
图1 结合表示学习和迁移学习的跨领域情感分类框架
Fig.1 Architecture of cross-domain sentiment analysis
随着Amazon, Yelp和IMDB等在线评论网站的迅速发展, 有越来越多的用户对不同领域的产品进行评论, 表达观点。利用这些大规模用户生成的文本进行情感分析(sentiment analysis), 发现用户对事件或产品的态度以及倾向性[1]。跨领域情感分类(cross-domain sentiment classification)作为情感分析和自然语言处理(natural language processing, NLP)的重要组成部分[2], 旨在利用源领域与目标领域的有用知识, 对目标领域的文本进行情感分析, 挖掘用户的观点和态度。这对消费者意见反馈[3]和社交媒体研究[4]等有重要意义。
在跨领域情感分类研究中, 人们通常利用迁移学习的方法, 从有大量标注数据的源领域中获取有用的知识, 迁移到缺乏标注数据的相关目标领域中,以期提高算法在目标领域上的性能。这些方法主要分为以下两大类[5]。
1)基于特征表达的跨领域情感分类。根据不同领域之间的通用潜在特征来寻找新的特征空间,主要采用结构对应学习[6](structural correspondence learning, SCL)、谱特征对齐算法[7](spectral features alignment, SFA)、迁移成分分析[8](transfer component analysis, TCA)或高斯迁移过程[9]等方法来减少领域间的特征分布差异。这些方法大多数使用人工设计的规则或N元文法提取句子特征, 往往忽略上下文关系及重要单词与句子的情感信息, 无法很好地对跨领域大规模文档进行表示。
2)基于实例加权的跨领域情感分类。原理是调整源领域的训练数据权重, 使其尽可能符合目标领域分布。例如, 采用迁移学习适应提升算法[10-11](boosting for transfer learning, TrAdaBoost)、核均值匹配[12](kernel mean matching, KMM)和直接重要性估计[13]等方法, 学习实例权重参数。另外, 有些研究通过主动学习[14-15], 对迁移数据进行有选择的标注, 从而进行跨领域情感分类。但是, 在迁移过程中会不可避免地出现噪声数据, 即存在负面迁移的问题, 反而降低跨领域情感分类的性能。并且, 对于大规模标注文本, 在深度学习方法[16-17]上已经取得高性能, 是否有必要进行迁移学习值得探讨。
本文提出一种将文本表示方法与迁移学习算法相结合的跨领域文本情感分类方法。首先利用训练好的词向量和分层注意力网络[17](hierarchical attention network), 对源领域与目标领域的文档进行特征提取, 从而获得文档级的分布式表示。接着, 通过类噪声估计方法, 从源领域的文本样本中筛选出与目标领域分布相符的高质量样例, 迁移这些样例,以便扩充目标领域的数据集, 进一步利用支持向量机[18](support vector machine, SVM)来训练情感分类器。在目前公开的大规模产品评价数据集上进行的实验表明, 本文方法的性能优于目前主流的情感分类方法, 可以有效地提高迁移样本的质量, 从而提高跨领域情感分类的性能。
为了方便研究, 本文的跨领域情感分类问题可描述为, 给定目标领域的训练数据集Dt和源领域的训练数据集Ds,Y={ci}为情感类别(i=1,2,...,nc),nc为情感类别数, 且源领域与目标领域的数据分布不一致。利用T={D×Y}找到一个最优映射F, 使得F:S→Y,其中D=Dt∪Ds,S为目标领域的测试数据。
本文的跨领域情感分类方法框架可分为 3 个阶段, 如图 1 所示。
