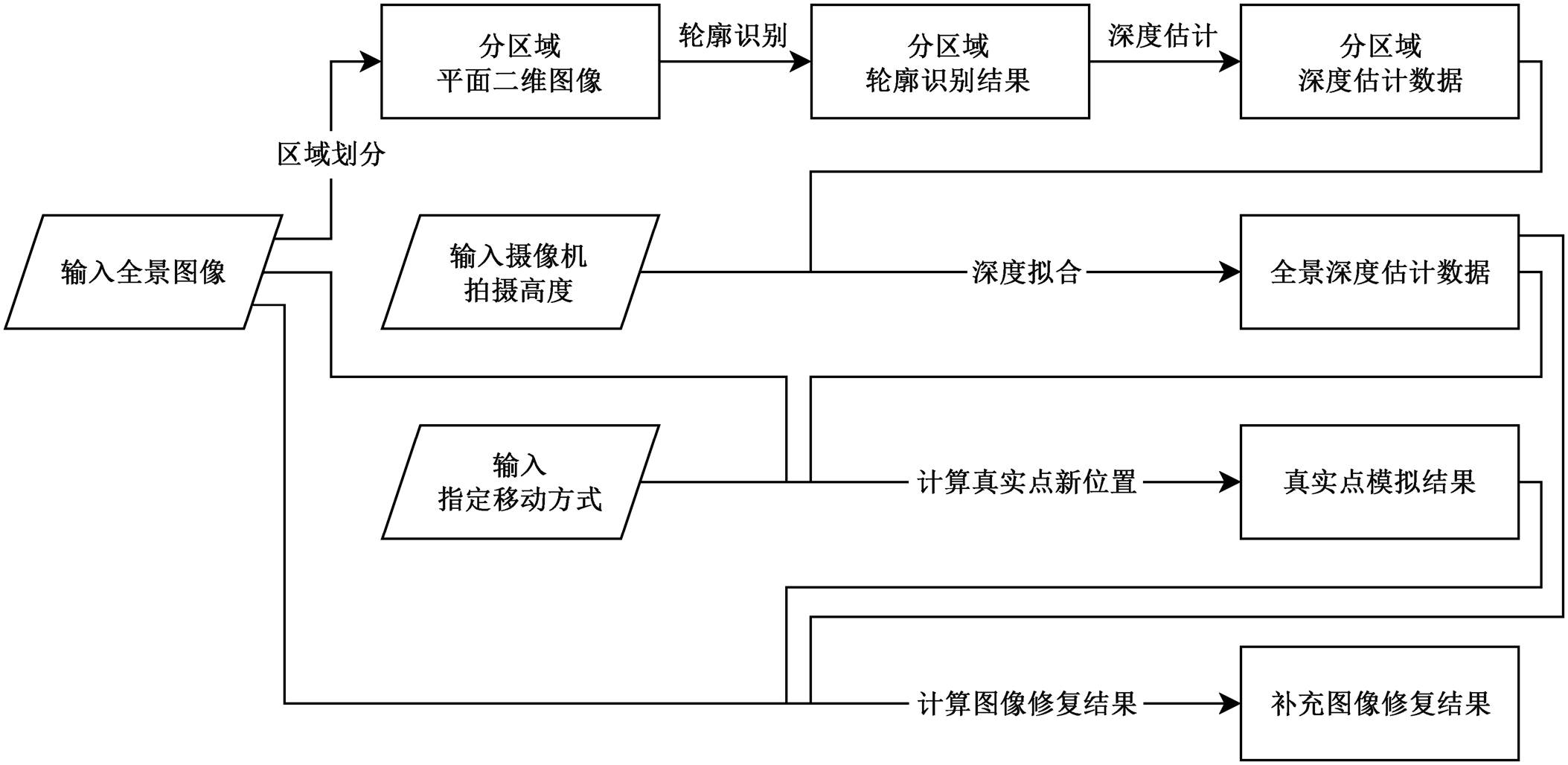
图1 本文方法数据流
Fig. 1 Data flow of our method
北京大学学报(自然科学版) 第59卷 第2期 2023年3月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 2 (Mar. 2023)
doi: 10.13209/j.0479-8023.2022.109
国家重点研发计划(2021YFF0500900)资助
收稿日期: 2022‒04‒05;
修回日期: 2022‒04‒26
摘要 提出一种基于全景影像的野外虚拟环境快速构建方法, 通过对全景影像进行轮廓识别、深度估计和图像修复等处理, 得到基于图像的场景信息, 根据用户的位置渲染对应的全景图像, 获得支持有限范围内 6 自由度沉浸式漫游的虚拟野外环境, 并从图像质量的用户主观感受及客观指标两个方面对该方法的实用性进行验证, 证明该方法使用较方便, 具有较好的应用效果, 可用于虚拟化野外地质教学。
关键词 野外环境; 虚拟地理环境; 全景影像; 6自由度漫游; 图像修复
虚拟野外地理场景是通过虚拟表达的方式, 将野外地理场景数字化, 在 6 自由度的虚拟空间中实现对野外教学场地的沉浸式观摩、考察、研讨和分析等。虚拟野外地理场景的构建有助于相关教学内容的展示和研讨, 提升教学的灵活性、安全性和可操作性。
按场景构建所依据的数据源, 可将目前常用的虚拟野外场景构建方式分为以下 3 类: 1)使用无人机搭配倾斜摄影技术, 从高空拍摄的图像; 2)使用三维激光扫描点云数据; 3)使用拍摄的街景图数据。对于具有高沉浸感和高自由度的小范围场景, 上述 3 类方法分别存在沉浸感不足、数据采集与处理困难以及多张街景图之间不连贯的问题。
全景相机能提供较大的视角, 方便和快速地获取大视角范围内的所有目标实体影像。作为一种可供选择的数据源, 全景图像可以避免上述缺陷。全景图像是一种能显示各方向视角的图像载体, 具有旋转不变性, 能保留真实纹理, 在虚拟场景构建中可以发挥视角大、贴近人类观测情况的优势, 沉浸感强, 与全场景三维建模相比, 具有成本低、场景构建效率高等优势。
本研究提出基于全景图像的虚拟野外场景构建方法, 将全景影像作为数据源, 以图像修复(photo inpainting)和图像内容重建的方式, 构建有限范围内 6 自由度漫游的野外虚拟场景并生成画面, 提升场景的沉浸感和逼真度, 以期为野外教学提供支撑手段。
为了实现基于全景图像构建虚拟场景的目标, 需要对全景图像进行内容物轮廓的识别, 对图像内各目标进行深度估计, 并对被遮挡区域使用图像修复技术生成纹理信息后再进行最终效果的渲染。图像内容物轮廓的识别可通过经典的边缘检测方法实现; 基于神经网络实现的深度生成模型, 可帮助对图像内目标进行深度估计; 部分方法使用基于机器学习的技术, 可以连续完成这两项工作。
Eigen 等[1]采用 Multi-scale 卷积神经网络给出一种单目深度估计方法, Godard 等[2]实现基于自监督的深度估计, Wofk 等[3]提出一个实时的低功耗的单目深度估计框架。野外场景下, Ranftl 等[4]构建的MiDaS 模型取得较好的效果, Xian 等[5]和 Miangoleh等[6]对该模型做了改进。
各种基于生成对抗网络(generative adversarial networks, GAN)的图像修复技术可预测及生成图像中目标被遮挡区域的纹理信息。Zhu 等[7]提出名为视觉对象网络(visual object networks, VON)的方法, 使用对抗学习框架, 对物体的 3D 形状及其纹理贴图信息建模。Nazeri 等[8]提出先由神经网络生成轮廓假想图, 再对纹理缺失区域进行填充的 Edge-Connect 模型。Tucker 等[9]提出生成多平面图像的方法。Shih 等[10]和 Mildenhall 等[11]实现基于静态图片生成多视角的 3D 动画效果。
上述方法对平面二维图像以及规整室内环境下全景图像的实现效果良好。针对室内场景全景影像的深度估计任务, Zioulis 等[12]提出 OmniDepth 方法, 利用两种不同结构的模型, 分别对同一场景进行深度估计模型训练。针对室内全景图的图像修复任务, Xu 等[13]和 Kotadia 等[14]在引入室内场景符合Manhattan 布局以及建筑轮廓形状为长方体的离散组合等关于布局的假定后, 各自提出一种神经网络结构, 从单一室内全景影像生成同场景的新视角。
