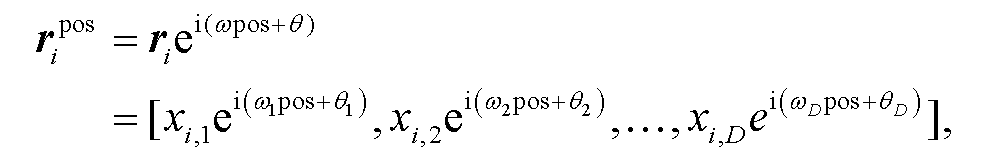 (1)
(1)摘要 提出一个基于多通道压缩双线性池化的模型, 对文档中的候选情感‒原因句子对进行排序。该模型利用图注意力网络提取包含位置信息的情感特定化表示和原因特定化表示, 通过局部关系学习模块, 进一步学习情感与原因句子之间的局部关系表示, 再使用多通道压缩双线性池化来融合学习情感‒原因候选句子对表示。最后, 对候选句子对进行排序。实验结果表明, 与最新模型相比, 所提模型在多方面表现更优。
关键词 情感分析; 情感‒原因句子对提取; 图注意力网络; 局部关系提取; 多通道压缩双线性池化
随着社交媒体的发展, 情感分析领域越来越受到研究人员的关注。研究文本中隐含的情感及其成因, 对商业决策、舆情管控和信息预测等应用场景具有重大的应用价值。对此, Lee 等[1]首先提出情感‒原因提取任务: 在文档中, 给定一个已标注的情感句子, 提取出导致情感发生的原因句子。针对这一任务, 有人采用基于语法规则的方法[2‒3], 也有人采用基于机器学习的方法[4‒6]。近年来, 随着深度学习的发展, 也有不少人采用深度记忆网络[7]、互注意力神经网络[8]和多层次神经网络[9]等基于深度神经网络的方法。
上述方法都需要将标注好情感标签的句子作为模型输入。Xia 等[10]认为这种先标注句子的情感, 再根据标注好的句子去检测对应原因的方法限制了其实际应用。为了使情感‒原因提取任务更具有泛用性, 他们提出情感‒原因句子对提取任务: 给定一个文档, 提取出所有的情感句子以及对应的原因句子。他们提出一种两步走的方法, 用于提取情感‒原因句子对, 但存在的误差传播问题。针对这一问题, Ding 等[11]提出一种情感‒原因句子对二维矩阵方法, Wei 等[12]提出一种情感‒原因句子对排序方法, Fan 等[13]则从序列标注的角度出发, 提出一个基于转移系统的解决方案。
我们发现, 上述模型存在句子间缺乏高效信息交互和融合的问题。为了解决这一问题, 本文进一步考虑句子间的相对位置信息和局部关系, 结合多通道信息融合的思想, 提出一个基于多通道压缩双线性池化的情感‒原因句子对提取模型。
给定一个包含若干句子的文档 d=[c1, c2, …, c|d|] (|d|是文档的句子数), 任务目标是提取出情感‒原因句子对集合:
p = {…, (cemo, ccau), …},
其中, cemo∈d, 是一个情感句子; ccau∈d, 是其对应的原因句子。值得注意的是, 一个文档中可能包含若干不同的情感‒原因句子对, 且一个情感句子可能有多个对应的原因句子。
如图 1 所示, 本文模型的整体框架主要由 3 个部分组成: 第一部分为带有位置信息的情感、原因特定化表示学习, 分别学习包含位置信息的情感、原因句子向量表示; 第二部分建模每一个候选句子对中情感句子与原因句子之间的局部关系; 第三部分使用多通道压缩双线性池化方法来融合情感特定化表示、原因特定化表示和局部关系表示, 并进一步将候选句子对排序, 得出最后结果。
对于一个给定的文档 d = [c1, c2, …, c|d|], 包含|d|个句子。对于每个句子 c i= (wi,1, wi,2, …, wi,|ci|), 包含|ci|个单词(其中 i 表示该句子在文档中的位置)。我们以 BERT 为句子编码器去获取句子 ci 的向量表示 ri, 因此文档 d 的句子编码向量为[r1, r2, …, r|d|]。
本文模型采用两路图注意力网络(graph attention network, GAT)[14]对句子进行学习, 并分别产生包含位置信息的情感特定化表示以及原因特定化表示, 即该句子作为情感或原因时的向量表示。在情感与原因特定化表示之间进行两两配对, 产生情感‒原因候选句子对。
2.2.1 复数值句子位置嵌入
相对位置信息对情感‒原因句子对提取任务具有重要作用[15]。现有研究多将位置信息表示为一个独立的向量, 没有在训练中将位置信息融入情感、原因特定化表示之中。Wang 等[16]提出一种复数值嵌入的方法, 对绝对位置信息和相对位置信息进行建模。受此工作启发, 本文改进复数值嵌入方法, 并运用在句子的表示学习中, 使得情感、原因句子特定化表示具有更强的位置相关性。假设句子ci 的向量表示为 ri = [xi,1, xi,2, …, xi,D], 其中 D 是向量 ri的维度, 复数值位置嵌入定义如下:
(1)其中, pos(1≤pos≤|d|)是句子 ci 在文档 d 中的位置, ω 和 θ 是可学习的参数, ω 决定句子对位置 pos 的敏感程度。根据欧拉公式
 (2)
(2)
复数值句子位置嵌入可以进行如下转化:
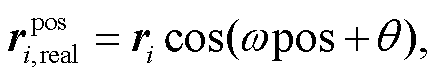 (3)
