融合角色指代的多方对话关系抽取方法研究
徐洋1 蒋玉茹1,2,† 张禹尧1 何威恺1
1.北京信息科技大学智能信息处理研究所, 北京 100101; 2.国家经济安全预警工程北京实验室, 北京 100044; †通信作者, E-mail: jiangyuru@bistu.edu.cn
摘要 在前期基于图网络的模型基础上, 引入角色指代信息, 提出融合角色指代的多方对话关系抽取模型。在构建图节点时加入角色节点, 将其与对应角色指代的词节点进行连接, 并使用图注意力网络进行编码。在DialogRE数据集上的实验效果与基线模型相比, F1值在验证集上提升2.9%, 在测试集上提升4.6%。
关键词 实体关系抽取; 层次化编码; 图注意力网络; 对话结构
近年来, 互联网中对话数据呈指数级增长趋势, 越来越多的有效信息隐藏在非结构化的信息中, 如何从海量数据中获取有效的信息已经成为自然语言处理研究中一项至关重要的任务。随着深度学习的发展, 已有研究者基于卷积神经网络和长短期记忆网络等神经网络模型, 在信息抽取任务中展开相关工作[1‒2], 提出的模型都具有很好的性能。2020 年, Yu 等[3]提出首个基于多方对话文本语料的人工标注数据集 DialogRE (如表 1 所示, 左侧为一段多方对话, 右侧为该对话中包含的待识别实体对及其关系类型), 并且基于该数据集的特点, 提出基于对话的关系抽取任务: 在一段对话中, 给定一组待识别实体对(实体 1, 实体 2), 通过机器理解对话, 挖掘实体对之间潜在的关系类型。
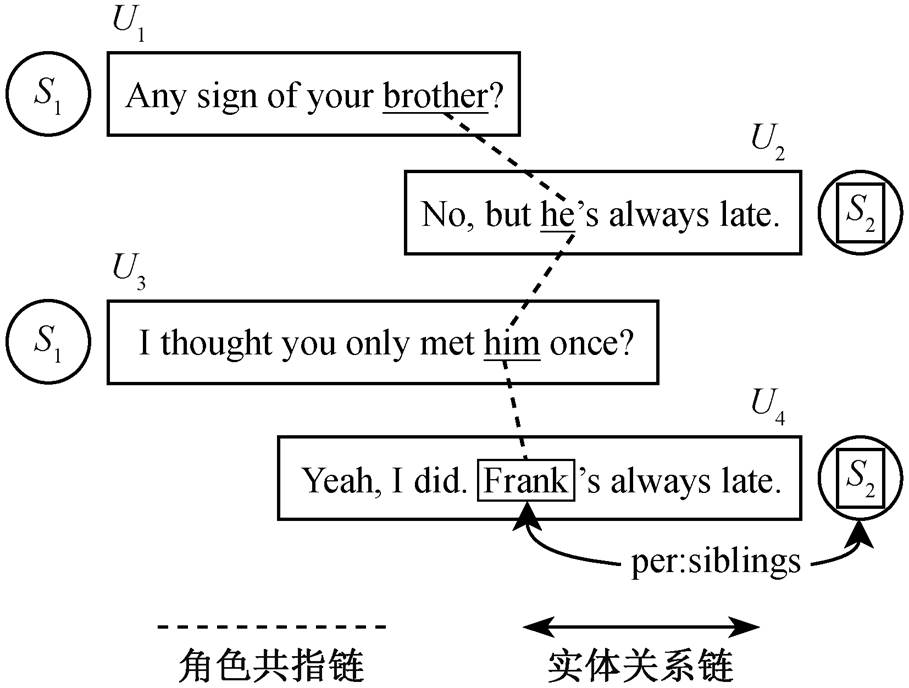
对话关系抽取是信息抽取的子任务之一。基于多方对话进行关系抽取, 在对话理解中也是关键的一步。对话这种特殊的文本体裁与一般的具有篇章结构的文本不同, 完整的对话内容存在于一问一答的发言人话语当中。不同的人发言方式风格迥异, 使得多方对话中的实体关系抽取十分困难。特别地, 在交替发言时, 对话参与者会使用名词或代词等不同的称谓去称呼同一个角色。传统的篇章关系抽取任务侧重于文本本身, 将传统的关系抽取模型[4‒5]直接应用于对话文本, 没有取得很好的效果。另外, 数据集 DialogRE 中共定义 37 种关系类型, 其中 96.7%的实体关系三元组都包含角色。与一般的篇章关系抽取任务不同, 对话关系抽取任务中更注重角色之间的关系或角色的社会属性。因此, 在对话文本的实体关系抽取任务中引入相关角色信息是必不可少的。图 1 中的对话片段来源于英文剧本《Friends》, 包含发言人 S1 和 S2 以及话语 U1~U4。如果想要进一步挖掘实体对(S2, Frank)之间的关系, 仅从对话的字面上很难直接得出结论。首先, Frank并不是直接的发言人, 是 S1 和 S2 两个发言人交替对话的产物。因此, 机器需要进行一定程序的逻辑推理, 首先识别出对话中出现的‘brother’, ‘he’, ‘him’, ‘Frank’等词具有共指关系(指向同一个实体 Frank), 才能得到在 S1 和 S2 的发言中提到的‘brother’正是指‘Frank’, 也就是 S2 的弟弟。因此, 在多方对话实体识别任务中, 如何有效地融入角色指代信息是当前研究的重点课题。
表1 DialogRE数据集示例
Table 1 Example of dialogre dataset

发言人对话文本(Utterance)实体关系待识别实体对(Argument pair)关系类型(Relation type) S1Hey Pheebs.R1(Frank, S2)per:siblings S2Hey!R2(S2, Frank)per:siblings S1Any sign of your brother?R3(S2, Pheebs)per:alternate_names S2No, but he’s always late.R4(S1, Pheebs)unanswerable S1I thought you only met him once? S2Yeah, I did.I think it sounds.y’know big sistery, y’know, ‘Frank’s always late.’
