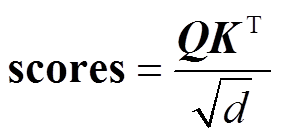 , (3)
, (3)摘要 针对中文拼写纠错, 提出两种新的改进方法。其一, 在 Transformer 注意力机制的基础上, 添加高斯分布的偏置矩阵, 用于提高模型对局部文本的关注程度, 加强对错误文本中错误字词和周边文字的信息提取。其二, 使用 ON_LSTM 模型, 对错误文本表现出的特殊语法结构特征进行语法信息提取。实验结果表明, 所提出的两种方法均能有效提高准确率和召回率, 并且, 将两种方法融合后的模型取得最高 F1 值。
关键词 拼写纠错; Transformer模型; 局部信息; 语法增强
在文字编写、内容审核以及文本识别等多个场景中, 经常出现两种文本错误。比如, 由 OCR 的错误识别或“五笔”输入法的错误输入导致的同形字错误; 或者, 在拼音输入法下, 由错误拼写导致的同音字错误。拼写纠错任务用于检测并纠正文本中出现的错误, 可以在很大程度上解决上述两类文本错误问题。然而, 目前关于中文纠错的研究较少, 缺少有效的通用方法。
拼写纠错是自然语言处理(natural language processing, NLP)领域的一个重要任务。在 20 世纪60 年代, 已经有学者对英文纠错展开研究, 其中比较著名的是 1960 年 IBM 在 IBM/360 和 IBM/370 上, 用 UNIX 实现的一个 TYPO 英文拼写检查器[1]。此后, 文本纠错任务研究取得长足的进展, 涌现很多优秀的算法模型。
纠错任务需要有监督的语料进行模型训练, 这种局限性往往导致在训练过程中没有充足的文本纠错语料可用。N-gram 模型很好地解决了这一弊端, 可利用大量无监督的语料来训练统计语言模型[2]。N-gram 是最简单、最常用的模型, 但该模型在使用困惑集对文本内部的字符进行替换时, 没有考虑上下文的语义信息, 经常造成虽然临近词正确, 但放在整个句子中却不符合逻辑的情况, 导致结果得分不高。
随着机器学习的逐渐兴起, 越来越多的学者把深度学习的方法运用到纠错任务中。一般将纠错任务当作文本生成任务, 此场景下应用最广泛的结构就是序列到序列结构(Seq2Seq)。比较常用的是基于 LSTM 的 Seq2Seq 模型[3]和 Transformer 模型[4], 这两种模型巧妙地将错误句子作为输入语句, 将正确的语句作为输出语句进行训练, 得到错误文本与正确文本之间的对应关系, 从而实现文本纠错。深度学习的优点在于, 模型可以学习到文本的深层信息, 加强对文本语义的理解, 也加深对文本结构的学习, 对获取推荐修改选项有更好的帮助。
可以将拼写纠错任务视为由错误句子产生正确句子的生成任务。在目前常用的生成模型中, RNN模型[3]在多数的生成任务中表现出色, 在文本生成和机器翻译等领域获得广泛的应用。但是, 经典的RNN 模型在处理长距离文本时, 容易出现梯度消失和梯度爆炸的问题, 所以本文采用 Transformer 模型[4], 对中文文本中的同音和同形字错误进行纠错处理。
在文本纠错过程中, 应注意以下两个方面。1)与英文不同, 中文文本字符之间没有空格, 且部分字符需要与另外的字符结合才具有一定的意义, 所以在处理中文文本时, 一般需要先对中文进行分词, 将文本拆分成字或词, 从而形成一个独立的单位。2)中文中没有“字错误”这种说法, 也就是说, 错误只会在词或句子级别产生。因此, 错误字符以及错误字符周边的信息是需要重点关注的内容, Yang等[5]提出一种关注局部信息的方法, 将局部性建模设计为一种可学习的高斯偏差。本文采用上述方法, 在局部范围内加强对错误文本特征的提取以及对错误规律的发现能力。
