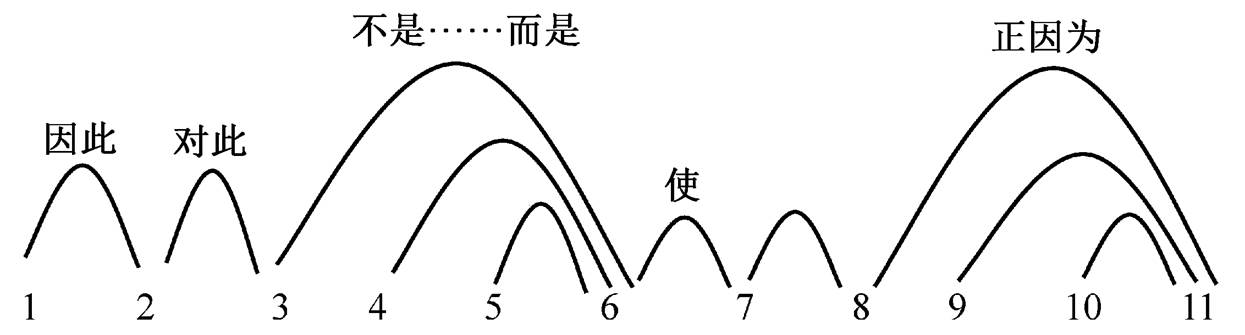
图1 例1的篇章小句关联结构
Fig. 1 Discourse clauses relevance structure of example 1
摘要 将篇章结构表示为小句关联结构, 与修辞结构等层次化篇章结构模式相比, 可以有效地刻画非连续和跨层级的小句之间的直接语义关联。首先, 提出篇章小句关联结构的形式表示、判断准则和形式限制, 并进行人工标注。然后, 对汉语篇章小句关联结构进行自动识别。在自建汉语篇章小句关联结构语料库上, 基于分类模型, 设计连接词和词汇等分类特征, 得到的最佳识别准确率达 92.70%。实验结果表明, 语料整体取样比独立取样取得的去环效果好; 词汇、小句距离及句域等分类特征对识别的贡献较大; 远距离和跨大句是小句关联识别的难点, 但相邻小句和同一大句内的小句对的不相关识别难度更大。
关键词 小句关联结构; 篇章结构; 篇章依存结构; 修辞结构
篇章结构分析主要是分析篇章单位间的结构关系, 在自动摘要、自动问答及机器翻译等研究中有重要应用。比较著名的篇章结构表示模式主要有修辞结构[1–2]和宾州语篇树库模式[3], 前者将篇章表示为一颗层次化结构树, 后者将篇章表示为一个个独立的篇章连接词的论元结构, 其中论元大致相当于篇章单位。二者本质上都是一种层次化结构, 不同在于, 前者是完整篇章结构树, 后者根据连接词的论元辖域, 可以推导出一定的篇章结构树, 但并不构造完整的结构树。Li 等[4]提出的篇章连接依存树模式融合了修辞结构的层次化模式和宾州语篇树库的连接词模式, 在获得完整篇章结构树的同时, 也能表示连接词论元结构, 本质上仍然是一种层次化结构。层次化结构不能刻画最小篇章单位间的直接语义关联, 特别是不能刻画非相邻和跨层级的最小篇章单位间的语义关联, 而这种关联在篇章中普遍存在。
为解决以上问题, 篇章依存结构[5–7]提供了形式表示的可能性。与传统句法依存结构[8]需确定词与词之间的中心和非中心关系类似, 篇章依存结构的核心在于确定最小篇章单位之间的中心和非中心关联。如何确定最小篇章单位间有无关联, 何为中心, 目前缺少相关研究。目前, 相应的篇章依存语料库或由修辞结构语料库简单转化而来[5], 或关系体系等略调以面向特定领域[6], 且均非基于汉语。
本文将篇章结构表示为小句关联结构, 小句即最小篇章单位[9]。与篇章层次结构相比, 它可以有效地刻画非相邻和跨层级的最小篇章单位之间的语义关联。小句关联与现有的篇章依存结构相关, 但不同。现有篇章依存结构一般在确定小句关联的同时确定中心, 小句关联结构仅关注小句之间有无关联, 更容易判断。在本文的小句关联结构上也可构拟中心, 但并不在建构小句关联的同时确定中心, 而是在确定所有小句关联结构之后, 才基于小句关联结构整体拟定中心。如果将进一步区分了中心的小句关联结构也称为“篇章依存结构”, 那么在这种篇章依存结构分析中, 小句关联是第一性的, 关联中心是第二性的, 小句关联分析更具基础性。
本文提出篇章小句关联结构的表示机制, 阐明小句关联的判断准则、形式限制等, 进行语料标注实验。在自建的汉语篇章小句关联结构标注语料上进行小句关联识别研究, 考察计算模型、语料取样和语言特征等对小句关联识别的影响。
小句(clause)是最小篇章单位, 两个有关系的小句构成一个小句关联对, 即为“小句关联”。例 1 为一个篇章小句关联结构, 图 1 为例 1 的篇章小句关联结构图式, 1, 2, …, 11 代表小句序列, 连线表示小句关联。小句关联结构整体上是一个无向无环图。
例 1一1 浦东开发开放是一项振兴上海, 建设现代化经济、贸易、金融中心的跨世纪工程, 2因此大量出现的是以前不曾遇到过的新情况、新问题。二3 对此, 浦东不是简单的采取“干一段时间, 等积累了经验以后再制定法规条例”的做法, 4 而是借鉴发达国家和深圳等特区的经验教训, 5 聘请国内外有关专家学者, 6积极、及时地制定和推出法规性文件, 7使这些经济活动一出现就被纳入法制轨道。三8去年初浦东新区诞生的中国第一家医疗机构药品采购服务中心, 正因为一开始就比较规范, 9运转至今, 10成交药品一亿多元, 11没有发现一例回扣。
与修辞结构等层次化结构相比, 小句关联突破篇章单位的线性顺序和层级限制, 准确地刻画了基本篇章单位之间的直接关系, 如 3-6, 4-6, 8-11 和9-11突破篇章单位线性顺序限制而直接关联, 2-3 和 7-8突破篇章单位不在同一大句(sentence, 由句号等句末点号标记, 例 1 中用一、二和三标记)的层级限制而直接关联。
