
图1 事件指代消解示例
Fig. 1 Example diagram of event coreference resolution
摘要 事件指代消解任务比实体指代消解难度大, 主要原因为事件描述在非结构化文本中分布稀疏, 且不具备同指关系的单链占很大比例, 同时事件自身承载的语义信息比实体更加丰富。为了准确地抽取文本中的同指事件, 针对以上特点, 提出一种融合篇章表征的事件指代消解模型。该模型通过 CRF 有效地区分非事件句、单链以及同指链, 同时利用分层注意力机制捕捉句子级别和篇章级别的重要信息。在 KBP2015 和2016 数据集上进行的事件指代消解实验验证了该模型的有效性, 在 CoNLL 评测标准下F1 值达到 43.07%。
关键词 事件指代消解; 篇章表征; 分层注意力机制
阅读文本、信息抽取的过程往往是对非结构化文本语义信息的理解和抽取, 作为语义信息的主要载体, 事件在自然语言处理的很多领域都起着关键的作用。从概念上来说, 事件对应某种状态的变化, 这种变化通常包括时间、地点和参与者, 例如某地区发生恐怖袭击事件, 某个国家的总统宣布辞职事件, 某家公司收购事件。
Vendler[1]提出, 在非结构化文本中, 事件被认为是文本跨度(text spans), 通常作为指示状态变化的动词或名词。在与事件相关任务的研究中, 这些指示状态变化的词被称为触发词(trigger), 某个具体事件的表述被称为事件描述(event mention)或事件句, 找到正确的触发词即可认为找到相应的事件描述。例如, 在 KBP2015 标注语料中, 事件描述“A pedestrain was killed in an accident Sunday morning on the Upper West Side of Manhattan.”描述一个 life-die 类型的事件, 其中“killed”作为触发词, 触发该事件的产生。
非结构化文本中的事件描述之间常存在多种复杂的关系, 如时序关系、包含关系和同指关系等, 了解这些事件描述之间的关系能够更好地帮助理解篇章内容, 捕捉关键的语义信息。本文主要研究其中的同指关系。
事件指代消解(event coreference resolution)指在非结构化文本中找到正确的触发词, 并判断这些触发词所触发的事件描述是否指向现实世界中的同一个事件, 若是, 则认为它们之间构成同指关系, 并将具有同指关系的事件描述构成一个同指链, 否则为单链。图 1 中的文本包含 10 个句子, 其中粗体的为触发词, 带下划线的为实体, 具有同指关系的触发词之间用箭头连接, 如“suicide”和“death”具有同指关系, 并且构成一个同指链, 而“attack”和“arrested”等触发词不和任何其他触发词构成同指关系, 即为单链。
目前, 事件指代消解任务的研究方法主要是构建大量的人工特征, 或完全借鉴实体指代消解任务。然而, 大量的特征不仅需要手动设计, 费时费力, 而且很难全面地捕捉篇章级别的语义信息, 也会因为一些不正确的规则约束导致错误传播, 影响模型的最终性能。尽管事件指代消解与实体指代消解在形式上很相似, 但与后者相比, 事件指代消解有以下 3 个难点, 因此, 完全套用实体指代消解的方法不能有效地处理该任务。1)篇章中触发词的数量很少, 分布稀疏, 如图 1 中的篇章只有 7 个触发词, 比例远远少于实体在篇章中的数量。2)篇章中的事件多为单链, 被反复提及的事件在很大程度上与篇章的主题相关。图 1 中单链的数量为 3, 而同指链的数量为 2, 并且构成指代链的事件句都描述了该篇文章的主题——“前巴基斯坦舞女自杀和受伤”事件。3)事件的语义信息更加丰富, 例如“Former Pakistani dancing girl”, 该实体能够很清晰地指向某个具体的人, 而“suicide”触发的事件却包含时间、地点和参与者等信息。
针对以上问题, 本文构建一种新的事件指代消解模型, 该模型在使用词级别的特征同时融合了篇章级别的特征信息, 并利用双向循环神经网络的变体和分层注意力机制, 学习不同层次的语义信息, 捕捉与篇章主题相关度高的内容。同时, 借助 CRF序列化标注, 将篇章内容划分为非事件句, 只构成单链的非同指事件句以及构成指代链的同指事件句(以下称非事件句、单链和同指链), 尽可能保留更多的同指事件句来参与后期的指代消解任务, 从而有效地提升模型的整体性能。
事件指代消解任务研究起步晚, 成果少, 主要受限于语料资源的匮乏。随着 ACE2005 语料对事件标注的扩充, TAC KPB 评测任务的展开以及跨篇章事件同指语料ECB, ECB+的公布, 出现事件指代消解任务的语料资源, 为该任务的研究奠定了基础。