拼写纠错模型以生成模型为最常见[3–4,6], 训练数据为原语句与目标语句构成的语对, 原语句编码后, 解码生成目标语句。在纠错任务中, 原语句与目标语句之间可能只有一个或几个字符有所不同, 在整个语句中的字符数量占比很小, 模型训练往往达不到很好的效果。Wang 等[7]通过构造大量的训练数据, 使该问题得到缓解。另外, 由于错误字符占比小, 使得原语句与目标语句之间的文本编辑距离很小, 但仍有可能导致原语句与目标语句相比, 在语法结构上发生较大的变化。针对此问题, 本文在原始模型的基础上, 采用 Shen 等[8]提出的 ON_ LSTM 方法, 对 LSTM 结构进行修改, 使其能够考虑到语句的语法结构对纠错效果的影响, 同时将ON_LSTM 模型作为 Transformer 模型的输入层, 帮助模型学习语句的语法结构。
Transformer的核心是使用自注意力机制, 该机制因高效的并行性及长距离信息依赖性, 在机器翻译、文本生成和对话系统等领域有重要的作用, 获得广泛的关注。该模型摆脱了传统RNN 模型长距离信息利用不充分、梯度消失和梯度爆炸的问题, 已应用于各种 NLP 任务中。
给定句子 x={x1, x2, …, xI }, 经过词向量层及位置编码层后, 由 3 个权重矩阵分别生成 query Q∈ R(I×d), key K∈R(I×d)和 value V∈R(I×d)。每一层的注意力结果可以通过下式计算:
Content=ATT(Q, K)V, (1)
其中, ATT(.)是点乘计算公式:
ATT(Q, K)=softmax (scores), (2)
, (3)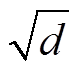 是固定因子, d 是模型的隐藏层维度, scores 是点乘计算得出的得分。
是固定因子, d 是模型的隐藏层维度, scores 是点乘计算得出的得分。
实际上, 纠错任务的特殊性在于错误文本与正确文本之间的差别很小, 而模型关注的范围过于宽泛, 所以模型的重点关注范围是错误文本周边一定范围内的字符, 提取错误字符特征, 加强模型对纠错任务的适应能力。
本文采用Yang等[5]局部模型的思想, 在自注意力得分的基础上, 添加一个类似高斯分布的二次函数偏置项, 用于减少对非错误部分的关注。如图1所示, 在原始分布的基础上添加以错误字符“柏”为中心的高斯分布, 使模型能够加强对该字符以及周边字符的注意力, 并且该高斯分布的参数是可训练的。共有两种分布模式: 高斯分布和强化的高斯分布。这两种分布模式都重点关注错误部分的信息, 区别在于强化的高斯分布减少了对错误点的预测, 增加对周边信息的关注, 以便提高模型的召回率。
计算注意力得分后, 将偏置 G 加入得分中, 用于掩盖自注意力的部分得分:
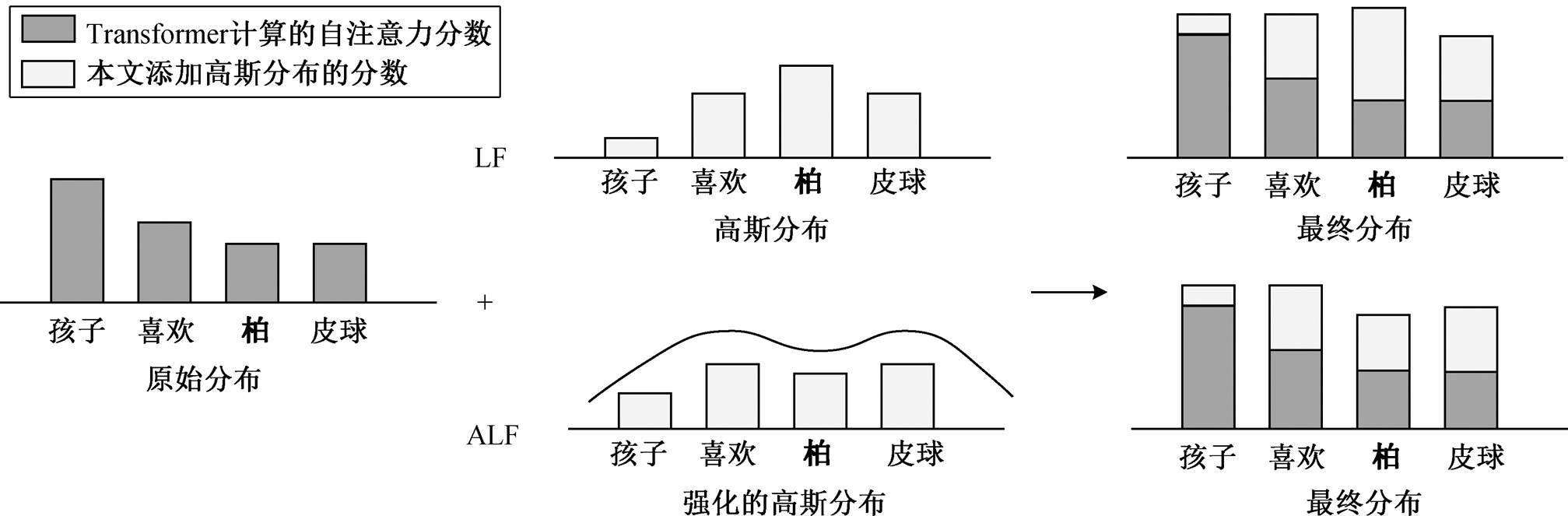
图1 两种不同的高斯分布
Fig. 1 Two different Gaussian distributions
ATT(Q, K)=softmax (scores+G), (4)
其中, scores 由式(3)计算得到, G 是添加的偏置项, 计算方法如下:
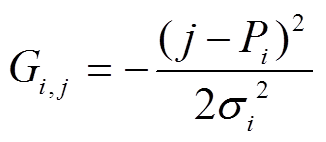 , (5)
, (5)其中, σi 表示标准差, 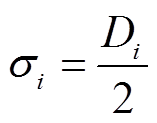 ; Di是一个窗口的大小; Pi是预测错误的位置; Gi,j∈[0, –∞]。Pi 和Di 的计算方法如下:
; Di是一个窗口的大小; Pi是预测错误的位置; Gi,j∈[0, –∞]。Pi 和Di 的计算方法如下:
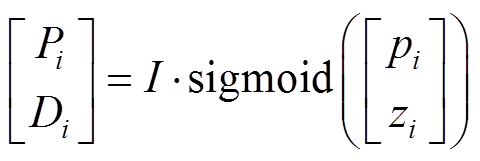 。 (6)
。 (6)参数 I 将标量 pi 和 zi 投影到 0 到句子长度之间, Pi 依赖 pi 和 zi 分别进行计算。值得注意的是, Anastaso-poulos 等[9]提出 Transformer 在不同的文本层中编码信息是有所区别的, 在较低的层, 模型对主要文本的语法结构编码, 而在高层, 模型对语义信息编码。为了加强模型对文本底层的结构信息编码, 仅在编码端和解码端的第一层使用该方法, 在其他层中, 编码方式与常规的自注意力保持一致。考虑到如果在所有的编码层中全部进行计算, 运行时间会变长, 故模型只在编码端和解码端的最底层添加偏置, 以期在效率上达到平衡。
1.2.1 中心位置预测
通过一层前线传播神经网络, 将 query 矩阵 Qi转化为位置隐藏状态矩阵, 然后通过线性投影 Up∈Rd, 将隐藏状态矩阵映射到标量pi:
pi=UpTtanh (WpQi), (7)
其中, Wp∈Rd×d是可训练的模型参数。
1.2.2 查询窗口
查询窗口 zi的计算方法如下:
zi=UdTtanh (WpQi), (8)
其中, Ud∈Rd是可训练的线性投影参数矩阵, 式(7)和(8)共享同一参数 Wp, 这样可以简化运算, 同时用不同的 Ud 和 Up 来计算窗口范围及中心点位置。
在计算注意力得分时, 通常需要对周边信息更多的关注, 并减少对本身信息的关注。所以, 本文对 LF 模型进行改进, 在式(5)的基础上添加偏置 b以及取绝对值的操作, 并设置 b 为 0.1, a 为 0.1。计算方法如下:
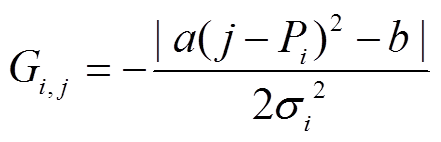 。 (9)
。 (9)与原始模型相比, 该模型减少了对本身及远距离内容的关注, 并加强周边范围内容的计算, 让模型学习更多错误的规律, 提升纠错效果。
错误文字会在很大程度上导致语法结构被破坏。如图 2 所示, 在例句“孩子喜欢拍皮球”中, 如果输入时将“拍”错误输入成“柏”, 可以明显地看出错误句子的语法结构发生较大的变化。为了提取被破坏的语法结构信息, 本文采用 Chollampatt 等[6]中层级结构的 LSTM, 并称之为 ON_LSTM。
模型的总体结构如图 3 所示, 在 Transformer 结构外添加 ON_LSTM 层, 将其输出结果与输入信息相加后送入 Transformer 模型。在左侧, 我们额外添加一层编码层。在内部的自注意力部分, 添加高斯偏置, 增加对错误部分信息的获取。最后, 将添加的编码层及右侧常规的 6 个 Transformer 编码层的输出信息进行融合, 送入解码端进行解码。不同于传统的 LSTM 结构, ON_LSTM 结构在编码过程中通过控制高层信息和低层信息的更新频率来学习句子的语法结构。本文将 ON_LSTM 产生的结构信息与原文的文本信息相加, 最后将得到的信息送入 Tr-ansformer 的编码层, 进行联合编码。这种结构类似Transformer 中编码部分的残差模块, 意在加强数据的流通性, 减少在深层模型中梯度消失的问题。
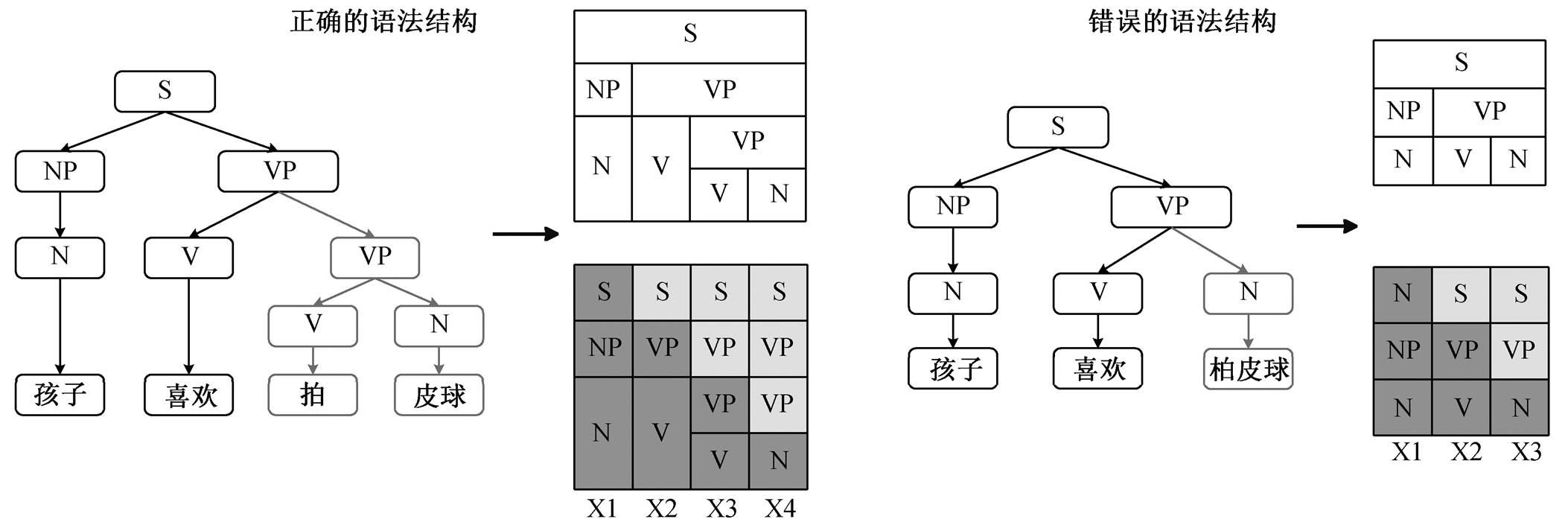
图2 因错误字引发的语法结构变化实例
Fig. 2 An instance of a syntax change caused by an error word
