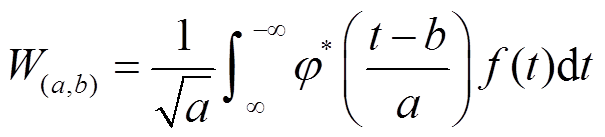 , (2)
, (2)摘要 为了准确而迅速地拾取大量地震事件的 P 波初至, 将深度学习方法引入微地震 P 波初至到时拾取研究中, 对卷积神经网络的结构进行改造, 以便适应地震波形数据的特点和 P 波初至拾取的要求。该算法只需要输入 10s 窗口的三分量地震波形数据, 就可以自动地判定 P 波初至时刻, 无需扫描连续波形, 运算时间远远小于长短窗、模板匹配等传统方法。使用该算法训练汶川地震主震后 2008 年 7—8 月 7467 条人工拾取的余震 P 波初至到时, 将得到的模型对测试集中 1867 条数据的计算结果与人工拾取结果对比,误差小于 0.5s 者占比达到 98.9%。在低信噪比条件下, 该方法仍能保持较好的拾取能力。
关键词 人工智能; 机器学习; 深度学习; 小波变换; 初至拾取
汶川地震主震发生后, 不断地有余震发生。为了更好地开展抗震救灾工作, 需要更快速和精准的手段来识别余震的初至时刻并构建余震地震目录。如果能够自动地识别这些微弱的地震信号和遗漏的早期余震, 找到余震震相的初至时刻, 将对完善地震目录、地震预警、全面分析地震活动性以及监测地震破裂区域的震后形变等具有重要意义。地震震相到时拾取是地震学研究的重要课题, 是地震预警、地震定位及地球内部结构等研究的基础。地震预警技术[1]是近二十年发展起来的一种减轻地震损失、减少人员伤亡、降低地震次生灾害的有效手段。通常情况下, 由于地震 P 波波速大于破坏性较大的 S 波和面波, 且地震波速度远远小于电磁波速度, 因此地震预警系统可在破坏性地震发生后, 基于近震源地区地震台站监测记录得到的地震波形数据, 快速地侦测地震, 在破坏性地震波到达特定目标区前, 发布地震警报。
从技术层面上看, 地震震相的自动拾取是实现基于地震台网地震预警的首要条件。在传统地震学中, 一般是在地震图上人工拾取震相。震相的自动识别开始于对海量波形数据的自动处理, 随着实时地震学的发展, 对震相的自动精确拾取受到越来越多的重视。对地震预警而言, 目前主要考虑的震相为容易自动拾取的 P 波震相和 S 波震相。在各种地震震相自动拾取方法中, 广泛应用的主要有两种, 一种是反映幅值瞬时变化的长短时窗比方法, 另一种是基于互相关技术的模板匹配滤波方法。这两种方法或者依赖于阈值的设定, 或者依赖于模板的选取, 在一定程度上限制了应用范围。人工智能领域中近年来广泛使用的神经网络模型可以根据输入的训练数据训练参数, 而不用人工设定参数, 可能更适用于不同地区不同性质的微地震震相到时拾取, 特别是在信噪比较低的情形下。
长短时窗比(STA/LTA)方法由 Stevenson[2]提出, Earle 等[3]完善了该方法, 并且将其应用于地震研究中。该方法利用有效信号与噪声的振幅差异, 通过两个长度不同的滑动时窗来判断初至时刻, 目前广泛应用于以微地震为代表的初至拾取研究中[4]。其中, 短时窗用于截取微弱的有用信号, 长时窗内信号的平均值则反映背景噪声水平, 包络线上短时窗内信号的平均值与长时窗内信号平均值的比值用来表征信号振幅的变化。与其他震相拾取方法相比, 该方法具有算法简单、计算速度快的特点, 对不同的震相均可拾取。但是, 该方法依赖于阈值的选取, 对于特定的情形, 需要人工设定阈值; 另一方面, 长短时窗比方法对信噪比的要求较高, 对信噪比较低的微地震拾取效果欠佳。
模板匹配滤波技术[5]是在滑动窗互相关检测技术的基础上发展起来的, 通过扫描连续波形来自动拾取震相, 是在信噪比较低的情况下提取微弱信号的一种有效方法。该方法将现有地震目录中记录的事件作为模板, 扫描连续波形, 从中识别出与模板事件波形有一定相似度的地震事件。与长短时窗比方法相比, 该方法具有在信噪比较低情况下仍适用的优点。然而, 该方法也有其局限性, 一方面检测出地震的数目依赖于所选取的模板数目, 另一方面, 只能识别重复的地震信号。与长短窗比方法类似, 该方法也需要设定互相关系数的阈值。近年来的新方法主要围绕这两种方法进行改进和优化, 选取不同的特征函数来计算长短时窗比, 如 Zhang 等[6]2017年将分形引入长短时窗比方法中。但是, 这些改进不能从本质上解决阈值的人工设定以及低信噪比情形下效果差的问题。
以上两类方法需要扫描连续波形, 存在运行速度慢的特点。如果能够将连续数据切割成相互独立的窗口作为输入, 将大大减少运算时间。此外, 长短窗比方法中的特征函数和阈值参数均需要人工选取, 若能避开人工的局限, 直接从数据中挖掘出特征和参数, 将大大简化初至拾取的流程。
随着大数据时代的来临, 人工智能领域取得飞速的发展, 一方面数据量呈指数式增长, 另一方面计算机硬件计算能力不断提升, 特别是随着 GPU广泛应用于深度学习计算中, 过去应用范围受局限的深度学习方法开始应用到各个领域中。深度学习方法具有结构更复杂、可训练参数更多以及无需人工选取特征等优点, 在众多领域逐渐超越传统机器学习方法, 得到更广泛的应用。