基于小句关联及其关联度的度量, 可以进一步推导出关联结构的中心及全文主旨。例 1 中, 小句6 与多个小句(3, 4, 5 和 7)直接关联, 并且与一些小句相对间接关联, 可推出其为相关关联对(3-6, 4-6, 5-6 和 6-7)的中心, 进一步推导出其为全段中心。与修辞结构的关系中心相比, 这种关联中心更具全局性, 也更具篇章本质。基于小句关联结构, 可以更准确地刻画篇章语义关系, 如连接词可以突破线性位置的连续性和单位层级限制, 跨篇章单位可以直接反映小句关联间关系, 如“不是……而是”和“正因为”分别反映非连续篇章单位 3-6 与 8-11 之间的关系, “对此”反映跨大句的小句 2-3 之间的关系。相比而言, 连接词反映的小句关联关系, 比在层次化结构中反映的语义关系更具体更准确。小句关联及篇章中心和语义即为我们进一步构拟的“篇章依存结构”。在篇章依存结构分析中, 小句关联分析更具基础性。由于其特别的结构表示, 小句关联分析在自动摘要、自动问答及机器翻译等研究中有独特的应用价值。
图1 例1的篇章小句关联结构
Fig. 1 Discourse clauses relevance structure of example 1
关联小句可构成仅含两个小句的最小复句, 这是小句关联的直观判断机制。两个关联小句如果要成为自然语篇, 还需删除或添加无关或有关衔接成分。例 2 给出例 1 的小句关联(部分), 删除了当前关联句对中无关的连接词(用删除号标记), 添加了相关的主语成分等(用括号标记)。
例 2 1-2:1 浦东开发开放是一项振兴上海, 建设现代化经济、贸易、金融中心的跨世纪工程, 2 因此大量出现的是以前不曾遇到过的新情况、新问题。
2-3: 2因此(浦东开发开放)大量出现的是以前不曾遇到过的新情况、新问题。3对此, 浦东不是简单的采取“干一段时间, 等积累了经验以后再制定法规条例”的做法,
3-6: 3 浦东不是简单的采取“干一段时间, 等积累了经验以后再制定法规条例”的做法, 6 而是……积极、及时地制定和推出法规性文件,
4-6: 4 而是(浦东)借鉴发达国家和深圳等特区的经验教训, 6积极、及时地制定和推出法规性文件,
5-6: 5(浦东)聘请国内外有关专家学者, 6积极、及时地制定和推出法规性文件,
6-7: 6(浦东)积极、及时地制定和推出法规性文件, 7使这些经济活动一出现就被纳入法制轨道。
……
在理论机制上, 小句关联判断的依据有如下两个。
1)语义连贯。从根本上讲, 对小句间语义连贯的判断可归结为小句间词汇和短语等构成要素的语义关联。例 2 用下划虚线标记小句关联间某些有语义关联的词汇和短语。如 1-2 中, 小句 1 的“跨世纪工程”与小句 2 的“新情况、新问题”有某种关联。一个小句与不同小句有关联, 往往是这个小句的不同部分与不同小句关联, 如在 2-3 中, 小句 3 的“采取……做法”与小句 2 的“情况、问题”关联(因果性关联), 在 3-6 中, 是小句 3 的“干一段时间, 等积累了经验以后再……”与小句 6 的“积极、及时……”构成某种关联(转折性关联)。
2)形式衔接。两个小句关联, 通常依附于小句的指代、连接词等衔接成分, 可从关联小句上得到解读, 或者关联小句本身语义自足, 无指代和连接词等需要解读。例 3 为例 1 中可能的两个小句关联2-3 和 2-6。
例 3 2-3: 2因此(浦东开发开放)大量出现的是以前不曾遇到过的新情况、新问题。3 对此, 浦东不是简单的采取“干一段时间, 等积累了经验以后再制定法规条例”的做法, (√)
2-6: 2因此(浦东开发开放)大量出现的是以前不曾遇到过的新情况、新问题。6(浦东)积极、及时地制定和推出法规性文件, (×)
通过对比发现, 两者都语义连贯, 甚至 2-6 更自然, 但最终选择 2-3, 而非 2-6。这是因为在 2-6 中, 小句6 的主语(“浦东”)为零指代, 需要得到解读, 而小句2 的主语为“浦东开发开放”, 不能从小句 2 得到较好的解读; 2-3 中, 小句 3 本身语义自足, 无指代需要解读。
小句 6 的主语(“浦东”)只能从小句 3 的主语(“浦东”)得到解读, 由此, 小句 6 与小句 3 构成 3-6 关联。“不是……而是”作为连接词, 需要从语义上得到解读。表面上“不是”在小句 3, “而是”在小句 4, 然而 3-4 关联的语义内容显然不符合“不是……而是”的语义表示(表“反转”)。对比之下, 3-6 关联的语义内容非常符合“不是……而是”的语义, 小句 3“干一段时间, 等积累了经验以后再……”与小句 6“积极、及时……”正好语义相反。由此, 3-6 关联可使其间的指代、连接词等均得到解读。
