
图1 模型处理框架
Fig.1 The processing framework of the proposed approach
作为自然语言处理(natural language processing,NLP)的重要任务之一, 篇章关系识别逐渐受到关注。篇章关系用于描述两个文本单元(子句、句子等)之间的逻辑衔接关系, 这两个文本单元称为基本篇章单元(elementary discourse unit, EDU)。自动识别两个 EDU 之间的篇章关系有助于自然语言处理的很多下游应用, 如问答系统[1]、自动文摘[2]和机器翻译[3]等。
根据篇章单元中是否存在连词, 篇章关系分为显式篇章关系(例1)和隐式篇章关系(例2)。由于文本单元中不存在对篇章关系具有指示作用的连词,使得隐式篇章关系的识别成为篇章关系识别任务中的主要问题。
例1 [因为]他今天生病了EDU1, [所以]没来上课EDU2。(显式因果关系)
例2 他生病了EDU1, 没来上课EDU2。(隐式因果关系)
例3 没来上课EDU1, 他生病了EDU2。
现有研究通常将隐式篇章关系的识别看成分类问题, 且基于英文的研究居多。与英文相比, 中文省略连词的现象更普遍[4], 但由于缺少规模较大的标准标注语料, 因此针对中文的研究较少。多数基于中文的研究是围绕 CoNLL 发布的篇章分析 share tasks 进行的。目前, 中文的隐式篇章关系识别主要是粗粒度的关系识别, 尚未见有关细粒度隐式篇章关系识别的研究报道。然而, 明确定位每个文本单元的篇章语义角色会更有意义。例如, 在具有“因果关系”的文本单元中, 识别出哪一个文本单元表示原因, 哪一个文本单元表示结果, 更有利于问答系统、文本蕴含等任务的研究。本文将这种能表示文本单元的逻辑语义角色的篇章关系称为细粒度篇章关系。相比粗粒度篇章关系, 细粒度篇章关系具有方向性, 属于同种粗粒度关系下的不同细粒度关系具有语义差异(如“原因在前”和“证据在前”, 二者都属于因果关系)。例2 的两个文本单元 EDU1 和EDU2 具有因果关系, EDU1 表示原因, EDU2 表示结果, 方向由 EDU1 指向 EDU2。若交换 EDU1 和EDU2 的位置(例3), 在粗粒度隐式篇章关系中, 同样被视为因果关系, 但实际上例3 与例2 并不相同。在例3 中, EDU1 表示结果, EDU2 表示原因, 方向由 EDU2 指向 EDU1。在细粒度隐式篇章关系中,例2 被视为“原因在前”关系, 例3 则被视为“结果在前”关系, 二者不应等同对待。由于已有的粗粒度隐式篇章识别方法没有考虑方向性, 因此不能直接用于细粒度隐式篇章关系的识别。
本文针对中文的细粒度隐式篇章关系识别进行研究, 借鉴 Braud 等[5]的思想, 基于标注数据较少的情况, 利用远距离监督方法自动标注大量显式篇章数据, 加入 EDU 中与连词的相对位置关系, 训练词表达, 将其用于细粒度隐式篇章关系分类, 取得较好效果。实验结果表明, 本文方法在 HIT-CDTB[6]的细粒度篇章关系数据集上达到 49.79%的准确率,与 Braud 等[5]的方法相比, 准确率提高 4%, 验证了本文方法的有效性。
对于英文, 主要基于宾州篇章树库(The Penn Discourse TreeBank, PDTB)进行粗粒度的隐式关系识别[7-9]; 中文的篇章关系标注语料主要是中文篇章树库(Chinese Discourse TreeBand, CDTB)[4]。Wang 等[10]采用特征工程的方法, 人工提取一些特征(如词对等), 再利用逻辑斯蒂回归算法进行分类。Schenk[11]提出并验证了, 对于隐式篇章关系识别任务, 人工构造大量语言学特征不是必须的, 可以使用神经网络自动学习特征。Rönnqvist 等[12]使用循环神经网络(Recurrent Neural Network, RNN)编码 EDU, 并引入注意力机制, 取得较好的效果。