人工智能在地震学领域的应用目前处于起步阶段。过去几十年来, 随着宽频带地震仪的普及, 地震数据的质和量都得到大幅度的提升, 为人工智能方法在地震学领域的应用提供了数据量方面的支持。地震波和声波同属机械波, 地震波数据与声波数据也有一些共同的特性, 这为将人工智能语音识别的一些方法拓展到对地震波数据的分析处理中提供了可能性。人工神经网络模型的雏形在 20 世纪40 年代就已提出, 20 世纪 90 年代就有人试图将其应用于震相的识别中[7], 但由于当时数据量和计算能力等多方面的限制, 没能取得好的效果。
鉴于上述背景, 本文另辟蹊径, 绕开上述两类方法的窠臼, 将人工智能领域的卷积神经网络结构引入地震波 P 波初至时刻拾取中, 并根据地震波波形数据的特性和 P 波初至拾取问题的特殊性, 对传统的卷积神经网络结构进行一定程度的调整, 充分利用深度学习方法在大数据量情形下的优势。我们将 P 波初至时刻拾取问题转化为一个监督学习中的回归问题, 通过对大量已经标记好到时的连续波形数据进行训练, 使机器学习得到一个可以重复使用的卷积神经网络模型。该模型一旦训练结束, 在实时拾取 P 波初至时, 只需要将连续波形数据切割成10s 的数据段作为输入, 即可迅速得到拾取到时结果, 无须对原始波形进行逐点扫描, 大大节省运行时间。此外, 在模型的训练过程中, 利用 GPU 加速, 使得训练时间也大大缩短。以本文具体使用的模型为例, 从输入数据到训练出最终模型只需要 4~ 5 小时。与长短时窗比方法相比, 该模型的构建既不需要人工选取振幅或能量等具有实际物理意义的特征函数, 也不需要选取阈值。该方法也不需要选取模板, 而是直接输入三分量连续波形数据, 输入数据被简单地归一化后, 即可通过训练好的模型得到拾取的到时时刻。在训练的过程中, 卷积神经网络通过一系列滤波器实现参数最优化, 从而从波形数据中找到识别初至的特征, 这一切都是机器通过训练习得的, 不需要人工挑选特征或模板。
根据中国地震台网中心的统计, 汶川地震主震发生后, 2018 年 5 月共有 6.0 级以上余震 5 次, 5.0~ 5.9 级余震 25 次, 4.0~4.9 级余震 161 次; 6 月共有 6.0级以上余震 0 次, 5.0~5.9 级余震 3 次, 4.0~4.9 级余震31 次; 7 月共有 6.0 级以上余震 1 次, 5.0~5.9 级余震2 次, 4.0~4.9 级余震 15 次。当震源周边的地震台站监测到这些余震信号时, 通过提取 P 波和 S 波的初至时刻, 可以确定余震的震中位置, 为抗震救灾工作提供重要信息。然而, 在现实情况中, 由于受到背景噪声水平、记录仪器分布等多种因素的影响, 许多微弱的地震信号被淹没在噪声中, 无法直接观测到。另一方面, 在大地震发生后的短时间内, 由于强震尾波的影响以及大量余震事件的发生, 波形相互重叠, 难以区分。
本文采用汶川地震后(2008 年 7 月 1—31 日)四川及邻省 16 个地震台站的三分量连续波形数据[8], 由国家数字测震台网数据备份中心提供。
本文将三分量连续原始波形分割成时间窗口长度为 10s 的片段, 数据原始采样率为 100Hz, 故数据格式为 1000×3 的二维矩阵。对每段数据进行 1Hz 高通滤波, 滤掉长周期背景波动。然后, 对每段数据的每一道分量单独进行归一化操作, 即将数据除以整段数据幅值绝对值的最大值, 使其最大值的绝对值为 1。本文采用人工标记好 P 波到时的三分量数据 9334 条, 从中随机抽取数据分为训练集、验证集和测试集。其中, 5974 条(64%)作为训练集, 用于训练模型参数; 1493 条(16%)作为验证集, 用于判断训练停止时刻; 1867 条(20%)作为测试集, 用于验证模型样本外的泛化能力, 各样本集之间数据量的比例按照惯例[9], 测试集与训练集和验证集之和的比例以及验证集与训练集的比例均取 1:4。
为了准确地拾取不同频率特性的地震 P 波初至, 本文使用连续小波变换, 将每一分量的原始数据转换为小波时频谱。小波基采用中心频率为 3 Hz, 频率带宽为 3Hz 的 Morlet 小波, 缩放因子取 10, 得到时间域为 0~10s, 采样率为 0.01s, 频率域为 1~ 10Hz, 频率间隔为 1Hz 的 1000×10×3 三维矩阵。分别将时间序列数据和小波变换时频谱数据作为输入进行训练, 并比较所得模型的识别能力。
本文以语音和图像识别领域常用的卷积神经网络模型结构为基础, 并针对地震波形数据的特点和到时拾取问题的特性, 对部分神经网络中的部分层级结构做了一定的修改。当以小波变换时频谱作为输入数据构建模型时, 每一个频率采样点使用与以上神经网络结构相同的模型, 最后通过一定方法计算不同频率采样点的回归值, 得到最终的到时结果。
