北京大学学报(自然科学版) 第59卷 第2期 2023年3月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 2 (Mar. 2023)
doi: 10.13209/j.0479-8023.2023.013
北京智芯微电子科技有限公司实验室开放基金资助
收稿日期: 2022-01-11;
修回日期: 2022-12-30
一种保障实时系统时间约束的处理器指令扩展
一种保障实时系统时间约束的处理器指令扩展
赵秀嘉1,2 李雷3 刘先华1,2,†
1.北京大学计算机学院, 北京 100871; 2.北京大学微处理器及系统教育部工程研究中心, 北京 100871; 3.北京智芯微电子科技有限公司, 北京 100192; †通信作者, E-mail: liuxianhua@pku.edu.cn
摘要 采用软硬件协同技术, 通过必要的硬件语义实现资源隔离, 基于高效的任务调度保障不同关键级别任务满足时间约束, 是当前混合关键系统设计的有效方法之一。本研究基于时序可预测的细粒度多线程处理器FlexPRET, 扩展设计实现时序指令, 并分别在硬件和编译器中添加对扩展指令的支持, 使得程序在代码中对最大执行时间进行时序约束语义描述。实验评测表明, 所实现的扩展指令可为用户提供更精细的时序控制。
关键词 指令扩展; 实时系统; 混合关键系统; 最坏执行时间
实时系统指系统行为的正确性不仅取决于计算的逻辑结果, 还取决于结果产生的时间的计算机系统[1]。目前, 实时系统已广泛应用于航空电子、汽车、工业自动化和医疗等领域, 人们越来越倾向于将多个复杂软件任务整合到一个硬件平台中, 降低硬件成本, 减小系统的尺寸、重量和功耗。这就要求单个处理器运行拥有不同重要性或安全性的任务, 由此产生混合关键系统(mixed-criticality sys-tem, MCS)[2]。混合关键系统中各个任务的关键性级别不同, 为防止任务或组件失败, 系统必须保证不同的调度策略和有限级别, 这就需要系统设计提供更好的隔离和调度。
在不同的应用领域, 关键级别的数量和定义各不相同, 但最少可以定义为两个级别: 安全关键级别(safety-critical)和非关键级别(non-critical)[3]。不同关键级的任务运行在同一硬件平台上, 共享处理器时间、内存和网络等资源。对混合关键系统来说, 高度集成的硬件平台需要保证不同关键级别任务对资源共享的灵活性和效率, 满足任务各自的关键级别, 同时需要减少资源共享导致的任务间的干扰, 因此任务之间的隔离(isolation)至关重要。实现隔离的方式有硬件隔离、软件隔离以及软硬件结合隔离, 但现有的隔离方式存在资源利用率不足的问题。自 Vestal[4]首次提出混合关键系统的概念以及一种基于抢先式的固定优先级调度方法之后, 研究工作集中在混合关键系统的调度问题上, 并且将任务的执行时间视为确定值[5]。在实际情况, 一个程序的执行时间受多种因素影响, 最坏情况下的执行时间很难被界定。
本文选择开放指令架构作为基础, 面向实时领域需求开展处理器指令扩展研究, 在资源隔离、线程调度和时间约束语义方面提供软硬件协同支持, 为适用于用电、配电和调度领域的硬实时自主嵌入式 CPU 内核提供设计建议。
1 相关研究
实时微处理器体系结构是微处理器领域的一个重要研究方向。与通用处理器追求最大吞吐量不同, 实时处理器要求具有紧凑且可计算的最坏执行时间。传统实时处理器采用较为简单的处理器结构, 避免复杂结构引入执行时间的不确定性。随着实时应用对处理器性能需求越来越高, 实时处理器正逐渐向多线程与多核结构发展。在多线程执行场景下, 共享资源竞争导致实时系统的确定性变差, 给实时处理器体系结构带来更大的挑战。
在隔离方面, 多线程实时处理器主要研究多线程资源竞争问题, 解决如何从微体系结构上为每个线程提供相对独立的资源, 进而获得可预测的执行时间。多核实时处理器则主要研究多处理器核之间的资源竞争问题, 如何将片内存储、片外存储和共享总线等资源有效分配给多个处理器核。
有的设计采用硬件隔离实现, 但难以充分利用硬件资源。美国亚特兰大大学的 DynOS、德国的Proteus、日本早稻田大学的 SPUMON 和北京航空航天大学的 RGMP 等都采用此类架构。为有效改善性能和能耗, 也有一些方案采用异构多核。该架构在能效性方面得到改进, 其软硬件整体架构仍类似上述的基于多处理器的双操作系统方案。国内外基于虚拟化方式的实时嵌入式操作系统隔离典型方案包括 VLX, OKL4 Microvisor, Xen on ARM, KVM/ ARM, Xtratum, Xvisor 以及基于 Xen 的其他衍生优化方案。还有一些基于轻量虚拟化的混合操作系统解决方案, 例如 RTAI, Linux/Rton, RTLinux 和基于L4 衍生出的 Fiasco 或者采用操作系统可适应性域(ADEOS)技术的 Xenomai 等。此外, 还可以在硬件中增加新的模式, 提供相应的软件支持, 采用软硬件结合的方式解决隔离和资源调度。如 TrustZone, TLR, ViMoExpress, SafeG, ARMithril, TMM 以及RTZVisor 等。但是, 此类设计在计算资源不足时, 可能对普通应用或软实时任务产生消极影响。