说明: 数据节选自Yu等[3]提出数据集DialogRE。
目前关注到对话角色的相关研究有两种方法。1)基于序列特征的研究[6‒7]: 将发言人和话语文本简单拼接后, 直接输入进编码器中, 没有进行不同发言人的区分。2)基于图的研究: 由于对话文本具有天然的图结构, 图神经网络[8]能够对其进行很好的建模, 并在对话情感识别和对话阅读理解等任务中取得不错的结果。Chen 等[9]受此启发, 将对话文本构建为图, 为发言人和发言内容分别构建不同的节点, 并引入词性和实体类型特征, 加强模型对对话的理解, 所构建的 DHGAT (document-level hete-rogeneous graph attention networks)模型也取得不错的结果。然而, 对话中的角色信息不仅包括发言人, 对话中代词和实体指向的非发言人角色也是其中关键的内容, 如果只使用发言人特征构建图, 会丢失对话中的大量指代信息, 不利于机器更好地理解对话内容。
本文在 Chen 等[9]的研究基础上, 基于图注意力网络模型[10]构建对话角色节点, 将外部知识库与人物指代信息相融合, 提出融合角色指代的多方对话关系抽取模型 CGAT (character-level graph attention networks)来提升对话关系抽取任务的性能。
1 相关工作
1.1 基于序列建模的实体关系抽取方法
在循环神经网络(rerrent neural network, RNN)开始大规模流行之前, 研究人员在卷积神经网络(convolutional neural network, CNN)的基础上做了许多工作。Nguyen 等[11]使用 CNN 进行关系抽取, Zeng 等[12]在 CNN 的基础上提出分段卷积神经网络(piecewise convolutional neural network, PCNN), 能自动提取句子级的特征, 但是这种单句策略无法充分利用句间信息。之后, Yang 等[13]提出双向 RNN网络再加上词级和句级注意力机制模型, 在一些数据集上取得不错的效果。Zhang 等[14]使用 PALSTM模型, 对篇章的全局位置信息进行编码。Zhou 等[15]使用 BiLSTM 模型, 提取实体间在较长距离跨度上的依赖关系。Xue 等[16]基于 BERT 提出 SimpleRE模型进行句子级关系抽取, 在不使用外部资源的情况下取得当时的最好性能。
1.2 基于图网络建模的实体关系抽取方法
图神经网络(graph neural network, GNN)将图结构表示的特征融入端到端的模型中, 取得显著的成果, 得到广泛应用。Zhang 等[17]使用图卷积神经网络(graph convolutional network, GCN)对文本进行建模, 提取关系的结构特征, 提升了模型抽取关系的能力。随后, Guo 等[18]提出一种基于全局注意力的图网络模型(attention guided graph convolutional network, AGGCN), 通过自注意力机制来改进图的传播方式, 增强图网络的学习能力。虽然 AGGCN取得当时最好的结果, 但图在传播过程中过度依赖外部解析器, 以至出现较多的传播错误。Xue 等[19]利用多视图图结构对对话进行编码, 提出的 GDPNet模型在解决长序列文本关系抽取上达到最好的效果。Christopoulou 等[20]等为了解决跨多句表达的关系抽取任务, 同样构建图进行基于文档的关系抽取模型, 以便进一步学习句内和句间特征。Zhou 等[21]使用注意力机制加强词的表达能力, 并引入发言人话语中简单的指代关系以及图推理增强模型的识别能力。
2 模型设计
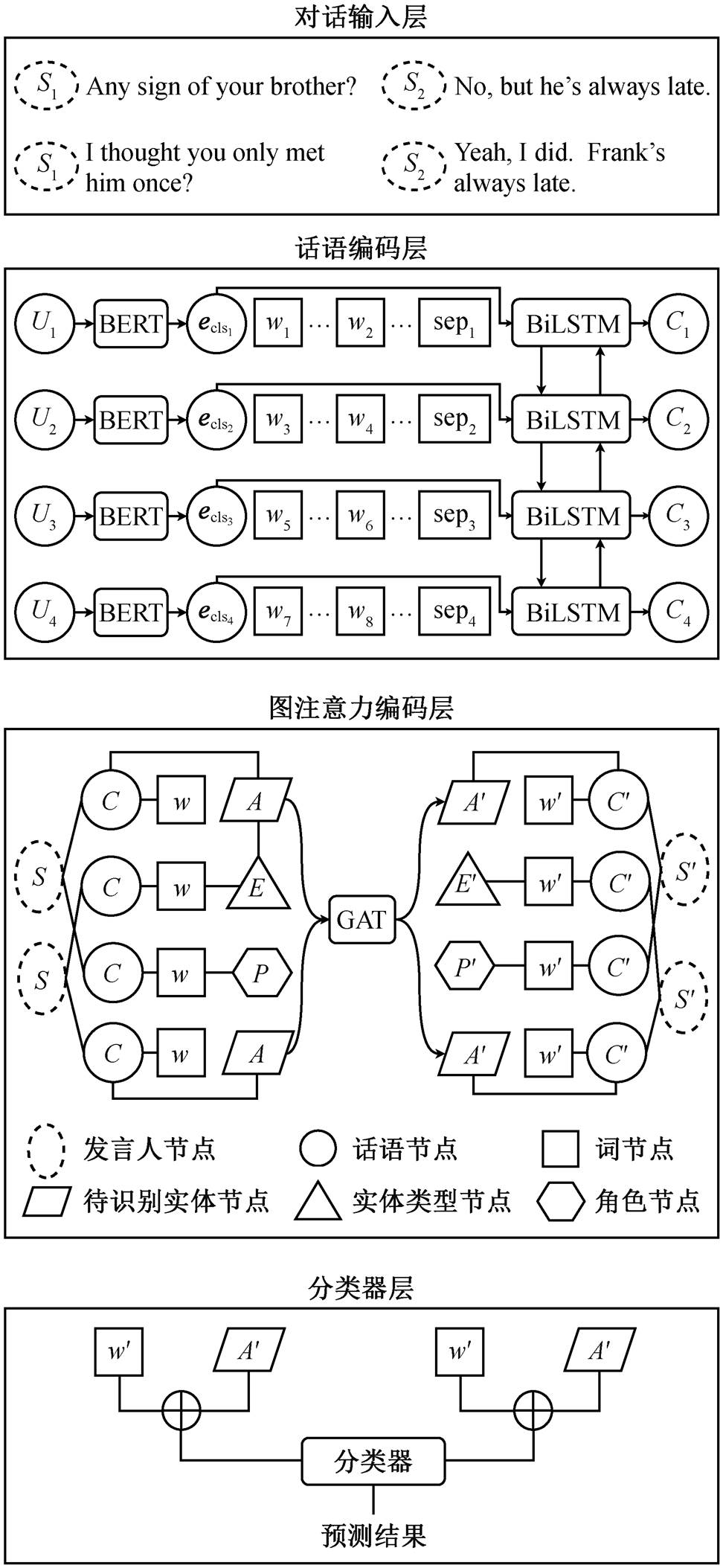
本文模型的整体架构如图 2 所示。对话输入层处理模型的输入部分, 预处理对话数据并提取相应特征。话语编码层主要对输入序列进行层次化编码, 获取话语的基础向量表示, 作为图注意力网络中话语节点的初始表示。图注意力网络编码层将一段对话构造成异构图, 创建不同的节点以及节点之间的连接方式, 获得对话的更全面的表示。分类器层将从图注意力网络中学到的节点信息输入分类器, 得到最终的实体关系预测结果。
2.1 话语编码层
