doi: 10.13209/j.0479-8023.2022.082
国家自然科学基金联合基金(U20A20204)资助
北京大学学报(自然科学版) 第58卷 第5期 2022年9月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 58, No. 5 (Sept. 2022)
收稿日期: 2021–10–26;
修回日期: 2022–02–21
摘要 为了提高训练后量化模型的性能, 提出一种基于离群值去除的模型训练后量化预处理方法。该方法仅通过排序、比较等简易的操作, 实现权重、激活值的离群值去除, 使模型在量化时仅损失少量的信息, 从而提升量化模型的精度。实验结果表明, 在使用不同的量化方法前, 采用所提方法进行预处理, 可显著地提升性能。
关键词 卷积神经网络; 训练后量化; 预处理; 离群值去除; 图像分类
随着算力的不断增强, 深度学习模型规模越来越大, 在各种计算机视觉任务中表现出越来越优异的性能[1–3]。但是, 资源有限的终端设备却难以部署庞大的模型, 即使勉强部署, 模型的实际推理速度也难以达到实际使用的要求。为在保证模型精度的情况下减小模型规模, 研究者提出模型剪枝[4–8]、模型量化[9–12]和自动化搜索[13–15]等模型压缩方法。其中, 模型量化为模型压缩中的一种主流的方法, 分为训练中量化和训练后量化。
训练中量化即在训练中模拟量化过程, 最大程度地减少量化带来的精度误差, 其代表作 IAO 由Jacob 等[10] 2017 年提出。该方法引入模拟量化, 通过线性量化方法, 将权重和激活值量化为 8 位定点数, 取得不错的效果。DoReFaNet[11]使用 tanh 函数进行非线性量化, 调整量化精度, 降低量化误差。虽然训练中量化可以取得优异的性能, 但由于必须在训练时就介入模型优化的特点, 并不适合快速的工程应用。
训练后量化指对训练好的浮点模型进行量化, 通常仅使用少量的校准信息来获得合适的量化参数。此类方法能在很短的时间内对模型完成量化, 非常适合应用部署, 目前很多主流的终端推理框架都使用此类方法。比如, 阿里巴巴的 MNN[16]框架采用 8 位线性量化的方法, 在嵌入式终端有优异的推理效果。
对模型进行量化后, 模型精度通常会有一定程度的下降, 而训练后量化方法下降的程度会更大。为了减小精度损失, 本文从量化的基本原理出发, 提出一种预处理方法, 即在量化前对模型权重和激活值进行离群值去除, 以期提高量化后模型的精度。
训练后量化中最重要的一点是找到合适的缩放因子值, 该值表示浮点值和量化值的比例关系。图1 展示 8 位对称量化时二者的对应关系, 其缩放因子值由最大、最小值中绝对值最大的决定。
可以看到, 图 1 中浮点值的最大值偏离其他值的距离过大, 导致量化值的空白区间过大, 无法很好地利用量化值有限的信息去表达原始模型的浮点值信息, 致使量化模型精度显著下降。本文将类似图 1 中最大值这样的值定义为离群值。由于卷积神经网络具有较强的鲁棒性, 去除离群值几乎不会影响原始浮点模型的精度。因此, 本文提出一种量化预处理方法, 在量化前将这些离群值去除掉, 从而有效地提升量化模型的精度。图 2 展示离群点去除后浮点值与量化值的对应关系, 其中去除的离群值对应量化的最值。量化分为权重量化和激活值量化, 本文将针对两种量化方法分别设计离群值去除方法。
权重即网络中的固定参数, 因此只需要将权重值的绝对值进行降序排列, 然后将排序靠前的权重值视为离群值。定义离群值百分比参数![]() , 即人为设定离群值占总参数值的百分比, 本文依据经验设为0.005%。离群值去除步骤如下。
, 即人为设定离群值占总参数值的百分比, 本文依据经验设为0.005%。离群值去除步骤如下。
1)对原始浮点模型权重进行求绝对值运算, 得到绝对值权重。
2)对绝对值权重进行降序排列运算, 得到排序权重。
3)将排序靠前占比为α的权重视为离群值, 并获得除去离群值后排序权重的最大值β。
4)将原始浮点模型中的离群值改变成绝对值为β, 符号(即正负)与原始浮点模型中符号相同的更新值, 即完成离群值的去除。
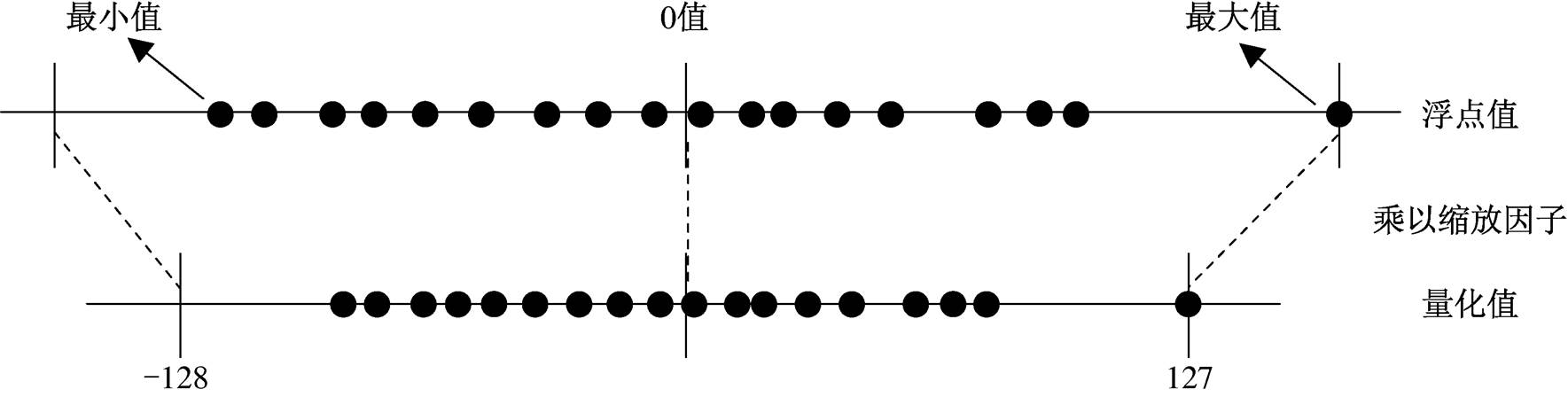
图1 8位对称量化浮点值、量化值对应关系
Fig. 1 Correspondence between floating point value and quantized value on 8-bit symmetric quantization

图2 离群值去除后8位对称量化浮点值与量化值对应关系
Fig. 2 Correspondence between floating point value and quantized value on 8-bit symmetric quantization after outlier removal
与权重不同, 模型的激活值随着输入图片的不同而变化, 因此无法像权重一样直接对离群值进行去除操作。本文采用阈值去除的方式, 在量化前求得离群值阈值 γ, 然后在量化时进行动态离群值去除。为了求得激活离群值阈值, 需要将部分图片进行推理, 获取模型激活值。考虑到训练后量化操作也需要图片, 因此本文使用与量化时相同的图片。去除离群值的步骤如下。
