基于深度学习的实体链接研究综述
李天然 刘明童 张玉洁† 徐金安 陈钰枫
北京交通大学计算机与信息技术学院, 北京 100044, †通信作者, E-mail: yjzhang@bjtu.edu.cn
摘要 介绍实体链接的概念和步骤以及基于深度学习的命名实体链接相关问题和研究现状, 分析实体链接研究中存在的问题及相应的解决模型, 并介绍相关数据集和评测方法。总结国际评测会议中实体链接的现状,展望未来的研究方向。
关键词 实体链接; 实体消歧; 实体识别; 知识库; 深度学习
随着大数据技术的发展, 海量信息的爆炸式增长导致信息过载, 也给用户获取准确的信息带来挑战。为了准确地获取目标信息, 人们需要处理大量的虚假信息、冗余信息和噪声信息。出现这一问题的原因是自然语言表达的多样性, 即一词多义和多词同义现象。
表述或指称(mention)指自然语言文本中表达实体的语言片段, 实体链接(entity linking, EL)指将文本中的表述链接到知识库(knowledge base, KB)中相应的实体(entity)来进行实体消歧(entity disambigua-tion), 帮助人类和计算机理解文本具体含义的任务。例如, 在文本“苹果发布了最新产品”中, 表述“苹果”在知识库中对应的实体有“苹果(科技产品)”、“苹果(苹果产品公司)”和“苹果(蔷薇科苹果属果实)”等, 实体链接就是将表述“苹果”链接到知识库中的“苹果(苹果产品公司)”, 消除其他义项导致的歧义的过程。实体链接能够利用知识库丰富的语义信息, 在许多领域发挥非常重要的基础性作用, 例如问答系统(question answering)、语义搜索(sem-antic search)和信息抽取(information extraction)等。实体链接也具有扩充知识库的重要功能, 可以用于更新实体和关系, 是知识图谱构建中的一个重要环节。实体链接研究中使用的知识库包括 TAP、维基百科、Freebase 和 YAGO 等。
近年来, 作为人工智能的关键技术, 深度学习方法在计算机视觉和自然语言处理等领域取得突破性进展, 使得人工智能迎来新一轮飞跃式发展。深度学习方法给实体链接任务提供强有力的工具, 得益于神经网络强大的特征抽象和泛化能力, 基于深度学习的实体链接方法逐渐成为研究实体链接的主流方法。与传统的统计方法相比, 深度学习方法有以下主要优势: 1)深度学习方法的训练是端到端的过程, 不需要手工定义相关特征; 2)深度学习可以学习特定任务的表示, 建立不同模式、不同类型和不同语言之间的信息关联, 从而实现更好的实体分析性能。
为了明确实体链接任务未来的研究方向, 以便更好地应用到其他领域, 本文对实体链接任务的研究现状进行总结。首先介绍实体链接的任务定义、关键技术、相关研究和发展历程, 重点介绍目前存在的问题, 然后对最近几年基于深度学习的实体链接相关问题和研究现状做系统性的介绍, 最后总结国际评测会议中实体链接的不足, 对未来的研究方向进行展望。
1 实体链接任务
1.1 实体链接任务
实体链接任务研究的对象为包含人名、地名和机构名在内的命名实体, 将非结构化文本中的表述指向其代表的真实世界实体, 关联到对应的知识库具体实体中, 主要解决实体名的歧义性和多样性问题。实体链接任务的关键技术包括候选实体生成和候选实体消歧。
候选实体生成是为文本中的指称生成一个知识库中的相关实体集合, 其首要任务是识别出文档中的实体指称, 即需要链接到知识库进行消歧的词或短语, 这一过程与自然语言处理中的命名实体识别任务较为类似。候选实体生成要求较高的召回率, 目的是召回尽可能多的指称的可能的链接对象, 用以提高实体链接的准确性, 同时尽可能排除不相关的实体, 从而减少计算量。
候选实体消歧是通过计算, 对实体集合中实体的相关性进行排序, 并选出最佳的对应候选实体的过程。
1.2 命名实体识别
候选实体生成的关键技术是命名实体识别, 包括识别出实体的边界和类型(人名、机构名、地名以及其他所有以名称为标识的实体)两个过程。候选实体生成和命名实体识别都需要识别出实体片段, 但命名实体识别意在识别出所有实体, 而候选实体生成侧重于找出在知识库中存在相应链接条目的实体指称。
实体链接中的指称识别主要使用早期命名实体识别中基于规则和字典的方法, 该方法也广泛应用于各种实体链接系统。通过充分利用维基百科提供的各类信息(重定向页面、排歧页面和锚文本等), 构建实体名称与所有可能链接实体的映射关系字典, 利用字典中的信息生成候选实体集合。此外, 文本中的实体通常用缩写词或实体全名的一部分来表示, 相应的全名通常出现在上下文中, 因此出现基于上下文的实体名称字典扩充法, 使用上下文信息来查找与缩写或局部词对应的实体全名, 从而扩展实体名称词典。
1.3 实体消歧
命名实体消歧是确定一个实体指称项所指向的真实世界实体的过程, 通过计算实体指称与候选实体之间的相似度并进行相似度排序来选择可能的候选实体, 主要方法有基于概率生成模型的方法、基于主题模型的方法、基于图的方法、基于深度学习的方法和无监督方法等。根据模型的差异, 可以大致划分为基于统计学习的实体消歧方法和基于深度学习的实体消歧的方法。基于统计学习的方法侧重于计算实体之间的相似度, 但需要借助有标注的实体链接语料库来进行。为了解决标注的语料库缺乏的问题, 相继出现半监督和弱监督的方法。基于深度学习方法的核心是构建多类型、多模态的上下文和知识的统一表示, 需要借助性能较好的消歧模型来进行。近年来, 得益于深度学习方法的进步, 基于深度学习的实体链接方法展示出明显的优势, 本文重点关注这类方法。
