
图1 UHSFS文件系统布局
Fig. 1 Layout of UHSFS
摘要 研究并实现面向 NVMe SSD 的用户态高性能共享式文件系统(UHSFS), 并提出简单弹性的数据布局技术、多粒度 IO 队列弹性分离技术以及多用户共享内存架构, 这些关键技术能够显著地提升元数据的操作性能和 IO 处理能力, 并且实现用户态文件系统的共享访问。实验结果表明, 与 UNFS, NVFUSE, BLOBFS 和BLUEFS 等用户态文件系统相比, UHSFS 的元数据操作性能和 Filebench 综合负载性能最优; IO 队列分离技术能够大幅度地提升吞吐量; 与 F2FS, XFS, Ext4 等内核态文件系统相比, UHSFS同样表现出性能优势。
关键词 用户态; 文件系统; NVMe协议; 固态硬盘
近年来, 机械硬盘正逐步被基于闪存(flash)介质的固态硬盘(solid state disk, SSD)取代。与此同时, 主机和外部设备之间的协议从 AHCI (advanced host controller interface)协议演变为 NVMe (non-volatile memory express)协议。与为机械硬盘设计的 AHCI 协议不同, NVMe 是专为固态硬盘构建的接口协议, 不仅可以发挥固态硬盘在快速读写方面的优势, 还可以充分利用多核 CPU 和大容量内存。NVMe 使用简化的命令集, 有效地解析和操作数据, 明确了读写操作的原子性支持, 每个 IO 队列最多可以管理 6.4 万条命令, 单个 NVMe 设备最多可以支持 6.4 万个 IO 队列[1]。
正是由于 SSD 与 NVMe 高效的配合, 存储器的硬件时延显著降低, 导致存储软件的时延成为存储系统整体时延的主要部分[2]。传统的内核态文件系统过于厚重, 内核存储栈存在大量的拷贝、上下文切换以及中断等软件开销, 导致读写延迟较大, 无法充分发挥 NVMe SSD 的硬件性能。人们转向研究用户态文件系统, 试图通过在用户态使用轮询机制来减少开销, 并消除不必要的上下文切换。因此, 轻薄而高效的用户态文件系统逐渐成为 NVMe SSD的重要选择, 亦成为学术界与工业界共同的研究热点。然而, 现有的面向 NVMe SSD 的用户态文件系统存在如下缺陷。
1)文件系统布局无法兼顾空间利用率和读写性能。现有的用户态文件系统往往将轻而薄作为设计目标, 因此在空间分配上的策略较为单一。例如, 对不同尺寸或流式写入的文件采用固定的分配方法, 导致空间利用率或性能低下。此外, 应用和文件系统各自实现日志[3], 也导致大量不必要的IO。
2)未充分发挥 NVMe SSD 的多队列高性能特性。多队列技术是 NVMe 的一个重要的提高性能的方法。借助于多队列技术, NVMe 实现按照任务、调度优先级和 CPU 核(core)分配不同队列。但是, SSD 具有读写不对称性, 大小文件的延迟同样存在差别, 现有的文件系统没有根据 IO 请求的特性区分队列, 性能存在一定的提升空间。
3)不支持多个应用程序对 SSD 的共享访问。由于文件系统处于用户态, 未经过操作系统的块设备驱动, 因此, 应用程序只能绑定 SSD 进行读写访问。显然, 这与传统的内核态文件系统的使用有较大的差异, 无法实现多个应用程序对 SSD 的共享访问, 而这种访问在一些场景(如多个客户共享读取一个热点视频)中十分重要。
针对上述问题, 本文面向 NVMe SSD 设计一个用户态文件系统 UHSFS (user-space high-performance shared file system), 主要贡献包括以下 3 个方面。
1)提出简单弹性的数据布局技术, 可以避免大量不必要的 IO, 提升小文件的空间利用率。利用NVMe 对原子操作的支持, 去除元数据操作的预写日志和维护 dentry 的开销, 在内存中同时维护两套索引, 实现快速的元数据操作。
2)提出多粒度 IO 队列弹性分离技术来解决读写混合 IO 的队列抢占问题。针对 NVMe 多队列的特性进行管理, 将轻量级的分类器用于调度 IO 请求被送至哪一种类型的队列中, 显著地降低 IO 请求的平均响应时间。
3)提出多用户共享内存架构来解决用户态文件系统无法被多用户进程共享访问的问题。在多个应用程序与文件系统之间, 通过共享内存的方式传递消息和数据, 实现 NVMe SSD 的多进程高效共享。
传统的内核态文件系统存在拷贝、上下文切换以及中断等方面的开销, 因此, 轻薄高效的用户态文件系统逐渐成为研究热点。近年来, 一些面向NVMe SSD 的用户态框架、驱动及文件系统被相继提出。
Intel 公司提出针对高性能 NVMe SSD 设备的存储性能开发工具包 SPDK[4], 将所有必需的驱动程序移动到用户空间, 避免系统调用, 并允许从应用程序进行零拷贝访问, 通过轮询方式检查操作完成情况, 以降低延迟, 通过消息传递机制来避免 IO路径中的锁冲突。BLOBFS[5]是基于 SPDK 实现的用户态文件系统, 功能较为简单, 没有提供齐全的 POSIX 接口, 不提供对目录的支持, 不支持原地址更新, 只能被一个进程独享使用。BlueStore[6]是一个针对 SSD 特性优化的存储引擎, 其中包含一个轻量级的文件系统 BLUEFS[7], 并含有用户态块设备抽象层 NVMEDevice, 调用 SPDK 的用户态块设备驱动。与 BLOBFS 相似, BLUEFS 只提供少量文件接口, 只支持顺序写和两层目录, 只能被一个进程独享使用。Yongseok[8]提出基于 SPDK 的 NVMe Driver 的用户态文件系统 NVFUSE, 使用类似 Ext3的文件系统布局, 并计划通过实现轻量级日志, 来进行文件系统的一致性管理, 目前开发不活跃。DashFS[9]是一种利用进程间通信机制的用户态文件系统, 同样是基于 SPDK 开发, 仅提供简单的文件操作, 不支持目录, 不考虑崩溃一致性, 研究重点在于通过微内核参与的方式实现进程的信任和安全认证, 但缺乏页缓存机制, 访问性能存在一定的提升空间, 并且缺乏对进程的死锁检测机制。
Kim 等[10]提出用户级 IO 框架 NVMeDirect, 通过允许用户应用程序直接访问存储设备来提高性能。与 SPDK 不同, NVMeDirect 可以与内核的传统IO 堆栈共存, 以便现有基于内核的应用程序可以在不同的分区上与 NVMeDirect 应用程序同时使用同一个 NVMe SSD。NVMeDirect 提供队列管理, 每个用户应用程序可根据其 IO 特性和需要来选择自己的 IO 策略。NVMeDirect 框架比 SPDK 框架简单, 框架线程直接操作设备的 IO 队列。然而, NVMe-Direct 是一个用户态调度的框架, 使用起来不方便。ForestFS[11]是 NVMeDirect 支持的用户态文件系统, 使用 ForestDB[12]进行文件系统元数据管理。与 BLOBFS 相比, ForestFS 支持多级目录和原地更新, 但代码量小, 功能较为简单。
