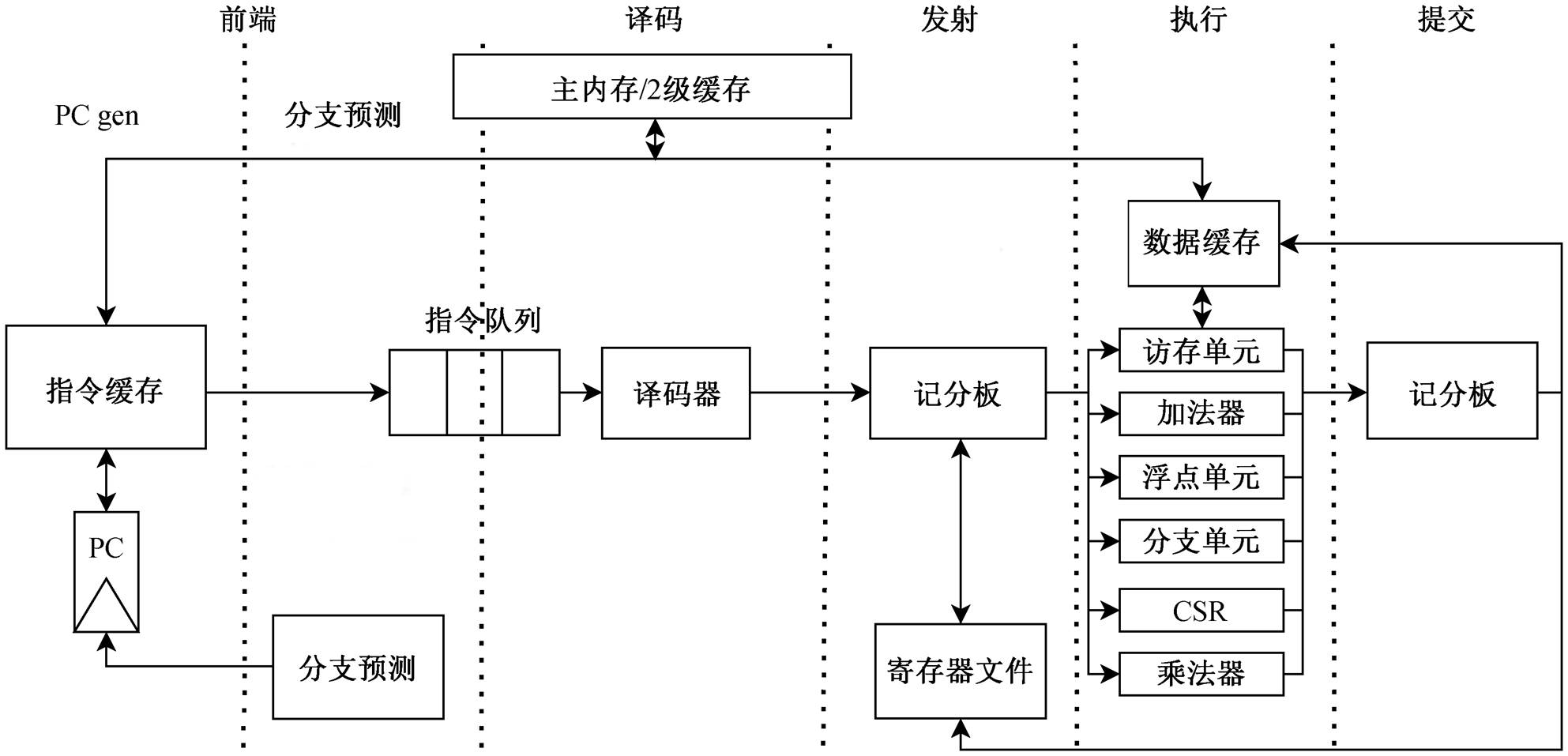
图1 ECore处理器流水线结构
Fig. 1 Pipeline structure of ECore processor
doi: 10.13209/j.0479-8023.2022.112
国家电网总部科技项目(5700-202141449A-0-0-00)资助
收稿日期: 2022–07–12;
修回日期: 2022–10–28
北京大学学报(自然科学版) 第59卷 第4期 2023年7月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 4 (July 2023)
摘要 为了提高高能效处理器的性能, 基于 ECore 嵌入式处理器平台, 在单反射按序流水线结构中引入两种轻量化的超标量结构——压缩指令双发射结构和选择性重命名结构。在 Verilator 生成的 C++模型上进行的模拟实验结果表明, 通过增加压缩指令双发射结构, 流水线双发利用率平均值达到 28%。通过增加选择性重命名结构, 因名称冒险导致的流水线停顿占比从 7.2%降至 0.6%。相对于优化前, 处理器的IPC提升 4.8%, 而功耗仅增加 2.5%。
关键词 高能效处理器; 双发射; 寄存器重命名
随着集成电路芯片集成度的不断提升以及电源电压等比例缩小趋势的放缓, 功耗成为处理器当前重要的设计瓶颈。有限的功耗预算促使微处理器设计在结构和实现方面发生质的改变——以能效性(energy efficiency)作为基本的、重要的设计指标[1]。微处理器设计应选择能以最小功耗代价取得最佳性能的方法, 以便达到高能效的设计目标。高性能满足日益增长的数据计算需要, 低功耗使得待机时间增长, 特别是在电力计量、测算等专用设备领域, 这类高能效处理器逐渐成为首选。
过去几十年来, 研究人员一直在高性能乱序处理器的微结构下, 在保持高性能基本上不变的情况下, 通过解决发射调度逻辑的复杂性[2–3], 减少对耗电结构的访问[4–6]来降低处理器的功耗, 达到高能效的目的。然而, 在微体系结构层面, 通过优化架构来降低处理器功耗, 收效甚微。
近来的研究在保证低功耗的情况下, 提升处理器性能的思路有了新的突破。主要方法是在低功耗按序处理器微结构下, 通过优化发射调度逻辑, 尽可能利用指令级并行和内存级并行, 使按序处理器的性能接近乱序处理器[7–11], 从而实现处理器的高能效。
基于满足高性能的乱序处理器, 通过降低耗能严重的发射单元复杂度以及减少对高耗电结构的访问等方式来降低处理器的功耗, 同时几乎不损失性能。由于高性能超标量处理器中的发射逻辑类似“中场发动机”, 逻辑复杂, 功耗占比高, 因此很多研究集中在发射逻辑的结构设计方面。
前端执行架构(front-end execution architecture, FXA)[12]通过两个执行单元(一个乱序执行单元(out-of-order execution unit, OXU)和一个有序执行单元(in-order execution, IXU))的配合, 可获得比传统乱序超标量处理器更低的功耗。延迟旁路架构(delay and bypass, DNB)[5]通过减少指令队列的深度和宽度来降低指令调度消耗的能量, 动态自适应指令发射队列(MLP-aware dynamic instruction window)[6]通过动态调整指令窗口的大小来适应可用的并行度(包括指令级并行和内存级并行)。
按序处理器因其复杂度低、功耗低的特性, 活跃在嵌入式处理器的舞台上。通过修改按序处理器的发射调度逻辑, 尽可能利用指令级并行和内存级并行, 使按序处理器的性能不断接近乱序处理器。目前相关研究主要有两类方法。
