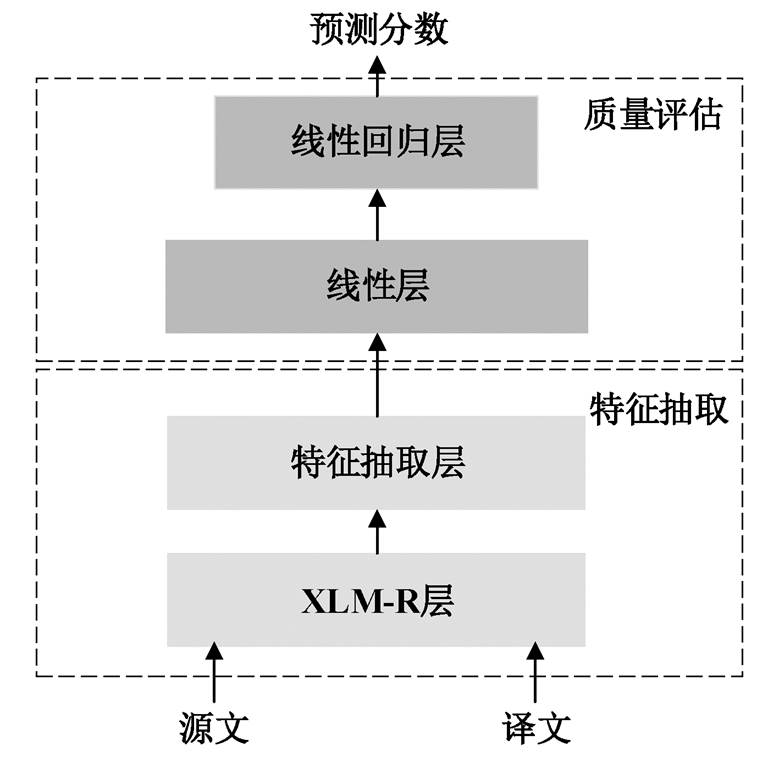
图1 OpenKiwi2.0模型流程
Fig. 1 Pipeline of OpenKiwi2.0 model
北京大学学报(自然科学版) 第59卷 第1期 2023年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 1 (Jan. 2023)
doi: 10.13209/j.0479-8023.2022.067
国家自然科学基金(61976148)资助
收稿日期: 2022-05-12;
修回日期: 2022-08-12
摘要 提出一种新的篇章约束辅助的译文质量评估模型, 不依赖参考译文, 为源文篇章中的每条句子的译文进行打分。首先从句子级别的语义表示和词级别的指代特征的角度建模源文和译文上下文之间的差异, 然后设计额外的损失函数, 使得模型在预测分数的同时, 尽可能地约束两者之间的差异。实验结果表明, 所提方法能有效提高译文质量评估的性能, 在 Pearson 相关系数上较基线系统最高可提升 6.68 个百分点。
关键词 篇章; 语义差异; 指代差异; 译文质量评估
机器翻译是计算机把一种源语言(source langu-age)翻译成目标语言(target language)的过程[1–3]。随着深度学习的发展, 神经机器翻译(neural machine translation, NMT)依赖于大规模的双语平行语料和复杂神经网络, 成为目前机器翻译领域的主流技 术[3]。然而, 受算法限制, 现有机器翻译评价指标BLEU[4]以及 METEOR[5]存在一些不足: 指标计算需要将机器翻译系统的输出与人工参考译文进行比较, 导致人力资源的耗费; 并且在评价篇章机器翻译系统的性能时, 仅关注参考译文和翻译译文的N-gram 匹配程度, 因而无法像人工一样结合篇章语境评价翻译结果。因此, 如何不依赖参考翻译, 自动地评价篇章级别的翻译质量是重要且有价值的。
质量评估(quality estimation, QE)[6–7]不依赖人工标注参考译文, 是一项仅关注源端文本 S 和机器翻译的输出译文 MT 来预测译文的人工后编辑率(HTER)的技术。QE 分数越高, 代表将 MT 修改成经人工校正的后期编辑文本(post editing, PE)所需的编辑次数越多, 译文质量就越差, 反之亦然。目前, 相关研究主要围绕基于神经网络的质量评估模型, 并且根据评估任务的不同, 可以分别单词级、句子级和篇章级。Kreutzer 等[8]为译文中的每个位置设置大小固定的窗口, 然后将对齐源文同窗口中的译文的表示拼接起来后送入到输出层, 计算并预测每个位置的标签, 实现单词级别的质量评估模型QUETCH。类似地, Martins 等[9]提出 NuQE 模型, 扩展了嵌入表示, 即在拼接源文和译文上下文表示的同时, 增加相应的词性(part-of-speech, POS)标签, 有效地增强了模型的表示能力。Kim 等[10–11]提出“预测器–评估器”模型, 预测器借助大规模的双语平行语料训练, 抽取单词的特征向量, 并将其输入评估器, 生成不同(单词/短语/句子)级别的质量分数。随着多语言预训练模型的发展, 利用多语言预训练模型可以代替预测器, 进而直接进入 QE 模型的预测训练。除单词级和句子级别的质量评估, 篇章级别的质量评估任务也逐渐被关注。相关研究表明, 篇章级别的信息对于评估翻译的质量也非常重要[12]。目前, 篇章级别的译文质量评估模型大概可分为两类。第一类是预测篇章的翻译分数。Specia等[13]扩展了句子级别的质量评估工具包 QUEST, 提出一种可以同时提取单词级、句子级和篇章级特征的 QUEST++开源工具包, 实现不同任务之间的交互。Ive 等[14]提出篇章级别的译文质量评估架构Deepquest, 首先利用双向循环神经网络编码表示源文和译文的单词, 然后通过求和或平均的方式表示成句子向量, 最后利用注意力机制, 将同一篇章中所有句子向量进行加权求和, 送入解码层, 对篇章分数进行预测, 并在 WMT2008–2017 年的 4 个语言对(DE-EN, EN-ES, EN-FR和EN-RU)的篇章级翻译语料上验证了实验性能。第二类是预测篇章中每条句子的翻译分数: 针对句子级质量评估任务不能捕捉与篇章相关的翻译错误问题, Chen 等[15]构建了一个新的中文到英文的篇章级译文质量评估语料, 并提出一种基于中心理论(center theory)[16]的篇章级质量评估模型, 实验证明, 该模型能有效地超过基线系统。
综上所述, 我们发现篇章译文质量评估的研究主要围绕搭建可为整个译文打分的系统展开, 例如Deepquest 和 QUEST++等。然而, 这样的自动打分机制并不利于找到篇章中的翻译错误。因此, 本文延续 Chen 等[15]的研究, 探究如何利用篇章信息评估源文篇章中的每条句子的译文质量, 提出一种新的可以利用篇章特征的质量评估模型训练策略, 从上下文语义相关性和指代信息两个方面来建模上下文之间的差异性, 在实现预测篇章中每条译文翻译分数的同时, 还可以约束源文和译文上下文之间的差异。
