
图1 相同词序列的不同句法结构
Fig. 1 Sentences with same word orders but different syntactic structures
摘要 为解决已有复述语义计算方法未考虑句法结构的问题, 提出基于句法结构的神经网络复述识别模型, 设计基于树结构的神经网络模型进行语义组合计算, 使得语义表示从词语级扩展到短语级。进一步地, 提出基于短语级语义表示的句法树对齐机制, 利用跨句子注意力机制提取特征。最后, 设计自注意力机制来增强语义表示, 从而捕获全局上下文信息。在公开英语复述识别数据集 Quora 上进行评测, 实验结果显示, 复述识别性能得到改进, 达到 89.3%的精度, 证明了提出的基于句法结构的语义组合计算方法以及基于短语级语义表示的跨句子注意力机制和自注意力机制在改进复述识别性能方面的有效性。
关键词 复述识别; 句法结构; 树结构神经网络; 注意力机制
自然语言理解是自然语言处理的终极目标, 其判定标准包括复述、翻译、问答和文摘, 复述处理的重要性可见一斑[1]。复述识别是复述处理的关键技术之一, 广泛应用于机器翻译[2–3]、自动问答[4–5]和文本摘要[5–6]等自然语言处理任务中, 如在机器翻译评测中识别同义表达, 提高评测系统的质量; 在自动问答中识别相同意思的问句, 提高问答系统的性能; 在文本摘要中检测句子的相似性, 从而更好地进行句子压缩和生成。近年来, 基于神经网络的复述研究成为热点, 并成为自然语言处理的重要方向之一。本文主要针对基于神经网络的复述识别方法开展研究。
早期的复述识别方法主要是基于特征工程的方法[7–10], 如利用机器翻译评价指标 BLEU 值计算句子相似度[9], 将语义角色标注信息作为特征[10], 该类方法依赖于句子间组成部分是否相同, 主要问题在于难以捕获表面形式差异大而语义相同的复述现象。后来, 基于神经网络的模型在语义计算和特征提取上显示出优势[11–17], 研究者利用神经网络, 将句子表示为低维连续的语义向量, 然后将语义向量作为特征, 用于复述识别。该类方法避免了复杂的特征工程, 并且可以提取句子的全局特征。基于神经网络的模型表明, 句子间的语义相关性越大, 它们在语义空间上的距离也越接近。已有的神经网络模型主要研究句子的语义表示方法, 即从词语到句子的语义组合方法, 同时利用神经注意力机制提取跨句子特征。
已有模型在复述语义组合计算和跨句子特征提取上仍存在以下问题。一方面, 在计算句子语义表示时, 没有考虑句法结构信息, 而是将句子视为序列化结构, 进行语义组合计算, 难以捕获细微的语义差别, 如“Show me the fights from New York to Florida.”和“Show me the fights from Florida to New York.”。同时, 序列化的方法无法体现词语在句法结构上的语义关系。然而, 自然语言的句子是按照一定的句法规则生成的, 即使构成词语和词序完全相同的句子, 如果句法结构不同, 其语义也会有所不同。如图 1 所示, 两个句子在序列上完全一致, 但有不同的句法结构, 在左边句法结构中, “with the telescope”修饰“the man”这个主语, 语义解释为“该男士有一个望远镜”; 在右边的句法结构中, “with the telescope”修饰“saw”这个动作, 语义解释为“我用望远镜看一个男士”。由此可见, 句法结构在理解句子语义上有重要作用, 可以更好地解释句子的语义表示。另一方面, 在学习跨句子的特征时, 序列化结构无法构建短语的表示, 主要关注句子间词语级的匹配信息[11,13], 无法有效地计算短语级的匹配信息,然而短语级的匹配信息对识别句子语义关系有重要的作用。
针对上述问题, 本文提出基于句法结构的复述识别模型, 设计树结构神经网络模型进行语义组合计算, 构建短语语义表示, 并基于短语表示设计跨句子注意力和自注意力机制, 以有效学习句子内部和句子间的特征, 改进复述识别精度。
复述识别指判定给定的两个句子 P 和 Q 在语义上是否一致。在基于神经网络的复述识别方面, 文献[12,16–17]中考虑句子的 n-gram 特征, 利用卷积神经网络建模, 并采用注意力机制提取跨句子特征,取得比传统基于特征工程的方法更好的性能。基于循环神经网络 BiLSTM 的模型也广泛地应用于复述识别。Wang 等[11]和 Duan 等[13]提出基于词语级语义匹配的方法, 主要关注句子间词级别的语义匹配信息, 采用注意力机制学习词对齐信息, 从而提取跨句子特征。Duan 等[13]扩展了先前的注意力机制, 设计多个注意力层, 用于提取跨句子特征, 并采用 BiLSTM 对注意力信息进行融合, 增加网络深度, 进一步改进了复述识别的性能。李天时等[14]在神经网络模型中融合语义角色信息, 以便利用更多的特征辅助复述识别。这些方法构建了基于序列化结构的神经网络复述识别模型。不同于先前的工作, 本文研究主要关注基于句法结构的语义组合计算和复述识别方法。