McCulloch 等[10]首先将生物神经网络中的神经元模型引入数学领域, 提出沿用至今的“M-P 神经元模型”。在该模型中, 神经元接收到来自 n 个其他神经元传递的输入信号, 这些输入信号通过具有权重的连接进行传递, 神经元接收到的总输入值会与神经元的阈值进行比较, 然后通过激活函数处理来产生神经元的输出。将诸如逻辑斯谛函数这样的非线性函数作为激活函数, 当神经网络的层数和结点数增加时, 理论上可以无限逼近任意非线性函数。因此, 神经网络模型具有极大的模型表达能力。
从理论上讲, 参数越多的模型复杂度越高, 这意味着它能完成更复杂的学习任务。但是, 这种模型通常训练效率低, 易陷入过拟合, 样本外测试效果差。随着数据量的提升, 深度学习模型(层数很多的神经网络模型)的表达能力大大加强。在深度学习领域, 卷积神经网络自提出以来, 就在图像识别和语音识别等领域有了广泛的应用[11]。鉴于地震波形数据与语音数据的相似性, 已经有人将卷积神经网络应用于地震信号和噪音的分类以及地震区域的定位工作中[12], 但将卷积神经网络应用于到时拾取问题的研究中还无人问津。
一个典型的神经网络结构主要由以下 5 个部分组成。
1)输入层: 在到时拾取问题中, 输入层为 1000 ×3×1 的三维矩阵, 1000 表示时间域的采样点数, 3 表示 N, E, Z 三个分量, 1 表示输入层的深度。从输入层开始, 卷积神经网络通过不同的神经网络结构将上一层的三维矩阵转化为下一层的三维矩阵, 直到最后的全连接层。
2)卷积层: 卷积神经网络中最重要的部分。与传统的全连接层不同, 卷积层中每一个节点的输入只是上一层神经网络的一小块, 即卷积核。在图像识别领域, 常用的卷积核大小为 3×3 或 5×5[13]。由于到时拾取问题的输入层长宽比非常大, 本文中每个卷积层的卷积核大小均采用 2×1。卷积层试图将神经网络中的每一小块进行更深入的分析, 从而得到抽象程度更高的特征。一般来说, 通过卷积层处理过的节点矩阵变得更深, 深度取决于过滤器深度。深度为 n 的过滤器表示通过卷积层将原始数据的一张图卷积成 n 张图。虽然每一层卷积核只利用临近两个采样点数据之间的关系, 但通过叠加多个卷积层, 模型可以捕捉到更多临近采样点之间的关系来构造特征。本文模型共叠加 5 个卷积层。
3)池化层: 池化层神经网络不改变三维矩阵的深度, 但可以缩小矩阵的大小。可以认为池化操作是将一张分辨率较高的图片转化为分辨率较低的图片。通过池化层, 可以进一步缩小最后全连接层中节点的个数, 从而减少整个神经网络的参数。使用池化层可以加快计算速度, 并防止过拟合, 在一定程度上避免模型对训练集拟合效果较好, 但对测试集拟合误差较大的问题。但是, 也有研究指出池化层对模型效果的影响不大[14]。通常情况下, 在将卷积神经网络应用于分类问题(如图像的分类)时, 池化层起到提取低频抽象特征的作用。由于到时拾取问题的关键不在于提取抽象特征, 而是找到数据特征的突变时间点, 所以使用池化层会丧失高频信息, 导致拾取结果的精度下降。因此, 本文模型结构中不使用池化层, 直接将多层卷积层连接起来。
4)全连接层: 卷积神经网络一般由 1~2 个全连接层给出最后的分类结果。经过多轮卷积层的处理后, 图像中的信息已经被抽象为信息含量更高的特征, 可以将卷积层看成自动图像特征提取的过程。完成特征提取后, 使用全连接层完成分类任务。Perol 等[12]在处理地震和噪音的分类问题时, 只使用一层全连接层, 共两个节点, 用于区分地震和噪音两类结果。他们在处理地震定位分类问题时, 也只用一层全连接层, 共 10 个节点(文献[12]中将分类结果分为 10 个地区块)。到时拾取是回归问题而不是分类问题, 要求输出连续的浮点数值, 而不是表示类别的整数, 因此需要更多的全连接层和节点来提高模型的表达能力。本文模型包含两个全连接层, 第一个有 1024 个节点, 第二个只有 1 个节点, 用于输出最后到时拾取结果。
5)柔性最大激活函数层: 主要用于分类问题, 计算得到当前样例属于不同种类的概率。由于到时拾取并非分类问题, 故本文模型不使用该层。
综上所述, 本文模型输入层为 1000×3×1 的三维矩阵, 输入层后连续叠加 5 个卷积层, 其过滤器深度分别为 6, 16, 16, 32 和 32, 提取的特征越来越深。除过滤器深度外, 5 个卷积层的其他参数均相同, 卷积核尺寸为 2×1, 卷积核的移动步长为 2, 激活函数为 ReLU 函数。ReLU 函数是人工神经网络中常用的激活函数, 当输入信号为负值时, 输出都是 0; 当输入信号为正值时, 输出等于输入。其表达式为
ReLU(x) = max(0, x), (1)
其中, x 为神经元的输入。ReLU 函数被认为有一定的仿生学原理, 并且在实践中通常比其他常用激活函数(如逻辑斯蒂函数)的效果更好, 因此广泛使用于计算机视觉[15]人工智能领域。
