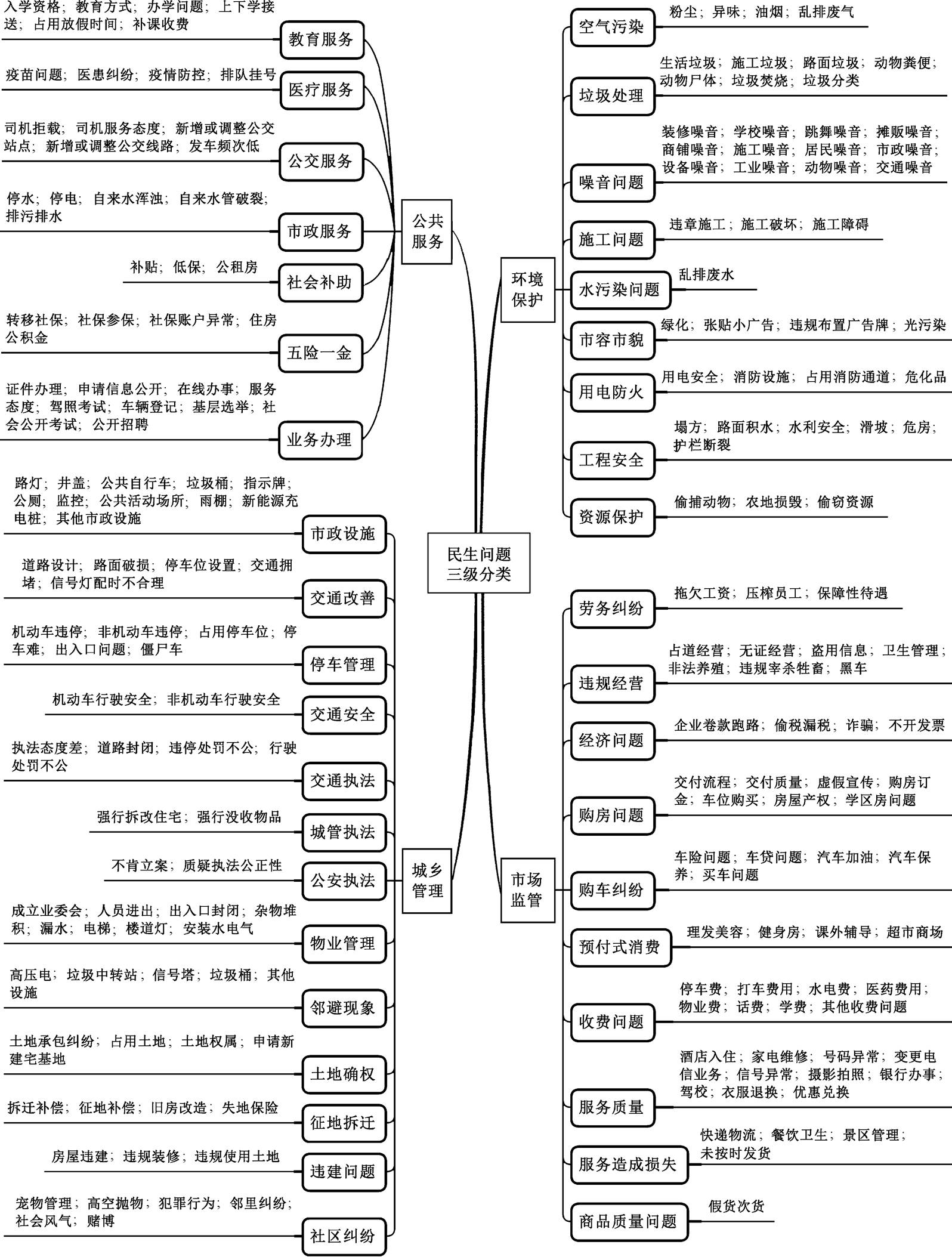
图1 基于政务热线数据的民生问题三级分类体系
Fig. 1 A three-level classification system for livelihood issues based on the hotline compliant data
北京大学学报(自然科学版) 第59卷 第3期 2023年5月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 3 (May 2023)
doi: 10.13209/j.0479-8023.2023.030
浙江省软科学研究计划重点项目(2021C25021)资助
收稿日期: 2022–05–17;
修回日期: 2022–06–23
摘要 基于 2017—2021 年浙江省 12345 政务热线数据, 从居民视角构建细粒度的民生问题三级分类体系, 并利用 BERT 预训练模型来构建文本分类模型, 将居民诉求文本转化为民生问题标签。研究结果表明, 在政务热线数据中加入 30%的人工生成诉求样本, 可以使模型的分类准确率提升约 10 个百分点, 准确率最高可达84.59%。对浙江省各类民生问题占比的分析结果表明, 环境保护、违规经营和市政服务等诉求的比例呈现下降趋势, 而公共服务、交通问题、购房问题和新兴消费模式的诉求比例呈上升趋势。研究结果有助于加强政府对于民情民意的了解, 提升数据驱动的社会治理能力。
关键词 民生问题文本分类; BERT; 政务热线数据; 数据治理
随着工业化和城镇化的快速推进, 我国的社会结构发生深刻的变化, 个体化的浪潮和多元的社会阶层, 产生纷繁复杂的利益诉求, 导致社会治理面临信息不透明、场景复杂和沟通不畅等挑战[1]。社会的模糊性与国家治理能力成反比, 两者之间呈此消彼长的关系[2]。
有效的治理首先要获得及时、全面和准确的民生信息, 才能形成清晰的治理图景[3]。随着决策者与居民之间层级架构的不断增加, 信息在自下而上的传递过程中越来越抽象和简单化[4], 这种信息不对称可能导致政府的资源配置与民众的治理需求产生错配。目前学界对民生问题的关注程度远不及对政府治理行为的讨论, 尤其对民众如何感知和理解民生问题缺乏清晰的认识[5]。
从我国社会的实际来看, 经济社会发展的不均衡使得不同区域的民生问题和治理需求存在巨大的差别[6]。对于民生问题的认知方法, 学界通常有三类实证研究方法。1)通过实地走访和案例剖析, 对某类民生问题进行深度分析[7], 这种方法覆盖范围较窄, 主要针对土地纠纷、物业矛盾和医患关系等涉及个人利益冲突的民生问题。2)基于统计年鉴或公报, 分析某类民生问题的时空变化规律[8], 这种方法适用于环境保护和公共服务等拥有丰富公开观测数据的领域。3)通过大规模问卷调查, 对某一类或多类民生问题进行分析[9], 这种方法覆盖面广, 但成本较高, 难以持续。总体来看, 实地走访、统计数据和问卷调查都属于碎片化地收集民生信息, 难以对民生问题进行持续性和系统性的跟踪。
通信技术的迅速发展推动社会治理向数字化和智能化转型, 城乡居民开始通过互联网、电话和社交媒体等途径主动参与社会治理, 自下而上地演化出“热线问政”的政企民互动方式。一些研究者从政府回应[10–11]、基层治理[12–13]和范式创新[14–15]等视角分析政务热线对治理能力和治理体系的系统性影响, 以期通过对政府治理的制度性重塑来提升社会治理效能。
在公众利用政务热线与政府沟通的过程中, 沉淀了海量反映民生问题和政府治理措施的非结构化文本, 为系统地分析民生矛盾和全面感知社会风险提供了良好的契机。一些研究者开始利用自然语言处理技术, 深度解构政务热线数据中的非结构化文本, 并在空间治理、邻里关系和公共服务等领域展开一系列的探索。从民生问题的文本分类技术来看, 现有研究可分为 3 类。第一类研究使用关键词作为过滤器, 对民生问题进行划分[16–18]。这种方法需要枚举某类问题的所有关键词, 也不支持模糊搜索, 难以在复杂的语境下触及居民的核心诉求。第二类研究使用隐狄利克雷分配模型等主题模型, 自动地划分民生问题[19–20], 主题模型属于无监督学习, 通过对语料的词频进行统计, 挖掘潜在主题, 并按主题的概率对文本进行聚类。该方法无需对民生数据进行标注, 仅通过分析词频, 就可以完成分类任务, 缺点在于自动生成的主题可能与预期差距较大, 各主题间的差异可能并不明显。第三类研究基于深度神经网络构建文本分类模型[21–22], 属于有监督学习方法。给定一组预先定义好的标签集和语料集, 模型的任务是根据已知的分类结果, 学习语料集到标签集的映射规则。文本分类模型虽然需要花费较多的精力制作标注集, 但可以根据研究需要, 自定义分类体系。总体来看, 现有研究的分类体系不够精细, 缺乏系统性的民生问题分类谱系, 分类结果的颗粒度较粗[17], 难以对精准治理提供有效的支撑。
为了精准地感知各类民生问题, 提升社会治理的清晰性, 必须构建细粒度、符合居民认知的民生问题分类方法, 从而为分析各类民生问题的时空规律、成因、影响和治理措施等要素提供依据。为此, 本文以浙江省为研究对象, 基于 BERT 预训练模型, 将 12345 政务热线数据中的居民诉求文本转为民生问题标签, 并讨论各类民生问题近年来的变化趋势。本文研究结果将有助于加强政府对民情民意的了解, 提升数据驱动的社会治理能力。
