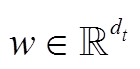 。对于辅助任务, 我们采用双层卷积神经网络对词向量进行卷积, 提取对应的文本特征 TS。对于主任务, 对词向量不做额外的预处理, 用 TE表示。
。对于辅助任务, 我们采用双层卷积神经网络对词向量进行卷积, 提取对应的文本特征 TS。对于主任务, 对词向量不做额外的预处理, 用 TE表示。摘要 不同于纯文本的情绪分析, 本文面向多模态数据(文本和语音)进行情绪识别研究。为了同时考虑多模态数据特征, 提出一种新颖的联合学习框架, 将多模态情绪分类作为主任务, 多模态情感分类作为辅助任务, 通过情感信息来辅助提升情绪识别任务的性能。首先, 通过私有网络层对主任务中的文本和语音模态信息分别进行编码, 以学习单个模态内部的情绪独立特征表示。接着, 通过辅助任务中的共享网络层来获取主任务的辅助情绪表示以及辅助任务的单模态完整情感表示。在得到主任务的文本和语音辅助情绪表示之后, 分别与主任务中的单模态独立特征表示相结合, 得到主任务中单模态情绪信息的完整表示。最后, 通过自注意力机制捕捉每个任务上的多模态交互特征, 得到最终的多模态情绪表示和情感表示。实验结果表明, 本文方法在多模态情感分析数据集上可以通过情感辅助信息大幅度地提升情绪分类任务的性能, 同时情感分类任务的性能也得到一定程度的提升。
关键词 多模态; 情绪识别; 联合学习; 情感分析
随着头条、抖音等社交媒体平台的迅速崛起, 人们越来越喜欢上传语音或视频等多模态内容来表达自己的情感(sentiment)和情绪(emotion)。挖掘多模态内容所包含的情感信息对于舆情发现和用户反馈等应用具有十分重要的意义[1–2]。因此, 越来越多的研究者专注于分析多模态数据的情感倾向, 多模态的情绪分析作为细粒度的情感分析备受关注。
在纯文本情绪分析领域, 已有较多研究工作利用情感信息帮助识别文本的情绪标签, 在一定程度上也可以提升情感的分类性能[3–4]。这些研究者认为句子的情感标签和情绪标签存在依赖关系, 例如: “Oh umm, my big scene is coming up. Big scene com-ing up.”, 本例的情绪标签为喜悦(Joy), 情感标签为正向(Positive)。例子中的场景是说话人在兴奋地等待他所演的镜头在荧幕上出现的一刻。如果我们判定句子所表达的情绪为喜悦, 那么可以容易识别本例中的正向情感。反之, 如果我们判定句子的情感是正向, 则可以淘汰掉一些负面的情绪, 如愤怒(Anger)、厌恶(Disgust)和悲伤(Sadness)等。因此, 采用联合学习方法可以有效地捕捉情感和情绪的共享信息, 达到情感、情绪分类任务同时提升的目的。然而, 在多模态情感分析领域, 目前还没有相关工作利用情感和情绪分类任务进行联合学习。
不同于纯文本分析, 如何利用多模态特征针对情感与情绪任务进行联合学习[5]是一大难题。一方面, 不同的模态存在各自的特性, 即单模态独立特征(uni-modal independent dynamics); 另一方面, 两个模态存在交互关系, 即多模态交互特征(multi-modal interactive dynamics)。例如: “I got no sleep last night!”, 我们仅通过文本信息很难判断其准确的情绪, 必须同时考虑其对应的语音信息, 若语音信息表现出大声的特征, 则可以确定该例子的情绪为愤怒, 若语音信息表现出低沉的语气, 则可以认为该例子包含悲伤的情绪。因此, 我们需要准确地捕捉文本与语音之间的联系, 更好地对单模态独立特征和多模态交互特征进行建模。
为了解决上述难题, 本文面向文本和语音模态数据, 提出一种基于情感信息辅助的多模态情绪识别方法, 通过联合学习的方式同时提升情感分类和情绪识别任务的性能。
近年来, 不少研究工作采用联合学习框架在情感分析上取得成效。在属性级情感分析任务上, Ma等[6]通过属性抽取和属性级情感分类两个任务进行联合学习, 极大地提升了属性级情感分类任务的性能。Chen 等[7]提出联合模型, 针对情绪分类和情绪原因识别两个任务同时建模, 有效地提升两个任务的识别性能。
情绪分类和情感分类是情感分析中两个不同的子任务, 由于情绪标签与情感标签有着强烈的联系, 因此两个任务是紧密相关的。Gao 等[3]通过标注一个额外的带有情绪标签和情感标签的数据集来提升两个任务的性能。然而, 在现实场景下难以获取类似的数据集。Wang 等[4]采用整数线性规划(ILP)对情绪和情感分类任务进行联合学习, 通过约束条件获取情绪分类器的输出与情感分类器的输出之间的联系。
不同于以往的联合学习研究, 我们将联合学习框架扩展到对包含文本和语音信息的多模态内容进行探索。
