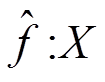
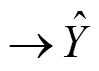 。
。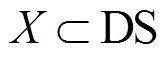 为训练数据,
为训练数据,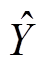 为模型
为模型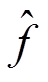 输出的预测值。设模型的参数为 θ, 参数空间为
输出的预测值。设模型的参数为 θ, 参数空间为 , 则模型训练过程的目标是获得
, 则模型训练过程的目标是获得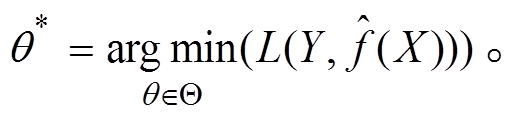 这里
这里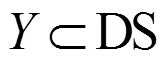 表示训练集中模型预测输出的真实标记,
表示训练集中模型预测输出的真实标记,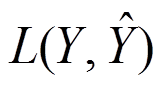 代表损失函数。
代表损失函数。北京大学学报(自然科学版) 第60卷 第1期 2024年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 60, No. 1 (Jan. 2024)
doi: 10.13209/j.0479-8023.2023.074
国家自然科学基金(62072156)资助
收稿日期: 2023–05–15;
修回日期: 2023–07–31
摘要 当前基于神经网络模型的查询建议研究往往单独采用查询日志会话中的查询序列作为训练数据, 但由于查询本身缺乏句法关系, 甚至缺失语义, 导致神经网络模型不能充分挖掘和推理查询序列中各种词或概念之间语义关系。针对这一问题, 提出一种基于交叉注意力多源数据增强(MDACA)的 Transformer 模型框架, 用于生成情境感知的查询建议。采用基于 Transformer 的编码器-解码器模型, 利用交叉注意力机制, 融合了查询层、文档语义层以及全局查询建议信息。实验结果表明, 与目前方法相比, 该方法能生成具有更高相关性的情境感知查询建议。
关键词 查询建议; 数据增强; 交叉注意力; 情境感知; Transformer模型
搜索引擎的查询建议(query suggestion)[1–7]能够自动帮助用户准确、便捷地构造查询词, 可以显著地提升用户的搜索体验。同时, 改善查询建议功能也是增强搜索引擎在个性化和智能化等方面性能的重要途径。近年来, 随着深度神经网络技术的兴起, 在自然语言处理(natural language processing, NLP)领域, 研究如何利用深度神经网络强大的表示学习(representation learning)能力来提升各类任务的性能, 已经成为当前的研究热点[1,8–10]。基于神经网络模型的查询建议方法[1,11–17]能够有效地解决传统查询建议存在的诸如模型特征表达能力差、数据稀疏性等问题, 生成具有更高相关性和覆盖度的查询建议, 已成为当前查询建议研究的主流方法。
这些方法目前存在的一个问题是: 在训练过程中大多单独将查询日志会话中的查询序列作为训练数据, 由于查询是用户从一个句法和语义完整的句子中提取出若干关键词构造而成, 使得查询本身缺乏句法关系, 甚至缺失语义。这种缺陷为擅长从大量具有丰富句法关系的完整句子中挖掘和推理各种词(或概念)之间语义关系的序列编码神经网络(如循环神经网络(recurrent neural network, RNN)以及Transformer模型等)设置了极大的障碍。
受计算机视觉(computer vision, CV)和 NLP 领域中数据增强(data augmentation)方法[18–20]的启发, 本文提出一个基于交叉注意力多源数据增强(multi-source data augmentation through cross-attention,MDACA)的Transformer模型框架, 用于生成情境感知的查询建议。该方法的主要思想是, 使用以下 3种数据源进行模型的训练。
1)使用原始查询日志会话中的查询序列作为训练数据。该数据包含查询情境(当前查询的历史), 因此模型预测的下一个查询具有个性化和局部 特性。
2)使用传统查询建议中的邻接模型(adjacency, ADJ), 生成当前查询的 top-k (前 k 个)查询建议作为训练数据。这种数据的生成基于整个查询日志会话的统计信息, 生成的训练数据只与当前查询有关, 而与查询情境无关, 因此模型预测的下一个查询具有全局特性。
3)使用搜索引擎生成当前查询的相关文档, 作为训练数据。这种数据对当前查询进行扩充, 将查询替换为语义相对完整的句子。模型可以利用这种数据生成当前查询与其相关文档之间的神经注意力向量, 从而捕获当前查询中的查询词与其相关文档中的词之间的语义关系。通过采用数据增强方法, 模型融合了查询层、文档语义层以及全局查询建议层等多个层次的信息, 与先前的研究方法相比, 能生成具有更高相关性的情境感知查询建议。
早期的查询建议研究主要依赖查询日志分析, 利用查询日志生成查询点击图, 然后使用各种基于图挖掘的技术来生成查询建议[2–4], 或者利用查询日志会话中查询之间的相邻和共现关系来获取与原查询相关的候选查询[7]。这类方法能够生成高相关性的查询建议, 但存在数据稀疏性问题, 即对一些未在查询日志中出现的查询或具有长尾效应的稀少查询[5], 往往不能给出有效的查询建议, 导致生成的查询建议覆盖度较低。还有一些研究利用外部文本语料库[5], 通过挖掘语料库中词与词之间的语义关系, 由原查询合成新的查询, 然后将其作为候选查询建议。这类方法不依赖查询日志, 具有较高的覆盖度, 但查询建议的相关性较低。造成传统查询建议研究存在诸多问题的一个原因是, 在生成训练数据时, 主要根据领域的先验知识, 通过特征工程(feature engineering), 使用手工方式来定义数据的特征, 因此常常忽略数据中一些隐藏的重要特征, 从而无法有效地捕捉底层数据中潜在的关系。