我们提出基于句法结构的神经网络复述识别模型, 采用基于树结构神经网络的语义组合计算方法以及基于注意力机制的特征提取方法, 主要框架如图 2 所示。模型输入 P={p1, …, pi, …, pm}和 Q= {q1, …, qj, …, qn}两个句子, 其中pi和qj分别表示句子 P 和 Q 中第 i 和 j 个词语, m 和 n 分别表示句子 P 和 Q 的长度。模型采用一个分类器预测句子P 和 Q 的语义关系。下面从基于句法结构的语义组合计算方法、跨句子的短语级注意力机制和自注意力机制 3 个模块详细地介绍我们提出的模型。
图1 相同词序列的不同句法结构
Fig. 1 Sentences with same word orders but different syntactic structures

图2 基于句法结构的复述识别模型整体框架
Fig. 2 Paraphrase identification framework based on syntactic srtucture
我们将短语树作为句法结构, 指导语义组合计算。短语句法树刻画句子内部词语之间的层次关系, 即先由词语构成短语, 然后由短语组合构成整个句子。在短语句法树中, 每一个叶子节点表示词语, 每一个非叶节点表示构成的短语, 根节点集成了所有孩子节点的信息, 通常被视为整个句子的表示。其中, 非叶节点仅包含两个孩子节点, 即左孩子节点 l 和右孩子节点 r, 孩子节点可以是词语, 也可以是已构成的短语。
我们设计了基于 TreeLSTM[18]的神经网络结构, 作为语义组合计算模型, 通过门控制机制(gate mechanism)选择输入信息, 在合成短语表示时选择性地关注诸如动词、名词等重要节点, 从而更好地编码短语的表示。在 TreeLSTM 神经网络中, 每一个 TreeLSTM 神经元包含两个向量, 记忆单元向量c 和隐藏状态向量 h。定义建立短语的左孩子节点的记忆单元向量和隐藏层向量为(cl, hl), 建立短语的右孩子节点的记忆单元向量和隐藏层向量为(cr, hr)。对于新合成的短语, 定义 cph 和 hph 为合成短语的记忆单元向量和隐藏层向量, cph 和 hph 的计算方法如式(1)~(3)所示:
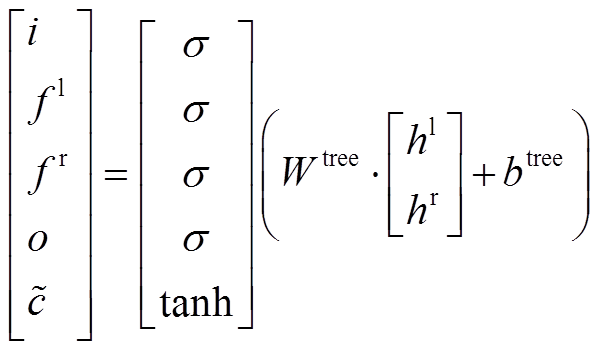 , (1)
, (1) , (2)
, (2)
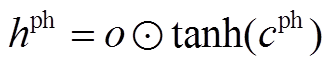 , (3)
, (3)
其中,σ 表示 sigmoid 函数,  表示两个向量的逐点乘积操作。i, fl, f r, o 和
表示两个向量的逐点乘积操作。i, fl, f r, o 和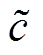 分别表示输入门、左孩子节点对应的遗忘门、右孩子节点对应的遗忘门、输出门和候选记忆单元。在我们的结构中, 短语表示是按照自底向上的规则组合生成的, 从而递增地得到整个句子的表示以及句法树中所有节点的表示。在此, 句子 P 和 Q 被表示为
分别表示输入门、左孩子节点对应的遗忘门、右孩子节点对应的遗忘门、输出门和候选记忆单元。在我们的结构中, 短语表示是按照自底向上的规则组合生成的, 从而递增地得到整个句子的表示以及句法树中所有节点的表示。在此, 句子 P 和 Q 被表示为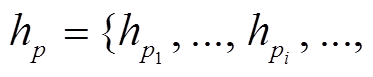
![]() 和
和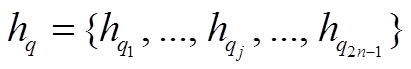 , 其中,
, 其中, 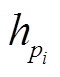 和
和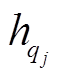 分别是 P 和 Q 中第 i 和 j 个节点的语义向量。在长度为 m 的句子对应的短语句法树中, 有 m 个叶子节点和 m−1 个非叶节点, 最后共得到 2m−1 个节点。接下来, 利用hp和hq学习跨句子特征。
分别是 P 和 Q 中第 i 和 j 个节点的语义向量。在长度为 m 的句子对应的短语句法树中, 有 m 个叶子节点和 m−1 个非叶节点, 最后共得到 2m−1 个节点。接下来, 利用hp和hq学习跨句子特征。
基于短语级语义表示, 设计跨句子注意力机制学习两个句子间的匹配信息。跨句子注意力机制从另一个句子中提取相关信息, 给定句子 P 和 Q 中每一个节点的表示, 首先计算每一对节点 i 和 j 的语义相关性得分, 采用双仿射注意力机制[19], 计算方法如式(4)所示:
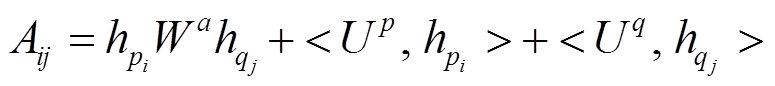 , (4)
, (4)其中, Wa, U p和U q表示学习参数, <x, y>表示两个向量之间的内积操作, Aij表示P中第i个节点和Q中第j个节点的语义相关度得分。
