一种融入背景知识的交互文本立场分析方法
刘常健1 杜嘉晨1 冷佳1 陈荻1 毛瑞彬2 张俊2 徐睿峰1,†
1.哈尔滨工业大学(深圳)计算机科学与技术学院, 深圳 518055; 2.深圳证券信息有限公司, 深圳 518028; †通信作者, E-mail: xuruifeng@hit.edu.cn
摘要 提出一种融入背景知识的交互文本立场分析方法。该方法以交互文本作为查询, 从维基百科中检索相关的背景知识文本, 然后对背景知识文本进行编码, 并通过深度记忆网络获取相关的背景知识特征, 以此来增强交互文本的表示学习。在 3 个英文在线辩论数据集上的实验结果表明, 通过选取适当的背景知识嵌入层数以及背景知识嵌入层连接方式, 可以有效地提高交互文本立场分析性能。
关键词 立场分析; 交互文本; 背景知识; 深度记忆网络
作为绑定话题目标对象的细粒度情感分析, 文本立场分析的目的是将文本中表达的立场分类为“支持/反对/中立”或“支持/反对”。交互文本立场分析的研究对象是 Q-R 对形式的交互文本, 其中 Q 为引述(Quote), R 为应答(Response)。在该任务中, 需要联合建模引述和应答以及两者间的交互语境, 进而判断对于引述 Q做出的应答 R 所持的立场。
现有的文本立场分析方法主要包括基于机器学习和基于深度学习的方法。其中基于机器学习的方法以特征构造和筛选为主。此外, 结合弱监督方法进行语料扩充, 也是一种提高模型性能表现的方法。基于深度学习的文本立场分析方法以循环神经网络为代表, 对文本进行序列建模, 通过联合话题目标对象, 学习与任务更相关的表示。这些方法在文本立场分析问题上取得一定进展, 但因局限于单纯利用交互文本本身的特征, 缺乏对背景知识的利用, 使得交互文本立场分析的性能受到限制。
表 1 展示一个交互文本立场分析样本实例。该实例是从肯尼迪与尼克松关于古巴卡斯特罗政权局势的讨论中节选的文段。在该实例中, 肯尼迪表达了美国对古巴具有影响力, 以及对古巴人民自由选举权的支持, 尼克松则顺水推舟地表明美国所具有的强大军事力量足以将古巴卡斯特罗政权赶下台, 也揭示了肯尼迪的军事企图。两者都表示了对古巴卡斯特罗政权的否定, 但是尼克松从侧面表达了对肯尼迪论点的反对态度。因此, 对于该实例, 正确的交互文本立场应为反对。
表1 交互文本立场分类数据实例
Table 1 Data instance of interactive stance classificaion

引述Kennedy: “There is not any doubt we had great influence in Cuba, and I think it is unfortunate that we did not use that influence more vigorously to persuade Castro to hold free, open elections, so that the people of Cuba could have made the choice.”肯尼迪: “毫无疑问, 我们在古巴有很大的影响力, 我认为很不幸, 我们没有更积极地利用这种影响力说服卡斯特罗举行自由、公开的选举, 这样古巴人民就可以做出选择。” 应答Nixon: “What we must remember too is that the United States has the military power - and Mr. Castro knows this - to throw him out of office tomorrow or the next day or any day that we choose.”尼克松: “我们必须记住的是, 美国拥有军事力量——卡斯特罗先生也知道这一点——明天、第二天或我们选择的任何一天都要把他赶下台。” 背景知识1. President Eisenhower's New Look policy had emphasized the use of nuclear weapons to deter the threat of Soviet aggression. 艾森豪威尔总统的新政策强调使用核武器来威慑苏联的侵略威胁。2. In his 1960 presidential race, Kennedy strongly criticized Eisenhower’s inadequate spending on defense. 在1960年的总统竞选中, 肯尼迪强烈批评艾森豪威尔在国防方面的开支不足。3. Kennedy used the military as a political instrument more often than any other postwar president, … 肯尼迪把军队作为政治工具使用的次数比战后任何一位总统都要多…4. Some historians criticize Nixon for not taking greater advantage of Eisenhower's popularity … 一些历史学家批评尼克松没有充分利用艾森豪威尔的声望…