2 实体链接技术的发展
早期的研究大多侧重于单独为每个实体指称进行消岐, 利用实体指称的上下文信息为每个指称生成每个候选实体与上下文的相关性得分。然而, 同一篇文章内被链接的实体之间可能存在制约关系, 会影响最终的链接结果, 因此应综合考虑多个实体间的语义关联, 进行协同的实体链接。根据可利用信息的不同和链接决策之间是否独立, 可以将现有的实体消歧模型分为局部模型和全局模型。
局部模型利用实体指称周围的局部文本上下文信息, 独立地解决每个实体指称的歧义问题[1‒4], 仅关注如何将文本中抽取到的实体链接到知识库中, 忽视同一文档中不同实体间存在的语义联系。
全局模型鼓励文档中所有指称的目标实体在主题上保持一致性, 通过计算不同目标实体之间的主题一致性、实体关联度、转移概率和实体流行度特征等进行消歧5‒10], 通常基于 KB 建立实体图, 用来捕获文档中所有已标识指称的连贯的实体。具体而言, 将文档中的实体指称及其候选实体构建为图结构, 其中节点为实体, 边表示其关系, 利用实体指称间、候选实体间以及实体指称与候选实体间的关系进行协同推理。这种图提供局部模型无法使用的高度区分性语义信号[11]。
由于实体链接是一个相对下游的任务, 性能受限于命名实体识别任务的准确性, 中文的实体链接任务还受到中文分词任务影响, 上游任务的错误会带来不可避免的噪音。同时, 实体间还存在多样性和歧义性问题(多样性指同一个实体对应多个名称, 歧义性指同一个名称有多个含义), 给实体连接任务带来很大的困难。目前, 实体链接任务存在以下难题。
1)传统的基于机器学习的实体链接方法需要完整而标注准确的数据集, 然而人工标注的数据集(尤其是中文和其他语言的权威数据集)较为缺乏。词向量模型的出现在一定程度上有效地解决了这一问题, 该模型采用无标注的文本为输入数据, 将词表征为低维向量。但是, 传统的词向量模型不能有效地表示上下文语序信息, 其语义表示能力还需要改进。同时, 有些带标签的数据集仅能在有限的领域使用, 可能导致过拟合问题或域偏差。
2)与英语 Wikipedia, YAGO 和 Freebase 等知识库相比, 中文百科全书和其他语言的知识库起步相对较晚, 目前还不成熟。
3)尽管全局模型已经取得重大进步, 但仍有一定的局限性: 同样遭受数据稀缺问题的困扰, 并且无法引入潜在的区分特征; 联合推理机制导致计算量极大, 尤其是在文档较长的情况下, 实体图可能包含数百个节点。
3 基于深度学习的实体链接方法
为减少对人工和语言学知识的依赖, 实体链接任务逐渐转向借助深度学习中神经网络强大的特征抽象和泛化能力, 学习文本中潜在的语义信息等基本特征。基于深度学习的实体链接方法, 将不同含义、不同类型的信息映射到同一特征空间, 并对多源信息和多源文本之间的关系进行建模, 从而获得不同类型和不同模态的上下文与知识的统一表示。
3.1 实体指称识别和候选实体集生成的方法
在实体指称的识别方面, 传统的方法大多利用维基百科中的重定向页面、消歧页面、类别信息和超链接信息来构建实体别名词典, 充分地反映实体指称与其候选实体之间的映射关系。Bunescu 等[12]利用这些信息, 使用实体的标题、重定向名称以及消歧名称作为实体的名称集合, 并将从名称到实体的一对多映射关系集成到一个字典中, 进行指称识别。在候选实体集生成方面, 已有研究通过统计维基百科以及其他公开知识库中的实体表述和实体共现情况来解决, 但这种统计方法不分领域, 也不设上限, 从而导致候选集中包含大量噪声。以往的实体链接任务使用的知识库是 2014 年的维基百科(Wiki_2014), 随着维基百科 2018 版本的发布, 实体链接模型切换到规模更大、内容更丰富的 Wiki_ 2018上(4.1节将详细介绍两版维基百科的信息)。
3.2 基于深度学习的实体消歧局部模型
对于局部模型, 早期的研究大多侧重于设计有效的人为特征和复杂的相似性度量, 以便获得更好的消歧性能。相反, He 等[13]学习实体的分布式表示来测量相似性, 不需要人为特征, 单词和实体保留在联合语义空间中, 可以直接基于向量相似性进行候选实体排名。他们使用自编码器模型, 实体表示由上下文文档表示和类别表示组成; 基于深度神经网络(deep neural networks, DNN), 学习实体的文档表示; 使用卷积神经网络获取类别表示; 从使用简单的启发式规则过渡到将单词和实体用连续空间中的低维向量表示, 自动从数据中学习实体的表述和实体的特征, 最后对候选实体综合排名, 链接到对应的实体。随后, Sun 等[14]提出将表述和实体以及上下文进行嵌入式表示, 通过卷积神经网络提取特征, 最后计算表述与实体的相似度, 并进行链接。在文献[14]的基础上, Francis-Landau 等[15]加入用堆叠去除噪声的自动编码器来分别学习文本的上下文和实体的规范描述页面, 在一定程度上提升了链接性能。
