
图1 多跳路径
Fig.1 Multi-hop path
摘要 为了对知识库(KBs)进行补全, 提出一种新的基于路径的推理方法, 使用注意力机制, 将实体与其类型相结合, 共同对路径中的实体进行表示, 并使用注意力机制对每条路径预测的关系向量与给定关系的表示向量之差的绝对值进行汇总来计算模型的置信度。在基准数据集 WN18RR 和 FB15k-237 上的实验结果表明, 与现有的基于路径的关系推理方法相比, 所提方法具有更好的性能。
关键词 知识库(KBs)补全; 基于路径的推理; 注意力机制
知识库(knowledge bases, KBs)是由实体和有向的实体关系组成的网络, 以(头实体, 实体关系, 尾实体)的形式存储事实三元组。目前, 大规模的KBs (如 WordNet[1]、Freebase[2]和 YAGO[3])已广泛用于不同的领域(如推荐系统[4]和问答系统[5])。KBs将实体作为节点, 实体关系作为有向边, 组成大规模的事实三元组。但是, 现实世界的 KBs 中往往存在缺失, 会对其下游任务造成影响。
基于路径的推理方法通过组合实体对之间的路径来推断实体对之间未知的关系。事实上, 通过利用 KBs 中两个或多个关系组成的多跳路径进行更复杂的推理, 对 KBs 的补全更有帮助。如图 1 所示, 三元组事实(奥巴马, 国籍, 美国)可通过观察 KBs中“奥巴马-出生地-檀香山-位于-夏威夷-属于-美国”这条路径来推断。
在 KBs 中, 任意两个实体之间都存在大量的多跳路径。因此, 在基于路径的关系推理中, 准确的推理往往来自多条路径信息的整合[6]。图 2 中, 4 条路径都不直接包含“史蒂夫·乔布斯的国籍是美国”这个信息, 如果综合考虑这些路径, 将从这 4 条路径中获得许多支持这一事实的证据。
Lao 等[7]提出基于路径的推理方法 PRA(path ranking algorithm), 该方法将每条路径都视为一个原子特征, 使得它很难适用于拥有数亿计路径的大规模 KBs。为了解决这个问题, Neelakantan 等[8]提出一种基于神经网络的 Path-RNN 方法, 但未将路径中的实体作为输入, 且对每一个给定的关系单独训练一个模型, 没有充分地共享模型参数。为了提高Path-RNN 算法的性能, Das 等[9]进行扩展, 纳入实体信息, 且只训练一个 RNN 模型来预测所有的关系类别, 不仅共享模型参数, 还提高了模型精度。上述工作证明了基于路径的推理方法的有效性[7-10], 但存在以下两方面的问题。
图1 多跳路径
Fig.1 Multi-hop path
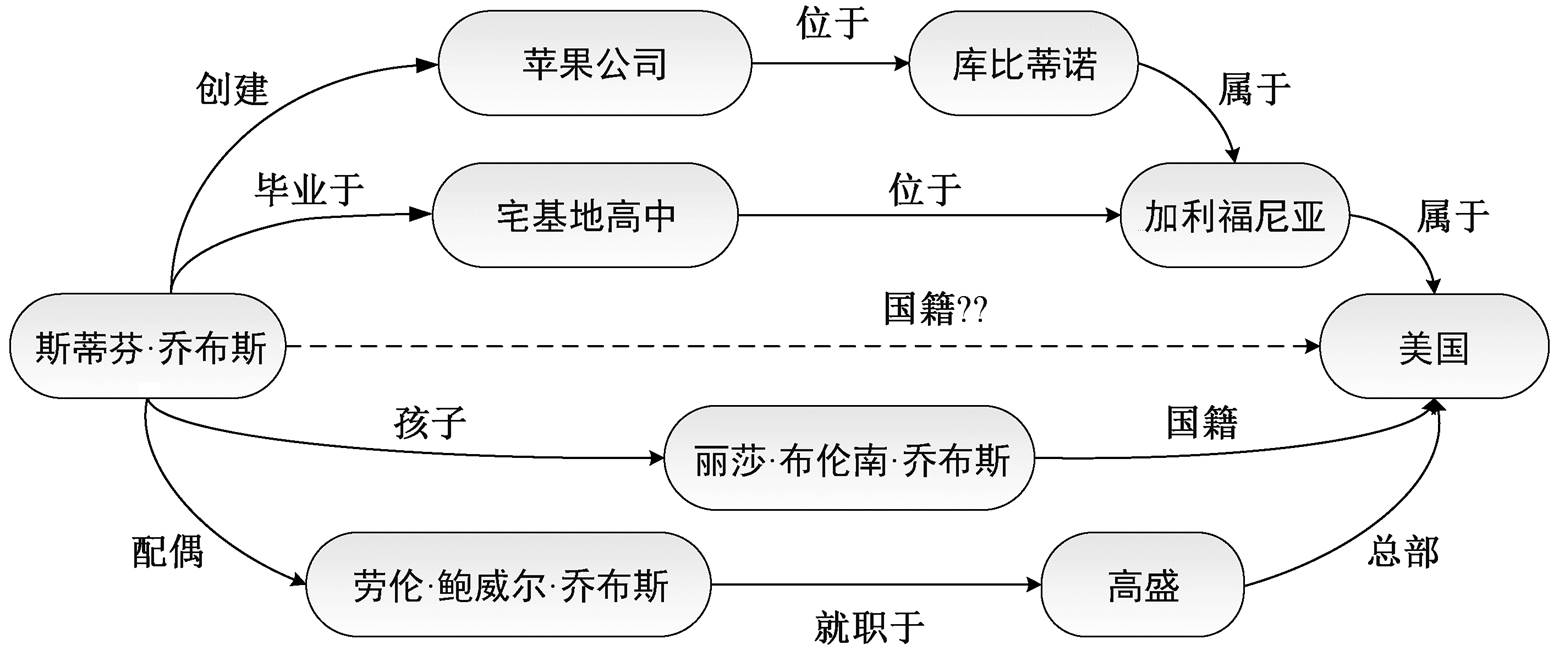
图2 多跳路径集合[6]
Fig.2 Multi-hop path collection[6]
1)忽略路径中实体与实体类型的依赖关系。在 KBs 中, 实体出现的频率是重尾分布。由于大多数 KBs 中都标注了实体的类型, 对于出现频率较低的实体, 很难学习到良好的实体表示。例如图 1 中, 奥巴马有总统、政治家、律师和美国公民等实体类型。为了解决重尾分布的问题, Jiang 等[6]和 Das 等[9]将实体类型映射到向量空间, 并将实体对应的不同实体类型的表示向量平均值作为该实体的表示向量, Zhu 等[11]则将实体对应的不同实体类型的表示向量之和作为该实体的表示向量。在上述两项研究中, 仅使用实体类型, 均未利用实体类型与实体之间的相互依赖关系。