近年来, 多线程逐渐应用于实时领域, 通过在处理器设计中提供专门的实时支持, 从而在保证处理器实时性的同时提高系统线程性能、线程灵活性和硬件资源利用率。将同时多线程处理器应用于实时领域的研究最早始于 2000 年前后, 其主要思想是尽量保证某一线程不受其他线程的影响, 被优先保护的线程则具有较高的性能, 同时也具备一定的可预测性。有些研究面向硬件保障最差预估执行时间 WCET 展开, 包括 Komodo, VISA, RVMP, SPEAR, JOP, PRET, DMT, ARPRET 和 ARPAMT 等。有些研究面向细粒度多线程支持展开, 例如 PTARM, XMOS X1, Merasa 以及 FlexPRET 等。还有一些研究在软件调度资源技术方面进行优化, 例如 IMA System, VxWorks 653 RTOS 和 RTSS-2009等。
混合关键系统调度可以分为固定优先级调度和动态优先级调度。固定优先级调度通过基于应答时间分析(response time analysis, RTA)和松弛时间调度(slack scheduling)以及周期转换(period transfor-mation)等来优化调度方法。动态优先级调度主要基于最早截止时间优先调度(earliest deadline first, EDF)的思想进行任务调度。
混合关键系统还有一个问题是, 常见的通用指令系统并未提供对程序的时序行为进行约束的指令, 很大程度上是因为对时序行为的约束依赖于处理器微结构的设计以及软件工具链的实现。对时序行为做精确描述的硬件模型通常也不可用或难以实现。尽管设计人员可以通过硬件编程的定时器对程序的时序进行控制, 但这种方法会受硬件定时器的实现以及配置方式和中断处理方式等因素的影响, 可编程性也比较差。
目前, 虽然一些编程语言和编程模型(如 Ada, Real-Time Euclid 和 PTIDES 等)中包含时序控制的特性, 但在指令系统中实现时序控制仍需要硬件来实现以及编译工具链的支持。指令系统中的时序指令比编程语言更加底层, 可以为硬件设计提供更精确的实时语义。例如 Ip 等[6]提出一条时序指令 dead, 用于指定一段代码的最短执行时间。为实现这条指令, Ip 等[6]在处理器中添加多个专门用于计时的寄存器, dead 指令以这些寄存器作为目的操作数, 接受源操作数作为计数值。当 dead 指令运行时, 首先等待计时寄存器归零, 然后将计数值重新写入计时寄存器中。dead 指令的效果相当于运行指定数量的空操作指令。在需要精确指定代码时序的程序中, 相比手动插入多条空操作, 使用该指令可以在有效地减少代码数量的同时, 提供正确且精确的时序语义, 但缺点是处理器无法利用空闲的时钟周期。
Bui 等[7]进一步提出在指令系统层面可以表达的 4 种时序语义: 1)保证代码块执行至少需要指定的时间; 2)执行代码块, 当执行时间超过约定时间时, 代码执行完成后跳转; 3)执行代码块, 当执行时间超过约定时间时, 立即跳转; 4)保证代码块执行至多不超过指定的时间。Bui 等[7]还提出表达这 4 种语义的 6 条伪指令。set_time 和 delay_until 两条伪指令可以表达第 1 种语义; branch_expired 可以表达第 2 种语义; expection_on_expire和 deactivate_ exception 配合可以表达第 3 种语义; 对于第 4 种语义, Bui 等[7]指出不能在运行时保证代码块的最长执行时间, 而是需要通过静态分析技术, 在编译或链接时刻保证代码块的执行时间边界。Liu[8]将这 6 条指令的前 5 条精简为 4 条, 并在基于 PTARM 的实时处理器中实现: 使用 get_time 指令替代 set_time 指令获取当前时间, 这样就可以使用 get_time 和普通分支指令实现 branch_expired。
Antolak 等[9]提出多核时序可预测处理器, 并添加 4 条时序指令。处理器为每个硬件线程配备多个最后期限计数器, 当计数器被激活时, 每个时钟周期计数器的数值都会减 1。当计数器减为零时, 当前线程会被挂起, 引发中断处理超时情况。用户可通过 SD (set deadline)指令向指定的计数器写入最后期限, 然后 AD (activate deadline)和 DD (deactiv-ate deadline)指令分别激活和停用指定的计数器。WFD (wait for deadline)指令会挂起线程直到对应计数器的数值变为 1。为防止超时情况的发生, WFD 指令之后应紧跟 SD 指令设置新的最后期限。这 4 条扩展时序指令实际上支持了 Bui 等[7]提出的 4 种时序语义的第 1 条和第 3 条。由于每个硬件线程配备多个计数器, 该处理器能够灵活地应对程序存在多个时间约束的情况。Broman 等[10]报道了基于 LLVM进行的时序语义扩展工作, 进一步将 mtfd 伪指令拆分为 mt 和 fd, 用来标记代码块的开始和结束, 并给出这段代码不能超过的时间界限, 但他们只给出 mt 和 fd 指令的定义, 并未具体实现。
