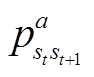 移到下一个状态 st+1。在强化学习中, 定义两种函数来衡量策略的好坏: 状态值函数 V 和动作值函数 Q, 如式(1)和(2)所示:
移到下一个状态 st+1。在强化学习中, 定义两种函数来衡量策略的好坏: 状态值函数 V 和动作值函数 Q, 如式(1)和(2)所示: 述评
北京大学学报(自然科学版) 第59卷 第6期 2023年11月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 6 (Nov. 2023)
doi: 10.13209/j.0479-8023.2023.086
国家自然科学基金(62176004, U1713217)、东湖高新区国家智能社会治理实验综合基地项目、北京大学新工科专项、北京大学–辛巴科技项目和北京大学高性能计算平台资助
收稿日期: 2022–11–28;
修回日期: 2023–04–25
摘要 介绍与机器人学习有关的基本概念与核心问题, 梳理机器人学习的相关方法和最新进展。依据数据类型, 将机器人学习的方法分为基于强化学习的方法、基于模仿学习的方法、基于迁移学习的方法和基于发展学习的方法, 并对相关研究进行总结和分析, 探讨机器人学习领域目前存在的挑战和未来发展趋势。
关键词 机器人学习; 强化学习; 模仿学习; 迁移学习; 发展学习
机器人学是一门综合计算机科学、运动学和动力学、传感技术、控制技术以及认知发展理论等众多科学理论的交叉学科。自 20 世纪 50 年代第一台工业机器人手臂[1]问世以来, 机器人领域引起诸多学者的研究兴趣。机器人具有精度高、速度快、可交互和灵活机动等特点, 能够帮助人甚至代替人完成各种困难危险、繁琐多变的工作。随着人工智能技术和机器人技术的快速发展, 机器人研究在农业生产、工业制造、医疗服务、航空航天和深海探索等领域已取得一系列的进展, 并得到广泛应用。
如何使机器人获得适应真实环境的各项技能, 是机器人领域的核心课题。2015 年, 美国国防高等研究计划署在加州举办 DARPA 机器人挑战赛, 包括美国、德国、意大利、中国、日本和韩国在内的 25 支队伍参加该项赛事, 参赛的机器人包含多款世界上最先进的仿人机器人, 例如 CHIMP, DRC-HUBO, IHMC 和 RoboSimian 等[2–3]。该赛事主要受到日本 2011 年福岛核泄漏事故的启发, 专注于让机器人面对各种灾难场景的救援任务, 旨在通过比赛, 提高机器人在恶劣和危险环境中的适应水平, 帮助人类更好地面对这些问题。遗憾的是, 在比赛过程中, 机器人整体上表现欠佳, 不仅完成任务耗时很长, 还遇到一系列问题: 电机失效, 制动失灵, 在行走过程中跌倒, 没有找准目标就执行任务, 等等, 甚至需要技术人员当场进行修复。2017 年, 加州大学伯克利分校、谷歌和微软等机构发起第一届机器人学习会议 CoRL, 目的是借助机器学习的方法, 有效地攻克机器人领域的难题[4]。此后, 越来越多的研究者开始关注机器人自主学习这一领域。到目前为止, 斯坦福大学[5]、加州大学伯克利分校[6]、DeepMind[7–8]、百度[9]、Google[10]和 ParisTech[11]等机构围绕机器人学习这一任务开展一系列深入的研究, 取得诸多进展, 但仍存在诸多亟待解决的问题: 如何高效率、低成本地使机器人学习到新的技能; 如何使机器人学到的技能能更好的适应新环境, 更快地适配于其他机器人, 等等。
机器人是一种能够通过编程和自动控制来执行诸如作业或移动等任务的机器[12]。1967 年, 机器人的定义首次被提出, 其中有两个定义比较具有代表性。森政弘与合田周平提出“机器人是一种具有移动性、个体性、智能性、通用性、半机械半人性、自动性、奴隶性等 7 个特征的柔性机器”; 加藤一郎强调机器人应当具有仿人的特点, 即具有如下 3 个条件的机器可以称为机器人: 1)具有脑、手、脚等三要素的个体; 2)具有非接触传感器(用眼、耳接受远方信息)和接触传感器; 3)具有平衡觉和固有觉的传感器。尽管他们对机器人的定义不尽相同, 但是可以发现一个共性: 机器人应具有协助人或代替人执行任务的能力, 即机器人应具备一定的技能。机器人的技能指机器人在某个特定目的下执行的连续动作序列, 比如趋近技能、抓握技能、爬行技能和行走技能等[13]。因此, 如何使机器人获得各项技能, 一直是机器人研究领域的核心课题。
机器人学习指机器人模拟实现人类的学习行为, 并像人类一样通过不断学习来改善自身的性能, 从而大幅提高自适应能力和智能化水平。机器人从无到有获得技能的这一过程称为技能习得。传统机器人的技能习得一般采用固定的编程方式, 通常通过人工示教的方式来完成。这种方式不仅费时费力, 当机器人在长期使用的过程中因机械磨损引起机械参数改变时需要重新校准, 而且随着应用的深入, 当面临复杂多变的非结构化应用场景时会显得力有未逮。因此, 设计具有多模态感知和自主决策的机器人技能学习系统, 使机器人像人一样有能力在动态变化的未知环境中通过与环境交互进行自主学习, 是更具潜力的途径。
目前的机器人学习主要以机器学习算法为基础。我们对机器人学习的相关研究进行总结梳理, 依据数据类型, 将机器学习的方法分为 4 类: 基于强化学习的方法、基于模仿学习的方法、基于迁移学习的方法和基于发展学习的方法。
强化学习(reinforcement learning, RL)是机器学习的一个重要分支, 在学习过程中, 智能体与环境不断交互, 通过试错的方式来学习最优策略的马尔科夫决策过程(Markov decision-process, MDP), 其目标是最大化累计回报[14]。强化学习最早起源于最优控制问题, 1957 年, Bellman[15]提出用于解决最优控制问题的马尔科夫决策过程, 为日后强化学习的形式化奠定了基础。强化学习的另一个起源来自对动物行为的实验观察。研究者发现动物在面对相同的情景时会表现出不同的行为, 它们更倾向于表现出能够引起自身满足感的行为, 而对那些会给自己带来不适的行为则尽量避免[16]。换言之, 在与环境的互动过程中, 动物通过不断试错来巩固自己的行为, 这种试错的思想与机器人通过与环境交互来学习的想法不谋而合。强化学习系统由 4 个基本部分组成: 状态集合 S、动作集合 A、状态转移概率矩阵 P 和奖励函数 R[17]。智能体在当前状态 st 下, 根据策略 π 选择动作 at, 并作用于环境, 根据奖励函数得到环境反馈的奖励 rt 后, 以转移概率移到下一个状态 st+1。在强化学习中, 定义两种函数来衡量策略的好坏: 状态值函数 V 和动作值函数 Q, 如式(1)和(2)所示:
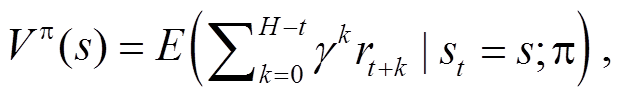 (1)
(1)
 (2)
(2)
其中, H 为轨迹序列的长度, 0<γ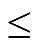 1 为折扣因子。
1 为折扣因子。
基于强化学习框架的机器人学习方法可以分为3 个阶段: 策略执行阶段、样本收集阶段和策略优化阶段[18]。在策略执行阶段, 机器人依据当前策略π 不断与环境交互, 直到到达终止状态。在样本收集阶段, 根据得到的轨迹系列(τ: s0, α0, s1, α0…, sH)计算累计奖赏 R(τ):![]()
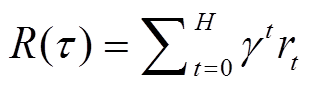 。 (3)
。 (3)
在策略优化阶段, 机器人根据状态值函数 Vπ(s)或动作值函数 Qπ(s,a)对策略进行优化。
