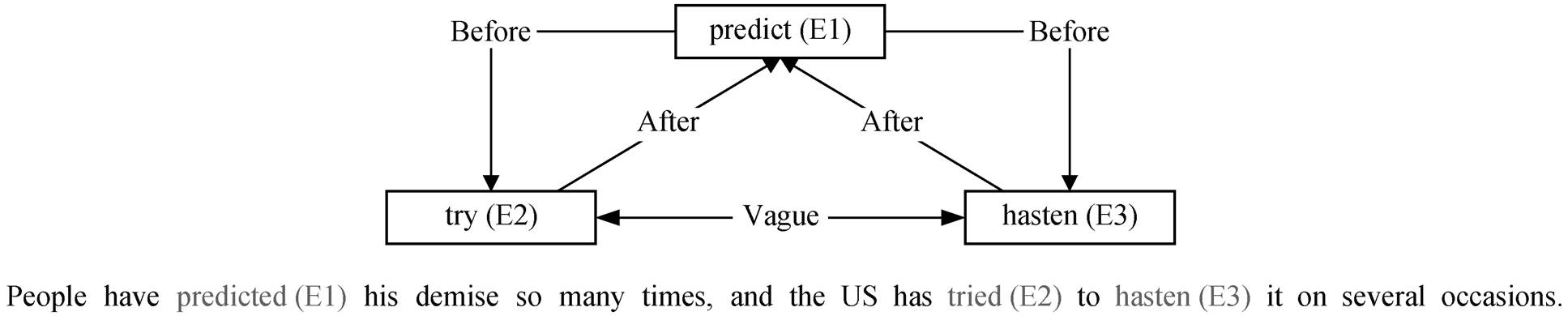
图1 事件时序关系抽取样例
Fig. 1 Example of sampling event temporal relation extraction
北京大学学报(自然科学版) 第59卷 第1期 2023年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 1 (Jan. 2023)
doi: 10.13209/j.0479-8023.2022.066
国家自然科学基金(61972003)、教育部人文社科基金(21YJA740052)和北京市教育委员会科学研究计划项目(KM202210009002)资助
收稿日期: 2022‒05‒13;
修回日期: 2022‒07‒25
摘要 针对事件时间关系不对称的问题, 采用将事件表示映射到双曲空间的方法, 进行事件时序关系抽取。通过简单的运算, 用预训练的词向量与外部知识构建事件的词嵌入表示。在公开发布的数据集上的实验结果表明, 模型的F1值比基线模型普遍高2%, 能够提升事件时序关系抽取的效果。
关键词 事件时序; 关系抽取; 双曲空间词嵌入
事件时间排序是理解事件演变的一项重要任务。事件‒事件时间关系的提取旨在自动提取给定的一对事件的时间顺序, 并构建时序图[1]。除词法、句法和语义等因素外, 对自然语言的成功理解取决于准确地检测事件及其随时间演变的能力[2]。研究事件时序关系的目的是建立事件之间在时间上的先后关系, 这项研究在文本分类、问答系统和智能推荐等自然语言处理领域有着越来越重要的作用。目前, 国内外主流的事件时序抽取方法主要为端到端的分类抽取和构建事件图, 即基于图结构的事件时序抽取方法。事件时序关系抽取的目标是对含有多件事件的文本, 依据事件发生的时间排序。
事件之间的顺序关系可以分为 4 种: 之前(Be-fore)、同时(Equal)、之后(After)和不明确(Vague)。一般将 Before, Equal 和 After 这 3 种事件时序视为事件间有时间的先后顺序, 而将第 Vague视为事件之间无特定的时间关系。如图 1 所示, 事件提及中包含 3 种事件类型: 预测(predict)、尝试(try)和加速(hasten)。根据语义可知, 预测事件发生在加速事件之前, 尝试事件发生在预测事件之后, 而尝试事件与加速之间没有明显的时间关系。
现有的事件时序关系识别方法通常是先将文档中的事件两两配对, 然后识别各个事件对的时序关系。本文模型将带触发词标记的事件句作为输入, 通过编码器, 从事件句中提取出事件时序关系表示, 再对事件对的时序关系进行分类。如图 1 所示, 事件间的时间关系并非完全是线性的, 因为一个原因必须先于其结果, 时间与因果关系密切相关, 在许多情况下, 一种关系甚至决定另一种关系[3]。
图1 事件时序关系抽取样例
Fig. 1 Example of sampling event temporal relation extraction
本文基于事件时序关系的这种分层结构, 将预训练语言模型中的事件词嵌入映射的双曲空间来计算嵌入表达, 并通过简单的运算, 将含有事件时序信息的外部知识引入模型, 并使用知识奖励函数来优化损失值计算方法。
近年来, 事件时序关系抽取主要基于深度神经网络的模型, 将很大部分事件时序关系抽取视为分类问题, 通常是构建事件对, 对每对事件进行时序分类计算。也有部分事件时序关系抽取使用基于图神经网络的模型。Cheng 等[4]提出一个以事件为中心的模型, 允许跨多个时序链接关系(temporal link, TLINK)管理动态事件表示, 通过多任务学习处理 3个 TLINK 类型, 以便充分利用数据集内部的完整信息(如两个具有相同提及的 TLINK 可以共享信息)。Han 等[5]提出一种连续的预训练方法, 使预训练语言模型(pre-trained language model, PTLM)具有关于事件时间关系的目标知识。Yan 等[6]提出基于时间推理的关系提取问题, 并提出一种预测两个给定实体在给定时间点是否具有关系的解决方案。Balles-teros 等[7]提出的模型以一个文本内的一对事件及其区间作为输入, 用来识别它们之间的时序关系。Li 等[8]将新闻文章表示为事件图, 然后将整个图压缩为其显著子图, 构建以时间轴为基础的新闻摘要。Wen 等[9]提出一种基于图注意网络的方法, 在由共享实体参数和时间关系构造的文档级事件图上传播时间信息。
