北京大学学报(自然科学版) 第61卷 第6期 2025年11月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 61, No. 6 (Nov. 2025)
doi: 10.13209/j.0479-8023.2025.066
融合文本嵌入和机器学习的作者身份验证方法研究
王新民 1,2,† 朱文卿 2 韩卓希 3 刘豪 2
1.北京大学大数据分析与应用技术国家工程实验室, 北京 100871; 2. 北京大学长沙计算与数字经济研究院, 长沙 410205; 3.北京大学海洋研究院全球互联互通研究中心, 北京 100871; †通信作者, E-mail: wangxinmin@pku.edu.cn
摘要 基于深度学习与机器学习相结合的方法, 构建面向作者身份验证的标注数据集, 并采用 BERT 和动态相似度阈值策略来提升标签质量。然后, 提出一种融合 BERT 文本嵌入和 XGBoost-BO 的作者身份识别模型, 该模型通过结合 BERT 强大的特征提取能力、XGBoost 高效的分类性能以及贝叶斯优化的超参数搜索策略, 实现对作者身份的准确判断。同时, 探讨动态相似度阈值策略在提升作者相似度判定准确性方面的有效性, 以及贝叶斯优化在自动调整 XGBoost 超参数、提升模型综合性能方面的显著作用。实验结果表明, 该方法在各项指标上均优于其他对比算法, 可为作者身份验证提供新的思路和方法。
关键词 作者身份验证; 动态相似度阈值; BERT; XGBoost; 贝叶斯优化
在数字化时代的大背景下, 文本信息的爆发式增长为众多领域带来丰富的资源, 同时也催生一些新的挑战[1]。其中, 如何在海量文本数据中准确地识别作者身份, 消除作者姓名歧义, 成为文本分析、信息安全和信息检索等方面亟需解决的关键问题[2], 尤其在一些专业领域(如国际政策研究、科学研究、学术论文出版和知识产权保护等), 研究成果的真实性和可靠性关系到政策的制定、学术交流的效率以及社会发展的方向[3]。作者身份验证(au-thorship verification)、消除姓名歧义是文本分析和信息检索领域的关键技术。应用这一技术, 可以防止将研究成果归属错误的作者, 避免学术混淆和研究资源的浪费, 有助于加强学术诚信, 防止学术不端行为, 加强知识产权保护, 对推动公正、透明的学术评价体系具有重要意义[4]。此外, 作者姓名消歧的精确性对构建详尽的行业知识图谱[5]和增强学术及政策研究[6]的影响力也至关重要。
目前, 作者身份识别的复杂性主要源于文本信息的多样性和隐蔽性[7], 传统的基于文本统计特征或关键词匹配的方法已难以满足高精度作者身份识别的需求。特征表示模型大多依赖于抽取的显式特征, 对文本内容的深层语义理解相对有限, 阮光册等[8]提出多特征融合方法, 采用作者、单位和时间等外部特征与关键词、标题和摘要等内部语义特征的组合, 利用基于 BERT 和 XGBoost 的分类模型解决同名消歧问题。尽管这种方法有效地提升了部分领域的作者身份判别精度, 但对外部特征的依赖性较强, 在缺乏外部特征支持或处理文本深层语义时可能受限。与此同时, 其他方法(如近邻传播聚类算法)在处理大规模数据和复杂数据结构时可能遇到性能瓶颈, 且聚类结果的优劣往往取决于相似度计算的精确度和初始聚类中心的选择[9]。通过比较文档间的特征(如字符 N-Gram 频率)来判断作者身份的方法, 受特征选择和距离度量方法的影响较大, 对于短文本或者特征不明显的文本, 效果并不理 想[10]。基于 TF-IDF 的方法主要依据词频和逆文档频率来计算关键词的重要性, 进而判断文本的相似度, 但忽略了词汇之间的语义关系, 无法捕捉到文本中的长期依赖关系。对于包含复杂结构的文本(如嵌套句子、多义词或专业术语丰富的文本), TF-IDF 方法难以准确地提取有效的关键词[11]。尽管BERT-CharCNN 结合了 CharCNN 对字词级的特征提取和 BERT 对句子段落级的特征提取优势, 但仍然无法捕捉更复杂的上下文关系, CharCNN 更侧重于局部特征的提取, 这种简单的拼接方式未能充分利用各层特征之间的互补性[12]。在社交媒体的作者身份验证任务中, 层次循环孪生网络得到应用。该网络架构由两个具有相同权重的循环神经网络构成, 能够利用孪生网络机制, 有效地衡量文档间的相似性, 但与 BERT 这类深度双向预训练模型相比, 层次循环孪生网络的特征表示能力仍然显得有所局限[13]。基于知识图谱嵌入技术, 结合从知识图谱中生成的多模态字面信息来实现作者身份识别的方法, 侧重于利用构造的知识图谱结构和字面信息, 但高度依赖特定场景下丰富的知识图谱结构[14]。
鉴于现有技术在作者身份验证领域存在的局限性, 特别是在处理复杂文本结构和深层语义理解方面的不足, 本文深入探索基于深度学习与机器学习相结合的方法来解决这一问题[15]。BERT(Bidirec-tional Encoder Representations from Transformers)模型在文本特征提取方面具有强大的能力, 尤其在捕捉文本的深层语义关系和上下文依赖方面[16]。然而, 单纯依赖 BERT 模型进行分类可能受到计算效率和资源消耗方面的限制。因此, 本研究考虑将BERT 与高效的机器学习算法相结合, 以期在保持高精度的同时, 提高模型的运行效率和实用性。XGBoost(Extreme Gradient Boosting)是一种优化的梯度提升算法, 因其高效的分类性能和良好的可扩展性[17], 成为与 BERT 结合的理想选择。为了进一步优化模型性能, 本文引入贝叶斯优化(Bayesian optimization, BO)策略, 自动调整 XGBoost 的超参数, 从而避免手动调整参数的主观性和低效性[18]。这一策略不仅能够提高模型对数据的泛化能力, 还能在一定程度上降低过拟合的风险。