(3) (4)
(4)
其中, 和
和 分别是复数值嵌入的实数和虚数部分。为了能用于神经网络的输入, 我们将这两部分拼接起来, 作为最终的复数位置嵌入向量
分别是复数值嵌入的实数和虚数部分。为了能用于神经网络的输入, 我们将这两部分拼接起来, 作为最终的复数位置嵌入向量 :
:
 (5)
(5)2.2.2基于图注意力网络的情感/原因特定化表示学习
为了加强句子之间的信息交互, 本文模型采用两路 GAT 对句子信息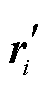 进行全局更新, 分别获取融合位置信息的情感特定化表示
进行全局更新, 分别获取融合位置信息的情感特定化表示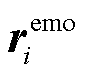 和原因特定化表示
和原因特定化表示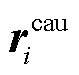 。
。
以情感特定化表示学习为例说明处理流程。将ri与拼接成, 作为第 i 个句子的向量表示:
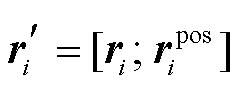 。 (6)
。 (6)
图1 本文模型整体框架
Fig.1 Overview of the proposed model
本文模型将文档中每个句子 ci 拼接所得的当成一个节点, 节点之间(包括自身)两两连接, 构成全连接图, 并利用 GAT 来深度聚合节点与邻接节点之间的信息。GAT 的实现公式如下:
 (7)
(7)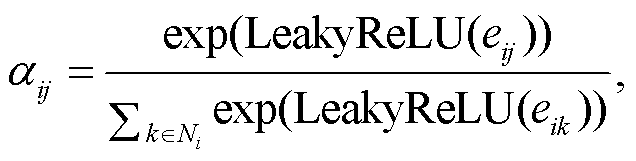 (8)
(8)
 (9)
(9)
其中, wT 和 W 是可学习参数, eij 是注意力互相关系数, tanh, LeakyReLU 和 ReLU 是激活函数, Ni 是节点i 的邻接节点, aij 是节点 i 与 j 之间的注意力权重。
通过 GAT 的信息交互, 得到句子 ci 的情感特定化表示。同理, 通过另一路 GAT 的信息交互, 得到原因特定化表示。然后, 将和分别输入两个 sigmoid 函数中, 获取情感预输出 和原因预输出
和原因预输出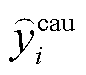 :
:
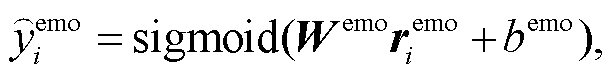 (10)
(10) (11)
(11)
其中, W emo, b emo, W cau 和 bcau 都为可学习参数, sigmoid 为激活函数。
2.2.3 情感‒原因候选句子对生成
在得到文档的情感特定化表示 remo 和原因特定化表示 rcau 后, 模型进一步生成情感‒原因候选句子对。两个句子之间的相对距离是情感‒原因句子对的关键, 如果太大, 它们之间的因果关系就较小, 则组成一个情感‒原因句子对的可能性就很小。因此, 本模型设定一个窗口范围 k, 只有相对距离在 k 之内的句子对才可以成为候选情感‒原因句子对。于是, 可以从文档 d 中构建一个候选情感‒原因句子对集合:
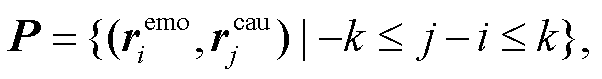 (12)
(12)其中, 是句子 ci 的情感特定化表示, 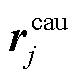 是句子cj 的原因特定化表示,j - i 表示句子 ci 与 cj 的相对位置。
是句子cj 的原因特定化表示,j - i 表示句子 ci 与 cj 的相对位置。
对于每一个候选句子对( ), 现有研究大多只关注于句子 ci 和 cj 本身, 对两个句子之间的局部信息有所忽略, 没有进一步进行提取学习, 导致当它们之间的相对距离较大时, ci 与 cj 的联系较弱, 无法提取其相互关系。为了克服这一缺点, 本文把句子 ci 与 cj 之间的句子也考虑进来, 提出一种局部关系表示学习方法, 用于增强 ci 与 cj 之间的联系。
), 现有研究大多只关注于句子 ci 和 cj 本身, 对两个句子之间的局部信息有所忽略, 没有进一步进行提取学习, 导致当它们之间的相对距离较大时, ci 与 cj 的联系较弱, 无法提取其相互关系。为了克服这一缺点, 本文把句子 ci 与 cj 之间的句子也考虑进来, 提出一种局部关系表示学习方法, 用于增强 ci 与 cj 之间的联系。
如图 2 所示, 局部关系学习模块通过包含注意力机制的 BiLSTM 模型来学习两个句子之间的局部信息。针对每一候选句子对(情感句子 ci 与原因句子 cj, 假设 i≤j), 为了尽可能保留句子原有的信息, 提取从 ci 到 cj 之间的所有句子表示 r = [ri, ri+1, …, rj]作为 BiLSTM 模型的输入, 从而学习到对应的句子隐藏表示 H。然后, 通过注意力机制对 H 进行融合, 得到情感‒原因之间的局部关系表示 :