篇章中所有小句联通, 但小句的联通不可有环, 这是篇章整体小句关联结构的形式限制。对于 n 个小句构成的语篇, 小句关联数目(X)为 n−1。当 X< n−1 时, 小句不能完全联通; 当 X>n−1 时, 小句联通但产生环。
小句均联通是篇章整体性的形式要求, 小句关联无环是语义表示最简性的形式要求, 难点在小句关联无环的限制。在例 1 中, 仅从语义连贯和形式衔接来看, 小句关联 4-5, 4-6 以及 5-6 均可接受, 见例4。
例 4 4-6: 4而是(浦东)借鉴发达国家和深圳等特区的经验教训, 6积极、及时地制定和推出法规性文件,
5-6: 5(浦东)聘请国内外有关专家学者, 6积极、及时地制定和推出法规性文件,
4-5: 4而是(浦东)借鉴发达国家和深圳等特区的经验教训, 5(浦东)聘请国内外有关专家学者,
建立4-5, 4-6 和 5-6 之间的关联, 从整体上形成一个有环的结构。这时可从语义的直接关联和间接关联上进行辨析, 以消除关联环。这里认定, 4-6 和5-6 为直接关联, 4-5 为间接关联。原因是 4-6 与 5-6之间有内在的逻辑联系, 即 4 和 5 均是 6 的某种实现条件; 而 4-5 间并无内在的逻辑联系, 只是相对于 6 而言, 有同样的地位, 形成“并列”。间接关联可以依据直接关联推导得到, 所以小句关联结构仅关注直接关联。
基于以上分析, 进行语料库标注一致性实验。对两名学中文的本科生进行训练, 结合例证说明判断准则和形式限制等, 并进行数篇语料的标注校正指导。采用汉语宾州树库[10]的新闻语料, 开发相应标注平台与评估平台, 进行双盲标注与评估。在 20篇新闻语料上, 小句切分①本文均采用李艳翠等[9]的小句切分标准;的 Kappa 值为 94.6%, 小句关联的 Kappa 值为 90.1%。标注实验结果表明, 篇章小句关联结构分析具有较强的可行性和合理性。
我们可将小句关联识别视为判断任意两个小句有无关联的分类问题。本文在自建的汉语小句关联语料库上, 利用决策树模型、逻辑回归模型和贝叶斯模型, 采用相关分类特征训练分类器, 考察分类器、语料取样和分类特征等对自动识别的影响。
2.1.1 连接词
F1: 两个小句包含的连接词及其位置。
F2: 两个小句包含的连接词是否为一对关联词。
连接词连接两个关联小句, 不同连接词的结构位置不同, 对关联小句的分布方向也有不同预测。如例 1 中小句 2 的连接词“因此”, 预测小句 2(结果)的关联小句(原因)在前, 而不在后; 小句 8 的连接词“(正)因为”预测小句 8(原因)的关联小句(结果)在后, 而不在前。关联词由不同词对构成, 如“尽管……但”, 往往预测各自所在的小句相关联。对连接词的识别及是否关联词的识别, 主要利用汉语篇章结构语料库(CDTB1.0)[4]的连接词信息。
2.1.2 词汇
F3: 两个小句包含的相同词及词性。
F4: 两个小句包含的相同词个数。
F5: 两个小句包含的同义词个数。
F6: 两个小句包含的同类词个数。
F7: 两个小句包含的相同词、同义词和同类词的个数。
相关联小句通常描述相关事物或动作。若两个小句中出现相同词, 且为实词(名词、动词、形容词和副词), 则两个小句的关联程度大。两个小句中出现相同词、同义词和同类词越多, 两个小句的关联程度越大。同义词和同类词的确定是根据哈尔滨工业大学的《同义词词林扩展版》② http://www.ltp-cloud.com/download#down_cilin;。
F8: 两个小句的句子相似度。
F9: 两个小句的词汇最大相似度。
两个小句的句子相似度越大, 小句的关联程度越大。两个小句所含词的最大相似度越大, 小句的关联程度越大。采用 Synonyms③ https://github.com/huyingxi/Synonyms的 compare 方法得到句子相似度和词语相似度, 比较两个小句中所有词语的相似度, 找到最大相似度。
F10: 共现词(名词、动词、形容词和副词)出现个数。
共现词指在同一篇章中以一定频率一起出现的词。两个小句的共现词越多, 关联程度越大。从关联句对中提取所有的名词、动词、形容词和副词, 统计它们在关联句对中同时出现的次数p, 将 p 与这两个词在语料中出现次数乘积的比值作为一对词的分数 score。若 score 大于某个阈值, 则这对词为共现词。阈值为(0, 1)之间的数, 通过计算找到可以获得最高准确率的阈值, 最终确定为0.001。
2.1.3 句法
F11:在句法结构上, 两句相同词有共同的祖先节点(不超过 3 层)的次数。
F12: 在句法结构上, 两句同义词有共同的祖先节点(不超过 3 层)的次数。
F13: 在句法结构上, 两句同类词有共同的祖先节点(不超过 3 层)的次数。