目前的隐式篇章关系识别研究主要着眼于粗粒度篇章关系, 对更有应用价值的细粒度篇章关系识别缺乏关注。现有的方法采用人工构造特征, 代价大且存在稀疏问题。虽然低维的密集的词表达可以有效地解决稀疏问题, 但通用词向量只编码语义信息, 与特定任务无关, 且标注的数据过少, 无法直接训练词表达。因此, Braud 等[5]提出, 不直接将显式标注数据作为隐式篇章关系识别的训练数据[13], 而是用来训练词表达, 通过分析 EDU 中出现的词与连词的共现情况, 可以获得不同词语对不同篇章关系的使用分布情况, 将词的修辞功能编码到密集的词表达中。实验证明, 这种方法比简单的语义编码更有效。
方向性是细粒度篇章关系的独特性质, 对细粒度隐式篇章关系的识别具有重要意义。在粗粒度隐式篇章关系识别中, 通常的做法是通过词的向量表达获得篇章单元的向量表达, 然后将两个篇章单元的向量表达直接进行拼接后送入分类器[5,14]。然而,这样的方法在细粒度篇章关系识别任务上并不合理。由于篇章关系具有方向性, 如果底层编码不将方向性考虑进去, 那么A⊕B与B⊕A(其中A和B表示两个句子向量, ⊕表示拼接操作)的编码对上层分类器来说是相同的, 但它们在细粒度篇章关系中并不属于同种关系, 这对细粒度篇章关系识别效果有影响。本文利用大量自动标注的显式篇章数据训练词表达, 为了结合细粒度篇章关系的方向性特性,在训练词表达时, 引入每个词相对于连词的位置信息。
在已公开的中文篇章关系标注语料中, 哈尔滨工业大学标注的中文篇章关系语料 HIT-CDTB 提供了细粒度篇章关系标注。本研究的语料使用 HITCDTB。
首先使用远距离监督方法自动标注的大量显式篇章数据训练词表达, 然后将训练的词表达作为细粒度隐式篇章分类器的输入, 整体流程见图 1。
图1 模型处理框架
Fig.1 The processing framework of the proposed approach
高质量词表达的训练必须基于大量的显式篇章数据, 由于 HIT-CDTB 语料中标注的样例较少(7910条), 因此本研究需要自动标注大量显式篇章数据。由于训练的词表达是基于和连词的共现统计, 所以在自动标注时只需要确定连词和边界, 不需要确定 EDU 间的具体关系。连词识别和 EDU 的确定是自然语言处理的另一种任务, 并非本文的研究重点,因此本文采用远距离监督的方式进行自动标注。远距离监督方法在关系抽取[15]和微博情感分析[16]等任务中广泛使用。由于海量数据可以减小噪声的影响以及学习算法具有容噪能力, 在这些任务中, 将获得的海量文本直接作为训练数据, 取得较好效果。本文使用包含 409416986 个词的新闻语料, 得到包含 264 个不同连词的共 7399347 个带噪声的显式篇章样例。
2.1.1 确定连词
连词是篇章关系的重要指示线索, 但是并没有一个对连词的具体定义。在 HIT-CDTB 的标注准则中, 由于没有限制连词的形式, 导致连词中出现较长的短语以及“一九九三年”等确切的时间词, 这些词作为连词的候选, 被匹配到的可能性较小, 并且会扩大连词向量空间模型的维度, 使得构建出的词表达维度过大。因此, 在获取候选连词的时候,对从 HIT-CDTB 中获得的连词进行筛选: 1)不考虑形如“在……情况下”等的连词; 2)去除在 HITCDTB 中出现次数为1的连词; 3)去除具体时间。
