基于语境相似度的中文分词一致性检验研究
刘伟 黄锴宇 余浩 黄德根†
大连理工大学计算机科学与技术学院, 大连 116023; †通信作者, E-mail: huangdg@dlut.edu.cn
摘要 提出一种基于语境相似度的中文分词一致性检验方法。首先利用词法和句法层面的特征, 设计基于构词、词性和依存句法的分类规则, 再使用预训练词向量, 对不一致字串所在语境的语义信息进行编码, 通过语境间的语义相似度对不一致字串进行分类。在人工构建的 36 万字分词语料库中进行分词一致性检验, 结果表明该方法能够有效地提高中文分词一致性检验的准确率。进一步地, 使用 3 种主流中文分词模型在修正一致性后的分词语料中重新训练和测试, 结果表明该方法可以有效地提高分词语料库的质量, 3 种中文分词模型的 F1 值分别提高 1.18%, 1.25%和 1.04%。
关键词 中文分词; 一致性检验; 语料库构建; 语境相似度
中文分词是中文自然语言处理的一项基础性的重要任务。随着深度神经网络模型的发展, 现有的神经网络分词方法在基准(benchmark)数据集(例如Bakeoff-2005 和 Bakeoff-2008)上的 F1 值都已达到96%以上[1]。这些方法的分词性能与中文分词训练集的语料质量密切相关, 构建高质量的分词语料库是有监督中文分词方法的前提条件。分词一致性, 即同一字串在相同的语境下是否具有一致的切分形式, 是衡量一个分词语料质量的重要指标[1-2]。由于不同标注人员对分词单元的界定具有一定的主观性[3], 并且对“分词单位”的理解以及自身的语感也存在差异, 所以尽管存在统一的分词标准, 标注人员在标注过程中也很难完全达成一致。这就导致人工构建的分词语料存在大量的不一致性, 一些处于语料库中不同位置但具有相同语义的字串, 其切分形式却不一致。
本文对中文分词评测常用的 5 个基准语料库(AS, PKU, MSR, CITYU 和 CTB6)进行分词一致性统计, 结果如表 1 所示。可以看出, 5 个数据集均存在不同程度的分词不一致现象, 从而影响中文分词模型的性能。Ma 等[2]在基准数据集上训练得到效果较好的分词模型, 在进行错误分析后, 发现有1/3 的分词错误是由语料库的分词不一致导致的。另外, 分词不一致现象不仅存在于基准数据集的训练数据中, 也出现在测试数据中, 测试答案中出现分词不一致的情况会导致该数据集的可靠性下降。因此, 解决语料库中的分词不一致问题既可以提升语料的质量, 为模型训练提供更好的帮助, 又可以降低非分词方法导致的分词错误, 对提高中文分词方法的性能有重要的意义。
目前, 对中文分词的研究集中在提高分词方法的准确度方面[1-3], 针对语料库分词一致性检验的研究尚不多见。孙茂松[4]首次指出并分析了中文分词语料库中的一致性问题。刘江等[5]将分词一致性检验作为一个二分类问题, 在抽取的不一致字串中训练一个基于支持向量机的分类器, 然后对候选字串进行分类。苗玺等[6]采用基于规则和歧义字段词典的方法, 穷举语料中所有由歧义切分导致的不一致字段, 建立歧义字段词典, 通过检索词典对不一致字串进行分类, 并利用规则对字串进行修正。刘博等[7]提出规则与统计相结合的一致性检验方法, 首先使用基于构词和实例的规则, 确定大部分字串的类别, 然后针对规则无法覆盖的字串, 使用向量空间模型对不一致字串进行聚类, 最后得到字串的类别。
上述方法在一定程度上解决了中文分词语料库的一致性检验问题, 但是对有标注的不一致字串和基于实例的规则较为依赖, 由于有标注的字串和实例不能覆盖所有的情况, 所以存在适用性不强的问题。另外, 构建基于字串构词特征的规则时, 对句法和语义层面的信息利用较少。
针对这些问题, 本文提出一种基于语境相似度计算的中文分词一致性检验方法, 使用基于构词、词性和依存句法的规则, 对不一致字串进行分类, 利用字串在词法和句法层面的特征。这些规则中不包含实例, 具有较好的适用性。为进一步利用语义信息, 使用预训练的 Word2Vec[8-9]词向量, 对不一致字串所在语境的语义进行编码, 通过计算语境间的语义相似度, 对不一致字串进行分类, 从语义层面区分不同类型的不一致字串。为验证本文方法的有效性, 我们构建一份 36 万字的新闻领域分词语料库, 抽取其中的不一致字串, 人工标注类别, 并使用该语料库对本文的方法进行验证。该语料经过分词一致性检验和修正后, 已经应用于实际的分词评测任务中。最后, 选择主流的分词模型, 在修正分词不一致现象前后的语料库中分别训练, 对比模型的分词效果, 验证语料库的分词一致性对分词模型的影响。
