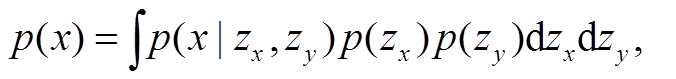 (1)
(1)摘要 针对使用句法可控的复述生成模型生成对抗样本时模型性能受限于复述平行语料的领域和规模的问题, 提出仅需要单语语料训练的无监督的句法可控复述生成模型, 用以生成对抗样本。采用变分自编码方式学习模型, 首先将句子和句法树分别映射为语义变量和句法变量, 然后基于语义变量和句法变量重构原始句子。在重构过程中, 模型可以在不使用任何平行语料的情况下学习生成句法变化的复述。在无监督复述生成和对抗样本生成任务中的实验结果表明, 所提方法在无监督复述生成任务中取得最佳性能, 在对抗样本生成任务中可以生成有效的对抗样本, 用以改进神经自然语言处理(NLP)模型的鲁棒性和泛化能力。
关键词 无监督学习; 句法可控复述生成模型; 对抗样本
对抗样本指添加细微干扰的实例, 广泛用来测试模型对细微变化样本的处理能力和改进模型性能[1]。通常, 图像数据中的小扰动不易被人类察觉。由于文本的离散性质, 文本中的变化(如字符或单词的改变)很容易被人类识别。Ettinger 等[2]发现, 基于深度神经网络模型的分类器容易受到对抗性样本的攻击, 这些对抗样本通过引入训练集中没有出现的词汇和句法变化而产生。将这样的对抗样本扩充到训练数据中, 可以有效地提高神经自然语言处理(natural language processing, NLP)模型的鲁棒性[3‒4]。
目前, 对抗攻击 NLP 模型的研究集中在字符和词级别, 如在字符层面注入噪声[5‒6], 或在单词层面添加和删除单词[7‒8]来生成对抗样本。不同于前人的工作, 本文主要关注生成句法层面的对抗样本, 即语义一致但句法形式多样的样本。这类样本反映语言表达形式的多样性, 广泛存在于自然语言中。为了获取这样的对抗样本, Iyyer 等[4]使用句法可控的复述生成模型来生成句法层面的复述句, 发现这些句法多样的复述句可以欺骗一个精度较高的分类模型, 但需要大规模复述平行语料训练。对很多语言和领域来说, 复述平行语料库往往很少, 而构建大规模的复述语料成本很高。相反地, 单语语料在不同语言和领域中很容易获得。
为了摆脱模型对复述平行语料的依赖, 本文提出无监督的句法可控复述生成模型, 仅使用单语语料训练就可以生成句法变化的复述, 其核心思想是学习句子语义与句法之间的对应关系。在模型中, 我们利用完全句法树或模板作为句法信息。完全句法树(完全树)指不带叶子节点的成分句法树的序列化表示, 模板通过抽取成分句法树的前两层结构得到, 例如, 句子“That’s baseball.”的完全句法树和模板分别是“(S(NP (DT))(VP(VBZ)(NP(NN)))(.))”和“(S (NP)(VP)(.))”。在训练阶段, 我们使用单语语料学习模型。在测试阶段, 模型可以根据给定的不同句法信息来生成句法变化的复述。我们采用变分自编码的方式学习模型, 设计两个隐变量来分别捕捉句子的语义和句法信息, 然后联合语义和句法隐变量来重构原始句子, 从而学习句子语义与句法之间的对应关系。进一步地, 为了提高句法的可控性, 我们设计基于生成对抗网络的方法来分离这两个变量, 并就语义对句法的重构依赖进行建模。此外, 我们引入多任务学习目标, 确保这两个变量可以更好地编码语义和句法信息。
近来, 复述生成任务受到越来越多的关注[9‒10]。与现有的复述生成方法相比, 本文工作聚焦于句法控制的复述生成, 即根据给定的目标句法来生成句法变化的复述句。
近来兴起的受控生成研究旨在控制生成句的情感[11‒12]或政治倾向[13]等属性。此外, 有一些研究试图控制生成句的结构[4,14](如给定的句法)。其中, Iyyer 等[4]采用句法树信息, Chen 等[14]采用句法范例来控制复述生成。本文工作与 Iyyer 等[4]的工作关系最密切, 不同之处在于, 我们的模型是基于无监督的复述, 在没有任何复述平行语料的情况下学习句法控制的复述生成。
Kingma 等[15]提出用于图像生成的 VAE 方法, Bowman 等[16]成功地将 VAE 应用于 NLP 领域, 表明 VAE 能够从隐空间生成更流利的句子。近年来, VAE 广泛用于各种自然语言生成任务中[12‒14,17‒18]。我们的目标是使用句法树来控制生成句的句法结构, 受引入句法的变分自编码方法[18]启发, 本文使用两个变分自编码器, 引入两个隐变量来分别捕获语义和句法信息, 同时借鉴隐空间分离的方法[17], 采用对抗网络分离句法和语义变量, 提高句法的控制能力。
本文提出的无监督的句法可控复述生成模型整体框架如图 1 所示。模型以变分自编码模型(varia-tional auto-encoder, VAE)[9,15]为基础。给定一个句子 x=[x1,…,x|x|]及与它对应的句法树 y=[y1,…,y|y|], 将 x 和 y 分别编码为隐变量 zx 和 zy, 然后联合两个隐变量, 重构出句子 x, 隐变量 zx 和 zy 分别捕获语义信息和句法信息。句子x出现的概率可以通过下式计算:
(1)本文定义自编码的损失(包括重构损失和 Kullback-leibier (KL)散度损失)计算公式如下:
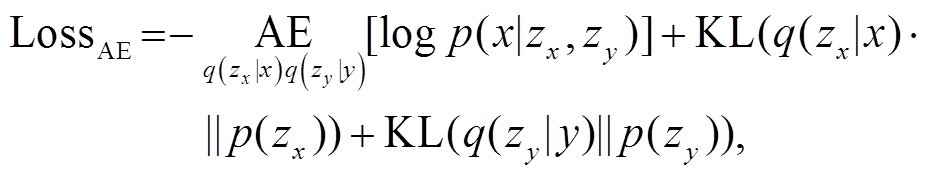 (2)