近年来, 越来越多的机器人在强化学习框架下进行学习[19]。2004 年, Kohl 等[20]提出一种机器学习方法来优化四足机器人的前进步态。他们使用策略梯度强化学习方法, 自动搜索机器人可能的策略参数集, 以便找到最快的步态参数。实验结果在 Sony Aibo 机器人上得到验证, 如图 1 所示。Kim 等[21]用非线性模型来拟合直升机的动力学特性, 并基于强化学习框架用该模型来学习直升机的自主控制, 成功地实现直升机的自主飞行。Tedrake 等[22]提出一种基于统计的策略梯度方法, 优化双足机器人的在线行走控制, 使得机器人可以在 20 分钟内学会快速行走。Ko-ber 等[23]提出参数化运动基元(parametri-zed motor primitives)的概念, 并将策略梯度的方法与参数化运动基元相结合, 用于学习机器人手臂的复杂运动控制。
在强化学习过程中, “获取观察值—采取行动”这一流程中经常出现错误, 导致系统只能得到局部最优解。Luo 等[24]提出一种分层运动建模的方法, 用于解决机器人自主实现运动技能。随着深度学习技术的不断发展, Levine 等[25]提出一种端到端的策略梯度强化学习算法, 用于机器人的视觉运动控制, 其策略利用卷积神经网络(convolutional neural net-work, CNN)来表示。Wei 等[26]在没有任何运动策略先验的情况下, 提出一种基于双 DQN 的深度强化学习框架, 用于实现轮式机器人对目标高效、流程的追逐任务, 并在 Turtlebot 机器人上得到验证。Yamada 等[27]结合运动规划和强化学习的优点, 提出基于运动规划器增强的强化学习方法 MoPA-RL (Motion Planner Augmented RL)。该方法可用于在有障碍物条件下的机器人手臂操作任务, 如图 2 所示。同样是将运动规划和强化学习结合起来, Xia 等[5]提出针对机器人移动操作(mobile manipulation)任务的 ReLMoGen 框架。该框架利用强化学习方法来预测子目标, 并通过运动规划器来规划完成子目标所需的动作序列。与单纯的运动规划不同, Bra-kel 等[9]提出基于自进化的步态生成器来引导强化学习训练, 通过自主学习, 机器人能探索出合理的步态, 并穿越各种高难度场景。2022 年, Weerakoon等[28]采用一个经过充分训练的深度强化学习网络, 实现机器人在不平整户外地形中进行可靠的自主导航。与之前的导航方法相比, 在高海拔地区, 采用该方法的机器人轨迹的成功率提高 35.18%, 累计海拔梯度降低 26.14%。
与单纯使用神经网络相比, 强化学习与环境交互实现自主学习, 无需大量带标签的数据集即可学到新的技能, 并且具有较好的理论保证。同时, 强化学习的一般性、易扩展性和泛化性也是其在机器人学习领域得到广泛应用的原因之一。

图1 Aibo机器人以291 mm/s小跑的步态快照[20]
Fig. 1 Snapshots of the Aibo trotting at 291 mm/s[20]

图2 在有障碍物条件下的机器人手臂操作技能自主学习[27]
Fig. 2 Manipulation tasks in obstructed environments[27]
尽管基于强化学习的方法通过与环境交互不断试错, 可以学习到很多复杂的技能, 但是由于需要大量的样本, 过多的交互次数会对机器人硬件造成不可逆转的损耗, 因此基于强化学习的方法的时间代价和成本代价非常庞大。通过现实环境中存在的大量示范数据去学习范例背后策略的模仿学习(imi-tation learning), 是解决这一问题的有效方法[29]。模仿学习又称示教学习(learning from demonstration), 与纯粹的强化学习不同, 模仿学习在降低学习过程中搜索空间的复杂度、减少学习过程所需的样本量以及加快学习时间等方面具有非常显著的效果。随着人工智能技术的不断发展, 模仿学习逐渐成为机器人学习领域的核心研究方向之一[29]。
模仿学习省去了传统编程方式中机器人标定和任务位置标定等步骤, 只需示教者根据自己的任务要求进行轨迹示教, 并通过动作编码回归得到一条优化的机器人运动轨迹[30]。传统的模仿学习主要包括示教、引导和回放 3 个过程[31–32]。1996 年, Muench 等[33]提出一款全新的支持交互式示范编程的人机交互系统, 用来探究如何形式化一个模仿学习的任务、如何在新的环境中复现已有技能以及如何评价模仿学习的好坏等机器人模仿学习中的关键问题, 并取得一定的成果。Hovland 等[34]根据人类示范数据, 利用隐马尔可夫模型(Hidden Markov Model, HMM)学习装配技能。Schaal[35]研究模仿学习如何帮助仿人机器人学习技能, 并提出 3 个关键问题: 有效的运动学习、动作和感知之间的联系以及运动基元的模块化运动控制, 成为众多学者对机器人模仿学习研究的重要基础。Calinon 等[36]提出基于目标导向的模仿学习方法, 实现机器人提取演示任务的目标, 并成功地确定能够满足这些目标的模仿策略。Peter 等[37]结合动态运动基元(dynamic motion primitive, DMP), 实现机器人打乒乓球这项技能。
鉴于单纯的使用模仿学习方法易使训练得到的策略陷入局部最优解, 从而导致机器人运动技能的学习不如人意, 一些学者尝试将模仿学习与强化学习相结合。Luo 等[38]分别采用随机策略梯度强化学习和模仿学习来完成基于 DMP 模型的仿生策略学习过程, 并利用 DMP 模型的不变性, 采用高斯过程(Gauss process)回归, 推广推搡恢复策略, 最终实现一种在线自适应推搡恢复控制策略。该策略在仿真机器人和实际双足仿人机器人 PKU-HR5 上均得到有效的验证, 效果如图 3 所示。
Guenter 等[39]基于一个由速度轨迹调制的动态系统生成器, 通过与强化学习结合, 设计一款在受约束情况下能够让机器人手臂趋近任务的系统, 以便允许其在面对有障碍物的情况下能够快速调整轨迹。Hester 等[40]提出将示教数据添加到 DQN回放记忆单元(replay memory), 有效地提升学习效率。在预训练阶段, 他们从演示数据中进行小批量采样, 并通过 4 种损失来更新网络: 1 步双 Q 学习损失(1-step double Q-learning loss)、n 步双 Q 学习损失(n-step double Q-learning loss)、大边缘分类损失(large margin classification loss)以及 L2 正则损失(L2 regularization loss)。损失函数计算公式如下所示:
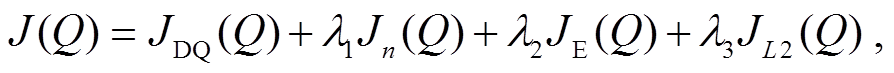 (4)
(4)
其中,
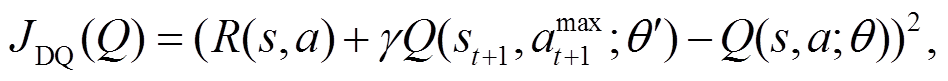 (5)
(5)
 (6)
(6)
随着深度学习技术的不断发展, 越来越多的研究者将深度学习的方法应用于机器人模仿学习中, 其中一个广泛使用的方法是由 Goodfellow 等[41]提出的生成对抗网络(generative adversarial network, GAN)。GAN 由生成器(generator)和判别器(discri-minator)两部分组成, 生成器负责生成能够骗过判别器的样本, 判别器负责判断样本是真实的样本还是生成器生成的样本。Ho 等[42]把生成对抗网络结合到模仿学习中, 提出生成对抗模仿学习(genera-tive adversarial imitation learning, GAIL)算法。该算法的生成器由策略模型表示, 判别器由回报函数模型表示。在此基础上, Merel 等[43]基于GAIL 实现人体运动捕捉数据的模仿学习, 使一个虚拟 3D 仿真机器人能够学习人的多种运动行为, 如行走、跑步和起立等。随后, Tsurumine 等[44]探索一种用于机器人布料操作任务的生成对抗模仿学习方法 P-GAIL。与 GAIL 不同的是, P-GAIL 采用基于价值函数的深度强化学习方法来训练, 可以在策略更新时考虑平滑度和因果熵, 从而实现快速稳定的机器人模仿学习。尽管 GAIL 在模仿学习领域取得非常重要的进展, 但由于 GAIL 的训练比较繁琐, 形式比较复杂, 因此适用性不强。针对此问题, Peng 等[45]基于强化学习和模仿学习, 提出一个可扩展性很强的虚拟机器人运动生成框架DeepMimic。该框架不仅能够模仿多种如跑步、跳跃、翻转等复杂的运动技能, 还可以将模仿动作的目标与任务目标相结合, 高效准确地完成任务。Peng 等[46]将DeepMimic 方法用于四足机器人 Laikago 的运动控制中, 取得很好的效果, 如图 4所示。