Micron 公司提出面向 NVMe SSD 的用户态驱动 UNVMe[13], 驱动和客户端应用合并在一个进程内, 性能较好, 但限制一个 NVMe 设备在同一时刻只能被一个应用程序访问。基于 UNVMe, Micron公司提出 UNFS[14], 但只支持同步接口, 不支持异步接口, 不提供崩溃一致性保证。
除此之外, 还有很多面向 NVMe SSD 的用户态文件系统, 包括 Rustfs[15], Moneta-D[16], CRUISE[17], BurstFS[18], SCFS[19]和 BlueSky[20]等, 由于尚未开源,因此测试中未进行对比。依赖内核的用户态文件系统不在本文的讨论范围, 虽然开发简便, 但性能十分不理想[21]。
综上所述, 面向 NVMe SSD 的用户态框架、驱动和文件系统的优势在于, 支持零拷贝, 以轮询方式访问来减少中断, 并针对 SSD 的某些特性做了相关的优化, 可以减少软件带来的开销。存在的共性问题在于文件系统布局无法兼顾空间利用率和读写性能, 未充分利用 NVMe SSD 多队列特性的性能优势, 难以支持多个应用程序对 SSD 的高效共享访问, 这些都制约了 NVMe SSD 的发展。
UHSFS 以页(page)为最小粒度进行空间的分配和读写, page 固定设置为 4KB。同时, 利用 NVMe原子操作, 实现元数据更新的一致性保证。如图 1所示, UHSFS 的文件系统布局包括超级块(super block)、索引节点(inode)和数据区(data zone)三部分。
超级块大小为 2MB, 记录文件系统类型、版本号等不可变信息以及元数据区大小等可变信息。
索引节点: 单个大小为 4KB, 记录文件或目录的元数据。对于每个索引节点, 头部包含 256B 的索引节点编号(ino)、256B 的目录全路径和 512B 的元数据(如创建时间、修改时间和权限等), 剩余 3KB 则根据索引节点类型使用不同布局。
数据区: 包括小数据区和大数据区。不同尺寸的文件通常是不同的文件类型, 并天然地具备访问频率和生命周期的差异。UHSFS 利用这一特性, 将小文件集中在小数据区存储, 大文件分配粒度则与 SSD 擦除粒度对齐, 从而减少闪存转换层(flash translation layer, FTL)垃圾回收的开销[22], 在性能和空间利用率上取得平衡。
图1 UHSFS文件系统布局
Fig. 1 Layout of UHSFS
与 XFS 和 Ext4 等内核态文件系统不同, UHSFS的布局结构中不包含空间位图(bitmap)和预写日志(journal), 而是在文件系统挂载时执行 inode 块读取和解析, 并在内存建立文件系统索引树和空闲空间列表。该设计以降低启动速度为代价, 减少需要持久化的元数据类型和数量, 从而降低元数据更新时的 IO 次数。上述设计使单一文件的元数据修改仅涉及文件 inode 块, 极大简化了一致性模型。inode块的更新可以直接通过 NVMe 的原子操作完成, 而不必使用日志机制。
数据采用弹性分配策略, 同时兼顾空间利用率和读写性能。文件 inode 的格式和内容随文件长度而变化, 以便优化不同尺寸文件的空间分配。对于小于 3KB 的小尺寸文件, 直接内联存储在 inode 中, 可以有效地减少 IO 次数, 提升空间利用率和数据读写性能。对于大于 3KB 的文件, 首先在小数据区以 4KB 为粒度分配数据块进行存储, 当文件长度超过 2MB 时, 将文件原有的 4KB 数据块拷贝合并为1 个 2MB 的数据块, 之后使用 2MB 或其倍数大小, 从大数据区分配数据块。对于流式写入的文件, 数据区分配方式可能会很快地跨越上述多个阶段, 造成inode 布局的变化, UHSFS 通过数据块的延迟分配来避免不必要的数据搬迁。
在内存空间中, UHSFS 同时维护两套索引: 哈希索引和 B 树索引。在全路径操作时(例如打开文件), 通过哈希索引计算得到索引节点的位置, 无需执行逐级解析。在相对路径操作时(例如遍历目录中的文件), 用 B 树索引查询即可快速返回结果。当对元数据进行增加、删除和修改等操作时, 两套索引之间采用异步方式保持一致, 即全路径操作时首先更改哈希索引, 完成后再异步更改 B 树索引, 相对路径操作时则相反。这样会取得优异的元数据性能, 但以短暂的不一致时间窗口为代价。正是由于两套索引的存在, UHSFS 不维护目录条目信息(dentry), 而是在文件inode中存储文件的全路径。此外, 目录 inode 仅在 mkdir 操作被调用时创建, 以便提供对空目录的支持。目录重命名操作被拆分为针对每个文件的重命名操作, 这一过程不是原子的, 但通常不会产生难以接受的一致性问题。
现有的混合式 IO 队列存在弊端。Chen 等[23]的研究表明, 工作负载的性质很大程度地影响 SSD 的性能, 特别是写操作导致混合读写工作负载的高读取延迟和吞吐量下降。在 SSD 上进行混合读写操作, 可能会因以下原因相互干扰。
1)两个操作共享许多关键资源, 例如差错检测和修正(error checking and correction, ECC)引擎以及锁保护映射表等。Lee 等[2]指出, 混合读写产生的相互干扰在 NVMe 设备上仍然存在, 同一个提交队列中的读请求可能必须等到与其竞争的写请求完成, 从而增加了请求延迟。
2)写操作和读操作都可能在内部生成后台操作, 如预读和异步写回等。
3)混合读写可以屏蔽某些 SSD 的内部优化。例如, 闪存芯片通常提供高速缓存模式来传输一系列读或写操作。闪存有两个寄存器: 数据寄存器和缓存寄存器。当处理一系列读或写操作时, 在缓存寄存器与控制器之间传输一页数据的同时, 另一页数据可以在闪存介质与数据寄存器之间移动。但是, 这种流水线操作必须在一个方向上执行, 而混合读和写将中断流水线操作, 降低读写效率。
NVMe 协议提供多个队列来处理 IO 命令, 当前Linux 内核中的 NVMe 驱动程序在主机系统中为每个 CPU 核创建一个提交队列和一个完成队列, 以便避免加锁和缓存冲突, 而用户态驱动在队列管理上更加灵活, 每个用户应用程序都可以根据其 IO 特性和要求来选择自己的 IO 完成方法和调度策略。考虑到现有混合式 IO 队列存在弊端, 结合 NVMe协议天然具备的多队列特性, 本文进行 IO 队列的弹性分离设计, 如图 2 所示。所有的队列被分为 4种类型: 大粒度读、大粒度写、小粒度读和小粒度写, 每一种类型会有 0 或多个队列。当一次 IO 请求发送给用户态驱动时, 一个轻量级的分类器用于调度该 IO 请求被发送至哪一种类型的队列中。