第一类方法需要乱序架构的支持, 通过记录乱序执行的发射序列, 将其在按序内核中重放执行。在由乱序核和按序核组成的细粒度异构多核系统中, 动态调度迁移策略(dynamic schedule migra-tion for heterogeneous cores, DynaMOS)[7]将在乱序核心中重复出现的发射序列加载到按序核心中执行, 以便实现整体能效的提升。加载切片核心微架构(load slice core, LSC)[13]中构造出可以进行内存级并行的指令组或切片, 其中包含生成访存地址的指令。将该类切片放在两个单独的队列中, 切片相对于其余指令乱序执行, 但切片内部和剩余指令之间仍然按顺序执行。Freeway (maximizing MLP for slice-out-order execution)[11]建立在 LSC 的基础上, 通过添加一个用于发现额外独立负载的有序队列, 达到比 LSC 更多的内存级并行性。
第二类方法不需要乱序架构的支持, 在按序架构下充分利用指令级并行和内存级并行的特点来提升处理器的性能。级联调度窗口技术(cascaded in-order scheduling windows, CASINO)[9]通过改造按序发射的核心, 增加一个很小的推测性指令调度窗口, 达到乱序调度的大量性能优势, 实现高性能、低复杂度的核心优化改造。相比于按序处理器, CASI-NO 内核的性能提高 51%, 与乱序处理器的性能相差不到 10%; 能源效率与按序和乱序内核相比, 分别提高 25%和 42%。
综上所述, 现代高性能处理器多为乱序发射结构, 在提升处理器性能方面需要乱序架构的支持, 相关研究也较多。本文主要针对嵌入式处理器, 并依赖按序结构低复杂度、低功耗的特点, 研究如何在按序架构下适当增加轻量化的超标量设计, 在保持处理器功耗基本上不变的前提下, 尽可能提升处理器的性能。
本文使用的 ECore 处理器是一款面向工控嵌入式领域的按序单发射处理器, 它支持 RISC-V ISA (包括压缩指令)[14], 实现特权态的 1.10 扩展[15]。ECore 处理器的结构(图 1)为 6 级流水线, 分别为地址生成(PC generation)、取指阶段(instruction fetch)、译码阶段(instruction decode)、发射阶段(issue sta-ge)、执行阶段(execute stage)和提交阶段(commit stage)。地址生成及取指阶段统称为前端(front-end)。
采用 Mibench[16]嵌入式基准测试程序, 使用Spike 指令级模拟器[17]对处理器的动态执行信息进行统计, 结果如表 1 所示。可以发现, 压缩指令所占比例非常高(41.45%~71.66%, 平均 55.07%); 连续两条压缩指令的占比较高(23.86%~64.73%, 平均 43.14%); “热”寄存器(x8~x15)的使用占比非常高(61.13%~ 93.43%, 平均 73.54%)。
指令流中有大量的压缩指令, 并且两条连续的压缩指令具有与单条 32 位指令相同的取指宽度, 如果针对压缩指令添加双发射机制, 则可以在较小的硬件开销代价下提高流水线的吞吐量, 从而改善处理器的性能。
RISC-V ISA 中强制对某些类别的压缩指令使用一小组特定的寄存器, 因此绝大多数生成的压缩指令仅使用某部分特定寄存器(即 32 个可用物理寄存器中的 8 个), 从图 2 也可以看出 8 个“热”寄存器的使用率很高。基于寄存器使用不平衡这一现象, 可以设计选择性寄存器重命名结构, 减少重命名寄存器资源, 有效地降低寄存器堆的面积和功耗。