由于本文基于和连词的共现情况来构造词表达, 因此连词的个数决定最后词表达的维度。连词越多, 自动标注得到的显式数据就越多, 映射的关系类型也越多, 能够减少依赖连词的编码映射不到关系的情况。但是, 连词过多, 会导致词表达维度过大, 这与我们要训练低维密集词表达的初衷相背。因此, 参考一般词向量的维度, 选择 HIT-CDTB 中标注的筛选后的频度前 300 的连词, 考虑到用于自动标注的语料可能没有某些候选连词的情况, 在考虑位置关系后, 最后得到的词表达维度应该小于等于 300×2。
采用远距离监督的方法, 直接通过匹配候选连词得到的连词是有歧义的[17], 包括两个方面: 1)该连词是否具有指示篇章关系的作用; 2)连词与篇章关系不是一一对应的。对于第二种歧义, 由于本文的自动标注不需要确定具体的关系, 因此可以忽略。对于第一种歧义, 目前多通过人工构造特征训练连词分类器[6,11]进行消歧。
由于中文连词的歧义现象占少数[18], 并且考虑到连词分类器的准确率如果达不到 100%同样会带来噪声, 因此为了简化标注过程, 本文不对连词进行消歧。本文通过使用大量数据来弥补不进行连词分类带来的噪声。再者, 出现在形如“blue and red”这样句子中的“and”, 如果考虑其语义, 将词语视为一种最基本的篇章单元, 此处的“and”同样表示两种颜色的并列关系。因此, 连词的歧义对于学习词的修辞能力是没有影响的。
2.1.2 确定EDU边界
作为浅层篇章分析的重要任务之一, EDU 边界确定相对较难[19]。Braud 等[5]先构造特征训练分类器, 定位篇章单元是构成句间关系还是句内关系,然后通过启发式规则来确定 EDU 边界。Hooda 等[20]利用长短期记忆(Long Short-Term Memory, LSTM)网络来识别 EDU (在 PDTB 里面, 将 EDU 叫做 Argument, 简称 Arg), 将 EDU 的识别视为序列标注问题,使用 LSTM 捕获特征, 判断输入序列的每个词是属于 Arg1, Arg2, connective, 还是 None, 从而进行 Arg的确定。由于该任务不是本研究的主要工作, 因此本文采用简单的模板[21](形如[EDU1, connectives EDU2])来确定 EDU, 即两个 EDU 在同一个句子中。Wu 等[21]的研究表明, 在数据量足够的情况下, 基于这样简单的模板是足够的。此外, 本文对海量数据的标注并不需要确定具体关系, EDU 的边界确定是为了限制连词与词的相关应该在某一范围内, 本文将这一范围限制在同一个句子中。基于海量数据可以涵盖大多数词与连词的假设, 使用该模板得到的海量文本对于学习词与连词的关系是足够的。
连词向量空间模型是标准向量空间模型的变体[22], 不同连词的个数确定底层向量空间的维度,通过统计每个词在不同文本单元中与不同连词的共现情况, 将每个词映射为连词个数维的实值向量。
在细粒度隐式篇章关系识别中, 要考虑篇章关系的方向性, 不能直接应用粗粒度隐式篇章关系识别的方法。如例4(a)中, EDU1 是因, EDU2 是果, 关系由 EDU1 指向 EDU2, 而例4(b)中 EDU1 是果,EDU2 是因, 关系由 EDU2指向 EDU1。
例4(a)出生之后小仙女的呼吸平顺EDU1, 并不需要额外的氧气EDU2。
