
图1 模型框架
Fig.1 Model structure
摘要 基于文本交互信息对文本语义匹配模型的重要性, 提出一种结合序列生成任务的自监督学习方法。该方法利用自监督模型提取的文本数据对的交互信息, 以特征增强的方式辅助基于神经网络的语义匹配模型, 构建多任务的文本匹配模型。9 个模型的实验结果表明, 加入自监督学习模块后, 原始模型的效果都有不同程度的提升, 表明所提方法可以有效地改进深度文本语义匹配模型。
关键词 自监督学习; 文本语义匹配; 多任务学习
文本语义匹配研究两个文本之间语义等价的度量或语义相似匹配度问题, 是自然语言处理的基础任务之一。在基于深度神经网络信息检索(neural IR)的研究中, 文本语义匹配(semantic matching)旨在通过对两个文本进行分布式表示建模, 用更丰富的形式表示查询和文档的含义, 实现基于相似性学习的语义匹配[1-3]。语义匹配的计算方法可用于处理Query-Doc 搜索[4]、Question-Answer 匹配[5]和自然语言推理[6]等任务。语义相似度的计算结果可以用于辅助自然语言处理领域的其他任务, 例如文本聚类[7]和机器翻译[8]。
文本语义匹配方法可以分为四大类: 基于字符串的方法、基于语料库的方法、基于世界知识的方法和其他方法[9]。基于字符串的方法只计算字符串的匹配程度, 不考虑语义信息; 基于语料库的方法通过构建词袋模型或者利用搜索引擎, 从现有的语料库中得到计算文本相似度的信息; 基于世界知识的方法从规范的知识库中提取信息计算相似度; 其他方法包括句法分析和多种方法互相结合的混合方法。近几年, 神经网络构建深度文本语义匹配模型的方法得到广泛的应用, 取得一些重要的进展。这些模型最初用于信息检索领域中查询项与文档之间的相似性度量, 同样也可以解决文本语义匹配问题。Guo 等[10]将现有的深度文本语义匹配模型分为基于表示的模型[4,11-12]、基于交互的模型[11,13-16]以及混合模型[17], 基于表示的模型为每个文本分别构建固定维度的向量表示, 然后在潜在空间内执行匹配; 基于交互的模型计算两个文本词汇之间的交互(这种交互可以是标识值或者是句法或语义相似值), 然后从交互矩阵中整合得出匹配分数; 混合模型主要指多种机制混合的模型, 例如 DUET[17]模型由两个子模型组成, 用于提取句子对的不同特征。这3 类深度文本语义匹配模型各有优势。一个好的文本语义匹配模型不仅能够有效地学习文本的语义信息, 还能够捕获文本之间的交互信息。
近年来, 自监督学习(self-supervised learning)受到广泛关注。Liu 等[18]将自监督学习模型归纳为三大类, 分别是生成式模型(generative)、对比式模型(contrastive)和对抗式模型(adversarial)。生成式模型以自编码器(autoencoder)为代表; 对比式模型通过对比正负样本来学习表示; 对抗式模型保留由编码器和解码器组成的生成器结构, 生成器可为对抗式模型提供强大的学习表示能力。在自然语言处理领域中, 在自监督学习概念提出之前, 已经有语言模型体现自监督学习的思想。例如, Mikolov 等[19]提出的 Word2Vec 模型实现中心词预测(CBOW 模型)和邻近词预测(Skip-Gram 模型); Skip-Thought Vectors[20]、BERT[21]以及之后提出的诸多预训练语言模型的预训练任务中包含自监督学习的任务。自监督学习框架包含一个区别于下游核心任务的自动打标签的 Pretext (辅助)任务, 通过数据不同部分的交互, 实现数据的学习表示, 并将学习到的中间特征层表示或者模型权重用于下游的监督学习预测任务中, 从而降低对大量标记数据的需求, 并且充分利用每条数据可能关联的多种模式。
多任务学习[22]旨在利用任务之间相互联系的信息来改进模型的泛化性能。Lee 等[23]使用一个与本文模型框架类似的多任务学习模型, 探讨将图片的旋转预测任务和常规的图片分类任务同时训练。其中旋转预测任务是一个自监督学习模型。其Pretext 任务是将图片进行翻转, 通过预测翻转角度实现自监督学习模型的构建。根据深度神经网络中参数共享的方式, 多任务学习模型结构分为硬参数共享和软参数共享[24]。硬参数共享通常是多个任务共享隐藏层的参数, 输出时进行分支。软参数共享指每个任务都有自己的模型和参数, 然后使用一定的机制(如 L2 距离)在模型之间建立联系。
本文在现有的深度文本语义匹配模型基础上,设计自监督学习来提取文本之间更深层次的交互信息, 提升基于深度神经网络的文本语义匹配的效果, 包含以下两个机制。
1)本文设计的自监督 Pretext 任务通过句子对互换生成, 获取文本之间基于序列转换的深层交互信息, 以特征增强的方式来辅助现有的深度文本语义匹配模型。