话语编码层采用层次化的编码方式, 通过高低两种层级对输入进行初步编码, 提取话语特征。输入为一段对话 D={U1, U2, …, UN}, 其中 Ui 表示一段对话中第 i 个话语, i∈(1, N)。具体地, Ui={w1, w2, …, wM}, 其中 wj 表示一段对话中第 j 个词, j∈(1, M)。首先将对话 Ui 输入进低层级编码器, 使用 BERT 对话语进行编码, 得到话语编码结果 ei。eclsi 为 ei 在[CLS]位置的表征向量, 表示当前话语的基本语义信息。此时, 各个话语之间的信息仍然相互独立, 因此采用高层级编码器 BiLSTM, 将对话中的话语信息有效地结合起来, 由于对话具有时序性, 采用BiLSTM 网络模型能很好地捕获对话的这一特征。将一段对话 D 中各个 Ui 经 BERT 编码后的 eclsi 进行拼接, 构成一段对话的完整表示 ecls, 输入高层级编码器中, 获取包含上下文的完整对话编码结果 C, 每个 eclsi 对应的高层级话语编码结果为 Ci, 如式(1)~(3)所示:
ei = BERT(Ui), (1)
ecls =[ecls1; ecls2; …; eclsN] , (2)
C=BiLSTM(ecls)。 (3)
2.2 图注意力网络编码层
2.2.1 节点构建
本文基于对话构建的异构图包含 6 种节点, 每种节点表示的信息以及初始化方式如表 2 所示。
2.2.2 边构建
本文基于对话构建的异构图中包括6种边, 分别为单词‒话语边、发言人‒话语边、待识别实体‒话语边、单词‒实体类型边、待识别节点‒实体类型边以及单词‒角色边。以上6种边中, 除单词‒话语边用单词对应的词性进行初始化外, 其他边均采用随机的方式进行初始化。
2.2.3 图注意力网络
本文使用图注意力网络, 将话语信息、实体类型信息以及角色信息传递到单词、发言人以及待识别实体节点上。以节点pi的信息更新为例, 设pj为pi的邻接节点, qij为pi与pj两节点之间的边。首先通过消息函数获取节点pi和pj的信息, 再利用聚合函数, 使用注意力机制计算节点间的信息, 随后传递到节点pi中, 完成节点pi信息的更新。式(4)为消息函数, 式(5)和(6)为聚合函数, 在图注意力网络中通过这两部分进行节点间信息的获取和传递, 完成图中节点的更新。
F(pi, pj) = LeakyRelu(aT(Wi pi; Wj pj; qij), (4)
αij = softmax(F(pi, qj)), (5)
其中, aT, Wi, Wj和Wz为可学习参数, α表示注意力分数, σ为激活函数。
2.2.4 图注意力网络传播过程
本文构建的图边是无向的, 传播过程是有向的。图注意力网络在一定程度上能够获取节点间的信息, 但一次传播获得的信息是较为浅层的。因此, 本文进行7次节点间的传播, 多次更新对话中的节点信息, 有助于模型更深入的理解对话。
图3示意本文设计的传播方式。第1次传播使用话语节点更新单词节点、发言人节点和待识别实
表2 图注意力网络节点信息
Table 2 Node information of graph attention network

节点类型节点表示的信息 初始化方式 单词节点(Word)对话中的单词信息预训练BERT初始权重初始化 话语节点(Utterance)对话中的话语信息话语编码器的输出结果 发言人节点(Speaker)对话中话语的发言人信息根据发言人随机初始化 实体类型节点(Entity_type)对话中单词的实体类型信息根据实体类型随机初始化 角色节点(Character)对话中包含的角色信息根据角色随机初始化 待识别实体节点(Argument)对话中需要进行关系识别的实体信息根据待识别实体随机初始化
体节点, 第2次传播使用单词节点和待识别实体节点更新实体类型节点, 第3次传播使用单词节点更新角色节点, 第4次传播使用实体类型节点更新单词节点和待识别实体节点, 第5次传播使用角色节点更新单词节点, 第6次传播使用单词节点、发言人节点和待识别实体节点更新话语节点, 第7次传播使用话语节点更新单词节点、发言人节点和待识别实体节点。至此传播结束。
式(7)~(13)为本文设计的传播过程计算公式, 其中GAT代表式(4)~(6)的计算过程。
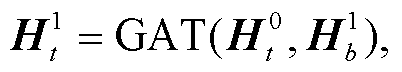 (8)
(8)
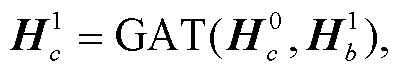 (9)
(9)
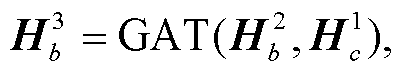 (11)
(11)
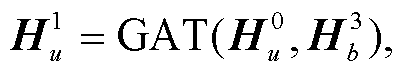 (12)
(12)
本文沿用Chen等[9]的思路, 将单词节点、发言人节点和待识别实体节点统一描述为基础节点, 其矩阵表示为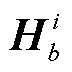 , 实体类型节点和话语节点的初始矩阵表示为
, 实体类型节点和话语节点的初始矩阵表示为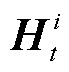 和
和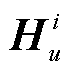 。差别在于本文提出的方法将新增的角色节点表示为
