表1 La格虚词添接规则
Table 1 Rules of adding function words in La case

后加字La格虚词 不自由虚词自由虚词 སསུན或ལ ག、བ或~དཏུ ང、ད、ན、མ、ར或ལདུ འ或无ར或རུ
摘要 基于藏文 La 格(ལ་དོན།)例句的自动分类在藏语自然语言处理领域的重要性, 根据藏文 La 格的用法和添接规则, 在对藏文 La 格例句进行分类并定义分类概念的基础上, 提出一种融合双通道音节特征的藏文 La 格例句自动分类模型。该模型首先使用 word2vec 和 Glove 构建双通道藏文音节嵌入, 分别在每路卷积中融合双通道音节特征, 丰富输入特征的表达和提高卷积层的空间表征能力; 然后在每一路卷积均使用结合层级注意力机制的 Bi-LSTM 学习时序特征后, 拼接多路特征, 提高上下文时序特征的学习能力; 最后通过全链接层和Softmax 层实现藏文 La 格例句自动分类。实验结果表明, 该模型在测试集上的藏文 La 格例句分类准确率达到 90.26%。
关键词 自然语言处理; 双通道音节特征; 藏文La格例句; 自动分类
八格(རྣམ་དབྱེ་བརྒྱད་པོ།)是两大藏文语法典籍《三十颂》和《音势论》的主要研究内容, 古今藏文文法学者无一不对藏文八格及其使用进行研究[1]。八格中第二、四和七格都用 La 格虚词表示。藏文 La 格例句的自动分类技术在藏文语法功能研究、语言理解、语义角色标注、语义分析和情感分析等自然语言处理任务中也具有广泛的应用价值。同时, La 格又是小学藏语文课本中必学的关键知识点, 学生必须熟练掌握 La格的概念和用法, 学会区分 La 格例句的类型, 故研究 La 格例句的自动分类技术可以辅助初学者更快地学习藏文 La 格, 也可以帮助人们进行高效温习。
随着信息技术的发展, 神经网络广泛地应用于句子分类任务中, 常见的分类模型有卷积神经网络、循环神经网络和混合网络模型等。文献[2‒4]研究了基于卷积神经网络的句子分类方法; 文献[5‒6]研究了基于极性转移 LSTM 树结构网络和胶囊网络(CapsNets)的句子分类方法; 文献[7‒9]研究了基于混合神经网络的句子分类方法。现代藏文文法借鉴英汉文句子的分类方法, 对藏文句子的类型及分类方法进行研究, 为研究藏文句子的自动分类提供了理论依据。有关藏文句子自动分类的研究只有一些零散的文献报道。柔特等[10]研究了基于循环卷积神经网络的藏文句型分类方法, 实验结果表明, 该方法取得了较好的分类效果。Ban 等[11]研究了基于短语特征的藏文疑问句分类方法, 实验结果显示, 该方法的分类准确率达到 96.98%。
综上所述, 藏文 La 格例句的自动分类不仅在藏语自然语言处理领域具有广阔的应用前景, 而且在藏文 La 格的学习过程及教学过程中具有辅助作用。但目前尚未见到有关藏文 La 格例句自动分类的研究报道。本文首先根据藏文 La 格虚词的用法及添接规则, 对藏文 La 格例句进行分类, 并定义藏文 La 格例句的分类概念; 然后根据藏文 La 格例句的类型及分类概念, 提出一种融合双通道音节特征的藏文 La 格例句自动分类模型; 最后通过设计多组对比实验, 验证本文模型的优越性。
La 格是根据其虚词在藏文句子中的语法和语义功能以及添接规则而起的名称。La 格虚词由སུ་ར་རུ་ཏུ་ན་ལ་དུ 7 个形式组成。སུ་ར་རུ་ཏུ་དུ 为不自由虚词, 添接时受前一音节后加字的限制, 需分别在后加字为 ས 的音节后添接 སུ; 后加字为 ག་བ 和再后加字~ད之一的音节后添接 ཏུ; 后加字为 ང་ད་ན་མ་ར་ལ 之一的音节后添接 དུ; 后加字为 འ 或无后加字的音节后添接 ར 或 རུ。ན 和 ལ 为自由虚词, 不受前一音节后加字的限制, 可自由地添接。La 格虚词添接规则见表 1。
根据 La 格虚词的语法和语义功能及添接规则, 可以将 La 格虚词的用法分为表示业格(ལས་སུ་བྱ་བ།)、为格(དགོས་ཆེད།)、依格(གནས་གཞི།)、同格(དེ་ཉིད།)和时格(ཚེ་སྐབས།)的五类句型, 即业格句、为格句、依格句、同格句和时格句。
业格句: 表示在某一实施处所已经实施或正在实施的动作及将要实施动作的句子(བྱ་བའི་ཡུལ་ཞིག་ཏུ་བྱ་བ་གཞན་ཞིག་བྱས་པའམ་བྱེད་བཞིན་པ་དང་། བྱེད་འགྱུར་གང་རུང་སྟོན་པའི་ཚིག)[13]。如“བཀྲ་ཤིས་ཀྱིས་སློབ་ཁང་དུ་སློབ་སྦྱོང་ བྱས། (扎西在教室学习)”, 用 La 格虚词 དུ 将实施动作的处所 སློབ་ཁང་། (教室)和所实施的动作 སློབ་སྦྱོང་། (学习)连接后, 准确地表达了句意。