2)为了让自监督学习模型提取的交互信息能够与深度文本匹配模型建立动态关联, 本文使用多任务学习的方式, 将自监督学习模型训练过程中提取的交互信息作为动态特征, 参与文本语义匹配任务的调优, 以此改善两个模型的泛化性能, 使得提取的交互信息可以参与到深度文本语义匹配模型的学习中。
为了探讨所提出的自监督任务和多任务学习对基于表示、基于交互和混合模型的改进效果, 本文提出以下两个研究问题(research question, RQ)。
RQ1: 对于基于表示的文本语义匹配模型, 因其缺乏对交互信息的提取, 自监督学习模型提取的序列转换的交互信息能否成功地弥补这些模型的不足, 达到提升模型效果的目的?
RQ2: 对于基于交互的模型和混合模型, 因其已经提取文本之间的交互信息, 自监督学习模型提取的序列转换的交互信息是否会冗余?
本文选取 9 个基于神经网络的文本语义匹配模型, 在 5 份公开数据集上进行试验, 验证结合自监督学习的多任务文本语义匹配方法。
本文在现有深度文本语义匹配模型的基础上, 使用自监督学习模型提取句子对之间序列转换的交互信息, 并使用多任务学习的方式, 将提取的交互信息动态地参与深度文本语义匹配模型的训练。本文框架分为原始模型(original model, OM)和自监督模型(self-supervised Model, SSM)两部分(图1)。整体框架采用多任务学习的硬参数共享, 为这两部分模型构建联系。
图1 模型框架
Fig.1 Model structure
我们复现了 MatchZoo 工具库[25]中提供的 9 个基于深度神经网络的文本匹配模型, 在本文中用TSSM (text semantic matching model)表示。原始模型通过 TSSM, 学习得到两个句子的特征交互向量Vector_E。Vector_E 的计算方法如下。
1)给定两个句子集合 A={a1, a2, …, an}和 B={b1,b2, …, bn}, 各有 n 个句子, 并组成 n 个句对的数据集。将第 i (i∈[1, n])个句对中的 A 句子表示为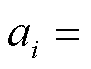
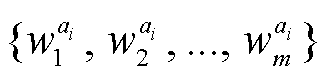 , 且
, 且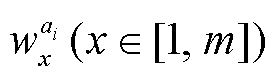 表示句子 ai的第 x 个字符/单词(中文文本为字符, 英文文本为单词)。m 表示图 1 中的 MaxLen, 即句子序列的最大长度。同样, 有
表示句子 ai的第 x 个字符/单词(中文文本为字符, 英文文本为单词)。m 表示图 1 中的 MaxLen, 即句子序列的最大长度。同样, 有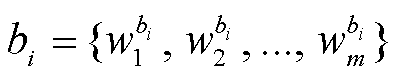 ,
,  。
。
2)将句对 i 的两个句子 ai 和 bi 通过 TSSM 的嵌入层得到嵌入表示, 即矩阵 Embed_ai∈Rm×Dim 和Embed_bi∈Rm×Dim, Dim 表示嵌入层维度, 实验中设为 300。
3)将句对 i 的两个句子的嵌入表示输入 TSSM, 得到 Vector_Ei:
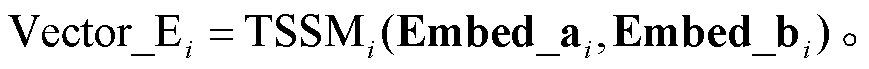 (1)
(1)4)将 Vector_Ei 输入以 Sigmoid 函数为激活函数的全连接层, 得到两个句子的相似度分数Simi:
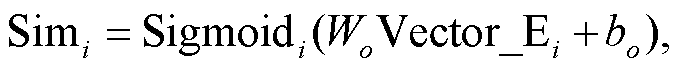 (2)
(2)
其中, Wo 和 bo 是可学习更新的参数。
将句子对的标签记为 L={y1, y2, ..., yn}, yi (i∈[1, n])表示第 i 个句子对的标签, 用二分类交叉熵作为损失函数:
LossOM =‒ (L∙log(Simi)+(1‒L)∙log(1‒Simi))。 (3)
本文设计的自监督模型通过序列生成, 用来提取句子对向量矩阵相互生成的交互信息, 并将该交互信息用于辅助文本语义匹配任务。SSM 的 Pre-text 任务是句子对的相互序列生成。具体算法如下。
1)SSM 的输入设计: 将句对 i 的两个句子 ai 和bi 采用 Skip-gram 算法分别训练, 得到 Word2Vec[21]向量表示, 即 , m 表示句子序列长度, Dim 表示向量维度, 并拼接得到矩阵W2V_ABi∈R2m×Dim:
, m 表示句子序列长度, Dim 表示向量维度, 并拼接得到矩阵W2V_ABi∈R2m×Dim:

2)SSM 的输出设计: 将句对i的两个句子 bi 和ai 的 Word2Vec 向量表示拼接, 得到矩阵 W2V_BAi∈R2m×Dim:
SSM 的输入是将句子对 AB 的矩阵 W2V_ABi∈R2m×Dim 作为输入, SSM 框架的标签是 W2V_BAi∈R2m×Dim。SSM 在训练过程中不改变序列长度, 使得每一个输入向量的输出与输出向量一一对应, 以W2V_ABi 生成 W2V_BAi 的训练方式, 可以使自监督模型提取的交互信息不仅蕴含两个句子的上下文语义信息, 也蕴含序列转换的信息。
