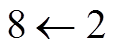 , 其他父亲节点都用远程边(remote edge)连接, 即虚线边
, 其他父亲节点都用远程边(remote edge)连接, 即虚线边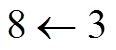 。所有的主边形成一个树状的结构, 而远程边导致的重入性形成DAG。UCCA 的另一个特征是存在不连续节点, 例如图 1 中的节点 4, 叶子节点 everything 在它的覆盖范围但不是它的子孙节点。
。所有的主边形成一个树状的结构, 而远程边导致的重入性形成DAG。UCCA 的另一个特征是存在不连续节点, 例如图 1 中的节点 4, 叶子节点 everything 在它的覆盖范围但不是它的子孙节点。摘要 考虑到句法结构与语义结构之间的紧密联系, 尝试将句法信息融入 UCCA 语义分析模型中来增强语义分析的性能。基于目前性能最好的基于图的 UCCA 语义分析模型, 提出并比较 4 种不同的融入依存句法信息的方法。采用 SemEval-2019 国际评测语义分析任务的英文数据集进行实验, 在本领域和跨领域两个数据集上的结果均表明, 句法增强的方法能够给显著地提高 UCCA 分析性能。引入 BERT 特征后, 句法信息仍然可以提供一定的帮助。
关键词 语义分析; UCCA; 句法分析
普适概念认知标注(universal conceptual cogni-tive annotation, UCCA)是近年提出的一种多语言通用的语义表示形式[1]。与其他语义表示形式(如AMR (abstract meaning representation))相比, UCCA具有形式简洁(标签少)、易于理解的特点, 不需要语言学专家参与就可以实现快速标注[2]。Birch 等[3]发现, UCCA 语义结构可以有效地帮助机器翻译结果评价任务。
如图 1 所示, UCCA 采用有向无环图(directed acyclic graph, DAG)来表示句子的语义结构。图中每个叶子节点依次对应句子中的所有单词, 每个非叶子节点对应一个单独的语义实体。非叶子节点之间的边上都带有类别标签, 代表孩子节点在父亲关系中扮演的角色。图 1 给出一个英文的 UCCA 示例, 它的中文意思是“毕业后, John 放弃了一切”, 其中包含两个主要场景, 分别为“John 毕业”和“John 放弃了一切”, 对应图中的节点 3 和节点 2。UCCA 图中的一个节点可能有多个父亲节点, 例如图 1 中的节点 8, 其中一个父亲节点用主边(primary edge)连接, 即实线边, 其他父亲节点都用远程边(remote edge)连接, 即虚线边。所有的主边形成一个树状的结构, 而远程边导致的重入性形成DAG。UCCA 的另一个特征是存在不连续节点, 例如图 1 中的节点 4, 叶子节点 everything 在它的覆盖范围但不是它的子孙节点。
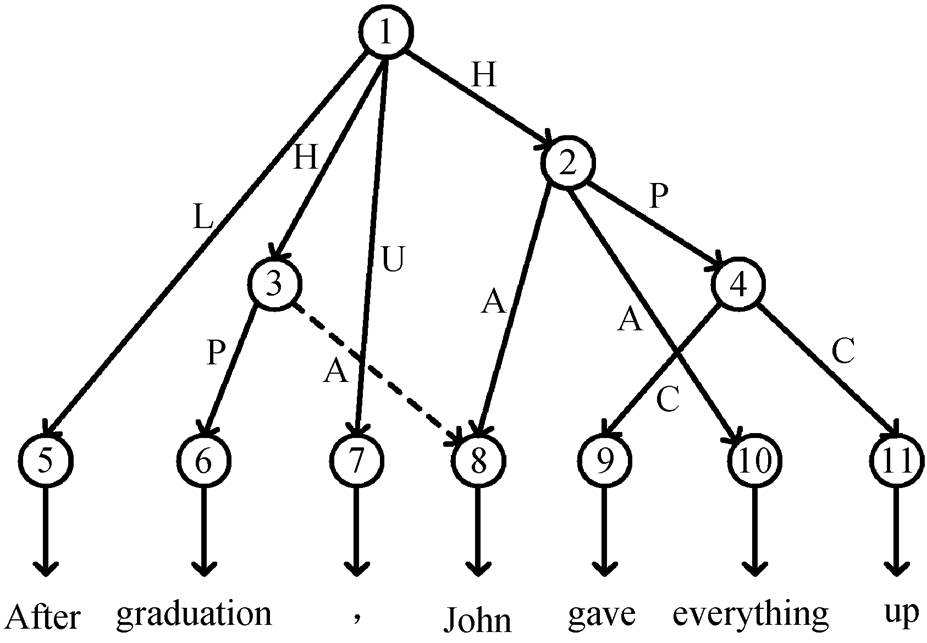
为方便说明, 每个非叶子节点都有编号
图1 UCCA示例
Fig. 1 An Example of UCCA
考虑到 UCCA 的这种结构, Hershcovich 等[4]首先提出基于转移的 UCCA 分析模型 TUPA。在前人工作的基础上, TUPA 增加了 swap 动作来解决不连续结构, 并区分主边与远程边。Jiang 等[5]提出一种基于图的 UCCA 分析模型, 他们将 UCCA 图通过规则转化为短语结构树, 且在标签上添加额外的信息用于将来的还原, 实验结果表明该模型比 TUPA 更加有效。之后, Hershcovich 等[6]又扩展了自己的工作, 将 UCCA 与 AMR, SDP (semantic dependency parsing)等其他语义分析联合进行多任务学习(multi-task learning, MTL)。其中, UCCA 作为主任务而其他语义分析作为辅助任务, 由此构建一个通用的基于转移的多任务学习模型, 表明其他语义任务对于UCCA 有着不可忽视的辅助作用。
除不同的语义表示之间有共性外, 前人的工作还表明句法和语义是互补互助的。例如, Xia 等[7]在语义角色标注任务中尝试多种不同方式产生句法特征, 直接作为编码器的额外输入, 结果显示出句法对浅层语义分析的有益性; 江腾蛟等[8]提出语义角色标注与依存句法分析相结合的评价对象——情感词对抽取规则; 张志远等[9]尝试基于语义和依存句法特征的评论对象抽取方法。上述结果都表明了两者结合的有效性。
事实上, UCCA 与句法结构之间也有很强的联系, 比如依存句法树的树根往往对应 UCCA 图中的一个场景谓词。我们在 Jiang 等[5]工作的基础上, 首次提出并尝试 4 种不同的方法, 利用依存句法分析来提高 UCCA 语义分析的性能。英文数据上的实验结果表明句法信息能有效地帮助 UCCA 语义分析, 而融入 BERT[10]之后, 句法模型产生的显示句法信息就明显弱化, 只能提供有限的帮助。