本研究使用的政务热线数据全部采集自浙江省“民呼我为”统一平台, 该平台融合了 12345 热线电话、移动信访等多个渠道的申诉、咨询、建议和举报信息。考虑到数据的完整性和时效性, 本研究选择上报时间在 2017 年 1 月 1 日至 2021 年 12 月 31 日之间的申诉、求决和建议类共计 173 万个样本。每条样本的重要字段包括“上报时间”、“问题属地”、“诉求内容”和“归属部门”, “上报时间”是居民提交诉求的时间。“问题属地”指诉求描述的问题所在的区县。“诉求内容”记录了居民诉求的非结构化文本, 平均每条诉求文本包含 126 个中文字符。如果居民通过 12345 热线电话发起诉求, 接线员会详细记录诉求内容并整理成文本, 保存至“诉求内容”字段中; 如果居民通过网页或手机 APP 提交诉求, 则“诉求内容”直接保存诉求原文。“归属部门”是负责处理诉求事件的政府部门。
为了将诉求文本转化为各类民生问题, 必须构建高精度的文本分类模型。由于少数居民在某次诉求中可能一次性地反映多个问题, 因此居民诉求的文本分类算法在理论上属于多标签分类算法, 即一条诉求可能被贴上多组标签。相比于单标签分类, 多标签分类更复杂, 如最基本的二元关联法(binary relevance)将多标签分类问题分解为 N 个独立的二分类算法(N 为标签总数), 导致多标签算法的预测空间为 2N, 远高于单标签算法的 N 种结果。随着 N值加大, 算法的学习难度和预测误差显著上升。考虑到浙江省 12345 热线数据中绝大多数居民(约占96%)在一次投诉时仅反映一类民生问题以及多标签分类算法的复杂性, 本研究构建单标签文本分类算法。在单标签文本分类算法中, 分类体系、训练集和算法均会对分类结果的准确性产生影响。
1.2.1构建民生问题分类体系
本研究构建民生问题的三级分类体系, 其中一级分类包含 4 个大类, 二级分类包含 39 个中类, 三级分类包含 195 个小类(图 1)。分类体系的构建过程如下。首先逐条分析 5 万条居民诉求文本, 结合住房和城乡建设部发布的市政事件分类行业标准[23], 构建第三级分类体系; 然后根据类别相似度, 将第三级分类合并为第二级分类, 并且参考中央对政府职能的描述, 将二级分类归并为公共服务、城乡管理、环境保护和市场监管 4 个大类[24]; 接下来, 利用构建好的分类体系训练文本分类模型, 观察分类结果, 优化分类体系; 最后重复上述流程, 直至分类结果的准确率不再提升。其中, 第三级分类体系具有如下两个特征。
特征 1: 通过细化分类体系, 使各类民生问题间形成清晰的边界。虽然民生问题种类繁多, 但各类问题的特征较为明确, 可以通过枚举的方式, 罗列每一类民生问题的范畴, 使各类问题之间形成清晰的边界, 消除在定义上模棱两可的类别。不断拆分模糊的民生问题, 是保持各类问题之间互斥性的关键。
特征 2: 将诉求文本中同时且频繁出现的多个琐碎问题进行合并。针对特征繁多、内涵复杂的民生问题(如物业、商品房交付和公共卫生等), 居民常常详细罗列问题的各类细节, 此时看似居民反映了多个问题, 但本质上仍然是围绕同一类问题展开说明。
1.2.2生成合成训练集
本研究使用的训练集为合成训练集, 既包括真实的居民诉求文本, 也包括人工生成的“伪诉求文本”。合成训练集的构建方法如下。
首先, 从 173 万条居民诉求中随机采集 5 万个样本, 构成“居民实际诉求标注集”。标注员从分类体系的第三级分类中挑选一个或多个标签对样本进行标注。每个样本至少经过两位标注员的交叉验证, 一致性超过 95%。在标注后的样本中, 95.8%的样本含有一个标签, 4.0%的样本含有两个标签, 仅有 0.2%的样本标签数量超过两个, 标签基数(平均每个样本的标签数)为 1.04, 远小于标签种类数, 说明大多数居民在一次诉求中仅反映一类问题。从标签的数量特征看, 文本分类模型对绝大部分样本要实现的是单标签分类, 而非多标签分类。因此, 本研究在标注集中剔除全部多标签样本, 仅保留单标签样本。
然后, 构建“人工生成诉求标注集”。在人工生成诉求标注集中, 诉求内容记录的并非居民的真实诉求, 而是反映各类民生问题基本特征的关键词或关键句。表 1 中对比了民生问题“发车频次低”在居民实际诉求与人工生成诉求之间的差异。在实际诉求中, 居民可能会详细描述发车频次、等待时间和造成的困扰等细节, 而人工生成的诉求则直接列出“公交车”、“等了好久没有车”等典型的关键词或短语。
