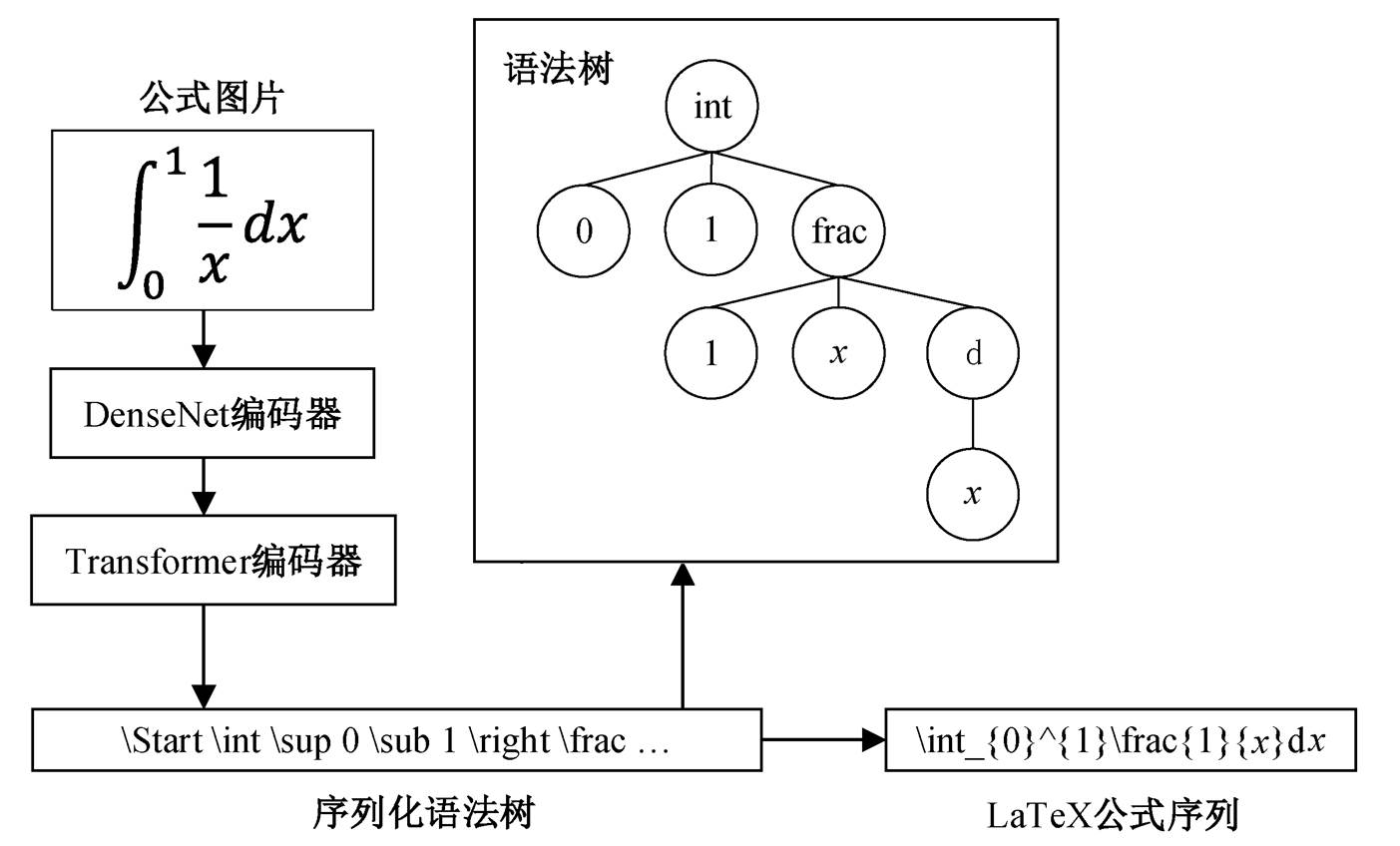
图1 Transformer树解码器框架
Fig. 1 Framework of Transformer tree decoder
北京大学学报(自然科学版) 第59卷 第6期 2023年11月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 6 (Nov. 2023)
doi: 10.13209/j.0479-8023.2023.085
收稿日期: 2022–11–16;
修回日期: 2023–01–10
摘要 目前对数学公式进行树结构解码的方法大多基于循环神经网络的结构, 训练效率低, 训练过程复杂,基于此问题, 提出一种基于 Transformer 结构的手写数学公式识别模型, 可以直接对公式的语法树进行解码。在手写公式识别任务多个数据集上的实验结果表明, 所提出的 Transformer 树解码方法都取得超越Trans-former 序列解码方法的性能, 并展现出超越循环神经网络树解码方法的潜力。
关键词 手写数学公式识别; Transformer; 树解码器; 图表理解
作为光学文字识别(optical character recognition, OCR)的一部分, 手写公式识别在文档理解、图表理解、AI 作业批改和 AI 解题等领域发挥着重要作用。现有的手写公式识别系统大多使用基于卷积神经网络(CNN)和循环神经网络(RNN)[1]的编码器–解码器模型[2–4]。这些模型将手写公式识别任务建模为图像到序列的解码任务, 卷积神经网络负责将图像编码, 循环神经网络负责将编码后的图像信息解码为公式。编码器–解码器模型是近年来自然语言处理领域应用最广泛的模型, 在许多任务中都有巨大的应用潜力。在同样用于解码序列、可以替换循环神经网络的更强大的 Transformer 模型[5]出现后, 基于 Transformer 的编码器–解码器模型开始在目标检测和语义分割[6–7]等视觉任务中得到应用。在手写公式识别任务中, 解码器不仅可以解码公式的LaTeX 序列, 还有直接解码数学公式语法树的潜力。相比于 LaTeX 序列, 语法树显式地存储了数学公式中的结构信息, 更加接近数学公式的本质。解码语法树能显著地降低公式的结构错误率, 且对具有复杂空间关系的公式具有更强的鲁棒性。Alva-rezMelis 等[8]提出能用于解码树结构的编码器–解码器。Zhang 等[9]提出在手写公式识别任务中使用两个 RNN 解码器, 分别负责父节点和子节点的解码, 并将父子节点信息交由全连接层, 解码出父子节点间的关系, 由此不断循环, 解码出整棵语法树。但是, 目前的树解码方法并不适用于基于 Transformer模型的解码器。
图1 Transformer树解码器框架
Fig. 1 Framework of Transformer tree decoder
本文提出适用于 Transformer 模型解码的语法树序列化方法以及对应的训练策略, 使得 Transfor-mer 模型也能够进行树结构解码。此方法能够与任何序列解码方法融合, 具有可迁移性。
本文提出的基于 Transformer 的语法树解码框架如图 1 所示。将训练集中的 LaTeX 序列形式的数学公式建树后, 重新序列化, 用于训练模型。训练好的模型可以从图片解码出序列化形式的语法树, 再从语法树序列中还原出语法树或 LaTeX 形式的 序列。