两个小句含有相同词、同义词和同类词, 且在句法结构上, 其标记相同祖先节点(不超过 3 层)的次数越多, 关联程度越大。采用 ctbparser④ Paskin, Mark A. Cubic-time parsing and learning algorithms for grammatical bigram models. Computer Science Division, University of California, 2001;对语料句法进行分析。如例 1 的小句对 3-6 出现相同词“制定”, 同时出现标记相同祖先节点(不超过 3 层) VP, 分别为“制定法规条例”、“制定和推出法规性文件”的结构标记。
2.1.4 小句距离与句域
F14: 两个小句的距离。
F15: 两个小句是否在同一个大句中; 若在同一大句中, 大句包含小句的数目。
F16: 特征 F14 与 F15 的组合。
两个小句的距离越近, 其关联的可能性越大。同属一个大句的小句, 关联的可能性大于不属同一个大句的小句。同时, 属于同一大句的小句对, 该大句包含的小句数越少, 大句中小句对的关联程度越大; 当一个大句有且仅有两个小句时, 这两个小句必然关联。
在汉语宾州树库[8]的前 100 篇语料上进行标注, 得到 2439 个小句, 1956 个小句关联对, 构成汉语篇章小句关联语料库, 作为实验语料。采用 sklearn⑤https://scikit-learn.org/stable/index.html;对提取的特征进行分类, 使用 10 次 10 折交叉的方法进行验证。共提取 6944 条小句对特征, 其中有4988 条负例, 1956 条正例, 正负比例为 2:5。为了均衡正负比例, 使用随机抽取正例的方法扩充数据集, 使正负比例为1:1。
2.3.1 分类器
使用决策树模型(RandomForestClassifier)、逻辑回归模型(LogisticRegression)和贝叶斯模型(Mul-tinomialNB)三个分类器⑥https://scikit-learn.org/stable/supervised_learning.html#supervised-learning, 采用以上全部分类特征进行小句关联的自动识别。实验结果见表1。
由表 1 可知, 分类模型的效果为决策树模型>逻辑回归模型>贝叶斯模型。其中, 决策树模型的准确率为 92.7%。贝叶斯模型通常假设属性之间相互独立, 当属性个数比较多或属性之间相关性较大时, 贝叶斯的分类效果不好。逻辑回归模型擅长分析线性关系, 特征空间很大时效果并不好, 对极值比较敏感, 容易受极端值的影响。本文使用的分类特征较多, 且同义词、同类词等不同特征之间有一定的关联, 决策树模型对于这种情况的处理表现较好, 对大型数据源也可在较短时间得到良好结果。
2.3.2 去环与语料取样
小句关联结构整体上为无环结构。上文将小句关联视为独立个体, 并没有考虑小句关联结构的整体无环性。这里加入去环操作, 即当整个段落中小句关联形成环时, 则从识别出的小句关联中去掉关联可能性最低的, 直至形成一个无环图。我们通过独立取样和整体取样, 对比去环效果。
独立取样: 使用 10 次 10 折交叉方法, 对数据集随机抽取小句对, 构建训练集和测试集。整体取样: 随机抽取单个段落进行划分, 使用 10 次 10 折交叉方法, 随机抽取正例, 对数据集进行扩充, 使得数据集的所有小句对均能构成完整的段落。分别在独立取样语料和整体取样语料上进行去环实验, 实验结果见表 2 和 3。
根据表 2 和 3 可知, 独立取样对去环影响不大, 整体取样对去环影响较大。整体取样去环后, 小句关联的正确率和召回率明显提高, 尤其是正例正确率和负例召回率的提高幅度较大。因此, 在小句关联识别中需采用整体取样。但是, 整体取样去环后, 最好的识别效果与最佳分类器相比有变化: 决策树性能降低, 其他分类器性能变好, 最好的为逻辑回归模型, 平均准确率为 88.89%。因此, 需结合这些变化改进识别方法。
2.3.3特征贡献
使用表 1 中效果最好的RandomForestClassifier 进行实验, 分别去除一类(组)特征后的实验结果见表4。
表1 不同分类器实验结果(%)
Table 1 Experimental results of different classifiers (%)

分类器平均结果负例正例 准确率召回率F1准确率召回率F1准确率召回率F1 RandomForestClassifier92.70 92.6292.61 94.61 90.38 92.4590.80 94.85 92.78 LogisticRegression87.36 87.34 87.3488.25 86.1687.1986.48 88.53 87.49 MultinomialNB84.66 84.6584.6585.30 83.73 84.51 84.03 85.5884.79