Ganea 等[16]构造基于广泛的实体词共现数据的目标函数来调整传统的 Word2Vec 模型, 提高了词向量模型的语义表示能力。同时, 提出用局部和全局模型结合的方式进行链接, 奠定了后续研究中局部模型与全局模型联合训练这一研究方法的基础。他们在局部模型中提出使用软注意力(soft attention)和硬注意力(hard attention)来筛选上下文中的单词, 进一步提升链接性能。随后, Chen 等[17]通过分析文献[16]的链接错误案例, 发现模型经常将表述链接到类型错误的不正确实体。为了解决这一问题, 他们将基于 BERT[18]的实体相似性评分集成到最新模型的局部模型中, 更好地捕获潜在的实体类型信息, 最终纠正了文献[16]中大部分的链接错误。
3.3 基于深度学习的实体消歧全局模型
在早期的全局实体消岐研究中, Han 等[5]构建了基于知识库的实体图, 该实体图以实体指称和候选实体为节点, 包含指称与实体以及实体与实体的关系, 同时提出 PageRank\Random Walk 协同推理算法, 得到实体指称所指向的实体。其中, 基于图的随机游走算法如下。
输入: 初始化分布矩阵 v0 和图模型的转移概率矩阵 p
输出: 图的稳定状态 v*
1: 初始化v =v0
2: 循环
3: v =vnew
4: 计算 vnew = α×pT×v+(1−α)×v0
5: 直到 v稳定或者迭代次数超过某阈值
Hoffart 等[19]在文献[5]的基础上, 采用实体流行度和文本上下文相似度等, 对实体图中的实体指称‒实体边进行加权, 用映射实体一致性对实体‒实体边加权, 然后计算对每个指称只包含一条指称‒实体边的稠密子图, 得到指称‒实体映射结果。然而, 这些方法是不可微的, 因此很难集成进入神经网络模型。
对于全局模型的集体推理机制, 其计算量极大的缺点通过近似优化技术得到缓解。Globerson 等[20]将 Murphy 等[21]的循环信念传播(loopy belief propagation, LBP)用于集体推理。Ganea 等[16]通过截断拟合 LBP, 利用不滚动的可区分消息传递解决全局训练问题。为了解决训练数据不足的问题, Gupta 等[22]探索了大量维基百科超链接, 使用多种信息源(例如其描述和提及的上下文及细粒度类型), 为每个实体学习统一的密集表示, 无需任何特定领域的训练数据或人工设计的功能。但是, 这些潜在的注释包含很多噪音, 可能给简单的消歧模型带来错误。
针对相同子句中相同的两个表述链接到知识库中不同实体的情况, Le 等[23]在文献[16]的基础上, 对表述进行关系建模, 并以特征的形式加入全局模型中, 取得较好的性能。Guo 等[24]提出一种贪婪的全局命名实体消歧算法, 利用在知识库产生的子图上进行随机游走, 传播产生的概率分布之间的互信息, 链接性能得以提高。为了解决依赖局部上下文独立地解析实体的现有方法中可能因局部数据稀疏而失败的问题, Cao 等[25]将图卷积网络应用到子图上, 将实体链接的局部上下文特征与全局相关信息集成起来高效地学习, 提高了链接性能。尽管这些模型中各实体之间的语义依赖性能够通过构建神经网络自动建模, 然而外部知识库的指导始终被忽略。为了解决上述问题, Xue 等[26]采用具有随机游走层的神经网络, 利用外部知识来实现集体实体链接, 进一步提高链接性能, 证实通过探索外部知识库对不同实体之间的全局语义相互依赖性建模的方法是有效的。
为了解决全局模型尝试优化提及的所有链接配置而造成很高的时间复杂度、内存消耗和计算量的问题, Yang[27]提出从先前链接的实体中积累知识, 作为动态的上下文, 以便增强以后的链接决策的方法, 积累的知识包括链接实体的固有属性和紧密相关的实体。与其他全局模型相比, 该模型只需要遍历一遍所有实体指称, 就可以在训练和推理上产生更高的效率。在 5 个公开数据集上按不同的链接顺序和注意力机制的大量实验表明, 该模型具有良好的性能, 使处理长文档的大规模数据成为可能。
为了解决人工标注的数据集昂贵且缺乏的问题, Le 等[28]为未标记文档中的每个实体指称构建高召回率的候选实体列表, 使用候选列表作为弱监督, 用以约束文档级实体链接模型。他们使用 Wikip-edia 和未标记的数据来构建一个精确的链接器, 其性能可与使用昂贵的人工监督构建的链接器媲美。Le等[29]还针对不存在标记数据或标记数据非常有限(如法律领域或大多数科学领域)时实体链接工作进展甚微的现象, 提出将实体链接任务定义为一个多实例学习问题, 并依赖表面匹配来创建初始的嘈杂标签, 作为弱/远程监督的方法, 将实体链接问题构造为一个远程学习问题。
上述模型在 5 个跨领域的实体链接数据集上的测试结果如表 1 所示。Le 等[28]采用的是弱监督方法, 其他研究者均使用人工标注的数据集(4.1 节将详细介绍 6 个数据集)来训练。可以看到, Xue 等[26]在多个数据集上均取得最好的性能, 证明了外部知识库指导的有效性; Yang 等[27]在 MSNBC 数据集上取得最佳的效果, 在一定程度上解决了全局模型的联合推理机制造成高内存消耗和计算量大的问题; Le 等[28]取得可与其他使用人工监督构建的模型媲美的链接性能, 证明了采用弱监督来约束模型的有效性, 在一定程度上解决了人工标注的数据集缺乏问题。
表1 不同模型实验结果对比
Table 1 Comparison of experimental results of different models