基于上述分析, 本文首先构建一个作者身份验证数据集, 并且基于 BERT 和动态相似度阈值策 略, 用于优化标签生成质量。然后, 提出一种融合BERT 文本嵌入与 XGBoost-BO 的作者身份识别模型, 通过结合 BERT 强大的特征提取能力、XG-Boost 高效的分类性能以及贝叶斯优化的超参数搜索策略, 实现对作者身份的准确判断。最后, 探讨动态相似度阈值策略在提升作者相似度判定准确性方面的有效性, 以及贝叶斯优化在自动调整 XG-Boost 超参数、提升模型综合性能方面的作用。
1 研究设计
1.1 数据来源
在作者身份验证研究领域, 高质量的文本数据不仅是分析的基础, 更是验证结果准确性的重要保障。本文的研究数据聚焦于全球知名的政策研究机构以及智库及学术网站(表1), 这些平台不仅文本内容丰富、更新及时, 而且具有较高的权威性和专业性。
在识别目标页面时, 本研究基于网络爬虫技术进行网页抓取, 精准定位并提取数据列表中每一个具体页面网址, 并过滤掉无关噪声。随后利用分布式爬虫架构的优势, 部署多节点并行访问策略, 显著地提升了数据抓取的速度与效率。在爬虫访问具体页面时, 基于页面解析机制, 自动适应不同网页结构的动态变化, 精准地提取关键信息, 包括但不限于标题、网页地址、主要内容、作者、发布时间、涉及机构和组织等。
表1 国际政策相关网站
Table 1 International policy-related websites

序号获取信息网站 1WEF(世界经济论坛): https://www.weforum.org 2ILO(国际劳工组织): https://www.ilo.org 3OECD(经济发展与合作组织): https://www.oecd.org 4波士顿咨询公司: https://www.bcg.com 5兰德公司: https://www.rand.org 6东南亚地缘战略环境: https://fulcrum.sg 7俄罗斯国际事务委员会: https://russiancouncil.ru 8新加坡东南亚研究所: https://www.iseas.edu.sg 9南洋理工大学国际关系学院: https://www.rsis.edu.sg
在数据处理阶段, 首先利用自然语言处理(Na-tural Language Processing, NLP)语言检测模型, 对收集到的数据进行语言属性的智能判断。对于非中文内容, 通过集成的腾讯云翻译 API, 实现多种语言间的无缝互译, 确保所有数据在后续处理中保持语言的一致性。完成翻译后, 进一步调用 GPT 大模型接口, 对翻译内容进行深度语义理解、观点提炼与主题识别。
尽管基于 NLP 语言检测模型和腾讯云翻译 API可以实现非中文内容的无缝互译, 确保数据语言的一致性, 但不可避免地引入一些潜在的问题。特别是对于具有国际背景的作者姓名和专有名词, 翻译的准确性往往直接关系到后续作者身份验证的精确度。由于不同语言间的文化表达、姓名结构差异和翻译标准的多样性, 同一作者姓名在不同语言环境中可能存在多种翻译表达, 给作者身份验证带来额外的挑战。例如, 英文名“Angel”在中文中可能被翻译为“安琪”, 而“安琪”也是一个常见的中文名字; “Ambar Kumar Ghosh”在翻译为中文时, 可能会因为音译规则的不同而产生多个版本, 如“安巴尔·库马尔·戈什”和“阿姆巴尔·库玛·戈斯”等; 许多英文名字有常见的缩写形式, 如“J.K. Rowling”可能被翻译为“J.K. 罗琳”或“乔安妮·凯瑟琳·罗琳”。本文提出的融合文本嵌入和机器学习的作者身份验证方法能够实现高精度的作者身份验证, 可以有效地解决此类问题。
1.2 作者身份验证数据集
1.2.1 数据集构建
基于作者身份验证的特定目标, 本研究将作者姓名及背景信息作为核心特征。作者身份验证任务需要判断不同文本描述是否指向同一作者, 作者的背景信息(研究机构、研究方向、职务和参与项目等)包含最直接的强相关性身份识别线索, 提取的其他信息主要用于构建完整的数据库结构, 确保数据的可追溯性和研究的可重现性。
构建机器学习模型的数据集是进行有效模型训练和预测的关键步骤。首先, 对原始作者背景信息数据进行筛选和预处理, 包括去除无效数据、统一格式、进行中文分词以及去除停用词等。分词和去除停用词可以降低文本的特征维度, 并提高模型的训练效率。此外, 通过词干提取或词形还原等步骤进一步简化词汇, 使模型可以更准确地学习文本的内在信息。经过爬虫数据的标准化、特征提取与整合以及文本降维处理的结构化作者信息数据如表2所示。
根据文本特征的相似度计算结果, 将作者姓名和背景信息划分为同一作者和不同作者两个类别。在相似度阈值策略方面, 通过动态调整阈值, 可以更灵活地适应数据集的特定特征。将这些分类结果作为训练标签, 为后续模型训练提供指导。同时, 需确保标签生成的客观性, 避免主观偏差对模型性能的影响。
将生成的数据集划分为训练集、验证集和测试集。训练集用于模型参数的学习, 验证集用于调整模型参数, 测试集用于评估模型的性能。通过以上步骤, 构建一个经过预处理的高质量模型数据集。本文从国际政策相关网站共收集整理 602 条作者姓名及对应的作者背景信息数据, 经数据配对, 共生成 180901 个作者对数据, 数据集的基本构成如表3所示。我们构建的数据集具有通用性, 可以支持多种作者身份验证算法的研究和评估。
表2 预处理后的作者信息数据
Table 2 Preprocessed author information data

元数据特征属性数据信息 作者姓名中文姓名英文全名英文缩写页面URL、抓取时间、标题 作者背景研究机构研究方向职务参与项目名称