3)卷积层特征提取: 使用 C 层一维卷积层(Conv1D)构造多层卷积网络(multi-CNN), 提取W2V_ABi 的 N 元组特征, 并将这些特征进行拼接, 形成包含 N 元组特征的矩阵, 记为Ng∈R 2m×256C:
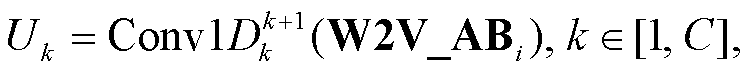 (4)
(4)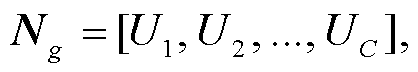 (5)
(5)
其中, 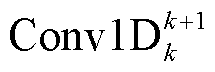 表示第 k 层 Conv1D 且卷积核宽度为 k+1, Uk表示第 k 层 Conv1D 的输出。
表示第 k 层 Conv1D 且卷积核宽度为 k+1, Uk表示第 k 层 Conv1D 的输出。
就 Multi-CNN 层数的设置而言, 对于中文文本, 考虑到其存在多字词语, 将 C 设置为 4, 卷积核大小分别为 2, 3, 4 和 5, 可以同时提取字向量矩阵的二元、三元、四元和五元特征; 对于英文文本, 将C 设置为 3, 卷积核大小分别为 2, 3 和 4, 用于同时提取字向量矩阵的二元、三元和四元特征。
4)序列特征提取和模型输出: 将步骤 3 中的多层卷积网络的输出作为自注意力机制层(Self-attention)[26]的输入, 以此提取 N 元组的序列特征, 同时 Self-attention 输出的每个节点都包含整个序列的信息。自注意力机制的输出经过标准化后, 使用以 Softmax 为激活函数的 Time Distributed 全连接网络, 得到 SSM 的输出, 记为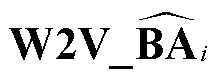 :
:
 (6)
(6)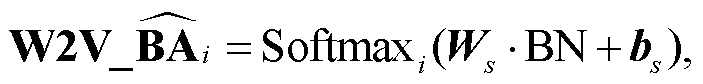 (7)
(7)
其中, Ws 和 bs 是可学习更新的参数。
余弦相似度考虑的是向量夹角的大小, 适用于判断生成的向量与真实向量的相似性。相比之下, MSE (均方误差)和 MAE (平均绝对值误差)更多地考虑预测值与真实值之间的距离, 未考虑相似性。SSM以余弦相似度作为损失函数:
 (8)
(8)本文提出的多任务学习框架首先需要将自监督学习过程习得的文本互换生成时的交互关系信息, 提供给下游核心任务(即原始模型)。具体地, 本文将 SSM 提取的经过归一化的交互信息(BN), 经过池化层求和平均, 得到向量 Vector_F:
 (9)
(9)然后, 将原始模型的 Vector_Ei 和交互信息 Vector_ Fi 拼接后, 输入以 Sigmoid 函数为激活函数的全连接层, 得到相似度分数 Sim_Scorei:
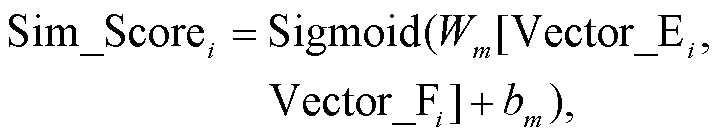 (10)
(10)
其中, Wm 和 bm 是可学习更新的参数。
在训练过程中, 多任务学习总体损失函数为
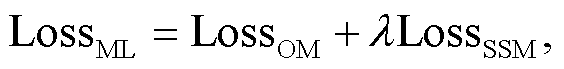 (11)
(11)其中, λ∈(0, 1)是自监督模型损失函数的权重系数。在本文实验中, λ取值为 0.5。
本文选用的数据集是文本语义匹配二分类任务的公开数据集, 包括微软研究释义语料库(MSRP)①https://www.microsoft.com/en-us/download/details.aspx?id=52398、2018 年微众银行智能客服问句匹配大赛数据集(CCKS18-T3)②https://www.biendata.xyz/competition/CCKS2018_3、天池“公益 AI 之星”挑战赛数据集(TCAI20)③https://tianchi.aliyun.com/competition/entrance/231776/introduction和首届全球人工智能技术创新大赛赛道三数据集 (GAIIC21-T3 和GAIIC21-T3M)④https://tianchi.aliyun.com/competition/entrance/531851/introduction。各数据集的分布情况见表 1。
表1 数据集分布情况
Table 1 Data set statistics

数据集训练集/对验证集/对测试集/对平均长度评价指标语种 MSRP4076-172518.92F1-Score英文 CCKS18-T3100000100001000011.37Accuracy中文 TCAI208747200260113.68Accuracy中文 GAIIC21-T370000-300006.47AUC中文 GAIIC21-T3M100000--6.47AUC中文