。差别在于本文提出的方法将新增的角色节点表示为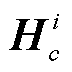 , 并增加两次更新过程。节点矩阵的上角标 i 表示该节点第 i 次更新后的结果。
, 并增加两次更新过程。节点矩阵的上角标 i 表示该节点第 i 次更新后的结果。
节点经过图注意力网络编码之后, 使用残差连接, 随后经过前馈神经网络 FFN, 获得节点最终的向量表示 pend, 如下式所示:
其中, p0 为节点的初始表示, pg 为节点经过图注意力网络之后的表示。
2.3 分类器层
经过图注意力网络编码层, 模型已经学习到较为充分的对话信息, 在分类器层的输入为待识别实体节点特征τx和τy及其对应的单词节点特征δx和δy。将两者包含的信息分别经过最大池化层(Max-Pooling), 得到对应的向量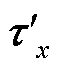 ,
,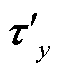 ,
,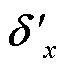 和
和 , 随后通过拼接组成新向量Res, 并将其输入全连接网络进行分类, 获得最终的实体关系预测结果Pre:
, 随后通过拼接组成新向量Res, 并将其输入全连接网络进行分类, 获得最终的实体关系预测结果Pre:
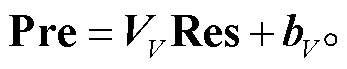 (16)
(16)
其中, VV和bV为可学习的参数。
3 实验设置
3.1 数据集
本文采用的实验数据包括两部分, 分别是由EmoryNLP团队构建的基于多方对话的角色识别数据集[22]和Yu等[3]构建的对话人物关系数据集DialogRE, 均基于英文剧本《Friends》进行标注, 其中角色识别数据集中标注数据仅包括前1~4季, 人物关系数据集中标注数据则包括1~10季全部数据。另外, DialogRE包含3个版本的数据, 本文选择Yu等[3]构建的第一版数据, 结合EmoryNLP标注的前4季人物指代信息, 验证所提模型的有效性。数据集中包括1788段对话, 按照3:1:1的比例划分训练集、验证集和测试集。对话中共标注506种角色, 37种实体关系类型, 19319个指代关系。较为完整的对话数据统计如表3和4所示, 训练集、测试集和验证集中对话实体关系平均个数和指代平均个数大体上一致。
3.2 评价指标
可以将实体关系抽取任务视为多分类任务。为了验证本文提出模型的有效性, 采用评价指标F1值对模型进行评价, 计算公式下:
F1 = 2PR/(P+R), (17)
其中, P表示精确率(Precision), R表示召回率(Re-call)。
3.3 参数设置
本文所用实验设备为GeForce RTX 3090, Cuda版本为11.2, PyTorch版本为1.7.0。将BERT 作为预训练模型, 版本为bert-small-uncased, 隐藏层维度为512, 丢弃率设置为0.15。实体类型、词性以及角色嵌入向量的维度为30, BiLSTM的隐藏层维度为128, 学习率设置为0.0005, 批量大小设置为8, 使用梯度累加策略, 梯度累加步数为2。图注意力网络的隐藏层维度设置为512, 注意力头数设置为8, 边的初始化隐藏层维度设置为50, 使用的激活函数为elu。
表3 角色指代信息统计
Table 3 Statistics of character coreference information

数据集对话个数话语个数每段对话平均话语个数包含指代的对话个数包含指代的对话占比/% 训练集1073140231341538.7 验证集35846861313938.2 测试集35744211214741.2
表4 角色信息和关系信息统计
Table 4 Statistics of character and relationship information

数据集角色总数平均每段对话角色个数平均每段对话发言人个数平均每段对话出现实体关系个数平均每段对话出现实体关系种类 训练集3813363 验证集1552363 测试集1472353
4 实验结果与分析
4.1 对比实验
本文基于DialogRE数据集, 引入角色指代信息进行实验, 为了验证本文提出模型CGAT的有效性, 分别采用基线模型CNN, LSTM, BiLSTM和DHGAT作为对比, 实验结果如表5所示。可以看出, 与DHGAT相比, CGAT的整体性能有一定程度的提升, 最终结果的F1值在验证集上高出2.9%, 在测试集上高出4.6%。
另外, 本文在单词节点初始化的部分采用Glove和Bert两种策略的编码方式。与使用Glove的模型相比, 使用Bert的模型F1值在验证集上高出1.2%, 在测试集上高出1.4%。
