
图1 动态社交历史的结构信息和时序信息
Fig. 1 Structural and temporal information of dynamic social history
北京大学学报(自然科学版) 第61 卷 第4 期 2025 年7 月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 61, No. 4 (July 2025)
doi: 10.13209/j.0479-8023.2024.120
国家重点研发计划(2021QY1502)资助
收稿日期: 2024–05–30;
修回日期: 2024–07–25
摘要 为了解决现有推特机器人检测方法对用户动态社交历史结构性和时序性的忽视以及特征融合引起的噪声累积问题, 构建社交时序知识图谱 STKG, 并提出一种推特机器人检测方法 STKGBot。在 STKG 中, STKGBot 使用关系增强图注意网络 RE-GAT 来学习静态社交关系特征, 使用时序增强图卷积网络 TE-GCN 来学习动态社交历史特征, 使用双线性模型进行特征融合。此外, STKGBot 使用对比学习来缓解特征融合引起的噪声累积。在两个公开数据集上的实验结果表明, STKGBot 的检测结果均优于当前最先进的模型。
关键词 推特机器人检测; 时序知识图谱; 图神经网络; 对比学习
推特机器人是一种能够管理社交账户的自动化程序, 在社交平台中通过模仿人类行为[1]来达成特定的目的, 其中存在许多恶意倾向, 例如扰乱政治选举、操纵公众舆论以及传播阴谋论。因此, 如何有效地进行推特机器人检测对维护社会安全和稳定至关重要。
推特机器人检测的目的在于区分推特用户是人类还是机器人。早期的推特机器人检测方法是通过用户的个人资料元数据等信息进行区分, 但这些信息易被人为修改, 从而降低检测性能。后来的研究集中在用户的推文内容等文本信息, 将各种自然语言处理(natural language processing, NLP)技术用于推特机器人的检测中, 如 Liu 等[2]使用预训练语言模型, 直接建模用户的推文嵌入。随着社交机器人开始窃取真实用户的推文内容来隐藏自身, 研究者开始寻求其新的社交特征。基于图的方法通过分析社区进行检测, 如 Feng 等[3]根据用户之间的跟随关系构建异构图。近年来, 为了整合用户的各种信息, 研究者将以前的方法组合起来, 形成混合检测方法, 通过不同的用户特征进行机器人检测。
虽然上述方法在机器人检测领域已经实现优秀的性能, 但仍然有两个问题未得到充分探索。
1)现有方法忽略动态社交历史的结构性和时序性。社交网络中, 用户的动态社交历史包含结构信息和时序信息, 推特机器人为达成不同的目的, 在不同的时间段用不同的社交行为进行互助, 以扩大影响力[4]。例如图 1(a)中, 在世界卫生组织正式命名新冠病毒(2020 年 1 月 20 日)之前, 部分机器人之间的转推行为并不明显, 但之后, 这些推特机器人通过互相之间的频繁转发行为来增加社会影响力, 因此关于新冠病毒的谣言激增。现有方法[2,5–6]往往只关注转推内容的文本内容(图 1(b)), 既忽略用户动态社交历史的社交结构, 也忽略其中的时序信息, 不利于检测机器人用户与人类用户之间的区别。例如, Ping 等[1]采用长短期记忆网络(long short term memory network, LSTM), 简单地建模用户推文的先后顺序, 但未详细考虑社交动态之间的结构性和时序性。
2)特征融合引起的噪声累积问题。社交用户是否为机器人由人工标注, 难免存在噪声[5], 同时, 由于推特平台对数据的限制, 用户的各种数据(例如粉丝用户数目和发推文的数目等)无法收集完全, 因此, 用户本身的各类特征信息存在噪声问题。混合检测方法通过融合不同的特征, 实现不同特征之间的交互, 但融合过程中可能放大不同特征之间的噪声。例如, Lei 等[6]将点积作为推文文本嵌入与图嵌入之间的相似函数; Cai 等[7]将推文和个人描述拼接作为文本信息, 通过知识蒸馏(knowledge distil-lation)注入图结果中; Liu 等[2]使用一个多头注意力 Transformer 来建模不同特征之间的关联性。以上方法采用不同的融合方法, 但没有考虑特征融合引起的噪声累积。
为了应对上述挑战, 本文构建社交时序知识图谱(social temporal knowledge graph, STKG), 并提出一种新的推特机器人检测模型 STKGBot(STKG for twitter bot detection)。在 STKG 中, STKGBot 建模静态社交关系特征和动态社交历史特征, 并进行特征融合。具体来说, 使用关系增强图注意力网络(he-terogeneity-enhanced graph attention network, RE-GAT)来捕获 STKG 中的静态社交关系特征, 使用时序增强图卷积网络(temporal-enhanced graph convo-lutional network, TE-GCN)来捕获 STKG 中的动态社交历史特征, 将双线性融合模型用于建模两种特征之间的交互, 并使用对比学习来缓解特征融合引起的噪声累积问题。最后, 在两个公开数据集进行实验, 结果表明 STKGBot 在推特机器人检测方面优于当前最先进的基线模型。
