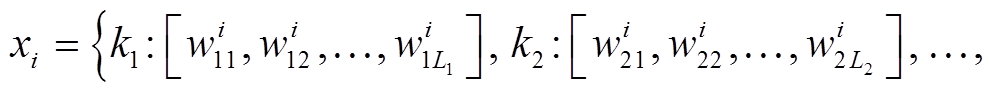
摘要 构建一种基于融合条目词嵌入和注意力机制的深度学习模型, 可以充分利用电子病案中的多种非结构化文本数据, 对病案首页的主要诊断进行自动 ICD 编码。该模型首先对含有病案条目的文本进行融合条目的词嵌入, 并通过关键词注意力来丰富词级别的类别表示; 然后利用词语注意力来突出重点词语的作用, 增强文本表示; 最后通过全连接神经网络分类器进行分类, 输出ICD编码。通过在中文电子病案数据集上的消融实验, 验证了融合条目词嵌入、关键词注意力和词语注意力的有效性; 与多个基准模型相比, 所建模型在对81种疾病的分类中取得最好的分类效果, 可以有效地提高自动ICD编码的质量。
关键词 自动ICD编码; 融合条目词嵌入; 关键词注意力; 词语注意力; 病案首页; 主要诊断
国际疾病分类(International Classification of Disease, ICD)是世界卫生组织(World Health Organ-ization, WHO)制定的国际统一的疾病分类方法。它根据疾病的病因、病理、临床表现和解剖位置等特性, 将疾病分门别类, 使其成为一个有序组合, 并用编码的方法来表示疾病。为了各国能够统一使用, 避免语言障碍导致编码不一致, ICD 编码统一采用英文字母加数字组合的形式, 如 C22.901(肝恶性肿瘤)。目前广泛使用的是 ICD-10, 全称为“疾病和有关健康问题国际统计分类”[1]。
病案是医院对患者病情记录的详细文件, 记录患者在诊疗过程中的病情以及最终的诊疗结果[2]。病案首页是整个病案信息最核心、最集中的部分, 记录患者的基本信息、疾病诊断、住院天数和医疗费用等, 是病案信息的综合反映。病案首页中的疾病诊断分为主要诊断和其他诊断, 主要诊断即患者本次就医的目的, 首要治疗的疾病; 其他诊断指患者本次也进行治疗的疾病(但不是最严重的), 或者以往就有的疾病。对病案首页的主要诊断进行 ICD编码是病案信息管理的核心技术, 也是医疗付费中疾病诊断相关分组(Diagnosis Related Groups, DRGs)[3]的基础和依据。很多医疗机构因为 ICD 编码的质量不如人意, 造成大量医疗付费的损失, 同时也对患者的后续治疗产生一定的影响。
对病案首页的主要诊断进行 ICD 编码并非易事。首先, ICD 编码规则相对复杂, 种类繁多, 有些编码表示的疾病非常相似, 不容易区分。第二, 住院患者往往存在多种其他疾病的诊断, 这些诊断会干扰对主要疾病的诊断判断, 进而影响主要诊断的ICD 编码。第三, 医生在书写病案时, 因为个人习惯或者为了提升书写效率, 往往会使用缩写或同义词, 导致临床诊断不够清晰明确, 给 ICD 编码人员带来困扰。因此, 通过人工对病案首页的主要诊断进行 ICD 编码, 不仅费时费力, 并且容易出错。如果能够对电子病案实现自动 ICD 编码, 不仅可以辅助病案编码员编码, 提高编码效率和质量, 还可以对已编码的病案进行自动核查和纠错, 对提高病案管理效率、降低病案管理成本和减少医疗付费损失十分重要。
本文构建一种基于融合条目词嵌入和注意力机制的深度学习模型, 充分利用电子病案中的多种非结构化文本数据, 对病案首页的主要诊断实现高质量的自动 ICD 编码。
对电子病案进行自动 ICD 编码一直是研究的热点[4]。Larkey 等[5]通过组合 3 种分类器: K-近邻(K-nearest-neighbor)、关联反馈(relevance feedback)以及贝叶斯独立分类器(Bayesian independence classi-fier), 对住院患者的出院记录实现自动 ICD-9 编码。Franz 等[6]通过比较 3 种面向诊断短语的自动ICD 编码方法, 发现基于三元语言模型(Trigram Language Model)的检索方法比基于医疗词典的检索方法更有利于自动 ICD 编码。Kavuluru 等[7]通过对电子病历进行特征提取和特征选择, 结合排序算法, 实现多标签的自动 ICD-9 编码。Koopma 等[8]基于规则并结合支持向量机(Support Vector Machines, SVM)构建一个文本分类模型, 可以对癌症病人的死亡证明进行自动 ICD 编码。Farkas 等[9]针对射线检查报告, 探索多标签的自动 ICD-9-CM 编码。早期的研究大多基于规则或采用特征工程的方法对文本建模, 没有考虑词语的上下文关系, 忽略了重要词语和句子的贡献, 不能很好地对内容丰富的电子病案进行表示。
