
“#”表示数字, 所有的词都已小写化
图1 抽取式方法和生成式方法生成的摘要对比
Fig. 1 Summaries generated by extractive and abstractive method
摘要 结合基于自注意力机制的 Transformer 模型, 提出一种基于编码器共享和门控网络的文本摘要方法。该方法将编码器作为解码器的一部分, 使解码器的部分模块共享编码器的参数, 同时使用门控网络筛选输入序列中的关键信息。相对已有方法, 所提方法提升了文本摘要任务的训练和推理速度, 同时提升了生成摘要的准确性和流畅性。在英文数据集 Gigaword 和 DUC2004 上的实验表明, 所提方法在时间效率和生成摘要质量上, 明显优于已有模型。
关键词 生成式; 文本摘要; 自注意力机制; 编码器共享; 门控网络
自动文本摘要旨在对给定的一段长文本进行压缩、精简, 并产生一段简洁、流畅且保留原文关键信息的短文本。文本摘要的意义在于缓解互联网时代人们面临的信息过载问题, 通过对文本进行压缩, 提取其主要信息, 可以大大降低用户的阅读成本, 帮助用户更高效地从互联网获取所需信息。
目前文本摘要方法可分为两大类: 抽取式方法(extractive)和生成式方法(abstractive)。图 1 展示两种方法生成的摘要。抽取式方法是按照一定的规则, 在原文中抽取句子、短语和词组成摘要。该方法产生的摘要通常较为冗长, 且多个摘要句之间可能产生语义不连贯的现象。生成式方法是通过阅读原文内容提取关键信息, 并重新组织文字生成摘要, 与人工做摘要的方式相似, 生成的摘要也较简洁, 近年来得到广泛应用。
本文提出的方法属于生成式方法。生成式方法遵循编码–解码框架, 编码器用于阅读原文, 并提取主要信息, 解码器根据编码器提取的信息生成摘要。以往的生成式方法通常使用循环神经网络作为编码器和解码器, 这些方法在文本摘要领域取得很好的效果。但是, 循环神经网络的结构特点——逐词处理序列, 使其难以并行化, 无论在训练阶段还是测试阶段, 效率都比较低, 当序列较长时, 这个问题尤为突出。
“#”表示数字, 所有的词都已小写化
图1 抽取式方法和生成式方法生成的摘要对比
Fig. 1 Summaries generated by extractive and abstractive method
Vaswani 等[1]提出完全基于注意力机制的 Trans-former 模型, 不使用循环神经网络, 可以减少训练时间, 并刷新机器翻译任务的表现。鉴于 Trans-former 良好的并行能力, 本文基于 Vaswani 等[1]提出的编码器共享和门控网络的 Transformer, 在解码器与编码器之间进行参数共享, 减少模型的参数, 强化对编码器的训练, 并使用多层感知机作为门控网络, 用以控制从编码器到解码器的信息流, 仅传递关键信息, 使得模型更关注原文中的重要信息, 以便生成更准确精简的摘要。
文本摘要任务在形式上与机器翻译任务相似, 输入为一个序列, 输出也是一个序列。近年来, 许多机器翻译领域的方法被应用到文本摘要任务中。Sutskever 等[2]提出 seq2seq 模型, 包括编码器和解码器两部分。编码器将输入序列映射到固定长度的向量上, 解码器根据该向量解码得到输出序列, 该模型用于解决英–法翻译问题, 取得巨大成功。Ba-hdanau 等[3]提出注意力机制, 使得解码器在产生输出序列时, 不只是利用一个固定长度的向量, 而是可以回看输入序列的信息, 大大提升机器翻译的效果。此后, 注意力机制成为处理所有序列到序列问题(如机器翻译、文本摘要和语音识别等)时必不可少的一个模块。
Rush 等[4]提出第一个生成式文本摘要方法, 使用带注意力机制的卷积神经网络作为编码器, 神经网络语言模型作为解码器, 并第一次使用 Giga-word 数据集和 DUC2004 数据集完成文本摘要任务。Hu 等[5]提出一个新的中文文本摘要数据集LCSTS来填补中文文本摘要数据上的空缺, 推动国内文本摘要领域的发展。Chopra 等[6]在文献[4]的基础上进行改进, 使用循环神经网络作为解码器, 编码器仍使用卷积神经网络, 提升了生成摘要的质量。Nallapati 等[7]提出完全基于循环神经网络的seq2seq 模型, 编码器和解码器都使用循环神经网络, 同时引入一些词汇特征(如词性和命名实体等), 进一步提升模型表现。