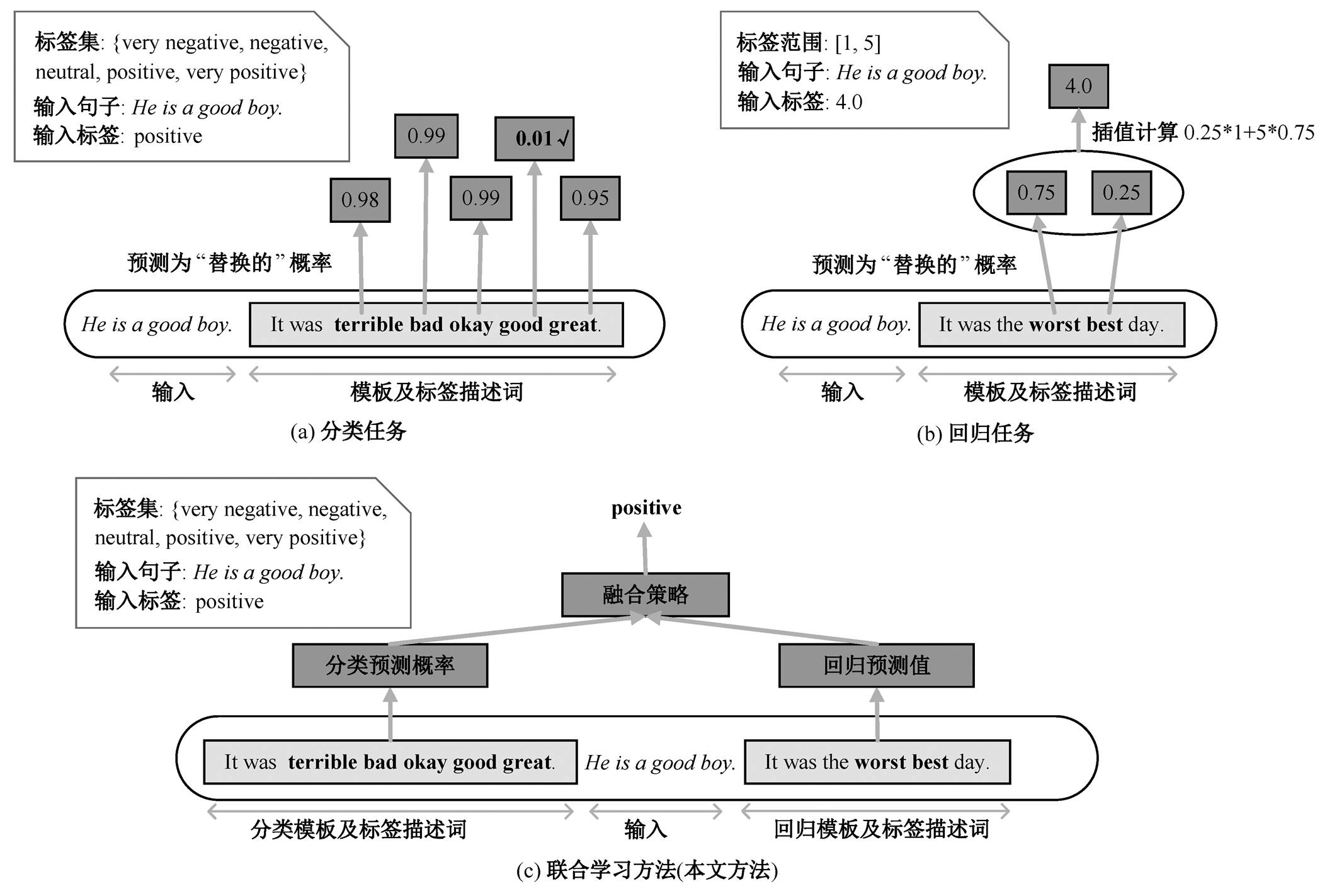
图1 分类任务、回归任务及联合学习方法示意图
Fig. 1 Schematic diagram of classification task, regression task and joint learning method
北京大学学报(自然科学版) 第59卷 第1期 2023年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 1 (Jan. 2023)
doi: 10.13209/j.0479-8023.2022.068
国家自然科学基金(62076176)资助
收稿日期: 2022-05-13;
修回日期: 2022-08-10
摘要 对于多类别的细粒度情感分类任务, 目前主流的少样本学习方法不能取得较好的性能。针对这一问题, 提出一种基于联合学习的少样本多类别情感分类方法。采用基于替换词检测任务的少样本学习方式, 将回归和分类的替换词检测模板以及标签描述词同时添加至输入语句, 从而将细粒度情感分类任务同时建模为分类问题和回归问题。在此基础上, 设计了不同的融合方法进行联合学习。实验结果表明, 与主流少样本学习方法相比, 该方法在F1-Score和正确率上都取得更优的结果。
关键词 情感分类; 少样本学习; 联合学习
情感分类是自然语言处理的重要研究领域之一, 广泛应用于分析人们对产品、服务和机构的情感、情绪和态度[1–2]。近年来, 基于微调机制的分类模型主导了情感分类方法研究。这些模型经过大规模预先训练(如 BERT[3], RoBERTa[4]和 ELECTRA[5]等)后, 通过再训练, 将知识从预训练模型迁移到对文本情感的划分。然而, 当没有足够的标记训练数据时, 标准的微调机制面临许多挑战, 难以取得理想的情感分类结果。因此, 出现一种新的研究方向, 即少样本情感分类, 研究如何在训练数据量很少的情况下完成快速学习, 并获得具有良好性能的情感分类模型。
近年来, 相继提出多种少样本学习方法, 如基于图神经网络的少样本分类方法[6]、基于元学习的少样本分类方法[7]、基于基于大型预训练语言模型的 GPT-3 方法[8]、基于掩码语言模型的少样本学习方法[9–11]以及基于替换词检测模型的少样本学习方法[12]。上述方法在许多简单的情感分类任务中取得惊人的表现, 如在二分类情感分类数据集 SST-2 上, 仅依靠每类 16 个训练样例, 基于掩码语言模型RoBERTa-base 的少样本学习方法可以达到 87%的正确率。然而, 对于复杂的细粒度情感分类任务, 无一例外都获得较差的结果。例如, 在 5 类情感分类数据集 SST-5 上, 同样依靠每类 16 个训练样例, 基于掩码语言模型 RoBERTa-base 的少样本学习方法仅达到 45%的正确率[12]。
受基于替换词检测预训练模型的少样本学习方法[12]启发, 本文提出一种基于联合学习的少样本多类别情感分类方法。该方法的主要思想是将多分类情感分类任务同时视为分类问题和回归问题, 并进行联合学习。首先, 为多类情感分类任务设计分类和回归所需的模板及标签描述词; 然后, 将分类和回归的模板以及标签描述词同时添加至输入, 利用替换词检测预训练模型, 预测出分类预测概率和回归预测值; 最后, 将分类预测概率和回归预测值进行融合, 作为最终结果。
情感分类是自然语言处理中重要的任务之一, 本文主要研究多类别的细粒度情感分类。在早期工作中, 大多数的情感分类方法基于传统的机器学习或基于规则方法[13–16]。Li 等[15]设计了一种支持向量回归和基于规则的情绪抽取方法, 对 6 类情感进行分类。Wen 等[16]提出一种基于序列分类规则的情感分类方法, 使用情感词汇和机器学习来获取句子中潜在的情感标签。随着深度学习的发展, 深度神经网络被用于情感检测。Socher 等[17]利用自然语言句子的内在树结构, 使循环神经网络(RNN)来计算句子的向量表示。Chen 等[18]将卷积神经网络(CNN)应用于情感分类。Tai 等[19]将各种形式的长–短期记忆网络(LSTM)应用于情绪分类。近年来, 随着 BERT[3]的发布, 基于 Transformer 架构[20]的深层双向语言模型在许多流行的 NLP 任务中取得最先进的水平, 显示了微调机制的强大性能, 后续的许多研究都围绕预训练模型展开[21]。许多优秀的预训练模型(如 RoBERTa[4]和 ELECTRA[5]等)相继出现, 多次刷新情感分类任务的各项记录。然而, 当标记训练样本极为稀缺时, 标准的微调机制表现较差。因此, 基于少样本的情感分类成为当前研究的一个热点方向。