2)计算置信度的方法没有充分地利用路径信息。在计算路径集合与实体对之间给定关系的置信度阶段, Das 等[9]采取对不同路径预测的关系向量与给定关系表示向量的内积取平均值、最大值或 LSE (LogSumExp)的方法, 不能有效地利用路径集合的信息。这是因为, 采用最大值的方法只有一条路径用于推理, 其他路径的信息被忽略; 连接实体对的路径集合通常非常大, 仅有几条路径可能有助于推断。所以, 取平均值的方法会使模型受到噪声影响; LSE 是最大值的平滑近似值, 不能有效地整合来自多条路径的信息。
针对上述问题, 本文提出一个新的基于路径推理的模型——基于路径推理的注意力机制模型, 将基于路径的推理转化为依据实体之间的一组路径来判断该实体对之间是否存在给定的关系。为了将KBs 中缺失的关系补全, 本文采用不需要逻辑规则且具有可解释性的基于路径的推理方法。
KBs 被定义为一个三元组, 也称关系事实,
X={(ei, rj, em)│ei, em∈E∩rj∈R},
其中, E 表示实体集合, R 表示关系集合。KBs 也可以表示为多关系网络 G, 其中节点代表实体, 边代表关系。每个三元组(ei, rj, em)都包含一个从 ei 到 em有向边 rj。ei 到 em 之间的路径用 p={ei, ri, ei+1, ri+1, …, rm-1, em}表示, 路径的长度定义为路径中的关系数量, 在路径 p 中为 m-i。对于 G 中的任一对实体 ei 和 em, 可以有 N 条不同的路径, 从而组成路径集合, Pim={p1, p2, …, pN}。本文的目标是从残缺的 KBs 中提取路径集合 Pim 来预测实体对 ei 与 em 之间是否存在缺失的关系r。
本文模型需要基于训练数据, 学习一个关系分类器, 然后使用它来预测测试集中实体对之间的关系, 即需要为实体对 ei 和 em 给定一个关系 r, 通过计算得到实体对 ei 和 em 的路径集合 Pim 与给定关系 r 的置信度得分, 据此判断 KBs 中 ei 与 em 之间是否存在缺失的关系 r。
本文提出的模型采用随机初始化的方式, 将每条路径中涉及的实体、实体对应的不同实体类型和路径中包含的关系映射到向量空间, 将向量作为模型的输入。在基于实体类型的注意力层中, 利用实体表示向量和实体类型表示向量计算不同实体类型的权重, 对不同的实体类型赋予不同的权重, 以便突出同一实体的不同实体类型在不同路径或关系中的差异以及个别实体类型对关系推理的重要性。在计算模型置信度的阶段使用注意力机制, 通过对每条路径预测的关系向量与给定关系的表示向量之差的绝对值进行汇总来计算模型的置信度。使用注意力机制, 将每条路径上产生的误差绝对值进行加权组合, 从而能够充分地利用多条路径的聚合信息。并且, 注意机制可以为每条路径自动地分配权重。使用向量差的绝对值体现了预测关系向量与给定关系的表示向量在向量空间中每个维度的差异, 便于后续对差异进行减小和优化。
本文提出的基于路径推理的注意力机制模型将实体 ei 与 em 之间的路径集合 Pim= {p1, p2, …, pN}作为输入, 并输出给定关系 r 连接 ei 和 em 的置信度P(r|ei, em)。如图 3 所示, 本文模型由基于实体类型的注意力层、实体编码层、关系编码层和基于关系路径的注意力层 4 层组成。
给定实体对 ei 与 em 之间的一条路径 p1={ei, ri, ei+1, ri+1, …, rm‒1, em}∈Pim 和路径中实体对应的实体类型集合{τi, …, τm‒1, τm}, 其中每个实体对应 n 个实体类型, 即 τk={tk,1, …, tk,n‒1, tk,n}。基于实体类型的注意力机制将实体{ei, …, em‒1, em}和对应的实体类型{τi, …, τm‒1, τm}作为输入, 对输入进行编码, 得到实体的最终表示[Ei, …, Em‒1, Em]。为突出部分实体类型对实体间关系的主导作用, 本文用注意力机制给不同实体类型分配不同的权重。实体 ei 的第 o 个实体类型 ti,o 在该层所占权重 αi,o 的计算方法如下:
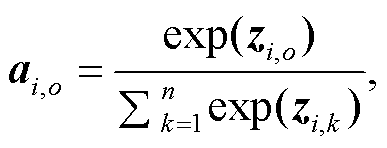 (1)
(1)其中,
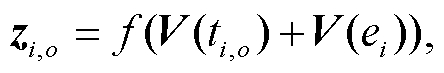 (2)
(2)
其中, zi,o 和zi,k是中间变量, zi,o 将V(ti,o)与V(ei)关联, zi,k将V(ti,k)与V(ei)关联; f(∙)表示前馈网络; V(ti,o)为实体ei的第o个类型ti,o的表示向量; V(ei)为实体ei的表示向量。利用式(1)和(2)得到不同实体类型的权重后, 为了规避实体的重尾分布问题, 本文利用实体类型表示向量来获得实体ei的最终表示Ei:
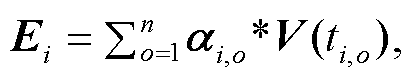 (3)
(3)其中, *表示Hadamard积。
为了充分利用实体的上下文信息, 实体编码层将实体的最终表示[Ei, …, Em-1, Em]作为本层的输入, 使用能缓解 RNN 长期依赖问题的 LSTM[12]对[Ei, …, Em‒1, Em]进行编码, 将 LSTM 每个时间步的隐藏状态[Hi, …, Hm‒1, Hm]作为本层的输出。
为了提高算法的性能, 将实体编码层的输出[Hi, …, Hm‒1, Hm]与关系表示向量[V(ri), …, V(rm‒1), V(rm)]按照时间步进行拼接, 得到本层的输入[[Hi; V(ri)], …, [Hm‒1; V(rm‒1)], [Hm; V(rm)]]。为了使路径中的实体数量与关系数量相匹配, 为每条路径增加相同的路径结束标志向量 V(rm)。对拼接之后的向量, 通过 LSTM 进行编码, 将 LSTM 最后一个时间步的隐藏状态作为路径 p1 提供给实体对 ei 与 em之间关系的预测向量 π1。
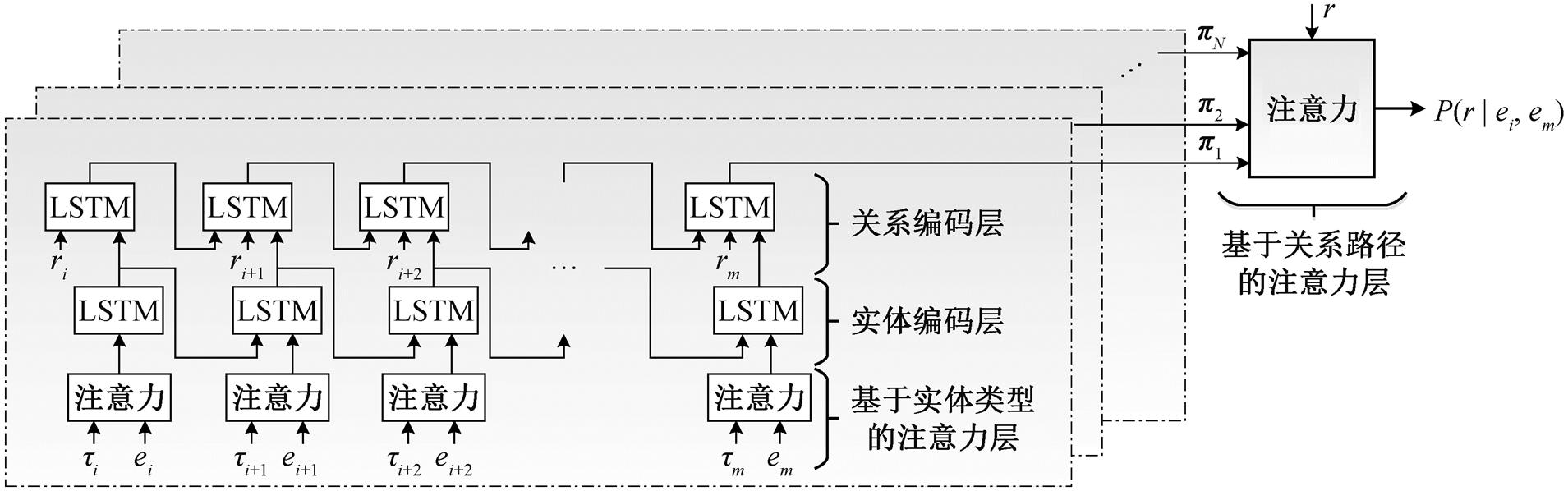
ei 代表路径中的实体, τi代表实体 ei 对应的实体类型, ri代表路径中的关系, r 代表给定关系, π1 代表路径 p1 预测实体 ei 与 em 之间的关系向量, P(r|ei, em)代表路径集合 Pim 与给定关系 r 的置信度
图3 基于路径推理的注意力机制模型
Fig.3 Attention mechanism model based on path reasoning
使用上述方法对路径集合 Pim 中剩余的 N-1 条路径进行编码, 最终得到预测关系向量集合 Π= [π1, …, πN‒1, πN]。同时, 使用一个可训练的向量 u来表示 ei 与 em 之间给定的关系 r, 使用向量 u 与每条路径的预测关系向量 πi 之差的绝对值Δi=|u-πi|来表示模型在每条路径上产生的误差。使用类似实体类型的注意力层, 对每条路径上产生的误差进行汇总, 并将汇总后的误差转化为对应的置信度 P(r|ei, em), 计算方式如下:
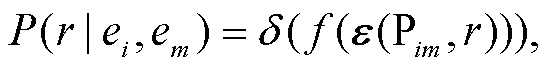 (4)
(4)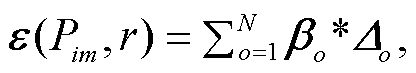 (5)
(5)
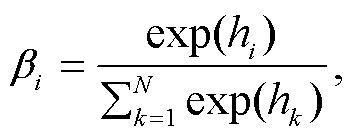 (6)
(6)
 (7)
(7)其中, δ(∙)表示 sigmoid 函数, βi 代表注意力机制在每条路径上分配的权重, ε(Pim, r)代表路径集合 Pim 与给定关系r之间的误差总和。
