表1 数据示例
Table 1 Data sample

文档片段标准问答对错误回答针对错误回答生成扩充问题 2021年5月15日, “祝融号”火星车成功登陆火星。问题: 什么登陆了火星?答案: 祝融号2021年5月15日什么时候登陆了火星
摘要 针对当前自动问答数据增强方法需要大量外部数据的问题, 提出一个面向问答模型缺陷的数据增强方法。首先, 在训练集上训练好问答模型、问题生成模型以及问答匹配模型; 然后, 获取问答模型在训练集上预测的所有答案, 并选取其中预测错误的答案; 再后, 使用问题生成模型对这些答案生成相应问题; 最后, 通过问答匹配模型对生成的问答对进行过滤, 保留其中质量较高的数据作为最终的增强数据。该方法不需要额外的数据与领域知识, 同时能够针对模型构造特定数据, 耗费较少的训练代价就能使模型性能提升。实验结果表明, 所提出的数据增强方法对 R-Net, Bert-Base 以及 Luke 均有效, 与其他数据增强方法相比, 在较少的增强数据规模下, 问答模型获得更好的性能提升。
关键词 数据增强; 问题生成模型; 自动问答模型; 质量控制
自动问答(question answering, QA)指在给定相应的文档下, 自动给出问题的答案。目前, 自动问答技术广泛应用于各个领域, 如客服、医疗问诊和阅读理解等。深度学习模型在自动问答任务中快速发展, 获得较高的精度。然而, 模型的高性能往往依赖于训练数据的大规模和高质量, 从而带来高昂的数据收集和标注成本, 尤其面对不同的领域, 需要重新进行数据收集及标注工作。自动数据增强技术能够降低这一成本, 同时帮助提升训练模型的鲁棒性, 因此具有广泛的应用场景。
数据增强在计算机视觉领域中较常应用, 但在自动问答领域, 无法简单地通过变换语料增强数据。问题生成(question generation, QG), 作为自动回答的对偶任务, 旨在依据文档及答案, 生成相关问题。之前众多相关研究集中在将问答模型与问题生成模型相结合, 进行联合学习[1-2]。虽然联合训练可以在一定程度上提高问答模型的准确率, 但不能从本质上增强数据。近几年, 研究者使用三步建模方法[3-4]扩充数据, 包括答案抽取、问题生成和质量控制。然而, 目前仍存在两个关键问题: 1)构建新数据依赖外部数据; 2)增强的数据过于庞大, 没有针对性, 导致训练成本大幅上升。
针对上述问题, 本文提出一种新的面向自动问答的数据增强策略, 无需引入外部数据, 而是充分挖掘原始数据潜力, 构建增强语料, 提升模型性能。具体来说, 首先在原始标注数据上训练 QA 模型, 然后依据模型回答错误的答案, 针对性地生成问题, 从而构造新的问答对, 最后通过问答匹配过滤机制, 筛选掉低质量数据, 构造出与 QA 模型强相关的语料, 混合到原始数据中重新训练, 有效地提升模型性能。
表 1 给出一个示例, 其中标准问题对应的答案应该是“祝融号”, 但模型错误地回答“2021 年 5月 15 日”。本文针对这样的错误回答, 在不引入外部数据的情况下构建新问题, 即“什么时候登陆了火星”, 将其用于二次训练模型, 显式地告诉模型原先的错误回答对应的问题, 从而提高模型对问题的辨别能力, 尤其是一些相似度很高, 但答案不一致的问题。
本文在 QA 数据集 SQuAD1.1[5]上进行评测, 实验结果表明, 数据增强策略能够有效地提升主流QA 模型的推理精度。同时, 有针对性地增强数据,使得扩充较少的数据即可达到提高 QA 模型精度的效果。本文提出的数据增强策略, 不依赖外部数据, 应用更加灵活, 可以为不同的自动问答领域提供有效的问答数据, 缓解问答模型因为训练语料不足以及相似问题回答不准确的问题。
文本数据增强技术中, 传统的方法主要针对数据本身的内容进行修改, 随着深度学习技术的广泛应用, 问题生成模型逐渐发展, 针对自动问答任务, 涌现一些基于问题生成方法的数据增强技术。
1.1.1局部修改
在文本数据增强方面, 一个常见且实现起来比较简单的操作是对文本进行增删与替换, Jungiewicz等[6]使用同义词林和 wordnet, Kobayashi [7]利用语言模型进行同义词替换, Wei 等[8]通过同义词替换、随机插入、随机交换和随机删除 4 种操作获取与原数据相似的新数据。这种方法在分类任务中有比较好的效果, 得益于部分分类任务中只有少数关键词对分类起作用, 使得模型对噪音的容忍度较高。
1.1.2全句修改
局部修改策略只考虑句子中的部分内容, 很可能导致一些语法或语义错误。为了解决这一问题, 有些学者尝试生成全新的句子, 其中回译技术[9]是一种比较常见的方法, 它通过机器翻译模型, 将原始数据转换成中间语言, 之后再还原, 在语义不变的同时, 得到更丰富的文本表示。此外, VAEs[10]和GAN[11]也被用于生成全新的数据。这些方法在简单数据上有不错的效果, 但没有考虑如何生成相互有联系的数据, 比如问答对。