图3 PKU-HR5推搡恢复策略演示[38]
Fig. 3 Illustration of PKU-HR5 push recovery with learned strategy[38]
Wei 等[47]提出一个基于模仿学习、强化学习与知识融合的端到端机器人导航方法。该方法通过模仿学习, 使得机器人获取与导航有关的先验知识, 并设计一个基于 CNN 的网络模型, 用于提取激光雷达传感器的特征, 最后利用强化学习算法, 学习一种高效稳定的导航策略。Li 等[48]将模仿学习与强化学习相结合, 提出一个用于语义场景图生成的学习框架, 使机器人能够自主生成一条合适的路径来探索环境。
尽管深度模仿学习在模仿学习这一领域已经取得突出的成果, 但是收集示范数据比较复杂且代价高昂。因此通过少量训练数据使机器人学习到新的技能具有迫切的需求和重大的意义。一些研究者考虑利用元学习来研究机器人的模仿学习。元学习, 即学习如何学习, 是一种通过在包含少量标记数据的大量相关任务的任务集上对策略进行训练的训练方式, 能够自动学习任务集中的共有知识。2017年, Finn 等[49]提出与模型无关的元学习算法 MAML (model-agnostic meta-learning), 用于强化学习问题, 并系统地阐述 MAML 在少样本模仿学习、元强化学习和少样本目标推断中的应用[50]。Duan 等[51]利用 MAML 形式化模仿学习问题, 提出一个基于模仿学习的元学习框架。由于该框架基于多种任务训练得到元学习策略, 基于新任务进行一次示教即可学得实现该任务的技能, 因此也称一次性模仿学习(one-shot imitation learning)。然而, 大多数元学习方法只专注于教机器人从单一的示范领域学习。鉴于人类可以从各种相关领域获得并合并知识, Hu 等[52]提出随机领域自适应元学习(random domain-adaptive meta-learning, RDAML)框架。该框架通过不同的随机采样参数, 教机器人从多个演示领域(如人类演示+机器人演示)学习。一旦训练完成, 经过训练的模型可以适应新的环境, 并给出相应的视觉演示。此外, 利用机器人过去的良好经验决策是近年来提出的模仿学习策略的一个全新的思路。Oh 等[53]提出自我模仿学习(self-imitation learning, SIL)方法。Luo 等[54]提出基于规划的自我模仿学习(self-imitation learning by planning)方法, 通过对当前策略的访问状态进行规划来自动收集用于模仿的演示数据。

每幅图的第1行是参考动作; 第2行是仿真机器人的动作; 第3行是实体机器人的动作
图4 通过模仿参考动作自主学习表演技能[46]
Fig. 4 Performing skills learned by imitating reference motions[46]
总体而言, 传统的模仿学习方法和深度模仿学习方法基于示教数据对策略进行初始化, 可以有效地提高机器人的学习效率, 但是, 获得大量的示教样本往往需要付出昂贵的代价。相比而言, 基于小数据学习的元学习模仿学习方法更具优势, 但是目前的元学习还局限于新任务的测试阶段, 明确机器人的训练环境和数据形式以及设计合适的元学习网络结构, 是需要解决的关键问题。
除元学习外, 迁移学习(transfer learning)也是一种可以利用少量训练数据使机器人学习到新技能的方法。迁移学习指机器人通过对过往经验或已有知识的再利用, 加快学习执行新任务的能力, 实现不同技能之间的迁移[55]。与先前学习技能有关的任务称为源任务, 新任务称为目标任务。在机器人学习领域, 迁移学习常常跟强化学习相结合, 将迁移学习中的任务形式化为强化学习中的 MDP, 即迁移强化学习[56–57]。迁移强化学习要实现不同 MDP 之间的迁移, 这些 MDP 有可能是动作空间不同, 有可能是状态空间不同, 也有可能是状态转移方程不同。迁移学习的一个直观想法是直接在实体机器人上进行任务迁移。Thrun 等[58]提出可以捕捉机器人及其环境的不变性的迁移学习方法, 实现移动机器人在未知室内环境的导航。Degrave 等[59]利用粒子群算法来实现四足机器人在不同地形上行走的迁移。Wang 等[60]利用受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)来实现双足仿人机器人从平面行走到斜坡行走的迁移。
直接在实体机器人上进行任务迁移的做法虽然可行, 但会造成机器人与环境之间的交互次数过多, 加快机器人的机械磨损, 并减少其使用寿命。针对上述问题, 一种可行的方法是先在仿真环境中进行训练, 然后在现实环境中部署(sim-to-real)。通过迁移学习, 将在仿真环境中训练好的稳定策略迁移到真实环境中, 策略在新环境中仅通过少量探索即可达到要求。然而, 仿真环境与现实环境通常因差距过大而不匹配, 即产生现实鸿沟(reality gap), 这是迁移学习中面临的一个非常重要的问题。
一种可行的办法是构造更真实的物理模拟器, 使得仿真过程中的环境及其生成的数据更接近现实环境。Koenemann 等[61]在仿真环境 MuJoCo[62]中实现全身的模型预测控制器(model predictive control, MPC), 并将其应用于实体机器人 HRP-2 的全身多点接触实验, 实现机器人在用桌子作为额外支撑来保持平衡的同时可以伸手触摸到目标物体, 如图5 所示。
James 等[63]利用深度 Q 网络在仿真环境中训练7 自由度的机器人手臂抓取物体, 并将策略直接迁移到实体机器人上。Johns 等[64]提出一个可以预测机器人手臂所有抓握姿势的评价函数, 用于平行爪抓取, 并综合使用仿真环境和实体环境中的深度图像数据, 利用卷积神经网络, 将深度图像映射到实际的抓取中。Tan 等[65]通过改进物理模拟器并学习可靠的策略来缩小仿真与现实的差距, 使四足机器人Minitaur 可以在仿真环境学习小跑和奔驰的步态控制后, 迁移到现实环境中。他们设计一个用来激励快速向前运动并惩罚高量能耗的奖励函数:
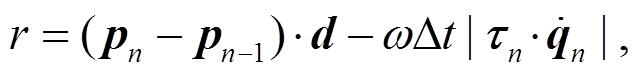 (7)
(7)
其中, pn 和 pn–1 是机器人基座在当前和前一个时间步的位置, d 是期望的运行方向, Δt是时间步长, τ 是电机扭矩, 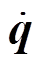 是电机速度。
是电机速度。
