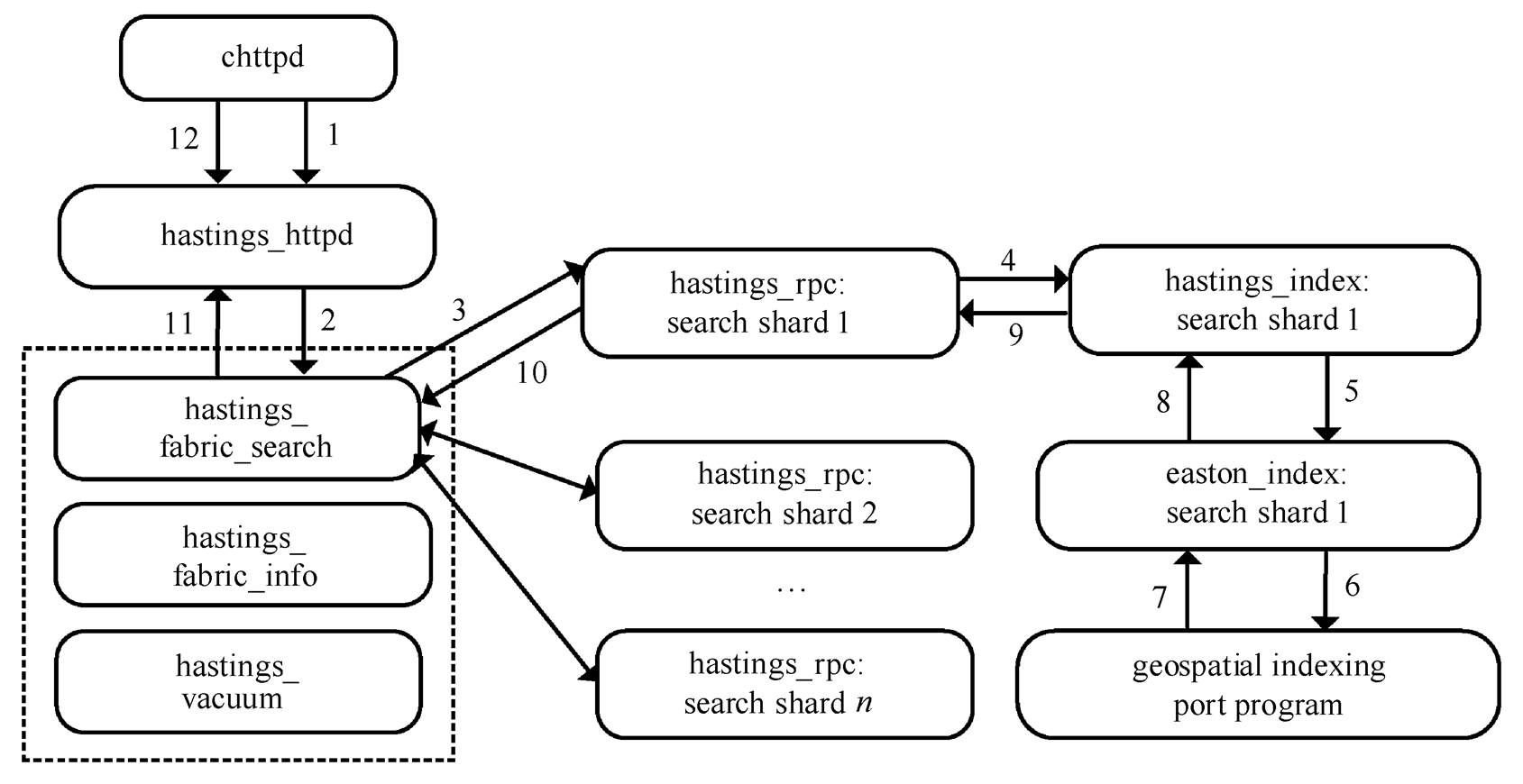
图1 插件集成法的查询流程
Fig. 1 Query process of the plug-in integration method
北京大学学报(自然科学版) 第59卷 第2期 2023年3月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 2 (Mar. 2023)
doi: 10.13209/j.0479-8023.2022.120
国家自然科学基金(41771425)资助
收稿日期: 2022–08–04;
修回日期: 2022–10–06
摘要 空间数据与区块链相结合, 能够为空间数据管理提供去中心化、安全、可信的技术支撑, 但存在查询速率低下、查询方式种类单一以及脱离区块链体系等问题。针对此问题, 结合空间数据库的高性能、函数种类丰富等特点, 提出一种区块链与空间数据库混合架构下的空间查询优化方法。该方法把 Hyperledger Fabric与空间数据库进行集成, 并区别于传统的链下查询方式, 提出一种区块链集成空间数据库的方法, 在智能合约中嵌入高效的空间操作函数, 并且分布式部署数据库, 从而保留区块链原有的分布式查询特点。在防篡改方面, 采取哈希加盐的安全存储机制和双重验证机制来加强安全性。实验结果表明, 该方法在性能和安全性方面都有优良的表现。
关键词 区块链; 超级账本; 空间数据库; 数据安全存储; 空间查询
近年来, 区块链技术在多个产业变革中起着重要作用, 区块链平台也从以比特币[1]为代表的区块链 1.0, 发展到以太坊[2]为代表的合同区块链 2.0, 再发展到区块链 3.0。区块链 3.0 应用于各类社会活动中, 用以保证公平、公正、公开, 其中的代表之一就是IBM开源的区块链Hyperledger Fabric[3]。
区块链与空间数据相结合, 不仅能利用区块链的去中心化、去信任化、可靠数据库以及开源可编程等技术特性来管理空间数据, 还能让区块链支持更多的地理空间应用场景(如基于位置的智能合约服务)。
现有的结合区块链与空间数据的研究主要分为两类。一类是改造区块链的结构来存储空间数据, 这类研究受限于区块链本身的结构特点, 不适用于复杂的空间数据, 在系统吞吐量和查询方式种类等方面有较大的局限性。另一类是在链下使用数据库来实现空间查询, 这类研究多采用单点式数据库, 需要脱离区块链体系, 仅能在链下查询, 并且无法保证链上与链下数据的关联性和一致性。
Hyperledger Fabric 作为区块链 3.0 的代表之一, 目前官方版本还不支持空间查询操作, 仅能使用第三方空间查询插件来实现。本文提出一种集成空间数据库与 Fabric 的空间查询优化方法, 以下称为集成数据库法。
1)针对空间数据查询性能低下和查询方法单一的问题, 采用空间数据库作为数据存储端, 把区块链数据同步到空间数据库, 并采用读写分离的流式复制架构。
2)针对链下与链上分离的缺陷, 建立 Peer 节点与数据库的关联, 在智能合约中集成空间查询操作, 保留分布式存储架构。
3)针对数据库可能会被篡改的风险, 采用安全存储机制, 并使用双重验证机制来防止数据库被篡改。
在实验部分采用 Hyperledger Fabric 与 PostGIS 空间数据库作为本方法的实例, 通过与 Fabric 使用第三方空间查询插件的方法进行对比, 证明本方法在空间数据的查询效率和查询方式上有显著的优势, 并在防篡改能力方面有良好的表现。
傅易文晋等[4]研究区块链 1.0, 2.0 和以 Block-DAG 为代表的体系架构及性能特点, 并分析了 3 种区块链架构应用于时空数据存在的局限性。华亚洲等[5]提出一种基于 Block-DAG 的区块链架构 ST_ Block-DAG, 提升了时空数据存储及查询效率。Qu 等[6–7]对时空区块链进行研究, 并通过引入加密签名的默克尔区块空间索引来支持快速空间查询。Liu 等[8]设计一个基于区块链的车辆本地广告系统, 将大规模的空间关键词分解并存储在区块链上, 使用两个链外模块化执行器来优化查询。马艳磊[9]使用以太坊区块链作为存储空间位置数据的分布式数据库, 将 GIS 领域常用的 geohash 空间索引引入以太坊的智能合约中。上述研究多应用于二维点数据, 并且需要使用 geohash 将二维数据处理成一维的文本数据, 导致效率低下, 且查询方式种类较为单一, 一般只支持单值查询和范围查询。