由于本文的侧重点在于挖掘角色指代信息对模型的影响, 因此需要进一步分析指代信息的添加对模型性能的影响。将验证集和测试集中包含和不包含指代信息的数据在Glove+CGAT模型和DHGAT模型中分别进行验证, 实验结果如表6所示。可以看出, 包含指代信息的样本数据中验证, 模型的实验结果相较于基线模型有所提高, 分别提高 0.6%和3.1%, 但对不包含指代的样本数据中模型实验效果并没有稳定增长或下降趋势。分析模型的设计过程, 该现象可能是由于在连接更新角色节点和实体类型节点时共享参数所导致。因为每个词节点都与实体类型节点一一相连, 实体类型的影响范围对整个图的传播过程影响更为明显, 本文下一步将继续在这方面进行验证。
表5 不同模型的实验结果
Table 5 Experimental results of different models
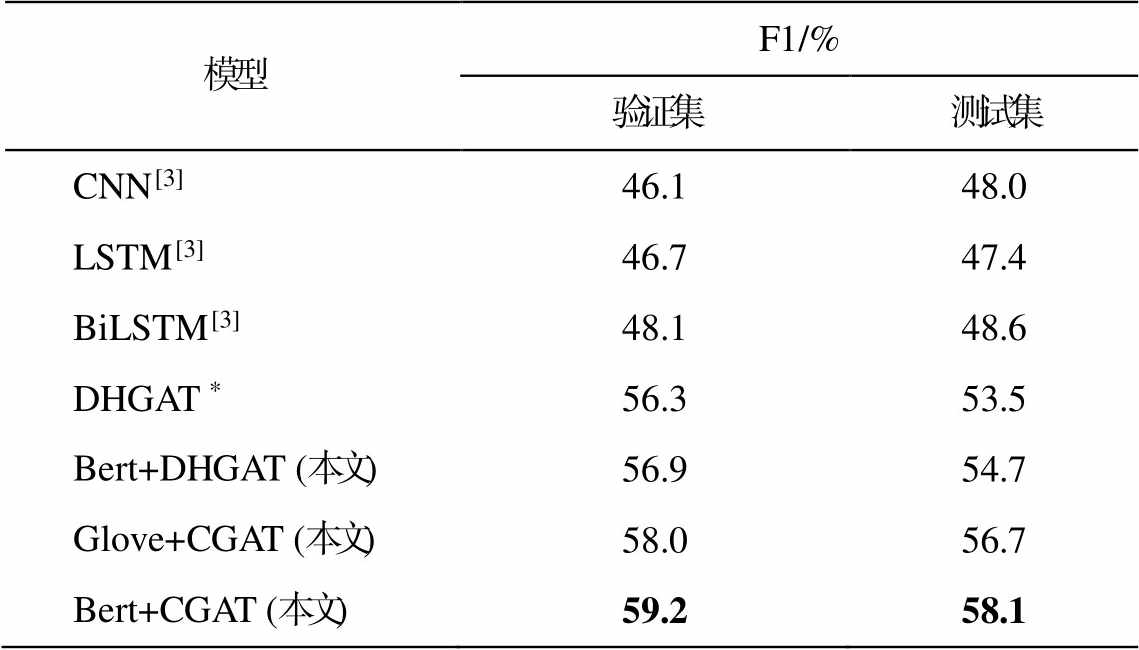
模型F1/% 验证集测试集 CNN[3]46.148.0 LSTM[3]46.747.4 BiLSTM[3]48.148.6 DHGAT *56.353.5 Bert+DHGAT (本文)56.954.7 Glove+CGAT (本文)58.056.7 Bert+CGAT (本文)59.258.1
说明: 粗体数字表示本文取得的最优实验结果; *表示本文所复现的模型实验结果, 下同。
4.2 角色节点不同表示方式的有效性分析
在图网络中, 角色节点与词节点相连接, 表明角色与指代词之间的关系。对于角色指代关系中角色这一特征的表示, 本文设置将角色节点抽象化和角色节点具体化两种方式。角色节点抽象化的创建方式如下: 随机初始化每段对话中出现的角色, 不将其映射到具体的人物, 每段对话间角色节点相互独立, 只在当前对话中有特定含义。角色节点具体化的创建方式如下: 使用全局角色词表, 初始化每段对话中出现的角色, 将其映射到具体的人物, 所有对话中的角色节点共享参数, 共同更新。
上述两种设置方式的实验结果(表7)表明, 使用抽象化的表示方法时, 模型的性能达到最优; 节点具体化之后, 模型的效果反而巨幅下降。通过分析语料发现, 在实验语料集中包含506个实体, 而在每段对话中平均只出现2~3个角色, 并且语料集中除主要人物外, 其他人物可能只出现一次。因此, 角色节点具体化的创建方式很难学习到相应角色的深层特征。
表6 包含(或不包含)指代信息的数据集上的实验结果
Table 6 Experimental results of dataset with/without coreference information
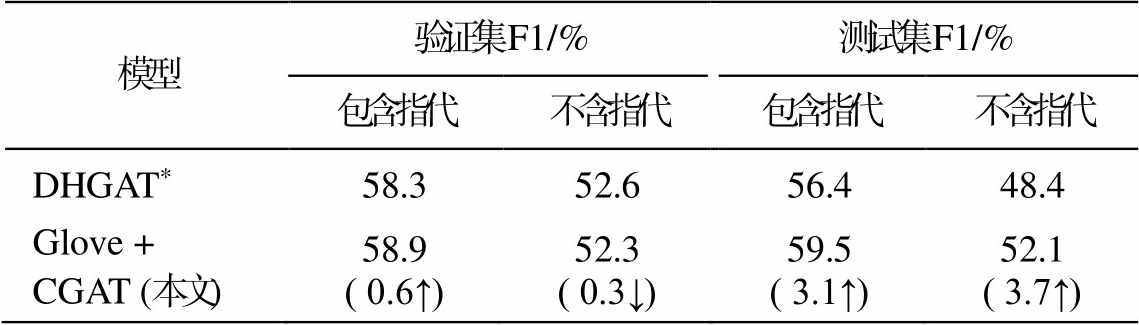
模型验证集F1/%测试集F1/% 包含指代不含指代包含指代不含指代 DHGAT*58.352.656.448.4 Glove + CGAT (本文)58.9( 0.6↑)52.3( 0.3↓)59.5( 3.1↑)52.1( 3.7↑)
说明: 括号内数字表示模型结果的变化幅度, 箭头表示实验结果提升(下降)。
表7 角色节点不同表示方式有效性分析结果
Table 7 Analysis on experimental results of different representations of character nodes
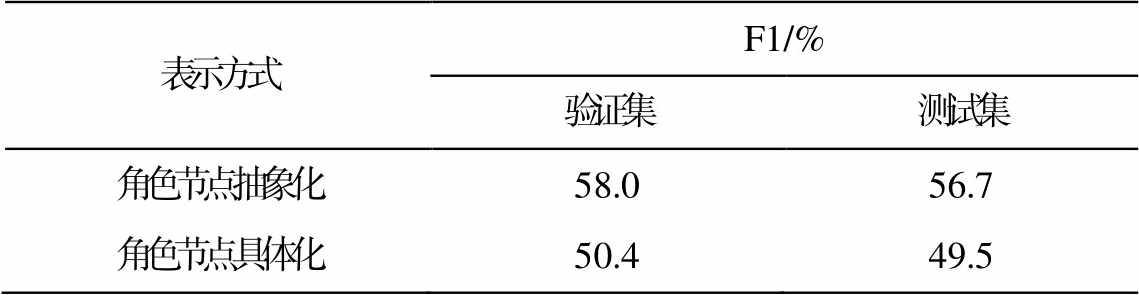
表示方式F1/% 验证集测试集 角色节点抽象化58.056.7 角色节点具体化50.449.5
4.3 词节点不同创建方式的有效性分析
在一段完整的对话表达中, 不可避免地存在许多重复出现的词。由于重复的词在不同句子中具有不同的含义, 因此在对这些重复的词进行选取时, 本文设置对话级词节点、句子级词节点和全局词节点3种方式。对话级词节点的创建方式如下: 在对话级过滤掉重复的词, 每个词在图中只出现一次。句子级词节点的创建方式如下: 在句子级过滤掉重复的词, 每个词在句子层级只出现一次。全局词节点的创建方式如下: 不过滤词, 一段完整对话中包含的词节点即为出现过的全部词。
上述3种不同设置方式的实验结果(表8)表明, 对话级词节点创建方式取得最优的结果。此外, 句子级词节点和全局词节点的实验结果中, 随着设置的词节点增多, 模型性能逐渐下降。
5 结语
本文提出融合角色指代的多方对话关系抽取模型CGAT, 基于图注意力网络, 对对话文本进行建模, 并引入对话中人物角色指代信息来预测对话中的实体关系, 增强对话中人物信息的表示。CGAT有效地利用指代信息, 完善对话内容中存在的角色信息, 增强指向同一实体的指代词之间的关系, 从而使模型更好地理解对话, 学习到实体之间的关系特征, 有效地提升模型的实验结果。下一步的工作将着重于有关对话的建模中, 如何设计更好的图神经网络的连接方式和传播过程。