针对未登录词问题(部分低频词不在词表中, 无法编码, 也无法生成为摘要序列的一部分), Gu 等[8]提出拷贝机制(copy mechani-sm), 使得模型在生成摘要时, 可以选择从输入序列复制一段话, 而不仅仅是从词汇表生成词语, 解决了上述问题。Zhou 等[9]提出选择性编码模型, 用于对输入序列的词进行筛选, 只保留关键信息, 从而实现对输入序列的选择性编码。Lin 等[10]提出全局编码模型, 使用卷积门控网络对输入序列进行筛选, 在文本摘要任务上达到领先水平。Paulus 等[11]将强化学习引入文本摘要中, 直接针对摘要的评分指标进行优化, 减轻了曝光偏差问题, 进一步提升摘要表现。Vaswani 等[1]提出新的序列到序列模型 Trans-former, 既不使用循环神经网络, 也不使用卷积神经网络, 而是完全依赖于注意力机制, 在序列自身各个词之间计算注意力权重, 得到每个词的上下文表示, 因此又称为自注意力机制。该模型的训练时间远远少于此前的序列到序列模型, 并刷新了机器翻译任务的BLEU得分。
本文基于 Vaswani[1]等提出的 Transformer 模型进行改进, 图 2 展示本文模型, 包含编码器、门控网络和解码器 3 个部分。编码器用于读取输入序列x={x0, x1, …, xn}, 并产生该序列对应的向量表示h= (h0, h1, …, hn); 门控网络用于对编码器的输出 h 进行筛选, 去除无用信息, 即对每个向量表示 hi 产生一个实数值 gi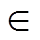 [0, 1], 进一步得到
[0, 1], 进一步得到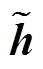 =(g0h0, g1h1, …, gnhn), 以达到筛选的目的; 解码器根据
=(g0h0, g1h1, …, gnhn), 以达到筛选的目的; 解码器根据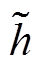 来产生摘要序列。
来产生摘要序列。
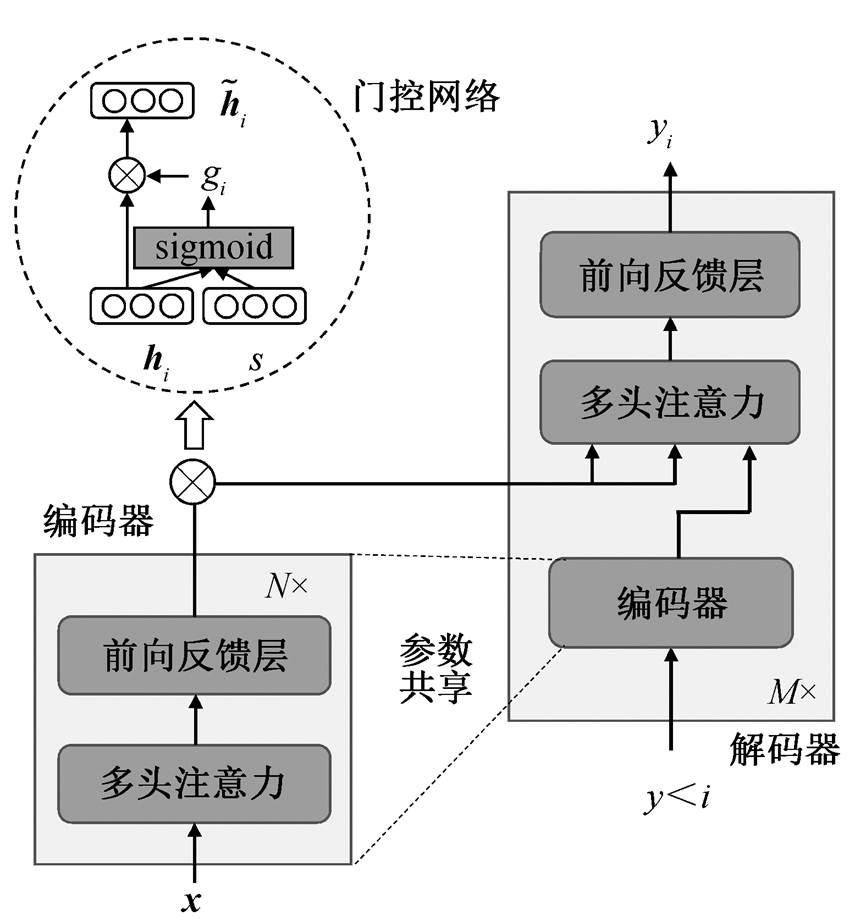
图2 本文模型概览
Fig. 2 An overview of proposed model
给定一段输入序列 x={x1, x2, …, xn}, 其中n表示序列长度。文本摘要系统的目标是输出一段摘要序列 y={y1, y2, …, ym}, 其中 m (m≤n)为摘要序列长度。在训练阶段, 我们训练模型, 使其生成的摘要y 尽量与参考摘要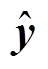 相同; 在测试阶段, 模型根据输入序列x来生成摘要序列。
相同; 在测试阶段, 模型根据输入序列x来生成摘要序列。
编码器的作用是读取输入序列, 并对每个词产生一个向量表示。为了高效地对输入序列进行编码, 我们使用基于自注意力机制的编码器, 相对于循环神经网络, 不需要逐词处理输入序列, 而是通过自注意力机制同时计算每个词的上下文向量, 因此有良好的并行能力, 计算复杂度较低。
如图 2 所示, 编码器可堆叠 N 层, 每层包括多头注意力层和前向反馈层。多头注意力层用于在输入序列内计算每个词关于其他词的注意力权重, 以便得到每个词的上下文表示, “多头”的意思是将输入映射到多个子空间, 并在这些子空间内计算上下文表示, 最后将计算结果拼接在一起, 如式(1)所示。
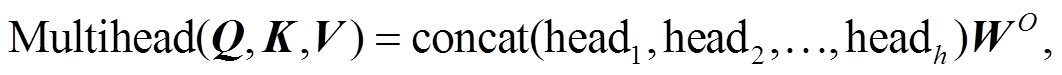 (1)
(1)其中,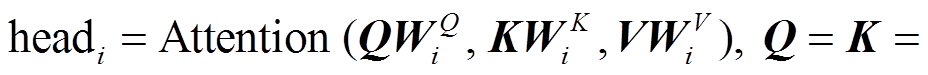
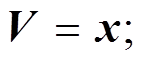 参数矩阵
参数矩阵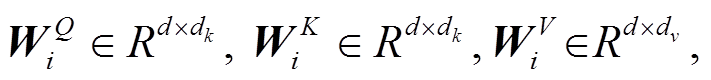
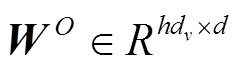 表示线性转换, 用于将输入映射到不同的子空间; dk和dv表示子空间的维度; h表示多头注意力层的头数; d 表示模型隐藏层大小。注意力函数为放缩点积注意力函数, 如式(2)所示:
表示线性转换, 用于将输入映射到不同的子空间; dk和dv表示子空间的维度; h表示多头注意力层的头数; d 表示模型隐藏层大小。注意力函数为放缩点积注意力函数, 如式(2)所示:
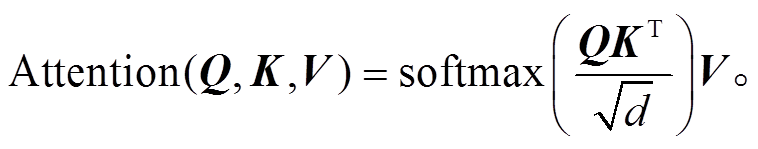 (2)
(2)