Jiang 等[5]提出一种简洁有效的方法, 用于分析UCCA 图, 核心思想是消除图中的远程边和不连续节点, 并且添加额外的标签, 用于之后的恢复, 将其转化为标准的短语结构树。给定图 1 中的 UCCA图, 他们通过以下算法将其转化为图 2 中的短语结构树。
1)移除远程边。对于那些拥有多个父亲节点的节点, 移除指向它的远程边, 只保留主边。为了之后的恢复, 在主边的标签上添加额外的“-remote”标记, 表明该节点还有其他的父亲节点与它有远程关系。
2)消除不连续节点。图 1 中的 4 号节点称为不连续节点, 因为它的叶子子孙不连续。由于主流的短语结构树分析器不能解决类似情况, 所以需要移动特定的边来消除这种不连续的结构。给定一个不连续节点 A=4, 首先处理最左侧的非子孙叶子B=everything, 从 B 出发依次向上遍历祖先节点, 直到找到一个节点 C=10, 它是一个不连续节点, 或者它的父亲节点是 A 和 B 的最小公共祖先。记 C=10的父亲节点为 D=2。然后, 移动边 D→C,使 C 成为 A 的孩子节点, 同时在该边的标签上添加额外的“ancestor 1/2/3/…”或“discontinuous”, 其中数字表示 D=2 到 A=4 经过的边数。经过此次移动后, 叶子节点 everything 成为 A 的子孙节点。重复上述操作, 直到图中的不连续结构都消除。
3)将边上的标签移动到节点上。由于结构树中的标签都对应每个节点而不是边, 必须将 UCCA图中边的标签都转移到它的孩子节点上, 同时给予根节点“ROOT”标签。
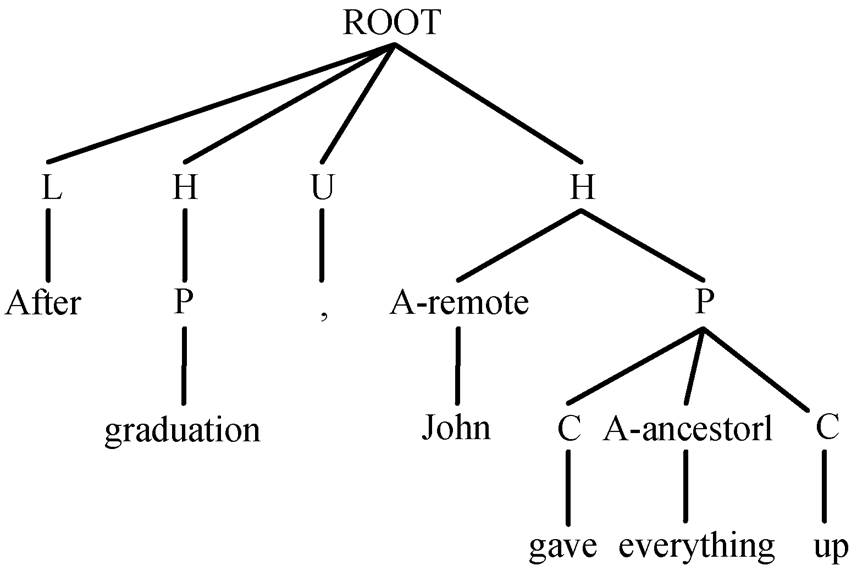
图2 由UCCA图转化而来的短语结构树
Fig. 2 Constituent tree converted from UCCA graph
Jiang 等[5]直接用 minimal span-based parser[11]作为短语结构树分析模型。给定输入句子 S=w1, w2, …, wn, 每个词 wi都转化为一个高维度的稠密向量:
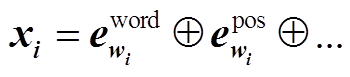 , (1)
, (1)其中, 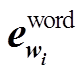 是通过查表操作获得的词向量,
是通过查表操作获得的词向量,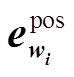 是 wi词性对应的向量。此外, Jiang 等[5]还利用语料中提供的自动依存标签①词性和依存标签由http://ufal.mff.cuni.cz/udpipe提供。和自动实体标签②命名实体标签标签由http://spacy.io提供。, 但是带来的提升非常有限, 所以本文舍弃这些自动特征。利用多层 BiLSTM 对这些词表示向量进行编码, 将最后一层的输出
是 wi词性对应的向量。此外, Jiang 等[5]还利用语料中提供的自动依存标签①词性和依存标签由http://ufal.mff.cuni.cz/udpipe提供。和自动实体标签②命名实体标签标签由http://spacy.io提供。, 但是带来的提升非常有限, 所以本文舍弃这些自动特征。利用多层 BiLSTM 对这些词表示向量进行编码, 将最后一层的输出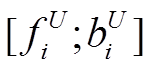 取出, 则 span 表示为
取出, 则 span 表示为
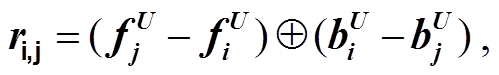 (2)
(2)
其中, 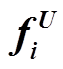 和
和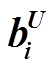 分别是第 i 个词对应最后一层正向和反向 LSTM 的输出向量。最后, 将这些 span 表示输入到 MLP 中, 计算 span 分割和标签的分数:
分别是第 i 个词对应最后一层正向和反向 LSTM 的输出向量。最后, 将这些 span 表示输入到 MLP 中, 计算 span 分割和标签的分数:
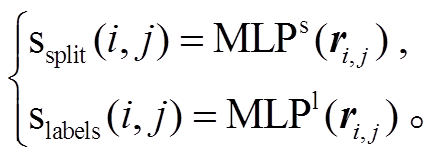 (3)
(3)预测时, 分析模型根据这两个分数贪心地自顶向下搜索来构建树[11]。