为格句: 表示为达到某一目的而实施动作行为的句子(དགོས་པ་གང་ཞིག་གི་ཆེད་དུ་བྱ་བ་བྱས་པ་སྟོན་པའི་ཚིག)[13]。如“ཡོན་ཏན་ལོན་པ་རུ་བརྩོན་འགྲུས་བསྐྱེད། (为了学到知识而努力)”,用 La 格虚词 རུ 将目的 ཡོན་ཏན། (知识)和为达到目的实施的动作行为 བརྩོན་འགྲུས། (努力)连接后, 准确地表达了句意。
依格句: 表示某物依存于添接 La 格虚词的某一地点的句子(ལ་དོན་གྱི་ཕྲད་སྦྱར་སའི་གཞི་དེ་ལ་ཆོས་ཤིག་གནས་པར་ སྟོན་པའི་ཚིག)[12]。如“སློབ་ཁང་དུ་སློབ་མ་ཡོད། (教室里有学生)”, 用 La 格虚词 དུ 将地点 སློབ་ཁང་། (教室)和依存物 སློབ་མ། (学生)连接后, 准确地表达了句意。
同格句: 表示某一事物改变成另一种事物, 使两者在动作行为变化的结果上具有“同一体”性质的句子(ལས་དང་བྱ་བའི་ངོ་བོ་གཅིག་ཏུ་མཐོང་བར་བྱེད་པ་དོན་སྟོན་པའི་ཚིག)[13]。如“རྒྱ་ཡིག་རྣམས་བོད་ཡིག་ཏུ་བསྒྱུར། (汉文翻译成藏文)”, 用 La格虚词 ཏུ 表述了某一事物 རྒྱ་ཡིག (汉文)译成另一种事物 བོད་ཡིག (藏文)后在变化结果上具有“同一体”性。
表1 La格虚词添接规则
Table 1 Rules of adding function words in La case
后加字La格虚词 不自由虚词自由虚词 སསུན或ལ ག、བ或~དཏུ ང、ད、ན、མ、ར或ལདུ འ或无ར或རུ
时格句: 表示实施某一动作行为时间的句子(བྱ་བ་གང་ཞིག་བྱེད་པའི་དུས་སྟོན་པའི་ཚིག)[13]。如“ཁོང་གིས་ལོ་གསུམ་ལ་ བསྐྱར་སྦྱོང་བྱས། (他复习了三年)”, 用 La 格虚词 ལ 将实施动作的时间 ལོ་གསུམ (三年)和实施的动作 བསྐྱར་སྦྱོང (复习)连接后, 准确地表达了句意。
藏文 La 格例句分类的主要任务是, 通过藏文La 格例句分类模型, 给定一个待分类的藏文 La 格例句集中每个句子的类别标签。该任务可以用数学符号直观地表达, 假定 LD = {(xi,yj)|1≤i≤n, 0≤j≤4}为训练样本集, 则利用设计的模型学习到一个映射 f: X→Y, 即藏文 La 格例句集到例句类别标签集的映射, 其中 xi∈X 表示第 i 个藏文 La 格例句, yi∈Y 表示例句 xi 所对应的类别标签。该映射关系见图 1。
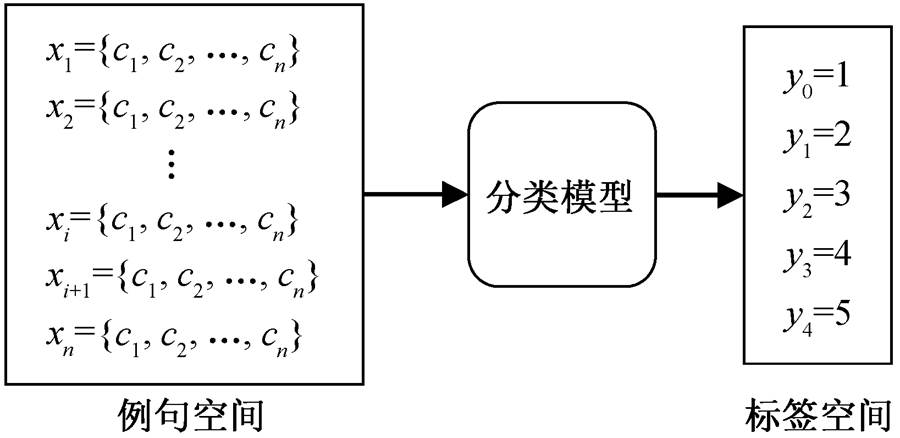
图1 藏文 La 格及其类别的映射关系
Fig.1 Tibetan La Case example sentences category relation
图1 中, 例句空间 X 中包含 n 个藏文 La 格例句, 通过藏文 La 格例句分类模型, 可以得到这些例句对应的标签空间 Y, 标签空间 Y 中包含 m 个类别标签。测试过程中, 通过分类模型, 每一个藏文 La格例句可获得对应的标签, 获得标签的过程就是藏文 La 格例句的自动分类过程。
融合双通道音节特征的藏文 La 格例句自动分类模型如图 2 所示。模型的输入为双通道音节嵌入, 分别为基于 Word2vec[14]和 GloVe[15]的音节向量, 可以增加文本表示的空间维度和特征多样性, 丰富特征的表达, 且不受特定分类任务的影响, 进而利于提升模型的泛化能力。与单通道音节嵌入相比,随着模型训练过程的进行, 在反向传播时对双通道嵌入层的权值进行动态调整, 使之从原本与藏文 La格例句分类任务关系不大的音节向量变成与该任务相关的语义表征向量, 提高了模型的收敛速度和句子特征表示的准确性。模型采用多路卷积提取空间特征, 每一路使用不同大小的卷积核提取不同感受视野的局部空间特征。为了避免多路卷积特征融合过程对特征时序造成破坏, 本文在每一路均使用结合层级注意力机制的双向长短期记忆网络学习时序特征, 并对各路特征进行拼接, 获得藏文 La 格例句的最终表示。最后, 通过全链接层和 Softmax 层进行藏文 La 格例句的自动分类。
