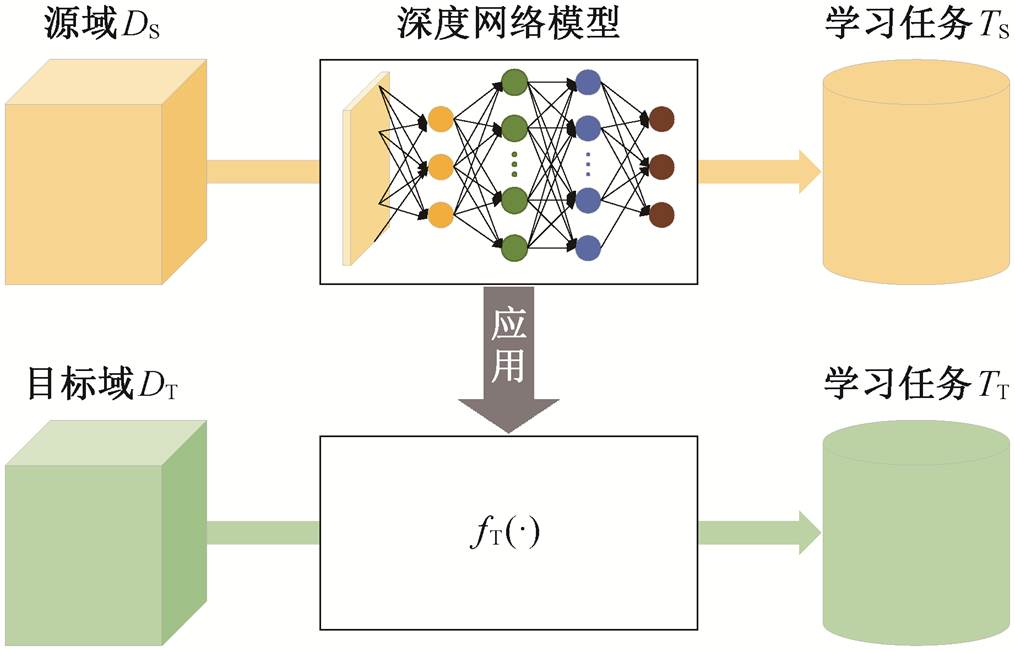
图1 预训练模型方法
Fig. 1 Pre-trained model
北京大学学报(自然科学版) 第61卷 第4期 2025年7月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 61, No. 4 (July 2025)
doi: 10.13209/j.0479-8023.2025.019
中国地质调查局地质调查项目(DD20230085)资助
收稿日期: 2024–04–17;
修回日期: 2024–05–06
摘要 针对普适型滑坡监测工作中新建监测坡面有效数据量少, 代表性不足, 难以开展高精度单坡建模的问题, 建立基于岩性分类的综合数据集, 开展模型预训练, 从而提升建模效果。通过综合数据集, 模型可以挖掘和利用多坡面监测数据中更丰富的变形特征。依据基础岩性对综合数据集进行分类, 构建不同的预训练模型, 并应用于对应岩性的新建坡面, 能够在保证数据集数量较为充足的同时, 增强分类数据集对不同类别坡体变形规律的表征能力, 通过提升预训练数据和目标域数据分布的一致性, 进一步提高建模效果。实例验证结果表明, 基于岩性分类综合数据集的预训练模型, 在对应岩性新建坡面上, 建模效果总体上显著优于单坡面模型和基于其他综合数据集的预训练模型, 可以为新建坡面位移预测工作提供有力的支持。
关键词 滑坡; 短期位移预测; 岩性分类综合数据集; 预训练模型; 新建坡面; 普适型滑坡监测
滑坡是一种斜坡岩土体在重力作用下发生位移的变形现象[1]。我国是世界上滑坡地质灾害最发育的国家之一, 滑坡数量约占全国地质灾害总量的70%, 且其时空分布不均[2]。2019 年以来, 自然资源部推进普适型地质灾害监测工作, 在全国地质灾害高发区开展广泛的仪器布设工作。目前, 普适型监测设备仍然在快速布设当中, 监测点数量不断上升, 存在大量监测期不足一年的新建坡面。及时开展新建坡面的位移预测建模工作, 有助于及早发现滑坡风险并采取相应措施, 从而避免潜在的人员伤亡和财产损失。
既有滑坡位移预测研究中, 传统方法通过研究水文、工程地质要素与滑坡运动之间的关系, 建立机理模型来预测位移[3], 需要详细的岩土工程勘察和实验数据, 难以快速、低成本地在大量坡面开展建模工作, 在普适型滑坡监测工作中适用性较差。随着滑坡监测数据的积累和机器学习技术的发展, 众多机器学习方法已应用到滑坡位移预测中。既有基于机器学习的方法从滑坡位移序列出发, 结合降雨、库水位等诱发因子数据, 使用 ARIMA[4]、支持向量回归[5](support vector regression, SVR)、长短期记忆网络[6](long short-term memory, LSTM)、循环神经网络[7](gate recurrent unit, GRU)及 Transfor-mer[8]等模型, 针对单一坡面进行建模, 并开展位移预测, 需要充足的坡体变形数据[4–8]。对于新建坡面, 现有监测数据中描述的变形过程十分有限, 尚无法对坡体的变形规律进行充分的表达, 难以支持既有单坡机器学习模式。
与常见的单坡监测工作不同, 普适型滑坡监测工作提供大量可利用的坡面监测数据。由此, 应当考虑采用数据增强的思路, 建立综合数据集来开展预训练模型建模, 挖掘综合数据集中的滑坡变形规律, 弥补新建坡面变形数据表征能力的不足。预训练模型(pre-training model)是人工智能领域的一个重要概念, 在自然语言处理和计算机视觉等领域广泛应用[9]。预训练模型的核心思想是, 首先在大规模数据集上进行预训练, 学习尽可能多的通用知识以及数据的内在规律, 并将知识编码到模型的结构参数中, 然后使用目标任务提供的有限标注的数据样本进行知识迁移, 从而得到针对目标任务的有效的深度学习模型[10], 可以有效地克服因目标任务数据不足而难以建模的问题。普适性滑坡监测工作开展以来, 积累了大量滑坡变形数据, 其中蕴含丰富的滑坡变形规律, 为预训练模型建模提供了可靠的数据基础。
考虑到不同类型监测点的滑坡变形规律各异, 本文提出依据基础岩性对滑坡监测数据进行分类, 从而在保证分类数据集数据量的同时, 提升其内部数据规律的一致性以及对该类别坡面形变规律的表征能力, 然后基于分类集成数据集分别开展预训练模型建模, 并将其应用于同类属性的新建坡面建模中, 以期取得更好的预测效果。
预训练模型的形式化定义表达如下: 给定一个源域 DS 和学习任务 TS, 一个目标域 DT 和学习任务TT, 预训练旨在利用 DS 和 TS 中的知识, 帮助提高DT 中预测函数 fT(·)的学习能力, 其中 DS≠DT 或 TS≠TT [11], 其基本原理如图 1 所示。预训练模型的核心思想是将模型在源域上进行预训练, 当目标域数据样本不充分时, 应用预训练模型完成预测任务, 从而解决目标域数据代表性不足、难以支撑机器学习模型建模的问题。开展模型预训练时, 需要保证用于模型训练的源域数据样本充分, 在目标域上应用预训练模型时, 需要保证源域和目标域的数据分布尽可能相同[12], 这样才能保证预训练模型在源域数据中提取的样本特征可以应用于目标域的任务之中, 提高预训练模型的预测效果。
图1 预训练模型方法
Fig. 1 Pre-trained model