近年来, 随着深度学习的兴起与发展, 一些学者将深度学习的技术应用到自动 ICD 编码中[10]。Scheurwegs 等[11]基于分布式语义表示, 对未标注的语料提出一种非监督的医疗实体抽取方法, 可用于辅助自动 ICD 编码。Duarte 等[12]利用门控循环单元(gated recurrent unit, GRU)和注意力机制(attention mechanism), 对癌症病人的死亡证明实现自动 ICD-10 编码。Mullenbach 等[13]则基于卷积神经网络(convolutional neural networks, CNN)和标签注意力(label attention), 对患者的出院记录实现自动 ICD编码。Shi 等[14]利用长短期记忆网络(long short-term memory, LSTM)和注意力机制对诊断描述建模, 实现多标签的自动 ICD 编码。Xie 等[15]进一步利用一个序列树长短期记忆网络(tree-of-sequence LSTM)来表示 ICD 编码的层级结构, 并提出一种对抗学习算法, 用来解决不同医生书写病历的风格差异问题, 并结合排序算法对多个标签进行排序, 显著地提高了多标签自动 ICD 编码的质量。Baumel等[16]基于两层的双向门控循环单元(bidirectional gated recurrent unit, BiGRU), 分别在句子和文档两个层面进行表示, 并加入句子注意力和标签注意力来增强句子和文本表示, 针对长文本的自动 ICD 编码有不错的效果。Xu 等[17]充分利用电子病历中的各种数据资源, 结合机器学习和深度学习的优势, 对不同类型的数据(非结构化、半结构化和结构化的数据)学习不同的分类器, 然后集成起来, 实现基于多模态的自动 ICD 编码系统。由于深度学习在文本建模上具有强大的表征能力, 不仅可以更好地表示词语和文本, 还可以学习到词语的上下文关系和重要词语的信息, 在文本分类领域展现出强大的优势, 因此, 深度学习成为目前研究自动 ICD 编码的主流方法。
本研究中所用的中文电子病案数据集来源于山东省某医院近 5 年(2012—2017年)住院患者的真实电子病案记录。数据集包含82375例住院患者的病案记录, 包括结构化的数据和非结构化的数据, 每类数据都有对应的病案条目(如年龄、性别、主诉、现病史和出院记录等)。由于数据内容丰富庞杂, 为了方便研究, 经过咨询病案编码员和临床医生, 我们选取其中6种对编码比较重要的非结构化文本数据进行建模。6种文本对应的病案条目分别是主诉、现病史、首次病程记录、检查报告、查房记录和出院记录。表1展示一例病案记录中这6种文本的简略内容以及对应的主要诊断和ICD编码。
本文的自动 ICD 编码问题可描述为, 给定含有病案条目的文本数据X, 输出对应的 ICD 编码Y, 目标是找到一个最优映射F, 使得F:X→Y。对任意的xi∈X, 可用式(1)表示:
 (1)
(1)
其中, kj为第j个病案条目,
 为第 i 个样本第j个病案条目的词语序列, Lj为序列长度。序列总长度为
为第 i 个样本第j个病案条目的词语序列, Lj为序列长度。序列总长度为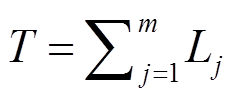 。对应的ICD编码集为 Y={ci}, i=1,2,…,nc,nc为ICD编码类别数。
。对应的ICD编码集为 Y={ci}, i=1,2,…,nc,nc为ICD编码类别数。
本文模型的基础框架为两层双向长短期记忆网络[18](bidirectional long short-term memory, Bi-LSTM)的文本编码器和一层全连接神经网络分类器, 并在文本编码器中引入3个模块: 融合条目的词嵌入模块、关键词注意力模块和词语注意力模块。模型的整体框架如图1所示。
电子病案中的病案条目说明文本描述的类型和主题, 反映患者在症状、检查和治疗等方面的具体表现。同一个词语, 在不同条目的文本中, 其意义和重要性可能有所不同。例如, 在现病史中, 对很多患者都会有这样的描述: “无咳嗽、咳痰、胸闷、胸痛”, 表明该患者没有明显的心肺疾病, 但如果在主诉中出现“咳嗽、咳痰、胸闷、胸痛”这些词语, 说明患者是有明显的心肺疾病的。因此, 病案条目不仅可以给词语提供主题信息, 还可以强化上下文的语境, 反映同一词语在不同文本中的差异。为了体现词语的这种差异, 我们设计融合条目的词嵌入模块, 在对文本的词语进行词嵌入的同时, 也对相应的病案条目进行词嵌入, 并将条目向量融入词向量中, 丰富词语的分布式表示。