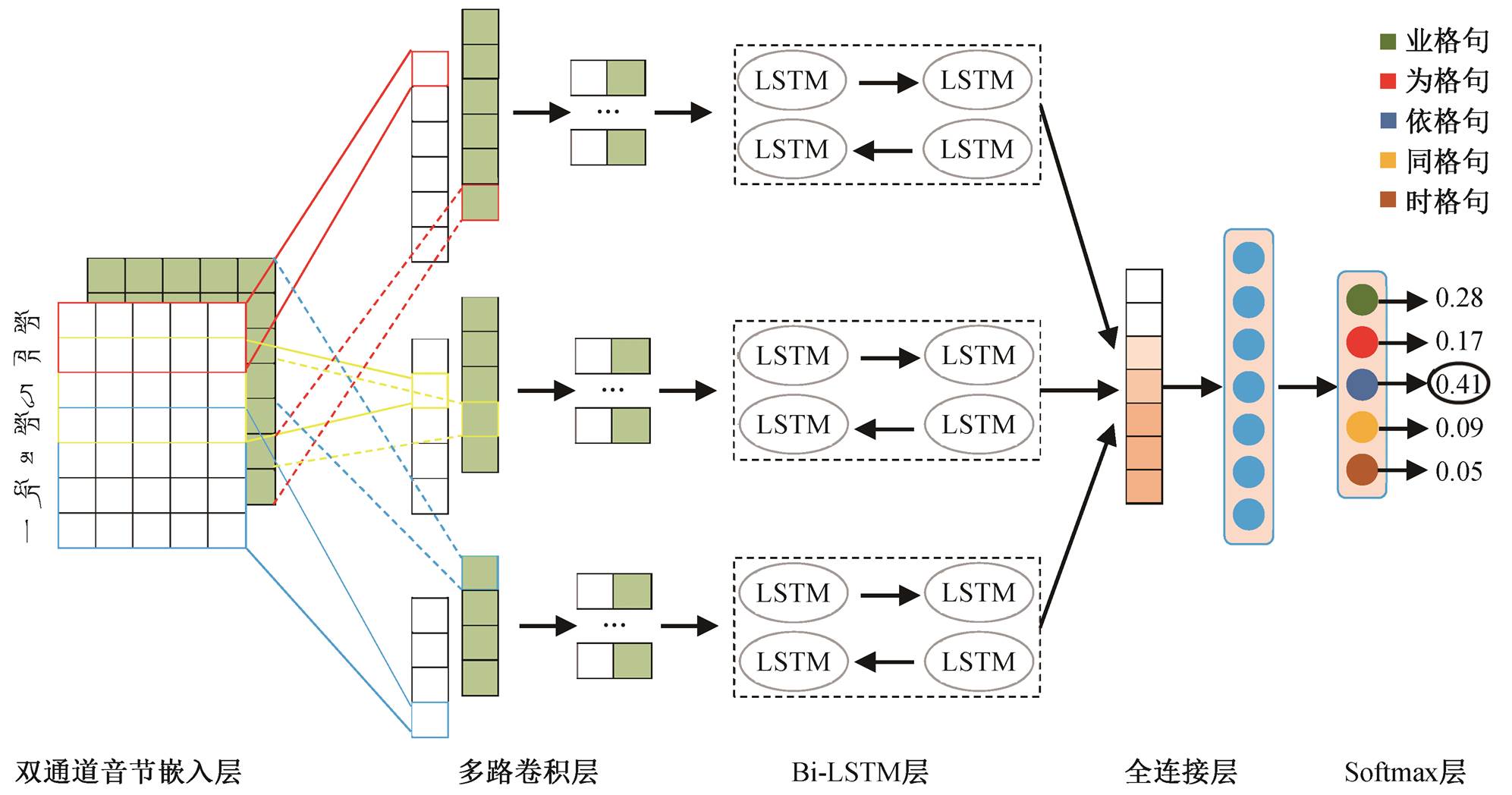
图2 融合双通道音节特征的藏文 La 格例句分类模型
Fig.2 An automatic classification model of Tibetan La case sentences with two channel syllable features
如图 3 所示, 卷积层的输入为双通道音节嵌入矩阵, 通过与特定大小的卷积核进行卷积操作, 得到两张不同的特征图, 之后进行特征融合。令嵌入矩阵最多可包含 n 个音节, 音节数大于 n 的句子将被截断, 不足 n 的则用 0 填充。假设 xi∈Rd 为当前句子中第 i 个音节的 d 维向量, 则句子的音节嵌入矩阵 X1:n 用式(1)表示。
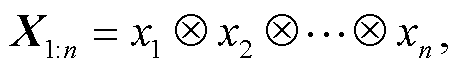 (1)
(1)其中, 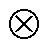 表示拼接运算。卷积操作需在音节嵌入矩阵 X1:n 上按时间轴自上而下地滑动卷积核 Wc∈Rhk来完成。h 为卷积核的感受视野大小, k 为音节嵌入的维度。特征音节 ci 是卷积核在音节 Xi:i+h-1 上滑动生成:
表示拼接运算。卷积操作需在音节嵌入矩阵 X1:n 上按时间轴自上而下地滑动卷积核 Wc∈Rhk来完成。h 为卷积核的感受视野大小, k 为音节嵌入的维度。特征音节 ci 是卷积核在音节 Xi:i+h-1 上滑动生成:

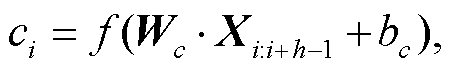 (2)
(2)
其中, f 是非线性激活函数, bc∈R 是偏置项。卷积核Wc在句子{X1:h, X2:h, …, Xn-h+1:n}上进行卷积生成的特征图C如下:
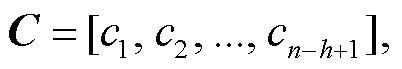 (3)
(3)由于嵌入层为双通道, 故通过卷积后可得到两张不同的特征图 C1 和 C2。使用大小为 1×1, 深度为2 的卷积核 Wf对 C1 和 C2 进行通道特征融合后的特征图 M 为
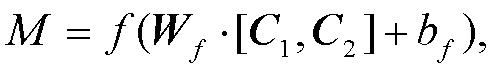 (4)
(4)
其中, f 代表非线性函数, bf 代表偏置项。得到融合双通道音节特征 M 后, 由于卷积神经网络通常会使用 N 个相同大小的卷积核进行卷积运算, 所以卷积后可以生成 N 个特征图组成的特征矩阵 Mo:
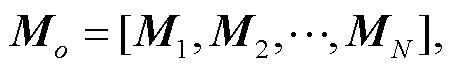 (5)
(5)由于卷积后的特征矩阵 Mo 的行维度较大, 所以需要进行降维处理。为了不丢失特征的时序性, 本文没有采用池化降维法, 改为使用步幅为 k 的卷积核 Wp 对特征矩阵 Mo 进行卷积降维, 降维后生成的特征矩阵 Mk:
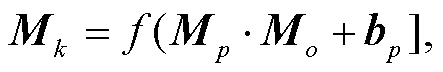 (6)
(6)
其中, f 为线性函数, bp 为偏置项。Mk保留了时序特征, 可以按行顺序输入到 LSTM, 完成时序特征的学习。
与主题分类和文本分类等任务相比, 藏文 La格例句分类任务没有特定属于某一类的特征字或词, 使得藏文 La 格例句的分类难度加大, 更依赖于上下文语义信息和语义关联度, 对特征的时序性要求更高。在输入 LSTM 前, 如果先融合多路卷积, 则无法保证特征的有序性, 造成特征质量下降, 影响 LSTM 对句子时序及语义信息的学习过程。所以, 本文模型在每一路卷积上均使用 Bi-LSTM 学习时序特征, 再拼接多路时序特征来表示最终的藏文La 格例句, 从而避免各路特征在进入 Bi-LSTM 前因融合而导致的特征质量下降问题。为了使模型能够根据上下文信息提高时序特征的学习能力和充分利用每个时刻的输出特征, 本文使用结合层级注意力机制的 Bi-LSTM 来提高 LSTM 输出的特征质量。结合层级注意力机制的 Bi-LSTM 层如图 4 所示。
LSTM 按时序接受 xi。LSTM 的最终输出可以由 ht表示, 其计算过程如下:
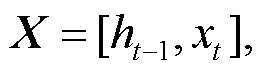 (7)
(7)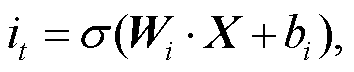 (8)
(8)
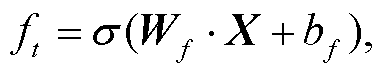 (9)
(9)
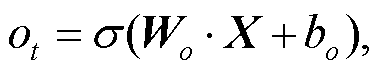 (10)