上述全景图的图像修复方法利用了室内场景的特性。考虑到野外场景的特殊性, 本文拟设计并构建一组方法, 可基于单一野外全景影像生成同场景不同视角的图像。
如图 1 所示, 本文方法的主要步骤如下。
1)输入全景图像和必要的参数(摄像机分辨率等), 指定移动方式。
图1 本文方法数据流
Fig. 1 Data flow of our method
2)识别野外场景物体的大致轮廓, 并对全景图像进行深度估计。此过程基于以下假定。
①拍摄条件为野外环境, 摄像机垂直方向与拍摄点地面垂直, 图像的正上方及其相邻区域为天空, 正下方及其相邻区域分别为相机底座和地面。
②图像的拍摄时间为日间, 晴天或阴天, 山体为有植被或无植被的岩石、沙、土等; 结合拍摄条件, 知道天空的色调为白、蓝等色, 山体的主色调为黄、绿等色, 两者能做明显的区隔。
③假定天空、云等上方目标与拍摄点的距离为无穷远。
3)移动方式为先垂直移动, 再水平移动, 生成移动后的图像。
在此框架下, 输入一张野外全景图像, 并在 6自由度交互操作中进行一次相对于拍摄点移动的操作, 可计算得到一组全景图像并输出, 即为该场景在给定视角下通过本方法计算得到的模拟图像。
对于野外场景全景图像, 没有直接进行深度估计的方式。本文方法是将全景图像转换为多个平面二维图像, 然后进行合并处理。
根据对被拍摄目标的假定, 可知天空会分布在图像的上半部, 地面会分布在图像的下半部, 山体、岩壁和植被等会分布在图像纵向上的中间区域。山体、岩壁和植被是我们重点关注的目标, 在实际观测的时候占据较大的视角, 可以按照各类目标的分布进行区域的分割。
用本文方法把全景图像分为 8 个区域, 相邻区域之间存在重叠, 并且所有位置都在至少一个区域内。区域划分的方式如下。
t(0 ≤ t ≤ 5)号区域:由 At, Mt, Ct, A(t+1) mod 6, M(t+1) mod 6和 C(t+1) mod 6组成。
天空区域: 由 T, A0~A5 组成。
地面区域: 由 B, C0~C5 组成。
可以用全景图像的经纬度, 对各区域进行如下描述。
分块 T经度 θ(°)范围为[0, 360), 即 0≤θ<2π, 纬度 φ(°)范围为[60, 90), 即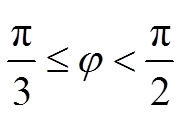 。
。
分块 At为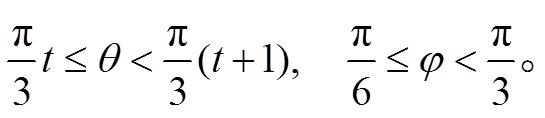
分块 Mt为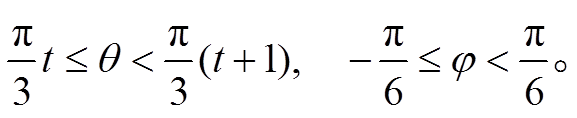
分块 Ct为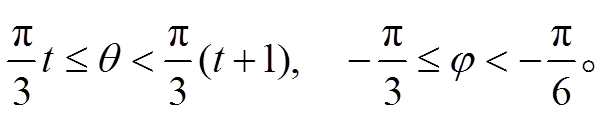
分块 B为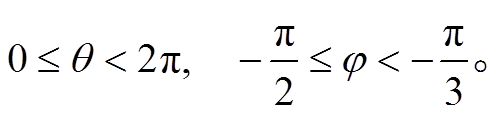
各分块在全景图像上的分布如图 2 所示, 其中橙色线框和绿色线框区域分别为 0 号区域和 3 号 区域。
将各区域在球面的重心进行极球面投影后, 可以将分割后各区域包含的图像信息视为一般平面二维图像, 并借助现有方法进行处理。其中, t(0≤t≤5)号区域的重心在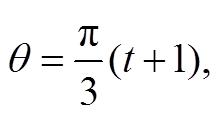 φ=0 处, 天空区域和地面区域的重心分别在
φ=0 处, 天空区域和地面区域的重心分别在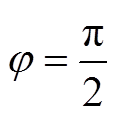 和
和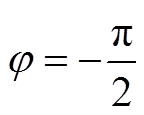 处。可以将投影后的 0~5 号区域分别视为一个水平方向显示野(HFOV)和垂直方向显示野(VFOV)均为 120°的方形区域, 将天空区域和地面区域视为各方向显示野均为 120°的圆形区域, 后续计算过程中使用各区域的正方形投影结果(取 HFOV=VFOV=120°)代替, 为区域的真超集, 且此类正方形在球面上以
处。可以将投影后的 0~5 号区域分别视为一个水平方向显示野(HFOV)和垂直方向显示野(VFOV)均为 120°的方形区域, 将天空区域和地面区域视为各方向显示野均为 120°的圆形区域, 后续计算过程中使用各区域的正方形投影结果(取 HFOV=VFOV=120°)代替, 为区域的真超集, 且此类正方形在球面上以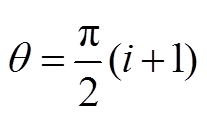 (0≤i≤3)处为顶点。图 3 给出各区域所用图像在球面上的分布示意图。