更多关于区块链结合空间数据的研究是把链上数据转移到链下进行分析。Peng 等[10]提出一种存储流行病地理信息的方法, 用户实时上传包括地理位置的社会数据到区块链, 再利用 GeoAI 来分析流行病的可疑病患。Li 等[11]把完整的溯源信息存储在链下的本地数据库, 在链上采用存储溯源条目的散列值。Daho[12]使用 IPFS/OrbitDB 来存储WKB 加密空间数据, 并计算 WKB 的哈希值, 再上传哈希值到以太坊, 防止数据被篡改。金虹杉等[13]对空间区块链进行研究, 在基于 Hyperledger Fabric 的框架上开发, 使用“链内+IPFS 链外扩展”的存储方案, 根据不同的阈值选择是否将数据直接上链存储。但是上述研究中, 区块链存储的不是原始值, 而是原始值的哈希值, 并且研究的重心放在链下数据的分析和查询, 容易将分布式存储转变成集中式存储, 从而丢失区块链的部分特性。
Hyperledger Fabric 不支持空间查询的功能, 世界状态的底层 CouchDB 只支持 JSON 富查询。目前不支持空间搜索的数据库常用的优化方法是把二维数组降维成一维文本[14], 例如 geohash 和网格编码等编码方式。这类方法的范围查询会导致 CouchDB采用全表扫描或全索引扫描, 反而导致整体性能下降。
Fabric 的 CouchDB 支持 hastings 和 easton 两个地理空间查询插件, 安装后也具备空间查询功能。hastings 完成地理空间搜索, easton 实现空间索引端口程序以及该程序的 API。整个地理查询的流程如图 1 所示, hastings 将请求文本经过切片处理, 调用各个分片的索引(R*-Tree 结构), 再将相应的查询请求通过 Erlang RPC 协议发送给 easton。easton 内部封装的 C++程序使用 spatialindex 和CsMap 等地理查询库, 计算得到空间查询的结果, 再将结果通过 Erlang RPC 协议发回给 hastings, 最后将分片的结果合并成 JSON 格式返回 CouchDB。本文将这种方法称为插件集成法, 后续实验中将插件集成法作为比对方法。
空间数据库的安全性和防篡改性也需要考虑。余涛等[15]提出一种关系查询解决方案 FabricSQL, 在数据库的存储上使用加盐和前哈希值来阻止一定的恶意篡改。本文在数据安全存储的实现中借鉴了这种思想, 并且进一步实现双重验证机制来保证数据不被篡改。
图1 插件集成法的查询流程
Fig. 1 Query process of the plug-in integration method
监听器迭代每个区块中的交易, 并针对有效的交易键值对构建完整的数据存储, 将链上的 Geo-JSON 格式转换成空间数据库对应的关系模式, 再存储到数据库中。每个 Peer 节点都绑定单独的数据库, 并在智能合约中内嵌入空间数据库相关的空间查询 API 来强化区块链的空间查询功能。数据库的安全存储借鉴 FabricSQL[15]的存储验证机制, 并进一步实现最新地理数据的安全存储机制。由存储验证机制和区块链的背书策略共同保证区块链的一致性和安全性。
系统模型如图 2 所示。用户应用程序调用 SDK来访问 Fabric, 根据用户所处的组织和通道调用相关的智能合约。各个组织的 Peer 节点将交易提交给排序节点, 排序节点把区块排序、打包后返回给 Peer节点, 账本则添加新打包的区块。监听器监听区块信息, 如果有新的区块生成, 则提取出来。区块信息通过转换函数把 GeoJSON 格式的空间数据转换成 PostGIS 支持的空间格式, 再将有效的每条数据更新到最新的状态, 并使用数据安全存储机制进行计算, 将哈希值存入 PosgreSQL 中。当用户查询空间数据时, 智能合约从 Peer 节点获取对应的数据库连接信息, 创建数据连接池, 再调用相关的空间查询 SQL 语句, 将空间查询结果返回用户。校验器使用双重验证机制来检验数据是否被篡改, 以此加强数据库的安全性。
普通的 JSON 格式并不适合存储复杂的空间信息, GeoJSON 是一种适用于地理编码的格式, 本文采用 GeoJSON 作为区块链存储的空间数据格式。
Peer 节点是 Fabric 的基本元素, 包含智能合约和账本, 账本由世界状态和区块链两部分组成, 世界状态底层能够使用 CouchDB 实现, 保存当前对象的最新值。Peer 节点和 CouchDB 为一一对应的关系, 每个 Peer 节点都拥有单独的 CouchDB。本文对于PostgreSQL 的分布配置也参照这种对应关系。单数据库节点部署存在以下两种模式。
1)单节点部署。图 3(a)中, 每个 Peer 节点都配置单独的 PostgreSQL, 互不干扰, 每个都拥有独立的空间数据存储、数据监听程序和数据校验器。
2)主从库部署。图 3(b)中有一个主库节点, 既能读也能写。多个从库节点只有读操作, 数据写入主库节点后, 主库将插入、更新、删除等事务操作复制到从库节点上, 从而保持两者一致。