:
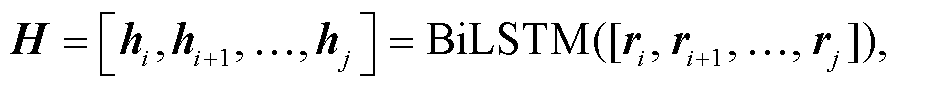 (13)
(13)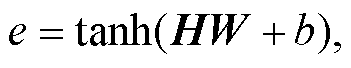 (14)
(14)
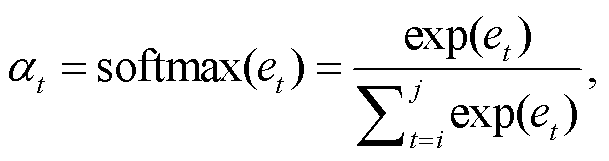 (15)
(15)
 (16)
(16)其中, [hi, hi+1, …, hj]是句子 ci 到 cj 对应的隐藏表示, W 和 b 是可学习参数, tanh 是激活函数, e 是注意力系数, αt 是注意力权重, 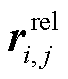 是句子 ci 与 cj 之间的局部关系表示。
是句子 ci 与 cj 之间的局部关系表示。
在求候选句子对的表示时, 现有方法只简单地将句子的情感特定化表示和原因特定化表示拼接起来, 不足以学习情感句子与原因句子之间的联系。双线性池化(bilinear pooling)[17]是特征融合的一种方法, 通过求取两个向量外积的方式来建模特征的高阶统计信息, 从而捕获特征之间的关系。这种方法在计算机视觉细粒度分类任务中取得不错的效果。然而, 两个向量的外积维度很高, 存在学习的参数数量过大问题。在此基础上, Fukui 等[18]提出多模态压缩双线性池化(multimodal compact bilinear pooling, MCB)方法, 有效地降低了维度, 并将其运用于跨模态看图答题领域, 将图像和文本两个模态的特征向量有效地融合, 取得很好的效果。
上述方法都是用于两个向量表示之间的融合, 而本文模型中有 3 个向量表示需要融合。为了有效地融合句子 ci 的情感特定化表示、句子 cj 的原因特定化表示以及局部关系表示这 3 个表示的信息, 我们将 Fukui 等[18]的方法改进到本模型中, 提出一种多通道压缩双线性池化(multichannel com-pact bilinear pooling, MCBP)方法来求取候选句子对表示 , 如图 3 所示。
, 如图 3 所示。
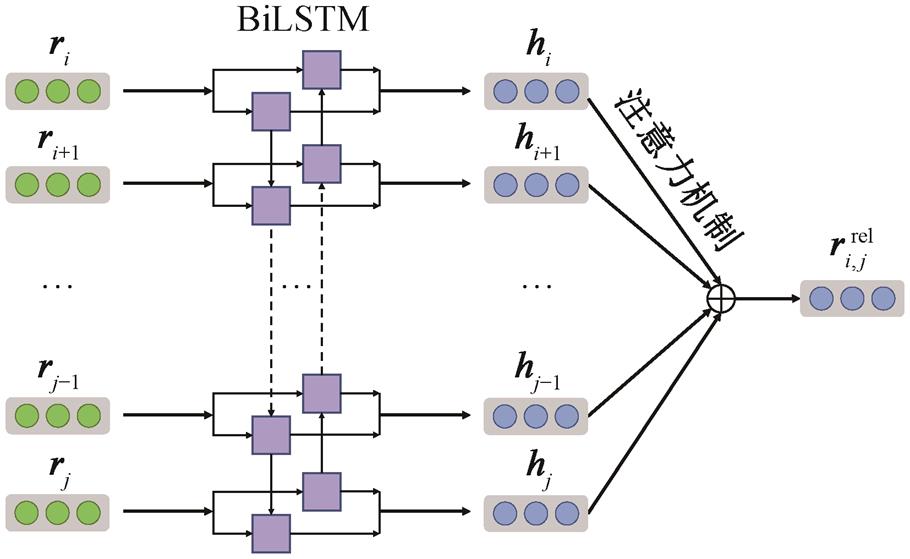
图2 局部关系学习模块
Fig.2 Local relation-aware module
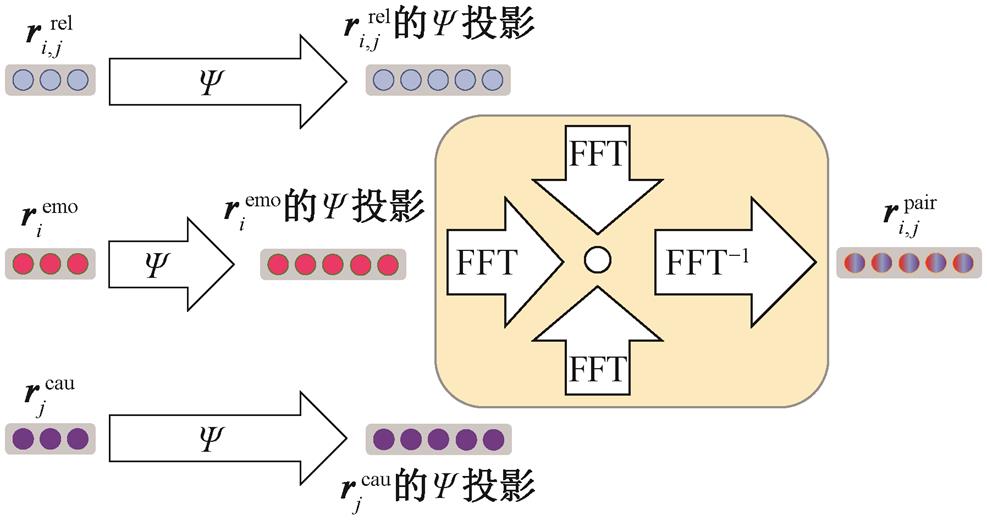
Ψ表示计数简述函数(Count Sketch), FFT和FFT‒1分别代表傅里叶变换和傅里叶逆变换
图3 多通道压缩双线性池化
Fig.3 Multichannel compact bilinear pooling
由于 3 个通道向量之间的外积维度过高, 我们利用计数简述函数Ψ18‒19">[18‒19], 将其从高维空间投影到较低维空间, 从而减少参数数量。3 个向量的外积的Ψ投影等价于每个向量先进行Ψ投影, 再进行卷积操作:
 (17)
(17)其中, 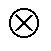 代表外积操作, *代表卷积操作。根据卷积原理, 时域内的卷积等价于频域内的乘积, 式(17)可以改写为
代表外积操作, *代表卷积操作。根据卷积原理, 时域内的卷积等价于频域内的乘积, 式(17)可以改写为
 (18)
(18)
其中, FFT 和 FFT-1 分别代表傅里叶变换和傅里叶逆变换,  表示按位相乘。
表示按位相乘。
通过 MCBP 模块, 我们得出每个候选情感‒原因句子对的表示。然后, 将输入 sigmoid 函数中, 获取情感‒原因句子对输出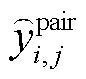 :
:
 (19)
(19)在测试阶段, 为了提取所有潜在的情感‒原因句子对, 本文模型采用一种基于情感词典的抽取方法[12]。对于分数排名前 N 的降序列表{p1, p2, …, pN}, 首先将拥有最高分数的 p1 提取出来作为预测结果。若在其他候选句子对中的情感句子也包含情感词典中的词, 则也将其提取出来作为预测结果, 从而得到多个情感‒原因句子对预测结果。
本文模型采用下式中的排序损失函数检测候选句子对的排序分数:
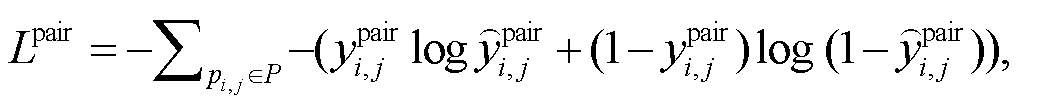 (20)
(20) 是情感‒原因句子对
是情感‒原因句子对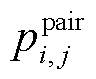 的真实值, 即当为一个情感‒原因句子对时, =1, 否则=0。
的真实值, 即当为一个情感‒原因句子对时, =1, 否则=0。
为了更好地学习情感特定化表示和原因特定化表示, 本文模型引入一个辅助损失函数来监督情感句子预输出和原因句子预输出:
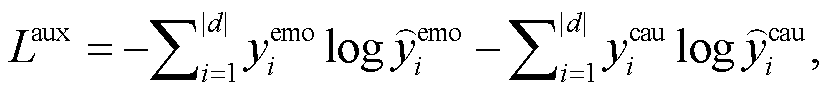 (21)
(21)其中, 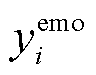 和
和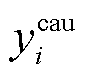 分别是文档中句子 ci 的情感和原因标签值。即当 ci 为情感句子时, =1, 否则=0。同理。
分别是文档中句子 ci 的情感和原因标签值。即当 ci 为情感句子时, =1, 否则=0。同理。
本文模型使用 Lpair 和 Laux 以及 L2 正则化的加权和作为最终损失函数:
 (22)
(22)其中, L 是最终损失函数, λ1, λ2, λ3∈(0, 1)是权重, ![]() 代表模型中的所有参数, ||θ||2是L2正则化。
代表模型中的所有参数, ||θ||2是L2正则化。
本文使用 Xia 等[10]提供的基准数据集进行实验, 验证模型的有效性。随机选择 90%的数据作为训练数据, 剩下的 10%作为测试数据, 重复进行 20次实验, 取平均值作为报告结果。使用准确率 P, 召回率 R 和 F1 值作为评价指标。此外, 分别评估模型在情感句子提取和原因句子提取这两个子任务中的表现。
本文模型词向量的维度为 200, 复数值位置向量的维度为 200, 产生候选句子对的窗口大小![]() 设置为 8, 情感特定化表示、原因特定化表示以及局部关系表示的维度都设置为 500, 经 MCBP整合后的候选句子对表示的维度设置为 3000。在训练阶段, 模型采用 Adam 优化器[20]更新参数, 批处理大小和学习率分别设为 4 和 0.001。对于 Loss函数, 参数 λ1, λ2 和 λ3 都设置为 1, L2 正则化设置为1×10−5。与 Wei 等[12]一样, 本文也将 ANTUSD[21]作为情感词典。
设置为 8, 情感特定化表示、原因特定化表示以及局部关系表示的维度都设置为 500, 经 MCBP整合后的候选句子对表示的维度设置为 3000。在训练阶段, 模型采用 Adam 优化器[20]更新参数, 批处理大小和学习率分别设为 4 和 0.001。对于 Loss函数, 参数 λ1, λ2 和 λ3 都设置为 1, L2 正则化设置为1×10−5。与 Wei 等[12]一样, 本文也将 ANTUSD[21]作为情感词典。
本文对比的基本方法如下: 1)ECPE-2steps[10]是一个两步走流水线框架, 有 Indep, Inter-CE 和 Inter-EC 共 3 种设置; 2)ECPE-2D[11]是一个联合框架, 是ECPE-2steps 的升级版本, 它以端对端的形式整合了 2D 情感‒原因句子对的表示、交互及预测, 有Inter-EC-, Inter-EC+WC 和 Inter-EC+CR 共 3 种设置; 3)Transition-based[13]用一个基于转移系统的模型, 将情感‒原因句子对提取转化为一个类似句法解析的有向图结构, 句子编码器分别使用 LSTM 和BERT; 4)RANKCP[12]是一个端对端的方法, 它从排序的角度出发, 建模句子之间的内在联系, 句子编码器分别使用多层次 RNN 和 BERT, 它是情感‒原因句子对提取任务中最先进的基准模型。
表 1 展示在情感‒原因句子对提取以及两个子任务(情感句子提取和原因句子提取)中结果的比较。值得注意的是, ECPE-2D, Transition-based 和RANKCP 在使用 BERT 作为句子编码器来获得句子表示时, 效果有所提升, 表 1 中主要与其 BERT 版本进行比较。与所有基准模型对比, 本文模型在情感‒原因句子对提取任务中的 F1 值、准确率和召回率都是最高的, 充分证明了本文模型的有效性。本文模型的 F1 值、准确率和召回率分别比 RANKCP (表现最优的基准模型)提升 1.88%, 2.87%和 0.85%。对比 RANKCP 模型, 本文模型的提升主要在于准确率。可能的原因是, 本文方法关注到情感句子与原因句子之间的局部关系信息, 并能有效地将情感特定化表示、原因特定化表示以及关系表示融合在一起, 最终提升了模型的准确率。
此外, 在情感句子提取和原因句子提取两个子任务中, 本文模型的表现也最佳。在情感句子抽取子任务中, 本文模型的准确率略低于 RANKCP 模型, 召回率略低于 ECPE-2D 模型, 但并不影响 F1 值的表现, 本文模型的 F1 值仍为最高值 90.76%。在原因句子抽取子任务中, 本文模型的 F1 值、准确率和召回率都最高。由于情感‒原因句子对抽取任务和两个子任务具有相关性, 也从另一方面证明了本文方法的有效性。