基于路径推理的注意力机制模型未使用外部工具产生的特征, 因此可以进行端到端的训练。为了预测每个关系, 本文使用训练集中的真假三元组作为正例((ei, r, em) DrTrain+)和负例((ei, r, em)DrTrain-)来训练模型。使用交叉熵损失函数对模型进行优化, 模型的损失计算方式如下:
DrTrain+)和负例((ei, r, em)DrTrain-)来训练模型。使用交叉熵损失函数对模型进行优化, 模型的损失计算方式如下:
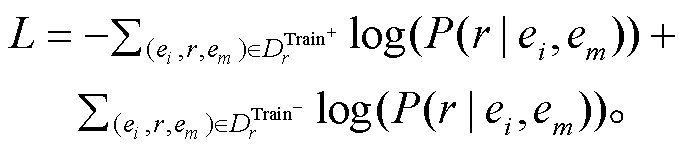 (8)
(8)在 FB15k-237 和 WN18RR 两个基准数据集上评估本文方法与基线方法。首者是常识 KBs Freebase[2]的子集, 后者则是英语词汇数据库 WordNet[1]的子集。表 1 列出两个数据集的统计数据。
参照 Liu 等[10]的方式处理数据。从每个数据集的所有真三元组 X 中建立一个完整的实验数据集:
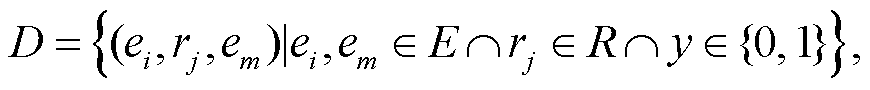
y 表示三元组是真还是假。该数据集包含额外的假三元组, 这些假三元组是基于个性化 PageRank 算法, 从 X 中采样得到。负采样是必要的, 因为两个基准数据集中只包含真三元组, 负例的数量对算法的性能有显著的影响[13]。本文为每个正例抽取 10个负例, 并将数据集分为 80%的训练集和 20%的测试集。因为基于路径的方法通常分别对每个关系进行建模, 所以会根据关系对数据做进一步的划分。
为了提取实体之间的路径, 本文用数据集中的真三元组构建 KBs。按照 Lao 等[7]的方法, 用反向关系扩充 KBs。使用双向广度优先算法(breath first search, BFS)提取路径。实验中, 最大路径长度的确定与数据集中三元组的连接紧密程度相关。对多跳路径来说, 最大路径长度越大, 在给定一种关系的情况下实体对之间的路径数量越多, 但无效路径被抽取的概率也越大, 不仅给实验带来噪声, 而且占用的空间和消耗的时间更多。本文根据 Liu 等[10]对最大路径的选择, 在 WN18RR 数据集中, 最大路径长度设置为 6; 在连接更密集的 FB15k-237 数据集中, 最大路径长度设置为 4。这样, 不仅能提供足够的路径用于训练, 而且消耗的资源较少。为每对实体随机抽取 200 条路径(即 N=200)。在 WN18RR数据集中, 使用 WordNet[1]中的实体上位词作为实体类型; 在 FB15k-237 数据集中, 使用 Xie 等[14]的实体类型数据。然后, 遵循 Das 等[9]的方法, 为FB15k-237 数据集中每个实体选择 7 种最常见的类型。对于 WN18RR 数据集, 对每个实体使用全部的上位词, 还使用预先训练的 Google News word2vec模型, 将实体类型映射到向量中。
表1 数据集FB15k-237和WN18RR的统计数据
Table 1 Statistics for the data set of FB15k-237 and WN18RR

数据集数量路径长度 关系实体三元组被测试的关系实体类型每个被测试关系的平均实体对每个实体拥有的实体类型最大值平均值 训练集测试集最大值平均值 WN18RR 1140943134720 980923803911888144.665.3 FB15k-2372351354525429010102916696 5219 76.443.5
