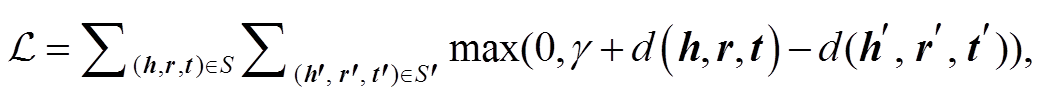
北京大学学报(自然科学版) 第59卷 第3期 2023年5月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 3 (May 2023)
doi: 10.13209/j.0479-8023.2023.002
国家自然科学基金(41971331)资助
收稿日期: 2022–04–28;
修回日期: 2022–05–11
摘要 地理知识图谱的表示学习需要根据正样本生成对应的负样本, 然而传统的负样本生成算法存在错误率高、地理知识图谱适配性差的问题。针对这一问题, 调整空间关系在地理知识图谱中的表达方式, 提出基于空间约束的负样本生成方法, 并将该方法应用至不同的知识图谱表示学习模型, 探讨其在地理知识图谱表示学习中的适配性。结果表明, 该算法具有较低的错误率, 同时适用于常见的两类知识图谱表示模型, 能够提高地理知识图谱表示学习的精度, 有助于地理知识图谱在地理研究中发挥更重要的作用。
关键词 地理知识图谱; 表示学习; 空间约束; 空间关系; 场所
空间(space)和场所(place)是表达和理解地理知识的基础, 其中被赋予含义的空间称为场所[1–2]。场所知识是人们在行为活动中产生的, 并不断精化的常识性认知, 是关联个体行为与地理空间的桥梁[3]。在地理信息科学中, 地理知识通常基于场所的特征和场所间的关系来表示。符号逻辑、地名辞典和地理本体等方法一度在地理知识表示中发挥重要作用[3–5], 但随着大数据和地理智能的发展, 海量时空信息的产生伴随着更高程度的复杂性和多样性, 进而导致地理知识的稀疏性和不完整性, 对场所表示提出新的挑战。
作为一种新兴的大规模结构化知识建模方法, 知识图谱(knowledge graph)[6]为形式化地组织地理知识提供了新途径。知识图谱是一个表示为 G=(E, R)的有向图模型, 其中 E 为实体集合, R 为边集合。G 中的一条事实表示为一个三元组(h, r, t), 其中 h∈E和 t∈E 分别为头实体和尾实体, r∈R表示 h与 t 之间的关系。在知识图谱中加入空间信息表达地理知识后, 产生地理知识图谱(geographic know-ledge graph), 其中的 h 和 t 表示地理实体[7–10]。尽管地理知识图谱还处于起步阶段, 但在地理知识组织[8]、地理问答[10]和地理知识推理[9,11]等方面已发挥明显的作用。
为了从知识图谱中推断新知识, 解决知识的稀疏性和不完整性等问题, 知识图谱表示学习方法被提出来, 用于学习实体和关系在连续向量空间中的嵌入表达[12]。知识图谱的嵌入表示模型主要分为平移距离模型(translational distance models)和语义匹配模型(semantics matching models)两类, 前者包括 TransE[13]、 TransH[14]、TransR[15]、TransD[16]和TransG[17]等系列模型, 后者包括 RESCAL[18]、Dis-Mult[19]和 ComplEx[20]等模型。这些方法也在地理知识图谱的嵌入表示中得到广泛应用。例如, Yan等[9]和 Qiu 等[11]均采用平移距离模型进行地理知识图谱的嵌入表示, 张雪英等[8]和 Mai 等[10]则采用语义匹配模型。
在知识图谱表示学习过程中, 生成负样本(ne-gative samples)是一个重要部分。知识图谱仅基于已知的事实, 以三元组的形式组织而成, 即数据集中只包含正样本, 因此需要生成每个正样本对应的负样本, 以便衡量知识图谱表示学习训练中的模型损失。损失函数的一般形式为
其中, S 表示正三元组集合, S′表示负三元组集合, 需要通过负样本生成算法来生成, 且满足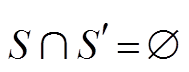 ; d(·)为评分函数; 超参数 γ 和 max(·)用于限定正负三元组评分函数值的差距。损失函数希望正三元组的评分函数尽量小, 负三元组的评分函数尽量大。基于开放世界假设[21], 不在知识图谱中的事实不知真假, 负样本只能通过启发的方式产生。由于通用知识图谱中关系的关联度较小, 或者难以通过归纳来总结其间的关系, 生成负样本只能采用随机替换的方法, 分为替换头实体、替换尾实体和替换关系 3种。这 3 种负样本生成方法都包含两个步骤: 1)从所有实体或者关系的集合中随机选取替换原三元组, 被替换后的三元组称为污化三元组(corrupted trip-let); 2)判断污化三元组是否存在于正三元组集合中。不包含在正三元组集合中的污化三元组可能为负样本, 也可能是未保存的正三元组(missing trip-let), 即错误负三元组(false negative triplet)。在已有的地理知识图谱嵌入表示研究中, 随机替换法仍然是生成负样本的主要方法[9–11]。
; d(·)为评分函数; 超参数 γ 和 max(·)用于限定正负三元组评分函数值的差距。损失函数希望正三元组的评分函数尽量小, 负三元组的评分函数尽量大。基于开放世界假设[21], 不在知识图谱中的事实不知真假, 负样本只能通过启发的方式产生。由于通用知识图谱中关系的关联度较小, 或者难以通过归纳来总结其间的关系, 生成负样本只能采用随机替换的方法, 分为替换头实体、替换尾实体和替换关系 3种。这 3 种负样本生成方法都包含两个步骤: 1)从所有实体或者关系的集合中随机选取替换原三元组, 被替换后的三元组称为污化三元组(corrupted trip-let); 2)判断污化三元组是否存在于正三元组集合中。不包含在正三元组集合中的污化三元组可能为负样本, 也可能是未保存的正三元组(missing trip-let), 即错误负三元组(false negative triplet)。在已有的地理知识图谱嵌入表示研究中, 随机替换法仍然是生成负样本的主要方法[9–11]。
然而, 传统的随机替换法未考虑地理实体间的空间关系, 导致负样本生成的正确率偏低。例如, 相邻的实体间不会存在包含关系, 距离越近的实体间具有相离关系的概率越小。引入这些空间约束, 可以明显地提升地理知识图谱负样本生成的正确率, 从而提高地理知识图谱表示学习的精度。同时, 现有的众多空间关系表达模型较为复杂, 需要对其进行对比分析和改进, 以期简化地理知识图谱的复杂度。因此, 本研究通过调整空间关系表达模型, 提出基于空间约束的负样本生成方法, 并探究该方法在地理知识图谱嵌入表示中的适配性, 促使地理知识图谱在地理研究中发挥更重要的作用。