例4(b)今天女足和朝鲜的比赛着实让我激动了一把EDU1, 比赛之精彩让我出乎意料EDU2。
因此, 基于上述观察, 假设文本中每个词在不同 EDU 中与连词的共现情况可以反映一个词在关系中的方向偏好, 即若某些词与“因为”共现, 出现在 EDU2 中, 与“所以”共现, 常出现在 EDU1, 那么这些词都常常用于表示原因, 在关系方向中处于指向的那一方, 使得这些词的词表达不仅编码了词与因果关系的语义联系, 同样编码了篇章关系的方向性。
本文构造词表达的方法如下。
对 EDU1 和 EDU2 中的词分别构建一个与连词的共现矩阵; 矩阵的每个元素表示对应的文本中其他词和连词的共现权重;V1表示出现在 EDU1 中的n1个词的集合,V2表示出现在 EDU2 中的n2个词的集合;C表示m个连词的集合, 得到构建的两个矩阵F1(维度为n1×m)和F2(维度为n2×m)。F1表示出现在 EDU1 中的不同词与各个连词的共现情况,F2表示出现在 EDU2 中的不同词与各个连词的共现情况, 因此同一个词就可以根据F1得到m维向量表达 vectorl, 向量的每一维表示该词出现在 EDU1 中与连词的关联; 根据F2得到m维向量表达 vectorr,向量的每一维表示该词出现在 EDU2 中与连词的关联。对任一个词, 就可以表示为一个 2m维的向量[vectorl; vectorr]。共现权重的计算公式见式(1)~(3), 采用文献[5]中效果最好的 PPMI-IDF。为了减少点互信息对低频词的偏向性, 计算时去掉词频小于等于 5 的词。
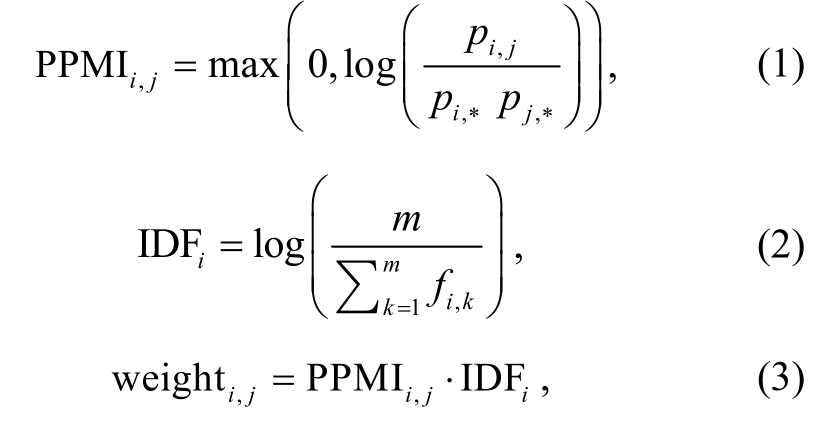
其中, weighti,j表示矩阵的第i行第j列对应的值, 即词wi和连词cj的共现权重。PPMIi,j表示wi和cj的非负点互信息值(PMI 小于 0 时, 取值为 0), 用于衡量词wi和连词cj的相关度, 从而映射到与特定关系的相关度, 计算见式(1), 其中pi,j表示wi和cj共同出现在一个 EDU 中的概率,pi,*和pj,*分别表示wi和cj出现的概率。IDFi用来规范化 PPMIi,j的值, 计算见式(2), 其中m表示不同连词数,fi,j表示wi和c共同出现在一个 EDU 中的频数, 如表1和2所示, 得到两个共现矩阵(部分)。
通过拼接表 1 和表 2 得到的词表达, 每个词就可以表示为 1 个 2m维的向量。如表 1 和 2 所示, 假设总共出现的连词只有 4 个, 则“好几年”可被表示为[0.12, 0, 0.47, 0.34, 0, 0, 0.04, 0.60]这样一个8维向量, 同样“不稳固”可表示为[0.35, 2.08, 0, 0.20, 0,0, 0, 1.82]。可以看到, 像“好几年”这种表时间的词,更倾向于与表时序关系的连词“后来”共现, 且更可能出现在 EDU1 中, 与 EDU2 构成先序关系。而“, ”这种词, 基本上与所有连词共现, 对应在各个维度上的值都是0, 对我们的模型不会产生影响。
表1 连词与词(EDU1)PPMI-IDF关联矩阵示例
Table 1 Illustrative example of PPMI-IDF association matrix between connectives and words of EDU1

?
表2 连词与词(EDU2)PPMI-IDF关联矩阵示例
Table 2 Illustrative example of PPMI-IDF association matrix between connectives and words of EDU2

?
