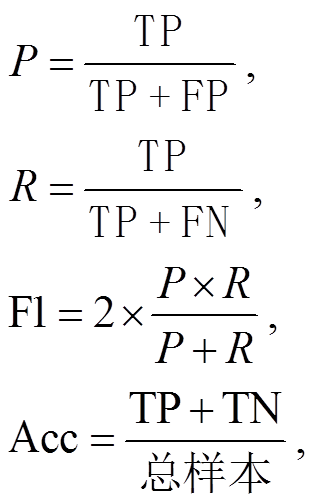北京大学学报(自然科学版) 第60卷 第1期 2024年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 60, No. 1 (Jan. 2024)
doi: 10.13209/j.0479-8023.2023.075
国家自然科学基金青年基金(62006212)、中国博士后科学基金(2023M733907)、信息物理社会可信服务计算教育部重点实验室开放基金(CPSDSC202103)和Project of Strategic Importance Grant of the Hong Kong Polytechnic University (1-ZE2Q)资助
收稿日期: 2023–05–17;
修回日期: 2023–07–31
ChatGPT可否充当情感专家?——调查其在情感与隐喻分析的潜力
张亚洲1,2 王梦遥1 戎璐3 俞洋1 赵东明4 秦璟2,†
1.郑州轻工业大学软件学院, 郑州 450002; 2.香港理工大学护理学院, 香港 999077; 3.郑州轻工业大学人事处, 郑州 450002; 4.中国移动通信集团天津有限公司人工智能实验室, 天津 3000201; †通信作者, E-mail: harry.qin@polyu.edu.hk
摘要 为了探索 ChatGPT 情感分析能力以及对主观性和隐喻性理解的潜力, 将 ChatGPT 在 5 个情感、幽默与隐喻基准数据集上展开评估, 通过与领域内最前沿的模型对比, 讨论其在不同任务上的优势与局限。此外, 还通过对比 ChatGPT 与人类在情感分析中的性能差别, 发现 ChatGPT 在情感、幽默与隐喻任务上与人类结果分别相差 9.52%, 16.64%和 6.69%。实验结果表明, 尽管 ChatGPT 在对话生成方面获得最佳表现, 但是其在情感理解方面仍具有改进的潜力。最后, 通过改善提示模板, 调查 ChatGPT 在情感理解场景下对提示模板的敏感性。
关键词 ChatGPT; 情感分析; 幽默检测; 隐喻识别
情感是人类生命体验的载体, 用于感知、辨析与理解人类潜在意图, 驱动人类的决策与行为。情感理解能力是人与机器的主要区别之一。鉴于人类语言的主观性, 人们可以通过语言表达各种情感状态, 如喜悦、愤怒和幽默等, 也可以通过语言感知他人的情感状态[1]。情感分析旨在利用语言规则、语料库和自然语言处理技术等, 帮助机器自动识别和分析人类的情感状态, 并准确地做出回应。目前主流的范式是借助 Transformer 预训练语言模型(pre- trained language models, PLMs)优良的上下文特征提取能力, 通过微调或提示捕捉情感线索, 快速完成情感预测[2]。
随着预训练语言模型日趋庞大, 参数量激增, 语言模型在下游任务中的性能显著提升, 自然语言处理领域开始迈入大语言模型时代。例如 GPT-3[3]以及 InstructGPT[4]等大型语言模型(large language models, LLMs)在语言生成、语言理解、文本分类以及语言翻译等任务中取得显著的进步。2022 年11 月, 由 OpenAI 公司发行的代表性大语言模型ChatGPT 引起学术界与工业界的关注。ChatGPT 基于 GPT-3.5 大型语言模型, 通过对齐人类的真实意图, 即采用基于人类反馈的强化学习(reinforcement learning from human feedback, RLHF), 在大规模无标注语料库上完成训练。与传统的强化学习相比, RLHF 利用人类提供的反馈[5]来指导模型进行学习(人类通过指导模型的行为来提供即时反馈, 模型可以在学习过程中利用这些反馈来调整自己的行为)。这种方法使得模型学习过程更加高效, 同时也提高了学习质量。ChatGPT 在诸多下游任务中展露最前沿的能力, 包括对人工输入的复杂问题提供高质量的答案, 编写代码[6], 识别人类情感, 在面临敏感话题(例如暴力和政治敏感等)时, 拒绝不恰当请求, 甚至可以根据后续对话自我纠正先前的错误, 等等。因此, 与传统的语言模型相比, ChatGPT拥有显著的人类语言理解优势, 是实现通用人工智能的主要途径之一, 已经作为智能助手广泛应用于各个行业。
ChatGPT 在取得巨大成功的同时, 亦引发研究者更多的思考与疑问。鉴于人类语言固有的主观性与隐喻性, 对 ChatGPT 情感理解能力的定量分析却鲜有涉及。首先, 情感表达与理解是一项非常抽象与主观的任务, 涉及个体差异(同一个情感表达被不同个体解读为不同情感)、情感多样性(悲伤夹杂着愤怒)、上下文性(同样的表达在不同语境下传达不同的情感)等多种因素, ChatGPT 的情感理解能力因而需要严谨的评估。面对更加高级的情感语言表达方式(例如幽默和隐喻等), 人类经常通过隐含映射和双关语等间接地表达情感, 那么 ChatGPT 如何处理语言的多义性、映射和隐含信息, 是否有潜力作为情感专家也亟需业界的正确评估。最后, 鉴于 ChatGPT 是根据人类设计的提示语生成答案, 调查ChatGPT 在情感理解场景下对提示模板的敏感性显得尤为必要。
本文主要关注 3 个问题: 1) ChatGPT 是否能够准确地理解人类情感?与人类判断情感的差距有多大?2) ChatGPT 是否能够准确地理解高级情感表达方式?3)不同的提示策略是否对 ChatGPT 的判定结果产生影响?