接下来, 对相关度得分做归一化处理, 对每一个节点, 计算其在另一个句子中的语义对齐信息, 如式(5)和(6)所示:
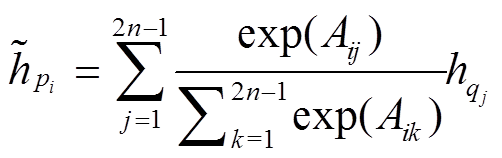 , (5)
, (5)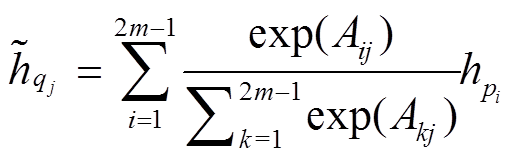 , (6)
, (6)
其中, 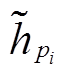 表示P中节点i经过注意力在Q中得到的语义对齐信息,
表示P中节点i经过注意力在Q中得到的语义对齐信息, 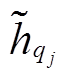 表示Q中节点 j 经过注意力在P中得到的语义对齐信息。直观上, 若节点i和j在语义上更为相关, 其对应的语义表示也更为接近, 从而得到较大的注意力权重。最终, 可以概率化地选择的信息作为对齐的语义向量。
表示Q中节点 j 经过注意力在P中得到的语义对齐信息。直观上, 若节点i和j在语义上更为相关, 其对应的语义表示也更为接近, 从而得到较大的注意力权重。最终, 可以概率化地选择的信息作为对齐的语义向量。
为了增强跨句子的特征, 进一步设计信息融合层, 计算方法如式(7)~(10)所示:
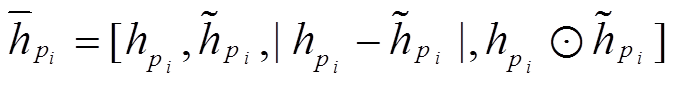 (7)
(7)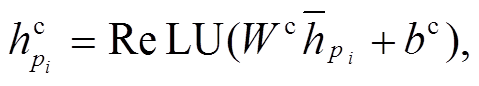 (8)
(8)
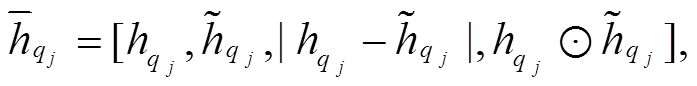 (9)
(9)
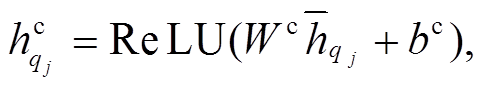 (10)
(10)其中, Wc和bc表示学习参数, 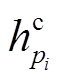 和
和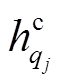 分别表示融合后节点i和j的表示。在此, 首先计算逐点的减法和乘积操作, 用于捕获语义相似性, 然后利用非线性变换ReLU函数进一步将各个表示结果进行融合, 并降低语义向量表示的维度。由此, 句子 P 和Q对应句法树中的节点被重新表示为
分别表示融合后节点i和j的表示。在此, 首先计算逐点的减法和乘积操作, 用于捕获语义相似性, 然后利用非线性变换ReLU函数进一步将各个表示结果进行融合, 并降低语义向量表示的维度。由此, 句子 P 和Q对应句法树中的节点被重新表示为
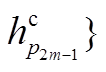 和
和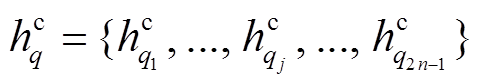 。
。
针对每一个句子, 我们采用自注意机制(self-attention mechanism)进一步捕获基于句法结构的上下文信息, 即使两个节点在句法树上路径较远, 仍然可以捕获相关的信息, 从而增强基于跨句子注意力机制的语义表示。对句子 P, 采用式(4)中的注意力机制方法计算句法树中任意两个节点的语义相关性得分 Sij, 然后计算基于自注意力机制的语义向量, 计算公式如下:
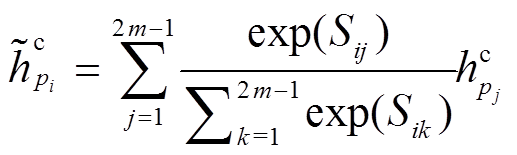 。 (11)
。 (11)对句子 Q 也采用相同的自注意力机制。直观上, 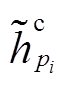 和
和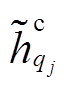 可以捕获对应句法树中每一个节点的信息, 增强节点基于全局上下文的语义表示。采用式(7)~ (10)的融合层, 进一步融合基于自注意力机制的语义表示, 节点 i 和 j 分别表示为
可以捕获对应句法树中每一个节点的信息, 增强节点基于全局上下文的语义表示。采用式(7)~ (10)的融合层, 进一步融合基于自注意力机制的语义表示, 节点 i 和 j 分别表示为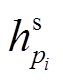 和
和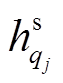 。
。
最后, 我们融合基于跨句子注意力机制和自注意力机制的信息来表示句法树中的每一个节点, 有效地捕获两个句子基于句法结构的语义信息, 作为复述识别的特征, 计算公式如(12)和(13)所示:
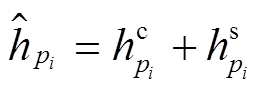 ,(12)
,(12)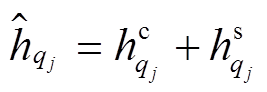 。 (13)
。 (13)
我们设计基于 BiLSTM[20]的叶子节点表示方法, 为了获取更加丰富的上下文信息来表示单词特征, 结合 LSTM 每一时刻的隐藏层向量 ht 和记忆单元向量 ct 表示每一个叶子节点的词语:
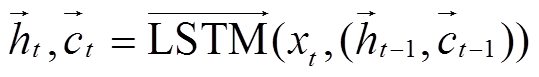 , (14)