本文使用反向传播算法来更新可训练的模型参数。本文模型中有如下超参数: 1)实体类型表示向量 V(ti,o), 其维度在 FB15k-237 中为 50, WN18RR 中为 300; 2)实体表示向量 V(ei), 其维度为 50; 3)关系表示向量 V(ri), 其维度为 50; 4)实体对之间给定关系的表示向量 u, 其维度为 100; 5)关系编码层和实体编码层中两个 LSTMs 的维度均为 150。在前馈网络 f(∙)中使用的激活函数是 Relu 函数。对所有可训练的参数采用随机初始化的方式赋初值, 用 Adam优化器[15]对模型进行优化。将 MAP 作为模型的评价标准(AP 是针对一种关系中所有实体对的平均精度, MAP 是针对所有关系的平均 AP)。实验中还将早期停止(early stopping)作为正则化手段, 防止模型过拟合。3.3 节和 3.4 节的实验都进行 5 次, 取 5次实验结果的平均值作为最终结果。
本文使用实体类型表示向量的平均值与实体类型表示向量之和来获取实体表示, 得到表 2 中的结果。可以看出使用均值或者和的方式取得的 MAP值都低于使用注意力机制, 说明使用注意力机制可以对实体进行更好的表示, 不仅可以增强实体与其类型的依赖关系, 还能提高实验结果的精度。
本文采取对每条路径预测的关系向量与给定关系向量的内积取平均值、最大值或 LSE 的方法获取置信度, 结果见表 3。可以看出, 基于关系路径的注意力层取得更好的实验结果。这是因为在汇总多条路径信息的过程中, 注意力机制不只依赖权重最大的路径, 或对所有路径分配相同的权重, 而是综合全部路径的信息, 并使用每条路径预测的关系向量与给定关系的表示向量之差的绝对值来计算每条路径的权重, 会便于后续对差异进行减小和优化。
表2 实体向量的不同获取方式对实验结果的影响
Table 2 Effect of different acquisition methods of entity vectors on experimental results

实体向量的获取方式MAP/% WN18RRFB15k-237 Avg(type)78.255.9 Sum(type)79.057.1 Attention(type, entity)79.657.4
说明: Avg(type)代表实体类型表示向量的平均值, Sum(type)代表实体类型表示向量之和, Attention(type, entity)表示基于实体类型的注意力层; 粗体数字表示本文方法的结果更好, 下同。
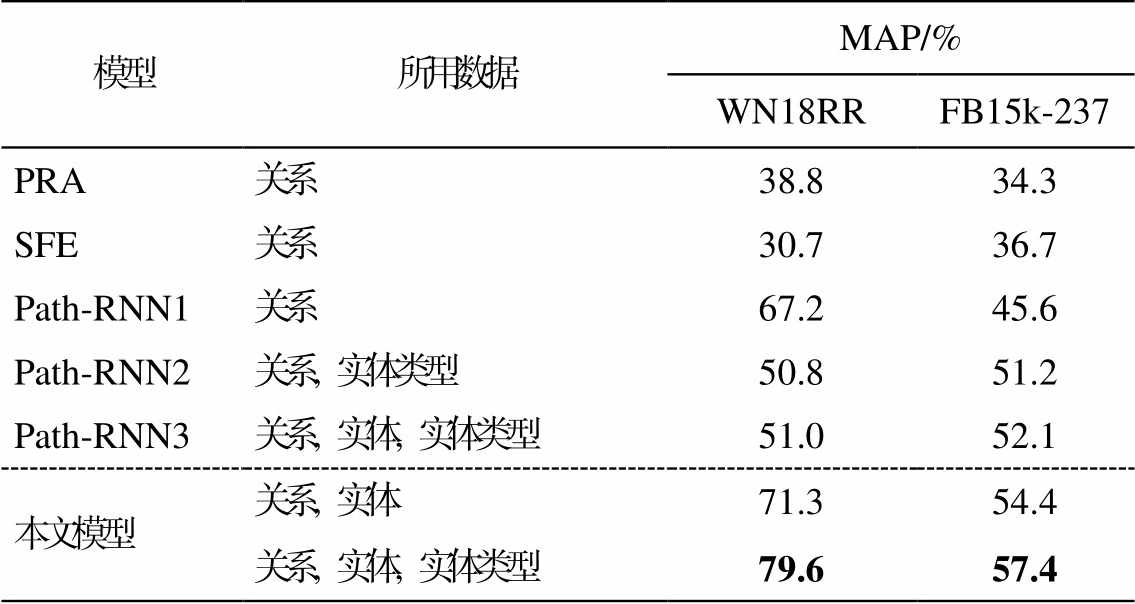
将本文提出的基于路径推理的注意力机制模型与以下基线模型进行比较, 在相同的数据集上获得的结果如表 4 所示。
1)PRA[7]将路径作为特征, 输入二进制对数线性分类器中, 判断实体对间是否存在给定的关系。
2)SFE[16]首先执行广度优先算法, 抽取每个实体周围的子图, 再对子图进行特征抽取, 得到特征向量, 进而实现KBs补全。
3)Path-RNN1[8]通过 PRA 模型获取需要的路径, 使用RNN对路径进行编码, 进而实现 KBs 补全。
4)Path-RNN2[9]和 Path-RNN3[9]使用 RNN 对路径进行编码, 使用注意力机制对路径集合进行汇总, 完成 KBs 的补全。其中, Path-RNN2 和 Path-RNN3使用的数据类型不同。
