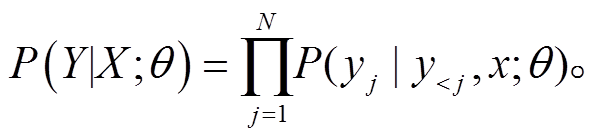 (1)
(1)
图1 双向重排序模型示意图
Fig. 1 Schematic diagram of bidirectional reranking model
摘要 在维吾尔语到汉语等低资源语料库上, 神经机器翻译的拟合训练容易陷入局部最优解, 导致单一模型的翻译结果可能不是全局最优解。针对此问题, 通过集成策略, 有效整合多个模型预测的概率分布, 将多个翻译模型作为一个整体; 同时采用基于交叉熵的重排序方法, 将具有相反解码方向的翻译模型相结合, 最终选出综合得分最高的候选翻译作为输出。在 CWMT2015 维汉平行语料上的实验结果表明, 与单一的Transformer 模型相比, 改进后的方法提升 4.82 个 BLEU 值。
关键词 神经机器翻译; 集成学习; 双向重排序; 维吾尔语
神经机器翻译(neural machine translation, NMT)是一种基于深度学习的机器翻译方法, 在获得大规模平行语料的同时, 可以得到较好的翻译性能。近年来, 随着深度学习技术的发展, 神经机器翻译极大地提高了机器翻译的质量, 在许多语言对上显示出最好的效果[1]。神经机器翻译的核心思想是建立一个基于神经网络的 Encoder-Decoder 模型, 通过将源语言句子编码为一个稠密向量, 然后从该向量解码出目标语言句子, 从而建立源语言与目标语言的映射关系[2]。传统的神经机器翻译是将循环神经网络[3](RNN)或卷积神经网络[4](CNN)作为Encoder-Decoder 模型的基础。最近, Vaswani 等[5]提出一种完全基于注意力机制的神经机器翻译模型 Transfor-mer, 该模型在 WMT2018 测评任务中取得单一模型最好的结果。
尽管 Transformer 模型在很多语言对上取得最好的翻译效果, 但在维吾尔语到汉语这种低资源语料库上, 神经网络的拟合训练很容易陷入局部最优解, 最终单一模型的翻译结果可能不是全局最优解。因此, 研究人员在 WMT 和 CWMT 等机器翻译评测任务中, 通过整合不同模型的预测结果来提升机器翻译的性能[6–7]。Vaswani 等[5]提出使用检查点平均法来获得更低的方差和更稳定的翻译结果。Sennrich 等[8]首先在 WMT16 测评任务中应用检查点集成的方法, 然后在 WMT17[6]测评任务中尝试独立集成的方法, 并取得显著的改善。李北等[9]分析了集成策略对于神经机器翻译的影响。以上研究在使用集成策略解码时, 大多使用同一个方向的翻译模型, 通过束搜索算法得到概率最大的翻译候选, 不能充分地使用每一个翻译模型内部的信息。
为了获得更好的翻译输出, 研究人员尝试了各种方法。Shen 等[10]提出两种新的基于感知器的重排序算法, 提高了机器翻译的质量。Kumar 等[11]提出一种用于统计机器翻译的最小贝叶斯风险的解码方法, 将预期的翻译错误损失降到最低, 从而提升了翻译质量。这些方法主要应用于统计机器翻译。Zhou 等[12]使用不同的系统, 得到有差异性的翻译结果, 通过系统融合的方式, 利用混淆网络来重构翻译结果。
本文基于 Transformer 结构[5], 通过设置不同的随机初始化种子, 生成多个正向翻译模型(从左到右)和逆向翻译模型(从右到左)。图 1 展示基本的双向重排序模型结构。对于输入句子 X, 为了得到更好的翻译列表, 我们使用集成策略对多个正向模型集成翻译产生 N-best 列表。计算候选翻译项对应于集成的每一个翻译模型的交叉熵以及每一个反向翻译模型对于 N-best 列表的交叉熵, 将不同的模型对当前翻译候选的交叉熵得分求和。由于神经机器翻译在解码时生成的序列概率是多个条件概率的乘积, 所以生成的句子序列越长, 概率值相乘的结果就越小, 更倾向于生成短序列。因此, 需对短句子进行基于句子长度的惩罚, 降低生成短序列的倾向。这种方式既可以充分利用集成的优势, 又可以有效地整合不同方向的翻译模型对候选翻译的评估。