(2)其中, p(zx)和 p(zy)表示先验分布, 两者相互独立且服从标准正态分布 N(0,1); q(zx | x)和 q(zy | y)分别表示上述两个隐变量的后验分布, 设置两者相互独立, 且分别服从正态分布 N(μx, σx2), (μy, σy2), 其中 μx, σx, μy 和σy 通过神经网络计算。
具体地, 给定一个句子 x 和对应的句法树 y, 首先通过句子编码器和句法编码器来获得语义表示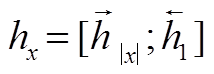 和句法表示
和句法表示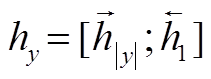 。对于语义变量zx, 使用神经网络来计算 q(zx | x)的均值 μx 和方差 σx2, 计算公式如下:
。对于语义变量zx, 使用神经网络来计算 q(zx | x)的均值 μx 和方差 σx2, 计算公式如下:

图1 模型整体框架
Fig. 1 Overview of proposed model
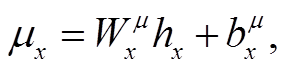 (3)
(3)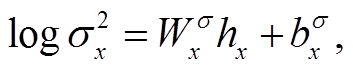 (4)
(4)
这里, 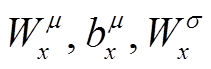 和
和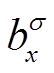 是可训练的参数。用相同的方式计算
是可训练的参数。用相同的方式计算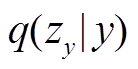 的均值和方差, 引入可训练参数
的均值和方差, 引入可训练参数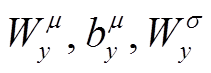 和
和 。
。
在训练阶段, 我们采用重参数技巧, 从上述两个后验分布中采样, 得到语义变量 zx 和句法变量 zy。解码过程如图 1 右侧虚线框所示, 对时间步 i, 将句法变量 zy 与前一时间步预测的词嵌入 ei–1 拼接, 作为解码器的输入; 将解码器输出的隐藏状态 hi–1 与语义变量 zx拼接, 用来预测当前时间步的词xi。
在生成阶段, 当给出相同的句子和不同的句法结构时, 本文模型可以生成句法可控的复述。我们通过最大后验概率(maximum a posteriori, MAP)推理得到语义和句法变量 zx 和 zy, 这样可以尽可能地保留语义和句法信息。之后, 解码过程与训练阶段保持一致。
Vinyals 等[19]提出一种基于 seq2seq 的成分句法分析方法, 其中包括一个编码器和解码器, 将一个句子输入到编码器, 通过解码器解码得到该句的成分句法树。受此启发, 我们认为句子编码器得到的向量表示 zx 可能同时包含语义信息和句法信息。为了提高句法的可控性, 我们希望每个隐变量(zx 或zy)只捕获各自的信息。为了实现这一目标, 我们采用多任务学习目标和对抗损失的方法[17],对这两个隐变量进行约束。
本文引入多任务学习目标, 用于确保这两个变量可以更好地编码语义和句法信息。对于语义变量, 使用 Softmax 分类器预测 zx 中句子的词袋分布(bag-of-word), 训练目标是相对于真实分布 t 的交叉熵损失。计算公式如下:
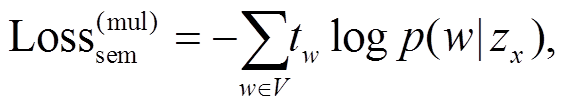 (5)
(5)其中, p(w|zx)表示预测的词概率分布, V表示使用的词典。
对于句法变量, 多任务损失训练模型根据 zy 能够预测出序列化的句法树y, 损失计算公式如下:
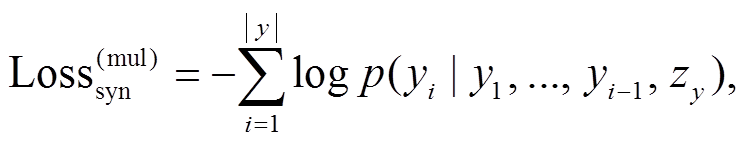 (6)
(6)其中, yi表示句法树 y 中的标签词。
上述多任务学习目标鼓励语义变量和句法变量包含对应的语义和句法信息。但是, 它们也可能包含另一方的信息, 如语义变量可能包含句法信息, 导致句法可控性能差。对此, 我们进一步引入对抗损失来阻止语义变量包含句法信息。具体地, 引入判别器, 根据 zx 预测句法树序列 y, 然后训练 VAE学习语义变量, 使判别器不能根据该语义变量预测句法树 y。判别器的训练方法类似式(6), 但梯度反向传播, 不会传给 VAE。可以将 VAE 视为一个生成器, 被训练来欺骗判别器, 使其通过最大化来对抗损失, 即最小化下式:
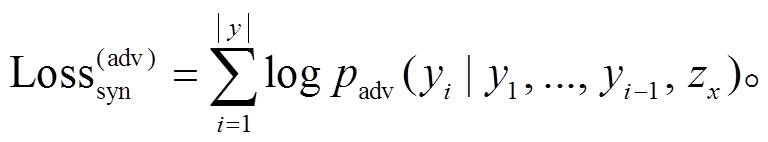 (7)
(7)在这一阶段, 判别器的参数不会被更新。
我们还就语义对句法的重构依赖建模, 用于提高句法的可控性。我们希望解码器在语义和句法变量同时存在的情况下才能重构原句, 而解码器无法仅根据语义变量重构原句。为了实现这一目标, 采用对抗重构损失[17]来阻止句子被单个语义变量 zx预测。我们引入另外的判别器, 训练其根据 zx 来预测句子, 通过最大化对抗重构损失, 训练 VAE 去欺骗判别器, 即最小化下式:
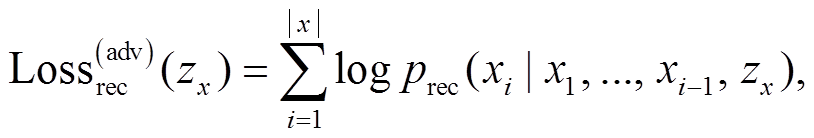 (8)
(8)其中, xi表示句子x中的一个词。
训练损失包括自编码损失、语义和句法的多任务损失、对抗损失和对抗重构损失:
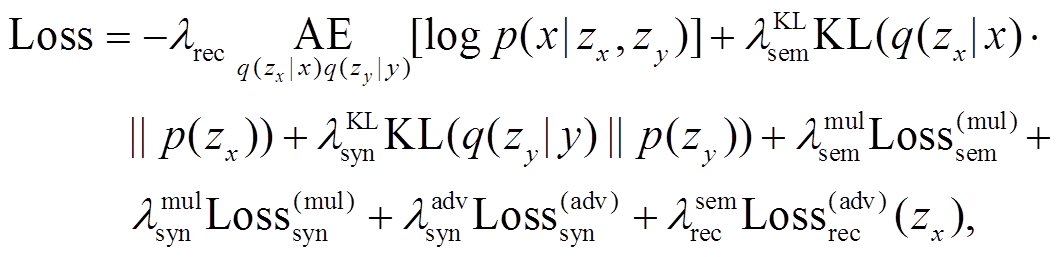 (9)
(9)其中, λ 代表超参数, 用来权衡各个损失的重要程度。编码器采用一层双向 GRU, 解码器采用一层单向 GRU。使用公开的 Glove300 维词向量作为预训练的词向量, 使用 Adam 优化器训练 VAE 模型, 使用 RMSProp 优化器训练判别器, 使用 KL-annealing和 word dropout 的技巧训练 VAE, 用 sigmoid 方法将 和
和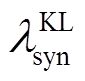 从零退火(anneal)到预定值。本文提出的句法可控的复述生成模型超参数设置如表 1 所示。在 One-billion-word 数据集上, 隐变量维度设为 150 效果较好; 在 Quaro 数据集上, 150 维与 100维模型性能基本上一致。因此, 我们将 Quaro 数据集上的隐变量维度设为 100 维。
从零退火(anneal)到预定值。本文提出的句法可控的复述生成模型超参数设置如表 1 所示。在 One-billion-word 数据集上, 隐变量维度设为 150 效果较好; 在 Quaro 数据集上, 150 维与 100维模型性能基本上一致。因此, 我们将 Quaro 数据集上的隐变量维度设为 100 维。
本研究的目标是通过句法可控的复述生成模型来生成对抗样本, 首先在无监督的复述生成任务中进行实验, 考察本文模型是否能够生成句法变化的复述; 然后验证模型是否能够为情感分析任务生成句法变化的对抗样本。
在给定一个输入句子的情况下, 复述生成的目的是生成一个表达形式与输入句不同, 但传达相同含义的句子。对于特定输入句子 x*和目标句法树y*, q(zx| x*)和 q(zy| y*)分别表示句法变量和语义变量的后验分布。在生成阶段, 通过 MAP 推理得到句法和语义变量:
表1 在Quaro, One-billion-word和SST数据集上使用的超参数
Table 1 Hyper-parameters used in dataset Quaro, One-billion-word and SST
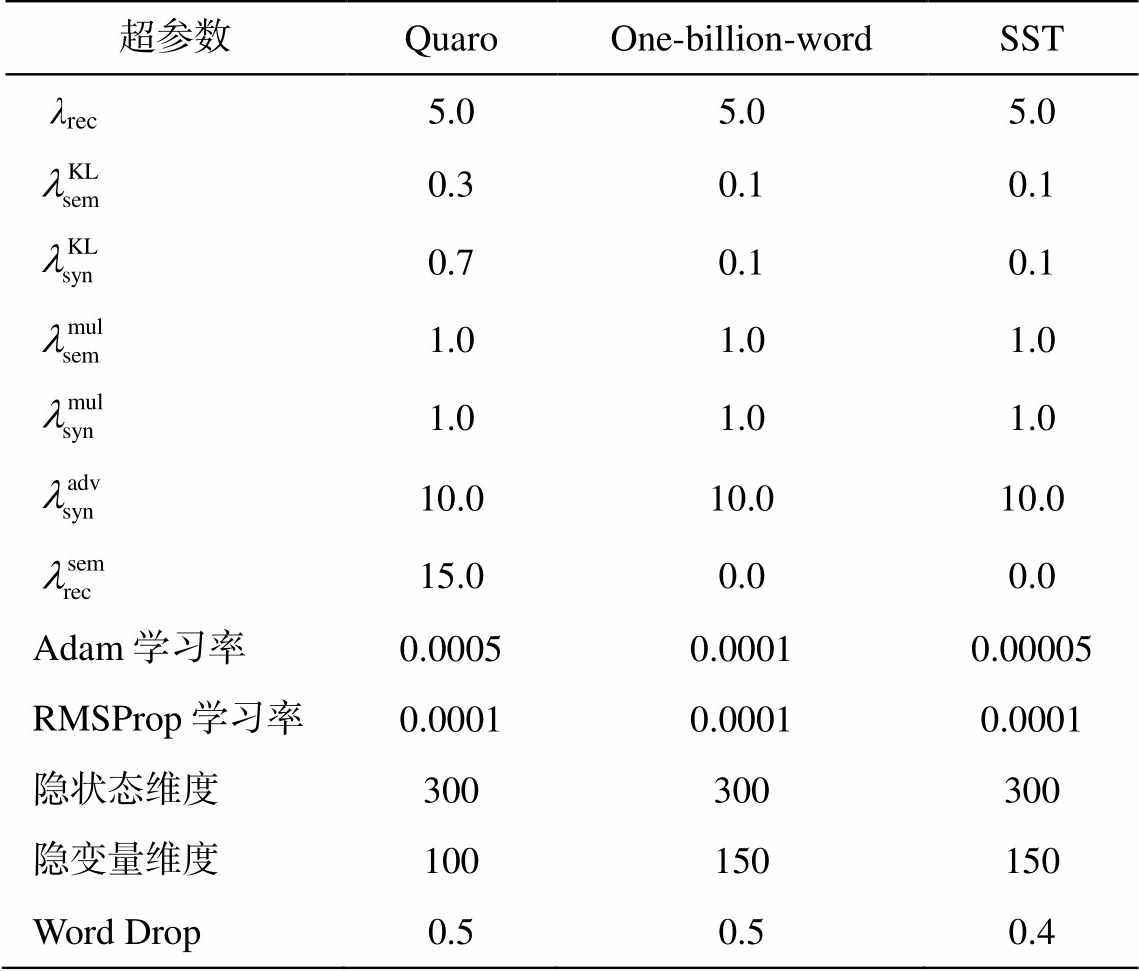
超参数QuaroOne-billion-wordSST λrec5.05.05.0 0.30.10.1 0.70.10.1 1.01.01.0 1.01.01.0 10.010.010.0 15.00.00.0 Adam学习率0.00050.00010.00005 RMSProp学习率0.00010.00010.0001 隐状态维度300300300 隐变量维度100150150 Word Drop0.50.50.4
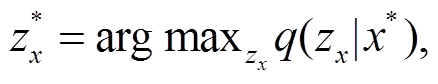 (10)
(10)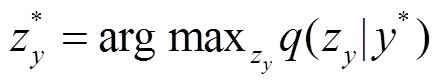 , (11)
, (11)
之后, 将 和
和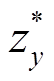 输入解码器中生成复述句。
输入解码器中生成复述句。
3.1.1 数据集
与 Bao 等[17]的方法相同, 本文使用 Quaro 数据集评测复述生成的质量。该数据集包括 140 K 对复述句, 260K 对非复述句, 按照标准数据集划分, 验证集和测试集分别包含 3 K 对和 30 K 对复述句。我们以未出现在验证和测试集中的非复述句对作为训练集, 使用斯坦福句法分析工具[20], 对训练集中所有句子以及验证集和测试集中的参考句进行句法分析, 得到句法树。
3.1.2评测指标
本文考虑两类自动评测指标, 旨在捕获模型不同方面的性能。对于语义指标, 分别计算生成句与参考句、原句的 BLEU 值, 分别表示为 BLEU-ref和 BLEU-ori。在理想情况下, BLEU-ref 值较高, BLEU-ori 值较低。对于句法指标, 分别计算生成句与参考句、原句的树编辑距离(TED), 分别表示为TED-ref 和 TED-ori。在理想情况下, TED-ref 值较低, TED-ori 值较高。我们还使用精确模板匹配(Match Accuary)来评测生成句符合目标句法模板的频率, 当生成句的模板(句法树的前两层)与参考句的模板一致时, 则认为匹配。根据开发集上的BLEU-ref值调整超参数。
3.1.3实验结果
对于语义指标, 本文方法在两种设置(使用完全树或模板)下的 BLEU-ref 值均优于现有无监督复述方法(表 2)。从 BLEU-ori 与 BLEU-ref 关系的散点图(图 2)看出, 本文方法的数据点位于其他方法的左上方。这些结果表明, 本文模型在无监督复述生成任务中的性能超过现有方法。在句法测评指标方面, 使用完全树或模板的 TED-ref 值分别为 3.47和 11.1, Match Accuracy 的精度分别为 88.72%和73.69%, 表明本文模型可以根据给定的句法结构生成复述(与表 2 中第 1 行相比)。同时, TED-ori 值分别为 11.5 和 7.33, 说明生成句与原句在句法结构上有一定程度的差异。