前向反馈层(feed forward networks, FFN)作用于多头注意力层的输出, 包含两个线性转换操作和ReLU激活函数[12], 用于增加模型的非线性拟合能力, 如式(3)所示:
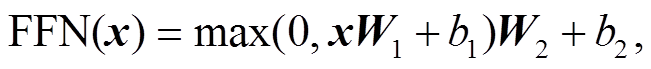 (3)
(3)其中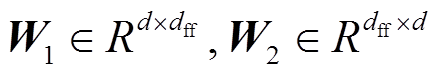 为线性转换; dff 为该层的隐藏层大小, b1和b2为偏置。
为线性转换; dff 为该层的隐藏层大小, b1和b2为偏置。
本文使用的参数为 h=4, d=256, dff=1024, dk=dv =d/h=64, 编码器层数 N=2。值得注意的是, 本文模型的编码器不仅负责对输入序列进行编码, 也会作为解码器的一部分, 对摘要序列进行编码。
输入序列中通常包含许多词, 其中只有少部分词包含整个序列的关键信息, 这些关键信息也正是模型在生成摘要时所需要的。为了使模型能对输入序列的关键信息进行筛选, 我们提出如图 2 所示的门控网络。
门控网络用于控制从输入序列到输出序列的信息流, 去除无用信息, 使解码器能更专注于从关键信息中生成摘要。门控网络的输入为原文序列的句子表示 s 以及该序列中某个词的词表示 hi; 输出为对 hi进行筛选得到的新向量表示 。参考 Devlin 等[13]的工作, 本文也将 h0 (输入序列的起始标识符对应的隐藏层表示)作为输入序列向量的表示, 即 s=h0。对于每个词表示 hi, 门控网络都会生成一个阈值gi:
。参考 Devlin 等[13]的工作, 本文也将 h0 (输入序列的起始标识符对应的隐藏层表示)作为输入序列向量的表示, 即 s=h0。对于每个词表示 hi, 门控网络都会生成一个阈值gi:
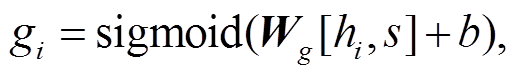 (4)
(4)其中, 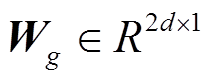 为线性转换, b 表示偏置。gi 越大, 表示该词越关键。通过 gi 来控制 hi 通往解码器的信息量, 得到筛选后的向量
为线性转换, b 表示偏置。gi 越大, 表示该词越关键。通过 gi 来控制 hi 通往解码器的信息量, 得到筛选后的向量 , 如式(5)所示:
, 如式(5)所示:
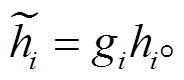 (5)
(5)
对每个词进行筛选后, 得到整个序列的向量表示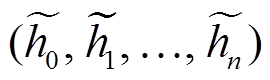 。然后, 此向量序列将传递给解码器, 用于生成摘要。
。然后, 此向量序列将传递给解码器, 用于生成摘要。
解码器根据门控网络的输出信息生成摘要序列。首先, 读取已经产生的摘要序列 y<i={y0, y1, …, yi−1}(开始时摘要序列仅包含开始标识符, 如“”), 并对其进行编码, 进而产生向量序列 s<i={s0, s1, …, si}。然后根据 s<i 和门控网络的输出, 预测摘要序列的下一个词 yi。依此类推, 最终得到摘要序列。
解码器的功能之一是对已经产生的摘要序列进行编码, 得到其向量表示。这一点与编码器的功能相似, 不同之处在于, 编码器是对输入序列进行编码, 而解码器该是对摘要序列进行编码, 但这并不影响两个模块功能上的相似性。基于这种相似性, 我们提出编码器共享(encoder-sharing)的解码器, 将编码器作为解码器的模块之一, 把已生成序列 y<i 的编码任务交给编码器。与文献[1]相比, 本文方法的优势如下。
1)整合了冗余的功能模块, 减少了模型参数, 降低模型复杂度。文献[1]使用一个额外的多头注意力层对摘要序列进行编码, 本文去掉这个模块, 将编码任务交给编码器。
2)文献[1]中, 编码器的训练数据只有输入序列, 本文还包括摘要序列, 通过更多数据的训练, 能够增强编码器的编码能力。
3)通过使用同一个编码器, 将输入序列和摘要序列映射到同一向量空间。解码器需要在两个序列之间计算注意力权重, 两个向量表示处于同一个向量空间, 更有利于点积注意力函数的计算, 能更清楚地挖掘输入序列与输出序列之间的关系。
解码器还包含另外两个模块: 多头注意力层和前向反馈层。多头注意力层用于在输入序列和摘要序列之间计算注意力权重(式(1)), 与编码器中的多头注意力层不同的是 Q=s<i, K=V=。前向反馈层用于增加模型的非线性拟合能力(式(2))。经过这两个层之后, 得到输出向量 mi, 最终经过 softmax 层预测下一个词, 如式(6)所示:
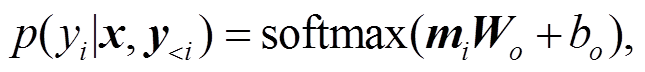 (6)
(6)其中,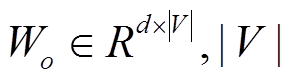 表示词汇表大小,
表示词汇表大小,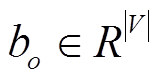 表示偏置。解码器可堆叠M层, 本文中 M=2, 其中多头注意力层和前向反馈层的参数配置与编码器相同。
表示偏置。解码器可堆叠M层, 本文中 M=2, 其中多头注意力层和前向反馈层的参数配置与编码器相同。
在训练阶段, 模型的目标是在给定输入序列 x后, 最大化地得到摘要序列 y 的概率, 因此目标函数是最小化的负对数似然函数:
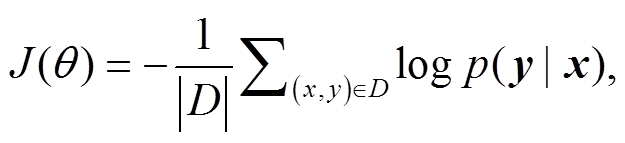 (7)
(7)其中, D 代表训练集, ![]() 表示模型参数集合,
表示模型参数集合, 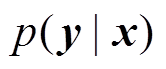 表示给定输入序列 x 的情况下, 得到摘要序列 y 的概率。
表示给定输入序列 x 的情况下, 得到摘要序列 y 的概率。
本文使用 Gigaword 数据集和 DUC2004 数据集, 详细情况如表 1 所示。对于 Gigaword 数据集, 我们使用 Rush[4]等预处理后的版本, 处理过程如下: 1) 所有英文单词都小写化; 2)数字用“#”代替; 3)出现次数少于 5 次的单词用未登录词标识符“
我们使用 ROUGE 指标[14]评估生成摘要的质量。ROUGE 指标主要评估模型生成摘要与标准摘要之间的重合度, 重合度越高, ROUGE 得分也越高。ROUGE 从 3 个粒度来评判重合度: 词、二元短语和最长公共子序列, 对应 3 个指标: ROUGE-1, ROUGE-2 和 ROUGE-L, 每个指标都包含精确率、召回率和 F1 值。F1 值用来评判模型在 Gigaword数据集上的效果, 召回率用来评判模型在 DUC2004数据集上的效果。
表1 Gigaword和DUC2004数据集的详细情况
Table 1 Details about Gigaword and DUC2004 dataset
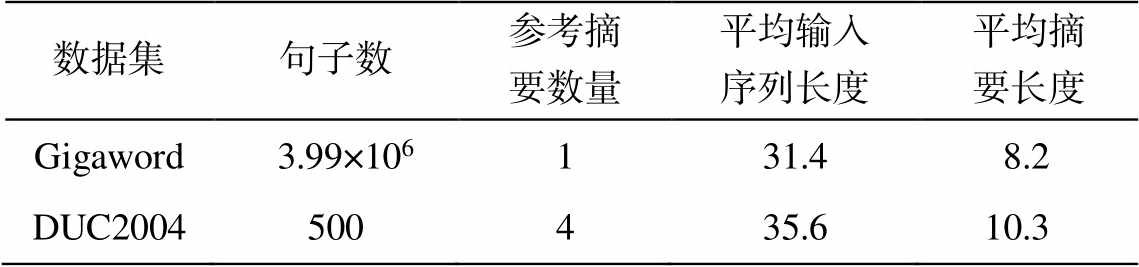
数据集句子数参考摘要数量平均输入序列长度平均摘要长度 Gigaword 3.99×106131.48.2 DUC2004500435.610.3
我们基于 Gigaword 训练集的源文本和摘要文本建立源词典和目标词典, 其大小分别为 90000 和68883; 词向量维度大小为 256; 编码器和解码器的层数都设置为 2, 所有的多头注意力层都包含 4 个头, 隐藏层神经元个数为 256; 前向反馈层的中间层大小为 1024; 使用位置编码[1], 以便利用序列的顺序信息, 各个网络层之间采用残差连接[15], 避免梯度消失; 使用 dropout 方法[16]来避免过拟合, 比率设置为0.1。
在训练阶段, 随机打乱训练集, 采用批量训练, 批大小设置为 64; 使用 Adam 优化器[17], 初始学习率设为 0.001, 在训练集上每训练两次后, 将学习率衰减至当前的一半。训练 10 个 epoch 后, 模型趋于收敛。使用一块 Nvidia GTX 1080ti 显卡进行训练。
在测试阶段, 使用束搜索方法来选择候选摘要序列, 束宽度设置为 5。束搜索倾向于选择较短的摘要句, 为了避免此缺点, 我们将搜索过程中各个候选摘要的得分除以其长度, 用以鼓励模型生成更长的摘要。
本文提出的两个模型如下。
ES-Trans: 编码器共享的 Transformer, 在文献[1]的基础上进行改进, 将编码器作为解码器的一部分。
Gated-ES-Trans: 在 ES-Trans 的基础上, 引入门控网络, 用以控制从编码器到解码器的信息流。
我们将本文模型与以下基线模型进行对比。
ABS[4]: 使用卷积神经网络作为编码器, 神经网络语言模型 NNLM 作为解码器, 首次在 Gigaword数据集上评估其文本摘要方法。
RAS[6]: 使用卷积神经网络作为编码器, 循环神经网络作为解码器。
Feats2s[7]: 编码器和解码器都使用循环神经网络, 是第一个完全基于循环神经网络的模型, 还使用了多个特征, 如词性和实体信息等。