本文在 5 个情感、幽默与隐喻基准数据集上, 对 ChatGPT(2023 年 3 月 23 版)展开评估, 通过与领域内 20 个最前沿模型的对比, 讨论其在不同任务中的优势与局限, 对比 ChatGPT 与人类在情感、幽默和隐喻分析方面的性能。此外, 还通过系统性地改变提示策略, 进一步分析提示策略对 ChatGPT 理解人类情感能力的影响。
1 相关研究
从谷歌的 T5 到 OpenAI GPT 系列, 大语言模型不断涌现, 例如, GPT-3, PALM[7], Galactica[8]和LLaMA[9]。这些 LLM 以包含千亿参数的模型架构为基底, 并在大量数据集上进行训练。这种缩放训练策略提高了语言模型对自然语言的理解和生成能力, 即便不更新其参数, 也在很多自然语言处理任务中带来显著的提升。例如, 在问答任务中, 这些LLM 通过理解问题和文本语境, 给出更加自然、流畅、准确的回答[10] (如 ChatGPT 模型); 在文本分类任务中, 通过对 LLM 进行微调, 可以获得比传统方法更好的准确率和泛化能力[11] (如 BERT 模型); 在机器翻译任务中, LLM 可用于语言表示和对齐, 帮助提高翻译的质量和效率(如 Transformer 模型)。
作为基于 GPT-3.5 的对话生成模型, ChatGPT在情感分析任务中得到广泛应用。例如, 在对话系统中, ChatGPT 可以生成更加自然的情感丰富的回复, 并且可以在情感分析任务中识别用户的情感表达。越来越多的研究人员根据各种基准进行评估, 探索 ChatGPT 的能力边界。Zhuo 等[12]对 ChatGPT的可靠性和稳定性进行定量分析, Jiao 等[13]对其多语言翻译能力做了初步探究, Bang 等[14]从多任务、多语言和多模态方面评估 ChatGPT 的生成能力。与已有研究不同, 本文的重心是调查 ChatGPT 在主观性任务中的表现, 特别是对幽默和隐喻等复杂情感语言的理解能力。通过一个全面的评估, 判定ChatGPT 是否有潜力作为一个情感专家或助手, 从而促进情感智能方向的研究。
2 评估方法
自然语言处理领域一直在追求更加智能化的算法模型, 用来模拟人类对语言的处理方式。本文围绕测试任务、实验数据、对比模型、评价标准和实验结果等, 对 ChatGPT 在情感分析领域的性能展开全面评估, 探索其在情感分析领域的应用潜力。
2.1 测试任务
本文将开展以下 4 项代表性情感分析任务。
1)主观性情感分析: 从主观性文本中自动识别和提取文本表达的情感状态, 分为积极、消极和中性 3 种。
2)方面级情感分析: 从文本中提取特定方面(如商品价格、服务质量和用餐环境等)的情感极性, 分为正面、负面和中性 3 种。
3)幽默检测: 判断文本中是否包含幽默元素, 将文本分为幽默和非幽默两类。
4)隐喻识别: 对文本中的隐喻进行识别和解释, 并判断句子表达的是褒义还是贬义情感。
2.2 实验数据
本研究选取 5 个广泛评测的中文情感数据集: SMP2020 微博情感分类数据集(Usual 和 Virus)、SMP2020 文本幽默检测数据集(Humor)、ASAP 中文评论分析数据集和隐喻式数据集(Metaphor)。Usual 和 Virus 数据集分别包含 6 类情绪, 将愉悦情绪(happy)归类为积极样本, 悲伤(sad)和愤怒(angry)情绪合并为消极样本, 无情绪(neutral)定义为中性样本。作为文本幽默数据集, Humor 包含幽默和非幽默标签, 用于幽默识别任务中。ASAP 是一个大型的中餐馆评论数据集, 用于方面类别的情感分析(aspect based sentiment analysis, ABSA)。Metaphor是一个中文隐喻数据集, 包含褒义和贬义标签, 用于隐喻识别任务。实验样本分布如表 1 所示。
本实验将以上 5 个数据集分别用于对比评估ChatGPT 和其他 SOTA 模型。本文调用 ChatGPTAPI进行评测。同时, 本文挑选一系列最前沿的情感分析模型用于情感、幽默和隐喻任务评测。它们分别是 CMCNN[15], Bi-LSTM+Attention[16], CapsNet-BERT[17], DMM-CNN[18], CBMA[19], ACSA-gene-ration[20], AC-MIMLLN[21], QA-BERT[22], SGCN[23], DSPN[24], XLNet[25], GCN-BERT[26], DeepMet-S[27], MGF[28], BGCN[29], KEG[30], SaGE[31], BSI[32], Transformer[33]和 IASPS[34]。其中, Bi-LSTM+ Attention, CMCNN, CapsNet-BERT, GCN-BERT, DSPN, XLNet 和 DeepMet-S 模型使用 Github 开源代码实现, DMM-CNN, ACSA-generation, CBMA, AC-MIMLLN, BSI 和 Transformer 根据相关文献模型和参数复现; MGF, BGCN, QA-BERT, IASPS, KEG, SaGE 和 BSI模型直接采用文献结果。
2.3 评估标准
本文采用精确率(precision, P)、召回率(recall, R)、微观 F1 值(Micro-F1)和准确率(accuracy, Acc)作为模型的性能评估指标。选择微观 F1 指标的原因是它在计算中考虑了每个类别的数量。评估指标的计算公式如下:
表1 数据集统计
Table 1 Data statistics