1 分词不一致现象分类
语料库分词一致性指同一字串在相同语境下具有一致的切分形式。不一致的切分形式往往呈现为“合”与“分”两种形式[6]。这里的语境指出现在字串前后的词(上下文)。相同的语境并非指完全相同的上下文, 只要字串表达相同的含义, 即认为是相同的语境。
根据是否需要将不一致字串修正为一致的切分形式, 可以将分词不一致现象分为以下两类。
1)第一类(Seg1): 同一字串在相同的语境中被切分为不同的形式。一个语料库应当遵循统一的分词规范, 同一字串只能有一种切分形式, 所以此类不一致字串需要被修正, 举例如下。
有关 规定 提出 的 评论 意见
定期 回顾 进展 并 提出 具体 行动 建议
它 还 向 受害者 提供 帮助
多数 他杀 案件 的 受害 者 也 是 男性
表1 benchmark数据集分词不一致统计
Table 1 Statistics of inconsistency of benchmark dataset

数据集统计量ASPKUMSRCITYUCTB6 训练数据总词数5449581110994723683911455630678811 不一致字串数58404839095841436143239716 不一致率10.72%3.52%3.55%4.22%5.85% 测试数据总词数1226101043721068734093652861 不一致字串数 30131411798350821 不一致率2.46%1.35%0.75%0.85%1.55%
2) 第二类(Seg2): 同一字串在不同的语境下切分形式不同, 但都表达了正确的语义。此类不一致是由于歧义而导致, 切分形式都是正确的, 不需要被修正, 举例如下。
保持 沉默 是 为了 不 丢掉 他 的 工作
将 其 转化 为 了通俗 易懂 的 训诫
抓住 了 前门 的 把手
菲尔 把 手 放 在 她 胸前
2 中文语料库分词一致性检验方法
可将语料库分词不一致检验视为一个二分类问题。对于自动抽取的不一致字串 S, 将其标记为Seg1 或 Seg2。对分词不一致的检验和修正分两步进行, 一致性检验只需为不一致字串标记类别, 不必进行修正操作, 目的是提高检验方法的适用性。对不同的分词语料库, 都可以使用本文提出的一致性检验方法, 依据语料库所遵循的分词规范, 制定相应的修正规则。
一致性检验方法整体上用层次化的流程进行。从原始语料库中自动抽取待分类的不一致字串及其所在的上下文语境, 构成一个不一致字串库。对字串库中的每个不一致字串依次进行分类。首先使用基础规则进行筛选, 如果分类结果为“不确定”, 则继续使用词性规则和依存句法规则, 分别对该字串进行分类。若词性规则和依存句法规则的分类结果相同, 则分类结束, 否则继续计算该不一致字串的语境相似度 sim, 与预先设置的阈值 k 进行比较, 确定最终的分类结果。
2.1 基于规则的方法
分析两类不一致现象的成因, Seg1 往往是由于标注人员对分词规范理解的不一致以及语感的差异导致的, Seg2 则是由语料中固有的分词歧义, 尤其是组合型歧义造成的。由于形成的原因不同, 两类不一致字串呈现的特征也有所不同, 可针对这些特征制定一些规则来对不一致字串进行分类。为便于表述, 定义“合”状态下的不一致字串为 S, “分”状态下的不一致字串为 S1/S2 或 S1/S2/S3。
2.1.1 基础规则
对标注后的不一致字串进行分析, 发现部分Seg1 类不一致字串具有一些明显的特征, 可通过制定相应的规则, 利用这些特征对 Seg1 类字串进行初步筛选。为了提高规则的普适性, 制定的规则不只针对某类特定的字串, 也没有在规则中包含实例, 而是针对所有不一致字串共有的特征。本文根据字串的词长以及构词等特征, 制定 5 条基础规则, 如果不一致字串符合其中 1 条规则, 则被分类为Seg1, 否则认为其类别不确定, 交给后续步骤进一步分类。5 条基础规则如下, 其中 Len(S)表示字串 S 的长度。