图1 ECore处理器流水线结构
Fig. 1 Pipeline structure of ECore processor
表1 使用Spike对Mibench进行动态信息统计(编译选项-O2)
Table 1 Using Spike to perform dynamic information statistics of Mibench (-O2)
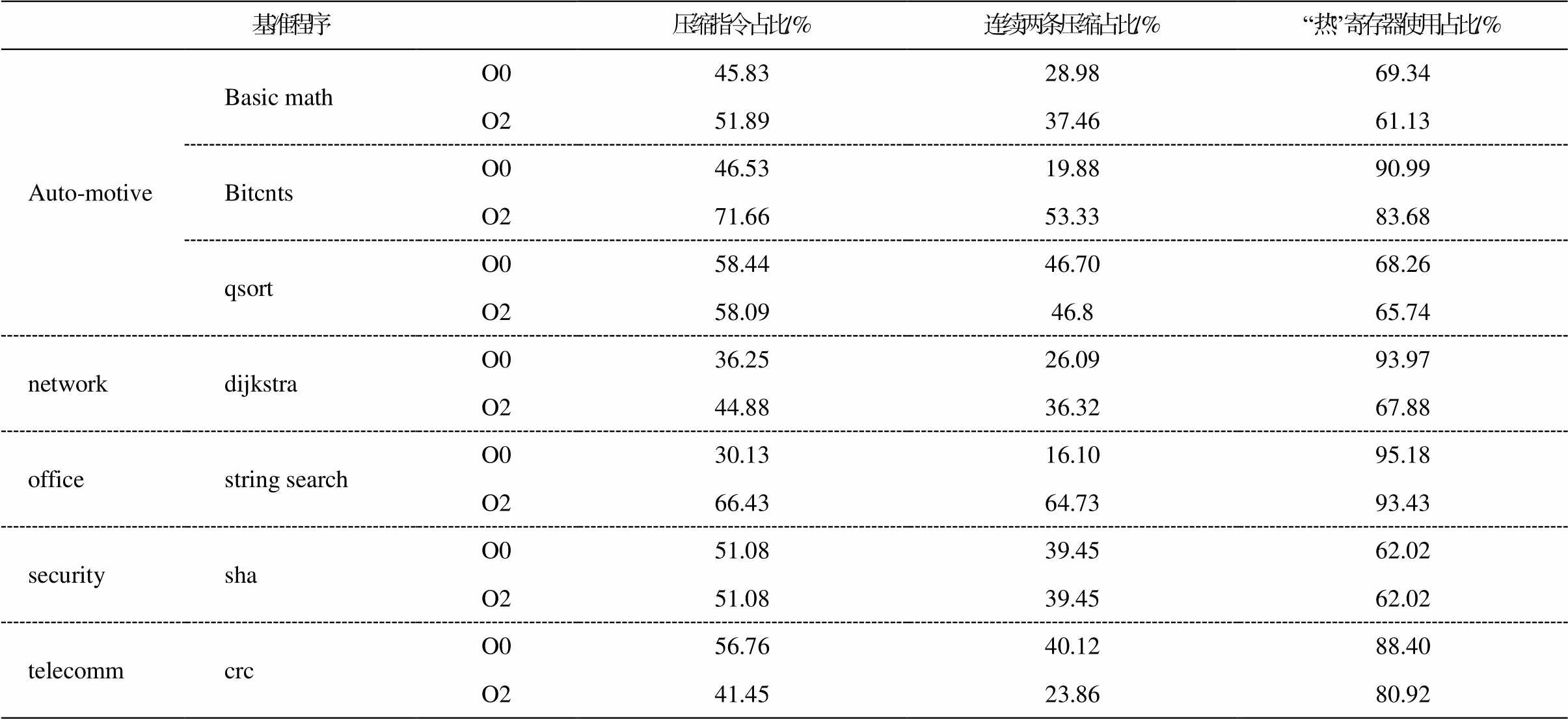
基准程序压缩指令占比/%连续两条压缩占比/%“热”寄存器使用占比/% Auto-motiveBasic mathO045.8328.9869.34 O251.8937.4661.13 BitcntsO046.5319.8890.99 O271.6653.3383.68 qsortO058.4446.7068.26 O258.0946.865.74 networkdijkstraO036.2526.0993.97 O244.8836.3267.88 officestring searchO030.1316.1095.18 O266.4364.7393.43 securityshaO051.0839.4562.02 O251.0839.4562.02 telecommcrcO056.7640.1288.40 O241.4523.8680.92
ECore 处理器在发射阶段的主要功能是接收重命名后的指令, 并将其发射到各个功能单元。发射阶段共进行三部分工作: 维护寄存器数据来源表、读取指令操作数以及发射指令。结构见图 2。
在不增加前端取指宽度的情况下, 每周期最多可以从前端指令队列中取到两条指令, 其一是两条连续的压缩指令, 其二是一条完整指令和一条压缩指令。ECore 处理器发射阶段支持上述两种情况的双发射, 可以提高流水线的吞吐, 从而获得性能提升。
发射阶段指令需满足以下 3 个条件: 1)源操作数可用; 2)功能单元空闲; 3)不存在数据依赖。
被发射的指令需要从寄存器文件中获取其源操作数, 因此在发射阶段会完成寄存器文件的例化。发射控制逻辑围绕寄存器数据来源表构建, 通过寄存器数据来源表记录每个物理寄存器的最新数据来源位置, 用于指令发射时读取源操作数。
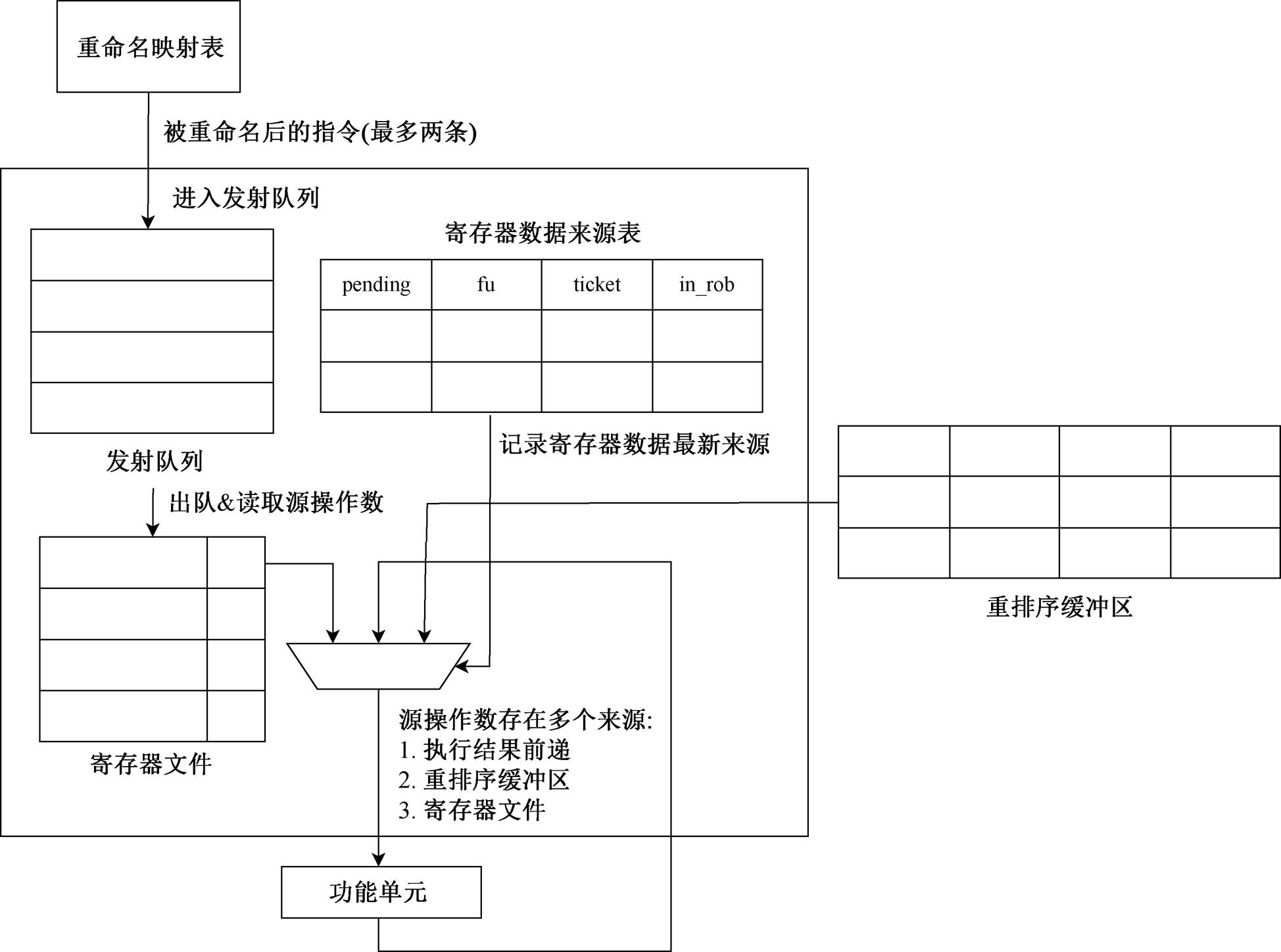
图2 发射逻辑内部结构
Fig. 2 Logic structure of issue logic
在重命名阶段(rename stage), 通过改变指令目的寄存器的实际存储位置, 消除指令间的名称相关(反相关(write after write, WAW)和输出相关(write after read, WAR)), 从而提高指令并行度。在 ECore处理器中, 基于压缩指令寄存器使用不平衡的现象, 设计和实现选择性寄存器重命名机制(图 3)所示。
重命名阶段有 3 个主要功能: 1)通过指令的源寄存器索引重命名映射表, 获取对应的物理寄存器号; 2)通过空闲列表, 为指令的目的寄存器分配新的物理寄存器资源, 同时对重命名映射表和寄存器文件进行数据和状态的更新; 3)指令提交时, 释放对应的重命名寄存器资源。重命名的内部结构见图 4, 功能的实现步骤如下。
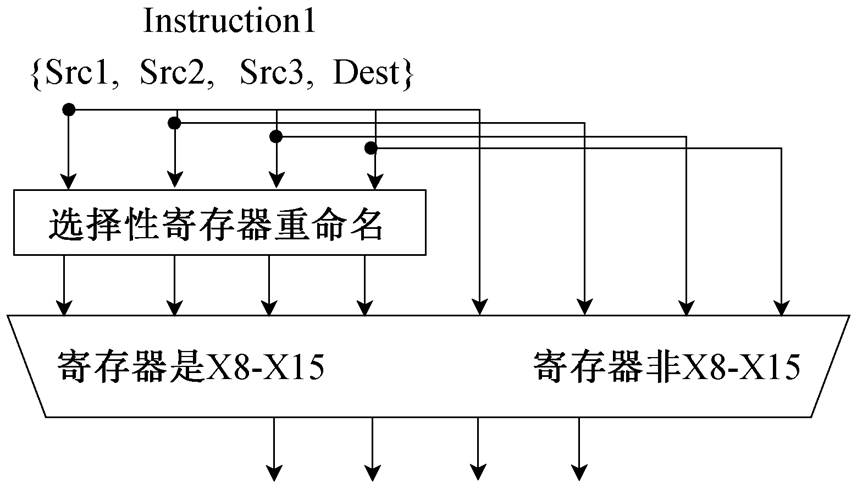
图3 选择性寄存器重命名机制
Fig. 3 Selective register renaming
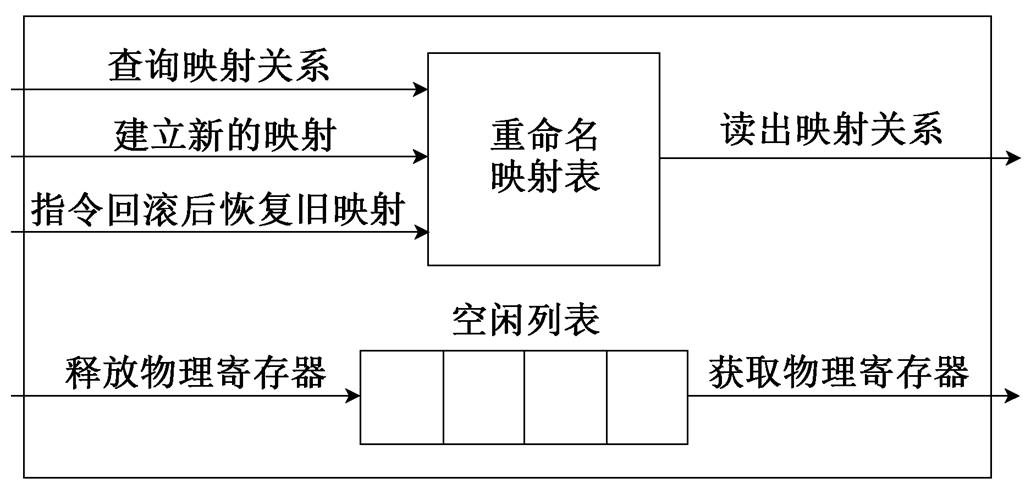
图4 寄存器重命名内部结构