数据集积极中性消极幽默训练集测试集训练集测试集训练集测试集训练集测试集 Usual2657906289599035781018–– Virus221677014605201801682–– ASAP169089017469161358620–– Humor––––––864728 Metaphor–––––––– 数据集非幽默贬义褒义 训练集测试集训练集测试集训练集测试集 Usual–––––– Virus–––––– ASAP–––––– Humor967542–––– Metaphor––21572252157225
其中, TP 代表真阳性, FP 代表假阳性, TN 代表真阴性, FN 代表假阴性。
3 实验结果
3.1 情感分析的实验结果
情感分析任务的分析结果如表 2 所示。可以发现, 在测试集上, ChatGPT 在情感分析任务中的表现可以媲美甚至超越其他模型。在 Usual 和 Virus数据集上, 主观性情感分析的 Macro-F1 分别为82.16%和 80.20%, 比一些传统的算法(如 Bi-LSTM +Attenion 以及 DMM-CNN 等)表现更好, 与使用BERT 模型提供词向量的 CMCNN 语言模型相比, ChatGPT 的 Macro-F1 在 Usual 和 Virus 数据集上分别提升 1.37%和 2.16%。但是与 LLM 相比, Chat-GPT 的优势并不明显, 相较于 MGF 模型, Macro-F1在 Usual 和 Virus 数据集上分别落后 1.70%和0.17%。从实验结果来看, ChatGPT 在不同数据集的情感分析任务中表现稳定。因此, ChatGPT 值得在实际应用中进一步探索。
作为更细粒度的情感分析任务, 在进行方面类别情感分析时, 模型需要同时注意文本中的内容特征、词性特征和位置特征, 并同时充分学习内容词、方面词和情感词之间的联系。从表 2 中 ASAP实验结果看, ChatGPT 比其他模型(如 QA-BERT 和CapsNet-BERT 等)表现良好, 比端到端方式的远监督金字塔网络 DSPN 提升 3.57%, 但相比语言模型ACSA-generation 降低了 0.71%, 相比语言模型 AC-MIMLLN 降低 0.44%, 表明 ChatGPT 虽然能够从长文本中准确识别方面词, 有效地捕捉文本中的上下文信息和情感表达, 但不能作为方面情感分析的最优模型。
3.2 隐喻和幽默任务的实验结果
从文本的语言表达层面来说, 人类情感可划分为显式情感和隐式情感, 隐式情感包含隐喻型和反讽型。目前, 隐喻没有被广泛承认的正式定义, 本文将隐式情感理解为: 在字面意义之外的、不包含明显的情感词, 但通过隐晦、间接的语言片段表达出主观情感。例如, “她的样貌也就只能做个备胎”, 虽然句中并未出现情感词汇, 但“备胎”却被隐喻为“替补选项”, 表达说话者的负面情感。在实际情况中, 语言模型对隐喻情感的分析可能更加复杂, 这是因为隐喻的含义通常依赖语境和个人经验, 存在不同的解释。因此, 对隐喻句子的情感分析需要考虑上下文、文化背景和作者意图等因素, 是一项更具挑战性的任务。本文采用的隐喻式数据集 Meta-phor 的情感示例如表 3 所示。
表2 情感分析任务实验结果(%)
Table 2 Experimental results of the sentiment analysis task (%)

任务模型UsualVirusASAPAccMacro-F1AccMacro-F1AccMacro-F1 主观性情感分析SGCN80.3675.8979.6273.77–– DMM-CNN81.2379.7380.1175.62–– CBMA83.2581.0782.1379.25–– BGCN74.3871.5075.2472.21–– MGF86.1983.8584.0780.03–– Bi-LSTM+Attenion84.3181.6980.8576.85–– CapsNet-BERT84.4482.8682.3376.50–– CMCNN85.2180.7983.1378.04–– ChatGPT86.0782.1684.1580.20–– 方面级情感分析DSPN––––81.9481.66 Bi-LSTM+Attenion––––77.7876.53 CapsNet-BERT––––78.9283.74 CMCNN––––76.1074.41 ACSA-generation––––86.3685.94 AC-MIMLLN––––85.6485.67 QA-BERT––––80.7883.19 ChatGPT––––85.2985.23
ChatGPT 在隐喻情感分析任务和幽默任务中的实验结果如表 4 所示。可以发现, 在更加复杂的隐喻情感分析任务中, 与几个基线模型相比, ChatGPT表现出色, 以 85.71%的 Macro-F1 超越 CCL 中文隐喻情感识别任务第一名约 1.01%, 比基于 RoBERTa的阅读理解(reading comprehension)式隐喻识别模型DeepMet-S 提升 1.94%。这是由于 ChatGPT 在大规模语料集的训练下, 从大量数据中学习到隐喻的模式和特征。
表3 隐喻式样本
Table 3 Sample of metaphorical data

类别样例 贬义1. 你们公司一年的销售额也赶不上我们一个月的。 2. 那些考了一辈子的老童生便是在某种程度上做了科举制度的人质。 褒义1. 有种活着诗里的感觉: 烟笼寒水月笼沙, 夜泊秦淮近酒家。2. 他像个骡子一样执着地努力着。
