
(a)视点在相机位置沿拍摄方向的渲染效果; (b)视点在相机位置, 朝向天空的渲染效果; (c)视点移动至远处的渲染效果
图1 3D Gaussian Splatting场景重建效果示意图
Fig. 1 Schematic diagram of 3D Gaussian splatting scene reconstruction effect
北京大学学报(自然科学版) 第61卷 第4期 2025年7月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 61, No. 4 (July 2025)
doi: 10.13209/j.0479-8023.2024.095
国家重点研发计划(2021YFF0500900)资助
收稿日期: 2024–04–18;
修回日期: 2024–05–13
摘要 提出一种与场景高斯椭球体分布相关的渲染质量指数计算方法。该方法利用场景的全景渲染图像计算渲染质量指数, 定量地评价全景图像的渲染质量, 并利用全景图像的 FID 值检验渲染图像与真实图像的语义一致性。实验结果表明, 该渲染质量指数可以有效地评估全景图像渲染质量, 符合人类的直觉认知, 并获得更高的计算性能, 可为保持虚拟野外考察过程中用户的交互沉浸感提供支持。
关键词 野外环境; 全景影像; 渲染质量; 三维重建; 场景理解
随着虚拟地理环境技术的发展, 虚拟野外考察技术为科学研究提供了新的可能性, 同时也为广大学生和研究者提供了更灵活的学习和研究方式。虚拟野外考察的一大重点便是虚拟野外地理场景的构建方法以及相应的场景交互方法。
3D Gaussian splatting技术是目前在三维场景重建与新视角渲染领域中最为亮眼的技术, 其分钟级的训练速度与实时进行新视角渲染的能力使得它迅速走入众多研究者的视野。它将显式建模和隐式渲染综合在一起, 利用“3 维高斯椭球体”实现隐式虚拟场景的新视角实时渲染, 为极具真实感的虚拟野外考察提供技术上的可能性。
在野外环境三维全景场景重建任务中, 该方法可以很好地重建被拍摄对象的场景信息, 如图 1 所示。树干在不同视角下的渲染图像十分逼真, 但是一旦改变画面的方向就会发现, 由于相机拍摄的视角有限, 在天空处没有进行重建, 出现场景空洞(图1(b)上部)。当我们将视点远离树干时, 由于漫游过远, 此处缺少多视角的训练图像, 重建质量较差, 同样出现空洞(图 1(c)下部), 渲染质量大大降低。以上两种因素均会导致用户在虚拟场景漫游过程中的沉浸感大打折扣。目前的做法是将相机拍摄图像作为训练数据, 使得渲染图像与其尽可能相似, 但忽略场景任意视点处的渲染图像, 无法保证任意视点的渲染图像质量。
(a)视点在相机位置沿拍摄方向的渲染效果; (b)视点在相机位置, 朝向天空的渲染效果; (c)视点移动至远处的渲染效果
图1 3D Gaussian Splatting场景重建效果示意图
Fig. 1 Schematic diagram of 3D Gaussian splatting scene reconstruction effect
全景相机可以提供较大的视场角, 快速采集相同位置的全方位影像, 用较短的时间采集到局部空间各方向的场景信息, 重建全景方向场景, 贴近人类实际观测的情况。本研究基于全景的野外视频数据, 提出基于三维场景重建方法 3D Gaussian Splat-ting 的渲染质量评估方法, 实现对重建三维场景中新视角渲染得到的全景图像的渲染质量判定, 便于掌握虚拟重建场景的高质量重建区域范围, 为野外考察和教学提供技术支撑。
近年来, 隐式重建三维场景技术得到研究者青睐。这种隐式方法将场景和物体对象编码, 使用多层感知机(multilayer perceptron, MLP), 将 3D 空间位置映射为隐式特征, 从中进行新视角图像的合成或提取物体模型。神经辐射场(neural radiance field, NeRF)方法[1]利用 MLP 表达一个三维场景, 获取三维空间中颜色与密度的分布, 推动新视角合成技术进入一个新的阶段。但是, NeRF 存在推理过程低效、只能表达一定范围内的物体等缺点, 难以进行实际应用。之后的研究人员基于 NeRF 框架进行改进。Barron 等[2–3]重新设计 NeRF 的参数编码, 解决不同分辨率下的锯齿像素问题和无法进行无边界场景表示的问题。Fridovich-Keil 等[4]提出 Plenoxels方法, 将体素网格作为显式空间数据表达方式, 提升推理速度。Attal 等[5]利用射线对空间进行编码, 以更紧凑的形式构建光场对空间的映射, 提升推理速度。Müller 等[6]提出 Instant-NGP, 利用哈希网格对场景进行显示编码, 结合隐式模型进行场景重建, 并通过 CUDA, 对模型推理过程进行编程, 实现第一个实时交互的 NeRF 类应用, 提出利用 CUDA 大幅度加速 NeRF 推理过程的解决方案。Kerbl 等[7]提出的 3D Gaussian Splatting (3DGS)方法以稀疏点云为初始模型, 并生成高斯椭球体, 利用“溅射”的方式, 将椭球投影到相机平面进行渲染, 可以实现新视角的实时渲染, 为虚拟场景漫游提供了可能性。Martin-Brualla 等[8]将拍摄图像时的曝光、天气和色调等参数作为外观维度, 嵌入 NeRF 的训练中, 使得 NeRF 模型可以适应各种光照环境的训练数据, 提升渲染质量的鲁棒性。Cheng 等[9]提出渐进式生成策略, 优化高斯椭球体的加密过程, 有效地提升场景的图像渲染质量。