由于 GPT-3 系列[8,22]的提出, 基于语言模型的少样本学习方法成为自然语言领域中热门的研究方向。GPT-3 将任务重新表述为语言模型问题, 添加任务提示和示例作为演示, 实现少样本学习能力。该方法已普遍应用于分类任务[23]、问答任务[24]和知识挖掘[25]。后续的研究尝试将少样本学习任务重构为完形填空问题[26](通过添加短语如“It was [mask]”), 以便重复使用预先训练过的语言模型(如LM prompt[27], PET[10]和 LM-BFF[9])。由于人工设计模板的不稳定, 许多研究开始探索自动搜索模板, Ben-David 等[28]提出一种基于 T5 语言模型的自动回归快速学习算法, 用于自动搜索模板。Liu 等[29]提出 P-Tuning 方法, 可以在连续空间中自动搜索更好的提示。Zhang 等[30]提出 DifferentiAble pRompT (DART)方法, 在连续空间中使用反向传播对提示模板和目标标签进行差异优化。
Li 等[12]提出一种新的少样本学习范式, 将下游任务转换为替换词检测任务, 并依靠替换词检测预训练模型(如 ELECTRA)来实现少样本学习。如图 1(a)所示, 首先将设计好的模板和标签描述词直接插入到输入中, 利用替换词检测预训练模型来预测出最合适(即最小“替换”概率)的标签描述词。此外, 通过将回归问题转换为插值问题, 还可以将此方法应用于回归任务。如图 1(b)所示, 通过预测两个极端类的概率来计算出最终的回归值。此方法简单直接, 在 16 个主流 NLP 数据集上的实验表明, 该方法进一步提升了少样本学习的表现。
本文在 Li 等[12]方法的基础上, 进一步提升基于少样本学习的多类情感分类性能。不同于 Li 等[12]处理多类情感分类的方式, 本文将多类情感分类任务同时视为分类问题和回归问题, 并设计 3 种不同融合策略来融合回归预测和分类预测, 进一步提高细粒度情感分类任务性能。
基于替换词检测预训练模型的少样本学习方法可以应用于分类任务和回归任务中[12]。
2.2.1 分类问题建模
假设一个分类任务有 K 个类别, 我们设计一个模板并为每个类别 i 设计标签描述词 LABEL(i), 然后将模板和所有标签描述词插入输入 x, 构造提示输入 xprompt, 如“x It was LABEL(1)... LABEL(k).”。
图1 分类任务、回归任务及联合学习方法示意图
Fig. 1 Schematic diagram of classification task, regression task and joint learning method
替换词检测预训练模型能够预测出每个标签描述词为“原始的”(=0)和“替换的”(=1)的概率, 即 P(y= 0|LABEL(i))和 P(y=1|LABEL(i))。句子 x 属于类别 i的概率定义为其标签描述词为“原始的”概率:
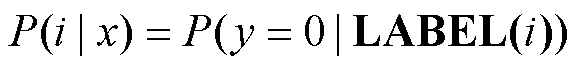 。 (1)
。 (1)
因此, 分类任务的最终预测为
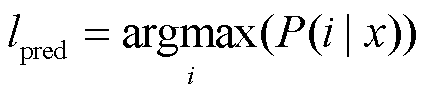 。 (2)
。 (2)
例如, 对于一个 5 类情感分类问题(very negative, negative, neutral, positive 和 very positive), 如图 1(a)所示。句子“He is a good boy.”的类别为 positive, 其提示输入 xprompt 为“He is a good boy. It was terrible bad okay good great.”。替换词检测预训练模型预测出标签描述词 good 具有最小“替换”概率0.01 (即具有最大“原始”概率 0.99), 表明在所有标签描述词中, good 为最合适的词, 因此其对应的标签positive为最终预测类别。
2.1.2 回归问题建模
假设一个回归任务的标签空间为[vl, vu], 我们首先将其转化为两个极端类{cl, cu}的插值问题。与分类任务相同, 重构出提示输入 xprompt, 如“x It was the LABEL(l) LABEL(u) day.”。然后, 依据式(1), 利用替换词检测预训练模型预测出句子x属于类别cl和类别cu的概率, 即 P(cl|x)和P(cu|x), 则回归任务的最终预测可由以下插值公式[12]计算:
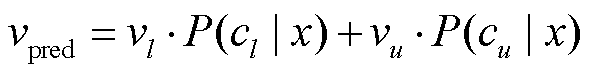 , (3)
, (3)
其中, 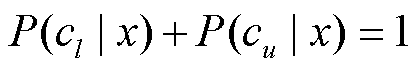 。
。