随着深度神经网络模型在 CV 和 NLP 等领域的不断发展, 当前查询建议研究主要集中在基于神经网络模型的方法[1,11–17], 其目标是利用各种神经网络模型和大规模数据集来提升搜索引擎查询建议系统的性能。根据采用的神经网络结构不同, 可以分为如下两种方式。1)基于 RNN 和注意力机制(at-tention mechanism)的方法[1,11–14]。如 Sordoni 等[1]提出一种层次循环 encoder-decoder 神经网络模型, 其encoder 和 decoder 均采用 RNN 结构, 利用模型的层次结构捕捉不同层面的查询语义信息, 用于生成情境感知查询建议。Dehghani 等[11]在单层 RNN 模型的基础上, 采用注意力机制[9]为查询中的查询词分配不同的权重。2)基于 Transformer 模型以及预训练语言模型(pre-trained language model, PLM)的方 法[15–17]。Transformer 模型是由 Vaswani 等[10]提出的一种最早用于神经翻译任务的神经网络模型, 目前已成为 NLP 应用领域的顶级模型之一。与 RNN模型相比, Transformer 模型引入一些新概念, 如多头自注意力机制和位置编码等, 使得 Transformer 模型具有并行化处理文本的能力, 极大地提高了特征学习能力。Han 等[15]提出一个基于图增强的序列到关注模型, 编码器端在层次 RNN 模型的基础上, 合并句子层图卷积网络和关键字层图卷积网络, 用于编码查询序列; 解码器端则采用 Transformer 模型, 用于解码多个编码器的输出。PLM 模型是在 Trans-former 模型的基础上进一步发展而来, 目前在 NLP领域已占据主导地位。Yu 等[17]提出一个小样本生成方法, 用于对话检索查询重写。该方法采用微调的 GPT-2 模型, 能有效地捕捉对话的上下文信息。
如何解决查询建议的个性化和多样化[6]等问题, 是当前查询建议研究的重要研究方向。情境感知(context-aware)的查询建议[1,4,7]使用查询情境(query context), 即在当前会话中, 将用户先前输入的查询序列作为后续查询的线索和依据, 其目标是生成个性化的具有较高相关性的查询建议。
数据增强[18–20]最早应用于 CV 领域。其基本思想是, 对有标记数据集中一定数量的图片进行诸如平移、缩放和旋转等几何变换, 由于图像本身的语义保持不变, 因此通过这种操作能够有效地增加训练数据的数量。通过数据增强, 能降低数据集中正负样本不平衡的比例, 增加训练数据的多样性, 进而提高模型的鲁棒性和泛化能力。Chen 等[18]提出一个结构简单的对比自监督学习算法 SimCLR, 先对数据集进行数据增强, 然后采用卷积神经网络对数据进行编码。同时, 采用对比目标损失函数, 使得正样本数据对之间的距离尽可能小, 负样本数据对之间的距离尽可能大。实验结果表明, 该方法超过了之前在 ImageNet 上基于自监督学习和半监督学习的方法。数据增强方法在 CV 领域得到广泛使用后, 又延伸到 NLP 领域。由于 NLP 领域数据具有离散性, 因此其应用方法与 CV 领域有所不同, 大致可以分为: 基于复述(praphrasing)、基于噪声(noising)以及基于采样(sampling)三类[19]。Abas-kohi 等[20]提出一个基于复述指导的数据增强方法LM-CPPF, 用于对大语言模型进行基于对比提示的小样本微调, 实验结果表明该方法在多个文本分类基准上均超过现有的方法。
本研究提出的基于交叉注意力多源数据增强(MDACA)的情境感知查询建议方法的问题描述 如下。
1)使用(q1, q2, …, qk, qk+1)表示查询日志中, 某个用户ui在给定的时间间隔(如 30 分钟)内向搜索引擎发出的查询序列。qk 为当前查询, 即当前用户正在发出的查询; qk+1 为目标查询, 为模型预测用户可能发出的下一个查询的真实标记; (q1, q2, …, qk–1)为 qk 的查询情境, 即当前查询qk的历史查询序列。
2)定义 Dk为给定一个用户查询 qk, 在搜索引擎返回的查询结果中, 与 qi 最相关的文档。训练数据集 DS={(q1, q2, …, qk, qk+1), Dk}, 模型输入为(q1, q2, …, qk)和 Dk, 模型预测输出的真实标记为 qk+1。
3) MDACA 模型的训练过程可定义为映射。为训练数据,为模型输出的预测值。设模型的参数为 θ, 参数空间为, 则模型训练过程的目标是获得这里表示训练集中模型预测输出的真实标记,代表损失函数。
图 1 描述 MDACA 查询建议模型的总体架构, 主要包含 4 个部分。
1)查询层编码器。首先将训练集中的查询序列(q1, q2, …, qk)表示为词嵌入向量, 然后使用Transformer编码器对其进行编码, 得到查询层编码向量。
2)ADJ 查询建议编码器。使用 ADJ 查询建议算法生成当前查询 qk 对应的查询建议序列(本文取top-5 候选查询建议), 然后使用 Transformer 编码器对其进行编码, 得到 ADJ 全局查询建议编码向量。