另一种方法是域适应(domain adaptation)。与构造更真实的物理模拟器不同, 它并不要求逼真的物理模拟器, 而是将仿真环境中(源域)训练得到的策略在现实环境(目标域)中进行再适应, 其背后的假设是, 不同的领域之间具有共同的特征, 在一个域中学习得到的行为和特征能够帮助在另一个域中学习。Christiano 等[66]利用从现实环境中得到的数据训练一个逆动力学模型, 并利用这个模型, 将仿真过程中学到的策略迁移到实体机器人 Fetch 上。Tzeng 等[67]利用成对约束(pairwise constraints)来学习不同域之间的共同特征, 在机器人状态估计的背景下解决视觉输入的域适应问题。然而, 在迁移到现实环境中时, 仍需要进行域适应训练, 域随机化(domain randomization)可以有效地避免进行适应训练。这种方法的主要思想是, 如果随机化仿真环境中的参数足够多样化, 那么也可以将真实环境视为仿真环境的一个变种。一种常见的方法是随机化视觉特征参数, 这种方法在基于视觉的机器人策略中经常被使用。Tobin 等[68]用仿真器随机化视觉特征参数后渲染得到的图像来训练物体检测器, 并将得到的物体检测器用于在真实机器人上进行抓取控制。除随机化视觉特征参数外, 利用随机化动力学参数来训练操作策略也被广泛应用。Peng 等[69]在训练过程中随机化仿真环境的动力学参数(如质量、摩擦力和阻尼系数等), 使生成的策略能够适应很多不同的动力学参数。他们在机器人手臂物体推动任务中进行方法验证, 成功地使机器人手臂可以将物体从随机初始化的位置移动到目标位置。然而, 在他们的工作中, 随机化仿真环境的动力学参数需要手动调整。为此, Chebotar 等[70]提出一种可以在与现实环境交互的过程中自动学习仿真环境动力学参数分布的域适应方法。该方法被用于两个任务: 插入孔内(swing-peg-in-hole)和打开抽屉(drawer opening)。也有研究者同时随机化视觉特征参数和动力学参数。Andrychowicz 等[71]利用强化学习方法, 在仿真环境中训练 Shadow 机器人灵巧手的操作策略, 并将得到的策略迁移到实体 Shadow 机器人灵巧手上, 成功地实现积木块在灵巧手中通过视觉感知从初始状态到目标状态的旋转操作, 如图6 所示。Du 等[6]提出一种通过迭代搜索过程, 自动使仿真中系统参数分布接近现实世界中参数分布的方法。
除现实鸿沟外, 迁移学习中还经常出现灾难性遗忘(catastrophic forget)问题, 即当学习完成一项新任务时, 会忘记之前的任务。针对这一问题, Rusu等[72]提出渐进式网络(progressive network), 该网络横向连接到先前任务习得的特征, 利用先验知识有效地避免遗忘。同年, 他们利用渐进式网络, 将机器人手臂的策略从仿真环境迁移到现实环境中[73], 如图 7 所示。Blum 等[74]采用记忆重放(memory re-place)方法, 对当前以及之前的环境信息进行联合优化, 有效地降低了灾难性遗忘的风险。Sharma 等[75]以机器人织物为背景, 研究自动确定在模拟中训练的模型何时可以可靠地转移到物理机器人上的策略。

图5 HRP-2机器人的全身多点接触实验[61]
Fig. 5 Whole-body multi-contact experiment on HRP-2[61]

图6 灵巧手将木块从初始状态旋转到目标状态[71]
Fig. 6 Manipulating a block from an initial configuration to the goal configuration with a five-fingered humanoid hand trained with reinforcement learning[71]
相比于隐式地借鉴人的机理的模仿学习, 发展学习指的是通过显式地借鉴人的认知发展机理来学习的机器人技能。皮亚杰提出关于儿童认知发展的 4 个阶段: 感知运动阶段、前运算阶段、具体运算阶段和形式运算阶段。越往后的阶段越能以更复杂的方式去理解世界, 该思想为机器人学习提供了理论基础。Brooks 等[76]提出实现智能的 4 个关键要素: 发展、社交、具身和融合, 并根据这些要素设计一个类人的智能系统。Weng 等[77]系统地提出机器人自主心智发展这一概念, 认为可以通过借鉴人从婴儿到成人的智能发育过程来实现机器人的智能, 借助自身携带的传感器和执行器与外部环境进行交互, 并像人一样在交互过程中逐渐提升智能水平。Asada 等[78]提出认知发展机器人(cognitive de-velopmental robotics, CDR), 这是设计仿人机器人的一种全新的方法。自此, 基于认知发展思想来研究机器人学习的发展机器人学(developmental robotics)成为机器人领域的一个核心内容[79–80]。
1998 年, Brooks等[81]研发的Cog机器人(图8(a))是最早用在认知发展机器人研究中的机器人之一, 用于社交学习[88]、主动视觉和启发式学习[89]等研究中。Kozima[82]开发的 Infanoid 机器人(图 8(b))广泛用于儿童与机器人的交互实验中, 用来研究人类的社交发展。SARCOS 公司[83]研发的 CB 机器人(图8(c))用于研究运动控制和社会学习任务, 以便更好地理解人与机器人之间的交互行为。Minato 等[84]开发的 CB2 机器人(图 8(d)), 全身覆盖分布式的触觉传感器, 主要用于研究机器人感知运动方面的发展。此后, 在欧盟第六和第七框架计划支持下, 一款外形为两岁儿童的仿人机器人 iCub(图 8(e))被研发出来[85]。iCub 的软件和硬件均是开源的, 使得它成为发展机器人研究中的一个基准平台。Ishihara等[86]开发一款婴儿机器人 Affetto(图 8(f)), 主要用于研究婴儿机器人与人类看护者之间的情感交流。Kerzel 等[87]开发的仿人机器人 NICO(图 8(g))用于神经认知建模和多模态人机交互方面的研究。此外, 还有 ASIMO[90], QRIO[91], Nao[92]和 PR2[93]等仿人机器人相继研制。
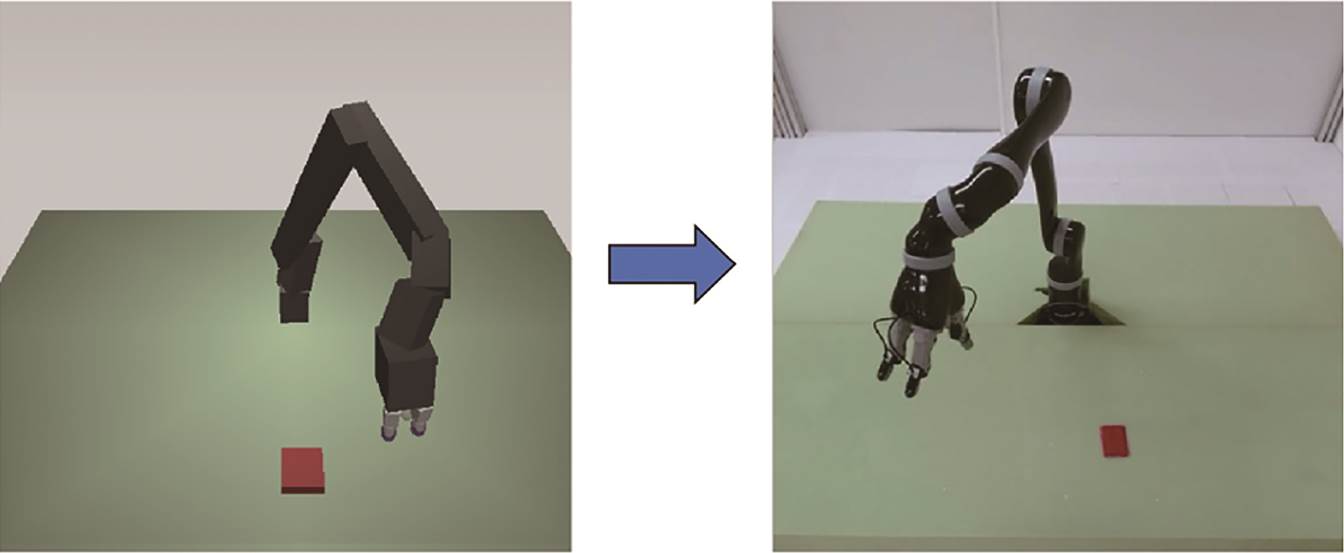
图7 仿真环境到真实环境的机器人手臂迁移学习[73]
Fig. 7 Sim-to-real transfer learning on a robot arm[73]

图8 用于研究认知发展学习的机器人[81–87]
Fig. 8 Robots for cognitive developmental learning [81–87]
通过内在动机(intrinsic motivation)来驱动机器人进行自主探索学习是发展机器人研究中的常用方法。内在动机的概念最出现在心理学中。Baldas-sarre[94]将内在动机行为定义为生物体在没有明确目标情况下“自由”选择的动作。内在动机可以划分为基于知识的内在动机和基于能力的内在动机。
1)基于知识的内在动机。可以分为基于新奇性的内在动机以及基于预测的内在动机两类[95]。Huang 等[96]开发一个整合了新奇性、习惯机制和强化学习的用于发展机器人的评价系统, 并在 SAIL移动机器人平台上得到了实验验证。Oudeyer 等[97]提出一个模拟内在动机的系统 IAC(intelligent ada-ptive curiosity), 用于驱动机器人在连续嘈杂的不均匀环境中自主发展学习, 最终产生越来越复杂的行为模式。Oudeyer 等[98]和 Gottlieb 等[99]对 IAC 系统做了进一步的阐述和完善。Nguyen 等[100]将内在动机学习和模仿学习结合起来, 提出一种社会指导性的内在动机系统 SGIM-D(socially guided intrinsic motivation by demonstration), 可在连续的高维机器人感知运动空间中在线学习反模型。Hester 等[101]提出 Texplore-Vanir 算法, 将基于随机森林的模型学习与两种新颖性内在奖励相结合, 一种探索模型预测不确定的地方, 另一种获得其模型尚未经过训练的新颖经验。