神经机器翻译是一种使用深度神经网络获取自然语言之间的映射关系的方法, 通常采用 Encoder-Decoder 架构, 通过编码器, 将给定的源语句子 X= (x1, x2, …, xn)编码为中间向量 Z, 解码器根据中间向量产生目标语言句子Y=(y1, y2, …, yn)。对编码器和解码器进行联合训练, 使给定源序列的目标序列的条件概率最大化:
(1)
图1 双向重排序模型示意图
Fig. 1 Schematic diagram of bidirectional reranking model
在 Transformer 模型提出之前, 大多数神经机器翻译模型都采用基于注意力机制[1]的循环神经网络(RNN)。这种方式在一些任务上取得不错的效果, 但由于 RNN 的序列特性, 导致在训练的过程中难以并行化, 对于长距离和层次化的依赖关系难以建立, 使得训练过程十分漫长, 从而影响翻译质量。
Transformer 摒弃了传统的循环神经网络的序列结构, 采用完全基于注意力机制的结构。在保证模型并行化的同时, 也改善了模型的表示能力, 准确性也有一定程度的提升[5]。
Transformer 同样采用 Encoder-Decoder 的架构, 它由 N 个堆叠的编码器和解码器层组成。采用全新的注意力机制: Encoder 端的自注意力机制、Decoder端的自注意力机制以及编码端–解码端的自注意力机制。如图 2 所示, Transformer 模型没有使用任何循环神经网络, 为了获得输入序列的顺序特征, 需要在词向量的基础上加入位置编码信息。
编码器由 N 个相同的层组成, 图 2 展示两个Encoder层的堆叠。每一层包含两个子层: 多头自注意力机制和传统的前馈神经网络。框内的虚线表示直连接网络, 是为了在较深的神经网络中减少信息的损失以及加速模型的收敛。使用残差链接和层正则化[13]来保证梯度的传递的稳定。解码器与编码器类似, 解码的过程中只能看到已经输出的信息, 需要将未输出部分进行遮掩, 因此使用带遮掩的多头注意力机制, 同时增加一个负责处理编码器输出的多头注意力机制。多头注意力机制用于从不同位置的不同表示子空间获取信息, 其基本单元是缩放的点积注意力模型。每一个头对应一个点积注意力模型, 计算公式如下:
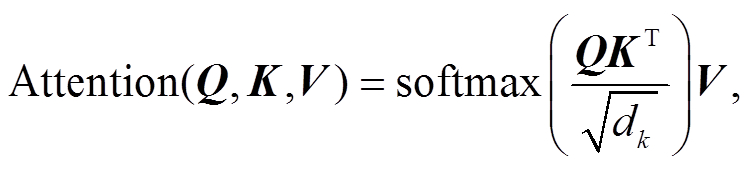 (2)
(2)其中, Q 表示查询矩阵, K 表示键值矩阵, dk 表示 K的维度, V 表示权重矩阵。多头自注意力机制就是采用多组 Q, K 和 V 得到不同的点积自注意力输出, 最后将这些输出连接起来作为最终的输出结果。
集成学习是一种联合多个学习器进行协同决策的机器学习方法[14], 通过整合多个学习器的决策结果, 有效地减小预测结果的方差和偏置[15], 可以显著地提升模型的泛化能力[16], 获得比单学习器更好的效果。近年来, 集成学习方法在机器翻译领域取得了较好的效果[17–19]。
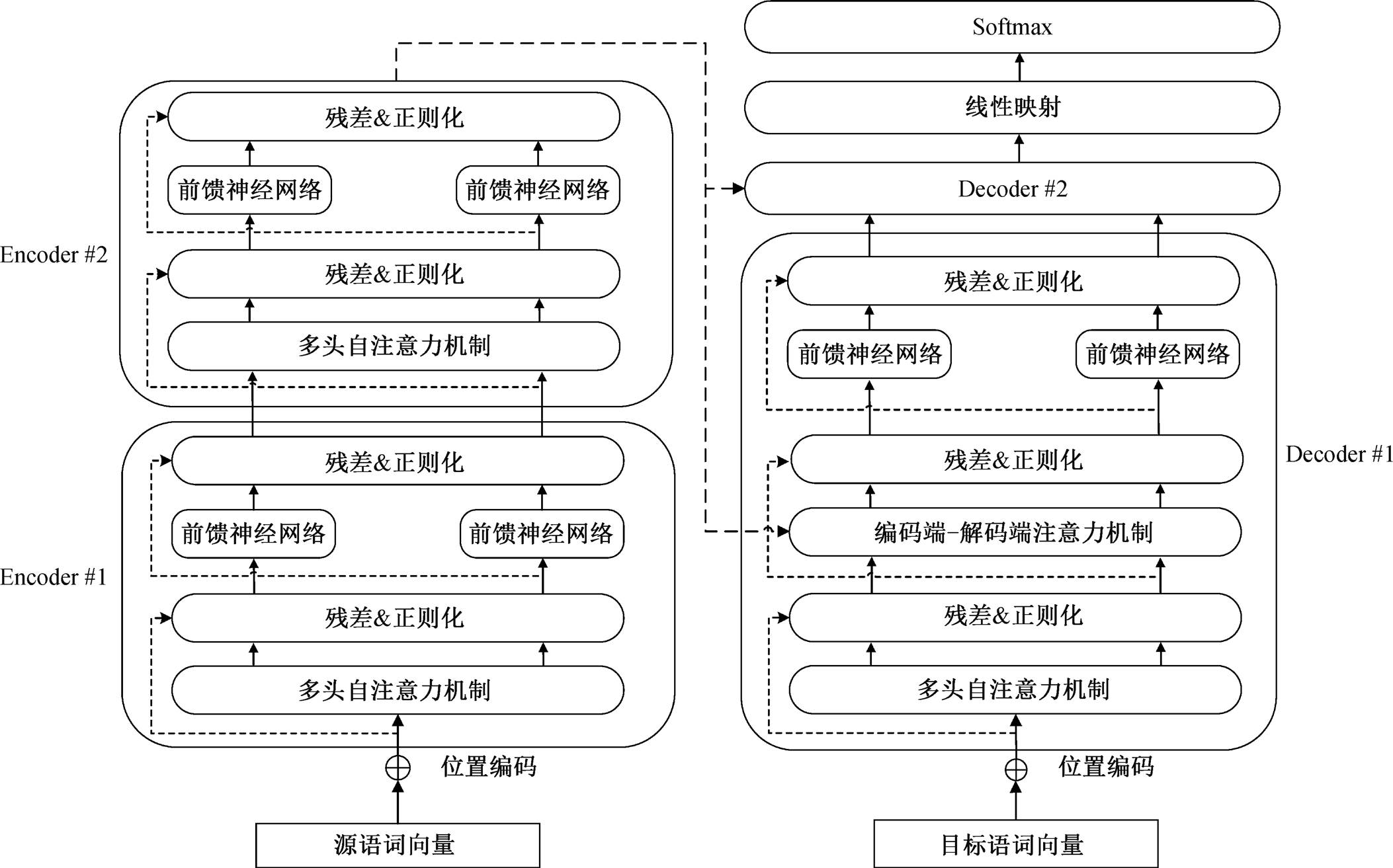
图2 Transformer模型示意图
Fig. 2 Transformer model diagram
机器翻译是一种序列生成任务, 在解码时, 每一个时序的输出都依赖于前一个时序的输出。模型会根据当前的语义信息, 计算得到概率分布向量(维度为词表大小), 经过 Softmax 操作, 得到归一化的向量表示, 向量中的每一个元素指代预测下一个词的概率。如图 3 所示, 机器翻译的集成学习策略是在解码的过程中通过整合不同模型得到的概率分布, 从而获得新的解, 进而预测下一个目标端词语。单一模型生成目标端单词的选择如式(3)所示, 集成学习方法生成单词的选择如式(4)所示。
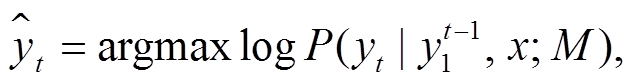 (3)
(3)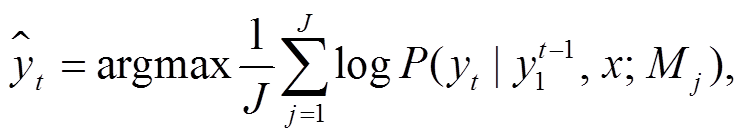 (4)
(4)
其中, yt表示在第 t 个位置将要输出的单词, 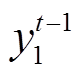 表示从句首到(