3)文档层编码器。通过搜索引擎得到查询序列(q1, q2, …, qk)中当前查询 qk 的相关文档 Dk, 然后使用 Transformer 编码器对其进行编码, 得到文档层编码向量。
4)查询解码器。将训练集中的目标查询 qk+1 表示为词嵌入向量, 将其与在步骤 1~3 得到的不同层次的查询编码向量一起, 输入 Transformer 解码器中。使用交叉注意力机制, 得到解码器输出向量, 然后对其做进一步的线性变换和 Softmax 变换, 最后得到模型的预测表示输出。
查询层编码器使用 Transformer 架构。本文中Transformer 编码器的输入由多个查询组成(q1, q2, …, qk), 每个查询使用符号
Transformer编码器第i层处理过程表示如下。
1)句子嵌入式表示。将原始的句子转换为词向量:
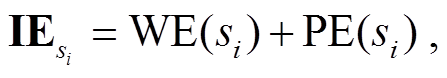 (1)
(1)
式中, si={w1, w2, …, wn}; 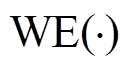 表示句子的词嵌入映射函数, 用于将句子si转换为词嵌入表示;
表示句子的词嵌入映射函数, 用于将句子si转换为词嵌入表示; 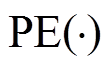 为位置编码函数[10], 用于编码句子 si 中每个词之间的顺序关系。
为位置编码函数[10], 用于编码句子 si 中每个词之间的顺序关系。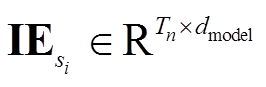 , 其中 Tn 为句子 si 中词的个数, dmodel 为句子嵌入的维度。
, 其中 Tn 为句子 si 中词的个数, dmodel 为句子嵌入的维度。
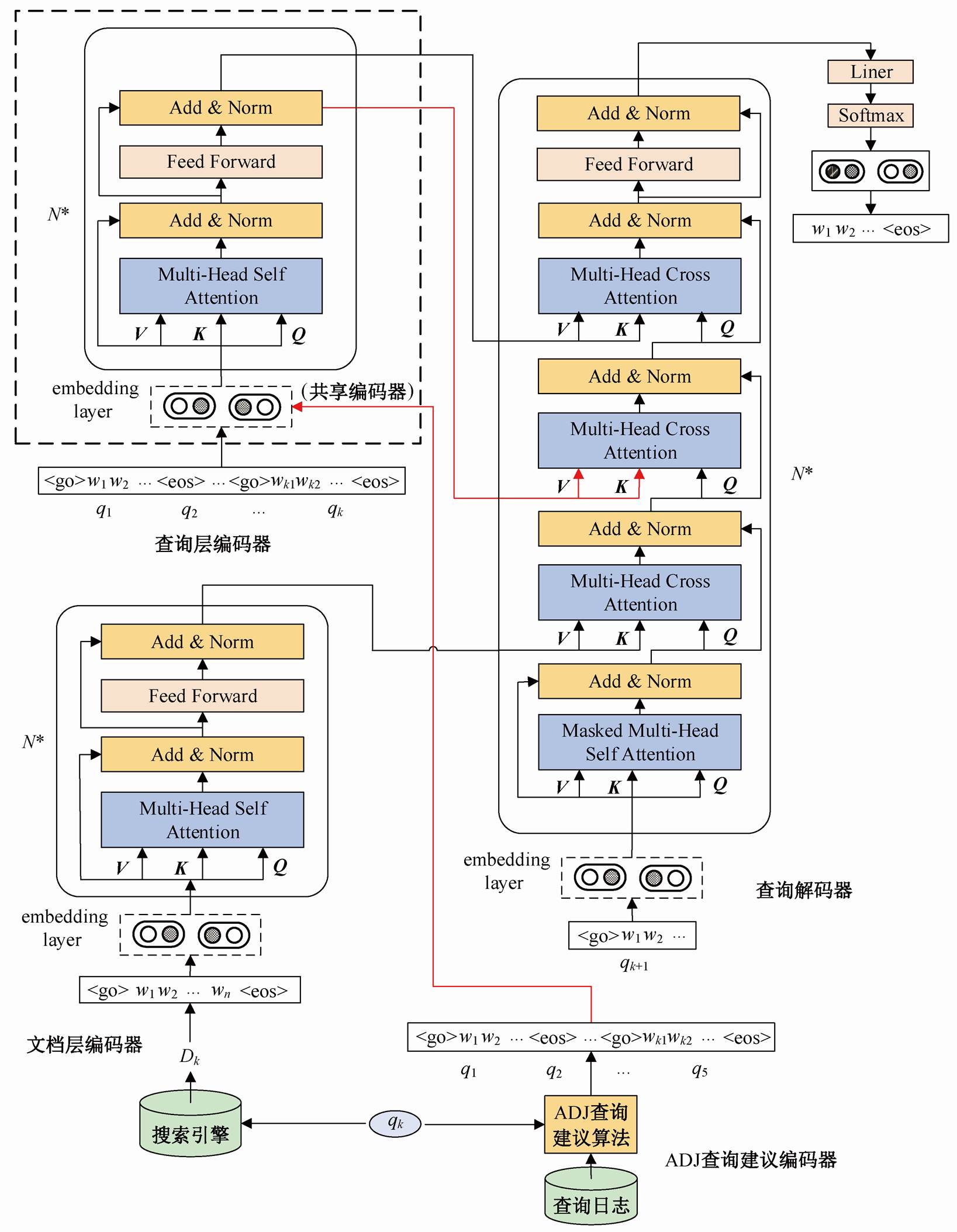
ADJ查询建议编码器和查询层编码器共享同一个Transformer编码器。红色箭头表示ADJ查询建议编码器流经相关模块的路径, 黑色箭头表示查询层编码器流经相关模块的路径
图1 基于交叉注意力多源数据增强的情境感知查询建议模型架构
Fig. 1 Architecture for the proposed MDACA based context-aware query suggestion model
2)多头自注意力机制:
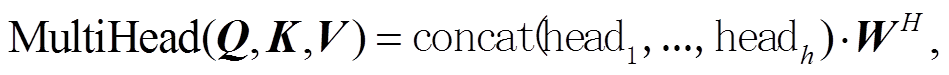 (2)
(2)
其中, Q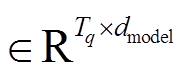 和 K=V
和 K=V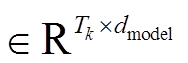 是由式(1)计算得到的句子嵌入表示; h 为头的个数;
是由式(1)计算得到的句子嵌入表示; h 为头的个数;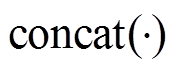 表示多头注意力的连接;
表示多头注意力的连接;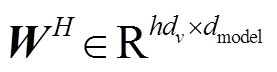 ; MultiHead(Q, K, V); headi 为第 i 个多头注意力:
; MultiHead(Q, K, V); headi 为第 i 个多头注意力:
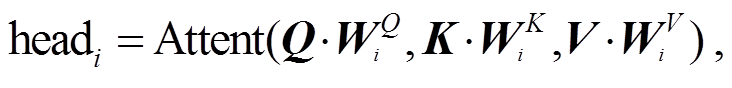 (3)
(3)
其中, 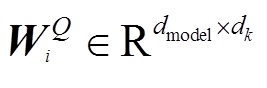 ,
, 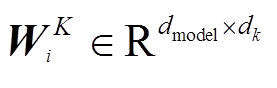 ,
, 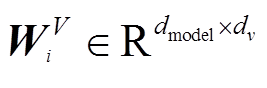 ,
,  ,
,
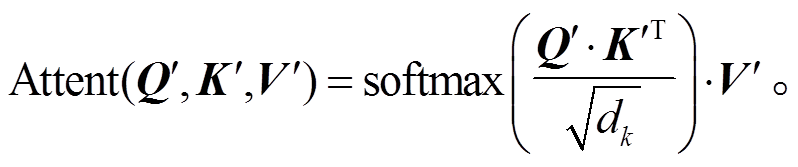 (4)
(4)
式(4)通常被称为缩放点积注意力(scaled dotproduct attention), 为式(3)的具体实现。其中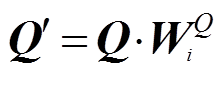 ,
, 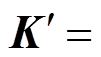
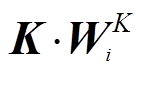 ,
, 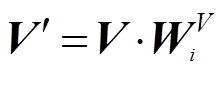 。
。
Transformer 编码器第 i 层的输出 TEout 表示为
 (5)
(5)
其中, MultiHead(·)为式(2)给出的多头自注意力; LN(·)表示层规范化, 对应图 1 中的 Add & Norm 层, 其作用主要是引入残差连接: 先将 Multi-Head Self-Attention 层的输入信息与输出相加, 之后再做规范化处理; 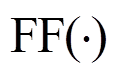 表示前馈处理, 使用全连接层对数据做进一步变换, 对应图 1 中的 Feed Forward 层。
表示前馈处理, 使用全连接层对数据做进一步变换, 对应图 1 中的 Feed Forward 层。
Transformer 编码器多层堆叠处理的方式是将第 i 层的输出作为第 i+1层的输入, 然后进行迭代处理。
ADJ 查询建议编码器首先使用ADJ查询建议算法[1,4,7]生成基于全局统计的查询建议。其算法的主要思想为, 任意给定一个查询会话(q1, q2…, qk), 统计在整个查询日志中直接跟随在查询qk之后出现的查询及其频度, 并按频度从大到小排序, 最后返回top-k 查询, 作为候选查询建议序列。可以看出, ADJ是一种非情境感知的方法, 即算法给出的查询建议只与 qk有关, 而与 qk之前输入的查询无关。并且, 该统计基于整个查询日志, 因此具有全局统计的意义。本文使用 top-5 查询作为候选查询建议序列。