1)基于分层注意力网络的跨领域情感文本表示学习。首先, 对目标领域训练数据和源领域训练数据进行预处理和词向量化; 随后, 构建分层注意力网络模型, 将目标领域的训练数据视为无噪声数据,在此基础上训练模型, 接着分别对源领域和目标领域的数据进行特征提取, 获取文本数据的分布式表示。
2)基于类噪声估计的样例迁移学习。对于源领域数据中的每一个样本, 利用基于Rademacher和分布的类噪声估计方法, 计算其与目标领域分布的误差, 并根据类噪声估计结果, 对源领域数据进行筛选, 剔除类噪声概率大于阈值的样本, 得到高质量的迁移数据。
3)基于支持向量机的情感分类。将目标领域的标注数据与第二阶段得到的源领域迁移数据进行融合, 得到最终的训练数据。在此基础上, 利用支持向量机情感分类器进行训练, 并在目标领域的测试集上得到情感类别值。
图1 结合表示学习和迁移学习的跨领域情感分类框架
Fig.1 Architecture of cross-domain sentiment analysis
分层注意力网络将文档中的局部语义作为注意力, 利用长短时记忆网络[19](long short-term memory,LSTM)学习文本的单词级和句子级表示, 进而得到文档级的分布式表示, 可以很好地捕获文本的局部语义特征。本文采用基于注意力机制的分层LSTM网络[17], 对跨领域文档进行表示学习, 将LSTM作为基础模型, word2vec[20]预训练好的词向量作为分层注意力网络的输入, 通过两层LSTM提取单词级和句子级表示, 并分别引入单词和句子的局部语义注意力, 最终得到情感文本的分布式表示。模型结构如图 2 所示。
假设ds 为源领域的一个情感文本, 且ds={s1,s2,...,sn},si表示文本中的第i个句子, 且si={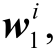
![]() 其中
其中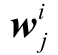 ∈
∈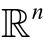 表示文本第i个句子中第j个单词的n维词向量。设li表示句子si包含的单词总数, 该文本的情感标签为y。
表示文本第i个句子中第j个单词的n维词向量。设li表示句子si包含的单词总数, 该文本的情感标签为y。
分层注意力网络可分为单词级和句子级表示学习。在单词级别的表示学习中, 句子中的每个单词映射到一个低维度的语义空间, 即用一个n维词向量表示。在LSTM的每一步中, 给定一个输入单词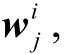 对当前单元状态
对当前单元状态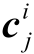 和隐藏状态
和隐藏状态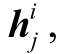 可以根据前一个单元状态
可以根据前一个单元状态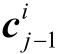 和隐藏状态
和隐藏状态 进行更新:
进行更新:
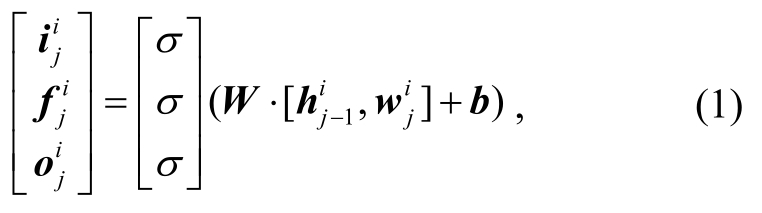
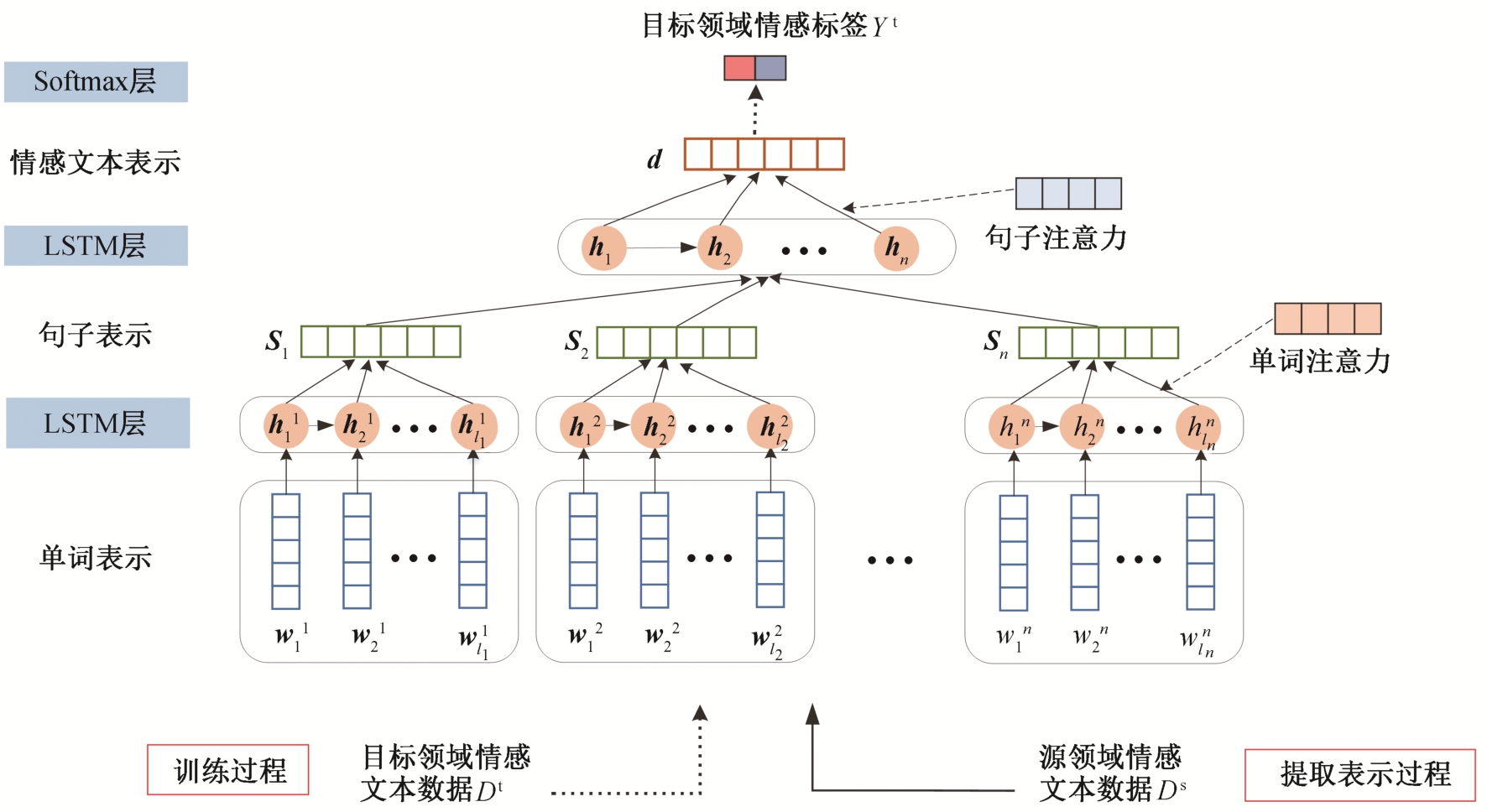
图2 基于分层注意力网络的跨领域情感文本表示学习模型
Fig.2 Model architecture of cross-domain representation learning based on hierarchical attention network
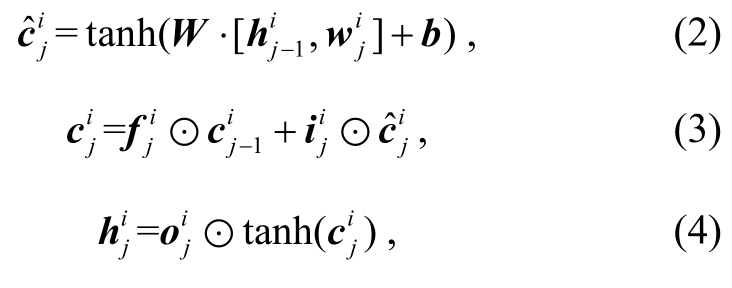
其中i,f和o是门限函数, ⊙表示矩阵乘法,σ表示sigmoid函数,W和b是模型中需要学习的参数。