人工生成诉求具有两个功能。一是使各类标签的样本量相对均衡。实际上, 浙江省各类民生问题的分布并不均衡, 噪音、房屋违建和垃圾清理等问题占比更高, 光污染和偷捕动物等问题占比较低。如果仅用原始诉求文本作为训练集, 则可能导致样本数量较少的标签训练次数不够, 使标签的特征难以被有效地学习。在训练集内融入一定比例的人工生成诉求, 有助于解决原始训练集样本量失衡的问题。二是帮助文本分类模型快速学习各类民生问题的特征。大部分标签可以通过诉求文本中的少量关键词或关键句进行判断, 比如当文本中出现“公交车班次较少”等描述时, 基本上可以判断该诉求的标签是“发车频次低”。相比于居民实际诉求, 人工生成诉求仅保留最具辨识性的语句, 这种方法对基于自注意力机制的文本分类模型十分有效。基于自注意力机制的学习过程可以理解为从文本中挖掘每个标签对应的关键字, 而人工生成标注集的优势在于可以人为地“告诉”模型各类民生问题的特征, 从而降低模型学到错误特征的可能性。人工生成诉求有一定的局限性, 只能覆盖各类民生问题的基本特征, 大量特征还需从居民实际诉求文本中学习。居民实际诉求标注集和人工生成诉求标注集构造完成后, 就可以生成合成训练集和验证集。合成训练集由居民实际诉求和人工生成诉求按照一定比例合成。为检验模型对实际诉求的预测能力, 验证集中不包含任何人工诉求, 完全由实际诉求构成。
图1 基于政务热线数据的民生问题三级分类体系
Fig. 1 A three-level classification system for livelihood issues based on the hotline compliant data
表1 以“发车频次低”为例对比居民实际诉求与人工生成诉求的差异
Table 1 Comparison between resident’s practical compliant and artificially-generated compliant taking the example of “low departure frequency”

训练集诉求文本标签 居民实际诉求来电人反映: 其是**村的村民, 以前**客车站到**的公交车一天有六班, 之后改成了一天三班(早上 2 班, 下午 1 班), 今早等了好几个小时都没有车, 给村民出行造成不便, 其建议多开 1 到2 个班次便于村民出行, 望相关部门处理发车频次低 人工生成诉求公交车, 等了好久没有车
1.2.3基于 BERT 预训练模型的居民诉求文本分类算法
算法任务可以概括为从 195 种标签中选择一个标签, 对居民诉求文本进行标注。为实现上百个标签的准确分类, 本文基于 BERT (bidirectional enco-der representation from transformers)预训练模型构建文本分类算法。BERT 是一个泛化能力很强的预训练模型, 由谷歌于 2018 年发布。其中 BERTBASE 和BERTLARGE 在 11 项自然语言处理任务中取得最佳成绩, 并将 GLUE 基准分别提升 4.5%和 7.0%, 两个模型均在 SQuAD1.1 和 SQuAD2.0 任务中超越人类, 为自然语言处理(NLP)带来里程碑式的改变。如图2 所示, BERT 模型的架构包含一个 Embedding 层以及若干双向 Transformer 编码器, BERT 模型的详细解释可参阅文献[25]。
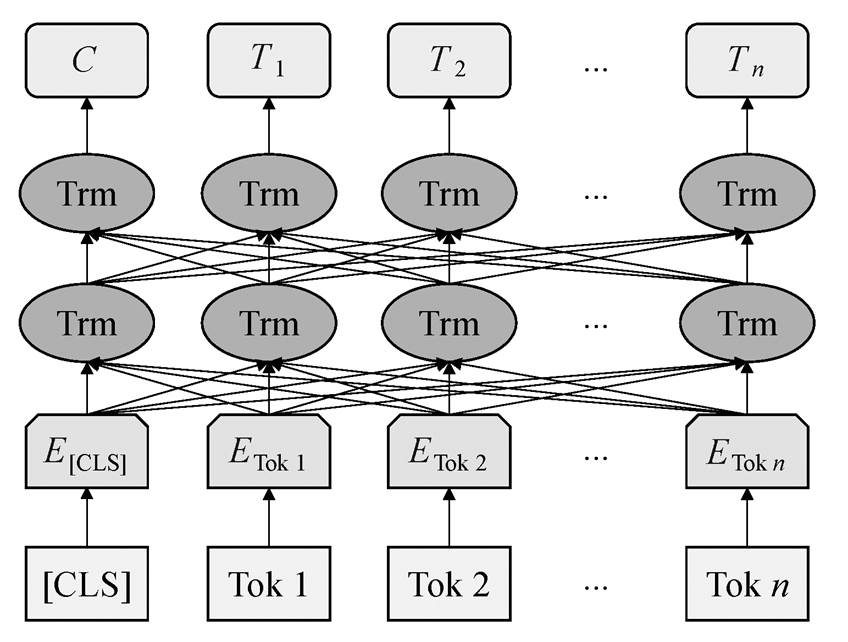
图2 BERT模型架构[25]
Fig. 2 Architecture of the BERT model[25]
BERT 预训练模型属于迁移学习, 即利用与具体任务无关的文本, 隐式地学习通用语言知识, 然后再通过特定的训练集微调参数, 从而完成特定的NLP 任务。图 3 给出算法的总体流程, 分为预训练(pre-training)、微调(fine-tuning)和预测(predicting)3个阶段。预训练的目标是学习某一门语言的通用语法和词汇特征, 预训练阶段的模型参数通常来自外界资源(如 Google AI Language)。可将预训练视为模型参数初始化的过程, 但相比于完全随机的初始化, 经过预训练后的参数蕴含丰富的语言规律, 极大地降低了后续开发者的训练时间, 并显著提升模型能力。针对下游的特定任务, 微调阶段根据训练集对预训练阶段产生的参数进行小规模调整, 使更新后的参数满足特定的研究需求。在预测阶段, 模型的参数不再改变, 仅对目标文本进行标注。
预训练阶段通常采用大规模的与特定 NLP 任务无关的文本语料训练参数, 目标是学习语言的规则和性质, 可理解为让机器从头学习一门语言。BERT 模型的预训练阶段包含两个任务: Masked LM (MLM)和 Next Sentence Prediction (NSP), MLM 任务可以描述为给定一句话, 随机擦除这句话中的一个或几个词, 模型需要根据剩余词汇, 预测被抹去的几个词分别是什么。NSP 任务可以描述为给定一篇文章中的两句话, 判断第二句话在文本中是否紧跟在第一句话之后。由任务描述可以看出, 预训练阶段使用的训练集完全可以通过原始语料自动生成, 无需人工标注。由于预训练模型的参数不受特定任务影响, 研究者可直接使用训练好的参数。本研究使用的预训练模型来自谷歌发布的 BERT-Base-Chinese①https://github.com/google-research/bert, 该模型使用中文维基百科为语料库, 包括 2500 万条句子。模型通过 12 层 Transformer 编码器进行组装, 隐藏层的维度为 768, 共计 1.1 亿参数。BERT-Base-Chinese 以字为粒度进行切分, 无需分词。