2 实时指令扩展的设计与实现
2.1 需求分析和硬件概述
实时系统的设计与实现与非实时系统存在若干不同。提升系统性能的若干处理器设计技术(如转移预测、高速缓存和推测式乱序执行等)均不能简单地应用于实时系统, 因为这些技术不能保证程序在最坏情况下的执行时间(worst case execution time, WCET)是较优的, 可能会损害系统的实时性。对实时系统尤其是混合关键系统来说, 并不是全部指令级并行或线程级并行技术都有利于对程序的 WCET进行分析。相反, 很多基于程序时间局部性的技术依赖程序的历史执行信息, 使得一条指令在最坏情况下的执行时间很难确定, 从而不利于程序 WCET的分析。这就要求处理器设计人员在保证时序可预测的情况下采用合适的技术在实时性和处理器性能之间进行权衡。
FlexPRET[3]是加州大学伯克利分校提出的基于RISC-V 指令系统的 32 位 5 级流水线处理器, 使用Chisel[11]语言, 采用细粒度多线程技术实现。它提供多种配置参数, 允许任务线程在基于硬件的隔离和高效的资源利用率之间进行权衡。该处理器采用多种技术, 提高了指令执行时间的可预测性, 如预测转移不发生及使用暂存内存(scratchpad memory, SPM)代替高速缓存, 使得分支指令和访存指令拥有固定延时, 等等。细粒度多线程的实现方式也减少了上述设计对处理器性能的影响, 同时实现线程的硬件隔离。
尽管 FlexPRET 处理器实现了对线程调度与线程隔离的基本硬件支持, 但其对指令时序约束的描述不够完整, 配套的编译及操作系统支持也不够完善, 表现在以下几个方面。1)底层功能封装不完善, 例如定时器功能需要用户使用自定义指令自行封装, 逻辑复杂; 任务配置和中断处理等都需要用户编写内联汇编来实现; 缺少线程间的通信机制, 等等。2)对时序指令的扩展仅能支持实时程序的基本运行, 无法分析和保证一个程序所需要的最长执行时间不超过预设阈值。
2.2 指令扩展
对于 Bui 等[7]提出的 4 种基本时序语义, 前 3 种在 FlexPRET 中均有实现, 但第 4 种并未支持。基于Broman 等[10]的研究, 本文实现了若干时序相关扩展指令, 如表 1 所示。前 6 条参照 FlexPRET 进行实现, 并根据硬件约束和软件开发需求进行合理的调整。后 3 条扩展指令根据 Bui 等[7]提出的原则进行设计, 使用硬件对时序可预测处理器的代码片段最长执行时间进行了约束。为满足最后的时间界限, Bui 等[7]讨论的“保证代码块执行至多不超过指定时间”的语义在本文中被拆分为 mt/mti 和 fd 指令后分别实现。mt/mti 标记代码块的开始, fd 标记代码块的结束。mt 指令复用了 RISC-V 中 custom3 的指令编码, 仅接受 rs1 这一个源操作数, 其中的值作为代码块的时间界限。mti 指令复用了 lui 的编码, 但目的寄存器必须设为 zero, 将编码中的 24 位立即数作为代码块的时间界限。fd 指令没有源操作数和目的操作数, 该指令检查当前时间是否超过 mt/mti 指定的时间界限, 如果超过预设的时间界限, 则引发 异常。
2.3 硬件线程调度和资源管理
FlexPRET 实现硬件的线程调度模块, 通过读取动态配置的自定义 CSR 寄存器, 决定每个周期开始执行的硬件线程指令。硬件中需要新增若干控制与状态寄存器(control and state register, CSR)来支持线程的硬件调度。硬件线程分为硬实时线程(hard-realtime thread, HRTT)和软实时线程(soft-realtime thread, SRTT)。HRTT 根据配置按固定速率调度, 以便提供硬件隔离并确保实时要求; SRTT 使用空闲时钟周期, 以便提高系统的吞吐量。CSR_tmode寄存器保存硬件线程状态(活跃或休眠)以及属性(HRTT 或 SRTT), 总共有 4 种取值: HA (活跃的HRTT)、SA (活跃的 SRTT)、HZ (休眠的 HRTT)和SZ(休眠的 SRTT)。CSR_slot 寄存器保存硬件调度器应该调度的线程顺序。32 位的 CSR_slot 寄存器被划分为 8 个 4 位的线程槽, 每个线程槽可以指定为线程编号, 标记该线程槽供指定某线程专用或未启用。
硬件采用轮转(round-robin)调度方式。当硬件调度器决定下一周期要调度的线程时, 首先根据上一周期调度线程寻找下一个已启用的线程槽。如果线程槽内是线程编号, 并且对应的线程状态为活跃, 则调度对应线程; 若对应的线程不活跃或线程槽为SRTT 专用, 则根据上一次调度的 SRTT 寻找下一个应调度的 SRTT 进行调度。总的来说, 硬件调度器依序循环读取 CSR_slot 寄存器中的线程槽来调度对应线程, 当线程槽内的线程休眠时或线程槽专为SRTT准备时, 再依序循环调度 SRTT。这种调度方式能够保证高优先级的 HRTT 以固定的频率必然被调度, 然后利用空闲周期对低优先级的 SRTT 进行调度, 在保障关键线程时序的情况下, 提高了处理器的吞吐率。需注意的是, 空闲周期对 SRTT 的调度可以使用更合理的软件调度算法来优化性能。
