表1 直接消减方法在VQA-CP v2.0数据集上的去偏效果
Table 1 Debias effect on VQA-CP v2.0 dataset using subtracting strategy

基准模型方法准确率/% UpdnpVQA39.80 pVQA– pQA51.49
北京大学学报(自然科学版) 第60卷 第1期 2024年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 60, No. 1 (Jan. 2024)
doi: 10.13209/j.0479-8023.2023.072
收稿日期: 2023–05–18;
修回日期: 2023–09–26
摘要 为了增强视觉问答模型的鲁棒性, 提出一种偏见消减方法, 并在此基础上探究语言与视觉信息对偏见的影响。进一步地, 构造两个偏见学习分支来分别捕获语言偏见以及语言和图片共同导致的偏见, 利用偏见消减方法, 得到鲁棒性更强的预测结果。最后, 依据标准视觉问答与偏见分支之间的预测概率差异, 对样本进行动态赋权, 使模型针对不同偏见程度的样本动态地调节学习程度。在 VQA-CP v2.0 等数据集上的实验结果证明了所提方法的有效性, 缓解了偏见对模型的影响。
关键词 视觉问答; 数据集偏差; 语言偏见; 深度学习
视觉问答(visual question answering, VQA)[1]是一项结合计算机视觉与自然语言处理的多模态任务,其目标是根据图片来回答问题。近年来, VQA 相关研究取得长足的进展。现有的视觉问答任务常用评测数据集(如 VQA v2.0[2])中, 训练集和测试集的分布是相近的, 当模型较好地拟合此类数据的训练集时, 更容易表现出优越的测试性能。然而, 真实场景中的数据集往往呈现不均衡的类别分布, 且难以避免长尾分布问题。因此, 当训练集与测试集存在较大的分布差异(甚至完全相反)时, 数据中的分布偏差常常使模型表现出较差的泛化能力。
常用的 VQA 数据集存在相同类别问题下答案分布不均衡的现象。例如, 在当前评测视觉问答任务的主流数据集 VQA v2.0 中, 以“How many”开头的问题, 大约 70%的答案为“2”; 以“What sport”开头的问题, 以“tennis”作为答案的约占 40%。因此, 模型在训练期间往往只简单地学习到问题与标准答案的表面相关性(配对关系), 从而在没有结合图片信息进行充分推理的情况下, 依据经验得出有偏见的预测结果, 表现出较强的语言偏见。为了探索解决这一语言先验性问题的途径, 前人通过重新分割和组织原有 VQA 数据集的方式, 构建训练集和测试集中相同问题类型下答案分布相反的数据集(如VQA-CP[3])。值得注意的是, 很多表现良好的 VQA模型在这类数据集上的性能大幅度下降。因此, 克服数据集分布不均衡导致的偏见问题至关重要。
针对上述问题, 有别于前人的工作[4–13], 本文尝试直接将标准分支与偏见分支的概率输出之差作为预测结果。首先, 构造两个不同的偏见学习分支来分别捕捉语言偏见以及语言和图片共同导致的偏见。一个分支通过对语言输入进行特征提取来识别和理解文本中的偏见, 另一个分支基于注意力机制来分析并捕捉语言和图片共同导致的偏见。进一步地, 在推理阶段, 将基础视觉问答模型的预测分值减去语言偏见模型的偏见分值, 得到的差值即为去偏后的预测概率, 最终取概率最大的预测标签作为答案输出。该方法通过消减捕捉到的偏见来降低模型对偏见的敏感性, 并生成更加无偏和准确的预测结果。最后, 根据标准视觉问答与偏见分支之间的预测概率差异, 对样本进行动态赋权。不同的差异意味着样本具有不同的偏见程度, 而赋予不同的权重, 可以调节模型对样本的学习程度。这种动态赋权的方式可以使模型更加灵活和准确地应对不同程度的偏见样本, 从而提高模型的整体性能。通过基于 VQA-CP v2.0 和 VQA v2.0 数据集的实验, 证明本文方法具有比基线模型更高的效能。
近几年, 处理视觉问答任务偏见问题的相关研究可以分为两大类: 数据增强方法[4–7]和非数据增强方法[8–13]。
1)数据增强的方法: 通过自动生成问题和图像对来扩展训练数据集, 以便平衡数据集存在的偏见。Teney 等[4]和Zhu等[5]通过从原有的数据集中构建不相关的问题–图像对来生成额外的数据, 以此在不引入新样本的方式下来平衡数据集。Chen 等[6]通过对图像中的关键对象和问题中的关键目标进行掩盖, 并分别对这些样本分配不同的答案来生成反事实的训练样本, 从而大大提高模型的视觉可解释性和问题敏感能力。Mutant 模型[7]从多个角度扩充训练样本, 包括去除图像的关键对象、反转图像中关键对象的颜色、否定问题的表达以及遮盖问题关键词等。数据增强的方法虽然效果很显著, 但新生成数据的质量往往难以保证, 同时还可能引入新的偏见。
2)非数据增强的方法主要分为两类。一类是引入先验知识来增强视觉灵敏度: HINT 模型[9]引入人类注意力来加强模型对图像的敏感度; 在 HINT模型的基础上, SCR 模型[10]提出自我批评的方法, 惩罚不正确答案对重要区域的敏感度, 取得更好的去偏效果。但是, 这类方法效果有限, 并且需要额外的人工标注, 成本较高。另一类常见的策略是引入一个辅助的单模态分支模型来检测偏见: Ramak-rishnan 等[11]引入仅问题分支, 并使用对抗正则化方法减少数据集偏见对模型的影响; Cadene 等[12]改善了对抗的做法, 提出融合仅问题分支来改变模型的预测结果, 从而降低有偏样本的重要性; Clark 等[13]使用问题类型和答案训练一个捕获偏见的仅问题分支, 再将仅问题分支的预测值嵌入基本模型的预测值中进行集成训练, 使模型的性能有较高的突破; Wen 等[8]注意到视觉模态的偏见效应, 构建仅问题和仅图像两个分支来同时消除两种偏见。