1)将量化时图片依次输入神经网络, 获取每层的激活值。
2)对激活值进行求绝对值的运算, 得到激活值的绝对值。
3)对激活值的绝对值进行降序排列运算, 得到排序激活值。
4)将排序靠前占比为 α 的激活值视为离群值, 获得除去离群值后排序权重的最大值, 并将其作为阈值![]() 。
。
5)量化时将绝对值大于 γ 的激活值视为离群值, 将其改变成绝对值为 γ, 符号(即正负)与原始激活值符号相同的更新值后再进行运算, 即完成离群值的去除。
虽然上述方法中激活离群值去除的实际操作是在量化中完成, 但去除操作十分简单, 且几乎不会耗费时间, 耗时操作实际上是在量化前完成的求阈值操作。因此, 本文提出的激活离群值去除方法依然可视为一种预处理操作, 可简单地应用于各种量化方法中。
在模型训练后, 结合上文所提两种方法进行量化前预处理, 消除离群值导致的量化中空白区间过大问题, 使量化模型对原始浮点模型进行更好的表达, 使量化模型的性能更加优异。图 3 展示使用本文预处理方法进行训练后量化的具体流程。
将本文提出的预处理方法结合不同的训练后量化方法, 在不同数据集以及不同网络结构上进行实验, 验证本文方法的有效性和普遍适用性。
本文采用规模不同的图像分类数据集 CIFAR-10[17]和 ImageNet[18], 在 VGG[19]、ResNet[20]和 Mob-ileNet[21]网络结构进行实验。所用数据集及对应网络结构概况如表 1 所示。

图3 预处理及量化流程
Fig. 3 Preprocessing and quantization process
本文采用阿里巴巴 MNN[16]框架中使用的几种量化方法, 包括最大绝对值(MAX_ABS)、相对熵(KL)和交替方向乘子(ADMM)方法。基于这 3 种方法的不同组合对模型进行训练后量化, 量化方法组合如表 2 所示。由于 8 位量化精度下降少, 在工程上被广泛使用, 因此本文的实验均使用 8 位量化方法。另外, 为进行公平的比较, 本文所用量化图片集图片数量均为 100 张。
首先, 在 CIFAR-10 上针对不同量化组合方法进行实验, 对比不采用和采用本文方法进行预处理的量化后模型 Top-1%准确率。表 3 展示的实验结果表明, 在不同的量化组合情况下, 使用本文提出的预处理方法后, 在不同网络结构中均可有效地提升量化后模型的精度, 验证了本文预处理方法的普遍适用性和有效性。
表1 本文所用数据集概况
Table 1 Overview of the datasets used in the article

数据集类别数训练数量/测试数量实验所用网络结构 CIFAR-101050000/10000VGG-16, ResNet-56/110, MobileNet ImageNet10001200000/50000ResNet-18/34
表2 本文所用量化方法组合
Table 2 Combination of quantization methods used in the article

量化组合激活量化方法权重量化方法 KL/MAX_ABSKLMAX_ABS KL/ADMMKLADMM ADMM/MAX_ABSADMMMAX_ABS ADMM/ADMMADMMADMM
表3 CIFAR-10数据集上准确率对比(%)
Table 3 Accuracy rate comparison on CIFAR-10 dataset (%)

量化组合VGG-16ResNet-56ResNet-110MobileNet未量化94.1593.6993.7292.15KL/MAX_ABS93.9693.2289.6591.67本文方法+KL/MAX_ABS 94.0793.3289.8791.85KL/ADMM93.8693.3689.3477.80本文方法+KL/ADMM94.0093.5589.7587.90ADMM/MAX_ABS93.9393.3492.8191.74本文方法+ADMM/MAX_ABS94.0193.6292.8992.06ADMM/ADMM93.9793.2592.8277.97 本文方法+ADMM/ADMM 94.1093.3692.9188.21
表4 ImageNet数据集上准确率对比(%)
Table 4 Accuracy rate comparison on ImageNet dataset (%)

量化组合ResNet-18ResNet-34Top-1%Top-5%Top-1%Top-5%未量化69.7689.0873.3191.42KL/MAX_ABS69.4488.8673.1391.34本文方法+KL/MAX_ABS 69.5388.9773.2091.38KL/ADMM69.3488.8873.0691.35本文方法+KL/ADMM69.5588.9873.1891.38ADMM/MAX_ABS68.5288.8469.7091.25本文方法+ADMM/MAX_ABS68.9588.8671.5391.30ADMM/ADMM68.5988.7969.6691.26 本文方法+ADMM/ADMM68.9788.8271.6591.37
为证明本文方法在大型数据集上依然适用, 在ImageNet 上对 ResNet-18/34 进行实验, 对比量化模型的 Top-1%和 Top-5%准确率。表 4 中实验结果证明, 使用本文方法在大型数据集上依然可有效地减少量化模型的精度损失, 具有明显优势。