作为结构化数据, 数学公式除可以用 LaTeX 序列表示外, 也可以用语法树来表示。数学公式的语法树定义有多种, 常见的定义是使用六叉树[9]。六叉树中的每个节点代表公式中的一个符号, 而每个节点最多可以有 6 个子节点, 分别代表字符间的 6种关系: 上标、下标、右延、上方、下方和里侧。图2是6种关系在公式及语法树中的示例。
语法树的一种形式化表达是使用若干形如(父节点, 子节点, 字符间关系)的节点三元组, 每个节点三元组都表示从父节点拓展出的一个子节点。Zhang 等[9]通过从根节点开始解码节点三元组, 不断拓展语法树, 最终解码出整颗语法树。但是, Zhang 等[9]对节点的建模仅保留了符号, 在解码父节点时无法分辨已解码的相同符号的节点, 故引入额外的记忆模块用于存储已解码的符号, 并通过点积相似度得到父节点符号位置。这种建模方式引入较复杂的结构和额外的参数量, 且无法直接迁移到Transformer 模型结构中。因此, 本文提出适用于Transformer 模型的手写公式树解码器模型, 模型结构如图 3 所示。
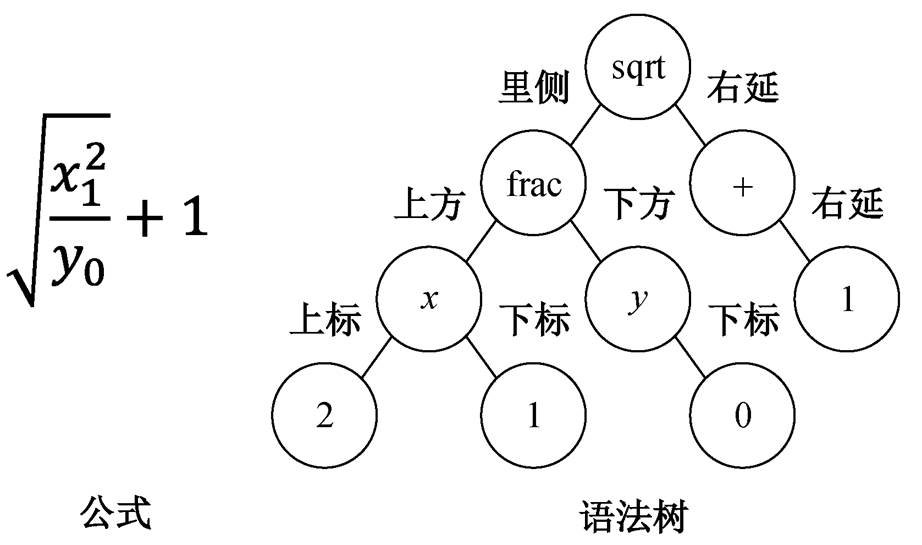
图2 数学公式语法树示例
Fig. 2 An example of syntax tree of mathematical expression
由于 Transformer 的解码方式是序列解码, 因此本文首先将语法树通过自定义的规则进行序列化, 从而将语法树解码问题转换为序列解码问题[10]。每棵语法树被序列化为一个由多个节点三元组序列(父节点指针、字符间关系、子节点符号)组成的长序列。父节点指针(记为 S)是词表中新增的一组特殊符号, 形式为“\X”。“\”为转义符, 用于与普通的数字符号做区分; X表示指针指向已解码的第 X 个子节点符号。为了统一节点三元组的表示, 解码出的第一个节点的父节点指针总是“\0”。父节点指针在词表中的总数量由数据集中公式的最长长度决定, 默认为 60 个。字符间关系(记为 R)同样为新增的一组特殊符号, 共 6 个, 分别代表字符间的 6 种关系。子节点符号(记为 T)为原词表中的 LaTeX 字符, 共 111 个。加上 3 个序列控制符(
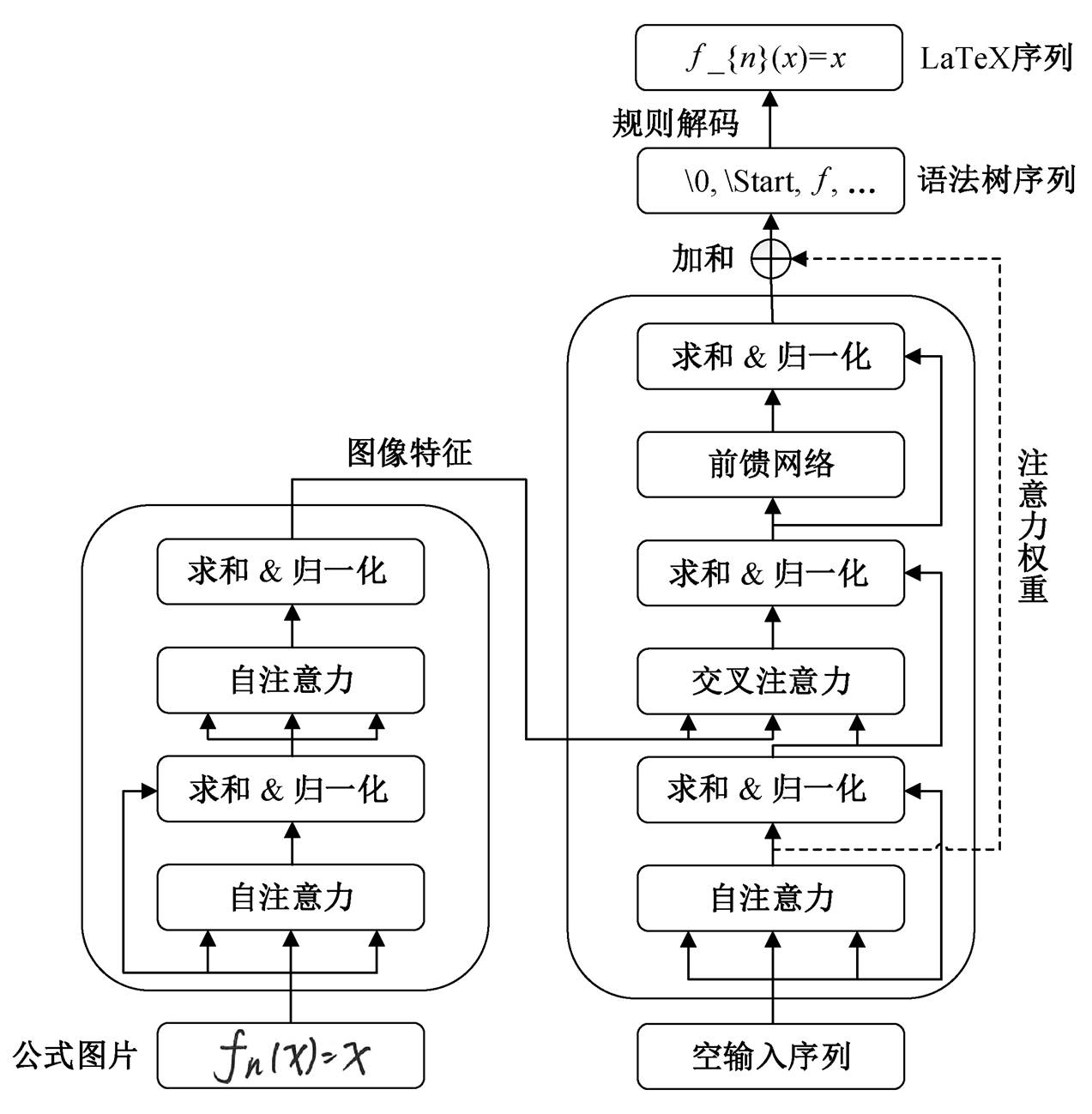
图3 Transformer手写公式树解码模型
Fig. 3 Handwritten mathematical expression syntax tree decoder base on Transformer
同一棵语法树同时对应多个正确的序列化结果, 比如, 节点三元组之间可以按树的前序遍历方式排列, 也可以按树的层序遍历方式排列, 而节点三元组内部的排列方式也有多种。本文默认将节点三元组按照前序遍历方式排列, 三元组内部则默认按照 S, R, T 的顺序排列。排列规则确定后, 同一棵序列化后的语法树可以使用同样的规则转换为唯一的 LaTeX 格式的公式序列。
表1 语法树词表示例
Table 1 Examples of the dictionary of syntax tree

字符类型字符示例 父节点指针S\0, \1, \2, \3, … 字符间关系R\Sup, \Sub, \Above, \Below, \Inside, \Right 子节点符号Tx, y, 1, 2, \int, \frac, +, –, …