在硬件实现方面, 处理器新增状态寄存器, 为线程存储当前时间和计时时间。每个周期寄存器CSR_clock 中的值会自增约定好的常数, 例如, 约定 100MHz 处理器每周期增加 10(代表 10ns)。为减少硬件面积和复杂度, CSR_clock 的位宽设置为 32位, 意味着 CSR_clock 约每 429.5ms 溢出一次。在每个周期, CSR_compare 中的数据都会与 CSR_clock进行比较, 如果 CSR_clock 中的时间到达 CSR_ compare, 则将硬件线程唤醒或产生异常或中断。此寄存器值的比较不能使用等值比较, 因为不能保证 CSR_compare 中的时间在 CSR_clock 之后。如果直接使用无符号数的比较运算, 也无法处理 CSR_ clock 加上一段时间之后溢出的情况。因此, 在硬件设计中采用无符号减法判断 CSR_clock 与 CSR_ compare 的差值, 从而处理时间差不超过 231 ns 以及CSR_compare 溢出的情况。对于程序中任何超过231ns (约 2.14s)的时序行为, 需要额外的软件代码来保证时序约束的正确性, 但超过 2s 的实时性需求在实际情况中并不多见。
表1 扩展实时指令语义描述表
Table 1 Semantics of extended instructions
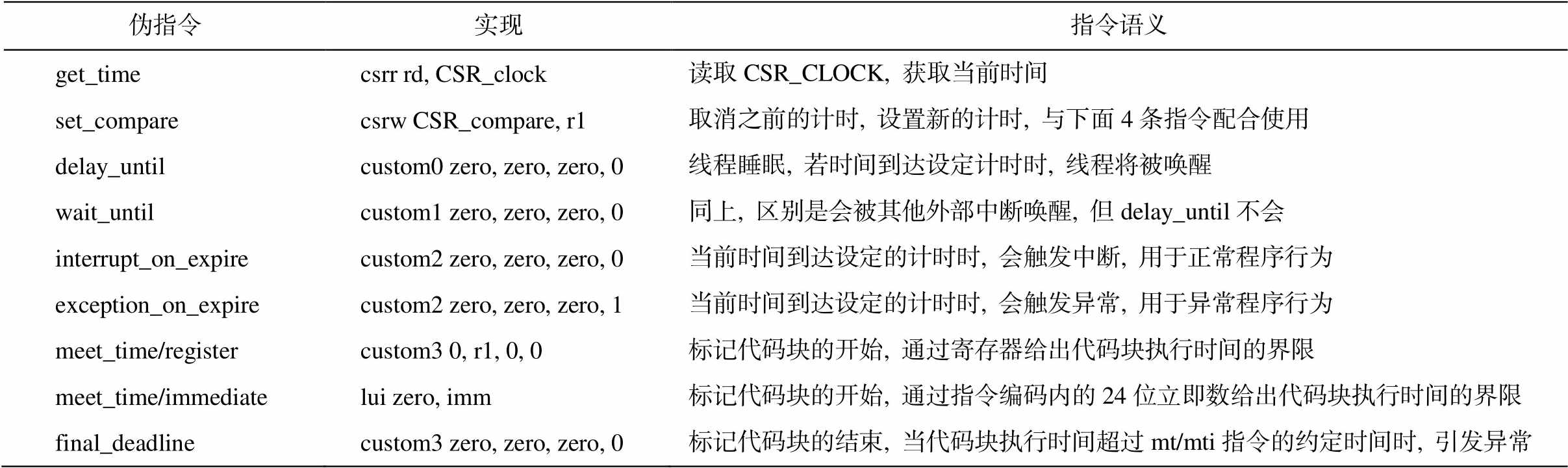
伪指令实现指令语义 get_timecsrr rd, CSR_clock读取CSR_CLOCK, 获取当前时间 set_comparecsrw CSR_compare, r1取消之前的计时, 设置新的计时, 与下面4条指令配合使用 delay_untilcustom0 zero, zero, zero, 0线程睡眠, 若时间到达设定计时时, 线程将被唤醒 wait_untilcustom1 zero, zero, zero, 0同上, 区别是会被其他外部中断唤醒, 但delay_until不会 interrupt_on_expirecustom2 zero, zero, zero, 0当前时间到达设定的计时时, 会触发中断, 用于正常程序行为 exception_on_expirecustom2 zero, zero, zero, 1当前时间到达设定的计时时, 会触发异常, 用于异常程序行为 meet_time/registercustom3 0, r1, 0, 0标记代码块的开始, 通过寄存器给出代码块执行时间的界限 meet_time/immediatelui zero, imm标记代码块的开始, 通过指令编码内的24位立即数给出代码块执行时间的界限 final_deadlinecustom3 zero, zero, zero, 0标记代码块的结束, 当代码块执行时间超过mt/mti指令的约定时间时, 引发异常
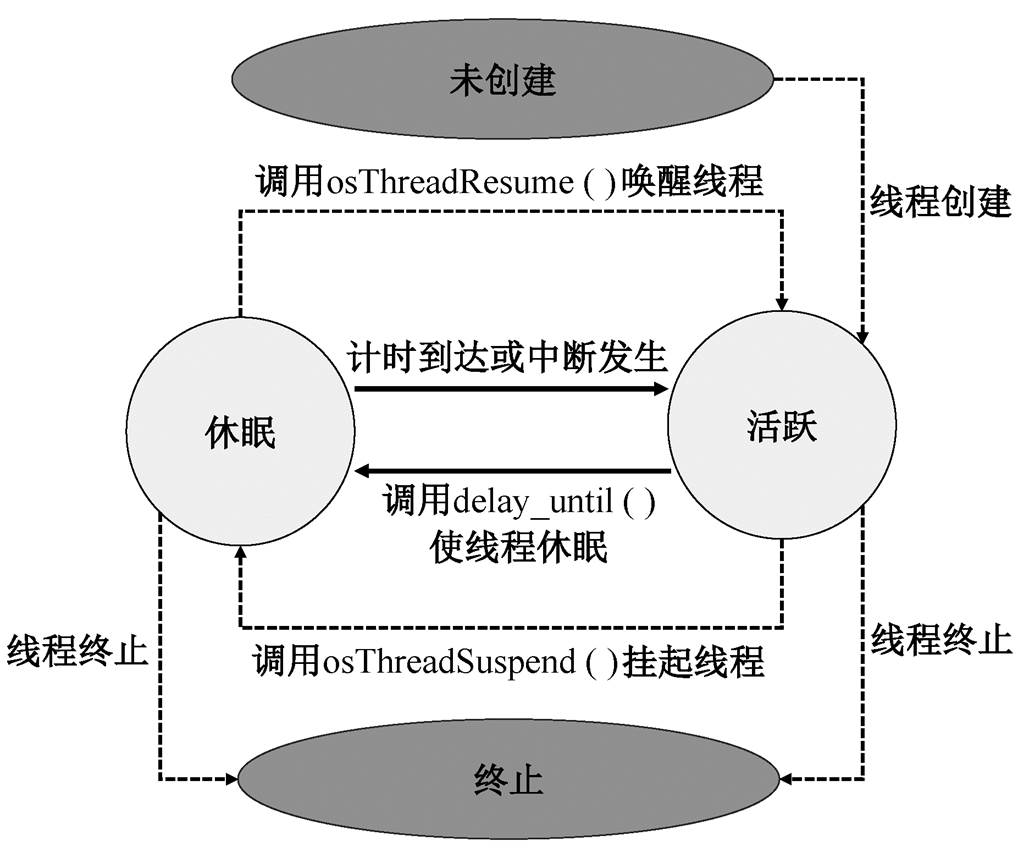
本文使用软件实现, 制定了一套默认情况下硬件线程槽分配和回收的原则, 保证用户在默认情况下创建线程时, 能够获得较好的实时性, 线程状态的迁移如图 1 所示。
在代码片段执行时长的软硬件语义保障方面, 为保证代码块执行不超过指定的时间, 本文在编译阶段进行静态分析并检查。由于程序的有些信息难以甚至无法在编译阶段得知, 因此引入 mt 和 fd 指令在运行时刻给予严格的保障。当 mt 和 fd 指令之间出现这种情况时, 本文从硬件层面上给予超时的判断和补救。因此对硬件来说, mt 和 fd 指令不能被视为两条仅供编译器识别的隐藏制导指令, 而是有各自独立时序语义的指令。
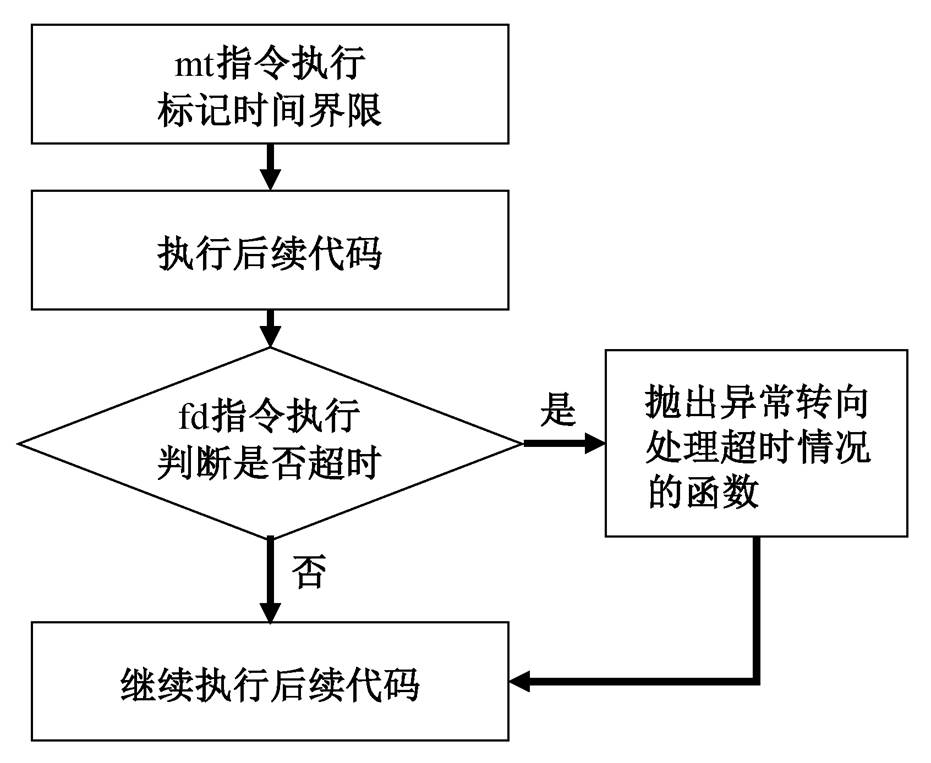
针对 mt 和 fd 指令, 本文对每个硬件线程新增一个 32 位的寄存器, 保存 mt 指令指定的时间与当前时间之和。mt 指令执行时, 会将时间之和写入该寄存器; fd 指令执行时, 会比较该寄存器的值与当前时间, 如果超时则引发异常。为便于统一处理, 此处的时间比较采用无符号数的减法和有符号数的比较运算。mt/fd 指令的硬件执行流程如图 2 所示。
3 配套软件设计与实现
3.1 编译支持
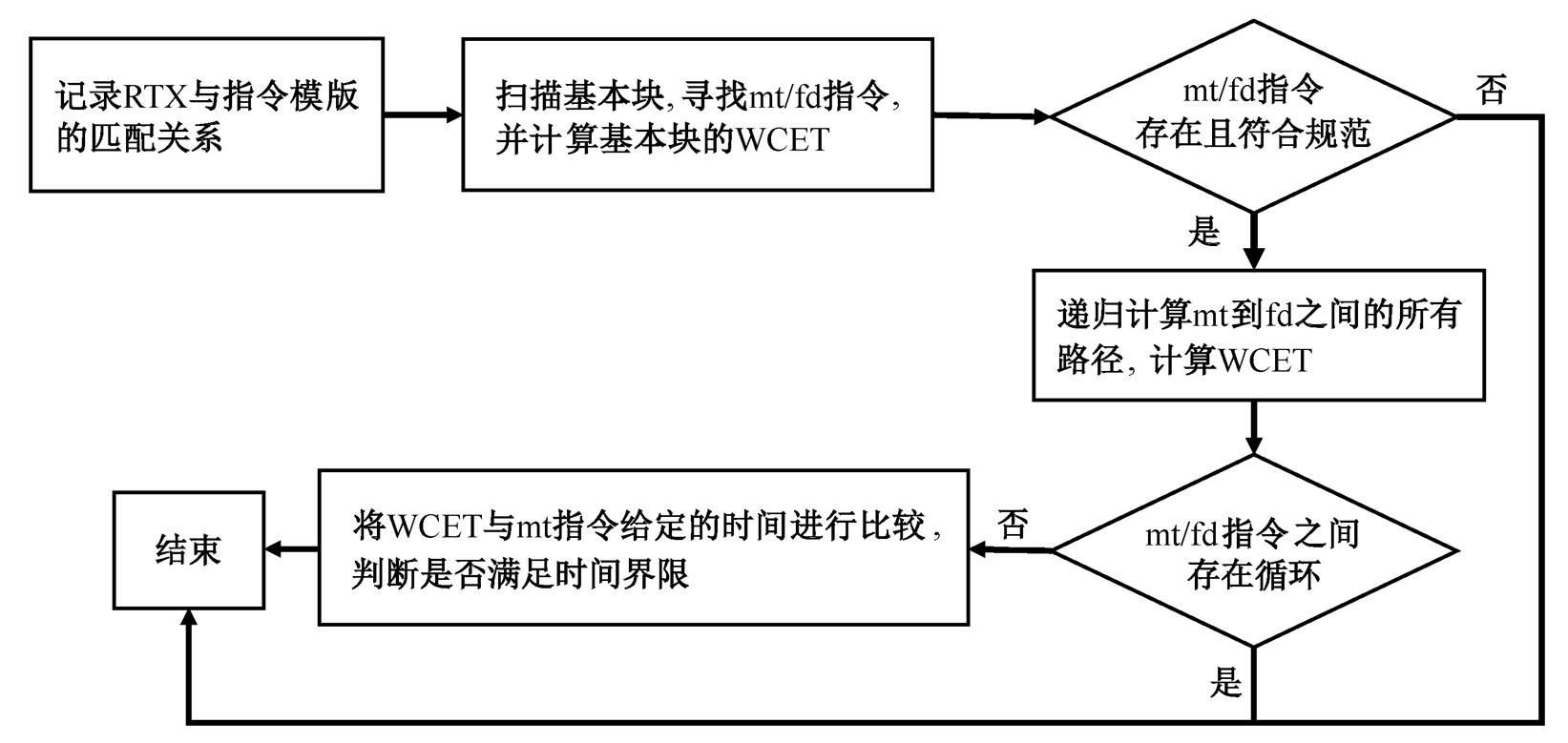