虽然上述重建方法可以实现高质量的重建, 但训练策略始终是将渲染图像与相机拍摄的图像之间进行损失函数的估计, 最终在一定范围内的场景渲染质量接近真实, 因此 NeRF 能够有效地解决室内、建筑和游戏等领域的三维重构。然而, 空旷的野外环境中有山体、树木和岩石等, 当视点远离相机位置或朝向相机没有拍摄到的方向时, 渲染得到的图像质量就会大幅度下降。从图 1 可以看出, 对渲染质量高的图像, 人眼可以判断当前画面的语义, 渲染质量低的画面中则存在较多的空洞或无意义的色块。因此, 需要寻找一种方法来区分 3DGS 场景中视点的渲染质量。遗憾的是, 这一目标领域的研究工作很少。
从本质上讲, 3DGS 场景是由大量高斯椭球体构成, 将椭球体溅射到渲染平面上, 形成渲染图像, 说明渲染质量与画面中椭球体的密集程度相关。在野外虚拟考察过程中, 视点观察方向可能是各个方向, 因此渲染质量评估也需要全方向的。本文提出的渲染质量评估方法以计算高斯椭球体全方向的密集程度为切入点, 如果经过训练后的高斯椭球体可以将视点密集地包围起来, 那么该视点的渲染质量将十分接近真实图像, 从而可以通过视点与离散高斯椭球体在空间中的包围关系来判断渲染质量。
与计算空间包围关系相似的工作是研究如何从离散点云中提取物体表面。如果空间中的一点处在离散点云表示的物体表面内部, 则意味着该点被离散点云全方位密集地包围着。这些研究工作对本文有一定的启示。Amenta 等[10]使用 Voronoi 图, 从稀疏点云中重建点云表示的模型表面。Kolluri 等[11]通过解决 Vonoroi 顶点上的图割问题, 解决表面细节度低的问题, 对噪声和异常值的鲁棒性更强。Ja-cobson 等[12]基于立体角概念以及点云法线数据计算, 得到场景的卷绕数分布, 从而区分物体内外边界。但是, 基于点云的算法效率依赖点的数量, 能够表达全景场景的点云规模, 会使得时间消耗成倍地增加。Wang 等[13]通过隐式函数方法, 利用 MLP得到空间的符号距离场(signed distance field)分布, 通过数值的正负来判断物体的内外。Lin 等[14]提出PGR 方法, 将表面法线和表面元素区域视为未知参数, 使用高斯公式, 将指标解释为某个参数函数空间的成员。受Lin 等[14]通过立体角推导高斯公式的启发, 我们将其与 3DGS 模型结合, 推导出等效的立体角计算公式, 进而提出渲染质量指数的计算方法, 用于判断场景的渲染质量, 利用该质量参数的分布情况, 可以确定场景高渲染质量的区域范围。
本文方法流程的主要框架如图 2 所示, 可以分为数据预处理、野外场景三维重建、渲染质量评价和渲染质量指标验证 4 个阶段。
1)数据预处理阶段: 使用全景相机, 拍摄和采集 6 目全景视频 V={Vi:1≤i≤6}, 进行视频抽帧, 去除鱼眼畸变, 得到 6 目无畸变图像帧序列 I={Iij:1≤i≤6, 1≤j≤n}, 通过稀疏重建得到每个图像帧对应的相机姿态 Cij, 并生成稀疏点云 S={si: 1≤i≤ns}。
2)野外场景三维重建阶段: 使用 3DGS 技术, 根据相机姿态 Cij 与稀疏点云 S 进行三维重建, 得到由 ng 个高斯椭球体 gi 表示的 3DGS 模型 G={gi:1≤ i≤ng}, 利用该模型在自由视点渲染立方体贴图投影(cubemap projection, CMP)格式全景图像 CP。
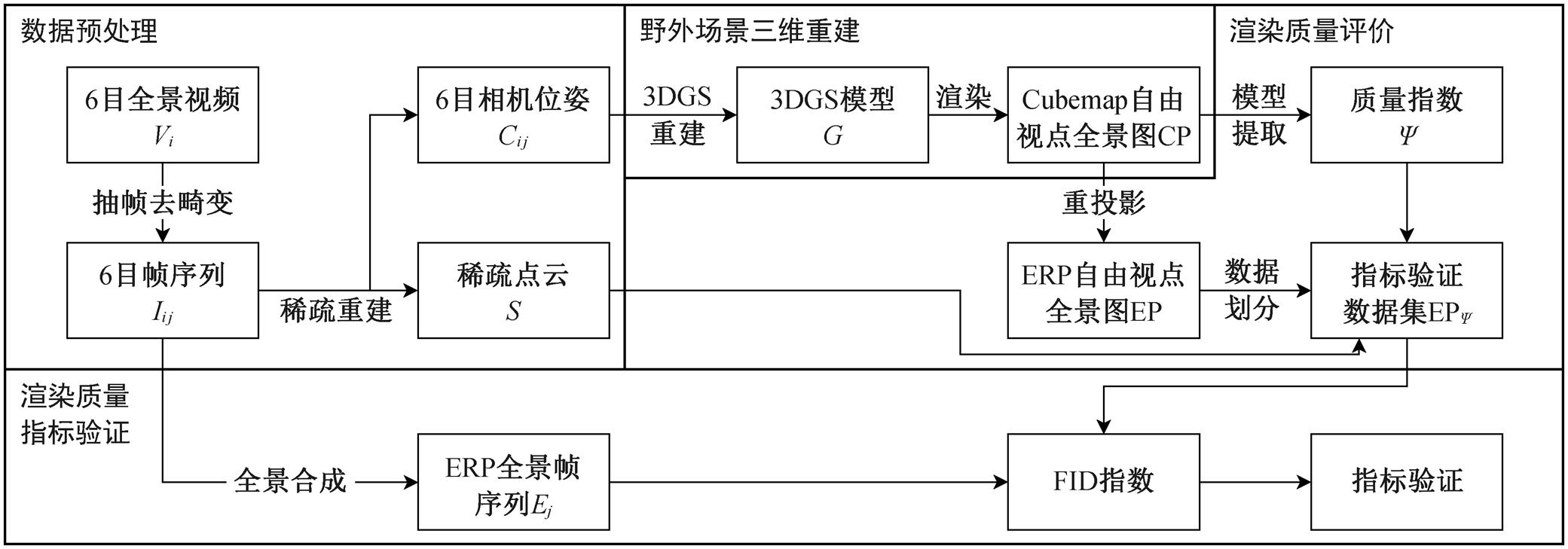
图2 方法流程
Fig. 2 Method flowchat
3)渲染质量评价阶段: 提出渲染质量指数的定义, 由 3DGS 场景数据 G 和全景图像 CP 计算得到渲染质量指数 Ψ; 进一步计算场景中各点的渲染质量指数, 将 Cubemap 格式全景图重投影, 生成等矩形投影(equirectangular projection, ERP)格式的全景图EP; 根据渲染质量指数, 将 EP 划分为不同的指标验证数据集 EPΨ。
4)渲染质量指标验证阶段: 对 6 目图像帧序列进行全景合成, 得到 ERP 格式的全景图帧序列 E= {Ej: 1≤j≤n}, 作为 GT 图像数据集; 使用 EPΨ 和 GT两个图像集计算 FID(fréchet inception distance), 验证本文渲染质量指数的有效性。
为了评估图像的渲染质量, 首先采集野外真实场景数据, 进行 3DGS 场景重建。我们预先假定山体、岩壁、植被、天空和地面等相对静态的野外场景会出现于拍摄画面的大部分区域, 且不出现其他移动的行人或车辆。相较于 3DGS 方法使用的数据集, 本文使用全景相机进行野外场景数据的采集,采用手持相机的方式对目标景物的图像进行拍摄。全景相机可以在任意点位同时获取 360°的场景数据, 因此重建的场景不会在某个方向出现空洞。

图3 全景图像投影格式
Fig. 3 Description of panoramic image projection formats
如图 3 所示, 本文主要使用等矩形投影(equi-rectangular projection, ERP)和立方体贴图投影(cube-map projection, CMP)两种全景图像的格式。ERP 是将全景图像映射到一个球面上, 然后将球面展开成矩形图像。这种投影方式能够较好地保持视角的比例, 但会导致中心区域的放大和边缘区域的形变。CMP 将全景图像分成 6 个相等的面来表示全景场景, 每个面代表一个方向(上、下、左、右、前、后), 如同立方体的 6 个面。将立方体每个面的像素投影到球面上, 就可以完成从 CMP 格式到 ERP 格式的全景图像投影转换。