在表 1 的实例中, 如果缺乏对政治事件和政治行为的背景知识, 则无法判断肯尼迪所表达的“支持古巴人民选举自由”与尼克松所表达的“美国拥有用于推翻卡斯特罗政权的军事力量”之间的关系, 进而导致交互文本立场的误判。相反地, 如果结合表 1 中的背景知识, 我们可以推断出尼克松实际上是对肯尼迪的论点持反对态度的。这就启发本文研究结合背景知识的交互文本立场分析方法, 通过对背景知识的表示学习和嵌入, 使得立场分析方法可以取得更高的性能。
本文方法可分为两个部分: 1)以交互文本作为查询, 从维基百科中检索相关背景知识文本; 2)应用多层的深度记忆网络进行背景知识嵌入, 用于增强交互文本立场分析。
1 相关工作
1.1 交互文本立场分析
以往文本立场分析相关的研究主要可以划分成基于机器学习的方法[1–3]和基于深度学习的方法[4–6]两大类。基于机器学习的方法主要依赖于特征筛选和构造以及基于统计机器学习的分类器。Abbott 等[1]结合词汇特征和依存关系特征, 对比朴素贝叶斯分类器和 JRip 分类器在文本立场分析任务上的效果。Rosenthal 等[2]的实验表明, 对话结构在文本立场分析中只有重要作用。Menini 等[3]利用情感特征、语义特征和形态特征, 构造支持向量机分类器, 解决政治领域的文本立场分析。基于深度学习的方法使用深度神经网络对文本进行特征表示学习, 用于立场分类。Augenstein 等[4]使用双向长短时记忆网络抽取文本特征, 用于文本立场分析。Liu 等[5]使用自注意力机制来构造句子特征表示, 用于自然语言推断。该方法也可以应用到交互文本立场分析中。Chen 等[6]提出的 BiLSTM-hybrid 从交互文本联合建模的角度, 结合自我注意力和交叉注意力两种机制, 捕捉与任务更相关的特征表示, 取得当时最佳的性能表现。
分类器在文本立场分析任务上的效果。Rosenthal 等[2]的实验表明, 对话结构在文本立场分析中只有重要作用。Menini 等[3]利用情感特征、语义特征和形态特征, 构造支持向量机分类器, 解决政治领域的文本立场分析。基于深度学习的方法使用深度神经网络对文本进行特征表示学习, 用于立场分类。Augenstein 等[4]使用双向长短时记忆网络抽取文本特征, 用于文本立场分析。Liu 等[5]使用自注意力机制来构造句子特征表示, 用于自然语言推断。该方法也可以应用到交互文本立场分析中。Chen 等[6]提出的 BiLSTM-hybrid 从交互文本联合建模的角度, 结合自我注意力和交叉注意力两种机制, 捕捉与任务更相关的特征表示, 取得当时最佳的性能表现。
1.2 深度记忆网络
2014 年, Weston 等[7]提出记忆网络(memory network), 其中心思想是构建一个任务相关的长期记忆模块, 在任务推理的过程中, 该记忆模块可以被读取或改写。Sukhbaatar 等[8]将深度记忆网络应用到问答系统中, 用于从给定的一系列句子中寻找相关线索来回答对应的问题。此外, 多跳的深度记忆网络可以从外部记忆中提取更抽象的特征, 进一步提升问答任务的性能。Tang 等[9]使用深度记忆网络实现面向方面的情感分类, 并通过实验发现深度记忆网络能够在该任务的多个数据集上取得显著性能提高。
1.3 背景知识嵌入方法
对于文本内容的准确理解通常离不开背景知识。但是, 目前自然语言处理方法往往对背景知识的利用不够充分, 导致大多数模型都遭遇性能瓶颈。因此, 近来的一些研究尝试为已有模型引入背景知识的支持。在短文本分类任务上, Wang 等[10]将短文本表示分为显式表示和隐式表示, 将用短文本检索相关的概念的特征序列直接拼接到原文本特征序列的末端, 作为该短文本的隐式表示。在自然语言推断任务上, Chen 等[11]在词级别上引入单词同反义关系以及上下位关系作为外部知识, 加强对前提–假设文本对的交互建模。在完型填空任务中, Mihaylov 等[12]从知识图谱中检索与文本内容相关的实体–关系–实体三元组背景知识, 并使用记忆网络对背景知识进行读取嵌入。本文方法与文献[12]相似, 不同之外在于本文研究的是交互文本立场分析的任务, 利用的是背景文本知识库, 而不是图结构的知识图谱。与图结构的知识图谱相比, 文本形式的背景知识容易大量获取, 并且能够表达更加丰富的语义。
2 总体框架
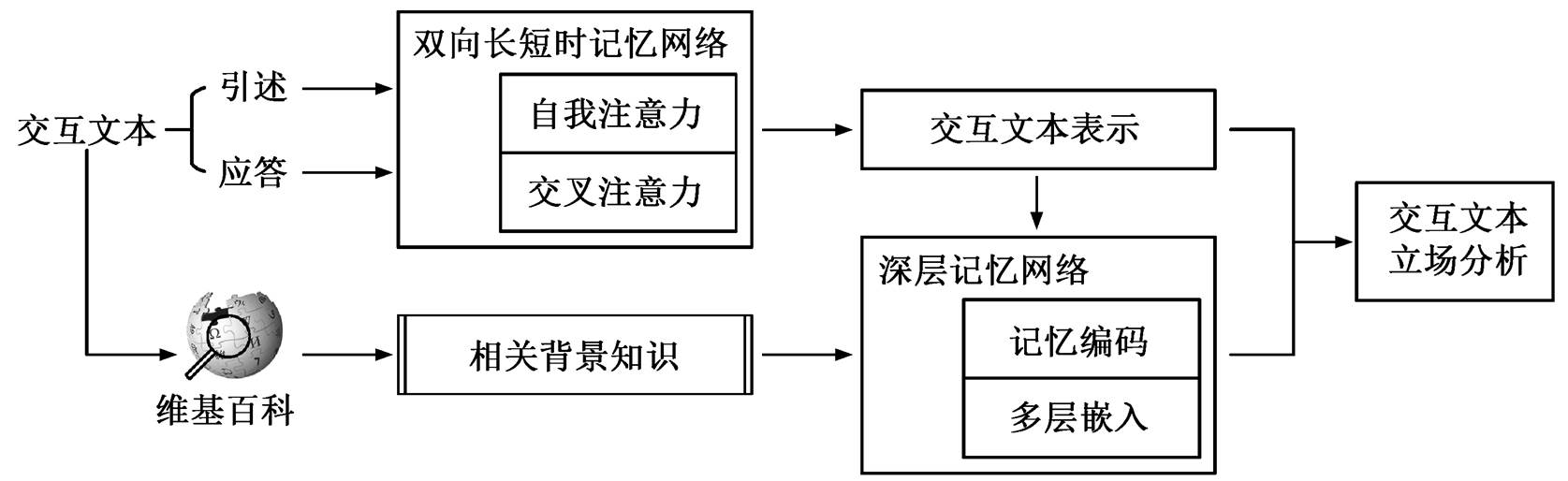