多模态情感分析结合语言以及非语言的信息去探测用户表达的情感, 已成为热点研究课题。为了简化问题, 早期的方法采用简化时序信息的操作对多模态内容进行情感分析[8]。Morency 等[1]通过将时序信息进行平均得到每个模态信息的表示, 然后进行拼接, 并把得到的多模态信息作为隐马尔科夫模型(HMMs)的输入特征, 获取最终的情感信息。类似地, Zadeh 等[2]和 Pérez-Rosas 等[9]采用拼接的多模态特征训练支持向量机(SVM)模型, 然而平均的信息无法有效地捕捉模态内部的信息和模态之间的交互信息, 因此这些方法难以对多模态信息进行有效的建模。
最近的多模态情感分析研究主要采用深度学习模型对模态内部信息和模态之间的交互信息进行建模[10–11]。Zadeh 等[5]采用张量融合网络的方法, 通过创建一个多维张量来捕捉多模态内容所包含的情感信息。Liu 等[12]在张量融合网络的基础上提出低阶的张量网络, 在提升性能的同时减少原模型的参数以及计算复杂度。Bertero 等[13]对长短期记忆网络(LSTM)进行扩展, 对多模态内容进行情绪识别。Zadeh 等[14]提出图记忆融合网络, 通过门控记忆单元存储模态内部信息以及模态之间的交互信息, 并加入动态融合图来反映有效的情绪信息。Hazarika等[15]采用多层门控循环单元(GRU)来存储当前多模态内容的说话人信息以及上下文信息, 并把 GRU的输出作为全局信息来分析当前多模态内容所包含的情绪信息。
虽然上述方法取得不错的效果, 但都只考虑多模态内容中的情绪信息或情感信息, 忽略了情绪与情感之间的联系。我们提出一种基于情感信息辅助的多模态情绪识别方法, 通过联合学习的方式, 可以同时提升情感分类和情绪识别任务的性能。
基于情感信息辅助的多模态情绪分类方法通过联合学习的方式来融合多模态数据集上的情绪信息和情感信息, 将情绪分类作为主任务, 情感分类作为辅助任务, 通过情感分类任务来辅助情绪分类任务。图 1 为基于联合学习方法的模型框架, 模型包含以下几个部分。1)特征表示层: 将多模态内容的文本和语音信息映射成特征, 作为神经网络的输入。2)任务私有/共享层: 通过私有网络层对模态内部信息进行编码, 通过共享网络层对主任务和辅助任务进行联合学习。3)模态交互层: 对主任务的文本和语音特征进行融合, 获取模态之间的交互信息, 对辅助任务亦如此。4)预测分类层: 使用单模态信息和多模态融合信息对主任务和辅助任务进行预测。
对于文本模态, 假设一句话语由 N 个词组成, 通过 GloVe 来获取对应的预训练词向量[16], 未知词通过随机向量初始化, 即每个词可表示为。对于辅助任务, 我们采用双层卷积神经网络对词向量进行卷积, 提取对应的文本特征 TS。对于主任务, 对词向量不做额外的预处理, 用 TE表示。
对于语音模态, 假设一句话对应的语音有 M帧信息, 通过 OpenSMILE[17]语音分析框架获取辅助任务的语音特征 AS。对于主任务, 采用基于梅尔频谱系数的语音特征, 把每一帧信息映射成包含静态数据(static)、一阶导数(delta)和二阶导数(double delta)的MFSC系数特征[18], 记为 AE。
首先, 采用私有的长短期记忆网络(LSTM)对主任务的文本特征 TE 进行编码, 表示如下:
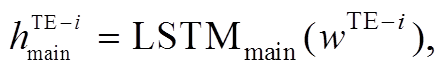 (1)
(1)其中, ![]() 是主任务中第
是主任务中第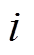 个词的词向量,
个词的词向量, 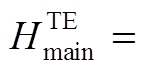
 是一句话语经过私有LSTM 后的文本模态独立特征表示序列。类似地, 可以得到主任务中语音模态独立特征表示序列
是一句话语经过私有LSTM 后的文本模态独立特征表示序列。类似地, 可以得到主任务中语音模态独立特征表示序列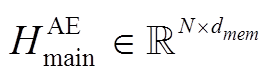 。
。
然后, 采用共享的 LSTM 层对主任务和辅助任务的文本特征共同编码, 表示如下:
 (2)
(2)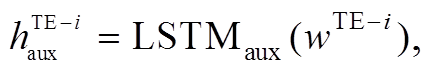 (3)
(3)
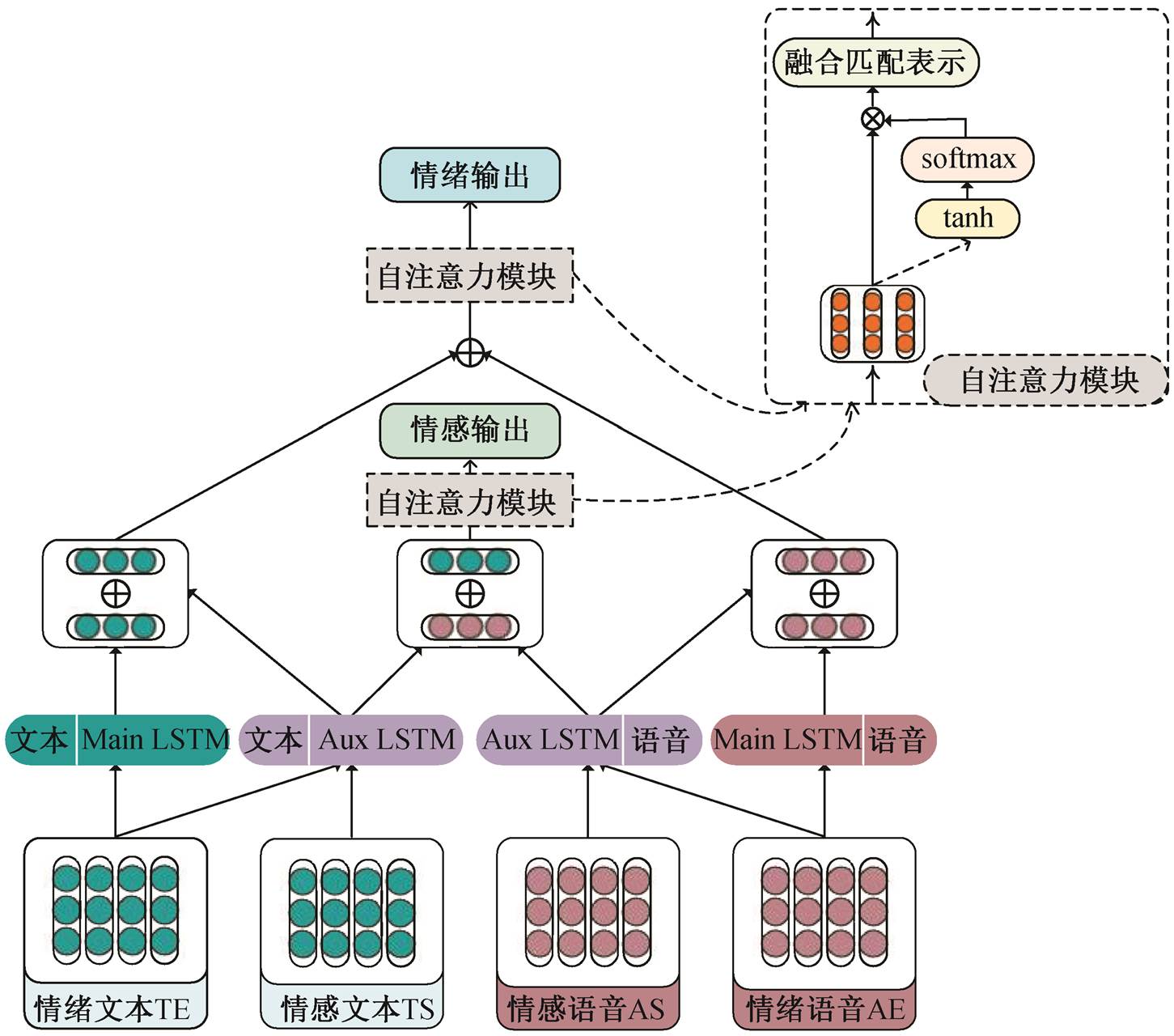
图1 联合多模态情绪与情感学习网络的模型框架
Fig. 1 Overall architecture of joint multimodal emotion and sentiment learning network
其中, 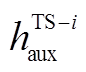 是辅助任务中第个词经过共享层后的隐层编码,
是辅助任务中第个词经过共享层后的隐层编码, 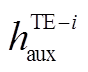 是主任务中第个词经过共享层后的辅助编码。对应地, 可以得到辅助任务的完整编码序列