本文针对当前训练后量化方法精度下降明显的问题, 提出一种基于离群值去除的训练后量化预处理方法, 通过去除训练后浮点模型权重和激活值的离群值, 可以减少量化的空白区间, 从而有效地提升量化模型性能。实验结果表明, 该方法在不同量化方法、数据集和网络模型中, 均可对模型量化产生正向的效果。
在未来的工作中, 我们将探索如何自适应地产生离群值百分比参数 α, 而非人为地设定, 从而取得更好的性能。
参考文献
[1]Redmon J, Farhadi A. YOLOv3: an incremental imp-rovement [EB/OL]. (2018–04–08)[2021–06–20]. https: //arxiv.org/ abs/1804.02767
[2]Zhou X, Wang D, Krähenbühl P. Objects as points [EB/OL].(2019–04–25)[2021–06–20]. https://arxiv.or g/abs/1904.07850
[3]He K, Gkioxari G, Girshick R, et al. Mask R-CNN [EB/OL]. (2018–01–24)[2021–06–20]. https://arxiv. org/abs/1703.06870
[4]Wen W, Wu C, Wang Y, et al. Learning structured sparsity in deep neural networks // Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelno, 2016: 2082–2090
[5]Zhou H, Alvarez J M, Porikli F. Less is more: towards compact CNNS // European Conference on Computer Vision. Cham: Springer, 2016: 662–677
[6]Han S, Mao H, Dally W J. Deep compression: compr-essing deep neural network with pruning, trained quantization and Huffman coding [EB/OL]. (2015–11–20)[2021–06–20]. https://arxiv.org/abs/1510.00149v3
[7]Liu Z, Sun M, Zhou T, et al. Rethinking the value of network pruning [EB/OL]. (2019–03–05)[2021–06– 20]. https://arxiv.org/abs/1810.05270
[8]Changpinyo S, Sandler M, Zhmoginov A. The power of sparsity in convolutional neural networks [EB/OL]. (2017–02–21)[2021–06–20]. https://arxiv.org/abs/170 2.06257
[9]Rastegari M, Ordonez V, Redmon J, et al. XNORNet: imagenet classification using binary convolutional neural networks // European Conference on Computer Vision. Cham: Springer, 2016: 525–542
[10]Jacob B, Kligys S, Chen B, et al. Quantization and training of neural networks for efficient integerarith-metic-only inference [EB/OL]. (2017–12–15) [2021–06–20]. https://arxiv.org/abs/1712.05877
[11]Zhou Shuchang, Wu Yuxin, Ni Zekun, et al. DoReFa-Net: training low bitwidth convolutional neural netw-orks with low bitwidth gradients [EB/OL]. (2018–02–02)[2021–06–20]. https://arxiv.org/abs/1606.06160
[12]Courbariaux M, Bengio Y. Binarynet: training deep neural networks with weights and activations constra-ined to +1 or –1 [EB/OL]. (2016–04–18)[2021–06–20]. https://arxiv.org/abs/1511.00363