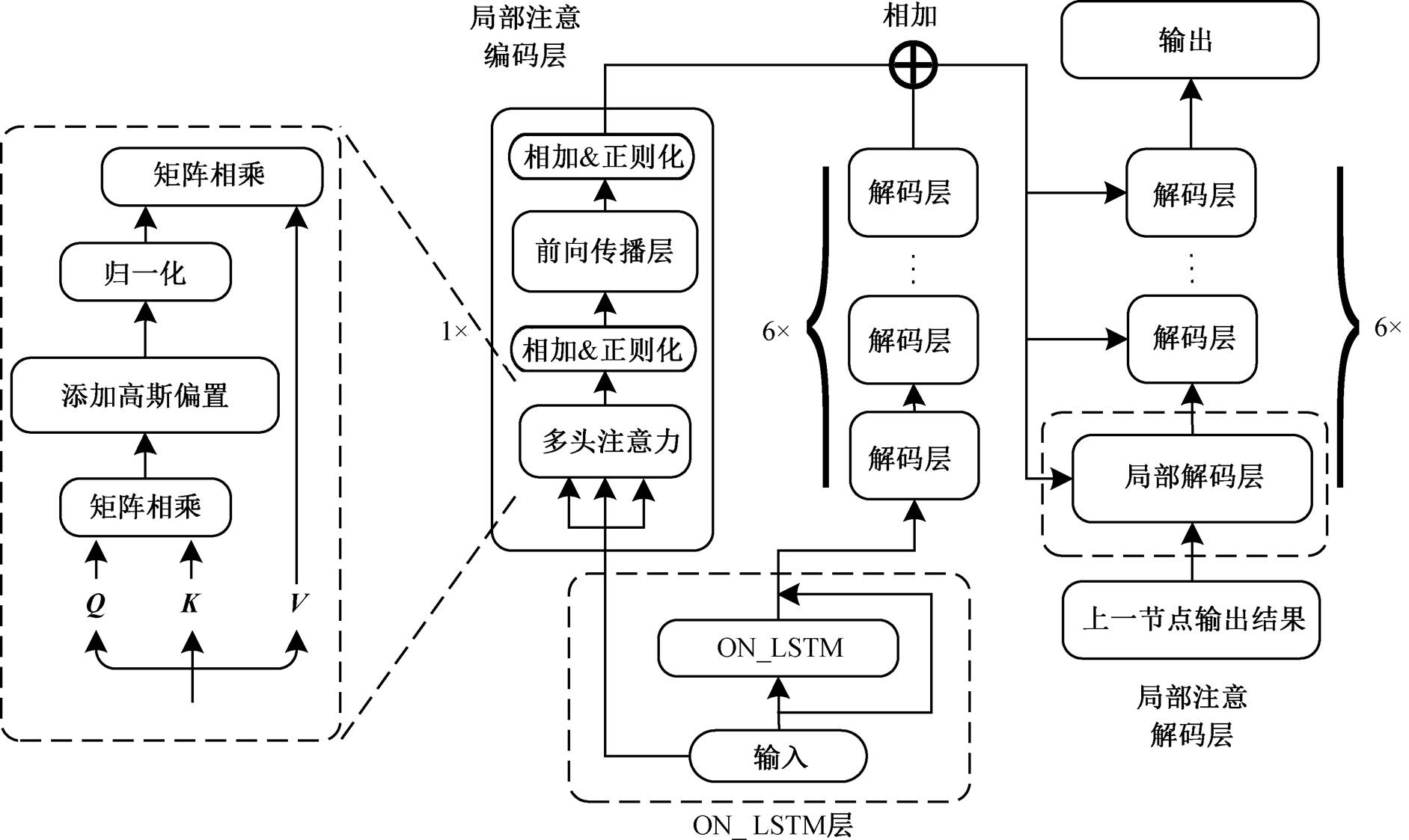
图3 模型的总体结构
Fig. 3 Overall structure of the model
训练数据分为两部分: 一部分是 Wang 等[7]提供的约 27 万条纠错数据集, 其中包括同音字和同形字错误; 另一部分来自文献[10]。测试集同样来自公开评测任务中提供的评测数据集, 具体信息如表 1 所示。由于数据全部是繁体中文, 为了适应简体中文任务, 我们使用开源工具 OpenCC(https://git hub.com/BYVoid/OpenCC)将繁体中文转化为简体中文。
表1 实验数据
Table 1 Experimental data

数据集数据名称数据量/行 训练集Wang等[7]271329 SIGHAN 2015 (训练)3437 总计274766 测试集SIGHAN 2015 (测试)1099
本文采用准确率、召回率和 F1 值作为模型的评价指标, 这些指标通常用于 CSC(Chinese spell correction)任务中的评价。表 2 列出模型的主要参数以及对应的数值。
在纠错任务中, Vaswani 等[4]提出的 Transfor-mer 效果超越传统的统计模型和 RNN 模型(如混淆集约束下的指针生成网络模型(Confusionset)[11]和基于 N-gram 的纠错模型(LMC)[12]), 结果如表 3 所示。在应用于纠错任务的 Transformer 模型中, 本文将 Wang 等[13]的方法作为基线模型。该模型采用transformer 结构, 并采用语法增强架构来提升模型效果, 我们称之为 DR 模型。DR 模型在 Transfor-mer 的基础上添加动态残差结构, 不仅帮助模型获取更加丰富的语义信息, 还可以有效地减少深层模型因模型过深导致的梯度消失问题。
表2 模型参数
Table 2 Model parameters
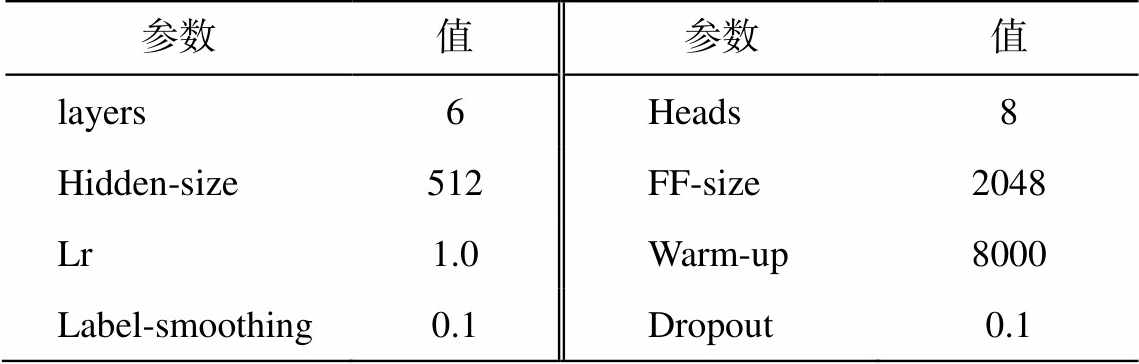
参数值参数值 layers6Heads8 Hidden-size512FF-size2048 Lr1.0Warm-up8000 Label-smoothing0.1Dropout0.1
表3 不同改进对模型性能的影响(%)
Table 3 Impact of different improvementson model performance (%)
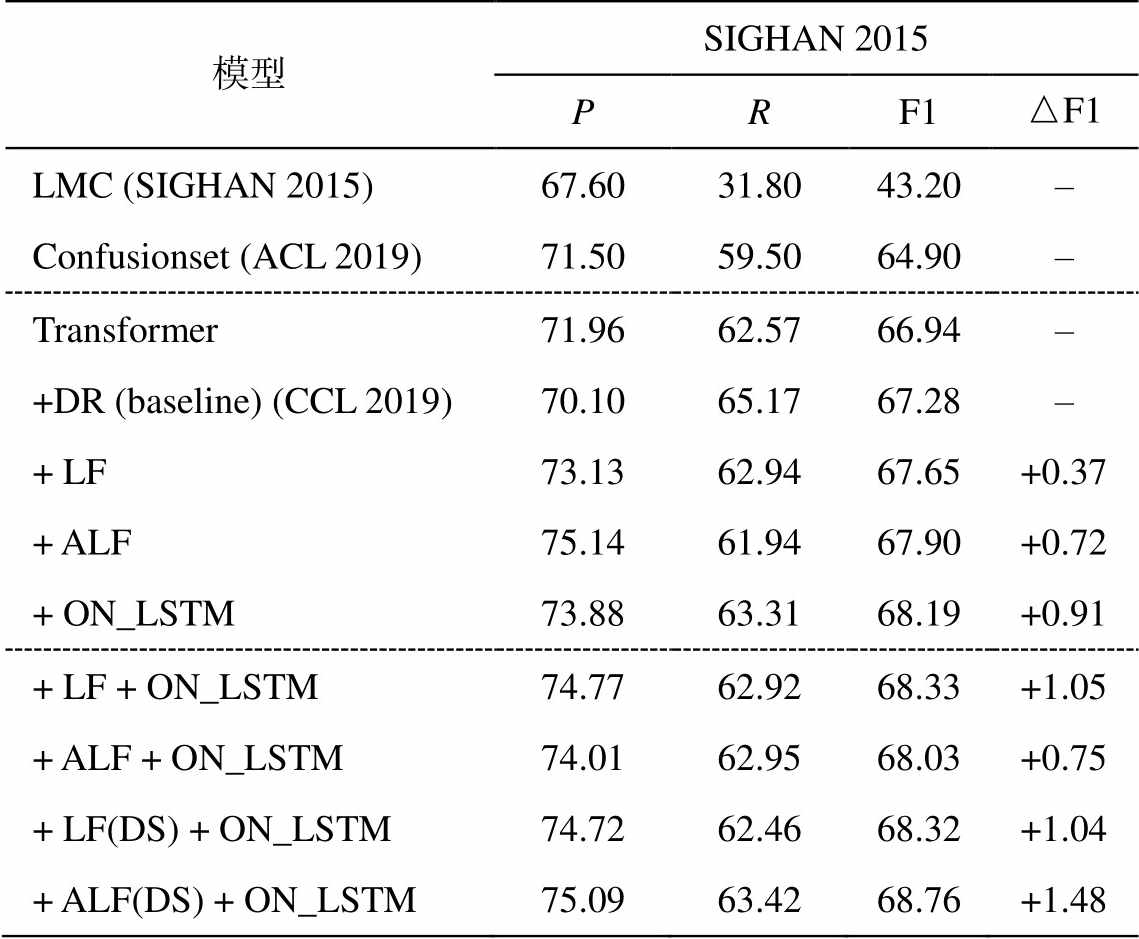
模型SIGHAN 2015 PRF1△F1 LMC (SIGHAN2015)67.6031.8043.20– Confusionset (ACL 2019)71.5059.5064.90– Transformer71.9662.5766.94– +DR (baseline) (CCL 2019)70.1065.1767.28– + LF73.1362.9467.65+0.37 + ALF75.1461.9467.90+0.72 + ON_LSTM73.8863.3168.19+0.91 + LF + ON_LSTM74.7762.9268.33+1.05 + ALF + ON_LSTM74.0162.9568.03+0.75 + LF(DS) + ON_LSTM74.7262.4668.32+1.04 + ALF(DS) + ON_LSTM75.0963.4268.76+1.48