为了从预测出的树还原到 UCCA 图, 前面的 3 个步骤需要逆向地执行, 即把标签移动到边上, 根据额外标签“-ancestor”向上移动边的一端, 恢复远程边。前两步都可以根据规则来完成, 但恢复远程边需要额外的模型来处理。给定一个远程节点 A(即标签带有“-remote”的边指向的节点)和候选父亲节点 B (除 A 及其父亲节点的其他所有非叶子节点外), 我们直接预测 B 到 A 的关系类别, 如果它们之间的关系标签是人为添加的“NOT-PARENT”, 则判断 B 不是 A 的父亲节点, 也就是没有远程边, 否则认为存在一条远程边 A←B。至于如何预测 B 到 A的关系标签, 我们借鉴目前效果最好的句法分析模型Biaffine Parser (Dozat and Manning [12])。假定它们叶子子孙节点的起始位置分别为 i, i'和 j, j', 首先用span 向量 ri,j 和 ri',j'分别表示它们, 然后经过两个MLP 产生ri,jchild 和 ri',j'parent, 最后用双仿射操作, 得到一个标签分数向量, 分值最大标签即为预测结果:
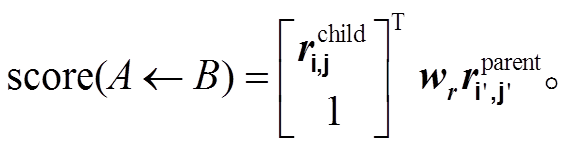 (4)
(4)它的维度是标签集合的大小, 包括人为添加的空标签。最终结果中, 如果预测出的不是“NOT-PARENT”标签, 则添加对应的远程边。该模型与短语结构分析器置于多任务学习框架下一起训练, 共享相同的输入以及编码器, 如图 3 中左侧虚线框内所示, 其中 MLP&Biaffine 就是用来恢复远程边(remote recovery)的子模型, 右侧的 MLPs 则用于解析短语结构树(constituent parsing)。
训练时, 将所有远程节点与候选父亲节点之间的交叉熵损失累加起来, 再加上分析树的最大边缘损失[11], 作为整个多任务学习框架的损失函数。
为了产生句法信息, 我们选取目前性能最好的Biaffine Parser[12]作为基础句法模型, 用它生成自动句法分析结果或者词表示向量。Biaffine Parser 模型利用深度双仿射操作来计算所有依存弧的分值, 然后用最小生成树解码算法得到一棵分值最大的树(如图 3 右侧虚线框内所示)。首先, 对于一个待分析的句子 S=w1, w2, …, wn, Biaffine Parser 模型采用 L层 BiLSTM 来编码句子的信息, 最底层 BiLSTM 第k 个位置的输入为词 wk 的词向量及词性向量的拼接向量 xi, 与 UCCA 分析模型类似。最顶层 BiLSTM 第 k 个位置的输出为 hk (即前向 LSTM输出和后向 LSTM 输出的拼接)。这些隐层表示输入到两个单独的 MLP 映射到低维度的词表示, 分别作为核心词和修饰词:
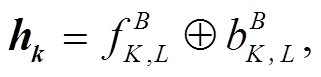 (5)
(5)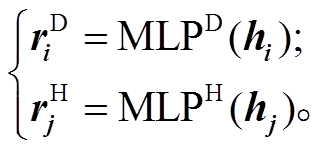 (6)
(6)
最后采用双仿射运算, 计算弧i到j的得分:
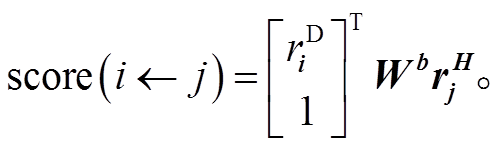 (7)
(7)类似地, 对于依存弧标签的分值 score(i j),同样用额外的 MLP 和双仿射操作来计算。对于每个词 wi及其正确的依存弧 wj 和标签 l, 损失函数为局部的交叉熵函数之和。
j),同样用额外的 MLP 和双仿射操作来计算。对于每个词 wi及其正确的依存弧 wj 和标签 l, 损失函数为局部的交叉熵函数之和。
从形式和结构上看, UCCA 与依存句法息息相关, 比如依存树中名词主语标签指向的节点对应UCCA 图中的一个参与者(Participate), 例如图 1 中节点 8 和图 4 中 John 节点; 依存树中动词短语也会对应 UCCA 图中的一个节点, 例如图 4 中 gave up 之间的标签 prt (phrasal verb particle)就代表这两个词是一个短语, 正好对应图 1 中 4 号节点。因此, 我们尝试用依存句法分析来增强语义分析的效果。记 为句法特征向量, 它被拼接在 UCCA 模型的输入 xi 之后, 即
为句法特征向量, 它被拼接在 UCCA 模型的输入 xi 之后, 即
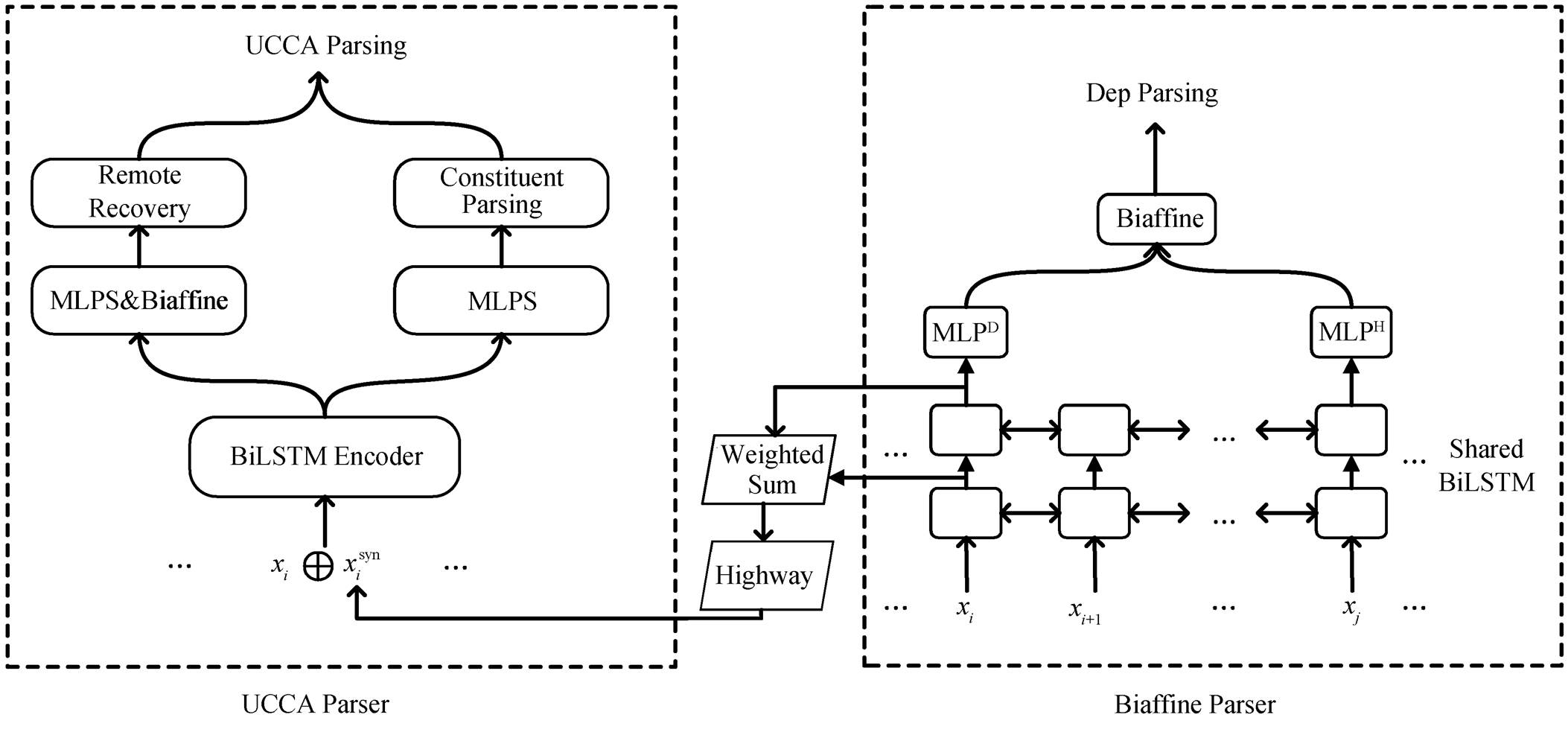
图3 基于句法感知微调词表示方法的框架
Fig. 3 Framework of syntax-aware fine-tuning word representation approach
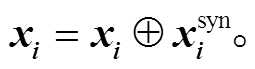 (8)
(8)下面介绍4种利用依存句法生成的方法。
依存句法树蕴含丰富的句法信息, 最简单的用法就是加入依存标签。我们尝试利用预训练好的BiaffineParser 模型预测输入句子的依存句法树。与词性标签一样, 将每个词对应的依存标签映射到一个固定维度的向量, 拼接在词表示向量之后, 并且随着训练一起微调, 如式(9)所示:
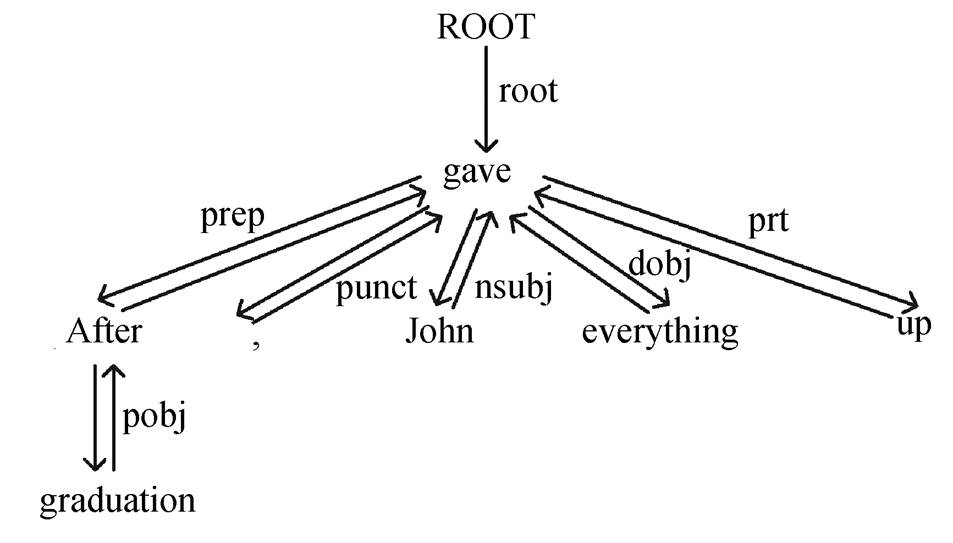
图4 双向的Tree GRU
Fig. 4 Bi-directional Tree GRU
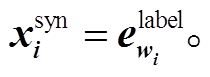 (9)
(9)与只使用依存标签相比, 树状递归神经网络(Tree-structured Recurrent Neural Network, Tree-RNN)[13–14]能够全局地编码整棵依存树, 并且得到每个词在整棵树中对应的位置信息和句法特征。树状的递归神经网络能更有效地帮助关系抽取[14–15]和机器翻译[16]等任务。我们使用类似 Chen 等[16]的双向 Tree-GRU (Tree-structured Gated Recurrent Unit)来编码预测出来的依存树。其中, 自下向上的 Tree-GRU 根据每个节点的输入及其所有孩子节点来计算隐状态, 如图 4 中自下而上的箭头所示, 详细计算过程见式(10)。
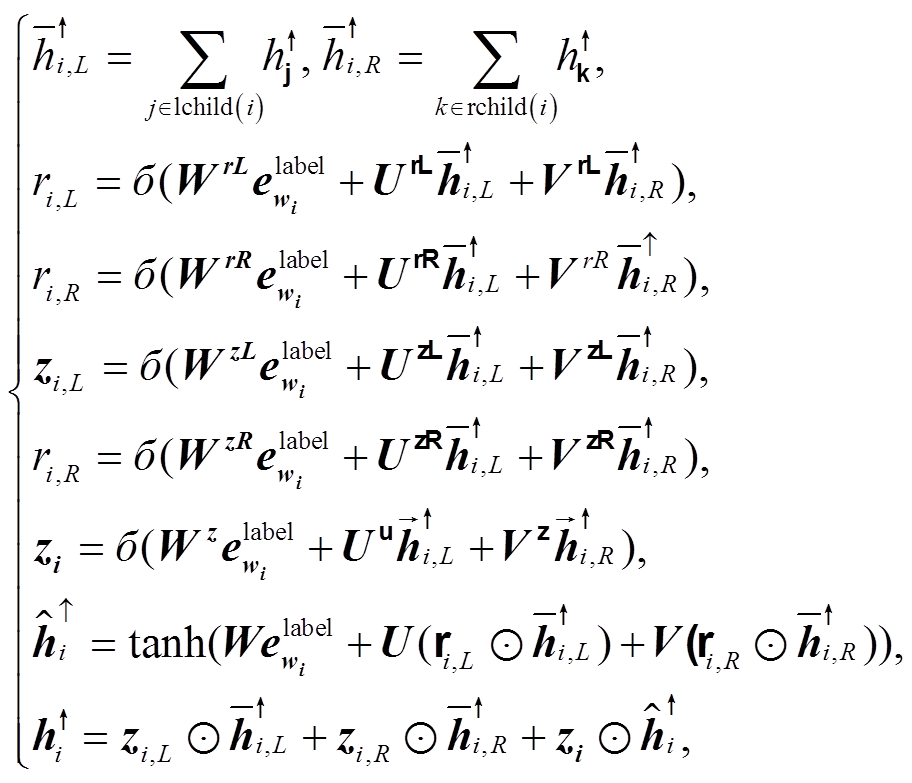 (10)
(10)式中, lchild/rchild(∙)表示左/右孩子节点集合。类似地, 自顶向下的 Tree-GRU 则根据各个节点的父亲节点来计算隐状态, 由于每个节点只可能有一个父亲节点, 所以该过程类似于常规的 LSTM, 如图4 中自上而下的箭头所示。最后, 将两个方向上的隐层状态拼接起来, 得到每个词的句法特征表示:
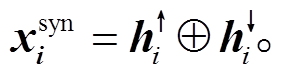 (11)
(11)
Peter 等[17]提出一种通用的预训练语言模型 E-LMo, 用于产生底层的特征表示, 作为下游模型的输入。这些基于上下文的向量蕴含丰富的文本信息, 能有效地帮助许多 NLP 任务。同样地, 除了依存树, 句法分析模型的编码器输出也蕴含许多句法信息, 最近的研究表明它对机器翻译也有巨大帮助[18]。因此, 我们结合两者的思想, 用预训练好的Biaffine Parser 模型来产生类似的固定特征向量, 作为 UCCA Parser 的额外输入, 各层的 BiLSTM 输出经过加权求和并乘上一个特定系数后, 直接拼接在 xi 之后:
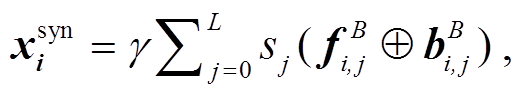 (12)
(12)其中, L 代表 Biaffine Parser LSTM 的层数, γ 和 sj 都是 UCCA parser 的参数, 随着训练调整; 而 Biaffine Parser 模型中的所有参数不再微调。这种方式能充分地利用编码器不同层次的信息, 同时让模型自动地平衡不同层次信息对语义分析任务的贡献。
如上所述, 句法产生的词表示在训练语义分析模型时不会微调, 导致语义分析模型与句法模型的耦合性比较低。为探讨更好的组合方式, 我们尝试同时训练 UCCA Parser 与 Biaffine Parser, 从而微调句法感知的词表示。该模型如图 3 所示, 左侧为语义分析模型, 右侧为句法分析模型。
当要分析句法时, 输入的句子仅仅通过 Biaf-fine Parser 部分, 所以句法模型的训练不会影响左侧的语义分析模型。当分析 UCCA 时, 输入的词表示向量首先通过 Biaffine Parser 的 BiLSTM, 然后将其各层的输出取出, 做一次加权求和, 并乘以一个特定任务系数, 最后经过一层 Highway, 目的是将词表示映射到不同的语义空间:
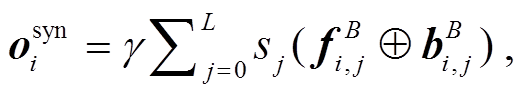 (13)
(13)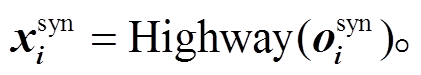 (14)
(14)
我们把得到的句法特征向量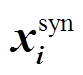 拼接在每个词表示xi上, 再把该扩展的词表示输入到 UCCA Parser 的BiLSTM 中, 最终分析出 UCCA 图。这样, 两个模型共享的不仅仅是最底层的词表示向量, 还有句法模型的编码器, 当 UCCA 的损失函数进行梯度回传时, 句法模型的编码器也会受到影响, 使其同时理解句子的语义信息, 从而微调产生的。我们没有设计成常规的 MTL 框架, 如两个模型直接共享一个编码器或像 Hershcovich 等[6]一样把多个任务的编码器并行组合, 是出于以下原因: 1)从任务本身来讲, 句法是理解语义的基础, 句法可能更适合作为理解语义的先验任务; 2)从抽象出来的任务来讲, 句法旨在分析词与词之间的关系, 而基于图的UCCA Parser 旨在分析 span 与 span 的关系, 比词级别更高层次, 因此我们将句法模型置于语义分析模型的先验位置。