表2 独立取样和整体取样的去环结果(%)
Table 2 De-ring results for independent and global sampling (%)
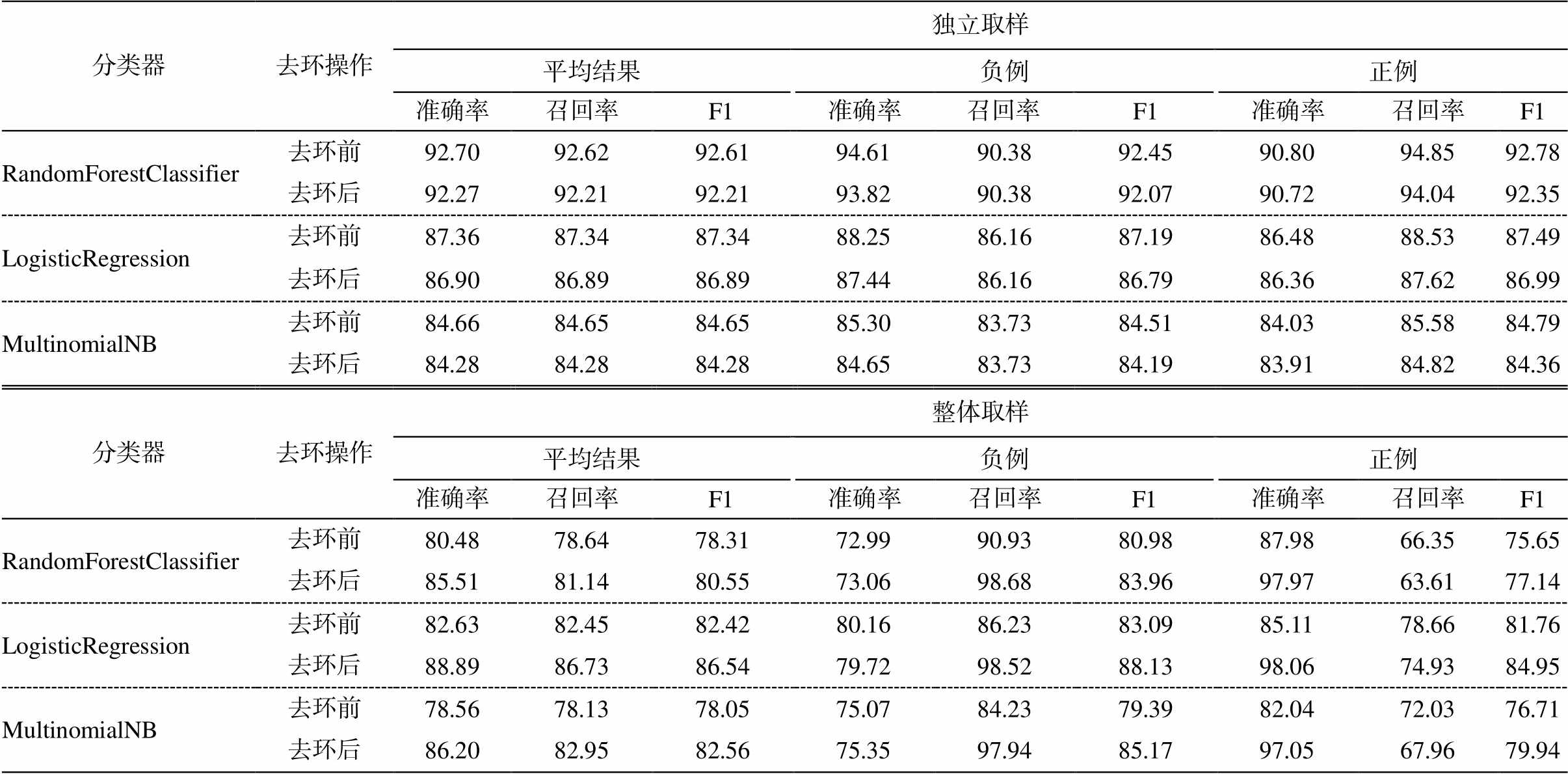
分类器去环操作独立取样 平均结果负例正例 准确率召回率F1准确率召回率F1准确率召回率F1 RandomForestClassifier去环前92.70 92.62 92.6194.61 90.38 92.45 90.80 94.85 92.78 去环后92.27 92.21 92.2193.82 90.38 92.0790.72 94.04 92.35 LogisticRegression去环前87.36 87.34 87.3488.25 86.16 87.1986.48 88.53 87.49 去环后86.90 86.89 86.8987.44 86.16 86.7986.36 87.62 86.99 MultinomialNB去环前84.66 84.65 84.6585.30 83.73 84.5184.03 85.58 84.79 去环后84.28 84.28 84.28 84.65 83.73 84.1983.91 84.82 84.36 分类器去环操作整体取样 平均结果负例正例 准确率召回率F1准确率召回率F1准确率召回率F1 RandomForestClassifier去环前80.48 78.64 78.3172.99 90.93 80.9887.98 66.35 75.65 去环后85.51 81.14 80.5573.06 98.68 83.9697.97 63.61 77.14 LogisticRegression去环前82.63 82.45 82.4280.16 86.23 83.0985.11 78.66 81.76 去环后88.89 86.73 86.5479.72 98.52 88.1398.06 74.93 84.95 MultinomialNB去环前78.56 78.13 78.0575.07 84.23 79.3982.04 72.03 76.71 去环后86.20 82.95 82.56 75.35 97.94 85.17 97.05 67.96 79.94
表3 独立取样和整体取样的去环结果的变化(%)
Table 3 Changes of de-ring results for independent and global sampling (%)
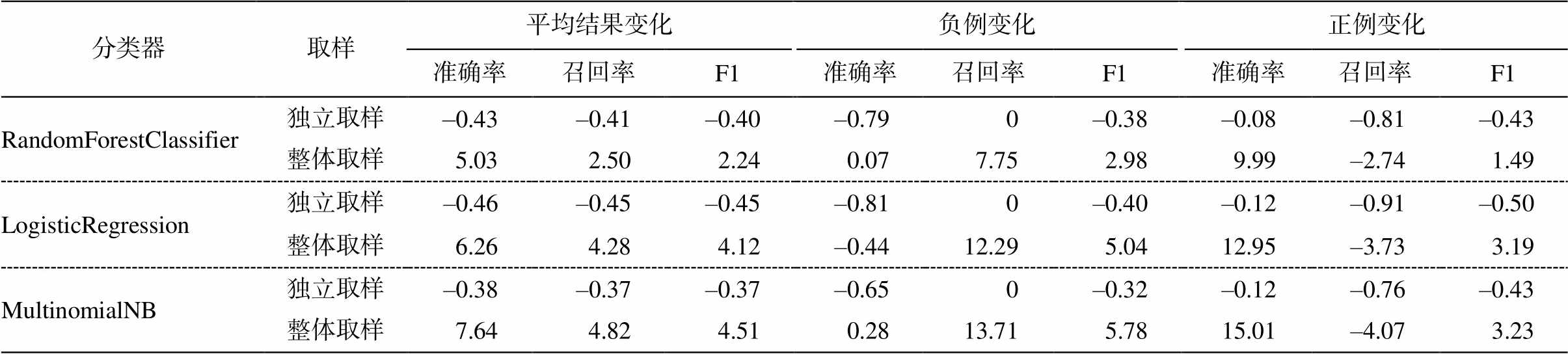
分类器取样平均结果变化负例变化正例变化 准确率召回率F1准确率召回率F1准确率召回率F1 RandomForestClassifier独立取样–0.43 –0.41 –0.40–0.79 0 –0.38–0.08 –0.81 –0.43 整体取样5.03 2.50 2.24 0.07 7.75 2.989.99 –2.74 1.49 LogisticRegression独立取样–0.46 –0.45–0.45–0.81 0 –0.40–0.12 –0.91 –0.50 整体取样6.26 4.28 4.12–0.44 12.29 5.0412.95–3.73 3.19 MultinomialNB独立取样–0.38 –0.37 –0.37–0.65 0 –0.32–0.12 –0.76 –0.43 整体取样7.64 4.82 4.51 0.28 13.71 5.7815.01 –4.07 3.23
从表 4 可以看出, 对小句关联有较大影响的特征主要有以下两组。1)两个小句包含共现词的数量 F10、两个小句的句子相似度 F8 和两个小句最大的词相似度 F9。去除特征 F8, F9 和 F10 后, 平均准确率下降 4.87%, 召回率下降 4.88%。2)两个小句的距离 F14、两个小句是否在同一个大句中及同一大句内小句的数目 F15 以及 F16。去除特征 F14, F15 和 F16 后, 平均准确率下降 4.7%, 召回率下降4.82%。其他特征对小句关联识别的影响不明显。
表4 特征贡献(%)
Table 4 Feature contribution (%)