知识图谱嵌入表示是将知识图谱中的实体表示为向量, 关系主要被表示为向量空间中的操作。常用的知识图谱表示学习模型包括平移距离模型和语义匹配模型, 表 1 总结和对比这两类模型。
最早被提出的平移距离模型是TransE[13], 它将关系视为实体在嵌入空间中的平移:
h+r=t, (1)
其中, h 为头实体向量, t 为尾实体向量, r 为头实体与尾实体的关系向量。TransE 模型的评分函数定义如下:
fr(h, t)=−|| h + r – t ||1/2。 (2)
TransE 模型因简单和高效而得到广泛应用, 但其模型假设在解决 1:N, N:1 和 N:N 问题时存在困难。例如, 对于给定的头节点 h 和关系 r 以及多个备选尾结点 ti (i = 1, 2, 3, …), TransE 会使得 h + r ≈ ti, 最终会使得 t1 ≈ t2 ≈ … ≈ ti。为了解决上述问题, 基于TransE 的多种模型变体被提出来。TransH[14]基于TransE 引入关系超平面, 使得头实体和尾实体在关系所对应的超平面上的投影满足平移关系, 即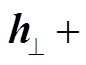
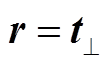 。TransH 模型的评分函数见表 1, 其中 wr表示关系投影向量。
。TransH 模型的评分函数见表 1, 其中 wr表示关系投影向量。
表1 知识图谱嵌入表示模型对比
Table 1 Comparison of knowledge graph embedding representation models

模型实体嵌入关系嵌入评分函数正则化 平移距离模型TransE−||h+r–t||1/2||h||2 =1, ||t||2 =1 TransH||h||2 ≤1, ||t||2 ≤1 TransR||h||2 ≤1, ||t||2 ≤1, ||r||2 ≤1 TransD||Mr h||2 ≤1, ||Mr t||2 ≤1||h||2 ≤1, ||t||2 ≤1, ||r||2 ≤1 语义匹配模型RESCALhTMr t||h||2 ≤1, ||t||2 ≤1, ||Mr||F≤1 DisMulthTMr t+hT r+tT r+hT Dt||h||2 =1, ||t||2 =1, ||r||2 ≤1 ComplEx||h||2 ≤1, ||t||2 ≤1, ||r||2 ≤1
虽然 TransH 能够在一定程度上缓解 TransE 对1:N, N:1 和 N:N 关系表示能力的问题, 但存在较强的理论限制, 即实体空间与关系空间在同一表示空间中, 然而关系与实体是两种完全不同的事物。考虑到这样的理论限制, TransR[15]引入关系超空间, 即每一个关系对应一个实体空间到关系空间的投影矩阵, 使得投影后的头实体和尾实体在关系投影空间中满足平移关系。表 1 中的 Mr 即为实体空间到关系空间的投影矩阵。TransD[16]则进一步考虑头尾实体投影的区别, 并简化 TransR 模型, 将投影矩阵分解为实体投影向量 wh 和 wt 与关系投影向量 wr的乘积。这样, 投影矩阵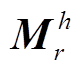 的定义如下:
的定义如下:
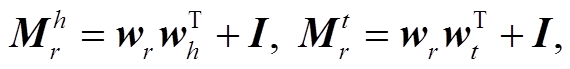 (3)
(3)
其中, I 表示单位矩阵。TransD 使用组合的投影矩阵, 分别对头尾实体进行投影, 使得在投影空间中满足平移关系。然而, 矩阵乘法带来巨大的运算量, 不利于表示学习的训练。
相较于平移距离模型将事实表示为平移关系, 语义匹配模型使用了基于相似度的评分函数。最早提出的语义匹配模型 RESCAL[18]将实体分布式表示为向量, 关系表示为矩阵, 将三元组的评分函数定义为
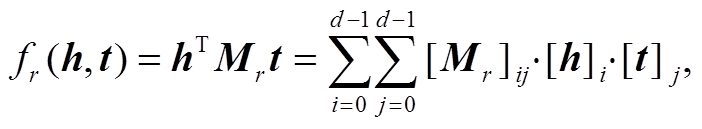 (4)
(4)
其中, 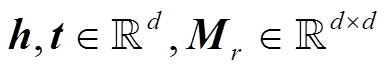 。DisMult 模型[19]通过将关系矩阵限定为对角阵, 简化了 RESCAL 模型, 其评分函数为
。DisMult 模型[19]通过将关系矩阵限定为对角阵, 简化了 RESCAL 模型, 其评分函数为
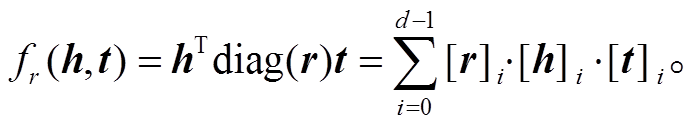 (5)
(5)
通过上述限定, DisMult 模型不仅减少了 RES-CAL 模型中每个关系对应的矩阵参数, 而且减少了评分函数的计算量。然而, 对任何头尾实体 h 和 t来说, DisMult 模型使得 hTdiag(r) t=tTdiag(r) h 成立, 因此 DisMult 模型对 RESCAL 模型过度的简化导致该模型仅能处理对称关系。为了解决这一问题, ComplEx 模型[20]被提出。ComplEx 模型通过引入复数空间来增强表示非对称关系的能力, 将头尾实体及关系分布式表示在复数空间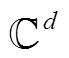 中, 其评分函数被定义为
中, 其评分函数被定义为
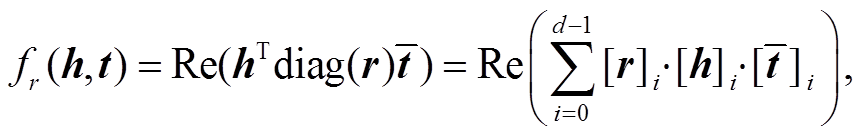 (6)
(6)
其中, 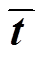 表示尾实体 t 的共轭向量, Re(·)表示取复数的实部。这样的评分函数解决了 DisMult 模型仅能处理对称关系的缺陷。
表示尾实体 t 的共轭向量, Re(·)表示取复数的实部。这样的评分函数解决了 DisMult 模型仅能处理对称关系的缺陷。
针对传统知识图谱表示学习不考虑空间约束、负样本生成的正确率低的问题, 本研究将空间关系模型引入地理知识图谱。现有的空间关系模型, 虽然精确度较高, 但往往过于复杂。为使空间关系模型与地理知识图谱更好地结合, 本文分别探讨空间拓扑关系、方位关系和度量关系在地理知识图谱中的改动和表达。