表8 不同词节点创建方式的实验结果
Table 8 Experimental results of different creation methods of word nodes
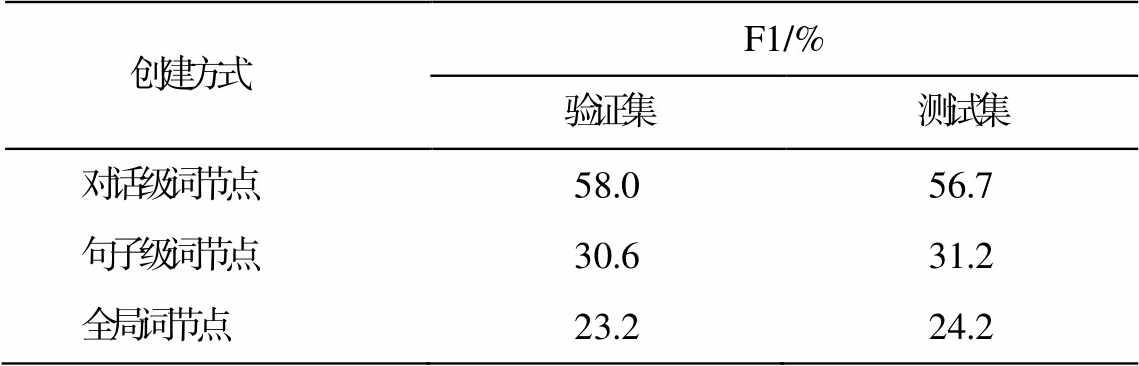
创建方式F1/% 验证集测试集 对话级词节点58.056.7 句子级词节点30.631.2 全局词节点23.224.2
参考文献
[1]Liu C Y, Sun W B, Chao W H, et al.Convolution neural network for relation extraction // International Conference on Advanced Data Mining and Applica-tions.Berlin: Springer, 2013: 231‒242
[2]Miwa M, Bansal M.End-to-end relation extraction using LSTMs on sequences and tree structures // Pro-ceedings of the 54th Annual Meeting of the Associa-tion for Computational Linguistics (Volume 1: Long Papers).Berlin, 2016: 1105‒1116
[3]Yu D, Sun K, Cardie C, et al.Dialogue-based relation extraction // Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.Se-attle, 2020: 4927‒4940
[4]Yoshino K, Mori S, Kawahara T.Spoken dialogue system based on information extraction using simil-arity of predicate argument structures // Proceedings of the SIGDIAL 2011 Conference.Portland, 2011: 59‒66
[5]Wang L, Cardie C.Focused meeting summarization via unsupervised relation extraction // Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue.Seoul, 2012: 304‒313
[6]Shi P, Lin J.Simple bert models for relation extrac-tion and semantic role labeling [EB/OL].(2019‒04‒ 10) [2021‒05‒20].https://arxiv.org/abs/1904.05255
[7]Joshi M, Chen D, Liu Y, et al.Spanbert: improving pre-training by representing and predicting spans.Transactions of the Association for Computational Linguistics, 2020, 8: 64‒77
[8]Scarselli F, Gori M, Tsoi A, et al.The graph neural network model.IEEE Transactions on Neural Net-works, 2008, 20(1): 61‒80
[9]Chen H, Hong P, Han W, et al.Dialogue relation extraction with document-level heterogeneous graph attention networks [EB/OL].(2020‒09‒14) [2021‒ 04‒22].https://arxiv.org/abs/2009.05092
[10]Veličković P, Cucurull G, Casanova A, et al.Graph attention networks [EB/OL] // Proceedings of the 6th International Conference on Learning Representa-tions.(2018‒02‒23) [2021‒04‒22].https://openreview.net/forum?id=rJXMpikCZ