然而, 并不是所有单词对句子表示的贡献程度都相同, 因此利用注意力机制来获取每个单词对句子表示的重要程度。具体地, 先通过一个全连接层得到隐藏状态 的表示
的表示 :
:
其中,Ww和bw为网络参数。然后, 计算单词的重要性, 即单词级的注意力权重
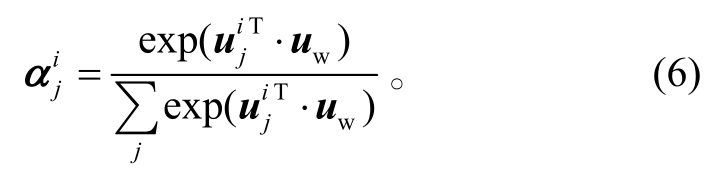
单词上下文向量uw经过随机初始化后, 在训练期间与模型参数共同学习更新。最后, 整合单词级的注意力权重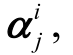 得到句子表示si:
得到句子表示si:
在句子级别的表示学习中, 将句子向量 [s1,s2,...,sn]送入LSTM层中, 使用类似的方法, 通过整合句子级的注意力权重ai, 得到文档表示d:
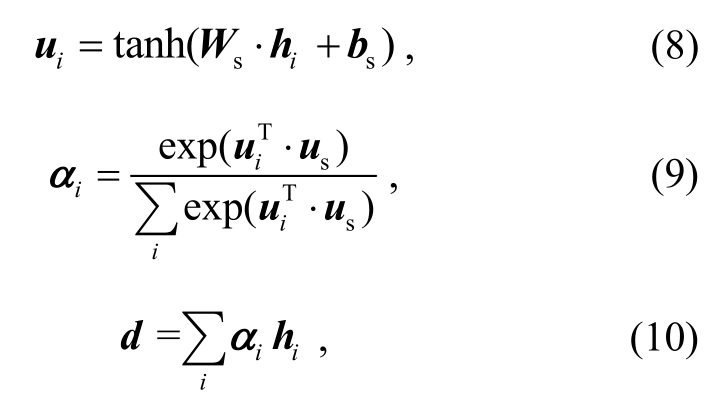
其中,Ws和bs为网络参数,us为句子上下文向量。
在基于分层注意力网络的跨领域情感文本表示学习的训练过程中, 将目标领域训练集Dt×Y作为模型的训练数据, 通过上述的特征提取阶段, 利用一个softmax函数, 对文本表示进行预测, 得到情感类别预测值 :
:
其中,Wc是 softmax 层的权值矩阵。通过最小化交叉熵损失函数, 逐层更新网络参数, 可获得一个在目标领域上的最优情感分类器。在文本表示学习的特征提取过程中, 目标领域的训练数据Dt与源领域的训练数据Ds分别通过训练好的模型, 提取其中最具代表性的文本特征作为文本的表示。
为解决迁移迭代过程中可能产生负面迁移, 造成跨领域情感分类器的性能下降的问题, 本文改进了基于Rademacher和分布的类噪声估计方法[21], 并将其引入样例迁移学习算法中, 利用类噪声检测方法筛选出迁移样本中的错误标注样本(即源领域中带有类噪声的样本)并剔除, 从而避免负面迁移的影响。
将无噪声的训练数据集记为D, 且 (x1,y1),(x2,y2),...,(xn,yn)是n个来自数据集D的数据, 其中xi为文本数据,yi为该文本数据的真实标签,yi=±1(i=1,2,...,n)。在类噪声问题中, 真实标签往往难以获得, 因此将实际数据集记为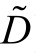 (即有噪声数据集
(即有噪声数据集 , 其中训练数据为
, 其中训练数据为![]() 这里
这里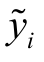 是实际标签, 可能与真实标签yi不同。因此,合理假设一个样本的真实标签与其最相似样本的标签相同。采用基于边权统计(cut edge weight statistic)的错误样本估计方法。首先, 计算每一个训练样本与其他样本之间的相似度并排序, 选取相似度最高的k个样本, 与之连接, 得到一个K近邻图。对于图中任意两个相连的节点(xi,yi)和(xj,yj), 定义其边的权重为
是实际标签, 可能与真实标签yi不同。因此,合理假设一个样本的真实标签与其最相似样本的标签相同。采用基于边权统计(cut edge weight statistic)的错误样本估计方法。首先, 计算每一个训练样本与其他样本之间的相似度并排序, 选取相似度最高的k个样本, 与之连接, 得到一个K近邻图。对于图中任意两个相连的节点(xi,yi)和(xj,yj), 定义其边的权重为
这里, sim(⋅)是相似度计算函数, 用于度量两个样本之间的相似度, 可以是余弦相似度(Cosine similarity)或基于欧氏距离(Euclidean distance)的相似度, 并且归一化后wij∈[ 0,1]。同时, 定义一个符号函数:

符号函数Iij表示一个样本和与其最相似的样本之间的差异。显然, 当两个输入样本的标签一致时,符号函数的输出为-1, 否则为1, 且P(Iij=1)=![]()