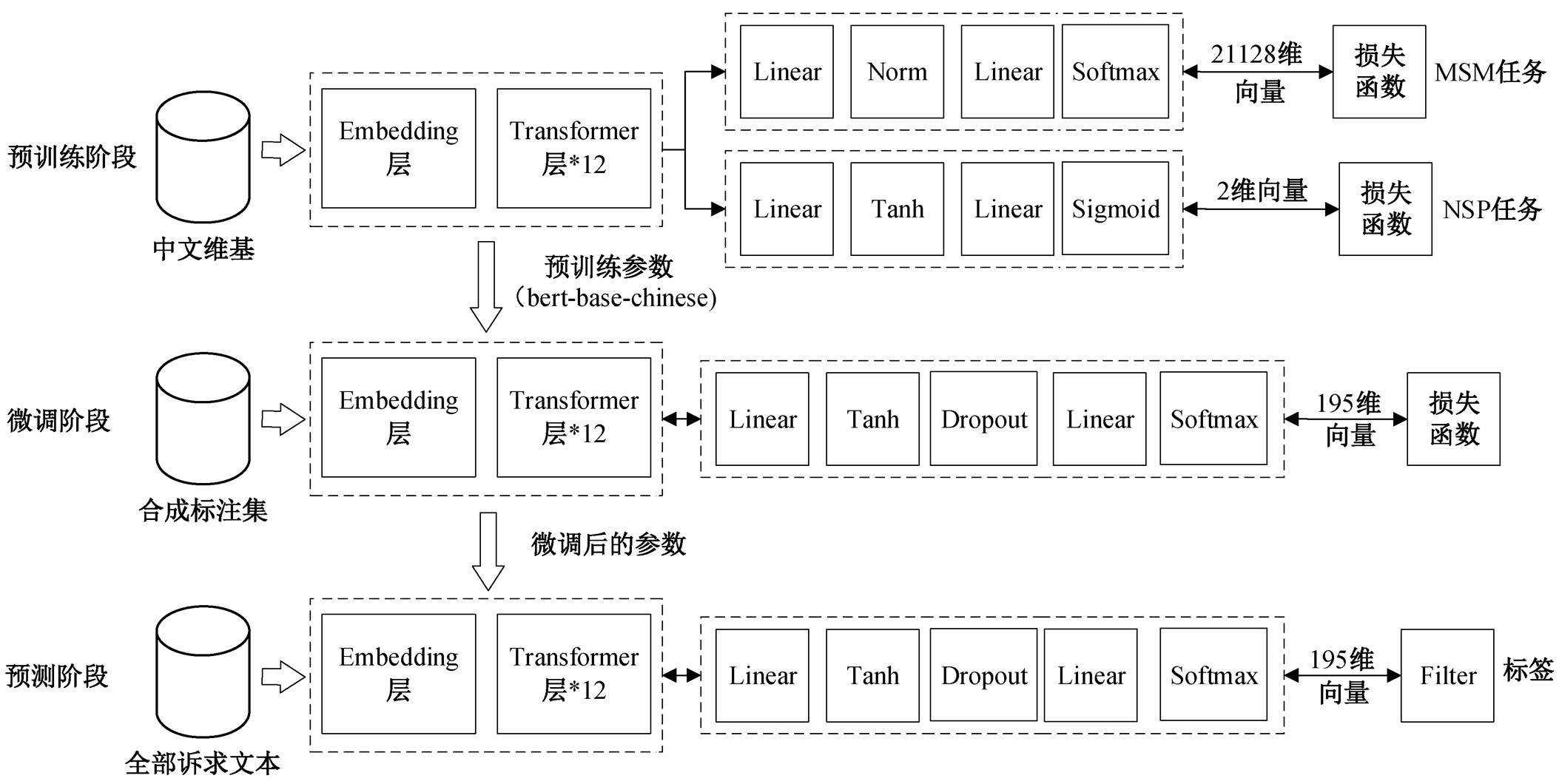
图3 文本分类模型的3个阶段
Fig. 3 Three phases of the text classification model
在微调阶段, 需要利用标注好的合成标注集对BERT-Base-Chinese 的参数进行微调, 使得在文本分类任务中取得更好的效果。在微调阶段, 本研究采用单标签样本对参数进行训练。微调模型与预训练模型的架构在 Embedding 层和 Encoder 层完全一致, 仅在输出层有所不同。首先, 第一个 Linear 层取出句子的第一个 token (即[CLS]对应的向量), 经过 Than 层进行激活, Dropout 层用于提升模型的泛化能力; 第二个 Linear 层为全连接层, 实现分类功能, 输出各类标签的相对得分, 最后通过 Softmax激活函数将得分转换成概率。本研究使用交叉熵函数衡量损失:
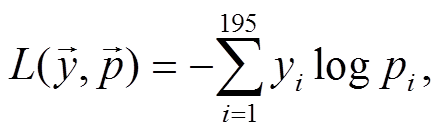 (1)
(1)
其中, 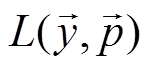 表示每条诉求文本的分类损失;
表示每条诉求文本的分类损失; 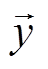 表示诉求文本的实际分类, 是一个 195 维的独热向量, 中的第 i 个元素 yi 表示诉求是否属于第 i 类标签, 若 yi 取 1, 表示该诉求属于第 i 类标签, 取 0 则相反;
表示诉求文本的实际分类, 是一个 195 维的独热向量, 中的第 i 个元素 yi 表示诉求是否属于第 i 类标签, 若 yi 取 1, 表示该诉求属于第 i 类标签, 取 0 则相反; 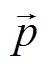 为文本分类模型的输出, 是 195 维的单位向量, 中的第 i 个元素 pi 表示诉求属于第 i 个标签的概率, 为 0~1 之间的小数。
为文本分类模型的输出, 是 195 维的单位向量, 中的第 i 个元素 pi 表示诉求属于第 i 个标签的概率, 为 0~1 之间的小数。
参数经过微调后, 即可对全部诉求进行分类。预测模型与微调模型的结构基本上一致, 唯一不同的是预测模型在 Softmax 激活函数后添加一个过滤器。由前文可知, Softmax 输出诉求文本属于各类标签的概率(即), 过滤器输出概率最大的标签, 即如果 pi 在向量中取值最大, 则第 i 个标签就是预测结果。
本文使用的 BERT 预训练模型来自 Hugging Face 的 Transformers 包②https://huggingface.co/docs/transformers/model_doc/bert。在训练阶段, 将训练周期设置为 3, 训练批次设置为 4, 并基于 Adam 优化算法, 更新神经网络权重。合成训练集和验证集的构造方法如图 4 所示, 首先从 173 万条居民诉求样本中随机抽取 5 万条样本进行标注, 剩余的 168 万条样本作为预测集; 然后在“居民实际诉求标注集”中剔除全部多标签诉求, 仅保留单标签诉求; 接着将“居民实际诉求标注集”按照 2:8 的比例划分成验证集和“居民实际诉求训练集”; 最后在“居民实际诉求训练集”和“人工生成诉求标注集”中按照某一比例进行有放回采样, 构造合成训练集, 在合成训练集中, 每类民生问题包含 300 个样本, 共计 58500 个样本。
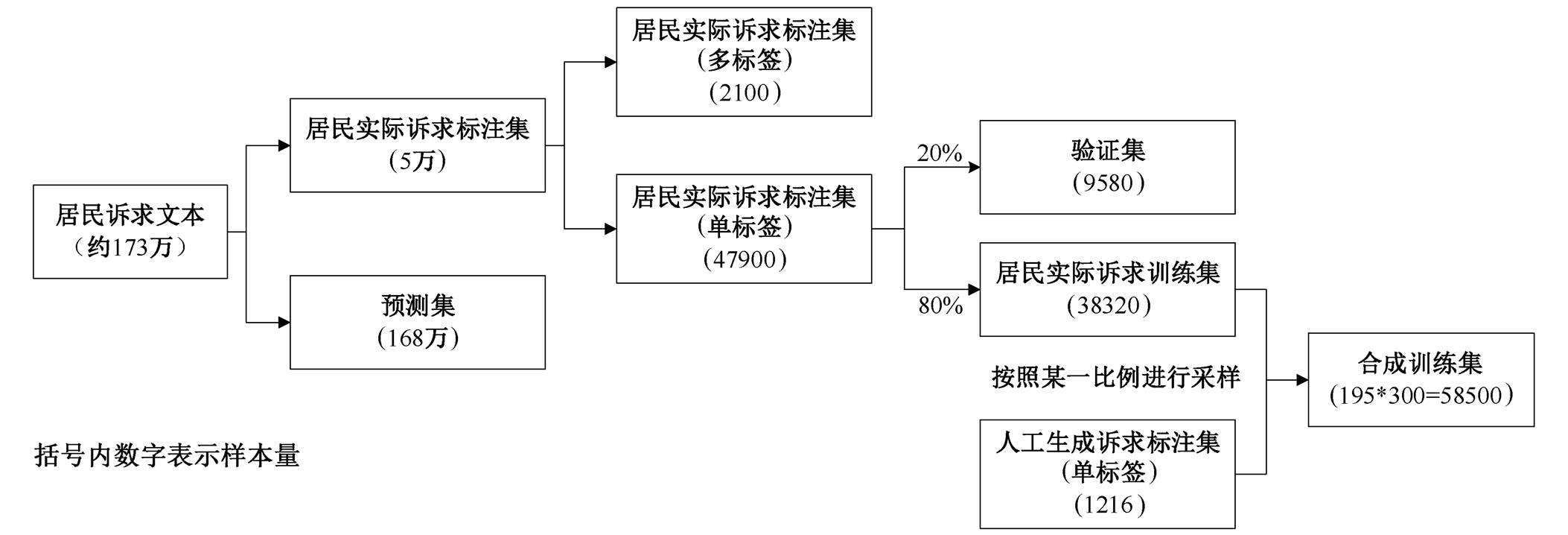
图4 各类标注集之间的关系
Fig. 4 Relationship between different tagging datasets
在合成训练集中, 实际诉求的比例(记为 α)会影响分类准确率。若 α 较大, 模型可以捕捉更多场景, 但也容易导致模型对典型问题的识别能力较弱; 若 α 较小, 模型更容易抓住各类问题的主要特征, 但泛化能力将减弱。图 5 给出准确率随 α 的变化情况。当实际诉求的比例为 70%时, 模型的分类准确率最高(84.59%), 当训练集内不加入任何人工生成诉求时(此时 α 为 1), 模型的分类准确度为 73.92%。相比之下, 在原始诉求中加入约 30%的人工生成诉求, 可以有效地提升 BERT 预训练模型对 12345 政务热线数据的分类准确度, 提升幅度大约为 10 个百分点。
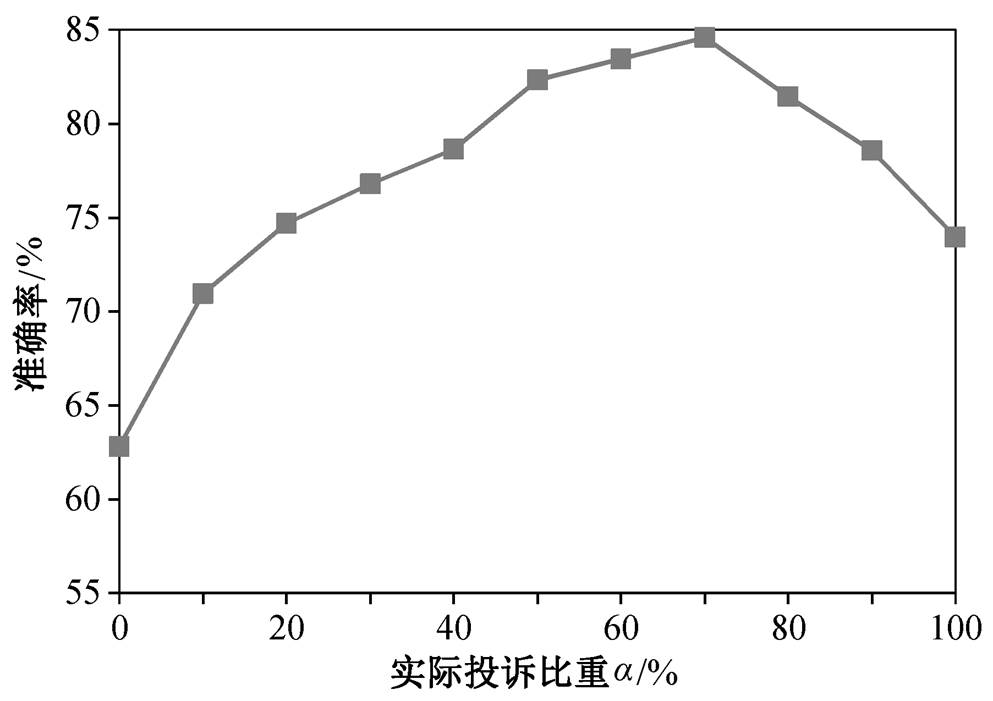
图5 根据准确率选择最优 α
Fig. 5 Selection of optimalαbased on the accuracy rate