自 Du 等[12]使用神经网络在 SQuAD 数据集上生成问题以来, 问题生成领域已经得到长足的发展, 作为自动问答的对偶任务, 它很适合辅助 QA 任务。Sun 等[1]和 Wang 等[2]将 QA 和 QG 作为联合学习任务, 共同提高性能。除联合学习外, QG 也可以辅助构造问答对。Du 等[13]直接从文档中生成问答对。Subramanian 等[14]提出两阶段数据增强策略, 先从文档中抽取答案, 再生成问题。Lewis 等[15]使用 NER 和语法解析器抽取答案。Alberti 等[3]则使用BERT 抽取答案, 同时引入 round-trip 过滤机制, 增加质量控制, 有效地提升了增强数据的质量。
上述方法都需要外部数据来增强新数据, 导致难以应用在某些标注数据稀缺的问答任务中。因此, 本文提出一种新的数据增强技术, 在不引入外部领域知识的前提下, 针对自动问答模型回答不准确的问题, 生成新的问答对, 同时控制数据质量, 获得质量更高的问答对数据。
表1 数据示例
Table 1 Data sample
文档片段标准问答对错误回答针对错误回答生成扩充问题 2021年5月15日, “祝融号”火星车成功登陆火星。问题: 什么登陆了火星?答案: 祝融号2021年5月15日什么时候登陆了火星
本文提出的数据增强策略, 不是以粗暴地增加训练数据数量为目的, 而是重点关注 QA 模型预测不准确的数据, 针对性地增强数据。QA 模型回答错误的原因主要是没有学好相应问题与上下文的关联, 通过 QG 模型扩充对应的问题, 可以显式地告诉模型, 它回答错误的答案所对应的正确问题, 能在一定程度上增强模型对问题的辨别能力, 减少之后出错的概率。与已有的数据增强方法相比, 可以在更少的增强数据上得到更多的性能收益, 同时降低训练成本。
为了生成对提升 QA 模型性能性价比更高的问答对, 本文提出的策略具体框架如图 1 所示。首先, 在原始标注训练集上训练 QA 模型, 将训练好的 QA模型在训练集上预测答案, 进行评估筛选, 挑选回答不准确或错误的答案。然后, 利用 QG 模型对这些答案生成相应的问题, 构建新的问答对。最后, 将新问答对和对应的上下文输入到质量控制模块QAMatch 中, 过滤掉不匹配的部分, 得到质量较高的增强数据, 混合到原始训练集, 重新训练 QA 模型。可依次循环这样的过程。下面介绍各模块的具体情况。
与已有的工作不同, 为了降低总体训练成本, 本文没有专门设置答案抽取模块, 而是利用 QA 模型隐式地实现这一功能。具体来说, 就是使用原始标注数据训练好 QA 模型之后, 将其在原始训练集T 上进行预测, 得到所有答案 A ={a1, a2, …, a|T|}。通过对 QA 模型的推理结果, 挑选其中的错误答案,
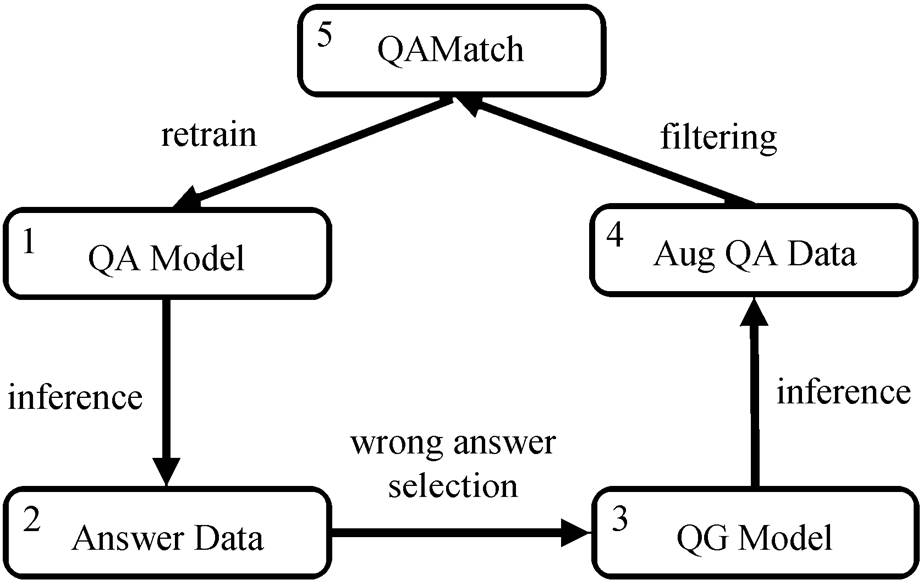
图1 框架图
Fig.1 Framework
形成过滤后的答案集合 A' ={ai+1, ai+2, …, ai+m}, 其中 m 表示被选取出来的答案总数。将上述工作形式化为
A=QA(C, Q), (1)
A'=wrong answer selection(A), (2)
其中, C 和 Q 分别表示原始标注数据中的上下文和问题。
为了进一步降低成本, 本文使用已经训练好的unilm 模型[16], 对挑选出来的答案 A'和对应的上下文C '进行提问, 得到 Q', 即
Q'= QG(C', A')。 (3)
unilm 模型是一个通过修改注意力掩码, 在一个框架内通用地处理自然语言理解任务与自然语言生成任务的预训练模型, 是目前问题生成领域的最优模型之一。
由于 QA 模型与 QG 模型之间存在误差, 增强的问答对中可能存在不匹配的数据, 所以需要通过质量控制模块过滤掉低质量的数据。常用的方法是Round-Trip[3]过滤机制, 通过将 QA 模型在新增的数据上进行预测, 保留答案一致的问答对。但是, 我们认为, 既然 QA 模型已经能够正确地回答, 再将其用于训练模型对模型性能的提升作用不大, 只需要保证上下文与问答对匹配即可, 不必强求 QA 模型能够回答正确。
因此, 本文利用 Bert[17]中的文本蕴含任务训练一个问答匹配模型[18], 将 SQuAD1.1 中的上下文与问答对三者之间通过“[SEP]”连接作为正例, 并用两种方法构造负例, 分别使用 SQuAD1.1 中同一段落下的不同问答对以及 SQuAD2.0[19]中的不可回答类型的问答对作为负例, 随后使用 Bert-large 参数初始化训练一个二分类模型, 判断上下文与问答对三者之间是否匹配。基于此方法, 可获得较高质量的问答对数据, 即
