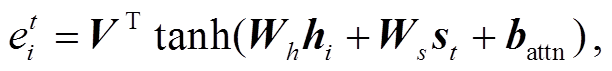 (1)
(1)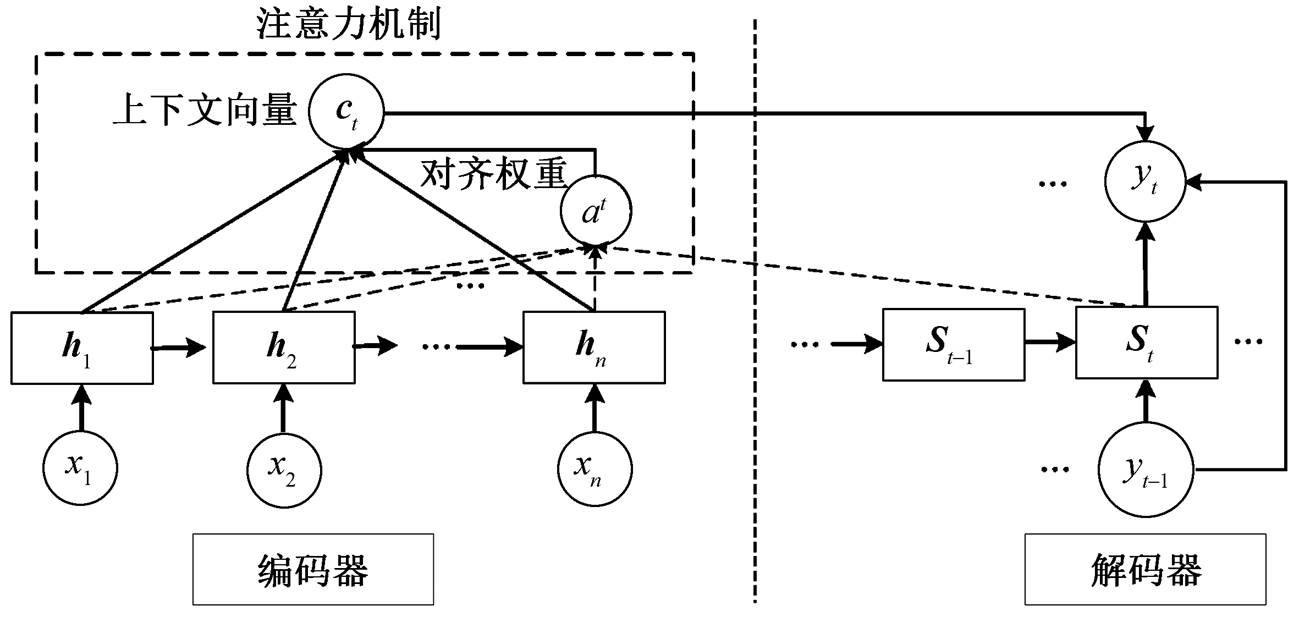
图1 基于注意力机制的复述生成模型
Fig. 1 Paraphrase generation model based on attention mechanism
摘要 基于神经网络编码–解码框架的复述生成模型存在两方面的问题: 1)生成的复述句中存在实体词不准确、未登录词和词汇重复生成; 2)复述平行语料的有限规模限制了编码器的语义学习能力。针对第一个问题, 本文提出在解码过程中融合注意力机制、复制机制和覆盖机制的多机制复述生成模型, 利用复制机制从原句复制词语来解决实体词和未登录词生成问题; 利用覆盖机制建模学习注意力机制的历史决策信息来规避词汇重复生成。针对第二个问题, 基于多任务学习框架, 提出在复述生成任务中联合自编码任务, 两个任务共享一个编码器, 同时利用平行复述语料和原句子数据, 共同增强复述生成编码器的语义学习能力。在Quora 复述数据集上的实验结果表明, 提出的联合自编码的多机制融合复述生成模型有效地解决了复述生成的问题, 并提高了复述句的生成质量。
关键词 复述生成; 自编码; 多任务学习; 多机制融合; 注意力机制; 复制机制; 覆盖机制
复述生成是自然语言处理的关键技术之一, 广泛应用于机器翻译[1]、文本摘要[2]和自动问答[3]等任务中。在机器翻译和文本摘要任务中, 利用复述可以生成多个参考译文和文摘, 使得自动评测系统的性能得到有效的提升。在自动问答中, 利用复述可以扩展检索文本, 提高检索系统的性能。主流的复述生成框架主要包括基于统计机器翻译以及基于神经网络的两种模型。近年来, 基于神经网络的复述生成方法成为重要的研究方向之一。本文主要针对基于神经网络编码–解码框架的复述生成方法展开研究。
神经网络模型在特征学习方面展示出明显优势, 研究者利用神经网络编码–解码框架建模复述生成[4–5]。在该框架中, 编码器用于获取原句子的语义表示, 解码器依赖于原句子的语义表示生成目标复述句, 学习语义表示成为复述生成的研究重点。Hasan 等[5]在基于编码–解码框架的模型中加入注意力机制, 改进长句生成质量。但该模型生成的复述句子存在实体词不准确、未登录词和词汇重复问题。此外, 由于复述平行语料资源十分有限, 已有方法对复述语料的利用不够充分, 在语义学习方面仍有改进的空间。
为了解决以上问题, 本文提出多机制融合的复述生成模型和联合自编码任务的复述生成模型。在多机制融合的模型中, 我们在编码–解码框架中的解码端融合注意力机制、复制机制和覆盖机制。其中, 复制机制从原句中复制词汇生成在目标句中, 以解决实体词和未登录词(低频词)的生成问题; 覆盖机制建模注意力机制的历史决策信息, 约束当前注意力机制的决策, 改善词汇重复生成的问题。同时, 为了充分利用有限的复述语料, 提高模型的语义学习能力, 本文基于多任务学习框架, 提出在复述生成任务中联合自编码任务, 两个任务共享一个编码器。在复述生成任务中, 模型利用平行复述语料学习编码器, 从而生成对应复述句; 在自编码任务中, 模型利用原句子学习编码器, 并解码生成原句子。
传统的复述生成方法主要采用基于规则[6]、基于复述模板[7]和基于词典[8]的方法。赵世奇[7]通过抽取复述模板进行模板匹配生成复述, 此类方法能够生成含有复杂句法变化的复述句, 但模板的覆盖率较低, 无法保证生成任意句子的复述句。之后提出的基于统计机器翻译的方法[9–10]在一定程度上提高了复述生成的质量。Wubben 等[10]提出一种基于短语 SMT 的框架, 利用大量单语可比新闻摘要作为训练数据, 但受模型学习能力的限制, 复述生成质量仍有待提高。