2)基于能力的内在动机。Wei 等[102]借鉴人类跌倒时的表现, 提出一种新的机器人跌倒保护方法。Luo 等[103]讨论机器人像婴儿一样自主学习手臂趋近能力(reaching)这一问题, 借鉴婴儿从出生到4 个月期间发展出手臂趋近能力的最新机理, 提出一个基于 motor babling 的三阶段学习框架, 如图 9所示。在第一阶段, 提出一种基于自动编码器的本体感知模型, 用于发展机器人的本体感觉; 在第二阶段, 提出一种简化的模拟注视功能的策略; 在第三阶段, 提出一个新的正演模型和两个反演模型。该框架在 PKU-HR6.0II 上得到验证, 表现出良好的适应性。
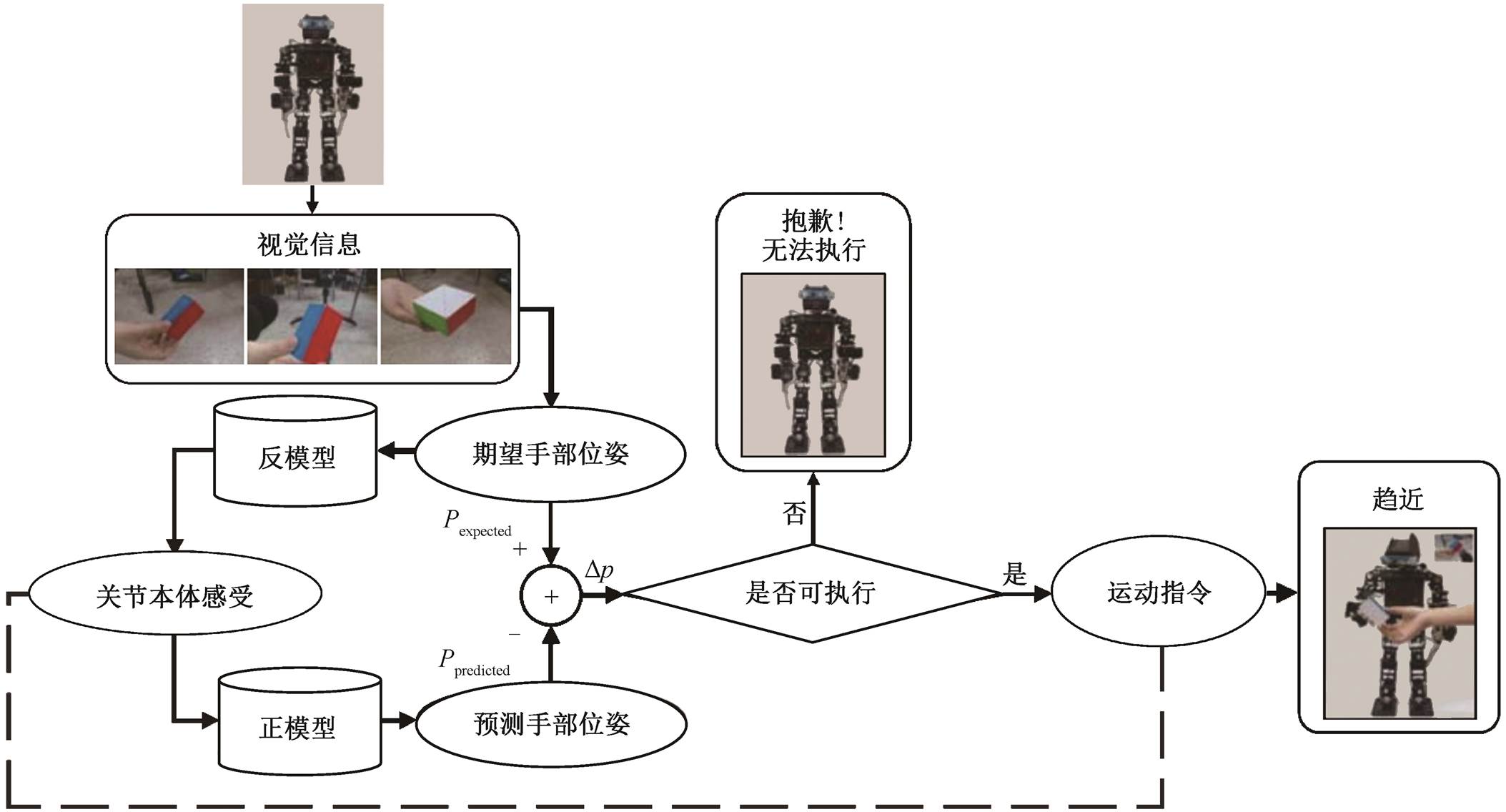
图9 机器人手臂趋近能力自主学习三阶段框架图[103]
Fig. 9 Three-stage framework for autonomous learning of robot reaching skills[103]
受 Wei 等[102]和 Luo[103]等启发, Liu 等[104]借鉴人类学习击鼓的过程, 提出机器人自主学习击鼓技能的新途径。机器人首先通过其运动系统和声音之间的重复感觉运动经验来发展学习它的内部模型, 然后在开放式学习方式下, 根据听觉反馈, 不断地调整动作, 该方法的整个框架如图 10 所示。Qureshi等[105]提出一种用于从人机交互经验中学习社交技能的强化学习框架, 机器人通过基于动作的预测模型来获得内在动机奖励。然而, 机器人并不能自主采样目标, 进行有效的探索。针对这一问题, Laver-sanne-Finot 等[11]提出内在动机驱动的目标探索框架IMGEPs (intrinsically motivated goal exploration pro-cesses), 用深度表示学习算法来学习目标的表示, 并将学习得到的表示作为探索算法的目标空间。随后, Vulin 等[106]受婴儿通过身体互动探索世界这一内在动机的启发, 使用力传感器来模拟触觉感知, 并利用触觉信息来提高机器人学习技能的能力。
除通过内在动机来驱动机器人进行自主探索学习外, 社交学习(social learning)也是发展机器人研究中的重要方法[95]。Meltzoff 等[107]发现新生儿出生后就展现出模仿他人表情和行为的本能。War-neken 等[108]在人类婴儿与灵长类动物的比较心理学研究中表示, 2 岁左右的儿童倾向于无私合作, 而在黑猩猩群体中则没有观察到这种现象。这些发展心理学的研究实例为机器人社交学习领域的研究提供了坚实的基础。Demiris 等[109]基于 AIM儿童心理学模仿模型, 在 HAMMER 框架上实现机器人模仿技能的获取。HAMMER 框架包括一组成对的正、逆模型, 其中正模型建立随机运动与视觉、本体感觉或环境结果间的关联, 与婴儿发展的运动蹒跚阶段类似[109–111], 该框架的具体结构如图 11 所示。Do-miney 等[112]对合作与共享意图的社交技能建模, 把一系列游戏动作存储为共享方案, 形成协作认知表征的核心。
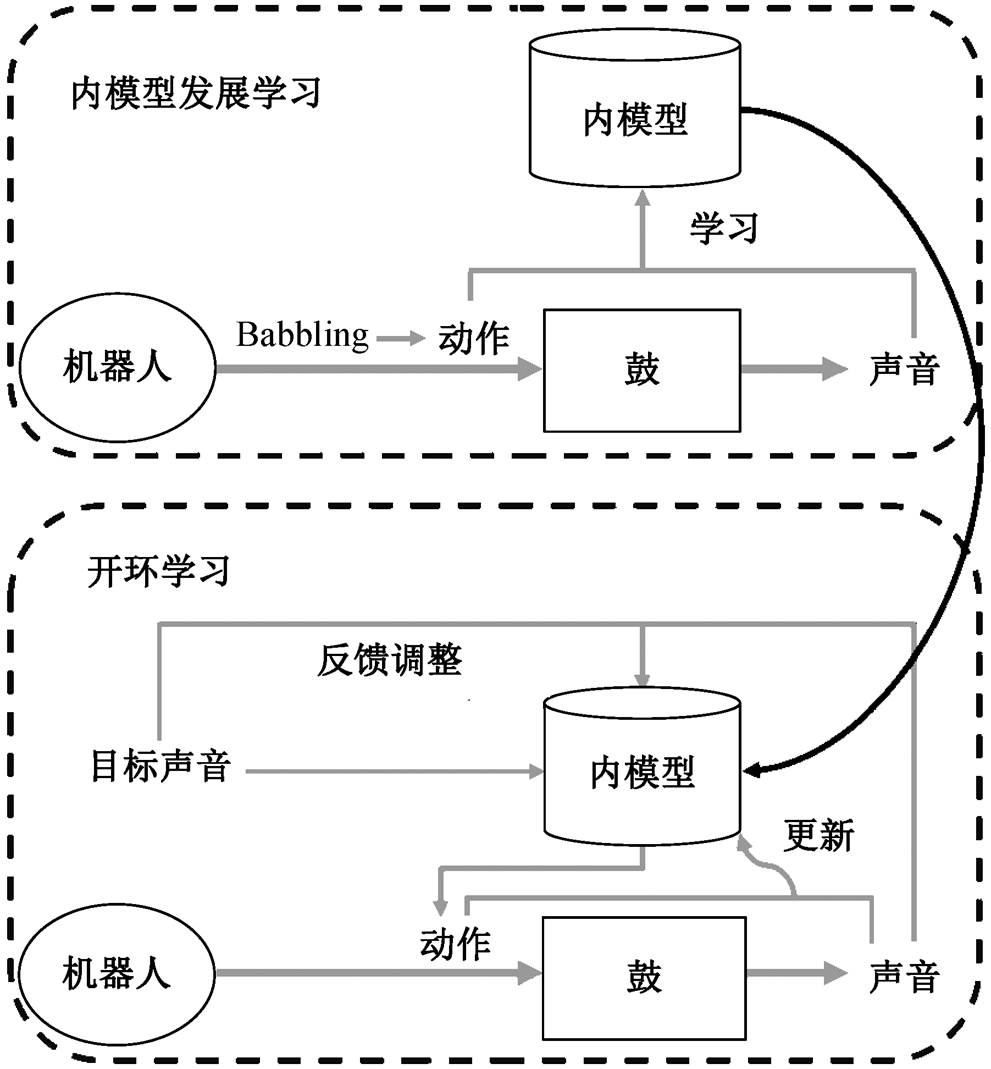
图10 机器人自主学习击鼓技能框架图[104]
Fig. 10 Framework for autonomous learning of robot playing drums[104]
无论是基于内在动机的自主探索学习还是社交学习, 都有效地借鉴了人从婴儿到成人的智能发展和技能学习过程。相比于传统的方法, 基于发展学习的方法的优点主要体现在 3 个方面[97,113]: 开放式学习、促进技能的再利用和层次化学习。基于强化学习的方法无需大量带标签的数据即可学到新的技能, 并且拥有较好的理论保证, 但是需要与环境交互不断试错, 会对机器人硬件造成不可逆转的损耗。基于模仿学习的方法无需与环境的交互数据, 但是需要大量的示教数据, 同样产生昂贵的成本。基于迁移学习的方法有效地降低了获取数据方面的代价, 却面临现实鸿沟与灾难性遗忘等问题。基于发展学习的方法另辟蹊径, 不再单纯以数据驱动的方式训练模型来获取技能, 而是通过借鉴人的行为机理, 让机器人习得新技能。四类机器人学习方法的性能对比如表 1 所示。
尽管当前机器人学习领域已经取得诸多成果, 但在降低训练成本、提高学习效率、减弱对数据的依赖性以及增强技能的鲁棒性与泛化性等方面仍然存在一些亟待解决的问题。本文提出目前机器人学习领域存在的挑战, 同时对机器人学习的未来发展趋势加以探讨。
无论是基于强化学习的方法还是基于迁移学习的方法, 若想使机器人能够实现自主学习, 均需要大量的训练数据。获得大量的训练数据往往代价高昂, 因此降低对数据的需求对机器人学习的发展具有重要价值。目前主流的研究方向大致可分成以下三类: 以在小数据下快速学习为主导思想的迁移学习[55]和元学习[49], 以有效利用旧数据为主导思想的离线强化学习(offline reinforcement learning)[114]和异策强化学习(off-policy reinforcement learning)[115–116], 以减少标注工作为主导思想的无监督、自监督和半监督模型。近年来, 这 3 个方向的研究均已取得一定的成绩, 但降低对数据需求的方法目前差强人意, 有待进一步的探索。
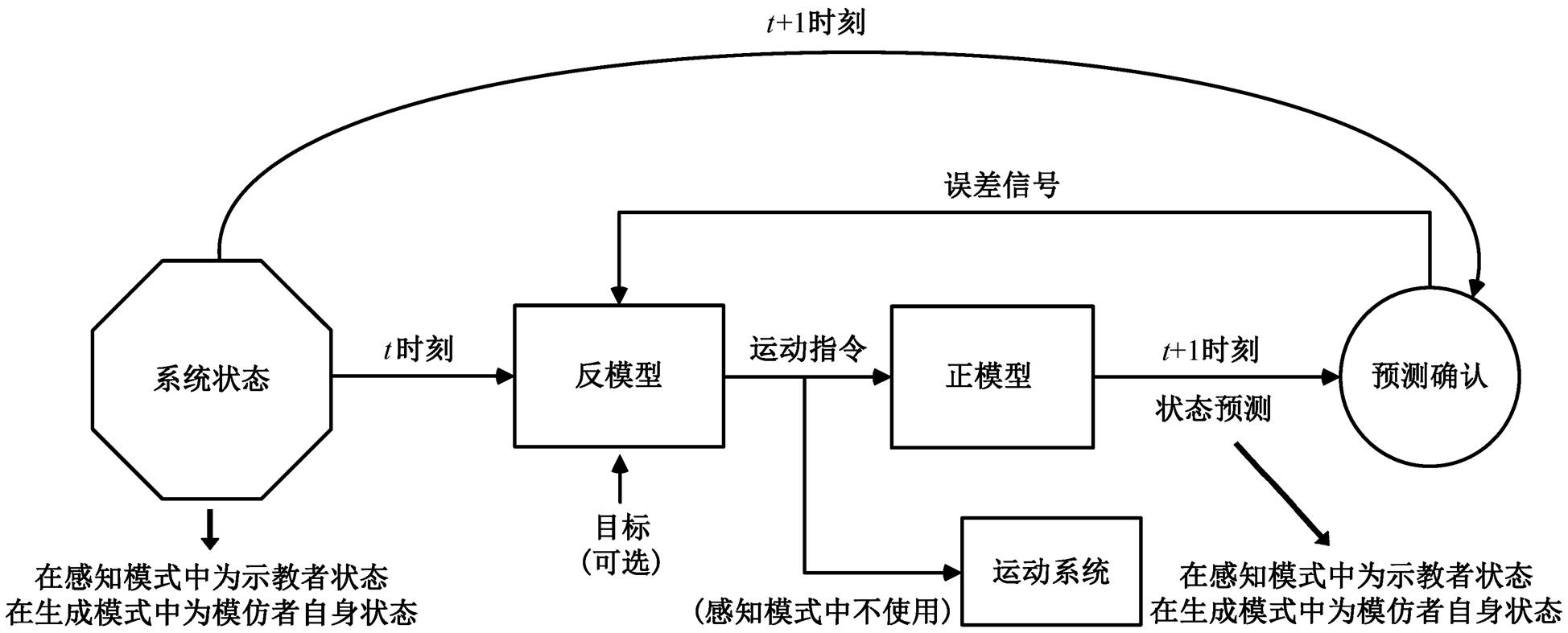
图11 HAMMER框架正、逆模型的基本结构[109]
Fig. 11 Basic structure of the forward model and inverse model in HAMMER[109]
表1 4类机器人学习方法的特点对比
Table 1 Comparison of the characteristics of autonomous learning

学习方法学习效率 学习成本 新环境中获取技能 新实体上获取技能 基于强化学习低(需要与环境不断交互、不断试错)高(不断试错可能会造成机器人硬件不可逆转的损耗)难难 基于模仿学习较高高(大量示教数据的获取往往需要较为高昂的代价)较难难 基于迁移学习高低较易, 但是需要解决现实鸿沟问题较易 基于发展学习较高较低较易较易
结合强化学习的模仿学习方法和结合强化学习的迁移学习方法可以获得更好的性能, 因此可以在一定程度上认为强化学习是机器人学习的基础, 也是实现具有自适应性、自学习能力的智能机器人的重要途径[117]。强化学习本身就是在尝试获得最大奖励, 因此如何设计合理的回报函数直接影响最后学到的策略优劣。然而, 很多强化学习问题的奖励往往是稀疏的(如 Montezuma’s Revenge 游戏[118]), 加上机器人庞大的状态空间和动作空间组合, 往往导致学习困难。针对上述问题, 很多研究者提出解决方法。一类方法是通过内在动机来驱动机器人进行自主探索学习, 另一类方法则是改善或细化学习方式。HER 通过“后见之明”改善稀疏奖励下学习困难的问题[119], 逆强化学习(inverse reinforce-ment learning)[120]则从专家示教中学习回报函数, 层次化学习(hierarchical reinforcement learning)也可以有效地解决上述问题[121–122]。然而, 目前大多数层次化学习工作都是人工指定并训练好层次[123–124], 这样的层次化学习不具有通用性。因此, 如何在训练过程中自动形成层次化结构, 逐渐成为层次化学习领域的前沿和热点。对于层次的划分有两种, 一种是时间上连续动作的抽象, 另一种是不同层级控制模块的抽象。前者的主要想法是自动学习连续的动作序列, 如 DDO[125]和 MLSH[126–127]等; 后者的主要思想是上层生成子目标交给下层完成, 如DIAYN[128], Chaining[129]和 DADS[130]等。总体而言, 层次化学习解决问题的能力有所突破, 但仍有很大的改进空间, 如何获得更加有效、合理的层次化结构的形成策略有待进一步探索。