从表 4 中 Path-RNN2 与 Path-RNN3 的对比实验结果可以看出, 添加实体信息有助于更准确地预测实体关系。本文模型同样添加了实体信息, 并在路径集合上使用注意力机制, 效果大大好于 Path-RNN3, 证明在实体类型上使用注意力机制能够增强实体与其类型的依赖关系, 进而增强路径的表示, 提高了实验结果的精度。在本文提出的模型中, 使用实体类型与不使用实体类型取得的结果有所差距, 证明实体类型与实体的依赖关系对模型性能的提升有益。与以上基线模型相比, 本文模型取得最好的结果, 尤其在 WN18RR 数据集上, MAP 提升18%, 说明本文提出的基于实体类型的注意力层, 使用注意力机制对每条路径预测的关系向量与给定关系的表示向量之差的绝对值进行汇总来计算模型置信度的方法是行之有效的。
表3 不同置信度的计算方式对实验结果的影响
Table 3 Influence of different calculation methods of confidence on experimental results
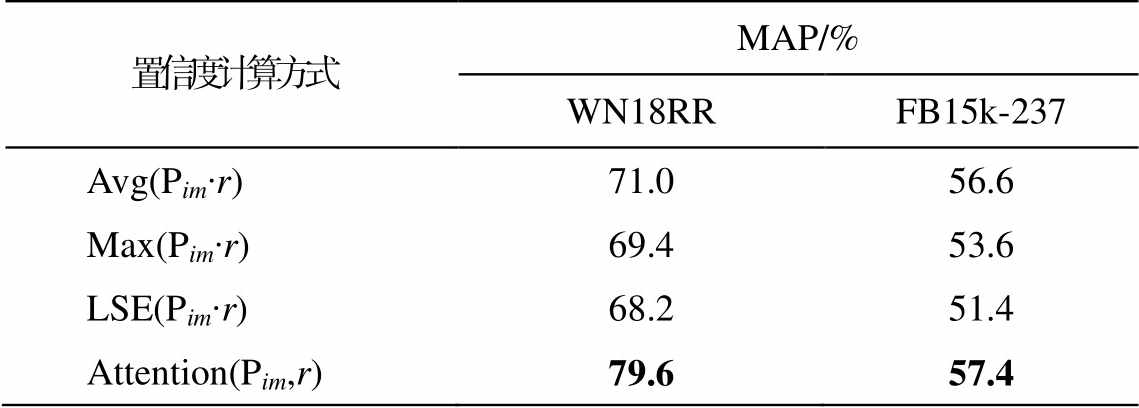
置信度计算方式MAP/% WN18RRFB15k-237 Avg(Pim∙r)71.056.6 Max(Pim∙r)69.453.6 LSE(Pim∙r)68.251.4 Attention(Pim,r)79.657.4
说明: Avg(Pim∙r), Max(Pim∙r)和 LSE(Pim∙r)分别代表对每条路径预测的关系向量和给定关系向量的内积取平均值、最大值和 LSE, Attention(Pim,r)代表基于关系路径的注意力层。
表4 与基线模型的比较
Table 4 Comparison with baseline model
模型所用数据MAP/% WN18RRFB15k-237 PRA关系38.834.3 SFE关系30.736.7 Path-RNN1关系67.245.6 Path-RNN2关系, 实体类型50.851.2 Path-RNN3关系, 实体, 实体类型51.052.1 本文模型关系, 实体71.354.4 关系, 实体, 实体类型79.657.4
本文实现基于路径的关系推理, 为 KBs 补全提供一种有效的新方法。本文引入基于实体类型的注意力层, 利用实体类型与实体的相互依赖关系, 对实体间关系的推理起到不可或缺的作用。本文提出计算模型置信度的新方法, 不仅使模型的整体效果大大提升, 还便于误差的减小和优化。在 WN18RR和 FB15k-237 两个基准数据集上的实验结果表明, 本文方法比基于路径排序的方法有显著的改进。
参考文献
[1]Miller G A.WordNet: a lexical database for English.Communications of the ACM, 1995, 38(11): 39-41
[2]Bollacker K, Evans C, Paritosh P, et al.Freebase: a collaboratively created graph database for structuring human knowledge // Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data.Vancouver, 2008: 1247-1250
[3]Suchanek F M, Kasneci G, Weikum G.Yago: a core of semantic knowledge // Proceedings of the 16th Inter-national Conference on World Wide Web.Banff, 2007: 697-706