例如, 对于一个取值范围为[1, 5]的情感回归问题, 如图 1(b)所示, 句子“He is a good boy.”的情感打分为 4.0, 其提示输入 xprompt 为“He is a good boy. It was the worst best day.”。替换词检测预训练模型预测出标签描述词 worst 的“替换”概率为 0.75 (即“原始”概率为 0.25), best 的“替换”概率为 0.25 (即“原始”概率为 0.75)。因此, 由插值公式(式(3))可计算出最终预测值为 4.0。
基于替换词检测预训练模型的少样本学习方法, 本文提出一种联合学习方法, 并应用于多类情感分类问题。首先, 为多类别情感分类任务同时设计分类和回归所需的模板及标签描述词, 并将其分别添加至输入 x 的头部和尾部, 得到 xprompt, 如“It was LABEL(1)...LABEL(k). x It was the LABEL(l) LABEL (u) day.”。
假设输入 x 属于第 i 个类别, 回归标签描述词的位置为[p1, p2], 分类标签描述词的位置为[t1, …, ti, …, tk]。我们通过以下方式构造 xprompt 的训练目标值 yprompt。
1)对于分类标签描述词, 我们将第 i 个标签描述词的目标值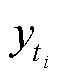 设置为 0, 即认为是“原始的”, 相反, 将其他分类标签描述词设置为 1, 即认为是“替换的”。
设置为 0, 即认为是“原始的”, 相反, 将其他分类标签描述词设置为 1, 即认为是“替换的”。
2)对于回归标签描述词, 首先依据回归标签值vtarget 和式(3), 推出输入 x 属于极端类 cl 和 cu 的期望概率, 即
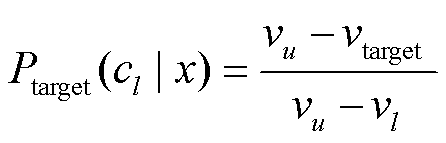 , (4)
, (4)
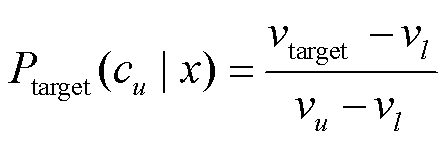 。 (5)
。 (5)
然后设置回归标签描述词 LABEL(l)和 LABEL(u)的目标值分别为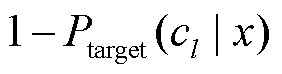 和
和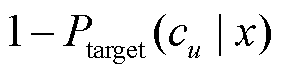 。
。
3)对于原始句子 x 和模板, 将其设置为 0, 即认为是“原始的”。
例如, 对于一个如图 1(c)所示的 5 类情感分类问题(very negative, negative, neutral, positive和very positive), 句子“He is a good boy.”的类别为posi-tive, 则其提示输入 xprompt 为“It was terrible bad okay good great. He is a good boy. It was the worst best day.”, 其中, terrible, bad, okay, good 和 great 分别为分类问题中类别 very negative, negative, neutral, positive 和 very positive 的标签描述词, worst和 best 为回归问题中极端类别 cl 和 cu 的标签描述词。xprompt 的训练目标值 yprompt 如图 2 所示。
所有提示输入及其训练目标值都用于更新替换词检测预训练模型的参数, 本文采用二值交叉熵损失函数进行训练。
在预测阶段, 首先将输入 xtest 重构成提示输入, 然后分别由式(1)和(3)得到回归预测值 vtest-reg 和分类预测概率 Ptest-cla(i|xtest)。为了融合回归预测值与分类预测概率, 我们设计 3 种不同的融合策略。
1)层次筛选方式。首先利用回归预测 vtest-reg 筛选出两个待选类别, 然后由分类预测概率确定最终预测类别:
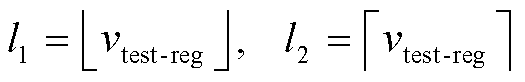 , (6)
, (6)
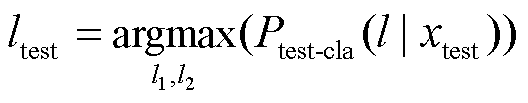 。 (7)
。 (7)
2)概率加权方式。首先将回归预测值转换为类别概率形式。具体做法为, 计算回归预测值 vtest-reg与各类别 i 的绝对距离, 然后, 归一化绝对距离的倒数:
 , (8)
, (8)
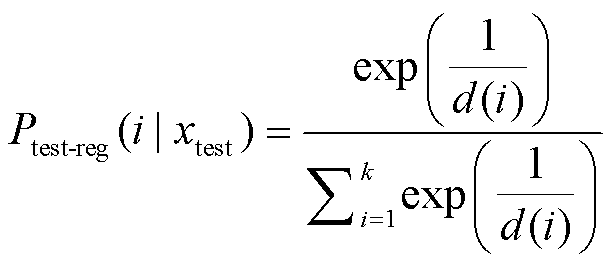 。 (9)
。 (9)
然后, 用此概率值与分类预测概率进行加权融合:
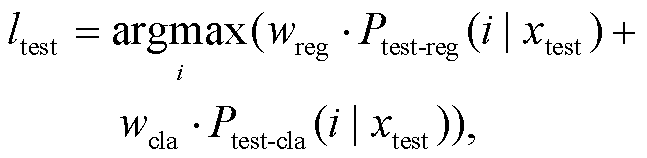 (10)
(10)
其中, wreg和wcla分别为回归和分类输出的权重, 具体取值需在开发集中进行调试。
3) 权重距离方式。首先利用式(8)计算出各类别 i的绝对距离 d(i), 然后将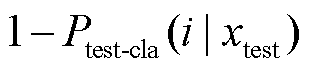 作为权重, 计算出各类别的权重距离, 最后取最小权重距离对应的类别作为最终预测:
作为权重, 计算出各类别的权重距离, 最后取最小权重距离对应的类别作为最终预测:
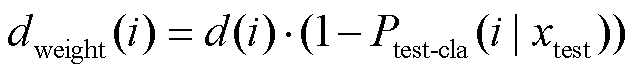 , (11)
, (11)
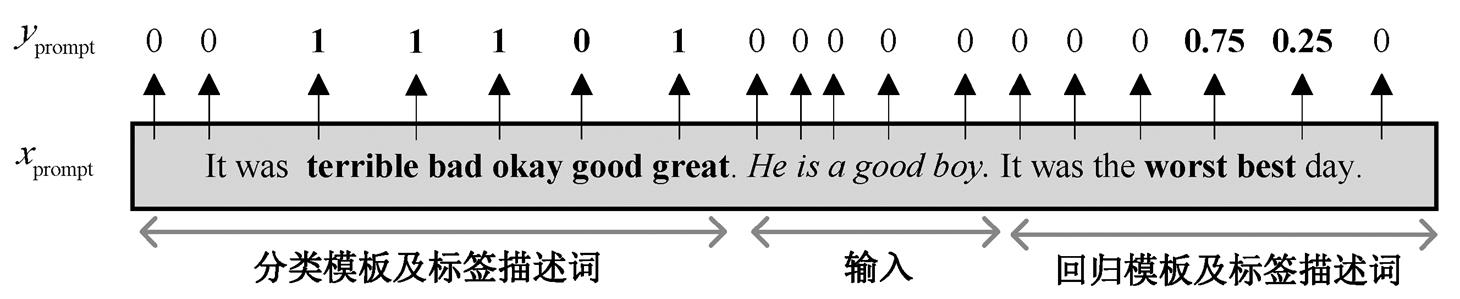
图2 本文方法的提示输入及对应的训练目标值
Fig. 2 Training target value of the prompt input
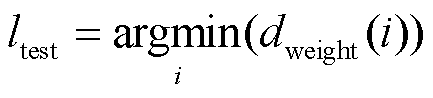 。 (12)
。 (12)
将本文提出的方法与主流的少样本学习方法进行比较, 并验证本文方法在不同模板、标签描述词和训练样本数量情况下的有效性。
本文实验在 SST-5 数据集[17]上进行。SST-5 是斯坦福大学发布的一个细粒度情感分类数据集, 主要针对电影评论来做情感分类, 属于单个句子的文本分类任务。语料库包括 5 个细粒度情感类别(very negative, negative, neutral, positive和very positive), 8544 个训练样本, 2210 个测试样本。本文采用精准率、召回率、F1-Score 和准确率作为情感分类的评价指标。
由于训练数据规模极小, 所以少样本学习实验往往对训练集的划分和超参数的设置十分敏感, 不同的训练集划分方式或不同的超参数设置都可能造成结果的大幅度波动[31–32]。在本文实验中, 为了得到可靠的结论, 我们遵循Li等[12]的评估方式, 采用多训练集划分和网格搜索超参数策略来确保少样本实验结果的稳定性。
训练集和开发集划分: 采用 5 个不同的随机种子{13, 21, 42, 87, 100}, 依次从 SST-5 原始的 8544个训练数据中抽样出 5 组不同的训练数据和开发数据, 每组训练样本数量和开发样本数量相同。实验中, 依次利用 5 组不同的划分来训练和调试模型, 并统计每组结果, 最终汇报各指标的平均结果及标准差。
超参数设置: 对于每一组划分, 首先利用开发集并借助网格搜索策略, 获得适应此划分的最佳超参数设置, 然后基于最佳超参数设置训练模型, 在SST-5 完整的 2210 个测试样本上测试。实验中采用的超参数如表 1 所示, 表中的集合表示此参数值需要通过网格搜索最终确定。
基于 5 组不同的划分进行实验, 其中每组训练数据和开发数据都包括 80 个样本, 即每个类别含16 个样本。为了验证本文提出的联合学习方法的有效性, 我们基于相同的评估策略与以下基准方法进行比较。
表1 主要超参数设置
Table 1 Main hyperparameter settings

超参数数值 批大小{4, 8} 学习率{1×10–5, 2×10–5, 3×10–5, 4×10–5, 5×10–5} 权重衰减2×10–3 迭代次数50 最大长度256
1)Majority: 预测所有测试样本为 5 类中数量最多的类别。
2)Fine-tuning (RoBERTa): 采用 RoBERTa 预训练模型的标准微调方法。
3)Fine-tuning (ELECTRA): 采用 ELECTRA 预训练模型的标准微调方法。
4)LM-BFF[9]: 基于预训练掩码语言模型的少样本学习方法, 将下游任务转换为完型填空问题。
5)P-Tuning[29]: 基于预训练掩码语言模型, 在连续空间中自动搜索提示模板的方法。
6)DART[30]: 基于预训练掩码语言模型, 在连续空间上, 使用反向传播对提示模板和目标标签进行差异优化。
7)基于替换词检测预训练模型方法[12]: 与本文方法相比, 该方法只采用分类方式做情感分类任务。
本文方法与主流少样本情感分类方法的性能对比如表 2 所示。在微调方法中, 少样本学习方法总是优于标准的微调机制, 进一步验证了少样本学习方法的有效性。在少样本学习方法中, 主干网络采用替换词检测模型 ELECTRA 明显优于采用掩码语言模型 RoBERTa, 显示了替换词检测预训练模型具有强大的少样本学习能力。在各个评价指标上, 本文方法均取得了最高的性能表现, 与基于替换词检测预训练模型方法[12]相比, 正确率提升 1.7%, F1-Score 提升 1.3%。在结果的稳定性方面, 本文方法依然表现优异, 在 5 个不同的划分下, 各个指标的标准差都未超过 1.0。上述结果说明, 针对多类别的细粒度情感分类任务, 本文提出的联合学习方法的有效性和稳定性都较好。
为了验证本文方法在不同模板和标签描述词下的有效性, 我们设计两组不同的模板和标签描述词, 并依次对 3 种融合方式进行测试。两组模板如下: 1)模板1 “Worst Bad Ordinary Better Best:x It was terrible great.”; 2)模板2: “It was terrible bad okay good great. x It was the worst best day.”。实验结果如表 3 所示。