Openkiwi是一个基于Pytorch实现的用于译文质量评估任务的框架[17], 支持不同语言对的单词级和句子级质量评估任务。基于该框架, 实现了QUETCH[8]、NUQE[9]、预测器–评估器(predictor-estimator)[10–11]和 APE-QE[9]等几种当前最流行的QE 模型。随着预训练模型的出现, 自然语言处理任务直接采用基于大规模语言预训练的语言模型进行微调, 即可达到很好的翻译效果。考虑到中文到英文的篇章译文质量评估语料规模较小以及本文关注的是篇章内每条译文的质量, 所以本文基线系统以及相关实验均基于 Moura 等[18]开源的 OpenKiwi 2.0框架① https://github.com/unbabel/openkiwi实现, 如图1所示。
图 1 中, 支持预训练模型 XLM-R 的“特征提取器–评估器”的句子级质量评估模型包含特征抽取(feature extractor)和质量评估器模块(quality esti-mator), 具体的训练过程如算法 1 所示。跨语言预训练模型 XLM-R[19]的全称为 XLM-RoBERTa, 是基于Transformer[20]的语言模型, 依赖于掩码语言模型目标函数, 能够处理 100 种不同语言的文本。使用大规模多语言预训练的模型可以显著地提高跨语言迁移任务的性能[21]。
算法1 句子级译文质量评估训练算法
输入 源文 X={x1,…, xn}, 译文 Y={y1, …, ym}, 其中n 和 m 分别表示相应句子单词数
图1 OpenKiwi2.0模型流程
Fig. 1 Pipeline of OpenKiwi2.0 model
输出 预测译文质量分数p
1.利用特殊分隔符拼接源文和译文 I={<s>, x1,…, xn, s>, <s>, y1,…, ym, s>}
2.借助预训练模型 XLM-R 编码 I, 获得隐层向量 h= {h<s>, hx1, …, hxn, hs>, h<s>, hy1, …, hym, hs>}
3.抽取特征向量f={h[0];avg(h[n+2:])}
4.对特征向量 f 进行处理, 得到新的特征表示 f'= FNN2(tanh(FNN1 (f)))
5. 利用回归器预测质量分数p=FNN4(tanh(FNN3 (f' )))
算法 1 中的第 1 行属于数据预处理。第 2~4 行对应图 1 的特征抽取层, 首先利用预训练模型获得蕴含上下文表示的隐层向量, 之后借助前馈神经网络层(feed-forward neural networks, FNN)和激活函数 tanh(·), 对预先抽取的特征向量 f 进行加工, 得到新的特征向量 f ', 第 5 行对应图 1 的译文质量评估器, 采用回归器预测每个译文的质量分数 p。训练过程采用均方误差(mean squared error, MSE)来衡量预测分数 p 和 HTER 的分数差距, 指导模型训练朝正确的方向进行。
篇章通常使用指代和省略等手段去保证文本的一致性和连贯性。利用这些篇章现象, 可以更好地辅助篇章级译文的质量评估。Chen 等[15]以中心理论为基础, 通过流水线式的方法抽取源文和译文的优选中心词, 并以优选中心词为核心, 对比源文与译文的差异。这种方法依赖于优选中心词的抽取,受限于语料规模, 性能较低。此外, 篇章级 QE 与句子级 QE 较大的差别体现在指代现象, 所以我们猜想利用篇章译文与源文之间的指代差异可以更好地提升篇章 QE 的性能。
如图 2 所示, 借助指代消解技术, 分别对源文(SRC)、人工后编辑译文(PE)和机器翻译译文(MT)进行指代消解, 并将抽取出的指代链用加粗字体表示, 其中, #n 代表篇章中的第 n 条句子。
以图 2 为例, 借助 PE 可以观察到: 1)MT 的#3漏译了 SRC 中的“经表决”; 2)对于 SRC 的同一实体“张光军”, MT 对应 4 种不同的表述, 且存在翻译错误和上下文翻译不一致的问题。可以发现, 要想找到翻译的问题, 不仅需要横向对比源文和译文, 还需要纵向对比上下文之间的差异。
通过上述实例分析, 我们认为: 1)翻译质量越好的译文, 与源文的语义差异越小, 反之则大; 2)源文和译文通过指代表达出来的上下文连贯性的强度应该尽可能保持一致。本文在基线系统 Open-Kiwi2.0 的基础上, 提出新的利用篇章特征的译文质量评估模型训练策略, 模型结构如图 3 所示。本文方法在实现预测分数的同时, 还增加了对上下文语义差异约束和指代信息差异约束。
本文模型将同一篇章相邻的两个句对放入同一个训练批次(batch)进行训练, 输入序列分别为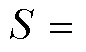
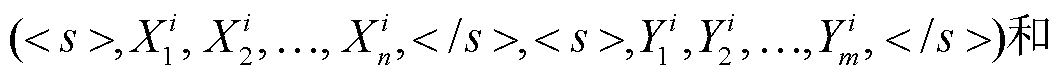
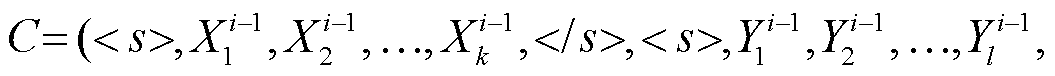