特征平均结果负例正例 准确率召回率F1准确率召回率F1准确率召回率F1 全部特征92.70 92.62 92.61 94.61 90.38 92.4590.80 94.85 92.78 –F192.60 92.49 92.49 94.71 90.02 92.3090.49 94.97 92.68 –F292.67 92.59 92.59 94.46 90.49 92.43 90.87 94.70 92.74 –(F3+F4+F5+F6+F7)92.70 92.60 92.6094.72 90.24 92.4290.68 94.97 92.77 –(F8+F9+F10)87.83 87.74 87.7389.64 85.35 87.4486.02 90.13 88.03 –(F11+F12+F13)92.88 92.79 92.7994.78 90.58 92.6390.98 95.01 92.95 –(F14+F15+F16)88.00 87.80 87.7890.81 84.11 87.3385.20 91.49 88.23
2.3.4 小句关联的距离
小句对之间的距离对判断两个小句是否关联有重要影响。根据语料库统计(表 5), 两个小句距离越近, 相关的可能性越高; 距离越远, 相关的可能性越低。其中, 相邻句对的相关比例为69.44%。
在整体取样语料上, 使用表 2 中表现最好的LogisticRegression 分类器, 对相邻和不相邻小句对的关联程度进行识别, 结果见表6。
从表 6 可以看出: 1)不相邻小句对的识别难度大于相邻小句对, 前者平均识别准确率比后者低7.16%; 2)无论小句是否相邻, 难点均在不相关识别方面, 不相关识别比相关识别的准确率平均低24.44%。3)相邻小句对不相关识别的准确率比相关识别低 35.73%, 甚至比不相邻小句对的不相关识别低 19.94%。因此, 小句对的不相关识别, 尤其是相邻小句对的不相关识别难度更大。
2.3.5 小句关联的句域
小句关联的句域, 即小句是否在同一大句, 对小句关联有影响。根据语料库统计(表 7), 同一大句内的小句对相关的概率远大于不在同一大句内的小句, 前者是后者的 2 倍多。
在整体取样语料上, 使用表 2 中表现最好的LogisticRegression 分类器, 对在/不在同一大句的小句对识别结果见表8。
从表 8 可以看出: 1)不在同一大句的小句对的识别难度大于在同一大句的小句对, 前者平均识别准确率比后者低 3.15%; 2)无论小句是否在同一大句, 小句对不相关识别比相关识别的准确率平均低19.26%; 3)同一大句的小句对不相关识别上, 准确率比相关识别低 24.15%, 甚至低于不在同一大句内的小句对不相关识别。因此, 小句对的不相关识别, 尤其同一大句内的小句对不相关识别难度更大。
表5 小句对之间的距离与相关程度的关系
Table 5 Relationship vs. distance in clause pairs
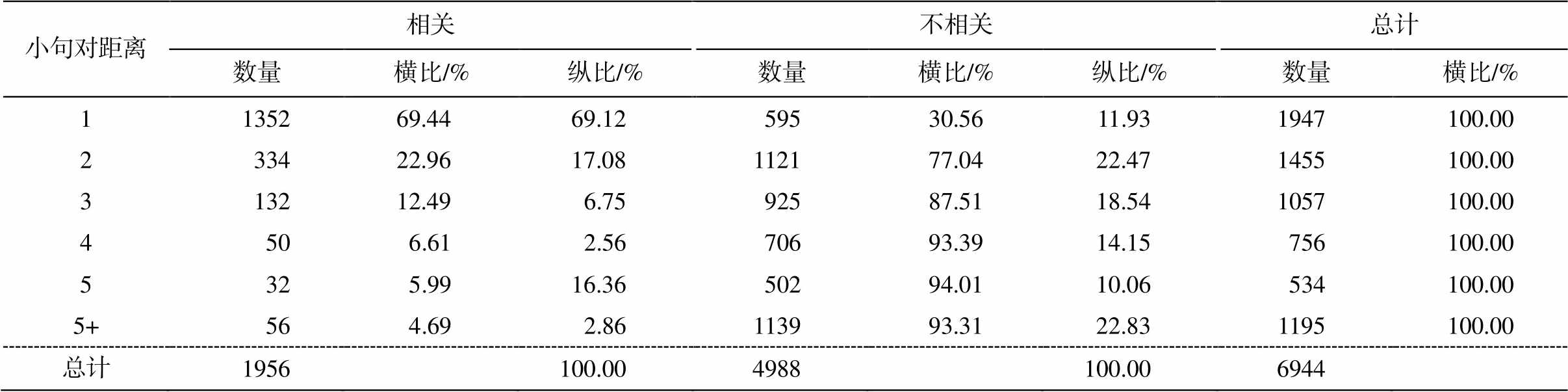
小句对距离相关不相关总计 数量横比/%纵比/%数量横比/%纵比/%数量横比/% 1135269.4469.1259530.5611.931947100.00 233422.9617.08112177.0422.471455100.00 313212.496.7592587.5118.541057100.00 4506.612.5670693.3914.15756100.00 5325.9916.3650294.0110.06534100.00 5+564.692.86113993.3122.831195100.00 总计1956100.004988100.006944
表6 相邻和不相邻小句对的识别(%)
Table 6 Identification of adjacent and non-adjacent clause pairs (%)

小句对距离平均结果不相关相关 准确率召回率F1准确率召回率F1准确率召回率F1 相邻93.24 90.80 91.48 62.75 91.88 74.5798.48 90.61 94.38 不相邻86.08 84.11 81.6082.69 99.39 90.27 95.83 40.23 56.67
表7 小句对是否在同一大句与相关程度的关系
Table 7 Relationship vs. clause pairs in or out of the same sentence

小句对句域相关不相关总计 数量横比/%纵比/%数量横比/%纵比/%数量横比/% 在同一大句1350 46.2669.02 156853.7431.44 2918100.00 不在同一大句606 15.0530.98 342084.9568.56 4026100.00 总计1956 100.00 4988100.00 6944