交互文本立场分析问题是给定交互文本(即引述–应答对), 判别应答对于引述所表达的立场, 主要有“支持/反对”和“支持/中立/反对”两种立场划分, 两者区别不大。记引述为 Q, 应答为 R, 通过一个特征抽取器对两者之间的交互特征(P)进行建模。以往交互文本立场分析方法给定分类器 f, 直接基于交互文本表示 P 进行立场分类, 即有预测标签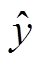 y=f(Q,R)= f(P)。本文引入背景知识 BK, 基于 BK和交互文本表示 P 对标签进行推断, 即有预测标签=f(Q, R, BK)=f(P, Z), 其中 Z 是与引述–应答对相关的背景知识表示。本文模型的总体框架可以分为交互文本特征抽取模块、背景知识检索及记忆嵌入两部分, 如图 1 所示。本文采用 Chen 等[6]提出的 BiLSTM-hybrid 模型, 通过交互文本特征抽取模块对 Q-R 对进行交互建模。
y=f(Q,R)= f(P)。本文引入背景知识 BK, 基于 BK和交互文本表示 P 对标签进行推断, 即有预测标签=f(Q, R, BK)=f(P, Z), 其中 Z 是与引述–应答对相关的背景知识表示。本文模型的总体框架可以分为交互文本特征抽取模块、背景知识检索及记忆嵌入两部分, 如图 1 所示。本文采用 Chen 等[6]提出的 BiLSTM-hybrid 模型, 通过交互文本特征抽取模块对 Q-R 对进行交互建模。
3 基于维基百科的背景知识检索
维基百科具有广阔的话题覆盖面, 对于交互立场分析任务是很好的背景知识来源。本文首先建立一个检索系统, 从维基百科中抽取与交互文本话题相关的背景知识文本。背景知识检索过程包含文本查询构建和背景知识检索, 流程如图 2所示。
要从维基百科中检索相关背景知识, 首先需要从原始文本构建查询, 但文本中的停用词或话题无关词有可能会引入噪声。为了尽可能地降低噪声对检索的影响, 查询的构建需要达到两个目的: 1)限定维基百科检索范围; 2)保持文本话题领域下背景知识的丰富性, 使得检索结果与人类的背景知识尽可能相近。为了对数据进行预处理, 检索系统借助Stanford CoreNLP[13]工具对 Q-R 对形式的交互文本进行去标点符号、去停用词、统一英文大小写等操作, 然后提取其中的动词和名词以及人名、地名和组织名。这些实词通常是语义表达的关键。对于有预置话题目标的数据集, 可以把相应的话题目标直接加入查询, 作为背景知识的领域限定。受 Turney等[14]工作的启发, 本文使用基于 N-grams 统计的方法从句子的动词、名词子序列中抽取短语词组, 通过计算短语词组与话题目标的互信息, 筛选出话题目标相关词。
检索系统根据已得到的查询文本与目标文本之间的词频率–逆文档率(TF-IDF)词袋表示的点积相似性, 检索与上下文相关的背景知识文本。检索系统采用的 TF-IDF 词袋表示中考虑了 Uni-gram 和Bi-gram 等计数, 并分别采用常数项 1 和 0.5 进行统计值平滑。检索系统对目标文本进行文档、段落和句子 3 个级别的筛选后, 保留 TF-IDF 相似度最高且为正值的不超过 10 个句子作为背景知识文本。
4 背景知识深度嵌入
基于 Sukhbaatar 等[8]和 Tang 等[9]的研究, 本文构建一种基于多层的深度记忆网络的背景知识嵌入模型, 利用双向长短时记忆网络(BiLSTM), 将背景知识编码为外部记忆, 并且结合注意力机制来提取与当前交互文本相关的背景知识特征, 嵌入交互文本表示。
检索得到的背景知识需要转化为相应的特征表示, 才能够作为深度记忆网络中可读写的外部记忆。首先, 每个交互文本对应的背景知识 BK 包含多个句子, 将句子中的词映射至词向量空间后, 独立地对各个句子使用 BiLSTM 进行记忆编码, 得到输出的隐状态序列, 并记为对应句子的记忆编码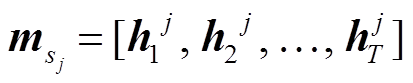 。然后, 按句子长度的维度,将不同句子的隐状态序列进行拼接, 得到 BK 相应的外部记忆矩阵
。然后, 按句子长度的维度,将不同句子的隐状态序列进行拼接, 得到 BK 相应的外部记忆矩阵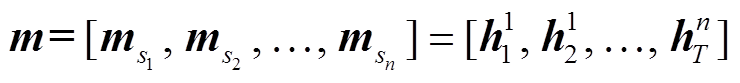 。
。
为了引入背景知识, 本文采用注意力机制, 从背景知识的记忆编码中抽取出与当前交互文本最相关的特征。在交互本文立场分析模型中, 通过拼接引述和应答的文本特征, 得到交互文本表示 P。考虑到交互文本特征与背景知识文本特征之间存在差异, 在对交互文本表示 P 进行背景知识嵌入之前, 通过一个变换层, 将交互文本的表示映射到背景知识的空间中, 得到Z0:
其中可学习的参数包括权重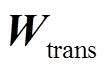 和偏置 btrans, Z0 表示文本特征经过变换映射后的结果, 也是背景知识嵌入层的初始输入。