1)若 S 中包含数字、字母或标点, 则分类为Seg1, 否则类型不确定。
2)若 Len(S) >= 4, 则分类为 Seg1, 否则类型不确定。
3)若 S 对应不一致字串 S1/S2/S3, 即 S 被切分为 3 段, 则分类为 Seg1, 否则类型不确定。
4)若 Len(S1) = 1 ∧ S2∈prefix_dict (前缀词表), 则分类为 Seg1, 否则类型不确定。
5)若 Len(S2) = 1∧ S2∈suffix_dict (后缀词表), 则分类为Seg1, 否则类型不确定。
2.1.2 基于词性的规则
通过实验发现, 不一致字串的词性之间存在一定的相关性。对于 Seg1 类型的不一致字串, “合”与“分”状态下, 字串中至少有一个片段的词性相同; 对于 Seg2 类型的不一致字串, “合”与“分”状态下, 片段的词性都不同。对自动抽取的不一致字串进行词性标注, 部分例子如表 2 所示。
根据上述不一致字串间词性的相关性, 制订以下规则, 其中POS(S)为字串S的词性。
1)若 POS(S)=POS(S1)∨POS(S)=POS(S2), 则分类为 Seg1。
2)若 POS(S)!=POS(S1)∧POS(S)!=POS(S2), 则分类为Seg2。
2.1.3 基于依存句法的规则
依存句法用于描述句子中词语间的依存关系, 即词语间在语义上搭配关系。在 Seg1 类的不一致字串中, “合”与“分”的状态下表达的词义相同。对“分”状态下的不一致字串 S1/S2 进行依存句法分析, 可以得到 S1 与 S2 间的依存关系 D1。如果将“合”状态的字串 S 人为地切分成“分”的形式 S1/S2, 之后在其所在的句子中进行依存句法分析, 也能得到一个 S1 与 S2 间的依存关系 D2。由于 Seg1 类型的字串在两种状态下表达的语义相同, 则依存关系D1 与 D2 也是相同的。Seg2 类型的不一致字串之间的依存关系不存在这样的特点。
例如, Seg1 类型的不一致字串“副作用”在图 1的句子(a)中是合起来的, 而在句子(b)中是分开的。人为地将句子(a)中的“副作用”切开为“副/作用”, 然后对两个句子进行依存句法分析, 可以看到句子(a)中的“副作用”被切开后, “副”和“作用”间的依存关系与句子(b)中“副”和“作用”间的依存关系是一致的, 都是 ATT (定中关系)。图 2 中, 对 Seg2 类型的不一致字串“遍地”, 同样将句子(a)中的“遍地”切开为“遍/地”, 然后对句子(a)和(b)进行依存句法分析, 可以看到“遍”与“地”的依存关系分别是 ATT (定中关系)和 MT (虚词成分), 两者的依存关系不一致。
表2 不一致字串间词性相关性示例
Table 2 Examples of POS relationship between inconsistent string

字串类型字串S“合”形式“分”形式 Seg1各种用_p 各种_r 不同_a 的_u 非_h 传统_a 方法_n面临_v 各_r 种_q复杂_a 问题_n 最低所_u 需_v 最低_a收入_n 水平_n社会_n 保护_v 最_d 低_a标准_n 入境诸位结构井去年_t , _w澳门_n 入境_v旅客_n 数字_n正如_p 在座_v 诸位_r可能_v 知道_v建立_v 了_u 复杂_a 结构井_n的_u 概念_n入_v 乡_n 从_p 乡_n , _w 入_v 境_n问_v 俗_a得到_v 了_u 诸_r 位_q在_p 下面_f 给予_v影响_v 复杂_a 结构_n 井_n的_u 产能_j 因素_n Seg2上将负责_v 调查_v 的_u 海军_n 上将_n柯克兰德_n月球_n 上_f 将_d面临_v 的_u 严峻_a 现实_n 不过不过_c只能_v 和_p 它_n 斗争_v 到底_v也_d 逃_v 不_d 过_v政治_n 的_u 控制_v 你好一起才能你好_l , _w 吉姆_n 。_w与_p 用户_n 一起_s讨论_v 这些_r 问题_n女工_n 具有_v 多种_m 才能_n我_r 的_u 发型_n 和_c 西装_n 也_d 比_p 你_r 好_a仅_d 有_v 一_m 起_q案件_n 定罪_v等_u 机会_n 错过_v 了_u 才_d 能_v发现_v