为了检验模型情感特定化表示和原因特定化表示学习的有效性, 我们比较 BiLSTM 与 GAT 两种神经网络及不同位置嵌入方法组合的效果, 如表 2 所示, 其中“绝对位置嵌入”代表对不同的句子位置pos (1≤pos≤|d|)进行随机初始化, 从而得到其位置嵌入。
表1 本文模型与基准模型的比较结果(%)
Table 1 Comparison of proposed method with baseline models (%)

方法情感‒原因句子对提取情感句子提取原因句子提取 F1PRF1PRF1PR ECPE-2Steps[10]Indep58.1868.3250.8282.1083.7580.7162.0569.0256.73 Inter-CE59.0169.0251.3583.0084.9481.2261.5168.0956.34 Inter-EC61.2867.2157.0582.3083.6481.0765.0770.4160.83 ECPE-2D(BERT) [11]Inter-EC67.4770.7364.8688.8886.2291.8270.9673.4668.79 Inter-EC+WC68.8972.9265.4489.1086.2792.2171.2373.3669.34 Inter-EC+CR68.3769.3567.8588.7885.4892.4470.8772.7269.27 Transition-based[13]LSTM64.3465.1563.5482.5680.8084.3966.3667.4265.34 BERT67.9973.7463.0784.7487.1682.4469.7475.6264.71 RANKCP[12]RNN66.1066.9865.4685.4887.0384.0668.2469.2767.43 BERT73.6071.1976.3090.5791.2389.9976.1574.6177.88 本文模型75.4874.0677.1590.7690.6790.9177.8177.1478.68
说明: 粗体数字为同一评价指标的最高值, 下同。
在不使用神经网络进行情感特定化表示和原因特定化表示学习时, 模型的效果很差, 说明句子间信息交互的重要性。GAT 的效果比 BiLSTM 好, 说明将文档建模成全连接图并进行信息交互的方法是有效的, 图注意力机制使句子之间的相关性更强。
对 GAT 而言, 不使用位置嵌入时模型的效果最差, 表明加入位置嵌入的必要性。使用绝对值位置嵌入与不使用位置嵌入的效果相差不大, 这是由于绝对值位置嵌入实际上只是建模了句子的绝对位置关系, 并不能很好地建模句子之间的相对位置关系, 因此并没有带来明显的效果提升。本文采用的复数值位置嵌入方法能有效地将句子的位置信息融入句子向量表示中, 使得情感特定化表示和原因特定化表示更具位置相关性。
为了检验局部关系表示模块的有效性, 本文根据真实标签中情感句子与原因句子的相对距离, 将测试集划分成相对距离≤1 和相对距离>1 两个子集, 并在这两个子集上对比去掉局部关系模块和完整模型的结果(表 3)。可以看到, 对于相对距离≤1 的子集, 去掉关系感知模块之后, 模型效果只有小幅下降; 对于相对距离>1 的子集, 因为情感句子与原因句子的相对距离变大, 增大了识别难度, 所以在去掉关系感知模块之后, 识别效果大大下降(F1, P 和R 分别下降 11.16%, 15.49%和 7.4%), 说明对于相对距离较大的情况, 本文局部关系学习模块充分地考虑到两者之间其他句子的信息, 从而提高了模型整体的效果。
表2 不同神经网络和位置嵌入方式的效果(%)
Table 2 Effect of different neural networks and position embeddings (%)

神经网络位置嵌入方式F1PR 不使用不使用48.4146.2850.86 BiLSTM不使用67.4364.7370.58 绝对位置嵌入69.2667.4371.56 复数值位置嵌入71.3870.0673.12 GAT不使用72.8771.0374.86 绝对位置嵌入73.2571.4175.23 复数值位置嵌入75.4874.0677.15
表3 局部关系表示模块的效果比较(%)
Table 3 Effect of local relation-aware module (%)

相对距离 方法F1PR ≤1去掉局部关系80.9877.9584.39 完整模型82.1885.0584.52 >1去掉局部关系33.0431.1135.43 完整模型44.2046.6042.83
表4 不同融合方式的效果(%)
Table 4 Effect of different fusion methods (%)