目前, 针对事件指代消解任务的研究思路主要有基于管道模型和基于联合学习模型。其中基于管道模型的处理方法是先进行事件识别(event detec-tion), 再研究事件指代消解, 如 Liu 等[2]先通过 Bi-GRU 抽取事件, 再通过浅层先行树计算同指事件。Lu 等[3]将指代消解分成事件类型识别、时态识别和事件同指 3 个模块分别进行研究。Nguyen 等[4]同样采用管道模型的思路, 利用深度神经网络对该任务进行研究。管道模型符合常见的指代消解研究思路, 但具有一个显著的缺点——错误传播, 事件识别任务性能的好坏会在很大程度上影响后续的指代消解任务。也有研究人员在假设事件都被正确抽取的情况下, 将指代消解部分作为一个单独的子任务, 如 Chen 等[5]抽取词性和事件论元等特征, 作为事件描述对的特征输入到最大熵模型中构建指代消解平台; 陆震寰等[6]利用卷积神经网络判断事件描述对之间是否具有同指关系。常见的基于联合学习的事件指代消解模型有 Lu 等[7]提出的结合事件识别和事件先行词识别的联合学习模型, 也有 Lee 等[8]在跨篇章语料中结合实体指代任务的联合学习模型。联合学习模型大多是基于各项任务的特征共享, 这种方法往往需要构建大量的特征工程。
图1 事件指代消解示例
Fig. 1 Example diagram of event coreference resolution
2017 年, Lee 等[9]在实体指代消解任务中提出一种基于端到端的神经网络模型, 该模型在实体指代消解任务上取得当时最好的性能, 后续有不少工作[10–12]在该平台的基础上进行改进。因此, 我们将该方法迁移到事件指代消解任务研究中, 并结合上述对事件同指情况的分析, 搭建一种融合篇章表征的事件指代消解平台。
需要说明的是, 由于各类语料库对事件同指的定义稍有区别, 这里我们遵循 TAC KBP 中 Event Nugget Detection and Coreference 对该任务的定义, 只针对篇章内的事件指代消解任务进行研究。
融合篇章表征的事件指代消解模型框架如图 2所示, 该模型沿用 Lee 等[9]针对实体指代的基本思路, 首先对输入文本的每个 Token 用 wd(1≤d≤N)进行特征表征, 随后从文本中抽取出满足条件的候选元素 pk, 并通过打分函数 Span Score, 保留得分最高的候选元素作为事件描述, 参与最终的事件描述对打分(Event Mention Pair Score)。在事件描述对打分模块中, 将保留的事件描述两两组成事件描述对, 最终判断这些事件描述对的同指关系。此外, 针对事件指代消解任务的特点和难点, 对实体指代模型进行修改, 最终构建的事件指代消解模型主要包括以下几个部分: 1)篇章级别的特征表征; 2)指代消解模块; 3)利用CRF区分非事件句、单链以及同指链, 进而优化模型。
为了获得篇章向量(document embedding), 模型使用分层注意力机制(图 2), 由 Bi-LSTM 编码输出的词级别表征和 Bi-GRU 编码输出的句级别的表征组成, 并分别通过注意力机制[13]捕捉触发词语义信息和事件句语义信息。

图2 融合篇章表征的事件指代消解模型框架
Fig. 2 Model framework diagram of event coreference resolution with document representation
2.1.1词级别表征
假设文本包含 L 个句子, 给定一个句子 si(1≤i≤L), 其中每个 Token 的向量表征 git(1≤t≤T)由词向量(word embedding)[14]、字符向量(characters embed-ding)[15]以及经过斯坦福词性标注工具标注后训练得到的词性向量(pos embedding)拼接而成。经过Bi-LSTM编码, 得到隐层状态的输出hit:
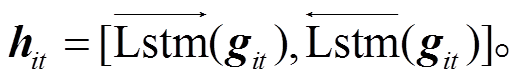 (1)
(1)接下来, 利用注意力机制为模型的每个隐层输出分配新的权值 αit, 同时为了使句子中的触发词能够获得更多的注意力, 本文构建一个标准的词级别注意力权值 αit*。如图 3(a)所示, 将是触发词的 Token 权重设为 1, 否则为 0, 并计算 αit 与 αit*之间的损失Lossh。
 (2)
(2)
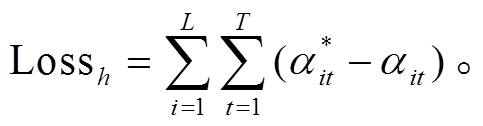 (3)
(3)2.1.2句级别表征