表示从句首到(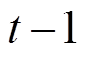 )位置输出的单词序列。x 表示输入单词序列。M 表示翻译中的解码模型(Mj 表示第 j个翻译模型), J表示集成的翻译模型数量。
)位置输出的单词序列。x 表示输入单词序列。M 表示翻译中的解码模型(Mj 表示第 j个翻译模型), J表示集成的翻译模型数量。
集成策略也存在一些限制。首先, 所有的翻译模型都必须使用同一个目标词汇表, 因为每一个单词的输出概率都是在同一个词表规模上不同模型的平均值。其次, 所有模型的解码方向必须一致, 这是由于在得到当前时刻的输出单词后, 需采用束搜索的方式生成候选翻译, 只有模型的解码方向一致, 才能生成更好的候选翻译。
在解码的过程中, 神经机器翻译会根据束搜索算法产生 N-best 的翻译列表, 但有时概率最大的翻译结果不一定是最佳翻译。如何通过重排序的方式在规模为 N 的候选翻译中找到最优翻译结果十分重要[20]。
本文通过计算交叉熵的方式来评估翻译列表中译文的质量。交叉熵[21]的定义如下:
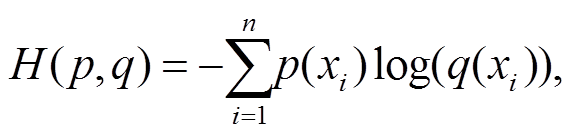 (5)
(5)其中, 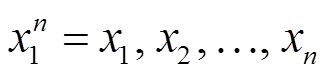 为源语言的句子, p(xi)为源语言词 xi 对应的候选翻译词的概率分布, q(xi)为翻译模型 q 翻译得到的候选翻译列表中对应词的概率。由于交叉熵越小模型的表现越好, 为了用分数来衡量模型的质量, 我们使用交叉熵的相反数作为候选翻译的最终得分。
为源语言的句子, p(xi)为源语言词 xi 对应的候选翻译词的概率分布, q(xi)为翻译模型 q 翻译得到的候选翻译列表中对应词的概率。由于交叉熵越小模型的表现越好, 为了用分数来衡量模型的质量, 我们使用交叉熵的相反数作为候选翻译的最终得分。
重排序策略可以应用于相同目标语言的任意模型, 因此通过集成策略改善 N-best 翻译列表的质量, 使用重排序方法选出更优的翻译候选。
为了更好地利用集成策略和重排序策略的优势[22], 本文将两种方式相结合, 称为双向重排序模型。通过维汉神经机器翻译中的实例, 说明双向重排序模型的有效性。
给定以下源语言和目标语言。
源语言:يالۇجياڭ دەرياسى چېگرا ھالقىغان چوڭ كۆۋرۈكى قاتارلىق قۇرۇلۇشلاردا ئەھمىيەتلىك قەدەم بېسىلدى.。
参考译文: 鸭绿江跨境大桥等建设迈出了有意义的步伐。
对于以上实例, 我们通过 4 个正向模型的集成翻译, 根据对数似然概率产生 12 个翻译候选, 对数似然概率对应图 4 中最后一列。计算列表中每一个候选翻译对应的集成翻译模型的交叉熵得分 F0~F3, 然后依次使用 4 个逆向翻译模型, 计算列表中的交叉熵得分 R2L0~R2L3。将所有交叉熵得分的和与基于翻译长度的惩罚因子的比值作为最终的结果, 将得分最高的翻译候选作为最终的翻译输出。通过这种方法, 选出与参考译文完全一致的候选翻译 6, 而不是对数似然最大的候选翻译1。
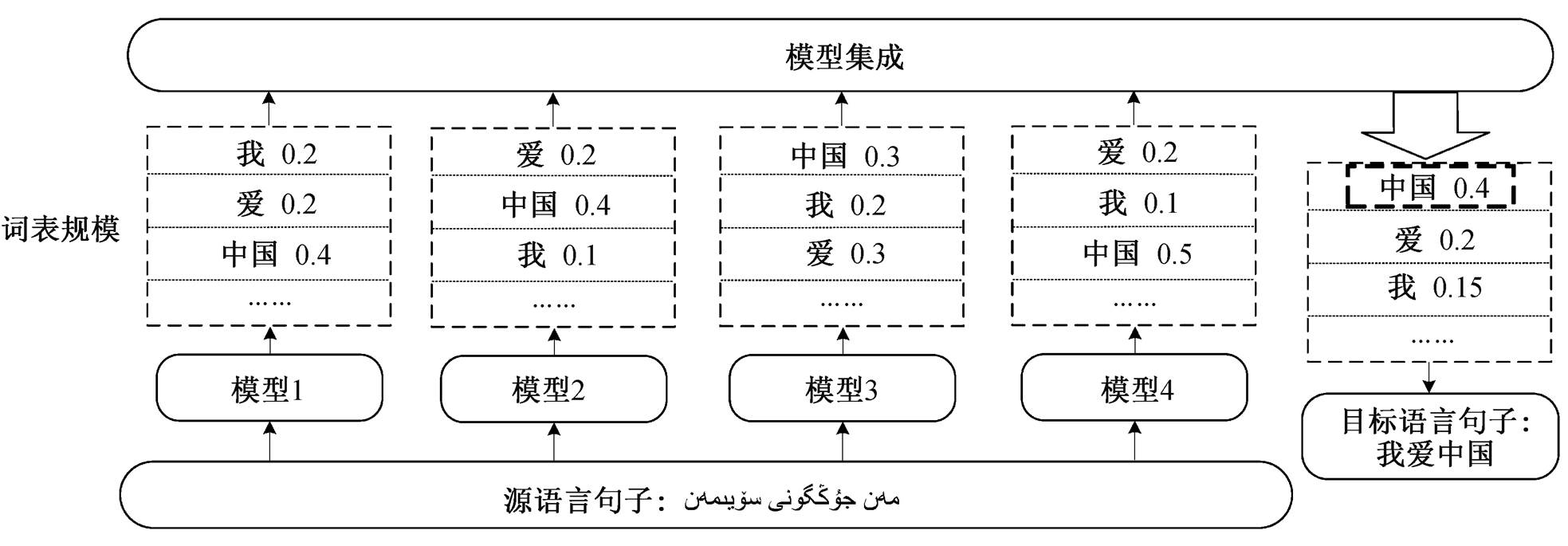
图3 模型集成示意图
Fig. 3 Schematic diagram of model ensemble
我们在 CWMT2015 提供的维汉双语平行语料上进行实验, 验证基于 Transformer 的双向重排序模型的有效性。首先, 对语料进行乱码过滤, 剔除混有乱码的语料。然后, 在训练集中过滤掉与开发集测试集相同的句对, 并对汉语进行基于字级别的处理。最终训练集包含维-汉平行句对 336224 句, 开发集包含 700 句, 测试集包含1000句。