如表 2 所示, 本文选取 9 个模型进行实验。OM的参数是 MatchZoo 工具库[25]的默认参数。SSM 的参数如表 3 所示。Multi-CNN 每一层的以及 Self-Attention 神经元数量固定为 256, 激活函数都是Relu。实验中, 对 MSRP, CCKS18-T3, TCAI20 和GAIIC21-T3 这 4 个数据集的训练集采用 10 折交叉验证, 选取效果最好的一折模型用于测试集进行测试。GAIIC21-T3M 的训练集是 GAIIC21-T3 的训练集和测试集的总和。GAIIC21-T3M 数据采用整个训练集 10 折交叉验证的方法, 对比 GAIIC21-T3 的测试, 前者评估数据标签分布较相似时模型的表现, 后者评估模型在独立测试数据上的表现。采用的评价指标包括 F1-score (MSRP)、Accuracy (CCKS18-T3 和 TCAI20)和 AUC (GAIIC21-T3 和 GAIIC21-T3M)。
本文设计了分解模型以及分解模型和 SSM结合的多任务模型。分解模型(Self-attention, SA)指将自监督学习过程中习得的文本交互信息 Vector_Fi输入以 Sigmoid 函数为激活函数的全连接层, 得到句子对的相似度分数。此模型评估自监督学习中的Pretext 任务学习的文本交互信息 Vector_Fi 是否可以独立用于文本相似度计算。基于此, 本文还设计了多任务模型 SA+SSM, 即将 SA 分解模型的损失函数与 SSM 模型的损失函数加权求和, 作为多任务SA+SSM 模型预测句子对的相似度, 加权方式与OM+SSM 多任务学习的损失函数相同, λ取值为0.5。
表2 深度文本语义匹配模型
Table 2 Neural semantic matching models

模型模型描述 基于表示的模型ARC-I[11]采用重复堆叠的一维卷积神经网络和一维最大池化层, 分别提取两个句子的 N-gram 特征, 没有对交互信息进行提取 DSSM[4]是第一个提出深度语义匹配的模型, 虽然可以提取句子的语义信息, 但缺少对句子对之间的交互信息的提取 CDSSM[12]是在 DSSM 的基础上, 通过使用使用卷积神经网络捕获句子的 N-gram 信息, 缺少对句子对之间的交互信息的提取 基于交互的模型ARC-II[11]弥补了 ARC-I 缺少对交互信息提取的缺点。本文实验使用相加得到两个 N-gram 信息的交互矩阵 DRMMTKS[13]在查询项与文档之间建立交互, 为每个查询项创建一个固定长度的匹配直方图, 输入全连接神经网络来得到相似度 K-NRM[14]使用高斯核函数(RBF kernel)来捕获词汇之间的软匹配(soft-match)信号特征, 将特征组合在一起, 经过全连接网络得到相似度 CONV-KNRM[15]是 K-NRM 的一个变体, 在形成 Translation 矩阵之前使用多个卷积神经网络来提取两个句子词汇之间的 N-gram信息 MV-LSTM[16]基于 Bi-LSTM 的语义模型, 两个句子的向量矩阵进行交互得到新的向量表示, 然后使用 Top-K 最大池化层和全连接神经网络进行降维, 得到两个句子的相似度 混合模型DUET[17]混合模型中的 Local 模型用于捕获词汇与词汇的匹配信息, 得到 L score; Distributed 模型学习两个句子的语义向量的交互信息, 得到 D score; 将 L score 和 D score 求和得到相似度
表3 神经网络参数设置
Table 3 Neural network parameters

数据集序列长度BatchSizeOM Embedding层输出维度SSM输入维度SSM输出维度Multi-CNN每层卷积核大小 MSRP3464(34, 300)(34, 300)(68, 300)2, 3, 4 CCKS18-T34064(40, 300)(40, 100)(80, 100)2, 3, 4, 5 TCAI202064(20, 300)(20, 300)(40, 300)2, 3, 4, 5 GAIIC21-T33764(37, 300)(37, 100)(74, 100)2, 3, 4, 5 GAIIC21-T3M3064(30, 300)(30, 100)(60, 100)2, 3, 4, 5
我们通过表 4 的实验结果讨论本文提出的两个研究问题。F1-Score, Accuracy 和 AUC 取值均在 0~1 范围内。
首先讨论 RQ1。通过表 4 基于表示的模型的实验结果可以看到, 加入 SSM 后, ARC-I 模型在 5 个数据集分别提升 2.8%, 2.7%, 2.9%, 3.9%和 1.4%; DSSM 模型分别提升了 0.5%, 5.1%, 21.1%, 16.2%和12.4%; CDSSM 的提升分别为 1.3%, 8.8%, 18.6%, 12.0%和 31.7%。由此可见, 基于表示的模型在加入 SSM 后, 在 5 个数据集上的效果都得到提升。自监督学习提取的交互信息能够弥补这些模型的不足。