经过上述的处理, 通过加权求和, 获得每个句子的向量表征 si, 为了减少模型在训练时需要学习的参数, 本文使用循环神经网络的另一种变体 Bi-GRU来编码获得句向量的隐层输出qi。
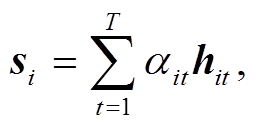 (4)
(4)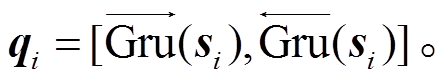 (5)
(5)
同样, 使用注意力机制为每个句子分配新的权重 βi, 并加权求和得到篇章表征 d。为了凸显文本中的事件句, 我们同样计算标准句级别注意力权值βi*与模型预测值 βi 之间的损失 Losss。βi*如图 3(b)所示, 它对应图 1 中 1~9 句事件的分布情况, 包含事件的句子设为1, 否则为0。
 (6)
(6)
图3 标准注意力权值
Fig. 3 Standard attention weight
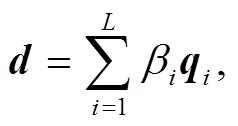 (7)
(7) (8)
(8)
2.2.1候选元素抽取
模型将融合了篇章向量的向量表征 wd 输入到Bi-GRU 网络中, 编码学习篇章的上下文信息, 得到隐层输出 xd:
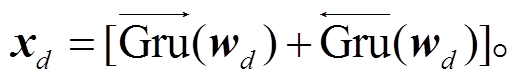 (9)
(9)经统计, 我们发现 KBP 语料中触发词长度范围集中在单个 Token 以及两个 Token 组成的词组, 很少出现 3 个及以上 Token 组成的词, 并且触发词的词性分布也具有特殊性, 因此我们选取篇章中长度小于 3 且具有某些词性①V*, NN, NNS, NNP, PRP, TO, JJ, DT, IN, RB, RP, AD (其中V*表示所有动词)。的单词作为候选元素。假 设篇章中候选元素的个数为 K, 我们用 start(k)和end(k)分别表示每个候选元素 pk (1≤k≤K)的起始位置和结束位置。
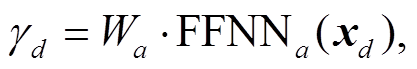 (10)
(10)
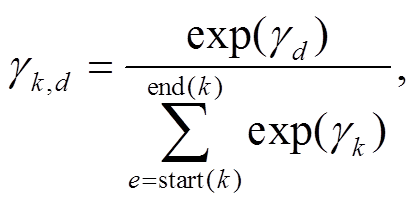 (11)
(11)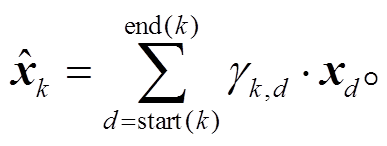 (12)
(12)
使用 Lee 等[9]的方法, 利用前馈神经网络 FFNNa 为每个 Token 分别新的权重 γd, 在 softmax 时只对候选元素进行计算, 并加权求和得到向量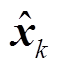 。最终, 候选元素的向量表征 pk由特征向量 ϕ(k)、以及隐层输出 xd 共同构成, 其中 ϕ(k)表示每个候选元素的长度大小。
。最终, 候选元素的向量表征 pk由特征向量 ϕ(k)、以及隐层输出 xd 共同构成, 其中 ϕ(k)表示每个候选元素的长度大小。
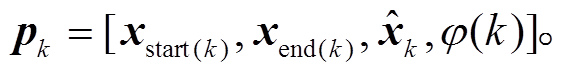 (13)
(13)2.2.2事件描述对同指判断
模型通过一个标准的前馈神经网络 FFNNm 对每个候选元素打分, 打分函数为 Sm(k),并设定阈值λ(λ=0.2)来保留得分最高的候选元素, 作为事件描述参与后期的指代消解。模型按照文本出现的先后顺序对事件描述排列,每个事件描述都要与其先行词对构成事件描述对,再利用一个前馈神经网络FFNNd 对每个事件描述对打分,打分函数为 Sd(u,k) (1≤u≤k-1)。
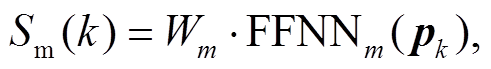 (14)
(14) (15)
(15)
如图 4 所示, 模型在对事件描述对打分的过程中加入文本类型(Genre)、事件类型(Type)以及时态属性(Realis)特征, 其中时态特征和事件类型特征采用二进制编码方式表示两个事件描述对的时态属性和事件类型是否一致, ϕ(u,k)表示这 3 个特征向量的拼接。最终, 每个事件描述对的得分由 Sm(k), Sm(u)和Sd(u,k) 3 个打分函数共同决定。模型最终的学习目标是使预测的同指分布情况接近标准的先行词元素集合 GOLD(i)以及损失函数 Losscluster 的结果最小化。
 (16)
(16) (17)
(17)
针对篇章中事件分布稀疏、单链数量多的问题, 模型在 Bi-GRU 层加入 CRF (conditional random field algorithm)序列化标注, 采用 BIO 标注方式对篇章进行分类, 如图2所示。