与上述方法不同的是, 本文的方法引入的辅助分支可以直接作用于任意视觉问答基础模型, 适用范围更广; 同时, 我们还依据标准视觉问答分支和偏见分支之间的差异, 构造动态调节机制来作用于损失函数, 从而进一步优化去偏效能。
本研究中, 我们尝试直接将标准分支与偏见分支的概率输出之差作为预测结果。在这种方式下, 针对语言偏见问题, 在模型的训练阶段, 我们沿袭前人的方法, 训练一个语言模态的问答模型来捕获语言先验知识; 在推理阶段, 我们将基础视觉问答模型的预测分值(pVQA)减去语言偏见模型的偏见分值(pQA), 得到的差值即为去偏后的预测概率, 最终取概率最大的预测标签作为答案输出。为了验证该方法的有效性, 我们选用经典的视觉问答模型Updn[14]作为基础模型, 并在数据集 VQA-CP v2.0 上进行初步实验。表 1 列出的实验结果表明, 该方法可以显著地提高视觉问答的准确率。然而, 只考虑语言偏差而忽略视觉信息带来的影响, 不能充分地去除偏见, 视觉信息导致的偏见效应[8]仍然未被充分探究。从图 1 的示例 1~3 中可以观察到, VQA 模型因受图片中模型最感兴趣的区域影响而预测出错误的答案“Water”。
表1 直接消减方法在VQA-CP v2.0数据集上的去偏效果
Table 1 Debias effect on VQA-CP v2.0 dataset using subtracting strategy
基准模型方法准确率/% UpdnpVQA39.80 pVQA– pQA51.49
为了进一步探索上述问题, 受前人捕获语言偏见的工作[11–13]启发, 我们首先观测仅使用图片来回答问题(VA 分支)的效果。如图 1 所示, 我们发现由VA 分支输出的概率分布中, 分值最高的答案始终为 Yes 或 No。主要原因在于, 通过图片信息直接预测答案的过程并不能使模型学到有效的知识。具体地说, 在 VQA-CP v2.0 数据集中, 一张图片往往对应多个自然语言问答实例, 因此在缺失问题引导的情况下, 模型仅仅捕捉到训练集中图片与答案的映射规律, 并将对应频率最高的答案(即 yes 或 no)作为最终的预测。因此, 单纯使用图片来捕获视觉偏见的做法仍然存在问题。我们继续对样例进行分析, 发现错误答案“Water”大多出现在“What”问题类型的样例中, 如图 1 中示例 1~3 所示。所以, 我们推测部分问题信息可能会与图片中的某些区域结合在一起, 与答案标签形成配对关系, 从而被模型在训练阶段利用, 即存在一种文本和视觉信息共同导致的混合偏见。
针对上述问题, 本文提出两个偏见检测分支模型, 即语言偏见检测分支和混合偏见检测分支, 分别捕获两种偏见, 并且将它们融入我们提出的直接消减策略当中, 得到去偏结果。考虑到单纯使用图片信息不能捕获视觉偏见, 我们为图片提供部分问题线索, 并且使用多头自注意力机制使它们充分交互, 从而得到融合视觉与文本线索信息的混合偏见特征。同时, 我们还探究不同偏见分支对不同类型问题的影响, 并设计基于问题类型的分段注意力机制来调节各类型问题的去偏过程。最后, 我们依据标准分支和偏见分支预测的相似性, 设计样本重赋权策略, 通过动态地调节损失函数, 进一步优化去偏过程。
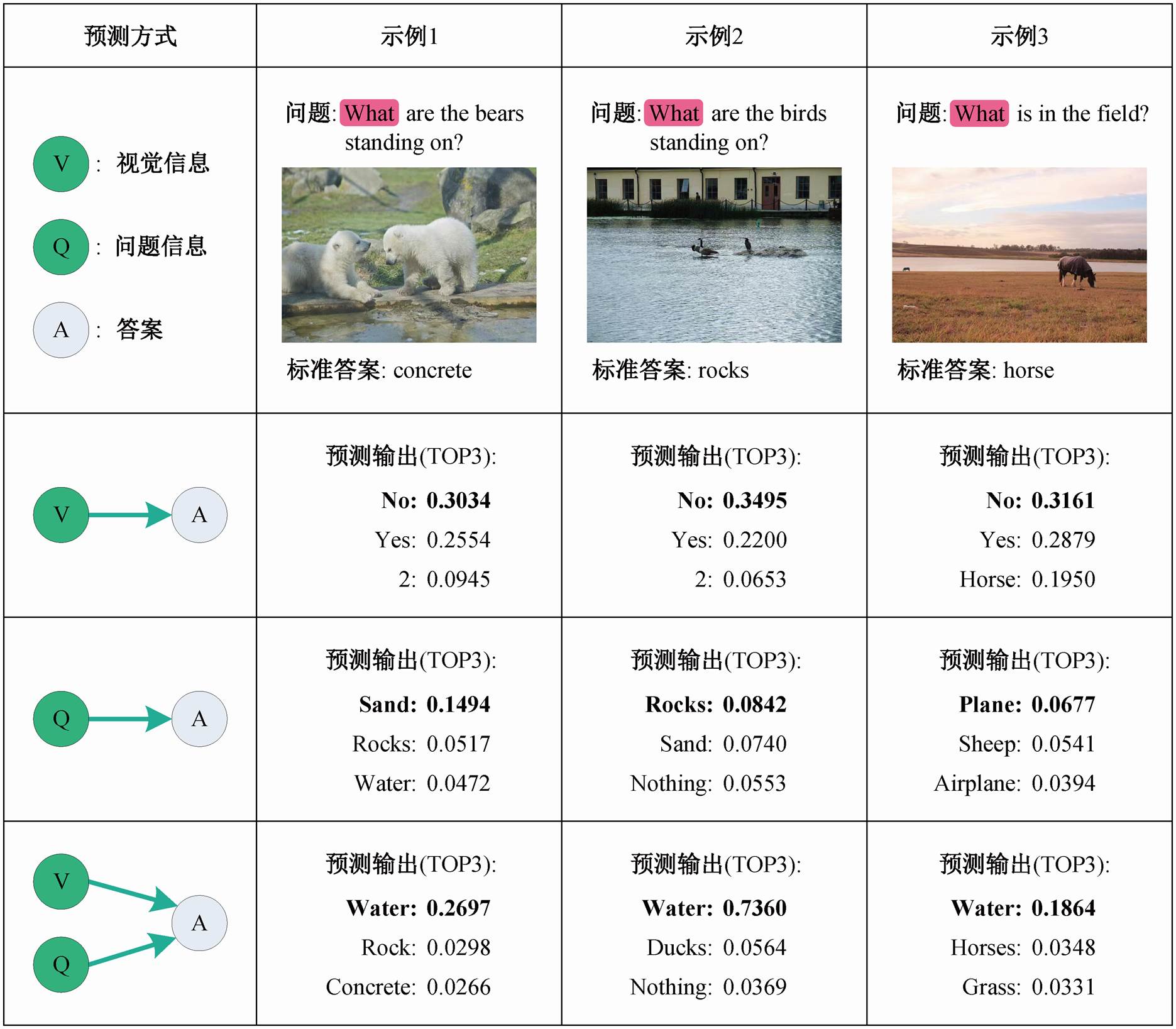
预测输出中粗体字表示模型预测的概率最大的答案, 下同
图1 在VQA-CP v2.0数据集上Updn模型预测答案的样例
Fig. 1 An example of the Updn model predicting the answer on VQA-CP v2.0 dataset
如图 2 所示, 本文模型的整体结构包括 3 个部分: 1)基础视觉问答模型, 例如Updn[14]; 2)偏见检测模型, 用于捕获语言偏见和混合偏见; 3)动态调节模块, 用于依据标准分支和偏见分支的相似性, 动态地调节损失函数的大小。
目前, 可以将视觉问答视为多标签分类任务。具体地说, 给定数据集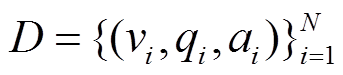 , 其中 vi, qi和αi分别代表第 i 个样本(样本总数为 N)中的图片、问题和答案, 任务的目标是根据自然语言问题和对应的视觉信息预测出正确的答案。通常, 视觉问答模型的预测概率分布可以建模为
, 其中 vi, qi和αi分别代表第 i 个样本(样本总数为 N)中的图片、问题和答案, 任务的目标是根据自然语言问题和对应的视觉信息预测出正确的答案。通常, 视觉问答模型的预测概率分布可以建模为
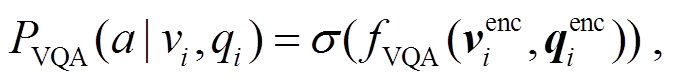 (1)
(1)
其中,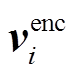 和
和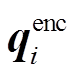 表示第 i 个经过编码后的视觉特征和问题特征;fVQA 表示答案映射函数, 将图片和问题的特征映射到答案空间; σ 表示 sigmoid 激活函数, 用来计算候选答案的概率分值。然而, 当测试集与训练集的“问题–答案”分布差异较大, 甚至相反时, 模型预测结果可能因偏见的影响而呈现较低的准确率和较差的泛化能力。因此, 本文提出一种偏见检测模型, 旨在充分地捕获不同形式的偏见特征, 并探究它们对传统视觉问答模型的影响。