在卷积层后设置一个随机丢失层, 随机丢失率为 0.5 (训练过程中每次更新参数时, 随机地断开50%输入神经元, 用于防止过拟合)。随机丢失层后设置一个压平层, 用来将输入“压平”, 即将多维输入一维化, 完成卷积层到全连接层的过渡。压平层后设置一个节点数为 1024, 激活函数为 ReLU 函数的全连接层。全连接层之后再设置一个随机丢失率为 0.5 的随机丢失层。最后一层是节点数为 1 的全连接层。
考虑到不同震级的地震具有不同的频率特性, 为了使模型对不同频率特性的地震波形数据都具有良好的识别能力, 本文进行基于小波变换的带通滤波。小波变换是一种具有较好时频局部化特性的方法, 具有可在时间域和频率域同时进行分析的特点, 在地震数据处理中广泛应用, 也应用于震相拾取工作中[16]。小波变换将信号分解成一系列小波函数的叠加, 这些小波函数均由一个小波基函数经过平移与尺度伸缩得到。利用这种不规则的小波函数, 可以逼近非稳态信号中尖锐变化的部分, 也可以逼近离散、不连续、具有局部特性的信号, 从而更真实地反映原信号在某一时间尺度上的变化。小波变换可以分为连续小波变换和离散小波变换。离散小波变换常用于降噪与数据压缩, 连续小波变化更适用于信号特征的提取。作为时间序列间歇式波动特征提取的工具, 连续小波变化广泛地应用于地球物理学研究中[17]。
在连续小波变换中, 移动带通滤波器的带宽(频率域窗口)随着滤波器中心频率的增加而扩大。通常定义一个实信号 f(t)的连续小波变换为如下卷积:
, (2)其中, 窗口函数 φ(t)为内核小波, *号表示共轭。参数 a 和 b 分别为小波变换的尺度和平移量。对于每个尺度 a, 小波核按 1/a 的比例缩放, 按 b 平移得到小波系数W(a,b)。
为了有效地提取原始波形中的时频信息, 小波基的选取十分重要。Farge[18]指出小波基选择时需要考虑的因素, 例如正交与非正交、负值与实值以及小波基的宽度与图形等。正交小波函数一般用于离散小波变换, 非正交小波函数既可用于离散小波变换, 也可用于连续小波变换[19]。在对时间序列进行分析时, 通常希望得到平滑连续的小波振幅, 因此非正交小波函数较合适。此外, 要得到时间系列振幅和相位两方面的信息, 就要选择复值小波, 因为复值小波具有虚部, 可以对相位进行很好的表达。Morlet 小波是高斯包络下的单频率正弦函数, 没有尺度函数, 是非正交分解, 并且是由 Gaussian调节的指数复值小波[20]。Morlet 小波的图形(图 1)和地震波信号也具有一定的相似性, 因此本文选择 Morlet 小波作为小波基函数。
小波时频谱卷积神经网络模型的输入数据为1000×10×3 的三维矩阵。使用中心频率为 3Hz, 频率带宽为 3Hz, 缩放因子为 10 的Morlet 小波基, 经过连续小波变换, 将每一分量的原始波形数据分别转换为小波时频谱, 其中频率域范围为 1~10Hz, 频率间隔为 1Hz。对频率域的每一个分量, 分别构造一个如 2.1 节所述的卷积神经网络模型, 通过训练得到 10 个结构相同、参数不同的卷积神经网络模型。将每个频率上的 1000×3×1 三维矩阵作为输入数据, 通过模型计算得到每个频率上的到时拾取值。对每个频率, 计算到时拾取值与该频率到时拾取值之差小于 1s 的频率个数。以该频率个数最大的频率作为基准频率, 计算到时拾取值与该频率到时拾取值之差小于 1s 的到时拾取值的平均值作为最终到时拾取值。
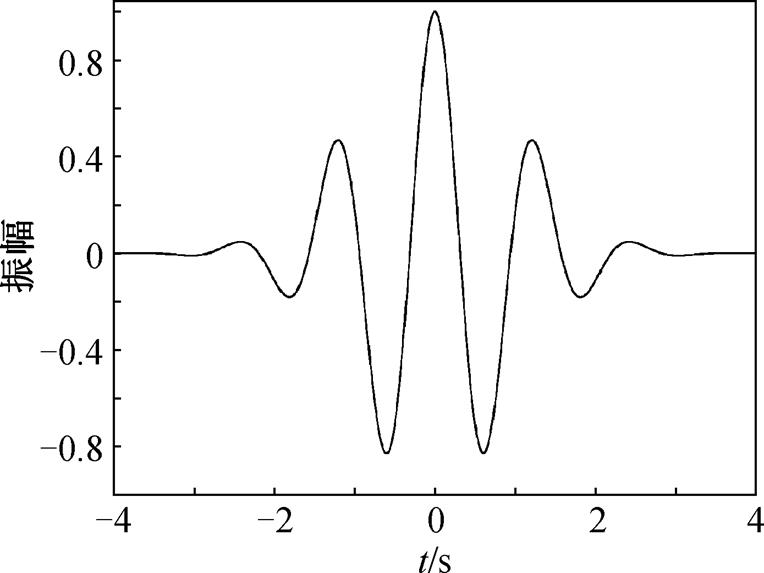
图1 Morlet小波基(据文献[20]修改)
Fig. 1 Morlet wavelet basis (after Ref. [20])
该神经网络模型的输入为固定长度窗口波形数据二维张量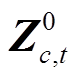 , 其中c=1, 2, 3, 代表N, E, Z三通道; t=1, 2, …, 1000, 代表时间采样点。模型通过6个卷积层和两个全连接层得到最终输出结果, 每一层都是由前一层卷积上一系列一维线性滤波器加总后再加上一个偏置项再进行非线性变换得到。
, 其中c=1, 2, 3, 代表N, E, Z三通道; t=1, 2, …, 1000, 代表时间采样点。模型通过6个卷积层和两个全连接层得到最终输出结果, 每一层都是由前一层卷积上一系列一维线性滤波器加总后再加上一个偏置项再进行非线性变换得到。
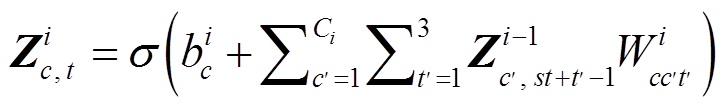 ,
, 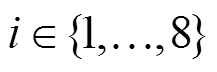 ,(3)
,(3)其中, 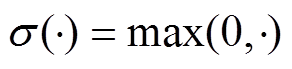 是非线性 ReLU 激活函数; s=2, 代表卷积层的步长。
是非线性 ReLU 激活函数; s=2, 代表卷积层的步长。