现有的推特机器人检测方法可以分为 4 个类型: 基于特征的方法、基于文本的方法、基于图的方法和混合检测方法。
基于特征的方法收集推特用户的各种信息(用户元数据和粉丝数据等), 然后将这些数据与分类算法相结合来识别推特用户。Kudugunta 等[8]利用用户元数据, 提出 SMOTENN 来缓解类别不平衡问题。基于文本的方法利用 NLP 技术(如注意力机制、词嵌入和预训练语言模型)来识别文本信息(如推特机器人的推文和描述)。基于图的方法重点关注用户之间形成的社交网络图, 将用户表示为节点, 并将用户之间的跟随关系建立为边。例如, Zhou 等[9]提出 SIRAN, 将跟随关系与初始残差连接相结合, 降低邻居聚集过程中的噪声。混合检测方法结合上述方法, 并引入一些新的技术进行机器人检测, 取得优秀的效果。
图1 动态社交历史的结构信息和时序信息
Fig. 1 Structural and temporal information of dynamic social history
本文将社交网络建模成静态部分和动态部分, 相比于现有方法, 首次同时考虑静态社交关系信息和动态社交历史信息, 通过整合这两种信息进行社交机器人检测。
时序知识图谱(temporal knowledge graph, TKG)是在传统静态知识图谱中引入时间信息来描述动态的事实。TKG 一般可以表示为不同时间片的 KG(knowledge graph)快照序列, 其中每个 KG 快照由同一时间片下并发的事实组成。
时序知识图谱推理旨在预测缺失的事实。RE-NET[10]在每个查询中编码与主题实体相关的历史事实。RE-GCN[11]考虑并发事实之间的结构依赖关系以及跨时间相邻事实, 以便学习 TKG 的时序演化 表征。
作为一种建模方式, 时序知识图谱在多个领域都有所应用[12–13]。本文主要利用时序知识图谱方法对推特社交用户的动态社交历史进行建模, 获取社交机器人的动态社交历史特征, 辅助进行推特机器人检测。
对比学习是一种自监督学习的范式, 它直接从未标记的数据中生成标签, 在图像识别、自然语言处理和图分类任务等领域取得显著成功。对比学习的目标是利用对比损失函数, 确保相似的实例在向量空间中的距离更近, 不相似的实例距离更远。Wu 等[14]将对比学习引入推特机器人检测领域, 通过不同的视角对图进行增强, 并利用图对比学习来建模社交网络图结构, 实现推特机器人检测。但是, 该方法没有充分考虑社会结构之外的其他特征, 如用户的动态社交历史行为。
本文利用特征融合, 建模社交时序知识图谱中不同特征之间的交互, 并使用对比学习来缓解特征融合引起的的噪声累积问题。
本文提出的社交时序知识图谱(STKG)可以表示为 G=(V, R, T, εt), 其中 表示实体集合, R表示关系集合, T 表示时间片的数目, εt 表示在时间片 t 上的事实集合, 每个事实可以表示为四元组(s, r, o, t), 每个四元组由头实体 s、关系 r、尾实体 o 和时间片 t 组成。U={u1, u2, …, u|u|}是用户集,
表示实体集合, R表示关系集合, T 表示时间片的数目, εt 表示在时间片 t 上的事实集合, 每个事实可以表示为四元组(s, r, o, t), 每个四元组由头实体 s、关系 r、尾实体 o 和时间片 t 组成。U={u1, u2, …, u|u|}是用户集, 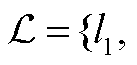
 是列表集, 其中|U|表示用户数目,
是列表集, 其中|U|表示用户数目,  表示列表数目,
表示列表数目,  表示实体数目。表 1 展示STKG 中包含的事实类型。
表示实体数目。表 1 展示STKG 中包含的事实类型。
本文构建的 STKG 包含静态和动态信息: 静态信息由静态社交关系信息组成, 不具有时间信息, 因此将其中的时间 t 设置为 0; 动态信息由用户的动态社交历史信息组成。为方便 STKGBot 建模两种信息, 本文将静态社交关系建模成静态图 M, M 中每个实体 vi 的邻居集合可以表示为 Ni; 将动态社交历史构建成图序列 K={K1, K2, …, KT}。
推特机器人检测的目的是预测用户  是人类账户还是机器人账户, 预测结果可以表示为
是人类账户还是机器人账户, 预测结果可以表示为 {0, 1}, 其中 0 表示人类, 1 表示机器人。
{0, 1}, 其中 0 表示人类, 1 表示机器人。
本文提出的 STKGBot 框架结构(图 2)由 RE-GAT、TE-GCN、融合模块和对比学习 4 个部分组成。RE-GAT 捕获 STKG 中的静态社交关系特征, TE-GCN 捕获 STKG 中的动态社交历史特征。通过融合模块, 将两种特征进行融合, 使用对比学习来缓解特征融合引起的噪声累积。最后, 综合所有特征, 得出预测结果。
由于通过用户的邻近社交社区而不是整个网络来表示用户的社交语义更有效[2], 因此, 在获取用户的静态社交特征之前, 本文对实体的邻近社交社区进行采样。