(10)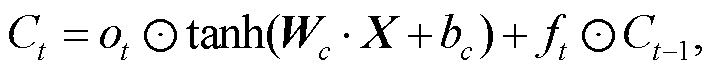 (11)
(11)
 (12)
(12)
其中, xi 表示第 i∈[0, t]时刻的输入向量, Ct 表示LSTM 的单元状态。it, ft 和 ot 分别表示输入门、遗忘门和输出门的特征值, σ 表示 Sigmoid 激活函数, Wi, Wf, Wo, Wc, bi, bf, bo 和 bc 分别为各个门需要学习的参数, X 表示 t -1 时刻隐藏层的值以及 t 时刻的输入。
由于本文使用 Bi-LSTM 学习时序特征, 所以Bi-LSTM 的输出为正向和反向 LSTM 输出的拼接, 用 ht 表示:
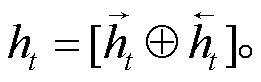 (13)
(13)由于 LSTM 只能学习到最后一刻的输出向量, 不能充分地利用每一时刻的输出, 所以本文使用层级注意力机制对各个时刻的输出进行加权融合。假设 hi 表示第 i 时刻 Bi-LSTM 层的输出向量, ei 表示 hi对整个 La 格例句语义表示的重要程度, ai 表示 hi 对整个 La 格例句语义表示贡献的权重, 则 Bi-LSTM层的注意力权重为

图3 卷积层的设计原理
Fig.3 Design principle of the convolution layer
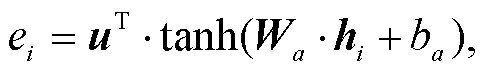 (14)
(14)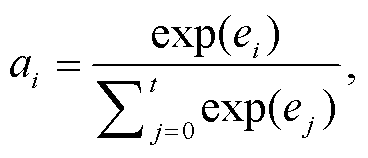 (15)
(15)
其中,uT, Wa和 ba都是网络需要学习的参数, tanh 为非线性激活函数。
至此, 我们已得到 Bi-LSTM 每一时刻的注意力权重, 对其进行加权求和, 便可得到整个 Bi-LSTM 层输出的最终特征向量 Q:
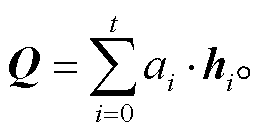 (16)
(16)本文 3 路卷积分别经过 Bi-LSTM 之后, 拼接形成的最终藏文 La 格例句向量为
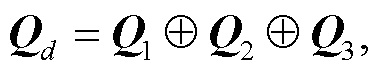 (17)
(17)
Qi 表示第 i 路卷积特征经过 Bi-LSTM 学习得到的藏文 La 格例句向量。
得到藏文 La 格例句的最终表示 Qd 后, 经过全连接层和 Softmax 层, 输出最终的预测类别。用 d (d∈dc)表示 Qd 经全连接层输出的向量, 则藏文 La格例句预测为 c 类的概率 Pc的计算方法如下:
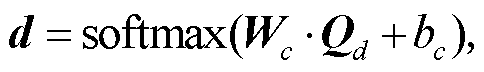 (18)
(18)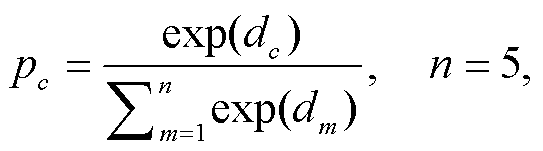 (19)
(19)
其中, c∈[1, 5], 表示藏文 La 格例句的某种类型, n表示类别数目, dc 表示 d 中属于类别 c 的分值, Wc 和bc 为全连接层需要学习的参数。
本文通过网络爬虫和人工录入等采集方式, 得到 95.4 MB 的藏文文本语料。首先以“ཀ+空格”、“ག+空格”、“ཤ+空格”及动词、形容词、终结词等句尾词加单垂符或双垂符为切分点, 对藏文文本语料进行分句(此分句不符合严格意义上现代文法中藏文句子的概念), 得到 33.6551 万条藏文句子。然后通过匹配藏文 La 格虚词及其添接规则的方式, 抽取 15 万条仅含一个藏文 La 格虚词的句子, 以保证语料质量为目的, 通过人工去除所有不符合现代藏文文法句子概念的句子和含 La 格虚词但不属于 La格的句子, 得到 2 万条藏文 La 格例句。其次, 以人工标注的方式, 用 1~5 的数字对每条藏文 La 格例句进行类别标注。最后, 为了确保标注质量, 通过人工逐条复核类别标签的方式, 完成藏文 La 格例句分类数据集的构建。
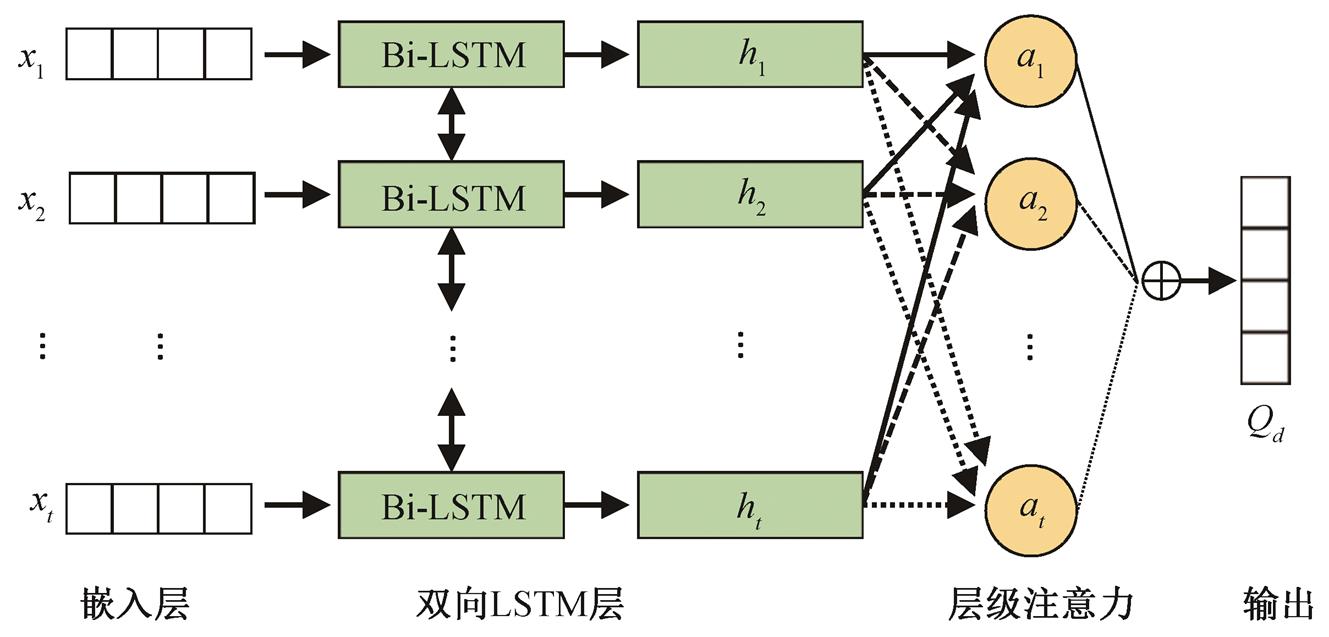
图4 结合层级注意力机制的Bi-LSTM层
Fig.4 Bi-LSTM layer combined with Hierarchical attention mechanism
实验时, 首先对藏文 La 格例句分类数据集进行预处理。在预处理过程中, 为了保证句子结构的完整性, 分别用 N, G, E 和 C 替换原文中的数字、希腊字母、英文和汉文, 并剔除其他不影响句子结构的非藏文字符。然后, 将数据按 8:1:1 的比例分成训练集、验证集和测试集。各类藏文 La 格例句的分布见表 2。