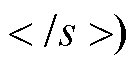 。S 代表通过特殊字符拼接的源语言篇章中, 长度为 n 的第 i 条源文句子和对应的译文序列; C 代表源语言篇章中, 与 S 相邻的长度为 k 的第i–1 条源文句子和对应译文通过特殊字符拼接的序列。值得注意的是, 当 S 对应篇章中的第一条句子时, C 选取为与 S 相邻的下一条句子。
。S 代表通过特殊字符拼接的源语言篇章中, 长度为 n 的第 i 条源文句子和对应的译文序列; C 代表源语言篇章中, 与 S 相邻的长度为 k 的第i–1 条源文句子和对应译文通过特殊字符拼接的序列。值得注意的是, 当 S 对应篇章中的第一条句子时, C 选取为与 S 相邻的下一条句子。

图2 篇章级别质量评估语料中的中英翻译示例
Fig. 2 Examples of Chinese-English translations in the document-level quality estimation corpus
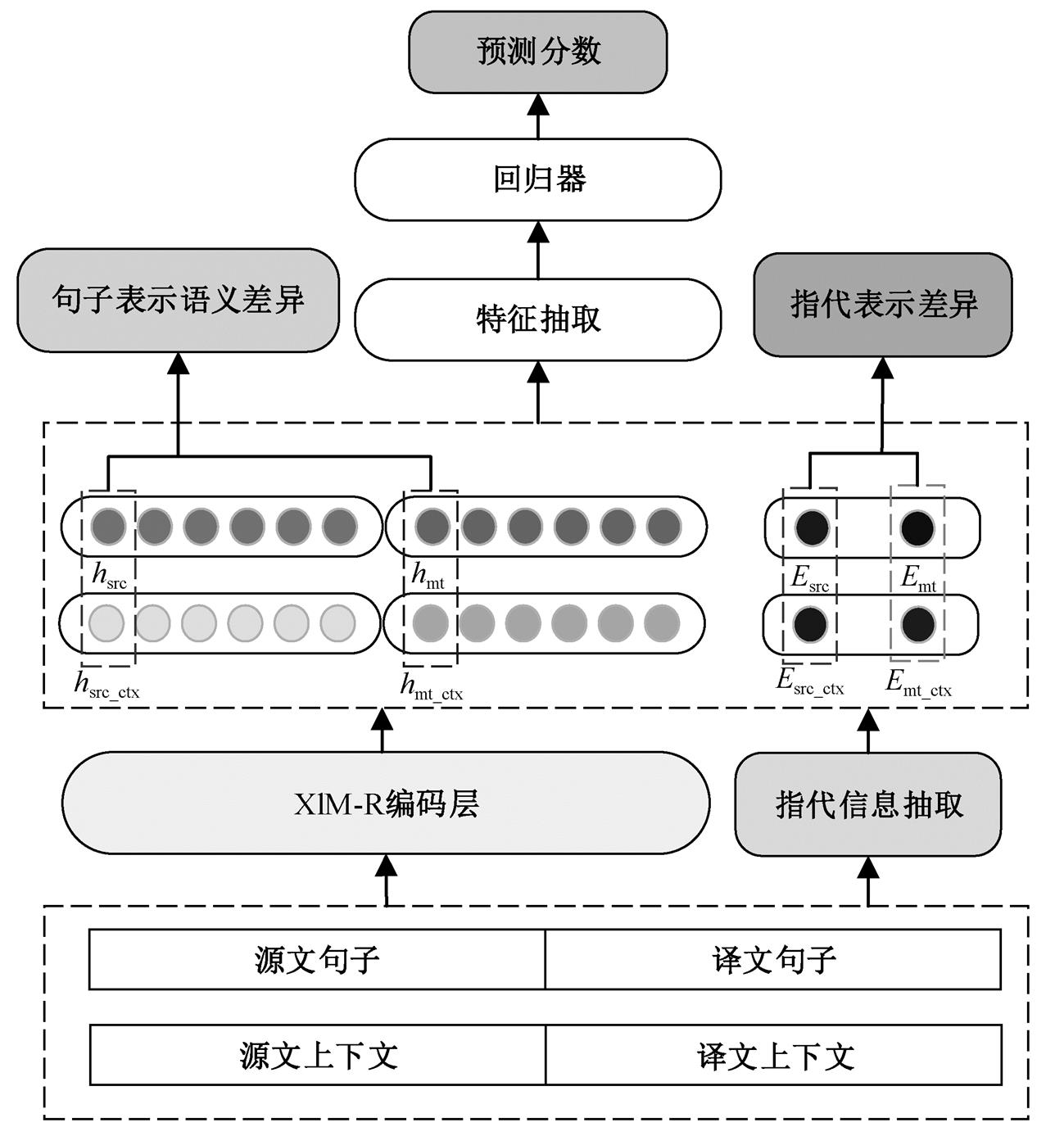
图3 篇章约束辅助的译文质量评估模型
Fig. 3 Framework of our document constrained quality estimation model
如图 3 所示, 输入序列经过 XLM-R 编码表示后,分别抽取源文、译文、源文上文和译文上文部分的第一个子词< s >的隐层表示, 作为相应部分的句子语义特征向量(如图 3 中左侧虛线框图部分), 并分别记为hsre, hmt, hsr_cx和hmt_ctx。
计算机无法直接处理非结构化的文本信息, 所以在模型学会区分不同类型的文本前, 需要先将文本转化为一个个的向量。同样, 要想利用篇章的指代信息, 也应该将指代链转化为向量表述。为此, 本文借助谷歌发布的预训练模型 BERT[22]帮助获得指代链表征, 具体步骤如下。
1)获取源文和译文篇章的指代链。本文利用中文指代消解工具获取源文篇章指代链, 利用英文指代消解工具获取译文篇章的指代链。具体地, 英文指代消解使用公开的 allennlp 消解工具②https://demo.allennlp.org/coreference-resolution, F1 值为79.6%; 中文指代消解模型的建立依赖 CoNLL 2012年发布的 OntoNotes 5.0 中文数据集③ https://catalog.ldc.upenn.edu/LDC2013T19, 采用 Lee 等[23]开源的端到端模型, 应用现有的计算资源进行训练而获得, F1值为65.39%。
2)生成源文和译文篇章中的指代链表征。BERT 是一种利用 Transformer 结构的预训练语言表示的方法, 可以实现上下文相关的单词表征, 有效地捕获一词多义之类的明显差异。本文先将源文和译文送入相应语言的预训练模型 BERT 中, 将输出的最后一层的隐藏状态作为单词的嵌入向量, 最后将位于同一条指代链上的所有单词向量求平均, 作为该指代链的向量表示。一个篇章有多少条指代链, 就对应有多少个指代表征。
3)初始化输入序列 S 和 C 的指代特征, 找到源文、译文、源文上文和译文上文中包含的指代链。由于一个序列中包含的指代链条数不同, 因此本文根据步骤 2 获得的指代表征进行池化或转换④ 池化方法有平均池化和最大池化等方案, 本文采用平均池化方法。操作, 将获得的向量作为序列的指代特征(如图 3 中右侧虚线框图部分所示), 分别标记为 Esrc, Emt,Esrc_ctx 和Emt_ctx。
2.3.1 上下文语义差异约束方案
篇章是由词和句子以复杂的关系链接, 能够完成一定交际任务的完整连贯的语义单元。高质量的篇章译文应该能合理地组织翻译结构, 保留源文文本块之间的语义关系, 例如因果关系和转折关系等。本文实验以上下文之间句子向量的欧式距离为度量上下文语义差异的标准。如图 3 所示, 首先利用预训练模型 XLM-R 获得输入序列的编码表示, 然后, 选取序列的第一个单词<s>的隐藏层向量表示作为句子向量, 之后通过分别计算源文和译文上下文之间的欧式距离来约束源文和译文上下文之间差异:
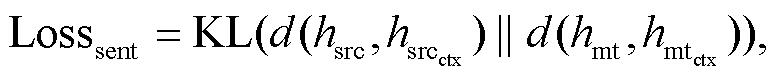 (1)
(1)
其中, d(∙)表示两个向量的欧式距离; KL(∙||∙)表示两个分布的 KL 散度, 描述源文上下文和译文上下文之间欧式距离的差异, 两者相似度越高, 则 KL 散度越小。
除采用第一个子词的向量表示作为句子向量表示外, 本文还对源文以及译文所有子词的表示进行平均池化和最大池化, 用来表示不同部分的句子 向量。
2.3.2 指代信息差异约束方案
从句子的角度出发, 借助句子的语义表示, 可以描述源文和译文上下文之间差异, 但不能关注到句子中词级别的差异。作为篇章分析的核心技术, 指代消解对篇章上下文衔接起着重要的作用, 并且这些位于篇章中的具有相同含义的实体特征恰好能在词级别关注细粒度的差异。
本文实验借助全连接层, 将初始化的指代特征映射到新的多维空间, 利用 KL 散度建模上下文之间指代特征的差异:
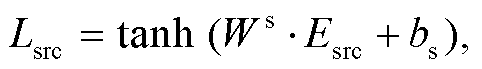 (2)
(2)