表3 作者对数据集的基本构成结构示例
Table 3 Examples of the basic composition structure of the dataset by paired authors
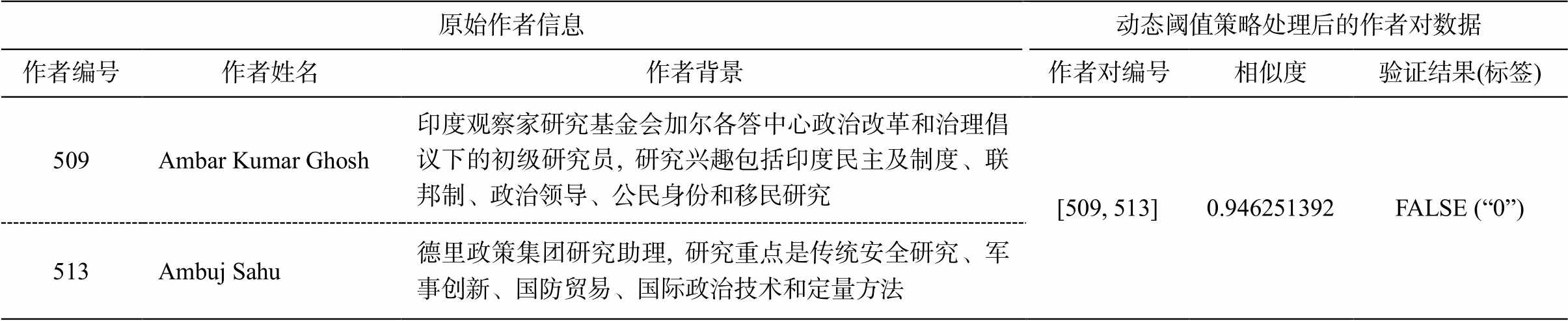
原始作者信息动态阈值策略处理后的作者对数据 作者编号作者姓名作者背景 作者对编号相似度验证结果(标签) 509Ambar Kumar Ghosh印度观察家研究基金会加尔各答中心政治改革和治理倡议下的初级研究员, 研究兴趣包括印度民主及制度、联邦制、政治领导、公民身份和移民研究[509, 513]0.946251392FALSE (“0”) 513Ambuj Sahu德里政策集团研究助理, 研究重点是传统安全研究、军事创新、国防贸易、国际政治技术和定量方法
1.2.2 相似度计算与动态阈值策略
本研究采用 BERT 模型生成文本的深度嵌入表示。作为预训练的深度双向 Transformer 编码器, BERT 模型在理解单词的复杂上下文关系方面具有显著优势[19]。本研究基于预训练的 BERT 模型、中文字符停用词表和相应的分词器, 对文本进行编码, 并在此过程中添加特殊标记[CLS]和[SEP]。
应用 BERT 模型处理编码后的文本, 生成包含所有 token 的嵌入向量矩阵。为了更全面地表示文本的语义信息, 我们将[CLS]嵌入向量与平均池化表示相结合, 形成最终的文本句子嵌入。[CLS]向量是专门用于表示整个句子全局语义的标记, 能够捕捉句子的核心语义信息。平均池化通过对所有token 的嵌入向量取均值, 生成一种更加均衡的全局语义表示, 特别是在长文本或语义信息分布不均的情况下, 能够弥补[CLS]向量因注意力机制对某些 token 信息覆盖不足的问题。随后, 将[CLS]向量和平均池化表示拼接为一个联合特征向量, 表示文本的整体语义。相比单独使用[CLS]或平均池化的方式, 结合方法的特征表示更全面, 能够更好地适配文本长度差异和语义分布的复杂性。
余弦相似度在高维向量空间中表现良好, 计算效率高[20], 因此我们采用余弦相似度作为度量标准, 计算不同作者信息之间的相似度。为了确定一个合适的相似度判定阈值, 我们定义两个独立的策略——基于相似度分布动态阈值和基于文本长度权重因子策略。基于相似度分布动态阈值策略通过对相似度分布的统计分析, 设定一个动态阈值, 以便适应数据集的具体特征。基于文本长度权重因子策略考虑文本长度对相似度的影响, 定义一个长度权重因子, 结合相似度分布, 动态地调整阈值。通过结合这两种策略, 我们定义了一个综合阈值, 更准确地衡量作者信息的相似性, 提高模型在构建作者相似度数据集时的准确性。
设 Sij 为作者 i 与 j 之间的余弦相似度, 其中 i 和 j表示作者索引。对于包含 N 个作者的数据集, 计算所有作者对(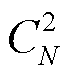 )之间的余弦相似度, 并求得均值 μ和标准差 σ。动态阈值 T1 基于相似度的均值 μ、标准差 σ和调节参数 k1 来定义:
)之间的余弦相似度, 并求得均值 μ和标准差 σ。动态阈值 T1 基于相似度的均值 μ、标准差 σ和调节参数 k1 来定义:
其中, k1 是一个正实数, 用于调整阈值相对于均值的标准差倍数。
设 Li 和 Lj 分别为作者 i 和作者 j 信息的文本长度, 根据文本长度的差异, 利用权重因子 λ 来调整阈值:
其中, λ0 是一个介于 0~1 之间的调节参数, 用于控制文本长度差异对权重因子的影响程度。
综合阈值 T2 结合了相似度分布动态阈值和文本长度权重因子, 计算方法为
如果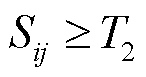 , 则判断作者 i 和作者 j 可能为同一作者; 如果
, 则判断作者 i 和作者 j 可能为同一作者; 如果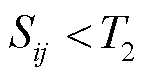 , 则判断作者 i 和作者 j 可能不是同一个作者。对于相似度高于综合阈值 T2 的作者对, 考虑到作者身份验证任务中存在严重的样本不均衡问题, 对这些候选样本进行人工逐一验证, 确保 “同一作者”关键少数类样本的高质量, 并将数据标签设置为 TRUE(“1”)。对于相似度低于 T2 的作者对, 考虑到数量庞大且为多数类样本, 则自动标注为“不同作者”, 数据标签设置为 FALSE(“0”)。这种标注策略既能保证关键少数类样本的准确性, 又能大幅度降低人工标注成本。
, 则判断作者 i 和作者 j 可能不是同一个作者。对于相似度高于综合阈值 T2 的作者对, 考虑到作者身份验证任务中存在严重的样本不均衡问题, 对这些候选样本进行人工逐一验证, 确保 “同一作者”关键少数类样本的高质量, 并将数据标签设置为 TRUE(“1”)。对于相似度低于 T2 的作者对, 考虑到数量庞大且为多数类样本, 则自动标注为“不同作者”, 数据标签设置为 FALSE(“0”)。这种标注策略既能保证关键少数类样本的准确性, 又能大幅度降低人工标注成本。
1.3 基于BERT文本嵌入和XGBoost-BO的作者身份识别模型
基于 BERT 文本嵌入和 XGBoost-BO 的作者身份识别模型旨在通过分析作者的文本信息, 准确地判断是否为同一人。首先, 利用 BERT 模型提取文本的深层语义特征, 然后通过 XGBoost 分类器进行分类, 并通过贝叶斯优化寻找最优的超参数组合, 以便提高模型的预测性能。