分离方式包括读写分离和大小分离。
1)读写分离。为了减少混合读写操作下的写干扰, 以往的研究将重点放在 IO 调度上, 提出提高读请求优先级的读首选调度方案。但是, 读首选调度仍然会增加读请求的延迟, 因为它在某些情况下不能完全消除写干扰[25]。本文采用将 UHSFS 的读写请求在底层 IO 提交队列分离的方法, 利用 NVMe多队列的特性, 最大程度地减少读写之间的干扰。
2)大小分离。大负载顺序写请求的性能显著好于小负载随机写请求。在文件系统中, 由于文件大小的不同、分配数据块的不连续性以及上层应用发出请求的不确定性, 可能在底层 IO 提交队列产生不同负载类型的写请求相混合的情况。例如, 当小文件频繁更新时, 会产生大量碎片化的随机写请求, 当这些随机 4KB 写请求与大页面的 2MB 顺序写请求相混合时, 可能降低文件系统的性能。Lu等[26]的研究表明, 将不同大小的负载进行分离能有效地降低写放大, 并提高性能。本文利用 NVMe 多队列特性, 将 UHSFS 大负载的顺序写请求和小负载的随机写请求分离。

图2 多粒度IO队列弹性分离技术
Fig. 2 Elastic separation of multiple IO queues technology
为了使得各 IO 的总体时间延迟 T 最小, 本文提出式(1), 即求得 Diq 来判断将当前 IO 放至哪个队列中。
 (1)
(1)其中, Q 为队列数量; B 为数据块大小类型数量; Rqb表示读延迟矩阵, rqb 表示队列 q 处理读 b 类型数据块的平均时间; wqb 表示写延迟矩阵, wqb 表示队列 q处理写 b 类型数据块的平均时间; tq 表示队列 q 当前等待时延, 根据队列 q 中等待处理的数据块动态计算得出; 需要处理的数据块用向量(a1, a2, ..., aB)表示, ab 表示需要处理的数据块大小类型为 b 的数据块的个数, 其中 a1 + a2 + ... + aB= N, 数据块编号从1 到 N; Vi为指示向量, 表示编号为 i 的数据块处理类型为读; Aib 为指示矩阵, 表示编号为 i 的数据块, 类型为 b; Diq 为指示矩阵, diq=1 表示编号为 i 的数据块, 由队列 q 处理。特别地, 对于单读或单写的队列(如单读队列 q), 可以将 wqb 设置为一个很大的值, 这样就将写分配到其他队列。
现有的用户态驱动在打开 SSD 设备后, 形成对SSD 设备的独占, 导致多个进程无法对 SSD 进行共享访问。当进程 2 需要访问 SSD1 的数据时, 有两种传统的方式: 一是先解除进程 1 与 SSD1 的绑定, 然后将进程 2 与 SSD1 绑定, 最后由进程 2 访问SSD1, 但这种方式非常低效; 二是由进程 2 发消息给进程 1, 由进程 1 将 SSD1 的数据发送给进程 2, 但这种方式的文件共享仅限于两进程之间共享, 其他进程无法共享。
本文通过对共享内存的管理来实现多个进程对多个 NVMe SSD 的共享访问, 同时通过共享的页面缓存来提升进程访问 SSD 的性能。共享内存框架由共享内存、应用进程、管理进程、UHSFS 文件系统和 SSD 组成。
共享内存是框架的核心, 包括 Globalfd, Ctrl_ head, CtrlBuf, Page_head 以及 PageBuf 共 5 个结构。进程间的消息包括控制消息和数据消息, 前者通过控制头 Ctrl_head 及缓存块 CtrlBuf 进行管理, 后者通过页头 Page_head 及页缓存 PageBuf 进行管理。同时, Globalfd 管理所有进程上打开的文件句柄, 保存文件打开的相关信息, 包括文件名、文件编号、存储位置、正在操作的存储块和长度等信息。PageBuf 可以给多个应用进程共享, 这样, 当一个进程打开文件进行读写后, 其他进程可以同时进行PageBuf 的共享访问, 从而减少对外存的访问量。
用户进程可以绑定一个或多个 SSD。每个进程均可以获得某个 NVMe SSD 的句柄(Handle), 并通过该 Handle 与管理进程交互, 实际完成读写操作。
管理进程负责对多个 NVMe 设备访问的管理、存储空间的管理以及发送读写请求。多个用户进程可以通过管理进程, 进行多个 NVMe SSD 的共享访问。死锁检测是管理进程的重要功能, 其定时向用户进程发送心跳消息, 结合加锁时间来判断是否出现进程已经异常关闭, 或在资源被死锁时, 进行资源的强制释放。
UHSFS 文件系统包含用户态驱动和文件系统核心, 实现用户态的 NVMe 协议栈, 负责与底层SSD 的协议交互, 对外提供文件接口。用户进程通过调用 UHSFS 提供的文件接口与 SSD 进行交互。
每个 SSD 被一个用户进程绑定。
如图 3 中虚线箭头所示, 当进程 2 访问与之绑定的 SSD2 的文件时, 先在共享内存检查文件数据是否已经存在, 如其他进程曾经在该文件之前访问过(热点数据), 则直接在共享内存将文件数据读出, 如果不存在, 则再从 SSD2 读取。图 3 中灰色实线箭头表示, 当进程 1 访问非与之绑定的 SSD2 文件时, 同样先在共享内存检查文件数据是否已经存在, 如不存在则向管理进程发送请求, 管理进程通知进程 2 将该文件数据读取至共享内存, 则进程 1 即可在共享内存访问该文件数据, 并且, 其他进程同样可以在共享内存直接访问该文件数据。
UHSFS 会将各个用户进程首次共享访问 SSD中的数据拷贝至共享内存, 对于访问特征相似的用户进程组, 大多数的文件数据直接在内存命中, 因此性能很高。然而, 由于共享内存的空间有限, 一般为 GB 级, 而单 SSD 的容量为 TB 级, 因此需要考虑在共享内存达到容量极限后, 将哪些数据从内存中置换出来。一种简单的方法是使用 LFU, LRU, ARC, FIFO 和 MRU 等经典的缓存替换算法, 然而这些算法未考虑在多个用户场景下访问热点重合的问题, 例如一个文件仅被一个用户访问, 而另一个文件同时被多个用户访问, 即便前者刚刚被访问, 后者也应拥有更高的重要性。就本文提出的共享内存而言, 共享是重要特征, 被共享访问的文件不能简单地因最近一段时间未访问而被换出。因此, 本文提出一种多用户多因子共享内存置换算法, 当共享内存已满, 需要要淘汰部分文件时, 以文件的 E值作为依据, 选取 Top N 个文件作为缓存淘汰对象, E值的计算公式如下:
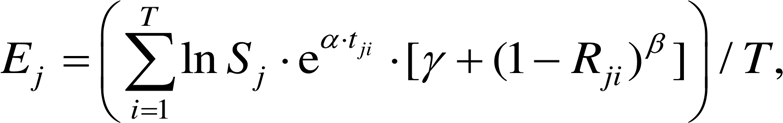 (2)
(2)其中, Ej 表示共享内存中第 j 个文件换出的指标, 指标越大, 表示越应该换出; Sj 表示共享内存中第 j 个文件的大小; T 表示一段时间周期; tji表示共享内存中第 j 个文件, 在 T 时间周期内, 在时间 i 内, 最近未被使用的时间; Rji 表示共享内存中第 j 个文件, 在 T时间周期内, 在时间 i 内的相关系数, Rji=Mji/N, N 为总进程数, Mji 为在时间 i 内, 对第 j 个文件有操作的进程的数量。α 表示 LRU 参数, 根据历史统计获取; β 表示相关性参数, 根据历史统计获取; γ 表示全相关参数, 取一个很小的数值, 为避免 为 0, 根据历史统计获取。
为 0, 根据历史统计获取。

图3 多用户共享内存框架
Fig. 3 Multi-user shared memory architecture
除在进程间利用共享内存外, 本文还提出更细粒度的, 非统一内存访问(non-uniform memory ac- cess architecture, NUMA)内的共享内存, 用来解决跨 NUMA 内存接触和访问 NVMe 设备的高延时问题。管理进程将负责请求处理的工作线程绑定在与NVMe 设备同 NUMA 节点的 CPU 上, 此外, 管理进程使用一个全局预分配的同 NUMA 节点的内存池作为数据缓冲。对于特定的 NVMe 设备, 工作线程是唯一的, 仅从同 NUMA 节点内存池中分配读写缓冲区。因此, 缓存命中率得以进一步提升, 对文件元数据以及数据的操作也可以在无锁的情况下完成, 降低了 CPU 开销。请求队列的存在也为进一步的 IO 优化提供了契机。总之, 管理进程通过为每个NVMe SSD 分配一个同 NUMA 的工作线程, 实现简洁高效的请求处理。
本研究在 Linux 系统中, 实现用户态文件系统UHSFS 及其关键技术, 并在 4 个方面测试 UHSFS的性能: 文件系统元数据操作性能、多粒度 IO 队列弹性分离技术、基于 Filebench 的综合负载以及与内核文件系统的对比。
所有实验都在一台多核 NUMA 架构的服务器上进行, 具体配置如表 1 所示。在前 3 个实验中, 都与开源的用户态文件系统进行比较, 包括 UNFS, NVFUSE, BLOBFS 和 BLUEFS。在最后一个实验中, UHSFS 与典型的内核态文件系统进行比较, 包括F2FS, XFS和Ext4。
由于测试中 SSD 支持块级别的原子写入, 因此, 对其以 4 KB 为单位进行格式化时, UHSFS所需要的原子性能够得到保证。
我们对目录、文件的 create 操作、stat 操作和remove 操作性能进行评估测试。文件测试时默认的数量为100 万, 由于 BLOBFS 文件创建性能过低, 实际测试的文件数量为 10 万。目录测试时是展平的目录结构, 即在同一目录下创建文件和目录, 由于目录支持较差, BLOBFS 和 BLUEFS 未进行相关测试。
文件元数据操作测试结果如表 2 所示, UHSFS的整体性能最优。与整体性能排名第二的 UNFS 相比, 文件 create 操作、stat 操作和 remove 操作中性能分别提升 5.1%, 7.6%和113.6%。
表1 实验服务器配置
Table 1 Experimental server configuration

项目内容 操作系统CentOS 7.6.1810 内核版本Linux 3.10.0-957 CPUIntel Xeon Silver 4114 CPU @ 2.20 GHz, 40cores 内存16 GB × 8 NVMe SSDHGST SN260 容量1.6 TB
表2 文件元数据操作性能测试结果(OPS)
Table 2 Test results of file metadata operation performance (OPS)

文件系统文件create操作文件stat操作文件remove操作 UHSFS2336460471325735 UNFS2222256179812048 NVFUSE67586667334019 BLUEFS10138691429204 BLOBFS484053226
在文件 create 操作中, UHSFS 和 UNFS 大幅领先于其他文件系统, 两者均使用较为简单的元数据布局。NVFUSE 使用类似 Ext3 的磁盘布局, 由于IO 次数较多, 在本次测试中表现不佳。BLUEFS 测试结果略好于 NVFUSE。BLOBFS 的性能远低于其他文件系统, 这可能是因为 BLOBFS 是专为RocksDB 设计的, 对文件和目录支持较弱。总体而言, UHSFS 在保持相同的性能水平的同时, 提供了更完善的功能和一致性保证, 其性能超过功能类似的 NVFUSE 和BLUEFS 一倍以上。
在文件 stat 操作中, 由于内存缓存的存在, UHSFS, UNFS 以及 NVFUSE 的性能大幅领先于BLOBFS 和 BLUEFS。虽然 BLOBFS 也使用内存缓存, 但文件管理采用简单的链表法, 搜索性能低下。UHSFS 的性能仅比 NVFUSE 略低, 这是因为 NVF-USE 的元数据编码效率较高。
在文件 remove 操作中, UHSFS 性能最佳。与create 操作相比, UNFS 的 remove 操作性能大幅降低, 进一步阅读代码发现, 为保持元数据区的连续性, UNFS 在文件 inode 删除时会移动数据区尾部的 inode, 对删除产生的空洞进行填充, 从而导致性能下降。
目录元数据操作测试结果如表 3 所示, 整体上呈现与文件操作相似的性能表现。UHSFS 的整体性能最优, 相较于整体性能排名第二的 UNFS, 在目录 create 操作、stat 操作和 remove 操作中性能分别提升 3.6%, 7.0%和 90.8%。UHSFS 仅在目录 stat操作性能略低于 NVFUSE。BLUEFS 和 BLOBFS 则由于目录支持不完善, 未能完成相关测试。
表3 目录操作性能测试结果(OPS)
Table 3 Test results of directory operation performance (OPS)

文件系统目录create操作目录stat操作目录remove操作 UHSFS2353460771425036 UNFS2270956774213121 NVFUSE50846762793768