表示第 i 个经过编码后的视觉特征和问题特征;fVQA 表示答案映射函数, 将图片和问题的特征映射到答案空间; σ 表示 sigmoid 激活函数, 用来计算候选答案的概率分值。然而, 当测试集与训练集的“问题–答案”分布差异较大, 甚至相反时, 模型预测结果可能因偏见的影响而呈现较低的准确率和较差的泛化能力。因此, 本文提出一种偏见检测模型, 旨在充分地捕获不同形式的偏见特征, 并探究它们对传统视觉问答模型的影响。
3.3.1语言偏见检测模型
一般将语言偏见视为仅仅根据问题文本得到的答案分布, 通常用如下方式得到:
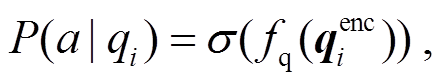 (2)
(2)
其中, fq 表示映射函数, 将问题特征直接映射到答案空间。
3.3.2混合偏见检测模型
为了捕获图片与文本共同导致的偏见, 我们设计一种混合偏见检测模型(如图 3 所示), 分别从底层特征级别和注意力结构级别两方面对图片提供问题线索的引导。
在前期处理阶段, 首先将训练集中的问题文本输入预训练模型BERT[15]中:
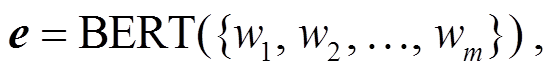 (3)
(3)
其中, e 表示问句单词集合{w1, w2, …, wm}经过 BERT编码后的向量。之后, 在特征级别上使用已标记好的问题类型的训练数据集来训练意图分类器。这里, 将问题的类型视为问题意图。在分类器的实现过程中, 我们从 BERT 编码后的文本特征中选择[CLS]标记对应的特征输送到多层感知机以及 Soft-max 归一化层中, 取概率分值最高的问题类型对应的下角标作为问题意图标签。计算方法如下:
 (4)
(4)
其中, ecls表示 e 中[CLS]标记对应的向量, idx 表示预测概率值最高的意图对应的下角标索引, yintent代表预测出的问题意图标签。在视觉问答训练过程中, 我们先在特征表示层面将意图标签投射到向量空间, 并与图片区域特征进行加和, 后接多头自注意力机制, 使它们充分地交互, 从而得到混合意图的视觉特征序列:
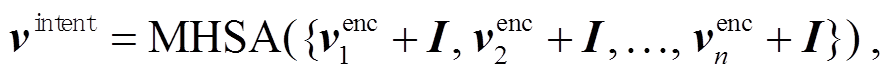 (5)
(5)
其中,venc 表示图片区域特征向量, I 表示当前文具对应的问题意图向量, MHSA(·)表示多头自注意力机制[16], vintent表示混合意图的视觉特征序列。
除在特征层面引入意图线索外, 与 Updn 类似, 我们在注意力机制层面直接利用问句信息来择取问题最有可能关注到的视觉区域。具体地说, 将式(1)中编码后的问题向量 qenc 进行平均池化, 得到整体问题文本特征 E:
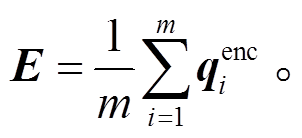 (6)
(6)
最后, 引入注意力机制来对混合文本线索的视觉特征进行聚合。值得注意的是, 考虑到不同的问题受到的偏见影响存在差异, 我们设计分段注意力权重的计算方法。具体地说, 我们依据答案类型的不同, 采取不同的查询向量来计算权重。对于推理难度较大的 Num 类型问题, 将完整的问题文本特征E 作为查询向量; 对于非 Num 类型的问题, 考虑到给予太多的文本线索会使偏见模型学习到正确的知识, 因此训练一个随机向量作为查询向量来计算混合意图的视觉特征权重, 加权求和后, 得到最终的混合偏见特征。这里的随机向量近似地代表用户对图片区域关注的随机倾向性。式(7)和(8)分别表示注意力权重 α 的计算和混合偏见特征 Bmix 的获取操作。
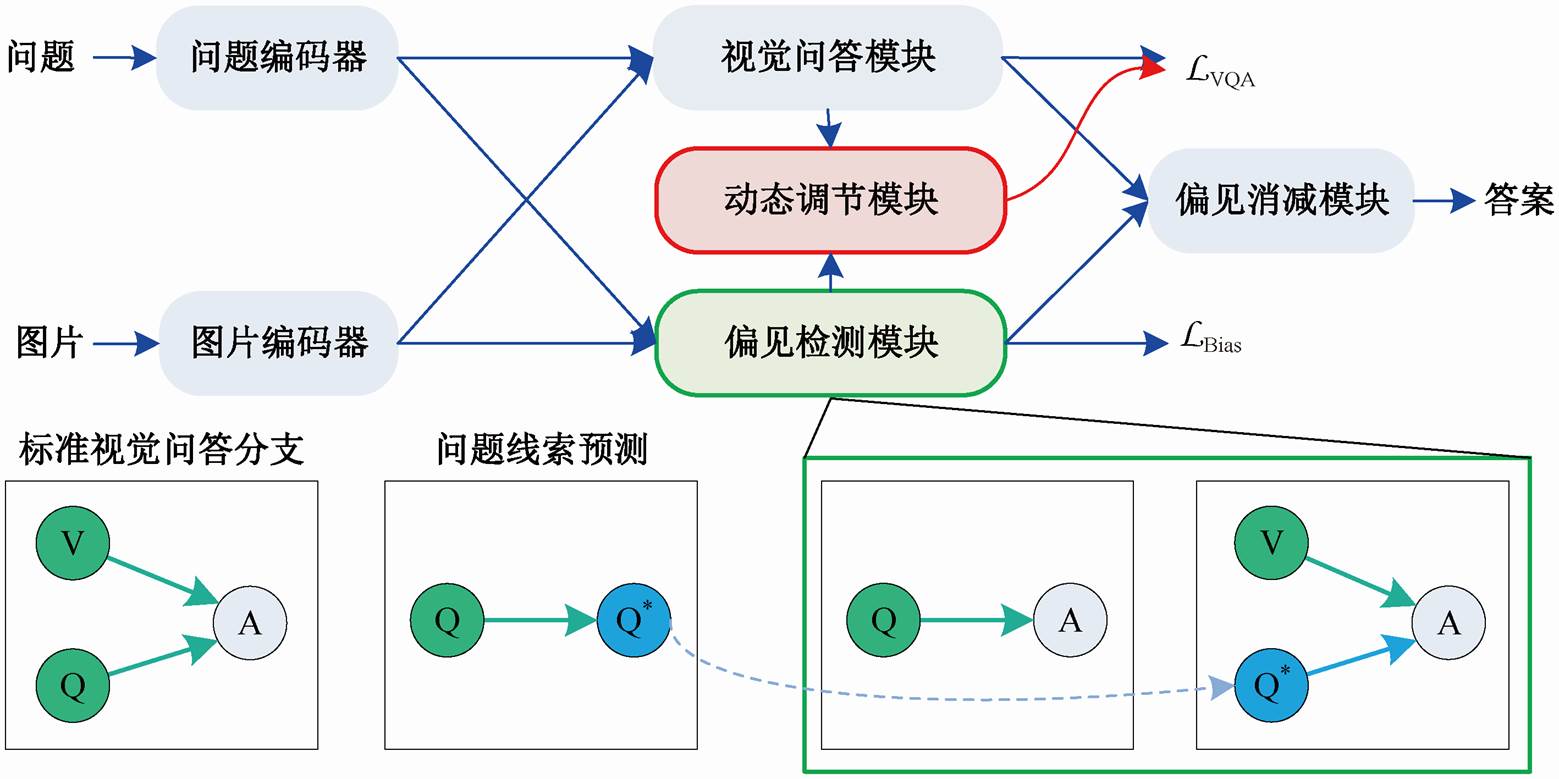
LVQA 和LBias 分别表示基础视觉问答模型和偏见检测分支模块的损失函数; Q*表示从问句中提取的问题类型, 下同
图2 本文模型的整体结构
Fig. 2 Overall structure diagram of the proposed model
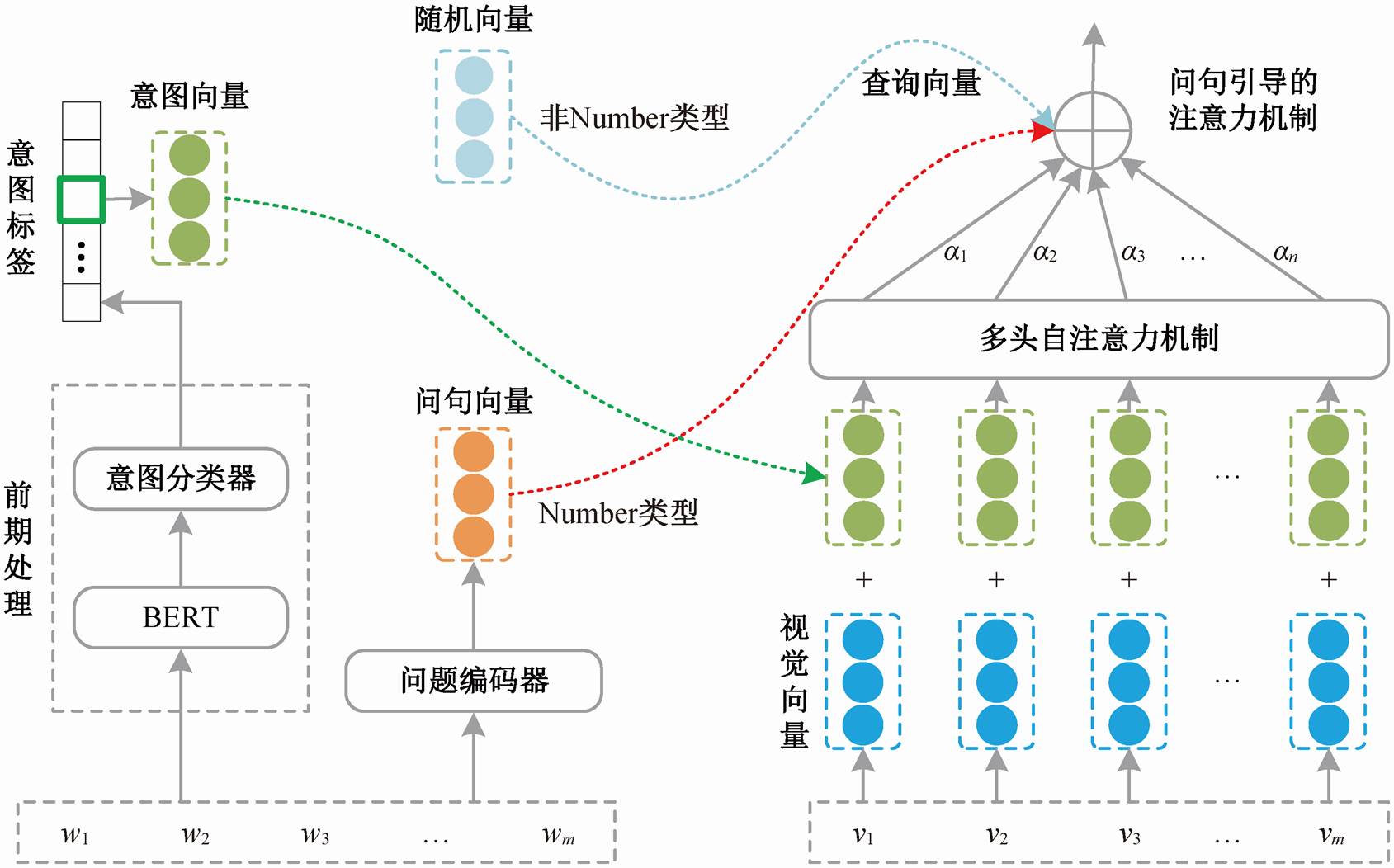
图3 混合偏见检测模型示意图
Fig. 3 Schematic diagram of mixed bias detection model
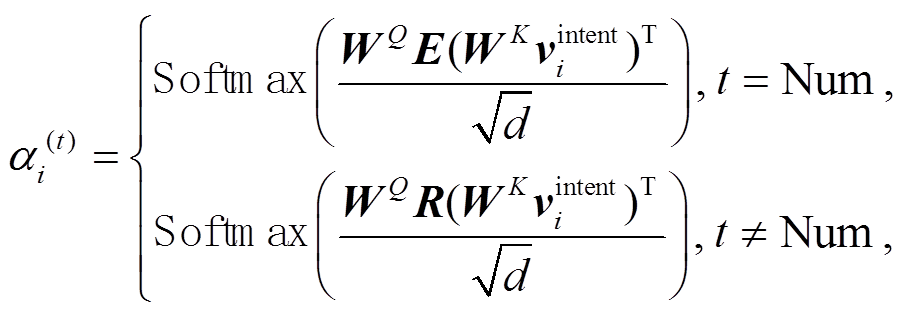 (7)
(7)
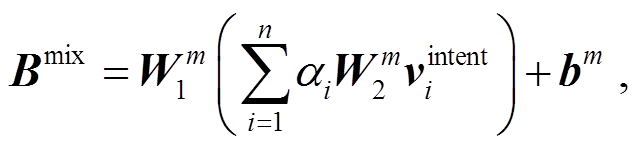 (8)
(8)
其中, R为初始化的随机向量, t为当前问题的答案类型, d为隐藏层的维度, WQ, WK, 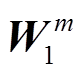 和
和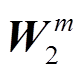 为训练权重, bm 为偏置量。
为训练权重, bm 为偏置量。
为了进一步增强去偏效果, 本文设计一种样本损失动态调节机制。具体地说, 我们依据标准视觉问答分支与偏见预测概率之间的分布差异, 计算出一个衡量样本偏见程度的权重因子, 用于调整损失函数的大小, 从而在模型训练过程中削弱对偏见样本的学习强度, 同时关注无偏样本的学习。
首先, 对所有偏见分支的输出概率加权求和, 得到 , 计算公式如下:
, 计算公式如下:
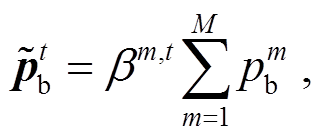 (9)
(9)
其中,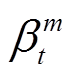 表示当问句对应的答案类型为 t 时, 第m 个偏见分支的超参权重系数; M 为偏见分支的总数;
表示当问句对应的答案类型为 t 时, 第m 个偏见分支的超参权重系数; M 为偏见分支的总数;![]() 表示第 m 个偏见分支的输出概率。
表示第 m 个偏见分支的输出概率。
然后, 为了衡量样本的偏见程度, 计算标准分支输出概率 ps 与的余弦相似度 εt:
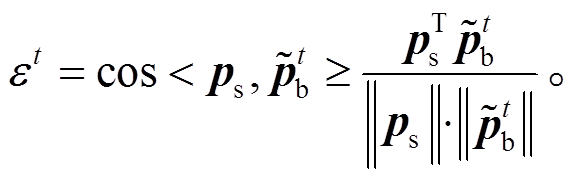 (10)
(10)
由于 ps 和的取值都大于等于零, 故 εt的取值在 0~1 之间。由余弦相似性可知, εt值越大, 标准分支和偏见检测分支的输出概率越接近, 样本存在偏见的可能性越大。
最后, 对于极有可能存在偏见的样本(余弦相似度大于当前问题对应答案类型为 t 时的临界值 ), 赋予较小的权重系数来削弱偏见的影响; 对于几乎不存在偏见的样本(余弦相似度小于临界值
), 赋予较小的权重系数来削弱偏见的影响; 对于几乎不存在偏见的样本(余弦相似度小于临界值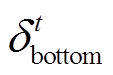 ), 通过增大权重系数来增加模型对这类样本的关注度。权重系数 ωt的计算公式如下:
), 通过增大权重系数来增加模型对这类样本的关注度。权重系数 ωt的计算公式如下:
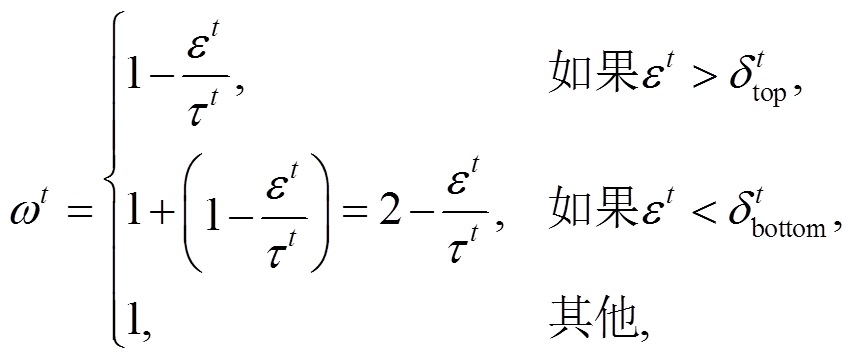 (11)
(11)
其中, τt 是超参数, 表示人工放缩的权重。
3.5.1模型训练
在模型训练阶段, 我们通过二元交叉熵损失函数, 分别优化基础视觉问答模型和偏见检测分支模块, 计算公式如下:
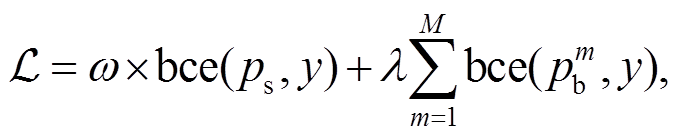 (12)
(12)
其中, λ 是超参数, 用于平衡基础 VQA 模型和偏见检测模型; N 是偏见分支的数目; y 是答案标签; bce(·)是二元交叉熵损失函数; ps表示基础 VQA 模型输出的概率;![]() 表示第 m 个偏见检测模型输出的概率。
表示第 m 个偏见检测模型输出的概率。
3.5.2模型推理
在测试阶段, 某一答案标签的概率分值表示为
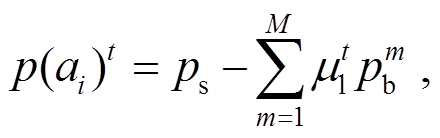 (13)
(13)
其中, t 是答案类型, 共有 3 种。考虑到不同偏见分支对各个类型问题的影响可能存在差异, 我们设置权重 μt 来调节去偏程度, 并且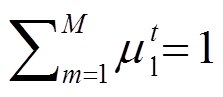 。
。
4.1.1数据集
针对视觉问答中的偏见问题, 目前常用 VQA-CP v2.0 数据集[3]来评估模型的性能, 在 VQA v2.0数据集[2]上测试模型是否过度纠偏。VQA v2.0 训练集包含 443757 个图像问题对, 验证集包含 214354个图像问题对, 测试集包含447793 个图像问题对。VQA-CP v2.0 数据集是对VQA v2.0 数据进行重新划分后得到的, 在同一类型的问题下, 该数据集的训练集和测试集答案分布差异较大。VQA-CP v2.0数据集的训练集包含 438183 个图像问题对, 不包含验证集, 测试集包含 219928 个图像问题对。在两个数据集中, 样本的问题类型分为 3 类: Yes/No, Num和 Other。
4.1.2评价方法
评价句子的正确性时, 需要考虑句法和句子语义的正确性。为了简化问题, 视觉问答的大多数数据集将生成的答案限制为单词或短语, 长度为 1~3个单词。当前通用的评估方法如式(14)[1]所示:
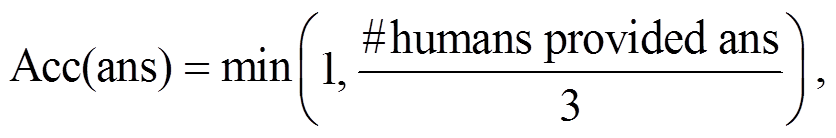 (14)
(14)
其中, Acc(ans)表示某样本下某个答案的准确率, #humans provided ans 表示人工给出该答案的次数。数据集会对每个问题收集 10 个人工答案, 如果某个答案被人工标注 3 次或以上, 则得分为 1; 如果某个答案没有被标注, 则得分为 0,即错误答案。在评估时, 需要将生成的答案与 10 个人工答案进行比较, 从而得到准确率。
4.1.3测试基准模型
我们在 Updn[14]和 LXMERT[17]两个视觉问答基础模型上测试本文提出的方法。Updn 模型是目前主流的视觉问答模型, 它使用一种自上而下和自下向上的注意力机制[16]; LXMERT 是一个基于 Trans-former[16]架构的多模态预训练模型。我们按照是否在 LXMERT 框架下加载预训练权重, 分两组进行实验。
4.1.4参数设置与实验环境
在 Updn 模型的训练过程中, 设置初始学习率为 5×10−4, 训练 batch 大小为 256, 共迭代 25 轮; 在LXMERT 模型的训练过程中, 设定初始学习率为5×10−5, 训练 batch 大小为 32, 共迭代 10 轮。我们使用 Pytorch 1.40 框架来实现本文提出的模型, 所有的计算均在 NVIDIA Tesla V100 GPUs 上进行。
表 2 对比本文方法和近年来提出的其他方法在VQA-CP v2.0 测试集以及 VQA v2.0 验证集上的性能。公平起见, 我们主要比较非数据增强的方法, 包括 SCR[10], AttAlign[9], HINT[9], AReg[11], DLR[18], GRL[19], RUBi[12], LM[13], LMH[13], Unshuffling[20]和Re-scaling[21]。其中, Unshuffling 方法通过划分数据集, 并为每个子集设置不同训练环境的方式来提高模型的泛化能力; Re-scaling 方法则根据训练数据的统计特征, 对样本进行重赋权来消减偏见。评测实验结果表明, 本文方法优于其他基线方法, 并可得到以下结论。