该模型的创新之处在于结合了 BERT 模型强大的特征提取能力和 XGBoost 高效的分类性能, 并通过贝叶斯优化进一步提升模型的参数配置。此外, 本文采用一种基于动态相似度阈值的标注策略, 结合 BERT 生成的嵌入向量对作者数据进行标注, 而非直接将相似度作为分类特征。该策略可以动态地调整不同数据对的相似度阈值, 更灵活地适应数据集中复杂的分布特性。通过这种组合, 不仅能够捕捉到文本中的细微语义差异, 还能通过优化后的模型参数实现更准确的分类结果。
1.3.1 特征提取: BERT模型嵌入向量
BERT 通过双向 Transformer 结构, 能同时考虑词语上下文, 并将文本转换为富含语义信息的嵌入向量[19]。具体来说, 对于输入文本 T, 经过 BERT的分词和编码后, 模型 fBERT 会输出一系列嵌入向量E=[e1, e2, …, en], 其中 ei 是第 i 个子词的 d 维向量。[CLS]标记的嵌入向量 eCLS=E[0]是表示整个输入文本的全局语义向量, 能够捕捉句子的核心语义信息。[SEP]标记的嵌入向量 eSEP 主要用于分隔句子或文本块, 帮助模型理解复杂文本的句子边界和块间关系。平均池化通过对所有嵌入向量 E 中的token 嵌入取均值, 生成一种对文本整体内容具有均衡覆盖的全局语义表示 eavg, 从而弥补[CLS]向量因注意力机制对文本部分信息覆盖不足的问题, 特别是在长文本或语义信息分布不均时, 有助于均衡句子的语义表示。
为了判断作者背景的描述是否为同一作者, 对输入的两段作者文本信息提取嵌入向量, 生成特征表示:
其中, 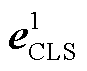 和
和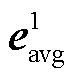 分别表示第一段作者文本信息的[CLS]向量和平均池化向量,
分别表示第一段作者文本信息的[CLS]向量和平均池化向量, 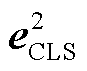 和
和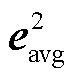 表示第二段文本的对应嵌入。拼接后的特征向量 X 同时包含两段文本的全局语义信息, 该向量是后续 XGBoost 分类器进行分类的基础。通过这种方式, 我们有效地将复杂的文本信息转化为具有丰富语义表示的高维向量。
表示第二段文本的对应嵌入。拼接后的特征向量 X 同时包含两段文本的全局语义信息, 该向量是后续 XGBoost 分类器进行分类的基础。通过这种方式, 我们有效地将复杂的文本信息转化为具有丰富语义表示的高维向量。
1.3.2 模型训练: XGBoost结合贝叶斯优化策略
在模型训练与优化阶段, 我们选用 XGBoost 作为核心分类器。XGBoost 是一种高效的集成学习算法, 通过迭代操作, 构建多个弱分类器来逼近最优解。为了优化 XGBoost 模型的性能, 我们采用贝叶斯优化策略来搜索最优的超参数组合。贝叶斯优化通过构建一个代理模型, 近似地表示超参数与模型性能之间的映射关系, 并利用该模型指导搜索过程, 用较少的迭代次数找到接近最优的超参数组合[21]。在贝叶斯优化中, 目标函数隐式地充当代理模型的角色, 基于当前的随机超参数组合, 每次评估一个不同的代理模型。通过这种方式, 贝叶斯优化可以在超参数空间中高效地搜索最优的超参数组合, 而不需要显式地构建一个复杂的代理模型。目标函数f(Θ)的表达式如下:
f(Θ)接收超参数空间 Θ 作为输入, 并输出模型在验证集 Dval 上的性能评估值。MΘ 表示使用超参数空间 Θ 训练后的机器学习模型。EP 函数的实现取决于选择的性能评估指标, 本文选用 F1-Score 作为 Θ的选择依据。模型训练与优化的具体流程如表4 所示。
2 研究结果
2.1 模型性能评估
2.1.1 评价指标
为揭示模型预测结果与实际标签之间的关系, 引入混淆矩阵(confusion matrix)进行分析。混淆矩阵通过矩阵形式展示预测结果, 其 4 个核心元素分别为真正例(true positive, TP)、假正例(false positi-ve, FP)、真反例(true negative, TN)和假反例(false negative, FN)。本文还采用召回率(Recall)、精确率(Precision)以及 F1 分数(F1-Score)等评价指标, 全面评估模型的综合性能。
2.1.2 实验结果与分析
本研究在 180901 个作者对数据集中随机划分出 20%作为测试集, 用来评估模型的性能。为确保评估的公正性与有效性, 严格保证测试集中的作者对样本与训练集及验证集中的作者对样本不重复。在作者身份验证任务中, 单个作者可能以不同的配对形式分别出现在训练集和测试集中, 这是配对分类任务的典型特征。由于模型的核心目标是学习作者特征间的语义相似性规律, 而非记忆特定作者的个体特征, 因此这种数据划分方式能够有效地评估模型的泛化能力[22]。测试集由 36181 个作者对数据构成, 为确保评估基准的可靠性和实验结果的客观性, 我们对测试集进行人工逐一验证, 最终确认其中 81 个数据对为同一作者。
表4 模型训练与优化流程
Table 4 Model training and optimization process

操作描述实现细节 1. 特征划分将划分为训练集 Dtrain 和测试集 Dtest 2. 特征标准化将 Dtrain 和 Dtest 标准化处理, 即和 σ 分别为特征均值和标准差 3. 定义超参数空间令, 其中 η 为学习率, d 为树最大深度, subsample 为子样本比例, … 4. 定义目标函数f(Θ)用于评估给定 Θ 下模型在验证集 Dval 上的性能 5. 定义代理模型f(Θ)隐式地充当代理模型, F1-Score 作为 Θ 的选择依据 6. 贝叶斯优化初始化定义初始超参数 Θ 分布, TPE策略选择下一个评估点 Θ, 设定收敛准则 7. 迭代评估更新迭代评估超参数 Θi , 训练代理模型, 用验证集 Dval 评估f(Θi) 8. 确定最优超参数通过迭代, 找到使得f(Θ)值最大的超参数组合 Θj 9. 最优模型训练用最优超参数组合 Θj 重新训练 XGBoost 10. 模型评估用测试集 Dtest 评估最优模型性能