我们制定以下规则, 对不一致字串进行分类: 将“合”状态下的不一致字串 S 人工切分为“分”的形式 S1/S2, 之后对所有不一致字串所在的句子进行依存句法分析, 统计句子中 S1 与 S2 的依存关系, 若所有的依存关系均相同, 则分类为 Seg1, 否则为Seg2。
2.2 基于语境相似度计算的方法
根据两类不一致字串的定义可知, Seg1 类的不一致字串在“合”与“分”两种形式下所处的语境具有较高的相似度, 而 Seg2 类字串中二者所处的语境相似度较低。字串的语境使用一个[-N, N]的窗口来描述: 选取不一致字串前后各 N 个词作为该字串的语境。为了将语境向量化, 本文将语境中每个词对应的预训练词向量的加权平均值作为字串在一个句子中的语境向量。不一致字串与距其较近的词往往能形成一些固定的搭配, 例如“一/个/人”和“个人/所得税”, 其中“一”和“所得税”决定了“个人”的切分形式, 所以较近的词在语境中的贡献也更大。进行加权平均计算, 可以为较近的词赋予更大的权值。进一步地, 对一个字串在其出现的所有句子中的语境向量取均值, 得到这个字串整体的语境向量。
定义 w-i 和 wi 为不一致字串前后的第 i 个词, ei和 e-i 为 wi 和 w-i 对应的词向量, 则某一切分形式(“分”或“合”)下的不一致字串的整体语境向量 Env定义如下:
其中, m 表示包含该切分形式的不一致字串的句子总数, envj 表示第 j 个句子中该字串的语境向量:
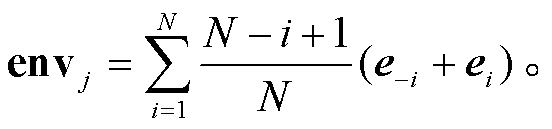 (2)
(2)
设“合”与“分”两种形式下的字串对应的整体语境向量为 Env1 和 Env2, 则该不一致字串的两种切分形式之间的语境相似度 sim 可以用 Env1 与 Env2间的欧氏距离来表示:
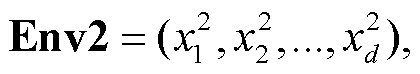 (4)
(4)
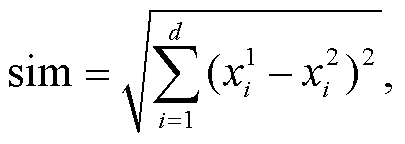 (5)
(5)
其中, d表示语境向量的维度,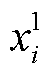 与
与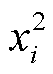 分别表示语境向量 Env1 和 Env2 中第 i 维的值。为 sim 设置一个阈值 k, 如果一个不一致字串的语境相似度 sim 低于 k, 则将其分类为 Seg1, 否则为 Seg2。
分别表示语境向量 Env1 和 Env2 中第 i 维的值。为 sim 设置一个阈值 k, 如果一个不一致字串的语境相似度 sim 低于 k, 则将其分类为 Seg1, 否则为 Seg2。
3 实验结果与分析
3.1 实验语料及设置
我们从 WMT18 中英平行语料中抽取 1 万句新闻领域中文语料, 由两名标注人员依据基于 PKU分词规范改进的细粒度分词规范进行人工标注, 作为本文分词一致性检验的实验数据集(corpus_ raw)。语料 corpus_raw 中共有 36 万字, 217173 个切分单位。人工标注过程中产生的 Seg1 和 Seg2类不一致字串的数量和占比如表 3 所示。
本文使用准确率 ACC 作为一致检验方法的评价指标:
表3 不一致现象统计
Table 3 Statistics of inconsistency

不一致类别出现次数占比/% Seg182643.81 Seg29900.46
实验中, 词性标注工具基于 Transformer[10]模型训练得到, 遵循 PKU 词性标注规范。用开源句法分析工具 DDParser[11]对语料中的句子进行依存句法分析。使用 Li 等[12]开源的中文预训练词向量, 该词向量是使用 Skip-Gram 模型并结合负采样方法在人民日报语料中训练得到, 维度为 300。计算不一致字串的语境时, 选取的窗口大小 N=4, 分类阈值 k= 6.5。