普适型滑坡监测点数量众多, 覆盖区域广泛, 已积累大量滑坡监测数据, 使用这些数据建立综合数据集, 可以覆盖大量滑坡的变形规律, 为预训练模型提供充足的训练数据, 符合预训练方法的理论和技术要求。预训练模型在训练过程中挖掘和利用了大量滑坡变形特征, 在识别和预测滑坡位移方面, 相对于使用有限的单一坡面数据开展单坡建模, 拥有更高的准确性和更强的泛化能力[10]。
为了保证预训练模型的效果, 在目标域上应用预训练模型时, 需要预训练数据和目标域数据的分布尽可能相同[12]。各监测点气候条件、地质构造等存在差异, 导致其变形规律不完全一致。利用这些坡面监测数据建立综合数据集, 必将囊括不同的滑坡变形规律, 在预训练模型应用过程中, 可能导致源域与目标域数据分布的相似性较差, 影响模型应用效果。因此, 应对综合数据集进行有效的分类, 使类内滑坡数据具有相似的变形规律, 提升分类数据对相应类别坡面变形规律的表征能力, 再针对各组数据分别建立预训练模型, 并将之应用于同类型的新建坡面位移预测。这样, 就可以有效地应对源域数据与目标域数据分布相似性问题, 改善预训练模型的建模和应用效果。需要注意的是, 数据类别不宜过多、过细, 否则会导致组内数据量少, 影响预训练模型的学习和拟合效果。建立一个理想的分类综合数据集, 本质上是在全集数据量有限的前提下, 在组内数据量与组内变形规律一致性这两个要素间取得一种平衡。
坡面的地质信息对滑坡变形规律的表征起到重要作用[13], 因此可以利用典型地质信息对滑坡变形数据进行分类, 得到包含不同变形特征的分类综合数据集。在普适型滑坡监测工作实施过程中, 施工单位对坡体基础的地质信息进行调查, 提供了相对准确的坡体基础数据。然而, 受限于勘察条件和经费条件, 相较于精细的地质勘探工程, 这些调查资料较为简略, 数据精度有限, 且坡面地质要素(如构造和动力类型等)常常存在不同程度的数据缺失。
基础岩性分类体系相对简单, 亦是影响滑坡变形规律的重要因素[13], 具体表现在以下 3 个方面。
1)基础岩性会影响滑坡体的形成和发展。当基岩为软弱的或易溶解的松散岩层时, 易被侵蚀和削蚀, 形成空洞和孔隙, 导致上方岩层滑动和断裂, 从而形成滑坡体。
2)基岩的稳定性也会影响滑坡变形规律。当基岩稳定性较差时, 本身容易破裂和变形, 上方岩层容易发生位移和滑动, 从而加速滑坡体的运动。
3)基岩的性质还会影响滑坡体的形态和规模。例如, 当基岩为硬质岩石时, 不易变形和破裂, 滑坡体通常较小; 当基岩为软弱岩石时, 滑坡体则通常较大[13–14]。
总之, 基于基础岩性这一重要地质要素对数据集进行分类, 可在兼顾分类数据集数据量的同时, 提高分类数据集对该类坡面形变规律的代表性。岩石分为火山岩、沉积岩和变质岩三大类[15], 普适型滑坡监测提供的地质资料中, 坡面基岩性质划分亦遵循此分类体系。因此, 本文选取基础岩性作为分类依据, 依照上述分类体系进行构建分类多坡综合数据集。
本文提出的基于分类综合数据集的新建坡面位移预测流程见图 2。首先选取监测时间较长、变形特征较明显的滑坡监测数据, 构建岩性分类综合数据集; 然后使用深度学习模型, 在分类数据集上分别开展预训练, 学习不同类型的滑坡变形规律, 得到各类别对应的预训练模型; 最后根据新建坡面所属类别, 应用相应的预训练模型, 进行坡面位移预测。通过该流程, 可以在新建坡面缺乏历史变形数据, 难以进行单坡建模时, 快速实现模型部署和位移预测, 为滑坡预警、预报工作提供技术支持。
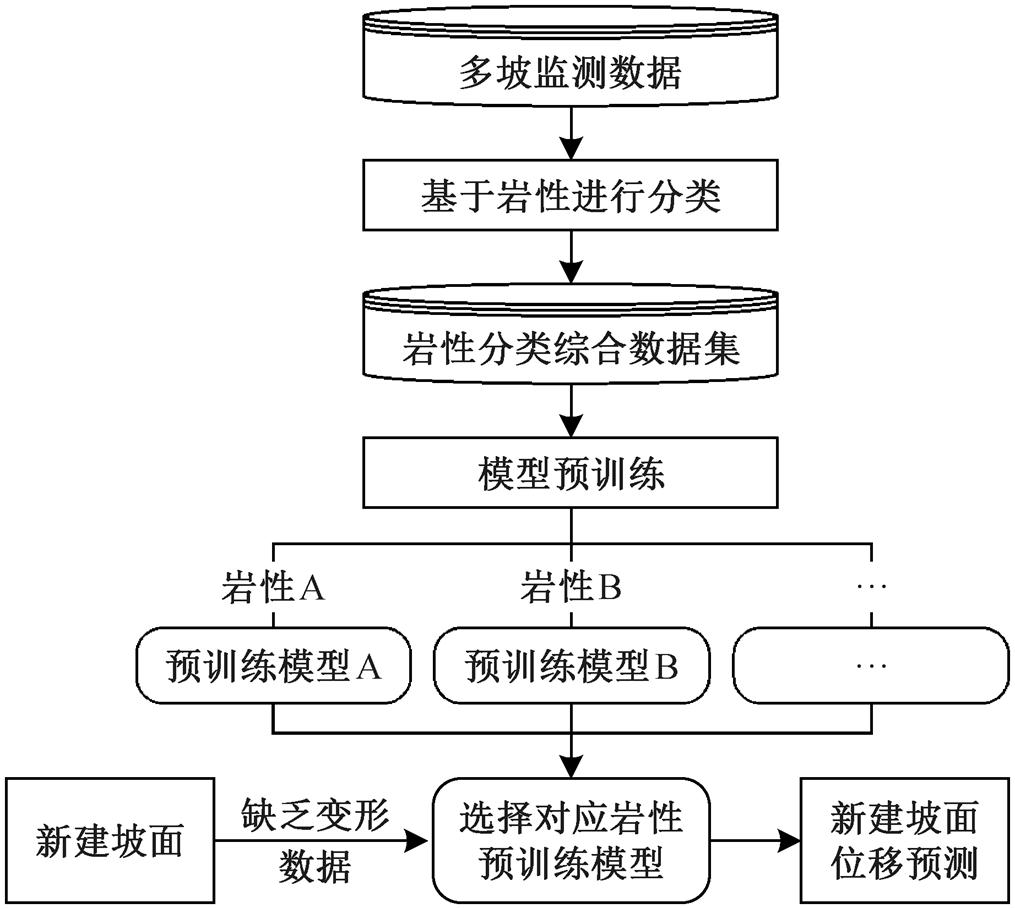
图2 基于分类综合数据集的新建坡面位移预测流程
Fig. 2 Flowchart of displacement prediction for newly-established monitoring slopes based on lithology-classified integrated dataset
为验证本文新建坡面位移预测方法的实际应用效果, 用 304 个坡面的监测数据进行实例建模。首先构建岩性分类数据集和对应的预训练模型, 然后选择常见的单坡模型和基于全集数据的预训练模型作为基线模型, 开展预测效果的对比分析。
实例数据由中国地质环境监测院提供, 共计304 个坡面, 主要分布于福建省和四川省, 均为降雨驱动型滑坡的实测数据。这些监测坡面布设有雨量计、裂缝计或 GNSS 位移计, 已开展一年以上的连续监测, 大部分具备较明显的变形特征。
在普适型滑坡监测工作中, 受设备和传输网络稳定性等因素影响, 存在数据缺失、噪声影响等现象, 需要对监测数据进行预处理, 主要涉及数据重采样和缺失值补偿。普适型滑坡监测数据重采样的时间间隔会影响位移预测效果[16], 我们借鉴既有研究成果, 选取 6 小时的时间间隔对所有监测数据进行重采样[8]。既有研究成果表明, 普适型滑坡监测数据中的噪声多为偶发性数值抖动, 变分模态分解 (variational mode decomposition, VMD)方法可以有效地去除这些噪声[8]。因此, 本研究采用 VMD 方法进行数据降噪处理。
研究样本中, 152 个坡面的基础岩性为沉积岩, 138 个坡面的基础岩性为火山岩, 14 个坡面的基础岩性为变质岩。由于变质岩坡面的数量与另外两类坡面的差距非常大, 难以满足综合数据集创建和后期测试工作的需要, 本研究中将变质岩坡面的数据剔除, 最终构建的基于基础岩性分类的综合数据集包括“沉积岩数据集”和“火山岩数据集”两大类, 分别包含 152 个和 138 个坡面。