针对 RQ2, 由表 4 看到, 加入 SSM 后, ARC-II 模型在 5 个数据集上的性能分别提升 1.9%, 0.1%, 1.5%, 6.0%和 7.5%; DRMMTKS 模型分别提升 2.9%, 2.7%, 1.1%, 28.6%和 36.0%; K-NRM 加入 SSM 分别提升 2.1%, 4.4%, 11.9%, 33.9%和 47.4%; CONV-KNRM 分别提升 3.1%, 2.1%, 16.5%, 4.4%和 10.2%; MV-LSTM 分别提升 5.0%, 3.0%, 4.6%, 8.9%和11.6%; 对于混合模型 DUET 的提升分别是 2.4%, 2.0%, 2.6%, 8.4%和 9.3%。实验结果表明, 在基于交互的模型和混合模型的实验中, 加入 SSM 后效果均有提升, 说明 SSM 基于句子序列转换提取的交互信息与这些模型提取的交互信息并不冲突, 也不冗余, 并且能够有效地增强原始深度匹配模型提取的交互信息, 提升模型的整体效果。
通过比较分解模型 SA 与原始模型 OM 在 5 个数据集上的实验结果, 发现 SA 模型在其中 3 个数据集上的效果优于所有 OM 模型。这说明, 本文设计的自监督辅助任务能够学习到有效的、可用于文本相似度计算的文本交互信息。同时, 结合 SA 的多任务模型 SA+SSM 也在一个数据集(GAIIC21-T3)上取得最优结果。在其他 4 个数据集上取得最佳结果的是本文提出的结合自监督学习的多任务模型(OM+SSM), 说明其对下游任务是有效的。
进一步分析同一个数据集下不同模型的提升情况。表 5 展示结合自监督模型后各个数据集效果的提升效果。可以看到, 对于 MSRP 数据集, 9 个模型的提升效果都不太明显, 平均提升 2.44%。该数据集的句子提取自多个新闻网站, 每个句子都来自不同的新闻文章, 很好地消除了句子之间可能存在的语义相似性, 也可能导致句子之间主题的共性较少且主题复杂, 显示 SSM 在应对不同主题的句子对相互生成的鲁棒性较弱。对于 CCKS18-T3 数据集, 所有模型的提升效果也不够好, 平均提升 3.42%。该数据集来自微众银行智能客服问句匹配, 其核心是句子对之间的意图匹配, 而 SSM 缺少对语句意图特征的提取和表示, 显示基于序列生成的自监督模型缺乏深层语义特征提取的能力。对于其他 3 个数据集, 增加自监督学习带来的模型提升都较明显。TCAI20 是新冠疫情相似句判断, GAIIC21-T3(M)是人工智能助手对话短文本匹配。这些数据集的语句之间主题较为相近, SSM可以提取出质量较高的交互信息。
表4 实验结果(%)
Table 4 Comparing model performances (%)

模型MSRP(F1-Score)CCKS18-T3(Accuracy)TCAI20(Accuracy)GAIIC21-T3(AUC)GAIIC21-T3M(AUC) 基于表示的 OM模型与 OM+SSM多任务模型ARC-I75.5169.5374.8885.3493.08 ARC-I+SSM77.6471.4077.0488.6994.35* DSSM80.2473.2268.7276.8681.78 DSSM+SSM80.6476.9383.1989.2991.96 CDSSM79.7570.4770.8879.8369.51 CDSSM+SSM80.7576.6784.0389.4291.56 基于交互的 OM模型和混合 OM模型与 OM+SSM多任务模型ARC-II77.4171.2375.2180.5383.87 ARC-II+SSM78.8571.3276.3785.3790.18 DRMMTKS78.8175.7387.0268.5167.03 DRMMTKS+SSM81.09*77.7488.02*88.1191.16 K-NRM78.1374.0173.8867.0163.10 K-NRM+SSM79.7777.2582.7089.7593.04 CONV-KNRM77.7376.4274.5483.6181.95 CONV-KNRM+SSM80.1778.03*86.8687.3190.28 MV-LSTM76.0475.1779.6781.1883.63 MV-LSTM+SSM79.8777.4383.3688.4393.30 DUET76.6974.7883.5382.3485.39 DUET+SSM78.5676.2585.6989.2993.37 分解模型与 SA +SSM多任务Self-attention (SA)80.5075.5781.0389.7593.13 SA+SSM80.7675.7982.6989.88*94.12
说明: 加粗斜体数字表示 OM+SSM 模型优于 OM 模型的结果; 粗体星号表示各数据集的最佳结果; 分解模型 SA 优于 OM 模型的结果用下划线表示。