我们从训练集中学习得到字节对编码(BPE)的规则[23], 其中设置 BPE 词表的大小为 32000。将学习到的规则应用于所有训练集、开发集和测试集, 这样可以有效地减少未登录词出现的频次, 提升翻译的效果。根据经过 BPE 处理的源语言和目标语言的训练集, 生成联合词汇表, 将词汇表规模设置为 36K, 将训练集中的句子长度限制为 100。采用基于 Moses 的 multi-bleu-detok.perl 的脚本[24]来计算BLEU值, 通过BLEU值来衡量翻译的质量。
我们使用 Marian 作为实验的模型框架[25]。使用 Transformer 模型作为实验的基线模型, 参数采用Transformer_base 的设置。编码端和解码端的层数都是 6 层, 词向量的维度为 512, 前馈神经网络为2048 维, 学习率为 0.0003, 采用 5 个 K80GPU 进行训练。采用 Adam 算法作为优化算法, 通过 AAN网络[26]来加速 Transformer 的解码过程, 将 Swish 作为激活函数。在训练中使用早停机制, 参数设置为 5, 在整个训练语料上进行 108 轮。解码的过程中, 我们使用 Beam-search 策略, beam-size 的大小设置为12。基于该参数的单模型, 在测试集上的 BLEU 值为50.17。
我们采用束搜索的方法生成 N-best 翻译候选。通常, 束搜索的大小会大于或者等于候选翻译的规模 N。本文设置束搜索的大小与 N-best 相等。在生成翻译时, 对 N-best 中每一个候选翻译进行交叉熵打分, 选择得分最高的候选翻译作为最终的翻译输出。图 5 展示不同的翻译模型在不同 N-best 规模下BLEU 值的变化, 包含从左到右的正向翻译模型、从右到左的逆向翻译模型以及双向重排序模型。本节使用的模型都是单一的翻译模型, 没有使用集成的方法来生成翻译。

图4 多模型集成的双向重排序实例
Fig. 4 An example of bi-directional reranking for multi-model ensemble
从图 5 可以看出, 从左到右的正向翻译模型, 在 N-best 为 9 时, BLEU 值最高(50.49)。当 N-best 的规模达到 12 时, BLEU 值趋于平稳。从右到左的逆向翻译模型, 在 N-best 为 8 时, BLEU 值最高(50.74)。当 N-best 的规模达到 11 时, BLEU 值趋于稳定。双向重排序模型, 随着 N-best 的增大, BLEU 值也逐渐增大, 在 N-best 为 11~15 时, BLEU 值趋于稳定, 在 N-best 为 15 时最高(52.03), 表明随着翻译候选列表的增大, 双向重排序模型能够较好地选择最佳翻译候选。基于以上的实验结果, 下面的实验中将N-best设置为12。
为了验证重排序策略的有效性, 我们在从左到右的 4 个模型(L2R)和从右到左的 4 个模型(R2L)中分别对比 N 为 12 时重排序策略和最大概率的翻译质量。从表 1 可以看出, 除第 3 个正向翻译模型中最大概率的策略高于重排序策略外, 其余重排序模型的翻译质量都高于最大概率, BLEU 值平均提升0.33。
图 6 展示从左到右、从右到左的解码以及双向重排序多模型集成的 BLEU 值与集成模型数量的关系。在双向重排序模型中, 我们进行以下两组实验。
1)将从左到右的正向模型作为翻译模型, 将从右到左的逆向模型作为重排序模型(重排序(L2R))。
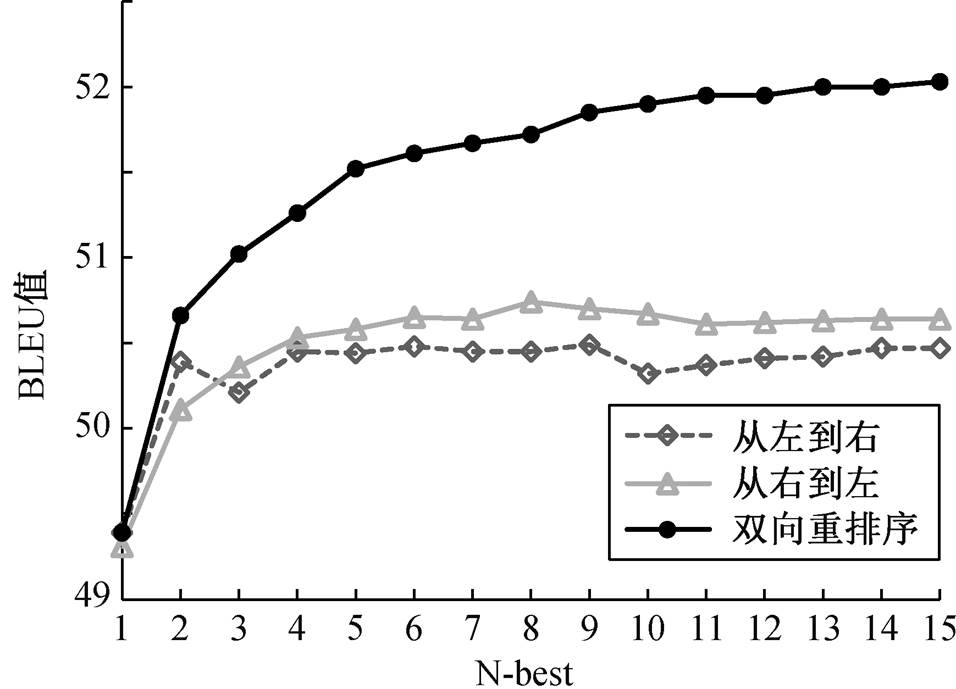
图5 BLEU值与N-best的关系
Fig. 5 Relationship between BLEU value and N-best
表1 重排序策略对BLEU值的影响
Table 1 Effect of reranking strategy on BLEU value
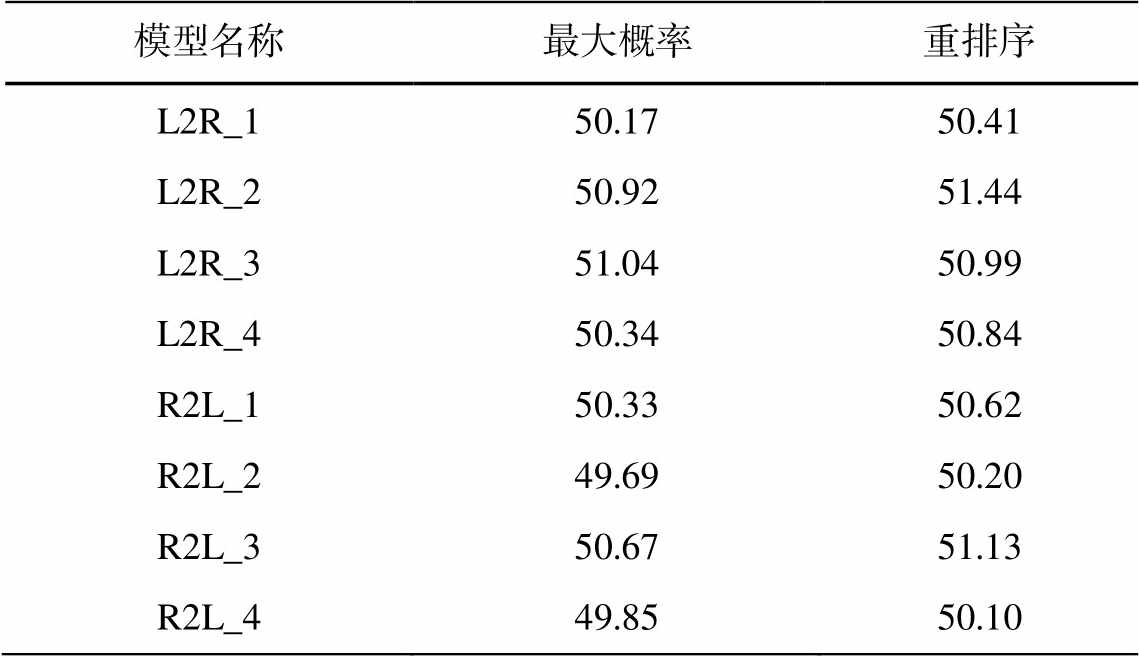
模型名称最大概率重排序 l2R_150.1750.41 L2R_250.9251.44 L2R_351.0450.99 L2R_450.3450.84 r2l_150.3350.62 r2l_249.6950.20 R2L_350.6751.13 R2L_449.8550.10