总之, 得益于简洁可靠的元数据管理机制, 在提供更完善的功能的同时, UHSFS 保持较高的元数据操作性能。UHSFS 的元数据操作整体性能排名第一, 与排名第二的 UNFS 相比, 性能提升 3.6%~ 113.6%。
下面测试 UHSFS 文件系统在 IO 队列弹性分离功能开启、关闭时的性能差异。弹性队列的数据特征主要包括读写请求混合与分离、数据大小混合与分离以及读写请求和数据大小全混合与全分离。当开启 IO 队列弹性分离功能时, UHSFS 绑定多个 IO队列处理请求, 通过为队列分别设置极大的 wqb 或rqb 值, 达到将 IO 请求分别提交到指定队列的目的。当弹性分离功能关闭时, IO 请求将被以轮询(round-robin)方式均匀地分发到所有队列上。
为了测试读写请求混合与分离的效果, 我们模拟工作负载, 向 UHSFS 同时发出 100 万个随机读和100 万个随机写的 IO 请求。选取 4KB 和 64KB大小的文件, 分别验证 IO 队列深度为 16, 32, 128和 256 时的吞吐量, 测试结果如表 4 所示。开启UHSFS 的队列分离功能后, 各场景的吞吐量提高7.2%~65.5%。上述测试在 64KB 和 4KB 文件的提升最低值和最高值分别出现在不同的 IO 深度中, 效果不是随请求尺寸和 IO 深度而线性地变化, 本文认为这与不同负载时 SSD 的处理能力以及 SSD自身队列对用户态软件队列的削弱程度有关。
表4 读写请求混合与分离的性能测试结果(MB/s)
Table 4 Performance test results of mixing and separating read and write requests (MB/s)

IO深度4 KB64 KB 关闭分离开启分离性能提升/%关闭分离开启分离性能提升/% 1655799265.5128013737.2 32889126041.81285171433.4 128157517068.31156133115.2 2561631184313.0892124439.5
为了测试数据大小混合与分离的影响, 本节模拟工作负载先向 UHSFS 同时发出 100 万个 4KB 随机写和 10 万个 64KB 顺序写的 IO 请求, 然后, 向UHSFS 同时发出 100 万个 4 KB 随机读和 10 万个 64KB 顺序读的 IO 请求, 实验结果如表 5 所示。对于不同的队列深度, 弹性分离特性开启后, 吞吐量提升 9.81%~53.68%。随着队列深度的增加, 效果趋于明显, 经过软件重新排序的 IO 能够被 SSD 更高效地处理。
为了测试读写请求和数据大小全混合与全分离的影响, 模拟工作负载向 UHSFS 同时发出 50 万个4KB 随机写、50 万个 4KB 随机读、5 万个 64KB顺序写以及 5 万个 64KB 顺序读的 IO 请求, 实验结果如表 6 所示。读写请求和数据大小全分离后, 系统的吞吐量整体上提升 28.2%~55.7%。
为了验证 UHSFS 的整体性能, 使用 Filebench的 4 种负载 fileserver, varmail, webserver 和 web-proxy 进行测试, 配置为 Filebench 的默认配置, 实验结果如表 7 所示。UHSFS 目前支持的文件系统操作主要是文件的创建、重命名、读、写、删除以及目录的创建、删除、读目录等基本操作。为了能调用相关用户态文件系统的访问接口, Filebench 代码被少量地修改, 一些不支持的操作(如链接操作 link)被实现为空函数。BLOBFS 和 BLUEFS 不支持随机写, 并存在目录支持缺陷, 故未能完成相关测试。
表5 数据大小混合与分离的性能测试结果(MB/s)
Table 5 Performance test results of data size mixing and separation (MB/s)

IO深度写读 关闭分离开启分离性能提升/%关闭分离开启分离性能提升/% 1619924121.1 13620953.7 322142359.8 19928844.7 12821124214.7 27536231.6 25621324012.7 29735619.9
表6 读写请求和数据大小全混合与全分离的性能测试结果(MB/s)
Table 6 Performance test results of simultaneous mixing and separation of read / write requests and data sizes (MB/s)

IO深度关闭分离开启分离性能提升/% 1612516532.0 3213517328.2 12812616329.4 25612219055.7
表7 Filebench的4种负载测试配置
Table 7 Test configuration of four workloads in filebench

负载文件数文件平均大小/KB线程数 fileserver10000128 50 varmail100016 16 webserver100016 100 webproxy1000016 100
表 8 显示, UHSFS 的整体性能最优, 与整体性能排名第二的 UNFS 相比, 在 4 种负载中性能分别提升 11.7%, 38.0%, 35.3% 和 34.0%。对于 fileserver场景, UHSFS 的性能比 UNFS 和 NVFUSE 分别高约11.7%和 64.4%, fileserver 场景模拟文件服务器中文件的共享、读写等操作, 而这些操作对元数据的性能依赖度较高, 前述实验也证明 UHSFS 整体上具有更好的元数据性能, 故在此类负载下得以领先。对于 varmail 场景, UHSFS 的性能比 UNFS 以及NVFUSE 分别高约 38.0%和 33.3%, varmail场景中文件较小, UHSFS 的多粒度 IO 队列弹性分离技术起到一定的作用。对于webserver 场景, UHSFS 的性能比 UNFS 和 NVFUSE 分别高约 35.3%和 52.8%, 与 webproxy 场景相比, webserver 场景有更多的读操作, 因此表现出更高的 OPS 值。在 webproxy 场景中, UHSFS 的性能比 UNFS 和 NVFUSE 分别高约 34.0%和 52.6%。webproxy 是一个读取密集型工作负载场景, 涉及文件的追加和重复读取, 用户态多进程共享内存框架在此场景下也能发挥作用, 充当读缓存的角色。
表8 Filebench负载性能测试(OPS)