为了进一步验证算法的有效性, 本研究将基于BERT 预训练模型的文本分类算法与 TextCNN, Text-RNN 和 TextRCNN 模型进行比较。TextCNN, Text-RNN 和 TextRCNN 均使用 Li 等[26]发布的 word-2vec 作为词嵌入。该模型包括 35 万个词汇, 每个中文词汇由维度为 300 的向量表示, 其中 TextCNN模型的基本架构可参阅文献[27]。本研究用于测试的 TextCNN 模型仅对原文的卷积层进行部分调整: Kim[27]的原始模型使用过滤窗口为 3, 4 和 5的卷积核, 每个过滤窗口设置 100 个卷积核; 本研究中, 卷积核的过滤窗口分别设置为 2, 3 和 4, 每个过滤窗口设置 100 个卷积核。TextRNN 模型的基本架构可参阅文献[28], 本研究测试的 TextRNN 模型根据 Liu 等[28]的 Model-III 进行改造: 隐藏层使用两个 BiLSTM, 取前向和反向 LSTM 在最后一个时间步长上的隐藏状态, 然后对两个状态进行拼接, 最后经过一个 Softmax 层输出多分类结果, 其中隐藏层的尺寸为 128。TextRCNN 模型的基本架构可参阅文献[29], 相比于 TextRNN, TextRCNN 额外引入最大池化层, 池化层作用于每一个时间步长的输出, 从而对一个句子中全部词汇的特征进行考察。本研究测试的 TextRCNN 同样对原模型进行调整: 原始模型使用双向 RNN 捕捉词汇的上下文信息, 本研究使用效果更好的 BiLSTM 作为替代, 隐藏层的尺寸设置为 128。TextCNN, TextRNN 和 TextRCNN模型的相关代码已在 Github 上开源③https://github.com/649453932/Chinese-Text-Classification-Pytorch/tree/master/models。由于本研究面向的是多分类问题(即标签种类大于 2), 为评估全局性能, 使用宏精准度(macro average precision)、宏召回率(macro average recall)和宏 F 值(macro average F-Score)作为评估指标:
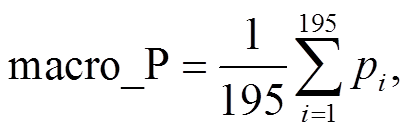 (2)
(2)
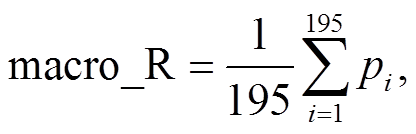 (3)
(3)
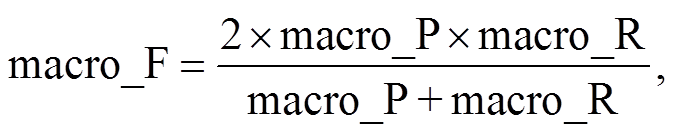 (4)
(4)
其中, Pi 和 Ri 分别表示第 i 类民生问题的精准度和召回率, macro_P, macro_R 和 macro_F 分别表示宏精准度、宏召回率和宏 F 值。由式(2)和(3)可知, 宏精准度和宏召回率分别为不同类别 Pi 和 Ri 的算术平均值。采用相同的训练集(其中居民实际投诉占 70%, 人工生成投诉占 30%)和验证集, 4 类模型在训练集和验证集上的性能指标如表 2 所示。基于 BERT 的文本分类模型在训练集上的宏精准度为 90.57%, 在验证集上降至 84.59%, 其泛化能力相比于其他 3 类模型没有明显的优势。相对于 Text-CNN 等模型, 基于 BERT 的文本分类模型无论在训练集还是验证集上的宏精准度和宏召回率均高于其他模型。与 TextCNN 模型相比, BERT 模型无需担忧过滤窗口设置造成的特征识别能力不足。在 Text-RNN 模型中, 句子中越靠后的词重要性越高, 属于有偏模型, 而 BERT 模型可以解决关键词在句子中所处位置对分类结果的影响, 并且模型的层数更深, 参数更多, 因而可以学到更多的特征。同时, 与LSTM 相比, 自注意力机制对长距离依赖和词义消歧的处理能力更强。
根据 BERT 模型的分类结果, 列出 2017—2021年每年的诉求热点, 如图 6 所示, 可以发现, 房屋违建的投诉最为频繁。浙江市场经济活跃, 民营经济发达, 在长期发展过程中, 各地产生大量违法建筑, 严重地浪费了宝贵的土地资源, 成为制约产业转型升级和美丽浙江建设的“绊脚石”。在此背景下, 浙江省开始严格整治违建。在整治过程中, 群众的投诉举报信息起到关键作用。利用这些信息, 治理部门能够做到“发现一起、查处一起、拆除一起”, 极大地调动了群众监督违建的积极性。其次是假货次货类诉求, 主要针对网络购物。近五年来, 浙江省线上购物的诉求比例已经超过线下, 尤其是 2020 年, 线上诉求与线下诉求的比例接近 7:3。随着浙江省对网络市场的监管逐渐严格, 假货次货问题在 2021 年获得好转。此外, 生活垃圾、施工噪音、道路破损、占道经营和排污排水等问题均是群众频繁反映的诉求。
2018—2021 年, 浙江省每年同比增幅较高的前10 位诉求见表 3。2018 年, 服务质量问题显著增长, 集中在美容美发和健身健美等预付式消费领域。2018 年是浙江省实施《中华人民共和国消费者权益保护法》办法的第二年, 办法的实施促进了消费者的维权意识, 这些行业乱象在随后几年逐渐得到整治。2019 年, 办事服务和物业问题较为突出。针对群众反映突出的办事难、流程多等问题, 浙江省通过“最多跑一次”改革, 将高频办事项目转移到线上。“最多跑一次”改革由浙江省率先发起并实施, 全国并无先例, 可借鉴的经验不多, 在改革之初难免产生流程不科学、系统不稳定等问题, 随着系统的不断优化以及居民对线上办事的逐渐适应, 在线办事的诉求比例逐年下降。2020 年, 新冠疫情的爆发导致疫情防控类诉求急速上涨。居家隔离对居民生活和企业生产造成不便, 针对工资拖欠、在线课堂和防疫补助等问题产生一系列诉求。2021年, 居民的生产和生活逐渐恢复正常, 交通需求相对于 2020 年显著增加, 与出行相关的公交、道路和出租车类投诉增幅较高。