从上述两个分类综合数据集中分别随机选取26 个坡面, 作为测试数据集, 用于评测建模效果, 剩余坡面则作为两个岩性分类对应的训练集, 用于模型训练。为了进一步验证岩性分类综合数据集方法的有效性, 从两类训练集中分别随机选取 63 个坡面, 组成混杂训练集, 同时将沉积岩训练集与火山岩训练集组合, 得到“全体训练集”。各数据集的具体构成如表 1 所示。
表1 训练集和测试集
Table 1 Training dataset and test datasets

数据集描述 沉积岩训练集126个基础岩性为沉积岩的坡面 火山岩训练集112个基础岩性为火山岩的坡面 混杂训练集从火山岩和沉积岩训练集中各随机选取63个坡面, 共126个 全体训练集全部的火山岩和沉积岩训练集坡面, 共238个 火山岩测试集26个基础岩性为火山岩的监测点(与训练集无重合) 沉积岩测试集26个基础岩性为沉积岩的监测点(与训练集无重合)
本文选取时序预测领域广泛应用的 Transfor-mer Encoder[17], LSTM[18]和 CNN[19]作为训练模型, 各模型的总体架构见图 3。使用 Pytorch 库提供的模型代码, 训练过程中的优化方法选择 AdamW, 损失函数选择 L1Loss, 学习率则采用适应性策略, 根据当前训练轮数进行动态调整[17–19]。
普适型滑坡监测工作中, 要求位移模型每日基于历史位移监测数据和对应的雨量信息, 结合雨量预报数据预测未来 3 日的滑坡位移量, 即预测时刻起 0~24 小时、24~48 小时和 48~72 小时对应的位移量[8]。在进行实例建模时, 需要确定一个合适的前溯时间长度来截取历史滑坡位移和对应雨量信息, 作为模型的输入。研究表明, 历史位移信息与未来位移量之间的相关度随着时间前溯先上升后下降, 在相距 9~12 日时出现相关性峰值[8]。因此, 本研究选取的历史位移和雨量数据长度为 30 日, 在确保高相关性时刻数据得到表达的同时, 防止无关数据进入模型而产生干扰。
本文使用 3 类模型(Transformer Encoder, LSTM和 CNN), 分别在表 1 中 4 个训练集上进行预训练, 得到对应的预训练模型, 之后分别在两个测试集上验证预测效果。为了与单坡建模效果对比, 使用上述 3 类模型, 对两个测试集中的坡面进行单坡建模。在单坡建模过程中, 为了模拟新建坡面建模场景, 限定将各坡面前 90 日的数据作为训练数据。
采用 RMSE 和 R2 指标, 对各个模型在测试集上的预测精度进行评判。为了充分模拟新建坡面的数据状况, 与前述单坡模型相似, 所有测试集坡面均只使用前 90 日的监测数据和对应雨量数据作为预训练模型的输入, 后续时段全部作为测试样例。
建模结果表明, 在火山岩训练集和沉积岩训练集上得到的分类预训练模型在对应岩性测试集上的预测精度更高, 预测效果优于其他预训练模型和单坡模型, 具有更低的 RMSE 值和更接近 1 的 R2 值。各模型在两类测试集上的表现分述如下。
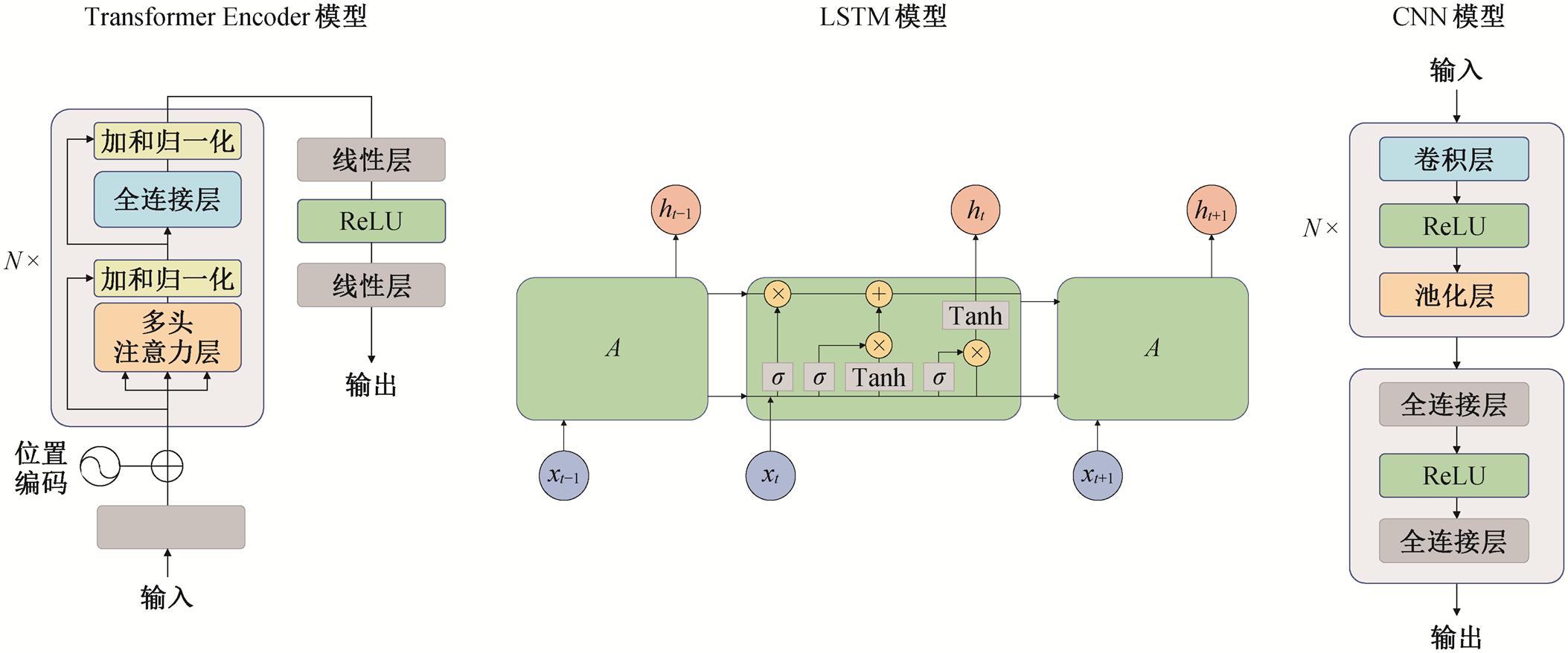
ReLU 为线性整流函数, Tanh 为双曲正切函数, σ 为 sigmoid 函数; xt−1, xt 和 xt+1 为对应时刻 LSTM 的输入, ht−1, ht 和 ht+1 为对应时刻 LSTM 的输出; N 表示同样模块的叠加层数
图3 Transformer Encoder, LSTM和CNN模型架构
Fig. 3 Structure of Transformer Encoder, LSTM and CNN
当置信度为 90%时, 3 个模型在火山岩训练集上得到的预训练模型的预测结果中, RMSE 和 R2 指标均显著优于在沉积岩训练集、混杂训练集和全体训练集上得到的预训练模型以及 3 类单坡模型(表 2 和3)。从表 2 可以看到, 3 个火山岩训练集预训练模型在测试集上的平均 3 日 RMSE 分别为 1.254, 1.356 和1.401mm, 比其他 3 类预训练模型降低 48%~68%, 比单坡建模降低 75%~78%。3 个火山岩训练集预训练模型在测试集上的平均 3 日 R2分别为 0.764, 0.687和 0.614, 比其他 3 类预训练模型高出 0.248~0.432, 更远高于单坡模型。在 3 种火山岩分类预训练模型中, TF Encoder 和 LSTM 模型的效果更佳。同时, 囿于极为有限的数据量, 3 类单坡模型的 RMSE指标明显劣于各种预训练模型, 其 R2 值均为负数, 说明其预测值与真实值差距明显, 不具备实用性。
从表 2 还可以看出, 在火山岩测试集上, 沉积岩训练集预训练模型预测效果逊于混杂训练集和全体训练集预训练模型, 原因是相较于另外两个预训练模型, 沉积岩训练集预训练模型使用的预训练数据与火山岩测试集中数据的特征差异最显著, 这也与预训练数据与目标域的数据分布要尽可能相同, 才能提升预训练模型应用效果的结论[12]一致。
为验证相关精度差异的可信度, 将表 2 中火山岩训练集预训练模型的精度指标分别与沉积岩训练集、混杂训练集和全体训练集对应的预训练模型及单坡模型的精度指标进行配对秩和检验。结果表明, 在置信度为 90%的前提下, 3 个在火山岩训练集上得到的预训练模型的预测效果显著更优(表 3)。