Table 8 Test results of filebench workloads performance (OPS)

文件系统fileservervarmailwebserverwebproxy UHSFS470653858594939056189 UNFS421412795870163141947 NVFUSE286332893962116236831
通过对比 UHSFS 与内核文件系统的性能, 验证用户态文件系统的优势。测试针对 64KB 文件顺序读、64KB 文件顺序写、4KB 文件随机读、4 KB 文件随机写, 并使用 32 深度的异步接口, 其中UHSFS 的异步接口基于用户态 NVMe 驱动实现, F2FS, Ext4和XFS则使用libaio。
如表 9 所示, 与内核态文件系统性能较优的F2FS 相比, UHSFS 的性能提升 2.2%~25.5%。对于64KB 顺序读写, 大部分文件系统都能达到带宽上限, UHSFS 的吞吐量略高于内核态文件系统, 可能是由于 UHSFS 在用户态实现, 中断和代码开销更小。在 4KB 随机读写场景中, UHSFS 的 IOPS 明显高于其他文件系统, 4KB 随机读 IOPS 领先排名第二的 F2FS 约 16.6%, 4KB 随机写则领先约 25.5%。UHSFS 的性能优势主要在于, UHSFS 将所有元数据缓存在内存中, 查找文件的开销大幅降低; UHSFS基于用户态 NVMe 驱动, 相对于内核态文件系统, 减少了上下文切换和中断造成的开销。
本次测试从多个方面验证了本文提出的相关设计和优化效果。元数据操作性能评估表明, UHSFS实现了与 NVFUSE 类似的更完善的功能, 同时提供了与 UNFS 同一水平的元数据操作性能, 综合表现最优, 显然得益于 UHSFS 简洁可靠的元数据管理机制。多粒度 IO 队列弹性分离技术评估验证了采用请求类型和数据大小作为特征进行弹性分离的有效性, 大幅提升 IO 的处理能力。在 Filebench 负载评估中, 各场景下 UHSFS 均表现良好, 优于其他用户态文件系统, 与内核态文件系统的对比也进一步表现出性能优势。对于用户态多进程共享内存框架, 本文进行相关功能验证, 鉴于其他用户态文件系统不支持共享访问的功能, 因此未进行相关的对比测试。总之, 本文提出的优化方法有效地拓展了用户态文件系统的应用场景, 同时提升了文件系统的整体性能。
表9 UHSFS与内核文件系统性能对比
Table 9 Performance comparison between UHSFS and kernel file systems

文件系统吞吐量/(MB·s-1)IOPS 64 KB文件读64 KB文件写4 KB文件读4 KB文件写 UHSFS64002291508928500736 F2FS62612242436421398974 XFS61442272398336323584 Ext453952118319488278528
本文面向 NVMe SSD, 研究用户态文件系统的共享访问与性能提升, 提出简单弹性的数据布局技术、多粒度 IO 队列弹性分离技术以及多用户共享内存架构等关键技术, 显著地提升元数据操作性能和 IO 处理能力, 并且实现用户态文件系统的共享访问。实验数据表明, UHSFS 在元数据操作测试中, 整体性能最优, 相较于排名第二的 UNFS, 性能提升 3.6%~113.6%。在队列分离技术测试中, 读写请求分离使得吞吐量提高 7.2%~65.5%, 数据大小分离使得吞吐量提升 9.81%~53.68%, 读写请求与数据大小全分离使得吞吐量提升 28.2%~55.7%。在Filebench 的综合负载性能测试中, UHSFS 的整体性能最优, 相较于排名第二的 UNFS, 在 4 种负载中性能分别提升 11.7%, 38.0%, 35.3%和 34.0%。在与内核文件系统的对比测试实验中, 相较于内核态文件系统性能较优的 F2FS, UHSFS 的性能提升 2.2%~ 25.5%。
与 NVMe SSD 相比, 以 3DXPoint 为代表的新型非易失性内存硬件具有更加卓越的性能, 因此软件的时延, 特别是文件系统的时延将占据更高的比例, 成为存储系统的新瓶颈。近年来, 一些面向非易失性内存的用户态文件系统[27–30]以降低时延为目标, 取得不错的效果, 但一致性方面仍存在较大的提升空间, 未来将围绕非易失性内存, 研究兼具高性能和强一致的用户态文件系统。
参考文献
[1] Landsman D, Walker D. AHCI and NVMe as inter-faces for SATA Express™ Devices [EB/OL]. (2013–11–15) [2020–02–01]. https://sataio.org/sites/default/ files/documents/NVMe%20and%20AHCI%20as%20SATA%20Express%20Interface%20Options%20-%20 Whitepaper_.pdf
[2] 陆游游, 舒继武. 闪存存储系统综述. 计算机研究与发展, 2013, 50(1): 49–59
[3] Lee W, Lee K, Sun H, et al. WALDIO: eliminating the filesystem journaling in resolving the journaling of journal anomaly // Proceedings of the USENIX An-nual Technical Conference. Berkeley, 2015: 235–247
[4] Yang Ziye, Harris J R, Walker B, et al. SPDK: a development kit to build high performance storage applications // Proceedings of the IEEE International Conference on Cloud Computing Technology and Sci-ence. Hong Kong, 2017: 154–161
[5] Intel. Storage performance development kit [EB/OL]. (2019–10–20) [2020–02–01]. https://spdk.io/