Entail-s2s[18]: 基于循环神经网络, 引入门控网络和文本蕴涵任务来进行多任务训练, 增强编码器提取关键信息的能力。
Seq2seq: 使用双向门控循环单元(gated recurrent unit, GRU)[19]作为编码器, 单向 GRU 作为解码器, 使用点积注意力函数。本文编写代码, 并在两个数据集上进行实现。
Transformer[1]: 既不使用循环神经网络, 也不使用卷积神经网络, 而是完全依赖于注意力机制。本文编写代码, 并在数据集上实验。
我们在英文摘要数据集 Gigaword 和 DUC2004上进行测试, 并报告各个模型对应的 ROUGE-1, ROUGE-2 和 ROUGE-L 得分, 使用封装了 ROUGE脚本的 pyrouge 工具(https://pypi.org/project/pyrouge)来计算得分。此外, 我们列出每个基线模型在训练集上训练一次的时间以及推理速度(推理阶段采用束搜索方法, 束宽度设置为 8), 用来对此模型的时间效率。
表 2 展示各个模型在 Gigaword 数据集上的ROUGE 指标的 F1 评分以及训练时间。本文模型Gated ES-Trans 在 ROUGE-1、ROUGE-2 和ROUGE- L 指标上的得分都明显优于其他模型, 与已有的最优模型 Entail-s2s 相比, 得分分别提升 0.82, 0.24 和0.28; 比 RAS 模型得分提升分别超过2.0, 1.5 和 2.0, 同时训练时间仅为其 1/3 甚至更少。Transformer 模型相比 , 本文模型 ES-Trans 大幅度提升 ROUGE 得分, 分别达到 2.90, 1.93 和 2.75。此外, 相对于已有的生成式方法, 本文方法大大缩短训练时间, 提升了推理速度, 加入门控网络后的 Gated ES-Trans 模型, 取得更高的 ROUGE得分, 说明了门控网络的有效性。
表2 在Gigaword数据集上各模型的ROUGE F1评分以及训练和测试时间
Table 2 ROUGE F1 score and training and testing cost of each model on Gigaword dataset
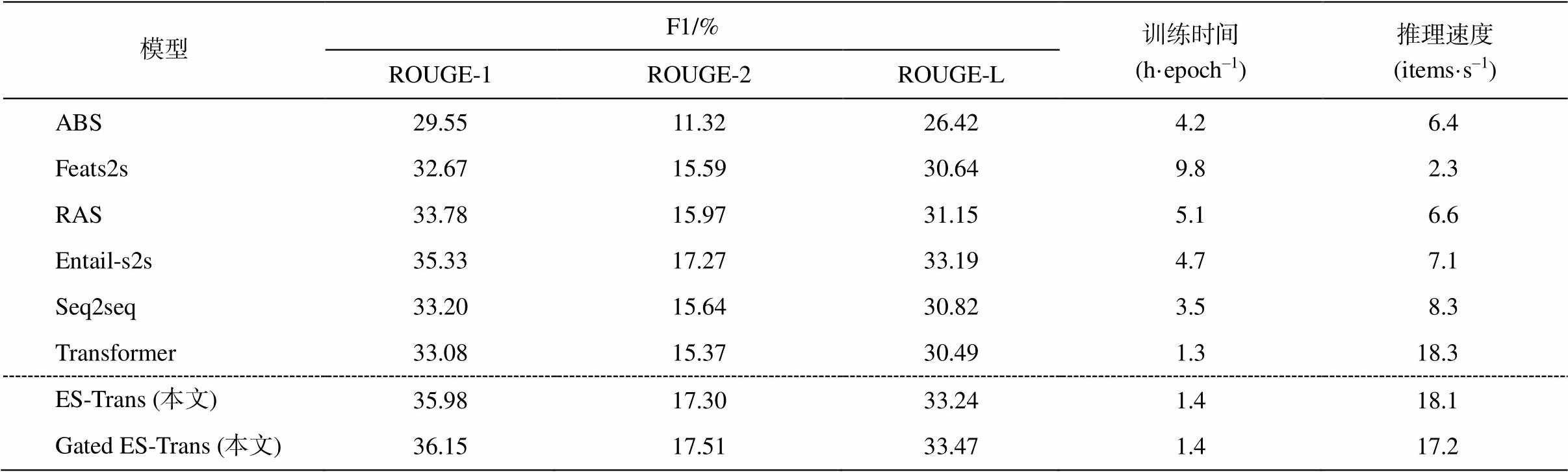
模型F1/%训练时间(h·epoch–1)推理速度(items·s–1) ROUGE-1ROUGE-2ROUGE-L ABS29.5511.3226.424.26.4 Feats2s32.6715.5930.649.82.3 RAS33.7815.9731.155.16.6 Entail-s2s35.3317.2733.194.77.1 Seq2seq33.2015.6430.823.58.3 Transformer33.0815.3730.491.318.3 ES-Trans (本文)35.9817.3033.241.418.1 Gated ES-Trans (本文)36.1517.5133.471.417.2
表 3 展示各个模型在 DUC2004 测试集上的ROUGE 召回率, 本文使用在 Gigaword 数据集上训练好的模型, 直接在 DUC2004 数据集上进行测试。可见, 本文方法 Gated ES-Trans 比 RAS 和Transformer 的 ROUGE-2 和 ROUGE-L 有明显提升, 与 Entail-s2s 的效果相当, ROUGE-1 和 ROUGE-2 评分稍低, 但ROUGE-L评分更高。
表3 在DUC2004测试集上各模型的ROUGE召回率评分(%)
Table 3 ROUGE recall of each model on DUC2004 dataset (%)
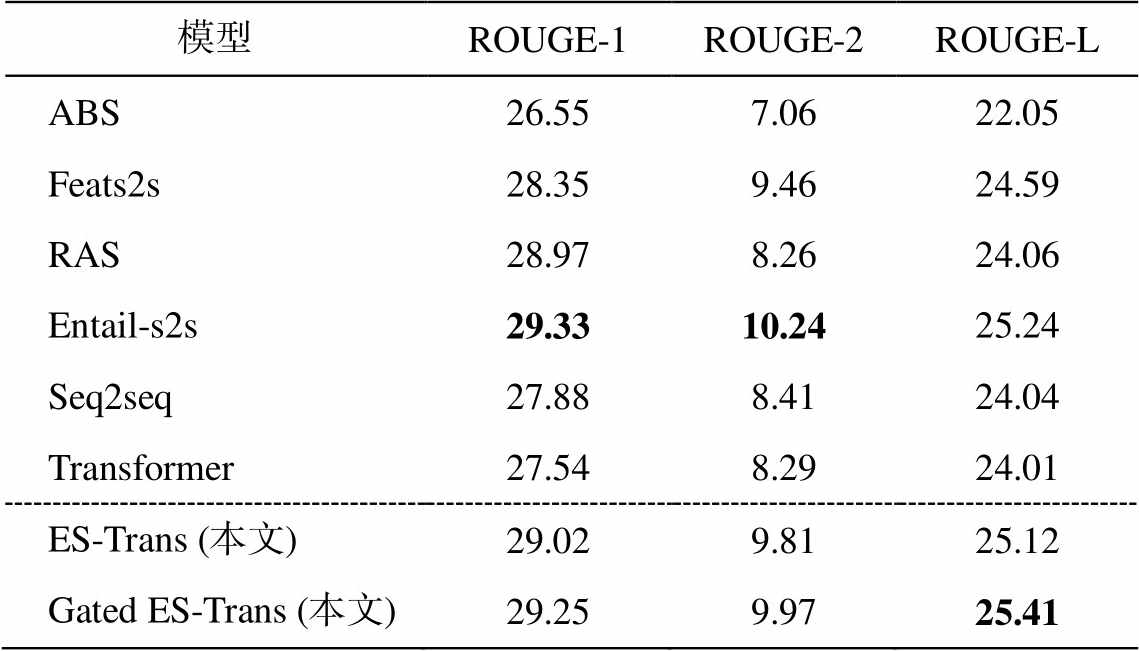
模型ROUGE-1ROUGE-2ROUGE-L ABS26.557.0622.05 Feats2s28.359.4624.59 RAS28.978.2624.06 Entail-s2s29.3310.2425.24 Seq2seq27.888.4124.04 Transformer27.548.2924.01 ES-Trans (本文)29.029.8125.12 Gated ES-Trans (本文)29.259.9725.41
说明: 加粗数字表示最优结果。