, (14) 。 (15)
。 (15)
对当前时刻 t, 整合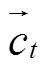 和
和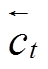 , 获得记忆单元表示
, 获得记忆单元表示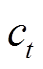 ; 整合
; 整合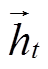 和
和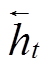 , 获得隐藏层表示
, 获得隐藏层表示 由于序列化的LSTM 网络在计算当前时刻的信息时传递了历史信息, 因此同一个单词在不同的上下文中, 会得到不同的词向量, 从而可以学习到基于上下文信息的词语特征表示, 参与基于句法结构的语义组合计算。
由于序列化的LSTM 网络在计算当前时刻的信息时传递了历史信息, 因此同一个单词在不同的上下文中, 会得到不同的词向量, 从而可以学习到基于上下文信息的词语特征表示, 参与基于句法结构的语义组合计算。
参考文献[11,13], 我们采用平均池化和最大池化操作, 分别整合 P 和 Q 对应句法树中节点的信息, 从而得到一个长度固定的语义向量, 计算公式如(16)~(18)所示:
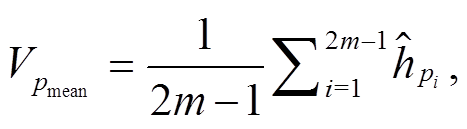 (16a)
(16a)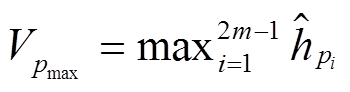 , (16b)
, (16b)
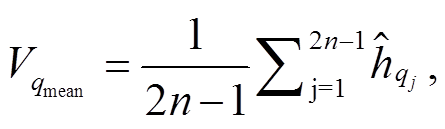 (17a)
(17a)
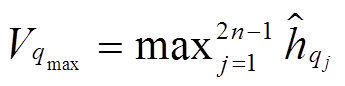 ,(17b)
,(17b)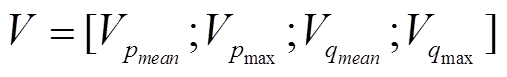 。(18)
。(18)
最后, 我们将语义向量 V 输入到多层感知机分类器, 预测两个句子互为复述的概率 。
。
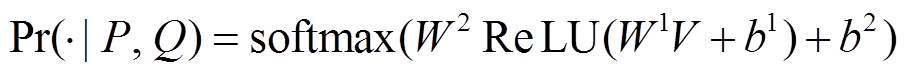 。(19)
。(19)我们利用前面提出的基于句法结构的语义计算方法, 搭建神经网络复述识别模型, 模型的训练目标和实施细节描述如下。
首先利用端到端的方法训练整个模型。目标函数采用交叉熵损失函数 Loss, 添加 l2 正则化项以防止过拟合, 通过超参数 λ 调整目标函数权重:
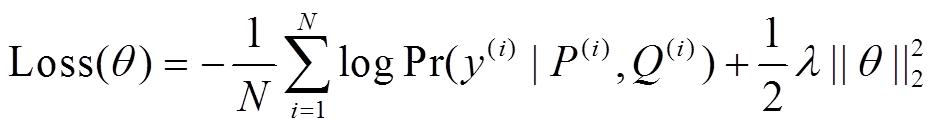 , (20)
, (20)其中, θ表示模型中所有的参数, N表示训练集大小, (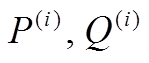 )表示句对,
)表示句对, 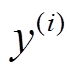 是相应句对的标签, =1表示句对间的语义关系是复述, = 0 表示句对间的语义关系是非复述。
是相应句对的标签, =1表示句对间的语义关系是复述, = 0 表示句对间的语义关系是非复述。
关于输入词向量表示, 本文采用 3 种类型的向量表示当前输入单词 xi: 预训练的词向量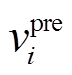 、可学习的词向量
、可学习的词向量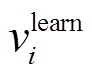 和词性标签向量
和词性标签向量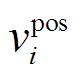 。与文献[11–13]一致, 预训练的词向量采用 Glove 840B[21]。最后, 我们采用一个非线性变换获得 3 个部分整合的词向量表示xi:
。与文献[11–13]一致, 预训练的词向量采用 Glove 840B[21]。最后, 我们采用一个非线性变换获得 3 个部分整合的词向量表示xi:
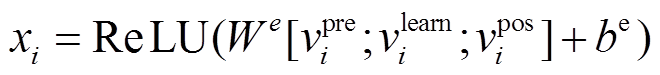 。 (21)
。 (21)我们设置预训练的词向量为 300 维, 可以学习的词向量为 30 维, 词性标签向量为 50 维, 所有的ReLU 层为 300 维, 设置 TreeLSTM 结构的隐藏层为300 维。在实验中, 预训练的词向量保持不变。我们采用 Adam 优化算法[22], 设置初始学习率为 2× 10−4, β1 为 0.9, β2 为 0.999。在每一轮迭代中, 学习率以 0.95 的频率衰减。设置 l2 正则化强度为 1× 10−6, 训练 batch 的大小为 64。为了防止过拟合, 我们使用 dropout 正则化技术[23], 设置词向量输入层的 drop 率为 0.2, ReLU 层输出层的 drop 率为 0.07。我们对预训练的词向量和最终整合的词向量使用batch normalization 正则化技术[24]。其中, dropout层作用在batch normalization层之后。