[13]Jin J, Yan Z, Fu K, et al. Neural network architecture optimization through submodularity and supermodul-arity [EB/OL]. (2018–02–21)[2021–06–20]. https:// arxiv.org/abs/1609.00074
[14]Baker B, Gupta O, Naik N, et al. Designing neural network architectures using reinforcement learning [EB/OL]. (2016–11–07)[2021–06–20]. https://arxiv.org/abs/1611.02167v1
[15]Zhang L L, Yang Y, Jiang Y, et al. Fast hardware-aware neural architecture search [EB/OL]. (2020–04– 20)[2021–06–20]. https://arxiv.org/abs/1910.11609
[16]Jiang Xiaotang, Wang Huan, Chen Yiliu, et al. MNN: A universal and efficient inference engine [EB/OL]. (2020–02–27)[2021–06–20]. https://arxiv.org/abs/2002. 12418
[17]Krizhevsky A, Hinton G. Learning multiple layers of features from tiny images [EB/OL]. (2009–04–08) [2021–06–20]. http://citeseerx.ist.psu.edu/viewdoc/do wnload?doi=10.1.1.222.9220&rep=rep1&type=pdf
[18]Deng J, Dong W, Socher R, et al. ImageNet: a large-scale hierarchical image database // IEEE Conference on Computer Vision and Pattern Recognition. Miami, 2009: 248-255
[19]Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2015–04–10)[2021–06–20]. https://arxiv.org/abs/140 9.1556
[20]He K, Zhang X, Ren S, et al. Deep residual learning for image recognition // IEEE Conference on Compu-ter Vision and Pattern Recognition. Las Vegas, 2016: 770–778
[21]Sandler M, Howard A, Zhu M, et al. MobileNetv2: inverted residuals and linear bottlenecks // Proceedin-gs of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018: 4510–4520
Post Training Quantization Preprocessing Method of Convolutional Neural Network via Outlier Removal
Abstract In order to improve the performance of post training quantization model, a quantization preprocessing method based on outlier removal is proposed. This method is simple and easy to use. The outliers of weight and activation value are removed only through simple operations such as sorting and comparison, so that the quantization model loses only a small amount of information and improves the accuracy. The experimental results show that the performance can be significantly improved by preprocessing with this method before using different quantization methods.
Key words convolutional neural network; post training quantization; preprocessing; outlier removal; image classification