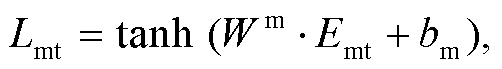 (3)
(3)
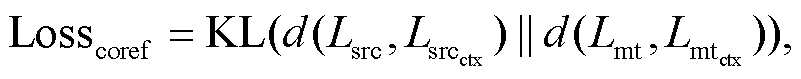 (4)
(4)
其中, Ws和Wm∈RdE×dmodel表示线性映射的权重, dmodel为模型的维度, dE为初始化的指代特征向量的维度, bs 和 bm 为偏置, 源文上文和译文上文的 Lsrc_ctx 和Lmt_ctx 计算过程与式(2)和(3)相同。
2.3.3 损失函数
本文实验在预测分数的同时, 增加源文和译文上下文之间的两个约束假设, 并对基线系统的优化目标函数做如下更新:
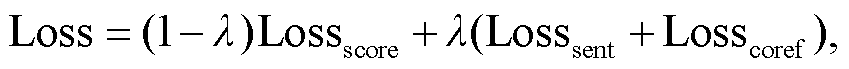 (5)
(5)
其中, Lossscore 与基线系统一致, 为预测分数部分的均方误差损失函数,Losssent 和 Losscoref 分别对应上述约束方案的损失函数。
通过实验可以发现, 当翻译质量较低时, 上文出现的翻译错误会延续到当前的句子, 导致经常出现篇章翻译的“错误传递(error propagation)”现象。一味强调两个约束假设的影响反而会产生误判, 因此对于两个约束假设的影响应该设定合适的比例, 本文设置 λ=0.1。
为验证本文提出的模型的性能, 本文使用 Chen等[15]开源的中–英方向上的篇章译文质量评估数据集⑤ https://github.com/ydc/cpqe。由于公开的数据集未划分训练集、测试集和验证集, 故本文参考篇章的长度采用随机划分的方式来划分数据集。该语料包含 112 个篇章(共 1996条句子), 每个篇章分别对应两个不同的机器翻译系统的结果(MT)、两个机器翻译的人工校正(PE)和两个 PE 文件对应的人工后编辑率(HTER)。本文以篇章为单位划分数据集, 随机挑选了 6 个篇章(102 条句子)作为验证集, 10 个篇章(154 条)作为测试集, 剩下的 97 个篇章作为训练集(1736 条)。
实验中的输入序列均采用 Transformers 库的XLM-Roberta-base 模型⑥ https://huggingface.co/xlm-roberta-base。其中, XLM-Roberta-base编码器层数为 12, 隐藏层维度为 768, 多头注意力机制为 12 个头; 初始化的指代链向量采用Transfor-mers 库的 BERT-base 模型, 输出维度为 768。Drop-out 率设置为 0.1, 优化器为 AdamW, 学习率设置为 1×10‒5, 批次大小为 8, 其余层的参数设置为基线系统 OpenKiwi 的默认参数。实验在一块 GeForce GTX 1080 Ti 上完成。
根据是否使用大规模的句子级质量评估语料, 本文定义两个基线系统。基线系统 1 (Baseline1)采用两阶段训练法: 第一阶段利用大规模 CCMT 竞赛的中英句子级的质量评估语料⑦ 该语料训练集、验证集和测试集分别包含10070, 1144和1385条句子。进行预训练, 达到初始化模型的相关参数的目的; 第二阶段在篇章级质量评估语料上进行模型的训练。基线系统 2 (Baseline2)仅利用篇章译文语料单步训练得到句子的翻译分数预测。
为了评价篇章约束辅助的译文质量评估的性能, 分析预测值与真实值的相关性, 本文采用皮尔森相关系数(Pearson)和斯皮尔曼相关系数(Spear-man)。Pearson 用于反映预测值与真实值的线性相关性, Spearson 反映预测结果排名与真实值排名的线性相关性。指标值越接近 1, 代表预测值越接近真实值, 模型预测的准确性越高, 评估系统的性能越好。Pearson 和 Spearson 的计算方法分别如式(6)和(7)所示。
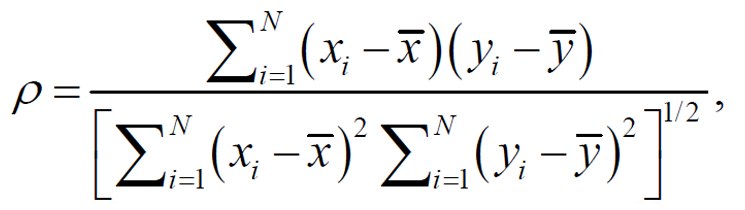 (6)
(6)
其中, x 和 y 分别表示预测值和真实值, ![]() 和
和![]() 分别表示预测值和真实值的均值。
分别表示预测值和真实值的均值。
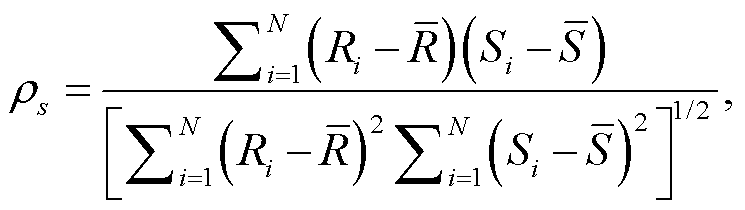 (7)
(7)
其中, Ri 和 Si 分别表示观测值 i 的取值的等级,  分别是 x 和 y 的平均等级, N 是观测值的总数量。本文在分析性能变化时, 主要参考 Pearson 指标。
分别是 x 和 y 的平均等级, N 是观测值的总数量。本文在分析性能变化时, 主要参考 Pearson 指标。
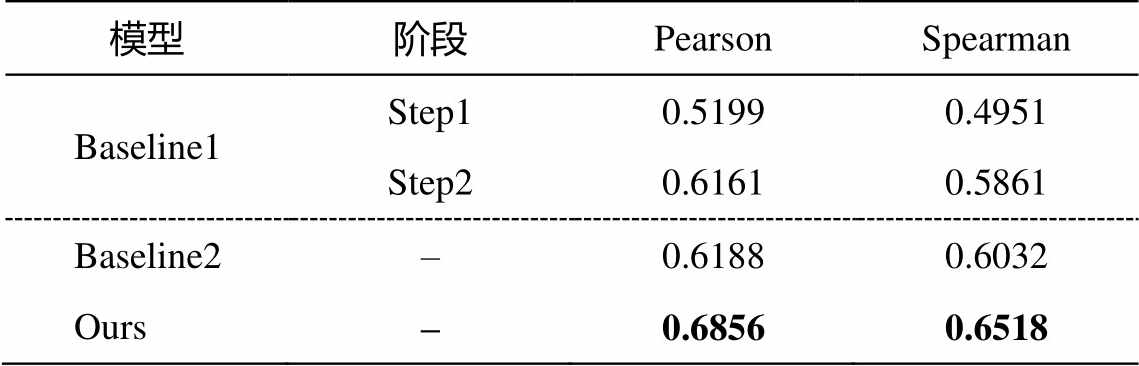
本文在中英篇章质量评估任务中的实验结果如表 1 所示。其中, Baseline1 包含两部分, step1 和step2 分别对应两阶段中模型在测试集上的性能, Baseline2 和 ours 分别表示单阶段训练的基线系统和本文的模型。