本节从 Gigaword 测试集中摘取两个例子, 展示本文最终模型与 Vaswani 等[1]的 Transformer 模型在两个示例上的摘要结果, 对比两个方法生成摘要的正确性和完整性, 如表4所示。
例 1 的主要内容为“斯里兰卡因战争动荡关闭学校”, 本文模型产生的摘要基本上完整地概括了这一内容, 与参考摘要相差无几。Transformer 模型产生的摘要明显地提取错重点, 其生成摘要内容“斯里兰卡发起对叛军的军事行动”虽然在原文中有所体现, 但并不是原文所要表达的主要意思。第二个示例描述了有关尼亚加拉飞机失事以及人员伤亡情况。Trans-former 模型产生的摘要, 正确地说明了人员伤亡情况, 但未说明原因, 存在信息遗漏; 本文模型完整地概括了伤亡情况及原因。两个例子证明了本文模型生成摘要的正确性及完整性。
本文提出基于编码器共享和门控网络的生成式文本摘要方法, 将编码器作为解码器的一部分, 使编码器不只对输入序列进行编码, 也能对已产生的摘要序列进行编码, 进而增强对编码器的训练; 同时引入门控网络, 对输入序列的信息进行筛选, 保留关键信息, 使得模型能根据原文的关键信息来生成摘要。在英文摘要数据集 Gigaword 和 DUC 2004上的实验证明, 本文提出的基于编码器共享和门控网络的方法能明显提升模型的训练速度和生成摘要的质量。
表4 Gigaword数据集中的两个示例以及模型对应的摘要
Table 4 Two examples from Gigaword and corresponding summarization

例1输入the sri lankan government on wednesday announced the closure of government schools with immediate effect as a military campaign against tamil separatists escalated in the north of the country . 参考摘要sri lanka closes schools as war escalates Transformer摘要sri lanka launches campaign against tamil rebels Gated ES-Trans摘要sri lanka closes schools as military campaign escalates 例2输入at least ## people were killed when a nigeria airways airliner crashed on landing monday at kaduna airport in the north of the country , airport officials said. 参考摘要nigerian plane crashes on landing killing at least ## Transformer摘要at least ## killed in nigeria Gated ES-Trans摘要at least ## killed in nigerian airways plane crash
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // 31st Conference on Neural Information Processing Systems. Long Beach: MIT Press, 2017: 6000–6010
[2] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks // 28th Conference on Neural Information Processing Systems. Montreal: MIT Press, 2014: 3104–3112
[3] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translation [EB/OL]. (2016–05–19) [2019–05–20]. https://arxiv. org/abs/1409.0473
[4] Rush A M, Chopra S, Weston J. A neural attention model for abstractive sentence summarization // Pro-ceedings of the 2015 Conference on Empirical Me-thods in Natural Language Processing. Lisbon: ACL Press, 2015: 379–389