邻近社区采样: 对于目标实体 vi, 采样的节点从 Ni 中选取。节点采样基于跳数 H 和每一跳的采样数 S。每一跳的随机采样包括用户实体和列表实体在内的节点, 直到达到阈值 S。重复上述操作, 直到达到跳数 H。获得 vi 的邻近社交社区 的过程可以表示为
的过程可以表示为
表1 STKG中的事实类型统计
Table 1 Statistics of fact types in STKG

头实体关系类型尾实体时间属性 用户跟随用户静态 用户关注列表静态 用户拥有列表静态 用户成员列表静态 用户转发用户动态 用户回复用户动态 用户引用用户动态

图2 STKGBot框架结构
Fig. 2 Framework of STKGBot
 (1)
(1)
其中,flcs 表示采样函数。
邻近社区编码: 用 RE-GAT 对静态社交关系特征建模。静态社交关系图 M 是由两个实体类型和4 个关系类型组成的异构信息网络。为了充分考虑用户的基本信息, 将用户和列表实体的数字元数据(粉丝数和账号创建日期等)以及类别元数据(性别和年龄等)连接起来, 作为初始节点特征:
 (2)
(2)
其中, 表示初始嵌入, m1 和 m2 表示数字元数据和类别元数据。
表示初始嵌入, m1 和 m2 表示数字元数据和类别元数据。
受 SimpleHGN[15]启发, 本文使用一种关系增强图注意网络 RE-GAT 来学习用户的静态社交关系特征, RE-GAT 的层数为 L。
在社交网络中, 不同的社交关系类型意味着不同的社交语义, 例如 ui 与 lj 之间的“拥有”和“成员”关系。为了对异构关系语义进行建模, 在计算每个GAT 层的注意力得分时, 添加边异构嵌入。每一层的注意力得分计算方法如下:
 (3)
(3)
其中, hi 和 hj 表示节点 i 和 j 的隐藏层嵌入,  表示节点 i 与 j 之间的关系异构性嵌入, W 和 Wr 表示可学习变换矩阵, ξ 表示 LeakReLU 激活函数, a 表示权重矩阵。
表示节点 i 与 j 之间的关系异构性嵌入, W 和 Wr 表示可学习变换矩阵, ξ 表示 LeakReLU 激活函数, a 表示权重矩阵。
由于低质量的标签可能降低图神经网络在图任务上的性能[9], 因此, 使用残差连接来减少来自邻居聚合的噪声。本文引入节点残差和关系残差。在节点嵌入的更新过程中, 使用 l-1 层嵌入作为节点残差:
 (4)
(4)
其中,  表示节点 vi 在 l 层的嵌入。l-1 层的注意力分数表示关系残差, σ 表示 RELU 激活函数。
表示节点 vi 在 l 层的嵌入。l-1 层的注意力分数表示关系残差, σ 表示 RELU 激活函数。
 (5)
(5)
β 是介于 0 和 1 之间的超参数。
为了缓解可能的过拟合问题, 在最后一层输出嵌入时使用 L2 标准化:
 (6)
(6)
hi 表示实体 vi 在 STKG 中的静态社交关系特征。
TE-GCN 用于学习用户在时序层面的社交行为特征。为了学习在时序层面的社交行为特征, 受时序知识图谱推理方法[11]启发, 本文使用一种时序增强图卷积网络 TE-GCN 来学习用户的动态社交历史特征。
3.2.1 结构特征建模
相比于 RE-GAT 构建结构特征时重点建模边的异构特征, 在建模时序知识图谱的结构特征时, 本文用一个 L 层的 TE-GCN 来学习结构特征:
 (7)
(7)
其中,  表示用户 s, o 和关系 r 在时间片 t下的第 l 层嵌入。
表示用户 s, o 和关系 r 在时间片 t下的第 l 层嵌入。
3.2.2 时序特征建模
对用户 u 而言, 在不同时间片上的社交行为可以反映其社交频率、社交偏好和社交趋势。为了捕获其中的时序特征, 本文通过时间门控单元来学习相邻图之间的时序关系:
 (8)
(8)
其中, Ä表示哈达玛积运算, 时间门 Ut 用于非线性变换:
 (9)
(9)
同样, 社交关系语义不仅与当前时间片的社交结构有关, 还与相邻时间片的社交关系有关, 因此, 时序知识图谱重点构建关系的时序特征, 可以分为全局表示 R 和演化表示 Rt。演化关系表示通过门控循环单元(gated recurrent unit, GRU)进行更新:
 (10)
(10)
更新前的演化关系表示 由每一个关系的表示
由每一个关系的表示 组成, 由下式计算:
组成, 由下式计算:
 (11)
(11)
其中, Pooling(·)表示池化操作,  为 t 时刻与关系r相关的用户集合 ur,t 在 t-1 时刻的演化表示,
为 t 时刻与关系r相关的用户集合 ur,t 在 t-1 时刻的演化表示,  表示关系 r 的全局表示。
表示关系 r 的全局表示。
最终, 将最后一层 L 的最后一个时间片 T 的GCN 节点嵌入作为用户的动态社交历史特征:
 (12)
(12)
其中, gi 表示实体 vi 在 STKG 中的动态社交历史特征, L 表示 TE-GCN 层数。
融合模块用于捕获 hi 与 gi 之间的相互作用, 它基于双线性模型, 采用 tucker 分解, 将张量分解为一个矩阵变换的核心张量, 每个模态有两个模态因子:
 (13)
(13)