表5 SSM对不同数据集的提升效果(%)
Table 5 Self-supervised model improvement by data set (%)

数据集ARC-I+SSMDSSM+SSMCDSSM+SSMARC-II+SSMDRMMTKS+SSMK-NRM+SSMCONV-KNRM+SSMMVLSTM+SSMDUET+SSM平均 MSRP2.80.51.31.92.92.13.15.02.42.44 CCKS18-T32.75.18.80.12.74.42.13.02.03.43 TCAI202.921.118.61.51.111.916.54.62.68.98 GAIIC21-T33.916.212.06.028.633.94.48.98.413.59 GAIIC21-T3M1.412.431.77.536.047.410.211.69.318.61
本文提出自监督模型的辅助任务, 以句子对中两个句子相互生成的方式, 获取文本之间基于序列转换的深层交互信息, 以特征增强的方式辅助下游模型。同时, 为了让自监督模型学习到的交互信息动态地参与文本匹配任务, 本文提出采用硬参数共享的多任务学习方式, 将文本匹配模型与自监督模型相结合。结果表明, 加入自监督学习框架后, 所有模型的效果均得到提升, 证明本文用的自监督学习模型构建多任务学习, 以特征增强的方式辅助文本语义匹配任务的设计是有效的。
本文的模型和方法存在一定的局限性。当数据集中的句子对存在比较复杂多样的主题, 或者句子对中之间存在深层次(比如意图)匹配时, 我们提出的自监督模型的提升效果不够显著。未来的研究中, 需要探讨在设计自监督模型时, 如何有效地应对文本对之间主题的复杂性, 如何提取深层意图语义的交互特征以及相似文本的语法结构交互特征。
参考文献
[1]Li H, Xu J.Semantic matching in search.Foundations and Trends in Information Retrieval, 2014, 7(5): 343-469
[2]Rao J, Liu L, Tay Y, et al.Bridging the gap between relevance matching and semantic matching for short text similarity modeling // Proceedings of the 2019 Conference on Empirical Methods in Natural Lang-uage Processing and the 9th International Joint Con-ference on Natural Language Processing (EMN LP-IJCNLP).Hong Kong, 2019: 5370-5381
[3]Chandrasekaran D, Mago V.Evolution of semantic similarity — a survey.ACM Computing Surveys (CSUR), 2021, 54(2): 1-37
[4]Huang P S, He X, Gao J, et al.Learning deep struc-tured semantic models for web search using click-through data // Proceedings of the 22nd ACM inter-national conference on Information & Knowledge Management.San Francisco, 2013: 2333-2338
[5]Chen D, Fisch A, Weston J, et al.Reading Wikipedia to answer open-domain questions // Proceedings of the 55th Annual Meeting of the Association for Computa-tional Linguistics (Volume 1: Long Papers).Vancou-ver, 2017: 1870-1879
[6]Parikh A, Täckström O, Das D, et al.A decomposable attention model for natural language inference // Pro-ceedings of the 2016 Conference on Empirical Me-thods in Natural Language Processing.Austin, 2016: 2249-2255
[7]杨开平.基于语义相似度的中文文本聚类算法研究[D].成都: 电子科技大学, 2018