Fig. 4 Logic structure of selective register renaming
1)寄存器重命名映射表的读取。根据指令源寄存器号, 从重命名映射表中读取对应的物理寄存器号。同一周期中两条重命名的指令之间可能相关, 会导致从重命名映射表内读取的结果不是最新的, 因此需要将后一条指令的源寄存器与前一条指令的目的寄存器进行比较, 如果相等, 则需要通过旁路技术进行传递。
2)重命名寄存器的分配。从空闲列表中分配物理寄存器给指令的目的寄存器, 同时对重命名映射表的内容进行更新, 将分配出去的重命名寄存器从空闲列表中移除, 并更新指针位置。
3)重命名寄存器的释放。重命名寄存器的释放发生在指令提交阶段, 除此之外, 当发生转移预测错误或异常时, 也会将错误指令占用的重命名资源释放掉。指令提交时, 重命名寄存器保存的结果被写回到体系结构寄存器, 相应的重命名资源被回收到空闲列表中。
对优化前后的处理器性能进行评估: 1)EC-ore 处理器为一个单发射、按序处理器, 支持压缩指令, 没有寄存器重命名; 2)ECore-RD 处理器为一个支持压缩指令双发射、按序处理器, 支持选择性寄存器重命名。测评环境参数配置如表 2 所示。处理器使用的基准测试程序通过 RISC-V 交叉编译工具链接成 ELF 可执行文件, 在 Verilator 高级仿真器生成的 C++模型上执行。
测试集选用 Michigan 大学推出的面向嵌入式系统的基准测试集合 MiBench(版本 1.0), 编译器为riscv64-unknown-elf-gcc 11.1.0, 编译选项为-march =rv32imac -mabi=ilp32 -O2。
表2 待评测处理器配置
Table 2 Default parameter configurations
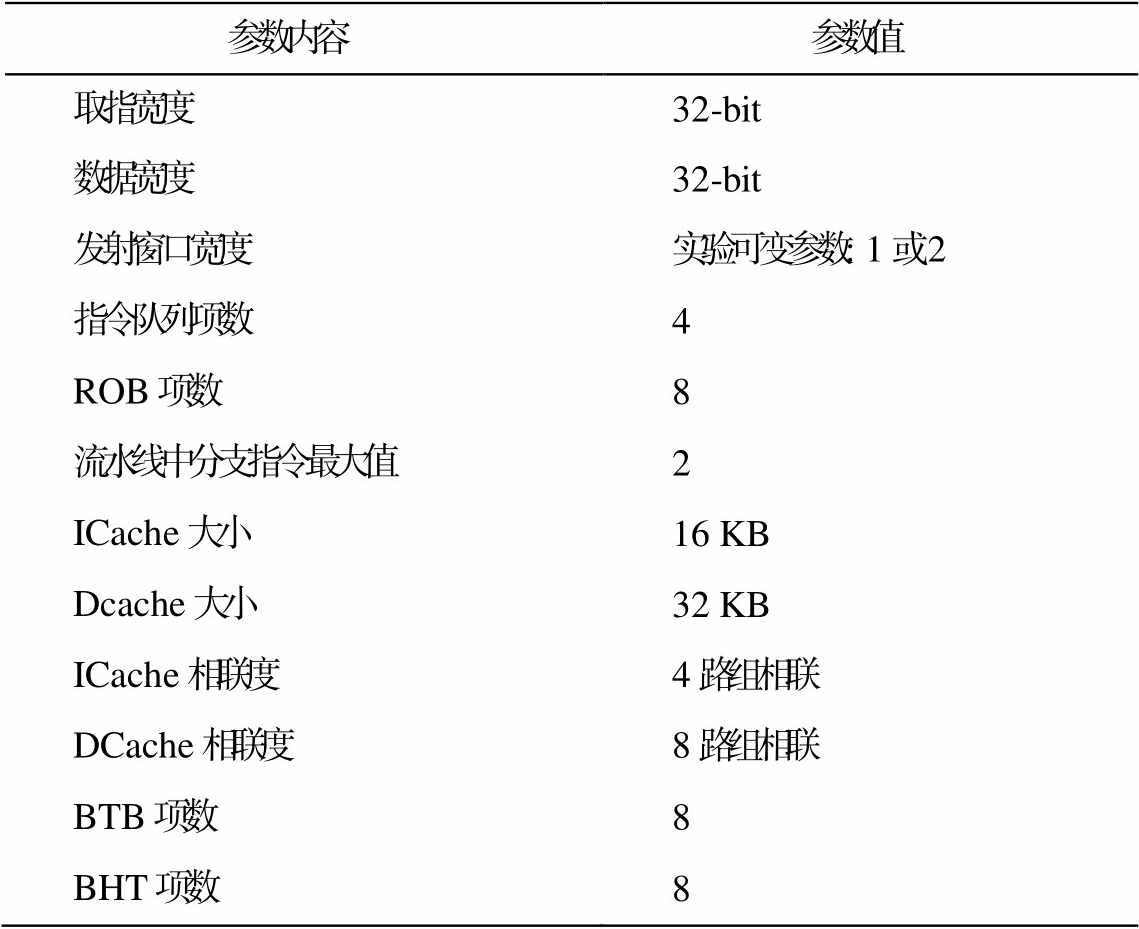
参数内容 参数值 取指宽度32-bit 数据宽度32-bit 发射窗口宽度实验可变参数: 1或2 指令队列项数4 ROB项数8 流水线中分支指令最大值2 ICache大小16 KB Dcache大小32 KB ICache相联度4路组相联 DCache相联度8路组相联 BTB项数8 BHT项数8
图 5 展示基准测试程序的压缩指令占比和连续压缩指令占比, 图 6 展示优化后的 ECore-RD 处理器双发利用率。可以看出, 经过 RISC-V 带压缩扩展编译后的所有基准测试程序中, 压缩指令的占比非常高(37.2%~81.9%, 平均 55.8%), 连续两条压缩指令的占比较高(30.2%~68.2%, 平均 44.3%)。经结构优化后, 压缩指令双发射结构在绝大多数基准测试程序中得到应用, 双发利用率为 6.8%~46.1% (平均 28.0%), 证明了压缩指令双发射结构的有效性。
图 7 展示基准测试程序中“热”寄存器占比, 图8 展示 ECore-RD 实现选择性寄存器重命名前后的冲突阻塞占比。在仅实现压缩指令双发的 ECore-RD 处理器中, 不使用选择性寄存器命名结构, 而是统计名称冒险(包括写后写和读后写)带来的流水线停顿占总停顿数量的比例。结果显示, 名称冒险带来的流水线停顿平均占总停顿数量的 7.2%。使用选择性寄存器重命名结构后, 这种冒险带来的流水线停顿平均降至 0.6%, 几乎消除了由于名称冒险带来的流水线停顿, 证明了选择性寄存器重命名结构的有效性。
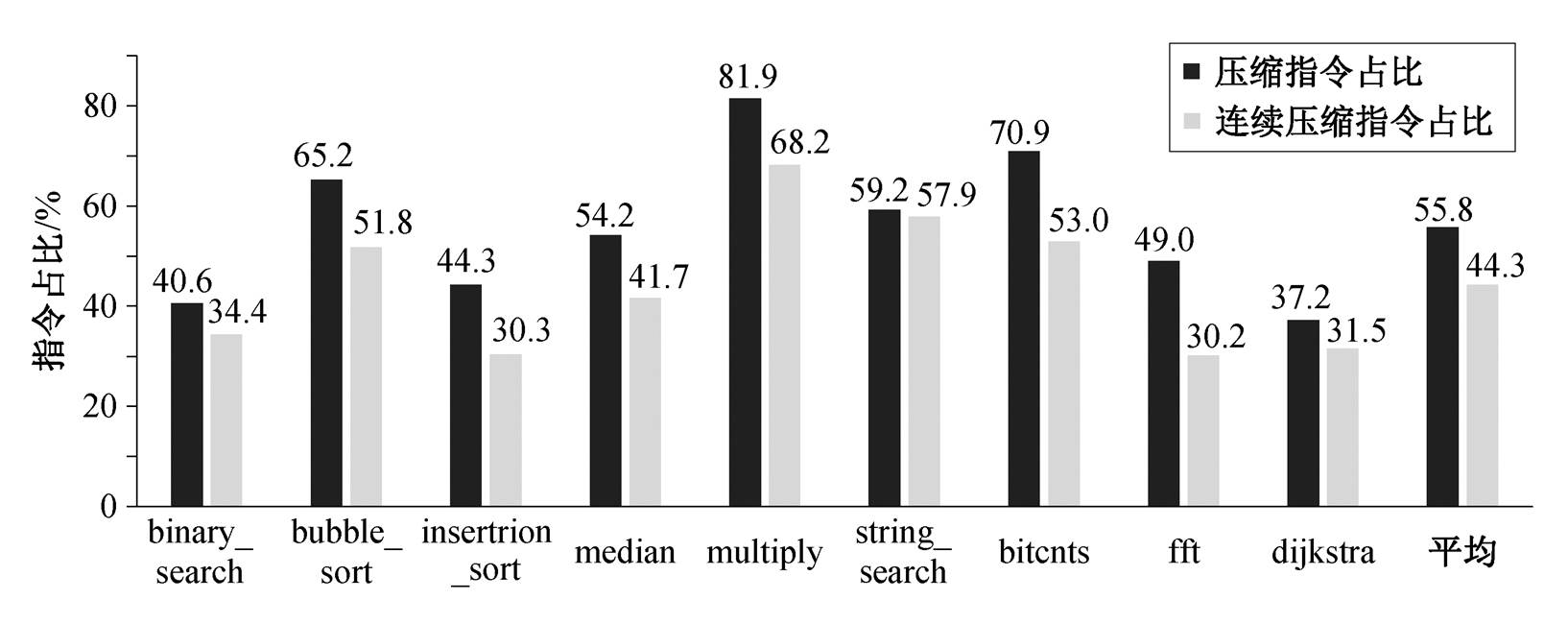
图5 基准测试程序的压缩指令占比和连续压缩指令占比