2018—2021 年, 浙江省每年同比降幅较大的前10 类诉求呈现 3 种趋势, 如表 4 所示。第一, 环境保护领域的诉求降幅明显, 包括空气污染、水污染和噪音污染在内的各类投诉均明显下降, 说明“美丽浙江建设”和“决战决胜污染防治攻坚战”等一系列治理措施取得显著成效; 第二, 违规经营类诉求降幅明显, 浙江省近年来大力整治无证经营、倚门设摊、占道洗车和流动摊贩等现象, 违规经营问题获得显著改善; 第三, 市政服务类诉求降幅显著, 为破解城乡二元机制带来的“市政服务不平衡”的难题, 浙江省不断加强城乡一体化建设, 农村停水、停电和路灯等市政问题得到极大的改善。
表2 四类模型在训练集和验证集的性能对比结果(%)
Table 2 Performance comparison of four models on the training set and testing set (%)

算法训练集验证集 宏精准度宏召回率宏F值宏精准度宏召回率宏F值 基于BERT的文本分类模型90.5786.4088.4384.5981.3682.94 TextCNN82.8578.9480.8578.1674.9776.53 TextRNN84.1780.3382.2079.6074.0176.16 TextRCNN84.8182.3583.5680.8376.2777.95

图6 2017—2021年浙江省排名前十的诉求
Fig. 6 Top 10 complaints from 2017 to 2021 in Zhejiang Province
表3 2018—2021年间增幅排名前10的投诉
Table 3 Top 10 complaints that rapidly grew from 2018 to 2021

增幅排名2018年2019年2020年 2021年 增幅排名2018年2019年2020年2021年 1出租车生活垃圾疫情防控疫苗问题6理发办卡漏水不肯立案快递物流 2假货次货在线办事难交房质量道路破损7快递物流社保办理快递物流漏水 3超市商场道路破损工资拖欠购房学区8餐饮问题学校占用假期补贴排污排水 4诈骗交房质量课外辅导公交站位置9交房质量证件办理办学失误公交线路 5健身房垃圾桶破损商家未按时发货出租车10办学失误保险账户异常诈骗工资拖欠
表4 2018—2021年间降幅排名前十的诉求
Table 4 Top 10 complaints that rapidly decreased from 2018 to 2021

降幅排名2018年 2019年 2020年 2021年降幅排名2018年2019年2020年2021年 1信号异常无证经营无证经营交房质量6占道经营不肯立案道路破损施工噪音 2施工障碍商铺噪音乱排废水占道经营7房屋违建假货次货乱排废气商家未按时发货 3公司保障诈骗排污排水不肯立案8停水乱排废气房屋违建诈骗 4停车管理乱排废水油烟餐饮问题9拆迁补偿出租车出租车疫情防控 5停电工业噪音路灯乱排废气10工资拖欠房屋违建生活垃圾假货次货
本文从居民视角构建包含 4 个大类、39 个中类以及 195 个小类的民生问题三级分类体系, 并基于 BERT 预训练模型, 将政务热线数据中的居民诉求文本转化为 195 种民生问题的标签。研究结果表明, 将人工生成诉求与居民实际诉求相结合, 可以提升分类的准确性, 当训练集中实际诉求样本的占比为 70%时准确率最高, 分类准确度可达 84.59%。利用分类结果, 本文梳理了浙江省各类民生问题2017—2021 年间的变化趋势, 发现环境保护、违规经营以及市政服务等城乡基础问题得到极大的改善, 但居民生活方式的转变、全球极端事件的爆发以及高质量公共资源的供需矛盾也导致诸如预付式消费陷阱、线上办事、疫情防控和公共资源矛盾等新的民生问题。
从理论价值来看, 本研究有助于清晰化居民视角下的民生问题。在政府注意力稀缺性的限制下, 将纷繁复杂的治理信息转变为清晰的民生问题治理体系是实现有效治理的关键。本研究综合考虑诉求分布的典型性和共现性等原则, 以政务热线数据为支撑, 构建居民视角下的民生问题分类体系, 对推动“治理信息”向“信息治理”转型具有重要意义。从应用价值来看, 本研究基于 BERT 预训练模型构建居民诉求文本分类算法, 既有助于形成以“居民需求”为核心而非以“部门业务”为核心的诉求流转机制, 又可以基于该算法对诉求的“主体”、“原因”、“影响”和“治理措施”等其他关键要素进行识别, 为数据驱动的社会治理开拓研究方向。
参考文献
[1] 高奇琦. 智能革命与国家治理现代化初探. 中国社会科学, 2020(7): 81–102
[2] 韩志明. 模糊的社会——国家治理的信息基础. 学海, 2016(4): 21–27
[3] 韩志明, 李春生. 城市治理的清晰性及其技术逻辑——以智慧治理为中心的分析. 探索, 2019(6): 44–53
[4] 钱坤. 从“治理信息”到“信息治理”: 国家治理的信息逻辑. 情报理论与实践, 2020, 43(7): 48–53
[5] 韩志明. 在模糊与清晰之间——国家治理的信息逻辑. 中国行政管理, 2017(3): 25–30