近年来, 复述生成的研究方法集中在基于神经网络的编码–解码模型。Prakash 等[4]通过深度网络来提高模型性能, 在编码–解码模型的 LSTM 网络层间加入残差网络。Gupta 等[11]在编码–解码模型的基础上, 加入变分机制, 引入随机采样学习多样性的复述生成。Li 等[12]将强化学习应用于编码–解码框架的复述生成任务中, 模型可以利用其他目标函数优化复述生成。Florin 等[13]在神经机器翻译编码–解码框架中利用迁移学习, 将训练好的文本蕴含任务的模型参数迁移到复述生成任务中, 解决复述语料不足导致模型训练不充分的问题。Iyyer 等[14]将句法结构信息作为输入变量约束生成的复述句, 学习可控制的复述生成。
虽然前人方法取得不错的成绩, 但利用编码–解码框架进行复述生成时, 复述句存在实体词无法准确生成、未登录词和词汇重复等问题。对此, 在前人研究的基础上, 本文联合自编码任务的多机制融合模型能够有效地改进复述生成质量。
复述生成任务是同语言内输入句子到输出句子间的转换问题, 即给定长度为 n 的输入原句 X = [x1, …, xn], 生成长度为 m 的复述句 Y =[y1, …, ym], 要求生成句 Y 与输入原句 X 语义一致, 来且在表现形式上有所差别。我们采用基于深度神经网络的编码–解码框架[15–16]构建复述生成模型, 在解码时, 采用注意力机制学习当前生成词最相关的上下文信息。引入复制机制, 从原句中复制词汇, 提高命名实体、未登录词和低频词的生成质量, 并融合覆盖机制, 对注意力机制的历史决策信息建模, 减少词汇重复生成。
基于注意力机制的复述生成模型如图 1 所示。我们采用循环神经网络 LSTM 作为编码器和解码器。其中, 编码器依次读取原句 X 中的每个词, 生成原句语义表示, 解码器根据原句语义表示, 逐词生成目标复述句。我们在解码过程中引入注意力机制[15–16], 根据当前解码器状态 st 和编码器状态 H= [h1, …, hn]动态地计算上下文语义向量 ct, 其中注意力权重越大的词, 在当前位置被给予越多的关注。
(1)
图1 基于注意力机制的复述生成模型
Fig. 1 Paraphrase generation model based on attention mechanism
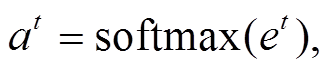 (2)
(2)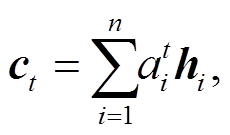 (3)
(3)
其中, 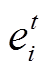 表示当前解码器状态 st 与编码器状态
表示当前解码器状态 st 与编码器状态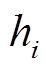 之间的对齐得分,
之间的对齐得分, 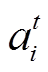 表示归一化后词的注意力权重。
表示归一化后词的注意力权重。
在解码时, 解码器利用 softmax 分类器预测下一个词的生成概率:
Pvocab(w)=softmax(U(tanh(V[yt−1, st, ct]+bv))+bu), (4)
其中, st =LSTM(yt−1, st−1), st表示当前解码器隐藏层状态;yt−1表示上一个已生成词的词向量;U, V,bv和bu表示可学习参数。