(0≤i≤3)处为顶点。图 3 给出各区域所用图像在球面上的分布示意图。
对平面二维图像的深度识别, 首先使用 MiDaS- v2[4]的原有架构, 用其数据集中的户外场景数据进行再训练, 以便得到适用于野外场景二维图像的深度估计模块, 用于上述 8 个区域内方形图像的深度识别。由于本文方法主要关注的内容几乎全部位于0~5 号区域, 对分块 T和 B的深度不敏感, 故不对其进行额外的考虑。
经过再训练的模型可对平面正方形图像进行拍摄目标轮廓划分和相对深度估计。结合拍摄条件的假定, 将图像内容标记为天空、地面和相机底座以及拍摄人、植被、山体和岩壁等, 得到识别结果(图 4)。
取得二维图像深度数据后, 对全景图像各区域内生成结果的相对距离数据进行深度拟合, 生成全景图像的深度估计绝对距离。
如图 5 所示, 在识别出地面区域中的地面元素点后, 根据摄像机距离地面的高度以及该地面元素所在纬度等信息, 判定该地面元素点与摄像机的距离, 计算公式如下:
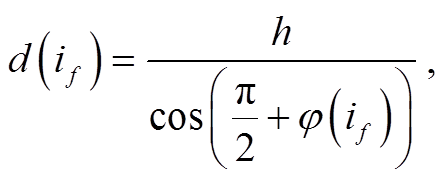 (1)
(1)
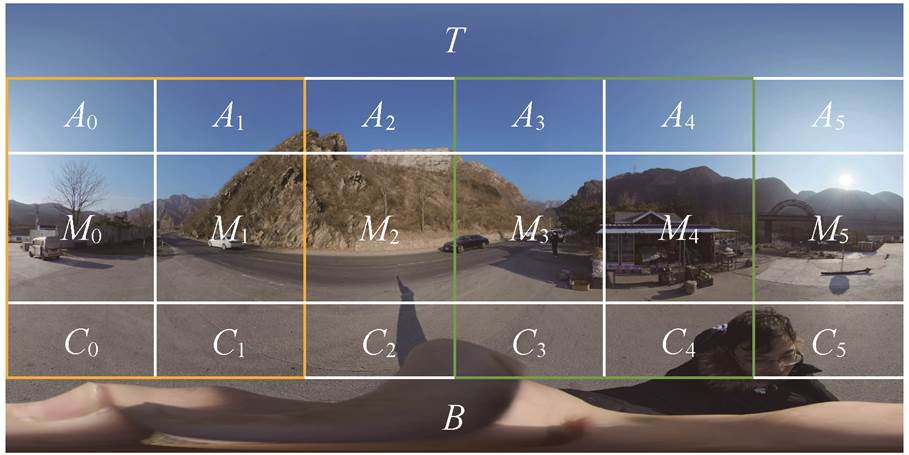
图2 全景图像的区域划分方式
Fig. 2 Region division mode of panoramic image
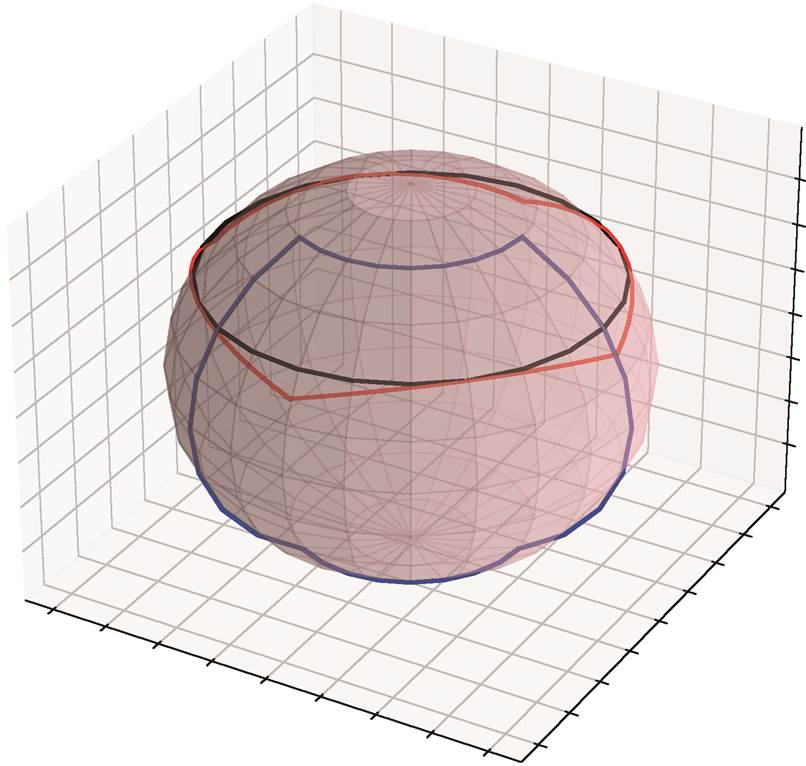
蓝色、黑色和红色的闭曲线分别为 5 号区域、天空区域和天空区域正方形投影结果在球面上的分布
图3 各区域在球面上的分布
Fig. 3 Distribution on the sphere of the regions

左图为输入图像, 右图为相对距离估计结果
图4 目标识别结果样例
Fig. 4 An example result of target recognition
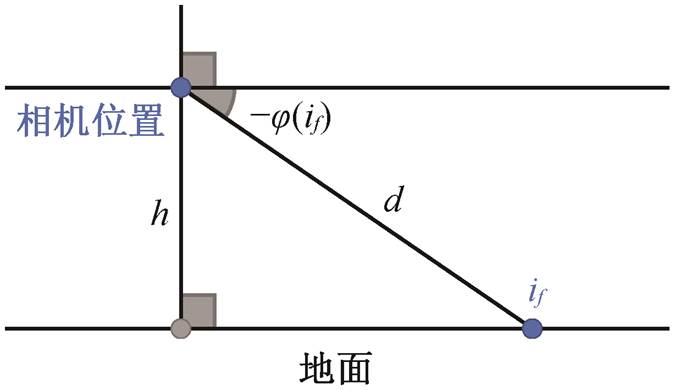
图5 判断地面元素与摄像机的距离
Fig. 5 Distance judgment of ground element and camera
其中, if为地面元素各点, h为摄像机高度, φ(if)和d(if)分别为 if点的纬度和估算距离。
对于地面区域的非地面元素点, 将相对距离按比例关系转换为绝对距离。置该比例关系为所有地面元素点的平均值r:
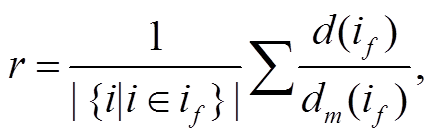 (2)
(2)
d(in) = rdm(in) ,(3)
其中, dm(if)为二维图像给出的相对距离, in为各非地面元素点。
0~5 号区域都与地面区域部分重叠。先估算重叠部分绝对距离与相对距离的关系, 再估计各区域内的绝对距离, 估计方式表示如下:
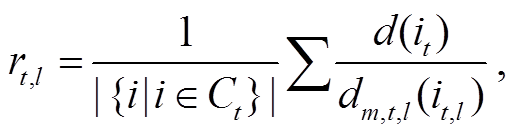 (4)
(4)
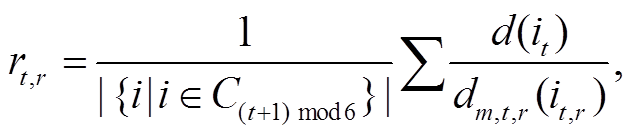 (5)
(5)
dt,l (i) = rt,l dm,t,l (i) ,(6)
dt,r (i) = rt,r dm,t,r (i) ,(7)
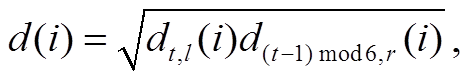 (8)
(8)
其中, rt, l和 rt, r为 t号区域左半部与右半部的比例关系, 由分块 Ct或 C(t+1)mod6 按与式(2)~(3)相同的方式确定, dm,t,l(it,l)和 dm,t,r(it,r)分别为 t号区域左半部和右半部各点 it,l的相对距离, dt,l(i), dt,r(i)和 d(i)分别为根据 t号区域左部和右半部及两部分结合的绝对距离估计值, 由于各 Ct, Mt, At所包含的部分恰好被0~5 号区域中的相邻两个覆盖, 所有像素点都能以两种方式计算出绝对距离, 本文方法将其几何平均值作为最终估计结果。
对天空区域的处理方式与地面区域相似。首先获取各分块 At的绝对距离, 计算得到比例关系 r:
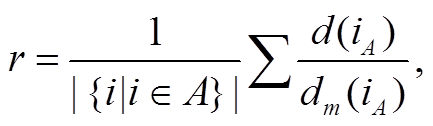 (9)
(9)
再计算区域 T中各点的绝对距离:
d(iT) = rdm(iT)。(10)
至此, 获得所有像素点的绝对距离估计值, 用于估计移动后的图像。