是主任务中第个词经过共享层后的辅助编码。对应地, 可以得到辅助任务的完整编码序列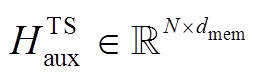 和主任务的辅助编码序列
和主任务的辅助编码序列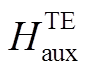
![]() 。我们对主任务和辅助任务的语音特征进行类似的操作, 得到辅助任务语音模态的完整编码序列
。我们对主任务和辅助任务的语音特征进行类似的操作, 得到辅助任务语音模态的完整编码序列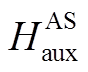 和主任务语音模态的辅助编码序列
和主任务语音模态的辅助编码序列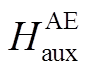 。
。
在这一层中, 我们对联合学习层获取的 6 个编码序列进行最大池化操作(maxpooling, 记为 mp)。以主任务中的文本模态为例, 表示如下:
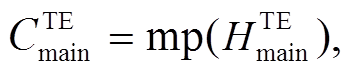 (4)
(4)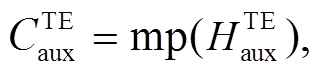 (5)
(5)
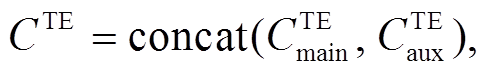 (6)
(6)
其中, 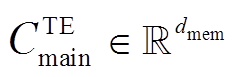 是主任务的文本模态独立特征表示序列经过最大池化后的编码表示,
是主任务的文本模态独立特征表示序列经过最大池化后的编码表示, 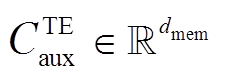 是主任务的文本辅助编码序列经过最大池化后的编码表示,
是主任务的文本辅助编码序列经过最大池化后的编码表示, 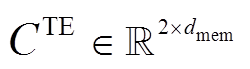 是主任务的文本模态的完整表示。类似地, 我们可以得到主任务的语音模态的完整表示
是主任务的文本模态的完整表示。类似地, 我们可以得到主任务的语音模态的完整表示 , 接着, 把主任务的文本和语音完整表示进行拼接(concat), 得到主任务的多模态融合表示
, 接着, 把主任务的文本和语音完整表示进行拼接(concat), 得到主任务的多模态融合表示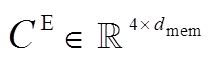 。对于辅助任务, 在得到文本和语音模态的最大池化表示
。对于辅助任务, 在得到文本和语音模态的最大池化表示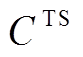 和
和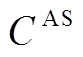 后, 我们对其进行拼接操作, 得到辅助任务的多模态融合表示
后, 我们对其进行拼接操作, 得到辅助任务的多模态融合表示![]()
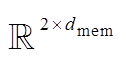 。
。
接下来, 我们采用自注意力机制加权主任务的多模态融合表示:
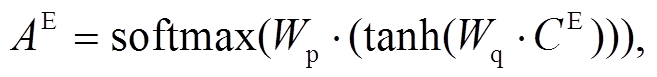 (7)
(7)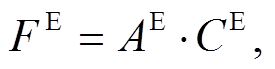 (8)
(8)
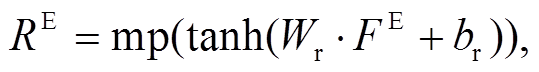 (9)
(9)
其中, 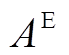 代表主任务多模态融合表示中文本和语音信息的重要程度, 通过可以计算得到多模态加权融合信息的表示
代表主任务多模态融合表示中文本和语音信息的重要程度, 通过可以计算得到多模态加权融合信息的表示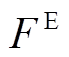 , 利用最大池化操作获取最终的多模态情绪加权融合表示
, 利用最大池化操作获取最终的多模态情绪加权融合表示![]() ; Wp, Wq和 Wr 网络层的权重, br 网络层的偏置。类似地, 我们可以得到辅助任务最终的多模态情感加权融合表示RS。
; Wp, Wq和 Wr 网络层的权重, br 网络层的偏置。类似地, 我们可以得到辅助任务最终的多模态情感加权融合表示RS。
对于主任务和辅助任务, 分别采用各自的单模态完整表示和多模态加权融合表示对多模态数据进行情绪或情感的预测。
以多模态情绪分类(主任务)为例, 通过 2.3 节的操作, 我们得到多模态的完整表示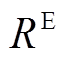 , 下面通过softmax层对情绪类别进行预测, 具体表示为
, 下面通过softmax层对情绪类别进行预测, 具体表示为
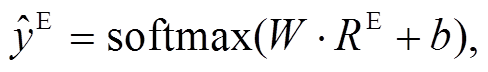 (10)
(10)其中, ![]() 是文本和语音模态融合后得到的多模态情绪分类结果, W和b 是 softmax 层的权重与偏置。类似地, 可以得到辅助任务的多模态情绪分类结果