表8 是否在同一大句的小句对识别结果(%)
Table 8 Identification of clause pairs in or out of the same sentence (%)

小句对句域平均结果不相关相关 准确率召回率F1准确率召回率F1准确率召回率F1 在同一大句90.7188.4188.7474.1296.7383.9398.2784.6190.93 不在同一大句87.5685.6384.2983.0999.3590.4997.4555.3170.57
本文将篇章结构表示为小句关联结构, 与篇章层次结构相比, 它可以有效地刻画小句间的直接关联, 特别是可以刻画非连续和跨篇章层级的小句间的直接关联, 并且无需判断中心(但可据小句关联结构推测中心), 更具基础性。本文提出小句关联的判断准则: 关联小句可以构成最小语篇, 理论上语义连贯且形式衔接。本文还提出小句关联结构的形式限制(即小句联通, 但无环)及其语义解释。标注一致性实验结果表明, 本文提出的篇章小句关联结构具有较强的可行性和合理性。
本文在自建的汉语篇章小句关联结构标注语料库上, 进行小句关联识别。采用决策树模型、逻辑回归模型和贝叶斯模型, 将小句关联识别作为判断任意小句有无关联的分类问题, 设计分类特征(连接词、相同词、同义词、同类词、共现词及有关句法结构相似度、实词及句子相似度、小句距离与句域等), 得到最佳识别准确率 92.70%。实验结果还表明, 语料整体取样比独立取样的去环效果好; 共现词数量、句子相似度、小句距离和小句句域等特征对小句关联识别贡献较大; 远距离和跨大句是小句关联识别的难点, 但相邻小句和同一大句内的小句对的不相关识别难度更大。
未来, 我们将在本文小句关联表示基础上, 进一步扩大汉语篇章小句关联结构标注语料库规模, 最终提供公开使用。同时, 我们将改进小句关联的识别方案与计算模型等, 提高小句关联识别性能, 并将研究基于小句关联的篇章中心识别等有关应用。
参考文献
[1] Mann W, Thompson S. Rhetorical structure theory: toward a functional theory of text organization. Text, 1988, 8(3): 243–281
[2] Carlson L, Marcu D, Okurowski M E. Building a discourse-tagged corpus in the framework of rheto-rical structure theory // Current and New Directions in Discourse and Dialogue. Dordrecht: Springer, 2003: 85–112
[3] Prasad R, Dinesh N, Lee A, et al.The Penn Discourse Treebank 2.0 // Proceedings of the 6th International Conference on Language Resources and Evaluation (LREC). Marrakech, 2008: 2961–2968
[4] Li Yancui, Feng Wenhe, Kong Fang, et al. Building Chinese discourse corpus with connective-driven de-pendency tree structure // Proceedings of the Con-ference on Empirical Methods in Natural Language Processing (EMNLP). Doha, 2014: 2105–2114
[5] Li Sujian, Wang Liang, Cao Ziqiang, et al. Text-level discourse dependency parsing // Proceedings of the 52nd Annual Meeting of the Association for Compu-tational Linguistics (ACL). Baltimore, 2014: 25–35
[6] Yang An, Li Sujian. SciDTB: Discourse dependency TreeBank for scientific abstracts // Proceedings of the 56th Annual Meeting of the Association for Compu-tational Linguistics (ACL). Melbourne, 2018: 444–449