融合方式F1PR 按位相加70.3567.7673.32 拼接73.4471.7175.40 MCBP75.4874.0677.15
通过对比向量表示之间不同的融合方式来验证本文 MCBP 模块的有效性。对于 3 个输入(情感特定化表示、原因特定化表示和局部关系表示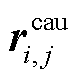 ), 采取按位相加、拼接和 MCBP 这 3 种融合方式来学习候选句子对的最终向量表示, 实验结果列于表 4。可以看出, 按位加的方法不能很好地获取最终表示, 所以效果最差。拼接的方法直接将向量拼接起来, 不会引入太多噪声信息, 所以效果好一点。本文提出的 MCBP 融合方法将 3 个特征表示有效地融合起来, 3 个评价指标(F1, P 和 R)都明显提高, 得到更有效的情感‒原因候选句子对表示。
), 采取按位相加、拼接和 MCBP 这 3 种融合方式来学习候选句子对的最终向量表示, 实验结果列于表 4。可以看出, 按位加的方法不能很好地获取最终表示, 所以效果最差。拼接的方法直接将向量拼接起来, 不会引入太多噪声信息, 所以效果好一点。本文提出的 MCBP 融合方法将 3 个特征表示有效地融合起来, 3 个评价指标(F1, P 和 R)都明显提高, 得到更有效的情感‒原因候选句子对表示。
本文提出一个基于多通道压缩双线性池化的模型(MCBP), 对文档中的候选句子对进行排序, 并通过消融实验验证每一个模块的有效性。本文的主要贡献如下: 1)所提模型利用 GAT 提取包含位置信息的情感特定化表示和原因特定化表示; 2)构建局部关系学习模块, 对情感句子与原因句子之间的局部关系进行学习, 增强远距离句子之间的联系; 3)使用 MCBP, 有效地融合多路特征向量表示并进行排序。实验结果表明, 在所有参与对比的方法中, 本文方法表现最优。
参考文献
[1]Lee S Y M, Chen Y, Huang C R.A text-driven rule-based system for emotion cause detection // Procee-dings of the NAACL HLT 2010 Workshop on Compu-tational Approaches to Analysis and Generation of Emotion in Text.Los Angeles, 2010: 45‒53
[2]Russo I, Caselli T, Rubino F, et al.Emocause: an easy-adaptable approach to emotion cause contexts // Association for Computational Linguistics.Portland, OR, 2011: 153‒160
[3]Gui L, Yuan L, Xu R, et al.Emotion cause detection with linguistic construction in chinese weibo text // CCF International Conference on Natural Language Processing and Chinese Computing.Berlin: Springer, 2014: 457‒464
[4]Ghazi D, Inkpen D, Szpakowicz S.Detecting emotion stimuli in emotion-bearing sentences // International Conference on Intelligent Text Processing and Com-putational Linguistics.Cham: Springer, 2015: 152‒ 165
[5]Song S, Meng Y.Detecting concept-level emotion cause in microblogging // Proceedings of the 24th In-ternational Conference on World Wide Web.Firenze, 2015: 119‒120
[6]Cheng X, Chen Y, Cheng B, et al.An emotion cause corpus for chinese microblogs with multiple-user structures.ACM Transactions on Asian and Low-Resource Language Information Processing, 2017, 17 (1): 1‒19