表2 本文方法与主流少样本情感分类方法性能对比(%)
Table 2 Comparison between proposed method and the main-stream few-shot sentiment classification methods (%)
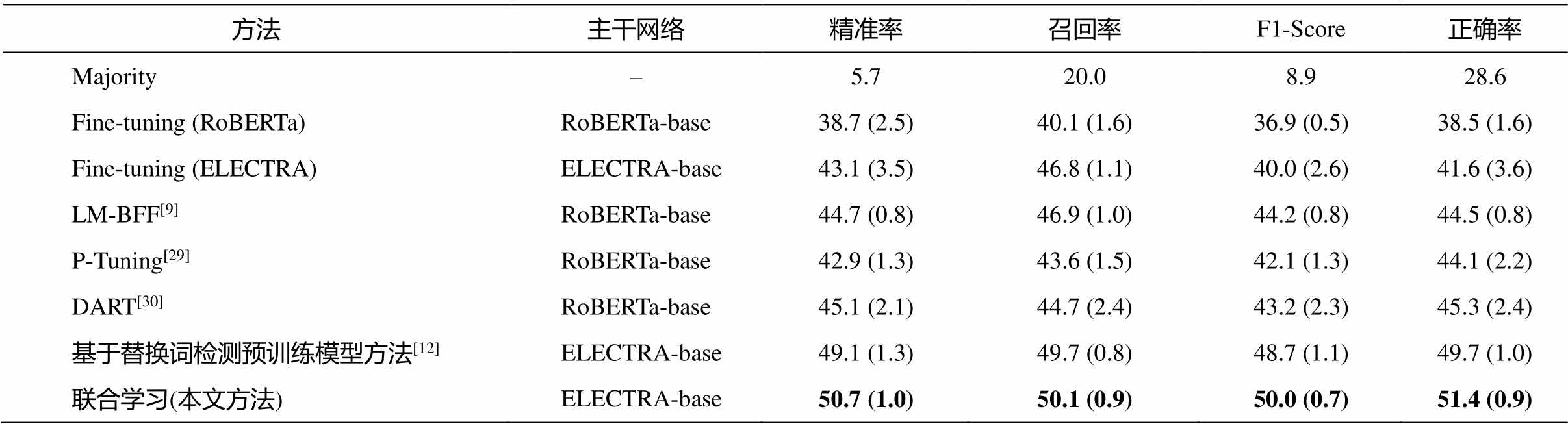
方法主干网络精准率召回率F1-Score正确率 Majority–5.720.08.928.6 Fine-tuning (RoBERTa)RoBERTa-base38.7 (2.5)40.1 (1.6)36.9 (0.5)38.5 (1.6) Fine-tuning (ELECTRA)ELECTRA-base43.1 (3.5)46.8 (1.1)40.0 (2.6)41.6 (3.6) LM-BFF[9]RoBERTa-base44.7 (0.8)46.9 (1.0)44.2 (0.8)44.5 (0.8) P-Tuning[29]RoBERTa-base42.9 (1.3)43.6 (1.5)42.1 (1.3)44.1 (2.2) DART[30]RoBERTa-base45.1 (2.1)44.7 (2.4)43.2 (2.3)45.3 (2.4) 基于替换词检测预训练模型方法[12]ELECTRA-base49.1(1.3)49.7 (0.8)48.7 (1.1)49.7 (1.0) 联合学习(本文方法)ELECTRA-base50.7 (1.0)50.1 (0.9)50.0 (0.7)51.4 (0.9)
说明: 括号中的数据为标准差, 粗体数字表示最佳结果, 下同。
从表 3 可以看出, 首先, 模板的设计和标签描述词的选取对模型的性能有着十分重要的影响, 在不同的模板和标签描述词下, 模型的表现具有差异, 其中模板 2 的整体表现要明显优于模板 1。其次, 单独采用分类方式或单独采用回归方式可以获得几乎相当的性能表现, 比如当基于模板 1 时, 回归的表现好于分类, 而基于模板 2 时, 分类的表现要好于回归, 但差距并不明显, 预示融合分类方式和回归方式会带来更好的表现和稳定性。最后, 无论是基于整体表现稍差的模板 1 还是表现较好的模板 2, 与单独分类或单独回归相比, 3 种融合策略均可带来性能的进一步提升。在不同的模板上, 各融合策略的效果不一, 比如, 在模板 1 上, 权重距离方式获得最优的结果, 然而在模板 2 上, 概率加权的方式更值得采用。
为了验证本文方法在不同训练样本数量下的有效性, 我们划分出 5 种不同数量的少样本数据集, 其训练样本总数分别为 40, 80, 160, 320 和 640, 即每个类别的样本数分别为 8, 16, 32, 64 和 128。基于表 3 中模板 2, 统计 3 种融合策略在正确率指标上的变化趋势, 结果如图 3 所示。首先, 随着训练样本的增加, 正确率不断提升, 并且在不同的训练数量下, 仍然可以得到与 3.4 节相似的结论, 即单独回归和单独分类方式具有相似的表现水平, 3 种不同融合方式几乎总是好于单独回归和单独分类方式。其次, 在正确率方面, 在每类样本数在不超过 32 的情况下, 层次筛选方式具有很好的表现。然而, 当样本数继续增加时, 层次筛选方式的性能不再突出, 但概率加权方式和权重距离方式的效果依旧表现优秀, 且两种融合方式具有相当的性能。
表3 本文方法在不同模板和标签描述词下的表现(%)
Table 3 Performance of proposed method under different templates and label description words (%)
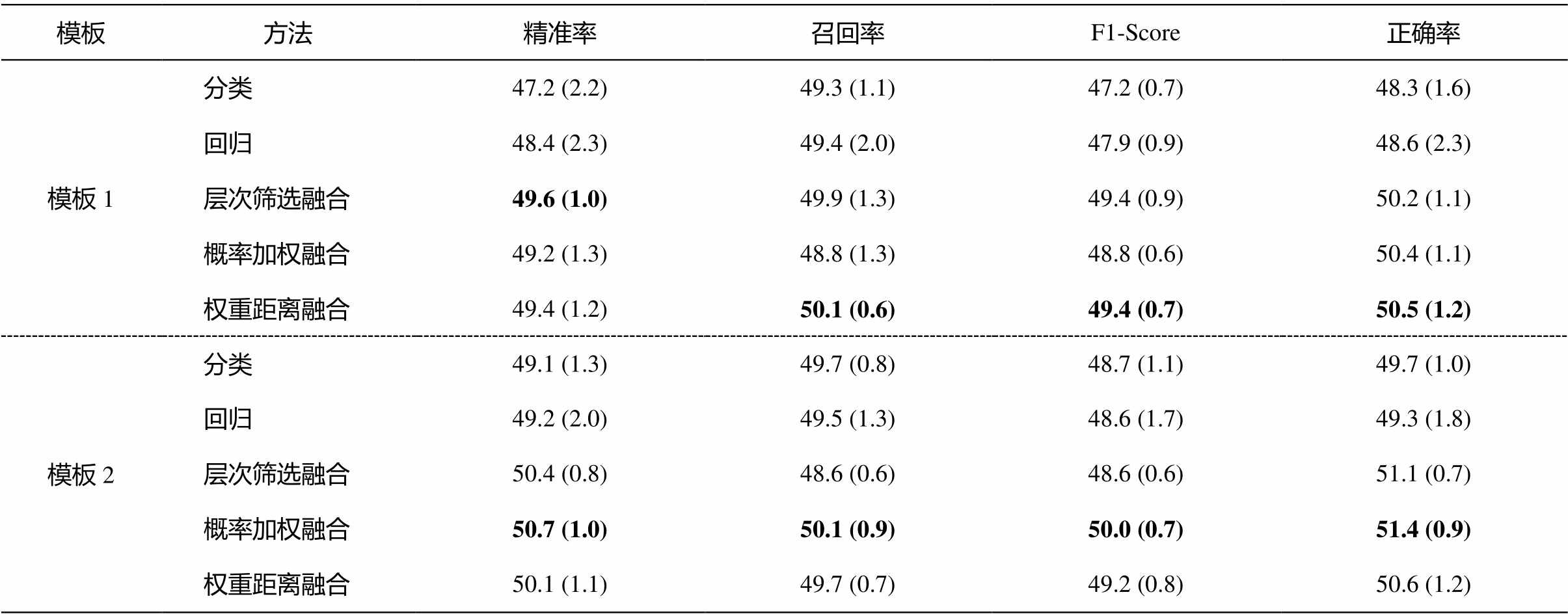
模板方法精准率召回率F1-Score正确率 模板1分类47.2 (2.2)49.3 (1.1)47.2 (0.7)48.3 (1.6) 回归48.4 (2.3)49.4 (2.0)47.9 (0.9)48.6 (2.3) 层次筛选融合49.6 (1.0)49.9 (1.3)49.4 (0.9)50.2 (1.1) 概率加权融合49.2 (1.3)48.8 (1.3)48.8 (0.6)50.4 (1.1) 权重距离融合49.4 (1.2)50.1 (0.6)49.4 (0.7)50.5 (1.2) 模板2分类49.1 (1.3)49.7 (0.8)48.7 (1.1)49.7 (1.0) 回归49.2 (2.0)49.5 (1.3)48.6 (1.7)49.3 (1.8) 层次筛选融合50.4 (0.8)48.6 (0.6)48.6 (0.6)51.1 (0.7) 概率加权融合50.7 (1.0)50.1 (0.9)50.0 (0.7)51.4 (0.9) 权重距离融合50.1 (1.1)49.7 (0.7)49.2 (0.8)50.6 (1.2)