给定复述句对(X,Y), 基于注意力机制的复述生成模型的训练目标是最大化句子Y的生成概率, 即最大化如下对数似然函数:
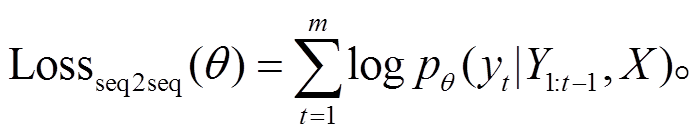 (5)
(5)本文在基于注意力机制的复述生成模型上融合复制机制[17–18]和覆盖机制[19], 如图 2 所示。我们对原句中的未登录词采用不同于集内词的解码方式。在解码时, 设置含有生成模式和复制模式两种模式的解码器。生成模式对集内词进行预测, 概率计算公式同式(4)。复制模式利用复制机制, 计算原句中未登录词的复制概率, 解决未登录词无法生成的问题。如图 2 所示, 在解码 t=3 时刻, 词 x3 在集内词表中不存在, 解码器选择复制模式, 利用复制机制从原句中复制词x3, 作为当前时刻的生成词。
在预测词语时, 融合复制机制的解码模型同时考虑原句中的词和目标词典中的词, 计算公式如下:
P(w)=PgenPvocab(w)+(1−Pgen)Pc(w), (6)
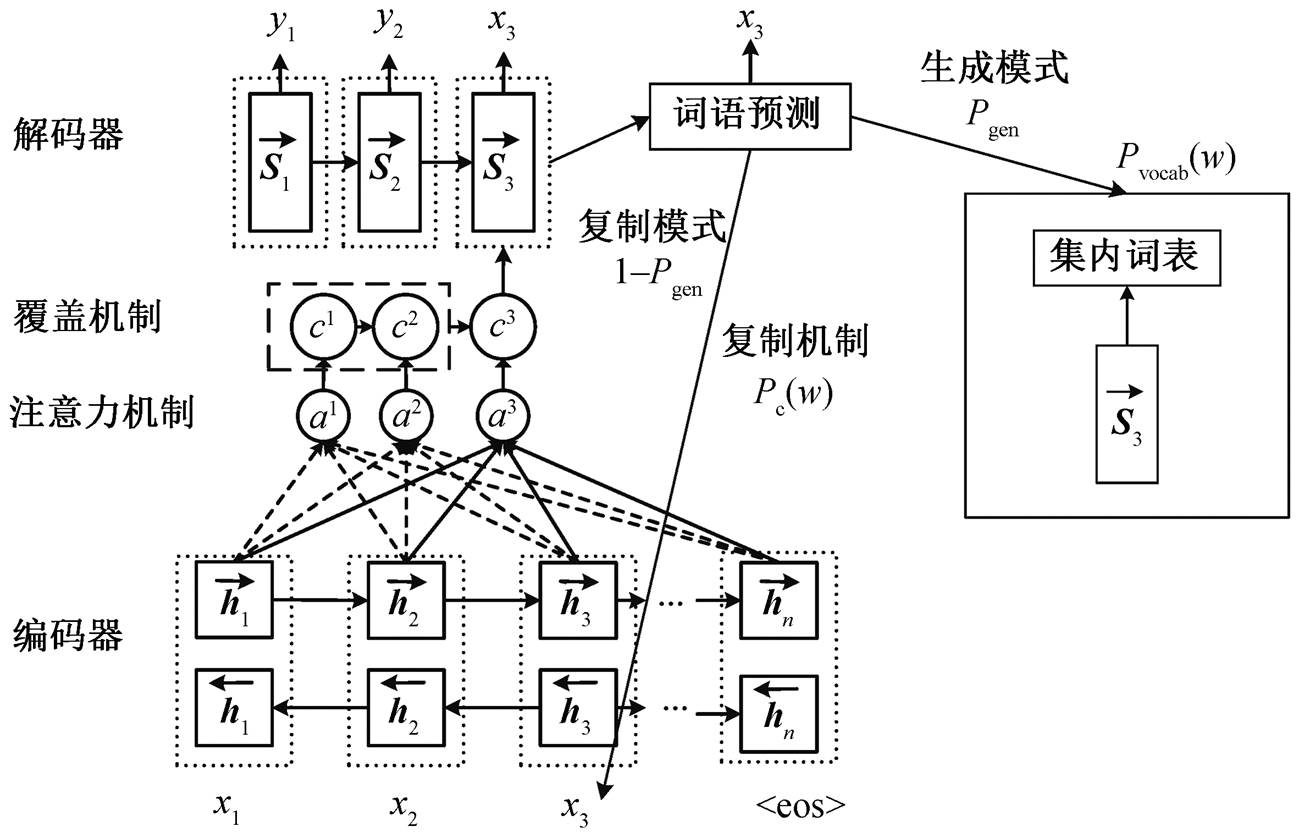
图2 多机制融合的复述生成模型
Fig. 2 Multi-mechanism fused paraphrase generation model
 (7)
(7)其中, Pgen 表示当前词选择生成模式预测的概率, 计算公式为式(8); 1−Pgen 表示当前词选择复制模式预测的概率; Pvocab(w)表示集内词 w 的生成概率; Pc (w)表示原句中词 w 的复制概率, 由式(2)计算。若词 w在原句中多次出现, 则加和每一个位置的注意力权重作为复制概率。当词 w 为未登录词时, Pvocab(w)= 0; 当词 w 在原句中不存在时, Pc (w)=0。
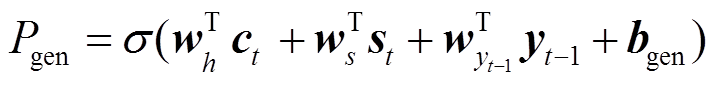 , (8)
, (8)
其中, wh,ws, 和 bgen 表示可学习的参数,σ 表示sigmoid函数。
和 bgen 表示可学习的参数,σ 表示sigmoid函数。
针对词汇重复生成问题, 我们引入覆盖机制。覆盖机制建模历史注意力决策信息, 对重复关注同一个词的决策进行惩罚, 使当前决策更多地关注原句中未被解码的词, 从而避免词汇的重复生成。覆盖机制利用注意力机制中的对齐向量, 引入覆盖向量 ct, 记录历史注意力信息:
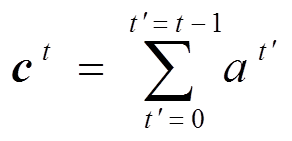 , (9)
, (9)其中, 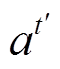 表示
表示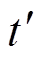 时刻原句中各个词语的注意力对齐权重, 计算公式为式(2)。
时刻原句中各个词语的注意力对齐权重, 计算公式为式(2)。
覆盖机制将覆盖向量 ct 输入到注意力计算公式(式(1))中, 使得注意力决策受到历史决策信息的约束。式(1)改写成式(10):
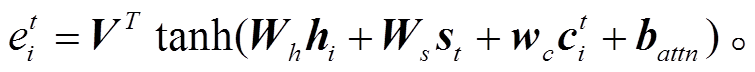 (10)
(10)其中, wc 表示可学习参数。我们利用覆盖损失函数[18]惩罚重复关注同一个词的注意力决策:
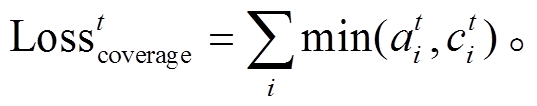 (11)
(11)
最终, 融合复制机制和覆盖机制学习目标函数如下:
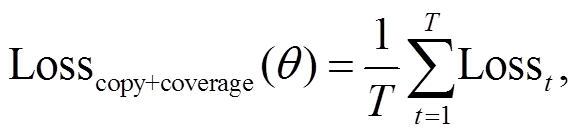 (12)