[7]Gui L, Hu J, He Y, et al.A question answering approach for emotion cause extraction // Proceedings of the 2017 Conference on Empirical Methods in Na-tural Language Processing.Copenhagen, 2017: 1593‒ 1602
[8]Li X, Song K, Feng S, et al.A co-attention neural network model for emotion cause analysis with emo-tional context awareness // Proceedings of the 2018 Conference on Empirical Methods in Natural Langu-age Processing.Brussels, 2018: 4752‒4757
[9]Xia R, Zhang M, Ding Z.RTHN: a RNN-transformer hierarchical network for emotion cause extraction // Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence.Macao, 2019: 5285‒5291
[10]Xia R, Ding Z.Emotion-cause pair extraction: a new task to emotion analysis in texts // Proceedings of the 57th Annual Meeting of the Association for Com-putational Linguistics.Florence, 2019: 1003‒1012
[11]Ding Z, Xia R, Yu J.ECPE-2D: emotion-cause pair extraction based on joint two-dimensional represen-tation, interaction and prediction // Proceedings of the 58th Annual Meeting of the Association for Com-putational Linguistics.Seattle, 2020: 3161‒3170
[12]Wei P, Zhao J, Mao W.Effective inter-clause mo-deling for end-to-end emotion-cause pair extraction // Proceedings of the 58th Annual Meeting of the Asso-ciation for Computational Linguistics.Seattle, 2020: 3171‒3181
[13]Fan C, Yuan C, Du J, et al.Transition-based directed graph construction for emotion-cause pair extraction // Proceedings of the 58th Annual Meeting of the Asso-ciation for Computational Linguistics.Seattle, 2020: 3707‒3717
[14]Veličković P, Cucurull G, Casanova A, et al.Graph attention networks // Proceedings of the 7th Interna-tional Conference on Learning Representations.Van-couver, 2018: 1‒12
[15]Gui L, Wu D, Xu R, et al.Event-driven emotion cause extraction with corpus construction // Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.Austin, 2016: 1639‒1649
[16]Wang B, Zhao D, Lioma C, et al.Encoding word order in complex embeddings [C/OL] // Proceedings of the 8th International Conference on Learning Re-presentations.(2019‒09‒26) [2021‒04‒26].https://op enreview.net/forum?id=Hke-WTVtwr