本文模型用于基于时间关系提取的相对事件时间预测, 包含词嵌入生成器、双曲嵌入知识拼接器和事件时间分类器 3 个模块。词嵌入生成器根据事件提及和事件触发词, 计算含有事件触发词信息的文本词嵌入表达式。双曲嵌入知识拼接器获取事件触发词的嵌入表示, 并将其映射到双曲空间, 然后将外部知识映射到低维空间, 并将映射向量与事件触发词嵌入向量拼接, 构成完整的事件嵌入表示。时间分类器对获取的词嵌入进行线性分类, 分类结果决定事件间的时序关系。本文模型的时间分类器中, 将外部知识作为奖励函数, 修改了损失函数。本文模型的总体结构如图 2 所示。
给定一段含事件触发词的事件提及文本, 将其输入词嵌入生成器。词嵌入生成器使用基于大规模无标签数据训练得到的预训练语言模型来计算文本词嵌入。生成文本词嵌入后, 使用事件触发词所在位置的嵌入向量作为事件的预训练文本表示。简单起见, 本文只使用事件提及范围的起始位置对应的词嵌入向量作为嵌入表示, 将事件 ei的起始位置标记为事件的嵌入表示。词嵌入生成器计算句子的上下文词嵌入向量, 本文用 H表示上下文化的词嵌入表示:
H= (h1, h2, …, ei, …, ej, …, hk), (1)
其中, hk是位置 k标记的上下文词嵌入表示, 接受分词信息(input_ids)、分段信息(token_type_ids)和掩码信息(attention_masks) 3 种张量。
本文使用任何给定的一个事件提及的对应开始位置的表示与外部知识向量 Ki的拼接作为事件的表示向量 ei。模型通过预训练获取包含事件时序信息的外部知识, 并生成词向量文件。本文模型通过双层全连接层和激活函数构成的前馈神经网络(feed forward network, FFN), 将词嵌入维度压缩, 生成知识向量 Gi:
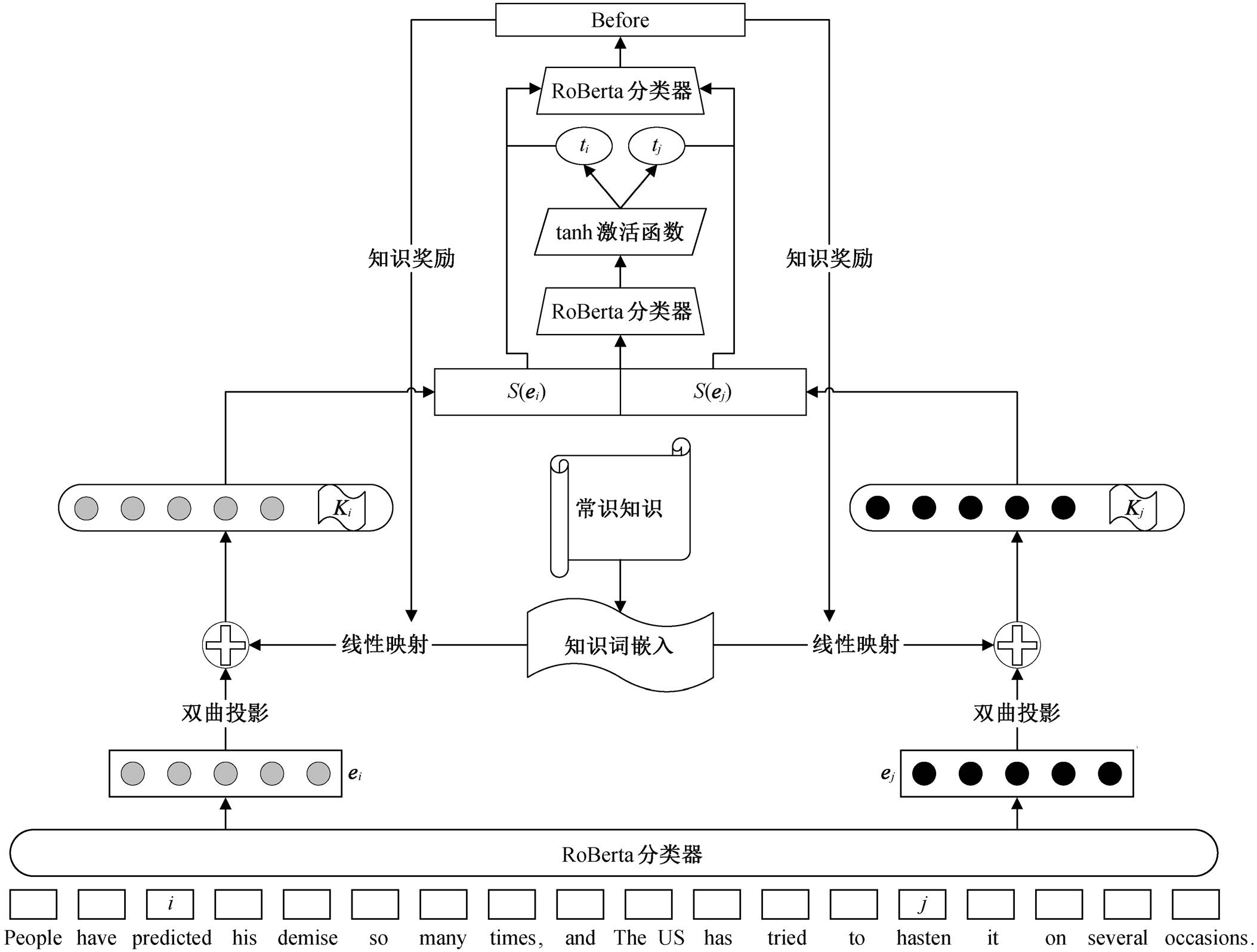
图2 本文模型的结构
Fig. 2 Structure of the proposed model
Gi = FFN(Ki)
= Relu(Linear2(Linear1(Embedding(Ki))))。 (2)
本文使用更新后的 TEMPROB[10]。TEMPROB是一个基于事件之间典型时序关系自动诱导的事件时序常识知识数据库, 构建了大量事件对之间的时序关系。如 accept 事件与 determine 事件之间, 有42%的可能性是 accept “Before” determine, 有 26%的可能性是 accept “After” determine; accept 事件与propose 事件之间, 有 77%的可能性是 accept “After” propose, 仅有 10%的可能性是 accept “Before” propose。该知识数据库中频次较少的时序关系被忽略了, Before 事件与 After 事件出现概率的总和并不是 100%。
时间关系是不对称和可传递的, 具有与层次关系相似的特性。因此, 本文模型将词嵌入映射到双曲空间的编码作为事件嵌入。对于包含事件对(ei, ej)的给定文本序列, 首先从事件 ei和 ej的 RoBERTa序列编码中提取上下文嵌入, 并与外部知识拼接; 然后使用指数映射函数, 将它们映射到双曲空间; 再通过双曲前馈层, 将嵌入投影到低维空间。计算公式如下:
ei= exp0(hi)⊕Gi, (3)
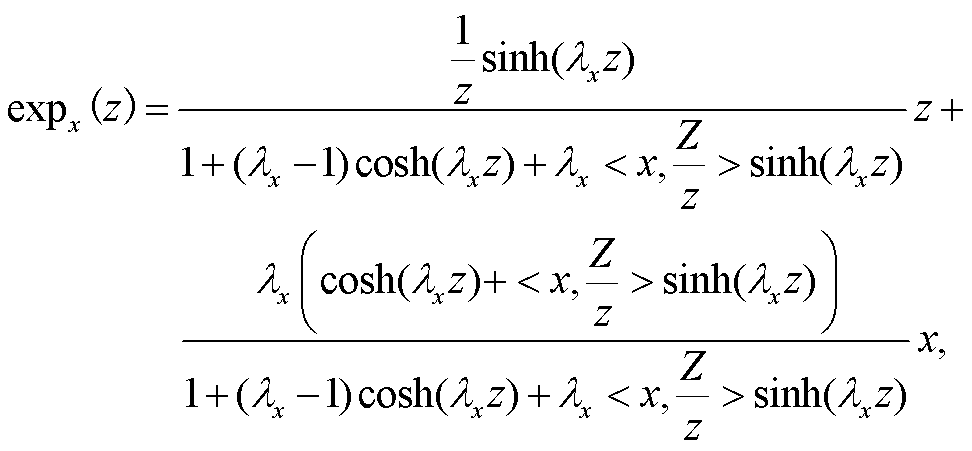 (4)
(4)