生成候选查询建议序列后, ADJ 查询建议编码器与查询层编码器共享同一个 Transformer 编码器, 对候选查询建议序列进行编码。因此其处理过程与查询层编码器相同。
文档层编码器的主要作用是获取当前查询 qk与其相关文档Dk之间的神经注意力向量, 该向量最终被输入解码器中, 用于查询建议的生成。
与查询层编码器和ADJ查询建议编码器的输入不同, 文档层编码器的输入 Dk 是由语义相对完整的句子组成, 本文中最大长度限制为 50 个词。与查询序列相比, Transformer 模型更适合处理像 Dk 这样句法关系和语义相对完整的句子, 更容易挖掘出当前查询 qk 与其相关文档 Dk 中各种词(或概念)之间语义关系。
除输入的差异外, 文档层编码器的处理过程与查询层编码器和 ADJ 查询建议编码器完全相同。
查询解码器使用 Transformer 模型, 其结构与查询层编码器基本上相同, 主要区别在于 Transformer解码器多了 3 层 Multi-Head Cross-Attention, 其主要作用是将前面生成的查询层编码向量、ADJ 全局查询建议编码向量和文档层编码向量的输出(图 1 中查询解码器中的 K 和 V)与 Transformer 解码器的Masked Multi-Head Self-Attention 层输出(图 1 中查询解码器中的 Q)逐级进行多头交叉注意力(Multi-Head Cross-Attention)进行计算, 建立输入查询序列与预测查询中词与词之间的关联。
对 Transformer 查询解码器的输出 Odec 进行如下变换:
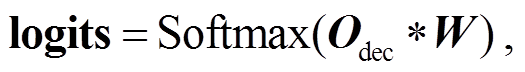 (6)
(6)
式(6)中, 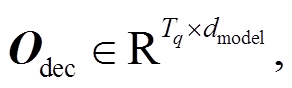
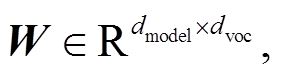 因此
因此![]()
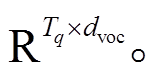 Tq 表示预测查询中词的最大个数, dvoc 表示词汇表的长度, logits 表示模型最终的预测输出。
Tq 表示预测查询中词的最大个数, dvoc 表示词汇表的长度, logits 表示模型最终的预测输出。
本文采用当前可公开使用的 AOL 搜索引擎查询日志作为训练和测试数据集, 该日志包含 2006 年3 月 1 日至 2006 年 5 月 31 日的用户查询数据。遵循Sordoni 等[1]的做法, 使用前对该查询日志进行预处理, 然后将其划分为如下 4 个数据集: 1)背景数据集 BackgroudSet, 包含 1872172 个会话, 主要用于生成 ADJ 查询建议; 2)训练数据集 TrainSet, 共包含 566136 个会话, 主要用于查询建议模型的训练, 包括本文提出的模型和用于对比的基线模型; 3)校验数据集 ValidSet, 包含 184315 个会话, 用于校验模型的性能; 4)测试数据集 TestSet, 包含 287671 个会话, 用于测试查询建议模型的性能。
对于查询 qi 对应的相关文档 Di 的生成, 本文采用如下离线方式: 1)如果查询日志中存在查询 qi 对应的点击 url, 且能下载, 则抽取该文档作为 Di; 2)构建两个基于本地的搜索引擎系统, 其中一个索引了 2005782 个英文页面集, 另一个为基于 Wikipedia的检索系统(下载最新的 Wikipedia 离线文档①https://dumps.wikimedia.org/enwiki/latest/, 并索引了文档中文章的标题、文本和类别)。对于不存在于查询日志中的文档, 则利用这两个搜索引擎系统, 生成查询相关文档 Di。
本文提出的 MDACA 查询建议模型的基本结构属于 Transformer 模型。针对现有基于深度神经网络的查询建议研究以及主要采用的两种神经网络模型(RNN 和 Transformer), 设计如下 3 种基线模型, 用来与本文方法进行对比实验。
HRED: Sordoni 等[1]提出的一种层次循环 encoder- decoder 神经网络模型, 其 encoder 以及 decoder 均采用 RNN 结构, 为经典的基于 RNN 结构的查询建 议模型。
HRED+Att: 在 HRED 模型的基础上, 为探究注意力机制[9]在提升查询建议模型性能方面的作用而实现的一个基于 encoder-decoder 架构的模型。
Transformer: 本文在基本 Transformer 模型[10]的基础上实现的一个基于 encoder-decoder架构的查询建议模型, 该模型单纯使用Transformer编码器和解码器用于查询建议的生成, 主要用于考察 Trans-former 模型在查询建议生成方面的性能。
传统的查询建议研究主要采用基于自动评价方式的查询建议覆盖度(Coverage)和基于人工评价方式的查询建议质量(Quality)等评价方法[4,7]。基于深度神经网络查询建议模型对几乎所有的查询序列都能输出预测查询, 因此采用覆盖度指标没有意义。本文对各种模型的实验性能对比均采用自动评价方法, 主要从相关性(relevance)方面评价查询建议模型的性能。本文采用 BLEU 指标[21], 该指标度量模型生成的句子与真实句子之间的 N-gram 词覆盖度, 是一种相关性指标。常用的 BLEU 指标有 BLEU-1~BLEU-4。指标的数值越大, 表示模型生成的句子越接近真实句子。