1)与去偏后的模型相比, 未经过去偏处理的视觉问答方法(如 SAN[22], GVQA[3]和 Updn)在 VQA-CP v2.0 数据集上的效果表现较差。本文提出的去偏策略在 Updn 以及两组 LXMERT 模型上均具有较明显的去偏效果。具体地说, 与基础的 Updn 模型相比, 本文方法的准确率提升约 15.45%; 与不加载预训练权重的 LXMERT 相比, 提升 15.76%; 与加载预训练权重的 LXMERT 相比, 提升 15.42%。从整体上看, 上述结果证明了本文方法在去偏任务中具有明显的有效性。
2)在 VQA-CP v2.0 有偏数据集上, 本文中提出的去偏策略在单个指标方面均取得最好的效果。与同样引入问答分支模型的 AReg(+14.31%)、GRL(+13.15%)、LM(+6.70%)、LMH(+3.47%)和 RUBi(+11.25%)相比, 本文方法简单, 效果更显著。从与其他基线模型的对比来看, 一方面, 再次体现出本文方法显著的有效性; 另一方面, 说明本文去偏策略尽可能地针对各个问题类型, 捕获了更充分的偏见信息。
表2 与已有视觉问答去偏模型的性能比较
Table 2 Performance comparison with existing visual question debias models

视觉问答模型基础模型在VQA-CP v2.0测试集上的准确率/%在VQA v2.0验证集上的准确率/%总体Yes/NoNumOther总体Yes/NoNumOther SAN−26.8838.3511.9642.9852.4170.0639.2847.84 GVQA−39.2357.9913.9822.1448.2472.0331.1734.65 Updn−39.7442.2711.9346.0564.3682.0243.3156.49 Updn*−40.0342.2912.6946.3464.3782.2243.4356.33 ARegUpdn41.1765.4915.4835.4862.7579.8442.3555.16 GRLUpdn42.3359.7414.7840.7663.27−−− SCRUpdn48.4770.4110.4247.2962.3077.4040.9056.50 AttAlignUpdn39.3743.0211.8945.0063.2480.9942.5555.22 HINTUpdn46.7367.2710.6145.8863.3881.1842.9955.56 DLRUpdn48.8770.9918.7245.5757.9676.8239.3348.54 RUBiUpdn44.2367.0517.4839.61−−−− LMUpdn48.7872.7814.6145.5863.2681.1642.2255.22 LMHUpdn52.0172.5831.1246.9756.3565.0637.6354.69 UnshufflingUpdn42.3947.7214.4347.2461.0878.3242.1652.71 Re-scalingUpdn47.0968.4221.7142.8855.5064.2239.6153.09 本文模型Updn55.4880.0632.0448.7263.2881.3242.7554.99 LXMERT (不加载预训练权重)−40.9141.6913.6447.9865.2683.1646.3656.65 本文模型(不加载预训练权重)LXMERT56.6782.9433.8249.1763.7482.4344.3254.66 LXMERT (加载预训练权重)−55.8156.1737.2160.7175.9091.4259.7568.28 本文模型(加载预训练权重)LXMERT71.2390.2360.7564.1374.2390.3558.9865.99
注: *实验结果取自本研究复现的模型, 其他用于比较的实验结果都取自原文献; 粗体数字表示最优结果, 下同。
3)在 VQA v2.0 数据集上, 与 Updn 基础模型相比, 大部分已有去偏方法的效果均有所下降, 说明当前的去偏模型存在一定的矫枉过正现象。本文提出的策略在 VQA v2.0 数据集上的测试准确率具有明显的竞争力, 在一定程度上证实本文方法引起的矫枉过正现象相对较弱, 模型的鲁棒性更强。
我们通过消融实验验证模型各部分的有效性, 结果如表 3 所示。所有模型均在与 4.1.4 节中相同的设置下训练。消融实验结果表明, 融合偏见检测分支与动态调节模块都具有明显的效果, 可以得到以下结论。
1)对于 VQA-CP v2.0 数据, 使用混合偏见检测模型在 Num 类型上的效果提升较为明显(+2.00%), 推测其原因可能是 Num 类型的问题更容易受到视觉和语言两种模态信息的影响。此外, 使用语言偏见检测模型在 VQA-CP v2.0 上对 Yes/No 类型问题的作用十分显著(+35.78%), 说明 Yes/No 类型问题的偏见主要由语言信息引起。
2)仅仅将两类偏见检测分支叠加使用时, 在VQA-CP v2.0 上取得比使用单个偏见分支更高的整体效果, 说明它们共同作用, 捕获到更充分的偏见特征, 同时也结合了两类偏见分支各自的优势。此外, 对 VQA v2.0 数据而言, 同时融合两种分支能够缓解矫枉过正的现象(−0.98%)。
3)单独使用动态调节机制时, 在 VQA-CP v2.0数据集上也取得一定的去偏效果(+1.80%), 在 VQA v2.0 数据集上比基础模型 Updn 有 0.06%的提升, 说明在去除偏见的同时, 动态调节机制矫枉过正的现象并不明显。
表3 消融实验结果
Table 3 Results of ablation experiment