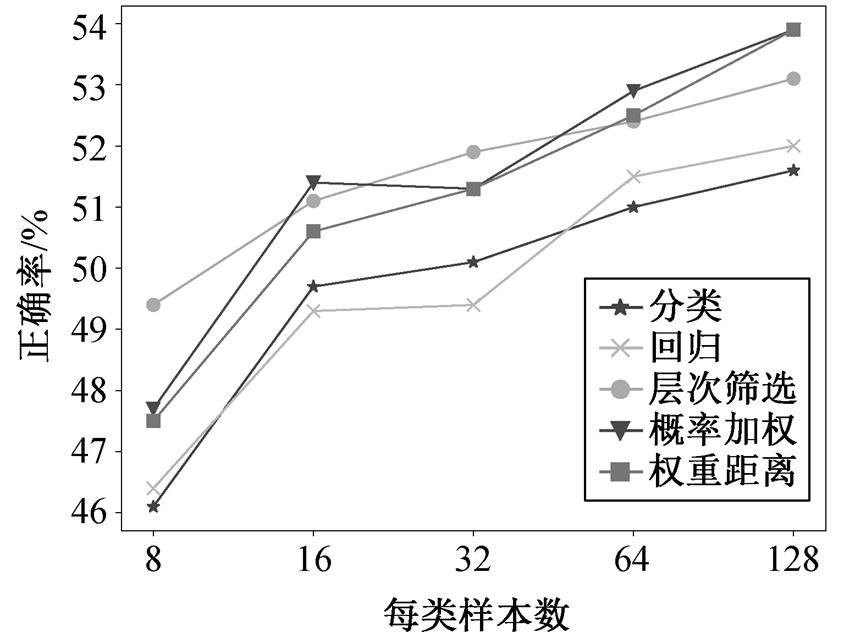
图3 不同训练样本数量下的正确率趋势
Fig. 3 Trend chart of accuracy rate under different number of training samples
本文提出一种针对少样本情感分类问题的联合学习方法。该方法将细粒度的多类情感分类任务同时建模为分类任务和回归任务, 并设计 3 种不同的融合策略来融合回归和分类预测中的信息。本文提出的方法简单有效, 在未引入任何新的训练参数的情况下, 仅仅通过在句子中添加多个模板和标签描述词, 将多类情感分类任务同时建模成回归问题和分类问题。在 STT-5 上的实验结果表明, 本文提出的方法优于目前已有的主流少样本学习方法, 有效地提升了多类情感分类问题性能。
在未来的工作中, 我们拟开展以下两方面的研究: 1)如何针对替换词检测的少样本学习方法, 自动设计优秀模板和标签描述词; 2)如何依据不同的样本数量、模板和标签描述词来确定最适应的融合方式。
参考文献
[1]Liu B. Sentiment analysis and opinion mining. Syn-thesis Lectures on Human Language Technologies, 2012, 5(1): 1–167
[2]Pang B, Lee L. Opinion mining and sentiment ana-lysis. Foundations and Trends in Information Retrie-val, 2008, 2(1/2): 1–135
[3]Devlin J, Chang M, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language under-standing [EB/OL]. (2018–10–11) [2022–05–12]. https:// arxiv.org/abs/1810.04805
[4]Liu Y, Ott M, Goyal N, et al. RoBERTa: a robust- ly optimized BERT pretraining approach [EB/OL]. (2019–07–26)[2022–05–12]. https://arxiv.org/abs/1907. 11692
[5]Clark K, Luong M, Le Q V, et al. ELECTRA: pre-training text encoders as discriminators rather than generators [EB/OL]. (2020–03–23) [2022–05–12]. https:// arxiv.org/abs/2003.10555
[6]王阳刚, 邱锡鹏, 黄萱菁, 等. 基于双通道图神经网络的小样本文本分类. 中文信息学报, 2021, 35 (7): 89–97
[7]熊伟, 宫禹. 基于元学习的不平衡少样本情况下的文本分类研究. 中文信息学报, 2022, 36(1): 104–116
[8]Brown T, Mann B, Ryder N, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 2020, 33: 1877–1901
[9]Gao T, Fisch A, Chen D. Making pre-trained language models better few-shot learners // Proceedings of the 59th Annual Meeting of the Association for Compu-tational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Bangkok, 2021: 3816–3830
[10]Schick T, Sch U Tze H. It’s not just size that matters: small language models are also few-shot learners [EB/OL]. (2020–09–15) [2022–05–12]. https://arxiv. org/abs/2009.07118