拼接在每个词表示xi上, 再把该扩展的词表示输入到 UCCA Parser 的BiLSTM 中, 最终分析出 UCCA 图。这样, 两个模型共享的不仅仅是最底层的词表示向量, 还有句法模型的编码器, 当 UCCA 的损失函数进行梯度回传时, 句法模型的编码器也会受到影响, 使其同时理解句子的语义信息, 从而微调产生的。我们没有设计成常规的 MTL 框架, 如两个模型直接共享一个编码器或像 Hershcovich 等[6]一样把多个任务的编码器并行组合, 是出于以下原因: 1)从任务本身来讲, 句法是理解语义的基础, 句法可能更适合作为理解语义的先验任务; 2)从抽象出来的任务来讲, 句法旨在分析词与词之间的关系, 而基于图的UCCA Parser 旨在分析 span 与 span 的关系, 比词级别更高层次, 因此我们将句法模型置于语义分析模型的先验位置。
实验数据 我们在 1.2.4 版本的 UCCA 英语维基百科语料(English Wikipedia corpus, 简称 English-Wiki)上进行实验, 并使用 1.2.2 版本的 UCCA《海底两万里》英法平行语料(Twenty Thousand Lea-gues Under the Sea English-French parallel corpus, 简称 English-20K)作为跨领域的测试数据。这些分割好的语料能够在 SemEval-2019 Task 1 的官方网站③https://competitions.codalab.org/competitions/19160上找到, 数据见表 1。在句法增强的实验中, 我们使用英文宾夕法尼亚树库(English Penn Treebank, PTB)作为依存句法的语料。经统计, 句法的语料与两个 UCCA 语料没有任何交叉。
评价指标 为了评估两个 UCCA 有向无环图的相似度, 我们使用 DAG F1 分数。从形式上讲, 给定在同一个句子上的两个 UCCA 图 Gp 和 Gg, 对于其中的任意一个非叶子节点 v, 定义 yield(v)为 v 的所有叶子子孙。当且仅当 yield(up)=yield(ug),并且它们的标签相同, Gp 中的一条边 C(vp→up)与 Gg 中的一条边(vg→ug)匹配。带标签的准确率和召回率即为两个图中匹配的边数分别除以 Gp 中的边数和Gg 中的边数, F 分数是准确率和召回率的调和平均值。我们使用官方提供的脚本来评估主边以及远程边的F值, 标点符号仅在评估时被排除在外。
表1 UCCA以及句法语料数据
Table 1 Statistics of UCCA and dependency corpus

语料训练集开发集测试集总数 句子词句子词句子词句子词 English-Wiki411312493551417784515158545142158573 English-20K00004921257449212574 PTB39832950028170040117241656684439481034093
所有的实验都采用 Adam 优化器[19], 学习速率为 0.001。迭代的最大次数设置为 100, 当 UCCA 开发集上的平均 F 值经过 15 次迭代后仍然没有提升时, 则训练提前结束。在使用句法感知微调词向量方法同时训练两个模型时, 我们从两个语料中分别选取一个 batch, 并更新一次参数。由于句法的训练集远大于 UCCA 的训练集, 我们设置句法的batch size 等于 UCCA 的 batch size 乘以它们训练集之间的相应倍数, 确保两个训练集在相同的 batch数中完全使用。
需要注意的是, 由于句法语料中的词性规范与UCCA 语料完全不同, 我们在两个基准模型上做了部分修改。为了保证句法模型能够接收 UCCA 语料中的句子, 我们将两个模型中的自动词性向量都替换成 Lample 等[20]的字符 BiLSTM。具体地讲, 就是把每个词的所有字输入到正向和反向的 LSTM 中, 将它们的输出拼接起来作为字符特征。我们在 PTB上单独训练一个 Biaffine Parser 模型, 它在测试集上的 LAS (Labeled Attachment Score)值达到 94.39%, 与 Dozat 等[12]的结果相当, 然后利用它生成 UCCA语料对应的依存句法树或者特征向量, 作为额外的输入资源。
为了进一步探究句法对语义分析的作用, 我们将加入 BERT 后的模型作为更强的基线模型。我们从官方提供的预训练英文 BERT 模型④本文使用的BERT模型来自https://github.com/google-research/bert中提取固定特征向量作为额外输入, 这些基于上下文的词表示来自 BERT 编码器的后 4 层, 像 ELMo 一样经过加权求和再乘以一个特定任务相关的系数, 拼接在词表示向量之后输入到上层的编码器。