神经网络模型需要根据数据集的大小、语言的特性以及不同任务进行调参。实验时, 所有模型的参数都已进行多次调整, 实验结果为各模型最优参数组合下的最佳结果。本文模型的具体参数如表 3所示。
本文选用分类任务中常用的评价指标精度(P)、召回率(R)、F1 值和准确率(ACC)对模型的性能进行评价。TP 表示预测为正的正样本, FP 表示预测为正的负样本, FN 表示预测为负的正样本, TN表示预测为负的负样本, 则精度(P)、召回率(R)、F1值和准确率(ACC)的计算公式如下:
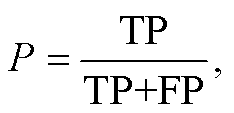 (20)
(20)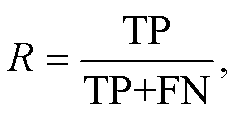 (21)
(21)
表2 藏文La格例句分布
Table 2 Tibetan La case example sentences distribution
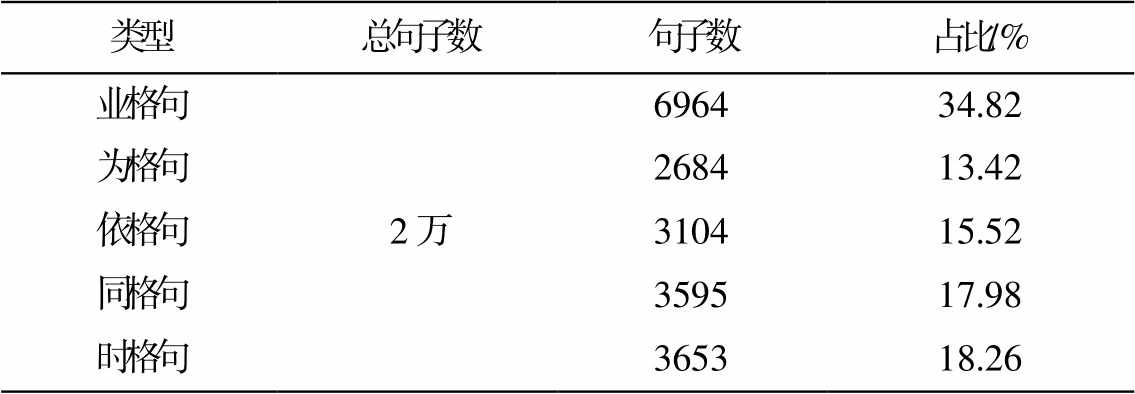
类型总句子数句子数占比/% 业格句2万696434.82 为格句268413.42 依格句310415.52 同格句359517.98 时格句365318.26
表3 模型参数
Table 3 Model parameters
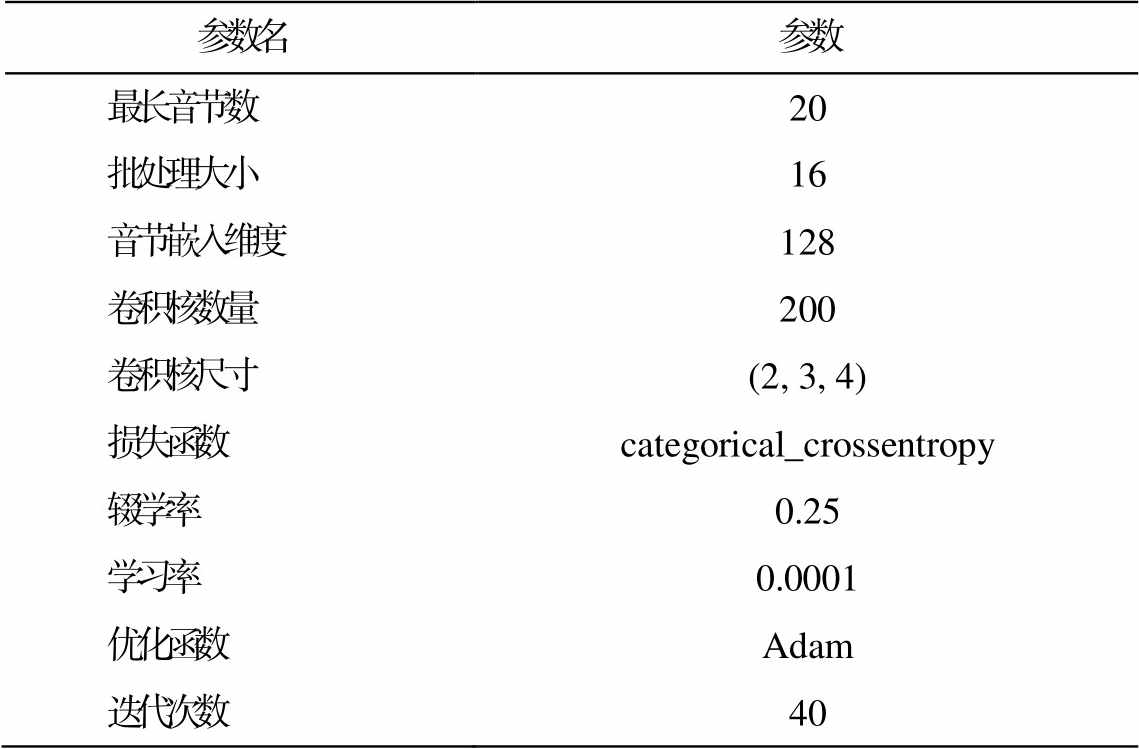
参数名参数 最长音节数20 批处理大小16 音节嵌入维度128 卷积核数量200 卷积核尺寸(2, 3, 4) 损失函数categorical_crossentropy 辍学率0.25 学习率0.0001 优化函数Adam 迭代次数40
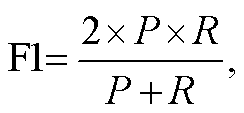 (22)
(22)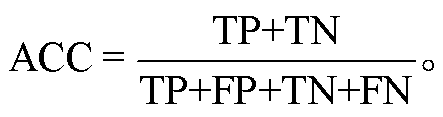 (23)
(23)
由于目前尚未查阅到有关藏文 La 格例句自动分类的文献, 加上没有公开的藏文 La 格例句分类数据集, 所以本文选用神经网络中常用于分类任务的 7 个经典模型作为基线模型来验证本文模型的有效性。
1) FastText[16]: 一种快速文本分类算法。
2) LSTM: 使用基于单向长短记忆网络文本分类方法[17]。
3) Bi-LSTM: 使用基于双向长短记忆网络文本分类方法[17]。
4) Bi-LSTM+Att[18]: 一种基于双向长短记忆网络和注意力机制的关系分类方法。
5) CNN[2]: 首次应用于句子分类的经典卷积神经网络模型。
6) RCNN[19]: 使用双向循环神经网络加最大池化的方法进行文本分类。
7) C-LSTM[17]: 使用单通道的多路卷积加长短记忆网络的方式进行文本分类。
SF-C+LSTM+Att 和 SF-C+Bi-LSTM+Att 为本文模型, SF 表示融合双通道音节特征, C 表示去掉池化层的卷积神经网络(CNN), Att 表示层级注意力机制(hierarchical attention mechanism)。
3.4.1 分类性能对比
为了验证本文模型的有效性, 分别在几种常用的经典分类神经网络模型上对比藏文 La 格例句的分类效果, 实验结果见表 4。
从表 4 可以看出, 与各种基线模型相比, 本文模型实验效果均有所提升, 比单一模型 FastText、LSTM, Bi-LSTM, Bi-LSTM+Att 和 CNN 的分类准确率分别提高 2.16, 3.10, 2.76, 2.51 和 1.76 个百分点, 比混合模型 RCNN 和 C-LSTM 的分类准确率分别提高 4.76 和 0.95 个百分点, 表明本文模型的分类性能更好。
本文模型性能更好的原因主要有三方面: 1)本文融合了双通道音节特征, 丰富了嵌入向量的语义信息; 2)本文采用多路卷积模式, 提取不同感受视野的文本特征, 丰富了文本表示; 3).本文在每路卷积后直接拼接结合层级注意力机制的 Bi-LSTM, 更合理地学习文本的时序特征以及每一时刻输出表征, 提高了最终文本表示的质量。另外, 通过实验发现, 影响本文模型性能的主要原因是部分藏文La 格例句无法根据其语法结构和浅层的语义信息来进行分类。例如: “ཤིང་ལ་ལོ་མ་ཡོད།、བ་ལང་ལ་རྭ་ཡོད།和རུ་བ་ཁ་མལ་ན་ཡོད།”属于依格句, 而“ཤིང་ལ་ཙན་དན་ཡོད།、བ་ ལང་ལ་དཀར་ཟལ་ཡོད།和 ནད་པ་ཁ་མལ་ན་ཡོད།”属于同格; “རྟ་ལ་ རྩྭ་བྱིན།”属于为格句, 而“རྟ་ལ་དུག་བྱིན།”属于业格句。可见, 这些藏文 La 格例句需要根据具体的语境及语用目的深入分析其语义才能正确分类。