3.2 分词一致性检验及修正实验
表 4 为所有一致性检验方法在语料库 corpus_ raw 上的实验结果, 其中 ACC1 为 Seg1 类型不一致字串的分类准确率, ACC2 为 Seg2 类型不一致字串的分类准确率, ACC_total 为所有不一致字串整体的分类准确率。可以发现, 在单独对 4 种方法的实验结果中, 使用简单基础规则进行分词一致性检验的结果最差。词性规则整体上的准确率最高, 达到72.36%, 对 Seg1 类不一致字串的检验效果最好, 准确率达到 75.68%, 对 Seg2 类型的效果不佳, 准确率仅有 44.65%。依存句法规则对 Seg2 类型的检验效果较好, 准确率达到 76.97%, 但对 Seg1 类型的效果不佳, 仅有 54.87%。基于语境相似度的方法对两种不一致字串均有较好的效果, 对 Seg1 类型的效果仅次于词性规则, 准确率达到 68.79%, 对 Seg2 类型的效果最好, 准确率达到 78.69%, 整体的检验准确率也仅次于词性规则, 准确率达到 69.85%。将基础规则分别结合其他 3 种方法进行 3 组实验的结果表明, 3 种方法均能在基础规则上进一步提高检验的准确率, 其中基于语境相似度的方法提升最明显, 整体的检验准确率由原来的 41.63%提高到 90.43%, 取得 3 种方法中最好的检验效果。最后将 4 种方法用层次化的方式进行融合, 得到最佳的校验结果, 整体准确率达到 91.11%。
表4 一致性检验结果(%)
Table 4 Result of consistency check (%)
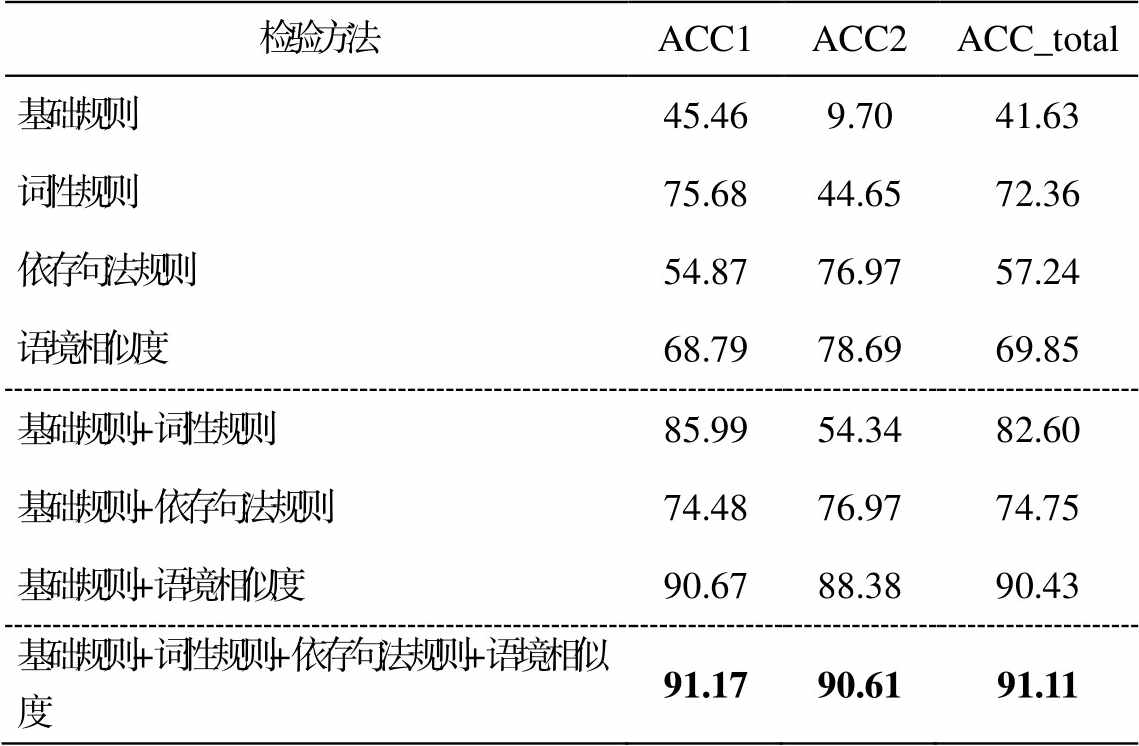
检验方法ACC1ACC2ACC_total 基础规则45.469.7041.63 词性规则75.6844.6572.36 依存句法规则54.8776.9757.24 语境相似度68.7978.6969.85 基础规则+词性规则85.9954.3482.60 基础规则+依存句法规则74.4876.9774.75 基础规则+语境相似度90.6788.3890.43 基础规则+词性规则+依存句法规则+语境相似度91.1790.6191.11
说明: 粗体数字表示性能最佳, 下同。
分词不一致的修正方法如下。根据分词语料遵循的分词规范制定修正规则库, 对规则能覆盖到的 Seg1 类字串直接进行修正。对规则未覆盖到的 Seg1 类字串, 则选取字串中出现频率高的切分形式作为正确的切分进行修正。为检验修正分词不一致字串后的语料对分词模型效果的影响, 本文选择两个中文分词基准模型: 基于预训练语言模型BERT[13]进行微调的 BERT-base 和仅在 BERT 的前3 层进行微调的分词模型 BERT-prune。在 corpus_ raw, corpus_manual 和 corpus_auto 语料库上分别使用上述两个模型进行 5 折交叉验证(实验结果取平均值), 分词结果采用精确率(P)、召回率(R)和F1 值进行评估, 结果如表 5 所示。corpus_raw 表示原始标注语料, corpus_manual 表示经过人工修正不一致性的标注语料, corpus_auto 表示基于本文提出的一致性检验方法自动修正不一致性后的标注语料。可以看出, 基准模型在 corpus_manual 上取得最好的分词效果, 说明修正语料库中的分词不一致现象有助于提高语料库质量, 而 corpus_auto 上的结果与 corpus_munual 接近, 表明本文提出的分词一致性检验方法可以有效地提升语料库的质量, 其改善效果接近人工修正的方法。
表5 5折交叉验证结果(%)
Table 5 5 fold cross validation (%)
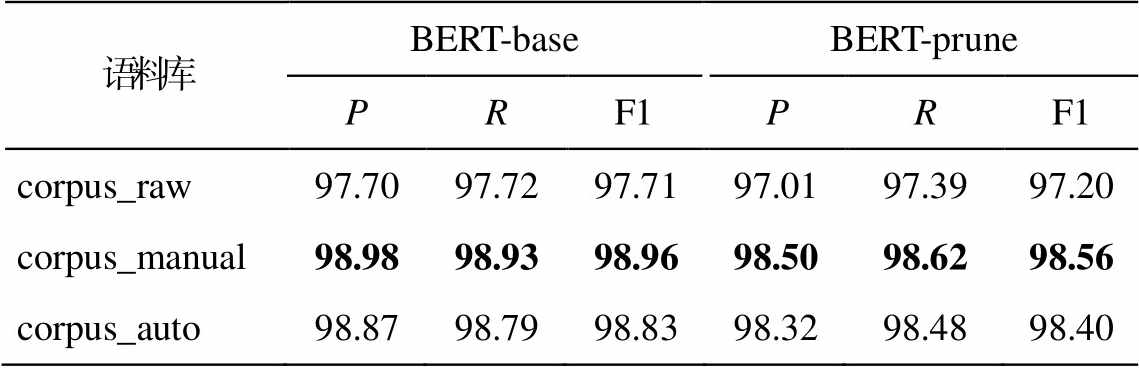
语料库BERT-baseBERT-prune PRF1PRF1 corpus_raw97.7097.7297.7197.0197.3997.20 corpus_manual98.9898.9398.9698.5098.6298.56 corpus_auto98.8798.7998.8398.3298.4898.40