本文共进行 3 组实验: 第一组对比不同模型的效果, 第二组验证局部关注模型以及强化局部关注模型的有效性, 第三组证明 ON_LSTM 的语法结构信息可以明显地提升模型的准确率和召回率等 指标。
对 Transformer 模型的改进如表 3 所示, 共有 3个独立模型以及一个融合模型, DR 模型为基线模型。LF 模型和 ALF 模型在 Transformer 的自注意力结构中添加高斯偏置, 其 F1 值比基线模型分别提高 0.37%和 0.72%。ALF 模型的准确率比基线模型有明显的提高, 并且 F1 值比 LF 模型提高 0.35%。
在 Transformer 模型中单独添加 ON_LSTM 结构使模型的 F1 值提升 0.91%, 证明了该结构的有效性。为了将 Transformer 模型和 ON_LSTM 结构的优势有效地融合在一起, 采用如图 3 所示的模型结构。值得注意的是, 融合实验的前两组(LF+ON_ LSTM 和 ALF+ON_LSTM)仅在编码的自注意力部分添加 LF/ALF 结构, 而后两组(LF(DS)+ON_ LSTM和 ALF(DS)+ON_LSTM)在编码和解码部分都采用LF/ALF 结构。从表 3 可以看出, 编码与解码同时采用 ALF 结构可以使模型达到最优的效果。
如表 3 所示, 与 LF 模型相比, ALF 模型准确率的提升幅度比较大, 召回率略微下降, 但 F1 值提升 0.35%。原因是 ALF 模型减少了对错误字符本身的关注, 在错误字符与正确字符之间对应关系的计算方面被弱化, 但加强了对周边范围内字符信息的关注, 会促使模型加强对错误字符的检测能力。模型训练结果如图 4 所示, ALF 模型在准确率提升幅度较大, 召回率与 LF 持平, F1 相对稳定, 但高于LF 模型。为更好地对比 LF 模型与 ALF 模型的纠错效果, 此部分实验没有添加如图 3 所示的额外结构, 仅在 Transformer 编码与解码的第一层添加 LF 和ALF。
Transformer 模型中共有三部分使用注意力模块, 本文分别在 Transformer 编码端的自注意力部分、解码端的前向注意力和自注意力部分添加 LF结构, 并进行多组实验。从表 4 可以看出, 在编码和解码部分的自注意力模块添加 LF 结构会使模型的 F1 值达到最高。
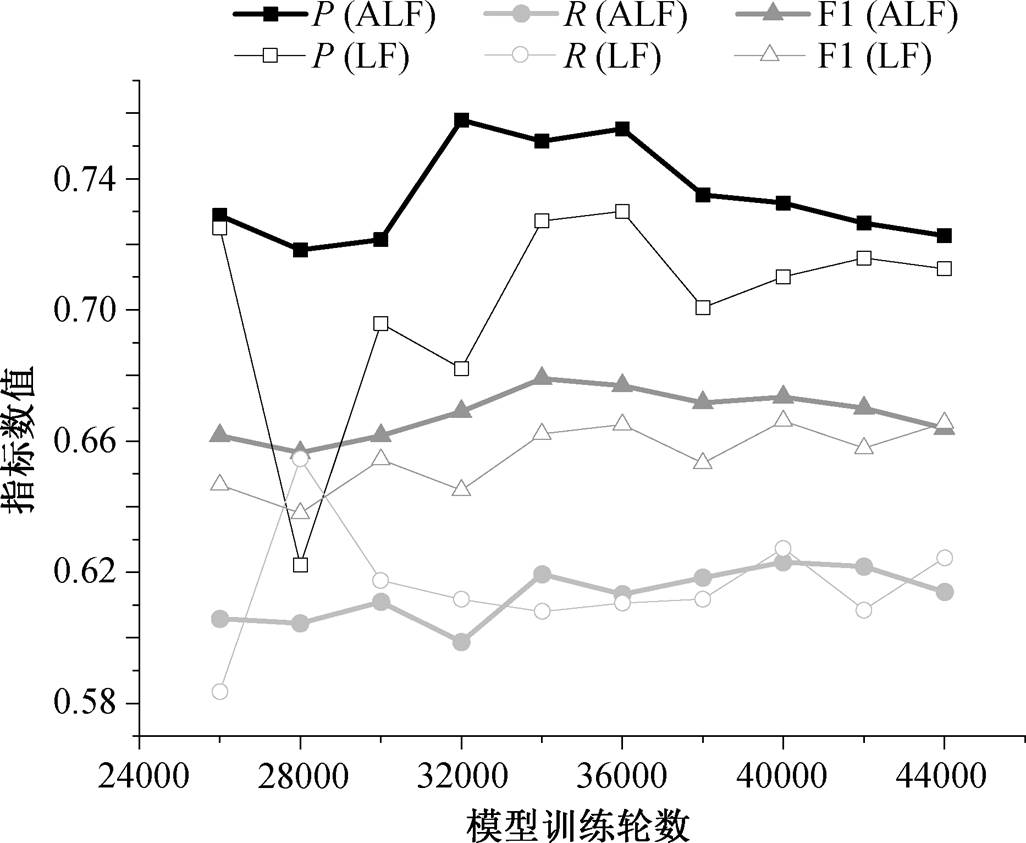
图4 ALF 和 LF 模型的准确率、召回率和 F1 值
Fig. 4 Accuracy, recall and F1 of ALF, LF model
为探究式(9)中参数 a 对 ALF 模型的影响, 分别设置 a=1, 2, 4, 0.1, 结果见表 5。以ES_DS_LF 作为参考, ALF 其他参数与 LF 保持一致, 则当 a=0.1 时, 模型的准确率最高, F1 值同样达到最高。
从表 3 可以看出, 添加 X+ON_LSTM 结构模型的准确率有明显的提升, 验证了之前的猜想: 纠错任务中, 语法结构是敏感的, 充分利用语法信息可以帮助模型提升准确率和召回率等指标。
为了验证 LSTM 结构和 ON_LSTM 结构对整体模型的影响, 进行第三组实验, 结果如表 6 所示。若直接将两种结构的输出结果传入 Transformer 模型, 纠错的准确率和召回率都有所下降, 但将两种结构的输出结果与输入信息相加后再传入Transfor-mer 模型, 纠错效果有很大的提升, 准确率的提升尤为明显。这是因为, 无论是 LSTM 层还是 ON_ LSTM 层输出的信息直接传入 Transformer, 都会导致极大的信息丢失, X+LSTM(X)/ON_LSTM(X)结构在输入 Transformer 模型之前, 在输入数据中获取了文本的其他特征, 与原文的信息融合之后, 对模型起到助推作用。因此, 该结构是对 Transformer 的一种信息补充, 无论是 LSTM 的时序关系结构, 还是 ON_LSTM 的语法结构, 都能有效地提高 Trans-former 模型的纠错效果, 而语法结构信息对 Trans-former 模型的纠错效果帮助最大。