从表 4 可以看出, ChatGPT 在幽默任务中的表现相对落后于其他模型, 与基于 BERT 的强化语境与语义信息的幽默识别模型 BSI 相比, ChatGPT 的Macro-F1 落后 7.34%, 与基于不一致、模糊、句法特性的幽默识别模型 IASPS 相比, Macro-F1 落后7.04%。幽默识别任务涉及对语言上下文和语义的深入理解, 而 ChatGPT 对这些因素的理解不一定是最优的。例如, 一些幽默句子中包含的网络用语“YYDS”和“No 作 No Die”, ChatGPT 不能识别它们的真正含义。此外, BSI 等语言模型更专注于特定类型的情感分析任务, 并且使用更好的架构和技术, 因此在幽默识别任务中表现更好。ChatGPT 还有很大的发展空间, 未来可以进一步优化模型, 以便适应更复杂的自然语言处理任务。
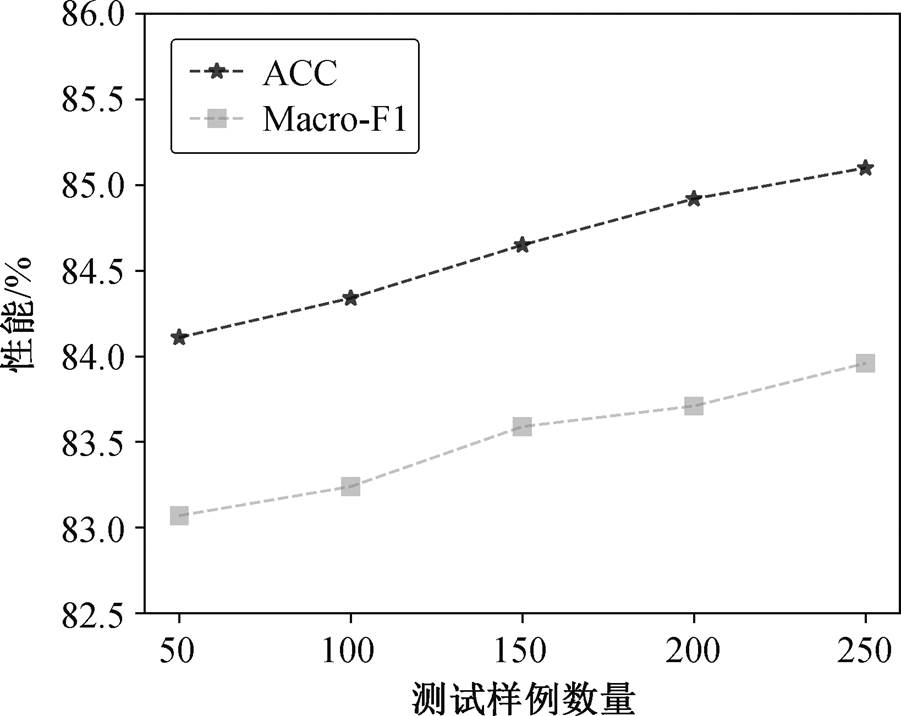
通过实验还发现, 在不改变问题线程的情况下, 随着测试样例的增加, ChatGPT 的性能也会相对提高(图 1)。可以看出, 准确率和 Macro-F1 随测试样例数同步增长, 表明ChatGPT 在不改变线程的情况下可以有效地学习到测试样例中的有效信息, 通过数据的反馈, 不断改进自身的情感分析能力, 从而不断优化自身模型。
表4 隐喻分析的实验结果(%)
Table 4 Experimental results of metaphorical analysis(%)

任务模型AccPRMacro-F1 隐喻识别XLNet82.7380.0680.4380.73 BERT84.5477.5083.1983.10 GCN-BERT79.4979.7879.4679.35 DeepMet-S80.4276.8176.2483.54 KEG83.7080.5377.4678.96 CCL top 183.2779.1681.8584.47 SaGE85.0183.1184.6384.22 ChatGPT85.7186.1285.2485.48 幽默检测CMCNN76.1378.5678.2574.55 BSI81.3781.4682.3181.82 Bi-LSTM+Attenion78.9677.2274.6875.33 Transformer79.4577.6274.2876.97 CapsNet-BERT80.1479.0376.4175.45 IASPS81.2178.7682.5381.52 ChatGPT77.0075.3473.5274.18
4 ChatGPT 与人类判断情感的差距
我们使用 SMP2020 微博情绪分类技术测评公开的两个数据集 Usual 和 Humor 以及 CCL2018 隐喻数据集 Metaphor 进行测试, 同时招募 5 名 18~35 岁不同社会身份(包括学生、工人、职员和商人等)志愿者, 经过语言理解测试后, 对这 3 个数据集进行情感、幽默和隐喻标注, 经过最大投票后获得最终标注结果。为了调查 ChatGPT 与人类情感标注的时间效率, 统计两者的分类用时(均为 5 次结果的平均值)。
如表 5 所示, ChatGPT 与人类评价在情感、幽默和隐喻数据集上均取得良好的分类结果(F1 值均超过 70%)。人类评价结果的准确率与 Macro-F1 均超过 90%, 与 ChatGPT 相比, 人类情感专家在Usual, Virus 和 Metaphor 数据集上的 F1 值分别提升9.52%, 16.64%和 6.69%。这一结果表明: 1)情感、幽默与隐喻分析是挑战性任务; 2)尽管 ChatGPT 在文本生成和代码生成等任务中取得令人瞩目的进步, 但其情感理解能力与人类仍然存在较大的差距。
表 6 给出几个 ChatGPT 识别错误的案例。识别错误的原因包括以下几个方面。
1)上下文理解能力。ChatGPT 虽然拥有强大的自然语言处理能力, 但它的上下文理解能力比不上人类。情感分析任务需要结合上下文来理解句子或文本的情感含义, 人类可以通过背景知识、语境和生活经验, 更好地理解和识别情感, 而 ChatGPT 需要依赖已有的语料库和模型训练数据。
表5 ChatGPT和人类在情感分析任务上的实验结果
Table 5 Experimental results of ChatGPT and human on sentiment analysis tasks

数据集方法情感分析t/sAcc/%P/%R/%Macro-F1/% UsualChatGPT86.0783.5382.0982.16307 人类专家94.0195.1089.3791.68561 HumorChatGPT77.0075.3473.5274.18298 人类专家93.0390.9990.6790.82547 MetaphorChatGPT85.7186.1285.2485.48428 人类专家92.1892.1992.5692.17573
表6 错误举例
Table 6 Example of error

样例输入ChatGPT识别 1听说你生病了, 莫名的伤心就上来了这句话的情感是积极的, 表达了对听说对象生病的关心和担心。 2为什么觉得有点好笑这个微博的情感倾向比较难判断, 因为它缺乏明显的情感色彩。它可能属于中性情感, 因为它既没有表达出明显的积极情感, 也没有表达出明显的消极情感。 3放烟花治肺炎, 新四大发明这句话是一个玩笑话, 它并不是真正的四大发明之一。因为烟花与治疗肺炎没有任何关系, 所以这句话的情感可以理解为“幽默”或“滑稽”。但是, 这种不负责任的言论不利于传播正确的信息和抗击疫情, 所以不应该轻易传播。
2)主观性识别。情感分析是一项主观性较强的任务, 人类在情感表达和理解方面具有很强的主观能力。然而, 对 ChatGPT 来说, 情感分析任务往往需要基于规则和标注的方法进行分类, 这种方法很难完全覆盖所有情感表达的多样性和主观性。