是文本和语音模态融合后得到的多模态情绪分类结果, W和b 是 softmax 层的权重与偏置。类似地, 可以得到辅助任务的多模态情绪分类结果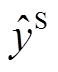 以及主辅任务的单模态文本和语音的分类效果
以及主辅任务的单模态文本和语音的分类效果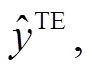
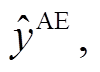
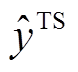 和
和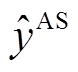 。
。
在网络训练过程中, 对主任务和辅助任务均采用交叉熵误差作为损失函数, 具体表示为
 (11)
(11)其中, K是训练样本的总数, C是类别的数目, 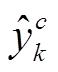 是第 k 个样本的预测标签,
是第 k 个样本的预测标签, 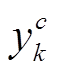 是第 k 个样本的真实标签。对于不同的任务,
是第 k 个样本的真实标签。对于不同的任务,  , 我们对式(11)产生的所有 Loss 进行线性组合作为最终的优化目标函数, 实验中采用 Adam 优化器[19]来优化模型的参数。
, 我们对式(11)产生的所有 Loss 进行线性组合作为最终的优化目标函数, 实验中采用 Adam 优化器[19]来优化模型的参数。
3.1.1 数据设置
本文实验使用多模态情感分析数据集 MELD (Multimodal Emotion Lines Dataset)[20]。MELD 数据集由 1432 个视频组成, 可被切分成 13708 个片段, 其中训练集 9989 个, 验证集 1109 个, 测试集 2610个。MELD 中包含 7 种不同的情绪, 分别是愤怒(Anger)、厌恶(Disgust)、恐惧(Fear)、喜悦(Joy)、中性(Neutral)、悲伤(Sadness)和惊讶(Surprise), 每种情绪在数据集中的数量分布见表 1 。另外, MELD中包含 3 种不同的情感, 分别是正向(Positive)、负向(Negative)和中性(Neutral), 每种情感在数据集中的数量分布见表2。
3.1.2 参数设置和评价标准
设置 LSTM 的隐层单元数量为 256, 批大小为128, 共进行 30 次迭代。我们根据 Poria 等[20]的方法选取加权平均的 F1 值(weighted average F1, 记为w-avg)作为综合评价标准, 数值越大代表性能越好。
表1 MELD中各情绪类别的样本数量分布
Table 1 Distributions of emotion categories in MELD

数据集愤怒厌恶恐惧喜悦中性悲伤惊讶 训练集1109271268174347106831205 验证集1532240163470111150 测试集34568504021256208281
表2 MELD中各情感类别的样本数量分布
Table 2 Distributions of sentiment categories in MELD
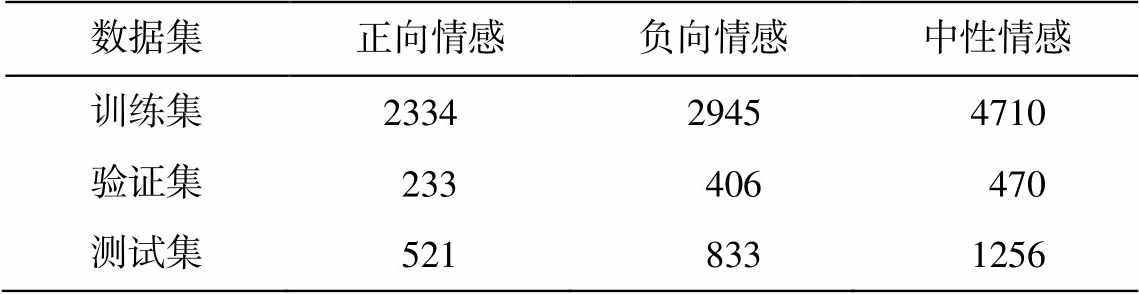
数据集正向情感负向情感中性情感 训练集233429454710 验证集233406470 测试集5218331256
在实验中, 我们将本文方法与一些最新的处理多模态情感分析的基线方法就文本、语音以及多模态融合 3 个方面的实验性能进行对比。这些基线方法简述如下。
1)TFN: 由 Zadeh 等[5]提出, 采用张量融合网络的方式, 通过创建一个多维张量来捕捉多模态内容的单模态和多模态信息。
2)MFN: 由 Zadeh 等[14]提出, 采用记忆融合网络的方式, 使用多视图门控记忆单元来存储随时间变化的模态内部信息以及模态之间的交互信息。
3)BC-LSTM: 由 Poria 等[8]提出, 采用上下文相关的多模态内容融合方式。作为 MELD 数据集上提出的基线方法, 该方法有着相当好的性能。
4)CMN: 由 Hazarika 等[21]提出, 采用两层门控循环单元(GRU)来分别存储说话人信息以及当前多模态内容的上下文信息, 通过融合双层 GRU 的输出来分析当前多模态内容所包含的情绪信息。
5)ICON: 由 Hazarika 等[15]提出, 基于 CMN 进行改进, 增加一个全局门控循环单元(GlobalGRU)存储当前多模态内容的全局信息, 进而对多模态内容进行情绪分析。
不同方法在情感分类和情绪分类任务的实验结果见表 3 和表 4。
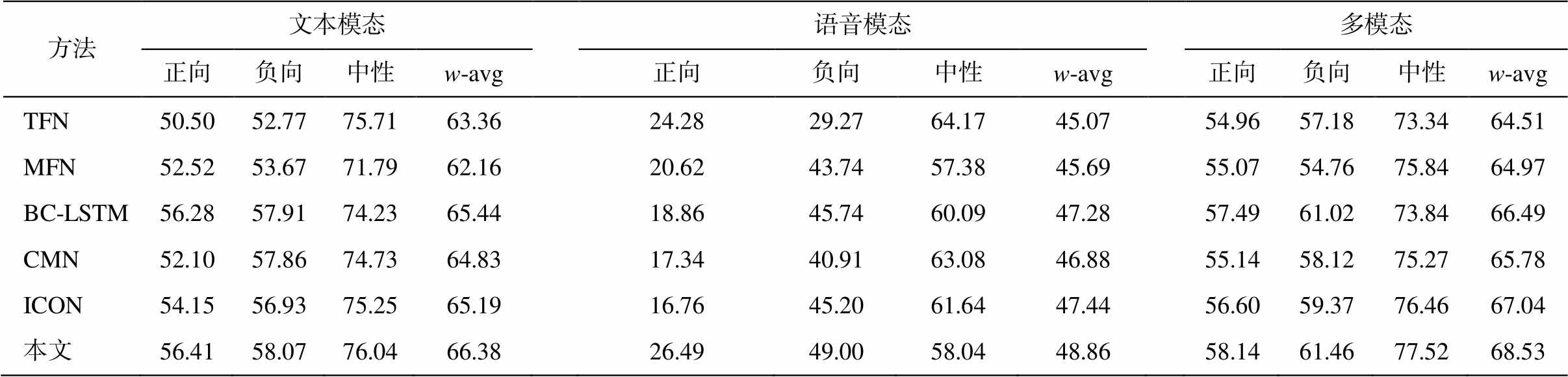
