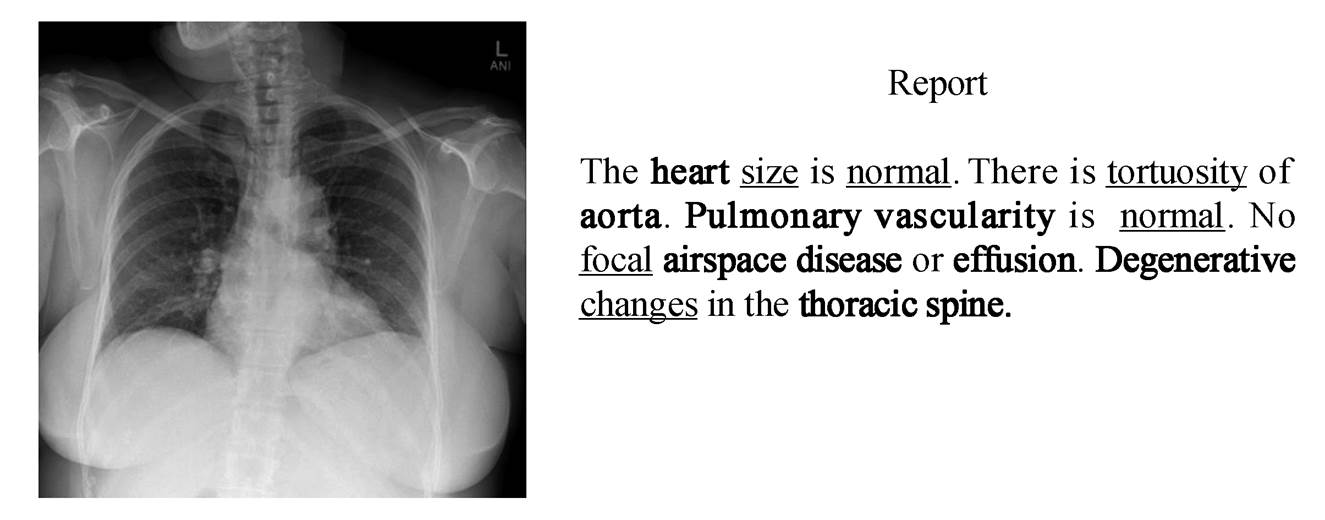
单下划线标注的单词代表初级单词, 加粗的单词表示关键单词
图1 标准的肺部放射学医疗报告示例
Fig. 1 A standard lung radiology medical report
北京大学学报(自然科学版) 第60卷 第1期 2024年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 60, No. 1 (Jan. 2024)
doi: 10.13209/j.0479-8023.2023.076
收稿日期: 2023–05–18;
修回日期: 2023–07–31
摘要 在使用深度学习模型自动生成放射学报告时, 由于数据的极度不平衡, 当前的模型难以识别异常区域特征, 从而导致对疾病的错判与漏判。为了提升模型对疾病的识别能力, 提高放射学报告的质量, 提出使用多尺度特征解析 Transformer(MFPT)模型来生成放射学报告。构建一个关键特征强化注意力(KFEA)模块, 以便加强对关键特征的利用; 设计一个多模态特征融合(MFF)模块, 以便促进语义特征与视觉特征的特征融合, 缓解特征差异造成的影响; 探索阶段感知(SA)模块在放射学报告任务中对初级特征的优化作用。最后, 在流行的放射学报告数据集 IU X-Ray 上, 与当前的主流模型进行对比实验, 结果表明, 所提模型取得当前最佳 效果。
关键词 注意力机制;特征融合;放射学报告;Transformer;图像–文本生成
图像描述是一个涉及自然语言处理和计算机视觉的跨模态任务, 目的是使计算机理解图片的内容并对其生成相应的描述[1–9]。在 Huang 等[8]提出的模型中, 注意力模块通过度量注意力结果与查询之间的相关性来提升效果, Wang 等[9]利用多特征预融合的方法来减少特征偏差造成的特征损失。放射学报告的生成任务由图像描述任务衍生而来, 图 1 为一份来自 IU X-Ray 数据集的放射学报告, 其中包含大量关键单词和初级单词。关键单词主要由医学专业单词构成, 初级单词主要由描述关键单词的形容词组成。模型对关键特征和初级特征的解析能力将直接影响这两种单词的预测准确度, 从而影响报告的质量。与普通图片相比, 放射学图片具有相似度高以及数据不平衡等特点, 因此, 现有的图像描述模型不能很好地适用放射学报告自动生成任务, 研究人员开始针对放射学报告生成的特点进行相应的研究[10–16]。
单下划线标注的单词代表初级单词, 加粗的单词表示关键单词
图1 标准的肺部放射学医疗报告示例
Fig. 1 A standard lung radiology medical report
Liu 等[10]首先预测医学单词, 然后有条件地生成与这些单词关系密切的单词来生成报告。这种方法过度依赖医学单词的预测准确度, 导致其仍然具有一定的限制性。Jing 等[11]提出使用标签特征来缓解关键特征和初级特征的损失, 但是忽略了对标签数量的学习, 致使模型引入新的特征偏差。Zhang等[12]通过构建医学知识图, 使模型能够了解不同疾病之间的关联, 从而提高对关键单词预测的准确度。但是, 他们未使用 Transformer 框架作为解码器, 并且没有考虑初级单词的生成, 致使关键单词与初级单词之间的依赖关联性不足以满足任务的需要。Song 等[13]使用一种新的方法来提升对关键单词和初级单词的预测精度, 将输入图片与正常图片进行对比, 学习两者之间的差距, 提升模型对疾病的预测能力。但是, 该方法随机提取的正常图片特征不可避免地与输入的正常图片特征有所差别, 导致模型对疾病的判断能力下降, 影响报告的整体质量。
模型对语义特征和视觉特征之间的多模态特征解析能力直接影响能否生成结构合适的报告。最近, 针对生成放射学报告任务的多模态模型研究取得一定的进展。Chen 等[14]提出一个跨模态记忆模块, 加强了模型对文本与图像之间映射关系的学习。Chen 等[15]设计一个具有记忆功能的内存模块和一个基于内存模块的归一化层来学习不同时期的多模态特征依赖关系, 使模型能生成结构合适的放射学报告。上述研究未对关键特征和初级特征进行优化处理, 导致模型对图像特征的理解不够充分, 从而影响模型对疾病的预测能力。You 等[16]提出Align Hierarchical Attention (AHA)模块来对齐标签语义特征和视觉特征, 但没有针对单词语义特征与视觉特征之间的差异进行优化, 导致生成的报告质量未达到预期。