其中, 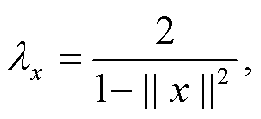 exp0(·)是双曲空间原点的指数映射, x和 z是空间内一点的坐标, ||·||表示欧式范数, <·, ·>表示欧几里得内积, S(ei)和 S(ej)是事件 ei和 ej的最终双曲词嵌入。
exp0(·)是双曲空间原点的指数映射, x和 z是空间内一点的坐标, ||·||表示欧式范数, <·, ·>表示欧几里得内积, S(ei)和 S(ej)是事件 ei和 ej的最终双曲词嵌入。
本文将上面的两个事件提及向量拼接起来, 使用 tanh 激活函数两层前馈神经网络, 将表示转换为事件的相对时间:
ti = tanh(Linear4(dropout(Linear3(S(ei)))))。 (5)
获得每个事件的相对时间后, 将该预测特征纳入事件‒事件时间关系的提取。相对时间预测和时间关系提取都是基于预训练语言模型的上下文化的表示, 因此采用多层线性全连接层, 将这两个任务连接起来, 同时保持可微性。本文还将事件对的外部知识权重作为奖励机制送入模型中去计算损失, 根据模型对数据集的感知构建事件字典, 根据事件与事件之间的历史关系生成事件字典。如图 1 的示例中, 预测事件 E1 (predict)与尝试事件 E2 (try)在不同的句子中出现多次。统计 E1 before E2 的次数、E1 after E2 的次数以及 E1 与 E2 同时的次数, 并计算总比例, 将出现频率的倒数作为奖励系数加入损失值计算, 以便提升对预测正确事件时序的奖励。为此, 本文构建 4 个权重矩阵: Wbefore, Wafter, Wequal和 Wvague。在不同的权重矩阵中, 统计事件对中各种时序关系出现的频率, 如该事件组合没有某种时序关系, 将其值设为 0.1, 最终保留在权重矩阵中的值是该值的倒数。在训练过程中, 使用交叉熵损失函数约束时序关系分类效果, 依据权重矩阵对交叉熵进行权重奖励:
Lt =−log(P(r=r(ei, ej)|ei, ej)⊕Wr (Ei, Ej), (6)
最终的训练目标损失函数为分类任务与知识奖励的损失组合。
基于 Python3.7 和深度学习框架 PyTorch1.8.2-LTS 进行实验, 在 GPU 上训练、验证并测试。实验中, 将 batch size 设置为 8, 学习率设置为 2×10−5, 使用 AdamW 优化器优化所有模型。
本文模型使用 MATRES[11]数据集。MATRES整理自 TempEval 研讨会的 275 篇新闻文章, 并在研讨会数据的基础上标注了新事件和时间关系。MAT-RES 包含 3 个来源的文件: TimeBank (183 个文件)、AQUAINT(72 个文件)和 Platinum(20 个文件)。本文遵循官方的划分, 将 TimeBank 和AQUAINT 用于培训, Platinum 用于测试。进一步地, 本文将 20%的训练数据分割为验证集。数据集标签详细信息如表 1 所示。
表1 MATRES数据集标签统计
Table 1 MATRES dataset tag statistics
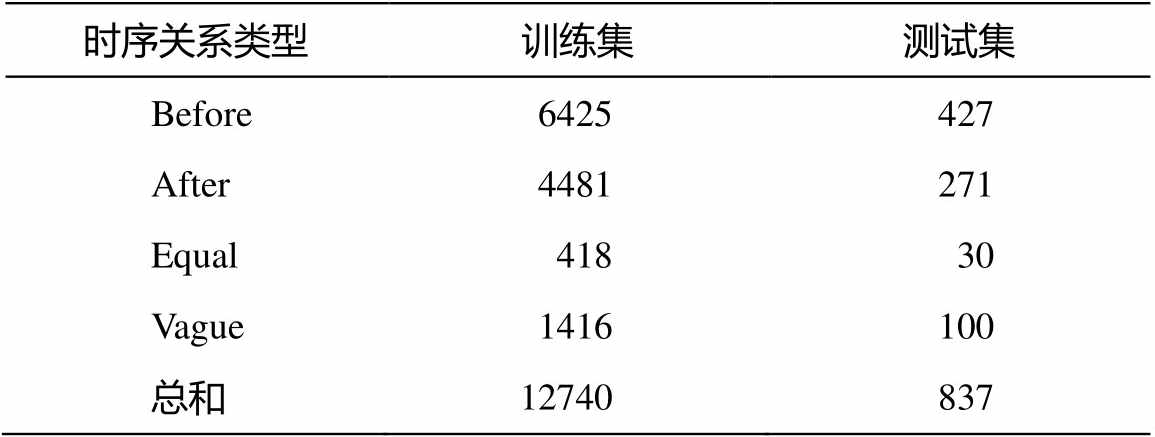
时序关系类型训练集测试集 Before6425427 After4481271 Equal41830 Vague1416100 总和12740837
本文使用的常识知识来自文献[10]。从模型的角度, 通过双层线性结构对常识知识进行微调; 针对某些事件无法在常识知识数据库中寻找到对应的常识知识这一问题, 通过构建零矩阵的方式进行 训练。
本文根据验证集对每个基线模型进行优化, 将准确率 P (precision)、召回率 R (recall)和 F1 值作为关系抽取效果的评价指标, 计算公式如下:
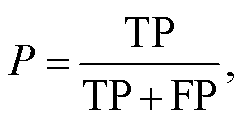 (7)
(7)
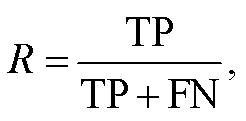 (8)
(8)
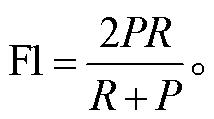 (9)
(9)