[11]Nguyen T H, Grishman R.Relation extraction: per-spective from convolutional neural networks // Pro-ceedings of the 1st Workshop on Vector Space Mode-ling for Natural Language Processing.Denver, 2015: 39‒48
[12]Zeng D, Liu K, Chen Y, et al.Distant supervision for relation extraction via piecewise convolutional neural networks // Proceedings of the 2015 conference on empirical methods in natural language processing.Lisbon, 2015: 1753‒1762
[13]Yang L, Ng T L J, Mooney C, et al.Multi-level attention-based neural networks for distant supervised relation extraction // 25th Irish Conference on Artifi-cial Intelligence and Cognitive Science.Dublin, 2017: 206‒218
[14]Zhang Y, Zhong V, Chen D, et al.Position-aware attention and supervised data improve slot filling // Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.Copenha-gen, 2017: 35‒45
[15]Zhou P, Shi W, Tian J, et al.Attention-based bidi-rectional long short-term memory networks for rela-tion classification // Proceedings of the 54th Annual Meeting of the Association for Computational Linguis-tics (Volume 2: Short Papers).Berlin, 2016: 207‒212
[16]Xue F, Sun A, Zhang H, et al.An embarrassingly simple model for dialogue relation extraction [EB/ OL].(2020‒12‒27) [2021‒05‒20].https://arxiv.org/ abs/2012.13873
[17]Zhang Y, Qi P, Manning C D.Graph convolution over pruned dependency trees improves relation extraction // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing.Brussels, 2018: 2205‒2215
[18]Guo Z, Zhang Y, Lu W.Attention guided graph con-volutional networks for relation extraction // Procee-dings of the 57th Annual Meeting of the Association for Computational Linguistics.Florence, 2019: 241‒ 251
[19]Xue F, Sun A, Zhang H, et al.GDPNet: refining latent multi-view graph for relation extraction [EB/OL].(2020‒12‒12) [2021‒05‒20].https://arxiv.org/abs/2012.06780