得到每个词的词表达后, 通过加和[9]EDU 中所有词的词表达, 得到每个 EDU 的向量表达为 2m维。然后, 将两个 EDU 的向量表达进行拼接, 得到4m的向量, 作为隐式篇章分类器的输入。为了回避句子长度不同带来的影响, 在加和形成每个 EDU的词向量后用L2范数进行规范化。
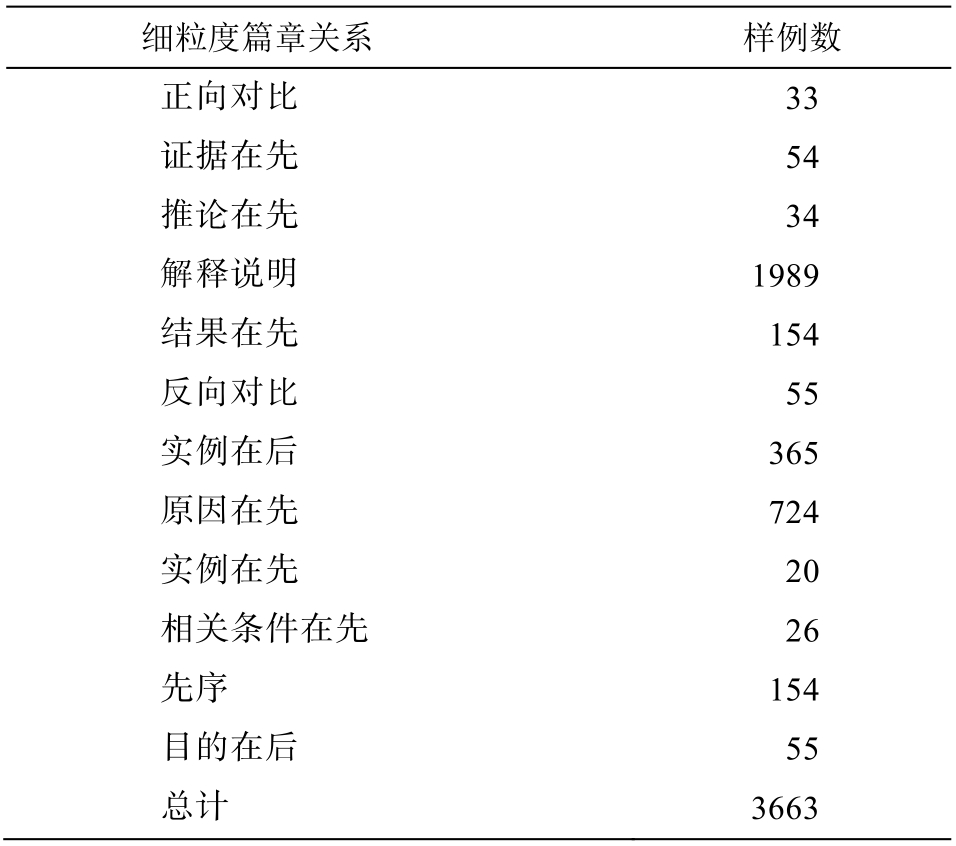
HIT-CDTB 是哈尔滨工业大学标注的篇章关系语料, 本文只使用该语料中的分句关系和复句关系样例。其中, 隐式样例15401 个, 提供了细粒度关系标签的隐式样例4084 个, 共包含 22 种细粒度关系。本实验只选择样例数大于 10 的关系类别作为最后的分类标签。该标注语料中存在某些样例缺失对应 EDU 的情况, 在删除缺失样例后, 共得到 3663个样例, 见表3。
从表 3 可见, 数据存在不均衡现象, 这是由篇章关系的真实分布决定的。已知的篇章关系的分布是偏斜的, 扩展关系(表 3 中“解释说明”关系是扩展关系的一种)的样例会比较多, 对于每种关系, 如果使用相同数量的样例来训练分类器, 可能会导致错误[23]。因此, 本文不对样本分布做干涉, 使其保持真实分布。
本文使用多项式逻辑斯蒂来建模分类器, 并与Braud 等[5]没有考虑位置的方法进行对比, 实验结果见表4和5。
从表 4 看出, 本文方法在细粒度隐式篇章关系识别任务上达到较好的效果, 准确率比 Braud 等[5]的方法有很大的提高, 说明在构建词表达时, 考虑词在不同文本单元中的出现情况, 对于细粒度隐式篇章关系识别的有效性。从表 5 可知, 在多数关系的识别效果上, 本文方法比 Braud 等[5]的方法有所提高, 但对于样例较少的关系类别, 本文方法的分类效果不理想。
表3 HIT-CDTB细粒度隐式篇章样例分布
Table 3 Distribution of fine-grained implicit discourse example in HIT-CDTB
?