与单节点部署相比, 主从库部署中只有一个主库具有写操作, 每个组织只需部署一个监听器和校验器, 就能有效地降低系统的运行负载。空间数据库的主要功能不涉及写入操作, 基本上为读取操作, 适用于读写分离的主从库部署。本文采用读写分离的主从库部署方案, 每个组织拥有一个主库来完成同步数据的写入操作, 每个 Peer 节点拥有独立的从库来完成空间查询的读取操作。
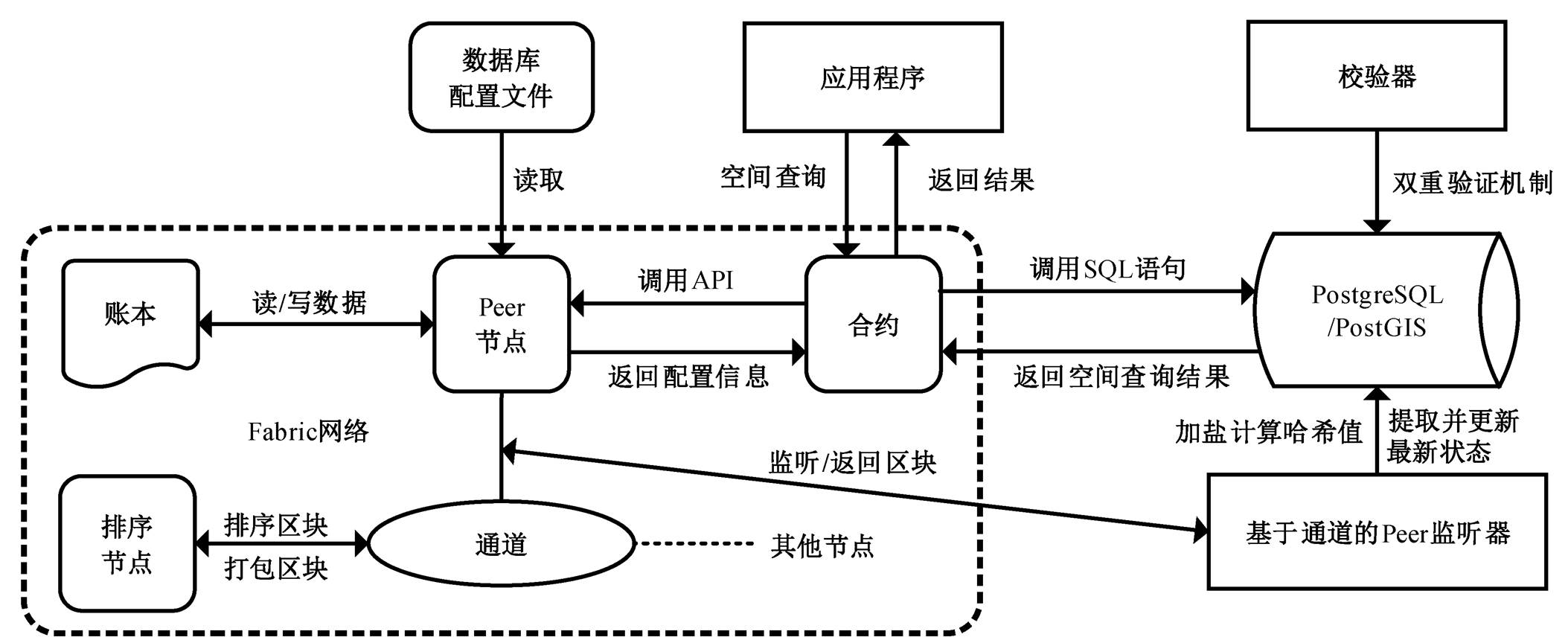
图2 系统模型
Fig. 2 System model
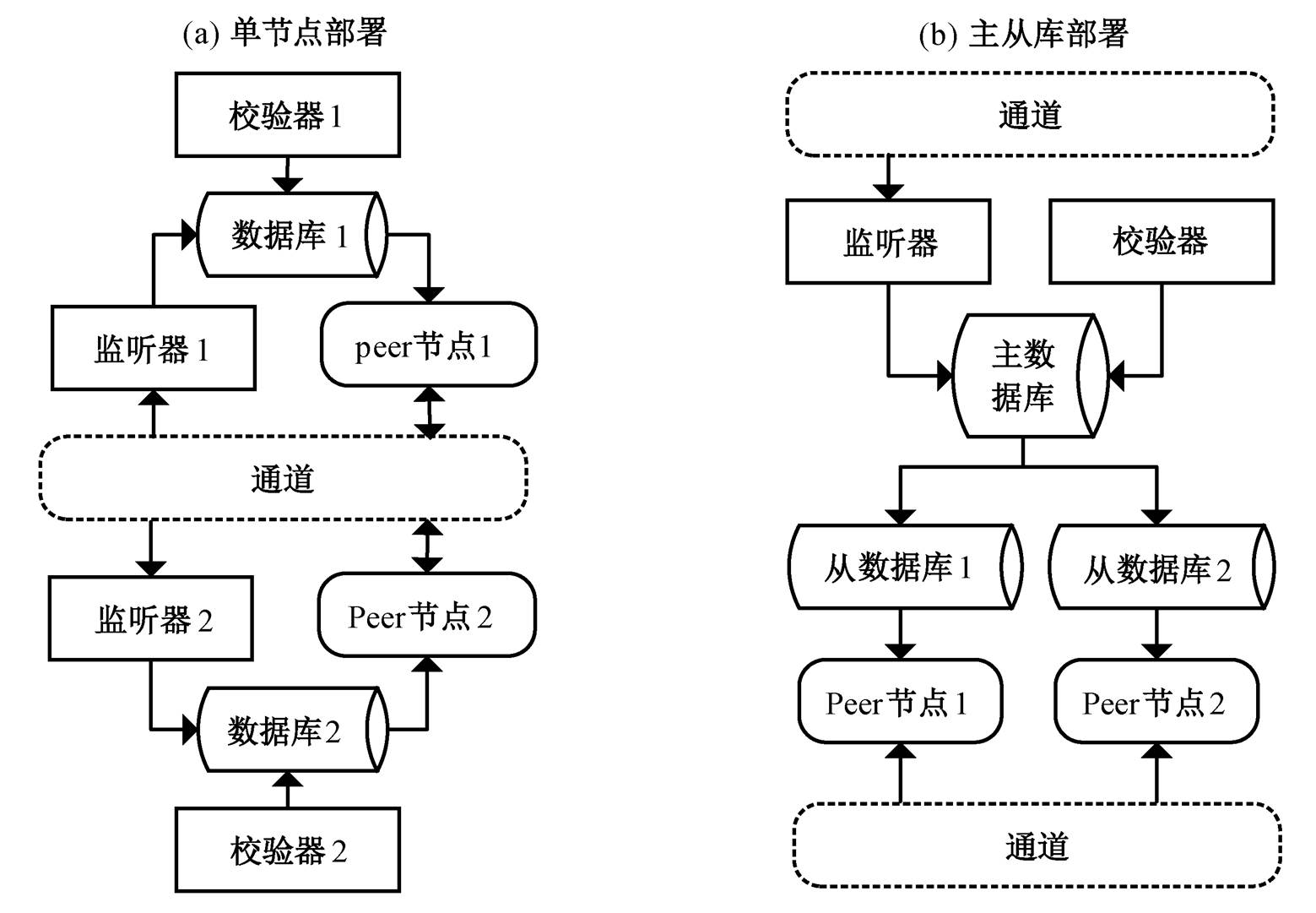
图3 数据库部署方案
Fig. 3 Database deployment solutions
与 FabricSQL 的历史数据表和哈希表设计不同, 本文空间数据库借鉴 Fabric 账本的设计, 共有 3 张表, 分别是最新空间数据表、历史数据表和哈希表。如果只包含历史数据表, 那么数据一旦被删改, 查询最新的空间数据就需要排序筛选, 这将增加延时和性能损耗。因此, 对于高频空间查询需求, 使用最新空间数据表更合适。推送空间数据到空间数据库并安全存储的整个过程如算法 1 所示。
算法1 推送空间数据至空间数据库
输入: 区块原始数据
1 network = getNetwork (channelName)
2 listener = network.addBlockListener (options)
3 blocks = processListener (listener)
4 for block of blocks
5 transaction = processBlocks (block)
6 geom = toGeom (transaction))
7 histoty = toHistory (transaction)
8 hash = toHash (lastHash,hitory,salt)
9 executeSQL (geom, hash, history)
算法 1 中 1~3 行主要是前期工作, 首先连接到Fabric 的通道网络, 再注册监听器。监听器会监听通道上的 Peer 节点, 获取最新的区块数据。第 4~9行处理新添加的区块, 筛选出有效的交易数据, 依次按照空间数据库中 3 张表的格式处理数据, 再执行 SQL 语句更新数据库。
算法 1 中第 6 行转换地理数据的过程如算法 2所示。
算法 2 处理最新空间数据表
输入: 区块的交易数据
输出: 返回SQL语句
1 switch (json.geometry.type)
2 case Point
3 geoJSON = processPoint (json)
4 case LineString
5 geoJSON = processLineString (json)
6 case Polygon
7 geoJSON = processPolygon (json)
8 pgFormatGeom = transfer (geoJSON)
9 if (json.gid exist in newGeomTable)
10 sql = update (pgFormatGeom)
11 else
12 sql = insert (pgFormatGeom)
13 return sql
算法 2 的 1~7 行先判断 GeoJSON 的几何类型, 再根据不同的几何类型进行处理。第 8 行将处理后的数据转换成空间数据库 PostGIS 支持的数据格式。9~12 行判断 gid 是否已经存在于最新的地理表中, 如果存在, 则更新旧数据, 否则就插入新数据。
但是, 智能合约不能直接使用数据库的空间查询, 如果使用传入配置明文的方式, 容易导致数据库信息泄露。同时, 由于区块链执行存在一致性, 每个 Peer 节点都会连接到同一个数据库, 容易导致数据库过载。智能合约中的空间查询也应该具备分布式查询的能力, 类似 Peer 节点与世界状态的关系, 每个 Peer 节点都单独配置 PostgreSQL 数据库, 将数据库嵌入 Peer 节点内, 把整体架构从集中式转换回分布式, 从而加强区块链与数据库之间的关联。
智能合约的 getState (key)函数是最常用的函数, 能够通过主键获取账本中的单条交易值。为避免修改智能合约 API 带来的问题, 通过在 Peer 节点内固定 key 值(例如“pg_config”)来直接回传连接信息给智能合约。根据实际情况, 每个 Peer 节点在启动前配置不同的主机名、端口号、账号和密码等连接信息, 启动后就能读取配置信息, 并且保存在“pg_ config”变量中。通过这种方式, 无需改动智能合约开发的 API, 就能让智能合约连接到每个 P eer 节点单独配置的空间数据库, 从而实现空间数据分布式的部署和查询。