表4 各种分类模型的对比实验结果(%)
Table 4 Comparison of experimental results of various classification model (%)
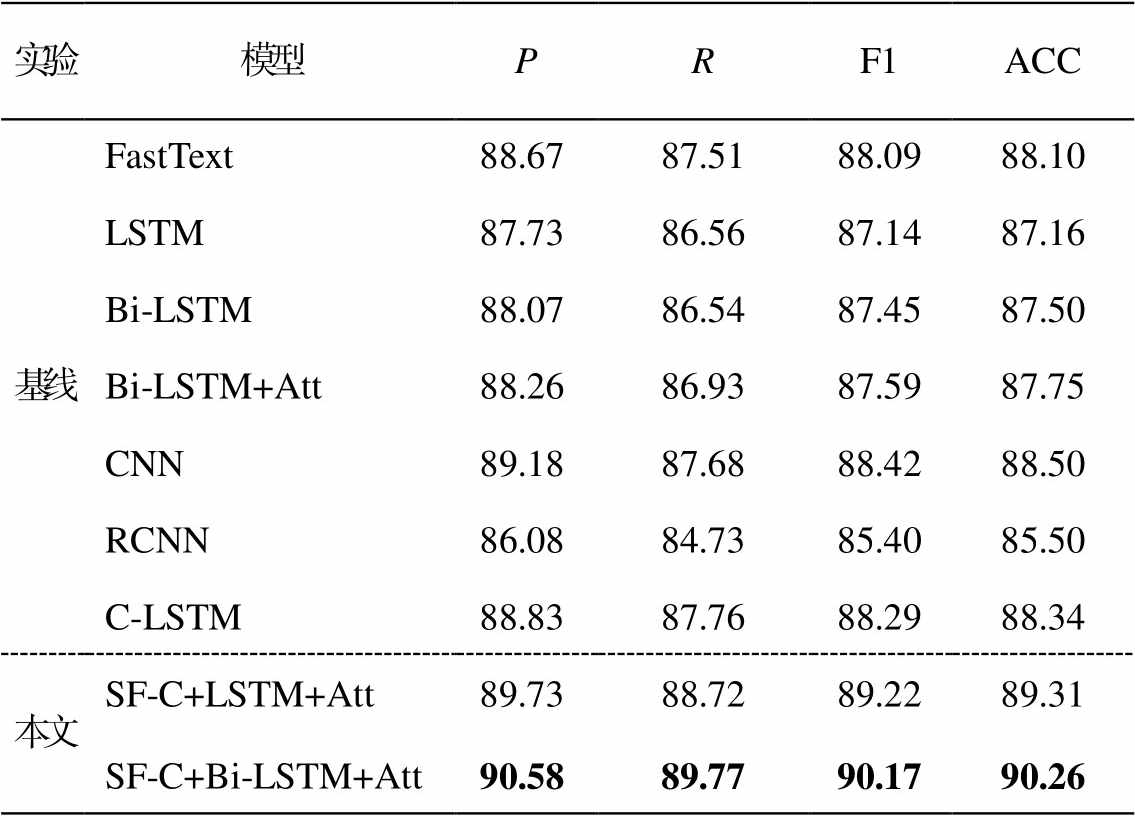
实验模型PRF1ACC 基线FastText88.6787.5188.0988.10 LSTM87.7386.5687.1487.16 Bi-LSTM88.0786.5487.4587.50 Bi-LSTM+Att88.2686.9387.5987.75 CNN89.1887.6888.4288.50 RCNN86.0884.7385.4085.50 C-LSTM88.8387.7688.2988.34 本文SF-C+LSTM+Att89.7388.7289.2289.31 SF-C+Bi-LSTM+Att90.5889.7790.1790.26
说明: 粗体数字表示性能最佳。
3.4.2 双通道音节特征的有效性验证
为了验证融合双通道音节特征的有效性, 分别考查融合双通道的音节级 Word2vec 和 GloVe 的模型性能以及使用单通道的音节级 Word2vec 或 Glo-Ve 的模型性能, 实验结果如图 5(a)所示。可以看出, 融合双通道音节特征的模型比使用单通道的音节级 Word2vec 和 GloVe 的分类准确率分别提高 1.1和 1.25 个百分点, 验证了融合双通道音节特征的有效性。
3.4.3 多粒度卷积模式的有效性验证
为了验证卷积模式对模型性能的影响, 考查不同卷积模式对本文模型性能的影响。模式 1 为单粒度卷积方式, 模式 2 为多粒度卷积方式, 均选择效果最佳的卷积核大小, 卷积核大小分别为 3 和(2, 3, 4), 实验结果如图 5(b)所示。可以看出, 融合双通道音节特征的多粒度卷积模式的分类准确率比单粒度卷积模式高 0.91 个百分点, 验证了多粒度卷积模式的有效性。
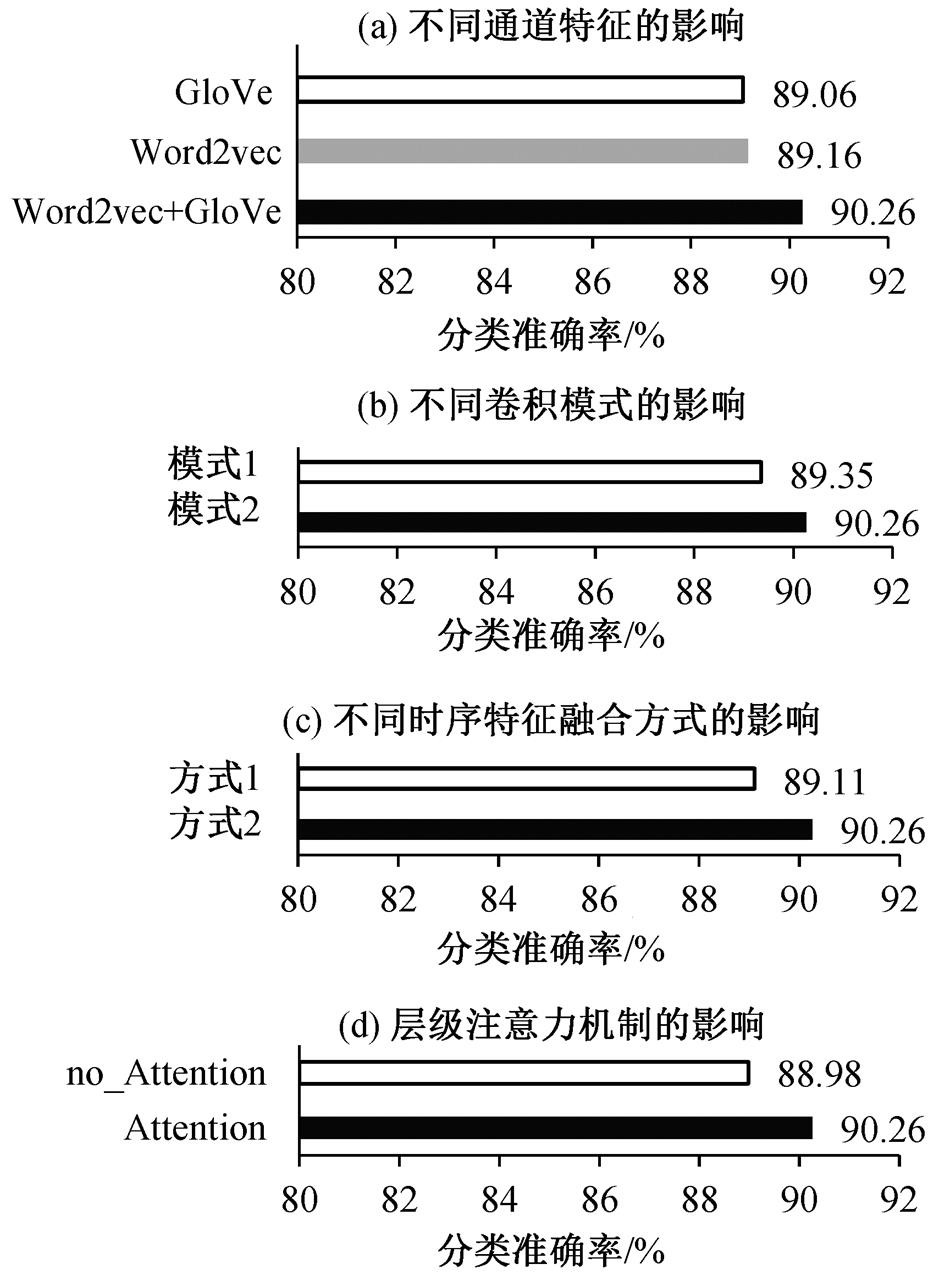
图5 不同特征学习方式对模型性能的影响
Fig.5 Effects of different feature learning methods on model performance
3.4.4 时序特征融合方式的影响
为了验证本文时序特征融合方式对模型性能的影响, 探究多路卷积与 Bi-LSTM 结合方式对最终模型性能的影响。方式 1 为先进行多路卷积特征的融合, 再通过 Bi-LSTM 学习时序特征的实验结果; 方式 2 为每一路卷积后直接用 Bi-LSTM 学习时序特征的实验结果, 实验结果如图 5(c)所示。可以看出, 时序特征学习方式 2 的分类准确率比方式 1 高 1.15个百分点, 表明每一路卷积后直接用 Bi-LSTM 学习时序特征的分类效果更佳。
3.4.5 层级注意力机制对模型性能的影响
为了验证层级注意力机制对本文模型性能的影响, 分别考查加层级注意力机制时以及不加层级注意力机制时模型的分类效果, 实验结果如图 5(d)所示。可以看出, 模型加层级注意力机制时的分类准确率比不加层级注意力机制时高 1.28 个百分点, 表明本文模型加层级注意力机制时分类效果更好。
本文提出一种融合双通道音节特征的藏文 La格例句自动分类模型, 使用 word2vec 和 GloVe构建双通道藏文音节嵌入, 分别在每路卷积中对双通道音节特征进行融合, 提高了卷积层的空间表征能力。为了更好地学习句子的时序特征, 模型通过在每路卷积之后直接使用结合注意力机制的双向LSTM 学习时序特征, 得到最终的句子表征, 避免了过早融合卷积特征而破坏句子的时序特征。实验结果显示, 模型的藏文 La 格例句分类准确率能够达到 90.26%, 分类性能优于几种基线模型。在未来的工作中, 我们将通过扩充数据, 研究融合双通道词特征的藏文 La 格例句分类方法, 并尝试融入词性特征, 进一步优化模型的分类性能。
参考文献
[1]吉太加.藏语语法研究.西宁: 青海民族出版社, 2016
[2]Kim Y.Convolutional neural networks for sentence classification // Proceedings of Empirical Methods on Natural Language Processing.Doha, 2014: 1746-1751