对比 Baseline1 两阶段训练的实验结果可以发现, 未经过篇章级质量评估语料微调的实验性能较差。我们认为, 篇章译文的评分不仅取决于当前句子的翻译, 也取决于该译文在篇章层面上的表现, 同句子级的评价标准不同, 会导致即使经过大规模句子级别数据的微调, 也不能达到很好的效果。对比两阶段微调后的训练 Baseline1 (step2)和单阶段训练Baseline2 的实验结果, 可以发现实验结果较为相近, 这是由于编码层采用了跨语言预训练模型XLM-R。相关研究也表明, 经过大规模语料训练的 XLM-R 模型能有效地应对多语言任务, 尤其是小规模的训练语料, 在此基础上增加少量下游参数, 就可以达到不错的模型性能[19]。基于上述分析, 其他实验都只在篇章译文质量评估语料上采用单步训练的方式。
从表 1 可以发现, 本文提出的约束方案(Ours)应用到基于预训练模型 XLM-R 的 OpenKiwi 质量评估系统后, 性能比基线系统明显提高, 比 Baseline2有 6.68 个百分点的提升, 表明本文方案在预测分数的同时增加源文和译文上下文之间的两个约束, 能有效地提升分数预测的性能。
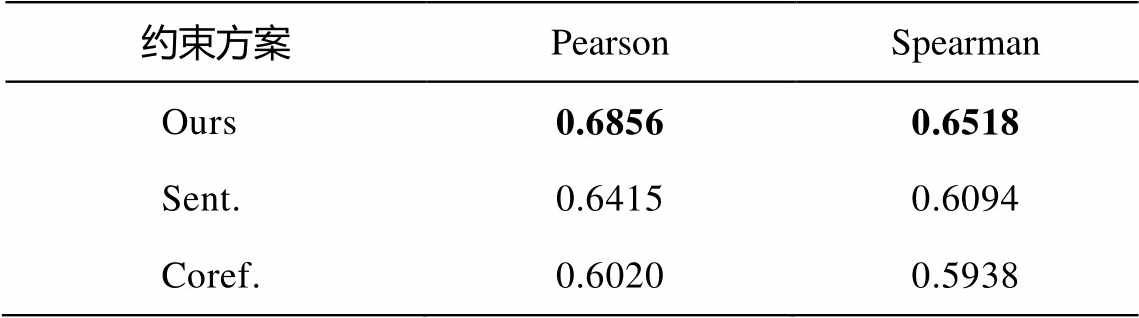
3.2.1 不同约束方案对模型性能的影响
为了分析不同约束方案对模型性能的影响, 本文开展了在预测质量分数的基础上只增加一种约束的实验, 结果如表 2 所示。“Sent.”表示在预测翻译分数的同时, 只增加对上下文的语义差异约束方案; “Coref.”表示在预测翻译分数的同时, 只增加对指代信息差异的约束方案。
从表 2 可以看出, 只增加对上下文的语义差异约束方案(Sent.)比同时考虑两种约束方案(Ours)低4.41 个百分点; 只增加指代信息差异的约束方案(Coref.)比同时考虑两种约束方案(Ours)低 8.36 个百分点, 甚至低于基线系统 Baseline2。实验结果表明, 上下文语义差异的约束(Sent.)是更重要的, 也进一步说明, 只有整体质量达到一定的水平, 由“错误传递”得到的虚假一致性才能被有效地抑制。
表1 约束方案在中英译文质量评估测试集上的性能
Table 1 Performance of constraint scheme on the Chinese-English translation quality assessment test set
模型阶段PearsonSpearman Baseline1Step10.51990.4951 Step20.61610.5861 Baseline2–0.61880.6032 Ours–0.68560.6518
说明: 粗体数字表示性能最佳, 下同。
表2 不同约束方案对模型性能的影响
Table 2 Effect of different constraint schemes on model performance
约束方案PearsonSpearman Ours0.68560.6518 Sent.0.64150.6094 Coref.0.60200.5938
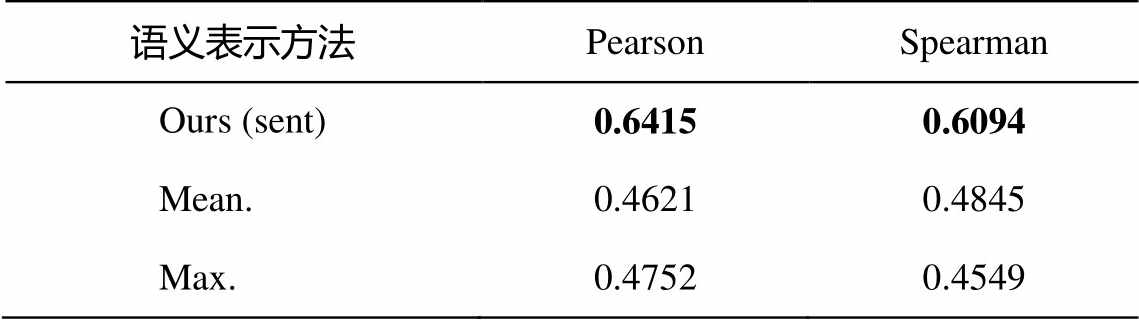
3.2.2 不同句子级别语义特征表示对该实验结果的影响
受 Kim 等[24]启发, 基于预训练语言模型获取句子表征, 可以通过“CLS 池化”、“平均池化”或“最大池化”反应不同的句子特征。为了进一步对比 3 种池化方式对模型性能的影响, 首先利用源文和译文的第一个子词的隐层表示作为句子语义特征向量, 然后分析不同的句子特征向量对实验性能的影响(图3)。
实验结果如表 3 所示。其中, “Mean.”采取平均池化的方式来表示句子向量, 将输入序列 S 和 C 中各部分的子词的隐层表示的均值作为相应部分的句子特征向量; “Max.”采用最大池化的方式来表示句子向量, 将输入序列 S 和 C 中各部分的子词的隐层表示的最大值作为相应部分的句子特征向量。结果表明, 使用第一个子词的隐层表示实验效果最好, 且其他方案相对于原始方案有大幅度的下降, 充分说明了本文方法的有效性。
3.2.3 实例分析
我们从测试集中选取一个篇章译文质量评估实例, 进一步分析本文模型对质量评估性能的改进。
表3 不同句子级别语义特征表示对实验结果的影响
Table 3 Impact of different sentence-level semantic feature representations on the experimental results
语义表示方法PearsonSpearman Ours (sent)0.64150.6094 Mean.0.46210.4845 Max.0.47520.4549
如图 4 所示, 通过对比同一篇章(共包含 13 条句子)内的句子的真实分数 HTER 与基线系统 Baseline2和本文模型 Ours 的预测分数可以看出, 本文模型Ours 预测的分数整体上更接近真实值。如图 4 所对应的篇章中, 第 5 条、第 8 条和第 9 条句子上的变化最为明显。
如表 4 所示, 本文选取性能差异较大的实例进行直观的展示。该实例为图 4 对应篇章的第 8 条句子。可以发现, 相较于人工后编辑译文 PE, 机器翻译译文 MT 存在明显的翻译错误。比如, 在句子级别, 源文的“1991―1998”, MT 只翻译了 1991 年; “室副主任”中的“室”翻译位置错误; 重复翻译了“主任”等问题。在篇章级别, MT 未能直接翻译出“he”, 存在漏译的现象。相较于不考虑篇章信息训练的基线系统, 本文提出的 QE 模型预测分数 0.4537 更接近真实的 HTER 值 0.5000, 表明本文的模型能更好地捕捉到译文的翻译错误程度。