和偏置 btrans, Z0 表示文本特征经过变换映射后的结果, 也是背景知识嵌入层的初始输入。
单一嵌入层中的注意力计算可能无法处理交互文本与背景知识之间的复杂关系, 因此本文采用多层的深度记忆网络, 通过堆叠背景知识嵌入层来迭代细化背景知识嵌入表示, 为交互文本立场分析任务学习更有效的特征表示。如图 3 所示, Z0 输入背景知识嵌入层后, 通过多层迭代对背景知识进行嵌入, 其中每一步迭代都是对外部记忆矩阵的一次读取。例如, 在第 k–1 步迭代中, 通过注意力计算层, 计算 Zk–1 与外部记忆矩阵之间的注意力权重, 并依据该权重对记忆矩阵加权求和, 输出当前交互文本的背景知识嵌入表示Zk:
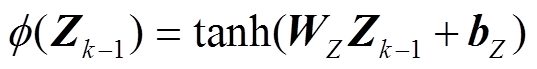 , (3)
, (3)
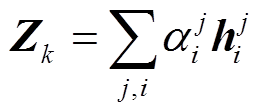 , (4)
, (4)
这里, 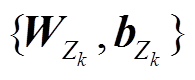 是第
是第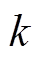 层的可学习参数, 不同层次之间的参数可以通过以下两种方式进行连接。
层的可学习参数, 不同层次之间的参数可以通过以下两种方式进行连接。
1)共享式(MemNN-share):不同背景知识嵌入层之间的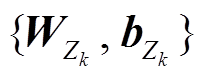 相等, 即
相等, 即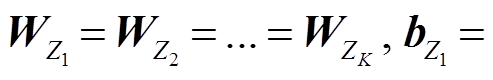
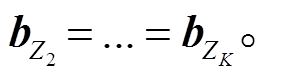 这种连接方式减少了深度记忆网络的参数, 并且降低了训练难度, 因此训练速度较快。
这种连接方式减少了深度记忆网络的参数, 并且降低了训练难度, 因此训练速度较快。
2)堆叠式(MemNN-stack)背景知识嵌入层之间的不相等。这种连接方式能够提取更复杂的特征表示, 但训练难度较大。
假设模型进行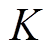 层背景知识嵌入, 则最后得到的交互文本背景知识嵌入表示为
层背景知识嵌入, 则最后得到的交互文本背景知识嵌入表示为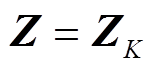 。为了结合背景知识推断交互文本立场, 将 Z 与交互文本表示 P 拼接, 然后通过线性分类器进行标签预测:
。为了结合背景知识推断交互文本立场, 将 Z 与交互文本表示 P 拼接, 然后通过线性分类器进行标签预测:
5 实验与结果分析
5.1 数据集及实验设置
本文的实验在 3 个公开的英文在线辩论数据集上进行: IAC数据集(Internet Argument Corpus)[15]、DP 数据集(Debatepedia)[3]和 ABCD 数据集(Agree-entbyCreateDebaters)[2]。各个数据集中的交互文本立场类标分布如表 2 所示。为与以往的基线方法进行对比实验, 本文的实验在 IAC 和 DP 数据集上将准确率(Accuracy)作为交互文本立场分类的评价指标[1,3], 在 ABCD 数据集上将宏平均 F1 值(Macro-average F1)作为评价指标[2]。
考虑到 3 个英文数据集的发布时间, 我们选取2016–12–21 的英文维基百科离线副本作为背景知识来源。经过预处理后, 保留 5075182 篇文档, 其中包含 9008962 个不同的单词或符号。在检索系统中, 为了兼顾速度和性能, 将维基百科中的文档数据转换为 Bi-gram 的组织形式, 通过 murmur3 哈希算法[16]进行存储。
本文实验的模型参数设置分为以下两个部分。
1)交互文本建模部分。交互文本引述和应答的文本长度均设为 64(过长则截断, 过短则用补全), 词向量维度设为 300, 由 GloVe[17]预训练词向量初始化, BiLSTM 的隐状态特征维度均设为 128。
2)深度记忆网络部分。每个交互文本的背景知识包含至多 10 个相关句子, 每个句子的文本长度也设为 64 (过长则截断, 过短则用补全), 词向量维度和 BiLSTM 的隐状态特征维度与交互文本建模相同。背景知识嵌入层的层数 K 以及连接方式(share/stack)为性能对照实验中的控制变量, 根据模型在验证集上的性能选取最优值。
表2 在线辩论数据集交互文本立场类标分布
Table 2 Stance labels distribution of online debate datasets
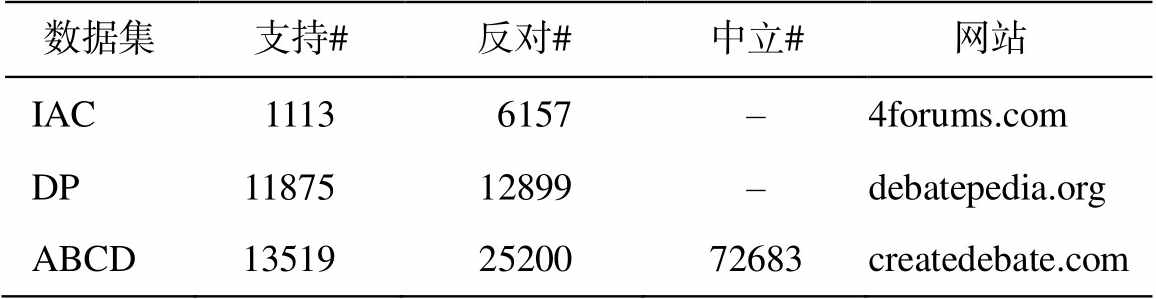