Fig. 5 Proportion of compressed instructions and the proportion of continuous compressed instructions of the benchmark
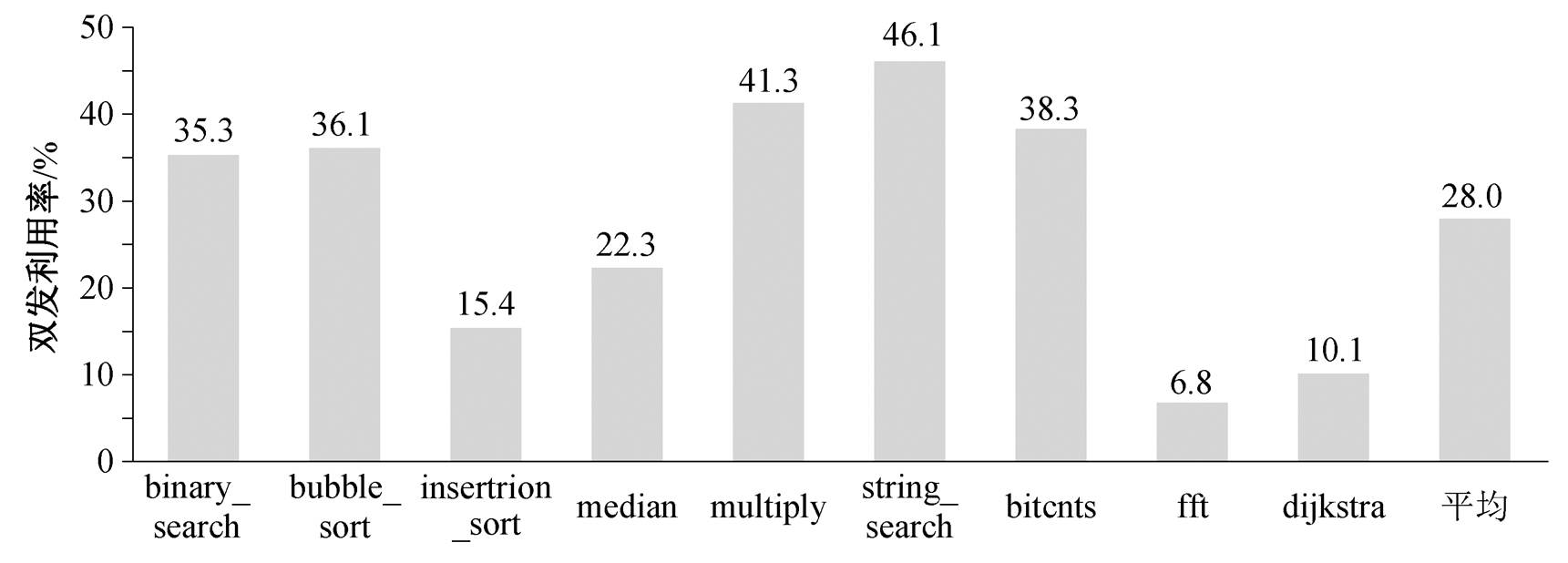
图6 ECore-RD的双发利用率
Fig. 6 Double-issue utilization of ECore-RD
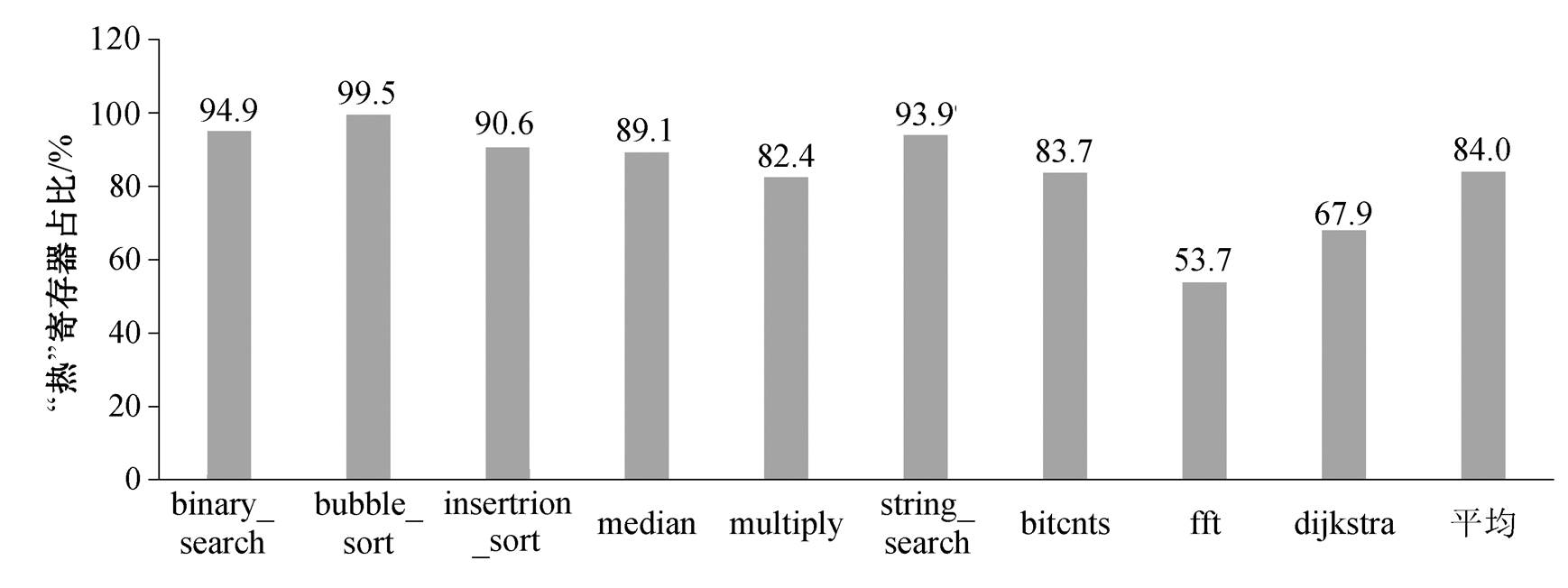
图7 基准测试程序的“热”寄存器占比
Fig. 7 “Hot” register percentage in benchmark
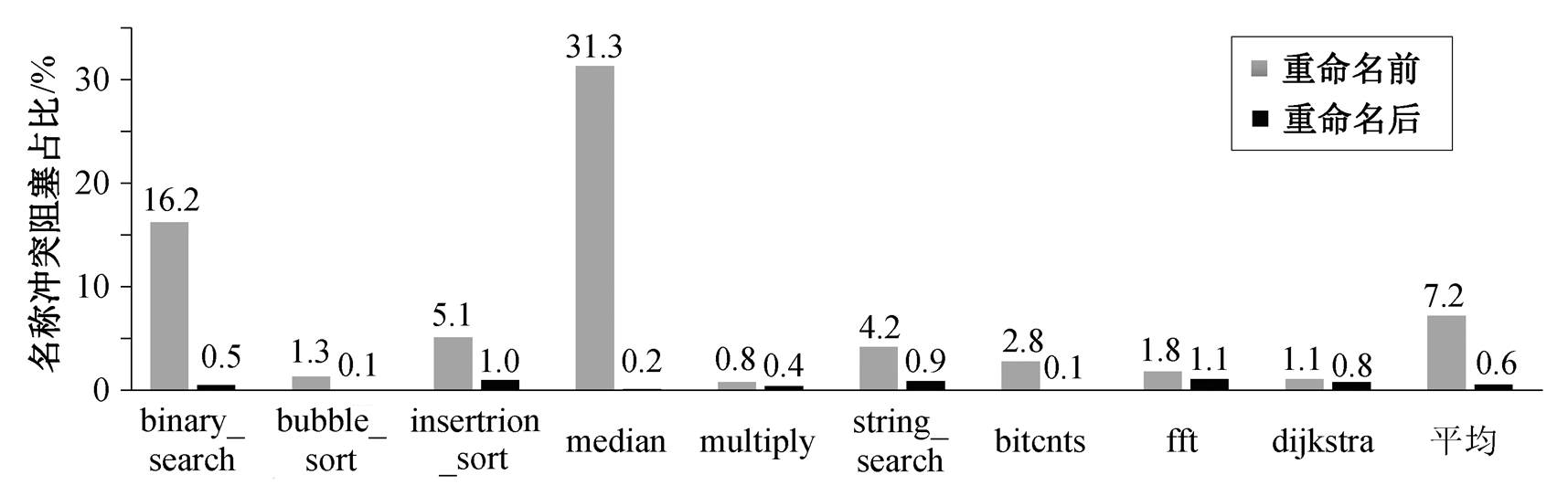
图8 ECore-RD实现选择性寄存器重命名前后的冲突阻塞占比
Fig. 8 Conflict blocking ratio before and after ECore-RD selective register renaming
以 ECore 处理器的 IPC (平均每周期完成指令数量)为基础, 图 9 显示 ECore-RD 处理器的 IPC 增益。可以看出, 增加选择性寄存器重命名及压缩指令双发射结构后, 大多数基准程序的 IPC 有所提高, 平均提升 4.8%, 最好的 IPC 提升 10%。
使用 Xilinx 公司推出的 FPGA 综合工具 Vivado 2018.2[18]进行 FPGA 实现, 时钟频率为 100MHz, 并进行功耗统计。使用 Vivado 的向量模式方法进行分析, 主要输入为综合后的门级网表电路 netlist 以及模拟后生成的 SAIF(switching activity interchange format)文件。该文件记录节点翻转率等动态仿真信息, 其输出为功耗统计报告。
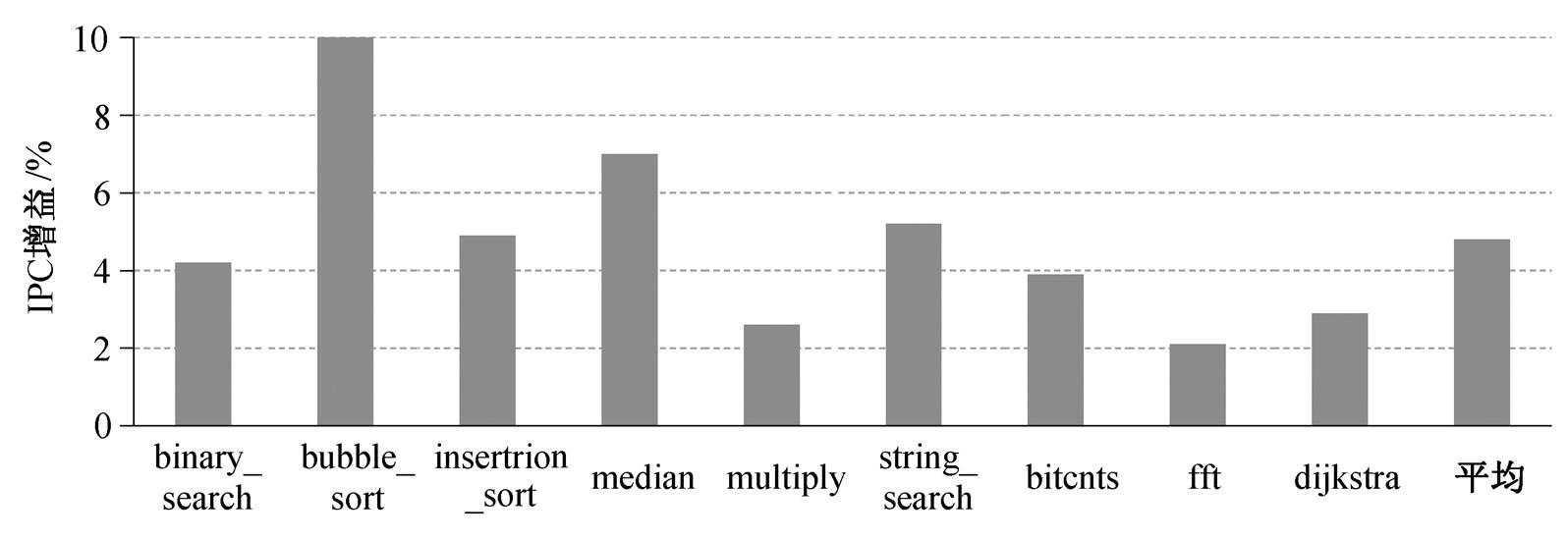
图9 以ECore为基准的ECore-RD处理器的IPC增益
Fig. 9 IPC gain of ECore-RD processor based on ECore
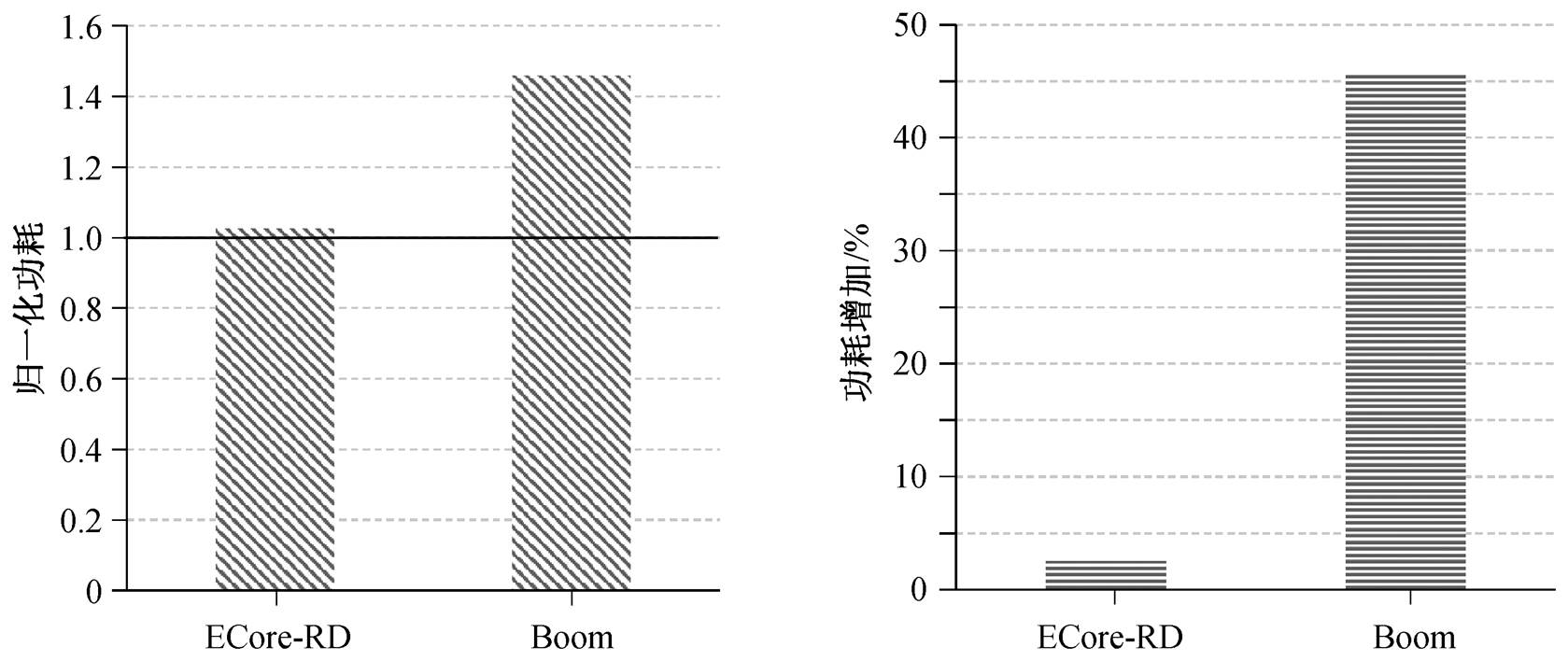
图10 处理器功耗评测结果
Fig. 10 Evaluation results of power consumption of different processors
对 ECore, ECore-RD 和 BOOM 进行能效对比。BOOM (Berkeley out-of-order machine)处理器[19]是伯克利大学提出的开源乱序超标量处理器, 流水线为 10 级, 其发射宽度可配置。我们将其配置为双发射结构。
图 10 显示相对于 ECore 处理器, ECore-RD 和BOOM 处理器的归一化功耗数据及功耗增加情况。ECore-RD 处理器的功耗仅增加 2.5%, 而 BOOM 处理器的功耗增加 45.7%。
本文针对处理器动态执行过程中压缩指令占比较高、寄存器使用不平衡的现象, 基于 ECore 嵌入式处理器平台, 在按序流水线结构中引入适当的超标量结构——压缩指令双发射和选择性重命名结构, 来实现高能效处理器的设计目标。实验结果表明, 通过增加压缩指令双发射结构, 流水线双发利用率平均值达到 28%。通过增加选择性重命名结构, 名称冒险导致的流水线停顿占比从 7.2%降至 0.6%。相对于优化前, 处理器的 IPC 提升 4.8%, 功耗仅增加 2.5%。但是, 与其他轻量化超标量结构(如 CAS-INO)相比, 性能增益并不高。这是因为, 为尽量保持原有面积开销而不增加复杂设计, 本文依然采用按序发射结构。将 CASINO 由原有的按序发射改为乱序发射, 需要增加硬件资源(如重命名和按序提交等)来解决各种冒险问题, 面积开销增加, 设计逻辑更加复杂。此外, 本文与 CASINO 使用不同的基准测试程序, 对评测结果不能只做简单的比较。综上所述, 本文提出的结构对原有处理器的改动和面积增加都较小, 同时改进后的功耗增加也很少, 因此更适用于嵌入式处理器场景。