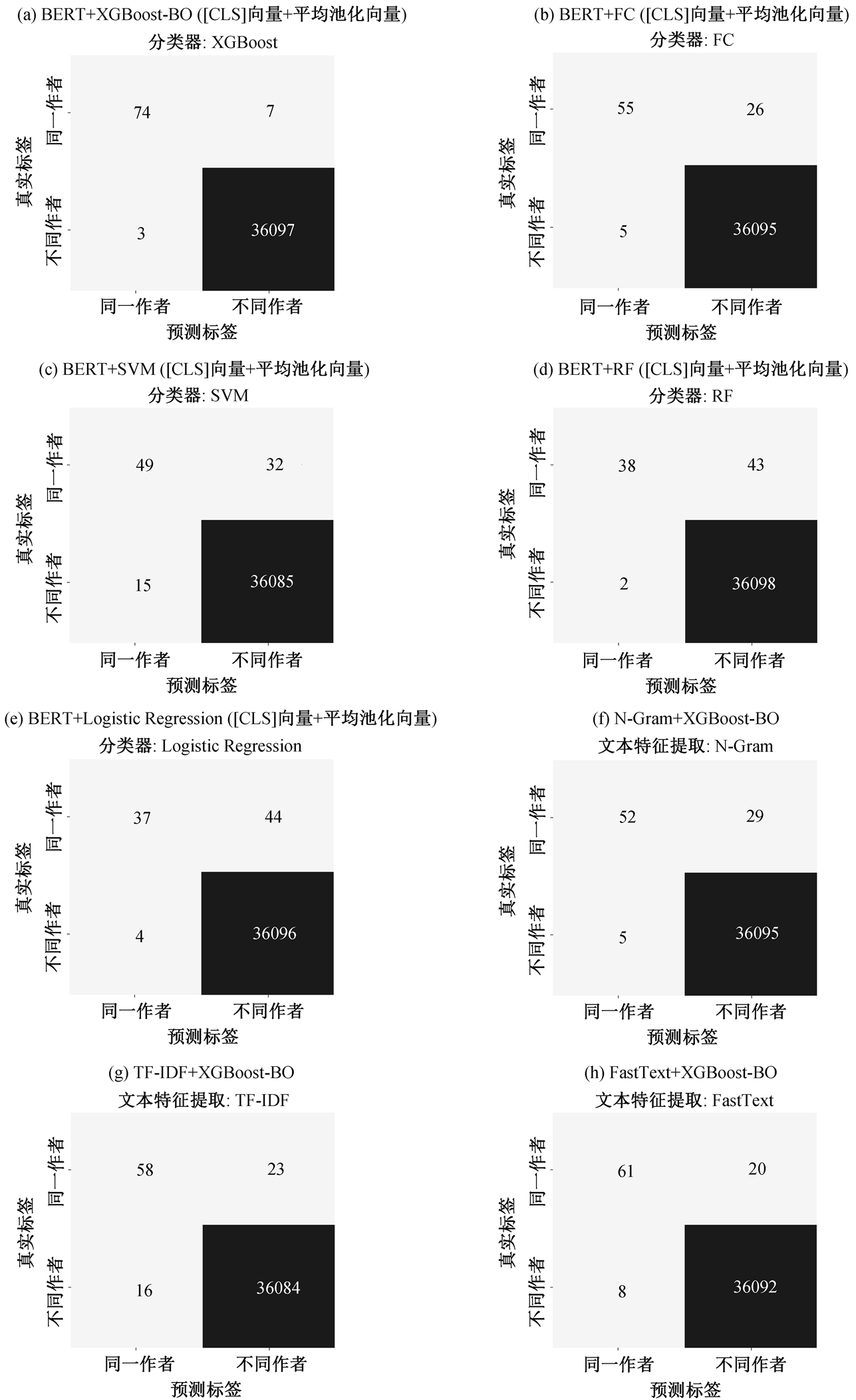
针对测试集内出现的显著样本不均衡问题, 我们主要聚焦于真实标签为“同一作者”(标签为 1)的预测结果, 以此作为衡量模型关键少数类识别能力的核心指标, 实验结果如表5 所示。同时, 对于真实标签为“不同作者”的预测结果, 其预测指标普遍达到 0.99 左右, 既体现模型在多数类上的高准确率, 也印证了我们的标注策略能够在保障关键少数类样本质量的同时, 使得多数类自动标注具有合理的可靠性。
从表5 可以看出, 基于 BERT 文本嵌入和 XG-Boost-BO 的模型在 Precision, Recall 和 F1-Score 指标上分别达到 0.96, 0.91 和 0.94, 显著优于其他对比方法。与传统分类器(SVM[23], RF[24]和 Logistic Re-gression[25])结合 BERT 的方法相比, 该模型有效提升了分类器的超参数配置效率, 在 Recall 和 F1-Score 上实现大幅度提升, 展现更强的少数类识别能力。为了确保实验结果的公正性与可比性, 本研究对 BERT 与不同分类器的组合方法进行统一的超参数基础调优。对使用的分类器(SVM, RF, Logistic Regression 和 XGBoost)都采用相同的网格搜索策略进行调优。与 XGBoost 相比, 传统分类器在处理BERT 生成的高维特征嵌入时, 更容易受到模型复杂度不足和样本不均衡问题的限制, 导致分类性能下降。
表5 作者身份验证实验结果
Table 5 Experimental results of authorship verification
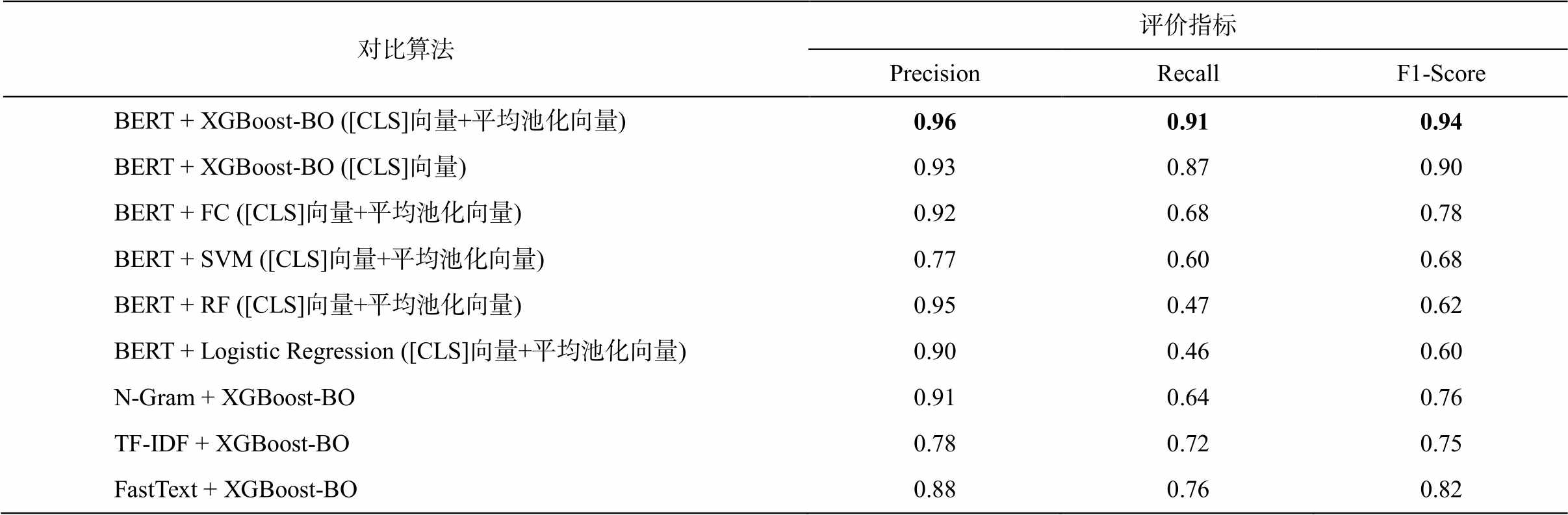
对比算法评价指标PrecisionRecallF1-Score BERT + XGBoost-BO ([CLS]向量+平均池化向量)0.960.910.94 BERT + XGBoost-BO ([CLS]向量)0.930.870.90 BERT + FC ([CLS]向量+平均池化向量)0.920.680.78 BERT + SVM ([CLS]向量+平均池化向量)0.770.600.68 BERT + RF ([CLS]向量+平均池化向量)0.950.470.62 BERT + Logistic Regression ([CLS]向量+平均池化向量)0.900.460.60 N-Gram + XGBoost-BO0.910.640.76 TF-IDF + XGBoost-BO0.780.720.75 FastText + XGBoost-BO0.880.760.82
说明: 类别为同一作者, 标签为“1”; 粗体数字表示性能最佳, 下同。
在文本特征提取方面, N-Gram 依赖固定的上下文窗口, 难以捕捉长距离语义依赖。TF-IDF 主要基于词频统计, 忽略了词汇之间的语义关联, 因此在复杂语义分析任务中表现较差。FastText 通过子词嵌入捕捉一定的语义信息, 但缺乏上下文感知能力, 难以建构复杂句法关系。BERT 通过双向 Transfor-mer 架构分析全局上下文, 能够捕捉深层语义特征, 有效地区分语义相似但词汇表达不同的文本, 增强了对同一作者文本之间细微语义差异的识别能力。
从表5 的实验结果对比可以发现, 相比于单一使用[CLS]向量, 结合[CLS]向量和平均池化向量方法的分类性能提升, Recall 指标提高 0.04, 意味着模型在识别“同一作者”样本时的能力更强, 漏判的数量更少, 验证了[CLS]和平均池化向量组合特征生成方法在捕捉文本全局语义方面的有效性。
为了验证分类器选择的合理性, 同时开展基于BERT 嵌入的全连接神经网络(FC)对比实验。全连接网络输入层的维度根据嵌入方式确定([CLS]+平均池化组合), 输出层使用两个神经元进行二分类, 网络使用 ReLU 激活函数, 引入 dropout 机制。与全连接神经网络相比, XGBoost 在处理 BERT 提取的高维语义特征时表现出较大的优势。全连接网络虽然具有强大的非线性拟合能力, 但在面对高维特征和不均衡数据时, 容易出现过拟合现象, 导致对少数类样本的识别能力不足。相比之下, XGBoost 通过调整 scale_pos_weight 参数, 可以有效地平衡正负样本权重, 在保持较高 Precision 的同时, 还可以显著地提升 Recall 性能, 验证了本文分类器选择的合理性和有效性。
为了更细致地分析不同模型的性能, 我们采用混淆矩阵作为辅助工具, 全面展示不同模型在不同类别上的预测表现, 结果如图 1 所示。
2.2 讨论
2.2.1 动态阈值调整对作者相似度判定结果的影响
本研究结合基于相似度分布动态阈值和文本长度权重因子两种策略的优势来定义综合阈值, 提高了正确样本的识别率, 从而可以更准确地衡量作者信息的相似性结果。由表6 可以看出, 虽然固定阈值在某些情况下能够提供一定的判定依据, 但由于其无法适应数据集的复杂性和多样性, 导致在判断作者相似性时出现较高的错误率。在仅使用基于文本长度权重因子 λ 调整固定阈值或相似度分布动态阈值 T1 的情况下, 整体上的判定效果不及综合使用两种策略。
尽管综合阈值 T2 策略在提升判定相似度标签划分边界方面取得显著成效, 但相似度分布调节参数 k1 和文本长度差异权重 λ0 的设置仍然需要大量的人工干预。此外, 筛选后的标签结果还需要经过后期的人工样本清洗, 才能确保输入模型的数据准确可靠。