CRF 层的参数由一个转移矩阵 A 构成, Ax,y 表示从第 x 个标签到第 y 个标签的转移得分。假设篇章的标签序列为 Y={y1, y2, y3, y4, ..., yN}, 模型对标签序列 Y 的打分函数为 Score(Y)。整个篇章的打分等于各个位置的打分之和, 而每个位置的打分一部分由Bi-GRU的输出xd决定, 另一部分由 CRF 的转移矩阵 A 决定, 模型使用函数 softmax 得到归一化后的概率, 并计算其损失得分Losscrf。
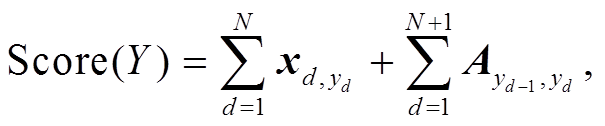 (18)
(18)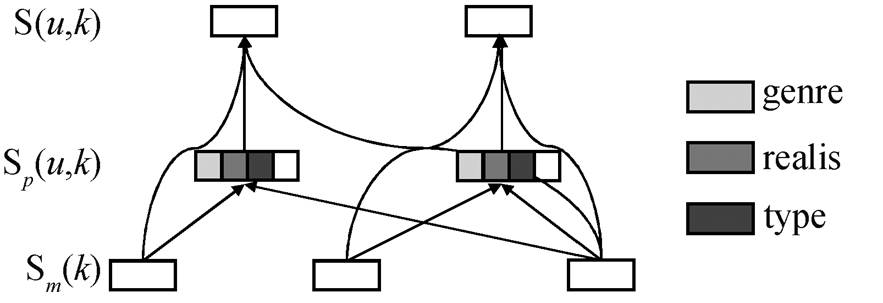
图4 事件描述对打分
Fig. 4 Event mention pair Score
 (20)
(20)最终, 利用门控机制控制各项损失的权重, 得到损失函数 Loss 的值, 其中 a, b, c, d∈[0, 1]。
Loss=aLosscrf+bLosscluster+cLossh+dLosss, (21)
a+b+c+d=1。 (22)
实验采用 Lu 等[7]在英文语料上的数据集配置, 包括选自 LDC2015E29, E68, E73, E94 的 648 篇作为训练语料, 其中 509 篇作为训练集, 139 篇作为验证集, LDC2016E72 中的 168 篇作为测试语料。我们使用评测指标 MUC[16]、B3[17]、CEAFe[18]和 BLANC[19]以及它们的均值 CoNLL 和 AVG-F 对模型性能进行评测。
CoNLL=(MUC+CEAFe+B3)/3, (23)
AVG-F=(MUC+CEAFe+B3+BLANC)/4。 (24)
对 Token 进行向量表征时, 模型使用的 Word Embedding 和 Characters Embedding 分别是已训练的 300 维 GloVe 以及由通道数为 100, 卷积核大小为 5 的卷积神经网络训练得到的 100 维向量。在训练篇章表征时, 模型分别使用 Bi-LSTM 和 Bi-GRU。我们对这两层的输出分别进行线性变换, 变换矩阵 Ww 和 Ws 的输出维度为 600 和 400。此外, 考虑到计算成本, 模型在构建事件对时, 将最大先行词匹配数量 M 设置为 150, 筛选后的候选元素个数为 Q, 先行候选元素的搜索空间设为 min{Q, M}。表 1 给出本实验详细的参数配置, 在特征维度一栏中, Span size 表示候选元素的长度大小, Genre 指 KBP语料的文本类型, 分别有新闻类文本(newswire)和论坛类文本(discussion fourms)。
我们做了几组对比实验, 结果如表 2 所示。其中, Baseline 是搭建的一个基准平台, 没有加入 Doc embedding 和 CRF 序列化标注等工作, 同时用 Bi-LSTM 代替 Bi-GRU 学习篇章的上下文信息的实验结果。Doc embedding 和 CRF 两组实验指分别在Baseline 的基础上加入篇章表征 d 和 CRF 序列化标注。最后一组 Doc+CRF 实验就是本文最终的事件指代消解模型。从表 2 可以看出如下几点。
表1 实验参数配置
Table 1 Configuration of experiment parameters

Word Bi-LSTMSentence Bi-GRU Document Bi-GRU FFNNm,p特征维度 优化器学习率 Hidden dim: 300Hidden dim: 200Hidden dim: 200Hidden dim: 150Pos embedding dim: 20Adam0.0001 Number layers: 1Number layers: 1Number layers: 1Number layers: 2Span size embedding dim: 20 Dropout: 0.5Dropout: 0.5Dropout: 0.2Dropout: 0.2Type embedding dim: 20 Realis embedding dim: 20 Genre embedding dim: 20
表2 事件指代消解实验结果
Table 2 Experimental results of event resolution

实验MUCB3CEAFe BLANCCoNLLAVG-F Lu等[7]27.4140.9039.0025.0035.7733.08 Baseline43.4738.9337.3030.5639.9037.57 Doc embedding45.1540.3339.1731.9741.5539.16 CRF45.3041.1640.4633.6842.3140.15 Doc+CRF46.9042.0940.2234.6043.0740.95