数据集支持#反对#中立# 网站 IAC11136157–4forums.com DP1187512899–debatepedia.org ABCD135192520072683createdebate.com
在模型训练过程中, 模型优化器 Adam[18]的学习率为 1×10–3, 一阶和二阶动量衰减系数分别为0.9 和 0.999, 数值稳定量为 1×10–8, 权重衰减系数为 1×10–5。所有模型的批训练数据大小为 32, 除ABCD 数据集 (已被划分出固定的训练集和测试集)外, 其他两个数据集均使用五折交叉验证的方式获得相应模型的交互文本立场分析性能。
5.2 基线系统
本文选用以下几个基线系统进行对比。
1)JRip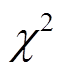 : Abbott 等[1]提出的基于 JRip分类器的模型。JRip 是一种基于决策树的规则学习方法, JRip在 Jrip 的基础上增加特征选择, 包括词汇特征和依存关系特征。
: Abbott 等[1]提出的基于 JRip分类器的模型。JRip 是一种基于决策树的规则学习方法, JRip在 Jrip 的基础上增加特征选择, 包括词汇特征和依存关系特征。
2)SVM: Menini 等[3]提出的基于向量机分类器的模型, 其特征包括情感特征、语义特征以及形态特征。
3)ME+structure: Rosenthal 等[2]提出的基于最大熵分类器的模型, 其特征包括词汇特征、风格特征、情感特征和对话结构特征。
4)NLI: Liu 等[5]提出的自然语言推断模型, 该模型使用 BiLSTM 分别对前提(Premise)和假设(Hy-pothesis)进行编码, 然后通过自注意力机制构造句子特征。
5)BiLSTM-hybrid: Chen 等[6]提出的结合自注意力机制和交叉注意力机制的交互文本推断模型。
5.3 实验结果分析
首先评估 IAC, DP 和 ABCD 数据集中的立场分析性能, 本文方法与基线方法的对比如表 3 所示。可以发现, 在 DP 数据集上, MemNN-share 和MemNN-stack 均可取得最好的交互文本立场分析性能, 优于绝大多数基线方法, 精确率比主要对比方法 BiLSTM-hybrid 提升 1.7%; 在 ABCD 数据集上, MemNN-share 比 BiLSTM-hybrid 的宏平均 F1 值提升 0.5%; 综合考虑数据规模、计算效率和性能表现, 与 stack 链接方式相比, share 链接方式能更有效地提取背景知识的特征。结果表明, 选取适当的控制变量(背景知识嵌入层数以及嵌入层连接方式), 并结合背景知识的交互文本立场分析, 可以取得更好的性能表现。
表3 交互文本立场分析实验结果(%)
Table 3 Experiment results on interactive text stance classification (%)

模型准确率(IAC)准确率(DP)F1值(ABCD) JRip[1]68.2–– SVM[3]–74.0– ME+structure[2]––77.6 NLI[5]74.992.476.5 BiLSTM-hybrid[6]77.093.676.9 MemNN-share76.795.377.4 MemNN-stack77.195.377.3
说明: ME+structure 使用 ABCD 数据集特有的对话结构特征, 故在ABCD数据集上性能较高。加粗数字表示最好的结果。
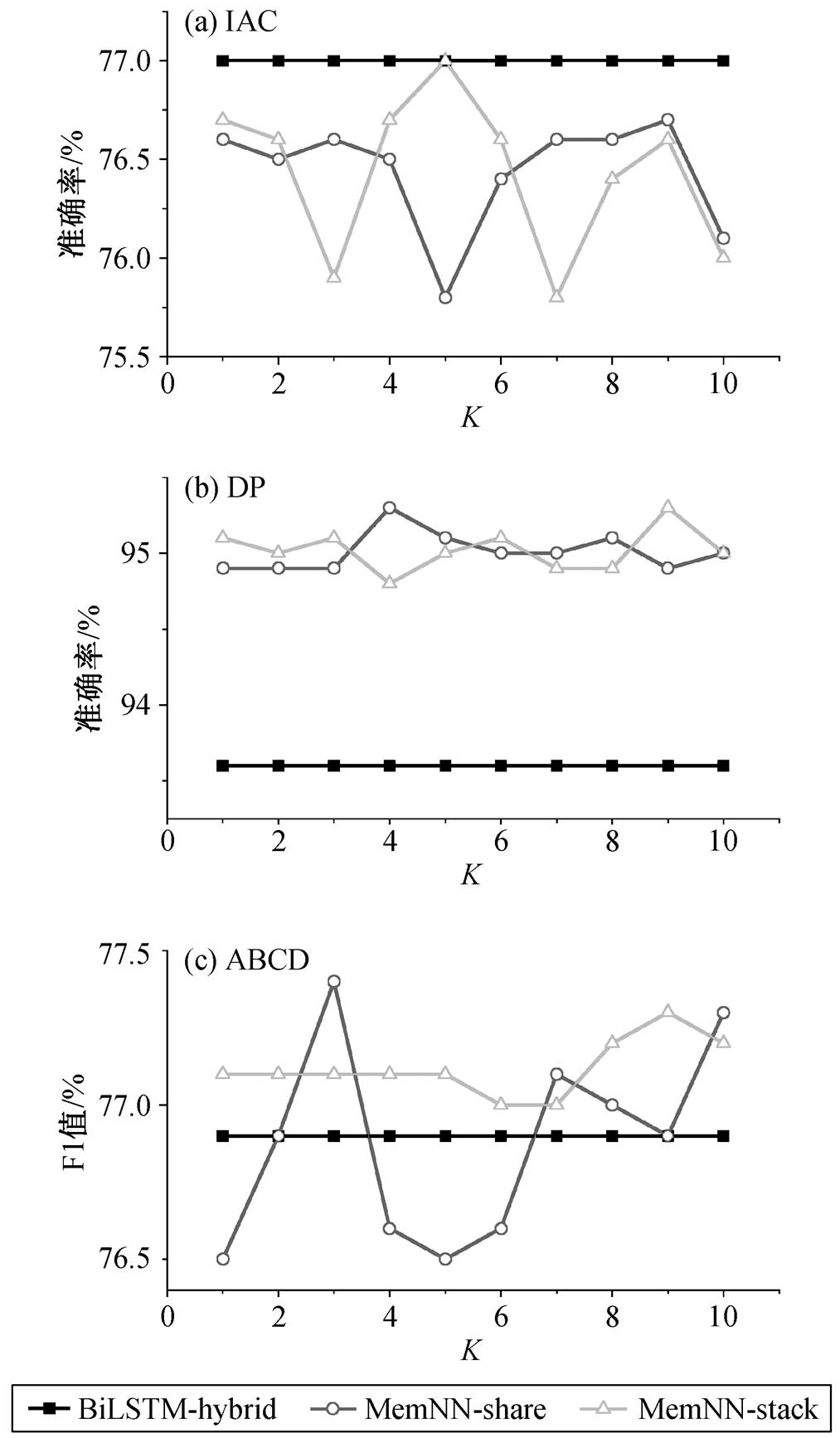
为了研究嵌入层层数 K 和嵌入层连接方式对模型在各个数据集上的性能的影响, 我们对比不同控制变量取值下 3 种模型的性能差异, 结果见图4。
在 IAC 数据集上(图 4(a)), MemNN-share 以及MemNN-stack 分别在嵌入层的层数为 9 和 5 时达到最佳性能, 准确率分别为 76.7%和 77.0%。当层数为 1 时, 可以认为MemNN-share 和 MemNN-stack是两个等价的模型, 性能也比较接近。随着层数增加, 两者的性能均上下波动, 其中 MemNN-stack 的层数在 3~5 之间时, 性能呈现上升态势; MemNN-share 的层数为 5 时性能最差, 但 5 层之后到 9 层为止, 性能不断上升。但是, 与 BiLSTM-hybrid 相比, 两种改进模型的性能几乎没有变化。