数据库还存在被篡改的风险, 需要使用一种安全机制来防范。算法 1 的第 7 行把区块号码、时间戳和原始的交易数据信息插入历史数据表中, 唯一新增的数据是 dataHash, 算法 2 执行后返回的数据再通过 SHA256 得到的哈希散列值就是 dataHash。
算法 1 的第 8 行是数据安全存储的核心部分, 即数据加盐取哈希散列。盐值为一段长串的随机字符串, 加盐即在哈希散列中附加这段随机字符串, 以便提高安全性, 整体的计算方法如下:
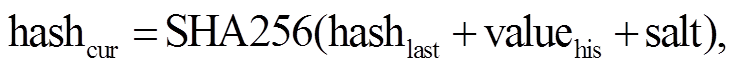 (1)
(1)
其中, hashcur 表示当前这条交易数据的哈希值, hashlast表示哈希表中上一条的哈希值, valuehis 表示插入历史表返回的数据, salt 表示盐值。
交易数据的安全存储机制借鉴区块链的前哈希值思想, 将历史数据与哈希表中上一条交易的哈希值相加, 目的是让每条交易数据都有关联, 一旦篡改数据, 则需要将所有的交易数据和哈希表中的哈希值全部进行修改, 增大作恶的难度和成本, 再加上盐值, 增加安全性和破解难度。
数据安全存储之后, 还需用双重验证机制来检验, 分别保障历史数据表和最新空间数据表。双重验证机制的基本原理为校验器定时遍历数据表, 再根据表中的数据重新计算一遍哈希值。一旦空间数据被篡改, 计算得到的哈希值会与数据库预存的哈希值不一致, 系统会及时发现并报错。如果哈希值已被篡改, 那么遍历哈希表就会发现前后关联的哈希值对应不上, 系统也将报错。前者称为验证机制一(见算法 3), 后者称为验证机制二。相较于 Fabric-SQL 的单值查询并同时验证机制, 本文设计的双重验证机制将验证和查询解耦分离, 缩短了查询时间, 同时校验范围也变为从头到尾的整体范围。
算法 3 验证机制一
输入: 最新空间数据表、历史数据表和哈希表
输出: 数据被篡改则报错
1 for key of newGeoTable
2 geom = select * from newGeoTable where id=key
3 dataHash = SHA256 (geom)
4 history = select * from historyTable where key= geom.id order by id desc limit 1
5 if (history.dataHash != dataHash)
6 return false
7 hashCollection = select * from hashTable where hid=history.id, history.id–1
8 {lastHash, curHash} = hashCollection
9 calHash = SHA256 (lastHash, hitory, salt)
10 If (calHash != curHash)
11 return false
验证机制一主要针对最新空间数据表。校验器不断遍历最新空间数据表, 计算当前的哈希值, 再与历史数据表中当前 id 存储的数据哈希值进行比对, 若有不同就会报错, 防止最新空间数据表被篡改。同时获取历史数据表和哈希表中的当前值, 根据式(1)重新计算哈希值, 判断是否等于数据库中的哈希值。只有所有的数据都一一对应, 才能说明最新空间数据表是可信的。
验证机制一能够覆盖最新空间数据表中的所有值, 但是不能覆盖历史数据表中的所有值。这是因为最新空间数据表的数据根据 key 值可能会执行插入或更新操作, 而历史数据表会记录所有的增删改操作, 两者并非完全一致, 因此需要用验证机制二来保证历史数据表不被篡改。验证机制二针对历史数据表和哈希表, 整体的过程与算法 3 的 7~11 行相同, 只是遍历的对象变为历史数据表的每一条数据。校验器获取历史数据表的当前值后, 再获取哈希表中上一条 id 的哈希值, 然后根据式(1)重新计算哈希值, 判断是否与数据库中的哈希值相同。
相较于直接比对区块链和数据库的验证机制, 这种双重验证机制能脱离区块链, 只需读取数据库的数据, 从而降低区块链的运行负载, 缩短交易响应时间, 在安全和性能之间取得比较良好的平衡。
实验的硬件环境为 AMD EPYC 7551 32 核处理器和 98G 内存的 Ubuntu 服务器。区块链系统使用Hyperledger Fabric v2.3.1 搭建项目环境, 每个组织拥有 3 个节点。使用 Node.js 编写智能合约、交互操作的 SDK 程序、监听区块以及同步数据的脚本程序。