本文提出一个篇章约束辅助的译文质量评估模型, 从句子级别的语义表示和词级别的指代特征角度, 对源文和译文上下文之间的差异进行建模, 更新了训练目标, 提高了译文质量评估的性能。实验结果表明, 相较于基线模型, 本文模型有明显的性能提升, 其中句子级别的差异约束对模型性能的提升更有效, 在此基础上再引入指代约束可以进一步提升系统的性能。最后, 借助篇章实例, 进一步展示了本文模型的优势, 这将有利于从篇章角度找到细粒度的翻译错误, 例如是否使用了不符合上下文语义的单词, 是否对省略进行补全, 是否使用了正确的时态, 等等。
表4 例子分析实验结果
Table 4 Example analysis of experimental results

源文/译文实例 源文(SRC)1991―1998年中国工程物理研究院总体工程研究所技术员, 室副主任, 室党支部书记、副主任 人工后编辑译文(PE)from 1991 to 1998, he served as technician, deputy director of the general engineering research institute of the chinese academy of engineering and physics, deputy director of the office, secretary and deputy director of the party branch. 机器翻译译文(MT)1991: technician, room deputy director of the general engineering institute of china institute of engineering physics, deputy director of the branch branch, deputy director.
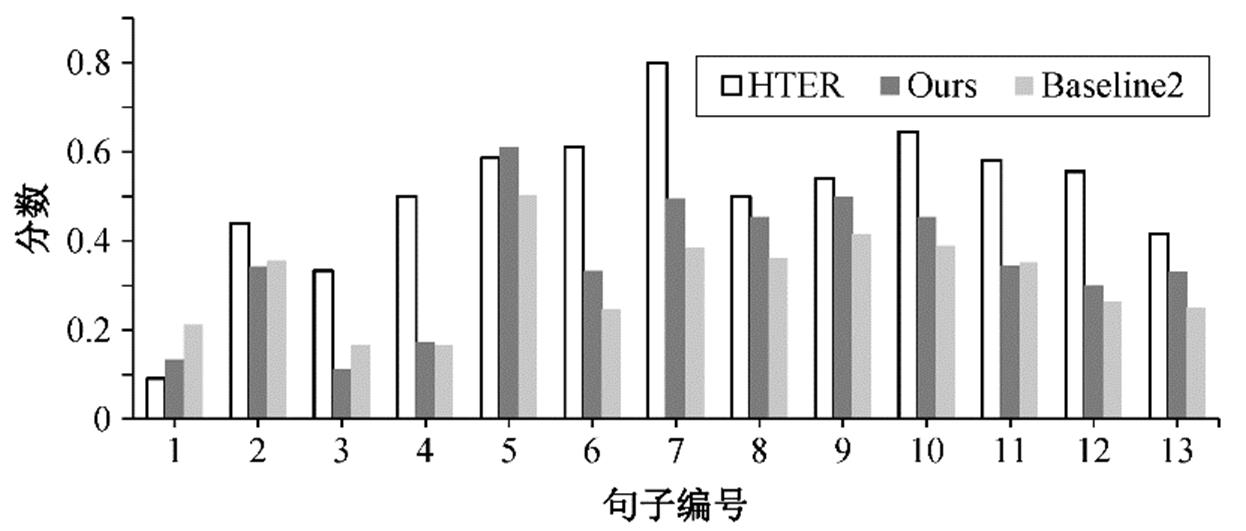
图4 不同模型预测分数同真实分数的对比
Fig. 4 Comparison of predicted scores and true scores of different models
虽然本文提出的篇章约束辅助的训练方法能提高质量评估的性能, 但是该方法只利用了相邻句子的特征, 未来的研究中可以进一步探索利用篇章更大范围甚至全局的特征来辅助篇章译文质量评估任务。
致谢 研究工作得到苏州大学计算机科学与技术学院硕士研究生陈世男同学的帮助, 在此表示衷心感谢。
参考文献
[1]赵铁军. 机器翻译原理. 哈尔滨: 哈尔滨工业大学出版社, 2000
[2]Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate [EB/OL]. (2014–09–01) [2016–05–19]. https://arxiv. org/abs/1409.0473
[3]李亚超, 熊德意, 张民. 神经机器翻译综述. 计算机学报, 2018, 41(12): 2734–2755
[4]Papineni K, Roukos S, Ward T, et al. BLEU: a method for automatic evaluation of machine translation // Proceedings of the 40th annual meeting of the Asso-ciation for Computational Linguistics. Philadelphia, 2002: 311–318
[5]Banerjee S, Lavie A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments // Proceedings of the ACL work-shop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization. Prague, 2005: 65–72
[6]陈志明, 李茂西, 王明文. 基于神经网络特征的句子级别译文质量估计. 计算机研究与发展, 2017, 54(8): 1804–1812
[7]Martins A F T, Junczys-Dowmunt M, Kepler F N, et al. Pushing the limits of translation quality estima-tion. Transactions of the Association for Computa-tional Linguistics, 2017, 5: 205–218