空间拓扑关系描述的是空间点、线、面之间的邻接、关联和包含关系, 常用的空间拓扑关系表示模型有交集模型和 RCC 模型。常见的交集模型为四交模型(4-IM)[22–23]和九交模型(9-IM)。四交模型是将空间实体划分为内部和边界, 用 2×2 的矩阵表示。九交模型在四交模型的基础上扩充, 将空间实体的外部也纳入空间拓扑关系的范围, 用 3×3 的矩阵表示。RCC 模型包括 RCC8 和 RCC5[24]。RCC8 模型将空间拓扑关系分为 8 种: PO (partial overlap-ping)、TPP (tangential proper part)、NTPP (nontan-gential proper part)、EQ (equal)、NTPP−1(nontan-gential proper part−1)、TPP−1 (tangential proper part−1)、EC (external connected)和 DC (disconnected)。RCC5在 RCC8 的基础上将空间拓扑关系简化, 不区分TPP 与 NTPP, 只用 PP (proper part)表示包含关系; 不区分 TPP−1 与 NTPP−1, 只用PP−1 (proper part−1)表示被包含关系; 不区分 EC 与 DC, 只用 DR(discrete)表示。因此, RCC5 包括 PO, PP, EQ, PP−1和 DR 这5 种空间拓扑关系。由于 DC 关系无法构成地理知识图谱中的三元组, 本文将 RCC5 中的 DR 关系细分为 EC 和 DC, 改动后的模型称为 RCC5+, 包括相邻关系(EC)、包含关系(PP)、被包含关系(PP−1)、重叠关系(PO)、相等关系(EQ)和相离关系(DC)。这6 种关系具有互斥性, 即任意两个空间实体之间只能存在一种拓扑关系。前 5 种拓扑关系都源于连接关系 C, 表明具有该拓扑关系的实体在空间上是相近的。
方位关系指两个空间实体之间方向与位置的相对关系。通常以一个空间实体为中心, 描述另一个空间实体位于它的哪个方位。方位关系的表达分为主方位关系(cardinal direction relations)和内方位关系(internal direction relations)两种, 主方位关系包括投影法[25–26]、锥形法[27]和 MBR 法[28–29]等, 内方位关系包括 ICD 系列模型[30]等。然而, 投影法难以得到东西南北这些正方位关系, MBR 法的方位关系矩阵难以转化成知识图谱中的三元组, 因此锥形法更适合表达地理知识图谱中的空间关系。
空间对象的度量属性包括面积和周长等一元度量属性以及距离等二元度量属性。在知识图谱表示学习中, 实体的一元属性通常效果不佳, 因此很少使用[12], 因此本研究主要关注空间对象的距离这一二元属性。为便于构建地理知识图谱的三元组, 空间关系中的距离需要用定性的方式表达, 例如远和近。然而, 定性距离与确定远近的距离阈值以及空间实体的尺寸等因素紧密相关。因此, 本研究采用TopN 邻近关系, 即给定距离的空间实体中, 最邻近的 N 个空间实体具有邻近关系。在空间实体稀疏的区域, 为防止过度识别距离较远的实体, 需要引入距离阈值来限制邻近关系的范围。
在地理知识图谱构建及其嵌入表示的过程中, 需要区分上述 3 类空间关系的重要程度, 尤其是考虑远距离空间对象之间的空间关系表达, 防止地理知识图谱的复杂度过高。从空间拓扑关系的角度看, 相离关系(DC)是大部分远距离空间实体对应的拓扑关系, 对于地理知识图谱, 其中大多数是无意义的, 因此 DC 不构成空间三元组。对于方位关系, 距离较远的实体间的方位是不重要的, 因此只需表示空间距离较近的空间实体的方位关系。对于度量关系, 距离较远的实体间不应具有邻近关系, 因此需设置邻近关系的距离阈值。综上所述, 地理知识图谱中的空间约束关系表达应以空间拓扑关系为主,方位关系和度量关系作为补充, 并且, 空间约束关系的表达应集中在距离较近的空间实体间, 远距离的空间实体一般不构成三元组。
与通用知识图谱的一般关系相比, 地理知识图谱中的空间关系具有更明显的关联。利用这些空间约束, 可以显著地提升地理知识图谱负样本生成的正确率。基于前面提出的空间约束表达方式, 本文在生成地理知识图谱负样本过程中引入拓扑关系的互斥性和空间邻近性。
替换三元组的头实体或尾实体, 可以生成负样本。以头实体为例, 将(h, r, t)中的头实体 h 替换为h′。如图 1 所示, 首先需要找到与尾实体t存在 r′关系的三元组(h′, r′, t)集合, 其中 r′指除去关系 r 的剩余拓扑关系。如果集合不为空, 那么(h′, r′, t)三元组集合中所有 h′与尾实体 t 构成的(h′, r, t)都为正确的负三元组。若集合为空, 则考虑空间邻近性。
如图 1 所示, 黑色区域为原三元组尾实体 t, 左上方灰色区域为原三元组头实体 h, 剩余区域为待替换空间实体, 关系为 r = EC。图 1 中灰色区域, 已知与原三元组尾实体 t 存在 EC 关系; 图 1 中条纹区域, 地理知识图谱中没有存储它们与 t 的关系, 最可能与 t 不存在 EC 关系的实体是与 t 不连接的实体, 因此可将与 t 存在 RCC5+拓扑关系的实体排除在外。与原三元组尾实体 t 直接存在 RCC5+拓扑关系的实体称为 1 阶邻近实体, 与 1 阶邻近实体存在RCC5+拓扑关系的实体称为 2 阶邻近实体。邻近阶数 N 越大, 排除在外的实体越多, 与 t 不连接的概率越大。图 1 中, N=1 将去除周围 6 个空间实体, N=2将去除周围 7 个空间实体, 待选 h′则为最外层的 3 个, 这些 h′与 t 构成的(h′, EC, t)则为正确负三元组。当采用的空间邻近性备选 h′集合为空时, 则采用传统的负三元组生成算法。
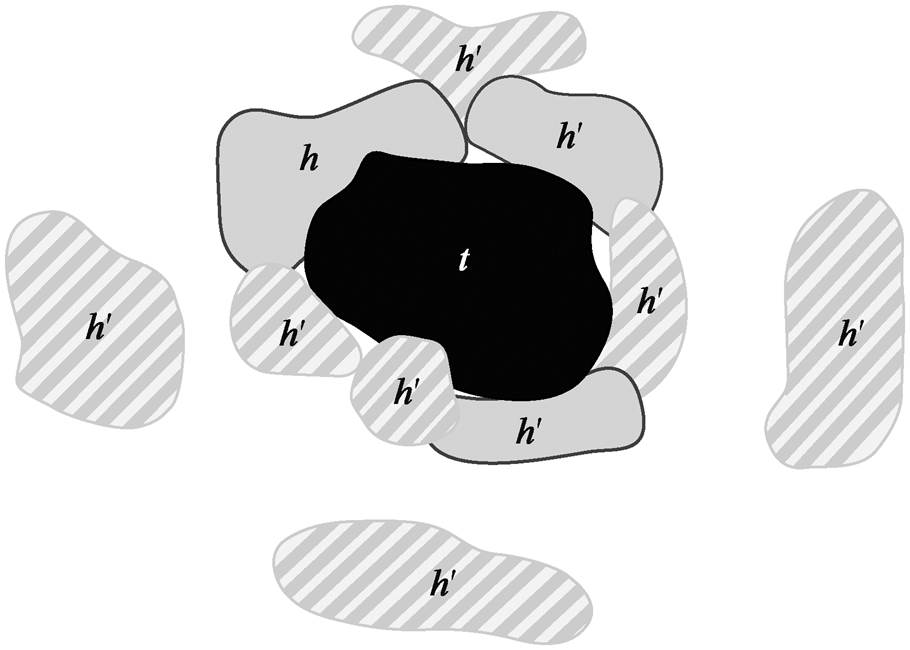
图1 基于空间邻近性生成负三元组
Fig. 1 Generating negative triplet based on spatial proximity
形式化的空间负三元组头实体算法如下。
数据及参数: 输入三元组(h,r,t), 输出三元组(h′,r,t), 实体集合 E, 空间关系集合 R, N阶邻近
1. 判断 r 是否为空间关系, 是则进入 2, 否则使用随机替换, 返回(h′, r, t)
2. 找到的 h′的集合 H′, 其中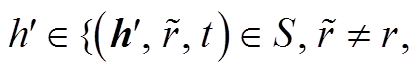
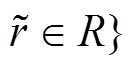
3. 若 H′为空则转 4, 否则随机返回(h′, r, t), 其中 h′∈H′