Q'', A''= QAMatch(C', Q', A'), (4)
其中, Q''和A''是最终挑选出来的增强问答对。
为了选择最佳的数据增强策略, 本文提出并对比 3 种增强策略: 1)直接增强, 获取模型在最佳状态下的增强数据; 2)早停增强, 获取模型在欠拟合状态的增强数据; 3)多模型增强, 混合多个模型的增强数据, 验证增强数据的通用性。
1)直接增强: QA 模型在训练集上训练到最佳状态后, 通过 2.1 节所述的一轮流程获取增强数据。通过这一方法, 在 QA 模型 R-Net[20]、Bert 和 Luke[21]上分别获得 5376, 3685 和 1938 条增强数据, 验证其对最佳状态模型的提升效果。
2)早停增强: 在 QA 模型训练过程中提前终止训练, 获得欠拟合状态下的模型, 此时性能略低于完整状态下的模型性能。我们认为在模型训练不充分时增强得到的数据, 更能暴露它的缺陷。此时, 除最终会预测错误的数据外, 还有部分需要进一步学习的数据也会被挑选出来。通过这一策略, 从Bert 中获得 6138 条增强数据。
3)多模型增强: 因模型的增强数据有限, 所以对 R-Net 和 Luke 应用直接增强策略, 对 Bert进行早停增强策略, 将这 3 个模型扩充得到的数据混合在一起, 去除冗余数据后, 最终得到 12844 条增强数据, 用于验证其他模型增强数据的通用性, 同时评估模型性能的变化。
本文使用的数据集是 SQuAD1.1。该数据集通过众包, 从 536 篇英文维基百科文章中构建 107785个问答对, 包括训练集、开发集和测试集。由于官方没有公布测试集, 并且现在无法提交模型测试, 所以本文将原始训练集随机选取 90%作为新训练集, 剩下的 10%作为新开发集, 将原始开发集作为新测试集。重新划分后的数据及训练参数设置如表 2 所示。
表2 参数说明
Table 2 Parameters description
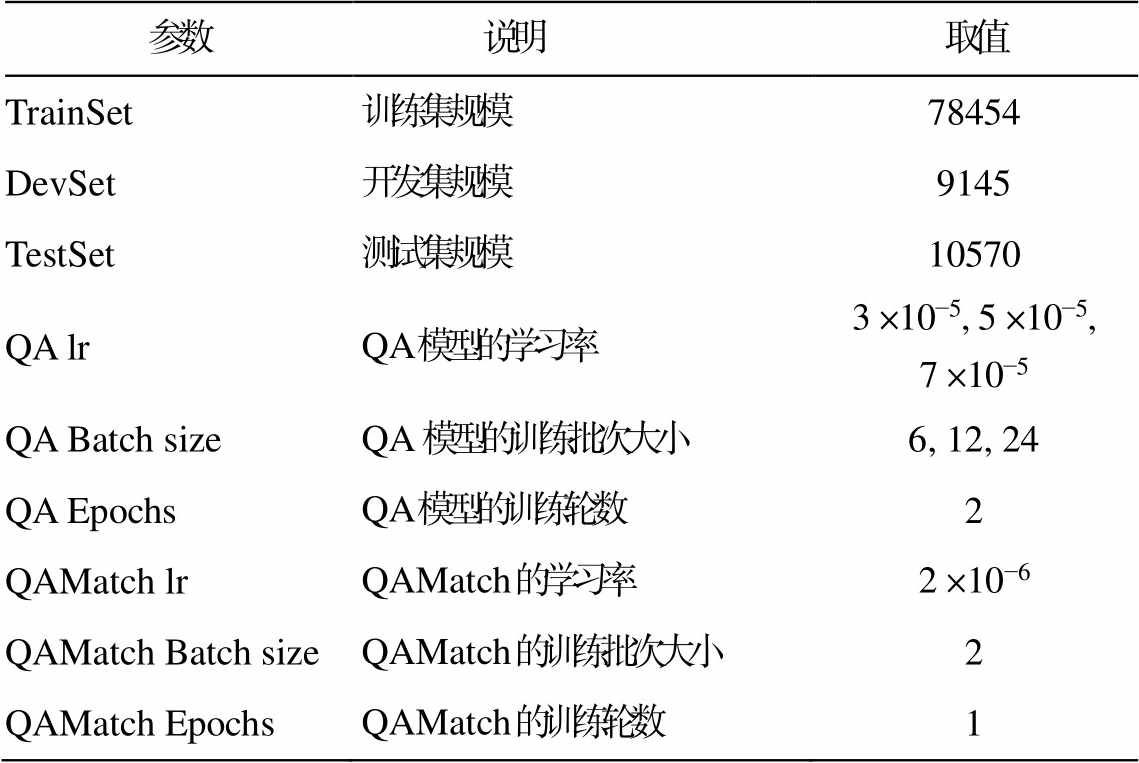
参数说明取值 TrainSet训练集规模78454 DevSet开发集规模9145 TestSet测试集规模10570 QA lrQA 模型的学习率3×10−5, 5×10−5, 7×10−5 QA Batch sizeQA模型的训练批次大小6, 12, 24 QA EpochsQA 模型的训练轮数2 QAMatch lrQAMatch 的学习率2×10−6 QAMatch Batch sizeQAMatch 的训练批次大小2 QAMatch EpochsQAMatch 的训练轮数1
为了验证本文数据增强方法的有效性以及对QA 模型性能提升的影响, 本文实验采用如下几种对比方法。
1)EDA[8]: 通过同义词替换、随机插入、随机交换以及随机删除来扩充原句。本文对每一个问题进行修改, 共获得 706086 条新数据。
2)Back-Translation[9]: 通过机器翻译模型, 将每一个问题先翻译成德文, 再翻译回英文, 获取更丰富的文本表述。本文通过该方法得到 78454 条新数据。
3)Simple effective[22]: 将原文中的答案用占位符替换后作为问题。本文通过该方法获得 2258655条新数据。
4)HarvestQA[13]: 将英文维基百科文章转换成问答对来增加数据。本文通过该方法获得 1204925条新数据。
5)Bert AG[4]: 使用 NLTK 从训练集中抽取答案所在句作为上下文, 将原始问题替换为“where’s the answer ?”, 使用 bert-base-uncased 初始化训练 Bert,得到一个答案抽取模型, 随后将训练集中不包含原始答案的句子作为测试集, 推理出答案后, 使用unilm 生成问题, 最终获得 28009 条数据。
QA 模型采用目前主流的自动问答模型中非预训练模型 R-Net、预训练模型 Bert (base)和 Luke (large)进行对比, 其中 Luke 模型是目前 SQuAD1.1数据上的最佳模型之一。
为了对比 QA 模型在不同增强策略下的性能变化, 本文将 2.5 节所述的 3 种方法分别在 Bert-base模型上进行对比。如表 3 所示, 多模型增强策略因为混合了多个模型的针对性增强数据, 获得最好的效果。
为进一步了解不同模型增强数据带来的影响, 本文还对多个模型的增强数据进行混合训练。从表4 可以看出, 其他模型的增强数据对 Bert 也有不错的提升效果, 并且数据规模越大, 性能提升越明显, 说明本文的方法通用性较好, 添加更多模型的扩充数据, 可以进一步提升 QA 模型的性能。