本文采用 6 镜头全景相机, 其机身均匀地环绕装载 6 个超广角鱼眼镜头, 水平方向等间距地间隔60°, 支持各个镜头分别导出拍摄画面, 也可进行软件拼接, 形成 ERP 格式全景图像。本文所用数据集通过手持全景相机在野外真实场景的不同点位步行拍摄视频进行采集, 每个点位的采集时间控制在约2 分钟。
为了完成后续的三维重建工作, 从相机中导出6 目全景视频 Vi, 通过抽帧, 获得 6 目相机拍摄的图像帧(图 4(a)), 根据相机鱼眼镜头参数对图像进行去畸变处理, 获得透视成像的图像帧序列 Iij (图 4 (b)), 相邻两个镜头所拍摄图像的重合度可以达到50%, 便于系数重建过程中进行特征匹配。
COLMAP[15–16]是一个通用的稀疏重建与多视图重建的集成应用程序, 提供便捷的图形与命令行界面, 可以从图像集合中恢复三维结构。本文使用COLMAP, 对去畸变后的图像帧序列进行特征提取与匹配。通过稀疏重建, 得到每张图像的相机位姿Cij 以及稀疏点云的分布 S, 结果如图 5 所示。图 5 (b)~(d)中, 采用连续的红色矩形相机位姿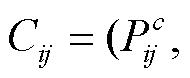
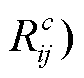 , 包含每个相机在场景中的位置
, 包含每个相机在场景中的位置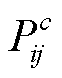 以及旋转矩阵
以及旋转矩阵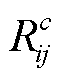 。该处场景是一个狭长的峡谷, 而稀疏点云对场景中的岩壁和地面等近处景物还原较好, 但缺乏远处景色和天空等大范围特征(如图 5(a)和(d)中绿色框线对应的位置)。
。该处场景是一个狭长的峡谷, 而稀疏点云对场景中的岩壁和地面等近处景物还原较好, 但缺乏远处景色和天空等大范围特征(如图 5(a)和(d)中绿色框线对应的位置)。

图4 图像帧数据示意图
Fig. 4 Schematic diagram of image frame data
本文基于相机位姿和稀疏点云, 使用 3DGS 技术进行三维场景重建, 方法流程如图 6 所示。从稀疏点云 S 中通过初始化, 生成由若干高斯椭球体 gi构成的 3DGS 模型 G, 每个高斯椭球体 gi 具有独立的位置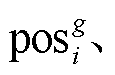 透明度
透明度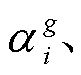 协方差
协方差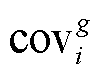 以及特征向量
以及特征向量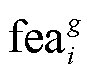 。决定每个椭球体在视点看到的形状, 而决定其颜色
。决定每个椭球体在视点看到的形状, 而决定其颜色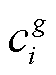 , 最后通过公式
, 最后通过公式
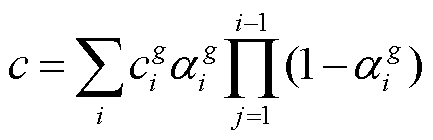 (1)
(1)
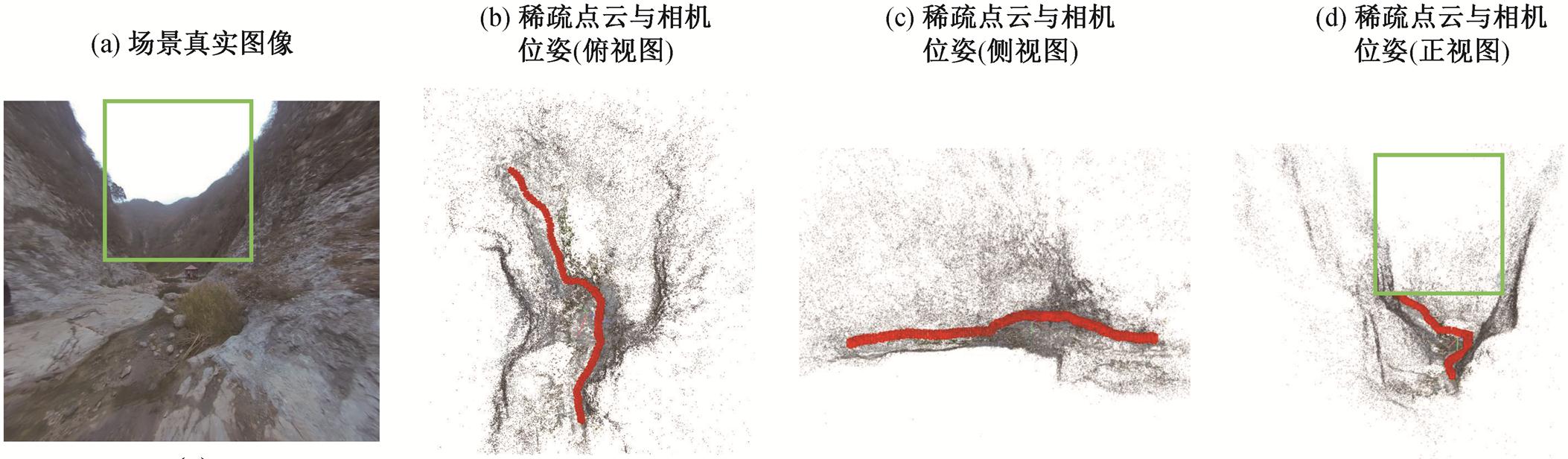
图5 场景稀疏重建结果示意图
Fig. 5 Schematic diagram of scene reconstruction results
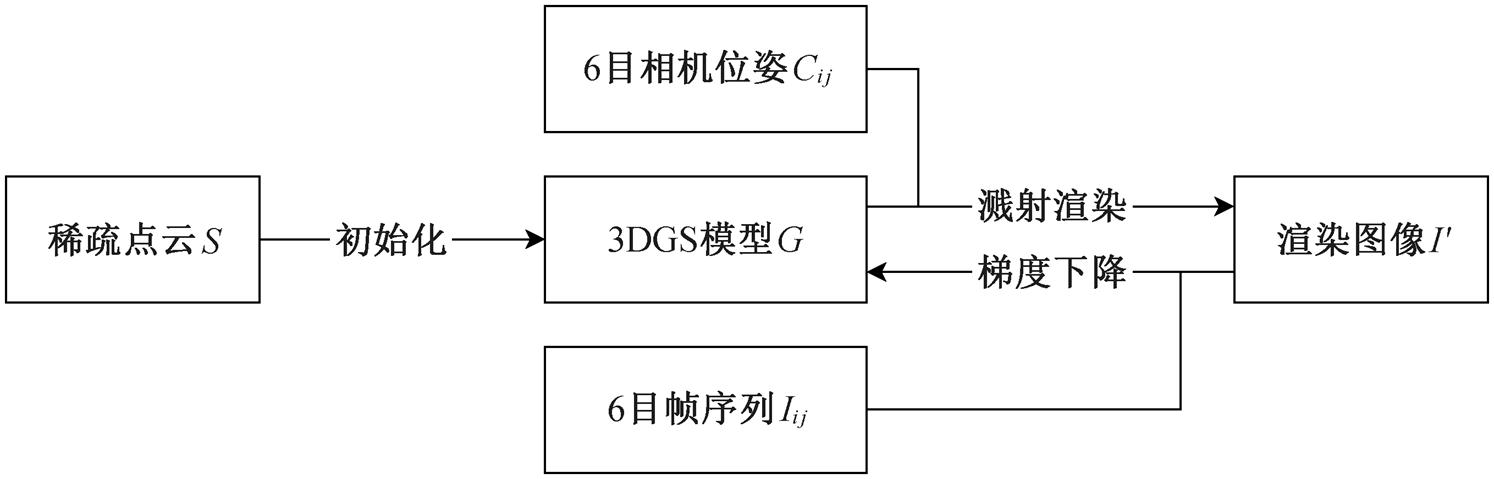
图6 3DGS技术流程
Fig. 6 Flowchart of 3DGS technology
进行透明度合成, 得到像素颜色 c, 进而得到渲染图像 I′。
模型中需要另外给定规模参数j和背景颜色Cb。规模参数j可以整体缩放所有椭球体的大小, 默认取值为 1。背景颜色 Cb 用来控制渲染图像的底色, 默认为黑色, 当椭球体分布稀疏, 产生场景空洞时, 渲染图像中就会出现黑色的底色。
将真实拍摄图像作为训练数据, 可以逐渐优化这些椭球体的参数, 使得渲染图像与真实场景无异。在此过程中, 高斯椭球体 gi 并非与稀疏点云 Si完全一一对应, 3DGS 会根据点云分布的具体情况进行复制和分裂操作, 改变椭球体的分布, 使得最终效果与真实场景更贴切。正因为如此, 我们在前面COLMAP 重建过程中没有成功重建的区域(如天空和远处的景物等)在这一步得以重建出来, 并且重建的三维场景具有渲染全景图像的能力。图 7(a)展示经过训练后 3DGS 模型 G 的高斯椭球体分布情况, 表示近处山体的高斯椭球体因由点云初始化生成而分布密集, 表示天空的大而稀疏的椭球体则是在训练过程中动态地生成, 最终这些椭球体对应的渲染结果如图 7(b)所示。通过渲染 6 个方向的图像并将它们拼接, 我们可以得到任意视点的 Cubemap 格式全景渲染影像(图 7(c)), 便于后续处理。
2.2.1 渲染质量与重建场景的位置关系
在虚拟野外考察任务中, 用户观察场景的方向可能是任意方向, 因此在重建的全景场景中, 渲染的图像质量也需要考虑全部视角的渲染结果, 而不是单一方向的渲染图像。因此, 本文使用全景图像来评估某一视点的渲染图像质量, 一个视点的图像渲染质量较高, 主要体现在图像中的场景空洞以及无意义的色块较少。