(12)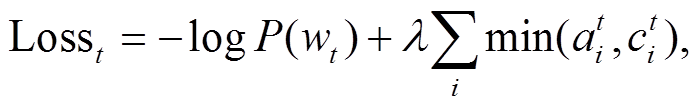 (13)
(13)
其中, −logP(wt)表示生成词 wt 的损失函数, P(wt)通过式(6)获得。超参数 λ 用来对覆盖损失进行加权平衡。
基于多任务学习框架[20–21], 我们提出联合自编码任务的复述生成模型, 在多机制融合的编码–解码复述生成模型中, 联合学习自编码任务和复述生成任务, 两个任务共享一个编码器, 整体框架如图3 所示。
复述生成任务 利用平行复述语料 Dp((Xn,Yn)∈Dp)对模型进行训练学习。在给定原句 Xn 时, 解码器(Decoder2-Paraphrase)可以生成与原句语义一致且表现形式不同的复述句 Yn。复述生成任务(文本转换 Xn→Yn)的目标即最大化概率 p(Yn | Xn), 以使生成高质量的复述句 Yn。如图 3 中示例, 给定原句“Austin writes the novel of Persuation.”, 编码器编码学习原句的语义表示, 之后经过复述生成解码器, 生成对应的复述句“Austin is the author of Persua-tion.”。
自编码任务 利用原句子集(无复述句对)Du(Xn∈Du)训练模型, 学习原句的语义表示, 通过与复述任务的联合学习, 共同提升编码器的语义表示能力, 使得给定原句 Xn 时, 自编码器可以生成原句本身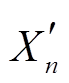 。与复述任务类似, 自编码任务(文本转换 Xn→)通过最大化条件概率 p(|Xn)对自编码任务的模型参数进行优化。如图 3 中示例, 给定原句“Austin writes the novel of Persuation.”, 编码器编码学习原句语义表示, 之后经过自编码解码器, 生成原句本身“Austin writes the novel of Persuation.”。
。与复述任务类似, 自编码任务(文本转换 Xn→)通过最大化条件概率 p(|Xn)对自编码任务的模型参数进行优化。如图 3 中示例, 给定原句“Austin writes the novel of Persuation.”, 编码器编码学习原句语义表示, 之后经过自编码解码器, 生成原句本身“Austin writes the novel of Persuation.”。
本文融合自编码任务的复述生成模型, 采用交叉熵损失函数作为训练目标函数, 模型的目标函数如下:
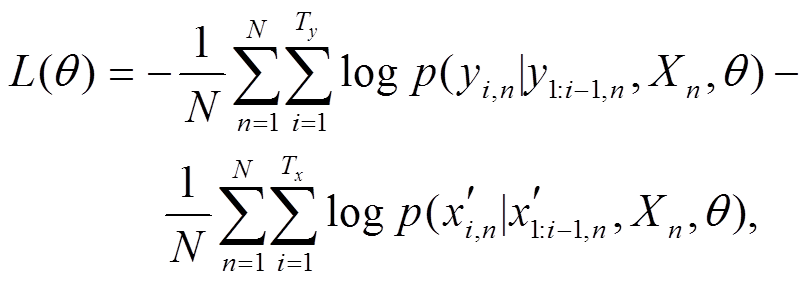 (14)
(14)其中, 第一项表示复述生成任务的损失, 第二项表示自编码任务的损失; 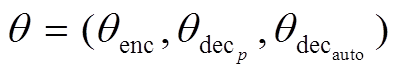 表示模型所有参数集合, θenc表示编码器网络的参数集合,
表示模型所有参数集合, θenc表示编码器网络的参数集合,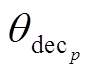 表示复述生成任务的解码器参数集合,
表示复述生成任务的解码器参数集合,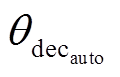 表示自编码任务的解码网络参数集合; N 表示输入训练集样本个数, Ty表示复述句中含有 Ty 个词, Tx 表示生成的原句中含有 Tx 个词, yi,n 表示复述句 Yn 中第i个词yi。
表示自编码任务的解码网络参数集合; N 表示输入训练集样本个数, Ty表示复述句中含有 Ty 个词, Tx 表示生成的原句中含有 Tx 个词, yi,n 表示复述句 Yn 中第i个词yi。