4. 设置邻近集合 Q={h, t}, n=0
5. 将包含 Q 中元素的三元组另一实体放入 Q中, n = n+1, 若 n = N 则转 6, 否则转 5
6. 随机生成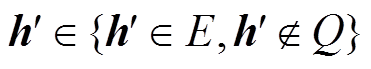 , 返回(h′, r, t)
, 返回(h′, r, t)
类似地, 空间负三元组尾实体算法如下。
数据及参数: 输入三元组(h,r,t), 输出三元组(h,r,t′), 实体集合 E, 空间关系集合 R, N阶邻近
1. 判断 r 是否为空间关系, 是则进入 2, 否则使用随机替换, 返回(h, r, t′)
2. 找到的 t′的集合 T′, 其中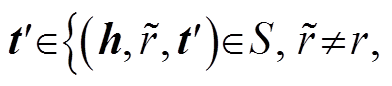
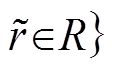
3. 若T′为空则转 4, 否则随机返回(h, r, t′), 其中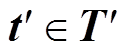
4. 设置邻近集合Q={h, t}, n=0
5. 将包含 Q 中元素的三元组另一实体放入 Q中, n=n+1, 若 n=N则转 6, 否则转 5
6. 随机生成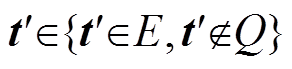 , 返回(h, r, t′)
, 返回(h, r, t′)
空间负三元组关系算法较为简单, 采用拓扑关系的互斥性替换不同的拓扑关系即可, 算法如下。
数据及参数: 输入三元组(h,r,t), 输出三元组(h,r′,t), 空间关系集合 R
1. 判断 r是否为空间关系, 是则进入 2, 否则使用随机替换, 返回(h, r′, t)
2. 随机生成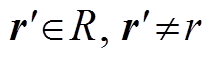 , 返回(h, r′, t)
, 返回(h, r′, t)
与一般机器学习或深度学习的评价任务及指标不同, 地理知识图谱表示学习使用以下两个任务进行精度评价。1)链接预测: 给定缺失头实体或尾实体的三元组, 让模型去检测知识图谱中所有实体最符合这个缺失实体的得分, 并排序(表 2); 2)三元组分类: 判断测试三元组是不是正确的三元组, 即二分类的准确率。
平均序的计算公式如下:
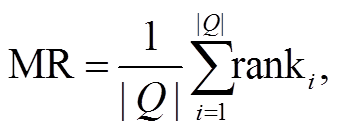 (7)
(7)
式中, 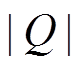 是预测的三元组总数, ranki 是第 i 次预测正确实体的排列顺序。MR 越小说明预测精度越高, 效果越好。
是预测的三元组总数, ranki 是第 i 次预测正确实体的排列顺序。MR 越小说明预测精度越高, 效果越好。
平均相互序的计算公式如下:
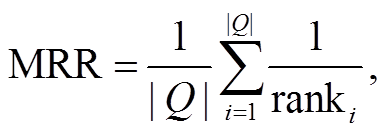 (8)
(8)
MRR≤1, 其值越大说明预测精度越高, 效果越好。
N 命中率的计算公式如下:
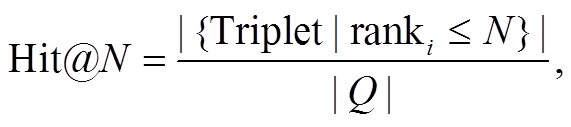 (9)
(9)
式(9)中, Triplet 表示链接预测中的三元组, 分子为预测实体排列顺序小于等于 N 的集合的元素个数, Hit@N 越大说明预测精度越高, 效果越好。
表2 链接预测任务精度评价指标
Table 2 Accuracy evaluation indexes of link prediction

指标说明 平均序(MR)链接预测中正确实体的平均位次 平均相互序(MRR)链接预测中正确实体的平均相互次序 N命中率(Hit@N)链接预测正确实体前N名命中率
为构建地理知识图谱, 本文使用中国省级行政区划数据、北京城市区划数据、北京市五环内商圈数据[31]、北京五环内交通小区数据、北京市 250m×250m 格网数据和北京市兴趣点数据(图 2)。其中, 商圈单元是基于北京市兴趣点数据, 用模糊集方法[31]得到的。针对每个商圈包含的兴趣点及其签到量进行核密度估计, 利用等值线截取的方法划定各个商圈的范围。地理知识图谱中的实体信息如表 3 所示, 其中的空间关系信息如表 4 所示。
3.2.1负样本生成算法实验结果
为了检验负样本生成算法的效果, 按照不同比例, 将构建的地理知识图谱划分成多个数据集(表5)进行负样本生成实验。
基于表 5 中 8 组数据集, 分别使用传统负样本生成算法和基于空间约束的负样本生成算法, 随机生成 100 万个负样本。通过检验生成的负样本是否位于本文构建的地理知识图谱中, 即可判断生成的负样本正确与否(因为本文构建的地理知识图谱中包含实体间所有的拓扑关系)。
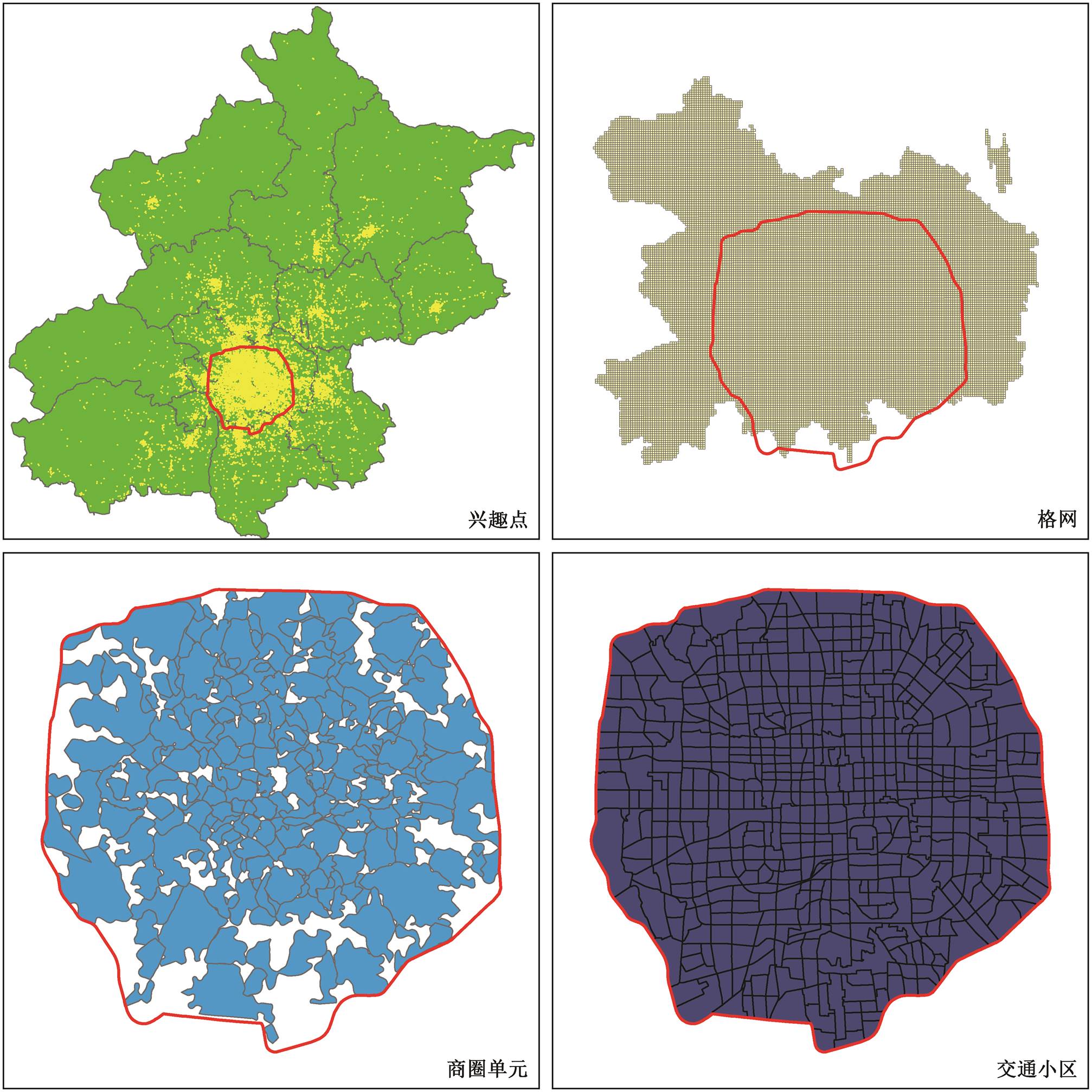
图2 知识图谱地理数据
Fig. 2 Geographic data of knowledge graph
表3 地理知识图谱实体信息
Table 3 Statistics of entities in geographic knowledge graph
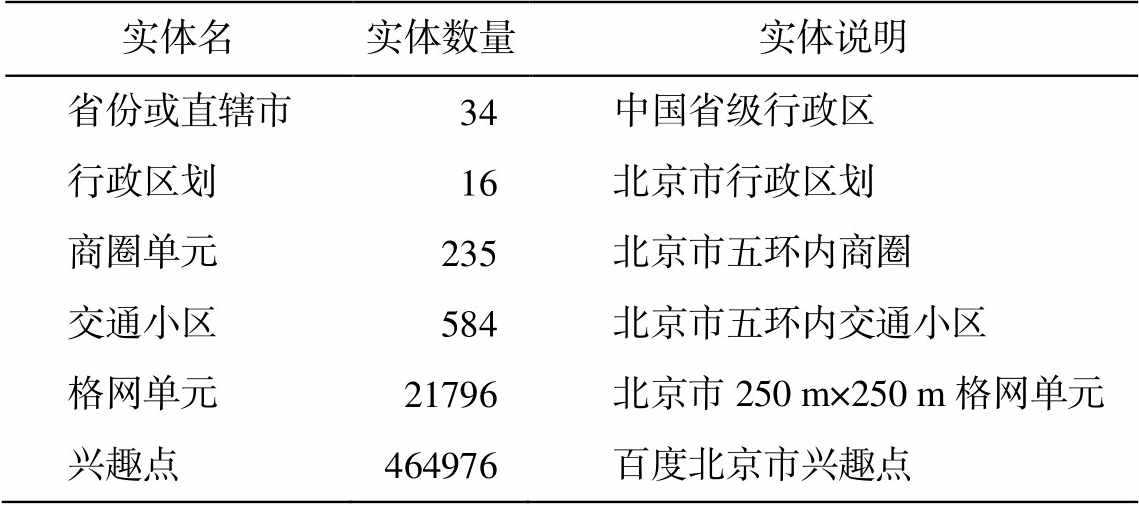
实体名实体数量实体说明 省份或直辖市 34中国省级行政区 行政区划 16北京市行政区划 商圈单元 235北京市五环内商圈 交通小区 584北京市五环内交通小区 格网单元 21796北京市250 m×250 m格网单元 兴趣点464976百度北京市兴趣点
表4 地理知识图谱空间关系信息
Table 4 Statistics of spatial relations in geographic knowledge graph
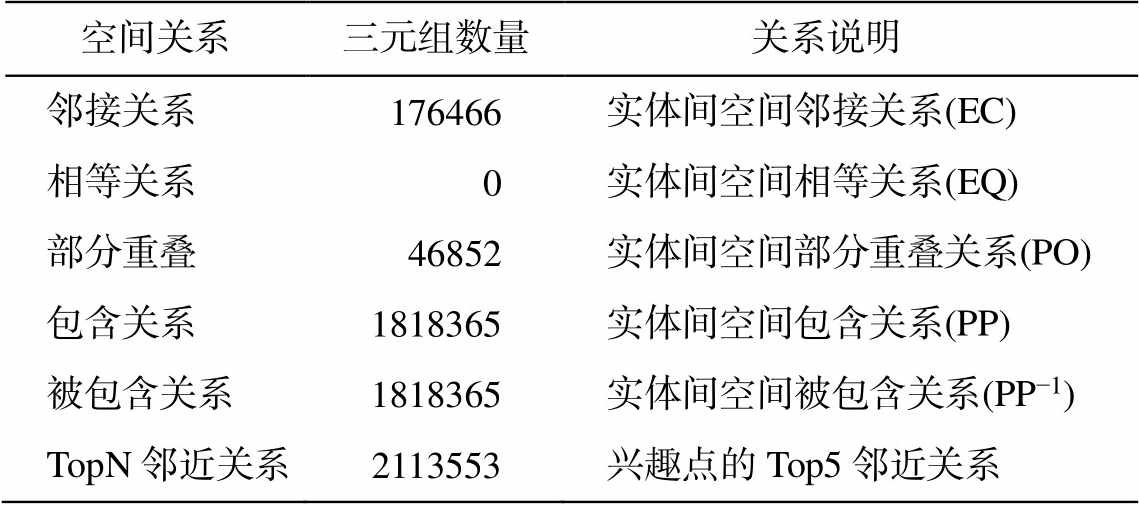
空间关系三元组数量关系说明 邻接关系 176466实体间空间邻接关系(EC) 相等关系 0实体间空间相等关系(EQ) 部分重叠 46852实体间空间部分重叠关系(PO) 包含关系1818365实体间空间包含关系(PP) 被包含关系1818365实体间空间被包含关系(PP−1) TopN邻近关系2113553兴趣点的Top5邻近关系
表5 负样本生成数据集
Table 5 Datasets for negative samples generation
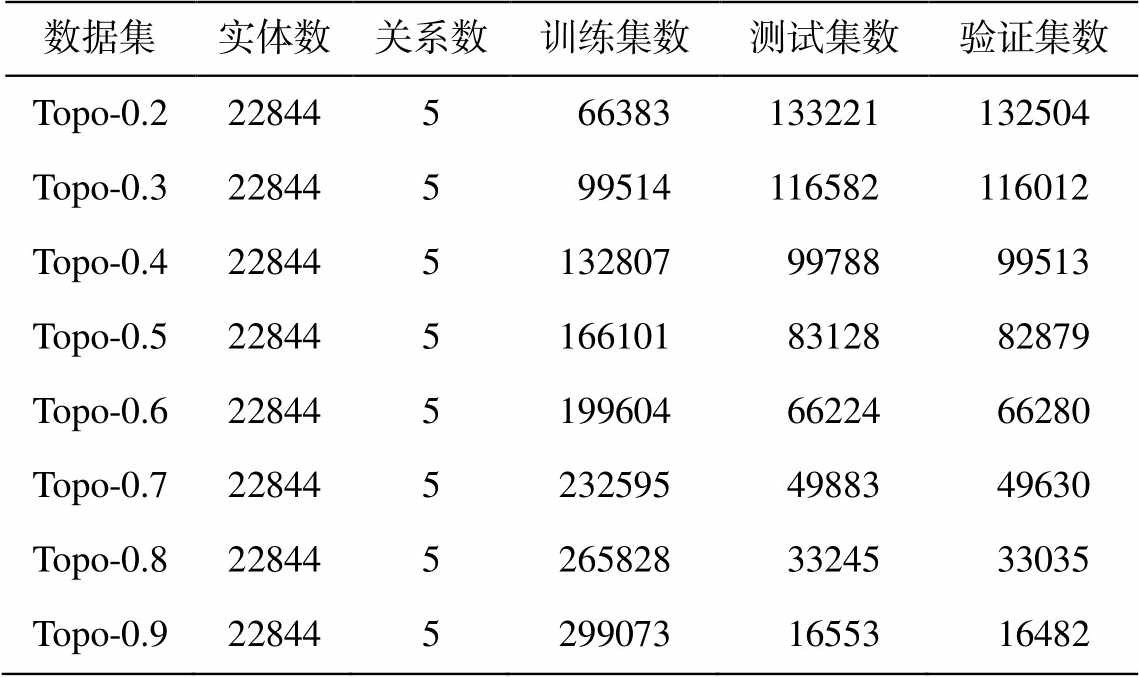