[8]Wieting J, Berg-Kirkpatrick T, Gimpel K, et al.Beyond BLEU: training neural machine translation with semantic similarity // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.Florence, 2019: 4344-4355
[9]陈二静, 姜恩波.文本相似度计算方法研究综述.数据分析与知识发现, 2017, 1(6): 1-11
[10]Guo J, Fan Y, Ai Q, et al.A deep relevance matching model for ad-hoc retrieval // Proceedings of the 25th ACM International on Conference on Information and Knowledge Management.Indianapolis, 2016: 55-64
[11]Hu B, Lu Z, Li H, et al.Convolutional neural network architectures for matching natural language sentences // Proceedings of the 27th International Conference on Neural Information Processing Systems―Volume 2.Montreal, 2014: 2042-2050
[12]Shen Y, He X, Gao J, et al.Learning semantic re-presentations using convolutional neural networks for web search // Proceedings of the 23rd International Conference on World Wide Web.Seoul, 2014: 373-374
[13]Guo J, Fan Y, Ji X, et al.DRMMTKS [EB/OL].(2019-10-05) [2021-08-14].https://github.com/NT MC-Community/MatchZoo
[14]Xiong C, Dai Z, Callan J, et al.End-to-end neural adhoc ranking with kernel pooling // Proceedings of the 40th International ACM SIGIR conference on re-search and development in information retrieval.Tokyo, 2017: 55-64
[15]Dai Z, Xiong C, Callan J, et al.Convolutional neural networks for soft-matching N-grams in ad-hoc search // 11th ACM International Conference.Los Angeles, 2018: 126-134
[16]Wan S, Lan Y, Guo J, et al.A deep architecture for semantic matching with multiple positional sentence representations // Proceedings of the AAAI Confer-ence on Artificial Intelligence.Phoenix, 2016: 2835-2841
[17]Mitra B, Diaz F, Craswell N.Learning to match using local and distributed representations of text for web search // Proceedings of the 26th International Con-ference on World Wide Web.Perth, 2017: 1291-1299
[18]Liu X, Zhang F, Hou Z, et al.Self-supervised lear-ning: generative or contrastive [EB/OL].(2021-03-20) [2021-08-14].https://arxiv.org/abs/2006.08218
[19]Mikolov T, Chen K, Corrado G, et al.Efficient esti-mation of word representations in vector space [EB/ OL].(2013-09-07) [2021-08-14].https://arxiv.org/ abs/1301.3781