在沉积岩测试集上得到的结果与火山岩测试集的结果具有高度相似性。在置信度为 90%的前提下, 沉积岩训练集得到的预训练模型预测结果的RMSE 值显著优于火山岩训练集、混杂训练集和全体训练集预训练模型以及单坡模型(表 4 和 5)。表 4显示, 3 个沉积岩训练集预训练模型在测试集上的平均 3 日 RMSE 值分别为 2.243, 2.573 和 2.579mm, 比其他 3 类预训练模型降低 25%~43%, 比单坡建模降低 60%~66%。3 个沉积岩训练集预训练模型在测试集上的平均 3 日 R2值分别为 0.573, 0.524 和 0.493, 比其他 3 类预训练模型高出 0.149~0.335, 远高于单坡模型。在 3 种沉积岩分类预训练模型中, Transfor-mer Encoder 模型的效果更佳。
与基于火山岩测试集的实验结果相似, 3 类单坡模型的 RMSE 指标明显劣于各种预训练模型, 其R2 值均为负数, 不具备实用性。
从表 4 还可以看出, 与火山岩测试集建模结果类似, 火山岩训练集预训练模型的预测效果与混杂训练集预训练模型大致相当, 但逊于全体训练集预训练模型, 再次表明预训练数据与目标域的数据分布差异越大, 应用效果就越差[12]。
表2 各模型在火山岩测试集上的测试结果
Table 2 Testing results of each model on the volcanic landslide test dataset
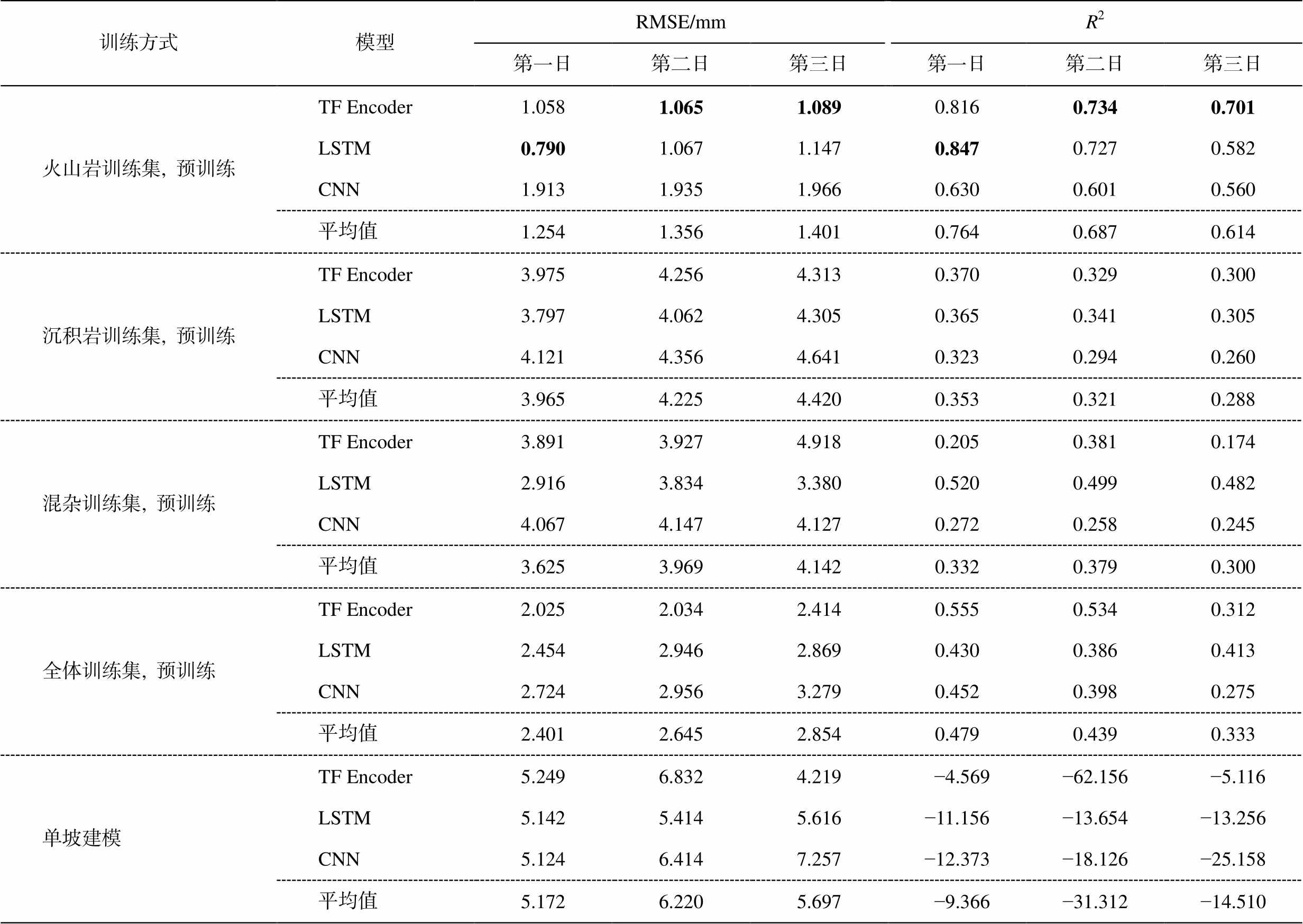
训练方式模型RMSE/mmR2第一日第二日第三日第一日第二日第三日 火山岩训练集, 预训练TF Encoder1.0581.0651.0890.8160.7340.701 LSTM0.7901.0671.1470.8470.7270.582 CNN1.9131.9351.9660.6300.6010.560 平均值1.2541.3561.4010.7640.6870.614 沉积岩训练集, 预训练TF Encoder3.9754.2564.3130.3700.3290.300 LSTM3.7974.0624.3050.3650.3410.305 CNN4.1214.3564.6410.3230.2940.260 平均值3.9654.2254.4200.3530.3210.288 混杂训练集, 预训练TF Encoder3.8913.9274.9180.2050.3810.174 LSTM2.9163.8343.3800.5200.4990.482 CNN4.0674.1474.1270.2720.2580.245 平均值3.6253.9694.1420.3320.3790.300 全体训练集, 预训练TF Encoder2.0252.0342.4140.5550.5340.312 LSTM2.4542.9462.8690.4300.3860.413 CNN2.7242.9563.2790.4520.3980.275 平均值2.4012.6452.8540.4790.4390.333 单坡建模TF Encoder5.2496.8324.219 −4.569−62.156 −5.116 LSTM5.1425.4145.616−11.156−13.654−13.256 CNN5.1246.4147.257−12.373−18.126−25.158 平均值5.1726.2205.697 −9.366−31.312−14.510
说明: 粗体数字表示最佳值。
表3 火山岩训练集预训练模型与其他模型精度指标差异的显著性检验结果
Table 3 Significance test between results of volcanic dataset pre-training models and other models
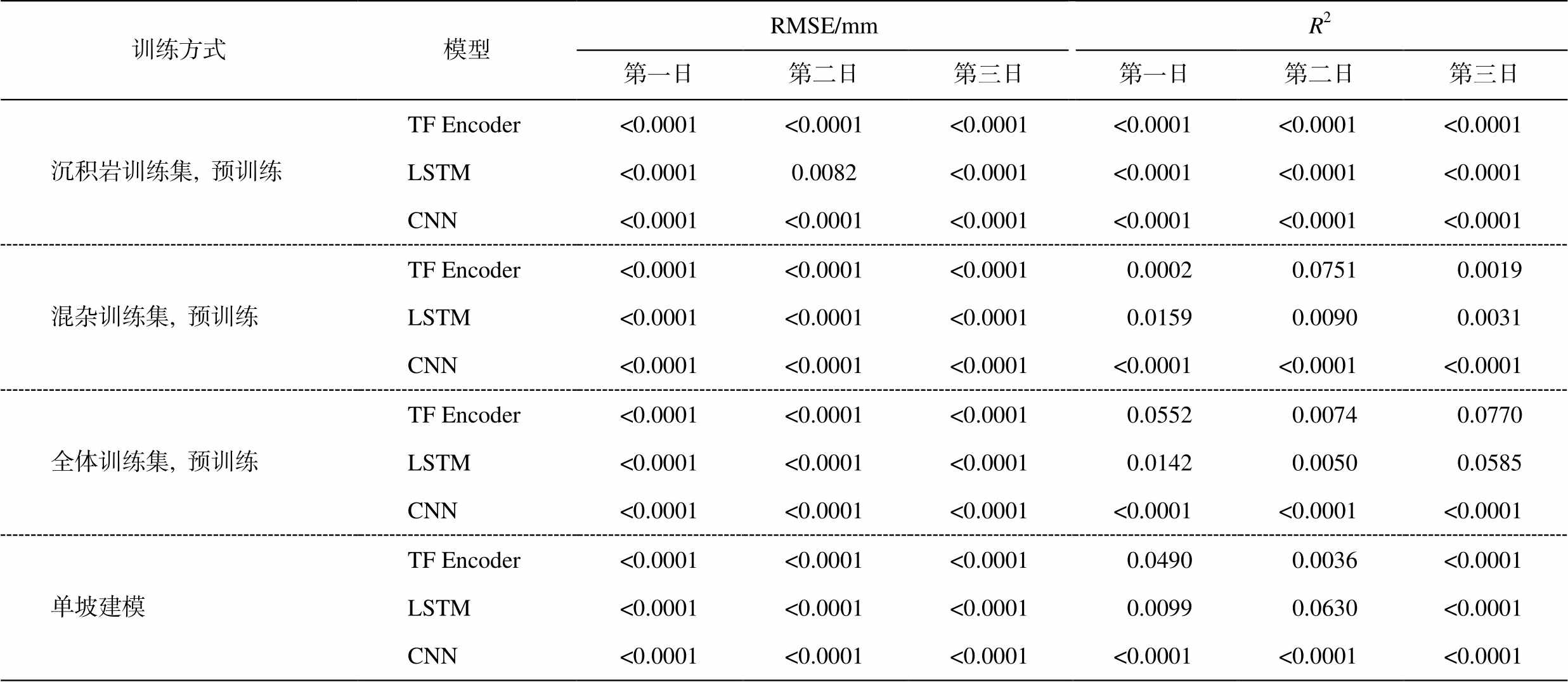
训练方式模型RMSE/mmR2第一日第二日第三日第一日第二日第三日 沉积岩训练集, 预训练TF Encoder<0.0001<0.0001<0.0001<0.0001<0.0001<0.0001 LSTM<0.00010.0082<0.0001<0.0001<0.0001<0.0001 CNN<0.0001<0.0001<0.0001<0.0001<0.0001<0.0001 混杂训练集, 预训练TF Encoder<0.0001<0.0001<0.00010.00020.07510.0019 LSTM<0.0001<0.0001<0.00010.01590.00900.0031 CNN<0.0001<0.0001<0.0001<0.0001<0.0001<0.0001 全体训练集, 预训练TF Encoder<0.0001<0.0001<0.00010.05520.00740.0770 LSTM<0.0001<0.0001<0.00010.01420.00500.0585 CNN<0.0001<0.0001<0.0001<0.0001<0.0001<0.0001 单坡建模TF Encoder<0.0001<0.0001<0.00010.04900.0036<0.0001 LSTM<0.0001<0.0001<0.00010.00990.0630<0.0001 CNN<0.0001<0.0001<0.0001<0.0001<0.0001<0.0001