本文以英语复述识别数据集 Quora 作为实验数据来验证所提方法的有效性。我们采用标准的数据划分规则[9]。原始数据集没有句法标注信息, 因此我们采用伯克利句法分析器(https://github.com/ slavpetrov/berkeleyparser)预处理数据, 获取句子的短语句法结构树。我们也采用斯坦福句法分析器获取句法结构, 但不同的句法分析器得到相近的复述识别精度, 可能的原因是这些句法分析器有相近的句法分析精度。表 1 给出 Quora 英语复述数据的统计信息。
与文献[11–13]一致, 我们使用准确度评价模型性能, 利用开发集选择性能最好的模型参数用于测试阶段。我们和已有公开发表的基于神经网络的复述识别系统进行性能比较, 结果如表 2 所示。
从表 2 可以看出, 相比于 Wang 等[11]提出的基于序列化结构 BiLSTM 语义组合计算和基于神经注意力的词对齐复述识别系统 BiMPM, 我们的模型在准确度上取得 1.13 点的提高。相比于 Gong 等[12]提出的基于 CNN 模型的语义表示和融合方法 DIIN, 本文的模型的准确度提高 0.24 个点。相比于 Duan等[13]提出的基于序列化结构的多层神经注意力机制的复述识别系统 AF-DMN, 本文模型的准确度提高 0.58 个点。与已有的基于序列化结构的复述识别模型的比较结果表明, 本文提出的基于句法结构的神经网络复述识别模型, 采用树结构的神经网络模型进行语义组合计经网络复述识别算, 学习短语级的语义表示和对齐, 对于改进复述识别系统具有有效性。
表1 Quora英语复述数据集统计信息
Table 1 Statistical information of Quora English paraphrase data

数据集训练集开发集测试集词语数平均句长 PQ Quora384K10K10K107K1212
表2 与已有基于神经网络的复述识别系统的性能比较
Table 2 Experiment results on paraphrase indentification compared with previous models
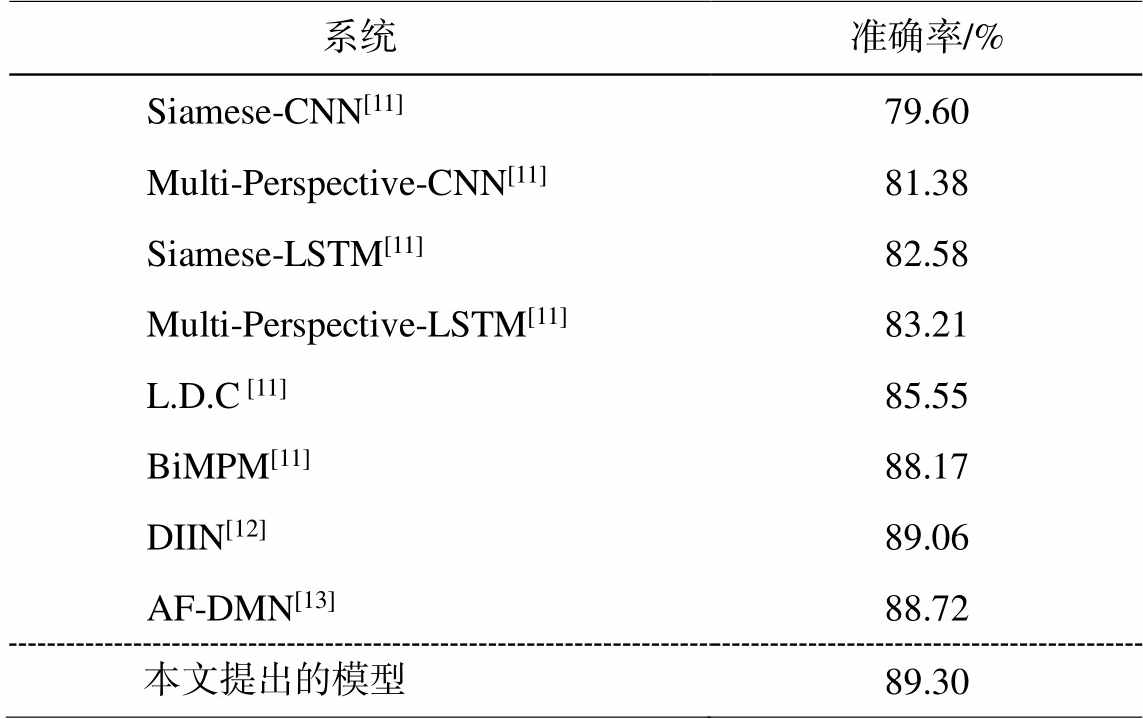
系统准确率/% Siamese-CNN[11]79.60 Multi-Perspective-CNN[11]81.38 Siamese-LSTM[11]82.58 Multi-Perspective-LSTM[11]83.21 L.D.C [11]85.55 BiMPM[11]88.17 DIIN[12]89.06 AF-DMN[13]88.72 本文提出的模型89.30
分析模型中各个部分对最终复述识别精度的影响, 实验结果如表3所示。
从表 3 看出, 基于短语级语义表示的注意力机制通过学习两个句子间短语级的语义匹配信息, 有效地改进了复述识别的性能。模型(a)没有使用注意力机制, 未考虑句子间的短语对齐信息, 仅使用句法树根节点的语义表示作为整个句子的表示, 复述识别准确度达到 86.1%。模型(b)加入基于短语级语义表示的跨句子特征, 利用注意力机制学习两个句子基于句法树的语义对齐关系, 在准确度上提高2.7 个百分点, 表明引入跨句子的短语级特征对复述识别十分重要。模型(c)进一步加入自注意力机制, 可以捕获更多句法上下文信息以增强语义表示, 准确度达到 89.3%, 进一步改进了复述识别的性能。与基于序列化结构的多层注意力神经网络复述识别模型[13]相比, 我们基于句法结构的模型仅使用一个跨句子注意力层和一个自注意力层, 含有更少的参数, 但取得更高的准确度。实验结果表明, 本文提出的基于句法结构进行语义组合计算的模型以及基于短语表示的跨句子注意力机制和自注意力机制, 可以有效地学习语义特征, 提高复述识别的精度。
表3 模型各个部分有效性分析结果
Table 3 Effect analysis of each component

系统准确率/%参数大小/M 开发集测试集 (a) 无注意力机制86.286.14.1 (b) +跨句子注意力机制89.288.84.6 (c) +自注意力机制89.589.35.1
为了进一步验证模型对短语的表示和对齐能力, 我们进行可视化分析。给定互为复述的句对{P: “a molecule of water is two hydrogen atoms and one oxygen atom.”和Q: “2 hydrogen, 1 oxygen atoms combine to make up a molecule of water.”}, 图 3 给出对应的句法树, 图 4 给出两个句子间的句法树对齐结果。从图 3 和 4 可以看到, 尽管两个句子的句法结构差异较大, 模型仍有效地捕获了该句对间的短语对齐信息, 如: P 中短语节点 21 “two hydrogen atoms and one oxygen atom”和 Q 中短语节点 11 “2 hydrogen, 1 oxygen atoms”在语义表示上对齐概率较大。可视化的分析结果证明, 本文提出的基于句法结构的语义组合计算方法和基于短语级语义表示的对齐方法, 可以有效地学习跨句子语义特征, 从而改进复述识别性能。