表2 与已有无监督复述方法的性能比较结果
Table 2 Experiment results on unsupervised paraphrase generation compared with previous models

模型BLEU-ref ↑BLEU-ori ↓TED-ref ↓TED-ori ↑Match Accuracy/% 输出原句30.49100.0011.40057.22 VAE-SVG-eq (有监督)[9]22.90–––– VAE (无监督)[16] 9.25 27.23––– CGMH[10]18.85 50.18––– DSS-VAE[17]20.54 52.77––– 本文方法: 使用完全树43.93 32.94 3.4711.588.72 本文方法: 使用模板23.56 54.2111.107.3373.69
说明: ↑表示值越大越好, ↓表示值越小越好; 粗体数字表示性能最佳, 下同。
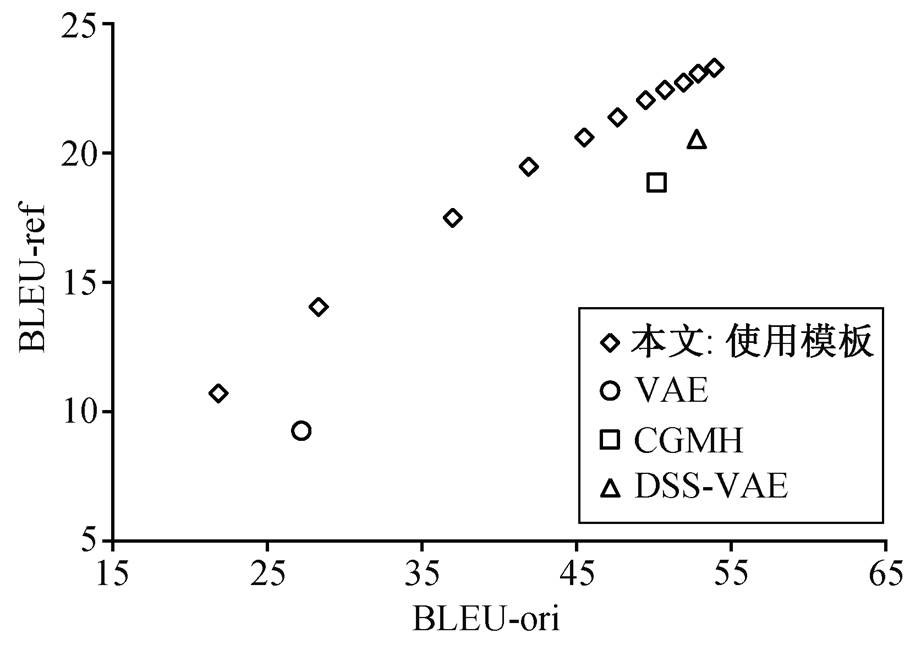
图2 BLEU-ori与BLEU-ref的关系
Fig. 2 Relationship between BLEU-ori and BLEU-ref
由于完全句法树包含更细粒度的句法信息, 能够指导模型正确地进行语义等价的词替换, 因此使用完全句法树可以产生非常高的语义和句法指标。然而, 当只使用句法模板(即句法树的前两层)时, 本文方法在 BLEU-ori 和 Match Accuracy 上都获得较高的精度, 表明生成的复述句在句法结构上变化较大, 符合给定的目标句法结构, 同时能够有效地保留原句的语义信息。
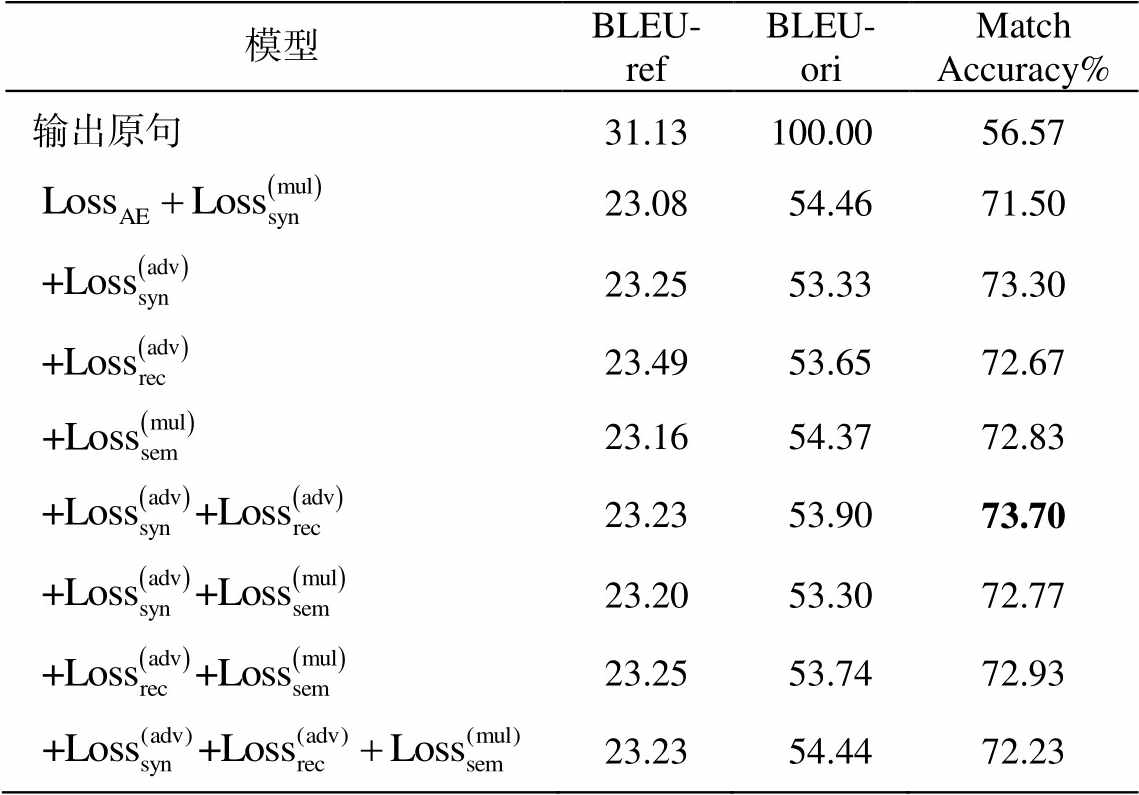
为了分析模型中各个部分对句法可控复述生成性能的影响, 我们训练多个版本的模型, 并记录使用句法模板时模型在验证集上的 BLEU-ref, BLEU-ori 和 Match Accuracy。从表 3 可以看出, 模型各部分对语义指标(尤其是 BLEU-ref)的影响较小。对于 atch Accuracy, 基础模型
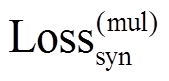 取得71.5%的性能, 证明了本文方法的有效性。增加
取得71.5%的性能, 证明了本文方法的有效性。增加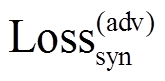 ,
, 或
或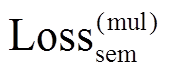 可以获得不同程度的收益, 当同时增加
可以获得不同程度的收益, 当同时增加 和
和 时, 模型取得最佳的性能。但是, 增加所有的辅助损失不会进一步提高性能, 可能的原因是增加词袋损失会导致模型倾向于生成接近原句的输出。
时, 模型取得最佳的性能。但是, 增加所有的辅助损失不会进一步提高性能, 可能的原因是增加词袋损失会导致模型倾向于生成接近原句的输出。
下面探究本文模型是否可以生成句法变化的对抗样本以及生成的对抗样本是否可以提高目标模型的鲁棒性。
3.2.1实验设置
与 Iyyer 等[4]的方法相同, 在来自电影评论语料库的数据集 Stanford Sentiment Treebank (SST-2)[21]上评估句法变化的对抗样本。SST-2 包含句法变化程度较高的复杂句子, 但数据集的规模相对较小。我们采用“预训练和微调”的方式来训练本文句法控制的复述模型, 首先使用来自 One-Billion-Word 语料[22]预处理的 210 万个句子预训练本文模型, 然后在 SST-2 数据集上对模型进行微调。情感分类模型使用Bi-LSTM[23]。
表3 消融分析结果
Table 3 Results of ablation analysis
模型BLEU-refBLEU-oriMatch Accuracy% 输出原句31.13100.0056.57 23.08 54.4671.50 23.25 53.3373.30 23.49 53.6572.67 23.16 54.3772.83 23.23 53.9073.70 23.20 53.3072.77 23.25 53.7472.93 23.23 54.4472.23
对于 SST-2 训练集和开发集中的样本, 用 One-Billion-Word 和 SST-2 数据集中最频繁的 15 个句法模板生成 15 个复述, 在后处理步骤中删除与原句语义差别较大的复述, 即使用阈值(BLEU, 1-3-gram)对生成的复述进行过滤。随后, 用在训练集上生成的复述扩充训练数据。对抗训练过程如图 3 所示, 虚线箭头表示直接用 SST-2 训练集来训练情感分类模型, 实线箭头表示使用本文模型为 SST-2 训练集样本生成句法变化的复述, 并用这些复述扩充训练集, 重新训练情感分类模型。通过这种方式, 我们获得两个训练好的情感分类模型。
在对抗样本生成实验中使用的 15 个句法模板如下: (S(NP)(VP)); (S(PP)(,)(NP)(VP)); (S(S)(,)(NP)(VP)); (S(NP)(ADVP)(VP)); (S(S)(,)(CC)(S)); (S(“) (S)(,)(”)(NP)(VP)); (S(CC)(NP)(VP)); (S(S)(CC)(S)); (S(SBAR)(,)(NP)(VP)); (S(ADVP)(,)(NP)(VP)); (S(VP));(S(S)(:)(S)); (S(ADVP)(NP)(VP)); (NP(NP)(PP)); (FRAG(ADJP))。