[20]Christopoulou F, Miwa M, Ananiadou S.Connecting the dots: document-level neural relation extraction with edge-oriented graphs // Proceedings of the 2019 Conference on Empirical Methods in Natural Lan-guage Processing and the 9th International Joint Con-ference on Natural Language Processing (EMNLP-IJCNLP).Hong Kong, 2019: 4927‒4938
[21]Zhou M, Ji D, Li F.Relation extraction in dialogues: a deep learning model based on the generality and specialty of dialogue text.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 2015‒2026
[22]Zhou E, Choi J D.They exist! Introducing plural mentions to coreference resolution and entity linking // Proceedings of the 27th International Conference on Computational Linguistics.Santa Fe, 2018: 24‒34
Research on Dialogue Entity Relation Extraction with Enhancing Character Information
XU Yang1, JIANG Yuru1,2,†, ZHANG Yuyao1, HE Weikai1
1.Institute of Intelligent Information Processing, Beijing Information Science and Technology University, Beijing 100101; 2.Beijing Laboratory of National Economic Security Early-Warning Engineering, Beijing 100044; † Corresponding author, E-mail: jiangyuru@bistu.edu.cn
Abstract A multi-party dialogue relationship extraction model that integrates character reference information is proposed based on a previous model of graph attention network.Specifically, this article adds character nodes in graph, connects them with the word nodes referred by the corresponding character and uses graph attention networks for encoding.The F1 score based on DialogRE Dataset improved by 2.9% on the valid set and 4.6% on the test set compared with the baseline model.
Key words entity relation extraction; hierarchical encoding; graph attention network; dialogue structure
doi: 10.13209/j.0479-8023.2021.107
收稿日期: 2021-06-08;
修回日期: 2021-08-15
国家自然科学基金(61602044, 61772081)和北京市自然科学基金(4204100)资助
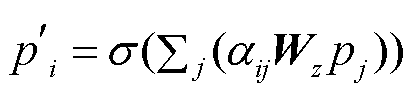 。 (6)
。 (6)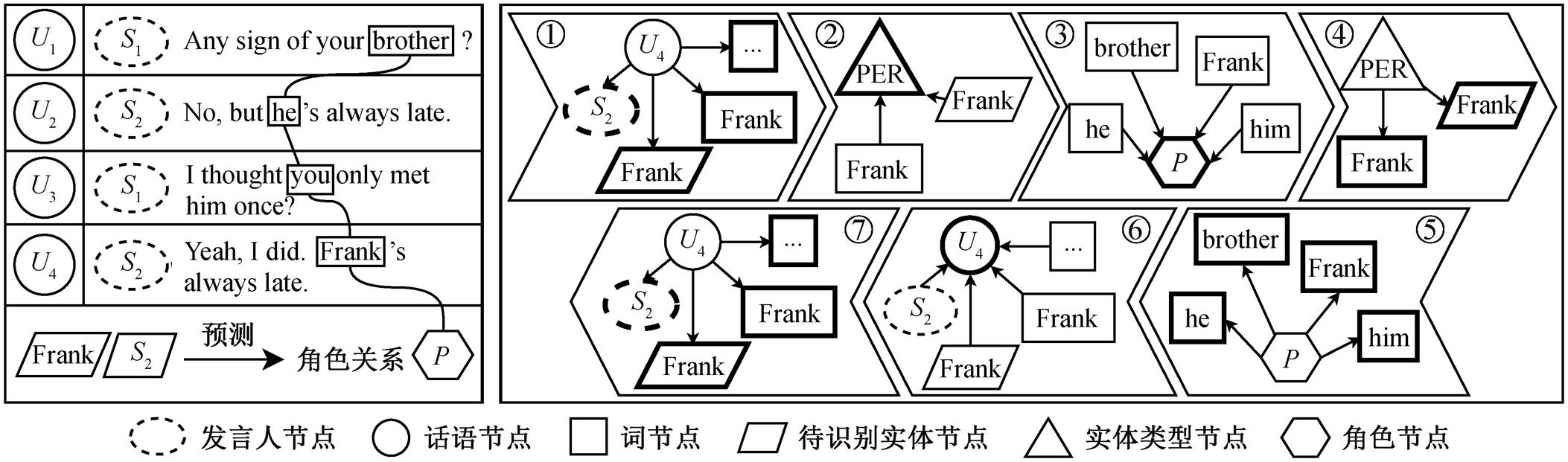
 (7)
(7)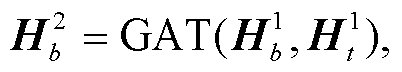 (10)
(10)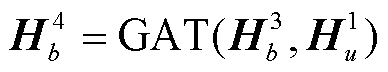 。 (13)
。 (13)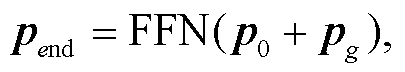 (14)
(14)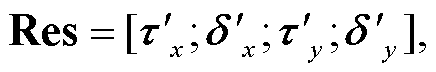 (15)
(15)