由于训练数据是全景数据, 不会出现缺少某一方向景物的情况, 因此可以利用 3DGS 模型在视点处渲染并合成全景图像。为了获得渲染质量较高的全景图像, 视点中每个方向都应该分布一定数量的高斯椭球体, 椭球体越密集, 渲染出的景物特征越清晰。3DGS 的训练策略使得相机拍摄位置处各方向的椭球体分布较均匀和密集, 渲染得到的全景图像没有场景空洞, 并且与真实景物的图像一致。当靠近场景边缘的椭球体时, 渲染图像中这个方向的椭球体就会变得稀疏, 甚至缺失, 从而出现场景空洞。无意义色块的出现也是因视点过于靠近某些椭球体而渲染出来的, 在这些情况下, 图像的渲染质量就会降低。
图 8 和 9 示意图像渲染质量的变化。在 3DGS模型中选取 A 和 B 两个点(图 8), 分别渲染全景图, A 点位于场景中地面上方, 靠近相机路径, 其渲染全景图(图 9(a))各方向景物渲染良好, 渲染质量较高。B 点则位于岩壁处, 视野空缺的方向缺少投影到相机平面上产生颜色的椭球体, 视野中呈现大片黑色, 其渲染全景图(图 9(b))出现明显的视野空缺, 图像渲染质量降低。可以找到一个最小包络体 M, 将这些表示场景边缘的椭球体包裹起来, 本文定义的高渲染质量的视点均分布在 M 内部。这样, 我们的研究工作就与从稀疏点云确定物体表面的工作建立了联系。上述 A 点位于 M 的内部, 而 B 点位于 M的边缘, 高渲染质量的全景图应该全部处于 M 内部, 我们可以通过视点与最小包络体 M 的这种拓扑关系来判断渲染质量。
2.2.2 渲染质量指数理论推导
对于一个封闭连续曲面S, 细分得到离散面元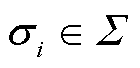 , 我们可以使用立体角F来判断点 m 在曲面之内还是之外, 其定义如下:
, 我们可以使用立体角F来判断点 m 在曲面之内还是之外, 其定义如下:
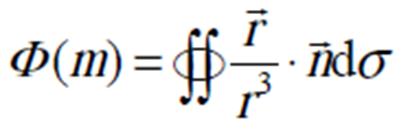

图7 3DGS场景重建结果与渲染图像
Fig. 7 3DGS scene reconstruction result and render images

图8 3DGS场景示意图
Fig. 8 Schematic diagram of 3DGS model

图9 3DGS模型分别在点A (a)和B (b)处的渲染全景图
Fig. 9 Rendered panoramas of the 3DGS model at points A (a) and B (b)
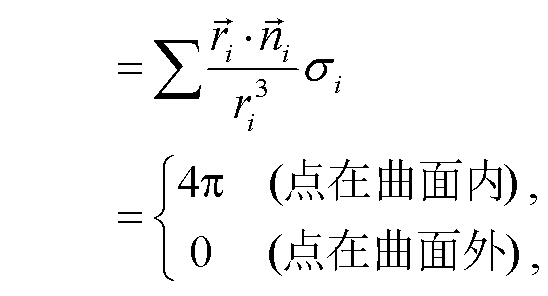 (2)
(2)
其中, 下角标 i 为各离散面元的编号, 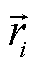 为点 m 到离散面元的矢径,σi 为面元的大小,
为点 m 到离散面元的矢径,σi 为面元的大小, 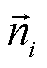 为面元的法线方向。式(2)也可以理解为求每个面元对该点的立体角之和, 在曲面S为封闭且连续的理想情况下, 点 m 在曲面内外只会呈现 4π 和 0 两个分立值。
为面元的法线方向。式(2)也可以理解为求每个面元对该点的立体角之和, 在曲面S为封闭且连续的理想情况下, 点 m 在曲面内外只会呈现 4π 和 0 两个分立值。
在 3DGS 渲染过程中, 将视点 p 视野中的椭球体沿着特定方向投影到相机平面上, 这一过程叫做溅射(splatting)。溅射的结果是若干透明度变化的椭圆光斑, 最后按照深度值由大到小的顺序合成颜色。理想情况下, 视点立体角需要由最小包络体M的表面计算得到, 但是M难以求得, 我们需要用3DGS 模型的高斯椭球体来估算与立体角近似的指标, 从而定量地描述渲染质量随视点位置的变化。如图 10(a)所示, 用锥体表示单个椭球体对视点 p 的立体角, 在同一个锥体中, 该立体角的大小保持不变, 因此本文使用相机平面上的光斑来代替计算椭球体的立体角大小, 同时也利用 3DGS 的渲染技术来加速计算, 避免逐个椭球体的计算。我们通过调整, 将椭球体 gi 的颜色设置为白色, 背景颜色 cb 设置为黑色, 使得椭球体的投影结果是大小不一的白色渐变光斑。相机平面上像素的像素值对应椭球体在该像素方向的覆盖程度。如果渲染结果全部为白色, 则可以理解为视点在所有方向都被椭球体完全遮盖。反之, 若某处的像素值为灰色或黑色, 即表示该方向缺少足够的椭球体, 遮盖程度不足。
若干椭球体在相机平面上的光斑可能相互重叠, 因此每个像素的像素值反映多个椭球体共同的覆盖程度, 而前后遮挡的椭球体投影到相机平面后, 只会形成一个光斑, 因此利用像素值计算遮挡程度时, 不会对两个完全遮挡的光斑进行两次计算。基于椭球体光斑的覆盖程度, 可以计算得到等效的立体角。
设 x, y 是相机平面上的像素坐标, 则可将其像素值 px(x, y)映射到(0, 1)的范围视为该像素的椭球体覆盖程度。由于像素是正方形且边长为 1, 那么每个像素由椭球体覆盖的面积可以由式(3)估算:
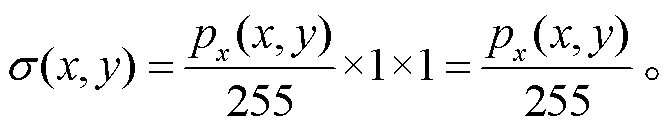 (3)
(3)
渲染平面上每个面元像素的法线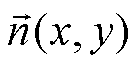 相同, 但视点的
相同, 但视点的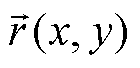 各不相同, 因此对不同的像素还需要计算相应的系数
各不相同, 因此对不同的像素还需要计算相应的系数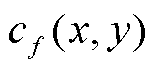 , 由像素颜色计算立体角的公式改写为