3.2.2评价指标
我们使用以下指标来评估模型性能。
1)Dev Broken[4]。得开发集样本生成的句法变化的复述过滤处理后, 输入预训练情感分类模型。如果原句 x 预测是正确的, 但至少有一个复述的预测不正确, 则认为 x 被“Broken”。Dev Broken 指开发集样本通过复述被“Broken”的占比。在该实验中, 以 Dev Broken 作为主要评测指标, 用于衡量不同方法的文本攻击效果。
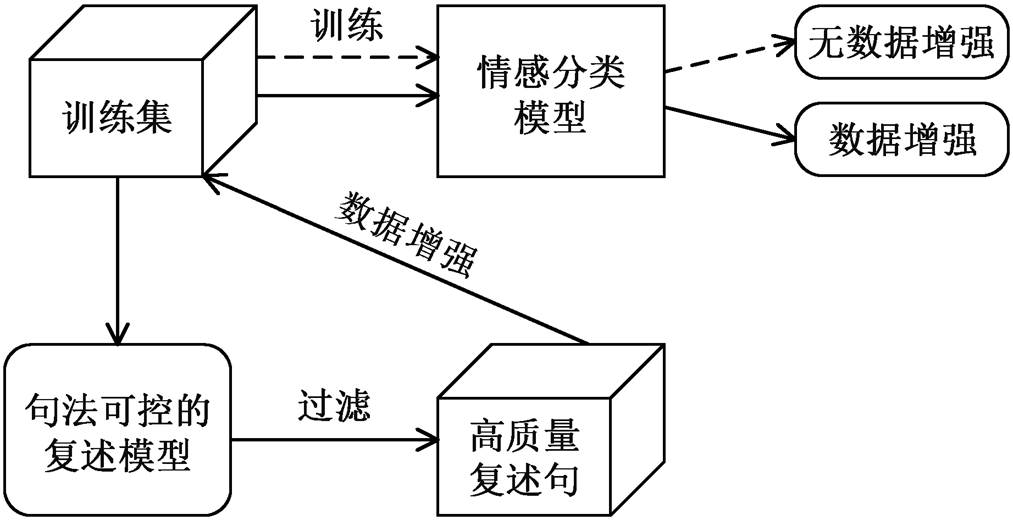
图3 对抗训练过程
Fig. 3 Adversarial training procedure
2)Validity[4]。由于生成的句法变化的复述可能丢失情感词, 为了衡量生成的对抗样本的有效性, 随机选取 100 个对抗样本进行人工评测。要求众包员工为给定的对抗样本选择合适的标签(如积极或消极), 然后将员工的判断与原始的开发集样本标签进行比较。
3)Test Accuracy: 衡量分类模型在测试集上的准确率。
3.2.3实验结果
将本文生成对抗样本的方法与前人的两种方法(NMT-BT 和 SCPN)进行比较, 实验结果如表 4 所示。其中, NMT-BT[4]是神经机器翻译回译方法; SCPN 是 Iyyer 等[4]提出的句法控制的复述生成模型, 该模型需要大规模复述平行语料训练。
从表 4 可以看出, 本文方法获得 63.0 的 Validity得分和 18.92 的 Dev Broken, 性能与 NMT-BT 非常接近, 表明本文模型可以生成合法的对抗样本。用本文无监督复述方法生成的句法变化的复述扩充训练数据, Dev Broken 值从 18.92 降至 17.76, 表明在这些句法变化的复述上训练可以提高情感分类模型对句法变化的鲁棒性, 同时不影响分类模型在原始测试集上的准确率。
SCPN 和 NMT-BT 也获得很高的性能, 这归功于平行语料库的使用。这两个模型都使用大规模的平行语料库进行训练, 生成的复述句包括词汇和句法变化。对于没有平行语料可用的低资源语言, 本文无监督的方法将非常有效。
3.2.4 不同阈值对目标模型性能的影响
为了更好地分析句法变化的复述对分类模型性能的影响, 我们使用不同的阈值过滤复述句, 用来扩充训练集, 重新训练分类模型, 并记录模型在测试集上的准确率, 结果见表 5。当阈值设置为最小值 0.4 时, 没有降低模型的性能, 表明本文模型具有良好的生成质量。随着阈值增大, 模型的性能提高, 阈值为 0.85 时达到最好的性能, 这是在复述质量与多样性之间权衡的结果。阈值越大, 过滤后的复述质量越好, 但多样性越差, 因此当阈值为 0.9时并没有达到最佳性能。这些结果也显示, 本文方法具有成为一种数据增强技术的潜力。
表4 生成对抗样本方法的性能比较结果
Table 4 Experiment results of adversarial example generation compared with previous models

模型Validity无数据增强数据增强 Test AccuracyDev BrokenTest AccuracyDev Broken NMT-BT[4]68.183.1020.2082.3020.00 SCPN[4]77.183.1041.8083.0031.40 本文方法63.083.2318.9283.2117.76
表5 不同阈值对目标模型性能的影响
Table 5 Influence of different thresholds on the target model

阈值句子数量Test Accuracy/%阈值句子数量Test Accuracy/% 无数据增强 684283.230.702940283.74 0.407558183.580.752314884.32 0.506287683.210.801806084.04 0.604547783.450.851391584.65 0.653682484.320.901049683.91
说明: 因为模型参数的随机初始化, 所以记录3次运行结果的平均值。
表6 生成的复述示例
Table 6 Examples of Generated paraphrases
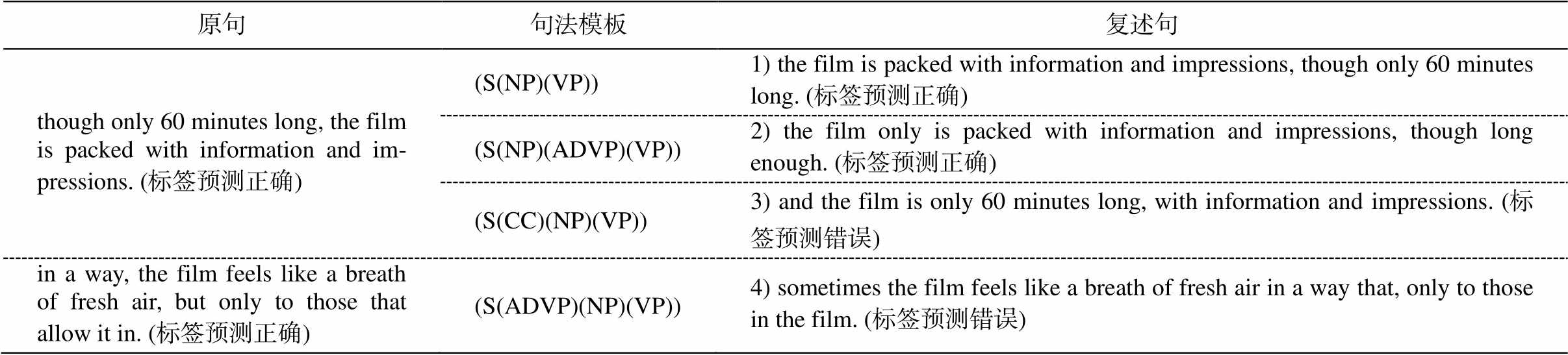