我们使用误差逆传播算法进行训练, 基于梯度下降策略, 按目标的负梯度方向对参数进行调整。对每个训练样例, 首先将输入示例提供给输入层神经元; 然后逐层将信号前传, 直到产生输出层的结果; 再计算输出层的误差, 将误差逆向传播至隐层神经元; 最后根据隐层神经元的误差, 对连接权和阈值进行调整。该迭代过程循环进行, 直到达到预设的停止条件。本文使用的停止条件为早停策略, 即将样本内数据分成训练集和验证集, 训练集用来计算梯度, 更新连接权和阈值, 验证集用来估计误差。若最近的 1000 次训练中训练集误差降低而验证集误差升高, 则停止训练, 同时返回具有最小验证集误差的连接权和阈值。训练过程中采用最小二乘误差作为损失函数的计算损失, 使用学习速率为0.001的自适应矩估计法来优化参数。
基于时间域波形数据卷积神经网络模型, 对5974 条训练集数据进行训练, 调整参数, 将整个数据集中的 1867 条数据作为测试集, 当测试集数据结果的最小二乘误差在最近的 1000 次训练中都未减小时, 停止训练。为了便于评价模型的泛化能力, 我们将训练集和测试集结果的误差分布做成直方图(图2)。
图 2(a)显示 7467 条训练集+验证集样本波形数据通过时间域波形数据卷积神经网络模型计算得到的到时拾取结果与人工拾取到时之间的误差分布, 人工拾取到时的标注精度为 0.1s, 65.8%的误差小于 0.1s, 89.6%的误差小于 0.2s, 98.4%的误差小于0.5 s。
图 2(b)显示 1867 条测试集样本波形数据通过时间域波形数据卷积神经网络模型计算得到的到时拾取结果与人工拾取到时之间的误差分布, 42.8%的误差小于 0.1s, 67.4%的误差小于 0.2s, 90.6%的误差小于 0.5s。可见, 该模型在测试集的表现比训练集有较大的下降, 误差大于 1.0s 的仍有 2.1%。因此, 我们对其中误差小于 0.1s 和大于 1.0s 的数据分别画出波形进行分析, 结果如图3所示。
从图 3 看出, 对信噪比较高的数据, 该模型有不错的表现。图 3(a)显示使用时间域波形数据卷积神经网络模型对测试集中一条三分量波形数据拾取P 波初至到时的结果, 模型拾取到时比人工拾取到时滞后 0.03s。由于人工拾取到时的标注精度为 0.1s, 故可以认为对该条数据的拾取结果是准确的。
对于信噪比较低的数据, 该模型的识别能力较弱。图 3(b)显示使用时间域波形数据卷积神经网络模型对测试集中某条低信噪比数据拾取 P 波初至到时的结果, 模型拾取到时比人工拾取到时滞后 1.1 s, 可见模型的表现不理想。
不同的微地震可能具有不同的频率特性, 在不了解震源机制的情况下, 很难确定滤波频率。如果能够先对波形数据进行小波变换, 将不同频段的特征输入提取到卷积神经网络中, 就可以让机器去学习在不同频段拾取到时而得到不同的模型, 从而将频率因子纳入模型中。
在新的模型中, 我们首先对数据做小波变换, 然后分别训练不同频率的神经网络模型参数。对于输入数据, 每一个频段由机器给出一个返回结果, 如图 4 中黄线所示。对于每个频段, 计算所有其他频段的机器返回结果与该频段的机器返回结果之差小于 1.0s 的频段数, 选取最大者对应的频段为基准频段, 最终输出结果为与该基准频段结果之差小于1.0s 的所有频段输出结果的平均值。对于同样的数据, 该模型只比人工拾取结果滞后 0.03s, 在 0.1s的精度范围内, 比不做小波变换的模型表现更好。
与 3.1 节的模型同样, 我们统计了该模型在训练集和测试集误差的分布情况。图 5(a)显示使用时间域波形数据卷积神经网络模型对 7467 条训练集+验证集样本波形数据计算得到的到时拾取结果与人工拾取到时之间的误差分布, 人工拾取到时的标注精度为 0.1s, 78.9%的误差小于 0.1s, 97.1%的误差小于 0.2s, 99.9%的误差小于 0.5s。图 5(b)显示使用时间域波形数据卷积神经网络模型对 1867 条测试集样本波形数据计算得到的到时拾取结果与人工拾取到时之间的误差分布, 人工拾取到时的标注精度为0.1s, 68.5%的误差小于 0.1s, 90.0%的误差小于 0.2s, 98.9%的误差小于 0.5s。表 1 列出两个模型的误差统计分布, 可以看出, 小波变换明显地提高了模型的识别精度。
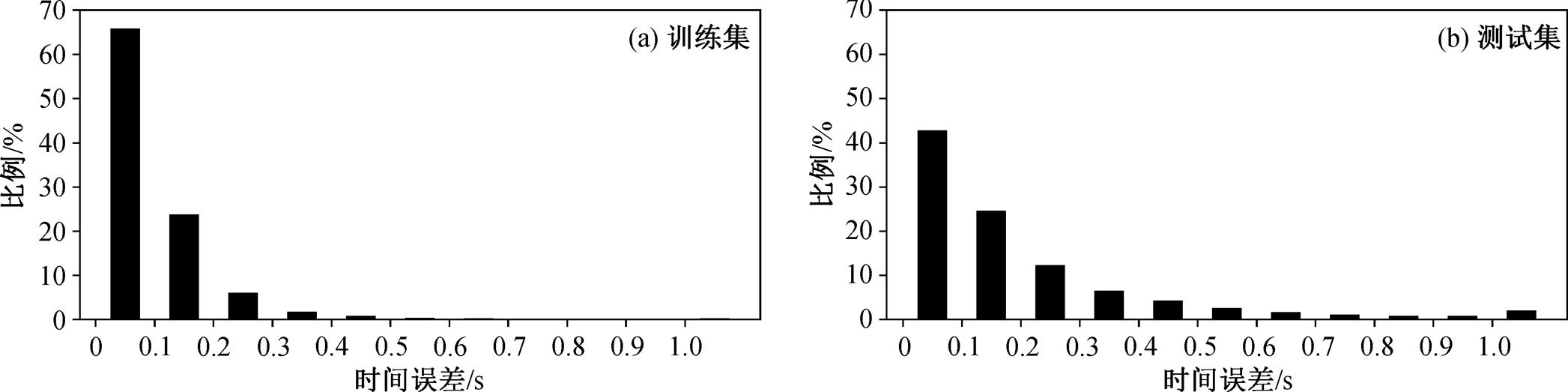
图2 时间域波形数据卷积神经网络模型拾取到时与人工拾取到时误差分布
Fig. 2 Distribution of errors between time domain CNN model and manual picking results
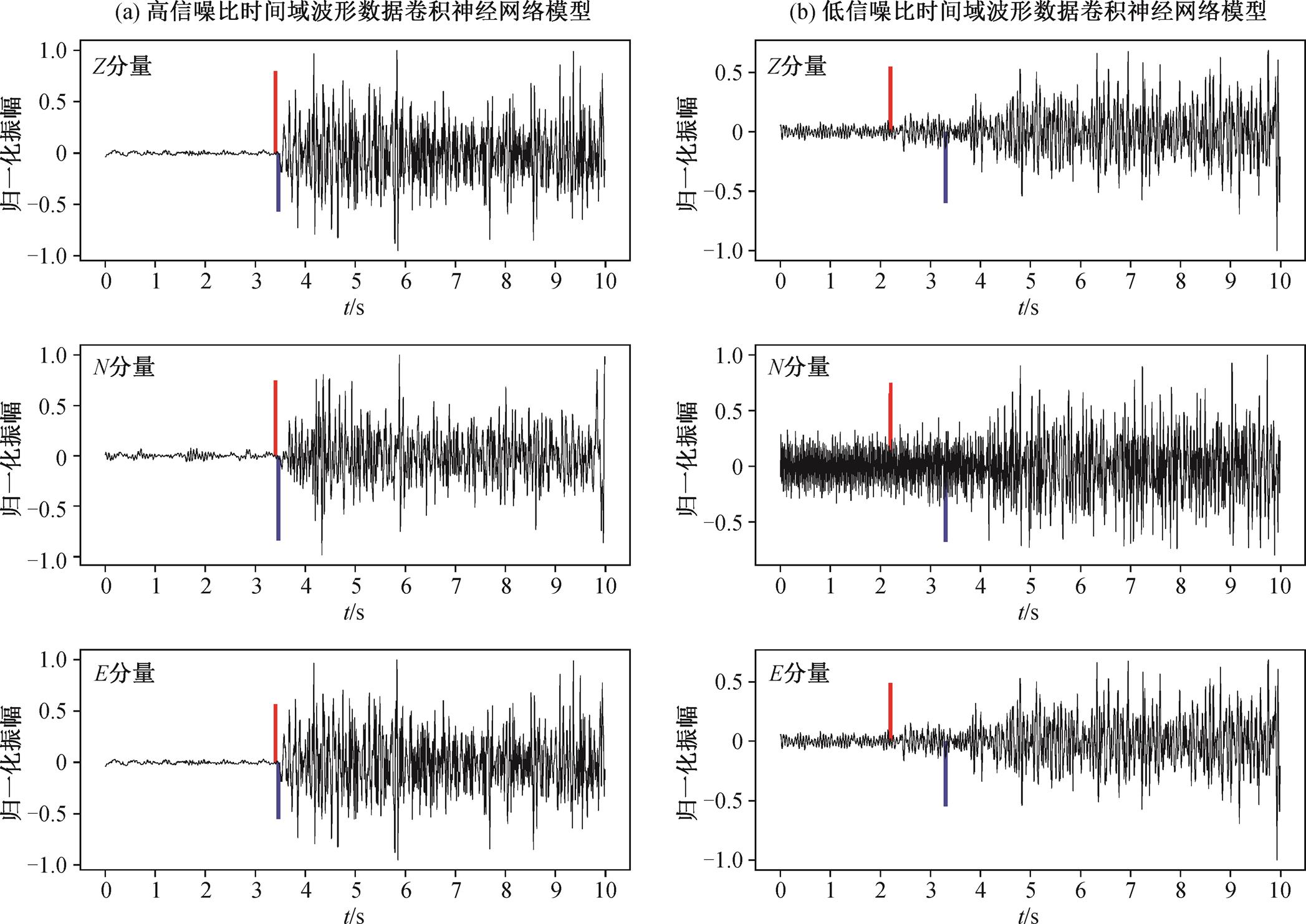
红线表示人工拾取的到时, 蓝线表示模型拾取的到时。下同
图3 高信噪比和低信噪比时间域波形数据卷积神经网络模型拾取到时与人工拾取到时对比
Fig. 3 Comparison of time domain CNN model and manual picking results in high SNR circumstance and low SNR circumstance