3.3 基准语料库验证实验
使用本文提出的方法, 对 PKU 语料进行分词一致性检验, 并对检验结果进行统计分析, 结果如表6 所示。本文在全部数据、训练集和测试集上分别检验, 并统计 Seg1 类不一致字串的总数以及这些字串在训练集和测试集中出现的次数。另外, 对切分形式在训练集和测试集内部一致, 而在两个数据集之间不一致的字串也进行统计。例如, 字串“生产总值”在训练集中共出现 66 次, 均是“合”的形式, 而在测试集中共出现 16 次, 全被切分成“生产/总值”。可以看到, 不仅在训练集和测试集内部均存在大量的分词不一致, 而且训练集与测试集之间的不一致字串也占不一致字串总数的12.3%。
与 3.2 节的实验步骤相似, 将未做分词一致性修正的语料记为 PKU_raw, 仅在训练数据上进行自动修正的语料记为 PKU_only_train, 仅在测试集上进行自动修正的语料记为 PKU_only_test, 对训练集与测试集整体进行自动修正的语料记为 PKU_ both, 分别使用 3 种主流的神经网络分词模型, 在上述语料中重新训练与测试。3 种分词模型分别是基于 BERT 微调的分词方法 BERT-base 和 BERT-prune 和基于双向长短期记忆网络的方法 BiLSTM[2], 实验结果如表7所示。
从表 7 可知, 相对于原始的 PKU 语料库(PKU_ raw), 仅修正训练集, 模型的测试结果只略微提升, 这是因为如果仅修正训练集而不修正测试集, 测试集的答案仍会存在不一致的错误, 重新训练后模型改善的效果难以通过存在噪声的测试集体现出来。如果只修正测试集, 结果反而略有下降, 这是因为模型存在分词不一致的错误, 修正后的测试答案使不一致的错误更加凸显。当整体修正训练集与测试集中的不一致字串后, 模型的 F1 值相对于 PKU_raw有明显的提升, 这是由于整体修正不仅消除了每个数据集内部的分词不一致, 还额外地修正了训练集与测试集之间的分词不一致。因此, 语料库的训练数据中不一致字串的高频出现会对分词模型的训练产生影响, 使得模型产生大量分词不一致的错误。本文提出的分词一致性检验方法可以有效地检验分词不一致的字串, 提高分词语料库的质量。
表6 PKU语料库Seg1类不一致字串统计
Table 6 Statistics of Seg1 string in PKU corpus
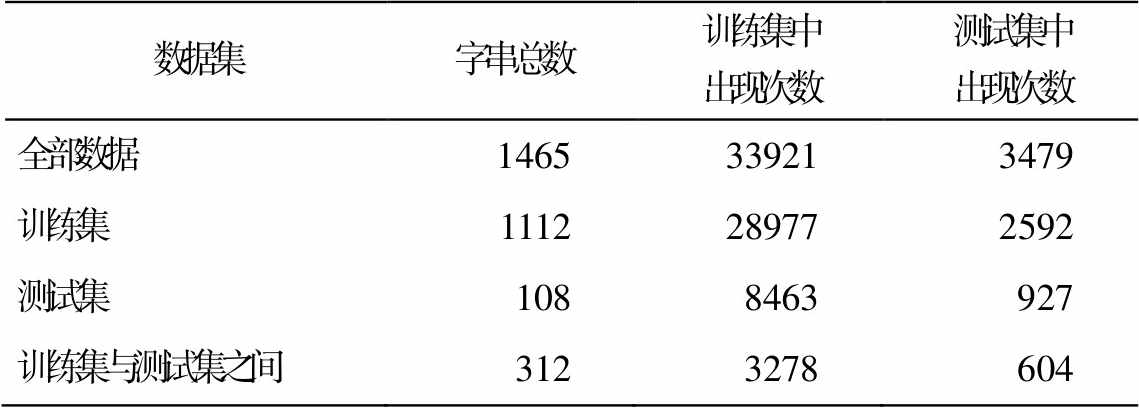
数据集字串总数训练集中出现次数测试集中出现次数 全部数据1465339213479 训练集1112289772592 测试集1088463927 训练集与测试集之间3123278604
表7 PKU语料库实验结果(%)
Table 7 Result of PKU corpus (%)

语料库BERT-baseBERT-pruneBiLSTM PRF1PRF1PRF1 PKU_raw97.0396.3596.6996.5296.0696.2994.5193.7994.15 PKU_only_train97.2096.4696.8396.7996.2696.5394.7794.0194.39 PKU_only_test97.0296.2796.6496.5196.0096.2694.4693.7994.12 PKU_both98.1097.6497.8797.6797.4097.5495.4994.9095.19
4 结论
本文提出一种基于语境相似度计算的中文分词一致性检验方法。首先, 使用基于构词、词性和依存句法的规则, 利用词法和句法层面的特征, 对分词不一致的字串进行分类。然后, 为进一步提高分类的准确率, 利用预训练词向量, 对不一致字串所在语境的语义进行编码, 通过计算语境间的语义相似度, 对不一致字串进行分类。最后, 依据分词规范和词频统计信息, 对分词不一致的字串进行自动修正。实验结果表明, 基于语境相似度的方法, 能够提高分词一致性检验的准确率。并且, 在分词语料库中使用本文的方法进行分词一致性检验并自动修正后, 重新训练的模型取得更好的分词效果, 证明语料库的质量明显提升。对于基准分词语料库的一致性修正提升了分词方法间对比的可靠性, 减少了非分词方法导致的分词错误, 通过提高训练数据源头的质量, 显著地提升了中文分词模型的性能。另外, 本文提出的方法还可以辅助人工进行分词语料标注, 自动检验人工标注过程中产生的分词不一致, 提高语料库标注质量。