原句句法模板复述句 though only 60 minutes long, the film is packed with information and im-pressions. (标签预测正确)(S(NP)(VP))1) the film is packed with information and impressions, though only 60 minutes long. (标签预测正确) (S(NP)(ADVP)(VP))2) the film only is packed with information and impressions, though long enough. (标签预测正确) (S(CC)(NP)(VP))3) and the film is only 60 minutes long, with information and impressions. (标签预测错误) in a way, the film feels like a breath of fresh air, but only to those that allow it in. (标签预测正确)(S(ADVP)(NP)(VP))4) sometimes the film feels like a breath of fresh air in a way that, only to those in the film. (标签预测错误)
表 6 展示两组由本文方法生成的复述句, 其中复述句 3 和 4 为生成的对抗样本, 与原句语义一致, 结构不同, 情感分类模型不能正确地预测其标签, 证明本文模型可以为情感分类模型生成句法变化的对抗样本。
3.2.5生成实例分析
本文提出一种无监督句法可控复述生成模型, 无需复述对齐语料训练。采用变分自编码学习方式, 使用两个隐变量分别捕获句子的语义和句法信息。通过联合这两个隐变量来重构原始句子, 从而学习句子语义和句法之间的对应关系。为了提高句法的可控性, 设计基于生成对抗网络的方法来分离这两个变量, 并就句法和语义变量的重构依赖性进行建模。
实验结果表明, 本文方法在无监督复述生成任务中取得最好的结果, 可以生成符合目标句法结构的复述句。生成对抗样本的实验结果进一步证明本文模型能够生成高质量的对抗样本, 当使用生成的样本扩充训练数据时, 在不损害原始测试集性能的情况下, 可以有效地提高模型的鲁棒性。
在后续工作中, 我们将探索将词或短语级别的变化与本文模型相结合的方法, 以期生成更加多样化的对抗样本。
参考文献
[1] Zhang W E, Sheng Q Z, Alhazmi A, et al. Adversarial attacks on deep learning models in natural language processing: a survey. ACM Transactions on Intelligent Systems and Technology, 2019, 11(3): 24
[2] Ettinger A, Rao S, Daumé III H, et al. Towards lin-guistically generalizable NLP systems: a workshop and shared task // First Workshop on Building Lin-guistically Generalizable NLP Systems. Copenhagen, 2017: 1‒10
[3] Jia R, Liang P. Adversarial examples for evaluating reading comprehension systems // Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen, 2017: 2021–2031
[4] Iyyer M, Wieting J, Gimpel K, et al. Adversarial example generation with syntactically controlled pa-raphrase networks // North American chapter of the Association for Computational Linguistics. New Or-leans, 2018: 1875‒1885
[5] Ebrahimi J, Rao A, Lowd D, et al. HotFlip: white-box adversarial examples for text classification // Procee-dings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, 2018: 31‒ 36
[6] Gao J, Lanchantin J, Soffa M L, et al. Black-box generation of adversarial text sequences to evade deep learning classifiers // 2018 IEEE Security and Privacy Workshops (SPW) . Los Alamitos, 2018: 50‒56
[7] Liang Bin, Li Hongcheng, Su Miaoqiang, et al. Deep text classification can be fooled // IJCAI-18. Stock-holm, 2018: 4208–4215