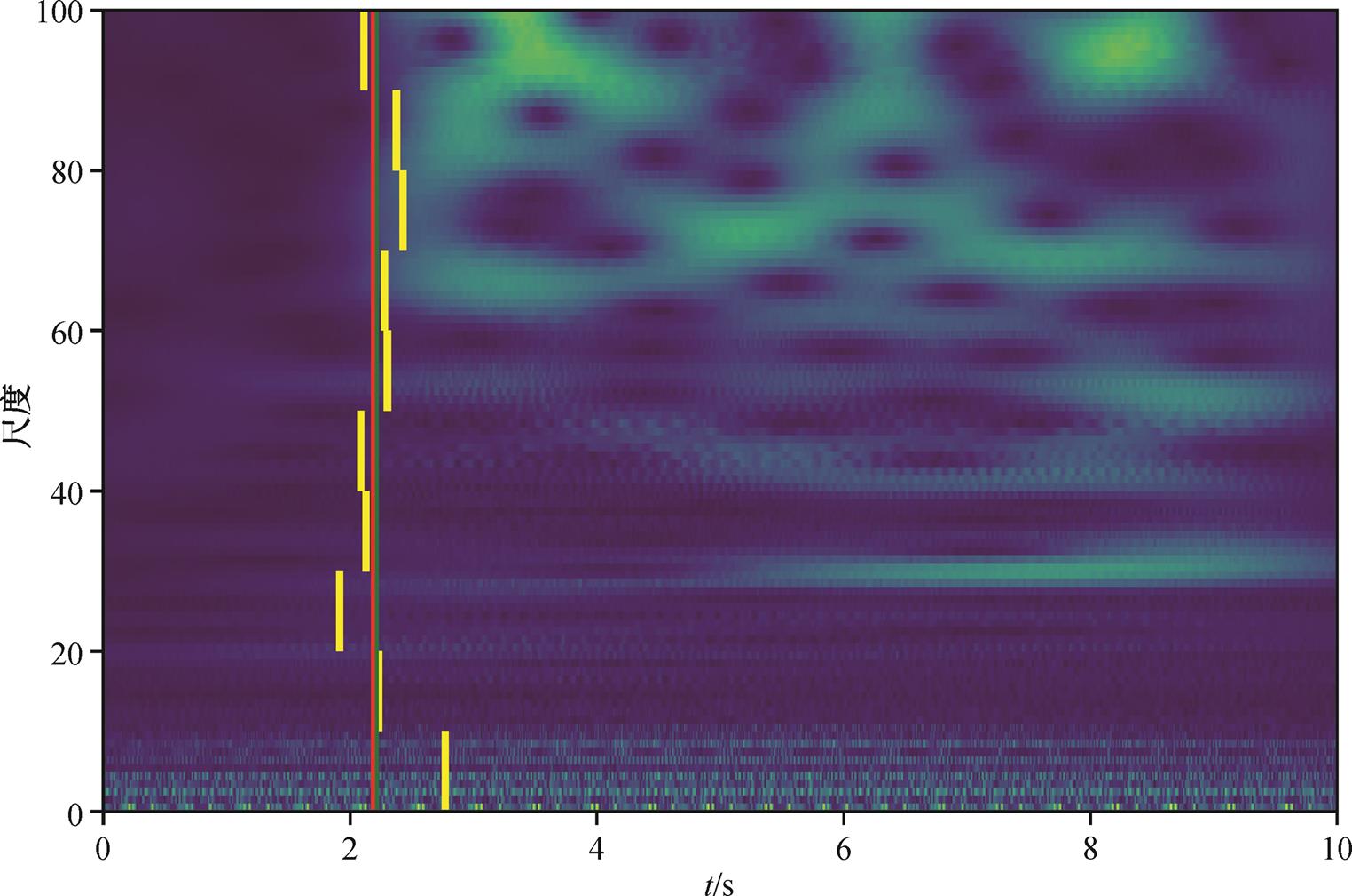
黄色竖线表示不同频率模型拾取的到时, 绿色竖线表示模型最终给出的到时, 红色竖线表示人工拾取的到时
图4 小波时频谱卷积神经网络模型拾取到时与人工拾取到时对比
Fig. 4 Comparison of wavelet time-frequency map model and manual picking results
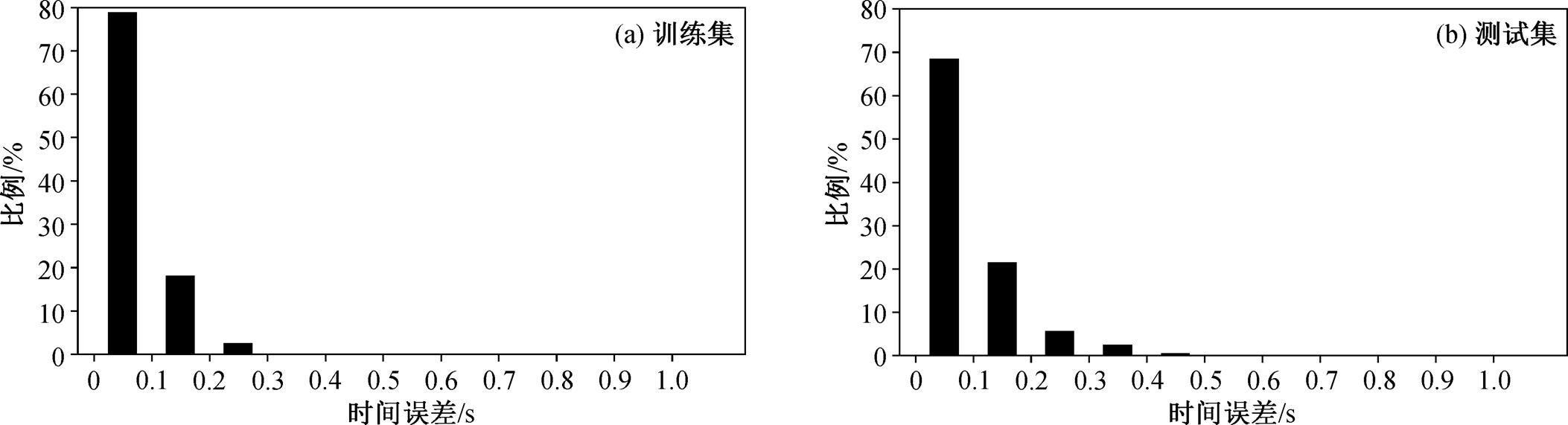
图5 小波时频谱卷积神经网络模型拾取到时与人工拾取到时误差分布
Fig. 5 Distribution of errors between wavelet time-frequency map CNN model and manual picking results
对比 3.1 节与 3.2 节的结果可知, 信噪比是模型拾取精度的重要影响因素。本文训练集和测试集的数据是随机划分的, 未对信噪比做任何要求。为了测试模型对信噪比的稳定性, 选取其中信噪比较高的数据, 通过叠加不同比例的白噪声来对比信噪比对模型拾取结果的影响程度。图 6(a)为使用小波时频谱卷积神经网络模型对某条原始波形数据计算得到的到时拾取结果(图 6 只展示 Z 分量波形图), 模型拾取到时比人工拾取到时提前 0.06s。由于人工拾取到时的标注精度为 0.1s, 故可以认为该条数据拾取准确。图 6(b)~(h)依次为图 6(a)中原始波形叠加其振幅最大值的 10%, 20%, 30%, 40%, 50%, 60%和 70%白噪声后的叠加波形以及使用小波时频谱卷积神经网络模型计算得到的到时拾取结果, 拾取误差分别为−0.02, 0.09, 0.06, −0.04, 0.03, 0.40 和0.59s。由于人工拾取到时的标注精度为 0.1s, 故可以认为叠加 50%振幅白噪声时的拾取结果较准确; 当白噪声大于 50%振幅后, 随着信噪比降低, 拾取精度逐渐下降。在信噪比不是特别低的情况下, 该模型对于信噪比的稳定性较好, 拾取结果没有受到很大的影响。
表1 时间域与小波时频谱卷积神经网络模型在测试集的误差分布对比
Table 1 Comparison of the error distribution between the time domain and the wavelet time spectrum convo-lution neural network model in the testing dataset

模型误差/% < 0.1 s< 0.2 s< 0.5 s 时间域CNN42.867.490.6 小波变换时频谱CNN68.590.098.9
本文分别构造两个卷积神经网络模型来拾取 P波初至, 一个直接使用时间域波形数据输出结果, 另一个先使用 Morlet 小波基对原始数据进行小波变换, 然后对不同尺度下的小波变换波形分别构造数个结构相同的卷积神经网络模型, 综合不同尺度下的模型输出值而得到最终拾取结果。对比两种模型的测试集结果误差, 经过小波变换的模型对 P 波初至的拾取准确度更高, 误差小于 0.1s 的占 68.5%, 小于 0.2s 的占 90.0%, 小于 0.5s的占 98.9%。
通过对可以准确拾取的原始数据叠加不同比例的白噪声, 分析该小波变换卷积神经网络模型在不同信噪比下的拾取准确度, 结果表明, 当白噪音与原始波形振幅之比小于 50%时, 拾取误差仍然小于0.1s, 可见在较低信噪比的情况下, 该模型仍能保证准确地拾取 P 波初至到时。当白噪音与原始波形振幅之比达到 70%时, 该模型基本上失去拾取 P 波初至到时的能力。
除在低信噪比情况下仍能适用的优点外, 本模型还具有运算速度快的特点。运算的主要耗时在于模型的训练, 一旦模型训练完成, 本文中 9334 条10s 长度的波形数据在不到 1s 的时间内就能全部输出拾取结果。中国地震局地球物理研究所与阿里云计算有限公司联合主办的阿里云天池“余震捕捉 AI大赛”要求震相拾取精度为 0.6s, 在此赛事中, 我们的模型对测试集中 1867 条数据的计算误差小于 0.6s 的占 99.1%, 取得相当高的样本外准确率。该模型不仅可以准确地识别训练过的样本, 对没有经过训练的新样本的识别也有很高的准确率。因此可以预期, 将该模型应用于新的地震事件自动地拾取 P 波初至, 在大大节省运行时间的前提下, 也能取得高准确率。
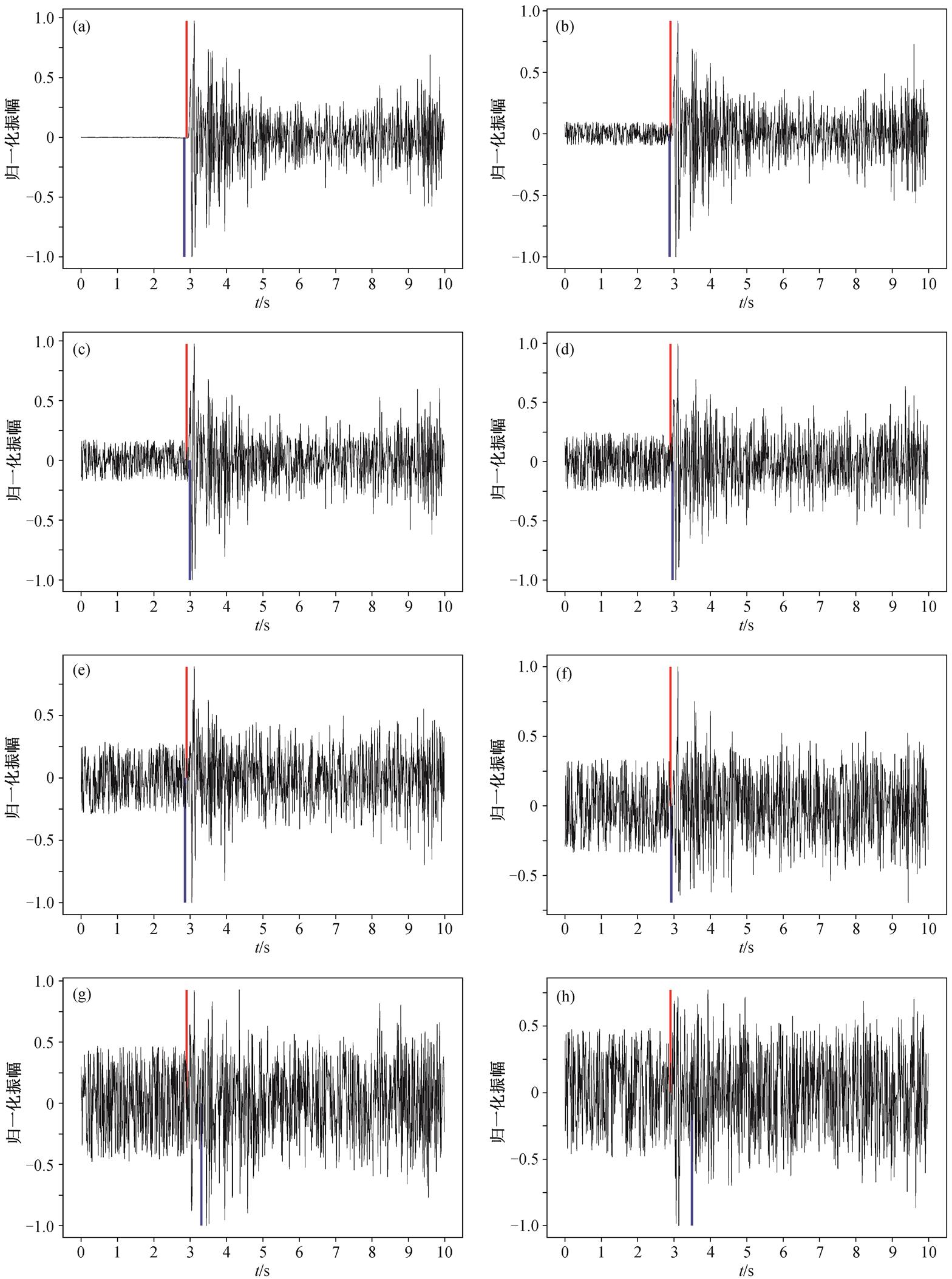
图6 不同信噪比下数据小波时频谱卷积神经网络模型与人工拾取到时对比
Fig. 6 Comparison of wavelet time-frequency CNN model and manual picking results of data with different SNR