准确率 P是针对预测结果对模型进行评估, 通过计算预测正确的案例数(true positive, TP)与总的预测案例数(true positive + false positive, TP+FP)之比来衡量模型预测结果的准确程度。召回率 R是针对原有样本对模型进行评估, 通过计算预测正确的案例数(TP)与样本中正例的总数(true positive + false negative, TP+FN)之比来描述模型预测样本中正例的准确程度。F1 值是综合以上两种计算方法, 对模型进行总体评估。本文认为准确率和召回率在评估模型效果时同等重要, 因此计算两者的调和平均数来展示模型的性能。
为了验证本文提出的知识驱动的事件双曲嵌入方法的有效性, 与以下基线方法进行比较。
1)使用 MAP 推理的基于双向长短期记忆模型的联合事件时间关系提取模型[12]。
2)结合预训练语言模型嵌入、常识先验(TEM-PROB)和整数线性规划(integer linear programming, ILP)的长短期记忆方法[13]。
3)通过约束学习框架来建模事件‒事件关系的联合约束学习方法[14]。
4)一种基于语义特征和结构化推理的管道系统[15]。
将训练 30 个 epoch 得到的模型用于测试集上, 抽取事件时序关系, 结果如表 2 所示。不难看出, 与基线模型相比, 本文模型的 F1 值有不低于 2%的 提升。
为了测试本文模型各个模块的性能, 我们进行消融实验, w/o project 实验中去除事件双曲词嵌入, w/o knowledge 实验中去除事件外部知识, w/o award 实验中去除外部知识奖励函数, 实验结果见表 3。可以看出, 去除每个模块都导致模型性能有所下降, 其中去除事件的双曲空间词嵌入模块对模型性能影响最大。
可以观察到, 去除双曲词嵌入模块实验结果的F1 值下降约 0.8 个百分点, 证明双曲词嵌入对事件的建模效果比欧几里得方法好; 去除外部知识实验结果的 F1 值下降约 0.5 个百分点, 可见外部知识对模型性能的提升效果不如双曲词嵌入; 去除外部知识奖励函数实验的模型性能最差。消融实验结果显示, 各个模块都在不同程度上提升了模型的性能。
为了证明本文模型的有效性, 使用表 4 所示的两个案例来对比本文模型与 CogCompTime 模型的预测效果。
案例 1 中, 事件 told 与事件 happened 之间的正确标签是 After, 事件 happened 发生在前, 事件 told发生在后, CogCompTime 错误地预测为 Before, 本文模型正确地预测为 After。CogCompTime 预测错误的原因在于训练数据中 Before 事件比例较大, 较多的数据导致模型倾向于预测 Before。本文模型将事件词嵌入, 使用双曲空间进行词嵌入表达, 更容易捕获事件间的层级关系, 因此可以计算出正确的结果。
案例 2 中, 事件 apologized 与事件 happened 之间的正确标签是 Vague, 这两种事件之间没有时序关系。CogCompTime 错误地预测为 Before, 本文模型正确地预测为 Vague。这是因为在训练过程中, 属于 Vague 关系事件对的数据比较少(约占 10%), CogCompTime 无法准确地预测。本文模型使用外部知识奖励来提升稀缺的 Vague 和 Equal 案例的权重, 因此可以准确地预测出 Vague 关系。
表2 本文模型与基线模型效果对比(%)
Table 2 Compare the baseline model with our model (%)

模型PRF1 BiLSTM−−75.50 LSTM+TEMPROB+ILP71.3082.1076.30 Joint Constrained Learning73.4085.0078.80 CogCompTime61.6072.5066.60 本文模型77.5184.7580.97
说明: 粗体数字表示最佳结果, 下同。
表3 消融实验结果(%)
Table 3 Result of ablation experiments(%)