本文基于 GCC 4.9.2/RISC-V 完成扩展指令的编译支持。GCC (GNU compiler collection)编译器支持多种前端语言和后端体系结构。GCC 后端会将GIMPLE 表达式转换为寄存器传输级表示(register transfer language, RTL), 在 RTL 的基础上可以进行代码生成和体系结构相关的优化。最后 GCC 会把RTL 转换为对应体系结构的汇编语言, 然后由汇编器和链接器生成二进制文件, 完成整个编译流程。GCC 以优化遍(optimization pass)的方式对相关转换流程做分步操作。GCC 编译器对 mt/fd 指令的支持流程如图 3 所示。其他时序指令不在需要编译阶段生成, 而是采用内联汇编实现相应功能。本文通过在 GCC 上添加一个优化遍, 并复用 RISC-V 处理器的链接器和汇编器, 完成对扩展时序指令的支持。本文中, 编译器对时序指令的检查和分析通过一个简单的合并数据流来实现。
尽管 mt/fd 指令和 exception_on_expire 指令的效果在硬件上类似, 但 mt/fd 指令给编译器等分析工具提供了清晰的代码边界划分, 可以将潜在的相关时序超时信息在编译阶段暴露给用户, 并基于其语义使用硬件, 在实际超时情况下进行异常处理(例如补救或告警)。此外, mt/fd 指令采用独立计时器, 可与 delay_until 同时使用, 从而能够同时保证一段代码的最短和最长执行时间的语义(图 4)。
图 4 中代码的第 1, 4 和 5 行使用 delay_until 指令保证第 3 行运算所需时间不少于 5μs; 第 2 和 6 行使用mt/fd 指令保证了第 3 行运算所需时间不多于10 μs。该语义是 exception_on_expire 指令所不能表达的。这一指令的语义也可以用于保障不同执行路径之间的执行时间差, 从而规避侧信道攻击风险。
3.2 编程和运行接口设计实现
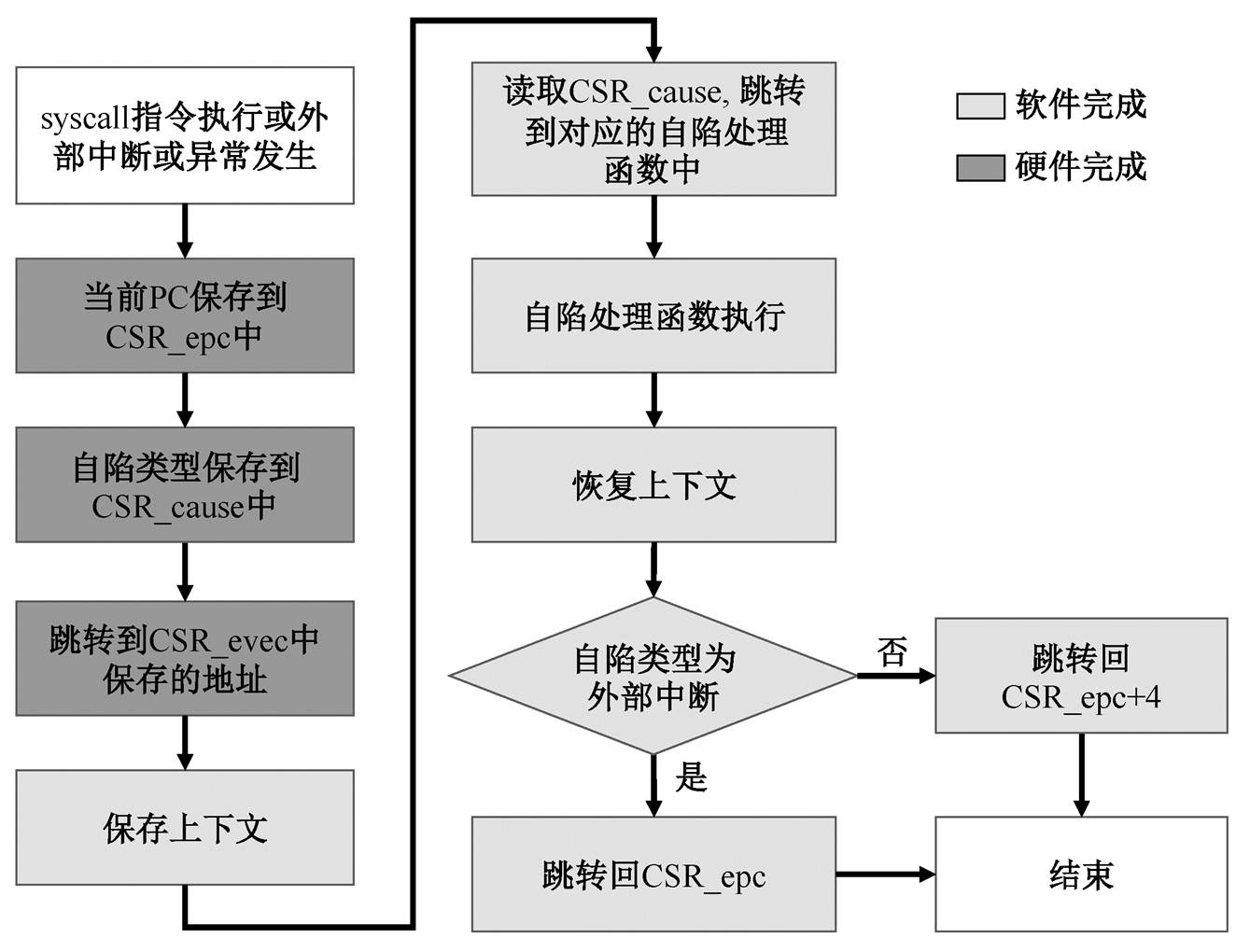
为了保障程序的良好运行, 本文在硬件基础上实现符合 CMSIS-RTOS2[12]标准定义的内核信息控制模块、线程管理模块、定时器管理模块和互斥量管理模块中的接口, 同时配合硬件自陷机制, 实现异常和中断的处理, 处理方式如图 5 所示。处理器核的实现采用的是细粒度多线程的硬件调度模式, 而 CMSIS-RTOS2 的线程模型与其有较大的不同。本文在尽可能兼容 CMSIS-RTOS2 线程模型的同时, 提供了扩展的自定义接口, 方便编程人员在理解细粒度硬件线程调度的基础上, 通过扩展接口实现更丰富的线程控制和调度功能。
硬件记录的线程状态标记为活跃态和休眠态, 处于活跃态的线程并不总占用 CPU 时间。在本文的软件接口实现和硬件线程状态接口进行匹配时, 活跃态对应 CMSIS-RTOS2 中的就绪态和运行态, 休眠态对应阻塞态, 同时添加终止态, 表示线程创建后内核还未开始调度的状态以及线程退出后的状态。除线程状态不同之外, 线程优先级也需要做相应的处理。在硬件实现中定义两种关键级别, 分别对应硬实时线程和软实时线程。本文实现将硬实时线程映射到 CMSIS-RTOS2 中的 osPriorityNormal优先级, 将软实时线程映射到 osPriorityRealtime 优先级, 对其余的优先级别不做支持。
4 功能验证和性能评测
本研究的硬件配置采用 8 个硬件线程, 64KB 的指令 SPM 和 64KB 的数据 SPM, 运行主频为 100MHz, 在此配置下进行功能验证和性能评测。本研究的软件评测环境基于 Chisel 2.2.27 生成 c++模拟器, 可以模拟周期精确的硬件行为。本文在 FPGA环境对设计进行功能验证, EDA 工具选取 Xilinx 公司的 Vivado/2020.2 套件, FPGA 使用 Xilinx Artix7 xc7a100tcsg324-1 开发板。
本文软件实现采用 CMSIS-RTOS2 的配套官方测试样例进行功能测试。当对程序进行适当修改, 添加 mt/fd 检测时, 本文实现的编译器能够给出提示信息, 告知用户 mt 到 fd 指令之间的代码在不同调度频率下是否会超过预期时间。图 6 展示编译器未发现时序违例的情况以及编译器发现程序中存在时序违例并进行告警的情况。
对于 mt 和 fd 指令之间存在函数调用的情况, 编译器无法直接计算函数的执行时间, 但同样会给出警告信息。此时计算出的时间信息中未包含函数的执行时间, 用户需自行保证函数的执行时间不会超过时间界限。由于编译器无法在编译时刻静态地对所有情况进行运行时间的估算, 所以本文的硬件实现会在运行时检查 mt 与 fd 之间的时间界限。当执行到 fd 指令时, 硬件会将当前的时间界限与 mt指令指定的时间界限进行比较, 在超时的情况下抛出异常。图 7 的测试代码实现的语义是第 5 行的循环至少花费 500ns 的时间运行, 但是在第 3 行的约束下, 需要保证在 1000ns 内执行完毕。实际上, 循环100 次的操作用时远远超过 1000ns, 所以该代码会在运行时超时。当执行到 fd 指令时, 硬件会将当前的时间界限与 mt 指令指定的时间界限进行比较, 在超时的情况下抛出异常, 如图 8 所示。