1)与目前性能最好的 Lu 等[7]的联合学习模型相比, 基准模型 Baseline 虽然部分评测指标(如 B3和 CEAFe)的结果略逊一筹, 但从综合评测 CoNLL和 AVG-F 来看, Baseline 模型的性能都高出 4 个百分点。联合学习模型的核心思想是通过多任务间的特征共享以及建立任务之间的相互约束来提高各项任务的性能。在 Lu 等[7]的联合学习模型中, 不仅对每个单任务进行特征抽取, 同时两两任务之间也要构建大量特征, 这些特征工程费时费力。我们提出的模型无须构建复杂的人工特征, 只需几种常见的词向量和词性向量, 就能够达到很好的效果。
2)由于事件包含的语义信息远多于实体, 且文本中的同指事件句大多跨句子分布, 因此篇章级别的语义信息有助于模型理解整篇文本的语义内容, 同时分层注意力机制能够帮助模型更好地捕捉事件句和触发词。通过对比 Baseline 与 Doc embeding 的实验结果, 验证了篇章语义信息对本任务的作用, 各项评测结果的性能都得到提升, 其中综合评分提升 1.6 个点左右。
3)通过前面的分析可知, 相较于实体, 触发词分布稀疏, 且单链的数量较多, 成为事件指代消解任务研究的一个难点。在本任务中, 我们并不关注于事件的具体类型, 只关注与同指链之间的关系, 且单链不参与后期的消解过程, 因此可以利用 CRF对模型进行优化。对比 Baseine 与 CRF 的实验结果证实, 有效地区分篇章中的非事件句、单链及同指链, 能够提升事件指代消解任务性能, 在综合评分下提升 2.4 个点左右。
4)Doc+CRF 的性能比 Doc embedding 和 CRF两组都有所提升, 证明两种方法之间是相互兼容的, 都能够同时对本任务起到一定的作用。最终, 模型Doc+CRF 的各项评测指标性能都超越文献[7], 证明了我们的模型在事件指代消解任务上的有效性。
本文提出一种融合篇章表征的事件指代消解模型, 将端到端的基于神经网络的实体指代消解模型很好地迁移到事件指代消解任务中, 并通过比较事件与实体的区别对模型进行改进。通过分析语料发现, 事件承载的语义内容远比实体复杂, 并且篇章中的事件数量有限, 大多只被提及一次, 不会与其他事件句构成同指关系。针对这些问题, 我们首先加入篇章特征来丰富语义表征, 并且在加入篇章特征的过程中, 利用分层注意力机制, 抓住句子中的触发词语义和篇章中的事件句语义信息, 同时利用 CRF 序列化标注, 区分哪些是不构成指代关系的事件, 从而更多地保留同指事件描述参与后期的指代消解任务。经过各项评测, 证明我们对事件指代消解任务的分析以及模型的改进是正确和有效的。
我们的模型还存在不足和需要改进的地方。例如, 在后期判断与先行词的同指关系时采用贪心组合的方式, 即每个候选元素都要与其前面的所有先行词两两组队。这种方式带来的弊端是事件对的数目以平方数量级增多, 并且事件对中负例的数量远远多于正例。在后续的研究中, 可以通过设置约束规则, 减少不必要的事件配对, 从而使模型获得更好的性能。
参考文献
[1] Vendler Z. Verbs and times. Philosophical Review, 1957, 66(2): 143–160
[2] Liu Z Z, Araki J, Mitamura T, et al. CMU-LTI at KBP 2016 event nugget track [C/OL] // TAC. Gai-thersburg, MD. (2016) [2019–04–14]. https://tac. nist. gov/publications/2016/participant.papers/TAC2016.LTI_CMU.proceedings.pdf
[3] Lu J, Ng V. UTD’s event nugget detection and core-ference system at KBP 2016 [C/OL] // TAC. Gaithers-burg, MD. (2016)[2019–04–14]. https://tac.nist.gov/ publications/2016/participant.papers/TAC2016.UTD.proceedings.pdf