表3 不同扩充策略的效果(%)
Table 3 Performance of different augment methods (%)
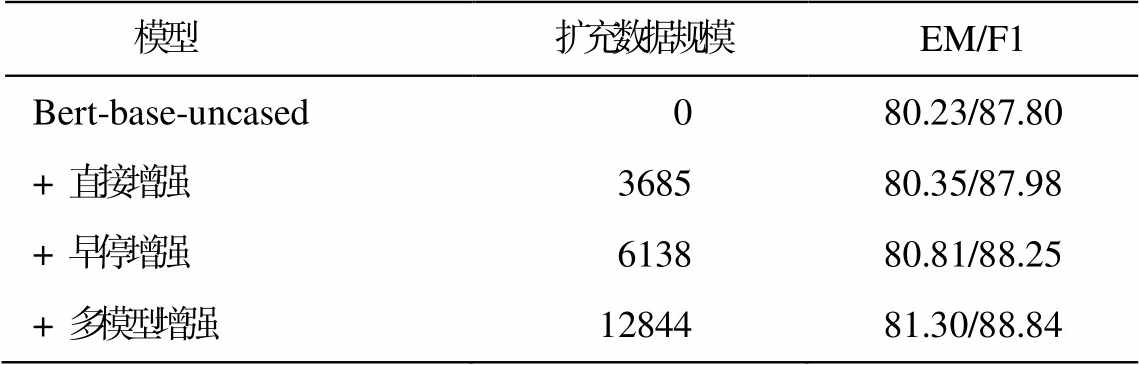
模型扩充数据规模EM/F1 Bert-base-uncased080.23/87.80 + 直接增强368580.35/87.98 + 早停增强613880.81/88.25 + 多模型增强1284481.30/88.84
表4 混合训练的性能(%)
Table 4 Performance of mix training (%)
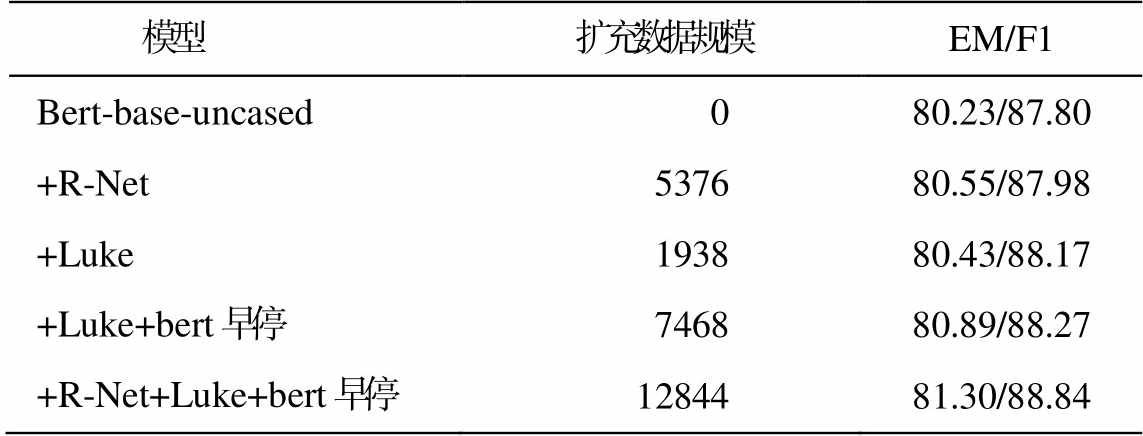
模型扩充数据规模EM/F1 Bert-base-uncased080.23/87.80 +R-Net537680.55/87.98 +Luke193880.43/88.17 +Luke+bert早停746880.89/88.27 +R-Net+Luke+bert早停1284481.30/88.84
为了验证本文提出的增强策略优势, 在不同的新增数据规模下对比不同数据增强方法的 QA 模型性能。以 3685 条数据①本文Bert直接增强策略的新增数据数量。为基准, 选取其 1 倍、5 倍及10 倍数量进行对比, 结果如表 5 所示。在新增数据规模较小(3685)时, 几种方法差别不大, 但 Back-Translation 方法可以增加模型的鲁棒性, 从而获得最好的性能。随着数据量的提升, EDA 和 Back-Translation 引入的噪音导致模型性能降低。由于答案抽取及所用 QG 模型的性能较低, 导致 HarvestQA增强数据质量较差, QA 模型性能严重下跌。Bert AG 从句子中抽取答案, 效果较好, 但在同等数据规模, 甚至新增 36850 条数据时, 模型性能的提升均低于本文方法。由于本文针对 QA 模型构建特定的增强数据, 因此仅在新增 12844 条问答对时, QA模型就表现出较高的性能。
表5 不同扩充数据规模下的性能(%)
Table 5 Performance of different augmented data size (%)
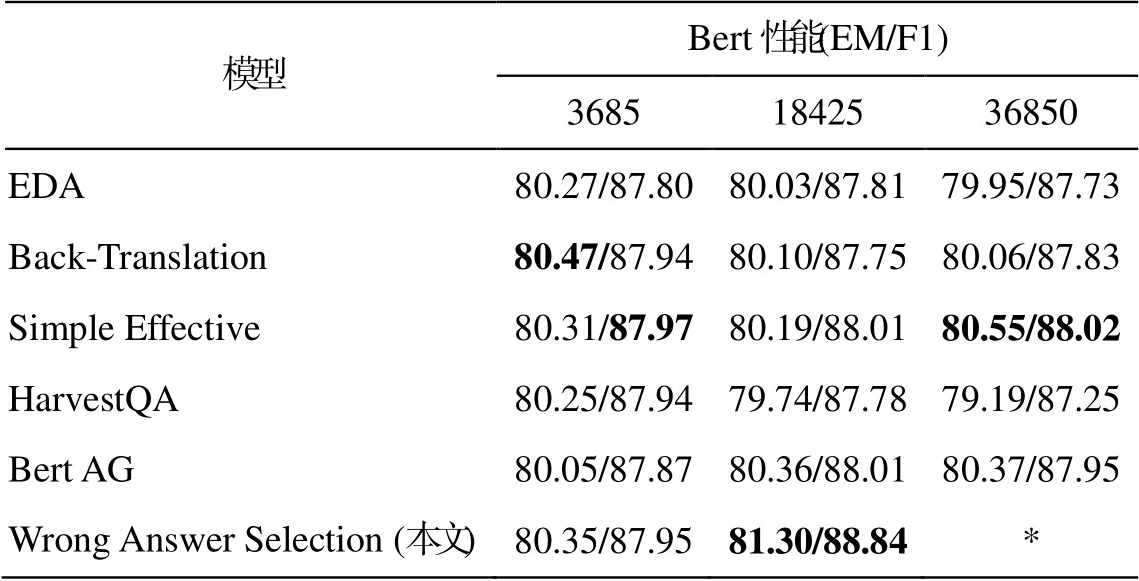
模型Bert性能(EM/F1) 36851842536850 EDA80.27/87.8080.03/87.8179.95/87.73 Back-Translation80.47/87.9480.10/87.7580.06/87.83 Simple Effective80.31/87.9780.19/88.0180.55/88.02 HarvestQA80.25/87.9479.74/87.7879.19/87.25 Bert AG80.05/87.8780.36/88.0180.37/87.95 Wrong Answer Selection (本文)80.35/87.9581.30/88.84*
说明: Wrong Answer Selection (本文)在 18425 条数据下的实验结果是多模型增强的模型性能, 实际数据量为 12844, 由于数据量不足, 未进一步实验, 用*表示; 粗体数字表示最佳性能, 下同。
为了进一步分析本文方法在不同训练数据规模上对模型的提升效果, 分别从训练集中随机抽取10%, 50%和 100%的数据, 混合增强数据训练 QA模型, 实验结果如表 6 所示。可以看到, 本文提出的数据增强策略对不同的 QA 模型都有效。由于实验数据是在模型较为完善的状态下构建的, 所以在更多数据量(50%和 100%)的情况下, 本文模型的表现更加优异, 不过在欠拟合状态(10%)下表现不佳, 可能是因为此时模型性能不稳定, 针对更完整模型构建的增强数据难以发挥其优势。
质量控制旨在过滤掉增强数据中质量不合格的部分。在 Bert 模型上比较 QAMatch 和 Round-Trip两种过滤方法, 结果如表 7 所示, 其中 QAMatch- SQuAD2.0 表示负例来自 SQuAD2.0 中不可回答数据, QAMatch-SQuAD1.1 表示负例来自 SQuAD1.1 中同一段落的不同问答对。实验结果表明, 在扩充数据较少时, Round-Trip 的性能优于 QAMatch; 当扩充数据较多时, QAMatch 性能更好, 并且 QAMatch-SQuAD2.0 的表现更加稳定。这可能是因为来自SQuAD2.0 的负例比 SQuAD1.1 更加多样化, 从而带来更好的泛化性能。本文其余实验结果都是基于QAMatch-SQuAD2.0 得到的。