参考文献
[1]Huang Kaiyu, Huang Degen, Liu Zhuang, et al.A joint multiple criteria model in transfer learning for cross-domain Chinese word segmentation [C/OL] // Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.2020 [2021-04-08].https://aclanthology.org/2020.emnlp-ma in.318
[2]Ma J, Ganchev K, Weiss D.State-of-the-art Chinese word segmentation with Bi-LSTMS // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing.Brussels, 2018: 4902-4908
[3]黄昌宁, 赵海.中文分词十年回顾.中文信息学报, 2007, 21(3): 8-19
[4]孙茂松.谈谈汉语分词语料库的一致性问题.语言文字应用, 1999(2): 88-91
[5]刘江, 郑家恒, 张虎.中文文本语料库分词一致性检验技术的初探.计算机应用研究, 2005, 22(8): 52-54
[6]苗玺, 郑家恒.中文语料库分词不一致的分类处理研究.山西大学学报(自然科学版), 2006, 29(1): 22-25
[7]刘博, 郑家恒, 张虎.规则与统计相结合的分词一致性检验.计算机工程与设计, 2008, 27(7): 1814-1816
[8]Mikolov T, Chen K, Corrado G, et al.Efficient estimation of word representations in vector space [EB/OL].(2013-09-07)[2021-06-01].https://export.arxiv.org/abs/1301.3781
[9]Mikolov T, Sutskever I, Chen K, et al.Distributed representations of words and phrases and their com-positionality // Advances in neural information pro-cessing systems, Harrahs and Harveys, Lake Tahoe, 2013: 3111-3119
[10]Vaswani A, Shazeer N, Parmar N, et al.Attention is all you need // Procedings of Advancesin Neural Information Processing Systems.Long Beach, 2017: 5998-6008
[11]Zhang Shuai, Wang Lijie, Sun Ke, et al.A practical chinese dependency parser based on a large-scale dataset [EB/OL].(2020-09-02)[2021-06-01].https:// arxiv.org/abs/2009.00901
[12]Li Shen, Zhao Zhe, Hu Renfen, et al.Analogical reasoning on chinese morphological and semantic relations // Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).Melbourne, 2018: 138-143