例如, 采用前序遍历时, 图 2 对应语法树的一种序列化方式为
损失函数为序列化语法树中每个字符分类损失的加权平均, 可以通过为 S, R 和 T 这 3 种不同类型的字符赋予不同的重要性权重 α (默认均为 1), 来设置模型对树结构的学习偏好:
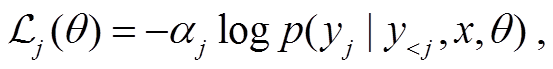 (1)
(1)
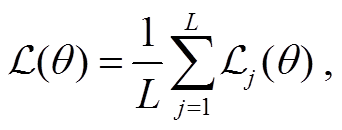 (2)
(2)
其中, αj为不同类型字符的重要性权重, θ 为模型参数, yj为第 j 个位置的字符, x为图像。
在序列化的语法树中, 指针符号的语义为直接指向已解码序列中的某个词, 这种建模方式类似摘要生成任务中的指针生成网络。故本文参考指针生成网络[11–12]中指针生成器的结构, 提出适用于树结构生成的指针解码网络结构。
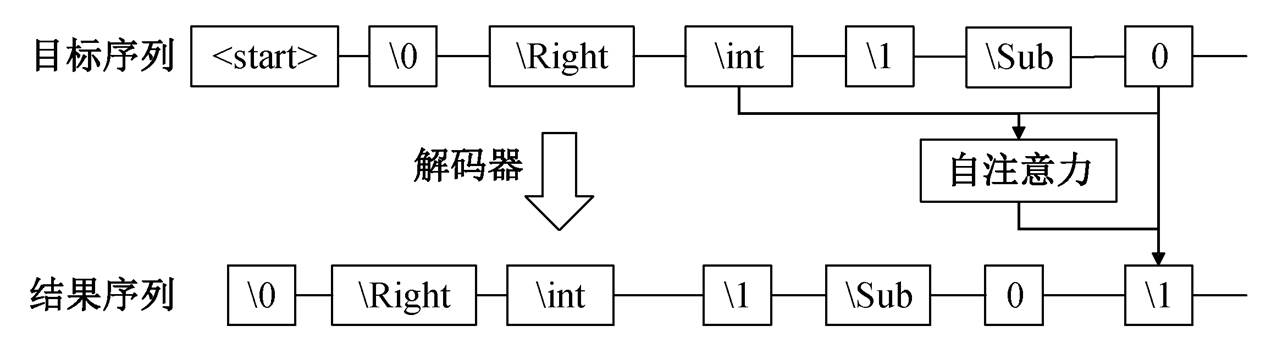
图4 指针解码模块
Fig. 4 Pointer decode module
设词表长度为 V, 解码器在解码每个字符时, 都需要给出词表中每个字符的得分 r, 并通过 soft-max 操作得到当前字符的归一化概率 p。在解码S 符号(即父节点指针符号)时, 通过引入对已解码序列的自注意力得分 a来修正解码器得分 r。最终的得分为解码器得分 r 与自注意力得分 a 之和:
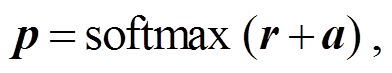 (3)
(3)
其中, 向量 p, a 和 r 的维度均为 V。
如式(4)所示, 自注意力得分 a 是通过将解码 S符号时指向已解码的 T 符号的自注意力权重向量pattn(维度为最大序列长度 L)经过一次可选的线性变换 WV×V, 转换为词表中 S 符号的得分, 并将词表其余类型符号得分置零而得到:
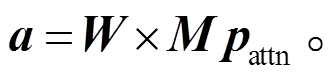 (4)
(4)
因为 S 符号的语义即为指向第 X 个已解码的 T符号的指针, 所以解码 S 符号过程中, 对 T 符号的自注意力权重可以将 T 符号的位次直接作为对应 S 符号的得分使用。由于 T 符号总是出现在序列中序号被 3 整除的位置, 所以注意力权重 pattn 可以通过一个预置的矩阵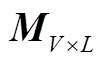 来转换成词表得分。矩阵元素
来转换成词表得分。矩阵元素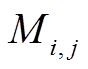 仅在 i 为 S 符号词表编号且j为该指针所指节点的 T 符号位置时为 1, 其他情况下则为 0。
仅在 i 为 S 符号词表编号且j为该指针所指节点的 T 符号位置时为 1, 其他情况下则为 0。
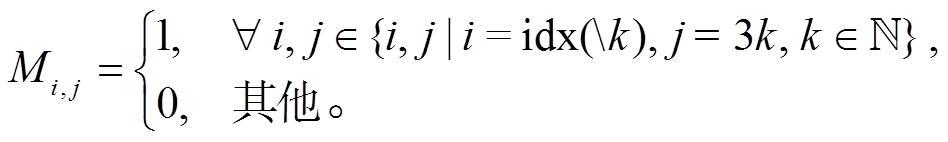 (5)
(5)
如图 4 所示, 解码器在解码第 3 个节点的 S 符号时, 前两个节点的 T 符号\int 和 0 的自注意力将分别转换为词表中 S 符号\1 和\2 的得分。若模型解码时更关注第一个节点符号\int, 则该 S 符号的解码结果会更偏向于\1, 即第 3 个节点的父节点指针更偏向于指向第一个节点。