表6 不同策略在不同训练数据规模下的效果(%)
Table 6 Performance of different augment methods to model with different source data size (%)
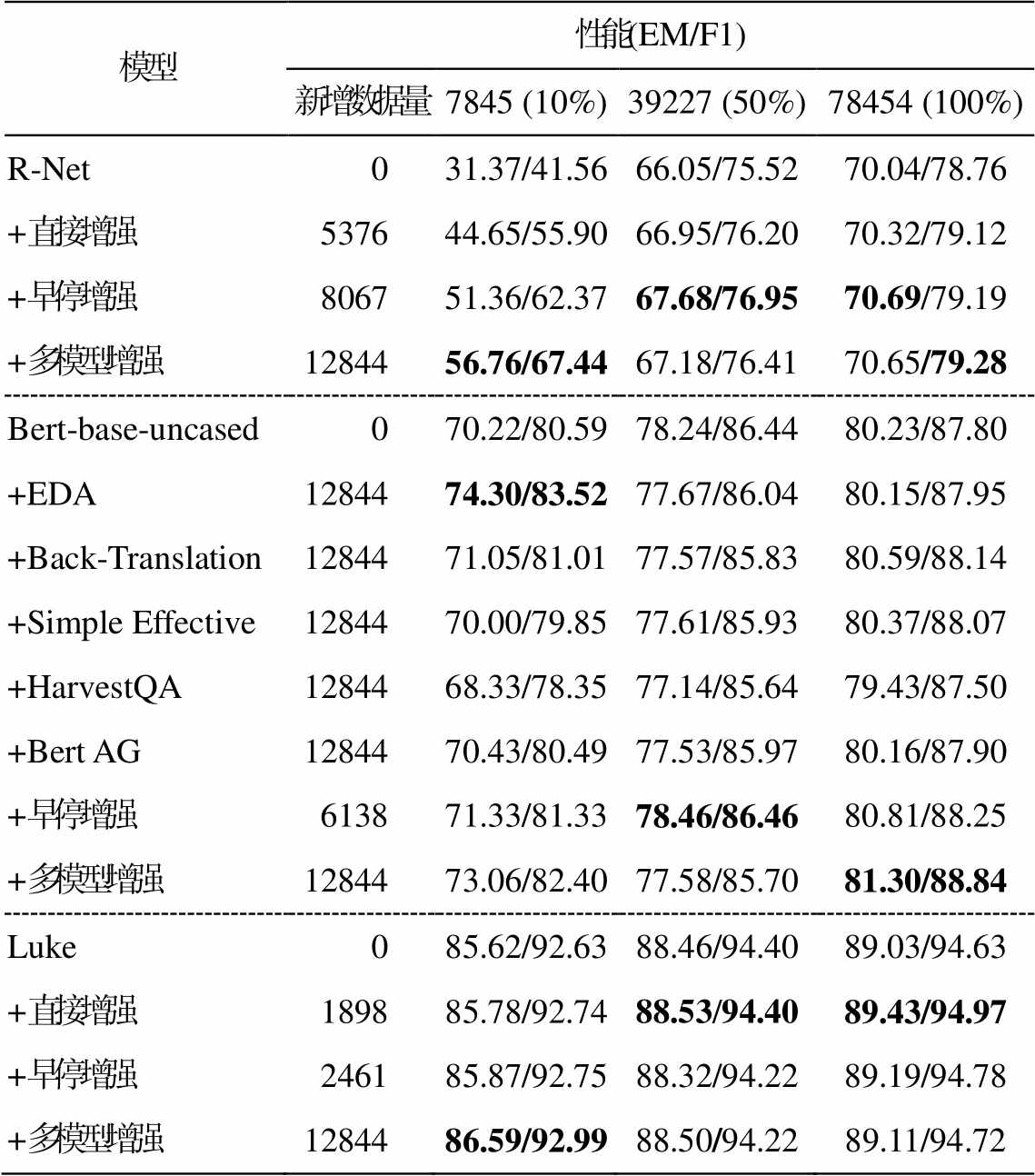
模型性能(EM/F1) 新增数据量7845 (10%)39227 (50%)78454 (100%) R-Net031.37/41.5666.05/75.5270.04/78.76 +直接增强537644.65/55.9066.95/76.2070.32/79.12 +早停增强806751.36/62.3767.68/76.9570.69/79.19 +多模型增强1284456.76/67.4467.18/76.4170.65/79.28 Bert-base-uncased070.22/80.5978.24/86.4480.23/87.80 +EDA1284474.30/83.5277.67/86.0480.15/87.95 +Back-Translation1284471.05/81.0177.57/85.8380.59/88.14 +Simple Effective1284470.00/79.8577.61/85.9380.37/88.07 +HarvestQA1284468.33/78.3577.14/85.6479.43/87.50 +Bert AG1284470.43/80.4977.53/85.9780.16/87.90 +早停增强613871.33/81.3378.46/86.4680.81/88.25 +多模型增强1284473.06/82.4077.58/85.7081.30/88.84 Luke085.62/92.6388.46/94.4089.03/94.63 +直接增强189885.78/92.7488.53/94.4089.43/94.97 +早停增强246185.87/92.7588.32/94.2289.19/94.78 +多模型增强1284486.59/92.9988.50/94.2289.11/94.72
表7 QAMatch和Round-Trip的对比(%)
Table 7 Comparison of QAMatch and Round-Trip (%)

增强策略QAMatch-SQuAD2.0QAMatch-SQuAD1.1Round-Trip 新增数据数量EM/F1新增数据数量EM/F1新增数据数量EM/F1 直接扩充368580.35/87.98344580.38/87.91265880.53/88.20 早停扩充613880.81/88.25574481.03/88.49381880.76/88.30 多模型扩充1284481.30/88.841186680.98/88.34623080.75/88.20
表8 基于错误选择的扩充数据示例
Table 8 Examples of wrong select

示例上下文标准问答对扩充问答对 1…The nine student-run outlets include three newspapers…问题: How many student news papers are found at Notre Dame?答案: three问题: how many student-run outlets are there in notre dame ?答案: nine 2Charles III…His son Alberto died on the way to Palermo and is buried in the city…问题: whose son died on the way to Palermo and is buried there?答案: Charles III问题: What was the name of Charles III ’s son ?答案: Alberto
表8 展示两个扩充数据示例。在示例 1 中, 标准答案为“three”, 而 QA 模型错误地回答“nine”。本文结合上下文和该答案, 使用 QG 模型扩充相应的问题, 针对性地构建一个全新的高质量问答对, 填补原始训练集的空白。示例 2 中情况类似。添加扩充问答对重新训练后, QA 模型在两个示例中都能回答正确。
本文的数据增强策略能够针对问答模型构建特定的问答对, 在较小的增强数据规模下, 有效地提升模型性能, 与现有的数据增强方法相比, 具有更高的性价比。