依据文献[21-22], 对于任意样本![]() 其类噪声率定义为
其类噪声率定义为
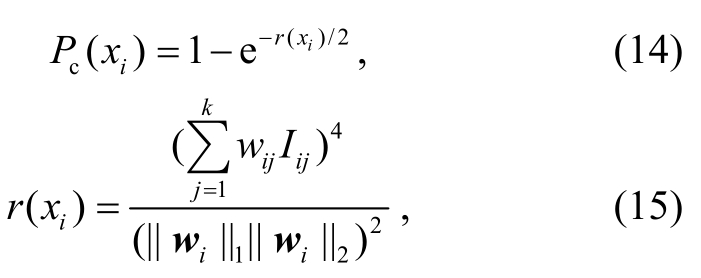
其中, ||⋅||1和||⋅||2分别为L1和L2范数,Iij为两个样本(xi,yi)与 (xj,yj)之间符号函数的计算结果,k表示选取最相似样本的个数,wi=(wi1,wi2, …,wik)∈L2。类噪声率表示迁移样本在目标领域中被错误标注的概率, 类噪声率大的样本会有更大的概率对迁移过程产生负面影响。
根据文献[23], 在有类噪声训练数据集上训练的分类器与真实最优假设之间的误差(即分类器的性能), 对于一个确定的机器学习问题, 其影响因素仅有类噪声率。在估计类噪声的基础上, 可以进一步估计迁移样本集合TS的误差界:

其中,δ是平滑系数,N是与特征空间相关的常数。迁移样本集合的误差界用于对当前迭代周期所训练的情感分类器质量进行评估。
基于类噪声估计的样例迁移学习算法的具体过程如算法 1 所示。
算法1 基于Rademacher和分布类噪声估计的样例迁移学习算法。
输入: 目标领域上的有标注数据L;源领域上的无标注数据U; 分类器C;最大迭代次数T;检测周期TD;当前周期n;当前周期的候选迁移样本集合TSn=Ø;已迁移样本集合TS=Ø;每轮迭代添加的正面样本数p和负面样本数q;每个周期估计的测试误差边界ε=1(i=1,2,...,n)。
输出: 迁移样本集合TS。
1n=1
2 for iter ←1 toT×TDdo
3 在L上训练分类器C
4 使用C对U进行分类, 将置信度最高的p个正面样本和q个负面样本加入TSn
5 if iter %TD==0 then
6 forxi∈ TS ∪TSndo
7 对样本xi建立K近邻图, 并根据式(14)计算类噪声率Pc(xi)
8 end for
9 根据式(16)进一步估计TS ∪ TSn的误差界εn
10 使用类似方法估计TS的误差界εn-1
11 ifεn>εn-1then
12 break
13 else
14 对于TSn中的每个样本xi, ifPc(xi)>θthenTSn← TSn-{xi}
15 TS=TS ∪ TSn,n++, TSn=Ø
16 end if
17 end if
18 end for
支持向量机[24]是一种监督学习方法, 在情感分类任务[18]上表现出优异的性能, 且具有泛化错误率低、计算开销小等优势。利用支持向量机建立一个超平面作为决策面, 使类别间隔最大化, 即
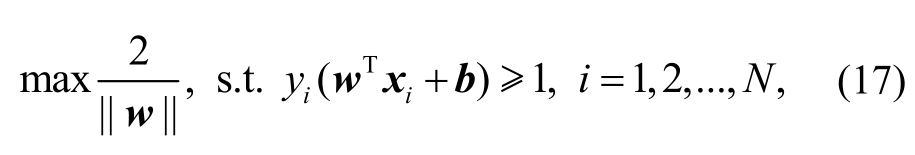
其中,xi与yi分别表示训练样本及其对应标签,N为训练集大小,w和b为待求解的参数。
第一阶段, 目标领域训练数据Dt与源领域训练数据Ds, 通过基于分层注意力网络, 分别得到对应的情感文本表示Xt与Xs; 第二阶段, 利用基于类噪声估计的迁移样例筛选算法, 从源领域样本中挑选出高质量的迁移样本数据Xs′ ⊂Xs, 合并目标领域与源领域的训练数据, 得到X=Xt ∪Xs′; 第三阶段, 利用合并数据集X×Y, 训练支持向量机情感分类器, 并在目标领域的测试集S上得到情感类别的预测值。
为了与基础实验进行对比, 本文实验选用的数据集是IMDB电影评论数据集以及Yelp网站上 2013年和 2014年的餐馆评论数据集[17], 具体的统计信息如表 1 所示。这 3 个公开数据集均包含大规模的英文评论文本以及对应的情感类别, 并且数据分布不一致。
由于Yelp2013和Yelp2014的情感类别(1~5)与IMDB (1~10)有所差异, 因此要对数据进行处理。
表1 实验数据集的统计信息
Table 1 Statistics of the datasets

?