为了加强模型的特征解析能力, 缓解多模态特征之间的特征差异, 本文提出使用多尺度特征解析Transformer (multi-scale feature parsing Transformer,MFPT)模型来生成放射学报告, 以便减少对疾病的误判和错判, 生成更高质量的放射学报告。本文构建了一个 KFEA (key features enhance attention)模块, 对关键特征进行特征强化, 提高对关键单词的预测准确性。设计一个 MFF (multi-modal feature fusion)模块, 促进语义特征与视觉特征融合, 调整报告的结构。本文还探索了 SA (stage awareness)模块在医疗报告领域中对初级特征的强化作用。
本研究使用序列到序列(sequence-to-sequence, Seq2Seq)的方法来自动生成放射学报告。首先使用视觉提取器, 提取放射学图像特征作为初始序列 X, 编码解码后得到最终的报告 Y :
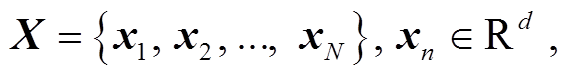 (1)
(1)
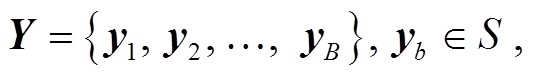 (2)
(2)
其中, xn 是提取到的第 n 个patch特征, d 是映射的特征向量的大小, yb 表示生成序列中第 b 个单词对应的张量, S 表示生成报告中的所有单词的集合。
如图 2 所示, 本文提出的多尺度特征解析 Trans-former (MFPT)模型由视觉提取器、编码器和解码器三部分组成。本文工作主要体现在解码器中的KFEA 和 MFF 模块以及编码器中的 SA 模块。
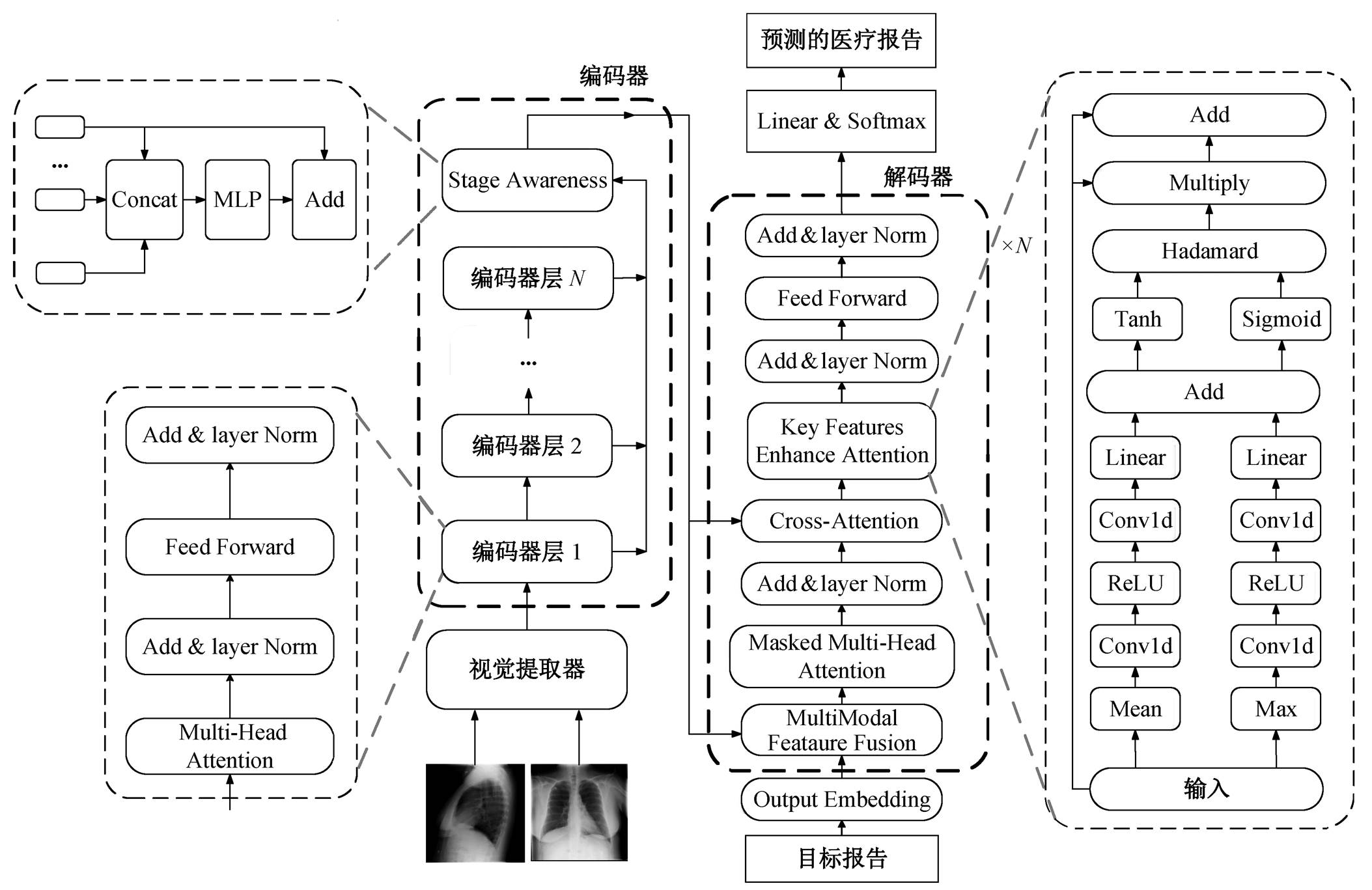
图2 多尺度特征解析Transformer模型整体结构
Fig. 2 Multi-scale feature parsing Transformer model overall structure
视觉提取器 本文使用预训练过的 ResNet-101模型[17]作为视觉提取器来提取视觉特征, 如式(3) 所示:
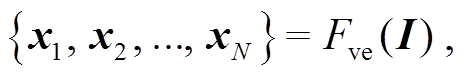 (3)
(3)
其中, Fve 代表视觉提取器的提取操作, I 表示输入的放射学图片所对应的张量空间。
编码器 本文的编码器与 Vanilla Transformer的编码器有所不同, 我们额外使用一个阶段感知模块来整合不同编码器层数之间的初级特征。此模块用下式表示:
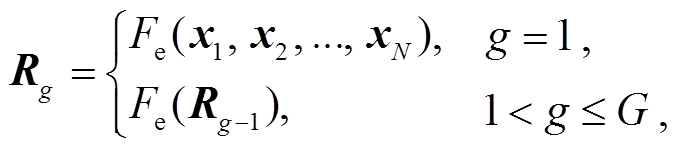 (4)
(4)
![]() (5)
(5)
其中, Fe 代表编码器, Rg 表示第 g 层编码器的输出, Z 表示编码器最终的输出, SA 表示阶段感知模块的操作。
解码器 解码器的设计是在 Vanilla Transformer的解码器基础上增加 KFEA 模块和MFF模块, 解码器根据编码器的输出 Z={z1, z2, …, zN}和已经预测完的单词序列, 生成下一个单词, 计算过程如下:
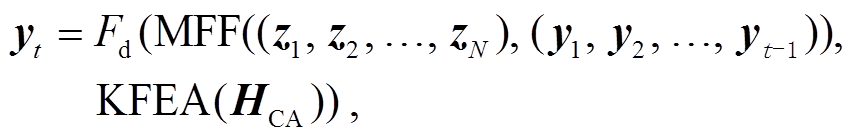 (6)
(6)
其中, yt表示在第 t 个时间步长预测的单词序列所对应的张量, Fd 表示解码器, HCA 表示交叉注意力模块的输出。
损失函数 本文采用与 Chen 等[15]相同的损失函数来训练模型, 具体表示为
其中, θ 表示模型的参数。
受 Zeng 等[18]的启发, 我们使用 SA 模块来减少训练过程中初级特征的损失。该模块分为两步执行, 第一步对不同的编码层设置不同的权重, 如式(8)所示:
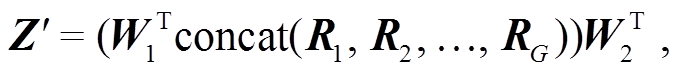 (8)
(8)
式中, 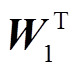 和
和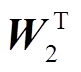 是可训练的投影矩阵,Z'是编码器在执行 SA 模块过程中的隐藏状态, concat 表示拼接操作。第二步是在最终的输出中添加未整合过的特征, 以便减少计算过程中无关数据的扰动, 保留原有视觉特征, 用式(9)表示:
是可训练的投影矩阵,Z'是编码器在执行 SA 模块过程中的隐藏状态, concat 表示拼接操作。第二步是在最终的输出中添加未整合过的特征, 以便减少计算过程中无关数据的扰动, 保留原有视觉特征, 用式(9)表示:
![]() (9)
(9)
式中, μ表示一个可调节的权重因子。
传统的特征融合方法如图 3 所示, 它使用单一的语义特征作为查询向量, 直接对视觉特征进行过滤查询。具体来说, 首先将目标报告所对应的文本序列送入嵌入层形成语义特征; 然后使用 Masked Multi-Head Attention 模块对语义特征进行注意力运算, 经 Add&layer Norm 层处理; 最后, 将结果作为查询向量输入交叉注意力模块中, 与经过编码器的视觉特征进行交叉注意运算, 从而实现多模态的融合。这种方法忽略了视觉特征与语义特征之间的特征差异, 特征融合过程中计算跨度过大, 限制了模型的推理能力。
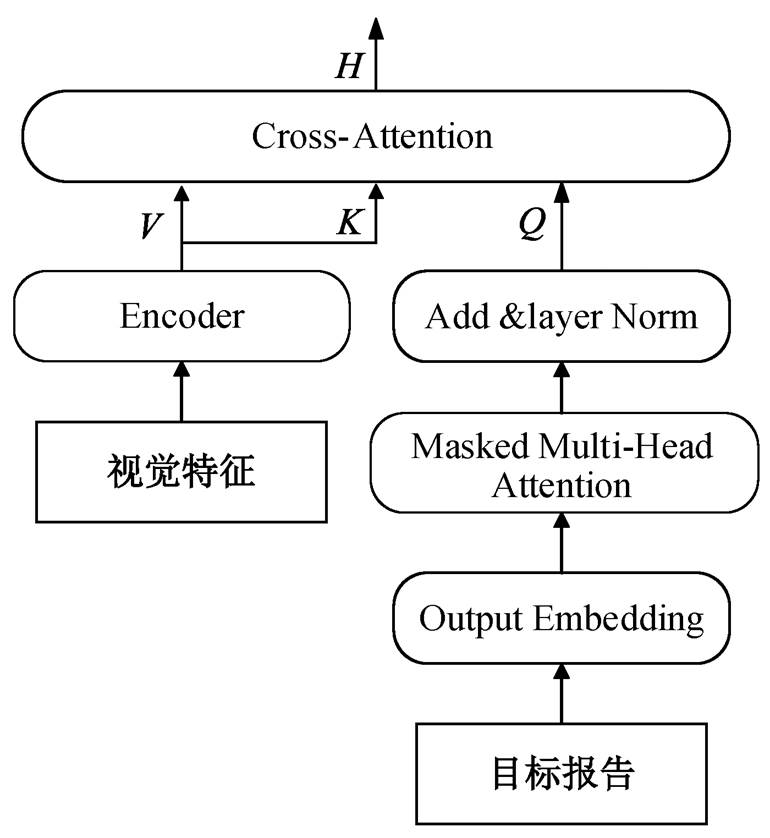
图3 传统的特征融合方法
Fig. 3 Traditional feature fusion method
如图 4 所示, 本文提出使用多模态特征融合模块来解决这一问题。该模块将语义特征和关键的视觉特征作为查询向量, 帮助模型建立视觉特征与语义特征之间的联系。首先提取视觉关键特征, 然后使用多模态特征融合模块, 将其与语义特征进行预融合后, 再进行传统的特征融合计算。计算公式可表示为
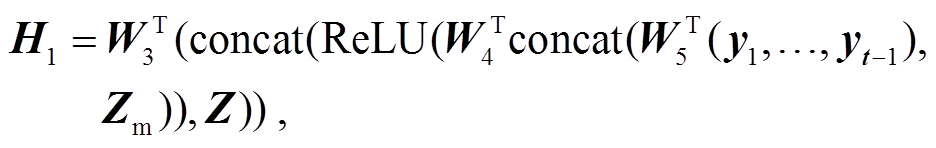 (11)
(11)
![]() (12)
(12)
式中, Zm表示视觉关键特征, Mean 表示平均运算, H1 表示在执行 MFF 模块过程中的隐藏状态, 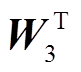 ,
, 和
和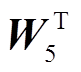 表示可训练的投影矩阵, σ代表 Sigmoid激活函数,
表示可训练的投影矩阵, σ代表 Sigmoid激活函数, 表示哈达玛积, H2 表示 MFF 模块的输出, H3 表示交叉注意力模块的查询向量, MMSA 表示 Masked Multi-Head Attention 模块。之后, H3 被输入交叉注意力模块中, 生成当前的隐藏状态 H。
表示哈达玛积, H2 表示 MFF 模块的输出, H3 表示交叉注意力模块的查询向量, MMSA 表示 Masked Multi-Head Attention 模块。之后, H3 被输入交叉注意力模块中, 生成当前的隐藏状态 H。
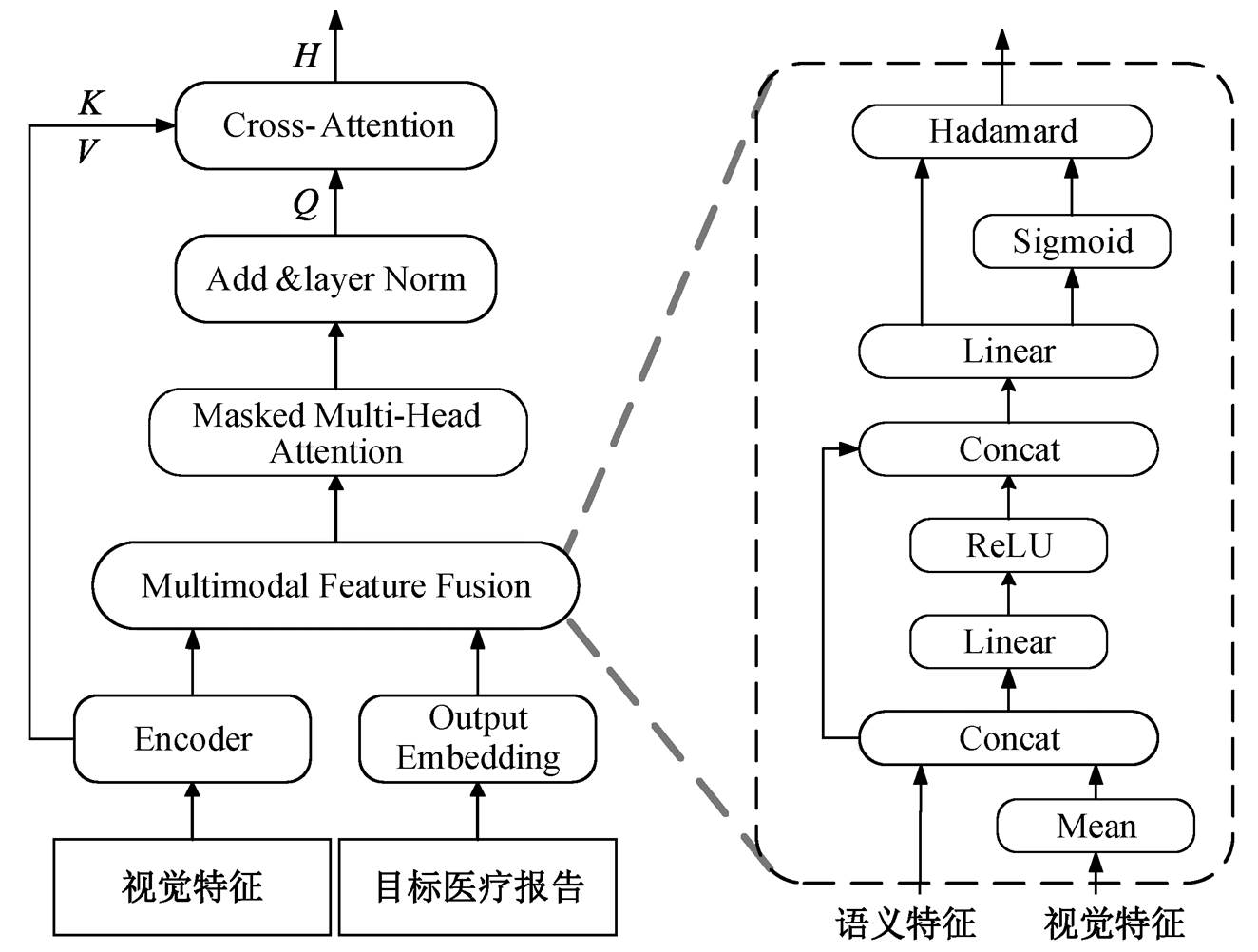
图4 多模态的特征融合方法MFF
Fig. 4 Multi-modal feature fusion method MFF
以往的研究中大多使用交叉注意力模块输出的隐藏状态, 直接预测放射学报告, 但由于关键单词比普通单词出现频率低, 导致模型不能生成合适的关键单词。在进行交叉注意力运算时, 视觉特征难以满足关键单词的查询要求, 不可避免地损失了部分关键特征。本文使用 KFEA 模块, 利用全局特征和突出特征对上下文特征进行注意力计算, 从而提高对关键特征的特征利用能力。计算流程如下:
![]() (15)
(15)
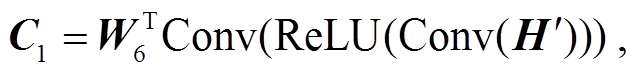 (16)
(16)
 (17)
(17)
![]() (18)
(18)
其中, H'和H״表示全局特征和突出特征, C1和C2 分别表示运算过程中的上下文特征,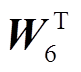 和
和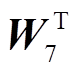 表示可训练的投影矩阵, Conv 表示卷积运算, C 表示最终输出的上下文特征。
表示可训练的投影矩阵, Conv 表示卷积运算, C 表示最终输出的上下文特征。
本文采用广泛使用的公共放射学数据集 IU X-Ray[19], 其中包括 7470 张胸部 X 光图像和3955 份报告。采用与主流模型相同的 7:1:2 的比例划分训练集、验证集和测试集。根据当前主流的研究惯例, 去除没有报告的图片, 将所有字母转换为小写, 并且剔除特殊符号等影响因素。用 BLEU[20], METE-OR[21]和 ROUGE[22]指标来评估本文模型。其中, BN表示 N-grams 为 N 时的 BLEU 指标。