[4] Nguyen T H, Meyers A, Grishman R. New York University 2016 System for KBP event nugget: a deep learning approach [C/OL] // TAC. Gaithersburg, MD. (2016)[2019–04–14]. https://tac.nist.gov/publications/ 2016/participant.papers/TAC2016.NYU.proceedings.pdf
[5] Chen Z, Ji H, Haralick R. A pairwise event corefer-ence model, feature impact and evaluation for event coreference resolution // Proceedings of the Workshop on Events in Emerging Text Types. Borovets, 2009: 17–22
[6] 陆震寰, 孔芳, 周国栋. 面向多语料库的通用事件指代消解. 中文信息学报, 2018, 32(1): 51–58
[7] Lu J, Ng V. Joint learning for event coreference resolution // Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vancouver, 2017: 90–101
[8] Lee H, Recasens M, Chang A, et al. Joint entity and event coreference resolution across documents // Pro-ceedings of EMNLP-CoNLL 2012. Jeju Island, 2012: 489–500
[9] Lee K, He L, Lewis M, et al. End-to-end neural coreference resolution // Proceedings of the 2017 Conference on Empirical Methods in Natural Lan-guage Processing. Copenhagen, 2017: 188–197
[10] Zhang R, Santos C N, Yasunaga M, et al. Neural coreference resolution with deep biaffine attention by joint mention detection and mention clustering // Pro-ceedings of the 56th Annual Meeting of the Associa-tion for Computational Linguistics (Volume 2: Short Papers). Melbourne, 2018: 102–107
[11] Luo H, Glass J. Learning word representations with cross-sentence dependency for end-to-end co-reference resolution // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, 2018: 4829–4833
[12] Lee K, He L, Zettlemoyer L. Higher-order corefer-ence resolution with coarse-to-fine inference // Pro-ceedings of the 2018 NAACL-HLT (Volume 2: Short Papers). New Orleans, 2018: 687–692
[13] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate [EB/OL]. (2015–04–24) [2019–01–30]. https://arxiv. org/pdf/1409.0473.pdf
[14] Pennington J, Socher R, Manning C. Glove: global vectors for word representation // Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, 2014: 1532–1543