本文采取归并方案, 利用![]() , 将IMDB的情感类别label映射到五分类标注体系中。由于五分类体系较难向更多分类映射, 所以本文实验仅仅针对Yelp不同年份数据之间的迁移以及IMDB数据集向Yelp数据集的迁移。
, 将IMDB的情感类别label映射到五分类标注体系中。由于五分类体系较难向更多分类映射, 所以本文实验仅仅针对Yelp不同年份数据之间的迁移以及IMDB数据集向Yelp数据集的迁移。
为了评估算法的性能, 我们选用分类算法中常用的两个评价指标[25]: 准确率(Accuracy)和均方根误差(root mean square Error, RMSE), 计算公式如下所示。
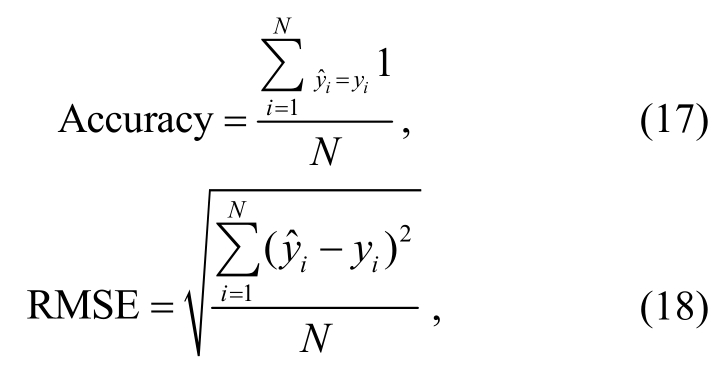
其中,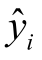 表示第i个样本的预测标签,yi表示其正确标签,N为测试集的大小。
表示第i个样本的预测标签,yi表示其正确标签,N为测试集的大小。
对于word2vec与分层注意力网络中的参数, 为便于对比, 沿用文献[17]中的参数设置, 将每个情感文本映射为一个200维的情感文本表示向量。
在基于类噪声估计的样例筛选过程中, 选取统计学中常用的置信度标准0.05作为阈值[26], 即: 若一个样本的类噪声率Pc(xi)> 0.95, 则认为这一样本xi是负面迁移样本。另外, 由于在文献[21]的类噪声检测算法中仅考虑二分类问题, 而本文所解决的是多分类问题, 故对原始的类噪声检测算法进行适当的改进, 以便统计相似样本中的标签差异: 针对五分类的数据集, 对于情感类别相差为1的相似样本, 不认为这两个样本的情感有明显差异; 对于情感类别相差为 2 及以上的相似样本, 则认为有明显差异。因此, 本文将五分类标签分为正、中、负3档: 1 和 2 为负面, 3 为中性, 4 和 5 为正面。总之,重新定义类噪声估计中的符号函数, 当且仅当两个样本的标签有正负面差异时才输出1, 否则输出-1。
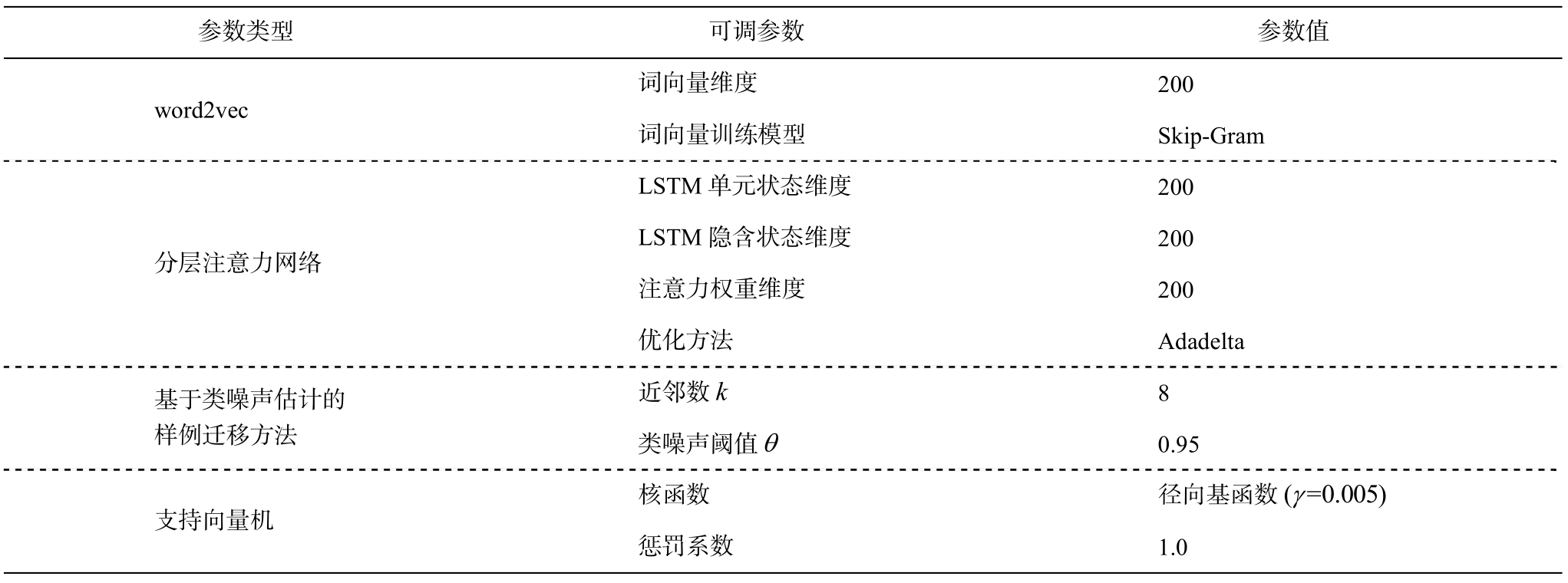
本文实验参数的设置如表 2 所示。
在Yelp两个不同年份数据集上, 分别采用卷积神经网络(CNN)、分层LSTM网络(NSC)以及基于分层注意力网络(NSC+LA)的文本表示学习方法, 进行情感分类实验, 结果如表 3 所示。
表2 参数设置
Table 2 Parameters setup
?