在仿真环境中训练模型可以大大减少实体机器人的交互次数, 降低机器人的损耗, 从而有效地降低训练代价。同时, 在仿真环境中训练还可以避免出现安全隐患, 并且可以采用并行训练的方法来提高训练速度[70]。然而, 模拟器对物理环境的建模存在一定的误差, 因此在仿真环境中学习到的最优策略难以直接在现实环境中应用。尽管域适应[66–67]、域随机化[68–69,71,131]和渐进式网络[72–73]的提出与应用在一定程度上解决了这一问题, 但是如何在具有较大差别的仿真环境与物理环境之间快速准确地实现技能迁移, 仍然是机器人操作技能学习的重要研究方向。
除上述问题外, 如何让机器人更好地借鉴生物的机理, 以便习得相应技能; 如何提高习得技能的鲁棒性, 使其可以快速适用于新的环境, 或适配于新的实体机器人; 如何管理已获得的技能, 并将已有技能自主地结合, 形成新技能; 针对相同的任务, 如何使机器人在不同的环境中自主选择最优策略等也可能会成为机器人学习这一领域未来的研究 热点。
与传统的采用固定编程方式的机器人相比, 机器人学习可以使机器人具有一定的学习和决策能力, 充分适应复杂多变的非结构化应用场景, 展现良好的自主性、适应性与智能性, 是机器人能够在农业生产、工业制造和医疗服务等领域广泛应用的重要基础。
随着人工智能技术与机器人技术的快速发展, 基于强化学习的方法、基于模仿学习的方法、基于迁移学习的方法和基于发展学习的方法普遍应用于机器人学习领域。同时, 随着深度学习在计算机视觉、语音信号处理和自然语言处理等领域的广泛应用, 机器人学习方法与深度学习相结合也取得一系列重大成果。但是, 由于机器人运动场景和操作任务的特殊性, 机器人学习往往需要较高的时间代价和较昂贵的成本, 因此如何降低学习成本, 实现高效的技能学习是未来的一个重要研究方向。此外, 让机器人习得的技能更具自主性与适应性, 实现真正的智能化, 也将是机器人研究领域的前沿与热点。最后, 由于深度学习的可解释性较差, 基于深度学习的机器人学习方法仍然缺乏一定的理论支撑, 还需进一步的研究和论证。
参考文献
[1] Nof S Y. Handbook of industrial robotics. New Jersey: John Wiley & Sons, 1999
[2] Ackerman E, Guizzo E. Darpa robotics challenge: amazing moments, lessons learned, and what’s next. IEEE Spectrum, 2015, 3(7): 34–41
[3] Atkeson C G, Babu Benzun P W, Banerjee N, et al. What happened at the DARPA robotics challenge finals // The DARPA Robotics Challenge Finals: Humanoid Robots to the Rescue. Berlin: Springer, 2018: 667–684
[4] Michie D, Spiegelhalter D J, Taylor C C, et al. Machine learning. Neural and Statistical Classification. London: Ellis Horwood, 1994
[5] Xia F, Li C, Martín-Martín R, et al. Relmogen: Inte-grating motion generation in reinforcement learning for mobile manipulation // IEEE International Con-ference on Robotics and Automation (ICRA). Xi’an, 2021: 4583–4590
[6] Du Y, Watkins O, Darrell T, et al. Auto-tuned sim-to-real transfer // IEEE International Conference on Ro-botics and Automation (ICRA). Xi’an, 2021: 1290–1296
[7] Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning [EB/OL]. (2019–07–05)[2023–05–09]. https://arxiv.org/abs/1509. 02971
[8] Heess N, Dhruva T B, Sriram S, et al. Emergence of locomotion behaviours in rich environments [EB/OL]. (2017–07–10)[2023–05–09]. https://arxiv.org/abs/1707. 02286
[9] Brakel P, Bohez S, Hasenclever L, et al. Learning coordinated terrain-adaptive locomotion by imitating a centroidal dynamics planner // IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Kyoto, 2022: 10335–10342
[10] Levine S, Pastor P, Krizhevsky A, et al. Learning hand-eye coordination for robotic grasping with large-scale data collection // International Symposium on Experi-mental Robotics (ISER). Tokyo, 2016: 173–184
[11] Laversanne-Finot A, Péré A, Oudeyer P Y. Intrinsically motivated exploration of learned goal spaces. Frontiers in Neurorobotics, 2021, 14: 555271
[12] 郭彤颖, 安东. 机器人系统设计及应用. 北京: 化学工业出版社, 2016
[13] Cangelosi A, Schlesinger M. Developmental robotics: from babies to robots. Cambridge: MIT press, 2015
[14] Sutton R S, Barto A G. Introduction to reinforcement learning. Cambridge: MIT Press, 1998
[15] Bellman R. A markovian decision process. Journal of Mathematics and Mechanics, 1957, 17(56): 679–684
[16] Sutton R S, Barto A G. Reinforcement learning: an introduction. Cambridge: MIT Press, 2018.