该模块包括两个独立的词嵌入层, 分别对词语和对应的病案条目进行词嵌入, 并将获得的两个词向量拼接起来, 作为融合条目的词向量。融合条目的词向量vj,t可用下式表示:
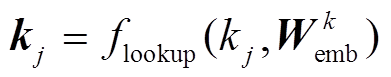 , (2)
, (2)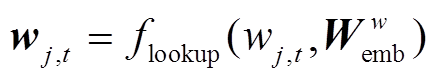 , (3)
, (3)
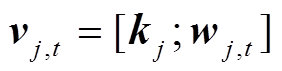 , (4)
, (4)
其中, 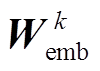 和
和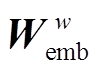 分别为病案条目和普通词语对应的词嵌入矩阵, 是模型需要学习的参数;
分别为病案条目和普通词语对应的词嵌入矩阵, 是模型需要学习的参数; 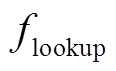 是查表函数。融合条目的词向量 vj,t 将输入到第一层BiLSTM中进行编码, 获得词语的初步表示。
是查表函数。融合条目的词向量 vj,t 将输入到第一层BiLSTM中进行编码, 获得词语的初步表示。
不同的ICD编码有不同的关键词, 这些关键词对分类模型十分重要, 因此, 我们在词语表示层引入关键词信息, 通过关键词注意力形成词级别的类别表示, 进一步丰富词语的表示, 并将该表示与分类模型相结合, 提升分类性能。该模块包括关键词提取和关键词注意力两个过程, 如图2所示。
表1 一例病案记录的简略内容以及对应的主诊断和ICD编码
Table 1 A brief description of a medical record and corres-ponding main diagnosis with ICD code

病案条目文本内容主要诊断ICD编码 主诉右上腹痛1周肝恶性肿瘤C22.901 现病史患者于1周前无明显诱因出现腹痛, …… 尿色深黄, 呈浓茶色, 体重无明显变化 首次病程记录中年男性患者, 右上腹痛1周。既往“糖尿病”病史8年, …… 谷丙转氨酶44 IU/L 检查报告肝脏形态欠规整, 左叶增大……脾脏形态明显增大, 腹膜后见广泛迂曲血管影 查房记录患者腹痛有所缓解, 无恶心、呕吐。……保肝退黄、利胆治疗, 继续观察病情变化 出院记录患者入院后完善相关辅助检查, ……建议院外继续保肝治疗, 肿瘤内科、介入科随诊

图1 模型整体框架
Fig. 1 Model framework
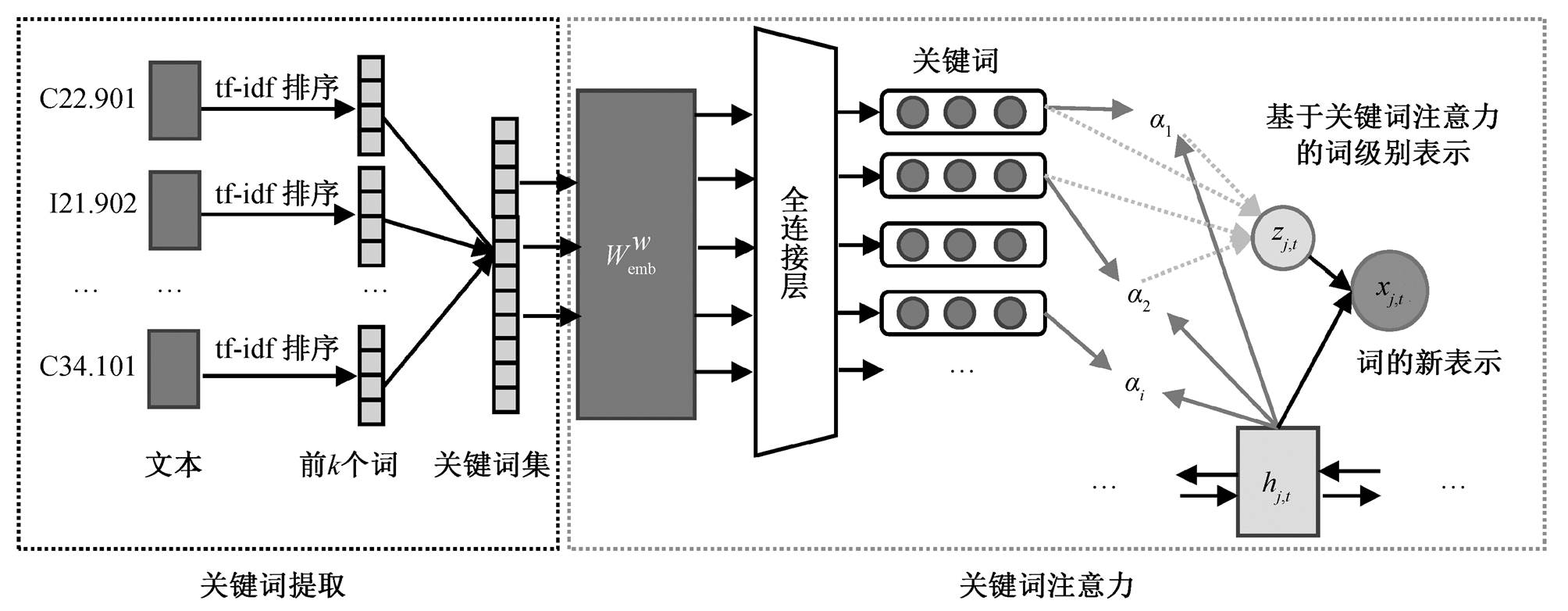
图2 关键词注意力模块
Fig. 2 Keyword attention module
3.2.1基于TF-IDF算法的关键词提取
在进行关键词注意力之前, 先基于TF-IDF(term frequency-inverse document frequency)算法[19]提取各类ICD编码的关键词。首先, 将所有文本合并成一类文本, 然后计算每个词语在不同ICD编码中的TF-IDF值并进行排序, 最后针对每个类别, 选取TF-IDF值最大的前k个的词语作为类别关键词。在某一类文档 dj 中的词语 ti 的 TF-IDF 计算公式如下:
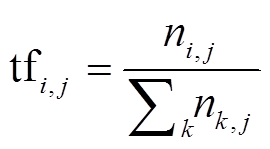 , (5)
, (5) , (6)
, (6)
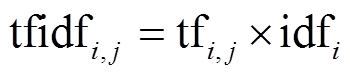 , (7)
, (7)
其中, ni,j是该词在文档dj中出现的次数, 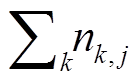 是文档 dj 中所有词语出现的次数之和, |D|是语料库中的文档总数, |{j:ti∈dj}|为包含词语 ti 的文档数目。表 2 列出部分 ICD 编码的前 10 个关键词。
是文档 dj 中所有词语出现的次数之和, |D|是语料库中的文档总数, |{j:ti∈dj}|为包含词语 ti 的文档数目。表 2 列出部分 ICD 编码的前 10 个关键词。
3.2.2 关键词注意力
将关键词提取出来之后, 组成关键词集, 然后经过普通的词嵌入矩阵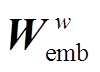 和一个全连接神经网络, 得到关键词的表示, 再与第一层 BiLSTM 的输出(词语的初步表示)进行关键词注意力操作, 获得每个词语基于关键词注意力分布的词级别表示。将该表示与词语的初步表示拼接起来, 组成词语的新表示xj,t, 计算方法如下:
和一个全连接神经网络, 得到关键词的表示, 再与第一层 BiLSTM 的输出(词语的初步表示)进行关键词注意力操作, 获得每个词语基于关键词注意力分布的词级别表示。将该表示与词语的初步表示拼接起来, 组成词语的新表示xj,t, 计算方法如下:
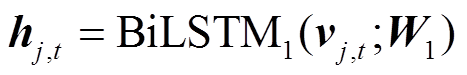 , (8)
, (8)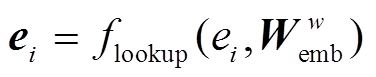 , (9)
, (9)
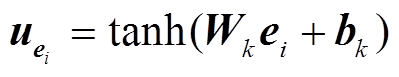 , (10)
, (10)
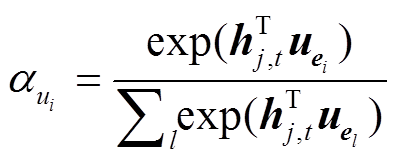 , (11)
, (11)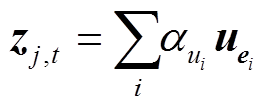 , (12)
, (12)
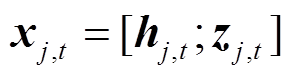 , (13)
, (13)
其中, W1是第一层BiLSTM的参数, hj,t是词语的初步表示; Wk 和 bk是全连接层的参数, uei 是关键词ei 的表示, zj,t 是基于关键词注意力分布的词级别 表示。
由于不同词语对文本语义的贡献不同, 因此, 基于 Yang 等[20]的研究, 我们在第二层的 BiLSTM中引入词语注意力模块, 获取每个词语对文本表示的重要程度, 用以突出重点词语的贡献, 弱化无关词语的影响, 可以更好地表示文本。具体地, 先通过一个全连接层得到隐状态 sj,t的表示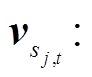
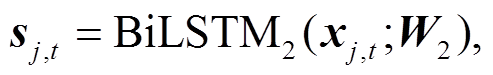 (14)
(14) (15)
(15)
其中, W2是第二层BiLSTM的参数。然后, 计算单词的注意力权重αj,t:
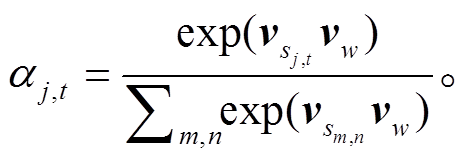 (16)
(16)词语上下文向量 vw经过随机初始化后, 在训练期间与模型参数共同学习更新。最后, 整合词语的注意力权重αj,t, 得到文本表示 d:
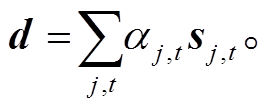 (17)
(17)
获得文本表示 d 之后, 经过全连接神经网络和softmax 函数, 得到 ICD 编码的类别预测值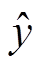 , 并通过最小化交叉熵损失函数, 逐层更新网络参数, 获得一个文本分类器, 实现自动 ICD 编码。该过程可由下式表示:
, 并通过最小化交叉熵损失函数, 逐层更新网络参数, 获得一个文本分类器, 实现自动 ICD 编码。该过程可由下式表示:
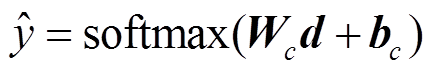 , (18)
, (18)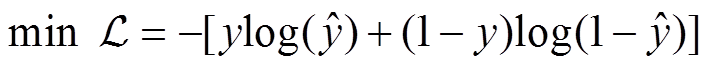 , (19)
, (19)
其中,Wc和bc是全连接神经网络的参数, 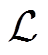 为交叉熵损失函数。
为交叉熵损失函数。
首先, 从数据集中抽取出选定的 6 种文本数据及其对应的 ICD 编码。由于数据集包含的 ICD 编码较多(约 640 种), 很多是不常见的疾病编码(如M34.902, 硬皮病), 对应的病例数很少, 不方便进行研究。因此, 我们把病例数小于 100 例的 ICD 编码过滤掉, 最终保留 81 种常见疾病的 ICD 编码, 共75431 例数据。其中训练集 60345 例(80%), 验证集7543 例(10%), 测试集 7543 例(10%)。图 3 展示训练集中病例数最多的前25种ICD编码的分布。
表2 部分ICD编码的前10个关键词
Table 2 Top 10 keywordss for some ICD codes

ICD编码关键词 I25.101胸闷, 冠心病, 双肺, 病情, 心脏, 胸痛, 发作, 血压, 未闻, 呼吸 I61.005基底节, 脑出血, 肢体, ct, 颅脑, 病情, 肌力, 破入, 瞳孔, 血压 C22.901肝癌, 腹部, 肝脏, ct, 占位, tce, 增强, iu, 保肝, 肿瘤 C15.901食管癌, 食管, 化疗, 淋巴结, 双肺, 放疗, 胃镜, 总数, 呼吸, 辅助 C16.902腹部, 胃癌, 淋巴结, 化疗, 切缘, 不适, 胃镜, 胃窦, 转移, 病理