[5] Hu Baotian, Chen Qingcai, Zhu Fangze. LCSTS: a large scale chinese short text summarization dataset // Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon: ACL Press, 2015: 1967–1972
[6] Chopra S, Auli M, Rush A M. Abstractive sentence summarization with attentive recurrent neural net-works // The 2016 Conference of the North Ameri- can Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego: ACL Press, 2016: 93–98
[7] Nallapati R, Zhou B, Santos C, et al. Abstractive text summarization using sequence-to-sequence RNNs and beyond // Proceedings of the 20th SIGNLL Confer-ence on Computational Natural Language Learning. Berlin: ACL Press, 2016: 280–290
[8] Gu Jiatao, Lu Zhengdong, Li Hang, et al. Incorpo-rating copying mechanism in sequence-to-sequence learning // Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: ACL Press, 2016: 1631–1640
[9] Zhou Qingyu, Yang Nan, Wei Furu, et al. Selective encoding for abstractive sentence summarization // Proceedings of the 55th Annual Meeting of the Asso-ciation for Computational Linguistics. Vancouver: ACL Press, 2017: 1095–1104
[10] Lin Junyang, Sun Xu, Ma Shuming, et al. Global encoding for abstractive summarization // Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne: ACL Press, 2018: 163–169
[11] Paulus R, Xiong Caiming, Socher R. A deep reinfor-ced model for abstractive summarization [EB/OL]. (2017–11–13)[2019–05–20]. https://arxiv.org/abs/170 5.04304
[12] Nair V, Hinton G E. Rectified linear units improve restricted Boltzmann machines // Proceedings of the 27th International Conference on Machine Learning. Haifa: Omnipress, 2010: 807–814
[13] Devlin J, Chang M, Lee K. BERT: pre-training of deep bidirectional transformers for language unders-tanding [EB/OL]. (2019–05–24) [2019–05–30]. https:// arxiv.org/abs/1810.04805