, 由像素颜色计算立体角的公式改写为
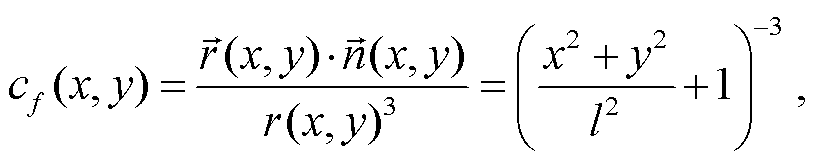 (4)
(4)
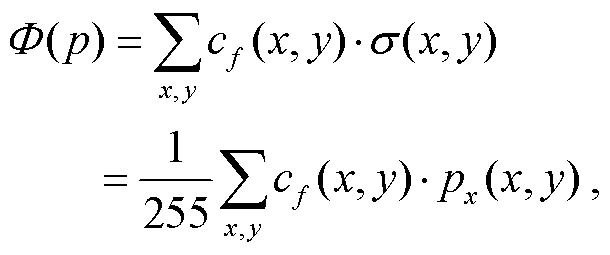 (5)
(5)
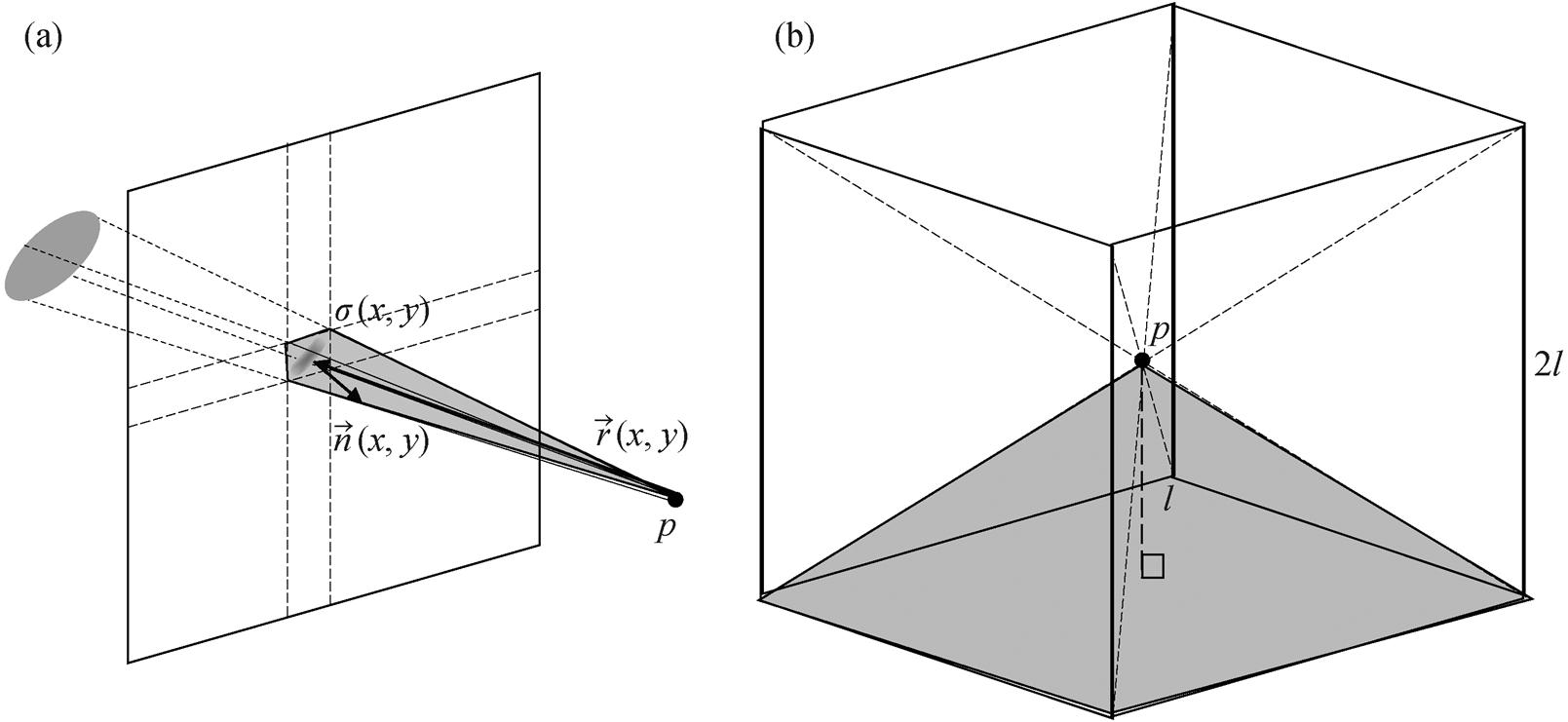
(a)高斯椭球体投影到相机平面示意图; (b) p点处投影生成 Cubemap 全景图的 6 个面示意图, 6 个相机平面构成一个边长为 2l的立方体, p 点位于立方体中心
图10 3DGS渲染过程示意图
Fig. 10 Schematic diagram of 3DGS rendering process
其中, l是视点 p 到渲染平面的距离, 为渲染图像分辨率的一半, cf (x, y)为立体角计算过程中与像素坐标(x, y)有关的系数。最终, 计算得到单个渲染图像对视点 p 的总立体角。
为了评估场景中视点 p 处的渲染质量, 需要对3DGS 在所有方向的渲染结果进行综合评估, 从而应用于全景场景。本文使用 Cubemap 的投影方式, 将 p 作为中心点, 沿着 6 个正交方向, 对场景进行投影渲染, 6 张图像用正方体 6 个面的方式包裹起来, 构成一张全景图像(图 10(b)), 从而根据立体角的概念, 给出场景中任意视点 p 处 3DGS 渲染质量指数 Ψ(p)的定义:
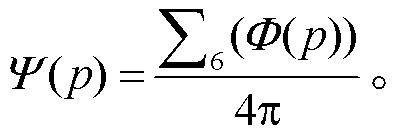 (6)
(6)
显然, 渲染质量指数 Ψ(p)可以用来表达视点 p在场景中被最小包络体 M 包裹的程度, 同样可以称为场景包裹度, 其值分布在(0, 1)范围内, 越接近 1, 对应的渲染质量越好。
2.2.3 规模参数对渲染质量的影响
在利用 3DGS 渲染图像时, 设置规模参数 j =1, 使每个椭球体的尺度调整到一个相对合适的范围, 渲染出的画面饱满且没有缺失。规模参数值越小, 高斯椭球体在渲染过程中溅射到画面上的光斑面积就越小, 渲染结果中会出现场景缺失现象。对于不同类型的景物, 3DGS模型中对应的高斯椭球体的分布特点有所不同。对于岩壁一类表面纹理特征明显的景物, 其高斯椭球体分布呈现小而密集的特征, 每个椭球体的溅射光斑很小, 在渲染图像中显示复杂多变的纹理特征。对于天空和水体等纹理简单的景物, 3DGS 模型会使用大而稀疏的椭球体来表示, 减少椭球体的使用数量。对于后者, 当观察视点靠近时, 这些溅射光斑较大的椭球体在渲染图像中就会转变为难以理解的无意义色块, 此时的渲染质量较差。通过降低规模参数, 这些椭球体的溅射光斑面积会迅速衰减, 由此产生的场景缺失现象可以帮助我们清晰地识别渲染质量降低的情况, 从而进行渲染质量评估。

图11 在场景中央和边界处j=0.5和j=1.0的规模参数下进行灰度渲染的结果
Fig. 11 Results of grayscale rendering at the center and boundary of the scene with scale modifier of j=0.5 and j=1.0

图12 3DGS渲染全景图像与渲染质量指数
Fig. 12 3DGS rendering panoramic images with render quality index
图 11 示意规模参数j分别为 1 和 0.5 时的画面渲染结果, 场景中岩壁纹理复杂, 其椭球体分布小而密集, 而旁边的水体纹理简单, 其椭球体分布大而稀疏。在视点靠近场景中央的相机拍摄位置, 当渲染质量较好时, 两种灰度的结果较为相似, 降低规模参数产生的场景空缺并不明显(图 11 中“场景中央, j =0.5”), 只有反射率较高的湖水以及远处的天空呈现少量的空缺, 而当视点靠近水体时, 表示水体的大而稀疏的椭球体在 j =0.5 时体现得十分明显, 此时的渲染质量迅速下降, 但在 j =1.0 时, 这种渲染质量降低的现象几乎体现不出来。
值得注意的是, 降低规模参数的方法只是为了增加区分度, 我们在实验中发现,j =0.5 就可以得到优异的结果。综上所述, 场景中视点 处场景渲染质量的评估需要在j =0.5 的条件下, 通过定量计算全景图像中最小包络体 M 的包裹程度来判断。我们根据视点 p 的位置对 3DGS 进行灰度渲染, 分别计算出 Cubemap 全景图像 6 个方向的立体角, 求和并归一化, 得到最终的渲染质量指数:
处场景渲染质量的评估需要在j =0.5 的条件下, 通过定量计算全景图像中最小包络体 M 的包裹程度来判断。我们根据视点 p 的位置对 3DGS 进行灰度渲染, 分别计算出 Cubemap 全景图像 6 个方向的立体角, 求和并归一化, 得到最终的渲染质量指数:
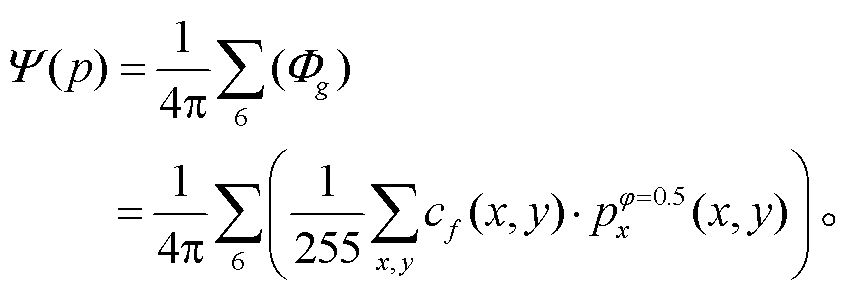 (7)
(7)
本研究野外场景拍摄设备为 Insta360 Pro2 相机, 实验环境的 CPU 为 Intel Core i7-10700K, GPU 为NVIDIA RTX3080, colmap 版本为 3.9, 使用 Python语言编写代码。使用手持全景相机, 在野外真实场景的不同点位, 步行采集视频, 每个点位的采集时间控制在约 2 分钟, 按照 1fps 的帧率进行抽帧, 生成图像帧序列, 得到本文所用数据集。
根据上述方法, 由采集的野外场景全景图像生成 3DGS 的场景模型。图 12 给出场景 1 中数个渲染CMP 全景图像与渲染质量指数的对应关系, 可以看到图像渲染质量与场景的包裹程度明显正相关, 并且, 即使 RGB 画面表现较好, 在靠近重建质量较低的景物(如水体和天空等缺少点云的景物)时, 渲染质量指数也会有一定程度的降低。