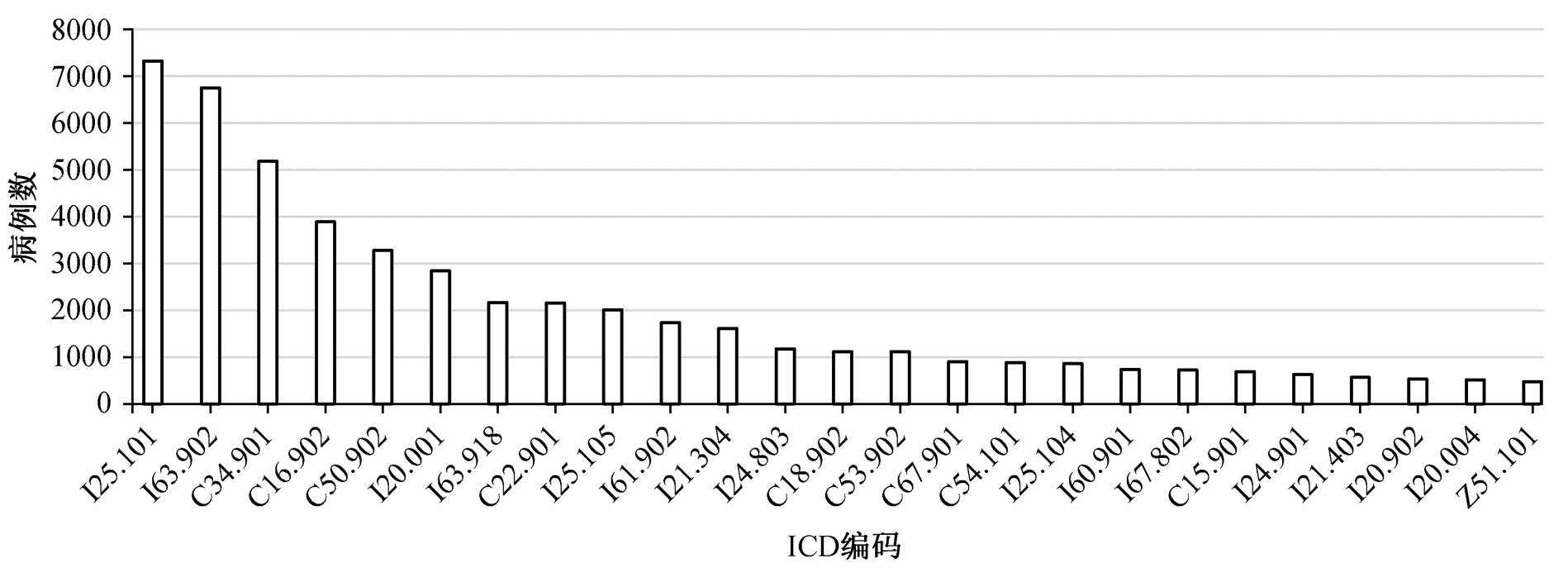
图3 训练集中部分ICD编码的分布
Fig. 3 Distribution of partial ICD codes in training set
从图 3 可以看出, ICD 编码的分布不平衡, 因此训练时针对病例数少于 500 例的 ICD 编码进行随机重采样, 保证每类 ICD 编码的病例数在 500 例以上。先用 jieba 中文分词工具对文本数据进行分词操作, 然后过滤掉数字、标点和低频词(词频低于 5 的词语)。
病案条目词向量的维度设为 50, 普通词向量维度设为 128, 两层 BiLSTM 的神经元数都设为 128, 每类 ICD 编码的关键词数设为 10, 损失函数采用Adam优化器优化, 学习率设为 0.001。
为了体现各个模块的作用, 我们进行消融实验, 通过比较去掉某个模块前后的效果, 验证这个模块的作用。No-EE (No-Entry Embedding)表示去掉融合条目词嵌入模块之后的模型; No-KA (No-Keyword Attention)表示去掉关键词注意力模块之后的模型; No-WA (No-Word Attention)表示去掉词语注意力模块之后的模型; BiLSTM 表示去掉所有模块之后, 仅包含两层BiLSTM和全连接层的模型。
我们还设置了几个基准模型: 基于 TF-IDF 特征表示的支持向量机[21] (SVM)模型、随机森林[22](Random Forest)模型、基于卷积神经网络的 Text-CNN[23]文本分类模型以及基于双层注意力网络的自动ICD编码模型 HA-GRU[16]。
针对多分类问题, 我们采用准确率(Accuracy)以及经过宏平均(Macro-averages)的精确率(Preci-sion)、召回率(Recall)和 F1 分数(F1-score)作为模型的评价指标。
实验结果见表 3。从消融实验的结果可以看出, 融合条目的词嵌入模块能够提升 1.27%的准确率和3.5%的 F1 分数, 对精确率和召回率也都有小幅度的提升, 说明通过融合条目的词嵌入方法来丰富词语的分布式表示, 确实能够增强分类效果, 提升自动 ICD 编码的质量。关键词注意力模块在准确率上提升 2.06%, 在 F1 分数上提升 5.61%, 说明基于关键词注意力形成的词级别表示能够利用关键词的类别信息, 有助于提升文本分类的性能。词语注意力模块的提升效果最明显, 在准确率上提升接近 10%, 在精确率、召回率和 F1 分数上都有大幅度的提升(20%以上), 说明在文本建模方面, 特别是对长文本分类来说, 词语注意力的重要性是毋庸置疑的。与不加 3 个模块的 BiLSTM 相比, 本文模型在准确率、精确率、召回率和 F1 分数上都有不同幅度的提升, 进一步证明了这 3 个模块的作用。
表3 实验结果
Table 3 Experimental result
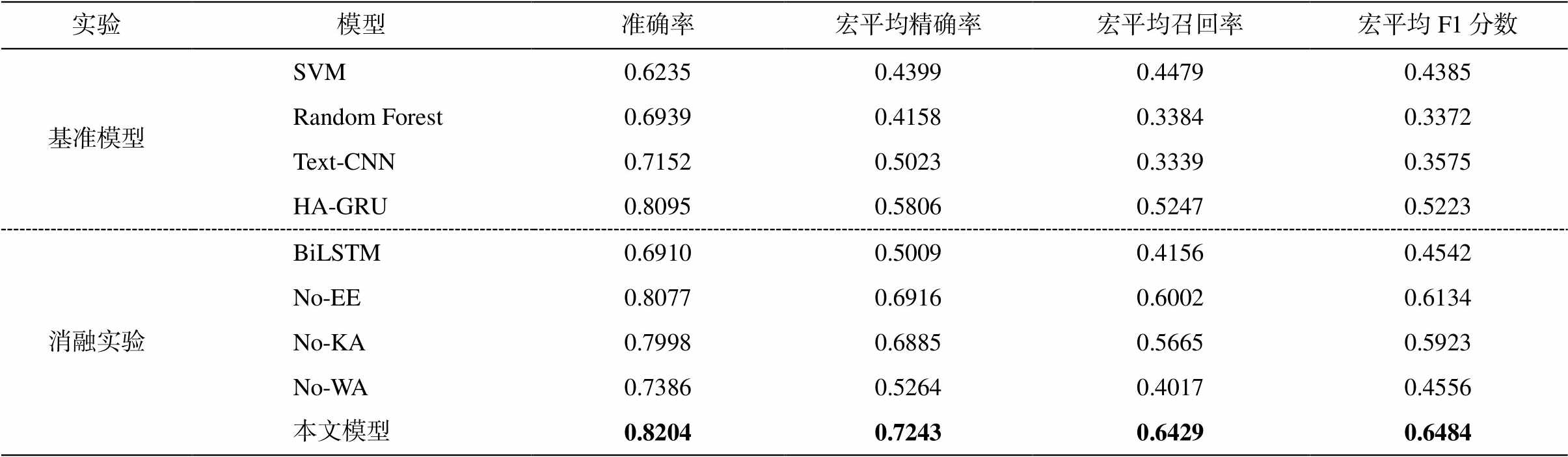
实验模型准确率宏平均精确率宏平均召回率宏平均F1分数 基准模型SVM0.62350.43990.44790.4385 Random Forest0.69390.41580.33840.3372 Text-CNN0.71520.50230.33390.3575 HA-GRU0.80950.58060.52470.5223 消融实验BiLSTM0.69100.50090.41560.4542 No-EE0.80770.69160.60020.6134 No-KA0.79980.68850.56650.5923 No-WA0.73860.52640.40170.4556 本文模型0.82040.72430.64290.6484
说明: 粗体数字表示最好的结果。
通过与基准模型的结果比较可以看出, 我们构建的模型明显优于传统的基于 TF-IDF 特征表示的支持向量机模型和随机森林模型, 体现了深度学习的优势。与基于卷积神经网络的 text-CNN 文本分类模型相比, 我们的模型在准确率上高出 10.5%, 在精确率、召回率和 F1 分数上的提升更明显, 体现了循环神经网络结合注意力机制在文本分类方面的优势。虽然我们的模型和 HA-GRU 模型都基于循环神经网络和注意力机制, 但我们在词向量中融入病案条目信息, 并在词语表示层引入关键词注意力, 使得词语的表示更为丰富。从实验结果来看, 与 HA-GRU 模型相比, 我们的模型在准确率上提升1.09%, 在 F1 分数上提升 12.61%, 在精确率和召回率上也有明显的提升。