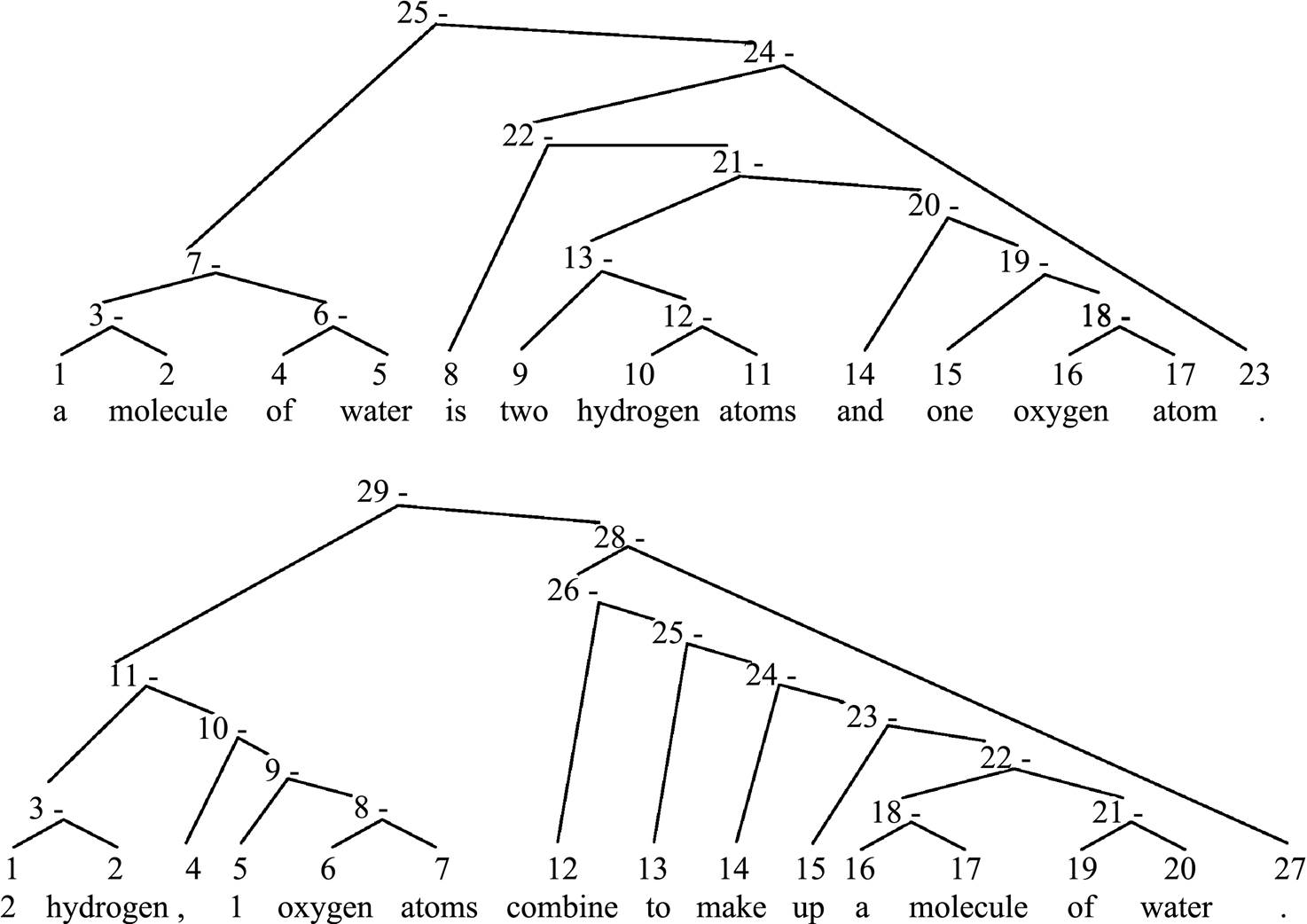
图3 复述句对P和Q的短语句法树
Fig. 3 Syntactic trees of paraphrase sentences P and Q
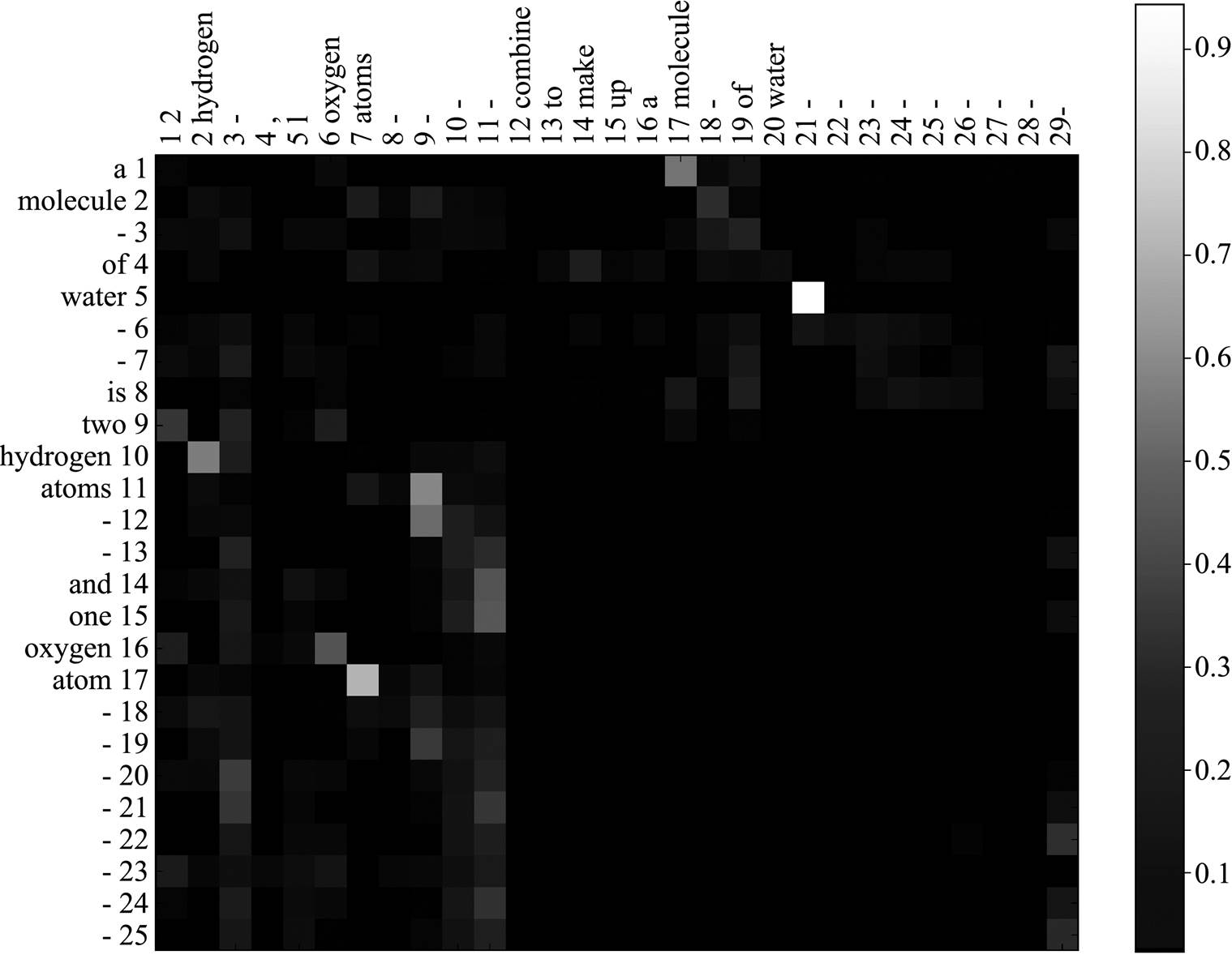
图4 互为复述句对的短语级对齐结果
Fig. 4 Phrase-level attention results for paraphrase sentences P and Q
本文提出一个基于句法结构的神经网络复述识别模型, 探索句法结构信息在神经网络语义组合计算方面的有效性, 扩展了基于序列化结构的词语级语义表示到基于句结构的短语级语义表示。同时, 设计基于短语级语义表示的注意力机制提取跨句子语义信息, 引入自注意力机制提取基于句法的上下文信息, 有效地将句子内部和句子间的特征相结合, 用于复述识别。实验结果显示, 本文所提模型明显提高了复述识别的精度。在未来的研究工作中, 我们需要探索模型深度在改进短语级语义匹配方面的有效性。同时, 需要探索在基于句法结构的模型中融入预训练语言模型的技术(如 BERT[25]), 以期进一步改进复述识别性能。
参考文献:
[1] 赵世奇, 刘挺, 李生. 复述技术研究. 软件学报, 2009, 20(8): 2124–2137
[2] Callisonburch C, Koehn P, Osborne M. Improved sta-tistical machine translation using paraphrases // Pro-ceedings of Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics. New York City, 2006: 17–24
[3] Liang Z, Chin Y L, Eduard H. Re-evaluating machine translation results with paraphrase support // Procee-dings of the 2006 Conference on Empirical Methods in Natural Language Processing. Sydney, 2006: 77–84
[4] Zhao Shiqi, Zhou Ming, Liu Ting. Learning question paraphrases for QA from encarta logs // Proceedings of IJCAI. Hyderabad, 2007: 1795–1800
[5] Regina B, Kathleen R M. Extracting paraphrases from a parallel corpus // Proceedings of the 39th Annual Meeting on Association for Computational Linguist-ics. Toulouse, 2001: 50–57
[6] Mani I. Advances in automatic text summarization. Cambridge: MIT Press, 1999
[7] Rada M, Courtney C, Carlo S, et al. Corpus-based and knowledge-based measures of text semantic similarity // Proceedings of AAAI. Boston, 2006: 775–780
[8] Zornitsa K, Andrés M. Paraphrase identification on the basis of supervised machine learning techniques // Advances in Natural Language Processing. Berlin: Springer, 2006: 524–533
[9] Finch A, Hwang Y S, Sumita E. Using machine trans-lation evaluation techniques to determine sentence-level semantic equivalence // Proceedings of the Third International Workshop on Paraphrasing. Jeju Island, 2005: 17–24