数据集实体数关系数训练集数测试集数验证集数 Topo-0.2228445 66383133221132504 Topo-0.3228445 99514116582116012 Topo-0.4228445132807 99788 99513 Topo-0.5228445166101 83128 82879 Topo-0.6228445199604 66224 66280 Topo-0.7228445232595 49883 49630 Topo-0.8228445265828 33245 33035 Topo-0.9228445299073 16553 16482
图 3 中, 横坐标表示生成负三元组的数据集中训练样本占总体数据集的比例, 纵坐标表示生成100 万个负三元组所包含的错误三元组个数; 圆点标识的折线为传统负三元组生成算法对应的错误负三元组个数, 随着训练集包含的空间关系增加, 所生成的负三元组错误数量也增加; 三角形标识的折线为空间负三元组算法对应的错误负三元组个数, 随着训练集包含的空间关系增加, 所生成的负三元组错误数量基本上保持在 100 个的水平。可以发现, 空间负三元组生成算法的效果远优于传统负三元组生成算法。传统负三元组生成算法只是基于开放世界假设, 通过随机替换正三元组成分获得不在知识图谱中的三元组来作为负三元组; 空间负三元组生成算法则考虑了空间关系间的互斥性, 生成负三元组的错误率大大降低。地理知识图谱中包含的空间关系越多, 会使得不包含的空间关系越少, 导致传统负三元组生成算法的错误率越高。这一结构表明传统负三元组生成算法并不适用于地理知识图谱表示学习, 发展基于空间约束的负样本生成算法是必要的。
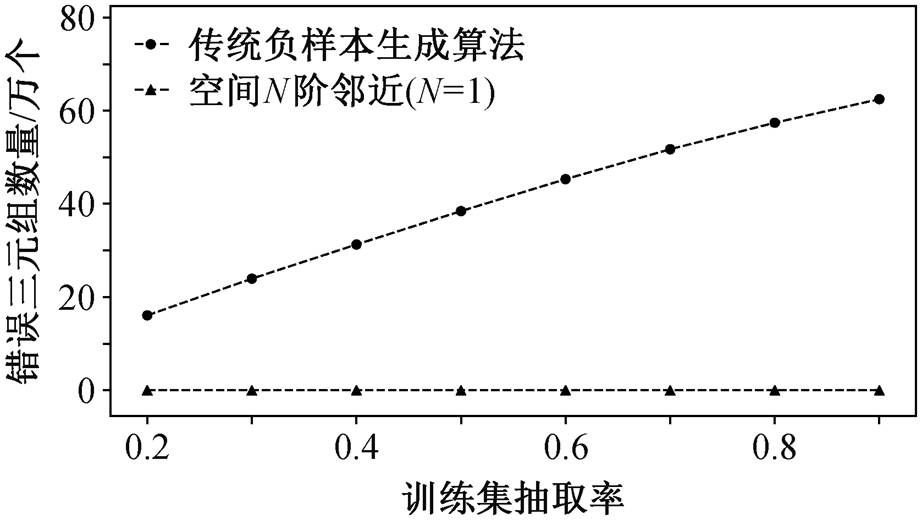
图3 传统负样本生成算法与基于空间约束的负样本生成算法结果对比
Fig. 3 Comparison of results between traditional negative samples generation method and spatially constrained negative samples generation method
空间负三元组生成算法考虑空间关系互斥性时, 可能由于所包含的空间关系数量不足, 不能找到互斥空间关系。然而, 拓扑关系是 Connect 关系的导出关系, 表明地理知识图谱中所表示的拓扑关系是对邻近空间实体的空间关系描述。因此, 空间负三元组生成算法引入 N 阶空间关系来排除邻近相关的空间实体, 增加负三元组生成的正确率。为了验证 N 阶空间关系引入对负三元组生成的效果, 我们进行不引入 N 阶空间关系(N=0)和引入 1 阶空间关系(N=1)的对比分析。
图 4 中, 圆点标识的折线为空间负三元组算法0 阶空间关系生成结果, 三角形标识的折线为空间负三元组算法 1 阶空间关系生成结果。无论是否引入 N 阶空间关系, 生成 100 万个负三元组的错误数量都低于 150 个。随着引入空间关系占比的增加(训练集抽取率上升), 错误数量明显下降。当空间关系占全集的 70%以下时, 引入 1 阶空间关系生成负三元组的错误率低于不引入 N 阶空间关系的错误率; 当空间关系占比大于 70%时, 引入 1 阶空间关系的错误率略高于不引入 N 阶空间关系。随着数据集空间关系占比增大, 其补集减小, 引入 N 阶空间关系会将一部分邻近空间实体从补集中去除, 使得虽然补集中错误候选实体的数量降低, 但错误实体的占比升高, 最后导致负三元组生成错误率增大。
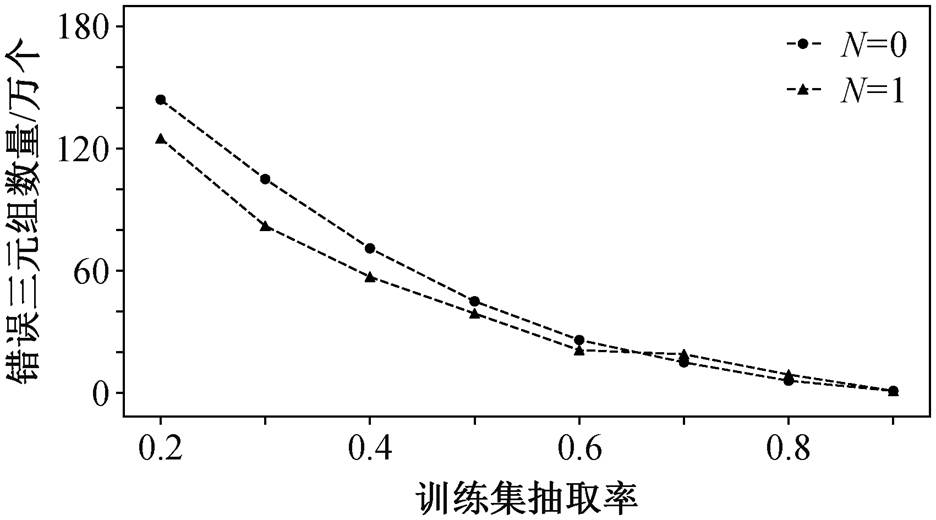
图4 引入N阶空间关系的负样本生成算法结果
Fig. 4 Results of spatially constrained negative samples generation with N-order spatial relations
上述两组对比实验的结果表明, 空间负三元组生成算法在地理知识图谱表示学习中的效果远优于传统的负三元组生成算法, 尤其在空间关系不充足的情况下, 空间负三元组生成算法引入 N 阶空间关系会进一步提高负三元组生成的正确率。
3.2.2地理知识图谱表示学习模型对比
在进行地理知识图谱表示学习时, 使用的仍然是传统的平移距离模型和语义匹配模型。为了研究这两类模型对空间负样本生成算法的适配性, 基于表 5 中的数据集 Topo-0.9, 对两类模型进行表示学习。平移距离模型包括 TransE, TransH, TransR 和TransD, 语义匹配模型包括 RESCAL 和 ComplEx。本文基于上述模型, 用空间负三元组生成算法训练10000 次, 使用的 Linux 服务器配置 Intel(R) Xeon (R) E5-2680 14 核 CPU, NVIDIA 1080Ti GPU, 训练模型程序均使用 30 个线程。
从图 5 可以看出, TransR 和 RESCAL 的训练时长远高于其他模型。这是由于 TransR 模型引入了关系空间(关系投影矩阵), 而 RESCAL 模型同样用矩阵表示关系。这两种模型进行大量的矩阵向量乘积操作, 大大地增加了训练时间。因此, 对于实时性高的应用场景, TransR 和 RESCAL 不适用于知识图谱的表示学习。
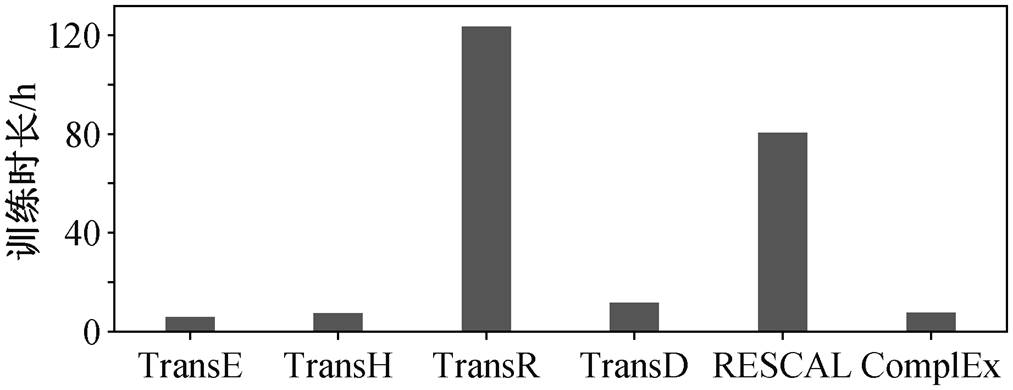
图5 表示学习模型的训练时长
Fig. 5 Training time of different representation learning model
本文使用精度指标 MRR, HIT@10, HIT@3 和HIT@1, 分别对各个模型的表示学习结果进行评估。图 6 显示, 平移距离模型中的 TransE, TransH, TransR 和 TransD 在综合结果评估中具有相似的精度表现。TransD 的精度略高于其他 3 种模型, 可能是由于 TransD 改进了 TransR, 将 TransR 中的关系投影矩阵分解为头实体投影向量和尾实体投影向量, 使得模型能够区分头尾实体的差别。语义匹配模型的精度则有较大的差异, 其中 RESCAL 模型的精度远高于平移距离模型, 而 ComplEx 模型的精度则远低于所有其他模型。这可能是由于 ComplEx模型引入了复数空间, 训练收敛速度较慢, 训练10000 次仍然存在欠拟合的问题。
为了进一步分析不同模型对空间关系中拓扑关系表示的学习效果, 对各拓扑关系表示学习的精度分别进行分析, 结果如图 7 所示。