从表 2 中第一主行的两个结果看, 显然该基于转移的模型效果不如基于图的分析模型, 平均 F 值比本文的基线模型低 4.4%~5.1%。在利用其他语义任务后, 本领域提升 0.7%, 跨领域提升 1.2%, 证明了不同语义任务之间的互助作用。
表 2 中第二主行展示基线模型以及使用 4 种句法增强方法后的结果。与 Jiang 等[5]的结果相比, 本文的基线模型在开发集上的平均 F 值几乎一样, 在两个测试集上分别有 0.2%和 0.4%的下降, 说明删除提供的自动依存标签和实体标签向量的影响并不大, 且字符 BiLSTM 能在一定程度上取代自动词性向量。使用 4 种句法增强的方法后, 3 个数据集上的平均 F 值都有显著提升(开发集提升 0.7%~1.4%, 本领域测试集提升 0.9%~1.6%, 跨领域测试集提升1.1%~1.9%), 表明句法能有效地增强 UCCA 语义分析。其中效果最差的是依存标签嵌入方法, 因为它仅利用依存树的局部信息, 不像 Tree-GRU 能够编码整棵树。句法感知词表示方法与 Tree-GRU 方法的效果十分接近, 我们认为这是因为句法编码器的各层输出本身就蕴含所有句法的隐式信息, 它与句法树的编码信息等价。4 种方法中效果最好的是微调句法感知词表示的方法, 它在 3 个数据集上的结果均最好。值得一提的是, 该模型训练完毕后, 句法模型的 LAS 值为 93.00%, 比直接预训练的模型降低超过 1%, 表明该方法在利用句法的隐式信息的同时, 牺牲了句法的部分性能, 强迫句法模型去学习语义知识, 从而产生的词表示可能还含有一定的语义信息, 更加适用于 UCCA 语义分析任务。
表 2 中第三主行展示加入 BERT 特征后的结果, 其中每一行的模型都加入 BERT 特征作为额外输入。本文基线模型的结果明显好于 Jiang 等[5]的模型, 是因为他们使用多语言 BERT, 而本文使用单语言 BERT。可以看到, 在 UCCA 基础模型上加入BERT 特征后, 平均 F 值有巨大的提升(本领域测试集提升 4%, 跨领域测试集提升 4.9%)。以此作为基准线, 使用 4种句法增强的方法, 除 Tree-GRU 的结果反而有些下降外, 其他方法仍然有一些提升(0.1%~ 0.4%), 最好的方法是直接利用依存标签。可能的原因是 Tree-GRU 这种全局的显示句法信息带来噪声,与 BERT 模型中的隐式句法信息产生冲突, 而依存标签这种局部的句法信息反而带来一定的帮助。
表2 引入句法的实验结果
Table 2 Results of experiments utilizing dependency data
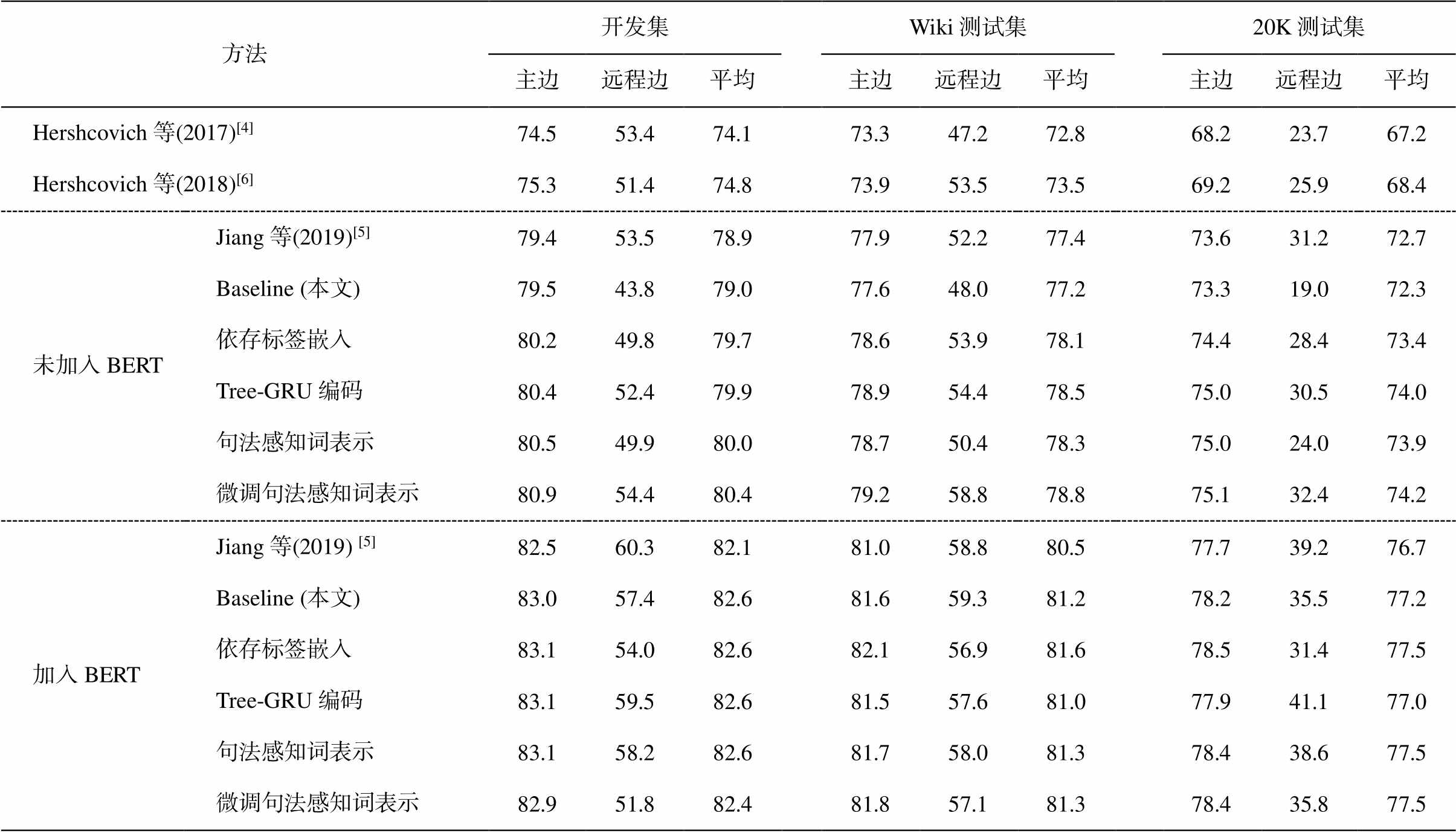
方法开发集Wiki测试集20K测试集 主边远程边平均主边远程边平均主边远程边平均 Hershcovich等(2017)[4]74.553.474.173.347.272.868.223.767.2 Hershcovich等(2018)[6]75.351.474.873.953.573.569.225.968.4 未加入BERTJiang等(2019)[5]79.453.578.977.952.277.473.631.272.7 Baseline (本文)79.543.879.077.648.077.273.319.072.3 依存标签嵌入80.249.879.778.653.978.174.428.473.4 Tree-GRU编码80.452.479.978.954.478.575.030.574.0 句法感知词表示80.549.980.078.750.478.375.024.073.9 微调句法感知词表示80.954.480.479.258.878.875.132.474.2 加入BERTJiang等(2019) [5]82.560.382.181.058.880.577.739.276.7 Baseline (本文)83.057.482.681.659.381.278.235.577.2 依存标签嵌入83.154.082.682.156.981.678.531.477.5 Tree-GRU编码83.159.582.681.557.681.077.941.177.0 句法感知词表示83.158.282.681.758.081.378.438.677.5 微调句法感知词表示82.951.882.481.857.181.378.435.877.5