大部分自动问答数据增强工作都需要外部数据, 同时大量冗余数据导致训练成本大幅上升。针对这两点, 本文提出一种具有针对性的数据增强方法, 充分挖掘原始数据潜能, 构建与自动问答模型强相关的数据, 有效地提升了自动问答模型性能。但是, 目前扩充的数据仍然很有限, 如何扩充更多高质量数据是未来工作的重点。
参考文献
[1]Sun Y, Tang D, Duan N, et al.Joint learning of question answering and question generation.IEEE Transactions on Knowledge and Data Engineering, 2019, 32(5): 971-982
[2]Wang H, Wu R, Li Z, et al.Triple-Joint modeling for question generation using cross-task autoencoder.Lecture Notes in Computer Science, 2019, 11839: 298-307
[3]Alberti C, Andor D, Pitler E, et al.Synthetic QA corpora generation with roundtrip consistency // Pro-ceedings of the 57th Annual Meeting of the Associa-tion for Computational Linguistics.Florence, 2019: 6168-6173
[4]Puri R, Spring R, Shoeybi M, et al.Training question answering models from synthetic data [C/OL] // Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).2020 [2021-03-13].https://aclanthology.org/2020.em nlp-main.468.pdf
[5]Rajpurkar P, Zhang J, Lopyrev K, et al.SQuAD: 100,000+ questions for machine comprehension of text // Proceedings of the 2016 Conference on Empiri-cal Methods in Natural Language Processing.Austin, 2016: 2383-2392
[6]Jungiewicz M, Smywinski-Pohl A.Towards textual data augmentation for neural networks: synonyms and maximum loss.Computer Science, 2019, 20(1): 57-83
[7]Kobayashi S.Contextual augmentation: data augmen-tation by words with paradigmatic relations // Procee-dings of the 2018 Conference of the North American Chapter of the Association for Computational Lin-guistics: Human Language Technologies, Volume 2 (Short Papers).New Orleans, 2018: 452-457
[8]Wei J, Zou K.EDA: easy data augmentation tech-niques for boosting performance on text classification tasks // Proceedings of the 2019 Conference on Em-pirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP).Hong Kong, 2019: 6382-6388
[9]Yu A W, D Dohan, Luong M T, et al.QANet: com-bining local convolution with global self-attention for reading comprehension [EB/OL].(2019-04-19) [2021-03-13].https://arxiv.org/abs/1904.09135,