2.2.2 贝叶斯优化对作者身份验证的影响
如表7 所示, 与未使用贝叶斯优化的 BERT+ XGBoost 模型相比, 融合了贝叶斯优化的 BERT+ XGBoost-BO 模型在 Precision, Recall 和 F1-Score 上均显著提高。Precision 从 0.89 提升至 0.96, Recall 从0.85 提升至 0.91, F1-Score 从 0.87 提升至 0.94。这些结果充分证明贝叶斯优化在自动调整 XGBoost 超参数方面的有效性。
表8 列出贝叶斯优化过程中探索的超参数空间及其最终确定的最优参数值。通过贝叶斯优化, 我们成功地找到一组最优的超参数组合, 这些参数可以在平衡模型复杂度和泛化能力方面发挥重要作用, 进而提升模型在作者身份验证任务中的性能。
3 结论
本文针对传统方法在处理复杂文本结构和深层语义理解方面的不足, 通过融合文本嵌入和机器学习的作者身份验证方法, 提出一种基于 BERT 文本嵌入和 XGBoost-BO 的作者身份识别模型。实验结果表明, 该模型在作者身份验证任务中取得显著的效果, Precision 高达 0.96, Recall 为 0.91, F1-Score为 0.94, 均优于其他对比算法。这一成果不仅验证了 BERT 模型在文本特征提取方面的强大能力, 也展示了 XGBoost 分类器与贝叶斯优化策略在提高模型对作者身份判别准确性方面的优势。
本文通过构建面向作者身份验证的数据集, 为模型训练和性能评估提供了坚实的基础。研究结果表明, 动态阈值调整策略在提升作者相似度判定准确性方面发挥了重要作用, 贝叶斯优化则有效地提高 XGBoost 模型的超参数配置效率, 进一步增强模型的泛化能力。这些发现不仅丰富了作者身份验证领域的研究内容, 也为后续相关研究提供了新的思路和方法。
表6 动态阈值调整(相似度判定条件)对作者相似度判定结果的影响
Table 6 Influence of dynamic threshold adjustment (similarity determination conditions) on author similarity determination results

相似度判定条件数量样本清洗(类别: 同一作者, label=1) label=0label=1正确样本量错误样本量 T0=0.98180228673411262 λ·T0180400501406 95 T1180375526409117 T2=λ·T1180493408398 10
表7 贝叶斯优化对作者身份验证的影响
Table 7 Influence of Bayesian optimization on authorship verification

贝叶斯优化对比算法PrecisionRecallF1-Score BERT+XGBoost ([CLS]向量+平均池化向量)0.890.850.87 BERT+XGBoost-BO ([CLS]向量+平均池化向量)0.960.910.94
说明: 类别为同一作者, 标签为“1”。
表8 贝叶斯超参数空间最优参数组合
Table 8 Optimal parameter combination in Bayesian hyperparameter space
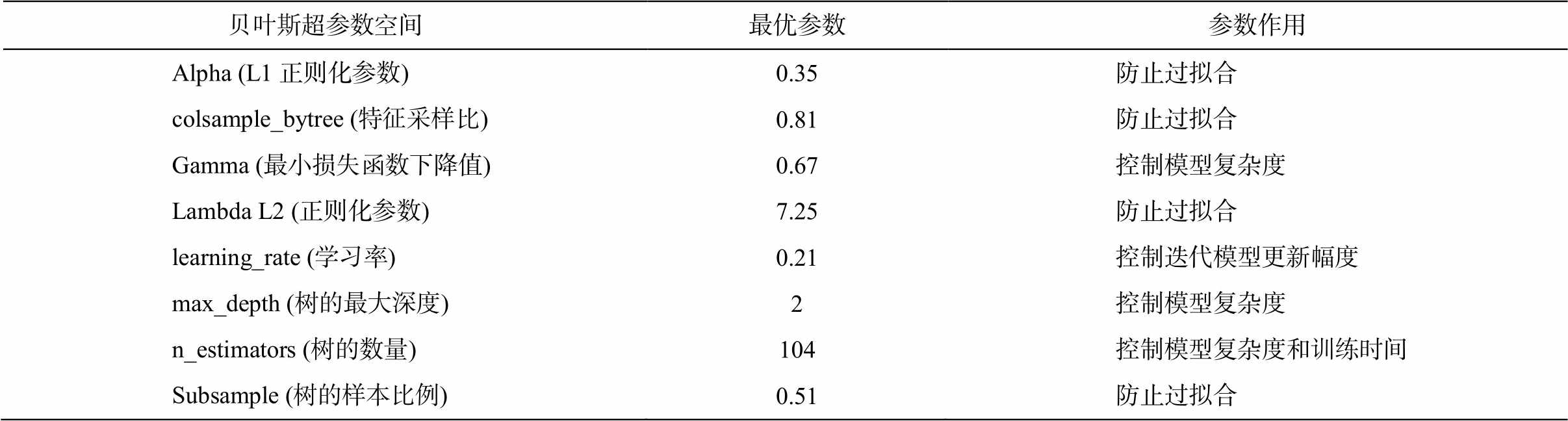
贝叶斯超参数空间最优参数参数作用 Alpha (L1正则化参数)0.35防止过拟合 colsample_bytree (特征采样比)0.81防止过拟合 Gamma (最小损失函数下降值)0.67控制模型复杂度 Lambda L2 (正则化参数)7.25防止过拟合 learning_rate (学习率)0.21控制迭代模型更新幅度 max_depth (树的最大深度)2控制模型复杂度 n_estimators (树的数量)104控制模型复杂度和训练时间 Subsample (树的样本比例)0.51防止过拟合
参考文献
[1] Ding S H H, Fung B C M, Iqbal F, et al. Learning stylometric representations for authorship analysis. IEEE Transactions on Cybernetics, 2019, 49(1): 107–121
[2] 邓可君, 华凯, 邓昌明, 等. 基于机器学习的论文作者名消歧方法研究. 四川大学学报(自然科学版), 2019, 56(2): 241–245
[3] Boukhers Z, Asundi N B. Deep author name disambi-guation using DBLP data. International Journal on Di-gital Libraries, 2024, 25(3): 431–441
[4] Hussain I, Asghar S. A survey of author name disam-biguation techniques: 2010—2016. Knowledge Engi-neering Review, 2017, 32: e22
[5] Gong J, Fang X, Peng J, et al. MORE: toward impro-ving author name disambiguation in academic knowle-dge graphs. International Journal of Machine Learning and Cybernetics, 2024, 15(1): 37–50