本文通过融合条目词嵌入和关键词注意力, 丰富了词语的表示, 并结合词语注意力, 对中文电子病案中的主诉、现病史、首次病程记录、检查报告、查房记录和出院记录 6 种非结构化的文本进行建模, 学习得到一个基于深度学习的文本分类模型, 可以对病案首页中的主要诊断进行自动 ICD 编码。通过消融实验以及与基准模型的对比实验, 验证了本文构建的自动 ICD 编码模型的有效性。
本研究的主要贡献如下。
1)之前的研究大部分集中在单一文本建模, 没有充分利用电子病案中的多种文本数据, 丢掉了部分有用信息。本文选取多种文本进行建模, 通过增加文本内容, 丰富和强化文本的类别特征, 可以更加全面地捕捉重要信息, 提高分类的效果。
2)在词嵌入层, 引入病案条目信息, 通过融合条目的词嵌入方法, 丰富词语的分布式表示, 可以体现同一词语在不同文本中的语义差异。
3)在词语表示层, 引入类别关键词信息, 通过关键词注意力, 形成基于关键词注意力分布的类别表示, 进一步丰富词语的词级别表示。
未来, 我们会将更多的文本数据和结构化的数据加入模型中, 进一步提升自动 ICD 编码的质量。由于本次研究的疾病种类比较少, 涉及的 ICD 编码也比较少, 将来我们会考虑增加对非常见病的建模, 扩大自动ICD编码的范围。
参考文献
[1] World Health Organization. International statistical classification of diseases and related health problems: instruction manual. Geneva: World Health Organiza-tion, 2004
[2] 卫生部. 病历书写基本规范(试行). 中国卫生法制, 2002, 10(5): 183–186
[3] Horn S D, Bulkley G, Sharkey P D, et al. Interhospital differences in severity of illness: problems for pro-spective payment based on diagnosis-related groups (DRGs). New England Journal of Medicine, 1985, 313 (1): 20–24
[4] Stanfill M H, Williams M, Fenton S H, et al. A syste-matic literature review of automated clinical coding and classification systems. Journal of the American Medical Informatics Association, 2010, 17(6): 646–651
[5] Larkey L S, Croft W B. Combining classifiers in text categorization // SIGIR. Zurich, 1996: 289–297
[6] Franz P, Zaiss A, Schulz S, et al. Automated coding of diagnoses—three methods compared // Proceedings of the AMIA Symposium. Los Angeles, 2000: 250–254
[7] Kavuluru R, Rios A, Lu Y. An empirical evaluation of supervised learning approaches in assigning diagnosis codes to electronic medical records. Artificial Inte-lligence in Medicine, 2015, 65(2): 155–166
[8] Koopman B, Zuccon G, Nguyen A, et al. Automatic ICD-10 classification of cancers from free-text death certificates. International Journal of Medical Informa-tics, 2015, 84(11): 956–965