FID (fréchet inception distance)[17]利用卷积神经网络提取图像的特征维度, 并比较两组图像特征维度的分布距离, 依此衡量两组图像之间的相似度。该指标将 Inception Net-V3 网络全连接前的 2048 维向量作为图像的特征向量。两组图像集 r 与 g 之间FID 值的计算公式如下:
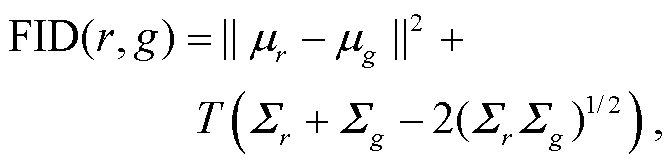 (8)
(8)
其中, mr 和mg 为两组图像的特征均值, Sr 和Sg 为两组图像的特征协方差矩阵, T 为计算矩阵的迹的算符。FID 值越小, 证明两组图像的分布越接近, 这个指标可以有效地反映人眼在理解图像的过程中对两组图像内容与特征的相似性判断。Inception Net-V3 网络使用 ImageNet 图像数据集进行训练, 该数据集包含 1000 个目标类别, 超过 120 万张图像, 且包含岩壁、植物、山谷和河流等各类对象, 具有很好的泛化性, 适用于本文使用的野外真实图像数据集。
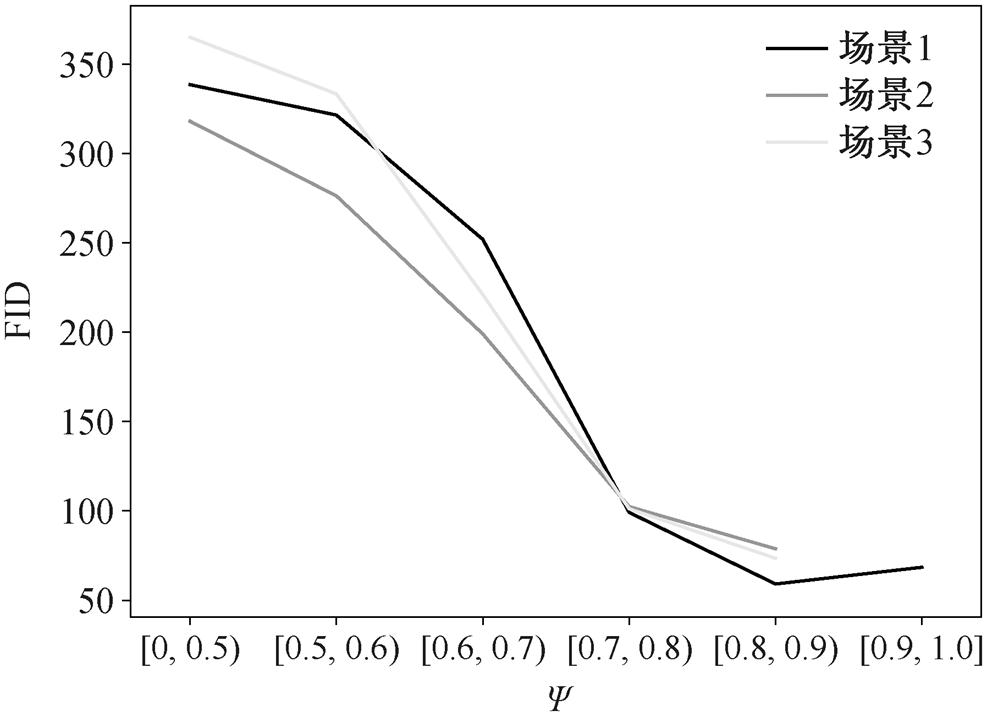
图13 不同场景中不同渲染质量指数对应的图像与相机拍摄图像的FID分布折线
Fig. 13 Line plot of the distribution of rendering quality index versus FID in different scenes
在利用3DGS虚拟场景进行视点渲染的任务中, 真实拍摄的野外图像可以清晰地表达场景中的景物特征, 渲染质量较高的重建图像也会将这些景物重新描绘出来, 因此人眼能够理解渲染图像与真实场景是一致的, 计算得到的 FID 值较小。然而, 渲染质量较低的图像中充斥着没有意义的光斑和线条, 提取的特征向量与真实图像有很大的区别, 计算得到的 FID 值较大。
为了利用 FID 定量地检验渲染质量评估方法, 首先将全景相机拍摄的真实图像合成为ERP格式全景图, 作为通过 FID 计算得到的真实图像数据 GT。
然后, 在重建的三维场景中随机取点, 进行 3DGS渲染, 生成 Cubemap 全景图, 计算渲染质量指数。
在随机取点的过程中, 本文使用三维高斯随机分布方法, 从相机位置出发, 以相机位置平均值作为高斯分布中心mr, 以其在 x, y, z 这 3 个方向的最大分布半径来求得高斯分布的协方差矩阵Sr, 并假设 3 个方向的分布彼此不相关, 从而将协方差矩阵简化为对角矩阵:

图14 不同场景下相机所处位置渲染质量指数各区间对应的全景示意图
Fig. 14 Panoramic schematic diagrams at camera positions under different scenes, corresponding to various rendering quality index ranges
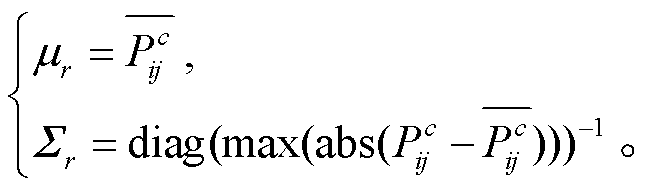 (9)
(9)
不断重复这个过程, 每个类别随机选取 100 张图像用于 FID 的计算。之后, 将 Cubemap 全景图转为 ERP 格式的全景图, 按照其渲染质量指数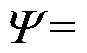 [0, 0.5), [0.5, 0.6), [0.6, 0.7), [0.7, 0.8), [0.8, 0.9), [0.9, 1.0], 分为 6 类, 分别与真实图像数据集 GT 进行FID 计算, 结果如图 13 所示。
[0, 0.5), [0.5, 0.6), [0.6, 0.7), [0.7, 0.8), [0.8, 0.9), [0.9, 1.0], 分为 6 类, 分别与真实图像数据集 GT 进行FID 计算, 结果如图 13 所示。
可以看到, 不同类别的 FID 值与渲染质量指数明显负相关, 较高渲染指数的图像计算得到的 FID值很小, 表明其渲染图像与真实图像的特征较为相近, 证明渲染质量指数较高的渲染图像的特征更符合野外真实场景拍摄的图像, 人眼更容易理解, 并容易判断当前的渲染场景与真实场景一致。
本文通过目视观察不同渲染质量指数的图像的几何特征, 定性地判断不同视点的渲染图像中, 景物的形状、走向和分布是否符合真实情形, 渲染图像中是否存在场景空洞, 是否存在大面积无意义色块。若全景图像中的景物符合真实情形, 则场景空洞的比例和大面积无意义色块的比例越小, 图像的渲染质量越高。
图 14 显示, 场景 2 和场景 3 由于其自身特点, 天空占据视角比例较大, 无法选出足够数量的Y= [0.9, 1.0]类别图像。可以看出, 随着渲染质量指数减小, 场景渲染质量也逐渐下降。Y=[0, 0.6)时, 画面充满场景空洞和无意义色块, 渲染质量极低。Y=[0.6, 0.7)时, 场景空洞和无意义色块仍然占一定的比例, 且景物外观模糊, 仅能辨认大致轮廓。Y= [0.7, 0.8)时, 部分景物渲染质量开始下降, 但只占画面的很小一部分。Y=[0.8, 1.0]时, 各方向景物的渲染质量基本上与真实画面一致。从 3 个场景可以明显看出, 在渲染质量指数大于 0.7 之后, 全景图的 FID 值保持在 100 以下, 全景图像的渲染质量足够高, 画面中的场景与真实场景足够相似, 人眼很容易理解画面中的大部分景物, 也说明本文提出的根据渲染质量指数评估 3DGS 模型渲染质量的方法足够有效。