其中, Ic 表示核张量, Mh 和 Mg 表示变换矩阵。
为了进一步降低计算复杂度, 将不同的嵌入融合到一个元素积的统一空间中:
 (14)
(14)
其中, fi 表示实体 vi 通过融合模块后得到的融合特征,  表示通过变换矩阵和激活函数得到的各个模块的最终嵌入,
表示通过变换矩阵和激活函数得到的各个模块的最终嵌入, 表示变换矩阵, q 表示转换后的维度。
表示变换矩阵, q 表示转换后的维度。
由于双线性融合没有边界限制[16], 所以可能导致特征融合引起噪声累积。为了解决此问题, 本文利用对比学习来辅助STKGBot的训练, 以便缓解噪声累积问题。具体来说, 将同一实体的特征对视为正样本, 将不同实体的嵌入对视为负样本(图 2)。优化目标是最小化正样本之间的距离, 最大化负样本之间的距离。距离由余弦相似度计算得出:
 (15)
(15)
为每个用户实体 ui 计算两种嵌入的距离之后, 对比学习损失函数可以表示为
 (16)
(16)
通过 RE-GAT, TE-GCN 和融合模块, 生成 3 种类型的嵌入, 分别为 hi, gi 和 fi。对于用户节点 ui, 通过线性层对每个嵌入生成预测, 然后计算交叉熵 损失:
 (17)
(17)
 (18)
(18)
其中, yi,k表示 ui 在不同维度下的预测结果, k∈{h, g, f}; ki, Wk 和 bk表示可学习的参数, 表示每种特征下的损失; di 表示标签。
表示每种特征下的损失; di 表示标签。
得到每个嵌入的损失后, 加权计算最终的分类损失:
 (19)
(19)
其中, ak 为可学习的权重参数。
最后, 将对比学习损失和分类损失相加, 得到训练损失:
 (20)
(20)
STKGBot 训练过程的伪代码如算法 1 所示。

4.1.1 数据集
将本文提出的推特机器人检测方法在 TwiBot-22 数据集[17]上进行评估。TwiBot-22 数据集于 2022年提出, 是推特机器人检测最全面的数据集, 由100 万个用户和 21870 个列表组成, 其用户信息(如推文信息等)覆盖的时间从 2008 年到 2022 年 3 月。由于推特平台的数据收集限制, TwiBot-22 中的信息集中在靠后的时间段。为了信息的完整性, 本文收集两个子数据集 Twi22-01 和 Twi22-02, 具体信息如表 2 所示。两个数据集的采样考虑不同的时间段, Twi22-01 考虑 2020 年 9 月 27 日到 2021 年 6 月 4 日, Twi22-02 考虑 2021 年 6 月 4 日到 2022 年 2 月 9 日, 在各自的时间段内收集有社交行为的用户实体, 进一步收集相关的列表实体。
表2 数据集信息统计
Table 2 Statistics of dataset information

数据集用户实体数列表实体数人类数目机器人数目起始时间末尾时间四元组数目 Twi22-0122693721605212968139692020年9月27日2021年6月4日4073475 Twi22-021196802083011386358172021年6月4日2022年2月9日2931933
在建模社交时序知识图谱的动态社交历史过程中, 以 12 小时为一个时间片, 每个数据集包含 500个时间片。在划分数据集时, 按 8:1:1 的比例划分随机训练集、验证集和测试集。
4.1.2 基准方法
为评估 STKGBot 的性能, 本文对比两种类型的 8 个基准方法: 1)通用的图神经网络(graph neural network, GNN)方法; 2)推特机器人检测方法。本文在 GNN 方法中的初始节点嵌入设置方式与 Bot-RGCN[3]相同。
1)GCN[18]: 聚合来自邻居的特征, 并从图数据中学习表示。
2)GAT[19]: 通过注意力机制建模邻居用户的重要性。
3)HGT[20]: 使用一个异构图 Transformer, 对异构图数据进行建模。
4)SimpleHGN[15]: 使用一种简单的异构图建模方法, 该方法采用增强的 GAT[19]作为主干。
5)BotRGCN[3]: 从推特网络中构造异构图, 并使用图卷积网络进行用户表示学习, 用于推特机器人检测。
6)Kudugunta 等[8]将合成少数类过采样技术与欠采样技术相结合, 缓解类别不平衡问题。
7)RGT[21]: 使用关系图 Transformer, 对推特网络中的异构性进行建模, 以便提高推特机器人检测的性能。
8)BotMoE[2]: 是一种混合检测方法, 使用社区感知的专家混合(MoE)层, 将用户分配到不同的社区, 以便进行机器人检测。
本文使用 GCN[18]作为 BotMoE 中的图编码器。
4.1.3 评价指标
现有研究中一般采用准确率(accuracy)和 F1 值作为评价指标[2,3,6,9,21]。但是, 人类和机器人的数量之间经常出现显著的差异(类别不平衡)。为了避免此问题, 本文将平衡准确率(Bacc)和 F1 值作为评估模型性能的指标。在类别不平衡的情况下, 这两个指标能更准确地反映模型的性能。
 (21)
(21)
 (22)
(22)
其中, TP, FP 和 FN 分别代表真正例、假正例和假负例。