实验数据来自作者所在实验室的北京市相关地图数据(图 4), 为 WGS84 坐标系下的经纬度数据, 范围为北纬 116.19°—116.54°, 东经39.84°—40.03°, 把主要数据集中至北京市主城区附近, 增加空间查询的命中率。POI 数据代表点数据, 包括餐饮和住宅等场所, 共有 8 万多条数据。道路数据代表线数据, 共有 6 万多条数据。建筑物数据代表多边形数据, 总共有 39 万多条数据。本文实验中, 点数据在上述给定的范围内随机抽取; 线数据在顶点数大于3 中随机抽取, 面数据在顶点数大于 10 中随机抽取。
插件集成法在每个 Peer 节点上都使用各自独立的 hastings 和 easton 插件。集成数据库法在每个Peer 节点上都配置 14 版本的 PostgreSQL 和 3.2 版本的 PostGIS, 每个组织都使用一套主从库架构, 主库仅作为同步写入的数据库, 从库作为组织中每个Peer 节点空间查询的数据库。
实验性能对比的方法为插件集成法, 两者都使用 Hyperledger Fabric 作为基础区块链平台, 都使用数据库集成的方法实现空间查询能力, 并且两者在空间查询的基本方法也大致相同, 能够作为有效的对比对象。插件集成法直接存储经纬度数据, 建立R*-Tree 索引。集成数据库法采用 geometry 存储空间数据, 建立 GiST (Generalized Search Tree, 通用搜索树)空间索引。
图4 北京市相关地图数据
Fig. 4 Beijing related map data
本节的实验主要测试插件集成法和集成数据库法在空间查询上的性能表现, 对比实验有 3 项, 分别是范围查询、几何关系和最邻近搜索(K-Nearest Neighbor, KNN)测试。范围查询使用圆范围内的空间数据作为查询测试项, 半径随机选取在 500m 至5km 范围内; 几何关系使用多边形和空间数据相交作为查询测试项。最邻近搜索使用距离目标点最近的50 个空间数据作为查询测试项。在地理围栏内, 随机生成测试使用的点或面, 目的是模拟多位用户查询, 减小数据库缓存带来的影响。
实验中使用 Caliper 作为 Fabric 区块链性能测试的工具, 设置客户端的数量为 5, 持续运行的时间为 30 分钟, 重复 5 次取平均值。数据集取自北京市的点、线和面。实验用选取的性能指标为 TPS (transaction per second, 每秒处理事务数), 在本实验中为每秒内空间查询语句执行完成的次数。速率控制器采取 fixed load 控制器, 用于取得指定积压事务数量下的最大 TPS。
图 5(a)为空间查询在不同数据量下的对比, 数据源为点数据, 积压事务数量为 20。图 5(b)为空间查询在不同积压事务下的对比, 数据源为点数据, 数据量为 1 万条。图 6 为空间查询在不同几何类型下的对比, 数据量为 1 万条, 积压事务数量为 20。
集成数据库法采用基于 GiST 的 R-Tree 空间索引, 基于 GiST 框架的空间索引在适配多个底层索引时有着优势, 但在查询效率上与单独的空间索引几乎无差别[16], 因此基于 GiST 的 R-Tree 索引在查询效率上基本等同于 R-Tree 索引。插件集成法使用R*-Tree 空间索引, 在理论上, R*-Tree 索引在性能上优于 R-Tree 索引, 因此 R*-Tree 索引在空间查询、几何查询和最邻近搜索算法上都会比 R-Tree索引有着更好或者接近的表现。
从图 5 和 6 可以看出, 集成数据库法的空间查询速率基本上是插件集成法的两倍以上, 主要有两点原因。1)插件集成法是针对 Fabric 的 CouchDB, CouchDB 使用 hastings 和 easton 两个插件才能实现地理查询功能, 插件之间需要进行通信。通信建立在 http 连接上, 因此整个查询的过程有比较大的时延。集成数据库法用的 PostGIS 直接在内部处理空间数据, 没有传给外部的通信时延。2)插件集成法使用大地坐标系, 相较于集成数据库法使用的平面坐标系, 需要大量的三角函数运算, 从而造成性能衰减严重。例如, 计算距离的平面坐标系的公式涉及一次对 sqrt 的调用, 而计算距离的球体坐标的公式包含两次 sqrt 调用、一次 arctan 调用、4 次 sin调用和两次 cos 调用。由于本实验给定的数据范围比较小, 集中在市区级别, 所以使用以米为单位的平面坐标系有助于提升性能表现。出于以上两点原因, 插件集成法的空间索引优势基本上被抵消, 并且造成的性能衰减占比更大, 因此集成数据库法在空间查询速度上会优于插件集成法。
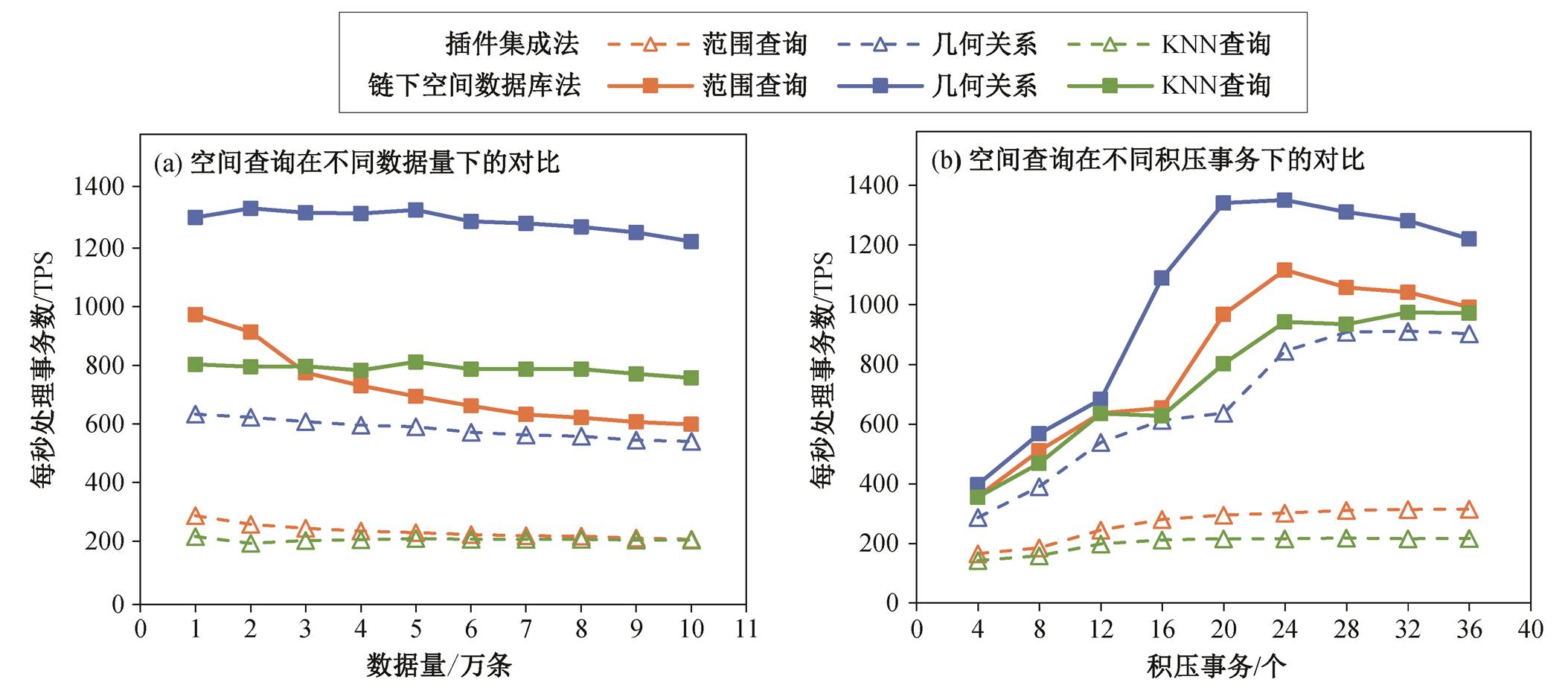
图5 空间查询在不同条件下的性能对比