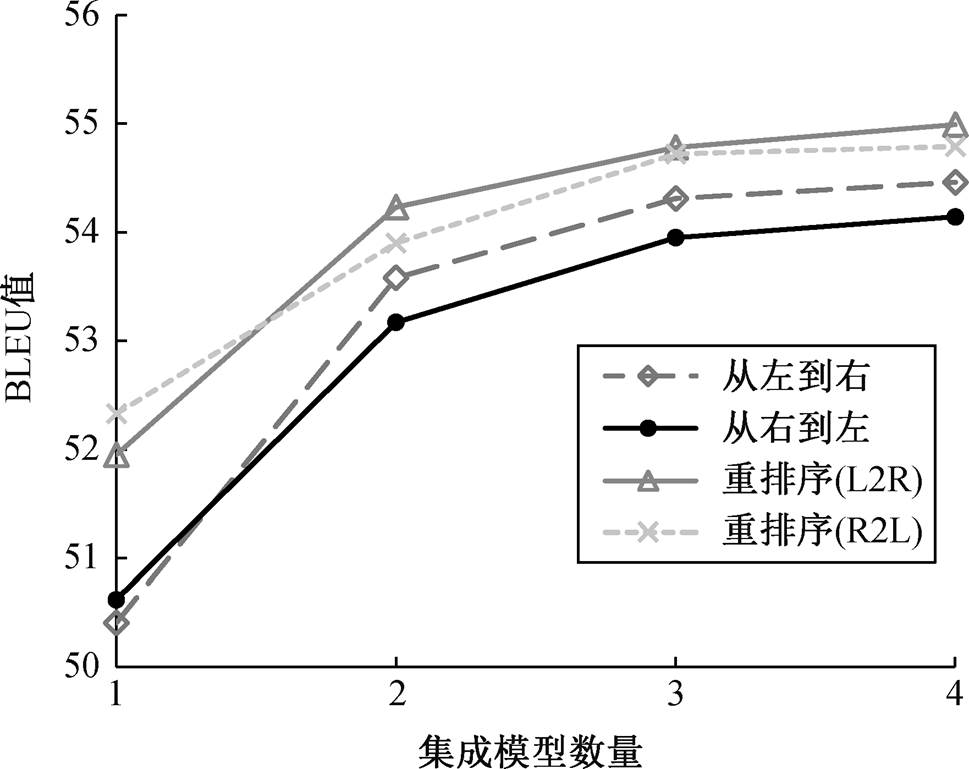
图6 BLEU值与集成模型数量的关系
Fig. 6 Relationship between BLEU value and number of ensemble models
2)将从右到左的正向模型作为翻译模型, 将从左到右的逆向模型作为重排序模型(重排序(R2L))。
从图6可以得到如下结论。
1)4 个翻译模型的 BLEU 值都随模型数量的增加而增加, 但增长速度变慢。集成 4 个翻译模型时, 翻译质量达到最优, BLEU 值分别为 54.99, 54.79, 54.46 和 54.14。双向重排序多模型集成的最好的结果比从左到右的正向单一翻译模型(L2R_1)的BLEU 值提升 4.58, 比从右到左的逆向翻译模型(R2L_1)提升4.37。
2)从左到右的集成翻译效果比从右到左的集成翻译效果稍有提高, BLEU 值平均高 0.22。说明翻译质量不仅与数据集和语言对相关, 也随解码方向的不同而变化。
3)重排序后模型的翻译效果显著高于单向的多模型集成, 说明重排序策略可以更好地选择最佳候选翻译。为了进一步验证重排序方法对集成翻译模型提升的效果, 我们进行如下对比实验。
集成了从左到右的 4 个正向翻译的模型后, 我们依次加入逆向的重排序策略, 结果如表 2 所示。可以看出, 随着重排序模型数量的增加, BLEU 值也随之提高, 与没有逆向重排序策略的集成模型相比, BLEU 值提高 0.53, 说明逆向重排序策略可以有效地提升集成翻译的质量。
表2 重排序策略对集成翻译的影响
Table 2 Impact of reranking strategies on ensembled translation

系统名称系统设置模型数量BLEU EnsemL2R_1, L2R_2, L2R_3, L2R_4454.46 Com-1Ensem + R2L_1554.85 Com-2Com-1 + R2L_2654.98 Com-3Com-2 + R2L_3754.94 Com-4Com-3 + R2L_4854.99
4)两个双向重排序模型的翻译效果差别不大, 正向翻译模型比逆向翻译模型的 BLEU 值高 0.2。我们认为这是由于 4 个正向翻译模型的 BLEU 值的均值比逆向翻译模型略高。这也从另一个角度说明提升单一模型的翻译效果能够在集成策略中更好地获得翻译候选, 从而提升翻译质量。
本文通过集成策略和重排序策略, 提升维吾尔语到汉语等低资源语言对上的翻译质量。由于重排序方法可以将具有与集成不同属性的模型组合在一起, 所以我们将正向模型与反向模型结合起来进行重排序。通过集成和双向重排序, 获得比单独集成更高的翻译质量。在 CWMT2015 维汉测试集上的实验表明, 当 N-best 的规模为 12 时, 经过 4 个正向模型的集成翻译和 4 个逆向模型的重排序, 得到的BLEU 值比基线系统提升 4.82 。此外, 通过对比不同方向的翻译效果, 验证了解码的方向对翻译质量也有影响。
如果能进一步提高单个模型的质量, 则集成和重排序方法都可以进一步提高翻译质量。因此, 我们未来将采用更多更具有差异性的模型来提升集成翻译的效果, 同时将更多的重排序方法进行融合, 得到更优的翻译候选。
参考文献
[1] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate [EB/OL]. (2016–05–19) [2019–02–01]. https://arxiv.org/ abs/1409.0473v4
[2] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks // Advances in Neural Information Processing Systems 27. Montreal, 2014: 3104–3112