4.1.4 实现细节
为了方便复现, 本文给出 Twi22-01 上的超参数设置(Twi22-02 与其相同), 如表 3 所示。对于所有的基线模型, 我们在其公布的最优参数上进行实验, 结果均为 5 次实验的平均值。
本文提出的 STKGBot 在两个数据集上与基线模型的对比实验结果如表 4 所示。
可以看出, 在两个数据集上, STKGBot 均能在Bacc 和 F1 值两个指标上取得最优。在 Twi22-01 数据集上, Bacc 高出次优基线 4.2%, F1 值高出次优基线 3.2%; 在 Twi22-02 数据集上, Bacc 高出次优基线14.56%, F1 值高出次优基线 12.14%。
表3 Twi22-01超参数设置
Table 3 Hyperparameter settings of Twi22-01

超参数参数值 优化器Adam 学习率10–3 Dropout0.3 图隐藏层维度256 融合层维度128 训练轮数200 采样H4 采样S256
表4 性能对比结果(%)
Table 4 Performance comparison results (%)

模型Twi22-01Twi22-02BaccF1BaccF1 GCN55.28 (0.1)18.48 (1.5)53.86 (0.9)13.98 (2.9) GAT54.37 (0.9)15.70 (2.8)54.81 (0.4)17.02 (1.2) HGT63.89 (1.1)40.00 (2.2)59.35 (1.3)29.72 (3.1) SimpleHGN64.27 (1.1)41.50 (2.1)67.29 (1.0)47.40 (1.7) Kudugunta等[8]68.74 (0)33.35 (0)71.03 (0)31.34 (0.1) BotRGCN56.22 (0.3)21.32 (0.9)58.17 (1.8)26.04 (3.4) RGT59.35 (0.4)30.45 (1.2)57.65 (1.0)25.42 (2.7) BotMoE60.77 (0.1)24.32 (0.1)52.83 (0.3)10.10 (0.1) STKGBot (本文模型)72.95 (0.8)44.73 (0.1)85.59 (0.1)59.54 (2.2)
说明: 粗体数字表示最优结果, 下划线数字为次优结果, 括号内数字为标准差。
Twi22-02 的时间范围比 Twi22-01 早, 且其中收集的用户行为更集中在靠后的时间, 因此 Twi22-02 的信息规模比 Twi22-01 小。但是, STKGBot 在Twi22-02 数据集上展现出比基线模型更显著的提升, 说明STKGBot在数据规模不大时仍然能展现出较强的性能。
为了验证 STKGBot 不同模块的有效性, 本实验中分别移除不同的模块来获得不同的变体: w/o static表示移除 STKG 中的静态信息和 RE-GAT, w/o dynamic 表示移除 STKG 中的动态信息和 TE-GCN, w/o fusion 表示移除融合模块, w/o contrastive 表示移除对比学习。在 Twi22-01 上的消融实验结果如表 5 所示。
从表 5 可知, 所有变体模型均出现不同程度的性能下降, 尤其是在 F1 指标上。值得注意的是, w/o static 的实验性能下降非常显著, 可见静态社交语义起到非常重要的作用, 用户之间的“跟随”关系仍然是机器人检测中不可忽略的因素。w/o fusion 和 w/o contrastive 的实验结果也表明社交时序知识图谱中静态社交关系特征与动态社交历史特征之间的交互对推特机器人检测的作用; 对比学习缓解了特征融合引起的噪声累积问题, 改进了实验结果。
表5 消融实验结果(%)
Table 5 Ablation study results (%)

消融设置BaccF1 STKGBot (完整模型)72.9544.73 w/o static68.5626.66 w/o dynamic72.5740.07 w/o fusion72.2137.24 w/o contrastive72.9341.84
邻近社区采样能更好地概括用户的邻近社交范围, 从而增强对用户社交语义的分析。本文设置不同的采样范围, 基于跳数 H 和每一跳的采样数目 S来探究邻近社区大小范围的影响。具体来说, 在Twi22-01 数据集上, H 设置为{1, 2, 3, 4, 5}, S 设置为{32, 64, 128, 256, 512}。实验结果如图 3 所示。
从图 3 可以看出, 当 H 和 S 的值非常小时, 模型性能显著降低, 表明用户的社交语义无法在很小的邻近范围内概括。然而, H 和 S 值的增加不一定意味着更好的实验结果。采样范围达到一定的规模, 则可以充分捕获用户的社交语义。总体而言, H比 S 更重要, 表示社交语义在用户节点和列表节点之间多跳传播。
STKGBot 主要涉及两个隐藏层维度: 图隐藏层维度和融合隐藏层维度。为了分析两个隐藏层维度对性能的影响, 本文设置不同的隐藏层维度, 在Twi22-01 数据集上进行实验, 结果如图 4 所示。