[17]Lin T Y, RoyChowdhury A, Maji S.Bilinear CNN mo-dels for fine-grained visual recognition // Proceedings of the IEEE International Conference on Computer Vi-sion.Santiago, 2015: 1449‒1457
[18]Fukui A, Park D H, Yang D, et al.Multimodal com-pact bilinear pooling for visual question answering and visual grounding // Conference on Empirical Me-thods in Natural Language Processing.Austin, 2016: 457‒468
[19]Charikar M, Chen K, Farach-Colton M.Finding fre-quent items in data streams // International Collo-quium on Automata, Languages, and Programming.Berlin: Springer, 2002: 693‒703
[20]Kingma D P, Ba J.Adam: a method for stochastic optimization // Proceedings of the 3th International Conference on Learning Representations.(2014‒12‒ 22) [2020‒05‒20].https://arxiv.org/abs/1412.6980
[21]Wang S M, Ku L W.ANTUSD: a large Chinese sen-timent dictionary // Proceedings of the Tenth Inter-national Conference on Language Resources and Eva-luation.Portorož, 2016: 2697‒2702
An Emotion-Cause Pair Extraction Model Based on Multichannel Compact Bilinear Pooling
Abstract The authors propose a model based on multichannel compact bilinear pooling to rank pair candidates in a document.The proposed model firstly extracts the emotion-specific and cause-specific representation containing position information via graph attention network, then further learns the local relation representation between emotion clause and cause clause through the local relation-aware module.Finally, these representations are fused via multichannel compact bilinear pooling to learn the emotion-cause pairs representation for effective ranking.Experimental results show that the proposed approach achieves the best performance among all compared approaches on the task.
Key words sentiment analysis; emotion-cause pair extraction; graph attention network; local relation-aware module; multichannel compact bilinear pooling
doi: 10.13209/j.0479-8023.2021.108
国家自然科学基金(62077015)资助
收稿日期: 2021-06-08;
修回日期: 2021-08-13