[3]Vieira J, Moura R S.An analysis of convolutional neural networks for sentence classification // Compu-ter Conference.Cordoba, 2017: 1-5
[4]高云龙, 左万利, 王英, 等.基于稀疏自学习卷积神经网络的句子分类模型.计算机研究与发展, 2018, 55(1): 179-187
[5]汪冉, 金忠.基于极性转移和 LSTM 的树结构网络与句子分类.计算机应用研究, 2019, 36(1): 64-67
[6]Fentaw H W, Kim T H.Design and investigation of capsule networks for sentence classification.Applied Sciences, 2019, 9(11): 2200
[7]Zhao Z, Wu Y.Attention-based convolutional neural networks for sentence classification // Interspeech.San Francisco, 2016: 705-709
[8]Yang L, Ji L, Huang R, et al.Multi-grained-attention gated convolutional neural networks for sentence classification.Intelligent Data Analysis, 2019, 23(5): 1091-1107
[9]李文宽, 刘培玉, 朱振方, 等.基于卷积神经网络和贝叶斯分类器的句子分类模型.计算机应用研究, 2020, 40(2): 19-22
[10]柔特, 才让加.基于循环卷积神经网络的藏文句类识别.中文信息学报, 2019, 33(12): 76-82
[11]Ban M, Cai Z, Cai R, et al.Tibetan interrogative sentence recognition and classification based on phrase features.MATEC Web of Conferences, 2021, 336(4): 06017
[12]毛尔盖·桑木旦.藏文文法概论.西宁: 青海民族出版社, 2005
[13]格桑居冕.实用藏文文法.成都: 四川民族出版社, 2004
[14]Mikolov T, Chen K, Corrado G, et al.Efficient estimation of word representations in vector space [EB/OL].(2013-09-07)[2021-04-08].https://arxiv.org/abs/1301.3781
[15]Pennington J, Socher R, Manning C.GloVe: global vectors for word representation // Conference on Empirical Methods in Natural Language Processing.Doha, 2014: 1532-1543
[16]Joulin A, Grave E, Bojanowski P, et al.Bag of tricks for efficient text classification // Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2, Short Papers).Valencia, 2017: 427-431
[17]Zhou C, Sun C, Liu Z, et al.A C-LSTM neural net-work for text classification.Computer Science, 2015, 1(4): 39-44
[18]Peng Z, Wei S, Tian J, et al.Attention-based bidirectional long short-term memory networks for relation classification // Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers).Berlin, 2016: 207-212