说明: 置信度为90%。
表4 各模型在沉积岩测试集上的测试结果
Table 4 Testing results of each model on the sedimentary landslide test dataset
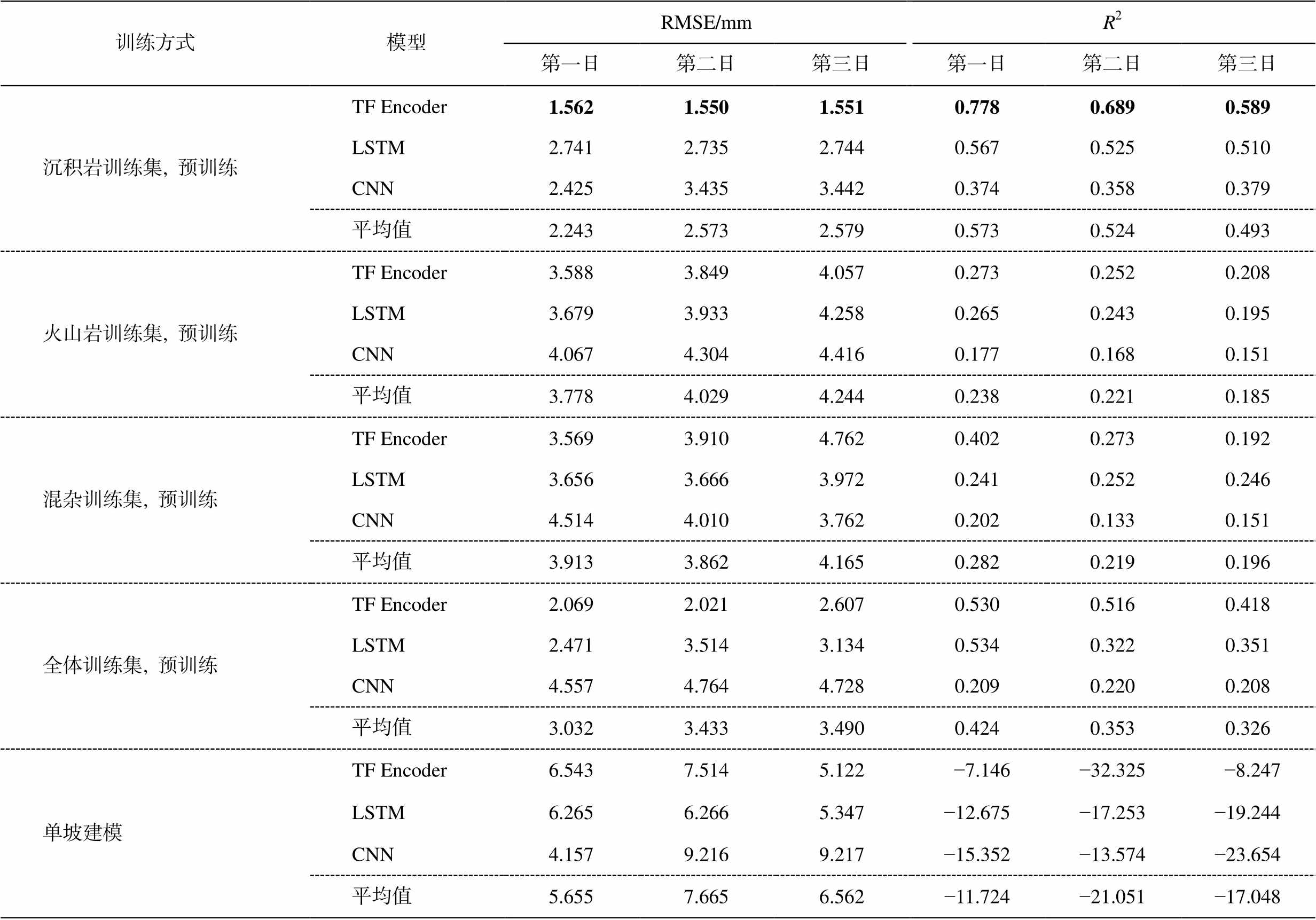
训练方式模型RMSE/mmR2第一日第二日第三日第一日第二日第三日 沉积岩训练集, 预训练TF Encoder1.5621.5501.5510.7780.6890.589 LSTM2.7412.7352.7440.5670.5250.510 CNN2.4253.4353.4420.3740.3580.379 平均值2.2432.5732.5790.5730.5240.493 火山岩训练集, 预训练TF Encoder3.5883.8494.0570.2730.2520.208 LSTM3.6793.9334.2580.2650.2430.195 CNN4.0674.3044.4160.1770.1680.151 平均值3.7784.0294.2440.2380.2210.185 混杂训练集, 预训练TF Encoder3.5693.9104.7620.4020.2730.192 LSTM3.6563.6663.9720.2410.2520.246 CNN4.5144.0103.7620.2020.1330.151 平均值3.9133.8624.1650.2820.2190.196 全体训练集, 预训练TF Encoder2.0692.0212.6070.5300.5160.418 LSTM2.4713.5143.1340.5340.3220.351 CNN4.5574.7644.7280.2090.2200.208 平均值3.0323.4333.4900.4240.3530.326 单坡建模TF Encoder6.5437.5145.122 −7.146−32.325 −8.247 LSTM6.2656.2665.347−12.675−17.253−19.244 CNN4.1579.2169.217−15.352−13.574−23.654 平均值5.6557.6656.562−11.724−21.051−17.048
说明: 粗体数字表示最佳值。
表5 沉积岩训练集预训练模型与其他模型预测效果的显著性检验结果
Table 5 Significance test between sedimentary dataset pre-training models and other models
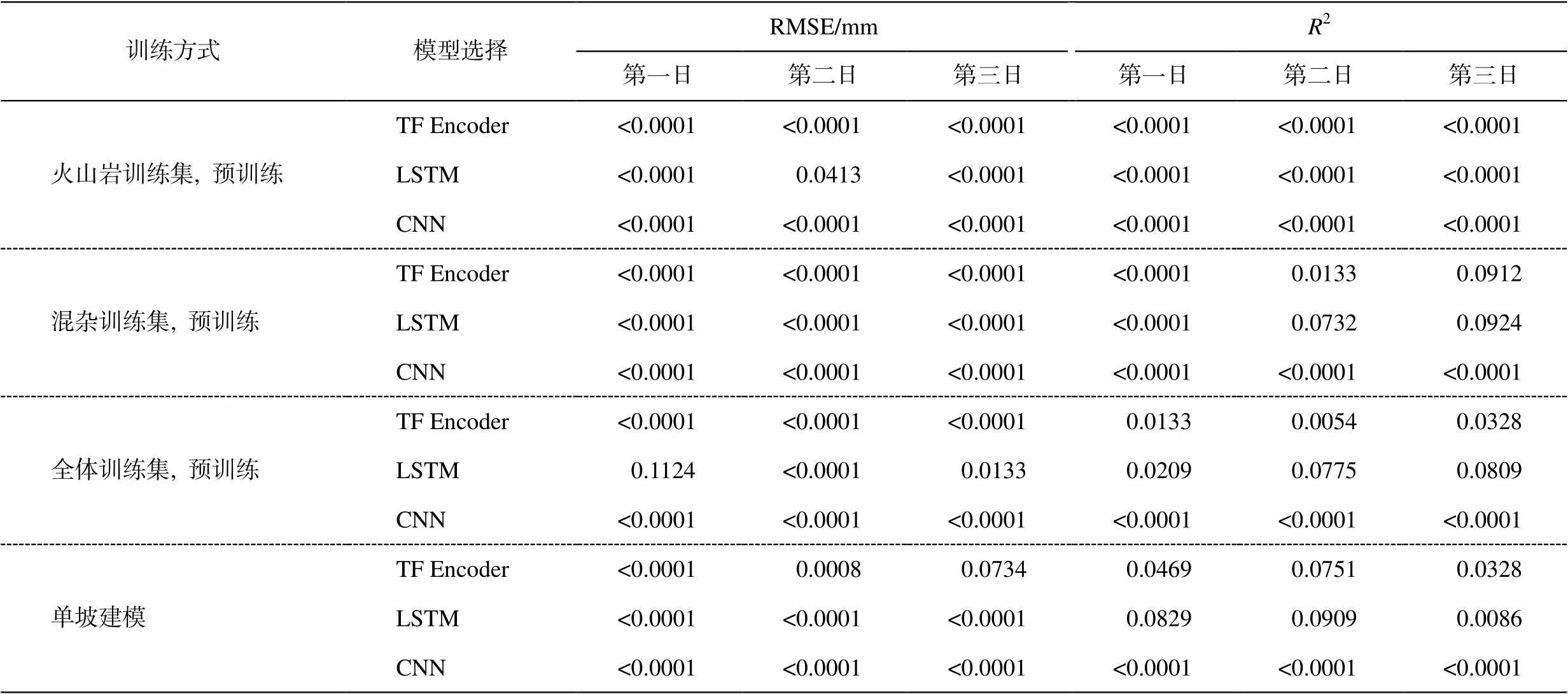
训练方式模型选择RMSE/mmR2第一日第二日第三日第一日第二日第三日 火山岩训练集, 预训练TF Encoder<0.0001<0.0001<0.0001<0.0001<0.0001<0.0001 LSTM<0.00010.0413<0.0001<0.0001<0.0001<0.0001 CNN<0.0001<0.0001<0.0001<0.0001<0.0001<0.0001 混杂训练集, 预训练TF Encoder<0.0001<0.0001<0.0001<0.00010.01330.0912 LSTM<0.0001<0.0001<0.0001<0.00010.07320.0924 CNN<0.0001<0.0001<0.0001<0.0001<0.0001<0.0001 全体训练集, 预训练TF Encoder<0.0001<0.0001<0.00010.01330.00540.0328 LSTM0.1124<0.00010.01330.02090.07750.0809 CNN<0.0001<0.0001<0.0001<0.0001<0.0001<0.0001 单坡建模TF Encoder<0.00010.00080.07340.04690.07510.0328 LSTM<0.0001<0.0001<0.00010.08290.09090.0086 CNN<0.0001<0.0001<0.0001<0.0001<0.0001<0.0001
说明: 置信度为90%。
配对秩和检验结果(表 5)表明, 在沉积岩测试集上, 沉积岩训练集预训练模型预测结果的 RMSE指标总体上显著更优, 只与全体训练集预训练LSTM 模型第一日预测结果有差异。观察 R2 指标差异的显著性可以发现, 在沉积岩训练集上得到的预训练模型的预测效果, 在沉积岩测试集上的 R2 指标均显著优于在火山岩训练集、混杂训练集和全体训练集上得到的预训练模型以及单坡模型。
实例建模试验结果表明, 基于综合数据集的预训练模型的预测效果均优于单坡模型, 说明增加有效数据量可以增强数据表征能力, 提高新建坡面位移建模的预测精度; 在对应岩性的坡面上, 基于岩性分类的预训练模型的建模效果优于基于混杂数据集和全体数据集的预训练模型, 说明岩性分类训练集在增加有效数据量的同时, 顾及了坡体的异质性, 提高了数据集对滑坡变形规律的代表性, 通过提升预训练数据和目标域数据分布的一致性, 提升了预训练模型的应用效果。