模型PRF1 本文模型77.5184.7580.97 w/o project76.9983.6580.18 w/o knowledge76.9884.0480.36 w/o award76.2984.9680.39
表4 案例分析
Table 4 Case study

案例编号案例模型预测结果 1Mr. Netanyahu told (E1) Mr. Erdogan that what happened (E2) on board the Mavi Marmara was “unintentional and Israel expresses regret over injuries and loss of life , ” according to the statement.正确标签After CogCompTimeBefore 本文模型After 2Israeli Prime Minister Benjamin Netanyahu apologized (E1) on Friday to Turkish Prime Minister Recep Tayyip Erdogan for a raid on a Turkish flotilla ship, a move that will help restore strained ties between the countries. The call, which happened (E2) as President Barack Obama wrapped up his first presidential visit to Israel, was an unexpected outcome from a Mideast trip that seemed to yield few concrete steps.正确标签Vague CogCompTimeBefore 本文模型Vague
为了更好地利用模型捕捉非对称事件的时间信息, 本文将常用的欧几里得式词嵌入信息替换为双曲空间的词嵌入编码方式, 在 MATRES 数据集上探索性地构建以双曲词嵌入为基础, 融合外部知识的事件时序关系抽取模型。实验结果表明, 与基线模型相比, 本文模型的预测效果有一定程度的提升。
参考文献
[1]Wen Haoyang, Ji Heng. Utilizing relative event time to enhance event-event temporal relation extraction // Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistic, Online Meeting, 2021: 10431–10437
[2]Tan X W, Pergola G, He Y L. Extracting event tem-poral relations via hyperbolic geometry // Procee-dings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online Meeting, 2021: 8065–8077
[3]Ning Qiang, Feng Zhili, Wu Hao, et al. Joint rea-soning for temporal and causal relations // Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Melbourne: Association for Computational Linguis-tics, 2018: 2278–2288
[4]Cheng F, Asahara M, Kobayashi I, et al. Dynamically updating event representations for temporal relation classification with multi-category learning // Findings of the Association for Computational Linguistics: EMNLP 2020. Association for Computational Lin-guist, Online Meeting, 2020: 1352–1357