[19]Lai S, Xu L,Liu K, et al.Recurrent convolution neural networks for text classification // Proceedings of the 29th AAAI Conference on Atrificial Intelligence.Austin, 2015: 2267-2273
An Automatic Classification Model of Tibetan La Case Example Sentences with Fusion Dual-channel Syllable Features
Abstract Based on the importance of automatic classification of Tibetan La case (ལ་དོན།) example sentences in Tibetan natural language processing, according to the usage and adding rules of Tibetan La case, this paper classifies Tibetan La case example sentences and defines the classification concept, and proposes an automatic classification model of Tibetan La case example sentences with fusion dual-channel syllable features.The proposed model first uses word2vec and Glove to construct a dual-channel Tibetan syllable embedding, and combines the dual-channel syllable features in each convolution respectively to enrich the expression of input features and improve the spatial representation ability of the convolutional layer.Then in each convolution, the Bi-LSTM combined with the hierarchical attention mechanism is used to learn the timing features, and the multi-channel features are spliced to improve the learning ability of the context timing features.Finally, the automatic classification of Tibetan La case example sentences is realized through the full link layer and the Softmax layer.Experiments show that proposed model has an accuracy of 90.26% in the classification of Tibetan La case example sentences on the test set.
Key words NLP; dual-channel syllabic features; Tibetan La case example sentences; automatic classification
doi: 10.13209/j.0479-8023.2021.106
收稿日期: 2021-06-12;
修回日期: 2021-08-07
国家自然科学基金(61662061, 61063033, 61966031)、国家重点研发计划(2017YFB1402200)、青海省藏文信息处理与机器翻译重点实验室项目(2020-ZJ-Y05)、青海省科技厅项目(2019-SF-129)和青海省重点实验室项目(2013-Z-Y17, 2014-Z-Y32, 2015-Z-Y03)资助