目前, 处理器发射策略仅针对连续的压缩指令, 对 IPC 的提升效果有限, 未来可进一步探讨通过较小的功耗开销实现完整乱序双发射的设计方案。
参考文献
[1] Borkar S, Chien A A. The future of microprocessors. Communications of the ACM, 2011, 54(5): 67–77
[2] Folegnani D, González A. Energy-effective issue logic // Proceedings 28th Annual International Symposium on Computer Architecture. Piscataway, 2001: 230–239
[3] Ponomarev D, Kucuk G, Ghose K. Reducing power re-quirements of instruction scheduling through dynamic allocation of multiple datapath resources // Procee-dings of 34th ACM/IEEE International Symposium on Microarchitecture, MICRO-34. Piscataway, 2001: 90–101
[4] Sembrant A, Carlson T, Hagersten E, et al. Long term parking (LTP) criticality-aware resource allocation in OOO processors // Proceedings of the 48th Interna-tional Symposium on Microarchitecture. New York, 2015: 334–346
[5] Alipour M, Kaxiras S, Black-Schaffer D, et al. Delay and bypass: ready and criticality aware instruction scheduling in out-of-order processors // 2020 IEEE In-ternational Symposium on High Performance Compu-ter Architecture (HPCA). Piscataway, 2020: 424–434
[6] Kora Y, Yamaguchi K, Ando H. MLP-aware dynamic instruction window resizing for adaptively exploiting both ILP and MLP // Proceedings of the 46th Annual IEEE/ACM International Symposium on Microarchi-tecture. New York, 2013: 37–48