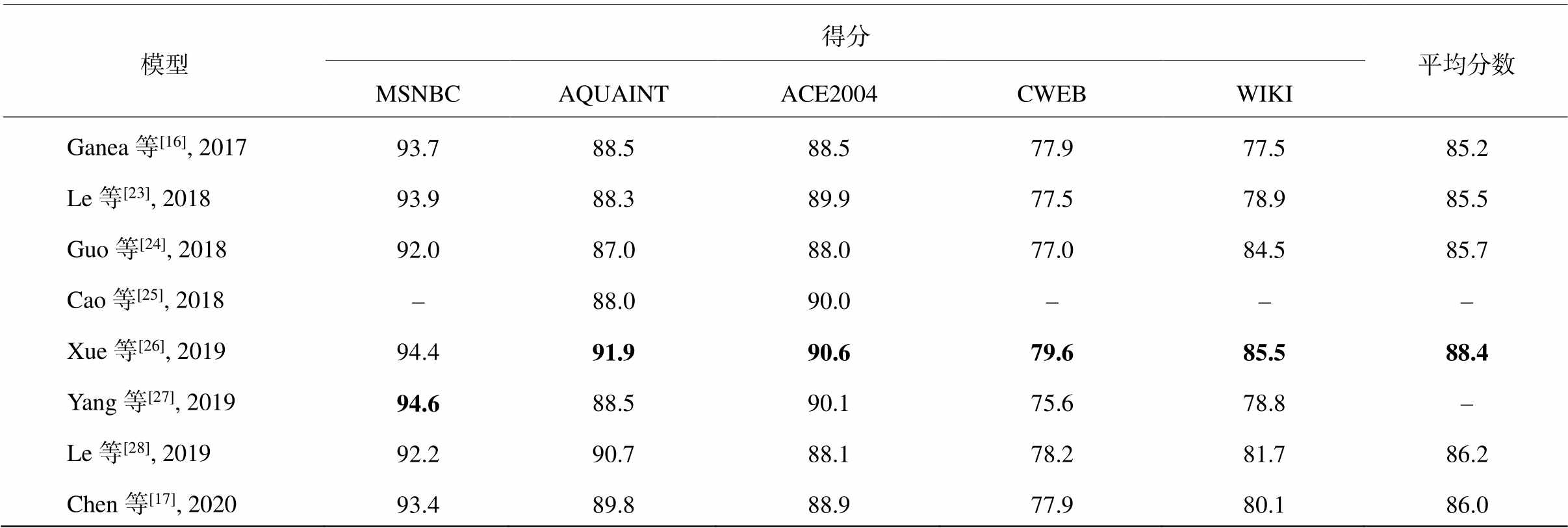
模型得分平均分数 MSNBCAQUAINTACE2004CWEBWIKI Ganea等[16], 201793.788.588.577.977.585.2 Le等[23], 201893.988.389.977.578.985.5 Guo等[24], 201892.087.088.077.084.585.7 Cao等[25], 2018–88.090.0––– Xue等[26], 201994.491.990.679.685.588.4 Yang等[27], 201994.688.590.175.678.8– Le等[28], 201992.290.788.178.281.786.2 Chen等[17], 202093.489.888.977.980.186.0
说明: 粗体数字为每个数据集上的最高得分。
在实验过程中, 随着实体指称数量的增加, 大部分全局模型的运行时间显著地增加。Yang 等[27]的模型运行时间保持线性增长, 同时保持较少的内存占用, 并且比 Le 等[23]的模型节约 80%左右的能耗, 再次证明他们的模型在处理大规模数据上的优势。由于需要在实体图上做推理, LBP 和基于 PageRank/ random walk 方法的时间复杂度为 O(k2n2)(k表示实体指称的数量, n 表示候选实体总数)。得益于只考虑相邻的指称, Cao 等[25]取得较低的时间复杂度O(kn2)。关于实体的表示, Chen 等[17]根据实体嵌入执行实体类型预测任务, 实验结果表明, 他们使用BERT[18]生成的实体嵌入的性能显著地超过 Ganea等[16]生成的实体嵌入, 表明他们的模型可以更好地捕捉实体的类型信息。
在非端到端的模型中, 分别处理实体指称检测和实体消歧两个步骤, 它们之间的重要依存关系被忽略, 由实体指称检测引起的错误将传播到实体消歧, 且不可能恢复。Kolitsas 等[30]提出第一个神经端到端的实体链接模型, 将所有可能的区域视为潜在的指称, 并学习其实体候选者的上下文相似性得分, 该方法对实体检测和实体消歧的决策均有用。他们利用关键组件(单词、实体和提及嵌入)证明, 工程化特征几乎可以被现代神经网络完全取代。
4 实体链接的评测方法
4.1 实体链接常用数据集
AIDA-CoNLL[19]是最大的人工标注的实体消歧的数据集之一, 是在 CoNLL 2013 实体识别数据集上标注的, 题材是路透社新闻。实体链接模型通常使用 AIDA-CoNLL 数据集中的 AIDA-train 作为训练集, AIDA-A 作为验证集, AIDA-B 作为测试集。测试集还包含 Guo 等[24]发布的 MSNBC, AQUAINT, ACE2004 和 WNED-WIKI (WW)以及 Gabrilovich 等[31]发布的 WNED-CWEB (CWEB)。在上述 6 个测试集中, 只有 AIDA-B 为域内数据, 另外 5 个测试集为不同领域的数据, 这增加了实体链接的难度, 容易造成过拟合或地域偏差问题。表 2 列出所有数据集的详细信息, 从每篇文档拥有实体指称的数量可以看出, 数据集存在一定的稀疏性问题。
实体链接通常使用的知识库为维基百科, 它是基于网络的免费百科全书, 包含有关传统百科全书主题及年历、地名词典和时事主题的条目, 分为2018 版和 2014 版。在规模上, Wiki_2018 知识库是Wiki_2014 的 1.5 倍左右, 蕴含更丰富的信息, 两者的详细数据如表 3 所示。其他常用的知识库还有Freebase, YAGO 和 DBpedia 等。
表2 实体链接数据集
Table 2 Datasets of entitiy linking
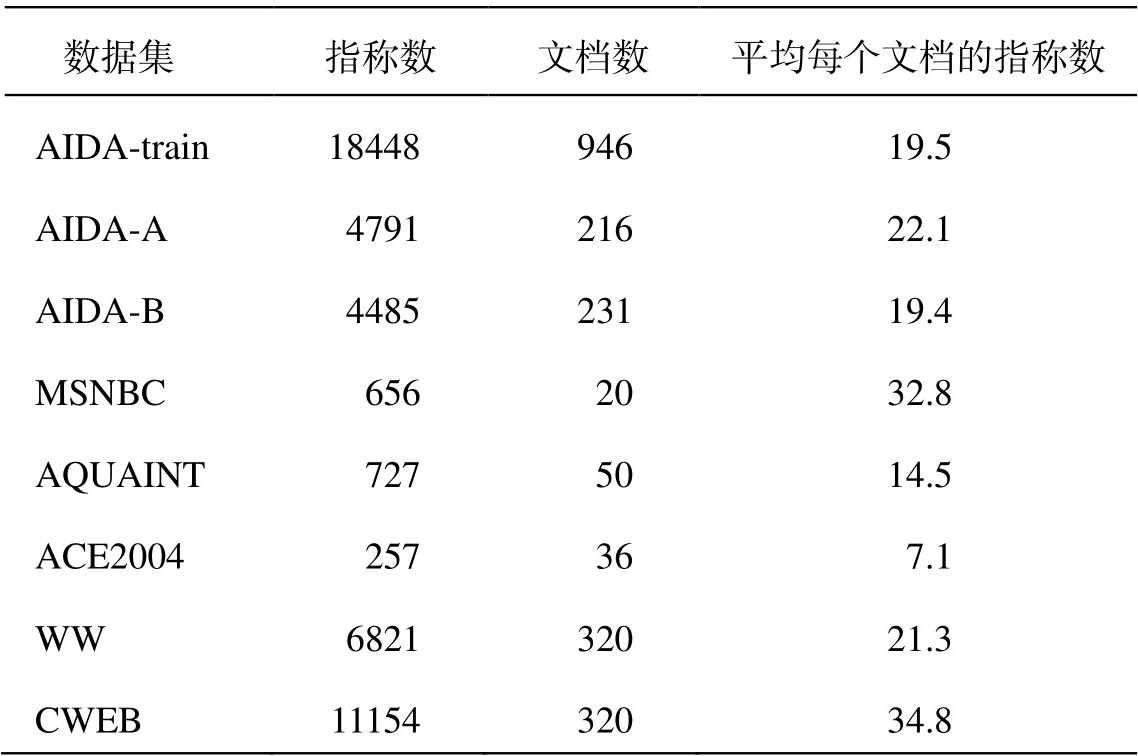
数据集指称数文档数平均每个文档的指称数 AIDA-train1844894619.5 AIDA-A479121622.1 AIDA-B448523119.4 MSNBC6562032.8 AQUAINT7275014.5 ACE2004257367.1 WW682132021.3 CWEB1115432034.8
表3 维基百科知识库的详细信息
Table 3 Detail information of Wikipedia

知识库文档数锚的数量大小/GB Wiki_201444590821861183411.16 Wiki_201896182962691603516.78
4.2 评测方法
随着实体链接研究的发展, 对比不同的实体链接方法也成为被关注的重点。通常采用准确率(P)、召回率(R)和 F1 值, 对实体链接模型的实验结果进行评估, 计算公式如下:

准确率重点关注所有待消歧的实体指称中有多少能够被正确地消歧, 召回率关注待消歧的实体候选集里含有正确实体的概率, F1值可以综合地评价模型的性能。
4.3 实体链接工具
Dexter[32]是当前常用的开源实体链接框架之一, 它利用维基百科中的词条来实现实体链接, 提供开发实体链接技术所需的工具。Dexter 是一个标准程序, 无需高性能硬件或安装其他软件(如数据库), 用户能够轻松地使用。流行的开源实体链接服务还包括 TAGME[33]和 AGDISTIS[34]等。TAGME是第一个对短文本片段(搜索引擎结果的片段、推文和新闻等)进行准确且即时注释的系统, 并将它们链接到相关的 Wikipedia 页面。AGDISTIS 能够有效地检测输入文本中一组命名实体的正确地址, 并将实体链接到对应的 DBpedia 界面。