[15] Turian J, Ratinov L, Bengio Y. Word representations: a simple and general method for semi-supervised lear-ning // Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Uppsala, 2010: 384–394
[16] Vilain M, Burger J, Aberdeen J, et al. A model-theoretic coreference scoring scheme // Proceedings of the 6th Conference on Message Understanding. Columbia, 1995: 45–52
[17] Bagga A, Baldwin B. Algorithms for scoring coreference chains // The First International Confer-ence on Language Resources and Evaluation Work-shop on Linguistics Coreference. Granada, 1998: 563–566
[18] Luo Xiaoqiang. On coreference resolution perform-ance metrics // Proceedings of HLT/EMNLP 2005. Vancouver, 2005: 25–32
[19] Larta R, Eduard H. BLANC: implementing the Rand index for coreference evaluation. Natural Language Engineering, 2011, 17(4): 485–510
Event Coreference Resolution with Document Representation
Abstract Event coreference resolution is more difficult than entity coreference resolution. The main reason is that the event mentions in the unstructured texts are sparse, and most of them do not have the coreference relationship, at the same time, the semantic information carried by the event itself is richer than entity. In order to accurately extract the coreferential events in the text, for the above characteristics of event coreference resolution, an event coreference resolution platform with text representation is proposed. This platform effectively distinguishes non-event mention, single-chain and coreference event mention through CRF, and uses hierarchical attention mechanism to capture important information at sentence level and text level. Experiments on KBP2015 and 2016 datasets verify the validity of the model, and the CoNLL evaluation standard reaches 43.07% of the F1 value.
Key words event coreference resolution; document representation; hierarchical attention mechanism
doi: 10.13209/j.0479-8023.2019.091
国家自然科学基金(61876118, 61836007)资助
收稿日期: 2019–05–14;
修回日期: 2019–09–19