[7] Padmanabha S, Lukefahr A, Das R, et al. DynaMOS: dynamic schedule migration for heterogeneous cores // Proceedings of the 48th International Symposium on Microarchitecture. New York, 2015: 322–333
[8] Weiser M. Program slicing. IEEE Transactions on Software Engineering, 1984, SE-10(4): 352–357
[9] Jeong I, Park S, Lee C, et al. CASINO core micro-architecture: generating out-of-order schedules using cascaded in-order scheduling windows // 2020 IEEE International Symposium on High Performance Com-puter Architecture (HPCA). Piscataway, 2020: 383–396
[10] Patsidis K, Konstantinou D, Nicopoulos C, et al. A low-cost synthesizable RISC-V dual-issue processor core leveraging the compressed Instruction Set Exten-sion. Microprocessors and Microsystems, 2018, 61: 1–10
[11] Kumar R, Alipour M, Black-Schaffer D. Freeway: ma-ximizing MLP for slice-out-of-order execution // 2019 IEEE International Symposium on High Perfor-mance Computer Architecture (HPCA). Piscataway, 2019: 558–569
[12] Shioya R, Goshima M, Ando H. A front-end execution architecture for high energy efficiency // 2014 47th An-nual IEEE/ACM International Symposium on Microar-chitecture. Piscataway, 2014: 419–431
[13] Carlson T E, Heirman W, Allam O, et al. The load slice core microarchitecture // 2015 ACM/IEEE 42nd Annu-al International Symposium on Computer Architecture (ISCA). Piscataway, 2015: 272–284
[14] Waterman A, Lee Y, Patterson D A, et al. The RISC-V instruction set manual volume 1: user-level ISA, ver-sion 2.0 [R]. Berkeley: University of California, 2014