有限范围的 6 自由度交互操作中, 可将视点移动方式可拆解为一个 3 自由度平移与一个 3 自由度旋转的复合。由于全景图像覆盖所有方向, 我们仅需计算平移后的全景图像即可, 即考虑朝向不变时的位置改变(图 6)。
对于原图像中已存在的每个像素, 可根据指定移动方式的平移部分, 使用上述对全景图像的绝对深度估计值, 计算该像素在新图像中的位置。本文方法将所有平移拆解为先垂直于水平面移动, 再平行于水平面移动, 原始图像中各像素的新位置由下列公式给出。垂直移动:
F(θ,φ,d,y)=(θ,atan2(dsinφ−y, dcosφ)) , (11)
水平移动:
P=dcosφcosθ–xcosα , (12)
Q=dcosφsinθ–xsinα , (13)
F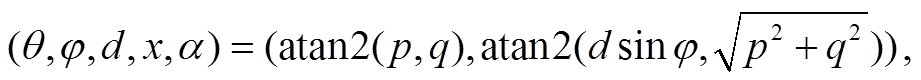 (14)
(14)
其中, θ和 φ分别为原始图像中该点的经度和纬度, d为该点的估计深度, y是向上垂直移动距离(向下移动时取负值), atan2 为根据给定点的直角坐标计算方位角的函数, x是水平移动距离, α是水平移动朝向。α, x和 y的物理意义如图 7 所示。
多个不同的原像素映射到相同位置时, 深度较小的像素将遮挡其他像素。对于未能在新图像中被映射到的位置, 寻找其附近可成功映射的像素对, 使用基于 GAN 的图像修复技术, 将其所在区域的缺失部分(图 8 中红色像素点)补全。该环节首先使用 EdgeConnect[9]的原有架构, 再使用 MiDaS-v2[4]的户外场景数据进行训练, 得到对各区域基于 GAN的野外场景平面图像修复技术模块。
基于此架构, 所有缺失部分可与至少一个分割后的子区域图像修复结果对应, 并按下述规则计算得到唯一结果。
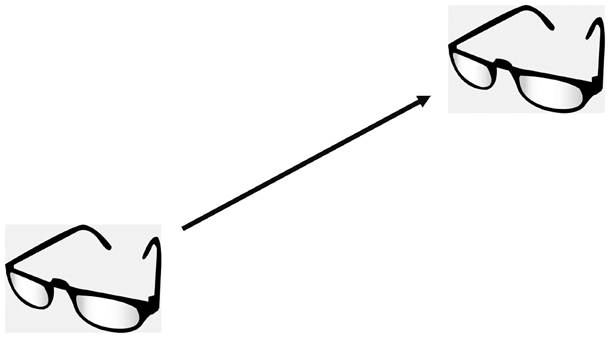
图6 视点的平移
Fig. 6 Translation of viewpoint
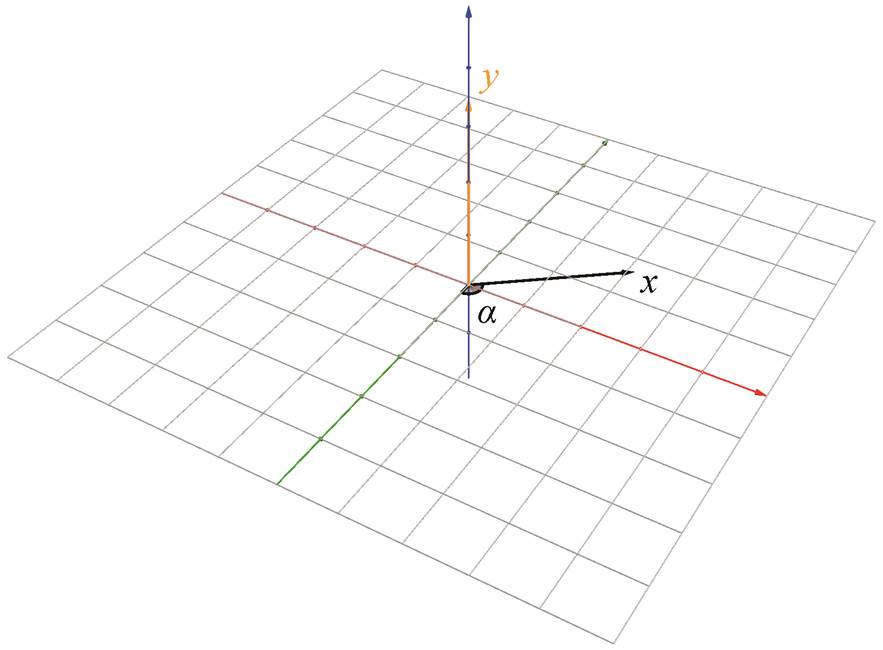
α表示坐标原点, 蓝色箭头指示垂直方向的正向, 红色和绿色箭头分别指向经度的0°和90°
图7 变量 α, x 和 y 示意图
Fig. 7 Schematic diagram of variables α, x and y

图8 映射图像缺失部分示意图
Fig. 8 Schematic diagram of the missing part
1)对于分块 T 的缺失部分, 通过天空区域的图像修复结果生成。
2)对于分块 Ai 的缺失部分, 通过 i 号、(i+1) mod6 号和天空区域的平面图像修复, 以该缺失点至各区域边缘的距离进行加权平均。计算此类点加权平均的方法如下: 考虑该点在上述 3 个区域的对应点颜色 pi, p(i+1) mod 6 和 psky 以及与各区域最近边缘的距离 di, d(i+1) mod 6 和 dsky, 定义该点的颜色为
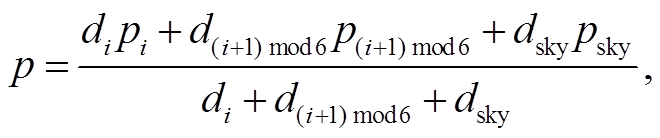 (15)
(15)
下述加权平平均方法同理。
3)对于分块 Mi 的缺失部分, 通过 i 号和(i+1) mod6 号的平面图像修复, 以该缺失点至各区域边缘的距离进行加权平均。
4)对于分块 Ci 的缺失部分, 通过 i 号、(i+1) mod6 号和地面区域的平面图像修复, 以该缺失点至各区域边缘的距离进行加权平均。
5)对于分块 B 的缺失部分, 通过地面区域图像修复结果生成。
得到所有图像修复结果之后, 新图像的每个像素点可获得唯一值, 形成一张全景图像。
具有 6 自由度头部跟踪能力的 VR 设备可以获得用户双目的位置。采用上述算法过程, 分别将视点位移设置为左眼和右眼对应的位移, 可得到两张全景图像, 将其分别输出到 VR 设备的左眼和右眼可视区域内, 即可为用户提供虚拟场景的双目视觉效果。
通过上述方法, 由采集的野外场景全景图像生成新的预测图像, 并将对应于野外场景偏移后的真实图像作为真值(ground truth, GT)进行对比分析。为便于演示和比较, 使用单目生成图像。
考虑到 GT 拍摄目标的实际分布位置与原图像之间存在相机底座和行人等移动目标位置的差别, 对于移动目标位置的分布, 基于整组图像中所有目标轮廓的检测结果, 经人工筛选得到轮廓范围的并集表示, 并在计算定量指标时将此部分忽略; 对于相机底座和拍摄人员在画面中所占据部分为全景图像最下方的情形, 分析时忽略全景图像的分块 B。完成上述设定后, 定义定性指标和定量指标。