[17] 刘建伟, 高峰, 罗雄麟. 基于值函数和策略梯度的深度强化学习综述[D]. 北京: 中国石油大学, 2019
[18] 刘乃军, 鲁涛, 蔡莹皓, 等. 机器人操作技能学习方法综述. 自动化学报, 2019, 45(3): 458–470
[19] Kober J, Bagnell J A, Peters J. Reinforcement learning in robotics: a survey. International Journal of Robotics Research, 2013, 32(11): 1238–1274
[20] Kohl N, Stone P. Policy gradient reinforcement lear-ning for fast quadrupedal locomotion // IEEE Internatio-nal Conference on Robotics and Automation (ICRA). New Orleans, 2004: 2619–2624
[21] Kim H J, Jordan M I, Sastry S, et al. Autonomous helicopter flight via reinforcement learning // Neural Information Processing Systems (NeurIPS). Vancou-ver, 2004: 799–806
[22] Tedrake R, Zhang T W, Seung H S. Learning to walk in 20 minutes. Fourteenth Yale Workshop on Adaptive and Learning Systems, 2005, 355: 1939–1412
[23] Kober J, Peters J R. Policy search for motor primitives in robotics. Neural Information Processing Systems (NIPS), 2008, 21: 849–856
[24] Luo D, Wang Y, Wu X. Autonomously achieving bipe-dal locomotion skill via hierarchical motion model- ling // IEEE 14th International Workshop on Advanced Motion Control (AMC). Auckland, 2016: 121–128
[25] Levine S, Finn C, Darrell T, et al. End-to-end training of deep visuomotor policies. The Journal of Machine Learning Research, 2016, 17(1): 1334–1373
[26] Wei Y, Liu T, Deng Y, et al. Learning to chase a ball efficiently and smoothly for a wheeled robot // IEEE 24th International Conference on Mechatronics and Machine Vision in Practice (M2VIP). Auckland, 2017: 1–6
[27] Yamada J, Lee Y, Salhotra G, et al. Motion Planner Augmented Reinforcement Learning for Robot Ma-nipulation in Obstructed Environments // Conference on Robot Learning (CoRL). London, 2021: 589–603
[28] Weerakoon K, Sathyamoorthy A J, Patel U, et al. Terp: Reliable planning in uneven outdoor environments using deep reinforcement learning // IEEE Internatio-nal Conference on Robotics and Automation (ICRA). Philadelphia, 2022: 9447–9453
[29] Argall B D, Chernova S, Veloso M, et al. A survey of robot learning from demonstration. Robotics and Au-tonomous Systems, 2009, 57(5): 469–483
[30] 于建均, 门玉森, 阮晓钢, 等. 模仿学习在机器人仿生机制研究中的应用. 北京工业大学学报, 2016, 42(2): 210–216
[31] Lozano-Perez T. Robot programming. Proceedings of the IEEE, 1983, 71(7): 821–841
[32] Segre A, DeJong G. Explanation-based manipulator learning: acquisition of planning ability through obser-vation // IEEE International Conference on Robotics and Automation (ICRA). St Louis, 1985: 555–560
[33] Muench S, Kreuziger J, Kaiser M, et al. Robot pro-gramming by demonstration (RPD) – using machine learning and user interaction methods for the deve-lopment of easy and comfortable robot programming systems // International Symposium on Industrial Robots (ISIR). Pasadena, 1994: 685
[34] Hovland G E, Sikka P, McCarragher B J. Skill acqui-sition from human demonstration using a hidden Markov model // IEEE International Conference on Robotics and Automation (ICRA). Minneapolis, 1996: 2706–2711
[35] Schaal S. Is imitation learning the route to humanoid robots?. Trends in Cognitive Sciences, 1999, 3(6): 233–242
[36] Calinon S, Guenter F, Billard A. Goal-directed imita-tion in a humanoid robot // IEEE International Confe-rence on Robotics and Automation (ICRA). Barcelona, 2005: 299–304
[37] Peters J, Mülling K, Kober J, et al. Towards motor skill learning for robotics // The 14th International Sympo-sium ISRR. Lucerne, 2011: 469–482
[38] Luo D, Han X, Ding Y, et al. Learning push recovery for a bipedal humanoid robot with dynamical move-ment primitives // IEEE-RAS International Confe-rence on Humanoid Robots (Humanoids). Seoul, 2015: 1013–1019
[39] Guenter F, Hersch M, Calinon S, et al. Reinforcement learning for imitating constrained reaching move-ments. Advanced Robotics, 2007, 21(13): 1521–1544
[40] Hester T, Vecerik M, Pietquin O, et al. Deep Q-learning from demonstrations // Association for the Advance-ment of Artificial Intelligence (AAAI). New Orleans, 2018: 3223–3230
[41] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Gene-rative adversarial networks. Communications of the ACM, 2020, 63(11): 139–144
[42] Ho J, Ermon S. Generative adversarial imitation lear-ning // Neural Information Processing Systems (Neur-IPS). Barcelona, 2016: 4565–4573
[43] Merel J, Tassa Y, Dhruva T B, et al. Learning human behaviors from motion capture by adversarial imitation [EB/OL]. (2017–07–10) [2023–05–09]. https://arxiv. org/abs/1707.02201
[44] Tsurumine Y, Cui Y, Yamazaki K, et al. Generative adversarial imitation learning with deep p-network for robotic cloth manipulation // IEEE-RAS International Conference on Humanoid Robots (Humanoids). Toron-to, 2019: 274–280
[45] Peng X B, Abbeel P, Levine S, et al. Deepmimic: Example-guided deep reinforcement learning of phy-sics-based character skills. ACM Transactions on Gra-phics, 2018, 37(4): 1–14
[46] Peng X B, Coumans E, Zhang T, et al. Learning agile robotic locomotion skills by imitating animals [EB/ OL]. (2020–04–02)[2023–05–09]. https://arxiv.org/abs/ 2004.00784
[47] Wei Y, Fang S, Lin W K, et al. Acquiring robot navi-gation skill with knowledge learned from demonstra-tion // IEEE International Conference on Development and Learning (ICDL). Beijing, 2021: 1–6
[48] Li X, Guo D, Liu H, et al. Embodied semantic scene graph generation // Conference on Robot Learning (CoRL). London, 2021: 1585–1594
[49] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks // Inter-national Conference on Machine Learning (ICML). Sydney, 2017: 1126–1135
[50] Finn C. Learning to learn with gradients phdthes [D]. Berkeley: University of California, 2018
[51] Duan Y, Andrychowicz M, Stadie B, et al. One-shot imitation learning // Advances in neural information processing systems, Long Beach, 2017: 1087–1098
[52] Hu Z, Li W, Gan Z, et al. Learning with dual demon-stration domains: random domain-adaptive meta-lear-ning. IEEE Robotics and Automation Letters, 2022, 7(2): 3523–3530
[53] Oh J, Guo Y, Singh S, et al. Self-imitation lear- ning // International Conference on Machine Learning (ICML). Stockholm, 2018: 3878–3887
[54] Luo S, Kasaei H, Schomaker L. Self-imitation lear-ning by planning // IEEE International Conference on Robotics and Automation (ICRA). Xi’an, 2021: 4823–4829
[55] Pan S J, Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2009, 22(10): 1345–1359
[56] Taylor M E, Kuhlmann G, Stone P. Autonomous transfer for reinforcement learning // International Conference on Autonomous Agents and Multiagent Systems (AAMAS). Estoril, 2008: 283–290
[57] Taylor M E, Stone P. Transfer learning for reinfor-cement learning domains: a survey. Journal of Machine Learning Research, 2009, 10(7): 1633–1685
[58] Thrun S, Mitchell T M. Lifelong robot learning. Ro-botics and Autonomous Systems, 1995, 15(1/2): 25–46
[59] Degrave J, Burm M, Kindermans P J, et al. Transfer learning of gaits on a quadrupedal robot. Adaptive Behavior, 2015, 23(2): 69–82
[60] Wang Y, Han X, Liu Z, et al. Modelling inter-task relations to transfer robot skills with three-way rbms // IEEE International Conference on Mechatronics and Automation (ICMA). Beijing, 2015: 1276–1282
[61] Koenemann J, Del Prete A, Tassa Y, et al. Whole-body model-predictive control applied to the HRP-2 huma-noid // IEEE/RSJ International Conference on Intelli-gent Robots and Systems (IROS). Hamburg, 2015: 3346–3351
[62] Todorov E, Erez T, Tassa Y. MuJoCo: a physics engi-ne for model-based control // IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Lisbon, 2012: 5026–5033
[63] James S, Johns E. 3D simulation for robot arm control with deep Q-learning [EB/OL]. (2016–12–13) [2023–05–09]. https://arxiv.org/abs/1609.03759
[64] Johns E, Leutenegger S, Davison A J. Deep learning a grasp function for grasping under gripper pose uncer-tainty // IEEE/RSJ International Conference on Inte-lligent Robots and Systems (IROS). Daejeon, 2016: 4461–4468
[65] Tan J, Zhang T, Coumans E, et al. Sim-to-real: lear-ning agile locomotion for quadruped robots [EB/OL]. (2018–05–16)[2023–05–09]. https://arxiv.org/abs/1804. 10332
[66] Christiano P, Shah Z, Mordatch I, et al. Transfer from simulation to real world through learning deep inverse dynamics model [EB/OL]. (2016–10–11)[2023–05–09]. https://arxiv.org/abs/1610.03518
[67] Tzeng E, Devin C, Hoffman J, et al. Adapting deep visuomotor representations with weak pairwise con-straints // the 12th Workshop on the Algorithmic Foun-dations of Robotics (WAFR). Mesa, 2020: 688–703
[68] Tobin J, Fong R, Ray A, et al. Domain randomization for transferring deep neural networks from simulation to the real world // IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Vancouver, 2017: 23–30
[69] Peng X B, Andrychowicz M, Zaremba W, et al. Sim-to-real transfer of robotic control with dynamics randomization // IEEE International Conference on Robotics and Automation (ICRA). Brisbane, 2018: 3803–3810
[70] Chebotar Y, Handa A, Makoviychuk V, et al. Closing the sim-to-real loop: adapting simulation randomi-zation with real world experience // IEEE International Conference on Robotics and Automation (ICRA). Montreal, 2019: 8973–8979
[71] Andrychowicz M, Baker B, Chociej M, et al. Learning dexterous in-hand manipulation. International Journal of Robotics Research, 2020, 39(1): 3–20
[72] Rusu A A, Rabinowitz N C, Desjardins G, et al. Progressive neural networks [EB/OL]. (2022–10–12) [2023–05–09]. https://arxiv.org/abs/1606.04671
[73] Rusu A A, Večerík M, Rothörl T, et al. Sim-to-real robot learning from pixels with progressive nets // Conference on Robot Learning (CoRL). Mountain View, 2017: 262–270
[74] Blum H, Milano F, Zurbrügg R, et al. Self-improving semantic perception for indoor localisation // Confe-rence on Robot Learning (CoRL). Auckland, 2022: 1211–1222
[75] Sharma S, Novoseller E, Viswanath V, et al. Learning switching criteria for sim2real transfer of robotic fabric manipulation policies // IEEE 18th International Conference on Automation Science and Engineering (CASE). Mexico, 2022: 1116–1123