Fig. 5 Comparison of spatial query under different conditions
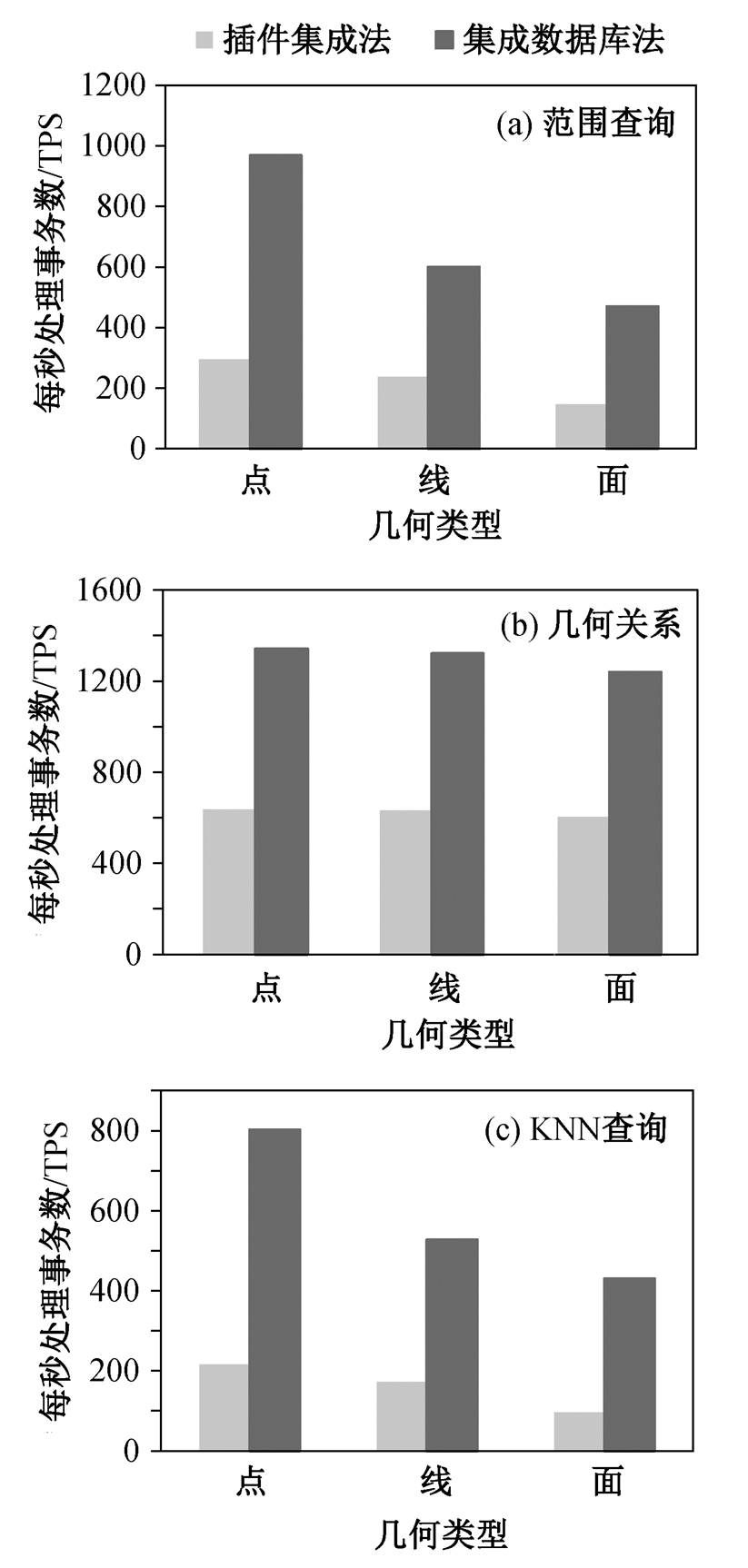
图6 空间查询在不同几何类型下的性能对比
Fig. 6 Comparison of spatial query under different geometry types
在图 5(a)的几何关系和 KNN 查询中, 插件集成法的 TPS 随数据量的增加而逐渐降低, 但集成数据库法的 TPS 只有小幅度波动, 此时区块链的执行速度成为限制本架构的主要因素。Fabric 空函数调用的 TPS 在 1600 左右, 即 Fabric 在此环境配置下执行速度的极限值。PostGIS 几何查询和 KNN 查询的TPS 基本上能够达到此水准, 此时区块链的执行速度成为限制本方法的主要因素。造成区块链空间查询瓶颈的原因有以下 3 个方面。
1)智能合约操作只能通过 Peer 节点来执行调用空间查询函数, 会增加时延, 导致性能下降。
2)Fabric 查询需要经过 CA 认证, 加密签名, 提交提案, 背书节点模拟执行智能合约再签名加密, 最后才返回响应, 每项操作都会造成延迟加大。
3)Fabric 频繁签名加密, 这是 CPU 密集型操作, 而空间查询的操作也是 CPU 密集型, 因此会造成CPU 资源的争抢, 进一步加大延迟。
图 5(b)显示空间查询速率随积压事务的变化而变化。插件集成法基本上不随着积压事务的变化而变化, 因为它已经达到性能极限。集成数据库法在积压事务为 24 时达到最大的查询速率, 此时整个系统的 3 个 Peer 节点达到最佳性能负载。
如图 6 所示, 查询速率也会随几何类型的复杂程度而变化, 几何模型越复杂, 查询速率越低。本实验中线数据的平均端点数为 4, 面数据的平均端点数为 19, 因此面数据的查询效率低于线数据。
插件集成法最大的缺点是空间字段不能与普通字段联合查询, 需在智能合约中再次筛选符合的结果, 容易造成性能瓶颈。集成数据库法使用开源的数据库 PostgreSQL, 能够联合任意字段查询, 支持几何和地理两种空间数据类型, 也具有多种空间索引, 空间函数也较为丰富, 因此集成数据库法的空间查询方式能够适用于更多的应用场景。
存储验证机制和区块链的背书策略两方面共同加强防篡改能力。存储验证机制能够在一定程度上保护数据库不被篡改, 区块链的背书策略能够保证各组织数据的一致性。本节实验针对防篡改能力, 依次修改空间数据库的最新空间数据表和历史数据表来展现数据被篡改的情况。
实验数据为随机生成的点数据, 先插入 10 万条数据, 再重新根据相同的 id 更新原来的 10 万条数据, 因此最新空间数据表拥有 10 万条数据, 而历史数据表拥有 20 万条数据。
采用验证机制一的校验器, 使用分页查询的方式, 遍历最新空间数据表, 每页取 1000 条数据, 每页的校验时间为 992ms。如图 7 所示, 当第 5 万条数据被更改后, 校验器在 50s 后发现根据第 5 万条数据计算得到的 dataHash 与历史数据表中存储的dataHash 不相同, 发出警告信息。
校验器使用验证机制二来确保历史数据表没有被篡改。校验器分页查询历史数据表, 每页取 1000条数据, 每页的校验时间为 430ms。当第 10 万条数据被更改后, 校验器在 43s 后发现根据第 10 万条数据计算得到的 hash 值与哈希表中存储的 hash 值不相同, 发出警告信息。
区块链的背书策略也能够提供安全保障, 背书策略定义了要背书一项交易使其生效需要的最小组织集合。要想对一项交易背书, 组织的背书节点需要运行与该交易有关的智能合约, 并对结果签名。当排序服务将交易发送给提交节点, 节点们将各自检查该交易的背书是否满足背书策略。如果不满足, 交易被撤销, 不会对世界状态产生影响。分离式的链下查询体系无法利用区块链的背书策略, 但对于集成且分布式的数据库方案, 可以直接利用原有的背书策略来增强安全性。本实验中智能合约设置的背书策略是两个组织分别需要至少一个 Peer节点签名。如图 8 所示, 我们修改组织二数据库中的最新空间数据表, 当调用智能合约时, 由于背书策略的限制, 两个组织需要同时满足背书策略, 才能被排序节点接受。此时其中一个组织的数据被篡改过, 导致两个组织的结果不相同, 因此背书策略报错, 智能合约异常结束。即便此时双重验证机制并没有及时检测到数据被篡改, 合适的背书策略也能够有效地监测到不同组织数据不一致的问题。

图7 最新空间数据表的防篡改测试
Fig.7 Anti-tampering test of the latest geographic table

图8 篡改不同组织的数据库