值得注意的是, 在相同训练集上得到的预训练模型中, Transformer Encoder 的预测效果整体上比LSTM 和 CNN 更优, 原因是其自注意力机制可以捕捉到时间序列中的长时间依赖, 对时序数据具有更强大的表征能力[20]。在后续建模应用实践中, 可以考虑优先采用 Transformer Encoder 模型。
为了直观地说明基于岩性分类数据集的预训练模型的预测效果, 从测试集中选取基础岩性属于沉积岩的春辉砖厂滑坡作为案例。该滑坡位于甘肃省定西市安定区符家川镇春辉砖厂北侧, 地理坐标为35°33′26″N, 104°17′21″E。滑坡体长约 100m, 宽约80m, 平均厚度约为 15m, 坡面整体上呈凸状, 坡度约为 35°, 坡向为 185°, 体积约为 1.2×105m3, 预测其为中等规模的滑坡体。变形迹象主要为前缘陡坎局部滑塌, 后缘拉张裂缝发育, 坡体现状稳定性较差, 发展趋势稳定性差。2021 年 6 月, 中国地质环境监测院与定西市自然资源局合作, 在该滑坡体上安装监测预警设备, 其累计位移与 6 小时累计降雨监测数据如图 4 所示。滑坡体在监测时段内发生两次较明显的变形, 均伴随明显的降雨过程。
使用 Transformer Encoder 模型, 分别在 4 个训练集上预训练得到的预训练模型对该滑坡的位移预测结果如表 6 所示。可以看出, 使用沉积岩训练集得到的预训练模型的位移预测精度最高, 3 日预测值的 RMSE 分别为 1.209, 1.315 和 1.440mm, 比其他3 个预训练模型低 27%~73%; 3 日预测值的 R2 达到0.877, 0.854 和 0.825, 比其他 3 个预训练模型高出0.153~0.687。在该滑坡面所属沉积岩测试集的 26个坡面中, 其 3 日平均 RMSE 值排名第 9, 其 3 日平均 R2 值排名第 8, 整体精度位于中上水平。
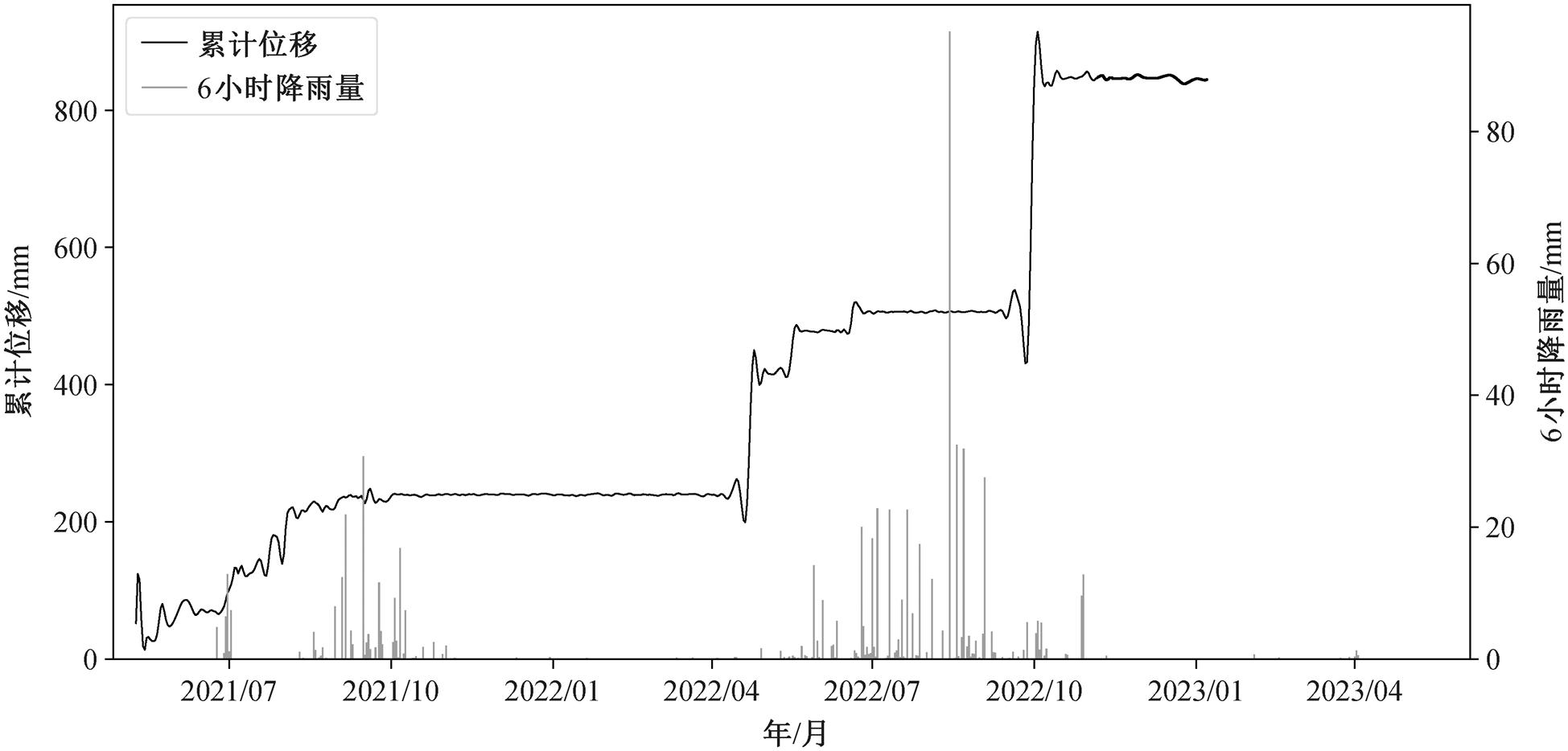
图4 春辉砖厂滑坡监测点降雨量和位移量
Fig. 4 Precipitation and displacement data at Chunhui Brick Factory slope
表6 Transformer Encoder在不同训练集上得到的预训练模型对春辉砖厂滑坡位移的预测效果
Table 6 Predicts result on Chunhui Brick Factory slope by pre-trained Ttransformer Encoder models based on different training datasets

数据集RMSE/mmR2第一日第二日第三日第一日第二日第三日 沉积岩训练集1.2091.3151.4400.8770.8540.825 火山岩训练集1.8101.9962.2710.7240.6640.565 混杂训练集1.9381.9581.9860.6830.6770.668 全体训练集4.1754.5895.3310.4710.3610.138
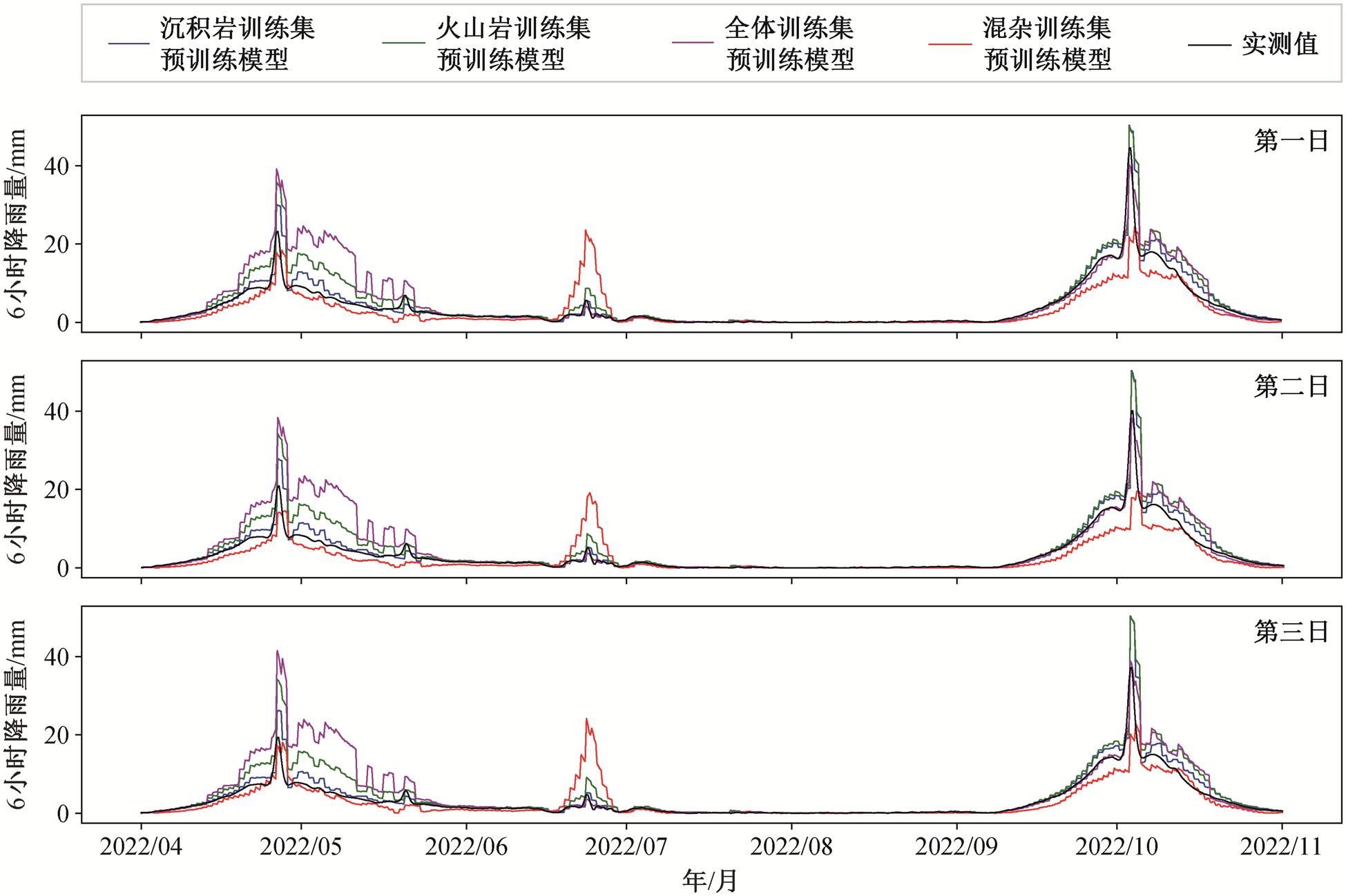
图5 各预训练模型对春辉砖厂滑坡显著形变位移的预测结果
Fig. 5 Prediction results during significant displacement periods by pre-trained models on the Chunhui Brick Factory slope
基于沉积岩训练集、火山岩训练集、混杂训练集和全体训练集的预训练 Transformer Encoder 模型对 2022 年 4 月至 2022 年 11 月两次坡面显著形变的位移预测效果如图 5 所示。可以看出, 全体训练集预训练模型对第一个位移峰值的预测结果明显偏高, 对第二个位移峰值的预测结果也有所偏差; 混杂训练集预训练模型对两个峰值的达峰时间预测效果较好, 峰值预测结果偏小, 且在两个峰值之间出现一段较大的预测偏差; 火山岩训练集预训练模型对达峰时间的预测效果较好, 但峰值预测结果明显偏大; 沉积岩训练集预训练模型对位移达峰时间的预测结果相对准确, 对峰值的预测更准确, 整体预测效果最佳。
本文针对以普适型滑坡监测为代表的坡面监测工作中新建坡面缺乏充足变形数据, 导致数据表征能力不足、难以有效地支持单坡位移预测建模的问题, 创建岩性分类综合数据集, 并构建预训练模型, 以期提升新建坡面的位移预测建模效果。实例建模试验结果表明, 新建坡面囿于极为有限的有效数据量, 单坡建模效果较差, 不具备实用性; 基于各类综合数据集的预训练模型的预测效果均明显优于单坡模型, 说明通过建立综合数据集, 可以提升数据集的有效数据量, 取得更好的训练效果; 在对应岩性的测试集上, 基于岩性分类数据集的预训练模型的建模效果总体上显著优于基于不同岩性分类数据集、混杂岩性数据集和全体数据集的预训练模型, 说明建立岩性分类数据集的技术方案在保证数据集中数据量得到明显增加的同时, 也提升了数据集内形变特征的一致性, 即提升了预训练数据与目标域数据分布的一致性, 可以取得更好的建模效果。本文研究成果可以为滑坡尤其是新建坡面的风险管理工作提供更好的决策支持, 也可以为相关预测建模工作提供参考。
后续工作中, 如能准确地调查和收集滑坡体的其他属性信息(如坡度、高程和坡向等), 亦可基于这些属性或其组合, 开展分类数据集创建和模型遴选, 深化和优化本文研究成果。同时, 随着新建坡面监测数据的不断积累, 监测数据对坡体变形规律的表征也会更加可信, 后续工作应及时结合坡面数据的积累, 对预训练模型进行迭代和精调, 实现模型的持续优化。