本文提出一种 3D Gaussian Splatting 渲染质量评估方法, 可以基于全景视频数据, 利用 3D Gaus-sian Splatting 技术进行三维场景重建, 并进行全景图渲染质量评估。利用 FID 进行质量评价指标验证, 发现该评估方法的指标数据和目视质量评估结果能较好地符合预期, 可以作为 3DGS 模型的渲染质量评估方法。
利用本文方法可以进行场景中任意视点渲染质量指数的快速评估, 进而可以从渲染质量指数的空间分布提取高渲染质量的场景范围, 应用于实际的虚拟野外考察。
目前的工作尚有不少可改进之处。本文缺少大量野外全景数据集进行方法的进一步验证。本文提出的方法适用于全景相机采集的数据集, 经典的无边界场景数据集由于缺少完整的视角(如天空方向), 导致渲染质量指数计算错误, 无法应用本文方法进行检验。本文方法适用于简单的野外场景, 若应用于城市楼房等遮挡关系复杂的场景, 即使没有充分采集室内的场景信息, 也会由于多层墙壁对应的高斯椭球体叠加, 导致渲染质量指数计算结果偏高, 不能真实地反映实际渲染质量。
参考文献
[1] Mildenhall B, Srinivasan P P, Tancik M, et al. NeRF: representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 2021, 65(1): 99–106
[2] Barron J T, Mildenhall B, Tancik M, et al. Mip-nerf: a multiscale representation for anti-aliasing neural radiance fields // 2021 IEEE/CVF International Con-ference on Computer Vision (ICCV). Montreal: IEEE Computer Society, 2021: 5835–5844
[3] Barron J T, Mildenhall B, Verbin D, et al. Mip-NeRF 360: unbounded anti-aliased neural radiance fields // 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, LA: IEEE Computer Society, 2022: 5460–5469
[4] Fridovich-Keil S, Yu A, Tancik M, et al. Plenoxels: radiance fields without neural networks // 2022 IEEE/ CVF Conference on Computer Vision and Pattern Re-cognition (CVPR). New Orleans, LA: IEEE Computer Society, 2022: 5491–5500
[5] Attal B, Huang J B, Zollhöfer M, et al. Learning neural light fields with ray-space embedding // 2022 IEEE/ CVF Conference on Computer Vision and Pattern Re-cognition (CVPR). New Orleans, LA: IEEE Computer Society, 2022: 19787–19797
[6] Müller T, Evans A, Schied C, et al. Instant neural graphics primitives with a multiresolution hash enco-ding. ACM Transactions on Graphics, 2022, 41(4): 102: 1–102:15
[7] Kerbl B, Kopanas G, Leimkühler T, et al. 3D gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 2023, 42(4): 139:1–139:14
[8] Martin-Brualla R, Radwan N, Sajjadi M S M, et al. Nerf in the wild: neural radiance fields for unconstra-ined photo collections // 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN: IEEE Computer Society, 2021: 7206–7215
[9] Cheng K, Long X, Yang K, et al. GaussianPro: 3D gaussian splatting with progressive propagation // In-ternational Conference on Machine Learning. Vienna: PMLR, 2024: 8123–8140
[10] Amenta N, Choi S, Dey T K, et al. A simple algorithm for homeomorphic surface reconstruction. Internatio-nal Journal of Computational Geometry and Applica-tions, 2002, 12(1/2): 125–141