[6] 王新, 卢垚, 袁雪, 等. 学术论文作者同名消歧方法研究进展. 农业图书情报学报, 2022, 34(10): 82–90
[7] 张洋, 江铭虎. 作者识别研究综述. 自动化学报, 2021, 47(11): 2501–2520
[8] 阮光册, 涂世文, 田欣, 等. 多特征融合的英文科技文献增量式人名消歧应用研究. 情报杂志, 2021, 40(9): 147–153
[9] 曾健荣, 张仰森, 王思远, 等. 基于多特征融合的同名专家消歧方法研究. 北京大学学报(自然科学版), 2020, 56(4): 607–613
[10] Koppel M, Schler J, Argamon S, et al. The “Funda-mental Problem” of authorship attribution. English Studies, 2012, 93(3): 284–291
[11] 武永亮, 赵书良, 李长镜, 等. 基于 TF-IDF 和余弦相似度的文本分类方法. 中文信息学报, 2017, 31 (5): 138–145
[12] 张辉, 王靖亚, 仝鑫. BERT-CharCNN联合模型微博作者身份验证研究. 江苏警官学院学报, 2020, 35 (6): 67–71
[13] Boenninghoff B, Nickel R M, Zeiler S, et al. Similarity learning for authorship verification in social media // 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2019: 2457–2461
[14] Santini C, Gesese G A, Peroni S, et al. A knowledge graph embeddings based approach for author name disambiguation using literals. Scientometrics, 2022, 127(8): 4887–4912
[15] Alghamdi J, Lin Y, Luo S. A comparative study of machine learning and deep learning techniques for fake news detection. Information, 2022, 13(12): no. 576
[16] Jin D, Jin Z, Zhou J T, et al. Is BERT really robust? a strong baseline for natural language attack on text classification and entailment // Thirty-fourth AAAI Conference on Artificial Intelligence, The Thirty-Se-cond Innovative Applications of Artificial Intelligence Conference and the Tenth AAAI Symposium on Educa-tional Advances in Artificial Intelligence. Palo Alto: Assoc Advancement Artificial Intelligence, 2020: 8018–8025
[17] Chen T, Guestrin C. XGBoost: a scalable tree boosting system // KDD’16: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Dis-covery and Data Mining. New York: Assoc Computing Machinery, 2016: 785–794
[18] Shen Y, Chen M, Cai S, et al. BERT-RF fusion model based on Bayesian optimization for sentiment classifi-cation // 2022 IEEE 2nd International Conference on Computer Communication and Artificial Intelligence (CCAI 2022). New York, 2022: 71–75
[19] Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language under-standing // 2019 Conference of the North American Chapter of the Association for Computational Lingui-stics: Human Language Technologies (NAACL HLT 2019). Stroudsburg: Assoc Computational Linguistics-ACL, 2019: 4171–4186
[20] Ajao O, Bhowmik D, Zargari S. Content-aware tweet location inference using quadtree spatial partitioning and Jaccard-Cosine word embedding // Brandes U, Reddy C, Tagarelli A. 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM). New York, 2018: 1116–1123