3)跨文化和跨语言差异。情感分析还面临跨文化和跨语言差异的问题。情感的表达和理解因不同文化和语言环境而异, 因此需要对不同的文化和语言进行针对性的处理和训练。在处理跨文化和跨语言情感时, ChatGPT 可能存在一定的困难。
4)数据不平衡和偏差。情感分析任务需要大量的标注数据来训练模型, 但是标注数据的质量和平衡性对模型的性能和准确度具有决定性的影响。如果数据集中的情感类别存在偏差或不平衡, 将导致模型对某些情感的分类能力不足, 从而影响整体性能。
综上所述, 情感分析任务具有很强的主观性和复杂性, ChatGPT 作为一种自然语言处理技术, 还需要进一步的改进和优化, 才能更好地处理这种任务。
此外, 本研究从大众点评商家用户评价中随机选取 800 条评论, 均分为互不重叠的两组(A 和 B)。将 A 组输入 ChatGPT 模型中, 输出预测情感结果, 然后让 3 位志愿者参考此结果进行最终标注, 判断该用户对商品的情感极性。3 位志愿者能够在 0.3小时完成 A 组 400 条评论的情感标注, 其中 6 条评论的情感标注错误, 准确率达到 98.50%。B 组不采用任何人工智能辅助工具, 由 3 位志愿者直接标注, 经过 1.6 小时才完成标注, 其中 11 条评论的情感标注错误, 准确率为 97.25%。上述结果表明 ChatGPT已经可以直接辅助商家判断用户对商品的评价, 帮助商家更好地改进商品质量。如果将其应用到大规模客户满意度调研中, ChatGPT 的时效性优势与分析准确率将会更加凸显, 可以推动客户满意度调研的智能化建设。
5 提示策略调查
ChatGPT 是一个基于“无监督学习”的大语言模型, 对于自然语言处理任务, 特定的任务提示会触发 ChatGPT 对文本的不同理解力。受文献[35–36]启示, 本文试图通过 ChatGPT 来生成对情感分析任务的 3 个提示(图 2)。实验中发现, 不同的提示模板在任务中的表现存在差异, 因此需找出一种提示策略(本文只针对问答类提示和填空类提示), 使得ChatGPT 的判定结果较优。
问答类或填空类提示策略的选择都有可能对情感分析任务的判定结果产生影响。如表 7 所示, 我们设计两个提示策略, 对于问答类提示, 本文给出精确的情感极性; 对于填空类提示, 则让 ChatGPT填上它认为的情感, 通过对比 ChatGPT 在两种提示下情感分析任务的性能指标, 判定哪种提示策略对ChatGPT 实现情感分析任务更友好。
从表 7 可以看出, 问答类提示策略可以更清楚地填补问题的答案(例如情感分析中的积极、消极和中性), 只要提供足够的上下文信息, ChatGPT 就可能做出更准确的回答。问答类提示策略通常需要ChatGPT 对问题进行理解, 然后提取相关信息, 因此 ChatGPT 只需要从问题中获取足够的信息, 便可在回答问题时提供最相关的情感分析结果, 这种提示方式会使 ChatGPT 更注重文本中的关键信息。对于填空类提示策略, 则要求 ChatGPT 根据给定的文本和填空部分进行分析, 这种提示方式使 ChatGPT更注重上下文的理解以及对文本的整体情感的分析。在一些情况下, 填空类提示策略可能带来更加准确的情感分析结果, 因为在填空类提示策略下, ChatGPT 会更加关注文本的整体情感和上下文语境, 而不仅仅是某个特定的单词或短语。
表7 提示模板
Table 7 Prompt template

#积极样本#消极样本#中性样本提示策略提示模板 110110110问答类提示对于这个句子: “[文本]”所表达的情感是积极、消极或中性? 填空类提示对于这个句子: “[文本]”所表达的情感是: _____
图 3 的实验结果表明, ChatGPT 使用填空类提示的性能指标均优于问答类提示。可以看出, 填空类提示的 F1 分值比问答类提示提高 5.41%, 表明填空类提示能提高 ChatGPT 对文本的理解力, 而不仅仅是分析文本中某个带有情感极性的词语, 更适合将 ChatGPT 用于情感分析任务中。
6 结语
本文在 5 个情感、幽默与隐喻基准数据集上, 对 ChatGPT 的情感理解能力展开评估, 通过与领域内最前沿模型对比, 验证 ChatGPT 的优势与局限性。实验结果表明, ChatGPT 能够取得良好的情感识别结果, 获得 86.07%的情感识别准确率。此外, 本文也对比 ChatGPT 与人类在情感分析中的性能, 在情感、幽默和隐喻任务中的准确率比人类结果低 9.52%, 16.64%和 6.69%。因此, 尽管 ChatGPT 在对话生成方面获得最佳表现, 但是其在情感理解方面仍具有改进的潜力。最后, 本文尝试通过改善提示模板, 表明 ChatGPT 在情感理解场景下对填空提示策略的适应性更好。总而言之, 与情感分析模型和人类情感相比, ChatGPT 在性能上尚需要进一步改善, 但是在 80.61%的案例中获得可接受的结果, 时间效率明显提升, 在实时性情感分析场景下, 可以作为情感分析助手, 辅助人类展开情感判断。
本文结果表明, ChatGPT 在理解语言方面表现出色, 但它仅能理解人类语言的表层含义, 对语言背后的深层含义和真正意图的理解能力仍然有限。因此, ChatGPT 在处理复杂的语言任务(例如推理和隐喻理解等)时, 表现不如人类。此外, Chat-GPT 在训练时仅通过海量的文本数据来学习语言规律和模式, 而缺乏外部知识和常识的补充。因此, 当需要进行跨领域或跨知识库的任务时, ChatGPT可能缺乏相关领域的专业知识和常识, 导致模型输出的错误或不准确。