参考文献
[1] 刘光代. 我国铁路沿线的滑坡灾害及防治. 路基工程, 1989(4): 11–18
[2] 唐辉明. 重大滑坡预测预报研究进展与展望. 地质科技通报, 2022, 41(6): 1–13
[3] Corominas J, Moya J, Ledesma A, et al. Prediction of ground displacements and velocities from groundwater level changes at the Vallcebre landslide (Eastern Py-renees, Spain). Landslides, 2005, 2: 83–96
[4] 李首位, 李益陈. 基于ARIMA模型的滑坡位移预测. 成都大学学报(自然科学版), 2015, 34(4): 421–424
[5] Miao F, Wu Y, Xie Y, et al. Prediction of landslide displacement with step-like behavior based on multial-gorithm optimization and a support vector regression model. Landslides, 2018, 15(3): 475–488
[6] Xu S, Niu R. Displacement prediction of Baijiabao landslide based on empirical mode decomposition and long short-term memory neural network in Three Gor-ges area, China. Computers & Geosciences, 2018, 111: 87–96
[7] Zhang Y G, Tang J, He Z Y, et al. A novel displacement prediction method using gated recurrent unit model with time series analysis in the Erdaohe landslide. Natural Hazards, 2021, 105: 783–813
[8] 田原, 庞骁, 赵文祎, 等. 基于transformer的滑坡 短期位移预测模型. 北京大学学报(自然科学版), 2023, 59(2): 197–210
[9] Chen F L, Zhang D Z, Han M L, et al. VLP: a survey on vision-language pre-training. Machine Intelligence Research, 2023, 20(1): 38–56
[10] Han X, Zhang Z, Ding N, et al. Pre-trained models: past, present and future. AI Open, 2021, 2: 225–250
[11] Pan S J, Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345–1359
[12] Neyshabur B, Sedghi H, Zhang C. What is being transferred in transfer learning?. Advances in Neural Information Processing Systems, 2020, 33: 512–523
[13] Yu X, Zhang K, Song Y, et al. Study on landslide susceptibility mapping based on rock-soil characteri-stic factors. Scientific Reports, 2021, 11(1): 1–27
[14] 杨忠平, 李绪勇, 赵茜, 等. 关键影响因子作用下三峡库区堆积层滑坡分布规律及变形破坏响应特征. 工程地质学报, 2021, 29(3): 617–627
[15] 宋青春, 邱维理, 张振春. 地质学基础. 北京: 高等教育出版社, 2005
[16] Wenyi Z, Juan M, Mingzhi Z, et al. Effects of sampling frequency on short-term prediction of landslide dis-placement: a case study of Kamenziwan landslide // Proceedings of the 2020 2nd International Conference on Big Data and Artificial Intelligence. New York, 2020: 144–148
[17] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in Neural Information Processing Systems, 2017, 30: 6000–6010