指针解码模块的目的是利用父节点指针 S 符号的语义, 将解码时的注意力权重转换为解码得分, 实现注意力权重的重复利用, 但是给 S 符号的解码带来额外的信息。解码时的注意力权重在网络推理时自然产生, 除线性变换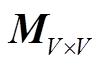 外, 不会给网络带来额外的参数量和过多的额外计算量。由于注意力权重具有概率分布的含义, 因此可跳过线性变换直接加在得分上, 以便规避模型参数量的增加。
外, 不会给网络带来额外的参数量和过多的额外计算量。由于注意力权重具有概率分布的含义, 因此可跳过线性变换直接加在得分上, 以便规避模型参数量的增加。
将本文提出的 Transformer 树解码方法在 CRO-HME 数据集[13–15]上进行实验, 与目前先进的手写公式识别模型进行对比, 并进行消融实验, 验证本文方法的有效性。
本文采用的网络结构为编码器–解码器结构。解码器部分为 Transformer 解码器, 除本文提出的指针解码模块外, 其余结构与文献[16]的单向 Trans-former 模型相同; 编码器部分采用与文献[3]相同设置的 DenseNet 卷积神经网络编码器。本文在数据集 CROHME 上进行实验, 数据集概况如表 2 所示。
手写数学公式识别任务主要有准确率和结构准确率两个评价指标。准确率是完全识别正确的公式在数据集中的比例, 结构准确率是识别结果结构正确的公式在数据集中的比例。结构准确率只关心模型解析出的语法树拓扑结构是否正确, 而不关心符号识别的准确率, 能较好地评价模型捕捉公式语法树结构的能力。
表2 CROHME数据集概况
Table 2 Overview of the CROHME datasets

数据集公式数量 训练集8836 CROHME 2014测试集986 CROHME 2016测试集1147 CROHME 2019测试集1199
表3 CROHME测试集上各方法对比
Table 3 Comparison of various recognition methods on CROHME datasets
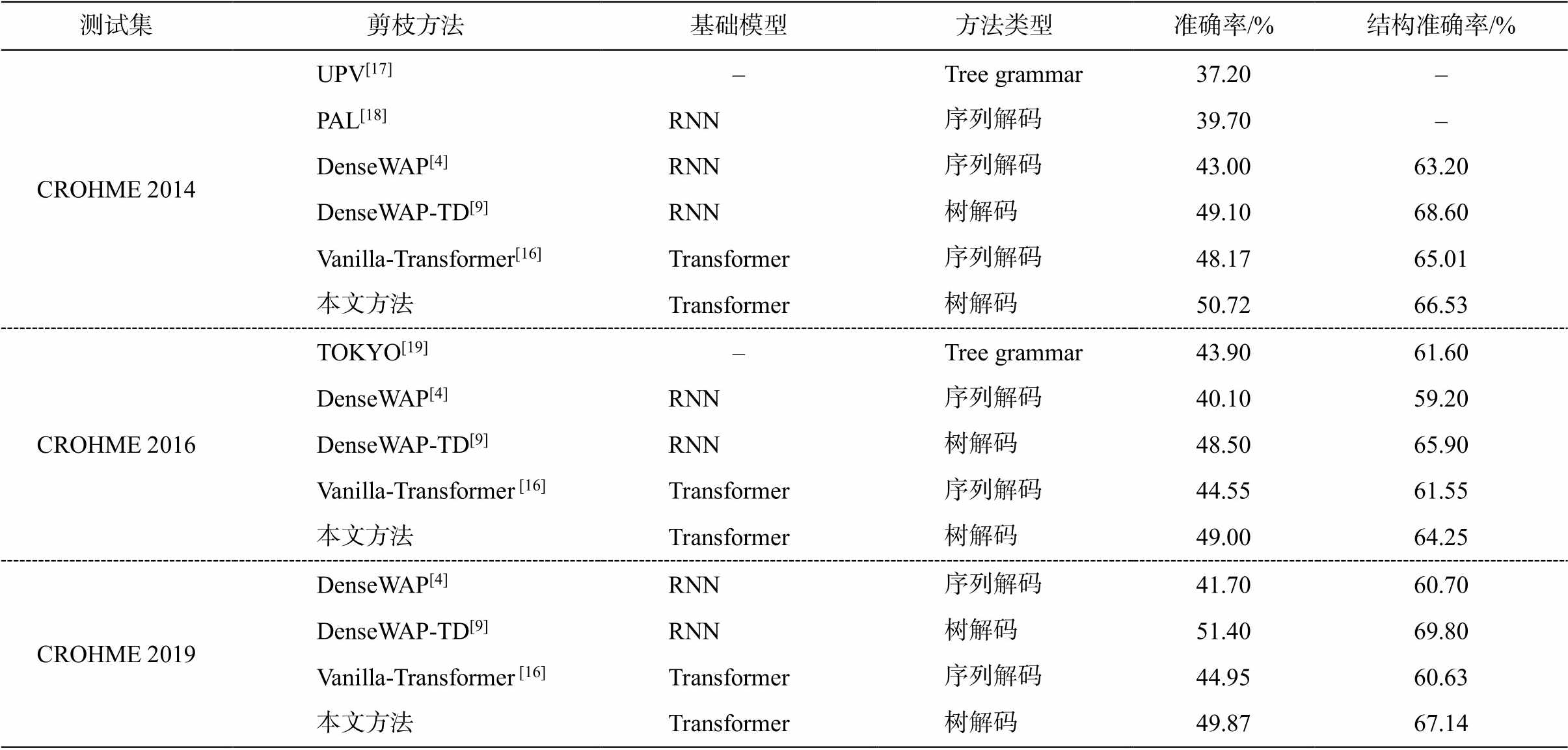
测试集剪枝方法基础模型方法类型准确率/%结构准确率/% CROHME 2014UPV[17]–Tree grammar37.20– PAL[18]RNN序列解码39.70– DenseWAP[4]RNN序列解码43.0063.20 DenseWAP-TD[9]RNN树解码49.1068.60 Vanilla-Transformer[16]Transformer序列解码48.1765.01 本文方法Transformer树解码50.7266.53 CROHME 2016TOKYO[19]–Tree grammar43.9061.60 DenseWAP[4]RNN序列解码40.1059.20 DenseWAP-TD[9]RNN树解码48.5065.90 Vanilla-Transformer [16]Transformer序列解码44.5561.55 本文方法Transformer树解码49.0064.25 CROHME 2019DenseWAP[4]RNN序列解码41.7060.70 DenseWAP-TD[9]RNN树解码51.4069.80 Vanilla-Transformer [16]Transformer序列解码44.9560.63 本文方法Transformer树解码49.8767.14