模型在VQA-CP v2.0测试集上的准确率/%在VQA v2.0验证集上的准确率/%总体Yes/NoNumOther∆Gap总体Yes/NoNumOther∆Gap Updn40.0342.2912.6946.34−64.3782.2243.4356.33− +动态调节41.8347.7412.9446.65+1.80064.4382.0044.0956.44+0.06 +语言偏见51.8978.0713.3948.73+11.8662.3481.2641.6753.41−2.03 +混合偏见40.6543.5814.6946.22+0.6263.0981.6142.5554.43−1.28 +语言偏见+混合偏见52.6277.9418.8948.60+12.5963.3981.5442.3555.15−0.98 +语言偏见+混合偏见+动态调节55.4880.0632.0448.72+15.4563.2881.3242.7554.99−1.09
说明: ∆Gap表示去偏模型与基础模型的准确率差值。
表4 分段注意力机制的有效性
Table 4 Effectiveness of segmented attention mechanism
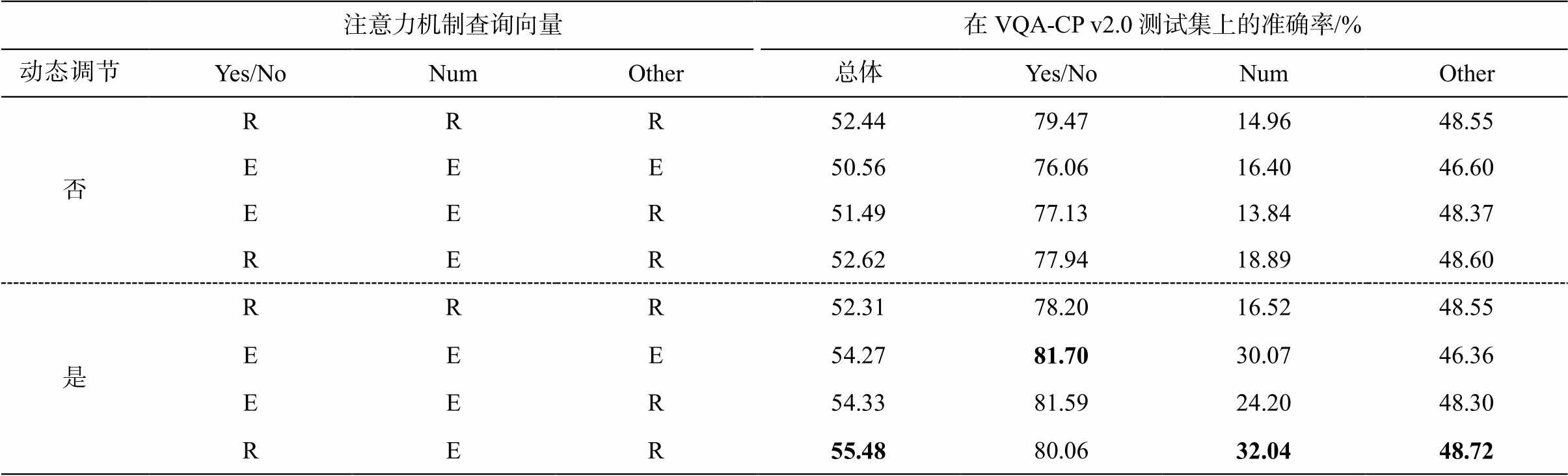
注意力机制查询向量在VQA-CP v2.0测试集上的准确率/%动态调节Yes/NoNumOther总体Yes/NoNumOther 否RRR52.4479.4714.9648.55 EEE50.5676.0616.4046.60 EER51.4977.1313.8448.37 RER52.6277.9418.8948.60 是RRR52.3178.2016.5248.55 EEE54.2781.7030.0746.36 EER54.3381.5924.2048.30 RER55.4880.0632.0448.72
说明: E表示使用问句向量作为查询向量, R表示使用随机初始化的向量作为查询向量。
4)将两类偏见检测分支与动态调节模块结合时, 在 VQA-CP v2.0 数据集上的整体去偏效果以及单个问题类型上的去偏效果达到最佳, 证明了本文提出的方法在视觉问答去除偏见任务中的有效性。
为了直观地验证问句引导的分段注意力机制的有效性, 针对在不同问题类型的样本中混合偏见模块是否使用分段注意力机制这一问题, 我们根据是否采用动态调节机制, 在 VQA-CP v2.0 数据集上分两组进行实验, 结果如表 4 所示。实验结果表明, 当单独针对 Num 类型的样本使用问句特征作为查询向量, 并使用随机特征表示作用于非 Num 类型问题的方式时, 在加入和不加入动态调节两种情况下均取得最明显的提升。给予 Other 类型问题太多的文本线索不利于模型消除 Other 类型样本的偏见, 推测是由于过多的文本线索与视觉信息结合时, 会直接得到 Other 类型问题的正确答案。另外, 我们发现当为 Num 类型问题分配问句特征作为查询向量时, 会对 Yes/No 类型问题起到更明显的提升作用, 在此情况下, 使用随机特征向量来计算 Yes/No类型问题的注意力权重, 促进了模型对Num类型和Other 类型问题的去偏能力。综上所述, 本文提出的分段注意力机制考虑到文本线索信息对不同类型问题的作用差异, 能够有效地提升去偏效果。
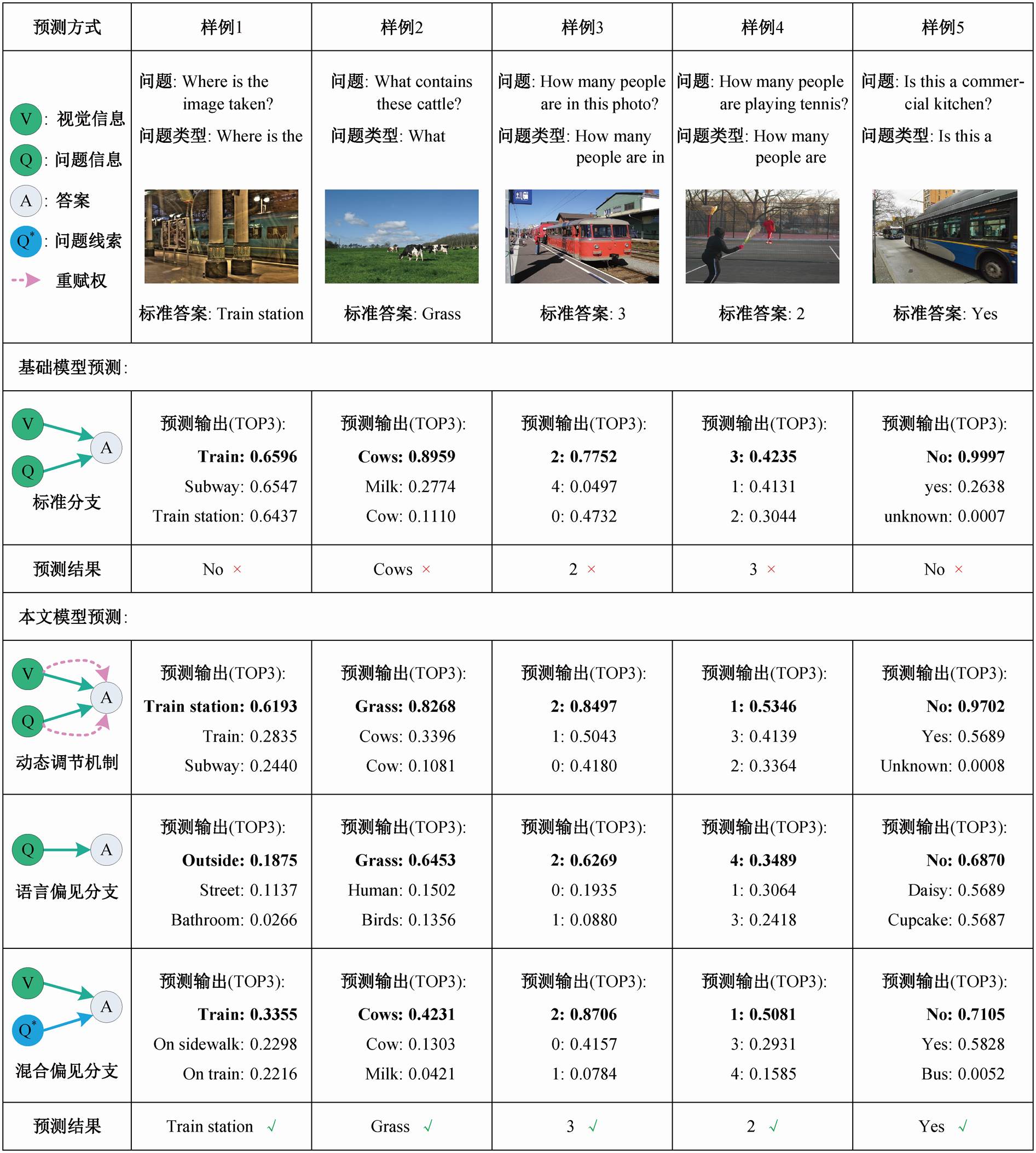
图4 在VQA-CP v2数据集上的去偏效果
Fig. 4 Debias effect on VQA-CP v2 dataset
为了更好地展示结果, 择取在 VQA-CP v2.数据集上以 Updn 作为基础模型的实验结果中的一些例子来进行深入的分析, 从而进一步证明我们方法的有效性。
图4中样例1和2的标准分支与混合偏见分支的预测输出分别为 Train 和 Cows, 说明模型受到视觉偏见影响的可能性更大。在此前提下, 仅使用动态调节机制可以使模型直接预测出正确答案(Train station 和 Grass), 同时在后续的直接消减策略下, 最终的答案也能保持正确性, 说明本文方法具备较强的克服视觉偏见能力。此外, 图 4 中样例 3~5 表明模型在动态调节机制和直接消减策略的共同作用下, 缓解了 Num 和 Yes/No 类型问题中存在的偏见问题, 更加充分地说明本文提出的去偏策略可以增强视觉问答模型的鲁棒性。总体而言, 本文方法在各个问题类型上都可以缓解偏见对模型的影响。
本文提出一种直接消减的去偏策略, 将基础视觉问答模型的输出减去偏见检测模型的输出作为最终的去偏结果。在之前已经提出语言偏见和视觉偏见的基础上, 本研究发现一种新的混合偏见检测分支——图片和文本共同作用导致的偏见, 并设计意图分类器来提取问题句子的意图, 引入分段注意力机制来将视觉特征与意图特征有效地结合, 从而获取混合偏见。最后, 依据标准视觉问答分支与偏见分支之间的差异性, 构造动态调节模块来控制样本的学习程度。实验结果表明, 本文提出的方法提高了现有 VQA 模型的推理分析能力, 减少了偏见对模型的误导性。
参考文献
[1] Antol S, Agrawal A, Lu J S, et al. VQA: visual question answering // Proceedings of the IEEE International Conference on Computer Vision. Santiago, 2015: 2425 –2433
[2] Goyal Y, Khot T, Summers-Stay D, et al. Making the V in VQA matter: elevating the role of image under-standing in visual question answering // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, 2017: 6904–6913