WCET 分析是检查实时程序是否满足时间界限的重要手段。我们采用 SWEET[13]对本研究软件实现中的重要接口进行 WCET 分析。SWEET 是瑞典Mälardalen 实时系统研究中心开发的基于流分析和抽象执行[14]的 WCET 分析工具, 基于 ALF 中间表示[15]进行分析。本文首先使用 ALF-LLVM 工具将待评测样例转换为 ALF 中间表示, 使用 SWEET 工具结合硬件时序信息, 得出待评测代码 WCET 的估计值, 最后与实际执行时间进行比较后得出结论。
SWEET 需要的时序模型信息可通过对硬件参数进行分析转换得到。本文评测在模拟器上运行实现的 CMSIS-RTOS2 软件接口。方便起见, 此处将线程调度频度设为每个时钟周期都可以切换线程, 如果需要针对其他调度频度进行分析, 只需将指令执行时间做相应的修改即可。WCET 分析与实际执行的周期数的对比结果见表 2。可以看出, 各接口的动态执行结果均未超过 WCET 估计值。因此, 得益于处理器时序可预测的设计特性, 可为用户运行混合关键系统的应用提供更精细的时序控制功能。
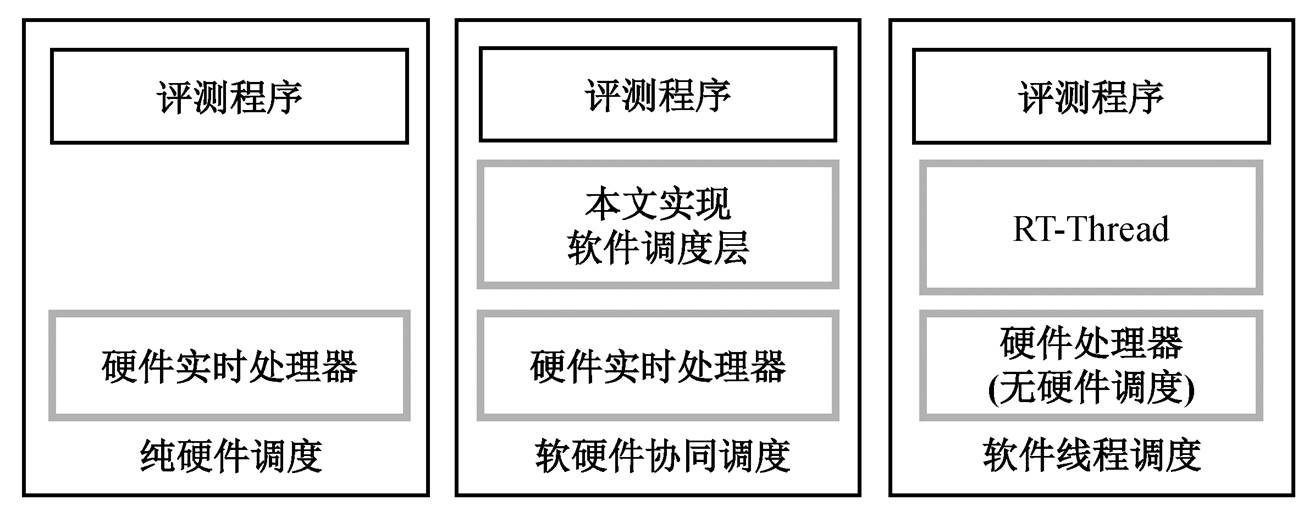
本文中的性能评测选取 Mälardalens 评测程序集[16]作为基准评测程序。3 组对照实验分别为处理器原生硬件调度线程、本文实现的管理软件结合硬件调度线程以及在无硬件调度的处理器上使用的纯软件方式调度线程。各组实验配置如图 9 所示。
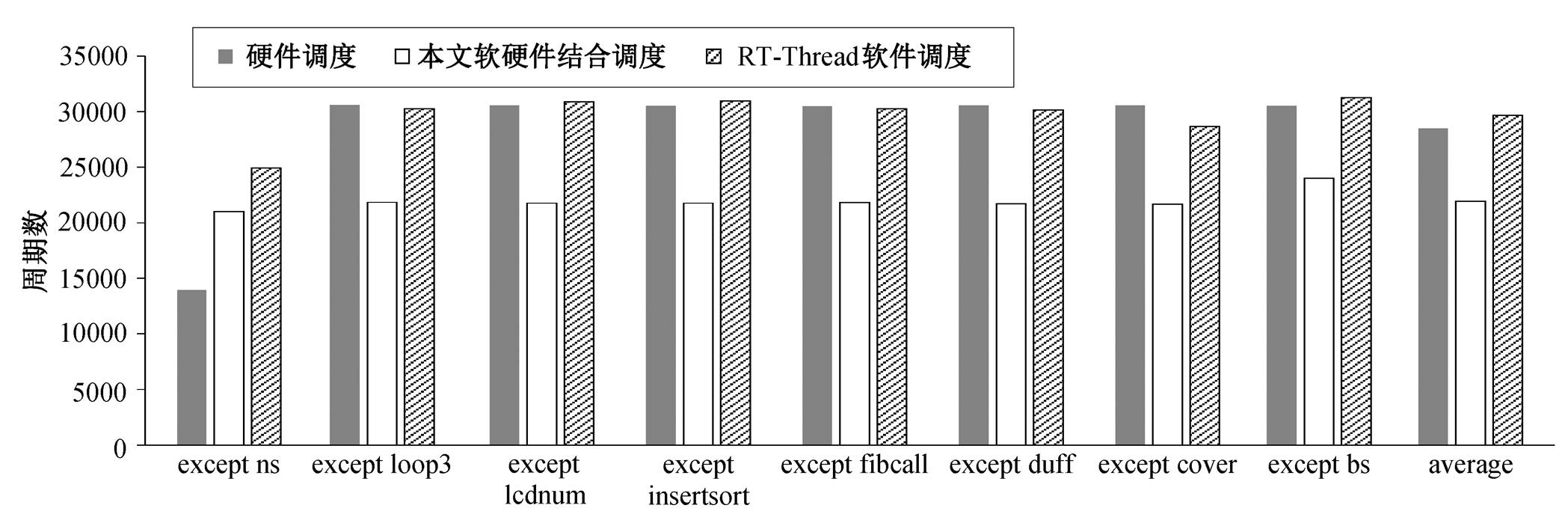
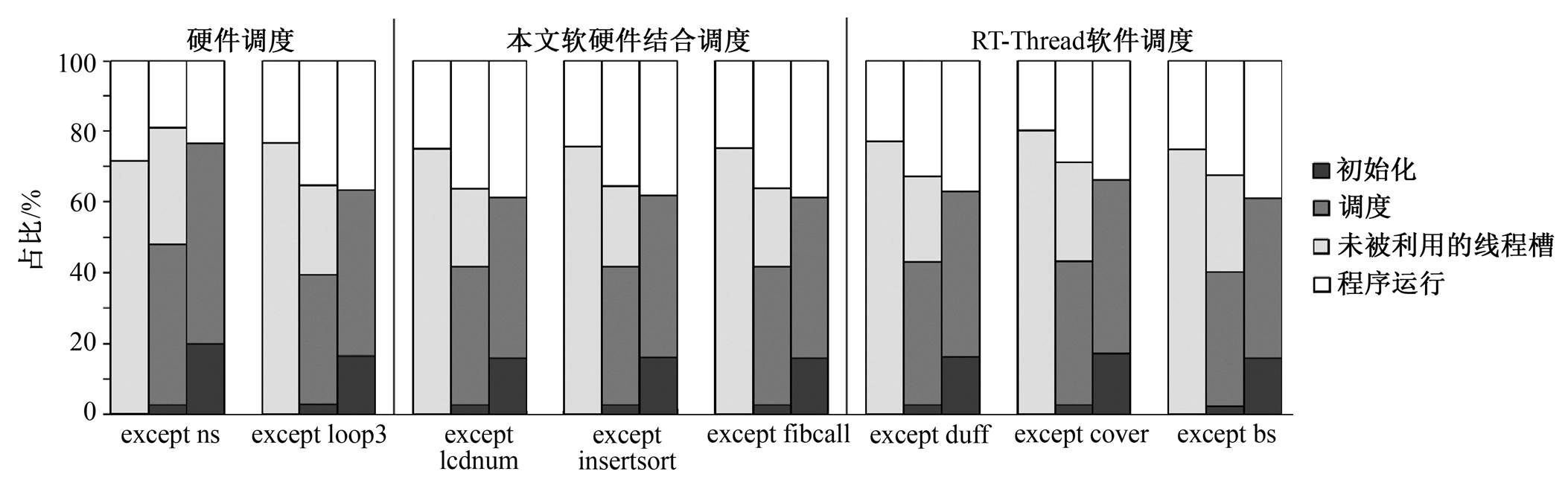
本研究从 8 个测试程序中分别挑选 7 个测试程序作为 7 个子线程, 然后分别使用 3 种调度方式运行。如图 10 所示, 本文方法的调度性能相比纯软件调度平均改进 26.0%, 与处理器原生硬件调度相比, 平均改进 22.94%。进一步的分析结果如图 11 所示, 处理器纯硬件调度有较多未被利用的线程槽, RT-Thread 软件调度的系统初始化和调度开销的占比较高, 而本文的软硬件协同调度效果介于二者之间。
表2 关键接口函数WCET分析结果
Table 2 WCET of important interfaces
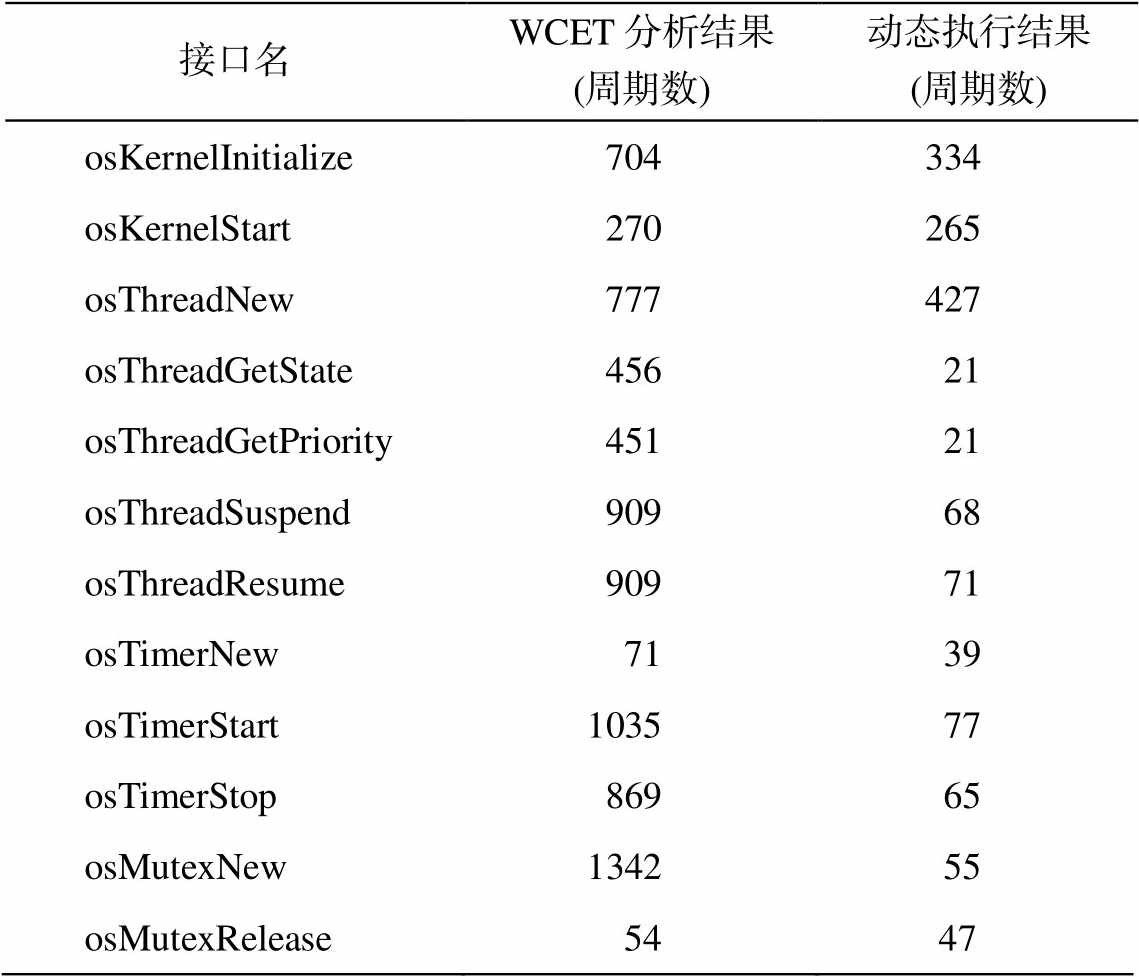
接口名WCET分析结果(周期数)动态执行结果(周期数) osKernelInitialize704334 osKernelStart270265 osThreadNew777427 osThreadGetState45621 osThreadGetPriority45121 osThreadSuspend90968 osThreadResume90971 osTimerNew7139 osTimerStart103577 osTimerStop86965 osMutexNew134255 osMutexRelease5447
本文还对所扩展的时序指令在 FPGA 上的资源利用率及功耗进行评测。如表 3 所示, 添加基本时序指令后, CSR 单元的面积增加较多。整个处理器消耗的资源中, LUT 数量增加 15.03%, FF 数量增加 18.14%。主要原因是时序指令的支持需要在 CSR模块中添加记录全局时间的寄存器(CSR_clock), 每个硬件线程需要添加一个用于比较时间的寄存器(CSR_compare), 还需要添加每个周期进行时间自增和时间比较的逻辑。此外, 控制通路还需要添加相关指令的控制信号以及相关异常和软中断的控制信号。
表3 处理器硬件添加扩展指令前后资源利用情况
Table 3 Resource Utilization of Extended Instructions
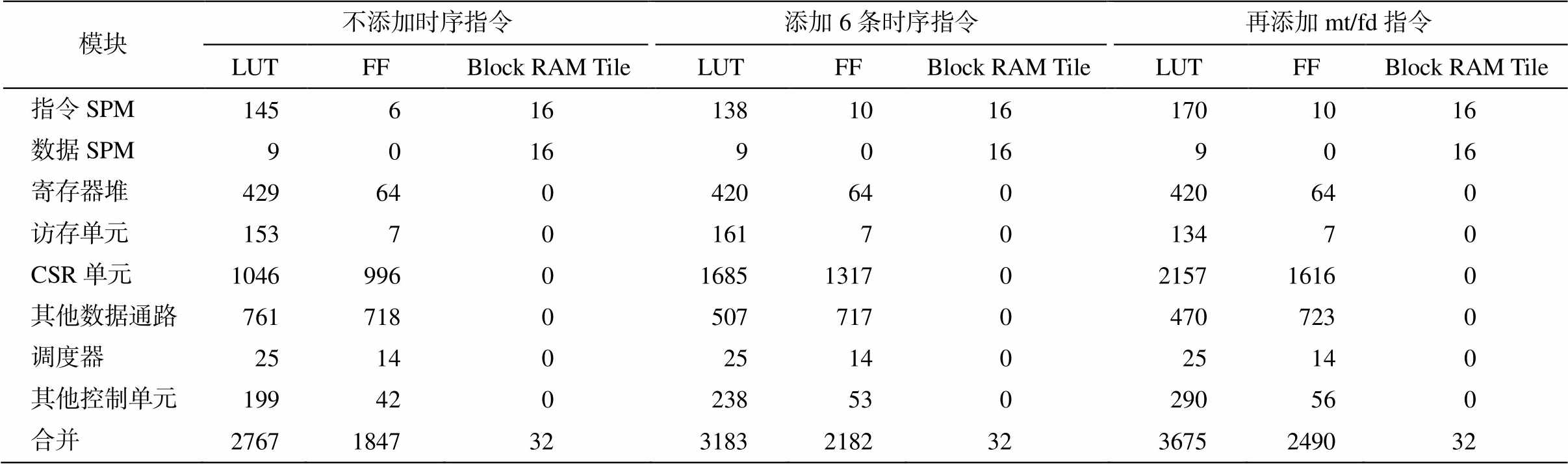
模块不添加时序指令添加6条时序指令再添加mt/fd指令 LUTFFBlock RAM TileLUTFFBlock RAM TileLUTFFBlock RAM Tile 指令SPM14561613810161701016 数据SPM901690169016 寄存器堆429640420640420640 访存单元153701617013470 CSR单元10469960168513170215716160 其他数据通路761718050771704707230 调度器251402514025140 其他控制单元199420238530290560 合并276718473231832182323675249032
本文对 mt/fd 扩展指令的实现为每个硬件线程添加 32 位的 CSR, 用于保存 mt 指令指定的时间界限, 并添加 fd 指令执行, 比较当前时间与时间界限的逻辑, 在控制通路上添加 mt 和 fd 的指令译码信号和相关的控制信号以及 fd 指令引发异常的逻辑, 在数据通路上添加 mt 指令设置时间界限的逻辑。如表 3 所示, 添加 mt/fd 指令后, LUT 数量增加15.46%, FF 数量增加 14.12%。进一步的功耗评估表明, 在 100MHz 时钟频率下, 添加 6 条时序指令后, 总片上功耗由 0.271 W 增至 0.286 W, 增加 5.54%; 进一步添加 mt/fd 指令后, 总片上功耗由 0.286W 变为 0.310W, 增加 8.39%。