表4 LF模型添加位置对于模型的影响(%)
Table 4 Influence of LF model adding position on model (%)

模型PRF1 +DSR_LF74.7160.6466.95 +ES_DSR_DS_LF72.2662.5367.04 +ES_DS_LF73.1362.9467.65
说明: ES, DS 和 DSR 分别代表编码层自注意力、解码层自注意力和解码层中对编码层的注意力。
表5 参数a对模型的影响(%)
Table 5 Effects of parameter a on the model (%)
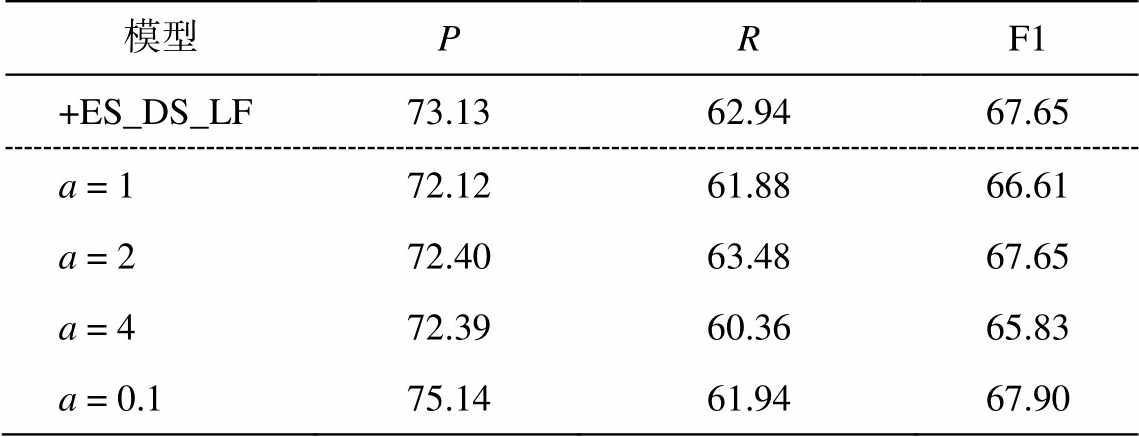
模型PRF1 +ES_DS_LF73.1362.9467.65 a = 172.1261.8866.61 a = 272.4063.4867.65 a = 472.3960.3665.83 a = 0.175.1461.9467.90
表6 LSTM和ON_LSTM结构的对比(%)
Table 6 Comparison results of LSTM and ON_LSTM structures (%)

模型PRF1 +LSTM71.3761.4166.02 +ON_LSTM71.5359.9065.20 +X+LSTM75.2861.1867.50 +X+ON_LSTM73.8863.3168.19
在将不同模型进行融合的过程中, 我们发现, 如果将 ON_LSTM 的结果直接输入带有高斯偏置的编码层中, 最终得到的结果性能会下降。因此, 语法结构信息会对 LF/ALF 产生影响。为了解决这个问题, 本文将输入的信息分为两个部分, 一部分通过 ON_LSTM 层直接进入 Transformer 的编码层, 另外一部分输入信息则送入带有高斯偏置的编码层中, 并将两部分结构的输出结果相加后送入编码层。实验证明, 这种方式可以优化模型结构, 加速收敛, 提升模型纠错率。
Transformer 对由字错误或词错误导致的句子的语法错误相对不敏感且纠错不准确, 而本文模型对此类型错误纠的正表现较好, 并且错误纠正的范围更大(图 5)。
本文从两个方面对 Transformer 模型进行改进。首先采用局部关注的思想, 在自注意力部分添加高斯分布偏置项, 用于提高模型对局部信息的关注, 然后针对拼写纠错任务的语法结构特点, 采用 ON_LSTM 结构, 加强模型对语法结构信息的获取。实验数据表明, 两种方法都会帮助模型提高纠错效果, 且二者的融合结构使模型提升更多。

图5 Transformer以及本文模型在不同错误语句上的表现
Fig. 5 Transformer and our model’s performance on different error statements
中文拼写纠错是一个依赖知识的任务, 知识是文本信息构成的知识库。在对错误字符进行处理时, 需要大量的先验知识, 所以将来的工作就是构建文本知识库, 用于辅助模型对错误文本进行检测和修改。
参考文献