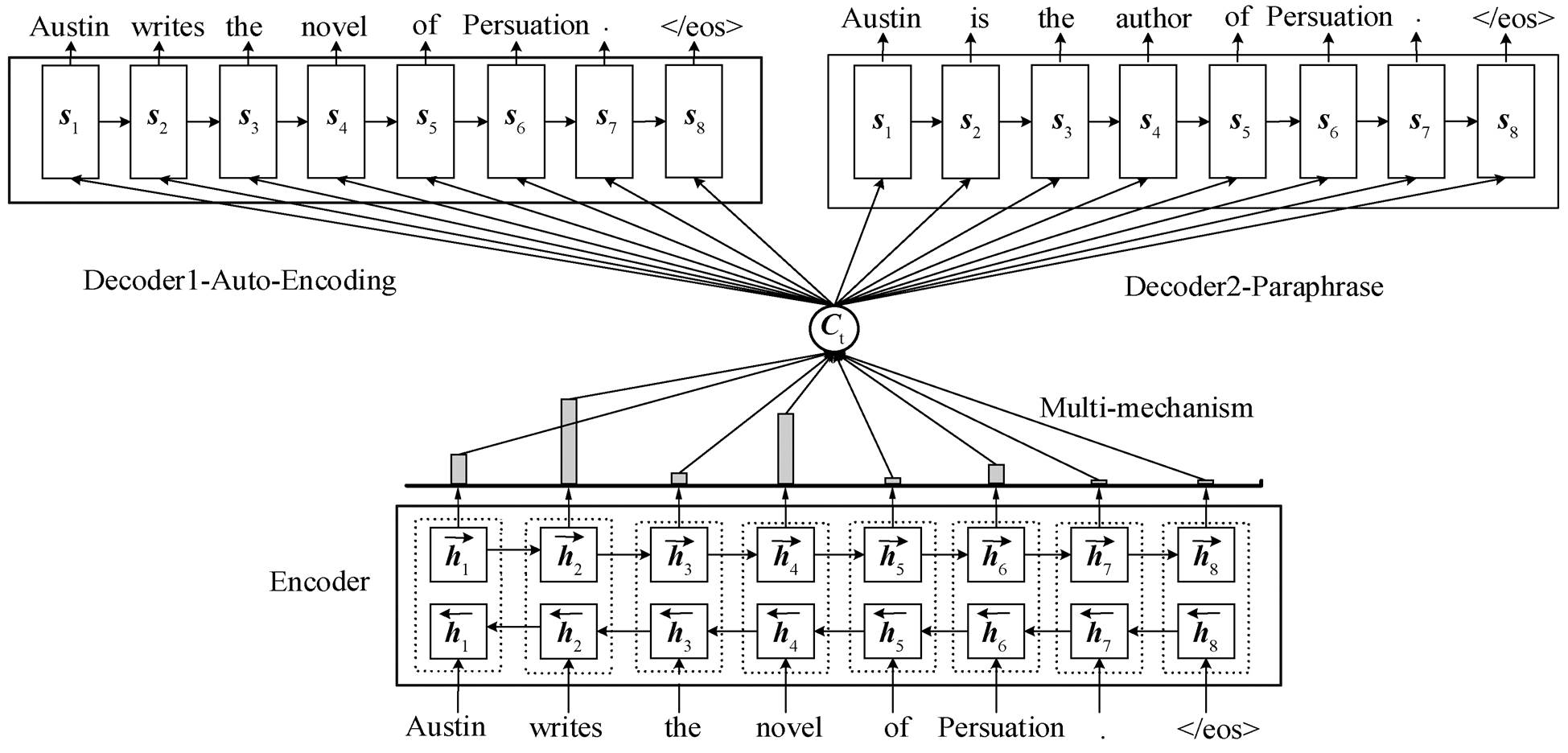
图3 联合自编码任务的复述生成模型
Fig. 3 Paraphrase generation model with joint auto-encoding learning task
本文在 Quora 问句复述语料上进行评测实验。Quora 包含 150k 复述句对, 其中 140k 复述句对作为训练集, 验证集和测试集各 5k。在多任务联合学习中, 复述生成任务利用平行复述句对(X,Y)训练模型, 自编码任务仅利用原句子集(X)。Quora 数据集在复述生成和自编码任务上的数据统计信息见表 1。
在预处理阶段, 过滤长度大于 40 的句子, 选择出现概率高的前 20k 词作为词典, 其中未登录词用UNK 表示。模型参数细节实施如下: 编码器采用两层双向 Bi-LSTM 网络, 两个解码器采用两层单向 LSTM 网络, 其中编码器中 Bi-LSTM 和解码器中 LSTM 的隐藏层大小设置为 500 维, 词向量维度设置为 500 维。设置 Batch 的大小为 64, 在层之间采用 dropout 正则化技术, 设置 drop 率的大小为 0.3。我们采用 Adam 优化算法[22]训练模型, 设置初始学习率为 0.001, 每一轮迭代中学习率以 0.88 的频率衰减。没有使用预训练词向量的方法, 所有参数均采用随机初始化的方法, 然后跟模型一起学习。
我们采用 ROUGE-1, ROUGE-2[23], BLEU[24]和METEOR[25]自动评测指标, 对复述生成进行评测。
采用基于注意力机制的编码–解码模型作为本实验的基线模型, 为了验证各个机制的性能以及多机制融合方法的有效性, 我们设置 3 组对比实验, 包括在基线模型中分别融合复制机制和覆盖机制以及同时融合复制和覆盖两种机制。实验结果如表 2所示。
从表 2 可以看出, 加入复制机制和覆盖机制有效地改进了模型的性能。其中, 仅融合复制机制的模型的所有评测指标比基线模型均至少提升 3 个点, 在 ROUGE-1 和 ROUGE-2 上分别提高 3.67 和 3.79, 在 BLEU 上提高 4.20, 在 METEOR 上提高 3.17, 验证了复制机制对改进复述生成质量的有效性。仅融合覆盖机制的模型在 ROUGE, BLEU 和 METEOR这 3 个评测指标上的提升效果不明显。与仅融合复制机制的模型相比, 同时融合复制机制和覆盖机制的模型进一步改进了模型性能, 在 ROUGE 值上提高 0.5 个点, 在 BLEU 和 METEOR 上也有一定程度的改进。与基线模型相比, 多机制融合模型的各个指标明显提升, 证明了本文提出的多机制(注意力机制+复制机制+覆盖机制)融合模型在提升复述生成质量整体性能方面的有效性。
表1 复述生成任务和自编码任务数据统计信息
Table 1 Data statistical information for paraphrase generation task and auto-encoding task

任务训练集验证集测试集词汇表(源/目标) 复述生成140 k (对)5 k (对)5 k (对)20 k/20 k 自编码140 k5 k5 k20 k/20 k
表2 多机制融合复述生成评测结果
Table 2 Experiment results on multi-mechanism fused paraphrase generation model