参考文献
[1]Satriano C, Wu Y M, Zollo A, et al. Earthquake early warning: concepts, methods and physical grounds. Soil Dynamics and Earthquake Engineering, 2011, 31(2): 106‒118
[2]Stevenson P R. Microearthquakes at Flathead Lake, Montana: a study using automatic earthquake process-ing. Bulletin of the Seismological Society of America, 1976, 66(1): 61‒80
[3]Earle P S, Shearer P M. Characterization of global seismograms using an automatic-picking algorithm. Bulletin of the Seismological Society of America, 1994, 84(2): 366‒376
[4]Liu H, Zhang J. STA/LTA algorithm analysis and improvement of microseismic signal automatic detec-tion. Progress in Geophysics, 2014, 29(4): 1708‒1714
[5]Gibbons S J, Ringdal F. The detection of low mag-nitude seismic events using array-based wave-form correlation. Geophysical Journal International, 2006, 165(1): 149‒166
[6]Zhang J, Tang Y, Li H. STA/LTA fractal dimension algorithm of detecting the P-wave arrival. Bulletin of the Seismological Society of America, 2017, 108 (1): 230‒237
[7]张范民, 李清河. 利用人工神经网络理论对地震信号及地震震相进行识别. 地震工程学报, 1998, 20 (4): 43‒49
[8]郑秀芬, 欧阳飚, 张东宁, 等. “国家数字测震台网数据备份中心”技术系统建设及其对汶川大地震研究的数据支撑. 地球物理学报, 2009, 52(5): 1412‒ 1417
[9]Ripley B D. Pattern recognition and neural networks. Technometrics, 1999, 39(2): 233‒234
[10]McCulloch W S, Pitts W. A logical calculus of the ideas immanent in nervous activity. Bulletin of Math-ematical Biology, 1990, 52(1/2): 99‒115
[11]LeCun Y, Bengio Y. The handbook of brain theory and neural networks. Cambridge: MIT Press, 1995, 255‒ 258
[12]Perol T, Gharbi M, Denolle M. Convolutional neural network for earthquake detection and location. Scien-ce Advances, 2018, 4(2): e1700578
[13]LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition. Procee-dings of the IEEE, 1998, 86(11): 2278‒2324
[14]Springenberg J T, Dosovitskiy A, Brox T, et al. Striving for simplicity: the all convolutional net [EB/ OL]. (2014‒12‒21) [2018‒04‒13]. https://arxiv.org/ pdf/1412.6806.pdf
[15]Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks // Proceedings of the Fourteenth In-ternational Conference on Artificial Intelligence and Statistics. Crete, 2011: 315‒323