对于同为 N:N 关系的包含关系(PP)和被包含关系(PP−1), 平移距离模型具有较为相似的精度表现。其中, TransR 模型因引入关系投影矩阵而导致欠拟合, 精度比其他平移距离模型低。各语义匹配模型的精度差异较大: RESCAL 模型优于所有平移距离模型; 由于欠拟合, ComplEx 模型的精度远低于所有表示学习模型。对于平移距离模型, 在包含关系中, TransH 和 TransE 的精度略高于 TransD 和TransR; 在被包含关系中, TransE 和 TransD 的精度略高于 TransH 和 TransD。
对于邻接关系(EC), 所有模型均在 HIT@10 和HIT@3 上有一致的精度。平移距离模型仍有相似的精度, 且 TransD 模型的表示学习精度远高于其他平移距离模型。对于语义匹配模型, RESCAL 模型的表示学习精度仍然远优于其他模型, 而 ComplEx模型由于欠拟合, 其表示学习精度远低于所有其他模型。
对于重叠关系(PO), 各模型的表示学习精度不同于其他关系, RESCAL 模型的精度远高于所有其他模型。其次, TransD 模型略高于 RESCAL 模型之外的其他模型。这种精度的差异与模型假设和关系性质有关。重叠关系为对称关系, 即(entity1, PO, entity2)→(entity2, PO, entity1)。对于平移距离模型, 对称关系会使得关系表示为零向量, 但平移距离模型却要求关系表示不为零向量。语义匹配模型要求极小化损失函数 Loss=hMt, 但该损失函数的定义要求为对称关系。因模型假设不同的缘故, 语义匹配模型能更好地表示对称关系。
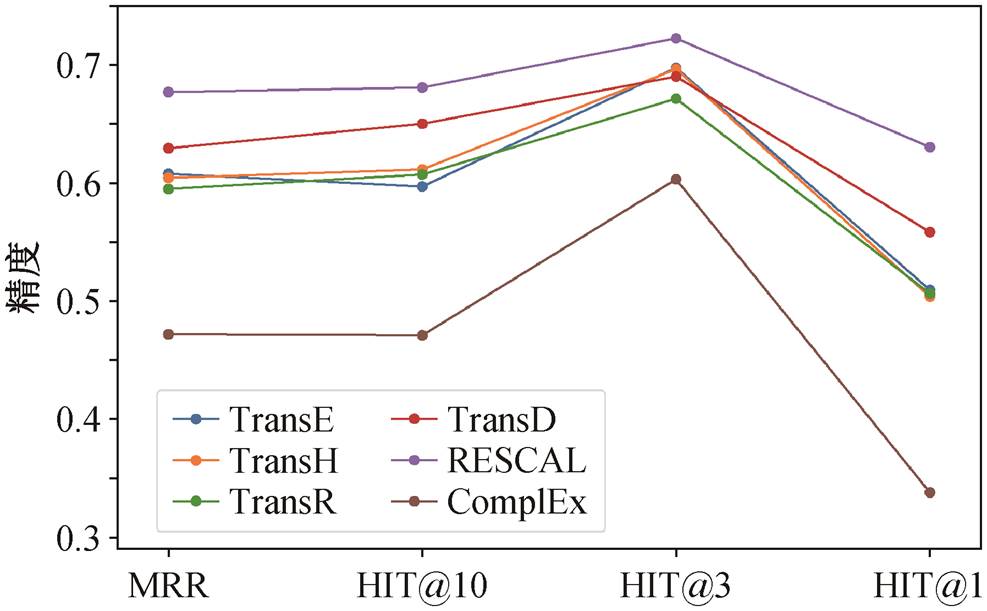
图6 地理知识图谱表示学习模型精度对比
Fig. 6 Comparison of accuracy of geographic knowledge graph representation learning models
上述结果表明, 语义匹配模型中的 RESCAL 模型更适合地理知识图谱的表示学习, 平移距离模型略差于 RESCAL 模型。同时, 考虑到模型训练耗时问题, 由于引入矩阵乘积运算, RESCAL 和 TransR模型训练耗时较长。综上所述, 同时考虑表示学习精度和训练耗时, TransD 模型具有仅次于 RESCAL的整体表示学习精度, 且模型训练耗时远低于RESCAL 模型, TransD 模型更适用于地理知识图谱的表示学习研究。
本研究提出基于空间约束的负样本生成方法, 并将其应用到地理知识图谱的表示学习中。首先, 对已有的空间关系表达方式进行调整, 使它们可以用于地理知识图谱中空间关系的表达, 同时保持知识图谱的复杂度不大幅度增加。然后, 根据调整后的空间关系表达方式, 提出基于空间约束的负样本生成算法。最后, 将基于空间约束的负样本生成算法应用到不同类型的表示学习模型中, 评估负样本生成算法的适配性。
本研究使用省份、区划、商圈单元、交通小区、格网单元和兴趣点进行地理知识图谱的构建, 其中空间关系的表达采用调整的 RCC5+模型。实验结果表明, RCC5+模型有能力表达常用地理知识图谱中的空间关系, 不会导致知识图谱的复杂度大幅度增加。与传统的基于随机替换的负样本生成算法相比, 基于空间约束的负样本生成算法具有更高的正确率, 尤其在空间关系不充足的情况下, 引入N阶空间关系的空间负样本生成算法, 可以进一步提高负三元组生成的正确率。基于空间约束的负样本生成算法适用于平移距离模型以及语义匹配模型这两大类常见的表示学习模型。语义匹配模型中的RESCAL 模型具有最高的精度, 缺点在于训练耗时较长。综合考虑表示学习精度和训练耗时, 平移距离模型中的 TransD 模型具有优异的表现。
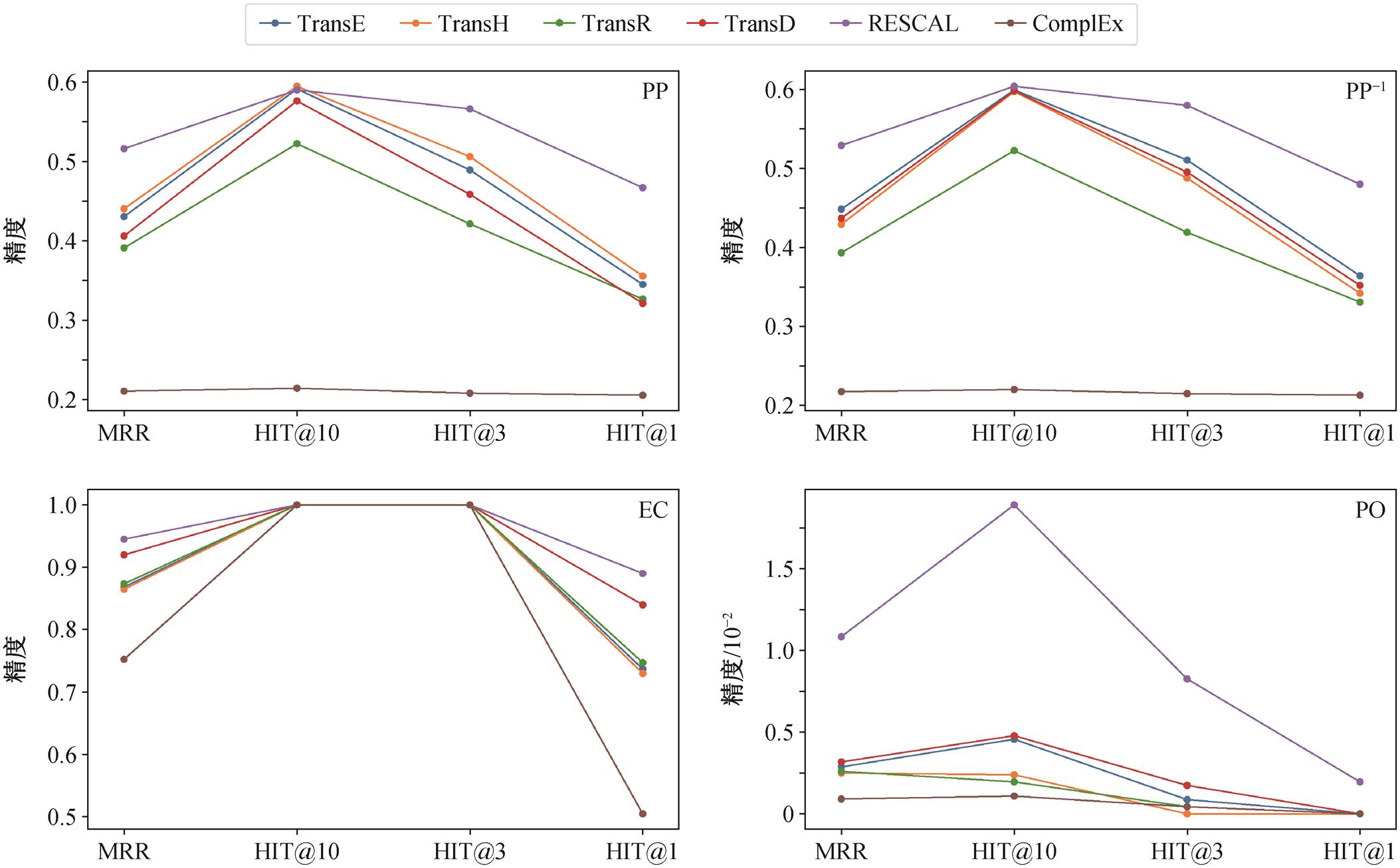
图7 不同模型的拓扑关系表示学习精度对比
Fig. 7 Comparison of accuracy of geographic knowledge graph representation learning models under different topological relations
本文的研究结果表明, 地理知识图谱能够对空间信息进行合理的组织和综合表示, 将在诸多领域产生较大的应用价值。例如, 地理知识图谱能够结合不同层次的空间分析单元数据, 对城市问题进行更综合的分析和研究, 也能够应用于地名消歧、地理问答和地理知识推理等领域。如果地理知识图谱能够进一步对模糊性关系建模, 那么还可以进行具有模糊性的空间推理。地理知识图谱的构建及其嵌入表示的继续发展, 将为上述领域提供更大的应用价值。
参考文献
[1] Relph E. Place and placelessness. London: Pion Press, 1976
[2] Tuan Y F. Space and place: humanistic perspective. Progress in Human Geography, 1974, 6: 233–246
[3] Purves R S, Winter S, Kuhn W. Places in Information Science. Journal of the Association for Information Science and Technology, 2019, 70(11): 1173–1182
[4] Goodchild M F. Formalizing place in geographic information systems // Burton L, Matthews S, Leung M, et al. Communities, neighborhoods, and health. New York: Springer, 2011: 21–33
[5] Scheider S, Janowicz K. Place reference systems: a constructive activity model of reference to places. Applied Ontology, 2014, 9(2): 97–127
[6] Paulheim H. Knowledge graph refinement: a survey of approaches and evaluation methods. Semantic Web Journal, 2017, 8(3): 489–508