我们遵循当前主流模型的实验设置, 将 Vanilla Transformer 作为 Base 模型。此外, 使用在 Image-Net 1K数据集预训练的 ResNet-101 模型提取网格特征, 多头注意力机制的头数设置为 8, 嵌入向量为512。IU X-Ray 数据集中包含一个患者的正面和侧面图像, 将其合并, 作为视觉提取器的输入。将每个 epoch 的速率衰减设置为 0.8, beam size 的大小设置为 3, 视觉提取器和其他参数的学习率分别设置为 1×10–4 和 5×10–5, batch size 的大小设置为 32。
将本文提出的模型与当前的主流模型 Ada-Att[23], M2Transformer[24], CMCL[25], R2Gen[15],CMN[14], PPKED[26], CA[13]和 GSKET[27]进行对比, 实验结果如表 1 所示。与图像描述模型 AdaAtt[23]和 M2Transformer[24]相比, 本文模型的性能提升明显, 表明需要为医疗报告生成设计专用模型。与文献[13–15,25–27]对比可知, 本文模型在各项指标中均优于当前主流模型, 表明对关键特征和初级特征进行强化利用, 对多模态特征进行预融合, 有助于生成更可靠的放射学报告。
通过消融实验, 对比 Base 模型与本文模型的效果, 结果如表 2 所示。可以看出, 与 Base 模型相比, 增加每个模块后性能都有所提升, 3 种模块随机组合也都能获得不错的效果。此外, 可以发现 KFEA模块的提升幅度最大, 证明在没有引进标签特征的情况下, 本文提出的针对关键单词优化方法获得良好的效果, 为缓解错判漏判问题提出了新思路。
表1 本文模型和已有模型的自然语言生成指标效果对比(%)
Table 1 Comparison of NLG metrics between the proposed model and existing models(%)

模型B1B2B3B4METEORROUGE AdaAtt[23]43.628.820.315.0–35.4 M2Transformer[24]46.331.821.415.5–33.5 CMCL[25]47.330.521.716.218.637.8 R2Gen[15]47.030.421.916.518.737.1 CMN[14]47.530.922.217.019.137.5 PPKED[26]48.331.522.416.8–37.6 CA[13]49.231.422.216.919.338.1 GSKET[27]49.632.723.817.8–38.1 本文方法51.535.025.018.821.138.3
说明: 粗体数字表示性能最优, 下同。
表2 Base模型与本文模型的效果比较(%)
Table 2 Comparison of the effect of the Base model and the model in this paper (%)

模型B1B2B3B4METEORROUGEAvg Base44.328.420.615.918.034.727.0 Base+SA44.928.821.116.518.335.427.5 Base+KFEA46.629.821.416.119.738.628.7 Base+MFF43.228.521.116.518.335.927.3 Base+SA+MFF45.129.521.917.318.335.928.0 Base+SA+KFEA49.431.923.017.419.538.930.0 Base+KFEA+MFF48.631.222.517.119.338.629.6 Base+SA+KFEA+MFF51.535.025.018.821.138.331.6
在数据集 IU X-Ray 上, 对 SA 模块中新引进的超参数 μ 进行消融实验, 结果如表 3 所示。可以发现, 当 μ=0.2 时, 综合指标达到最优效果, 超过 0.2后, 各项指标小幅度下降。
基于 IU X-Ray 数据集, 对本文模型进行复杂度分析, 结果如表 4 所示。与 R2Gen 模型[15]相比, 在使用更少参数的情况下, 本文模型能够获得更好的效果。