3.1.1定性指标
我们可以关注误差在全景图像中的分布位置, 定性地解释产生误差的原因。野外场景中, 全景图像从上到下的目标内容分别为天空、岩壁和植被等侧向目标、地面等低高度目标以及相机底座。
另外, 此类虚拟场景的构建应考虑人类的体验情况。对于给定的测试图像, 将各组图像交由邀请的被试人员, 统计被试群体认知中, 实际图像和计算图像哪个更接近人类理解的结果。
3.1.2定量指标
本研究选用图像处理算法中常用的平均绝对差值(mean absolute difference, MAD)和均方差 (mean squared difference, MSD)作为定量评估指标。由于被评估对象为三通道图像, 其公式中的相应指标具体可写为如下形式:
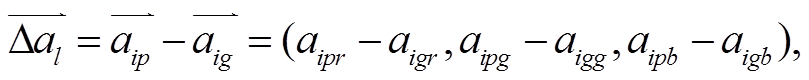 (16)
(16)
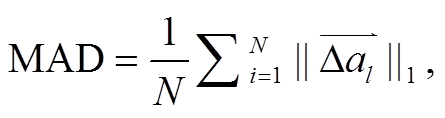 (17)
(17)
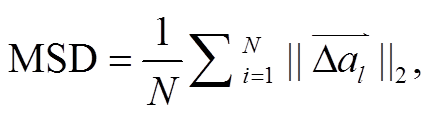 (18)
(18)
其中, N 为图像的像素数,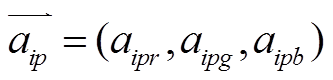 和
和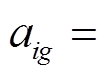
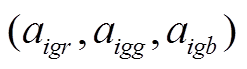 分别为预测图和 GT 的各点像素值, 用 3个颜色通道的向量形式表示。
分别为预测图和 GT 的各点像素值, 用 3个颜色通道的向量形式表示。
由于人类对图像模拟效果的异常值较为敏感, 本文将差向量长度的 90 百分位和 99 百分位数值作为额外指标, 分别记为 X(0.9N)和 X(0.99N)。
实验结果用本文方法结果与 GT 的差以及对照组与 GT 的差表示。根据比较方式, 分为两组实验。
第一组实验: 将对照组设置为原始输入图像, 被比较的对象为全景图像, 用于评估应用本文方法前后对效果的改善。
第二组实验: 将对照组设置为用 Shih 等[10]的方法计算得到的结果。因该方法的应用场景为平面图像, 被比较的对象设置为全景图像中指定的 HFOV和 VFOV 均为 120°的方形区域, 且范围与 0~5 号区域中的一个相等。此设置用于比较本文方法与已有方法的效果。
3.2.1应用本文方法前后对比
这里给出 4 组图片, 每组包含一个输入图像、一个输出图像和一个 GT (图 9)。将输入图像与 GT做差后, 各通道取绝对值得到 D0。将输出图像与GT 做差后, 各通道取绝对值得到 D1。图 10 展示组别 3 的 D0 (左图)和 D1 (右图), 相关定量指标的对比见表 1, 其中显示了 D1相对于 D0 的改善程度。
本文方法对距离拍摄点较近的目标进行输出图像位置的模拟, 是导致输出与 GT 的距离比输入小的主因。计算结果与 GT 的距离主要分布在两类区域: 1)岩壁的距离识别误差导致预测图像的岩壁轮廓与 GT 的岩壁轮廓不完全一致; 2)植物的枝叶导致划分区域困难, 如图 10 右图上方中央的岩壁上边缘和右侧树枝等。

图9 实验用全景图像
Fig. 9 Panoramic images for experiment
表1 应用本文方法前后对比
Table 1 Comparison before and after applying our method
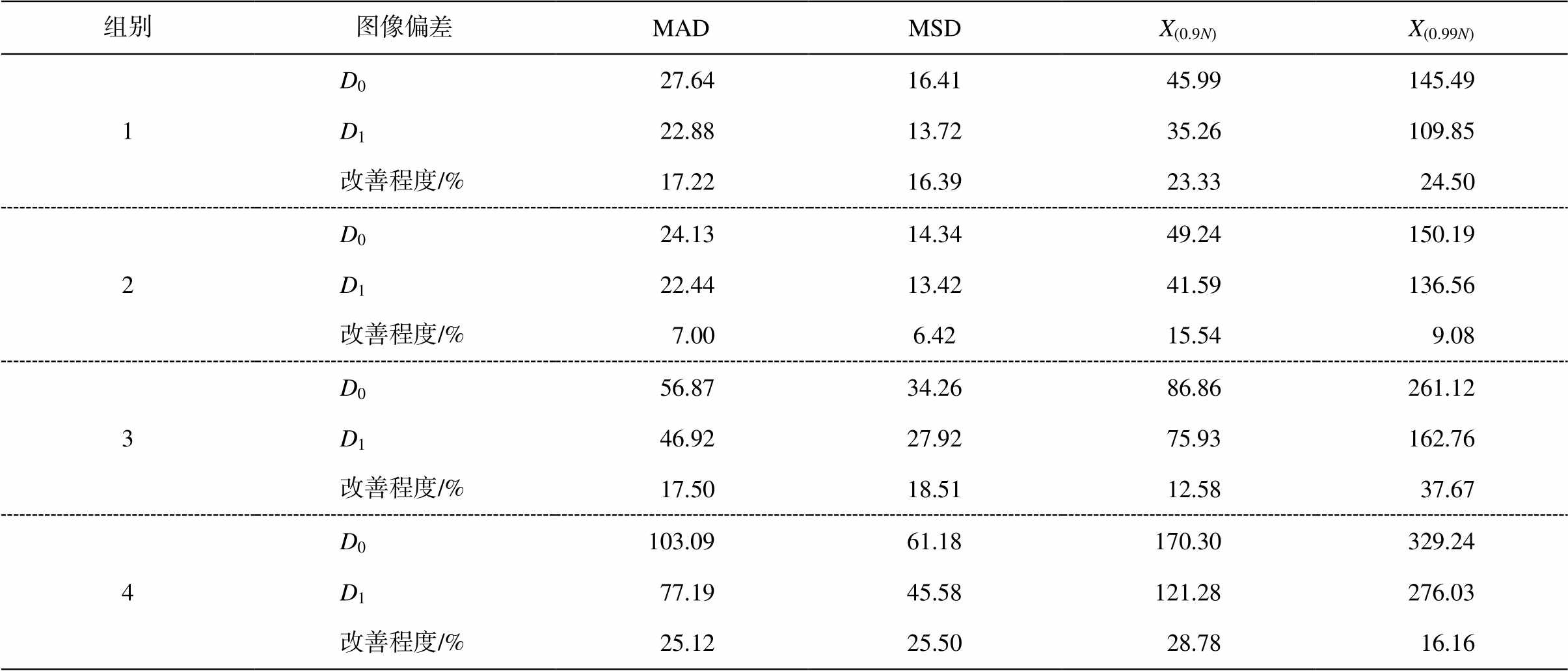
组别图像偏差MADMSDX(0.9N)X(0.99N) 1D0 27.6416.41 45.99145.49 D1 22.8813.72 35.26109.85 改善程度/% 17.2216.39 23.33 24.50 2D0 24.1314.34 49.24150.19 D1 22.4413.42 41.59136.56 改善程度/% 7.006.42 15.54 9.08 3D0 56.8734.26 86.86261.12 D1 46.9227.92 75.93162.76 改善程度/% 17.5018.51 12.58 37.67 4D0103.0961.18170.30329.24 D1 77.1945.58121.28276.03 改善程度/% 25.1225.50 28.78 16.16