[4]Wang Xiang, Wang Dingxian, Xu Canran, et al.Ex-plainable reasoning over knowledge graphs for re-commendation // Proceedings of the AAAI Confe-rence on Artificial Intelligence.Hawaii, 2019: 5329-5336
[5]胡月, 周光有.基于 graph transformer 的知识库问题生成 // 第 19 届中国计算语言学大会.海口, 2020: 324-335
[6]Jiang Xiaotian, Wang Quan, Qi Baoyuan, et al.At-tentive path combination for knowledge graph com-pletion // Proceedings of the 9th Asian Conference on Machine Learning.Seoul, 2017: 590-605
[7]Lao N, Mitchell T, Cohen W W.Random walk infe-rence and learning in a large scale knowledge base // Proceedings of the Conference on Empirical Methods in Natural Language Processing.Edinburgh, 2011: 529-539
[8]Neelakantan A, Roth B, Mccallum A.Compositional vector space models for knowledge base completion // Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics.Beijing, 2015: 156-166
[9]Das R, Neelakantan A, Belanger D, et al.Chains of reasoning over entities, relations, and text using recurrent neural networks // Proceedings of the 15th Conference of the European Chapter of the Associa-tion for Computational Linguistics.Valencia, 2017: 132-141
[10]Liu Weiyu, Daruna A A, Kira Z, et al.Path ranking with attention to type hierarchies // Proceedings of the AAAI Conference on Artificial Intelligence.New York, 2020: 2893-2900
[11]Zhu Qiannan, Zhou Xiaofei, Tan Jianlong, et al.Knowledge base reasoning with convolutional-based recurrent neural networks.IEEE Transactions on Knowledge and Data Engineering, 2021, 33(5): 2015-2028
[12]Hochreiter S, Schmidhuber J.Long short-term me-mory.Neural Computation, 1997, 9(8): 1735-1780