[10]Kingma D P, Welling M.Auto-encoding variational Bayes [EB/OL].(2014-05-01)[2021-03-17].https:// arxiv.org/abs/1312.6114
[11]Tanaka F, Aranha C.Data augmentation using GANs [EB/OL].(2019-04-19) [2021-05-07].https://arxiv.org/abs/1904.09135
[12]Du X, Shao J, Cardie C.Learning to ask: neural ques-tion generation for reading comprehension // Procee-dings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa-pers).Vancouver, 2017: 1342-1352
[13]Du X, Cardie C.Harvesting paragraph-level question-answer pairs from Wikipedia // Proceedings of the 56th Annual Meeting of the Association for Computa-tional Linguistics (Volume 1: Long Papers).Melbou-rne, 2018: 1907-1917
[14]Subramanian S, Wang T, Yuan X, et al.Neural models for key phrase detection and question generation [EB/OL].(2018-05-30) [2021-04-18].https://arxiv.org/abs/1706.04560
[15]Lewis P, Denoyer L, Riedel S.Unsupervised question answering by cloze translation // Proceedings of the 57th Annual Meeting of the Association for Computa-tional Linguistics.Florence, 2019: 4896-4910
[16]Dong L, Yang N, Wang W, et al.Unified Language Model Pre-training for Natural Language Unders-tanding and Generation // NeurIPS.Vancouver, 2019: 13042-13054
[17]Devlin J, Chang M, Lee K, et al.BERT: pre-training of deep bidirectional transformers for language under-standing // Proceedings of the 2019 Conference of the North American Chapter of the Association for Com-putational Linguistics: Human Language Technolo-gies, Volume 1 (Long and Short Papers).Minneapolis, 2019: 4171-4186
[18]Liu B, Wei H, Niu D, et al.Asking questions the hu-man way: scalable question-answer generation from text corpus // Proceedings of The Web Conference 2020.New York, 2020: 2032-2043
[19]Rajpurkar P, Jia R, Liang P.Know what you don’t know: unanswerable questions for SQuAD // Procee-dings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Pa-pers).Melbourne, 2018: 784-789
[20]R-Net: machine reading comprehension with self-matching networks [EB/OL].(2017-05-08) [2021-03-12].https://www.microsoft.com/en-us/research/wp-con tent/uploads/2017/05/r-net.pdf