在 DP 数据集上(图 4(b)), MemNN-share 和Mem-NN-stack 在不同的嵌入层层数时均比 BiLSTM-hybrid 有明显的性能提升。随着层数的增加, 两种模型的性能均有上升, 并在 95.0%附近小幅波动, 其中 MemNN-share 在第 4 层时达到最高点(95.3%), MemNN-stack 在第 9 层时达到最高点(95.3%), 均比基线方法性能提升 1.7%。实际应用中, 从参数空间大小的角度考虑, 9 层 stack 嵌入层的参数量是 4 层share 嵌入层的 9 倍, 但后者的性能与前者相当, 表明参数共享的有效性。
在 ABCD 数据集上(图 4(c)), MemNN-share 的层数在 1~3 之间时, 性能提升明显, 在层数为 3 时取得最优(77.4%), 随着层数的增加, 过高的层数对MemNN-share 性能的提升帮助不大。另一方面, 对于 MemNN-stack, 嵌入层层数在 1~7 之间时, 对性能的影响很小, 但其性能均高于基线方法, 并且从 7层开始逐步提升, 在 9 层达到最优(77.3%)。
对比本文方法在 3 个数据集上的性能表现可以发现, 在较大规模的 DP 和 ABCD 数据集实验中, 适当增加深度记忆网络背景知识嵌入层的层数, 有助于模型学习更有效的背景知识特征表示, 从而提升分类性能, 但过高的层数会导致模型的性能下降。在较小规模的 IAC 数据集上, 本文方法出现轻微的性能下降。经过分析发现, IAC 数据集中存在大量不需要背景知识支持的简单对话样本, 这些样本的应答直接表示了对引述的立场, 使得背景知识引入的收益下降。同时, 文本方法抽取的背景知识可能包含噪声, 会对模型性能产生轻微的副作用。
6 结语
针对目前文本立场分析方法缺乏背景知识支持的问题, 本文提出一种结合背景知识的交互文本立场分析方法。该方法首先以交互文本作为查询, 从维基百科中检索相关的背景知识, 利用双向长短时记忆网络, 将背景知识编码为外部记忆, 然后使用多层的深度记忆网络提取与当前交互文本相关的背景知识特征, 用以增强交互文本的特征表示。本文针对模型中的控制变量(背景知识嵌入层层数和嵌入层链接方式)设计对照实验, 研究不同控制变量对模型性能的影响。实验结果表明, 在适当的背景知识嵌入层数以及背景知识嵌入层连接方式设定下, 结合背景知识的交互文本立场分析, 可以取得优于基线模型的性能表现, 证明了本文方法的有效性。但是, 本文方法所抽取的背景知识还无法完全排除噪声, 对该问题的解决可以作为进一步研究的方向。
参考文献
[1] Abbott R, Walker M, Anand P, et al. How can you say such things?!?: recognizing disagreement in informal political argument // Workshop on Languages in So-cial Media (WLSM). Stroudsburg, 2012: 2–11
[2] Rosenthal S, Mckeown K. I couldn’t agree more: the role of conversational structure in agreement and disagreement detection in online discussions // Con-ference of the Special Interest Group on Discourse and Dialogue (SIGDIAL). Prague, 2015: 168–177
[3] Menini S, Tonelli S. Agreement and disagreement: comparison of points of view in the political domain // International Conference on Computational Lingui-stics (COLING). Osaka, 2016: 2461–2470
[4] Augenstein I, Rocktäschel T, Vlachos A, et al. Stance detection with bidirectional conditional encoding // Conference on Empirical Methods in Natural Langu-age Processing (EMNLP). Austin, 2016: 876–885
[5] Liu Yang, Sun Chengjie, Lin Lei, et al. Learning natural language inference using bidirectional LSTM model and inner-attention [EB/OL]. (2016–05–30) [2019–08–30]. https://arxiv.org/abs/1605.09090