[11]Schick T, Sch U Tze H. Exploiting cloze questions for few shot text classification and natural language infe-rence [EB/OL]. (2018–10–11) [2022–05–12]. https:// arxiv.org/abs/1810.04805
[12]Li Z, Li S, Zhou G. Pre-trained token-replaced detection model as few-shot learner [EB/OL]. (2022–03–07)[2022–05–12]. https://arxiv.org/abs/2203.03235
[13]唐慧丰, 谭松波, 程学旗. 基于监督学习的中文情感分类技术比较研究. 中文信息学报, 2007, 21(6): 88–94
[14]徐军, 丁宇新, 王晓龙. 使用机器学习方法进行新闻的情感自动分类. 中文信息学报, 2007, 21(6): 95–100
[15]Li W, Xu H. Text-based emotion classification using emotion cause extraction. Expert Systems with Appli-cations, 2014, 41(4): 1742–1749
[16]Wen S, Wan X. Emotion classification in microblog texts using class sequential rules // Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelli-gence. Québec, 2014: 187–193
[17]Socher R, Perelygin A, Wu J, et al. Recursive deep models for semantic compositionality over a sentiment treebank // Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Bulgaria, 2013: 1631–1642
[18]Chen Y. Convolutional neural network for sentence classification [D]. Waterloo: University of Waterloo, 2015
[19]Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks [EB/OL]. (2015–02–28)[2022–05–12]. https://arxiv.org/abs/1503.00075
[20]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in Neural Information Pro-cessing Systems, 2017, 30: 5998–6008
[21]岳增营, 叶霞, 刘睿珩. 基于语言模型的预训练技术研究综述. 中文信息学报, 2021, 35(9): 15–29
[22]Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners. OpenAI Blog, 2019, 1(8): 9–33
[23]Puri R, Catanzaro B. Zero-shot text classification with generative language models [EB/OL]. (2019–12–10)[2022–05–12]. https://arxiv.org/abs/1912.10165
[24]Liu J, Shen D, Zhang Y, et al. What makes good in-context examples for GPT-3? [EB/OL]. (2021–01–17)[2022–05–12]. https://arxiv.org/abs/2101.06804
[25]Davison J, Feldman J, Rush A M. Commonsense knowledge mining from pretrained models // Procee-dings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP). Hong Kong, 2019: 1173–1178
[26]Taylor W L. “Cloze procedure”: a new tool for mea-suring readability. Journalism Quarterly, 1953, 30(4): 415–433