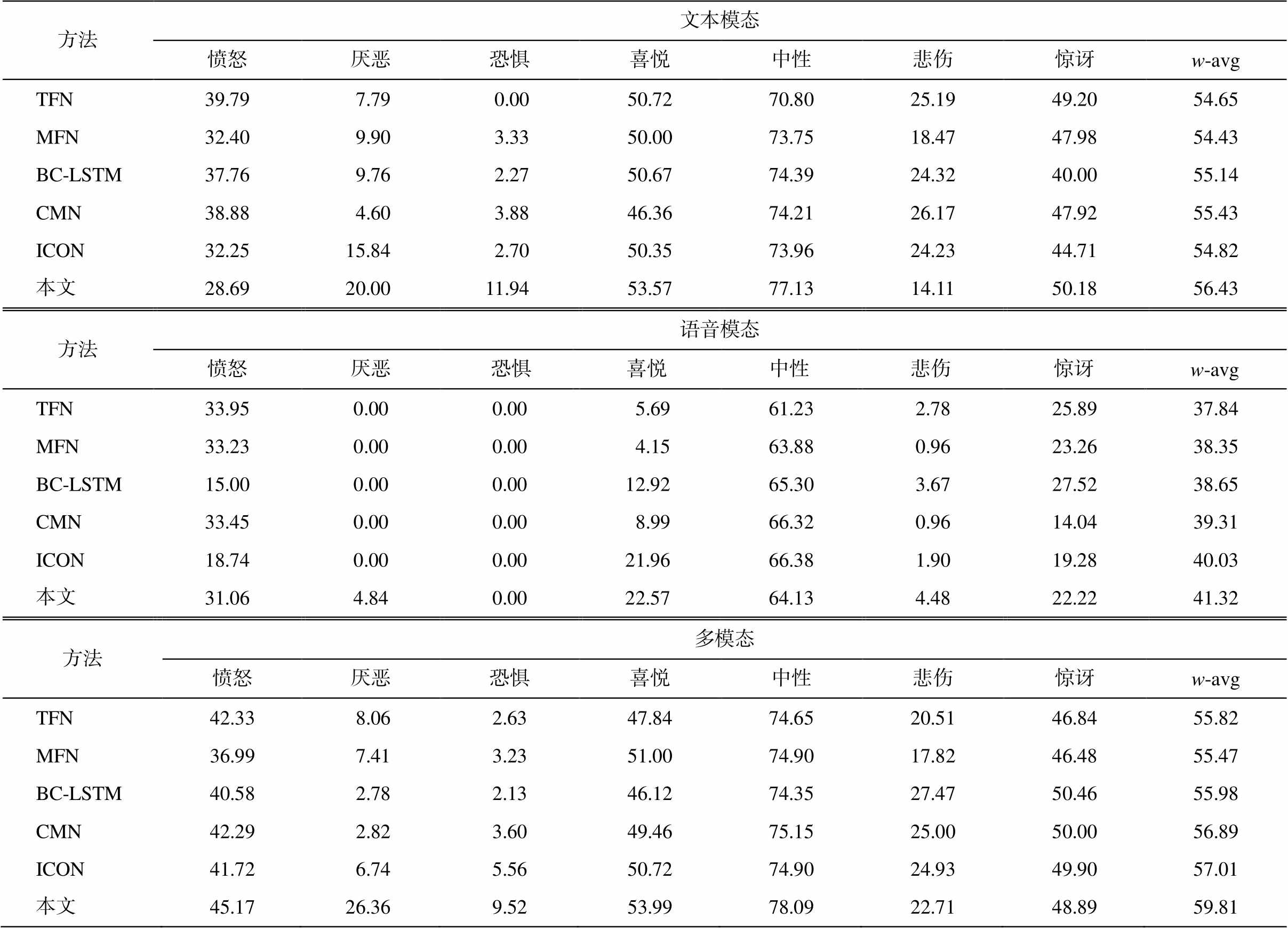
在文本模态实验中, 无论是在主任务还是辅助任务上, 捕捉上下文信息的方法 BC-LSTM, CMN和 ICON 的表现均优于 TFN 和 MFN。以上基线方法仅采用主任务或辅助任务的文本特征。本文方法在综合评价指标 w-avg 上表现最好, 在情绪分类任务上的性能比表现最佳的基线方法 CMN 高出1.00%, 在情感分类任务上的性能比表现最佳的BC-LSTM 高出0.94%, 表明文本模态的共享层的辅助表示可以同时提高主任务和辅助任务的性能。
在语音模态实验中, 无论是在主任务还是辅助任务上, 依然是捕捉上下文信息的方法比其他基线方法表现更好。以上基线方法仅采用主任务或辅助任务的语音特征。由于语音模态特征的表征能力较弱, 并且“厌恶”和“恐惧”类别的样本数目非常少, 导致我们的模型无法预测出对应的类别, 在个别类别上的表现无法达到最佳。不过, 本文方法在综合评价指标 w-avg 上的表现比所有基线方法好, 在情绪任务上的性能比表现最佳的方法 ICON 高出1.29%, 在情感分类任务上的性能比表现最佳的ICON 高出 1.42%, 表明语音模态的共享层的辅助表示可以同时提高主任务和辅助任务的性能。
在文本和语音融合的多模态实验中, 在情绪分类任务上, 虽然本文方法未能在“悲伤”和“惊讶”上达到最佳, 但在其他 5 个类别以及 w-avg 上表现最佳, w-avg 比所有基线方法分别高出 3.99%, 4.34%, 3.83%, 2.92%和 2.80%。在情感分类任务上所有类别均优于基线方法, w-avg 比 5 个基线方法分别高出4.02%, 3.56%, 2.04%, 2.75%和 1.49%。实验结果表明, 本文方法采用主辅任务共享层的文本和语音辅助表示可以同时提升情绪和情感分类的性能。
表3 MELD情感分类的F1值(%)
Table 3 F1 on sentiment classification in MELD (%)
方法文本模态语音模态多模态 正向负向中性w-avg正向负向中性w-avg正向负向中性w-avg TFN50.5052.7775.7163.3624.2829.2764.1745.0754.9657.1873.3464.51 MFN52.5253.6771.7962.1620.6243.7457.3845.6955.0754.7675.8464.97 BC-LSTM56.2857.9174.2365.4418.8645.7460.0947.2857.4961.0273.8466.49 CMN52.1057.8674.7364.8317.3440.9163.0846.8855.1458.1275.2765.78 ICON54.1556.9375.2565.1916.7645.2061.6447.4456.6059.3776.4667.04 本文56.4158.0776.0466.3826.4949.0058.0448.8658.1461.4677.5268.53
表4 MELD情绪分类的F1值(%)
Table 4 F1 on emotion classification in MELD (%)
方法文本模态 愤怒厌恶恐惧喜悦中性悲伤惊讶w-avg TFN39.797.790.0050.7270.8025.1949.2054.65 MFN32.409.903.3350.0073.7518.4747.9854.43 BC-LSTM37.769.762.2750.6774.3924.3240.0055.14 CMN38.884.603.8846.3674.2126.1747.9255.43 ICON32.2515.842.7050.3573.9624.2344.7154.82 本文28.6920.0011.9453.5777.1314.1150.1856.43 方法语音模态 愤怒厌恶 恐惧喜悦中性悲伤惊讶w-avg TFN33.950.000.005.6961.232.7825.8937.84 MFN33.230.000.004.1563.880.9623.2638.35 BC-LSTM15.000.000.0012.9265.303.6727.5238.65 CMN33.450.000.008.9966.320.9614.0439.31 ICON18.740.000.0021.9666.381.9019.2840.03 本文31.064.840.0022.5764.134.4822.2241.32 方法多模态 愤怒厌恶恐惧喜悦中性悲伤惊讶w-avg TFN42.338.062.6347.8474.6520.5146.8455.82 MFN36.997.413.2351.0074.9017.8246.4855.47 BC-LSTM40.582.782.1346.1274.3527.4750.4655.98 CMN42.292.823.6049.4675.1525.0050.0056.89 ICON41.726.745.5650.7274.9024.9349.9057.01 本文45.1726.369.5253.9978.0922.7148.8959.81