由于算力与成本限制, 本文仅针对大语言模型中最具代表性的 ChatGPT 展开调查, 忽略了其他已提出的大语言模型, 如 GPT-4, LLaMA 和 BLOOM等。此外, 本文提出 4 种情感测试场景, 忽略了其他类型的情感分析任务(如讽刺识别和欲望检测等)。对其他大语言模型展开全面的对比与评估, 对实现通用情感智能尤为必要, 也将是我们未来的研究方向。
参考文献
[1] Payal M. Unexpected surprise: emotion analysis and aspect based sentiment analysis (ABSA) of user ge-nerated comments to study behavioral intentions of tourists. Tourism Management Perspectives, 2023, 45: 101063
[2] Wang T, Roberts A, Hesslow D, et al. What language model architecture and pretraining objective works best for zero-shot generalization? // International Conference on Machine Learning. Baltimore, 2022: 22964–22984
[3] Tom B, Benjamin M, Nick R, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 2020, 33: 1877–1901
[4] Long Ouyang, Jeff W, Xu Jiang, et al. Training lan-guage models to follow instructions with human feed-back. Advances in Neural Information Processing Systems, 2022, 35: 27730–27744
[5] Cao Z, Wong K C, Lin C T. Weak human preference supervision for deep reinforcement learning. IEEE Transactions on Neural Networks and Learning Sys-tems, 2021, 32(12): 5369–5378
[6] Xu F F, Alon U, Neubig G, et al. A systematic eva-luation of large language models of code // Pro-ceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming. New York, 2022: 1–10
[7] Chen T, Allauzen C, Huang Y, et al. Large-scale language model rescoring on long-form data // 2023 IEEE International Conference on Acoustics. Rhodes Island, 2023: 1–5
[8] Taylor R, Kardas M, Cucurull G, et al. Galactica: a large language model for science [EB/OL]. (2022–11–16)[2023–05–30]. https://doi.org/10.48550/arXiv.2211. 09085
[9] Touvron H, Lavril T, Izacard G, et al. LLaMA: open and efficient foundation language models [EB/OL]. (2023–02–27) [2023–05–30]. https://doi.org/10.48550 /arXiv.2302.13971
[10] Wang Zengzhi, Xie Qiming, Ding Zixiang, et al. Is ChatGPT a good sentiment analyzer? A preliminary study [EB/OL]. (2023–04–10) [2023–05–30]. https:// doi.org/10.48550/arXiv.2304.04339
[11] Li Wenchang, Chen Yixing, John P L. Stars are all you need: a distantly supervised pyramid network for document-level end-to-end sentiment analysis [EB/ OL]. (2023–05–02)[2023–05–30]. https://doi.org/10.4 8550/arXiv.2305.01710
[12] Zhuo T Y, Huang Yuyin, Chen Chunyang, et al. Exp-loring AI ethics of ChatGPT: a diagnostic analysis [EB/OL]. (2023–05–29) [2023–05–30]. https://doi.org/ 10.48550/arXiv.2301.12867
[13] Jiao Wenxiang, Wang Wenxuan, Huang J, et al. Is ChatGPT a good translator? A preliminary study [EB/OL]. (2023–03–19) [2023–05–30]. https://doi.org/ 10.48550/arXiv.2301.08745