5 结语
本文介绍了实体链接任务的定义、核心技术、相关研究、目前存在的问题以及近几年基于深度学习的命名实体链接的研究状态。评测会议展示的研究现状表明, 尽管对实体链接已有多年的研究, 但依然存在一些问题。已有的研究大多专注于英文实体链接, 对非英语语言的实体链接关注较少; 缺少被广泛认可的实体链接评测框架, 不同的研究者在针对的问题、链接的步骤以及选用的评测数据集等方面存在较大的差异, 难以进行有效的比较。综上所述, 利用深度学习方法解决资源缺乏问题、在深度学习方法中融入知识指导以及考虑多任务之间的约束是当前的研究热点。展望未来, 实体链接可能的研究方向如下。
1)跨语言的实体链接。现有的研究大多针对某一种语言的实体链接, 未来可以使用双语言或多语言的知识库进行联合学习, 利用不同语言之间的互补性进一步提升实体链接的性能。同时, 可以利用高资源语言的丰富知识来帮助低资源语言的实体链接。Upadhyay 等[35]已将多种语言的监督相结合, 用来解决可用于监督的资源有限问题, 是首个训练一个模型用于多语言的方法, 让用于监督的资源得以高效地利用。
2)实体链接的评测框架。各项研究针对的问题、采用的方法和数据集不同, 难以进行有效的比较。未来需要探索开放的实体链接公共评测框架, 以便不同研究之间的直接对比, 推进实体链接技术的发展。Rosales-Méndez等[36]已提出一种模糊召回指标, 用来解决缺乏共识的问题, 并将在线 EL 系统选择的细粒度评估结果作为结论, 取得不错的效果。他们的方法还需要进一步扩展, 以便得到更广泛的应用。
3)端到端的实体链接。现有的研究大多只针对实体消岐这一单个阶段进行优化, 忽略实体指称识别阶段。未来可以利用多任务联合学习的方法, 将命名实体识别和实体链接任务联合起来进行学习。Kolitsas 等[30]已于 2018 年提出第一个神经端到端的实体链接模型, 展示了共同优化实体识别和链接的优势, 使实体链接的应用性能得以提升。然而, 他们将所有可能的区域视为潜在指称, 导致很高的时间复杂度和内存消耗, 有待进一步改善。
4)弱监督/无监督的实体链接。Le 等[28]的模型在很大程度上优于以前的方法, 是因为以前的方法使用相同形式的监督, 而 Le 等创造了有效的新型弱监督方式, 并且, 他们模型的性能够与专门为实体链接问题而训练的全监督模型相抗衡。这一结果暗示人工注释的数据对实体链接不是必须的, 还可以利用维基百科和网络链接, 这两个信息来源可能是相辅相成的。
参考文献
[1] Chen Z, Ji H. Collaborative ranking: a case study on entity linking // Proceedings of the 2011 Conference on Empirical Methods in Natural Language Proces-sing. Edinburgh, 2011: 771–781
[2] Chisholm A, Hachey B. Entity disambiguation with web links. Transactions of the Association for Com-putational Linguistics, 2015, 3: 145–156
[3] Lazic N, Subramanya A, Ringgaard M, et al. Plato: a selective context model for entity resolution. Tran-sactions of the Association for Computational Lin-guistics, 2015, 3: 503–515
[4] Yamada I, Shindo H, Takeda H, et al. Joint learning of the embedding of words and entities for named entity disambiguation // Proceedings of the 20th SIGNLL Conference on Computational Natural Language Lear-ning. Berlin, 2016: 250–259
[5] Han X, Sun L, Zhao J. Collective entity linking in web text: a graph-based method // Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. Beijing, 2011: 765–774
[6] Cassidy T, Ji H, Ratinov L A, et al. Analysis and enhancement of wikification for microblogs with con-text expansion // Proceedings of COLING, Mumbai, 2012: 441–456