[10] 吴晓锋, 宗成庆. 基于语义角色标注的新闻领域复述句识别方法. 中文信息学报, 2010, 24(5): 3–10
[11] Wang Z, Wael H, Radu F. Bilateral multi-perspective matching for natural language sentences // Procee-dings of International Joint Conference on Artificial Intelligence. Melbourne, 2017: 4144–4150
[12] Gong Yichen, Luo Heng, Zhang Jian. Natural lan-guage inference over interaction space [EB/OL]. (2018–05–26) [2019–01–26]. https://arxiv.org/abs/ 1709.04348
[13] Duan Chaoqun, Cui Lei, Chen Xinchi, et al. Attention-fused deep matching network for natural language inference // Proceedings of International Joint Con-ference on Artificial Intelligence. Stockholm, 2018: 4033–4040
[14] 李天时, 李琦, 王文辉, 等. 基于外部记忆单元和语义角色知识的文本复述判别模型. 中文信息学报, 2017, 31(6): 33–40
[15] 刘明童, 张玉洁, 徐金安, 等. 开放域上基于深 度语义计算的复述模板获取方法. 中文信息学报, 2018, 32(2): 94–101
[16] Fan Miao, Lin Wutao, Feng Yue, et al. A globaliza-tion-semantic matching neural network for paraphrase identification // Proceedings of the 27th ACM Inter-national Conference on Information and Knowledge Management. Turin, 2018: 2067–2075
[17] Yin W, Schütze H, Xiang B, et al. ABCNN: attention-based convolutional neural network for modeling sentence pairs. Transactions of the Association for Computational Linguistics, 2016, 4: 259–272
[18] Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured Long Short-Term Memory networks // Proceedings of the 53rd Annual Meeting of the Association for Computational Ling-uistics and the 7th International Joint Conference on Natural Language Processing. Beijing, 2015: 1556–1566
[19] Dozat T, Manning C D. Deep biaffine attention for neural dependency parsing [EB/OL]. (2017–03–10) [2018–03–10]. https://arxiv.org/abs/1611.01734
[20] Schmidhuber J, Hochreiter S. Long short-term memo-ry. Neural Comput, 1997, 9(8): 1735–1780
[21] Pennington J, Socher R, Manning C D. Glove: global vectors for word representation // Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, 2014: 1532–1543
[22] Kingma D P, Ba J. Adam: a method for stochastic optimization [EB/OL]. (2017–01–30) [2019–01–26]. https://arxiv.org/abs/1412.6980