本文方法在 CROHME 2014/2016/2019 数据集上的实验结果如表 3 所示。为保证方法比较的公平性, 所有方法都没有使用数据增强策略。从表 3 可以看出, 本文提出的 Transformer 树解码方法的性能可以与当前最先进的 RNN 树解码方法性能竞争。考虑到 Transformer 模型在其他领域已经展现出随着数据集规模增大而性能增强的特点, 可以期望在大数据集场景下, Transformer 树解码模型会具有更强的潜力。相比序列解码的 Transformer 模型, 本文方法取得更好的准确率和结构准确率表现, 尤其是在 CROHME 2016/2019 数据集上的性能远好于序列解码 Transformer 模型。
指针解码模块是本文提出的独立模块, 本文通过消融实验来验证该模块是否能协助模型解码父节点指针, 是否对模型推理结果有正面影响。实验结果如表 4 所示。可以看出, 指针解码模块能够在模型解码父节点指针时提供有效信息, 从而提升模型的最终性能。
本文依据数学公式树解码的建模方法, 针对Transformer 模型的特点, 提出一种基于Transformer模型的手写数学公式树解码模型。它通过将语法树序列化, 将树解码问题转换为序列解码的形式, 从而使其适用于 Transformer 模型。参考指针生成网络中生成指向文本中词语的指针的方法, 通过注意力机制协助模型生成父节点指针, 以期提高模型的识别性能。实验结果表明, 本文方法很好地将公式的树解码这一建模方法迁移到 Transformer 模型上, 超越普通的 Transformer 模型, 取得优异的性能。
表4 CROHME 测试集上消融实验
Table 4 Ablation study on CROHME datasets
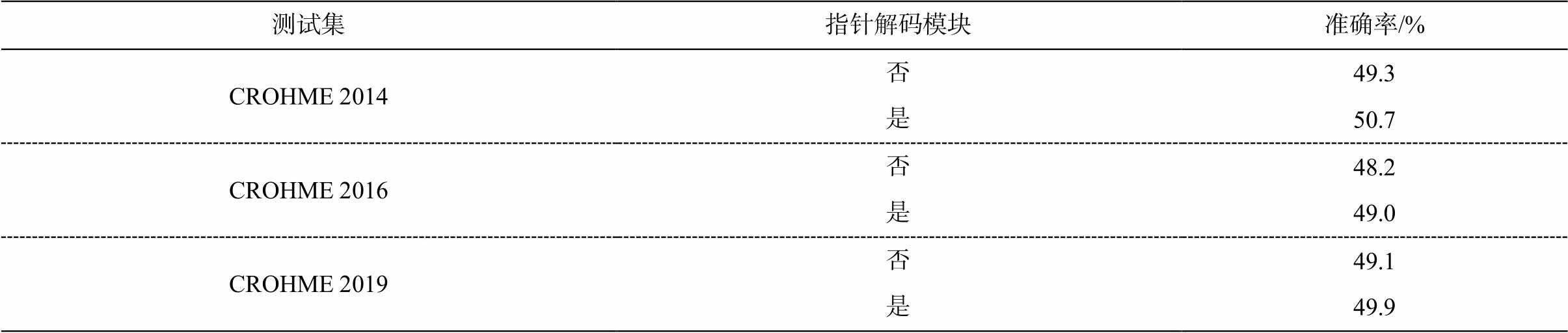
测试集指针解码模块准确率/% CROHME 2014否49.3 是50.7 CROHME 2016否48.2 是49.0 CROHME 2019否49.1 是49.9
但是, 本文方法存在一定的局限性。由于语法树的序列表示的序列长度更长, 相比传统的序列解码方法, 本文方法需要在解码上花费更长的时间。在未来的研究中, 我们将进一步探索更合适的建模方式, 比如直接从解码器注意力中解码出父节点指针, 以便减少解码序列的长度; 或以更合适的先验形式, 通过建模, 将语法树结构引入 Transformer 模型中[20], 提升模型的性能和效率。
参考文献
[1] Zhu X, Sobihani P, Guo H. Long short-term memory over recursive structures // International Conference on Machine Learning. Lille: PMLR, 2015: 1604–1612
[2] Zhang J, Du J, Zhang S, et al. Watch, attend and parse: an end-to-end neural network based approach to hand-written mathematical expression recognition. Pattern Recognition, 2017, 71: 196–206