[7] 陆锋, 余丽, 仇培元. 论地理知识图谱. 地球信息科学学报, 2017, 19(6): 723–734
[8] 张雪英, 张春菊, 吴明光, 等. 顾及时空特征的地理知识图谱构建方法. 中国科学: 信息科学, 2020, 50(7): 1019–1032
[9] Yan B, Janowicz K, Mai G, et al. A spatially exp- licit reinforcement learning model for geographic knowledge graph summarization. Transactions in GIS, 2019, 23(3): 620–640
[10] Mai G, Janowicz K, Cai L, et al. SE-KGE: a location-aware knowledge graph embedding model for geogra-phic question answering and spatial semantic lifting. Transactions in GIS, 2020, 24: 623–655
[11] Qiu P, Gao J, Yu L, et al. Knowledge embedding with geospatial distance restriction for geographic knowle-dge graph completion. ISPRS International Journal of Geo-Information, 2019, 8(6): 254–277
[12] Wang Q, Mao Z, Wang B, et al. Knowledge graph embedding: a survey of approaches and applications. IEEE Transactions on Knowledge and Data Enginee-ring, 2017, 29(12): 2724–2743
[13] Bordes A, Usunier N, Garcia-Duran A, et al. Transla-ting embeddings for modeling multi-relational data // Burges C J C, Bottou L, Welling M, et al. Advances in neural information processing systems. Red Hook, NY: Curran Associates, 2013: 2787–2795
[14] Wang Z, Zhang J, Feng J, et al. Knowledge graph embedding by translating on hyperplanes // Procee-dings of the 28th AAAI Conference on Artificial In-telligence. Québec City, 2014: 1112–1119
[15] Lin Y, Liu Z, Sun M, et al. Learning entity and relation embeddings for knowledge graph comple- tion // Proceedings of the 29th AAAI Conference on Artificial Intelligence. Hyatt Regency Austin, 2015: 2181–2187
[16] Ji G, He S, Xu L, et al. Knowledge graph embedding via dynamic mapping matrix // Proceedings of the 53rd Annual Meeting of the Association for Com-putational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing, 2015: 687–696
[17] Xiao H, Huang M, Zhu X. TransG: a generative model for knowledge graph embedding // Proceedings of the 54th Annual Meeting of the Association for Computa-tional Linguistics. Brelin, 2016: 2316–2325
[18] Nickel M, Tresp V, Kriegel H P. A three-way model for collective learning on multi-relational data // Pro-ceedings of the 28th International Conference on Ma-chine Learning. Bellevue, 2011: 809–816
[19] Yang B, Yih S W, He X, et al. Embedding entities and relations for learning and inference in knowle- dge bases [C/OL] // Proceedings of the International Conference on Learning Representations. (2015–08– 29) [2022–04–01]. http://arxiv.org/abs/1412.6572
[20] Trouillon T, Welbl J, Riedel S, et al. Complex em-beddings for simple link prediction // Proceedings of the 33rd International Conference on Machine Learning. New York, 2016: 2071–2080