[18] Hochreiter S, Schmidhuber J. Long short-term memo-ry. Neural Computation, 1997, 9(8): 1735–1780
[19] Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278–2324
[20] Zerveas G, Jayaraman S, Patel D, et al. A transformer-based framework for multivariate time series represen-tation learning // Proceedings of the 27th ACM SIGK-DD Conference on Knowledge Discovery & Data Min-ing. Singapore, 2021: 2114–2124
Displacement Prediction of Newly-Established Monitoring Slopes Based on Lithology-Classified Integrated Dataset
Abstract Limited monitoring data of newly-established monitoring slopes in universal landslide monitoring projects and their unavoidable poor representation ability of the deformation patterns have made the traditional single-slope modelling impossible. This paper proposes to classify the multi-slope integrated monitoring dataset based on the lithology of slopes and thus construct pre-trained models to apply to the newly-established monitoring slopes to improve the prediction performance. By integrating the monitoring data, the pre-train models can learn more deformation characteristics from the dataset than from only single-slope data. Moreover, by further classifying the integrated dataset based on the lithology of slopes, constructing different pre-training models, and applying them to newly-established slopes with corresponding lithology, it is feasible to enhance the classified dataset’s ability to represent the deformation patterns of corresponding kind of slopes while still ensuring the volume of dataset of each class is reasonable and, ultimately, to improve the pre-trained models by enhancing the consistency of the pre-training data and target domain data. A case study based on actual monitoring data shows that the pre-training models based on lithology-classified dataset perform overall significantly better on newly-established monitoring slopes with corresponding lithology than single-slope models or pre-training models based on other integrated dataset and may provide effective support for displacement prediction of newly-established monitoring slopes.
Key words landslide; short-time displacement prediction; lithology-classified integrated dataset; pre-training model; newly-established monitoring slope; universal landslide monitoring