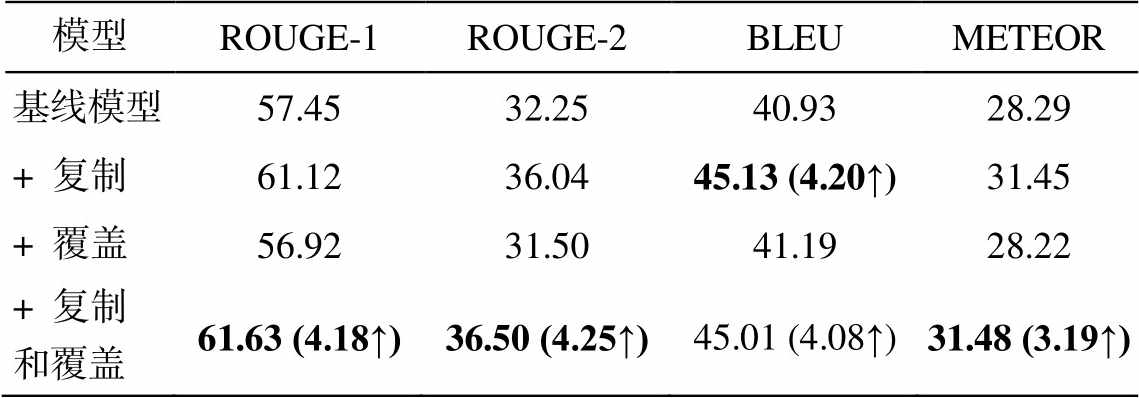
模型ROUGE-1ROUGE-2BLEUMETEOR 基线模型57.4532.2540.9328.29 + 复制61.1236.0445.13 (4.20↑)31.45 + 覆盖56.9231.5041.1928.22 + 复制和覆盖61.63 (4.18↑)36.50 (4.25↑)45.01 (4.08↑)31.48 (3.19↑)
说明: 粗体数字表示最佳结果,下同。
为了进一步验证覆盖机制的有效性, 我们分别统计基线模型和融合覆盖机制模型中存在词汇重复现象的复述句个数, 基线模型存在词汇重复的有127 个句子, 融合覆盖机制的模型存在 64 个句子, 融合覆盖机制和复制机制的模型有 45 个句子存在词汇重复(图 4)。可以看出, 覆盖机制能够有效地减少词汇重复生成的现象, 改进复述生成质量。
为了更好地学习编码器, 我们在自编码任务中采用正序解码和逆序解码两种不同的解码方式。其中, 正序解码按照原句编码的顺序进行解码, 逆序解码按照原句编码的相反顺序进行解码。联合自编码任务的复述生成模型的评测结果如表 3 所示, 本实验中采用第 2 节介绍的多机制融合复述生成模型作为基线模型, 其中 AutoEncoder 表示自编码输出为正序解码, ReversedAutoEncoder 表示自编码输出为逆序解码。
相较于基线模型, 联合自编码正序解码的复述生成模型在所有评测指标上均有所提升, 在 ROUGE-1 (ROUGE-2), BLEU 和 METEOR 上分别提高 0.94 (1.3), 0.82 和 0.54, 验证了联合自编码的多任务学习在改进复述生成质量方面的有效性。联合自编码逆序解码的复述生成模型在各个指标上均取得比正序解码更好的性能, 进一步验证提高编码器语义表示能力是改进复述生成的有效方法。与前人的最好工作[11–12]进行比较, 联合自编码逆序解码在 ROUGE- 2 和 BLEU 上分别提高 0.99 和 3.8, 进一步证明联合自编码任务的复述生成模型在提高复述生成质量方面的有效性。
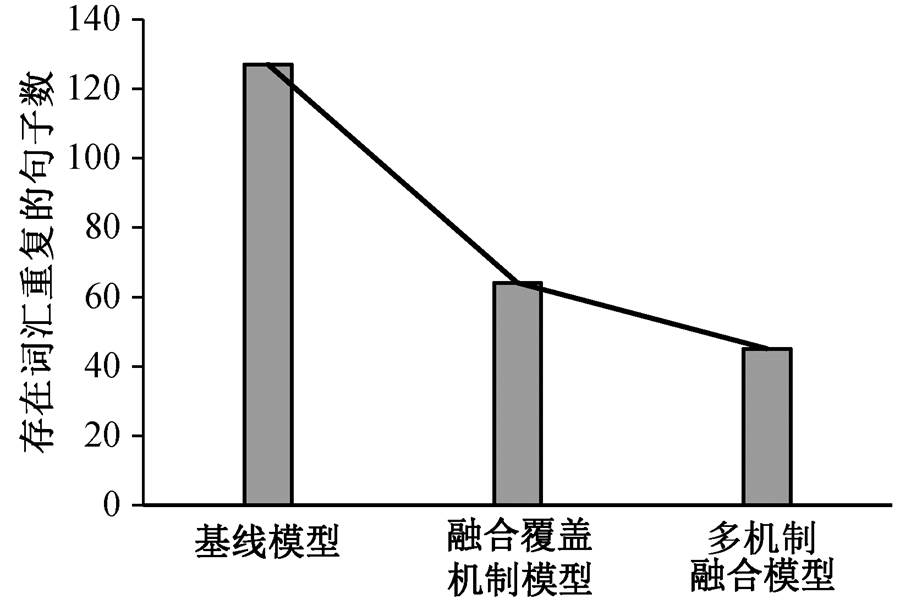
图4 覆盖机制减少词汇重复的统计信息
Fig. 4 Statistical information of reducing repeated words with coverage mechansim
表3 联合自编码任务的复述生成评测结果
Table 3 Experiment results on paraphrase generation with joint auto-encoding task

模型ROUGE-1ROUGE-2BLEUMETEOR 基线模型61.6336.5045.0131.48 AutoEncoder62.5737.8045.8332.02 ReversedAutoEncoder62.95 (1.32↑)38.54 (2.04↑)46.13 (1.12↑)32.10 (0.62↑) Li等[12]63.7137.5542.3331.54 Gupta等[11]−−38.3033.60