[14] Bang Yejin, Cahyawijaya S, Lee N, et al. A multitask, multilingual, multimodal evaluation of ChatGPT on reasoning, hallucination, and interactivity [EB/OL]. (2023–02–28)[2023–05–30]. https://doi.org/10.48550/ arXiv.2302.04023
[15] Liu Chang, Wang Jie, Liu Xuemeng, et al. Deep CM-CNN for spectrum sensing in cognitive radio. IEEE Journal on Selected Areas in Communications, 2019, 37(10): 2306–2321
[16] 李卫疆, 漆芳. 基于多通道双向长短期记忆网络的情感分析. 中文信息学报, 2019, 33(12): 119–128
[17] Jiang Q, Chen L, Xu R, et al. A challenge dataset and effective models for aspect-based sentiment analysis // Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, 2019: 6280–6285
[18] Mao Longbiao, Yan Yan, Xue Jinghao, et al. Deep multi-task multi-label CNN for effective facial attri-bute classification. IEEE Transactions on Affective Computing, 2020, 13(2): 818–828
[19] Wang Bingkun, Shan Donghong, Fan Aiwan, et al. A sentiment classification method of web social media based on multidimensional and multilevel modeling. IEEE Transactions on Industrial Informatics, 2022, 18(2): 1240–1249
[20] Liu Jian, Teng Zhiyang, Cui Leyang, et al. Solving aspect category sentiment analysis as a text generation task // Proceedings of the 2021 Conference on Empi-rical Methods in Natural Language Processing. Punta Cana, 2021: 4406–4416
[21] Li Yuncong, Yang Zhe, Yin Cunxiang, et al. A joint model for aspect-category sentiment analysis with shared sentiment prediction layer // China National Conference on Chinese Computational Linguistics. Hainan, 2020: 388–400
[22] Jia S, Cao J. The method for plausibility evaluation of knowledge triple based on QA // China Conference on Knowledge Graph and Semantic Computing. Singa-pore, 2022: 228–235
[23] 方澄, 李贝, 韩萍, 等. 基于语法依存图的中文微博细粒度情感分类. 计算机应用, 2023, 43(4): 1056–1061
[24] Amoroso F. Adaptive A/D converter to suppress CW interference in DSPN spread-spectrum communica-tions. IEEE Transactions on communications, 1983, 31(10): 1117–1123
[25] Yang Z, Dai Z, Yang Y, et al. XLNet: generalized autoregressive pretraining for language understanding. Advances in Neural Information Processing Systems, 2019, 32: 5754–5764
[26] Liu B. GCN-BERT and memory network based multi-label classification for event text of the Chinese government hotline. IEEE Access, 2022, 10: 109267–109276
[27] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521: 436–444
[28] 杨春霞, 姚思诚, 宋金剑. 一种融合字词信息的中文情感分析模型. 计算机工程与科学, 45(3): 512–519