5 结论
在混合关键系统的解决方案中, 多线程处理器可以较好地实现线程隔离。通过在指令系统中扩展实现时序相关描述的语义, 可为精确的程序时序控制和程序 WCET 分析提供支持, 能够更好地支撑实时系统任务运行。通过实现实时指令语义的支持, 可以在硬件资源利用率和实时任务性能保障方面取得较好平衡。实验表明, 在不增加太多硬件资源的情况下, 通过处理器扩展可以有效地丰富实时调度的功能支持。该项设计对于实时系统性能提升以及处理器安全性增强会带来良好影响。
参考文献
[1] Abuteir M. Architecture design for distributed mixed-criticality systems based on multi-core chips. Journal of Systems and Software, 2017, 123: 145–159
[2] Arbaud R, Juhász D, Jantsch A. Resource management for mixed-criticality systems on multi-core platforms with focus on communication // 2018 21st Euromicro Conference on Digital System Design (DSD). Prague, 2018: 627–641
[3] Zimmer M P. Predictable processors for mixed-criti-cality systems and precision-timed I/O [D]. Berkeley: UC Berkeley, 2015
[4] Vestal S. Preemptive scheduling of multi-criticality systems with varying degrees of execution time as-surance // 28th IEEE International Real-Time Systems Symposium (RTSS 2007). Tucson, 2007: 239–243
[5] Burns A, Davis R I. A survey of research into mixed criticality systems. ACM Computing Surveys (CSUR), 2017, 50(6): 1–37
[6] Ip N J H, Edwards S A. A processor extension for cycle-accurate real-time software // Proceedings of the IFIP International Conference on Embedded and Ubiquitous Computing (EUC). Seoul, 2006: 449–458
[7] Bui D, Lee E A, Liu I, et al. Temporal isolation on multi-processing architectures // Proceedings of the 48th Design Automation Conference (DAC). San Die-go, 2011: 274–279
[8] Liu I. Precision timed machines [D]. Berkeley: Uni-versity of California, 2012
[9] Antolak E, Pułka A. Flexible hardware approach to multi-core time-predictable systems design based on the interleaved pipeline processing. IET Circuits, De-vices & Systems, 2020, 14(5): 648–659
[10] Broman D, Zimmer M, Kim Y, et al. Precision timed infrastructure: design challenges // Proceedings of the Electronic System Level Synthesis Conference (ESLsyn). Austin, 2013: 1–6
[11] Chisel/FIRRTL Hardware Compiler Framework [EB/ OL]. (2019)[2022–05–16]. https://www.chisel-lang.org/