[8]Kreutzer J, Schamoni S, Riezler S. Quality estimation from scratch (QUETCH): deep learning for word-level translation quality estimation // Proceedings of the Tenth Workshop on Statistical Machine Transla-tion. Lisbon, 2015: 316–322
[9]Martins A F T, Kepler F, Monteiro J. Unbabel’s participation in the wmt17 translation quality estima-tion shared task // Proceedings of the Second Con-ference on Machine Translation. Copenhagen, 2017: 569–574
[10]Kim H, Jung H Y, Kwon H, et al. Predictor-estimator: neural quality estimation based on target word pre-diction for machine translation. ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP), 2017, 17(1): 1–22
[11]Kim H, Lee J H, Na S H. Predictor-estimator using multilevel task learning with stack propagation for neural quality estimation // Proceedings of the Second Conference on Machine Translation. Copenhagen, 2017: 562–568
[12]Voita E, Sennrich R, Titov I. When a good translation is wrong in context: context-aware machine transla-tion improves on deixis, ellipsis, and lexical cohesion // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, 2019: 1198–1212
[13]Specia L, Paetzold G, Scarton C. Multi-level transla-tion quality prediction with quest++ // Proceedings of ACL-IJCNLP 2015 system demonstrations. Beijing, 2015: 115–120
[14]Ive J, Blain F, Specia L. DeepQuest: a framework for neural-based quality estimation // Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe, 2018: 3146–3157
[15]Chen Y, Zhong E, Tong Y, et al. A document-level machine translation quality estimation model based on centering theory // China Conference on Machine Translation. Singapore: Springer, 2021: 1–15
[16]Walker M A, Joshi A K, Prince E F. Centering in naturally-occurring discourse: an overview [EB/OL]. (2013–07–24) [2022–01–02]. https://www.researchga te.net/publication/2585846
[17]Kepler F, Trénous J, Treviso M, et al. OpenKiwi: an open source framework for quality estimation // Pro-ceedings of the 57th Annual Meeting of the Associa-tion for Computational Linguistics: System Demon-strations. Florence, 2019: 117–122
[18]Moura J, Vera M, van Stigt D, et al. IST-unbabel participation in the WMT20 quality estimation shared task // Proceedings of the Fifth Conference on Machine Translation. Online Meeting, 2020: 1029–1036