[8] Feng S, Wallace E, Iyyer M, et al. Right answer for the wrong reason: Discovery and mitigation // Pro-ceedings of the 2018 Conference on Empirical Me-thods in Natural Language Processing. Brussels, 2018: 3719‒3728
[9] Gupta A, Agarwal A, Singh P, et al. A deep generative framework for paraphrase generation // AAAI. New Orleans, 2018: 5149‒5156
[10] Miao Ning, Zhou Hao, Mou Lili, et al. CGMH: con-strained sentence generation by metropolis-hastings sampling // AAAI. Honolulu, 2019: 6834‒6842
[11] Hu Zhiting, Yang Zichao, Liang Xiaodan, et al. To-ward controlled generation of text // Proceedings of the 34th International Conference on Machine Lear-ning. Sydney, 2017: 1587‒1596
[12] John V, Mou Lili, Bahuleyan H, et al. Disentangled representation learning for non-parallel text style transfer // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Flo-rence, 2019: 424‒434
[13] Prabhumoye S, Tsvetkov Y, Salakhutdinov R, et al. Style transfer through back-translation // Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, 2018: 866‒ 876
[14] Chen M D, Tang Q M, Wiseman S, et al. Controllable paraphrase generation with a syntactic exemplar // Proceedings of the 57th Annual Meeting of the As-sociation for Computational Linguistics. Florence, 2019: 5972–5984
[15] Kingma D P, Welling M. Auto-encoding variational bayes // ICLR. Banff, 2014: No. 6
[16] Bowman S R, Vilnis L, Vinyals O, et al. Generating sentences from a continuous space // Proceedings of The 20th SIGNLL Conference on Computational Na-tural Language Learning. Berlin, 2016: 10‒21
[17] Bao Yu, Zhou Hao, Huang Shujian, et al. Generating sentences from disentangled syntactic and semantic spaces // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Flo-rence, 2019: 6008–6019
[18] Zhang X Y, Yang Y, Yuan S Y, et al. Syntax-infused variational autoencoder for text generation // Procee-dings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, 2019: 2069‒ 2078
[19] Vinyals O, Kaiser L, Koo T, et al. Grammar as a foreign language // Proceedings of the 28th Interna-tional Conference on Neural Information Processing Systems. Cambridge, 2014: 2773‒2781
[20] Manning C D, Surdeanu M, Bauer J, et al. The Stan-ford CoreNLP natural language processing toolkit // Proceedings of 52nd Annual Meeting of the Associa-tion for Computational Linguistics: System Demons-trations. Baltimore, 2014: 55‒60