[13]Kadlec R, Bajgar O, Kleindienst J.Knowledge base completion: baselines strike back // Proceedings of the 2nd Workshop on Representation Learning for NLP.Vancouver, 2017: 69-74
[14]Xie Ruobing, Liu Zhiyuan, Sun Maosong.Represen-tation learning of knowledge graphs with hierarchi- cal types // Proceedings of the Twenty-Fifth Interna-tional Joint Conference on Artificial Intelligence.New York, 2016: 2965-2971
[15]Kingma D, Ba J.Adam: a method for stochastic opti-mization [EB/OL].(2014‒12‒01) [2021‒05‒30].https: //ui.adsabs.harvard.edu/abs/2014arXiv1412.6980K
[16]Gardner M, Mitchell T.Efficient and expressive knowledge base completion using subgraph feature extraction // Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing.Lisbon, 2015: 1488-1498
Knowledge Bases Completion Based onMulti-hop Paths
Abstract In order to complement knowledge bases (KBs), the authors propose a new path-based reasoning method, which uses the attention mechanism to combine entities and their types to represent the entities in the path and use the attention mechanism to summarize the absolute value of the difference between the relationship vector predicted by each path and the representation vector of the given relationship to calculate the confidence of the model.The results ofexperiment on benchmark data sets WN18RR and FB15k-237 show that the proposed model has better performance than the existing path-based relational reasoning methods.
Key words knowledge bases (KBs) completion; path-based reasoning; attention mechanism
doi: 10.13209/j.0479-8023.2021.103
收稿日期: 2021-06-08;
修回日期: 2021-08-13
国家重点研发计划(2018AAA0101601)资助