表4 细粒度隐式篇章关系识别结果
Table 4 Result of fine-grained implicit discourse relation classification

?
为了进一步分析原因, 进行 5 折交叉验证, 发现对于样例较少的关系类别, 预测精确率的抖动幅度较大。我们猜测是由于样例个数太少, 分类器未能进行有效的学习, 导致结果不好, 存在随机性,如图 2 所示(其中预测精确率始终为 0 的关系不显示)。对预测精确率始终为 0 的关系进行考察, 除该关系的样本数较少外, 在观察分类混淆矩阵后, 发现“证据在前”关系很大可能会被错分在“原因在前”的类别, “推论在前”关系很大可能会错分在“解释说明”关系类别。这些关系都存在语义上的相似性,当类别细化后, 连词到关系的映射就会改变, 一个连词映射的关系会增多。因为连词对关系的映射没有方向性, 就使得属于同种粗粒度的细粒度关系间学习到的特征可能会比较相似, 再加上数据分布不均衡, 从而导致误分类。但是, 这是由于细粒度篇章关系的语义差异引起的, 不是本文的研究重点,因此本文并未对该语义差异做特殊处理。忽略语义差异带来的错误, 本文方法考虑细粒度篇章关系的方向性, 在细粒度篇章关系识别任务中取得较好的效果。总体而言, 本文初次对中文细粒度隐式篇章关系进行研究, 取得有意义的结果。
表5 每个关系识别结果
Table 5 Result of per relation identification
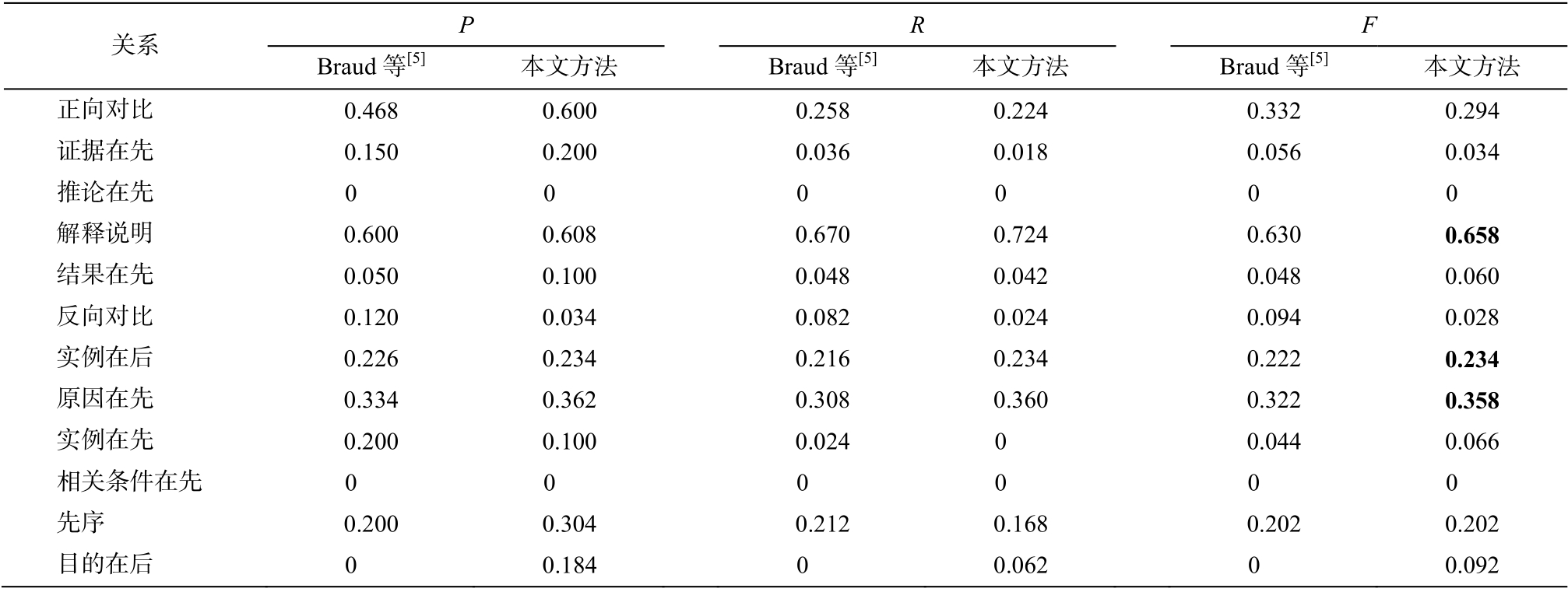
说明: 粗体数字表示最好的结果。
?