为了更好地了解本文模型生成的报告质量, 对一组前胸部和侧面胸部图像医学案例进行测试分析, 结果如图 5 所示。可以看出, 与 Base 模型相比, 本文模型可以生成更多更准确的关键单词和初级单词, 成功地捕捉到生成影像学报告所需要的关键特征和初级特征, 能够生成与 Ground-truth 基本上一致的描述。此外, 本文模型生成的报告明显长于Base 模型生成的报告, 说明本文模型采取的多模态融合策略更加有效。
本研究提出一个多尺度特征解析 Transformer (MFPT)的模型。在该模型中, 设计了一个关键特征强化注意力模块, 构建了一个多模态特征融合模块, 集成了一个阶段感知模块来生成影像学报告。本文模型在提升模型对关键特征和初级特征解析能力的同时, 促进了语义特征与视觉特征融合, 使得错报、漏报问题得到初步解决, 生成的放射学报告结构更加合理。但是, 本文模型未对疾病之间的关系进行学习, 具有一定的局限性。未来研究中将尝试建立并利用疾病关系知识图, 以便加强模型对疾病之间关系的理解。
表3 SA模块中加权因子 μ的消融结果(%)
Table 3 Ablation results of weighted factor μ in SA module (%)

μB1B2B3B4METEORROUGE 048.631.222.517.119.338.6 0.251.535.025.018.821.138.3 0.449.032.122.816.920.237.6 0.649.431.923.017.419.438.9 0.849.431.622.717.219.638.6
表4 复杂度分析结果
Table 4 Results of complexity analysis

模型参数量/MB1/%B2/%B3/%B4/%METEOR/%ROUGE/% Base56.9544.328.420.615.918.034.7 R2Gen78.4747.030.421.916.518.737.1 本文方法71.9151.535.025.018.821.138.3

Ground-truth 表示人工书写的报告, Base 表示基础模型生成的报告, Ours 表示本模型生成的报告。单下划线标注的单词代表初级单词, 加粗的单词表示关键单词
图5 Ground-truth、Base以及本文提出的模型的报告对比
Fig. 5 Comparison of reports from Ground-truth, Base, and the proposed model
参考文献
[1] Chen X, Fang H, Lin T Y, et al. Microsoft COCO cap-tions: data collection and evaluation server. Computer Science, 2015, 5: 1–7
[2] Anderson P, He X, Buehler C, et al. Bottom-up and top-down attention for image captioning and visual ques-tion answering // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018: 6077–6086
[3] Vinyals O, Toshev A, Bengio S, et al. Show and tell: a neural image caption generator // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, 2015: 3156–3164
[4] Xu K, Ba J, Kiros R, et al. Show, attend and tell: neural image caption generation with visual attention // Pro-ceedings of the International Conference on Machine Learning. Lille, 2015: 2048–2057
[5] Liu Fenglin, Liu Yuanxin, Ren Xuancheng, et al. Alig-ning visual regions and textual concepts for semantic-grounded image representations // Proceedings of the Annual Conference on Neural Information Processing Systems. Vancouver, 2019: 6847–6857