[1] Kukich K. Techniques for automatically correcting words in text. ACM Computing Surveys, 1992, 24(4): 377–439
[2] Huang Q , Huang P , Zhang X , et al. Chinese spelling check system based on tri-gram model // Proceedings of The Third CIPS-SIGHAN Joint Conference on Chinese Language Processing. Wuhan, 2014: 173–178
[3] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks // Advances in Neural Information Processing Systems. Montreal, 2014: 3104–3112
[4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // Neural Information Processing Sys-tems. Red Hook, 2017: 5998–6008
[5] Yang B, Tu Z, Wong D F, et al. Modeling localness for self-attention networks // Empirical Methods in Natural Language Processing. Brussels, 2018: 4449–4458
[6] Chollampatt S, Ng H T. A multilayer convolutional encoder-decoder neural network for grammatical error correction [EB/OL]. (2018–01–26)[2020–05–01]. https: //arxiv.org/abs/1801.08831
[7] Wang D, Song Y, Li J, et al. A hybrid approach to automatic corpus generation for Chinese spelling check // Empirical Methods in natural language pro-cessing. Brussels, 2018: 2517–2527
[8] Shen Y, Tan S, Sordoni A, et al. Ordered neurons: integrating tree structures into recurrent neural net-works [EB/OL]. (2019–05–08)[2020–05–01]. https:// arxiv.org/abs/1810.09536
[9] Anastasopoulos A, Chiang D. Tied multitask learning for neural speech translation [EB/OL]. (2018–04–26) [2020–05–01]. https://arxiv.org/abs/1802.06655