[21] Drumond L, Rendle S, Schmidt-Thieme L. Predicting RDF triples in incomplete knowledge bases with ten-sor factorization // Proceedings of the 27th Annual ACM Symposium on Applied Computing. New York, 2012: 326–331
[22] Egenhofer M J. A formal definition of binary to-pological relationships // International conference on foundations of data organization and algorithms. Pa-ris, 1989: 457–472
[23] Egenhofer M J, Franzosa R D. Point-set topological spatial relations. International Journal of Geographi-cal Information System, 1991, 5(2): 161–174
[24] Randell D A, Cui Z, Cohn A G. A spatial logic based on regions and connection // Principles of Knowledge Representation and Reasoning: Proceedings of the 1st International Conference. Cambridge, 1992: 165–176
[25] Frank A U. Qualitative spatial reasoning: Cardinal directions as an example. International Journal of Geographical Information Science, 1996, 10(3): 269–290
[26] Ligozat G É. Reasoning about cardinal directions. Journal of Visual Languages & Computing, 1998, 9(1): 23–44
[27] Haar R. Computational models of spatial relations [R]. College Park: University of Maryland at College Park, Computer Science Center, 1976
[28] Goyal R K. Similarity assessment for cardinal direc-tions between extended spatial objects [D]. Orono: The University of Maine, 2000
[29] Goyal R K, Egenhofer M J. Similarity of cardinal directions // International Symposium on Spatial and Temporal Databases. Redondo Beach, 2001: 36–55
[30] Liu Y, Wang X, Jin X, et al. On internal cardinal direction relations // International Conference on Spa-tial Information Theory. Ellicottville, 2005: 283–299
[31] 王圣音, 刘瑜, 陈泽东, 等. 大众点评数据下的城市场所范围感知方法. 测绘学报, 2018, 47(8): 1105–1113
A Spatially Constraint Negative Sample Generation Method for Geographic Knowledge Graph Embedding
Abstract Geographic knowledge graph representation learning requires generating the corresponding negative samples based on the positive ones. However, traditional negative sample generation algorithms suffer from high error rate and poor adaption to geographic knowledge graph. Aimming at this problem, a spatially constraint negative sample generation method was proposed by modifying the modeling of spatial relations. Then the method was applied to different knowledge graph representation learning models to explore its suitability in geographic knowledge graph embedding. Results show that the proposed method has a low error rate and is suitable for two common types of knowledge graph representation models. The spatially constraint negative sample generation method will improve the accuracy of geographic knowledge graph representation learning, which helps to advance geographical research.
Key words geographic knowledge graph; representation learning; spatial constraint; spatial relationship; place