3.3.1相关性实验结果
3 种基线模型 HRED, HRED+Att 和 Transfor-mer 尽量采用原始文献提供的参数。同时为了减少不同测试数据可能对模型生成查询建议性能产生的影响, 我们在 TestSet 数据集上分别随机抽取 5 组测试数据, 每组包含 1000 个测试数据, 进行查询建议生成的相关性实验, 最后取测试结果的平均值。实验结果如表 1 所示。
BLEU-1 类似一个 1 元词袋, 仅度量生成的句子与目标句子中包含的 1 元词在词袋上的覆盖度。BLEU-2~BLEU-4 体现不同程度词的顺序关系。与一般的句子相比, 查询由若干关键词组成, 本身缺乏句法关系。在语义上, 查询中词的顺序关系在很多情况下也变得不再重要。如查询“free cards online”和“online free cards”在查询语义上区别不大。因此, 与度量一般句子的 BLEU 指标有所不同, 对查询建议生成任务来说, 与 BLEU-3 和 BLEU-4相比, 使用 BLEU-1 和 BLEU-2 具有更好的相关性评价意义。
从表 1 可以看到, 本文提出的 MDACA 模型在BLEU-1~BLEU-3 指标上均超过其他 3 种模型。MDACA 的 BLEU-1 指标达到 40.175%, HRED+Att模型达到 34.657%, 而 HRED 模型仅取得 34.193%, Transformer 模型分值最低, 仅为 32.540%。根据 4种模型采用的 encoder 和 decoder 结构的不同, 可将它们分成两类: 1)采用层次 RNN 模型的 HRED 和HRED+Att; 2)采用Transformer模型的 Transformer和 MDACA。从表 1 中的数据可以得到如下结论。
1)如果单纯使用 Transformer 模型, 其性能低于层次 RNN 模型。其原因可能是, 层次 RNN 模型可以很好地提取查询序列中底层查询和高层会话的语义关系, 而 Transformer 模型是一种扁平结构, 其采用的多头自注意力机制、位置编码等技术本来能够很好地捕获句子中词之间的语义关系, 在查询建议的应用场景下, 用户查询往往较短, 查询本身缺乏句法关系, 查询中词的顺序关系不明显等, 这些特点抑制了 Transformer 模型优势的发挥。
表1 各种模型生成查询建议的相关性对比实验结果(%)
Table 1 Comparison of relevance experimental results for query suggestions generated by various models (%)

模型BLEU-1BLEU-2BLEU-3BLEU-4 HRED[1]34.19310.48010.4298.352 HRED+Att34.65712.0179.9219.284 Transformer32.5408.5859.7987.695 MDACA (本文方法)40.17516.95714.8477.408
注: 粗体数字表示性能最优, 下同。
2)使用注意力机制可以在一定程度上提高层次 RNN 模型的性能。如在 BLEU-1 和 BLEU-2 指标上, HRED+Att 模型比 HRED 模型提高约 1.36%和14.67%。
3)MDACA 模型可以较大幅度地提高模型的性能。如在 BLEU-1 和 BLEU-2 指标上, MDACA 模型比 HRED+Att 模型分别提高约 15.92%和 41.11%, 比 Transformer 分别提高约 23.46%和 97.52%, 充分证明了 MDACA 模型在提高查询建议相关性方面的有效性。
3.3.2消融研究
为了进一步评估本文提出的 MDACA 模型中各个组件对模型性能的影响, 本文进行相应的消融实验, 结果如表 2 所示。
表 2 中 MDACA 为原始方法, MDACA Without ADJ 为 MDACA 模型去除 ADJ 查询建议编码器后的方法; MDACA Without Transformer Shared 为 MDA-CA 模型中 ADJ 查询建议编码器与查询层编码器不共享 Transformer 编码器的方法; MDACA Without Document 为 MDACA 模型去除文档层编码器后得到的方法。
从表 2 可以看到, 去除各相应组件后, 与原始模型相比, 各个模型的 BLEU-1 和 BLEU-2 指标均出现一定程度的下降。MDACA Without Document的性能下降较多, 分别为 9.49%和 18.78%。MD-ACA Without ADJ 分别下降约 5.80%和 12.05%, MDACA Without Transformer Shared 分别下降约3.83%和 7.82%。实验结果表明, 文档层编码器对MDACA 模型性能的影响最大, 采用 ADJ 查询建议编码器和 Transformer 共享编码器均能不同程度地提高模型的性能。同时, 也验证了本文提出的采用多源数据融合方法对原始查询日志查询进行数据增强的有效性。
表2 消融实验结果(%)
Table 2 Ablation study for the proposed MDACA model (%)

模型BLEU-1 BLEU-2 MDACA (本文方法)40.17516.957 MDACA Without ADJ37.84314.913 MDACA Without Transformer Shared38.63615.631 MDACA Without Document36.36213.772
3.3.3案例研究