表 4 给出联合自编码复述生成模型的实例分析。通过与原句和参考复述句对比, 可以看出本文提出的多任务联合学习复述生成模型可以生成语义一致、语法正确、表达流畅且表达形式较为多变的复述句, 如复述句对“how do you cook chicken gizzards ?”和“what is the best way to cook chicken gizzards ?”在表达结构上由副词“how”转换为名词性短语“what is the best way to”, 再如在复述句对“why do people from different races or region have different facial features ?”和“why do people from different races differ in facial features ?”中, 将形容词短语“different facial features”转换为动词短语“differ in facial features ?”, 在句子表达结构和词性转换上均有较大的变化, 进一步验证本文所提模型的有效性。
本文基于神经网络编码–解码框架的复述生成模型, 提出在解码过程中有效地融合注意力机制、复制机制和覆盖机制的复述生成模型, 进一步改进复述生成的质量。复制机制解决了生成复述句中实体词不准确和未登录词的问题, 覆盖机制有效地缓解了生成复述句中词汇重复的问题。同时, 本文提出联合自编码任务的复述生成模型, 探索通过联合学习改进复述生成编码器学习能力来提高复述生成质量的方法, 充分利用平行复述语料和原句子数据, 增强复述生成编码器的语义编码能力。我们在公开的 Quora 问句复述数据集上进行评测试验, 结果显示本文提出的复述生成模型有效地提高了复述生成质量。今后的研究中, 我们将考虑在模型中融入已有的复述知识(如复述短语), 以期进一步提高复述生成句子的多样性。
表4 多任务学习生成的复述实例
Table 4 Paraphrase examples generated by multi-task learning model

序号 模型例句 1Referencewhat can I do with chicken gizzards ? Inputhow do you cook chicken gizzards ? AutoEncoderwhat is the best way to cook chicken gizzards ? ReversedAutoEncoderhow do you cook chicken gizzards ? 2Reference paraphrasehow do I do affiliate marketing without a website? Inputcan we do affiliate marketing without having a website ? AutoEncodercan we do affiliate marketing without having a website ? ReversedAutoEncoderIs there a way to get affiliate marketing without a website ? 3Referencewhy is there a facial difference in people with different races ? Inputwhy do people from different races or region have different facial features ? AutoEncoderwhy do people have different facial features in different races ? ReversedAutoEncoderwhy do people from different races differ in facial features ?