[10] Tseng Y H , Lee L H , Chang L P , et al. Introduction to SIGHAN 2015 bake-off for Chinese spelling check // Proceedings of the 8th SIGHAN Workshop on Chinese Language Processing (SIGHAN’15). Beijing, 2015: 32–37
[11] Wang D, Tay Y, Zhong L, et al. Confusionset-guided pointer networks for Chinese spelling check // Mee-ting of the Association for Computational Linguistics. Florence, 2019: 5780–5785
[12] Xie W, Huang P, Zhang X, et al. Chinese spelling check system based on N-gram model // Proceedings of the Eighth SIGHAN Workshop on Chinese Language. Beijing, 2015: 128–136
[13] Wang Chencheng, Yang Liner, Wang Yingying, et al. 基于 Transformer 增强架构的中文语法纠错方法. 中文信息学报, 2020, 34(6): 106–114
Chinese Spelling Correction Method Based on Transformer Local Information and Syntax Enhancement Architecture
Abstract Two new methods for improving Chinese spelling correction are proposed. The first one is to add Gaussian Bias matrices to the Transformer’s attention mechanism, which is used to improve the model’s attention to local text and to extract information from the wrong words and the surrounding text in the error text. Secondly, the ON_LSTM model is used to extract grammatical information on the special grammatical structure features exhibited by the error text. The experimental results show that both methods are effective in improving accuracy and recall, and the model after fusing the two methods achieves the highest F1 value.
Key words spelling correction; Transformer model; local information; grammatical enhancement
doi: 10.13209/j.0479-8023.2020.081
收稿日期: 2020–05–29;
修回日期: 2020–08–13
国家自然科学基金(61972003, 61672040)资助