[7] He Z, Liu S, Song Y, et al. Efficient collective entity linking with stacking // Proceedings of the 2013 Con-ference on Empirical Methods in Natural Language Processing. Seattle, 2013: 426–435
[8] Cheng X, Roth D. Relational inference for wikifica-tion // Proceedings of the 2013 Conference on Empi-rical Methods in Natural Language Processing. Seat-tle, 2013: 1787–1796
[9] Durrett G, Klein D. A joint model for entity analysis: coreference, typing, and linking. Transactions of the Association for Computational Linguistics, 2014, 2: 477–490
[10] Huang H, Cao Y, Huang X, et al. Collective tweet wikification based on semi-supervised graph regulari-zation // Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Balti-more, 2014: 380–390
[11] Eshel Y, Cohen N, Radinsky K, et al. Named entity disambiguation for noisy text // Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017). Vancouver, 2017: 58–68
[12] Bunescu R C, Pasca M. Using encyclopedic knowle-dge for named entity disambiguation // Proceedings of the 11th Conference of the European Chapter ofthe Association for Computational Linguistics. Trento, 2006: 9–16
[13] He Z, Liu S, Li M, et al. Learning entity representa-tion for entity disambiguation // Proceedings of the 51st Annual Meeting of the Association for Compu-tational Linguistics. Sofia, 2013: 30–34
[14] Sun Y, Lin L, Tang D, et al. Modeling mention, con-text and entity with neural networks for entity disam-biguation // Proceedings of the 24th International Conferenceon Artificial Intelligence. Buenos Aires, 2015: 1333–1335
[15] Francis-Landau M, Durrett G, Klein D. Capturing se-mantic similarity for entity linking with convolutional neural networks // Proceedings of NAACL-HLT. San Diego, 2016: 1256–1261
[16] Ganea O E, Hofmann T. Deep joint entity disambi-guation with local neural attention // Proceedings of the 2017 Conferenceon Empirical Methods in Na-tural Language Processing. Copenhagen, 2017: 2619–2629
[17] Chen S, Wang J, Jiang F, et al. Improving entity linking by modeling latent entity type information // Proceedings of the AAAI Conference on Artificial Intelligence. New York, 2020: 7529–7537