[3] Kalchbrenner N, Blunsom P. Recurrent continuous translation models // Proceedings of the 2013 Con-ference on Empirical Methods in Natural Language Processing. Seattle, 2013: 1700–1709
[4] Gehring J, Auli M, Grangier D, et al. Convolutional sequence to sequence learning // Proceedings of the 34th International Conference on Machine Learning-Volume 70. Sydney, 2017: 1243–1252
[5] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // Advances in Neural Information Pro-cessing Systems 30. Long Beach, 2017: 5998–6008
[6] Sennrich R, Birch A, Currey A, et al. The University of Edinburgh’s neural MT systems for WMT17 // Proceedings of the Second Conference on Machine Translation. Copenhagen, 2017: 389–399
[7] Tan Z, Wang B, Hu J, et al. XMU neural machine translation systems for WMT 17 // Proceedings of the Second Conference on Machine Translation. Copen-hagen, 2017: 400–404
[8] Sennrich R, Haddow B, Birch A. Edinburgh neural machine translation systems for WMT 16 [EB/OL]. (2016–06–27) [2019–02–01]. https://arxiv.org/abs/16 06.02891
[9] 李北, 王强, 肖桐, 等. 面向神经机器翻译的集成学习方法分析. 中文信息学报, 33(3): 42–51
[10] Shen L, Sarkar A, Och F J. Discriminative reranking for machine translation // Proceedings of the Human Language Technology Conference of the North Ame-rican Chapter of the Association for Computational Linguistics: HLT-NAACL 2004. Boston, 2004: 177–184
[11] Kumar S, Byrne W. Minimum Bayes-risk decoding for statistical machine translation [R]. Baltimore: Johns Hopkins Univ Baltimore MD Center for Language and Speech Processing (CLSP), 2004
[12] Zhou L, Hu W, Zhang J, et al. Neural system com-bination for machine translation [EB/OL]. (2017–04–21) [2019–02–01]. https://arxiv.org/abs/1704.06393