[5]Han Rujun, Ren Xiang, Peng Nanyun. ECONET: effective continual pretraining of language models for event temporal reasoning // Proceedings of the 2021 Conference on Empirical Methods in Natural Langu-age Processing. Association for Computational Lin-guistics, Online Meeting, 2021: 5367–5380
[6]Yan Jianhao, He Lin, Huang Ruqin, et al. Relation extraction with temporal reasoning based on memory augmented distant supervision // Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu-man Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, 2019: 1019–1030
[7]Ballesteros M, Anubhai R, Wang S, et al. Severing the edge between before and after: neural architectures for temporal ordering of events // Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Com-putational Linguist, Online Meeting, 2020: 5412–5417
[8]Li Manling, Ma Tengfei, Yu Mo, et al. Timeline summarization based on event graph compression via time-aware optimal transport // Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online Meeting, 2021: 6443–6456
[9]Wen Haoyang, Qu Yanru, Ji Heng, et al. Event time extraction and propagation via graph attention net-works // Proceedings of the 2021 Conference of the North American Chapter of the Association for Com-putational Linguistics: Human Language Technolo-gies. Online Meeting, 2021: 62–73
[10]Ning Qiang, Wu Hao, Peng Haoruo, et al. Improving Temporal Relation Extraction with a Globally Acqui-red Statistical Resource // Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). New Orleans, 2018: 841–851