[6] Liu Fenglin, Ren Xuancheng, Liu Yuanxin, et al. Exp-loring and distilling cross-modal information for image captioning // Proceedings of the International Joint Conference on Artificial Intelligence. Macau, 2019: 5095–5101
[7] Liu Fenglin, Ren Xuancheng, Liu Yuanxin, et al. sim-Net: stepwise image-topic merging network for gene-rating detailed and comprehensive image captions // Proceedings of the Conference on Empirical Methods in Natural Language Processing. Brussels, 2018: 137–149
[8] Huang L, Wang W, Chen J, et al. Attention on attention for image captioning // Proceedings of the IEEE Con-ference on Computer Vision and Pattern Recognition. Long Beach, 2019: 4634–4643
[9] Wang Y, Xu J, Sun Y. End-to-end transformer based model for image captioning // Proceedings of the AAAI Conference on Artificial Intelligence. Online Meeting, 2022: 2585–2594
[10] Liu G, Hsu T M H, McDermott M, et al. Clinically accurate chest X-ray report generation // Proceedings of the Conference on Machine Learning for Healthcare Conference. Ann Arbor, 2019: 249–269
[11] Jing B, Xie P, Xing E. On the Automatic generation of medical imaging reports // Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, 2018: 2577–2586
[12] Zhang Y, Wang X, Xu Z, et al. When radiology report generation meets knowledge graph. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34 (7): 12910–12917
[13] Song X, Zhang X, Ji J, et al. Cross-modal contrastive attention model for medical report generation // Pro-ceedings of the 29th International Conference on Com-putational Linguistics. Gyeongju, 2022: 2388–2397
[14] Chen Z, Shen Y, Song Y, et al. Cross-modal memory networks for radiology report generation. Computers & Electrical Engineering, 2022, 98: 1879–0755
[15] Chen Z, Song Y, Chang T H, et al. Generating radio-logy reports via memory-driven transformer // Pro-ceedings of the Conference on Empirical Methods in Natural Language Processing. Online Meeting, 2020: 1439–1449