[13] Lei Ba J, Kiros J R, Hinton G E. Layer normalization [EB/OL]. (2016–07–21) [2019–02–01]. https://arxiv.org/abs/1607.06450
[14] Hansen L K, Salamon P. Neural network ensembles. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1990, 12(10): 993–1001
[15] Dietterich T G. Ensemble methods in machine lear-ning // International workshop on multiple classifier systems. Berlin: Springer, 2000: 1–15
[16] Bauer E, Kohavi R. An empirical comparison of voting classification algorithms: bagging, boosting, and variants. Machine Learning, 1999, 36(1/2): 105–139
[17] Opitz D, Maclin R. Popular ensemble methods: an empirical study. Journal of Artificial Intelligence Research, 1999, 11: 169–198
[18] Xiao T, Zhu J, Liu T. Bagging and boosting statistical machine translation systems. Artificial Intelligence, 2013, 195: 496–527
[19] Liu Y, Zhou L, Wang Y, et al. A comparable study on model averaging, ensembling and reranking in NMT // CCF International Conference on Natural Language Processing and Chinese Computing. Hohhot, 2018: 299–308
[20] Och F J, Gildea D, Khudanpur S, et al. A smorgasbord of features for statistical machine translation // Pro-ceedings of the Human Language Technology Con-ference of the North American Chapter of the Asso-ciation for Computational Linguistics. Boston, 2004: 161–168
[21] 宗成庆. 统计自然语言处理. 北京: 清华大学出版社, 2013
[22] Imamura K, Sumita E. Ensemble and reranking: using multiple models in the NICT-2 neural machine trans-lation system at WAT2017 // Proceedings of the 4th Workshop on Asian Translation (WAT2017). Taipei, 2017: 127–134
[23] Sennrich R, Haddow B, Birch A. Neural machine translation of rare words with subword units [EB/OL]. (2016–06–10) [2019–02–01]. https://arxiv.org/abs/150 8.07909