Fig. 8 Tampering with the databases of different organizations
本文突破当前区块链结合空间数据工作的局限性, 针对空间查询功能不完善、效率低等问题, 选取 Hyperledger Fabric 区块链作为基础平台, 提出一种集成空间数据库的空间查询优化方法, 在智能合约中嵌入空间函数来完成空间操作, 并使用双重验证机制来确保数据库安全。实验结果表明, 该方法在性能测试中比现有的插件集成法有着更优异的性能表现。
未来, 对本文架构改进的方向是实现空间数据库和区块链的无缝集成, 例如, 直接将 Fabric 的世界状态改为高性能的空间数据库, 让空间数据库真正成为区块链的一个内部组件, 从而省去同步数据到空间数据库的步骤, 在性能和安全性方面都有所提升。此外, 将考虑将本文架构应用于真实场景, 例如土地认证/不动产登记、食品溯源、物联网和租房等方面, 这些场景有着高价值、空间属性高度依赖以及平台信任程度低等特点, 非常适用于区块链+GIS。
参考文献
[1] Nakamoto S. Bitcoin: a peer-to-peer electronic cash system [EB/OL]. (2008–11–01)[2022–09–17]. https:// bitcoin.org/bitcoin.pdf
[2] Wood G. Ethereum: a secure decentralised generalised transaction ledger. Ethereum Project Yellow Paper, 2014, 151: 1–32
[3] Androulaki E, Barger A, Bortnikov V, et al. Hyperled-ger fabric: a distributed operating system for permi-ssioned blockchains // Proceedings of the Thirteenth EuroSys Conference. New York: ACM, 2018: 1–15
[4] 傅易文晋, 陈华辉, 钱江波, 等. 面向时空数据的区块链研究综述. 计算机工程, 2020, 46(3): 1–10
[5] 华亚洲, 丁琳琳, 陈泽, 等. 面向时空数据的区 块链构建及查询方法. 计算机应用, 2022, 42(11): 3429–3437
[6] Nurgaliev I, Muzammal M, Qu Q. Enabling block-chain for efficient spatio-temporal query processing // International Conference on Web Information Systems Engineering. Cham: Springer, 2018: 36–51
[7] Qu Q, Nurgaliev I, Muzammal M, et al. On spatio-temporal blockchain query processing. Future Genera-tion Computer Systems, 2019, 98: 208–218
[8] Liu D, J Ni, Lin X, et al. Transparent and accountable vehicular local advertising with practical blockchain designs. IEEE Transactions on Vehicular Technology, 2020, 69(12): 15694–15705
[9] 马艳磊. 面向区块链位置证明的空间位置数据查询研究[D]. 武汉: 武汉大学, 2021
[10] Peng S, Bai L, Xiong L, et al. GeoAI-based epidemic control with geo-social data sharing on blockchain // 2020 IEEE International Conference on E-health Networking, Application & Services (HEALTHCOM). Shenzhen 2021: 1–6
[11] Li H, Yue P, Jiang L, et al. Blockchain technology for vector geographic provenance information organiza-tion and verification. Acta Geodaetica et Cartogra-phica Sinica, 2021, 50(6): 823–832