[16] You D, Liu F, Ge S, et al. Aligntransformer: hierarchi-cal alignment of visual regions and disease tags for medical report generation // Proceedings of the 24th International Conference on Medical Image Computing and Computer Assisted Intervention. Strasbourg, 2021: 72–82
[17] He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition // Pro-ceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, 2016: 770–778
[18] Zeng Pengpeng, Zhang Haonan, Song Jingkuan, et al. S2 transformer for image captioning // Proceedings of the International Joint Conference on Artificial Intel-ligence. Vienna, 2022: 1608–1614
[19] Demner-Fushman D, Kohli M D, Rosenman M B, et al. Preparing a collection of radiology examinations for distribution and retrieval. Journal of the American Me-dical Informatics Association, 2016, 23(2): 304–310
[20] Papineni K, Roukos S, Ward T, et al. BLEU: a method for automatic evaluation of machine translation // Pro-ceedings of the Annual Meeting of the Association for Computational Linguistics. Philadelphia, 2002: 311–318
[21] Denkowski M, Lavie A. Meteor 1.3: automatic metric for reliable optimization and evaluation of machine translation systems // Proceedings of the sixth work-shop on statistical machine translation. Edinburgh, 2011: 85–91
[22] Lin C Y. Rouge: a package for automatic evaluation of summaries // Proceedings of the Workshop on Text Summarization Branches Out (WAS 2004). Barcelona, 2004: 74–81
[23] Lu Jiasen, Xiong Caiming, Parikh D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning // Proceedings of the IEEE Con-ference on Computer Vision and Pattern Recognition. Honolulu, 2017: 3242–3250
[24] Cornia M, Stefanini M, Baraldi L, et al. Meshed-memory transformer for image captioning // Procee-dings of the IEEE Conference on Computer Vision and Pattern Recognition. Online Meeting, 2020: 10575–10584