表 3 列出使用 5 种模型生成的 8 个查询建议实例。其中, 查询序列的查询情境长度分别为 0~2。这里定义 n-context 为查询情境长度为 n 的 Session, 即当前查询 qk 前有 n=k–1 个查询, 加上目标查询qk+1, 整个 Session 的长度为 k+1。例如, 0-context Session 的长度为 2, 其余依此类推。因此, #1~#3 查询序列为 0-context 类型的 Session。从表 3 可以看出, ADJ 模型对两组测试查询序列不能生成预测查询。原因是传统的基于统计方法的查询建议模型存在数据稀疏性的问题, 很难做到高的覆盖度。基于神经网络的模型对所有的查询序列都产生了有意义的输出。
从表 3 可以发现, 与其他几种模型相比, 针对一些查询, 本文提出的 MDACA 模型可以给出粒度更细、含义更丰富的查询建议。例如对于#2 查询序列“frontier airlines com”, 不仅建议了同类型的一些航空公司, 并且给出一个提供廉价航班机票的网站“www cheapseats”。对于#3 查询序列“aol brow-ser”, 该模型建议了同类型的internet browser”, 同时推荐“aol update”和“aol antivirus”。对于#4 查询序列, MDACA 模型除给出查询建议“baseball bats”和“baseball shop”外, 还推荐著名的体育频道“espn baseball”, 另外, 还给出与“baseball bats”密切相关的美国球类运动服饰零售店“dickssportinggoods”。该模型还能做一定程度的语义联想和推理。例如对#5 查询序列, 模型通过对当前查询“enterprise”之前的查询“toyota”进行分析, 给出“toyota financial”的建议, 说明模型联想到“toyota”作为一个企业应该存在“财务”方面的业务。
本文提出一种基于交叉注意力多源数据增强(MDACA)的情境感知查询建议模型。该模型除使用查询日志会话数据外, 还采用数据增强方法, 使用搜索引擎获取查询相关文档, 对当前查询进行扩展; 使用 ADJ 模型, 根据查询日志会话的全局统计信息, 生成当前查询的若干相关查询建议作为训练数据, 并采用Transformer模型作为编码器和解码器。与目前多个代表性研究方法相比, 本文模型能够生成相关性更高的情境感知查询建议。
表3 各类模型生成的查询建议示例
Table 3 Samples of query suggestion generated by various models

序号查询情境+当前查询不同模型生成的查询建议ADJHREDHRED+AttTransformerMDACA (本文方法) #1verizoncomverizoncomverizon wirelessvz pix comverizon wirelessverizon wireless verizonwirelesscomverizon phone serviceverizon wireless comverizon phoneverizon ringtones verizon wirelessverizon home phonewww vz pix comsingular wirelessverizoncom billing wwwverizoncomverizon central comhow to get verizon telephone numberaol phoneverizoncom pay #2frontier airlines comfrontier airlines comfrontier airlines comfrontier airlines comfrontier airlinesfrontier airlines frontier airlinesamerica west airlinestravelocity comnorthwest airlinesunited airlines unitedairlinescomunited airlinessouthwest airlinesdelta airlinessouthwest airlines southwestairlinescomsouthwest airlinescheap airline ticketsalaska airlineswww cheapseats #3aol browseraol browseraol media playerdownload aol toolbarinternet exploreraol browser aol cookesaol browseraol browseraol browseraol update googleaol live helpsecurity question on aolaol explorerinternet browser setupwindows media playerclear browseraol upgradeaol antivirus #4baseball→baseball batsbaseball batsbaseball batsbaseball fieldbaseball scoresbaseball bats training aids for baseballbaseball glassesespn baseballbaseball batsbaseball shop batting glovesbaseball warehouse comfederal baseball batssports authorityespn baseball animated