[21] 崔佳旭, 杨博. 贝叶斯优化方法和应用综述. 软件学报, 2018, 29(10): 3068–3090
[22] Subramanian S, King D, Downey D, et al. S2AND: a benchmark and evaluation system for author name disambiguation. 2021 ACM/IEEE Joint Conference on Digital Libraries (JCDL). Champaign, IL, 2021: 170–179
[23] 严佩敏, 唐婉琪. 基于改进 BERT 的中文文本分类. 工业控制计算机, 2020, 33(7): 108–110
[24] 赵敬华, 谢婉瑜, 吕锡婷, 等. 基于 RF-BERT 和UGC 的用户需求识别及其发展趋势预测. 情报科学, 2024, 42(1): 132–142
[25] 段丹丹, 唐加山, 温勇, 等. 基于BERT模型的中文短文本分类算法. 计算机工程, 2021, 47(1): 79–86
Research on Authorship Verification Methods Integrating Text Embedding and Machine Learning
WANG Xinmin1,2,†, ZHU Wenqing2, HAN Zhuoxi3, LIU Hao2
1. National Engineering Laboratory for Big Data Analysis and Applications, Peking University, Beijing 100871; 2. Changsha Institute for Computing and Digital Economy, Peking University, Changsha 410205; 3. Center for Global Connectivity Studies at Institute of Ocean Research, Peking University, Beijing 100871; † Corresponding author, E-mail: wangxinmin@pku.edu.cn
Abstract Based on integrate deep learning and machine learning, an annotated dataset oriented towards authorship verification is constructed, employing BERT and dynamic similarity threshold strategy to enhance label quality. An authorship identification model integrating BERT text embedding and XGBoost-BO is proposed. This model combines the powerful feature extraction capabilities of BERT and the efficient classification performance of XGBoost. Additionally, Bayesian optimization is employed for hyperparameter search to achieve accurate authorship verification. Furthermore, the effectiveness of the dynamic similarity threshold strategy in enhancing author similarity determination accuracy is investigated, as well as the significant role of Bayesian optimization in automatically adjusting XGBoost hyperparameters to improve its overall performance. Experimental results demonstrate that the proposed method outperforms all baseline methods across various evaluation metrics, providing an effective solution for authorship verification.
Key words authorship verification; dynamic similarity threshold; BERT; XGBoost; Bayesian optimization
收稿日期: 2024–10–22;
修回日期: 2025–07–07
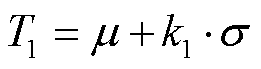 , (1)
, (1)
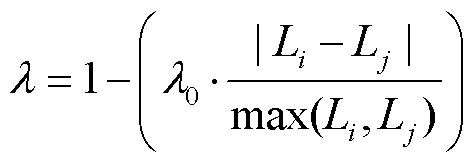 , (2)
, (2)
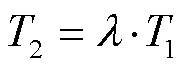 。 (3)
。 (3)
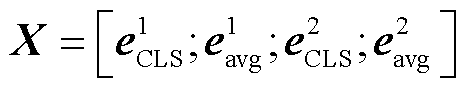 , (4)
, (4)
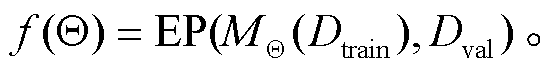 (5)
(5)