[29] 方澄, 李贝, 韩萍. 基于全局特征图的半监督微博文本情感分类. 信号处理, 2021, 37(6): 1066–1074
[30] Khan S, Naseer M, Hayat M, et al. Transformers in vision: a survey. ACM Computing Surveys (CSUR), 2022, 54(10): 1–41
[31] 张声龙, 刘颖, 马艳军. SaGE: 基于句法感知图 卷积神经网络和ELECTRA的中文隐喻识别模型// 第二十届中国计算语言学大会. 呼和浩特, 2021: 667–677
[32] Deepa M D. Bidirectional encoder representations from transformers (BERT) language model for senti-ment analysis task. Turkish Journal of Computer and Mathematics Education, 2021, 12(7): 1708–1721
[33] Cao H, Wang Y, Chen J, et al. Swin-Unet: Unet-like pure transformer for medical image segmentation // European conference on computer vision. Cham, 2022: 205–218
[34] 赵一鸣, 潘沛, 毛进. 基于任务知识融合与文本数据增强的医学信息查询意图强度识别研究. 数据分析与知识发现, 2023, 7(2): 38–47
[35] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 2020, 33: 1877–1901
[36] Wei J, Wang Xuezhi, Schuurmans D, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 2022, 35: 24824–24837
Can ChatGPT Be Served as the Sentiment Expert? An Evaluation of ChatGPT on Sentiment and Metaphor Analysis
ZHANG Yazhou1,2, WANG Mengyao1, RONG Lu3, YU Yang1, ZHAO Dongming4, QIN Jing2,†
1. School of Software Engineering, Zhengzhou University of Light Industry, Zhengzhou 450002; 2. School of Nursing, The Hong Kong Polytechnic University, Hong Kong 999077; 3. Human Resources Office, Zhengzhou University of Light Industry, Zhengzhou 450002; 4. Artificial Intelligence Laboratory, China Mobile Communication Group Tianjin Co, Tianjin 300020; † Corresponding author, E-mail: harry.qin@polyu.edu.hk
Abstract To explore the potential for subjective understanding, the subjectivity and metaphorical nature of ChatGPT, this paper evaluates ChatGPT on five sentiment, humor, and metaphor benchmark datasets and discusses its strengths and limitations on different tasks by comparing it with the most cutting-edge models in the field. In addition, this paper also compares the performance of ChatGPT and humans in sentiment analysis, with gaps of 9.52%, 16.64% and 6.69% in human results on sentiment, humor and metaphor tasks. The results suggest that although ChatGPT achieves the best performance in dialogue generation, it still has potential for improvement in sentiment understanding. Finally, this paper investigates ChatGPT’s sensitivity to cueing templates in an emotion understanding scenario by improving the cueing templates.
Key words ChatGPT; sentiment analysis; humor detection; metaphor recognition