[23] Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: a simple way to prevent neural networks from over-fitting. Journal of Machine Learning Research, 2014, 15(1): 1929–1958
[24] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift // Proceedings of 32nd International Conference on Machine Learning. Lille, 2015: 448–456
[25] Devlin J, Chang M W, Lee K, et al. Bert: pre-training of deep bidirectional transformers for language under-standing [EB/OL]. (2018–11–24) [2019–01–10]. https:// arxiv.org/abs/1810.04805
A Neural Paraphrase Identification Model Based on Syntactic Structure
Abstract Paraphrase identification involves natural language semantic understanding. Most previous methods regarded sentences as sequential structures, and used sequential neural network for semantic composition. These methods do not consider the influence of syntactic structure on semantic computation. In this paper, we proposed a neural paraphrase identification model based on syntactic structure, and designed a tree-based neural network model for semantic composition, which extended the semantic representation from word level to phrase level. Furthermore, this paper proposed a syntactic tree alignment mechanism based on phrase-level semantic representation, and extracted features by using cross-sentence attention mechanism. Finally, a self-attention mechanism was used to enhance semantic representation, which could effectively model context information based on syntactic structure. Experiments on Quora paraphrase dataset show that the performance of paraphrase identification has been improved to 89.3% accuracy.The results further prove that the proposed semantic composition method based on syntactic structure, phrase-level cross sentence attention and self-attention are effective in improving paraphrase identification.
Key words paraphrase identification; syntactic structure; tree-structured neural network; attention mechansim
doi: 10.13209/j.0479-8023.2019.092
国家自然科学基金(61876198, 61976015, 61370130, 61473294)、中央高校基本科研业务费专项资金(2018YJS025)、北京市自然科学基金(4172047)和科学技术部国际科技合作计划(K11F100010)资助
收稿日期: 2019–05–22;
修回日期: 2019–09–20