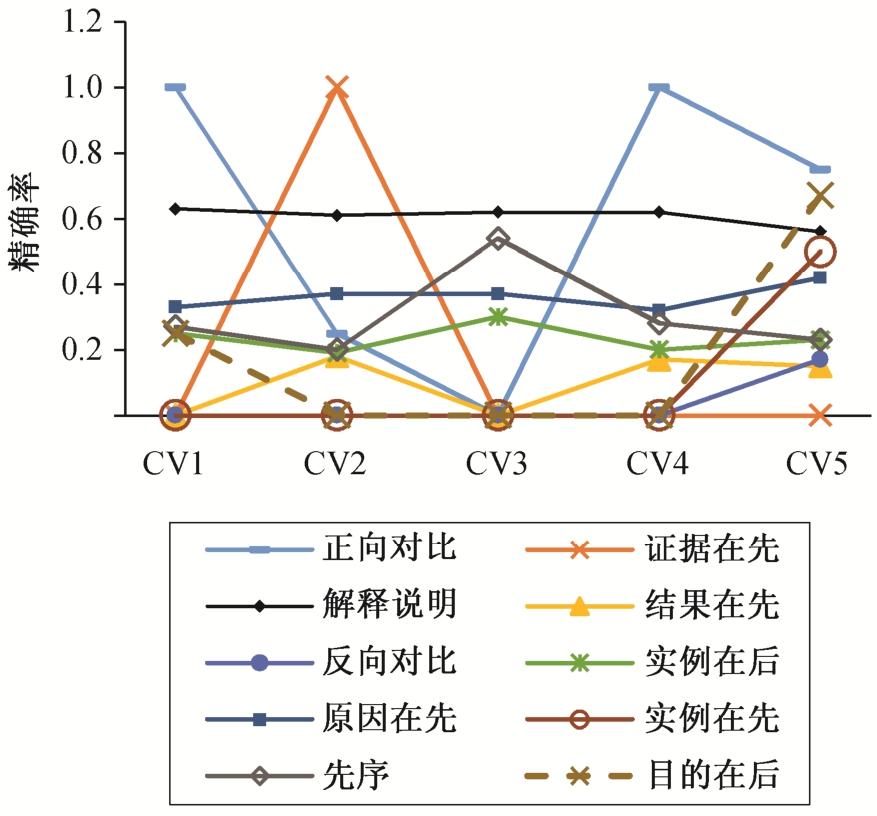
图2 五折交叉验证各个类别精确率
Fig.2 The precision of 5-fold cross validation in per relation
本文针对细粒度隐式篇章关系的识别任务, 基于篇章关系标注语料较少的现状, 利用大量自动标注的连词和与之对应的EDU, 采用基于统计的方法训练密集词表达, 利用词与连词的共现关系, 使得到的词表达能对自身的修辞功能进行编码, 加入词与连词的相对位置信息, 将每个词的关系语义角色偏向性编码到词表达。将该词表达用于细粒度隐式篇章关系识别, 取得较好的效果。
本文训练词表达的方法高效简单, 但点互信息不能很好地衡量两个词之间的相似性, 且倾向于低频词。在将来的工作中, 可以考虑使用其他更有效的衡量方式。另外, 作为初次尝试, 本文考虑细粒度篇章关系的方向性时, 采取的方法较简单, 将来可以进一步改善。
[1]Sun M, Chai J Y.Discourse processing for context question answering based on linguistic knowledge.Knowledge-Based Systems, 2007, 20(6): 511-526
[2]Yoshida Y, Suzuki J, Hirao T, et al.Dependencybased discourse parser for single-document Summarization // Conference on Empirical Methods in Natural Language Processing.Doha, 2014: 1834-1839
[3]Li J J, Carpuat M, Nenkova A.Assessing the discourse factors that influence the quality of machine translation // Meeting of the Association for Computational Linguistics.Baltimore, 2014: 283-288
[4]Zhou Y, Xue N.PDTB-style discourse annotation of Chinese text // Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics:Long Papers-Volume 1.Jeju: Association for Computational Linguistics, 2012: 69-77
[5]Braud C, Denis P.Learning connective-based word representations for implicit discourse relation identification // Empirical Methods on Natural Language Processing.Austin, 2016: 203-213
[6]张牧宇, 秦兵, 刘挺.中文篇章级句间语义关系体系及标注.中文信息学报, 2014, 28(2): 28-36
[7]Lin Z, Kan M Y, Ng H T.Recognizing implicit discourse relations in the Penn Discourse Treebank //Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1-Volume 1.Singapore: Association for Computational Linguistics, 2009: 343-351
[8]Ji Y, Eisenstein J.One vector is not enough: Entityaugmented distributional semantics for discourse relations [EB/OL].(2014-11-25)[2018-01-20].https://arxiv.org/pdf/1411.6699.pdf
[9]Rutherford A, Demberg V, Xue N.A Systematic study of neural discourse models for implicit discourse relation // Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers.Valencia, 2017: 281-291
[10]Wang J, Lan M.Two end-to-end shallow discourse parsers for English and Chinese in CoNLL-2016 shared task // Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics.Berlin,2016: 33-40