[24] Koehn P, Hoang H, Birch A, et al. Moses: open source toolkit for statistical machine translation // Procee-dings of the 45th Annual Meeting of the Association for Computational Linguistics. Prague, 2007: 177–180
[25] Junczys-Dowmunt M, Grundkiewicz R, Dwojak T, et al. Marian: fast neural machine translation in C++ [EB/OL]. (2018–04–04) [2019–02–01]. https://arxiv. org/abs/1804.00344
[26] Zhang B, Xiong D, Su J. Accelerating neural trans-former via an average attention network [EB/OL]. (2018–05–07) [2019–02–01]. https://arxiv.org/abs/1805. 00631
Analysis of Bi-directional Reranking Model for Uyghur-Chinese Neural Machine Translation
Abstract The fitting training of neural machine translation is easy to fall into a local optimal solution on a low-resource corpus such as Uyghur to Chinese, resulting in the translation result of a single model may not be a global optimal solution. In order to solve this problem, the probability distribution predicted by multiple models is effectively integrated through the ensemble strategy, and multiple translation models are taken as a whole. At the same time, the translation models with opposite decoding directions are integrated by the reordering method based on cross entropy, and the candidate translation with the highest comprehensive score is selected as the output. The experiment on CWMT2015 Uighur-Chinese parallel corpus shows that proposed method has 4.82 BLEU values improvement compared with a single transformer model.
Key words neural machine translation; ensemble learning; bi-directional reranking; Uyghur
doi: 10.13209/j.0479-8023.2019.093
新疆维吾尔自治区重点实验室开放课题(2018D04018)、国家自然科学基金(U1703133)、中国科学院青年创新促进会项目(2017472)和新疆维吾尔自治区高层次人才引进工程项目(Y839031201)资助
收稿日期: 2019–06–02;
修回日期: 2019–09–27