图3 不同采样设置下的实验结果
Fig. 3 Experimental results under different sampling settings

图4 不同隐藏层维度下的实验结果
Fig. 4 Experimental results under different hidden layer dimensions
从图 4 可知, 在一定范围内增加图隐藏层维度,可以提升模型的性能。但是, 当维度到达一定数值(如 128)后, 继续增加维度, 性能不会有显著的提升。融合隐藏层维度的实验结果则相对稳定, 没有显著的变化。考虑到训练效率, 设置图隐藏层维度为 128, 融合隐藏层维度为 32 较为合理。
为了更直观地解释STKGBot的有效性, 本文展示两个由 STKGBot 预测的用户案例, 如图 5 所示。在图 5(a)中, 一个机器人用户被混合检测方法错误地识别为人类, STKGBot 通过建模用户动态社交历史, 成功地识别出用户行为模式上的异常, 从而得到正确的预测结果。在图 5(b)中, 在仅依赖特征融合的情况下, 由于噪声累积问题, 一个用户被错误地识别为机器人, 通过对比学习, 成功地识别为人类用户, 增强了 STKGBot 的正确预测能力。
为了解决现有推特机器人检测方法对用户动态社交历史结构性和时序性的忽视以及特征融合引起的噪声累积问题, 本文构建社交时序知识图谱(STKG), 并且提出一种推特机器人检测方法 ST-KGBot。在 STKG 中, STKGBot 使用 RE-GAT 学习其中的静态社交关系特征, 使用 TE-GCN 学习其中的动态社交历史特征。此外, STKGBot 采用双线性融合模型将两种特征进行融合, 采用对比学习进行缓解融合引起的噪声累积问题。在两个机器人检测数据集上的实验结果中, STKGBot 取得最优性能。
本文研究存在以下局限性。
1)除文本信息外, 用户还发布视频和图片等其他社交信息, 并且除了推特, 还有微博和豆瓣等社交平台。由于数据获取困难, STKGBot 暂时没有考虑其他社交信息和社交平台。未来的研究中将会把这些信息整合到社交机器人检测中。
2)本文采用时序增强图卷积网络 TE-GCN 对用户动态社交历史进行建模。但是, 社交平台存在的固有限制, 给改进用户时序行为建模带来挑战。例如, 无法在平台得到所关注活动的精确时间。未来会采用更复杂的方法和数据抽取方式(例如用户之间的关注历史)来建模动态社交历史。

图5 案例分析
Fig. 5 Case study
参考文献
[1] Ping H, Qin S. A social bots detection model based on deep learning algorithm // 2018 IEEE 18th Internatio-nal Conference on Communication Technology (ICCT). Chongqing, 2018: 1435–1439
[2] Liu Y, Tan Z, Wang H, et al. BotMoE: Twitter bot detection with community-aware mixtures of modal-specific experts // Chen H H, Duh W J, Huang H H, et al. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Informa-tion Retrieval, SIGIR 2023. Taipei, 2023: 485–495
[3] Feng S, Wan H, Wang N, et al. BotRGCN: Twitter bot detection with relational graph convolutional networks // Coscia M, Cuzzocrea A, Shu K, et al. ASONAM’21: International Conference on Advances in Social Net-works Analysis and Mining, Virtual Event. Hague. 2021: 236–239
[4] Yang Y, Yang R, Peng H, et al. FedACK: federated adversarial contrastive knowledge distillation for cross-lingual and cross-model social bot detection // Ding Y, Tang J, Sequeda J F, et al. Proceedings of the ACM Web Conference 2023. Austin, 2023: 1314–1323
[5] Hays C, Schutzman Z, Raghavan M, et al. Simplistic collection and labeling practices limit the utility of benchmark datasets for twitter bot detection // Ding Y, Tang J, Sequeda J F, et al. Proceedings of the ACM Web Conference 2023. Austin, 2023: 3660–3669