[21]Yamada I, Asai A, Shindo H, et al.LUKE: deep con-textualized entity representations with entity-aware self-attention [C/OL] // Proceedings of the 2020 Con-ference on Empirical Methods in Natural Language Processing (EMNLP).2020 [2021-03-13]: https://acl anthology.org/2020.emnlp-main.523.pdf
[22]Dhingra B, Danish D, Rajagopal D.Simple and effec-tive semi supervised question answering // Procee-dings of the 2018 Conference of the North American Chapter of the Association for Computational Lin-guistics: Human Language Technologies, Volume 2 (Short Papers).New Orleans, 2018: 582-587
Data Augmentation Method for Question Answering
Abstract Aiming at the problem that the current data augmentation method for automatic question answering requires a large amount of external data, a new method oriented to the defects of the question answering model is proposed.Firstly, the question answering (QA) model, question generating (QG) model and question answering matching (QAMatch) model are trained on the training set.Secondly, all the answers predicted by the QA model on the training set are obtained and the wrong ones are selected.Then, the QG model is used to generate corresponding questions for these answers.Finally, the question-answer pairs are filtered by the QAMatch model and the high-quality data are retained as the final augmented data.This method does not require additional data and domain knowledge, and can construct specific data for QA model, improving the performance with less training cost.Experimental results show that the proposed data augmentation method is effective for R-NET, Bert-Base and Luke.Compared with other methods, the QA model achieves better performance improvement with less data scale.
Key words data augmentation; question answering model; question generation model; quality control
doi: 10.13209/j.0479-8023.2021.112
收稿日期: 2021-06-08;
修回日期: 2021-08-14
国家自然科学基金(62176174)资助