图10 实验用全景图像计算结果
Fig. 10 Calculation results of panoramic images for experiment
表2 对全景图像的用户感受结果
Table 2 User experience results of panoramic images
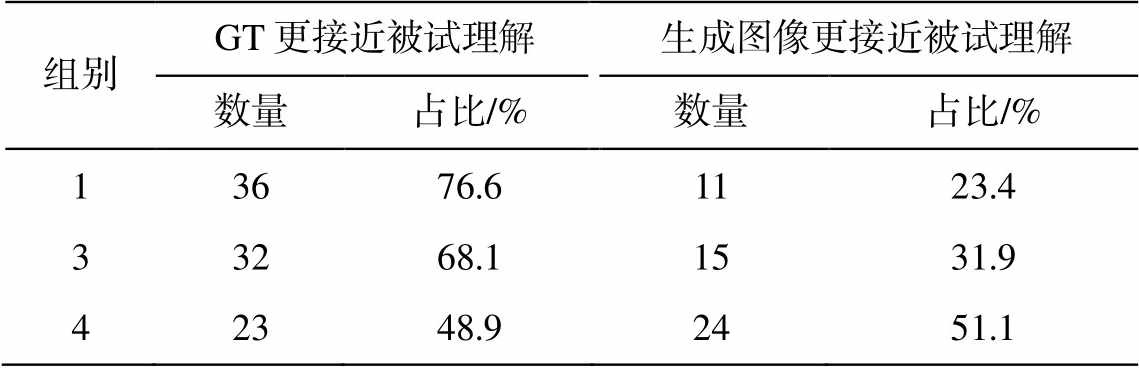
组别GT更接近被试理解生成图像更接近被试理解数量占比/%数量占比/% 13676.61123.4 33268.11531.9 42348.92451.1

图11 实验用方形图像
Fig. 11 Square images for experiment
我们询问被试, 根据每组的输入图像, 剩余两者之中何者更接近其理解。其中, 组别 2 的 GT 有公路上汽车位置的明显变化, 可能导致人类被试的主观感受产生偏差, 我们将其从本次试验中移除。用其他 3 个组别的图询问被试, 共获得 47 份有效回答。统计结果(表 2)表明, 在人类主观体验情况下, 本文方法生成的图像能使超过 1/5 的被试产生迷惑, 并认为本文方法生成的结果更接近他们理解的真实环境, 说明模拟图像足够真实。

图12 实验用方形图像计算结果
Fig. 12 Calculation results of square images for experiment
表3 本文方法与Shih等[10]的方法比较
Table 3 Comparison between Shih’s[10] and our method
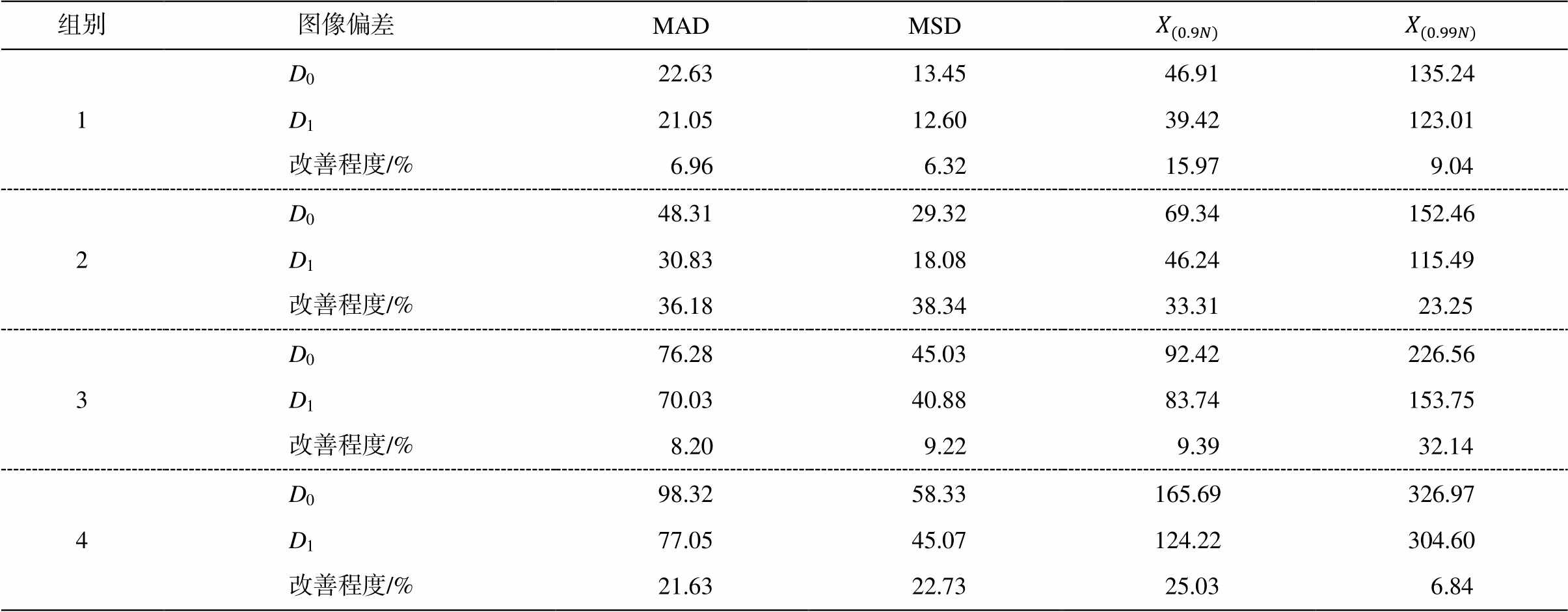
组别图像偏差 MADMSD 1D022.6313.4546.91135.24 D121.0512.6039.42123.01 改善程度/%6.966.3215.979.04 2D048.3129.3269.34152.46 D130.8318.0846.24115.49 改善程度/%36.1838.3433.3123.25 3D076.2845.0392.42226.56 D170.0340.8883.74153.75 改善程度/%8.209.229.3932.14 4D098.3258.33165.69326.97 D177.0545.07124.22304.60 改善程度/%21.6322.7325.036.84
3.2.2与已有方法比较
仍然给出 4 组图片, 每组包含一个输入图像、一个由 Shih 等[10]的方法生成的图像、一个本方法生成的图像和一个 GT。除 Shih 等[10]的方法生成的图像外, 剩下的 3 张图像为前述部分实验所用全景图像的同一个子区域。输入图像以外的其余图像如图 11 所示。
将 Shih 等[10]的方法生成的图像与 GT 做差后, 各通道取绝对值得到 D0。将本方法生成的图像与GT 做差后, 各通道取绝对值得到 D1。图 12 展示组别4 的 D0 (左图)和 D1 (右图), 相关定量指标对比见表 3。
本文方法与 GT 的距离主要分布情况与 3.2.1 节一致。本文方法的结果比 Shih 等[10]的方法更接近GT, 可能是由于全景图像中其他区域的内容对目标轮廓的识别、实际距离的识别和图像修复有帮助。生成效果图和对比图显示本文方法能生成较自然的岩石纹理和分块, 对树枝等目标的距离判断和图像修复稍好于已有工作, 但仍然存在很大的改进 空间。
我们询问被试, 根据每组的输入图像, 剩余两者之中何者更接近其理解, 共收取到 47 份有效回答。统计结果(表 4)表明, 在人类主观体验情况下, 与 Shih 等[10]的方法相比, 本文方法能生成更接近人类理解的图像。
本文提出一种基于实际拍摄全景影像构建有限范围 6 自由度虚拟场景的方法, 具有较好的应用效果。虽然本文的研究对象为野外场景, 但可通过更改算法框架中各个网络的参数, 针对不同的应用场景重新进行训练, 或选择更合适的网络结构, 将本方法应用于其他场景。
表4 对方形图像的用户感受结果
Table 4 User experience results of square images
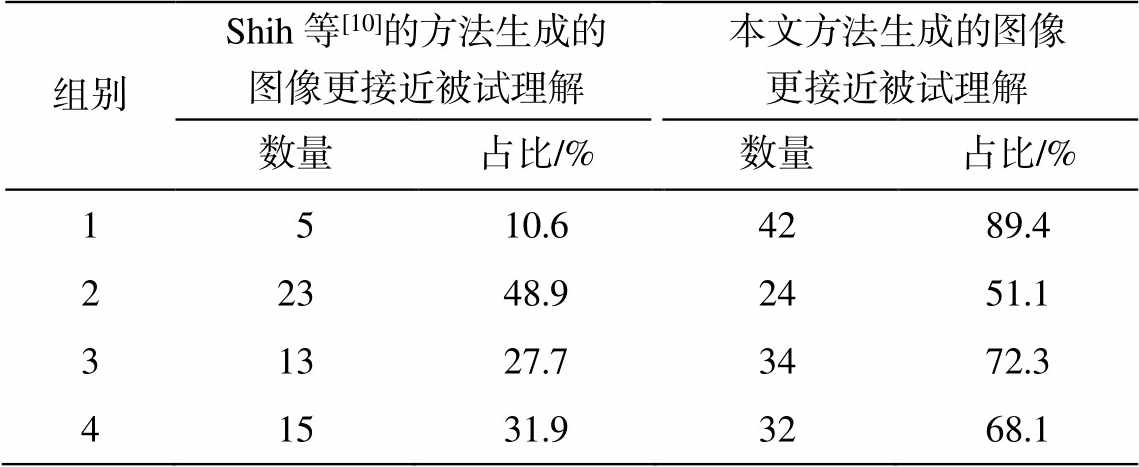
组别Shih等[10]的方法生成的图像更接近被试理解本文方法生成的图像更接近被试理解数量占比/%数量占比/% 1 510.64289.4 22348.92451.1 31327.73472.3 41531.93268.1