[11]Schenk N, Chiarcos C, Donandt K, et al.Do we really need all those rich linguistic features? a neural network-based approach to implicit sense labeling //Proceedings of the CoNLL-16 shared task.Berlin,2016: 41-49
[12]Rönnqvist S, Schenk N, Chiarcos C.A Recurrent neural model with attention for the recognition of Chinese implicit discourse relations // Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.Vancouver, 2017: 256-262
[13]Sporleder C, Lascarides A.Using automatically labelled examples to classify rhetorical relations: an assessment.Natural Language Engineering, 2008, 14(3): 369-416
[14]Qin L, Zhang Z, Zhao H.A stacking gated neural architecture for implicit discourse relation classification // Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.Austin, 2016: 2263-2270
[15]Angeli G, Premkumar M J J, Manning C D.Leveraging linguistic structure for open domain information extraction // Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers).Beijing, 2015: 344-354
[16]Magdy W, Sajjad H, El-Ganainy T, et al.Distant supervision for tweet classification using youtube labels // ICWSM.Oxford, 2015: 638-641
[17]Marcu D.The rhetorical parsing of unrestricted texts:A surface-based approach.Computational linguistics,2000, 26(3): 395-448
[18]姬建辉, 张牧宇, 秦兵, 等.中文篇章级句间关系自动分析.江西师范大学学报(自然科学版), 2015,39(2): 124-131
[19]Xue N, Ng H T, Pradhan S, et al.The conll-2015 shared task on shallow discourse parsing // Proceedings of the Nineteenth Conference on Computational Natural Language Learning-Shared Task.Beijing, 2015:1-16
[20]Hooda S, Kosseim L.Argument labeling of explicit discourse relations using LSTM neural networks[EB/OL].(2017-08-11)[2018-02-01].https://arxiv.org/pdf/1708.03425.pdf
[21]Wu C, Shi X, Chen Y, et al.Improving implicit discourse relation recognition with discourse-specific word embeddings // Meeting of the Association for Computational Linguistics.Vanvouver, 2017: 269-274
[22]Turney P D, Pantel P.From frequency to meaning:vector space models of semantics.Journal of Artificial Intelligence Research, 2010, 37: 141-188
[23]Pitler E, Louis A, Nenkova A.Automatic sense prediction for implicit discourse relations in text //Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP.Singapore: Association for Computational Linguistics, 2009: 683-691
Feature Learning by Distant Supervision for Fine-Grained Implicit Discourse Relation Identification