[11] Kolluri R, Shewchuk J R, O’Brien J F. Spectral surface reconstruction from noisy point clouds // Proceedings of the 2004 Eurographics/ACM SIGGRAPH Sympo-sium on Geometry Processing. Nice, 2004: 11–21
[12] Jacobson A, Kavan L, Sorkine-Hornung O. Robust inside-outside segmentation using generalized winding numbers. ACM Transactions on Graphics, 2013, 32(4): 33:1–33:12
[13] Wang P, Liu L, Liu Y, et al. NeuS: learning neural implicit surfaces by volume rendering for multi-view reconstruction. Advances in Neural Information Pro-cessing Systems, 2021, 34: 27171–27183
[14] Lin S, Xiao D, Shi Z, et al. Surface reconstruction from point clouds without normals by parametrizing the Gauss formula. ACM Transactions on Graphics, 2022, 42(2): 14:1–14:19
[15] Schonberger J L, Frahm J M. Structure-from-motion revisited // 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV: IEEE Computer Society, 2016: 4104–4113
[16] Schönberger J L, Zheng E, Frahm J M, et al. Pixelwise view selection for unstructured multi-view stereo // Computer Vision-ECCV 2016: 14th European Confe-rence, Amsterdam: Springer International Publishing, 2016: 501–518
[17] Heusel M, Ramsauer H, Unterthiner T, et al. Gans trai-ned by a two time-scale update rule converge to a local nash equilibrium. Advances in Neural Information Pro-cessing Systems, 2017, 30: 6627–6638
3D Gaussian Splatting Rendering Quality Estimation Based on Outdoor Panoramic Video Data
Abstract A rendering quality index calculation method related to the Gaussian ellipsoid distribution of the scene is proposed. Using the panoramic rendering image of the scene, the rendering quality index is calculated to quan-titatively evaluate the rendering quality of the panoramic image, and test the semantic consistency between the ren-dered image and the real image using the FID (fréchet inception distance) of the panoramic image. The experi- mental results show that this rendering quality index can effectively evaluate the rendering quality of panoramic images, conform to human intuitive cognition, and obtain higher computational performance, which can provide support for maintaining user interaction immersion during virtual field trips.
Key words outdoor environment; panoramic image; rendering quality; 3D reconstruction; scene understanding