[18] Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for lan-guage understanding // Proceedings of the 2019 Con-ference of the North American Chapter of the Asso-ciation for Computational Linguistics. Minneapolis, 2019: 4171–4186
[19] Hoffart J, Yosef M A, Bordino I, et a1. Robust dis-ambiguation of named entities in text // Proceedings of the Conference on Empirical Methods in Natural Language Processing. Edinburgh, 2011: 782–792
[20] Globerson A, Lazic N, Chakrabarti S, et al. Collective entity resolution with multi-focal attention // Procee-dings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, 2016: 621–631
[21] Murphy K P, Weiss Y, Jordan M I. Loopy belief propa-gation for approximate inference: an empirical study // Processing of the Fifteenth Conference on Uncer-tainty in Artificial Intelligence. Stockholm, 1999: 467–475
[22] Gupta N, Singh S, Roth D. Entity linking via joint encoding of types, descriptions, and context // Pro-ceedings of the 2017 Conference on Empirical Me-thods in Natural Language Processing. Copenhagen, 2017: 2681‒2690
[23] Le P, Titov I. Improving entity linking by modeling latent relations between mentions // Proceedings of the 56th Annual Meeting of the Association for Com-putational Linguistics. Melbourne, 2018: 1595‒1604
[24] Guo Z, Barbosa D. Robust named entity disambigua-tion with random walks. Semantic Web, 2018, 9(4): 459‒479
[25] Cao Y, Hou L, Li J, et al. Neural collective entity linking // Proceedings of the 22nd Conference on Computational Natural Language Learning. Brussels, 2018: 675–686
[26] Xue M, Cai W, Su J, et al. Neural collective entity linking based on recurrent random walk network learning // Processing of the 28th International Joint Conference on Artificial Intelligence. Macao, 2019: 5327–5333
[27] Yang X, Gu X, Lin S, et al. Learning dynamic context augmentation for global entity linking // Proceedings of the 2019 Conference on Empirical Methods in Natural Language. Hong Kong, 2019: 271–281
[28] Le P, Titov I. Boosting entity linking performance by leveraging unlabeled documents // Proceedings of the 57th Annual Meeting of the Association for Compu-tational Linguistics. Florence, 2019: 1935–1945
[29] Le P, Titov I. Distant learning for entity linking with automatic noise detection // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, 2019: 4081–4090