本文对基于多模态内容的情绪分类任务进行探索, 首次引入一种多模态的联合学习框架, 将多模态情绪分类作为主任务, 多模态情感分类作为辅助任务, 通过情感信息来辅助提升情绪分类任务的性能。我们采用私有网络层学习主任务的模态内部情绪信息, 通过共享层学习主任务的辅助情绪表示以及辅助任务的完整情感表示, 使用自注意力机制融合文本和语音模态信息来学习模态之间的交互信息。在多模态情感分析数据集上的实验结果表明, 本文方法可以通过情感辅助信息大幅度地提升情绪分类任务的性能, 同时情感分类任务的性能也得到一定程度的提升。
参考文献
[1] Morency L P, Mihalcea R, Doshi P. Towards multi-modal sentiment analysis: harvesting opinions from the web // Proceedings of the 13th International Con-ference on Multimodal Interfaces. Alicante, 2011: 169–176
[2] Zadeh A, Zellers R, Pincus E, et al. Multimodal sentiment intensity analysis in videos: facial gestures and verbal messages. IEEE Intelligent Systems, 2016, 31(6): 82–88
[3] Gao Wei, Li Shoushan, Lee S Y M, et al. Joint learning on sentiment and emotion classification // Proceedings of the 22nd ACM International Confe-rence on Information & Knowledge Management. San Francisco, 2013: 1505–1508
[4] Wang Rong, Li Shoushan, Zhou Guodong, et al. Joint sentiment and emotion classification with integer linear programming // Proceedings of International Conference on Database Systems for Advanced App-lications. Hanoi, 2015: 259–265
[5] Zadeh A, Chen Minghai, Poria S, et al. Tensor fusion network for multimodal sentiment analysis // Pro-ceedings of the 2017 Conference on Empirical Me-thods in Natural Language Processing. Copenhagen, 2017: 1103–1114
[6] Ma Dehong, Li Sujian, Wang Houfeng. Joint learning for targeted sentiment analysis // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, 2018: 4737–4742
[7] Chen Ying, Hou Wenjun, Cheng Xiyao, et al. Joint learning for emotion classification and emotion cause detection // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, 2018: 646–651
[8] Poria S, Cambria E, Hazarika D, et al. Context-dependent sentiment analysis in user-generated videos // Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vancouver, 2017: 873–883
[9] Pérez-Rosas V, Mihalcea R, Morency L P. Utterance-level multimodal sentiment analysis // Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Sofia, 2013: 973–982