[19]Conneau A, Khandelwal K, Goyal N, et al. Unsuper-vised cross-lingual representation learning at scale // Proceedings of the 58th Annual Meeting of the Asso-ciation for Computational Linguistics. Online Mee-ting, 2020: 8440–8451
[20]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in Neural Information Pro-cessing Systems. Long Beach, 2017: 6000–6010
[21]Conneau A, Wu S, Li H, et al. Emerging cross-lingual structure in pretrained language models // Procee-dings of the 58th Annual Meeting of the Association for Computational Linguistics. Online Meeting, 2020: 6022–6034
[22]Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for lan-guage understanding // Proceedings of the 2019 Con-ference of the North American Chapter of the Asso-ciation for Computational Linguistics. Minneapolis, 2019: 4171–4186
[23]Lee K, He L, Zettlemoyer L. Higher-order corefe-rence resolution with coarse-to-fine inference // Pro-ceedings of the 2018 Conference of the North Ame-rican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). New Orleans, 2018: 687–692
[24]Kim T, Yoo K M, Lee S. Self-guided contrastive learning for BERT sentence representations // Procee-dings of the 59th Annual Meeting of the Associa- tion for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Online Meeting, 2021: 2528–2540
Document Constrained Translation Quality Estimation Model
Abstract This paper proposes a new translation quality estimation model that does not rely on the reference translation to score the translation of each sentence in the source language. The authors model the sentence-level semantic difference and word-level referential difference between the source and translation and design additional loss function to make the model constrain the differences as much as possible when predicting scores. The experimental results show that proposed method can effectively improve the performance of quality estimation model. Compared with the baseline system, the proposed method improves the Pearson correlation coefficient by up to 6.68 percentage points.
Key words document; semantic difference; referential difference; translation quality estimation