[27]Jiang Z, Xu F F, Araki J, et al. How can we know what language models know?. Transactions of the Association for Computational Linguistics, 2020, 8: 423–438
[28]Ben-David E, Oved N, Reichart R. PADA: a prompt-based autoregressive approach for adaptation to un-seen domains [EB/OL]. (2022–01–27)[2022–05–12]. https://arxiv.org/abs/2102.12206
[29]Liu X, Zheng Y, Du Z, et al. GPT understands, too [EB/OL]. (2021–03–18) [2022–05–12]. https://arxiv. org/abs/2103.10385
[30]Zhang N, Li L, Chen X, et al. Differentiable prompt makes pre-trained language models better few-shot learners [EB/OL]. (2022–05–04) [2022–05–12]. https:// arxiv.org/abs/2108.13161
[31]Dodge J, Ilharco G, Schwartz R, et al. Fine-tuning pretrained language models: weight initializations, data orders, and early stopping [EB/OL]. (2020–02–15)[2022–05–12]. https://arxiv.org/abs/2002.06305
[32]Zhang T, Wu F, Katiyar A, et al. Revisiting few-sample BERT fine-tuning [EB/OL]. (2021–03–11) [2022–05–12]. https://arxiv.org/abs/2006.05987
A Joint Learning Approach to Few-Shot Learning for Multi-category Sentiment Classification
Abstract Most few-shot learning approaches can’t get satisfactory results in fine-grained multi-category sentiment classification tasks. To solve this problem, a joint learning approach is proposed to few-shot learning for multi-category sentiment classification. Specifically, we utilize the pre-trained token-replaced detection model as few-shot learners and concurrently reformulate fine-grained sentiment classification tasks as both classification and regression problems by appending classification and regression templates and label description words to the input at the same time. For joint learning, several fusion methods are proposed to fuse the classification prediction and regression prediction. Experimental results show that, compared to mainstream few-shot methods, the proposed approach apparently achieves better performances in F1-Score and accuracy rate.
Key words sentiment classification; few-shot learning; joint learning