[13]Devlin J, Chang M W, Lee K, et al.BERT: pre-train-ing of deep bidirectional transformers for language understanding [EB/OL].(2018-10-11)[2021-06-01].https://arxiv.org/abs/1810.04805
Consistency Check for Chinese Word Segmentation via Contextual Similarity
LIU Wei, HUANG Kaiyu, YU Hao, HUANG Degen†
School of Computer Science and Technology, Dalian University of Technology, Dalian 116023; † Corresponding author, E-mail: huangdg@dlut.edu.cn
Abstract The authors propose a method of consistency check for Chinese word segmentation based on contextual similarity.First, the classification constraints based on word formation, part of speech and dependency syntax are designed by using the features of morphology and syntax.Then, the semantic information of the context in which the inconsistent strings are located is encoded by using pretrained word embeddings, and the inconsistent strings are classified by semantic similarity between contexts.Experimental results show that proposed method can effectively improve the accuracy of consistency check for Chinese word segmentation.Further, three mainstream Chinese word segmentation models are used to re-implement in the revised Chinese word segmentation corpus.The result shows that proposed method can effectively improve the quality of Chinese word segmentation corpus, and the F1 scores of three Chinese word segmentation models are improved by 1.18%, 1.25% and 1.04% respectively.
Key words Chinese word segmentation; consistency check; corpus construction; contextual similarity
doi: 10.13209/j.0479-8023.2021.099
收稿日期: 2021-06-08;
修回日期: 2021-08-14
国家科技创新2030—“新一代人工智能”重大项目(2020AAA0108004)和国家自然科学基金(U1936109, 61672127)资助


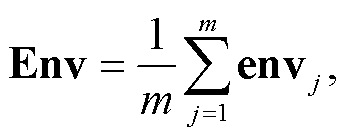 (1)
(1)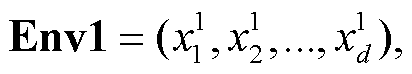 (3)
(3) (6)
(6)