batsbaseball tools comsuper baseballbaseball shoeswww dickssportinggoods #5toyota→enterpriseenterprisenational car rentalbudget and carscar rentalauto trade hertzenterprise car rentalcar rentalsavis cartoyota financial budgetcar rental ratesrentals and jacksonville floridaavis rentalcar insurance alamobudget car rentalused carsenterprise rentalcar rentals #6map of united states and canada →nigra falls informationmap of australianigra falls canadaus mapcanada map maps of nigra fallsmap of nigra fallsunited airlinesnigra falls united states mapwhere can
如何将本文提出的 MDACA 模型与预训练语言模型(如 BERT 和 GPT 等)相结合, 进一步提升情境感知查询建议系统的性能, 是未来的工作重点。
参考文献
[1] Sordoni A, Bengio Y, Vahabi H, et al. A hierarchi- cal recurrent encoder-decoder for generative context-aware query suggestion // Proceedings of CIKM. Mel-bourne, 2015: 553–562
[2] Song Y, Zhou D, He L. Query suggestion by constructing term-transition graphs // Proceedings of WSDM. New York, 2012: 353–362
[3] Mei Q, Zhou D, Church K. Query suggestion using hitting time // Proceedings of CIKM. Napa, 2008: 469–478
[4] Cao H, Jiang D, Pei J, et al. Context-aware query suggestion by mining click-through and session data // Proceedings of KDD. Las Vegas, 2008: 875–883
[5] Jain A, Ozertem U, Velipasaoglu E. Synthesizing high utility suggestions for rare web search queries // Pro-ceedings of SIGIR. Beijing, 2011: 805–814
[6] Hu H, Zhang M, He Z, et al. Diversifying query sug-gestions by using topics from Wikipedia // Proceedings of Web Intelligence. Atlanta, 2013: 139–146
[7] He Q, Jiang D, Liao Z, et al. Web query recommen-dation via sequential query prediction // Proceedings of ICDE. Shanghai, 2009: 1443–1454
[8] Cho K, Merrienboer B, Gülçehre Ç, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation // Proceedings of EMNLP. Doha, 2014: 1724–1734
[9] Bahdanau D, Cho K, Bengio Y. Neural machine trans-lation by jointly learning to align and translate // Proceedings of ICLR. San Diego, 2015: 1–15
[10] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // Proceedings of NIPS. Long Beach, 2017: 5998–6008
[11] Dehghani M, Rothe S, Alfonseca E, et al. Learning to attend, copy, and generate for session-based query suggestion // Proceedings of CIKM. Singapore, 2017: 1747–1756
[12] Wu B, Xiong C, Sun M, et al. Query suggestion with feedback memory network // Proceedings of WWW. Lyon, 2018: 1563–1571
[13] Ahmad W, Chang, K Wang H. Multi-task learning for document ranking and query suggestion // Proceedings of ICLR. Vancouver, 2018: 1–14