[20]Kiros R, Zhu Y, Salakhutdinov R R, et al.Skip-thought vectors // Advances in Neural Information Processing Systems.Montreal, 2015: 3294-3302
[21]Devlin J, Chang M W, Lee K, et al.Bert: pre-training of deep bidirectional transformers for language understanding // Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techno-logies.Minneapolis, 2019: 4171-4186
[22]Caruana R.Multitask learning.Machine Learning, 1997, 28(1): 41-75
[23]Lee H, Hwang S J, Shin J.Rethinking data augmen-tation: self-supervision and self-distillation [EB/OL].(2019-12-24) [2021-08-14].https://openreview.net/ forum?id=SkliR1SKDS
[24]Ruder S.An overview of multi-task learning in deep neural networks [EB/OL].(2017-06-15) [2021-08-14].https://arxiv.org/abs/1706.05098
[25]Guo J, Fan Y, Ji X, et al.Matchzoo: a learning, practicing, and developing system for neural text matching // Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval.Paris, 2019: 1297-1300
[26]Vaswani A, Shazeer N, Parmar N, et al.Attention is all you need // Advances in Neural Information Pro-cessing Systems.California, 2017: 5998-6008
Multi-task Semantic Matching with Self-supervised Learning
Abstract In semantic matching, the interaction information between pairs of texts is critical in predicting a matching score for the pairs.This paper proposes a multi-task learning framework with self-supervised learning for deep learning semantic matching problem.Specifically, a self-supervised model is designed for the paired sentences to regenerate each other with sequence-to-sequence generation method.Then a multi-task learning framework integrates the representation from the self-supervised generation with that of the deep matching model to predict the similarity score of the texts.Experimentations with 9 deep matching models prove that the proposed framework can improve the performances of the traditional deep matching models.
Key words self-supervised learning; semantic matching; multi-task learning
doi: 10.13209/j.0479-8023.2021.101
收稿日期: 2021-06-08;
修回日期: 2021-08-14
国家社会科学基金(17BGL068)和广东省自然科学基金(2018A030313777)资助