[3] Agrawal A, Batra D, Parikh D, et al. Don’t just assume, look and answer: overcoming priors for visual question answering // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018: 4971–4980
[4] Teney D, Abbasnejad E, Kafle K, et al. On the value of out-of-distribution testing: an example of goodhart’s law. Advances in Neural Information Processing Sys-tems, 2020, 33: 407–417
[5] Zhu X, Mao Z, Liu C, et al. Overcoming language priors with self-supervised learning for visual question answering [EB/OL]. (2020–12–17) [2023–04–10]. https://doi.org/10.48550/arXiv.2012.11528
[6] Chen L, Yan X, Xiao J, et al. Counterfactual samples synthesizing for robust visual question answering // Proceedings of the IEEE/CVF Conference on Com-puter Vision and Pattern Recognition. Seattle, 2020: 10800–10809
[7] Gokhale T, Banerjee P, Baral C, et al. Mutant: a training paradigm for out-of-distribution generaliza-tion in visual question answering [EB/OL]. (2020–10–16) [2023–03–22]. https://doi.org/10.48550/arXiv.2009. 08566
[8] Wen Z, Xu G, Tan M, et al. Debiased visual ques- tion answering from feature and sample perspectives. Advances in Neural Information Processing Systems, 2021, 34: 3784–3796
[9] Selvaraju R R, Lee S, Shen Y, et al. Taking a hint: leveraging explanations to make vision and language models more grounded // Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, 2019: 2591–2600
[10] Wu J, Mooney R. Self-critical reasoning for robust visual question answering. Advances in Neural Infor-mation Processing Systems, 2019, 32: 8601–8611
[11] Ramakrishnan S, Agrawal A, Lee S. Overcoming lan-guage priors in visual question answering with adver-sarial regularization. Advances in Neural Information Processing Systems, 2018, 31: 1541–1511
[12] Cadene R, Dancette C, Cord M, et al. Rubi: reducing unimodal biases for visual question answering. Adva-nces in Neural Information Processing Systems, 2019, 32: 839–850
[13] Clark C, Yatskar M, Zettlemoyer L. Don’t take the easy way out: ensemble based methods for avoiding known dataset biases [EB/OL]. (2019–09–09) [2023–04–20]. https://doi.org/10.18653/v1/D19-1418
[14] Anderson P, He X, Buehler C, et al. Bottom-up and top-down attention for image captioning and visual ques-tion answering // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018: 6077–6086