[6] Chen Di, Du Jiachen, Bing Lidong, et al. Hybrid neural attention for agreement/disagreement inference in online debates // Conference on Empirical Methods in Natural Language Processing (EMNLP). Brussels, 2018: 665–670
[7] Weston J, Chopra S, Bordes A. Memory networks [EB/OL]. (2015–11–29)[2019–08–30]. https://arxiv.org/ abs/1410.3916
[8] Sukhbaatar S, Szlam A, Weston J, et al. End-to-end memory networks // Conference on Neural Informa-tion Processing (NIPS). Montreal, 2015: 2440–2448
[9] Tang Duyu, Qin Bing, Liu Ting. Aspect level sen-timent classification with deep memory network // Conference on Empirical Methods in Natural Langu-age Processing (EMNLP). Austin, 2016: 214–224
[10] Wang Jin, Wang Zhongyuan, Zhang Dawei, et al. Combining knowledge with deep convolutional neural networks for short text classification // International Joint Conference on Artificial Intelligence (IJCAI). Melbourne, 2017: 2915–2921
[11] Chen Qian, Zhu Xiaodan, Ling Zhenhua, et al. Neural natural language inference models enhanced with external knowledge // Annual Meeting of the Associa-tion for Computational Linguistics (ACL). Melbourne, 2018: 2406–2417
[12] Mihaylov T, Frank A. Knowledgeable reader: enhan-cing cloze-style reading comprehension with external commonsense knowledge // Annual Meeting of the Association for Computational Linguistics (ACL). Melbourne, 2018: 821–832
[13] Manning C D, Surdeanu M, Bauer J, et al. The Stan-ford CoreNLP natural language processing toolkit // Annual Meeting of the Association for Computatio-nal Linguistics (ACL). Baltimore, 2014: 55–60
[14] Turney P D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews // Annual Meeting of the Association for Computational Linguistics (ACL). Philadelphia, 2002: 417–424
[15] Walker M A, Anand P, Tree J E F, et al. A corpus for research on deliberation and debate // International Conference on Language Resources & Evaluation (LREC). Istanbul, 2012: 23–25
[16] Weinberger K Q, Dasgupta A, Langford J, et al. Fea-ture hashing for large scale multitask learning // Inter-national Conference on Machine Learning (ICML). Montreal, 2009: 1113–1120