[6] 郭亮. 发达地区农村社会治理体系的特征、问题及其运行风险——以长三角农村地区为例. 湖湘论坛, 2021, 34(5): 37–46
[7] 郭亮. 地权纠纷与乡村治理的“困境”——来自湖北S镇的调查. 北京行政学院学报, 2010(4): 10–15
[8] 廖志恒, 孙家仁, 范绍佳, 等. 2006~2012年珠三角地区空气污染变化特征及影响因素. 中国环境科学, 2015, 35(2): 329–336
[9] 朱力, 袁迎春. 当前我国居民对社会矛盾的感知与解决方式——基于全国九市的问卷调查报告. 国家行政学院学报, 2018(2): 115–121
[10] 赵金旭, 王宁, 孟天广. 链接市民与城市: 超大城市治理中的热线问政与政府回应——基于北京市12345政务热线大数据分析. 电子政务, 2021(2): 2–14
[11] 孙宗锋, 姜楠. 政府部门回应策略及其逻辑研究 ——以 J 市政务热线满意度考核为例. 中国行政管理, 2021(5): 40–46
[12] 王亚华, 毛恩慧. 城市基层治理创新的制度分析与理论启示——以北京市“接诉即办”为例. 电子政务, 2021(11): 2–11
[13] 陈锋, 宋佳琳. 技术引入基层与社区治理逻辑的重塑——基于 A 市 12345 政府服务热线的案例分析. 学习与实践, 2021(4): 84–94
[14] 赵金旭, 赵德兴. 热线问政驱动社会治理范式创新的内在机理. 北京社会科学, 2022(2): 43–54
[15] 孟天广, 黄种滨, 张小劲. 政务热线驱动的超大城市社会治理创新——以北京市“接诉即办”改革为例. 公共管理学报, 2021, 18(2): 1–12
[16] Athens J, Mehta S, Wheelock S, et al. Using 311 data to develop an algorithm to identify urban blight for public health improvement. PLOS ONE, 2020, 15(7): e0235227
[17] 彭晓, 梁艳, 许立言, 等. 基于“12345”市民服务热线的城市公共管理问题挖掘与治理优化途径. 北京大学学报(自然科学版), 2020, 56(4): 721–731
[18] 赵娟, 王烨, 张小劲. 公众诉求与回应性监管: 基于政务热线大数据的社会性监管创新——对三类社会性监管领域的比较分析. 电子政务, 2021(2): 15–26
[19] Pu X, Long K, Chen K, et al. A semantic-based short-text fast clustering method on hotline records in Chengdu // 2019 IEEE Intl Conf on Dependable, Auto-nomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/Cy-berSciTech). Fukuoka, 2019: 516–521
[20] Wang Y, Taylor J E. Urban crisis detection technique: a spatial and data driven approach based on Latent Dirichlet Allocation (LDA) topic modeling // Procee-dings of the 2018 Construction Research Congress. New Orleans, 2018: 250–259
[21] Peng X, Li Y, Si Y, et al. A social sensing approach for everyday urban problem-handling with the 12345-complaint hotline data. Computers, Environment and Urban Systems, 2022, 94: 101790
[22] Luo J, Qiu Z, Xie G, et al. Research on civic hotline complaint text classification model based on word-2vec // 2018 International Conference on CyberEnab-led Distributed Computing and Knowledge Discovery (CyberC). Zhengzhou, 2018: 180–1803
[23] CJ/T 214—2007, 城市市政综合监管信息系统管理部件和事件分类、编码及数据要求[S]. 北京: 中华人民共和国住房和城乡建设部, 2007
[24] 中共中央关于全面深化改革若干重大问题的决定(2013 年 11 月 12 日中国共产党第十八届中央委员会第三次全体会议通过). 求是, 2013(22): 3–18