[9] Farkas R, Szarvas G. Automatic construction of rule-based ICD-9-CM coding systems // BMC Bioinforma-tics, 2008, 9(3): S10
[10] Shickel B, Tighe P J, Bihorac A, et al. Deep EHR: a survey of recent advances in deep learning techniques for electronic health record (EHR) analysis. IEEE Journal of Biomedical and Health Informatics, 2018, 22(5): 1589–1604
[11] Scheurwegs E, Luyckx K, Luyten L, et al. Assigning clinical codes with data-driven concept representation on Dutch clinical free text. Journal of Biomedical Informatics, 2017, 69: 118–127
[12] Duarte F, Martins B, Pinto C S, et al. Deep neural models for ICD-10 coding of death certificates and autopsy reports in free-text. Journal of Biomedical Informatics, 2018, 80: 64–77
[13] Mullenbach J, Wiegreffe S, Duke J, et al. Explainable prediction of medical codes from clinical text [EB/ OL]. (2018–04–16)[2019–04–10]. https://arxiv.org/abs /1802.05695
[14] Shi H, Xie P, Hu Z, et al. Towards automated ICD coding using deep learning [EB/OL]. (2017–11–30) [2019–04–12]. https://arxiv.org/abs/1711.04075
[15] Xie P, Xing E. A neural architecture for automated ICD coding // Proceedings of the 56th Annual Meet-ing of the Association for Computational Linguistics (Volume 1: Long Papers). Melbourne, 2018: 1066–1076
[16] Baumel T, Nassour-Kassis J, Cohen R, et al. Multi-label classification of patient notes: case study on ICD code assignment // Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence. New Orleans, 2018
[17] Xu K, Lam M, Pang J, et al. Multimodal machine learning for automated ICD coding [EB/OL]. (2018–10–31)[2019–04–15]. https://arxiv.org/abs/1810.13348v1
[18] Hochreiter S, Schmidhuber J. Long short-term memo-ry. Neural Computation, 1997, 9(8): 1735–1780
[19] Salton G, Buckley C. Term-weighting approaches in automatic text retrieval. Information Processing & Management, 1988, 24(5): 513–523