[3] Wu J W, Yin F, Zhang Y M, et al. Handwritten mathe-matical expression recognition via paired adversarial learning. International Journal of Computer Vision, 2020, 128: 2386–2401
[4] Zhang J, Du J, Dai L. Multi-scale attention with dense encoder for handwritten mathematical expression recognition // 2018 24th International Conference on Pattern Recognition (ICPR). Beijing, 2018: 2245–2250
[5] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // Advances in Neural Information Processing Systems. Long Beach, 2017, 30: 5998–6008
[6] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers // Computer Vision–ECCV 2020: 16th European Conference. Glasgow, 2020: 213–229
[7] Strudel R, Garcia R, Laptev I, et al. Segmenter: transformer for semantic segmentation // Proceedings of the IEEE/CVF International Conference on Com-puter Vision. Montreal, 2021: 7262–7272
[8] Alvarez-Melis D, Jaakkola T S. Tree-structured deco-ding with doubly-recurrent neural networks // Inter-national Conference on Learning Representations. Toulon, 2017: 1–17
[9] Zhang J, Du J, Yang Y, et al. A tree-structured decoder for image-to-markup generation // International Con-ference on Machine Learning. Online Meeting, 2020: 11076–11085
[10] Chen T, Saxena S, Li L, et al. Pix2seq: a language modeling framework for object detection [EB/OL]. (2021–09–22)[2023–01–10]. https://arxiv.org/abs/2109. 10852
[11] See A, Liu P J, Manning C D. Get to the point: sum-marization with pointer-generator networks. [EB/OL]. (2017–04–14)[2023–01–10]. https://arxiv.org/abs/1704. 04368