[25] Devlin J, Chang M-W, Lee K, et al. BERT: pre-trai-ning of deep bidirectional transformers for language understanding // Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techno-logies, Volume 1 (Long and Short Papers). Minnea-polis, 2019: 4171–4186
[26] Li S, Zhao Z, Hu R, et al. Analogical reasoning on chinese morphological and semantic relations // Pro-ceedings of the 56th Annual Meeting of the Associa-tion for Computational Linguistics (Volume 2: Short Papers). Melbourne, 2018: 138–143
[27] Kim Y. Convolutional neural networks for sentence classification // Proceedings of the 2014 Conference on Empirical Methods in Natural Language Proces-sing (EMNLP). Doha, 2014: 1746–1751
[28] Liu P, Qiu X, Huang X. Recurrent neural network for text classification with multi-task learning // Procee-dings of the Twenty-Fifth International Joint Con-ference on Artificial Intelligence (IJCAI). New York, 2016: 2873–2879
[29] Lai S, Xu L, Liu K, et al. Recurrent convolutional neural networks for text classification. Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015, 29(1): 2267–2273
Text Classification Model for Livelihood Issues Based on BERT:A Study Based on Hotline Compliant Data of Zhejiang Province
Abstract Using the 12345 hotline compliant data from 2017 to 2021 in Zhejiang Province, a fine-grained three-level classification system for livelihood issues was constructed from the perspective of social cognition. A BERT pre-training model was developed to convert complaint texts into labels for livelihood issues. The validation result showed that adding 30% artificial complaint texts in the training set could increase roughly the accuracy rate by 10 percent, and the accuracy rate could be as high as 84.59%. Moreover, livelihood issue proportions of environmental protection, irregular business and municipal services had shown downward trends, while proportions of public services, traffic managements, house purchase issues, and emerging consumption patterns had shown upward trends. This study showed great values of combining the deep learning technology with 12345 hotline compliant data in improving data-driven social governance capabilities.
Key words livelihood issue text classification; BERT; hotline complaint data; data-driven governance