[15] Devlin J, Chang M W, Lee K, et al. Bert: pre-training of deep bidirectional transformers for language under-standing [EB/OL]. (2018–10–11) [2023–04–12]. https: //doi.org/10.48550/arXiv.1810.04805
[16] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in Neural Information Processing Systems, 2017, 30: 5998–6008
[17] Tan H, Bansal M. LXMERT: Learning cross-modality encoder representations from transformers [EB/OL]. (2019–12–03) [2023–04–20]. https://doi.org/10.48550/ arXiv.1908.07490
[18] Jing C, Wu Y, Zhang X, et al. Overcoming language priors in VQA via decomposed linguistic representations // Proceedings of the AAAI Conference on Artificial Intelligence. New York, 2020, 34: 11181–11188
[19] Grand G, Belinkov Y. Adversarial regularization for visual question answering: strengths, shortcomings, and side effects [EB/OL]. (2019–06–20) [2023–04–11]. https://doi.org/10.48550/arXiv.1906.08430
[20] Teney D, Abbasnejad E, van den Hengel A. Unshuff-ling data for improved generalization in visual ques-tion answering // Proceedings of the IEEE/CVF Inter-national Conference on Computer Vision. Montreal, 2021: 1417–1427
[21] Guo Y, Nie L, Cheng Z, et al. Loss re-scaling VQA: revisiting the language prior problem from a class-imbalance view. IEEE Transactions on Image Proces-sing, 2021, 31: 227–238
[22] Yang Z, He X, Gao J, et al. Stacked attention net- works for image question answering // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, 2016: 21–29
Reducing Multi-model Biases for Robust Visual Question Answering
Abstract In order to enhance the robustness of the visual question answering model, a bias reduction method is proposed. Based on this, the influence of language and visual information on bias effect is explored. Furthermore, two bias learning branches are constructed to capture the language bias, and the bias caused by both language and images. Then, more robust prediction results are obtained by using the bias reduction method. Finally, based on the difference in prediction probabilities between standard visual question answering and bias branches, samples are dynamically weighted, allowing the model to adjust learning levels for samples with different levels of bias. Experiments on VQA-CP v2.0 and other data sets demonstrate the effectiveness of the proposed method and alleviate the influence of bias on the model.
Key words visual question answering; dataset bias; language bias; deep learning