[12] Jiang W, Li J, Chen M, et al. Improving neural text normalization with partial parameter generator and pointer-generator network // IEEE International Con-ference on Acoustics, Speech and Signal Processing (ICASSP). Toronto, 2021: 7583–7587
[13] Mouchere H, Viard-Gaudin C, Zanibbi R, et al. ICFHR 2014 competition on recognition of on-line handwri-tten mathematical expressions (CROHME 2014) // 2014 14th International Conference on Frontiers in Handwriting Recognition. Crete, 2014: 791–796
[14] Mouchère H, Viard-Gaudin C, Zanibbi R, et al. ICFHR2016 CROHME: competition on recognition of online handwritten mathematical expressions // 2016 15th International Conference on Frontiers in Hand-writing Recognition (ICFHR). Shenzhen, 2016: 607–612
[15] Mahdavi M, Zanibbi R, Mouchere H, et al. ICDAR 2019 CROHME + TFD: competition on recognition of handwritten mathematical expressions and typeset formula detection // 2019 International Conference on Document Analysis and Recognition (ICDAR). Syd-ney, 2019: 1533–1538
[16] Zhao W, Gao L, Yan Z, et al. Handwritten mathematical expression recognition with bidirectionally trained transformer // Document Analysis and Recognition–ICDAR 2021. Lausanne, 2021: 570–584
[17] Alvaro F, Zanibbi R. A shape-based layout descriptor for classifying spatial relationships in handwritten math // Proceedings of the 2013 ACM Symposium on Document Engineering. New York, 2013: 123–126
[18] Wu J W, Yin F, Zhang Y M, et al. Image-to-markup generation via paired adversarial learning // Machine Learning and Knowledge Discovery in Databases: European Conference. Dublin, 2019: 18–34
[19] Dai Nguyen H, Le A D, Nakagawa M. Deep neural networks for recognizing online handwritten mathe-matical symbols // 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR). Nanjing, 2015: 121–125
[20] Chen X, Liu C, Song D. Tree-to-tree neural networks for program translation. Advances in Neural Informa-tion Processing Systems. 2018, 31: 2552–2562
A Transformer-based Syntax Tree Decoder for Handwritten Mathematical Expression Recognition
Abstract Most of the existing tree-structured decoding methods of handwritten mathematical expression recog-nition are based on the recurrent neural networks, which have low training efficiency and complicated training process. In order to prove this problem, the authors propose a handwritten mathematical expression recognition model based on Transformer structure, which can decode the syntax tree of expressions directly. Experimental results show that the proposed tree-structured decoding method achieves better performance than the string decoding methods base on Transformer on several datasets of handwritten formula recognition tasks, and show the potential to surpass recurrent neural network tree decoding methods.
Key words handwritten mathematical expression recognition; Transformer; tree decoder; document comprehension