[25] Liu Fenglin, Ge Shen, Wu Xian. Competence-based multimodal curriculum learning for medical report generation // Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Online Meeting, 2021: 3001–3012
[26] Liu Fenglin, Wu Xian, Ge Shen, et al. Exploring and distilling posterior and prior knowledge for radiology report generation // Proceedings of the IEEE Confe-rence on Computer Vision and Pattern Recognition. Online Meeting, 2021: 13753–13762
[27] Yang S, Wu X, Ge S, et al. Knowledge matters: chest radiology report generation with general and specific knowledge. Medical Image Analysis, 2022, 80: 102510
Radiology Report Generation Method Based on Multi-scale Feature Parsing
Abstract When using deep learning models to automatically generate radiology reports, due to the extreme imbalance of data, it is difficult for current models to identify abnormal regional features, which leads to misjudgment and missed judgment of the disease. In order to improve the model’s ability to identify diseases and improve the quality of reports, the authors use a multi-scale feature parsing Transformer (MFPT) model to generate radiology reports. Among them, a key feature enhanced attention (KFEA) module is constructed to strengthen the utilization of key features. A multi-modal feature fusion (MFF) module is designed to promote the feature fusion of semantic features and visual features and alleviate the impact caused by feature differences. This paper explores the role of stage-aware (SA) module in optimizing primary features in radiology reporting tasks. Finally, compared with the current mainstream models on the popular radiology report dataset IU X-Ray, the results show that the proposed model has achieved the current best effect.
Key words attention mechanism; feature fusion; radiology report; Transformer; image-text generation