本工作探究句法对于 UCCA 语义分析的作用。我们提出并尝试 4 种不同的方法来利用句法信息, 包括基于依存标签嵌入的方法、基于 Tree-GRU 句法树编码的方法、基于句法感知词表示的方法以及基于句法感知微调词表示的方法。实验表明, 这些方法都能有效地提升 UCCA 语义分析性能, 其中基于句法感知微调词表示的效果最好, 因为它不仅使用编码器的隐式句法信息, 同时让句法模型倾向于学习语义知识。在引入 BERT 后, 由于语言模型本身能学习到隐式的句法信息, 依存句法模型产生的显示句法信息作用就削减了, 但除 Tree-GRU 这种全局的编码方法产生副作用外, 其他方法仍然有0.1%~0.4%的提升, 在一定程度上证明了依存句法对 UCCA语义分析的贡献。
参考文献
[1] Abend O, Rappoport A. Universal conceptual cognitiveannotation (UCCA) // Proceedings of ACL.Sofia, 2013: 228–238
[2] Abend O, Yerushalmi S, Rappoport A. UCCAApp: web-application for syntactic and semantic phrase-based annotation // Proceedings of ACL. Vancouver, 2017: 109–114
[3] Birch A, Abend O, Bojar O, et al. HUME: human UCCA based evaluation of machine translation // Pro-ceedings of EMNLP. Austin, 2016: 1264–1274
[4] Hershcovich D, Abend O, Rappoport A. A transition-based directed acyclic graph parser for UCCA // Pro-ceedings of ACL. Vancouver, 2017: 1127–1138
[5] Jiang Wei, Li Zhenghua, Zhang Yu, et al. HLT@ SUDA at SemEval-2019 Task1: UCCA graph parsing as constituent tree parsing [EB/OL]. (2019–03–11) [2019–04–04]. https://arxiv.org/pdf/1903.04153v1.pdf
[6] Hershcovich D, Abend O, Rappoport A. Multitask parsing across semantic representations // Proceedings of ACL. Melbourne, 2018: 373–385
[7] Xia Qingrong, Li Zhenghua, Zhang Min, et al. Syntax-aware neural semantic role labeling // Procee-dings of AAAI. New Orleans, 2018: 7305–7313
[8] 江腾蛟, 万常选, 刘德喜, 等. 基于语义分析的评价对象–情感词对抽取. 计算机学报, 2017, 40(3): 617–632
[9] 张志远, 赵越. 基于语义和句法依存特征的评论对象抽取研究. 中文信息学报, 2018, 32(6): 85–92
[10] Devlin J, Chang Mingwei, Lee K, et al. BERT: pre-training of deep bidirectional transformers for lan-guage understanding [EB/OL]. (2018–10–11) [2019–05–24]. https://arxiv.org/pdf/1810.04805.pdf
[11] Stern M, Andreas J, Klein D. A minimal span-based neural constituency parser // Proceedings of ACL. Vancouver, 2017: 818–827
[12] Dozat T, Manning C D. Deep biaffine attention for neural dependency parsing [EB/OL]. (2016–11–06) [2019–01–26]. https://arxiv.org/pdf/1611.01734.pdf
[13] Tai Kaisheng, Socher R, Manning C D. Improved semantic representations from tree-structured long short term memory networks // Proceedings of ACL. Beijing, 2015: 1556–1566