参考文献
[1] Zhang Lilin, Weng Zhen, Xiao Wenyan, et al. Extract domain-specific paraphrase from monolingual corpus for automatic evaluation of machine translation // Proceedings of the First Conference on Machine Translation (Volume 2, Shared Task Papers). Berlin, 2016: 511–517
[2] Zhao Sanqiang, Meng Rui, He Daqing, et al. Integra-ting transformer and paraphrase rules for sentence simplification [EB/OL]. (2018–10–26) [2019–03–01]. https://arxiv.org/abs/1810.11193
[3] Dong L, Mallinson J, Reddy S, et al. Learning to paraphrase for question answering [EB/OL]. (2017–09–01) [2019–02–11]. https://www.aclweb.org/antho logy/D17-1091/
[4] Prakash A, Hasan S A, Lee K, et al. Neural paraphr-ase generation with stacked residual LSTM net-works // Proceedings of COLING 2006: Technical Papers. Osaka, 2016: 2923–2934
[5] Hasan S A, Liu B, Liu J, et al. Neural clinical para-phrase generation with attention // Proceedings of ClinicalNLP. Osaka, 2016: 42–53
[6] McKeown K R. Paraphrasing questions using given and new information. Computational Linguistics, 1983, 9(1): 1–10
[7] 赵世奇. 基于统计的复述获取与生成技术研究[D]. 哈尔滨: 哈尔滨工业大学. 2009
[8] Kozlowski R, McCoy K F, Vijay-Shanker K. Gene-ration of single-sentence paraphrases from predicate/ argument structure using lexico-grammatical resour-ces // Proceedings of IWP. Sapporo, 2003: 1–8
[9] Quirk C, Brockett C, Dolan B. Monolingual machine translation for paraphrase generation // Proceedings of EMNLP. Barcelona, 2004: 142–149
[10] Wubben S, Van Den Bosch A, Krahmer E. Paraphrase generation as monolingual translation: data and eva-luation // Proceedings of INLG. Dublin, 2010: 203–207
[11] Gupta A, Agarwal A, Singh P, et al. A deep generative framework for paraphrase generation [EB/OL]. (2017 –09–15) [2019–02–01]. https://arxiv.org/abs/1709.05074
[12] Li Zichao, Jiang Xin, Shang Lifeng, et al. Paraphrase generation with deep reinforcement learning // Pro-ceedings of the 2018 Conference on Empirical Me-thods in Natural Language Processing. Brussels, 2018: 3865–3878
[13] Florin B, Traian R. Neural paraphrase generation using transfer learning // Proceedings of the 10th Internationa Conference on Natural Language Genera-tion. Santiago de Compostela, 2017: 257–261
[14] Iyyer M, Wieting J, Gimpel K, et al. Adversarial example generation with syntactically controlled paraphrase networks // Proceedings of NAACL-HLT, Volume 1 (Long Papers). New Orleans, 2018: 1875–1885
[15] Cho K, Van Merriënboer B, Gulcehre C, et al. Lear-ning phrase representations using RNN encoder-decoder for statistical machine translation // Procee-dings of EMNLP. Doha, 2014: 1724–1734
[16] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate [EB/OL]. (2014–09–01) [2018–03–01]. https://arxiv. org/abs/1409.0473
[17] Gu Jiatao, Lu Zhengdong, Li Hang, et al. Incorpo-rating copying mechanism in sequence-to-sequence learning // Proceedings of 54th ACL (Long Papers). Berlin, 2016: 1631–1640
[18] See A, Liu P J, Manning C D. Get to the point: summarization with pointer-generator networks // Proceedings of 55th ACL (Long Papers). Vancouver, 2017: 1073–1083
[19] Tu Zhaopeng, Lu Zhengdong, Yang Liu, et al. Modeling coverage for neural machine translation // Proceedings of 54th ACL (Long Papers). Berlin, 2016: 76–85
[20] Luong M T, Le Q V, Sutskever I, et al. Multi-task sequence to sequence learning [EB/OL]. (2015–11–19)[2018–06–01]. https://arxiv.org/pdf/1511.06114. pdf
[21] Caruana R. Multitask learning. Machine Learning, 1997, 28(1): 41–75
[22] Kingma D P, Ba J. Adam: a method for stochastic optimization [EB/OL]. (2014–12–22) [2018–06–01]. https://arxiv.org/pdf/1412.6980.pdf
[23] Chin Y L. Rouge: a package for automatic evaluation of summaries // In Text Summarization Branches Out: Proceedings of the ACL-04 Workshop (volume 8). Barcelona, 2004: 74–81
[24] Kishore P, Salim R, Todd W, et al. BLEU: a method for automatic evaluation of machine translation // Pro-ceedings of the 40th Annual Meeting on Association for Computational Linguistics. Philadelphia, 2002: 311–318
[25] Alon L, Abhaya A. Meteor: an automatic metric for mt evaluation with high levels of correlation with human judgments // Proceedings of the Second Workshop on Statistical Machine Translation. Prague, 2007: 228–231
A Multi-Mechanism Fused Paraphrase Generation Model with Joint Auto-Encoding Learning
Abstract Neural network encoder-decoder framework has become the popular method for paraphrase generation, but there are still two problems. On the one hand, there are such issues as inaccurate entity words, unknown words and word repetition in the generated paraphrase sentences. To solve the first problem, we proposed a multi-mechanism fused paraphrase generation model to improve the decoder. The copy mechanism was used to copy words form input sentence for improving the generation of entity and unknown words. The coverage mechanism was used to model historical attention information to avoid word repetition. On the other hand, the limited-scale parallel paraphrase corpus limits the learning ability of the encoder. We proposed to jointly learn auto-encoding task, which shares one encoder with paraphrase generation task. The joint auto-encoding task enhances the learning ability of the encoder. Experimental results on Quora paraphrase dataset show that the multi-mechanism fused paraphrase generation model with joint auto-encoding task can effectively improve the performance of paraphrase generation.
Key words paraphrase generation; auto-encoding; multi-task learning; multi-mechanism fusion; attention mechanism; copy mechanism; coverage mechanism
doi: 10.13209/j.0479-8023.2019.104
国家自然科学基金(61876198, 61976015, 61370130, 61473294)、中央高校基本科研业务费专项资金(2018YJS025)、北京市自然科学基金(4172047)和科学技术部国际科技合作计划(K11F100010)资助
收稿日期: 2019–05–23;
修回日期: 2019–09–20