本文工作需要进一步完善之处包括深度估计绝对距离的准确度、对植被等细节较多且不完全遮挡背景的物体的识别以及图像修复效果等。目前的方案对树林等场景的效果尚不够理想。
本文设计的方案仅要求单张全景图像。对于输入为双目图像的情况, 可利用立体视觉技术辅助距离量算。对于输入为全景视频的情况, 可结合基于光流或运动回复结构的算法来改善效果。另外, 某些特定的户外场景下, 存在用于辅助建构虚拟场景坐标或进行定位的物体(比如 Xu 等[13]的方法中用于提取室内场景特征的模块), 将有助于改善效果。
参考文献
[1] Eigen D, Puhrsch C, Fergus R. Depth map predic- tion from a single image using a multi-scale deep net-work // NIPS. Montreal: Curran Associates Inc, 2014: 2366‒2374
[2] Godard C, Mac Aodha O, Firman M, et al. Digging into self-supervised monocular depth estimation // IEEE/CVF International Conference on Computer Vi-sion. Seoul, 2019: 3827‒3837
[3] Wofk D, Ma F C, Yang T J, et al. FastDepth: fast monocular depth estimation on embedded systems // International Conference on Robotics and Automa-tion. Montreal, 2019: 6101‒6108
[4] Ranftl R, Lasinger K, Hafner D, et al. Towards robust monocular depth estimation: mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pat-tern Analysis and Machine Intelligence, 2022, 44: 1623‒1637
[5] Xian K, Zhang J, Wang O, et al. Structure-guided ranking loss for single image depth prediction // IEEE/CVF Conference on Computer Vision and Pat-tern Recognition. Seattle, 2020: 608‒617
[6] Miangoleh S M, Dille S, Mai L, et al. Boosting mono-cular depth estimation models to high-resolution via content-adaptive multi-resolution merging // IEEE/ CVF Conference on Computer Vision and Pattern Re-cognition. Online event, 2021: 9680‒9689
[7] Zhu J Y, Zhang Z T, Zhang C K, et al. Visual object networks: image generation with disentangled 3D re-presentations // NeurIPS. Montreal, 2018: 118‒129
[8] Nazeri K, Ng E, Joseph T, et al. EdgeConnect: genera-tive image inpainting with adversarial edge learning [EB/OL]. (2019‒01‒11) [2021‒09‒19]. https://arxiv. org/pdf/1901.00212.pdf
[9] Tucker R, Snavely N. Single-view view synthesis with multiplane images // Conference on Computer Vision and Pattern Recognition. Seattle, 2020: 548‒ 557