[15] Waterman A, Lee Y, Avizienis R, et al. The RISC-V instruction set manual volume 2: privileged architect-ture version 1.7 [R]. Berkeley: University of California, 2015
[16] Guthaus M R, Ringenberg J S, Ernst D, et al. MiBench: a free, commercially representative embedded bench-mark suite // Proceedings of the fourth annual IEEE international workshop on workload characterization. WWC-4 (Cat. No. 01EX538). Piscataway, 2001: 3–14
[17] Keller B. RISC-V, spike, and the rocket core [EB/OL].(2013)[2022–05–02]. https://inst.eecs.berkeley.edu/~ cs250/fa13/handouts/lab2-riscv.pdf
[18] Feist T. White paper: Vivado design suite [R]. San Jose, 2012
[19] Asanovic K, Patterson D A, Celio C. The Berkeley out-of-order machine (BOOM): an industry-competitive, synthesizable, parameterized RISC-V processor [R]. Berkeley: University of California, 2015
Design and Implementation of an Energy Efficient Dual-Issue Processor
Abstract In order to improve performance with stable power consumption, based on ECore embedded processor platform, which had a single-issue in-order pipeline structure originally, two lightweight superscalar structures were introduced: selective register renaming and dual issue of compact instructions. The experimental data showed that the average utilization of dual-issue structure reached 28% by adding dual issue logic. Using selective register renaming, the average stalling rate caused by name hazard reduced from 7.2% to 0.6%. Compared with the original design, the IPC increased 4.8% and the power consumption only increased 2.5%.
Key words energy efficient processor; dual-issue; register renaming