[12] Daho A B. Crypto-spatial: an open standards smart contracts library for building geospatially enabled decentralized applications on the ethereum block-chain. The International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences, 2020, 43: 421–426
[13] 金虹杉, 李文龙. 分布式GIS篇——基于Hyper-ledger Fabric的空间区块链研究[EB/OL]. (2020–11–30) [2021–09–17]. https://magazine.supermap.com/view-1000-16029.aspx
[14] Fox A, Eichelberger C, Hughes J, et al. Spatiotem-poral indexing in non-relational distributed databases // 2013 IEEE International Conference on Big Data. Silicon Valley: IEEE, 2013: 291–299
[15] 余涛, 牛保宁, 樊星. FabricSQL: 区块链数据的关系查询. 计算机工程与设计, 2020, 41(10): 2988–2995
[16] 薛露露, 张毅, 郭建聪. 对象关系型空间数据库的访问方式的改进. 计算机工程与应用, 2007, 43(30): 174–178
Spatial Query Optimization Methods by Integrating Blockchain and Database
Abstract The combination of spatial data and blockchain can provide decentralized, secure and trustworthy technical support for spatial data management, but there are currently problems such as low query rate, single type of query, and detachment from blockchain system. According to this problem, combined with the characteristics of high performance and rich function types of spatial database, a spatial query optimization method by integrating blockchain and database is proposed. The method integrates Hyperledger Fabric with spatial database, and differs from the traditional off-chain query method by proposing a blockchain-integrated spatial database method, embedding efficient spatial operation functions in smart contracts, and deploying the database in a distributed manner, so as to retain the original distributed query characteristics of the blockchain. In terms of tamper-proof, a hash-and-salt secure storage mechanism and double verification mechanism are used to strengthen the security. The experimental results show that the method has excellent performance and security.
Key words blockchain; hyperledger fabric; spatial database; secure data storage; spatial query