从表3可以看出, 分层注意力网络能较好地提取文本中的重要局部特征, 从而达到较好的情感分类性能。
作为参照, 先简单地向两个数据集添加来自其他训练集的样本, 不进行迁移数据的筛选, 使用支持向量机训练情感分类器, 实验结果如表 4 所示。
从表 4 可以看出, 将两个训练集直接合并后,分类效果明显下降, 主要原因在于两个数据集来自不同的领域, 领域之间的数据分布具有较大差异,直接迁移会产生负面影响。从在Yelp2013与IMDB之间进行的迁移实验可以看出, 简单合并之后出现的负面效果尤为明显, 这是由于Yelp2013与IMDB的数据规模相差不大, 负面迁移影响更显著。在Yelp2014上进行的实验中, 加入其他两个数据集之后, 性能略微提升, 并且, 由于Yelp2013与Yelp2014的数据分布较为类似, 性能提升较明显。但这仍说明简单合并数据集的方法不能有效地迁移不同领域的数据。
利用本文提出的算法, 对迁移数据进行基于类噪声估计的筛选, 并使用支持向量机训练分类器,实验结果如表 5 所示。
对比表 4 与表 5 可以看出, 与简单合并训练集相比, 对迁移数据进行筛选后, 各个数据集上的性能都有较大的提高, 说明利用基于类噪声估计的样例迁移算法可以有效地提升跨领域情感分类的性能, 表明对迁移数据进行基于类噪声估计的筛选可以避免负面迁移, 从而有效地提高迁移样本的质量。特别是在 Yelp2013 数据集上的实验结果, 比表4 中简单合并的准确率(0.618 和 0.628)有大幅度的提升, 表明进行高质量数据迁移的必要性。
以Yelp13标注数据+IMDB迁移数据的实验为例, 在近邻数k=8时, 选取IMDB训练集中两个类噪声率不同的样本进行对比, 如图 3 所示。图3(a)中,文本样本的情感标签为5, 通过类噪声估计方法计算得出类噪声率较小, 因为其与近邻的8个文本样本标签的差异不大, 可以认为该文本样本标注正确,较符合目标领域的数据分布。图3(b)中, 文本样本的标签为4, 与其近邻样本标签的差异较大, 类噪声率较大, 说明该样本在目标领域属于错误标注样本,与目标领域的数据相差较大, 极有可能造成分类器性能下降, 产生负面迁移。从图3可以看出, 基于Rademacher和分布的类噪声估计方法可以有效地过滤错误标注的样本, 从而进一步提升跨领域情感分类的性能。
表3 基于文本表示学习的基准分类实验
Table 3 Results of textual representation learning

说明: 加粗数字表示较好的结果, 下同。
?
表4 合并训练集的实验结果
Table 4 Results of merging training sets

Accuracy RMSE Yelp2013训练集+IMDB训练集 Yelp2013测试数据 0.618 0.742 Yelp2013训练集+Yelp2014训练集 Yelp2013测试数据 0.628 0.724 Yelp2014训练集+IMDB训练集 Yelp2014测试数据 0.632 0.711 Yelp2014训练集+Yelp2013训练集 Yelp2014测试数据 0.639 0.709
表5 基于类噪声估计的样例迁移学习实验结果
Table 5 Results of transfer learning based on class-noise estimation