[20] Yang Z, Yang D, Dyer C, et al. Hierarchical attention networks for document classification // Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Hu-man Language Technologies. San Diego, 2016: 1480–1489
[21] Joachims T. Text categorization with support vector machines: Learning with many relevant features // European Conference on Machine Learning. Chemnitz, 1998: 137–142
[22] Svetnik V, Liaw A, Tong C, et al. Random forest: a classification and regression tool for compound clas-sification and QSAR modeling. Journal of Chemical Information and Computer Sciences, 2003, 43(6): 1947–1958
[23] Kim Y. Convolutional neural networks for sentence classification [EB/OL]. (2014–09–03) [2019–04–20]. https://arxiv.org/abs/1408.5882
Automated ICD Coding Based on Word Embedding with Entry Embedding and Attention Mechanism
Abstract The authors propose a neural model based on word embedding with entry embedding and attention mechanism, which can make full use of the unstructured text in the electronic medical record to achieve automated ICD coding for the main diagnosis of the medical record home page. This method first embeds the words which contain the medical record entries into word embeddings, and enriches word-level representation based on keyword attention. Then, the word attention is used to highlight the role of key words and enhance the text representation. Finally, ICD codes are output by a fully connected neural network classifier. Ablation study on a Chinese electronic medical record data set shows that word embedding with entry embedding, keyword attention and word attention is effective. The proposed model gets the best results for 81 diseases classification compared with baselines and can effectively improve the quality of automated ICD coding.
Key words automated ICD coding; word embedding with entry embedding; keyword attention; word attention; medical record home page; main diagnosis
doi: 10.13209/j.0479-8023.2019.095
国家重点研发计划(2017YFC0804001)和国家自然科学基金(61672058, 61876196)资助
收稿日期: 2019–05–22;
修回日期: 2019–09–25