[6] Weil S A. Goodbye XFS: building a new faster storage backend for ceph [EB/OL]. (2017–09–12) [2020–02–01]. https://www.snia.org/sites/default/files/ DC/2017/presentations/General_Session/Weil_Sage%20_Red_Hat_Goodbye_XFS_Building_a_new_faster_storage_backend_for_Ceph.pdf
[7] Lee D Y, Jeong K, Han S H, et al. Understanding write behaviors of storage backends in ceph object store // Proceedings of the IEEE International Con-ference on Massive Storage Systems and Technology. Santa Clara, CA, 2017: 1–10
[8] Yongseok O. NVMe based file system in user-space [EB/OL]. (2018–12–09) [2020–02–01]. https://github. com/NVFUSE/NVFUSE
[9] Liu J, Andrea C A, Remzi H, et al. File systems as processes // Proceedings of the 11th USENIX Work-shop on Hot Topics in Storage and File Systems. Ber-keley, 2019: No. 14
[10] Kim H J, Lee Y S, Kim J S. NVMeDirect: a user-space I/O framework for application-specific optimi-zation on NVMe SSDs // Proceedings of the 8th USENIX Workshop on Hot Topics in Storage and File Systems. Berkeley, 2016: 41–45
[11] Kim H J. NVMeDirect _v2 forestfs [EB/OL]. (2018–05–03)[2020–02–01].http://github.com/nvmedirect/ nvmedirect_v2/tree/master/forestfs
[12] Ahn J S, Seo C, Mayuram R, et al. ForestDB: a fast key-value storage system for variable-length string keys. IEEE Transactions on Computers, 2015, 65(3): 902–915
[13] Mircon Technology Inc. UNMe [EB/OL]. (2019–05–02) [2020–02–01]. https://github.com/MicronSSD/un vme
[14] Mircon Technology Inc. User space nameless file-system [EB/OL]. (2017–04–07) [2020–02–01]. https:// github.com/MicronSSD/UNFS
[15] Hu Z, Chidambaram V. A rust user-space file system [EB/OL]. (2019–05–08) [2020–02–01]. https://github. com/utsaslab/rustfs
[16] Caulfield A M, Mollov T I, Eisner L A, et al. Provi-ding safe, user space access to fast, solid state disks. ACM SIGARCH Computer Architecture News, 2012, 40(1): 387–400
[17] Rajachandrasekar R, Moody A, Mohror K,et al. A 1 PB/s file system to checkpoint three million MPI tasks // Proceedings of the 22nd ACM International Symposium on High-Performance Parallel and Distri-buted Computing. New York, 2013: 143–154
[18] Wang T, Mohror K, Moody A, et al. An ephemeral burst-buffer file system for scientific applications // Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. Salt Lake City, 2016: 807–818
[19] Bessani A, Mendes R, Oliveira T, et al. SCFS: a shared cloud-backed file system // Proceedings of the USENIX Annual Technical Conference. Berkeley, 2014: 169–180
[20] Vrable M, Savage S, Voelker G M. BlueSky: a cloud-backed file system for the enterprise // Proceedings of the 10th USENIX Conference on File and Storage Technologies. Berkeley, 2012: 1–14
[21] Bharath K R V, Vasily T, Erez Z. To FUSE or not to FUSE: performance of user-space file systems // Proceedings of the 15th Usenix Conference on File and Storage Technologies. Berkeley, 2017: 59–72