[17] Pennington J, Socher R, Manning C D. Glove: global vectors for word representation // Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, 2014: 1532–1543
[18] Kingma D P, Ba J. Adam: a method for stochastic optimization [EB/OL]. (2017–01–30) [2019–04–21]. https://arxiv.org/abs/1412.6980
An Interactive Stance Classification Method Incorporating Background Knowledge
LIU Changjian1, DU Jiachen1, LENG Jia1, CHEN Di1, MAO Ruibin2, ZHANG Jun2, XU Ruifeng1,†
1. School of Computer Science and Technology, Harbin Institute of Technology (Shenzhen), Shenzhen 518055; 2. Shenzhen Securites Information Co. Ltd., Shenzhen 518028; † Corresponding author, E-mail: xuruifeng@hit.edu.cn
Abstract This paper proposes a stance classification method on interactive text by incorporating background knowledge. This method retrieves relevant background knowledge texts from Wikipedia by using the interactive text as query. The retrieved background knowledge texts are encoded and then ultilized to learn the representation of relavent background knowledge through deep memory network for improving the representation learning of interactive text. The experimental results on three English online debate datasets show that the performance of interactive stance classification can be effectively improved by incorporating background knowledge through choosing the appropriate number of background knowledge embedding layers and the connection method of background knowledge embedding layer.
Key words stance classification; interactive text; background knowledge; deep memory network
doi: 10.13209/j.0479-8023.2019.096
国家自然科学基金(U1636103, 61632011, 61876053)、深圳市基础研究项目(JCYJ20180507183527919, JCYJ20180507183608379)、深圳市技术攻关项目(JSGG20170817140856618)和深圳证券信息联合研究计划资助
收稿日期: 2019–05–20;
修回日期: 2019–09–27

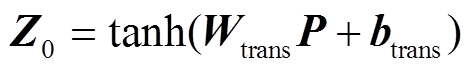 , (1)
, (1)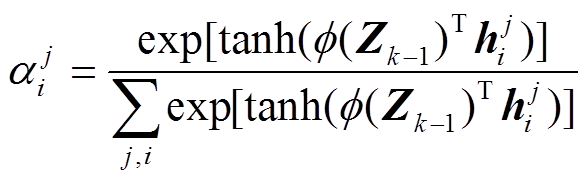 , (2)
, (2)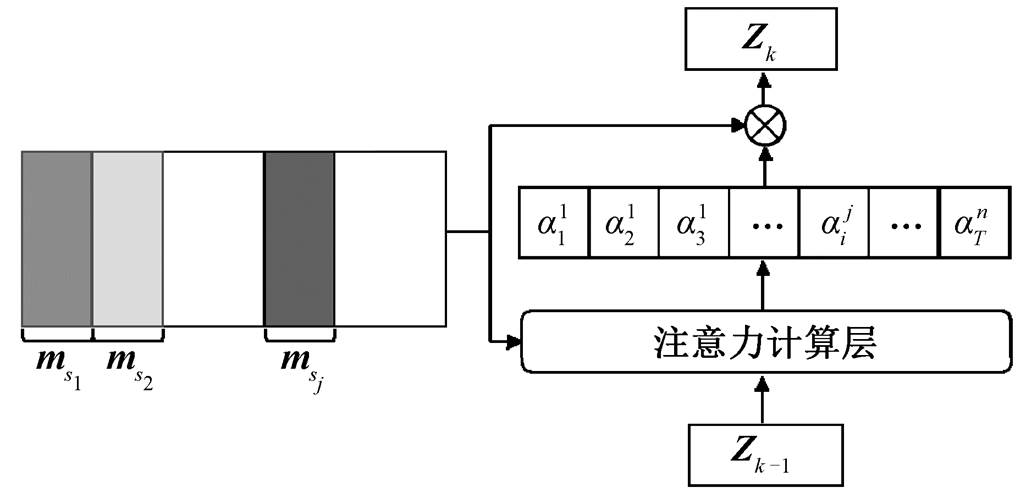
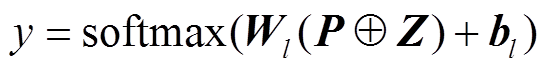 。 (5)
。 (5)