[10] Zhang Dong, Wu Liangqing, Li Shoushan, et al. Multi-modal language analysis with hierarchical interaction-level and selection-level attention // Proceedings of ICME 2019. Shanghai, 2019: 724–729
[11] Zhang Dong, Li Shoushan, Zhu Qiaoming, et al. Modeling the clause-level structure to multimodal sentiment analysis via reinforcement learning. Pro-ceedings of ICME 2019.Shanghai, 2019: 730–735
[12] Liu Zhun, Shen Ying, Lakshminarasimhan V B, et al. Efficient low-rank multimodal fusion with modality-specific factors // Proceedings of the 56th Annual Meeting of the Association for Computational Lin-guistics, Volume 1 (Long Papers). Melbourne, 2018: 2247–2256
[13] Bertero D, Siddique F B, Wu C S, et al. Real-time speech emotion and sentiment recognition for interac-tive dialogue systems // Proceedings of the 2016 Con-ference on Empirical Methods in Natural Language Processing. Austin, 2016: 1042–1047
[14] Zadeh A, Liang P P, Mazumder N, et al. Memory fusion network for multi-view sequential learning // Proceedings of the 32nd AAAI Conference on Artifi-cial Intelligence. New Orleans, 2018: 5634–5641
[15] Hazarika D, Poria S, Mihalcea R, et al. ICON: inte-ractive conversational memory network for multimo-dal emotion detection // Proceedings of the 2018 Conference on Empirical Methods in Natural Lan-guage Processing. Brussels, 2018: 2594–2604
[16] Pennington J, Socher R, Manning C. Glove: global vectors for word representation // Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, 2014: 1532–1543
[17] Eyben F, Wöllmer M, Schuller B. Opensmile: the munich versatile and fast open-source audio feature extractor // Proceedings of the 18th ACM Inter-national Conference on Multimedia. Firenze, 2010: 1459–1462
[18] Gu Yue, Yang Kangning, Fu Shiyu, et al. Hybrid attention based multimodal network for spoken lan-guage classification // Proceedings of the 27th Inter-national Conference on Computational Linguistics. Santa Fe, 2018: 2379–2390
[19] Kingma D P, Ba J. Adam: a method for stochastic optimization [EB/OL]. (2014–12–22) [2019–05–15]. https://arxiv.org/pdf/1412.6980.pdf