[14] Lin C. Rouge: a package for automatic evaluation of summaries // Proceedings of the ACL Workshop: Text Summarization Braches Out. Barcelona, 2004: 74–81
[15] He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition // 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, 2016: 770–778
[16] Srivastava N, Hinton G E, Krizhevsky A, et al. Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research. 2014, 15(1): 1929–1958
[17] Kingma D P, Ba J. Adam: a method for stochastic optimization [EB/OL]. (2017–01–30) [2019–05–20]. https://arxiv.org/abs/1412.6980
[18] Li Haoran, Zhu Junnan, Zhang Jiajun, et al. Ensure the correctness of the summary: incorporate entail-ment knowledge into abstractive sentence summariz-ation // COLING 2018. Santa Fe, 2018: 1430–1441
[19] Cho K, Merrienboer B, Gulcehre C, et al. Learning phrase representations using rnn encoder-decoder for statistical machine translateion // Proceddings of the 2014 conference on Empirical Methods in Natural Language Processing. Doha: ACL Press, 2014: 1724–1734
An Abstractive Summarization Method Based on Encoder-Sharing and Gated Network
Abstract This paper proposed an abstractive summarization method based on self-attention based Transformer model, which regarded encoder as part of decoder, and used gated network to control the information flow from encoder to decoder. Compared with the existing methods, proposed method improves the training and inference speed of text summarization task, and improves the accuracy and fluency of generating summary. Experiments on English summarization dataset Gigaword and DUC2004 demonstrate that proposed model outperforms the baseline models on both the quality of summarization and time efficiency.
Key words abstractive; summarization; self-attention; encoder-sharing; gated network
doi: 10.13209/j.0479-8023.2019.100
广东省科技计划项目(2015A030401057, 2016B030307002, 2017B030308007)资助
收稿日期: 2019–05–22;
修回日期: 2019–09–25