[12] CMSIS-RTOS2 Documentation [EB/OL]. (2022–05–02)[2022–05–16]. https://www.keil.com/pack/doc/cms is/RTOS2/html/index.html
[13] Lisper B. SWEET—a tool for WCET flow analysis // International Symposium on Leveraging Applica-tions of Formal Methods, Verification and Validation. Berlin, 2014: 482–485
[14] Gustafsson J, Ermedahl A, Sandberg C, et al. Auto-matic derivation of loop bounds and infeasible paths for WCET analysis using abstract execution // Pro-ceedings of the 27th IEEE Real-Time Systems Sym-posium (RTSS 2006). Rio de Janeiro, 2006: 57–66
[15] Gustafsson J, Ermedahl A, Lisper B, et al. ALF — a language for WCET flow analysis // Proceedings of the 9th International Workshop on Worst-Case Execu-tion Time Analysis (WCET 2009). Dublin, 2009: 1–11
[16] Gustafsson J, Betts A, Ermedahl A, et al. The Mälar-dalens WCET benchmarks: past, present and future // Proceedings of the 10th International Workshop on Worst-Case Execution Time Analysis (WCET). Bru-ssels, 2010: 136–146
Instruction Extension Ensuring Time Constraints in Real Time Processor
ZHAO Xiujia1,2 LI Lei3 LIU Xianhua1,2,†
1. School of Computer Science, Peking University, Beijing 100871; 2. Engineering Research Center of Microprocessor & System, Peking University, Beijing 100871; 3. Beijing Smart-Chip Microelectronics Technology Co., Ltd., Beijing 100192; † Corresponding author, E-mail: liuxianhua@pku.edu.cn
Abstract Hardware software cooperation is one of the effective methods for the design of mixed criticality system, which realize resource isolation by necessary hardware semantics, and ensure that different critical tasks meet time constraints based on efficient thread scheduling. Based on a fine-grained multithreaded processor FlexPRET, this paper designs and implements some temporal instruction extensions, and realizes relevant supports in the processor and compiler respectively, so that the program can describe the timing constraint semantics of the worst-case execution time. Experiments show that the extended instructions can provide users with more accurate timing control.
Key words instruction extension; real-time system; mixed criticality system; worst-case execution time