[11]Ning Q, Wu H, Roth D. A multi-axis annotation scheme for event temporal relations // Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Volume 1: Long Papers. Melbourne, 2018: 1318–1328
[12]Han Rujun, Ning Qiang, Peng Nanyun. Joint event and temporal relation extraction with shared represen-tations and structured prediction // Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMN-LP-IJCNLP). Hong Kong: Association for Computa-tional Linguistics, 2019: 434–444
[13]Ning Q, Subramanian S, and Roth D. An improved neural baseline for temporal relation extraction // Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong: Associa-tion for Computational Linguistics, 2019: 6203–6209
[14]Wang Haoyu, Chen Muhao, Zhang Hongming, et al. Joint constrained learning for event-event relation extraction // Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online Meeting, 2020: 696–706
[15]Ning Qiang, Zhou Ben, Feng Zhili, et al. Cogcomp-time: a tool for understanding time in natural lan-guage // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Brussels: Association for Computational Linguistics, 2018: 72–77
Exploration of Knowledge Driven Event Hyperbolic Embedding Temporal Relation Extraction Method
Abstract Aiming at the problem of asymmetric temporal relations of events, the event representation is mapped to hyperbolic space to extract temporal relations of events. The word embedding representation of the event is constructed by using the pre-trained word vector and external knowledge through simple operation. Experimental results on publicly released datasets show that the F1 value of the model is generally 2% higher than that of the baseline model, which can improve the effect of event temporal relation extraction.
Key words event temporal sequence; relation extraction; hyperbolic space word embedding