[14] Ahmad W, Chang K, Wang H. Context attentive do-cument ranking and query suggestion // Proceedings of SIGIR. Paris, 2019: 385–394
[15] Han F, Niu D, Lai K, et al. Inferring search queries from web documents via a graph-augmented sequence to attention network // Proceedings of WWW. San Francisco, 2019: 2792–2798
[16] Mustar A, Lamprier S, Piwowarski B. On the study of transformers for query suggestion. ACM Transactions on Information Systems. 2022,40(1): 18:1–18:27
[17] Yu S, Liu J, Yang J, et al. Few-shot generative con-versational query rewriting // Proceedings of SIGIR. Online Meeting, 2020: 1933–1936
[18] Chen T, Kornblith S, Norouzi M, et al. A Simple framework for contrastive learning of visual repre-sentations // Proceedings of ICML. Online Meeting, 2020: 1597–1607
[19] Li B, Hou Y, Che W. Data augmentation approaches in natural language processing: a survey. AI Open, 2022, 3(1): 71–90
[20] Abaskohi A, Rothe S, Yaghoobzadeh Y. LM-CPPF: paraphrasing-guided data augmentation for contrastive prompt-based few-shot fine-tuning // Proceedings of ACL. Toronto, 2023: 670–681
[21] Papineni K, Roukos S, Ward T, et al. BLEU: a method for automatic evaluation of machine translation // Pro-ceedings of ACL. Philadelphia, 2002: 311–318
A Context-Aware Query Suggestion Method Based on Multi-source Data Augmentation through Cross-Attention
Abstract Most existing neural network-based approaches for query suggestion use solely query sequences in query logs as training data. However, these methods cannot fully mine and infer all kinds of semantic relationships among words or concepts from query sequences because queries in query sequences inherently suffer from a lack of syntactic relation, even a loss of semantics. To solve this problem, this paper proposes a new neural network model based on multi-source data augmentation through cross-attention (MDACA) for generating context-aware query suggestions. Proposed model adopts a Transformer-based encoder-decoder model that incorporates document-level semantics and global query suggestions into query-level information through cross-attention. The experimental results show that in contrast to the current suggestion models, the proposed model can generate context-aware query suggestions with higher relevance.
Key words query suggestion; data augmentation; cross-attention; context-aware; Transformer model