[7] Yoshida Y, Suzuki J, Hirao T, et al. Dependency-based discourse parser for single-document summarization // Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, 2014: 1834–1839
[8] Hudson R A. Word grammar. Oxford: Blackwell, 1984
[9] 李艳翠, 冯文贺, 周国栋, 等. 基于逗号的汉语子句识别研究. 北京大学学报(自然科学版), 2013, 49(1): 7–14
[10] Xue N, Xia F, Chiou F D, et al. The Penn Chinese TreeBank: phrase structure annotation of a large corpus. Natural Language Engineering, 2005, 11(2): 207–238
Representation and Recognition of Clauses Relevance Structure in Chinese Text
Abstract The discourse structure is represented as the clause relevance structure, which can effectively describe the direct semantic association between discontinuous and cross-level clauses in a text, compared with the hierarchical discourse structure pattern such as rhetorical structure theory.Firstly, the scheme of clause relevance structure, its judgment criteria and formal constraints. The manual annotation experiments are conducted. Then, the automatic recognition of Chinese clause relevance structure is studied. On the corpus of Chinese discourse clause relevance structure we built, the best recognition accuracy is 92.70% based on the classification model, with the connectives, vocabulary and other classification features. The experimental results show that the ring-removing effect obtained by the overall sampling of corpus is better than that of independent sampling, and the features of vocabulary, clause distance and clause domain contribute greatly to the recognition. Long distance and cross sentences of clause pair are the difficulties of clause relevance recognition, but adjacent clauses and clauses in the same sentence are especially difficult to recognize as uncorrelated clauses.
Key words clause relevance structure; discourse structure; discourse dependency structure; rhetorical structure
doi: 10.13209/j.0479-8023.2019.094
国家社会科学基金(17BYY036)资助
收稿日期: 2019–05–19;
修回日期: 2019–09–21