Accuracy RMSE Yelp2013标注数据+IMDB迁移数据 Yelp2013测试数据 0.634 0.686 Yelp2013标注数据+Yelp2014迁移数据 Yelp2013测试数据 0.642 0.672 Yelp2014标注数据+IMDB迁移数据 Yelp2014测试数据 0.645 0.676 Yelp2014标注数据+Yelp2013迁移数据 Yelp2014测试数据 0.650 0.662
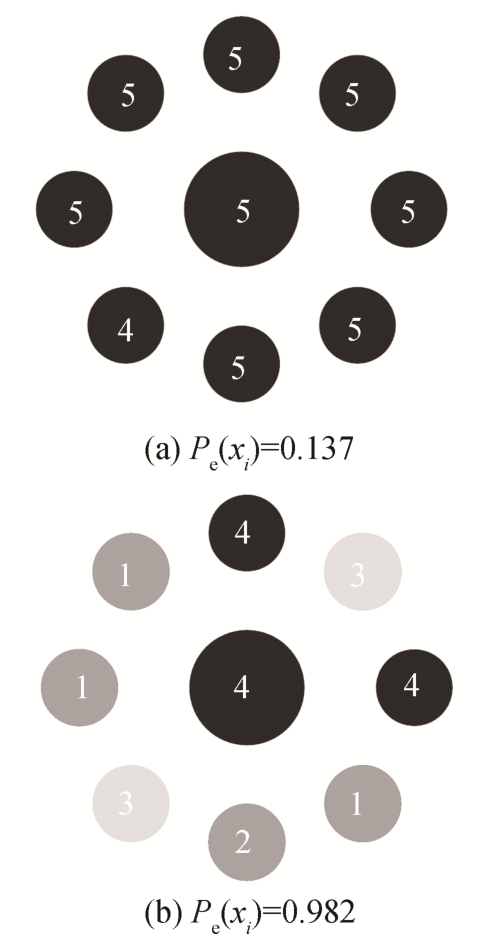
图3 不同类噪声率样本的比较
Fig.3 Comparison of samples over different class-noise rate
图4 表示近邻数k不同时, 在不同数据集上基于类噪声估计的样例迁移学习算法的准确率变化。可以看出, 当k为 7 或 8 时, 本文方法能达到较好的效果。
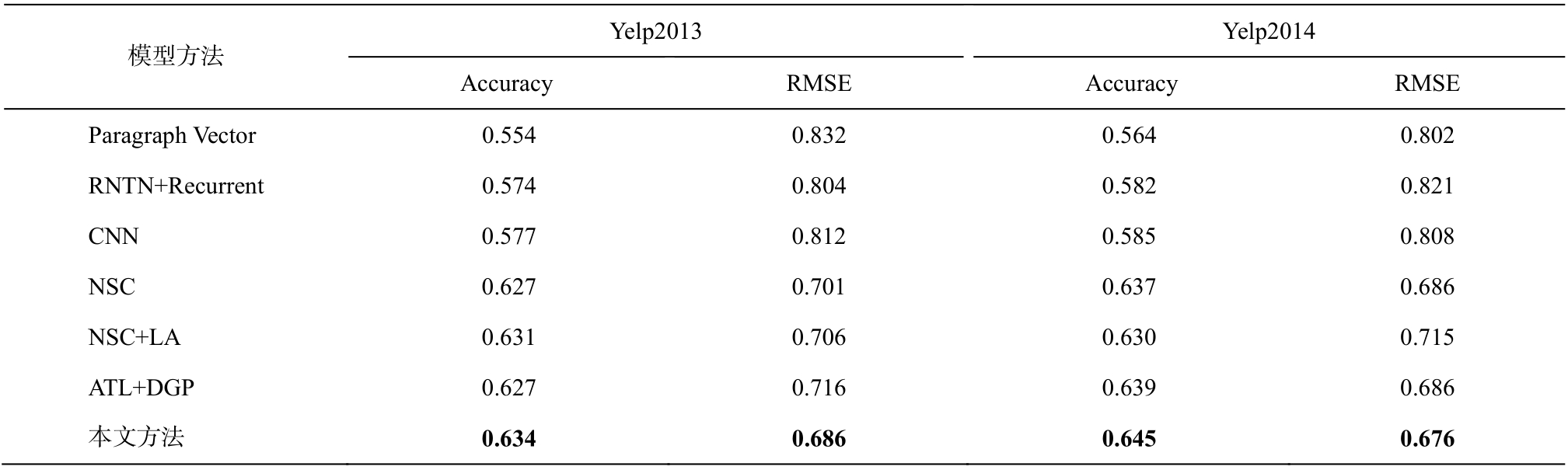
为了进一步说明本文提出的情感分类方法的有效性, 我们将该方法与目前主流的情感分类方法进行对比: 1)Paragraph Vector, 利用Le等[27]提出的文档向量表示训练支持向量机进行分类; 2)RNTN+Recurrent, 利用 Socher 等[28]提出的递归神经网络进行情感分类; 3)CNN, 利用 Kim[16]提出的卷积神经网络进行情感分类; 4)NSC 和 NSC+LA, 利用 Chen等[17]提出的两种文档级情感分类方法进行情感分类; 5)ATL+DGP, 基于深度高斯过程的非对称迁移学习[9]进行跨领域情感分类, 将 IMDB 训练集作为辅助数据, 利用分层注意力网络提取文本特征后利用深度高斯过程进行迁移学习。
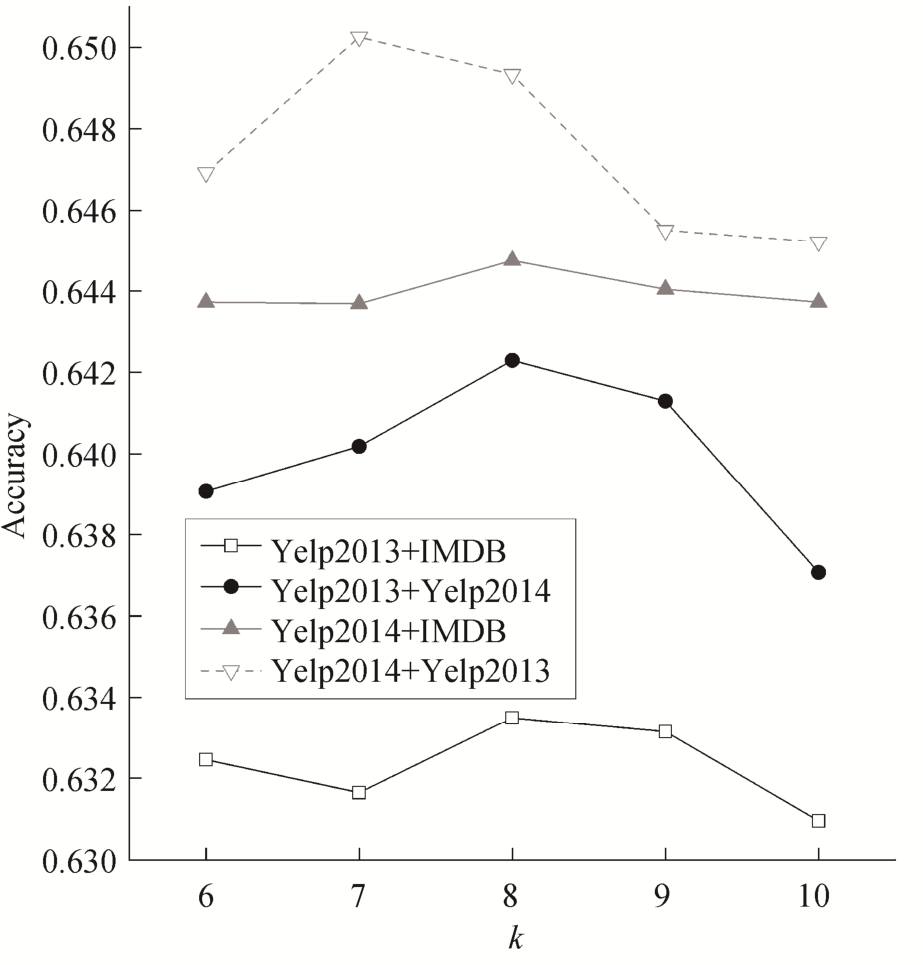
图4 近邻数k的取值对准确率的影响
Fig.4 Accuracy over parameterk
为了便于对比, 前5个对比实验的参数沿用文献[17]中的参数设置, ATL+DGP方法中高斯过程的参数与文献[9]一致, 实验结果如表6所示。值得说明的是, ATL+DGP方法在迁移学习中未能对负面迁移样本进行筛选, 因而分类效果不具优势。从表 6可看出, 本文提出的方法能有效地过滤造成负面迁移的样本, 在负面迁移出现之前停止迭代, 从而在文本表示学习的基础上提高大规模文本跨领域情感分类的性能。
针对跨领域情感分类方法中存在的文本表示忽略局部语义特征和负面迁移问题, 本文提出一种基于分层注意力网络的文本表示方法与基于样例的迁移学习算法相结合的跨领域情感分类方法, 引入基于类噪声估计的迁移数据筛选方法, 从源领域中选取高质量样本迁移到目标领域中, 以提高文本跨领域情感分类系统的性能。在公开的大规模产品评价数据集上的实验表明, 将表示学习与迁移学习相结合的方法可以提高文本跨领域情感分类系统的性能, 同时表明该方法可以有效地提升迁移样本质量,从而说明在大规模文本中引入迁移学习的必要性。由于方法达到较好性能需要大量标注数据集, 未来将进一步研究半监督任务中的大规模跨领域情感分类问题, 以便更好地应用于实际场景, 提高情感分类性能。
表6 跨领域情感分类实验结果
Table 6 Results of cross-domain sentiment classification
?