[14] Miwa M, Bansal M. End-to-end relation extraction using lstms on sequences and tree structures // Proc-eedings of ACL. Berlin, 2016: 1105–1116
[15] Feng Yutian, Zhang Hongjun, Hao Wenning, et al. Joint extraction of entities and relations using rein-forcement learning and deep learning. Computational Intelligence and Neuroscience, 2017, 2017: Article ID 7643065
[16] Chen Huadong, Huang Shujian, Chiang D, et al. Improved neural machine translation with a syntax-aware encoder and decoder // Proceedings of ACL. Vancouver, 2017: 1936–1945
[17] Peters M, Neumann M, Iyyer M, et al. Deep con-textualized word representations // Proceedings of NAACL. New Orleans, 2018: 2227–2237
[18] Zhang Meishan, Li Zhenghua, Fu Guohong, et al. Syntax-Enhanced nerual machine translation with syntax-aware word representations // Proceedings of NAACL. Minneapolis, 2019: 1151–1161
[19] Kingma D, Ba J. Adam: a method for stochastic optimization [EB/OL]. (2015–02–27) [2019–04–10]. https://arxiv.org/pdf/1412.6980.pdf
[20] Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition // Proceedings of NAACL. San Diego, 2016: 260–270
Syntax-Enhanced UCCA Semantic Parsing
Abstract Considering the close correlation between syntactic and semantic structures, this paper attempts to add syntactic information into the universal conceptual cognitive annotation (UCCA) semantic parsing model to enhance the performance of semantic parsing. Based on the state-of-the-art graph-based UCCA semantic parser, we propose and compare four different approaches for incorporating syntactic information. Experiments are conducted on the English benchmark dataset for the semantic parsing shared task of the SemEval-2019 conference. The results on both the in-domain and out-domain evaluation data show that syntax-enhanced methods can achieve significant improvements of UCCA parsing. After utilizing BERT, syntactic information is still beneficial to some extent.
Key words semantic parsing; UCCA; syntactic parsing
doi: 10.13209/j.0479-8023.2019.099
国家自然科学基金(61876116, 61525205)和江苏高校优势学科建设工程项目资助
收稿日期: 2019–05–22;
修回日期: 2019–09–19