[6] Lei Z, Wan H, Zhang W, et al. BIC: Twitter bot detec-tion with text-graph interaction and semantic consis-tency // Rogers A, Boyd-Graber J L, Okazaki N. Pro-ceedings of the 61st Annual Meeting of the Associa-tion for Computational Linguistics (Volume 1: Long Papers). Toronto, 2023: 10326–10340
[7] Cai Z, Tan Z, Lei Z, et al. LMBot: distilling graph knowledge into language model for graph-less deploy-ment in Twitter bot detection // Caudillo-Mata L A, Lattanzi S, Medina A M, et al. Proceedings of the 17th ACM International Conference on Web Search and Data Mining. Merida, 2024: 57–66
[8] Kudugunta S, Ferrara E. Deep neural networks for bot detection. Inf Sci, 2018, 467: 312–322
[9] Zhou M, Feng W, Zhu Y, et al. Semi-supervised social bot detection with initial residual relation attention networks // Morales G D F, Perlich C, Ruchansky N, et al. Machine Learning and Knowledge Discovery in Databases: Applied Data Science and Demo Track-European Conference. Turin, 2023: 207–224
[10] Leblay J, Chekol M W. Deriving validity time in know-ledge graph // Companion Proceedings of the Web Conference. Lyon, 2018: 1771–1776
[11] Li Z, Jin X, Li W, et al. Temporal knowledge graph reasoning based on evolutional representation learning // Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Informa-tion Retrieval. New York: Association for Computing Machinery, 2021: 408–417
[12] Chen W, Wan H, Guo S, et al. Building and exploiting spatial-temporal knowledge graph for next POI recom-mendation. Knowl Based Syst, 2022, 258: 109951
[13] Chang L, Chen W, Huang J, et al. Exploiting multi-attention network with contextual influence for point-of-interest recommendation. Appl Intell, 2021, 51(4): 1904–1917
[14] Wu Q, Yang Y, He B, et al. BotSCL: heterophily-aware social bot detection with supervised contrastive lear-ning // Antonacopoulos A, Chaudhuri S, Chellappa R, et al. Pattern Recognition — 27th International Con-ference. Kolkata, 2024: 53–68