[1]Subramaniyaswamy V, Logesh R, Abejith M, et al.Sentiment analysis of tweets for estimating criticality and security of events.Journal of Organizational and End User Computing, 2017, 29(4): 51-71
[2]Al-Moslmi T, Omar N, Abdullah S, et al.Approaches to cross-domain sentiment analysis: a systematic literature review.IEEE Access, 2017, 5: 16173-16192
[3]Wei Xiaocong, Lin Hongfei, Yu Yuhai, et al.Lowresource cross-domain product review sentiment classification based on a CNN with an auxiliary largescale corpus.Algorithms, 2017, 10(3): No.81
[4]Zhao Chuanjun, Wang Suge, Li Deyu.Deep transfer learning for social media cross-domain sentiment classification // Chinese National Conference on Social Media Processing.Singapore, 2017: 232-243
[5]李良豪.跨领域文本分类算法研究[D].北京: 清华大学, 2012
[6]Ziser Y, Reichart R.Neural structural correspondence learning for domain adaptation // Conference on Computational Natural Language Learning.Vancouver,2017: 400-410
[7]Pan S J, Ni Xiaochuan, Sun J T, et al.Cross-domain sentiment classification via spectral feature alignment// Proceedings of the 19th International Conference on World Wide Web.Raleigh, 2010: 751-760
[8]Pan S J, Tsang I W, Kwok J T, et al.Domain Adaptation via Transfer Component Analysis.IEEE Transactions on Neural Networks, 2011, 22(2): 199-210
[9]吴冬茵, 桂林, 陈钊, 等.基于深度表示学习和高斯过程迁移学习的情感分析方法.中文信息学报,2017, 31(1): 169-176
[10]Dai Wenyuan, Yang Qiang, Xue Guirong, et al.Boosting for transfer learning // Proceedings of the 24th International Conference on Machine Learning.Corvallis, 2007:193-200
[11]Huang Xingchang, Rao Yanghui, Xie Haoran, et al.Cross-domain sentiment classification via topicrelated TrAdaBoost // Proceedings of the 31st Association for the Advancement of Artificial Intelligence Conference on Artificial Intelligence.San Francisco,2017: 4939-4940
[12]Seah C W, Tsang I W, Ong Y S.Transfer ordinal label learning.IEEE Transactions on Neural Networks & Learning Systems, 2013, 24(11): 1863-1876
[13]Sugiyama M, Nakajima S, Kashima H, et al.Direct importance estimation with model selection and its application to covariate shift adaptation // Proceedings of the 21st Annual Conference on Neural Information Processing Systems.Vancouver, 2007: 1433-1440
[14]Hajmohammadi M S, Ibrahim R, Selamat A, et al.Combination of active learning and self-training for cross-lingual sentiment classification with density analysis of unlabelled samples.Information Sciences,2015, 317: 67-77
[15]Wu Fangzhao, Huang Yongfeng, Yan Jun.Active sentiment domain adaptation // Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.Vancouver, 2017: 1701-171
[16]Kim Y.Convolutional neural networks for sentence classification // Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing.Doha, 2014: 1746-1751
[17]Chen Huimin, Sun Maosong, Tu Cunchao, et al.Neural sentiment classification with user and product attention // Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.Austin, 2016: 1650-1659
[18]Luo Fang, Li Cheng, Cao Zehui, et al.Affectivefeature-based sentiment analysis using SVM classifier// Proceedings of the 20th International Conference on Computer Supported Cooperative Work in Design.Nanchang, 2016: 276-281
[19]Hochreiter S, Schmidhuber J.Long short-term memory.Neural Computation, 1997, 9(8): 1735-1780
[20]Mikolov T, Sutskever I, Chen Kai, et al.Distributed representations of words and phrases and their compositionality // Proceedings of the 27th Annual Conference on Neural Information Processing Systems.Lake Tahoe, 2013: 3111-3119
[21]Gui Lin, Xu Ruifeng, Lu Qin, et al.Negative transfer detection in transductive transfer learning.International Journal of Machine Learning and Cybernetics,2017, 9(2): 1-13
[22]Gui Lin, Lu Qin, Xu Ruifeng, et al.A novel class noise estimation method and application in classification // Proceedings of the 24th ACM International on Conference on Information and Knowledge Management.Melbourne, 2015: 1081-1090
[23]Angluin D, Laird P D.Learning from noisy examples.Machine Learning, 1988, 2(4): 343-370
[24]Ukil A.Support vector machine.Computer Science,2002, 1(4): 1-28
[25]Fatourechi M, Ward R K, Mason S G, et al.Comparison of evaluation metrics in classification applications with imbalanced datasets // Proceedings of the 7th International Conference on Machine Learning and Applications.San Diego, 2008: 777-782
[26]李贤平.概率论基础.2版.北京: 高等教育出版社,1997
[27]Le Q V, Mikolov T.Distributed representations of sentences and documents // Proceedings of the 31th International Conference on Machine Learning.Beijing, 2014: 1188-1196
[28]Socher R, Perelygin A, Wu J Y, et al.Recursive deep models for semantic compositionality over a sentiment Treebank // Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing.Seattle, 2013: 1631-1642
Cross-Domain Sentiment Classification Based on Representation Learning and Transfer Learning