[20] Poria S, Hazarika D, Majumder N, et al. MELD: a multimodal multi-party dataset for emotion recog-nition in conversations // Proceedings of the 57th Conference of the Association for Computational Linguistics, Volume 1 (Long Papers). Florence, 2019:527–536
[21] Hazarika D, Poria S, Zadeh A, et al. Conversational memory network for emotion recognition in dyadic dialogue videos // Proceedings of the 2018 Confe-rence of the North American Chapter of the Asso-ciation for Computational Linguistics: Human Lan-guage Technologies, Volume 1 (Long Papers). New Orleans, 2018: 2122–2132
Multimodal Emotion Recognition with Auxiliary Sentiment Information
Abstract Different from the previous studies with only text, this paper focuses on multimodal data (text and audio) to perform emotion recognition. To simultaneously address the characteristics of multimodal data, we propose a novel joint learning framework, which allows auxiliary task (multimodal sentiment classification) to help the main task (multimodal emotion classification).Specifically, private neural layers are designed for text and audio modalities from the main task to learn the uni-modal independent dynamics. Secondly, with the shared neural layers from auxiliary task, we obtain the uni-modal representations of the auxiliary task and the auxiliary representations of the main task. The uni-modal independent dynamics is combined with the auxiliary representa-tions for each modality to acquire the uni-modal representations of the main task. Finally, in order to capture multimodal interactive dynamics, we fuse the text and audio modalities’ representations for the main and auxiliary tasks separately to obtain the final multimodal emotion and sentiment representations with the self attention mechanism. Empirical results demonstrate the effectiveness of our approach to multimodal emotion classification task as well as the sentiment classification task.
Key words multimodal; emotion recognition; joint learning; sentiment analysis
doi: 10.13209/j.0479-8023.2019.105
国家自然科学基金(61331011, 61375073)资助
收稿日期: 2019–05–22;
修回日期: 2019–09–19