[30] Kolitsas N, Ganea O E, Hofmann T. End-to-end neu-ral entity linking // Proceedings of the 22nd Con-ference on Computational Natural Language Learning. Brussels, 2018: 519–529
[31] Gabrilovich E, Ringgaard M, Subramanya A. FACC1: freebase annotation of ClueWeb corpora, version 1 [EB/OL]. (2013‒06‒26) [2020‒07‒25]. http://lemurpro ject.org/clueweb09/FACC1
[32] Ceccarelli D, Lucchese C, Perego R, et al. Dexter: an open source framework for entity linking // Procee-dings of the sixth international workshop on Exp-loiting semantic annotations in information retrieval. New York, 2013: 17–20
[33] Ferragina P, Scaiella U. TAGME: On-the-Fly annota-tion of short text fragments (by wikipedia entities) // Proceedings of the 19th ACM International Confe-rence on Information and Knowledge Management. Toronto, 2010: 1625–1628
[34] Ferragina P, Scaiella U. AGDISTIS — graph-based disambiguation of named entities using linked data // Proceedings of the 13th International Semantic Web Conference. Riva del Garda, 2014: 457–471
[35] Upadhyay S, Gupta N, Roth D. Joint multilingual su-pervision for cross-lingual entity linking // Procee-dings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, 2018: 2486– 2495
[36] Rosales-Méndez H, Hogan A, Poblete B. Fine-grained evaluation for entity linking // Proceedings of the 2019 Conference on Empirical Methods in Natural Language. Hong Kong, 2019: 718–727
A Review of Entity Linking Research Based on Deep Learning
LI Tianran, LIU Mingtong, ZHANG Yujie†, XU Jin’an, CHEN Yufeng
School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044; † Corresponding author, E-mail: yjzhang@bjtu.edu.cn
Abstract The authors introduce the concept and steps of entity linking in detail, and the problems and research status of named entity linking based on deep learning in recent years, analyze the problems and corresponding solution models of entity linking and present related data sets and evaluation methods. The authors summarize the current status of entity linking in international evaluation conferences and analyze the future research directions.
Key words entity linking; entity disambiguation; entity recognition; knowledge base; deep learning
doi: 10.13209/j.0479-8023.2020.077
收稿日期: 2020‒06‒06;
修回日期: 2020‒08‒13
国家自然科学基金(61876198, 61976015, 61976016)资助

 。
。