[22] Xu Qiumin, Siyamwala H, Ghosh M, et al. Perfor-mance analysis of NVMe SSDs and their implication on real world databases // Proceedings of the 8th ACM International Systems and Storage Conference. Haifa, 2015: 1–11
[23] Chen Feng, Lee Rubao, Zhang Xiaodong, et al. Essential roles of exploiting internal parallelism of flash memory based solid state drives in high-speed data processing // Proceedings of the IEEE 17th International Symposium on High Performance Com-puter Architecture. Washington, DC, 2011: 266–277
[24] Lee M, Kang D H, Lee M, et al. Improving read performance by isolating multiple queues in NVMe SSDs // Proceedings of the 11th International Con-ference on Ubiquitous Information Management and Communication. Beppu, 2017: 1–6
[25] Wu Guanying, He Xubin. Reducing SSD read latency via NAND flash program and erase suspension // Proceedings of the 10th USENIX Conference on File and Storage Technologies. Berkeley, 2012: 117–223
[26] Lu Lanyue, Pillai T S, Gopalakrishnan H, et al. Wisc-Key: separating keys from values in SSD-conscious storage. ACM Transactions on Storage, 2017, 13(1): 1–28
[27] Chen Xianzhang, Sha E H, Zhuge Qingfeng, et al. UMFS: an efficient user-space file system for non-volatile memory. Journal of Systems Architecture, 2018, 89: 18–29
[28] Dong Mingkai, Bu Heng, Yi Jifei, et al. Performance and protection in the ZoFS user-space NVM file system // Proceedings of the ACM SIGOPS 27th Symposium on Operating Systems Principles. New York, 2019: 478–493
[29] Volos H, Nalli S, Panneerselvam S, et al. Aerie: fle-xible file-system interfaces to storage-class memory // Proceedings of the 9th European Conference on Computer Systems. 2014: No. 14
[30] Kwon Y, Henrique F, Tyler H, et al. Strata: a cross media file system // Proceedings of the ACM SIGOPS 26th Symposium on Operating Systems Principles. New York, 2017: 460–477
Research on Sharing Access and Performance Improvement Based on User-Space File System
Abstract This paper designs UHSFS, a user-space high-performance shared file system for NVMe SSD, proposing simple elastic data layout technology, elastic separation of multiple IO queues technology, and multi-user shared memory architecture. The metadata operation performance and IO processing ability are significantly improved, and the shared access of user-space file system is realized. Experiments show that UHSFS has the best metadata operation performance and Filebench workload performance, compared with user-space file systems including UNFS, NVFUSE, BLOBFS, and BLUEFS; queue separation technology can greatly improve IOPS and throughput; UHSFS also has better performance compared with kernel-space file systems including F2FS, XFS and Ext4.
Key words user-space; file system; NVMe protocol; solid state disk
doi: 10.13209/j.0479-8023.2020.107
国家重点研发计划(2018YFB1003304)、国家自然科学基金(61672283)和江苏省工业和信息产业转型升级专项资金资助
收稿日期: 2020–02–14;
修回日期: 2020–06–28