[15] Lv Q, Ding M, Liu Q, et al. Are we really making much progress?: Revisiting, benchmarking and refining he-terogeneous graph neural networks // Zhu F, Ooi B C, Miao C. KDD’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event. Singapore, 2021: 1150–1160
[16] Li X, Zhao X, Xu J, et al. IMF: interactive multimodal fusion model for link prediction // Ding Y, Tang J, Se-queda J F, et al. Proceedings of the ACM Web Con-ference 2023. Austin, 2023: 2572–2580
[17] Feng S, Tan Z, Wan H, et al. TwiBot-22: towards graph-based Twitter bot detection [EB/OL]. (2023–02–12) [2024–04–02]. https://arxiv.org/abs/2206.04564
[18] Dong H, Li T, Leng J, et al. GCN: GPU-based cube CNN framework for hyperspectral image classification // 46th International Conference on Parallel Proces-sing. Bristol, 2017: 41–49
[19] Veličković P, Cucurull G, Casanova A, et al. Graph attention networks [EB/OL]. (2018–02–04)[2024–04–02]. https://arxiv.org/abs/1710.10903
[20] Hu Z, Dong Y, Wang K, et al. Heterogeneous Graph Transformer // Huang Y, King I, Liu T Y, et al. The Web Conference 2020. Taipei, 2020: 2704–2710
[21] Feng S, Tan Z, Li R, et al. Heterogeneity-aware twitter bot detection with relational graph transformers. Pro-ceedings of the AAAI Conference on Artificial Intelli-gence, 2022, 36(4): 3977–3985
Twitter Bot Detection Method Based on Social Temporal Knowledge Graph
Abstract Existing Twitter bot detection methods often overlook the structural and temporal information of users’ dynamic social history, as well as the noise accumulation resulting from feature fusion. In order to address these limitations, this paper constructs STKG (social temporal knowledge graph) and proposes a Twitter bot detection method STKGBot (STKG for Twitter bot detection). In the STKG, STKGBot uses RE-GAT (heterogeneity-enhanced graph attention network) to learn the static social relationship feature, TE-GCN (temporal-enhanced graph convo-lutional network) to learn the dynamic social history feature, and a bilinear model for the feature fusion. In addition, STKGBot employs contrastive learning to alleviate the noise aggravation in the process of feature fusion. Experi-mental results on two public datasets demonstrate that STKGBot outperforms state-of-the-art models.
Key words Twitter bot detection; temporal knowledge graph; GNN; contrastive learning