[10] Shih M L, Su S Y, Kopf J, et al. 3D photography using context — aware layered depth inpainting // IEEE/CVF Conference on Computer Vision and Pat-tern Recognition. Seattle, 2020: 8025‒8035
[11] Mildenhall B, Srinivasan P P, Tancik M, et al. NeRF: representing scenes as neural radiance fields for view synthesis // European Conference on Computer Vi-sion. Online Meeting, 2021: 99‒106
[12] Zioulis N, Karakottas A, Zarpalas D, et al. Omni-depth: dense depth estimation for indoors spherical panoramas // European Conference on Computer Vi-sion (ECCV). Munich, 2018: 448‒465
[13] Xu J L, Zheng J, Xu Y Y, et al. Layout — guided novel view synthesis from a single indoor panorama // IEEE/CVF Conference on Computer Vision and Pat-tern Recognition. Online Meeting, 2021: 16433‒16442
[14] Kotadia Y, Mehta K, Manjrekar M, et al. IndoorNet: generating indoor layouts from a single panorama image. Singapore: Springer, 2020
Virtual Field Scene Construction Method Based on Panoramic Photo Inpainting
Abstract A fast construction method of field virtual environment based on panoramic image is proposed. Through the processing of panoramic image, such as contour recognition, depth estimation and photo inpainting, the image-based scene information is obtained.The corresponding panoramic image is rendered according to the user’s position, so as to obtain an immersive field virtual environment supporting 6-DOF roaming in a limited range; The practicability of this method is verified by the user's subjective feeling and objective index of image quality. The results show that theproposed method has a more convenient way of use and better application effect, and may be used in virtual field geological practice teaching.
Key words field environment; virtual geographic environment; panoramic image; 6-DOF roaming; photo in-painting