[76] Brooks R A, Breazeal C, Irie R, et al. Alternative essences of intelligence // Association for the Advan-cement of Artificial Intelligence (AAAI). Madison, 1998: 961–968
[77] Weng J, McClelland J, Pentland A, et al. Autonomous mental development by robots and animals. Science, 2001, 291: 599–600
[78] Asada M, MacDorman K F, Ishiguro H, et al. Cognitive developmental robotics as a new paradigm for the de-sign of humanoid robots. Robotics and Autonomous Systems, 2001, 37(2/3): 185–193
[79] Lungarella M, Metta G, Pfeifer R, et al. Developmental robotics: a survey. Connection Science, 2003, 15(4): 151–190
[80] Asada M, Hosoda K, Kuniyoshi Y, et al. Cognitive developmental robotics: a survey. IEEE Transactions on Autonomous Mental Development, 2009, 1(1): 12–34
[81] Brooks R A, Breazeal C, Marjanovi M, et al. The Cog project: building a humanoid robot // International Workshop on Computation for Metaphors, Analogy, and Agents. Aachen, 1998: 52–87
[82] Kozima H. Infanoid // Socially intelligent agents. Amsterdam: Kluwer Academic Publisher, 2002: 157–164
[83] Cheng G, Hyon S H, Morimoto J, et al. CB: a humanoid research platform for exploring neuroscience. Advan-ced Robotics, 2007, 21(10): 1097–1114
[84] Minato T, Yoshikawa Y, Noda T, et al. CB2: a child robot with biomimetic body for cognitive develop-mental robotics // IEEE-RAS International Conference on Humanoid Robots (Humanoids). Washington, 2007: 557–562
[85] Vernon D, Metta G, Sandini G. The iCub cognitive architecture: interactive development in a humanoid robot // IEEE International Conference on Develop-ment and Learning (ICDL). London, 2007: 122–127
[86] Ishihara H, Yoshikawa Y, Asada M. Realistic child robot “affetto” for understanding the caregiver-child attachment relationship that guides the child deve-lopment // Joint IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob). Frankfurt, 2011: 1–5
[87] Kerzel M, Strahl E, Magg S, et al. NICO — neuro-inspired companion: a developmental humanoid robot platform for multimodal interaction // IEEE Inter-national Conference on Robot and Human Interactive Communication (RO-MAN). Lisbon, 2017: 113–120
[88] Scassellati B. Theory of mind for a humanoid robot. Autonomous Robots, 2002, 12(1): 13–24
[89] Fitzpatrick P M, Metta G. Towards manipulation-driven vision // IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Lausanne, 2002: 43–48
[90] Shigemi S, Goswami A, Vadakkepat P. ASIMO and humanoid robot research at Honda // Humanoid Ro-botics: A Reference. Dordrecht: Springer, 2018: 55–90
[91] Geppert L. Qrio, the robot that could. IEEE Spectrum, 2004, 41(5): 34–37
[92] Gouaillier D, Hugel V, Blazevic P, et al. Mechatronic design of NAO humanoid // IEEE International Con-ference on Robotics and Automation (ICRA). Kobe, 2009: 769–774
[93] Bohren J, Rusu R B, Jones E G, et al. Towards autonomous robotic butlers: lessons learned with the PR2 // IEEE International Conference on Robotics and Automation (ICRA). Shanghai, 2011: 5568–5575
[94] Baldassarre G. What are intrinsic motivations? A bio-logical perspective // Joint IEEE International Confe-rence on Development and Learning and Epigenetic Robotics (ICDL-EpiRob). Frankfurt, 2011: 1–8
[95] Cangelosi A, Schlesinger M. Developmental robotics: from babies to robots. Cambridge: MIT Press, 2015
[96] Huang X, Weng J. Novelty and reinforcement learning in the value system of developmental robots // Procee-dings Second International Workshop on Epigenetic Robotics. Lund, 2002: 47–55
[97] Oudeyer P Y, Kaplan F, Hafner V V. Intrinsic motivation systems for autonomous mental develop-ment. IEEE Transactions on Evolutionary Computa-tion, 2007, 11(2): 265–286
[98] Oudeyer P Y, Kaplan F. What is intrinsic motivation? A typology of computational approaches. Frontiers in Neurorobotics, 2007, 1: no. 6
[99] Gottlieb J, Oudeyer P Y, Lopes M, et al. Information-seeking, curiosity, and attention: computational and neural mechanisms. Trends in Cognitive Sciences, 2013, 17(11): 585–593
[100] Nguyen S M, Oudeyer P Y. Socially guided intrinsic motivation for robot learning of motor skills. Autono-mous Robots, 2014, 36(3): 273–294
[101] Hester T, Stone P. Intrinsically motivated model lear-ning for developing curious robots. Artificial Intelli-gence, 2017, 247: 170–186
[102] Wei Y, Deng Y, Han X, et al. Biped robot falling mo-tion control with human-inspired active compliance // IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Daejeon, 2016: 3860–3865
[103] Luo D, Hu F, Zhang T, et al. How does a robot develop its reaching ability like human infants do?. IEEE Transactions on Cognitive and Developmental Sys-tems, 2018, 10(3): 795–809
[104] Liu T, Zhang J, Wu X, et al. Robot learning to play drums with an open-ended internal model // IEEE International Conference on Robotics and Biomimetics (ROBIO). Kuala Lumpur, 2018: 305-311
[105] Qureshi A H, Nakamura Y, Yoshikawa Y, et al. Intrinsically motivated reinforcement learning for human–robot interaction in the real-world. Neural Networks, 2018, 107: 23–33
[106] Vulin N, Christen S, Stevi S, et al. Improved learning of robot manipulation tasks via tactile intrinsic motivation. IEEE Robotics and Automation Letters, 2021, 6(2): 2194–2201
[107] Meltzoff A N, Moore M K. Newborn-infants imitate adult facial gestures. Child Development, 1983, 54(3): 702–709
[108] Warneken F, Chen F, Tomasello M. Cooperative active-ties in young children and chimpanzees. Child Deve-lopment, 2006, 77(3): 640–663
[109] Demiris Y, Meltzoff A. The robot in the crib: a developmental analysis of imitation skills in infants and robots. Infant and Child Development, 2008, 17 (1): 43–53
[110] Demiris Y, Hayes G. Imitation as a dual-route process featuring predictive and learning components: a biologically plausible computational model // Dauten-hahn K, Nehaniv C L. Imitation in Animals and Arti-facts. Cambridge: MIT Press, 2002
[111] Demiris Y, Johnson M. Distributed, predictive percep-tion of actions: a biologically inspired robotics ar-chitecture for imitation and learning. Connection Science, 2003, 15: 231–243
[112] Dominey P F, Warneken F. The basis of shared in-tentions in human and robot cognition. New Ideas in Psychology, 2011, 29(3): 260–274
[113] Baldassarre G, Mirolli M. Intrinsically motivated lear-ning in natural and artificial systems. Berlin Heidel-berg: Springer, 2013
[114] Pfau D, Vinyals O. Connecting generative adversarial networks and actor-critic methods [EB/OL]. (2017–01–18) [2023–05–09]. https://arxiv.org/abs/1610.01945
[115] Schulman J, Levine S, Moritz P, et al. Trust region policy optimization // International Conference on Ma-chine Learning (ICML). Lille, 2015: 1889–1897
[116] Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms [EB/OL]. (2017–08–28) [2023–05–09]. https://arxiv.org/abs/1707.06347
[117] 陈学松, 杨宜民. 强化学习研究综述. 计算机应用研究, 2010, 27(8): 2834–2838
[118] Kulkarni T D, Narasimhan K, Saeedi A, et al. Hierar-chical deep reinforcement learning: integrating tem-poral abstraction and intrinsic motivation [EB/OL]. (2016–04–20) [2023–05–09]. https://arxiv.org/abs/1604. 06057
[119] Andrychowicz M, Wolski F, Ray A, et al. Hindsight experience replay. 31st Conference on Neural Infor-mation Processing Systems (NIPS 2017). Long Beach, 2018: 1–11
[120] Asada M, Hosoda K, Kuniyoshi Y, et al. Cognitive developmental robotics: a survey. IEEE Transactions on Autonomous Mental Development, 2009, 1(1): 12–34
[121] Sutton R S, Precup D, Singh S. Between MDPs and semi-MDPs: a framework for temporal abstraction in reinforcement learning. Artificial intelligence, 1999, 112(1/2): 181–211
[122] Dietterich T G. Hierarchical reinforcement learning with the MAXQ value function decomposition. Journal of Artificial Intelligence Research, 2000, 13: 227–303
[123] Le H, Jiang N, Agarwal A, et al. Hierarchical imita-tion and reinforcement learning // International Confe-rence on Machine Learning (ICML). Stockholm, 2018: 2917–2926
[124] Tessler C, Givony S, Zahavy T, et al. A deep hierar-chical approach to lifelong learning in Minecraft // Association for the Advancement of Artificial Intel-ligence (AAAI). San Francisco, 2017: 3–6
[125] Fox R, Krishnan S, Stoica I, et al. Multi-level disco-very of deep options [EB/OL]. (2017–10–05) [2023–05–09]. https://arxiv.org/abs/1703.08294
[126] Frans K, Ho J, Chen X, et al. Meta learning shared hierarchies [EB/OL]. (2017–10–26) [2023–05–09]. https://arxiv.org/abs/1710.09767
[127] Nachum O, Gu S S, Lee H, et al. Data-efficient hierarchical reinforcement learning // Neural Informa-tion Processing Systems (NeurIPS). Montreal, 2018: 1–11
[128] Eysenbach B, Gupta A, Ibarz J, et al. Diversity is all you need: learning skills without a reward function [EB/OL]. (2018–10–09) [2023–05–09]. https://arxiv. org/abs/1802.06070
[129] Bagaria A, Konidaris G. Option discovery using deep skill chaining // International Conference on Learning Representations (ICLR). Addis Ababa, 2020: 1–21
[130] Sharma A, Gu S, Levine S, et al. Dynamics-aware unsupervised discovery of skills // International Con-ference on Learning Representations (ICLR). Addis Ababa, 2020: 1–21
[131] Lin X, Wang Y, Held D. Learning visible connectivity dynamics for cloth smoothing // Conference on Robot Learning (CoRL). London, 2021: 256–266
A Review of Robot Learning
Abstract The basic concepts and core issues related to robot learning are introduced and discussed, and the relevant researches are summarized and analyzed. Through comparing the relevant methods and recent progress, the authors classify the methods of robot learning into four categories based on data types and learning methods, namely reinforcement learning approach, imitation learning approach, transfer learning approach and developmental learning approach. Finally, current challenges and future trends in robot learning are listed.
Key words robot learning; reinforcement learning; imitation learning; transfer learning; developmental learning