[16]刘希强, 周蕙兰. 用于三分向记录震相识别的小波变换方法. 地震学报, 2000, 22(2): 125‒131
[17]Chakraborty A, Okaya D. Frequency-time decomposi-tion of seismic data using wavelet-based methods. Geophisics, 1995, 60(6): 1906‒1916
[18]Farge M. Wavelet transforms and their applications to turbulence. Annual Review of Fluid Mechanics, 1992, 24(1): 395‒458
[19]Grinsted A, Moore J C, Jevrejeva S. Application of the cross wavelet transform and wavelet coherence to geophysical time series. Nonlinear Processes in Geophysics, 2004, 11(5/6): 561‒566
[20]Torrence C, Compo G P. A practical guide to wavelet analysis. Bulletin of the American Meteorological Society, 1998, 79(1): 61‒78
Using Artificial Intelligence to Pick P-Wave First-Arrival of the Microseisms: Taking the Aftershock Sequence of Wenchuan Earthquake as an Example
Abstract In order to accurately and quickly pick up P-wave first-arrival of a large number of seismic events, deep learning method is introduced into the micro seismic P-wave first-arrival picking problem. The structure of convolution neural network is adjusted to apply to the characteristics of the seismic waveform data and first-arrival picking problem. The algorithm takes a 10s-window three-component seismic waveform data as input instead of scanning the continuous waveform. So the running time is far less than traditional methods such as STA/LTA and template matching. The algorithm is applied to aftershocks of 2008 Wenchuan earthquake in July and August, using 7467 manual picked first-arrival data as training dataset. Among the 1867 testing data, 98.9% of the P arrival times picked using this algorithm have an error less than 0.5 s compare to the results picked manually. This method can still maintain good pick-up capability under the condition of low signal-to-noise ratio.
Key words artificial intelligence; machine learning; deep learning; wavelet transform; first-arrival picking
doi: 10.13209/j.0479-8023.2018.036
国家重点研发项目(2018YFC1504203)、国家自然科学基金(41774047)和中国地质调查局地质调查项目(DD20160082)资助
收稿日期: 2018‒05‒18;
修回日期: 2018‒06‒24;
网络出版日期: 2019‒04‒03