[21] Socher R, Perelygin A, Wu J, et al. Recursive deep models for semantic compositionality over a senti-ment treebank // Proceedings of the 2013 Conference on Empirical Methods in Natural Language Proces-sing. Seattle, 2013: 1631‒1642
[22] Chelba C, Mikolov T, Schuster M, et al. One billion word benchmark for measuring progress in statistical language modeling // Conference of the International Speech Communication Association. Lyon, 2013: 2635‒2639
[23] Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks // Proceedings of the 53rd Annual Meeting of the Association for Computational Lin-guistics and the 7th International Joint Conference on Natural Language Processing. Beijing, 2015: 1556‒ 1566
Unsupervised Syntactically Controllable Paraphrase Network for Adversarial Example Generation
Abstract Prior work on adversarial example generation with syntactically controlled paraphrase networks requires large-scale paraphrase parallel corpora to train models. The performance of the model is seriously limited by the domain and scale of paraphrase parallel corpus. To solve this problem, this paper proposes an unsuprervised syntactically controlled paraphrase model to generate adversarial examples which only needs monolingual data. Specifically, variational autoencoder is used to learn model, which maps a sentence and a syntactic parse tree into semantic and syntactic variables, respectively. By learning to reconstruct the input sentence from syntactic and semantic variables, the model effectively learns to generate syntactic paraphrases without using any parallel data. Experiment results on unsupervised sentence paraphrasing and adversarial example generation demonstrate that the proposed model achieves new state-of-the-art results on unsupervised paraphrase generation and generate effective adversarial examples. These examples can be used to improve the robustness and generalization of NLP (natural language processing) model.
Key words unsupervised learning; syntactically controllable paraphrase network; adversarial example
doi: 10.13209/j.0479-8023.2020.079
收稿日期: 2020‒06‒09;
修回日期: 2020‒08‒15
国家自然科学基金(61876198, 61976015, 61976016)资助