医学信息学杂志, 2020, 41 (2): 21–28
[2] 叶琳, 罗铁清. 医疗数据治理综述. 计算机时代, 2021(5): 10–12
[3] Kumar P. Large language models (LLMs): survey, tech-nical frameworks, and future challenges. Artificial In-telligence Review, 2024, 57(10): no. 260
[4] Chang Yupeng, Wang Xu, Wang Jindong, et al. A sur-vey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 2024, 15(3): 1–45
[5] 徐月梅, 胡玲, 赵佳艺, 等. 大语言模型的技术应用前景与风险挑战. 计算机应用, 2024, 44(6): 1655–1662
[6] Chang C W, Hu M, Ghavidel B, et al. An LLM-based framework for zero-shot de-identifying flexible text data in protected health information enabling potential risk-informed patient safety. International Journal of Radiation Oncology, Biology, Physics, 2024, 120(2): e518
[7] Wang Leyao, Wan Zhiyu, Ni Congning, et al. Applica-tions and concerns of ChatGPT and other conversa-tional large language models in health care: systematic review. Journal of Medical Internet Research, 2024, 26: e22769
[8] 郭华源, 刘盼, 卢若谷, 等. 人工智能大模型医学应用研究. 中国科学: 生命科学, 2024, 54(3): 482–506
[9] 王海峰, 陈庆奎. 图形处理器通用计算关键技术研究综述. 计算机学报, 2013, 36(4): 757–772
[10] de Curtò J, de Zarzà I. Comparative analysis of rea-soning capabilities in foundation models // 2024 2nd International Conference on Foundation and Large Language Models (FLLM). Dubai, 2024: 141–149
[11] Huang Wei, Zheng Xingyu, Ma Xudong, et al. An em-pirical study of llama3 quantization: from LLMS to MLLMS. Visual Intelligence, 2024, 2(1): no. 36
[12] 滚流海, 吴娜, 曾以春. 医疗电商平台中大语言模型驱动的中文医学对话系统研究. 电子商务评论, 2024, 13(4): 1611–1620
[13] Samo H, Ali K, Memon M, et al. Fine-tuning mistral 7b large language model for python query response and code generation: a parameter efficient approach. VAW-KUM Transactions on Computer Sciences, 2024, 12 (1): 205–217
[14] Lehto T. Developing LLM-powered applications using modern frameworks. Sheffield: Packt Publishing, 2024
[15] 全国信息安全标准化技术委员会. 《信息安全技术—健康医疗数据安全指南》(GB/T 39725—2020) [EB/OL]. (2020–12–14)[2024–10–03]. https://std.samr. gov.cn/gb/search/gbDetailed?id=B691BB77876CD126E05397BE0A0AF3B3
[16] 黄峻, 林飞, 杨静, 等. 生成式 AI 的大模型提示 工程: 方法、现状与展望. 智能科学与技术学报, 2024, 6(2): 115–133
[17] 任中方, 张华, 闫明松, 等. MVC 模式研究的综述. 计算机应用研究, 2004, 21(10): 1–4
[18] Jones M. JSON Web Token (JWT)-RFC 7519. Internet Engineering Task Force (IETF) RFC [EB/OL]. (2015) [2024–10–03]. https://www.rfc-editor.org/bcp/bcp225. txt
[19] 张志立, 衡反修. 电子病历数据脱敏方法研究. 中国数字医学, 2022, 17(10): 100–103
[20] 刘荣管, 王兆栋, 邓兰华, 等. 基于数据元的医疗数据脱敏方法研究. 信息技术与信息化, 2023(7): 4–7
[21] heng Yaowei, Zhang Richong, Zhang Junhao, et al. Llamafactory: unified efficient fine-tuning of 100+ language models [EB/OL]. (2024–06–27)[2024–10–03]. https://arxiv.org/pdf/2403.13372
[22] 刘彦宏, 崔永瑞. 基于Word2Vec模型与RAG框架的医疗检索增强生成算法. 人工智能与机器人研究, 2024, 13(3): 479–486
Practice and Performance of Large Language Models in Medical Data Desensitization
Abstract To explore the performance of different mainstream big language models in desensitizing medical documents, a medical desensitization system based on large language models is designed. Mainstream open-source big language models Gemma2, Llama3, Qwen2, and Mistral are adopted as research objects, using the big language model management framework tool Olama for private deployment. By constructing a unified Prompt engineering template as input for the big language model, the ability of the big language model is called in the form of an interface to obtain target sensitive words in medical documents. Sensitive words are replaced to complete the desensitization of medical documents. On the virtual private server, the recognition of sensitive words in a single medical document can be completed within 52.420 to 123.380 seconds. In terms of performance in five types of medical document anonymizations, 12 types of sensitive word recognition, and the processing efficiency of large language models, Gemma2 demonstrates the best overall performance, followed by Llama3, Qwen2, and Mistral. The results show that even without GPU computing power, virtual dedicated servers can still complete sensitive word recognition and processing with high quality by deploying large language models, greatly improving the accuracy of medical document desensitization.
Key words large language model; privacy protection; data desensitization; electronic medical records; virtual private server
收稿日期: 2024–10–30;
修回日期: 2025–02–05